در این مطلب، ویدئو ابزارهایی برای پایتون با کارایی بالا – ایان اوزوالد | ODSC اروپا 2019 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:40:11
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:02,460 –> 00:00:07,320
[موسیقی]
2
00:00:07,320 –> 00:00:11,920
همه پس همانطور که کالوم می گوید نام من یان
3
00:00:11,920 –> 00:00:13,990
اسوالد است به این سخنرانی در مورد محاسبات با کارایی بالا خوش آمدید
4
00:00:13,990 –> 00:00:16,469
5
00:00:19,450 –> 00:00:23,680
و خودم را معرفی کردم و این اولین
6
00:00:23,680 –> 00:00:25,000
بار است که در پاییز برمی گردم، فکر می کنم چهار
7
00:00:25,000 –> 00:00:27,369
سال است که چهار سال پیش در مورد یک
8
00:00:27,369 –> 00:00:29,230
موضوع مرتبط صحبت کردم، بنابراین من بسیار خوشحالم که
9
00:00:29,230 –> 00:00:31,360
برگشتم و من بسیار خوشحال خواهم شد که هر گونه
10
00:00:31,360 –> 00:00:33,280
بازخوردی از شما که
11
00:00:33,280 –> 00:00:35,860
چند سال پیش در سخنرانی من بودید بشنوم و ما
12
00:00:35,860 –> 00:00:37,899
می توانیم در مورد تفاوت ها صحبت کنیم، بنابراین من یک
13
00:00:37,899 –> 00:00:39,789
دانشمند ارشد داده موقت
14
00:00:39,789 –> 00:00:40,870
هستم. این بدان معناست که من مشاور خود را اداره می کنم
15
00:00:40,870 –> 00:00:44,109
و شاهد
16
00:00:44,109 –> 00:00:46,030
تورم افسارگسیخته عنوان شغلی هستم که در چندین سال گذشته در حوزه ما رخ داده است،
17
00:00:46,030 –> 00:00:48,190
18
00:00:48,190 –> 00:00:50,140
جایی که با دو سال شما
19
00:00:50,140 –> 00:00:52,390
بالاتر از همه چیز ارشد می شوید من خوب بودم چگونه
20
00:00:52,390 –> 00:00:53,649
به عنوان یک مشاور مستقل
21
00:00:53,649 –> 00:00:55,120
با این چاه رقابت کنم. بدیهی است که من می
22
00:00:55,120 –> 00:00:56,949
توانم خودم را هر چیزی که می خواهم باشم، پس
23
00:00:56,949 –> 00:00:58,539
من فقط رئیس خواهم شد تا بتوانم
24
00:00:58,539 –> 00:01:00,579
دانشمند ارشد داده و t-boy و
25
00:01:00,579 –> 00:01:04,420
تنها دانشمند داده در شرکتم باشم که
26
00:01:04,420 –> 00:01:06,760
تقریباً 20 سال است که این کار را انجام می دهم. بنابراین من
27
00:01:06,760 –> 00:01:10,090
نیز احساس شرارت نمی کنم من به
28
00:01:10,090 –> 00:01:12,160
عنوان یک رئیس این کار
29
00:01:12,160 –> 00:01:14,170
را انجام میدهم، زمانی که هوش مصنوعی بود، قبل
30
00:01:14,170 –> 00:01:17,020
از اینکه اصطلاح علم داده را داشته باشیم و یکی
31
00:01:17,020 –> 00:01:19,150
از کارهایی که انجام میدهم این است که به سرعت به تیمها کمک میکنم تا
32
00:01:19,150 –> 00:01:21,460
برنامههای استراتژیک خود را بسازند و
33
00:01:21,460 –> 00:01:23,380
سپس امیدوارم. اینکه تیمها بر اساس آنها عمل کنند
34
00:01:23,380 –> 00:01:25,120
و چیزهایی را ارائه دهند که واقعاً
35
00:01:25,120 –> 00:01:27,520
کار میکنند، بنابراین من بسیار عملی
36
00:01:27,520 –> 00:01:29,590
هستم، من بسیار تمرینکننده هستم، برای من
37
00:01:29,590 –> 00:01:31,900
همه چیز در مورد انجام علم داده است که در
38
00:01:31,900 –> 00:01:33,430
مورد آن صحبت میکنم تا به خودم نشان دهم که من
39
00:01:33,430 –> 00:01:35,530
چه چیزی را میدانم. من در مورد آن صحبت می کنم، اما واقعاً
40
00:01:35,530 –> 00:01:37,480
برای من، همه چیز این است که به صورت عملی باشم
41
00:01:37,480 –> 00:01:39,970
و با آن کار کنم و همچنین برخی
42
00:01:39,970 –> 00:01:42,430
دوره های عمومی را برگزار کنم و در مورد آنها صحبت خواهم کرد و
43
00:01:42,430 –> 00:01:45,760
بعداً به آن ها اشاره خواهم کرد، بنابراین با یک
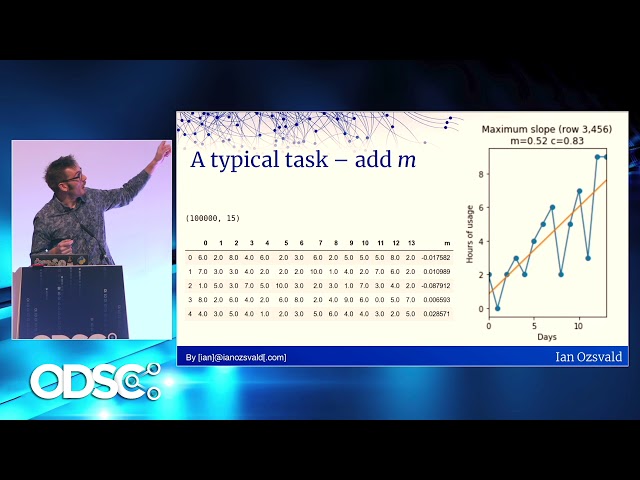
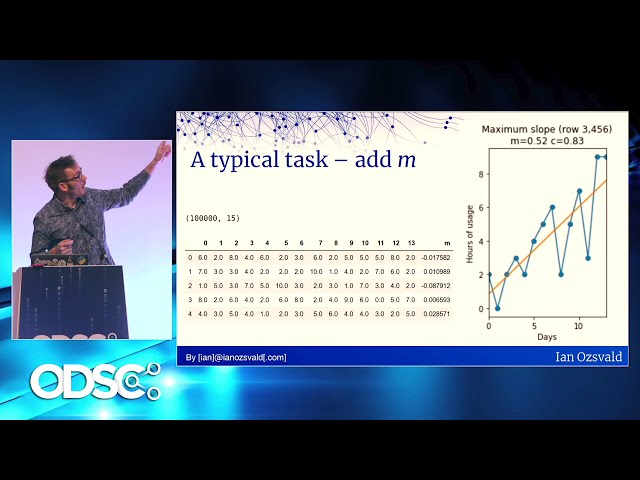
44
00:01:45,760 –> 00:01:47,770
سری سازمان های بزرگ کار می کنم.
45
00:01:47,770 –> 00:01:49,300
نام هایی که ممکن است بشناسید مانند کانال
46
00:01:49,300 –> 00:01:53,800
بیمه ITV TB و شرکت بیمه چندملیتی
47
00:01:53,800 –> 00:01:55,300
و مجموعه کاملی از شرکت های
48
00:01:55,300 –> 00:01:58,450
کوچک کوچکتر متوسط هستند و در
49
00:01:58,450 –> 00:02:00,370
ال حاضر من با یکی از شر
50
00:02:00,370 –> 00:02:02,200
ت های سرمایه گذاری خطرپذیر درجه یک کار می کنم که به آن
51
00:02:02,200 –> 00:02:03,760
ا در سفر علم داده و کمک به آنها کمک می کن
52
00:02:03,760 –> 00:02:06,340
. بنابراین موضوعی که به آن خواهیم پرداخت در اینجا
53
00:02:06,340 –> 00:02:09,190
بر اساس مشتریان و برخی از
54
00:02:09,190 –> 00:02:11,050
تجربیات مربیگری من در سال گذشته است، بنابراین
55
00:02:11,050 –> 00:02:12,730
این یکی در واقعیت است.
56
00:02:12,730 –> 00:02:14,950
57
00:02:14,950 –> 00:02:16,450
58
00:02:16,450 –> 00:02:19,319
59
00:02:19,319 –> 00:02:21,120
در حال اتمام نسخه خطی
60
00:02:21,120 –> 00:02:23,069
برای چاپ دوم ما در حال حاضر، می
61
00:02:23,069 –> 00:02:25,319
گویم فقط پنج هفته شام دارم که با
62
00:02:25,319 –> 00:02:26,400
د به کریسمس برسم و دس
63
00:02:26,400 –> 00:02:28,170
نوشته قرار است وارد شود، بع
64
00:02:28,170 –> 00:02:29,459
از ظهر امروز امضای کتاب را انجام خواهم دا
65
00:02:29,459 –> 00:02:31,290
. نسخه اول
66
00:02:31,290 –> 00:02:33,360
20 نسخه یا بیشتر خواهد داشت، شما بسیار خوش
67
00:02:33,360 –> 00:02:34,800
آمدید که بیایید و در صف قرار بگیرید و یکی از
68
00:02:34,800 –> 00:02:37,050
آن نسخه ها را دریافت کنید و من بسیار علاقه مند هستم
69
00:02:37,050 –> 00:02:38,340
که نظرات شما را در مورد آنچه که می
70
00:02:38,340 –> 00:02:39,540
خواهید از پایتون با کارایی بالا دریافت کنید
71
00:02:39,540 –> 00:02:42,090
قبل از ما بشنوم. ادامه دهید من می خواهم
72
00:02:42,090 –> 00:02:44,010
از همه شما عکس بگیرم برخی از
73
00:02:44,010 –> 00:02:45,390
شما ممکن است دوست نداشته باشید از آنها عکس گرفته شود در
74
00:02:45,390 –> 00:02:47,400
این صورت فقط اردک یا مخفی یا هر چیز دیگری
75
00:02:47,400 –> 00:02:49,920
بقیه شما دوست دارم یک
76
00:02:49,920 –> 00:02:52,500
عکس خندان شاد با دست
77
00:02:52,500 –> 00:02:54,060
تکان دهید و می دانم که هنگامی که یک
78
00:02:54,060 –> 00:02:55,920
بلندگوی تصادفی روشن دارید مرحله میگوید هی
79
00:02:55,920 –> 00:02:57,060
یک عمل فیزیکی انجام دهید، احتمالاً
80
00:02:57,060 –> 00:02:58,440
آن را انجام نمیدهید، من فقط میخواهم
81
00:02:58,440 –> 00:03:00,150
شما را تا زمانی که دستهایتان بالا برود، انتخاب کنم تا بتوانیم این کار را
82
00:03:00,150 –> 00:03:01,709
خوب و سریع انجام دهیم.
83
00:03:01,709 –> 00:03:03,390
84
00:03:03,390 –> 00:03:04,890
از آنجایی که فرض میکنم شما واقعاً
85
00:03:04,890 –> 00:03:08,150
میخواهید همینجا باشید، ما کاملاً میرویم
86
00:03:08,150 –> 00:03:11,040
از همه شما بسیار متشکرم، بنابراین
87
00:03:11,040 –> 00:03:17,130
بعداً در ورودی وبلاگ من قرار خواهد گرفت، بنابراین
88
00:03:17,130 –> 00:03:19,739
هدف امروز ما در مورد
89
00:03:19,739 –> 00:03:22,049
ایجاد کدهای پایتون برای دانشمندان داده صحبت خواهیم کرد.
90
00:03:22,049 –> 00:03:24,420
سریعتر این مبتنی بر برخی تجربههای مشتری واقعی
91
00:03:24,420 –> 00:03:26,880
است، به ویژه بر اساس
92
00:03:26,880 –> 00:03:29,130
استفاده از هندرها که سریعتر پیش میروند،
93
00:03:29,130 –> 00:03:30,600
ما به نمایهسازی نگاه میکنیم تا
94
00:03:30,600 –> 00:03:32,840
بفهمیم چه چیزی کند پیش میرود و
95
00:03:32,840 –> 00:03:35,220
چرا به تکنیکهای مختلف برای اجرای
96
00:03:35,220 –> 00:03:36,959
کدها برای اجرای سریعتر آن نگاه میکنیم و سپس
97
00:03:36,959 –> 00:03:38,670
به راههایی برای اجرای موازی
98
00:03:38,670 –> 00:03:41,370
و حتی جمعآوری همه آنها با
99
00:03:41,370 –> 00:03:43,410
حداقل تلاش و اینها تکنیکهایی هستند
100
00:03:43,410 –> 00:03:44,790
که در واقع در مشاوره روزانه من با مشتری استفاده میکنند،
101
00:03:44,790 –> 00:03:48,450
همچنین وقتی با
102
00:03:48,450 –> 00:03:50,010
کارایی بالا سر و کار داریم، فقط به این دلیل نیست
103
00:03:50,010 –> 00:03:52,380
که سریعتر پیش برویم. می تواند
104
00:03:52,380 –> 00:03:54,540
سریعتر پیش برود، ما باید به این فکر کنیم که چگونه
105
00:03:54,540 –> 00:03:56,280
ما به صورت جداگانه و یک لیست عملکرد بازاریابی T وجود دارد
106
00:03:56,280 –> 00:03:58,350
و بنابراین من
107
00:03:58,350 –> 00:03:59,700
در پایان به شما چند تامل خواهم داد و
108
00:03:59,700 –> 00:04:00,540
این یکی از چیزهایی است که من
109
00:04:00,540 –> 00:04:01,859
این بار در مورد بازتاب ها به کتاب اضافه کرده ام.
110
00:04:01,859 –> 00:04:04,230
در مورد اینکه چگونه
111
00:04:04,230 –> 00:04:07,590
در یک سناریوی دنیای واقعی واقعاً عملکرد بالایی
112
00:04:07,590 –> 00:04:08,640
داشته باشیم، اکنون باید مطمئن شویم که من در اتاق مناسب هستم،
113
00:04:08,640 –> 00:04:10,049
بنابراین میتوانید
114
00:04:10,049 –> 00:04:11,609
دستان خود را بالا ببرید، لطفاً اگر توسعهدهنده پایتون هستید،
115
00:04:11,609 –> 00:04:13,200
من فقط میخواهم احساسی داشته باشم.
116
00:04:13,200 –> 00:04:16,320
شما خوب هستید که اکثر شما چه چیزی را خوب می دانید و چه
117
00:04:16,320 –> 00:04:18,149
تعداد از شما از پانداها به طور
118
00:04:18,149 –> 00:04:20,608
ثابت استفاده می کنید، بسیار عالی است و
119
00:04:20,608 –> 00:04:21,959
اگر همچنان از numpy
120
00:04:21,959 –> 00:04:24,180
مستقیماً به طور مداوم استفاده می کنید، اوه عالی است،
121
00:04:24,180 –> 00:04:26,070
همه شما باید از
122
00:04:26,070 –> 00:04:30,210
این بحث بهره زیادی ببرید، پس ما میروم و خوب، بنابراین
123
00:04:30,210 –> 00:04:32,990
این یک عملکرد معمولی بالا است،
124
00:04:32,990 –> 00:04:34,910
من دادههای زیادی دارم، میخواهم
125
00:04:34,910 –> 00:04:37,010
یک چیز را محاسبه کنم و سپس
126
00:04:37,010 –> 00:04:39,770
این مثال را در یک لحظه از بین میبریم و سپس
127
00:04:39,770 –> 00:04:41,810
خیلی کند میشود و من میخواستم به
128
00:04:41,810 –> 00:04:43,280
اندازه کافی سریع بروم برای اینکه بتوانم کارم را به پایان برسانم،
129
00:04:43,280 –> 00:04:46,370
به تی بعدی می روم در این مورد بپرسید من
130
00:04:46,370 –> 00:04:48,320
میخواهم برخی از دادههای سری زمانی را تجزیه و تحلیل
131
00:04:48,320 –> 00:04:50,510
کنم. صد هزار ردیف از
132
00:04:50,510 –> 00:04:52,070
دادههای سری زمانی دارم که در اسلاید بعدی به شما نشان خواهم داد
133
00:04:52,070 –> 00:04:54,200
و سپس
134
00:04:54,200 –> 00:04:55,850
صد هزار ردیف داریم.
135
00:04:55,850 –> 00:04:57,500
ستونها نشاندهنده سریهای زمانی
136
00:04:57,500 –> 00:04:59,750
در هر سطر است که در آن ردیف یک
137
00:04:59,750 –> 00:05:01,850
شخص است و ما یک مشکل جعلی را
138
00:05:01,850 –> 00:05:03,680
در اینجا حل میکنیم.
139
00:05:03,680 –> 00:05:05,420
140
00:05:05,420 –> 00:05:07,280
141
00:05:07,280 –> 00:05:09,200
دادههای مشاهدهای آنها میدانند که
142
00:05:09,200 –> 00:05:11,000
شما روزانه چند ساعت از تلفن همراه خود استفاده میکنید
143
00:05:11,000 –> 00:05:13,220
و میخواهند آن را تجزیه و تحلیل
144
00:05:13,220 –> 00:05:14,900
کنند، آنها میخواهند آن را تجزیه و تحلیل کنند، شاید آنها در حال
145
00:05:14,900 –> 00:05:16,820
اعمال برخی تبلیغات هستند که میخواهند
146
00:05:16,820 –> 00:05:18,530
ببینند آیا وقتی تبلیغاتی اعمال میشود، برخی
147
00:05:18,530 –> 00:05:20,660
افراد بیشتر از تلفن خود استفاده میکنند. و برخی
148
00:05:20,660 –> 00:05:22,280
افراد کمتر از آن استفاده میکنند و
149
00:05:22,280 –> 00:05:23,660
شاید محدودیتهای جغرافیایی و
150
00:05:23,660 –> 00:05:25,220
چیزهای جالب دیگری وجود داشته باشد که ما
151
00:05:25,220 –> 00:05:27,320
به مؤلفه علم داده اهمیتی
152
00:05:27,320 –> 00:05:29,300
153
00:05:29,300 –> 00:05:31,460
154
00:05:31,460 –> 00:05:35,419
نمیدهیم. دارم 14 ستون
155
00:05:35,419 –> 00:05:37,400
به ارزش داده تعداد ساعاتی
156
00:05:37,400 –> 00:05:39,169
که شما هر روز از تلفن خود در طول دو هفته استفاده کرده اید
157
00:05:39,169 –> 00:05:41,210
و من می خواهم شیب خط را محاسبه کنم،
158
00:05:41,210 –> 00:05:43,220
بنابراین استفاده از آن بیشتر در طول دو هفته یا
159
00:05:43,220 –> 00:05:46,070
کمتر و این تبدیل به مشکل اساسی می شود
160
00:05:46,070 –> 00:05:47,030
که ما به دنبال آن هستیم. در
161
00:05:47,030 –> 00:05:50,000
زمانبندیهایی انجام میدهیم و سپس این را ایجاد میکنیم،
162
00:05:50,000 –> 00:05:51,500
میتوانیم این مشکل را بسیار سختتر کنیم به
163
00:05:51,500 –> 00:05:53,450
جای داشتن یک پنجره دو هفتهای، میتوانیم پنجرههای
164
00:05:53,450 –> 00:05:56,330
دو هفتهای به ارزش دو سال
165
00:05:56,330 –> 00:05:58,880
حدوداً 52 هفته در دو داشته باشیم،
166
00:05:58,880 –> 00:06:00,890
بنابراین صد برابر میشود. دادههای بیشتری برای پردازش و
167
00:06:00,890 –> 00:06:02,360
به جای داشتن صد
168
00:06:02,360 –> 00:06:04,610
هزار ردیف، شرکتهای مخابرات سیار
169
00:06:04,610 –> 00:06:06,080
کاربران زیادی دارند، بنابراین شاید شما یک
170
00:06:06,080 –> 00:06:07,700
میلیون یا ده میلیون مشتری برای
171
00:06:07,700 –> 00:06:09,530
تجزیه و تحلیل داشته باشید، بنابراین بسیار آسان است که این
172
00:06:09,530 –> 00:06:11,300
نوع مشکل را ده بار یا هزار بار اجرا کنید.
173
00:06:11,300 –> 00:06:12,860
بارها یا ده هزار بار
174
00:06:12,860 –> 00:06:14,690
کندتر و سپس باید آن را
175
00:06:14,690 –> 00:06:17,479
سریعتر کنیم تا آهسته اجرا شود.
176
00:06:17,479 –> 00:06:19,760
177
00:06:19,760 –> 00:06:22,550
178
00:06:22,550 –> 00:06:24,260
179
00:06:24,260 –> 00:06:26,960
تعدادی عدد صحیح s از
180
00:06:26,960 –> 00:06:29,510
تعداد ساعاتی که در اختیار داریم و سپس
181
00:06:29,510 –> 00:06:31,280
میخواهیم ستون M را اضافه کنیم، سمت راستترین
182
00:06:31,280 –> 00:06:32,810
ستون که شیب خط است و
183
00:06:32,810 –> 00:06:35,110
سپس آن نمودار سمت راست که ردیفهای
184
00:06:35,110 –> 00:06:37,850
3400 یا بیشتر از این مجموعه داده است، جایی که
185
00:06:37,850 –> 00:06:40,310
معلوم میشود بیشترین تعداد را دارد. افزایش
186
00:06:40,310 –> 00:06:42,169
شیب بنابراین ما M را محاسبه کرده ایم و سپس
187
00:06:42,169 –> 00:06:44,320
بیشترین افزایش را جستجو کرده ایم
188
00:06:44,320 –> 00:06:45,700
و این مثال در آنجا است و شما
189
00:06:45,700 –> 00:06:46,990
می توانید تصور کنید که بیشتر کاهشی
190
00:06:46,990 –> 00:06:51,400
برعکس به نظر می رسد، بنابراین بیایید به
191
00:06:51,400 –> 00:06:54,610
دو راه حل ممکن نگاه کنیم که من
192
00:06:54,610 –> 00:06:57,340
پیشنهاد می کنم که اگر از ایان پرسیده شود که
193
00:06:57,340 –> 00:06:59,920
زاویه یک در نهایت در شیب
194
00:06:59,920 –> 00:07:02,050
مجموعه ای از داده ها را پیدا کند، اولین کاری که من انجام می
195
00:07:02,050 –> 00:07:04,870
دهم این است که یک دانشمند داده عاقل کوشا بودن پایتون
196
00:07:04,870 –> 00:07:06,970
این است که به
197
00:07:06,970 –> 00:07:08,770
یادگیری scikit-learn روی بیاورم و از مدل رگرسیون خطی ساخته
198
00:07:08,770 –> 00:07:10,360
شده استفاده کنم. کار
199
00:07:10,360 –> 00:07:12,400
می کند، اشکال زدایی شده است، استفاده از آن آسان است که
200
00:07:12,400 –> 00:07:13,990
میلیون ها مثال را همکارانم متوجه خواهند شد،
201
00:07:13,990 –> 00:07:15,940
این است که ما
202
00:07:15,940 –> 00:07:18,310
از استفاده از این راه حل تعجب آور نیستیم، بنابراین این بهترین
203
00:07:18,310 –> 00:07:19,780
راه حل است که چند خط
204
00:07:19,780 –> 00:07:22,330
طولانی را در یک ردیف از داده ها از راه حل ارسال کردم.
205
00:07:22,330 –> 00:07:25,420
pandas dataframe من در آن سطر
206
00:07:25,420 –> 00:07:28,890
پاس دادم من رگرسیور خطی او را در
207
00:07:28,890 –> 00:07:33,340
ورودی های خود می گذارم که 14 روز است بنابراین 0 تا 13 را به عنوان
208
00:07:33,340 –> 00:07:35,350
یک ستون در ردیف
209
00:07:35,350 –> 00:07:37,090
داده ارسال می کنم که تعداد ساعات استفاده در
210
00:07:37,090 –> 00:07:39,940
روز است و به همین دلیل است که من جا می زنم. آن را و سپس
211
00:07:39,940 –> 00:07:41,650
از آن تناسب، ضریب اول را بیرون می آورم
212
00:07:41,650 –> 00:07:43,810
و سپس این
213
00:07:43,810 –> 00:07:47,230
شیب خط است و کار تمام است، زیرا
214
00:07:47,230 –> 00:07:48,520
من سخت کوش هستم، کمی جستجو
215
00:07:48,520 –> 00:07:49,870
کرده ام، به آن فکر کرده ام، شاید
216
00:07:49,870 –> 00:07:51,220
راه های دیگری برای حل وجود داشته باشد. این مشکل من
217
00:07:51,220 –> 00:07:53,050
متوجه شدم که در بسته numpy
218
00:07:53,050 –> 00:07:55,330
یک بسته فرعی جبر خطی وجود دارد
219
00:07:55,330 –> 00:07:57,130
که حاوی تابع حداقل مربع است
220
00:07:57,130 –> 00:07:59,890
که طبق صفحه راهنما می گوید
221
00:07:59,890 –> 00:08:01,090
که همان کاری را انجام می دهد که من
222
00:08:01,090 –> 00:08:02,710
به آن نیاز دارم، بنابراین من کنجکاو هستم.
223
00:08:02,710 –> 00:08:04,330
من مقداری کد می نویسم که همان
224
00:08:04,330 –> 00:08:08,020
کاری را انجام می دهد که X خود را تولید می کنم، یعنی 0 تا 13
225
00:08:08,020 –> 00:08:09,280
شناسه روز
226
00:08:09,280 –> 00:08:11,110
من است، برخی از کدهایی را که نشان دهنده
227
00:08:11,110 –> 00:08:13,450
ثابت محاسبه وقفه است
228
00:08:13,450 –> 00:08:14,560
، قرار می دهم زیرا در اینجا باید
229
00:08:14,560 –> 00:08:16,930
رهگیری را به صورت دستی مشخص کنم، آن دو
230
00:08:16,930 –> 00:08:18,730
ستون را روی هم گذاشتم. با هم از آنها عبور کنند به
231
00:08:18,730 –> 00:08:20,860
تابع حداقل مربع میروم و M خود را خارج میکنم
232
00:08:20,860 –> 00:08:22,720
و سپس میخواهم بررسی کنم که این
233
00:08:22,720 –> 00:08:23,950
چیزها یکسان عمل میکنند و بررسی
234
00:08:23,950 –> 00:08:27,520
کنم که آیا تفاوت سرعت وجود دارد یا نه، بنابراین
235
00:08:27,520 –> 00:08:29,470
اولین بیت پروفایل خود را انجام میدهم و از عملکرد درصد زمانی استفاده میکنم که
236
00:08:29,470 –> 00:08:31,150
درصد زمان استفاده
237
00:08:31,150 –> 00:08:33,010
آن است. در داخل ارزانتر به نوت بوک تعدادی
238
00:08:33,010 –> 00:08:34,360
از شما خوب است کسانی از شما که
239
00:08:34,360 –> 00:08:37,059
فوق العاده آسان نیست ما از توابع درصد جادو
240
00:08:37,059 –> 00:08:39,640
استفاده می کنیم ما از این جادو در داخل سوپر
241
00:08:39,640 –> 00:08:41,020
به نوت بوک استفاده می کنیم و یک تابع را اجرا می کند یک
242
00:08:41,020 –> 00:08:43,120
تابع راحت در این مورد زمانی
243
00:08:43,120 –> 00:08:45,130
که ما را اجرا می کند عملکرد در یک
244
00:08:45,130 –> 00:08:46,900
بلوک ثابت زمان برای اینکه بفهمیم چقدر طول می
245
00:08:46,900 –> 00:08:47,920
کشد و سپس مقداری آمار را به ما
246
00:08:47,920 –> 00:08:50,980
برگردانم، نسخه scikit-learn خود را اجرا می کنم و
247
00:08:50,980 –> 00:08:53,660
500 میکرو ثانیه طول می کشد
248
00:08:53,660 –> 00:08:56,070
آنجا من نسخه حداقل
249
00:08:56,070 –> 00:08:58,560
مربعی را اجرا می کنم و 196 طول می کشد.
250
00:08:58,560 –> 00:09:00,360
نیم برابر سریعتر، پس این یک
251
00:09:00,360 –> 00:09:00,810
جور عجیب است
252
00:09:00,810 –> 00:09:02,310
که چرا برای همان کار دو و نیم برابر سریعتر است.
253
00:09:02,310 –> 00:09:04,380
254
00:09:04,380 –> 00:09:05,850
255
00:09:05,850 –> 00:09:08,280
256
00:09:08,280 –> 00:09:09,810
257
00:09:09,810 –> 00:09:11,880
مشاور شغل من آنجاست e برای
258
00:09:11,880 –> 00:09:14,610
فعال کردن و تسریع چیزی،
259
00:09:14,610 –> 00:09:16,770
اما من در یک زمینه دفاعی
260
00:09:16,770 –> 00:09:18,120
کار می کنم، این چیزی است که سعی می کند مرا اخراج کند،
261
00:09:18,120 –> 00:09:19,470
تلاش می کند من را شرمنده کند، سعی می
262
00:09:19,470 –> 00:09:20,880
کند من را واقعاً احمق نشان
263
00:09:20,880 –> 00:09:23,280
دهد، بنابراین من همیشه در حال آزمایش هستم تا مطمئن شوم که آیا این کار را انجام داده
264
00:09:23,280 –> 00:09:24,510
ام. اشتباه است یا مشکلی
265
00:09:24,510 –> 00:09:27,450
در سیستم اصلی وجود دارد، بنابراین در اینجا
266
00:09:27,450 –> 00:09:29,340
ما دو مجموعه از نتایج را داریم که یکی
267
00:09:29,340 –> 00:09:30,720
دو و نیم برابر سریعتر از
268
00:09:30,720 –> 00:09:32,340
دیگری کار می کند، من نمی دانم چرا
269
00:09:32,340 –> 00:09:33,540
هنوز کد منبع را تکمیل نکرده ام ما
270
00:09:33,540 –> 00:09:35,970
فقط در یک لحظه به آن نگاه
271
00:09:35,970 –> 00:09:37,350
272
00:09:37,350 –> 00:09:38,670
273
00:09:38,670 –> 00:09:41,310
274
00:09:41,310 –> 00:09:43,560
275
00:09:43,560 –> 00:09:45,960
خواهیم کرد. دو آرایه از
276
00:09:45,960 –> 00:09:47,820
صد هزار نتیجه M از
277
00:09:47,820 –> 00:09:49,770
دو تابع مختلف و می گذرد،
278
00:09:49,770 –> 00:09:51,990
بنابراین من همان نتایج را دارم
279
00:09:51,990 –> 00:09:54,150
و وقتی می گوید آرایه ثابت تقریبا
280
00:09:54,150 –> 00:09:56,250
برابر است که به طور پیش فرض هفت رقم اعشار است
281
00:09:56,250 –> 00:09:58,260
و می توانید تعداد اعشار را مشخص کنید.
282
00:09:58,260 –> 00:09:59,400
مکان هایی که می خواهید
283
00:09:59,400 –> 00:10:01,470
محاسبه کنید بر خلاف، بنابراین ما می دانیم
284
00:10:01,470 –> 00:10:03,810
که دقیقاً تعداد مناسب یا
285
00:10:03,810 –> 00:10:09,030
مجموعه مناسبی از نتایج را دریافت می کنیم، بنابراین
286
00:10:09,030 –> 00:10:09,690
چه اتفاقی می افتد،
287
00:10:09,690 –> 00:10:11,850
چرا سرعت آن بسیار کندتر است، آیا کسی
288
00:10:11,850 –> 00:10:15,320
دوست دارد داوطلبانه حدس بزند که سفید کمتر
289
00:10:16,520 –> 00:10:21,110
می رود و داوطلب شود.
290
00:10:21,200 –> 00:10:26,060
scikit-learn یا
291
00:10:26,060 –> 00:10:27,680
پیاده سازی کاملاً درست است و
292
00:10:27,680 –> 00:10:29,060
این نکات بسیار مهمی است که به نظر می رسد
293
00:10:29,060 –> 00:10:30,860
scikit-learn کند است اما شاید
294
00:10:30,860 –> 00:10:32,180
کار دیگری انجام می دهد شاید
295
00:10:32,180 –> 00:10:33,610
واقعاً چیزی به نفع ما انجام می دهد
296
00:10:33,610 –> 00:10:36,380
و این کاملاً نکته درستی است بنابراین
297
00:10:36,380 –> 00:10:38,240
ما می توانیم از نمایه آهکی استفاده کنیم.
298
00:10:38,240 –> 00:10:40,780
استفاده کاربر از پروفایلر خط رابرت کرنز قبل از
299
00:10:40,780 –> 00:10:41,990
حق
300
00:10:41,990 –> 00:10:43,760
تقریباً همه در مورد این
301
00:10:43,760 –> 00:10:45,710
ماژول نمیدانند، بسیار عالی است،
302
00:10:45,710 –> 00:10:47,570
ما برای هر کد علمی خود یک خط به خط تجزیه و تحلیل
303
00:10:47,570 –> 00:10:49,040
میکنیم که زمان صرف آن کجاست،
304
00:10:49,040 –> 00:10:52,160
بنابراین میتوانید بفهمید که چه چیزی در یک مورد کند است.
305
00:10:52,160 –> 00:10:54,440
خط همیشه درخشان است، بنابراین سه
306
00:10:54,440 –> 00:10:56,030
رابط مختلف وجود دارد، یک جادوی
307
00:10:56,030 –> 00:10:58,040
درونی وجود دارد که نوتبوکها را اینجا قرار دهید،
308
00:10:58,040 –> 00:10:59,720
من در بالای صفحه از
309
00:10:59,720 –> 00:11:01,370
نمایه خط رابط برنامهنویسی استفاده میکنم.
310
00:11:01,370 –> 00:11:02,450
اما سه رابط مختلف وجود دارد
311
00:11:02,450 –> 00:11:05,230
که می توانید به راحتی در یک نوت بوک از آن استفاده کنید، من
312
00:11:05,230 –> 00:11:07,340
به شما می گویم که من می خواهم
313
00:11:07,340 –> 00:11:09,320
تابع برآوردی برازش را از scikit-learn
314
00:11:09,320 –> 00:11:12,380
315
00:11:12,380 –> 00:11:14,180
نمایه کنم و سپس آن را با elpida runs یک پروفایل خطی که اجرا نمی کنم صدا می زنم و به آن می دهم.
316
00:11:14,180 –> 00:11:17,600
s من به آن X و مقادیر نوشتم را
317
00:11:17,600 –> 00:11:20,360
در یک ردیف از مجموعه داده های خود ارسال کردم و از
318
00:11:20,360 –> 00:11:22,220
آن خواستم تا آمار
319
00:11:22,220 –> 00:11:24,800
مربوط به سرعت اجرای هر خط و زمان صرف شده در کجا
320
00:11:24,800 –> 00:11:26,570
321
00:11:26,570 –> 00:11:29,120
را چاپ کند. تعداد
322
00:11:29,120 –> 00:11:30,740
زیادی نور وجود دارد، تابع بسیار طولانی است
323
00:11:30,740 –> 00:11:32,120
که من بیشتر آنها را حذف کردهام، زیرا
324
00:11:32,120 –> 00:11:34,310
سه بخش وجود دارد که زمان
325
00:11:34,310 –> 00:11:37,970
میبرند دادههای از پیش پردازش شده X Y و سپس
326
00:11:37,970 –> 00:11:39,800
جبر خطی حداقل مربع را بررسی میکنند، بنابراین ما
327
00:11:39,800 –> 00:11:41,540
تابع مربع برگ دودمان خود را داریم.
328
00:11:41,540 –> 00:11:42,800
دقیقاً همان تابعی را که
329
00:11:42,800 –> 00:11:44,540
قبلاً استفاده می کردیم، به همین دلیل است که
330
00:11:44,540 –> 00:11:46,780
دقیقاً همان نتیجه را می گیریم، همان کار را انجام می دهد اما
331
00:11:46,780 –> 00:11:49,010
65٪ از زمان ما صرف این
332
00:11:49,010 –> 00:11:51,020
دو تابع دیگر می شود و این به این دلیل است که ما
333
00:11:51,020 –> 00:11:53,030
مقدار کمی داده یا یک داده را منتقل می کنیم.
334
00:11:53,030 –> 00:11:54,290
مقدار زیادی خرما از یک آمو کوچک تعداد زیادی
335
00:11:54,290 –> 00:11:56,870
از داده ها بارها در بررسی سربار زیادی وجود دارد که
336
00:11:56,870 –> 00:11:58,310
337
00:11:58,310 –> 00:12:00,590
معمولاً با scikit-learn
338
00:12:00,590 –> 00:12:03,320
تعداد زیادی آرایه کوچک را
339
00:12:03,320 –> 00:12:06,980
منتقل نمی کنیم، معمولاً در یک آرایه بزرگ ارسال می کنیم، بنابراین
340
00:12:06,980 –> 00:12:09,350
شاید ده هزار ردیف از داده ها چندین
341
00:12:09,350 –> 00:12:10,910
ستون داشته باشد و سپس ما کار خود را انجام می دهیم.
342
00:12:10,910 –> 00:12:12,950
جبر خطی کمترین مجذور تناسب ما را بر روی آن انجام میدهد،
343
00:12:12,950 –> 00:12:15,260
در عوض ما فقط در یک
344
00:12:15,260 –> 00:12:17,870
345
00:12:17,870 –> 00:12:19,790
ستون 14 موردی قرار میدهیم که در مقابل ستونی متشکل از 14 مورد قرار میگیرد و این کار را 100000 بار انجام میدهیم،
346
00:12:19,790 –> 00:12:22,730
بنابراین هزینههای سربار که
347
00:12:22,730 –> 00:12:25,010
باعث میشود یادگیری scikit استفاده ایمن باشد،
348
00:12:25,010 –> 00:12:25,760
مهم است.
349
00:12:25,760 –> 00:12:28,040
این هزینههای سربار در این زمینه جمع میشوند،
350
00:12:28,040 –> 00:12:30,080
بنابراین به همین دلیل است که کندتر کار میکند، بنابراین
351
00:12:30,080 –> 00:12:31,370
اینطور نیست که scikit-learn
352
00:12:31,370 –> 00:12:32,900
کند است، این مورد است که scikit-learn
353
00:12:32,900 –> 00:12:35,089
ایمن است و من مطمئناً
354
00:12:35,089 –> 00:12:37,370
چندین بار در توسعه خود با
355
00:12:37,370 –> 00:12:39,350
scikit سازگار بودهام. خوب یاد بگیرید میگوید ایان
356
00:12:39,350 –> 00:12:40,939
او را در چند نان در آن آرایه
357
00:12:40,939 –> 00:12:42,620
پاس کرده است، اما او در آن ستون به
358
00:12:42,620 –> 00:12:44,180
شکل اشتباهی عبور کرده است و البته
359
00:12:44,180 –> 00:12:45,649
چیزهای اشکال زدایی واقعاً عجیبی
360
00:12:45,649 –> 00:12:46,999
وجود دارد که از آنجا بیرون میآیند ممکن است برای من هزینه
361
00:12:46,999 –> 00:12:48,920
زیادی داشته باشد. اما sa بررسی fety در
362
00:12:48,920 –> 00:12:49,490
scikit-learn
363
00:12:49,490 –> 00:12:51,019
همه اینها را از بین می برد و فقط به این نکته اشاره کنید
364
00:12:51,019 –> 00:12:52,309
که من اشتباه کرده ام و می توانم
365
00:12:52,309 –> 00:12:54,290
سریع بروم و آن را برطرف کنم، بنابراین
366
00:12:54,290 –> 00:12:55,160
367
00:12:55,160 –> 00:12:58,519
اگر ما به صورت آنلاین روی
368
00:12:58,519 –> 00:13:00,470
مجموعه داده های بزرگی که به آن اعتماد داریم کار می کنیم زندگی من را آسان تر می کند. دادههای ما
369
00:13:00,470 –> 00:13:01,939
همه چیز ضد گلوله بود، به خوبی
370
00:13:01,939 –> 00:13:04,100
آزمایش شده بود، ممکن است اکثر بررسیها را نخواهیم
371
00:13:04,100 –> 00:13:05,120
و راهی برای خاموش کردن آنها در
372
00:13:05,120 –> 00:13:07,249
scikit-learn وجود ندارد، بنابراین شاید
373
00:13:07,249 –> 00:13:08,480
بخواهید بروید و از یک پیادهسازی جایگزین استفاده کنید،
374
00:13:08,480 –> 00:13:09,769
این کاری است که ما
375
00:13:09,769 –> 00:13:11,839
در اینجا انجام میدهیم. ما به دادههای خود اعتماد داریم،
376
00:13:11,839 –> 00:13:13,129
اما ارزش درک این را دارد
377
00:13:13,129 –> 00:13:14,689
که مکانیزمی برای درک اینکه چرا این
378
00:13:14,689 –> 00:13:16,579
کارها به کندی انجام میشوند، دارید
379
00:13:16,579 –> 00:13:18,139
تا بتوانید یک قضاوت مستدل داشته باشید که آیا میخواهید
380
00:13:18,139 –> 00:13:19,490
آن بررسیهای ایمنی را خاموش کنید
381
00:13:19,490 –> 00:13:21,079
و به سرعت آن را انجام دهید یا انجام دهید. شما
382
00:13:21,079 –> 00:13:22,249
میخواهید این بررسیهای ایمنی را انجام دهید زیرا همه چیز
383
00:13:22,249 –> 00:13:24,100
برای شما به اندازه کافی سریع کار میکند،
384
00:13:24,100 –> 00:13:26,749
بنابراین من توصیه میکنم هر زمان که چنین صحبتی میکنم، نمایهگر خط را به شما توصیه
385
00:13:26,749 –> 00:13:28,579
میکنم،
386
00:13:28,579 –> 00:13:29,930
معلوم میشود که اکثر شایعات هرگز
387
00:13:29,930 –> 00:13:32,240
به ایده پروفایلسازی نمیرسند، شاید
388
00:13:32,240 –> 00:13:34,430
در مدول پروفایل C باشد. e در پایتون و
389
00:13:34,430 –> 00:13:36,019
این کمی مکاشفه است، بنابراین بروید و
390
00:13:36,019 –> 00:13:37,610
نمایهگر خط را امتحان کنید، زندگی شما را
391
00:13:37,610 –> 00:13:38,930
بهتر میکند، میتوانید هر کدی از کدهای خود را
392
00:13:38,930 –> 00:13:41,480
با آن نمایه کنید و به شما کمک میکند تشخیص دهید
393
00:13:41,480 –> 00:13:43,309
که مشکل کجاست که فکر میکنید
394
00:13:43,309 –> 00:13:45,319
حقیقت ماجرا کجاست. نسبت به
395
00:13:45,319 –> 00:13:48,350
پیاده سازی شما و مجموعه داده های شما است،
396
00:13:48,350 –> 00:13:50,120
یک چیز است که من بعد از 15 سال انجام این کار مدام پیدا می
397
00:13:50,120 –> 00:13:52,129
کنم این است که مفروضات من به
398
00:13:52,129 –> 00:13:53,509
نوعی می نویسند، اما آنها نیز به نوعی اشتباه هستند
399
00:13:53,509 –> 00:13:54,949
و اگر بخواهم بروم و
400
00:13:54,949 –> 00:13:56,449
تلاش پیاده سازی را برای رفع مشکل
401
00:13:56,449 –> 00:13:58,429
انجام دهم. فکر میکنم اشتباه است، احتمالاً
402
00:13:58,429 –> 00:13:59,990
کار اشتباهی انجام میدهم، بهتر است
403
00:13:59,990 –> 00:14:01,819
از قبل آن را اندازهگیری کنم و
404
00:14:01,819 –> 00:14:03,410
سپس آن را به عنوان یک قضاوت مبتنی بر شواهد
405
00:14:03,410 –> 00:14:04,879
در مورد جایی که مشکل کند است که باید اصلاح کنم، انجام دهم،
406
00:14:04,879 –> 00:14:07,790
بنابراین اکنون میخواهیم آن را
407
00:14:07,790 –> 00:14:10,249
ادامه دهیم. راه حل حداقل مربع جبر خطی numpy،
408
00:14:10,249 –> 00:14:11,480
نه راه
409
00:14:11,480 –> 00:14:13,550
حل scikit-learn، زیرا این راه حل
410
00:14:13,550 –> 00:14:15,019
سریعتر است و ما به داده هایمان اعتماد داریم که داده های ما
411
00:14:15,019 –> 00:14:18,199
از نوع بطری سازهای همگن هستند، ما
412
00:14:18,199 –> 00:14:19,370
می دانیم که به نظر می رسد ما از آن بسیار
413
00:14:19,370 –> 00:14:21,379
راضی هستیم، فقط می خواهم شماره
414
00:14:21,379 –> 00:14:23,839
به سرعت و نتایج خود را دریافت کنم، اما
415
00:14:23,839 –> 00:14:25,339
من کاملاً مطمئن نیستم که از کدام راه حل پاندا
416
00:14:25,339 –> 00:14:26,660
استفاده کنم، بنابراین می خواهم
417
00:14:26,660 –> 00:14:27,679
مجموعه ای از آنها را بررسی کنم و اندازه گیری های زمانی را انجام دهم
418
00:14:27,679 –> 00:14:29,179
و سپس ببینم چه چیزی در انتها کاهش می یابد
419
00:14:29,179 –> 00:14:31,279
، بنابراین شروع می کنیم
420
00:14:31,279 –> 00:14:34,759
ساده ترین راه حل ممکن این است
421
00:14:34,759 –> 00:14:36,499
که اصطلاحی نیست Python این
422
00:14:36,499 –> 00:14:38,329
پاندای اصطلاحی نیست، بنابراین وقتی می گویم اصطلاحی
423
00:14:38,329 –> 00:14:40,189
منظورم روش استاندارد انجام آن نیست،
424
00:14:40,189 –> 00:14:42,019
ما همیشه با آن مواجه می شویم و اما این یک
425
00:14:42,019 –> 00:14:44,089
راه ساده برای انجام آن است، مطمئناً
426
00:14:44,089 –> 00:14:46,639
من اینگونه است استفاده از پانداها را هفت
427
00:14:46,639 –> 00:14:48,139
هشت سال پیش شروع کردم، زمانی که مدل ذهنی من برادرم در
428
00:14:48,139 –> 00:14:48,460
429
00:14:48,460 –> 00:14:50,620
مورد کارهایی که پانداها انجام میدهند شروع کردم،
430
00:14:50,620 –> 00:14:51,850
فقط یک خط را تکرار
431
00:14:51,850 –> 00:14:53,440
میکنم تا زمانی که کارم را شروع کنم و سپس
432
00:14:53,440 –> 00:14:55,030
راه بهتری برای انجام آن پیدا کنم. و
433
00:14:55,030 –> 00:14:56,280
اگر از زبان های دیگر وارد شده
434
00:14:56,280 –> 00:14:58,960
اید و با داشتن یک شمارنده و سپس عدم
435
00:14:58,960 –> 00:15:00,700
ارجاع به خط به خط، کار
436
00:15:00,700 –> 00:15:02,260
کاملا معقولی را انجام می دهید و
437
00:15:02,260 –> 00:15:04,780
در واقع من هنوز از این روش
438
00:15:04,780 –> 00:15:06,100
استفاده می کنم، اغلب از آن استفاده نمی کنم، اما زمانی که در حال رفع اشکال
439
00:15:06,100 –> 00:15:08,200
هستم کد دارای یک حلقه است که می توانم
440
00:15:08,200 –> 00:15:09,580
یک قطعه را بسازم نتیجه نهایی است و من می توانم
441
00:15:09,580 –> 00:15:11,620
نقاط شکست را در شرایط شرطی قرار دهم، فقط یک کار
442
00:15:11,620 –> 00:15:12,910
فوق العاده معقول برای انجام این کار، در واقع
443
00:15:12,910 –> 00:15:14,800
ما هنوز از این روش استفاده می کنیم، حتی اگر
444
00:15:14,800 –> 00:15:16,630
هر پست Stack Overflow به شما می گوید
445
00:15:16,630 –> 00:15:18,310
این کار را انجام ندهید که راه اشتباه
446
00:15:18,310 –> 00:15:20,590
انجام آن، روش کندتر است. این کار را انجام دهید،
447
00:15:20,590 –> 00:15:21,850
لزوماً روش اشتباهی برای انجام آن
448
00:15:21,850 –> 00:15:24,490
نیست، بنابراین ما محدوده را بالا آوردیم، بنابراین
449
00:15:24,490 –> 00:15:27,580
از 0 تا 99 999 بیش از
450
00:15:27,580 –> 00:15:30,400
صد هزار ردیف را تکرار می کنیم، یک شمارنده دریافت می کنیم
451
00:15:30,400 –> 00:15:32,380
و سپس وقتی
452
00:15:32,380 –> 00:15:34,540
می گوییم قاب داده داده می شود، وارد قاب داده می شویم. من این سطر
453
00:15:34,540 –> 00:15:35,920
را انجام دهیم تا
454
00:15:35,920 –> 00:15:37,930
شمارنده را انجام دهیم و وارد کادر داده می شویم
455
00:15:37,930 –> 00:15:39,670
و ردیفی را پیدا می کنیم که یک سری جدید می سازیم
456
00:15:39,670 –> 00:15:41,680
آن را بیرون می آوریم و سپس آن را به تابع خود منتقل می کنیم.
457
00:15:41,680 –> 00:15:42,700
458
00:15:42,700 –> 00:15:44,890
20 ثانیه طول می کشد
459
00:15:44,890 –> 00:15:46,900
و چون من حالت تدافعی دارم
460
00:15:46,900 –> 00:15:47,950
، در پایان می بینید که من در آنجا جستجو کردم
461
00:15:47,950 –> 00:15:49,870
تا مطمئن شوم که این
462
00:15:49,870 –> 00:15:51,400
نتیجه همان نتیجه ای است که
463
00:15:51,400 –> 00:15:53,260
قبلاً محاسبه کردم، من همیشه در این مورد بسیار تدافعی هستم
464
00:15:53,260 –> 00:15:54,730
و معمولاً دفاعی نیز هستم.
465
00:15:54,730 –> 00:15:57,730
بنابراین 20 ثانیه اما منطقی است این
466
00:15:57,730 –> 00:16:01,420
بزرگ نمیشود، بنابراین ما
467
00:16:01,420 –> 00:16:03,700
به پانداها نگاه میکنیم که چه کسی از
468
00:16:03,700 –> 00:16:06,760
آن استفاده کرده است، بله، بنابراین این یکی دیگر
469
00:16:06,760 –> 00:16:08,740
از روشهای رایج برای انجام آن است.
470
00:16:08,740 –> 00:16:10,420
من شخصاً تمایلی به استفاده از آن
471
00:16:10,420 –> 00:16:11,980
ندارم. نگاه کنید اگر قرار است
472
00:16:11,980 –> 00:16:14,830
یک خط را در یک زمان تکرار کنم، به ما یک تکرار کننده می دهد که
473
00:16:14,830 –> 00:16:17,320
اکنون به پایتون و پانداهای اصطلاحی اصطلاحی تبدیل می شود،
474
00:16:17,320 –> 00:16:19,990
نه فوق العاده
475
00:16:19,990 –> 00:16:22,060
کارآمد اما اصطلاحی، بنابراین راهی است
476
00:16:22,060 –> 00:16:23,230
که بقیه تیم شما
477
00:16:23,230 –> 00:16:25,660
متوجه می شوند که ما فقط روی یک لیست تکرار می کنیم.
478
00:16:25,660 –> 00:16:27,580
ما روی یک مجموعه تکرار می کنیم، روی
479
00:16:27,580 –> 00:16:30,010
هر یک از اشیای تکرارپذیر در پایتون
480
00:16:30,010 –> 00:16:31,330
تکرار می کنیم، بنابراین می توانیم روی ردیف ها و
481
00:16:31,330 –> 00:16:33,820
قاب داده پاندا را تکرار کنیم، این بدان معنی است که
482
00:16:33,820 –> 00:16:35,620
ما شاخصی تولید نمی کنیم
483
00:16:35,620 –> 00:16:37,240
که سپس به قاب داده ارسال می کنیم که
484
00:16:37,240 –> 00:16:38,770
باید کمی محاسبات انجام دهید به جای
485
00:16:38,770 –> 00:16:40,810
آن فقط شروع میشود که ردیفهای بازده
486
00:16:40,810 –> 00:16:42,790
یکی یکی کارآمدتر است، بنابراین به
487
00:16:42,790 –> 00:16:44,560
جای 20 ثانیه، همان نتیجه
488
00:16:44,560 –> 00:16:46,030
را در 12 ثانیه میگیریم، تقریباً دو
489
00:16:46,030 –> 00:16:48,250
برابر سریعتر است، بسیار جالب است،
490
00:16:48,250 –> 00:16:50,680
اصلاً به سرعت ما نیست. می تواند برود و خوب است
491
00:16:50,680 –> 00:16:54,820
و نوشتن آسان است واقعاً حدس میزنم اگر
492
00:16:54,820 –> 00:16:56,170
بگویم چه کسی درخواست میکند، همه ما دستهایمان را بالا میگیریم،
493
00:16:56,170 –> 00:16:57,310
زیرا درخواست
494
00:16:57,310 –> 00:16:59,650
بسیار استاندارد است
495
00:16:59,650 –> 00:17:01,300
496
00:17:01,300 –> 00:17:02,560
. جیمی را که قبلاً در سفر پانداهای شما بوده است،
497
00:17:02,560 –> 00:17:04,630
نگاه کنید به استفاده از این
498
00:17:04,630 –> 00:17:06,040
روش استاندارد انجام آن در کد
499
00:17:06,040 –> 00:17:07,690
شما بسیار سریعتر اجرا میشود، در نتیجه
500
00:17:07,690 –> 00:17:09,520
من به هفت ثانیه کاهش میدهم، ما
501
00:17:09,520 –> 00:17:10,720
502
00:17:10,720 –> 00:17:12,760
فقط برای سه بار افزایش سرعت داریم. استفاده از روش صحیح
503
00:17:12,760 –> 00:17:14,680
اعمال تابع در بسیاری از ردیفهای داده و
504
00:17:14,680 –> 00:17:17,050
این کاملاً اصطلاحی است، نه
505
00:17:17,050 –> 00:17:20,410
پانداهای اصطلاحی پایتون،
506
00:17:20,410 –> 00:17:21,940
بنابراین بسیار معقول است و
507
00:17:21,940 –> 00:17:23,949
نکته خوب این است که سه خط کد است که
508
00:17:23,949 –> 00:17:25,359
همکاران شما آن را درک میکنند و هیچ
509
00:17:25,359 –> 00:17:27,940
سردرگمی وجود ندارد. فقط کار کنید، میتوانید
510
00:17:27,940 –> 00:17:30,000
اعتماد کنید که این چیز کاملاً کار میکند،
511
00:17:30,000 –> 00:17:33,250
بنابراین ما از اعمال آن استفاده میکنیم که به اندازه کافی سریع کار میکند،
512
00:17:33,250 –> 00:17:35,680
اما او هنوز هم بزرگتر نمیشود.
513
00:17:35,680 –> 00:17:40,360
514
00:17:40,360 –> 00:17:48,730
515
00:17:48,730 –> 00:17:51,940
با
516
00:17:51,940 –> 00:17:55,000
پاندا اعمال می شود ما در یک
517
00:17:55,000 –> 00:17:57,520
سری، یک ردیف از داده ها را به عنوان یک شی سری
518
00:17:57,520 –> 00:17:59,470
به تابع زیرین خود منتقل می کنیم که تابع
519
00:17:59,470 –> 00:18:01,330
زیربنایی آن توابع حداقل مربعی
520
00:18:01,330 –> 00:18:03,820
سری به نام ردیف را می گیرند و
521
00:18:03,820 –> 00:18:05,440
Road یا مقادیری را می گیرند که مقادیر جاده را به سمت بالا می
522
00:18:05,440 –> 00:18:07,450
کشند تا آرایه numpy زیرین را بدست آورند.
523
00:18:07,450 –> 00:18:10,630
وقتی رورر را برابر true صدا می زنیم
524
00:18:10,630 –> 00:18:12,610
، یک شی سری در بالا نمی سازیم، بنابراین
525
00:18:12,610 –> 00:18:13,540
از تمام ماشین های اضافی سربار اجتناب می کنیم،
526
00:18:13,540 –> 00:18:15,880
اما آن شی سری
527
00:18:15,880 –> 00:18:17,230
528
00:18:17,230 –> 00:18:19,090
را می سازیم، زیرا تابعی که هدف است به آن نیاز ندارد، ما
529
00:18:19,090 –> 00:18:20,800
هیچ عملیات سری زمانی را در آنجا انجام نمی دهیم. ما
530
00:18:20,800 –> 00:18:23,980
از هیچ گونه دستکاری فانتزی پانداها
531
00:18:23,980 –> 00:18:25,870
در بالا استفاده نمی کنیم، من فقط می خواهم که زیربنایی به
532
00:18:25,870 –> 00:18:27,520
سمت راست باشد، بنابراین روهرر اعمال شده برابر با
533
00:18:27,520 –> 00:18:29,380
تجزیه واقعی در آرایه numpy زیرین است و
534
00:18:29,380 –> 00:18:31,960
از شر تمام ایجاد اشیاء موقت خلاص می شود،
535
00:18:31,960 –> 00:18:33,940
بنابراین سریعتر اجرا می شود،
536
00:18:33,940 –> 00:18:36,280
بنابراین بسیار زیبا و بسیار ساده است.
537
00:18:36,280 –> 00:18:38,260
اگر فقط روی
538
00:18:38,260 –> 00:18:40,360
آرایه numpy زیرین محاسبه میکنید و این
539
00:18:40,360 –> 00:18:41,920
کار را برای تعداد زیادی ردیف انجام میدهید، نمای خانه وجود
540
00:18:41,920 –> 00:18:44,860
541
00:18:44,860 –> 00:18:47,290
دارد. او نسخه را اعمال می کند
542
00:18:47,290 –> 00:18:49,210
و بارها اول از آنها
543
00:18:49,210 –> 00:18:51,940
روش ساده ای را برای انجام آن اعمال می کند و این
544
00:18:51,940 –> 00:18:53,770
امکان جالب دیگری را
545
00:18:53,770 –> 00:18:55,990
با کامپایل باز می کند که در مدت کوتاهی به آنها خواهیم رسید ،
546
00:18:55,990 –> 00:19:02,230
جایی که فلش های نشان دهنده
547
00:19:02,230 –> 00:19:03,670
جایی که من خطی نسبتاً
548
00:19:03,670 –> 00:19:05,290
مربع نامیده ام را نشان می دهد. دارای ردیفی هستیم که دیگر از
549
00:19:05,290 –> 00:19:07,270
مقادیر ردیفی استفاده نمی کنیم، این یک سری
550
00:19:07,270 –> 00:19:08,350
نیست، بلکه فقط مسیر
551
00:19:08,350 –> 00:19:11,320
درستی است
552
00:19:11,320 –> 00:19:17,000
که قبل از
553
00:19:17,000 –> 00:19:18,860
سه نفر از شما با یک Swifter مواجه شده است، پس یکی از
554
00:19:18,860 –> 00:19:22,280
ناراحتی های هنگام کار با پانداها این است
555
00:19:22,280 –> 00:19:27,590
که همیشه چند کار نمی کند. -هسته ای
556
00:19:27,590 –> 00:19:29,000
اغلب چند هسته ای نیست برخی
557
00:19:29,000 –> 00:19:30,470
از پیاده سازی های داخلی در حال
558
00:19:30,470 –> 00:19:31,880
بهبود هستند و ما باید به چند هسته ای برویم،
559
00:19:31,880 –> 00:19:33,680
اما در لپ تاپ من در اینجا من چهار
560
00:19:33,680 –> 00:19:35,900
هسته فیزیکی و چهار رشته هایپر
561
00:19:35,900 –> 00:19:38,780
دارم، بنابراین در کل هشت هسته دارم. اما من میخواهم از
562
00:19:38,780 –> 00:19:41,240
آنها برای تماسها استفاده کنم اغلب به این دلیل استفاده نمیشود،
563
00:19:41,240 –> 00:19:43,940
من فقط از یک هسته استفاده
564
00:19:43,940 –> 00:19:44,960
میکنم، بنابراین در آنجا نشستهام و به خوبی فکر میکنم
565
00:19:44,960 –> 00:19:46,520
که با ۲۵ درصد سرعتی که
566
00:19:46,520 –> 00:19:47,570
میتوانم آن را اجرا کنم و باید
567
00:19:47,570 –> 00:19:49,550
یک ساعت صبر کنم که واقعا خسته کننده است ای کاش
568
00:19:49,550 –> 00:19:52,070
این چیز سریعتر پیش می رفت، بنابراین ما
569
00:19:52,070 –> 00:19:55,100
این کتابخانه را داریم Swifter می گوید فکر می
570
00:19:55,100 –> 00:19:57,290
کنم الان دو ساله است، این یک
571
00:19:57,290 –> 00:19:58,970
پروژه واقعاً جوان است، پروژه واقعاً خوبی است
572
00:19:58,970 –> 00:20:00,470
573
00:20:00,470 –> 00:20:02,240
که اگر کنجکاو هستید، در این زمینه مشارکت
574
00:20:02,240 –> 00:20:04,280
داشته باشید. نویسندگان مشتاق دریافت
575
00:20:04,280 –> 00:20:06,050
مشارکت هستند، می توانید بروید و به
576
00:20:06,050 –> 00:20:08,480
این نگاه کنید و در بالای ماژول میز قرار
577
00:20:08,480 –> 00:20:10,600
می گیرد که در یک لحظه معرفی می شود
578
00:20:10,600 –> 00:20:13,520
و سپس به کد شما اجازه می دهد
579
00:20:13,520 –> 00:20:17,570
چند هسته ای اجرا شود و این کار را بسیار
580
00:20:17,570 –> 00:20:19,970
هوشمندانه انجام می دهد اما با هوشمندی وجود دارد که
581
00:20:19,970 –> 00:20:22,400
برخی از اکتشافات همیشه کار نمی کند. کاری
582