در این مطلب، ویدئو رگرسیون لجستیک در پایتون – یادگیری ماشینی از ابتدا 03 – آموزش پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:09
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,129
سلام به همه و به یک
2
00:00:02,129 –> 00:00:04,049
آموزش یادگیری ماشینی جدید از ابتدا خوش آمدید،
3
00:00:04,049 –> 00:00:06,450
امروز می خواهیم رگرسیون لجستیک را
4
00:00:06,450 –> 00:00:08,519
با استفاده از
5
00:00:08,519 –> 00:00:11,190
ماژول های داخلی پایتون و numpy پیاده سازی کنیم، اگر
6
00:00:11,190 –> 00:00:12,870
ویدیوی قبلی من در مورد
7
00:00:12,870 –> 00:00:15,179
رگرسیون خطی را ندیده اید، به شدت توصیه می
8
00:00:15,179 –> 00:00:17,640
کنم ابتدا آن را تماشا کنید. من برخی
9
00:00:17,640 –> 00:00:19,439
از مفاهیم را کمی با جزئیات بیشتر در
10
00:00:19,439 –> 00:00:22,140
آنجا توضیح دادم اما سعی می کنم
11
00:00:22,140 –> 00:00:23,910
دوباره تمام مفاهیم مهم را در این ویدیو پوشش
12
00:00:23,910 –> 00:00:26,400
دهم، بنابراین بیایید در مورد مفاهیم
13
00:00:26,400 –> 00:00:30,630
رگرسیون لجستیک صحبت کنیم تا همانطور که به یاد دارید
14
00:00:30,630 –> 00:00:33,960
در رگرسیون خطی داده های خود را با یک خطی مدل سازی کنیم.
15
00:00:33,960 –> 00:00:39,500
تابع W ضربدر X بعلاوه B
16
00:00:39,500 –> 00:00:43,200
بنابراین مقادیر پیوسته را خروجی می دهد
17
00:00:43,200 –> 00:00:47,010
و اکنون در رگرسیون لجستیک
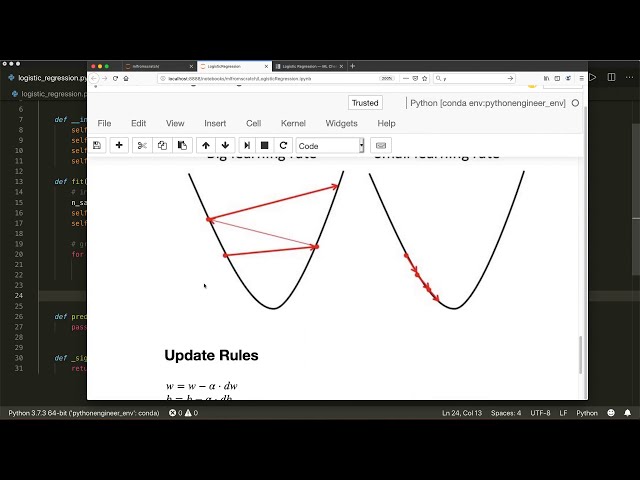
18
00:00:47,010 –> 00:00:50,070
مقادیر پیوسته نمی خواهیم بلکه یک احتمال می خواهیم
19
00:00:50,070 –> 00:00:53,969
و برای مدل سازی این
20
00:00:53,969 –> 00:00:56,520
احتمال تابع سیگموید
21
00:00:56,520 –> 00:01:00,570
را به مدل خطی خود اعمال می کنیم بنابراین
22
00:01:00,570 –> 00:01:05,400
تابع سیگموئید 1 روی 1 به اضافه
23
00:01:05,400 –> 00:01:10,740
تابع نمایی منهای X بنابراین
24
00:01:10,740 –> 00:01:14,340
این تابع سیگموئید است و من و X
25
00:01:14,340 –> 00:01:20,869
در مورد ما مدل خطی ما است
26
00:01:20,869 –> 00:01:24,420
بنابراین و این همان است یک
27
00:01:24,420 –> 00:01:28,380
احتمال بین 0 و 1 را خروجی می دهد، بنابراین اگر
28
00:01:28,380 –> 00:01:32,909
تابع سیگموید را رسم کنیم، می
29
00:01:32,909 –> 00:01:37,320
بینید که بین 0 و 1 است، بنابراین با این
30
00:01:37,320 –> 00:01:40,259
تابع می توانیم یک احتمال
31
00:01:40,259 –> 00:01:46,700
از داده های خود را مدل کنیم و اکنون با این
32
00:01:46,700 –> 00:01:51,390
خروجی تقریبی و می توانیم پس از آن باید
33
00:01:51,390 –> 00:01:55,290
پارامترهای W را ایجاد کنید، بنابراین وزن
34
00:01:55,290 –> 00:01:59,729
ما و بایاس ما و چگونه این کار را انجام دهیم،
35
00:01:59,729 –> 00:02:02,340
بنابراین من قبلاً در ویدیوی قبلی توضیح دادم،
36
00:02:02,340 –> 00:02:06,420
بنابراین روشی را اعمال می کنیم که
37
00:02:06,420 –> 00:02:10,288
به آن گرادیان نزول می گویند، بنابراین اول از
38
00:02:10,288 –> 00:02:13,980
همه به یک تابع هزینه نیاز داریم و او
39
00:02:13,980 –> 00:02:16,440
ما میانگین مربعات خطا را نداریم و
40
00:02:16,440 –> 00:02:19,500
دیگر اما از تابعی استفاده می کنیم که
41
00:02:19,500 –> 00:02:23,099
آنتروپی متقاطع نامیده می شود، بنابراین این
42
00:02:23,099 –> 00:02:26,700
فرمول است، من به جزئیات در مورد
43
00:02:26,700 –> 00:02:29,040
این موضوع نمی پردازم، اما برخی از خواندن های بیشتر را در توضیحات قرار می دهم،
44
00:02:29,040 –> 00:02:32,730
بنابراین با این
45
00:02:32,730 –> 00:02:37,349
فرمول آنچه را که ما انجام می دهیم آیا می خواهیم
46
00:02:37,349 –> 00:02:40,709
این را با توجه به پارامترهای W
47
00:02:40,709 –> 00:02:45,060
و B خود بهینه کنیم، بنابراین از گرادیان نزول استفاده می کنیم و
48
00:02:45,060 –> 00:02:49,470
این بدان معناست که از نقطه ای شروع می کنیم و
49
00:02:49,470 –> 00:02:53,239
سپس به طور مکرر پارامترهای خود را به روز می کنیم،
50
00:02:53,239 –> 00:02:56,310
بنابراین باید مشتق را محاسبه کنیم
51
00:02:56,310 –> 00:03:01,140
و سپس به مسیر برویم. از این
52
00:03:01,140 –> 00:03:03,930
مشتق تا زمانی که در نهایت به
53
00:03:03,930 –> 00:03:08,790
حداقل برسیم و سپس باید
54
00:03:08,790 –> 00:03:11,849
یک لبه به نام نرخ یادگیری تعریف کنیم، بنابراین
55
00:03:11,849 –> 00:03:15,209
نرخ یادگیری تعیین میکند
56
00:03:15,209 –> 00:03:18,389
که در هر مرحله چقدر به این سمت برویم، بنابراین
57
00:03:18,389 –> 00:03:21,030
این یک پارامتر مهم است که
58
00:03:21,030 –> 00:03:23,340
نباید زیاد باشد. از آن زمان
59
00:03:23,340 –> 00:03:25,530
ممکن است بالا بپرد و هرگز حداقل را پیدا
60
00:03:25,530 –> 00:03:29,630
نکند، اما همچنین نباید خیلی کم باشد
61
00:03:29,630 –> 00:03:31,799
متأسفیم
62
00:03:31,799 –> 00:03:36,510
و اکنون با این نزول شیب چیزی
63
00:03:36,510 –> 00:03:39,840
که داریم این است که قوانین به روز رسانی خود را داریم، بنابراین
64
00:03:39,840 –> 00:03:44,069
وزن ما وزن جدید ما
65
00:03:44,069 –> 00:03:47,459
وزن قبلی است – چون میخواهیم به
66
00:03:47,459 –> 00:03:51,060
سمت منفی برویم – نرخ یادگیری ما
67
00:03:51,060 –> 00:03:54,870
ضربدر مشتق است و
68
00:03:54,870 –> 00:03:59,549
برای بایاس ما یکسان است و سپس
69
00:03:59,549 –> 00:04:03,950
فرمولهایی وجود دارد که برای مشتقات خود نیاز داریم،
70
00:04:03,950 –> 00:04:06,569
بنابراین این فرمولها
71
00:04:06,569 –> 00:04:09,739
هستند و در واقع همان
72
00:04:09,739 –> 00:04:15,329
مشتقات خطی هستند. رگرسیون، بنابراین
73
00:04:15,329 –> 00:04:17,519
شما می توانید ریاضیات پشت آن
74
00:04:17,519 –> 00:04:20,010
را خودتان بررسی کنید، من همچنین چند لینک در توضیحات قرار خواهم داد
75
00:04:20,010 –> 00:04:22,830
و این تنها چیزی است که اکنون برای شروع نیاز داریم و
76
00:04:22,830 –> 00:04:25,210
77
00:04:25,210 –> 00:04:27,910
اکنون می توانیم رگرسیون لجستیک خود را پیاده سازی کنیم،
78
00:04:27,910 –> 00:04:31,300
بنابراین البته از numpy استفاده می کنیم.
79
00:04:31,300 –> 00:04:37,300
دوباره اجازه دهید numpy SNP را وارد کنیم و سپس
80
00:04:37,300 –> 00:04:40,470
کلاسی به نام رگرسیون لجستیک ایجاد می کنیم
81
00:04:40,470 –> 00:04:44,770
و این یک متد init خواهد داشت،
82
00:04:44,770 –> 00:04:49,599
بنابراین ما یک init داریم و در آن
83
00:04:49,599 –> 00:04:52,360
دقیقاً مشابه رگرسیون خطی است،
84
00:04:52,360 –> 00:04:55,090
بنابراین من مقداری نرخ یادگیری را
85
00:04:55,090 –> 00:04:57,520
در اینجا قرار می دهم که این کار را انجام می دهد. مقدار پیشفرض
86
00:04:57,520 –> 00:05:02,500
0.001 را دریافت کنید معمولاً نرخ یادگیری
87
00:05:02,500 –> 00:05:06,009
بسیار کوچک است و همچنین
88
00:05:06,009 –> 00:05:10,570
تعدادی تکرار و ITER و با
89
00:05:10,570 –> 00:05:15,639
پیشفرض 1000 دریافت میکند، بنابراین مشخص میکند
90
00:05:15,639 –> 00:05:17,860
که از چه تعداد تکرار برای
91
00:05:17,860 –> 00:05:21,370
نزول گرادیان استفاده میکنیم و سپس آنها را ذخیره میکنم.
92
00:05:21,370 –> 00:05:25,210
من می گویم خود L R برابر است با L R
93
00:05:25,210 –> 00:05:31,360
و خود و ITER برابر است و ITER است
94
00:05:31,360 –> 00:05:35,400
و سپس به سادگی چند
95
00:05:35,400 –> 00:05:40,360
وزن ایجاد می کنم اما در ابتدا آنها را روی هیچ تنظیم می کنم بنابراین
96
00:05:40,360 –> 00:05:43,539
وزن های ما هیچ هستند و تعصب ما
97
00:05:43,539 –> 00:05:46,570
هیچ هستند به سادگی که می دانیم اکنون
98
00:05:46,570 –> 00:05:49,840
باید بالا بیاییم. با آنها و سپس ما
99
00:05:49,840 –> 00:05:54,219
یک روش مناسب تعریف می کنیم، بنابراین در اینجا دوباره از
100
00:05:54,219 –> 00:05:57,370
قراردادهای کتابخانه scikit-learn پیروی
101
00:05:57,370 –> 00:06:00,630
می کنیم، بنابراین چند
102
00:06:00,630 –> 00:06:04,560
نمونه آموزشی و مقادیر برچسب های آموزشی را می گیرد
103
00:06:04,560 –> 00:06:09,699
، بنابراین این شامل مرحله آموزش
104
00:06:09,699 –> 00:06:12,880
و g می شود. فرود تشعشعی و سپس
105
00:06:12,880 –> 00:06:18,190
یک روش پیش بینی داریم و در اینجا
106
00:06:18,190 –> 00:06:21,490
نمونه های آزمایشی جدیدی را دریافت می کنیم که می خواهیم پیش بینی کنیم،
107
00:06:21,490 –> 00:06:24,190
بنابراین اینها روش هایی هستند که می خواهیم
108
00:06:24,190 –> 00:06:29,889
پیاده سازی کنیم و ورودی های ما در اینجا هستند بنابراین
109
00:06:29,889 –> 00:06:35,440
X یک عدد I و D بردار با اندازه M
110
00:06:35,440 –> 00:06:38,540
ضربدر n است که در آن
111
00:06:38,540 –> 00:06:41,570
m تعداد نمونه ها و n
112
00:06:41,570 –> 00:06:45,490
تعداد ویژگی های نمونه آن است و
113
00:06:45,490 –> 00:06:51,950
چرا یک بردار ردیف 1d یا به
114
00:06:51,950 –> 00:06:55,370
اندازه M است بنابراین برای هر نمونه آموزشی
115
00:06:55,370 –> 00:07:00,740
یک بردار داریم پس اکنون می توانیم ادامه دهیم پس
116
00:07:00,740 –> 00:07:04,430
اول از همه باید داشته باشیم برای شروع
117
00:07:04,430 –> 00:07:08,420
وزنهای خود را مقداردهی اولیه کنیم، بنابراین فرض کنید میخواهیم
118
00:07:08,420 –> 00:07:12,170
پارامترها را در آن وارد کنیم و برای این
119
00:07:12,170 –> 00:07:18,050
کار تعداد نمونهها و تعداد
120
00:07:18,050 –> 00:07:26,660
ویژگیها را به دست میآوریم، بنابراین این شکل X است، بنابراین
121
00:07:26,660 –> 00:07:29,720
شکل بعد اول
122
00:07:29,720 –> 00:07:31,970
را به تعداد نمونهها و
123
00:07:31,970 –> 00:07:33,650
بعد دوم به تعداد
124
00:07:33,650 –> 00:07:40,060
ویژگیها میپردازیم و سپس وزنهایمان را
125
00:07:40,060 –> 00:07:44,990
فقط با 0 شروع میکنیم، بنابراین یک بردار فقط
126
00:07:44,990 –> 00:07:49,400
با صفر اندازه تعداد ویژگیها
127
00:07:49,400 –> 00:07:54,920
ایجاد میکنیم و بایاس خود را در ابتدا روی 0 قرار میدهیم،
128
00:07:54,920 –> 00:07:58,310
همچنین میتوانید برای مثال از اعداد تصادفی
129
00:07:58,310 –> 00:08:00,950
برای مقداردهی اولیه استفاده