در این مطلب، ویدئو Python Neural Networks – Tensorflow 2.0 Tutorial – Text Classification P1 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:38
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,250
سلام بچه ها و به یک
2
00:00:02,250 –> 00:00:04,589
آموزش شبکه عصبی دیگر خوش آمدید اکنون در ویدیوی امروز در
3
00:00:04,589 –> 00:00:05,700
4
00:00:05,700 –> 00:00:08,700
مورد طبقه بندی متن با tensorflow 2.0 صحبت می کنیم و
5
00:00:08,700 –> 00:00:11,040
اکنون کاری که من می خواهم
6
00:00:11,040 –> 00:00:12,719
انجام دهم تا کاملاً شفاف باشد
7
00:00:12,719 –> 00:00:14,340
با شما بچه ها اینجا در ادامه مطلب را دنبال می کنیم.
8
00:00:14,340 –> 00:00:16,440
با آموزش های رسمی واقعی در مورد
9
00:00:16,440 –> 00:00:19,529
آموزش tensorflow 2.0 اکنون متوجه شدم
10
00:00:19,529 –> 00:00:21,359
که اینها در واقع بهترین
11
00:00:21,359 –> 00:00:23,100
ها از نظر ساختاری مشابه برای
12
00:00:23,100 –> 00:00:25,529
شروع برای درک
13
00:00:25,529 –> 00:00:27,449
شبکه های عصبی بسیار ابتدایی برای برخی از
14
00:00:27,449 –> 00:00:29,310
وظایف بسیار ساده هستند و سپس ما می خواهیم شروع کنیم.
15
00:00:29,310 –> 00:00:30,570
از آنهایی دور شوید که ما شروع به
16
00:00:30,570 –> 00:00:32,159
استفاده از داده های خود خواهیم کرد شبکه های
17
00:00:32,159 –> 00:00:34,200
خودمان معماری خودمان و شروع به صحبت
18
00:00:34,200 –> 00:00:35,610
در مورد برخی از مسائلی خواهیم کرد
19
00:00:35,610 –> 00:00:37,020
که وقتی واقعاً شروع به استفاده از
20
00:00:37,020 –> 00:00:39,899
آنها در داده های واقعی کردید تا
21
00:00:39,899 –> 00:00:41,520
کنون متوجه شده اید. و من قبلاً نظراتی
22
00:00:41,520 –> 00:00:43,829
را در مورد اینکه بارگیری دادهها بسیار آسان
23
00:00:43,829 –> 00:00:46,289
است و حتی پیشپردازش آنها را دیدهام،
24
00:00:46,289 –> 00:00:47,879
مانند مورد قبلی که
25
00:00:47,879 –> 00:00:50,219
همه چیز را بر 255 تقسیم کردیم، در دنیای واقعی واقعاً ساده شدم.
26
00:00:50,219 –> 00:00:51,960
27
00:00:51,960 –> 00:00:53,820
مطمئناً اطلاعات شما آنقدرها خوب نیست و چیزهای زیادی وجود دارد
28
00:00:53,820 –> 00:00:55,260
که باید با آنها بازی کنید
29
00:00:55,260 –> 00:00:57,989
و آنها را تغییر دهید تا واقعاً قابل استفاده باشند، بنابراین به
30
00:00:57,989 –> 00:00:59,760
هر حال ما این مورد را برای
31
00:00:59,760 –> 00:01:01,469
امروز دنبال می کنیم و اساساً روشی که
32
00:01:01,469 –> 00:01:03,690
کار می کند این است که خواهیم داشت. نقدهای فیلم
33
00:01:03,690 –> 00:01:05,188
و ما فقط آنها را طبقه بندی می کنیم که از
34
00:01:05,188 –> 00:01:07,830
آنها به عنوان مثبت یا منفی استفاده می کنند، اکنون
35
00:01:07,830 –> 00:01:10,049
کاری که ما انجام می دهیم این است که فقط به برخی
36
00:01:10,049 –> 00:01:12,119
از نقدهای فیلم نگاه می کنیم و سپس در
37
00:01:12,119 –> 00:01:13,229
مورد داده هایی که در مورد آن صحبت خواهیم کرد صحبت خواهیم کرد.
38
00:01:13,229 –> 00:01:15,299
معماری که از چیزهایی برای پیشبینی برخی
39
00:01:15,299 –> 00:01:17,100
مسائل استفاده میکند ممکن است رخ دهد و همه آنها
40
00:01:17,100 –> 00:01:19,200
اکنون نمیدانم چند قسمت ویدیو
41
00:01:19,200 –> 00:01:20,670
خواهد بود، سعی میکنم
42
00:01:20,670 –> 00:01:21,900
همه آن را یکباره ضبط کنم و فقط آن را
43
00:01:21,900 –> 00:01:23,909
بر اساس مدت زمانی که طول میکشد تقسیم کنم اما با توجه
44
00:01:23,909 –> 00:01:25,740
به صحبتهای کافی، اجازه دهید
45
00:01:25,740 –> 00:01:27,990
شروع کنیم، بنابراین آنچه که میخواهیم انجام دهیم این است
46
00:01:27,990 –> 00:01:31,020
که در فایل خود از اینجا شروع کنیم و دوباره
47
00:01:31,020 –> 00:01:32,130
این کار واقعاً خوب خواهد بود زیرا ما
48
00:01:32,130 –> 00:01:34,350
فقط میتوانیم نوعی از دادهها را از کارا بدزدیم،
49
00:01:34,350 –> 00:01:35,640
بنابراین از چه چیزی شروع میکنیم. انجام دادن فقط
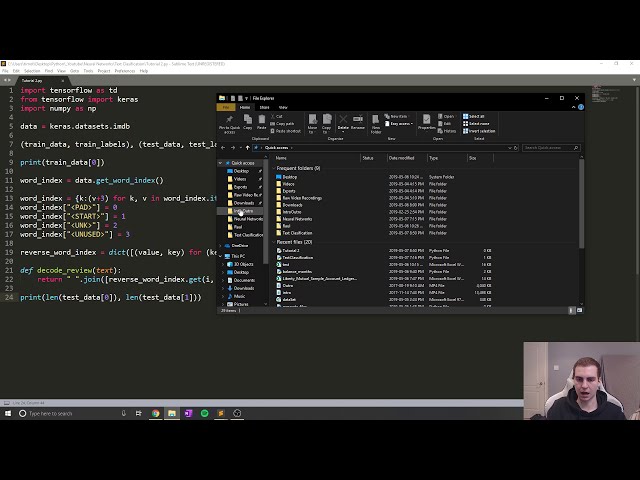
50
00:01:35,640 –> 00:01:40,020
وارد کردن tensorflow به عنوان TF است که میخواهیم
51
00:01:40,020 –> 00:01:42,140
بگوییم از tensorfl ow
52
00:01:42,140 –> 00:01:45,329
Chara را وارد کنید و سپس ما میخواهیم
53
00:01:45,329 –> 00:01:49,500
بگوییم که وارد کردن numpy به عنوان NP اکنون قبل از
54
00:01:49,500 –> 00:01:52,259
شروع من با یک مشکل سریع روبرو شدم وقتی که
55
00:01:52,259 –> 00:01:53,790
در واقع سعی میکردم این کار را انجام دهم
56
00:01:53,790 –> 00:01:54,810
فقط همراه با
57
00:01:54,810 –> 00:01:57,180
آموزش رسمی و این بود که دادههایی که
58
00:01:57,180 –> 00:01:59,280
میخواهم انجام دهم. grab here در واقع
59
00:01:59,280 –> 00:02:00,990
با نسخه فعلی کار نمی کند.
60
00:02:00,990 –> 00:02:02,100
61
00:02:02,100 –> 00:02:04,799
62
00:02:04,799 –> 00:02:06,630
63
00:02:06,630 –> 00:02:08,848
64
00:02:08,848 –> 00:02:11,670
65
00:02:11,670 –> 00:02:13,600
فقط میخواهم بگویم pip،
66
00:02:13,600 –> 00:02:15,880
فکر میکنم نسخه pip numpy یا
67
00:02:15,880 –> 00:02:17,740
چیزی شبیه به آن را دوست دارم، زیرا میخواهم ببینم چه
68
00:02:17,740 –> 00:02:20,410
نسخهای درست
69
00:02:20,410 –> 00:02:22,270
نیست، مثلاً شماره نسخه pip را میخواهم
70
00:02:22,270 –> 00:02:23,890
پیدا کنم که چه نسخهای است و سپس فقط
71
00:02:23,890 –> 00:02:26,830
به آن نسخه بروم، اوکی پس من
72
00:02:26,830 –> 00:02:28,450
نسخه numpy را پیدا کردم، کاری که اکنون میخواهیم انجام دهیم این
73
00:02:28,450 –> 00:02:30,670
است که فقط نسخه صحیح
74
00:02:30,670 –> 00:02:32,500
a numpy را نصب کنید تا برای این آموزش کار کند،
75
00:02:32,500 –> 00:02:34,330
اکنون این برای
76
00:02:34,330 –> 00:02:35,680
همه چیز در آینده خوب است و اگر میخواهید
77
00:02:35,680 –> 00:02:37,090
جدیدترین نسخه
78
00:02:37,090 –> 00:02:39,640
numpy را نصب کنید. بعد از انجام این کار راحت نیست، اما
79
00:02:39,640 –> 00:02:40,780
برای انجام این کار تنها کاری که می خواهم انجام دهم این است که بگویم
80
00:02:40,780 –> 00:02:43,870
نصب pip و سپس numpy در این مورد برابر است با
81
00:02:43,870 –> 00:02:46,540
یک امتیاز یک شش نقطه یک، من
82
00:02:46,540 –> 00:02:47,680
معتقدم نسخه ای که در حال حاضر استفاده می کنیم
83
00:02:47,680 –> 00:02:49,690
حداقل در آن زمان 0.3 است. از
84
00:02:49,690 –> 00:02:51,100
ضبط این، اما فقط آن را به
85
00:02:51,100 –> 00:02:52,930
این نسخه تغییر دهید و امیدوارم در آینده
86
00:02:52,930 –> 00:02:54,160
آنها این مشکلات را برطرف کنند تا مجبور نباشیم این کار
87
00:02:54,160 –> 00:02:56,110
را انجام دهیم، اما به هر
88
00:02:56,110 –> 00:02:58,330
حال من نصب می کنم که بله، شما باید
89
00:02:58,330 –> 00:03:00,430
دو برابر اضافه کنید. signs و من قبلاً
90
00:03:00,430 –> 00:03:02,230
این را نصب کردهام، بنابراین نباید
91
00:03:02,230 –> 00:03:04,270
کاری انجام دهم، اما شما بچهها فقط مطمئن
92
00:03:04,270 –> 00:03:05,530
شوید که انجام میدهید که من دستور را
93
00:03:05,530 –> 00:03:07,630
در توضیحات میگذارم بعد از انجام این کار، کاری که
94
00:03:07,630 –> 00:03:10,360
میخواهم انجام دهم این است که دادهها را بارگذاری کنم، برو
95
00:03:10,360 –> 00:03:13,840
بگو دادهها برابر است در این مورد مجموعه دادههای کارا
96
00:03:13,840 –> 00:03:18,730
نقطه من هستم آنچه هست من DB هستم اکنون فکر میکنم
97
00:03:18,730 –> 00:03:20,230
این مخفف
98
00:03:20,230 –> 00:03:22,300
یک پایگاهداده فیلم است که من واقعاً
99
00:03:22,300 –> 00:03:23,980
نمیدانم، اما به هر حال
100
00:03:23,980 –> 00:03:25,240
پایگاه داده همین است و ما همان کار را انجام خواهیم داد.
101
00:03:25,240 –> 00:03:26,590
ما در آموزش قبلی انجام دادیم
102
00:03:26,590 –> 00:03:28,330
که فقط این را به داده های آموزش
103
00:03:28,330 –> 00:03:29,710
و آزمایش تقسیم می کنیم برای انجام این کار،
104
00:03:29,710 –> 00:03:31,930
میگویم قطار زیرخط،
105
00:03:31,930 –> 00:03:34,210
برچسبهای زیرخط را کاما میگویم و سپس در این
106
00:03:34,210 –> 00:03:36,070
مورد میگوییم زیرخط را در دادهها تست کنید
107
00:03:36,070 –> 00:03:39,610
و سپس برچسبهای زیرخط را آزمایش
108
00:03:39,610 –> 00:03:41,950
109
00:03:41,950 –> 00:03:43,840
میکنیم در این مورد دادهها دادههای زیرخط را بارگیری میکنند و ما فقط یک چیز را اضافه میکنیم. در
110
00:03:43,840 –> 00:03:46,270
اینجا که تعداد کلمات زیرخط
111
00:03:46,270 –> 00:03:49,300
برابر است با ده هزار در این مورد در حال حاضر
112
00:03:49,300 –> 00:03:51,220
دلیلی که من این کار را انجام می دهم این است که این
113
00:03:51,220 –> 00:03:52,810
مجموعه داده حاوی تعداد
114
00:03:52,810 –> 00:03:54,340
زیادی کلمات مختلف است و کاری که ما در
115
00:03:54,340 –> 00:03:56,320
واقع با گفتن تعداد کلمات برابر با
116
00:03:56,320 –> 00:03:58,810
10000 انجام خواهیم داد، فقط برداشت است. کلماتی
117
00:03:58,810 –> 00:04:01,330
که 10000 پرتکرار هستند، به این معنی است
118
00:04:01,330 –> 00:04:03,340
که کلماتی را
119
00:04:03,340 –> 00:04:04,930
که معمولاً فقط یک یا دو بار تکرار میشوند حذف
120
00:04:04,930 –> 00:04:06,940
میکنیم، زیرا
121
00:04:06,940 –> 00:04:08,410
نمیخواهیم آنها را در مدل خود بیاندازیم
122
00:04:08,410 –> 00:04:10,720
و مواردی مانند بیشتر بودن را داشته باشیم. سخت تر از آن چیزی است
123
00:04:10,720 –> 00:04:12,010
که باید باشد و فقط داده
124
00:04:12,010 –> 00:04:13,990
هایی داریم که به نوعی نامربوط هستند، زیرا به
125
00:04:13,990 –> 00:04:16,930
وضوح بررسی های فیلم را با هم مقایسه خواهیم کرد
126
00:04:16,930 –> 00:04:18,850
و برخی کلمات وجود دارد که
127
00:04:18,850 –> 00:04:20,290
فقط در یک نقد قرار دارند،
128
00:04:20,290 –> 00:04:22,089
احتمالاً باید آنها را حذف کنیم زیرا هیچ نقدی وجود
129
00:04:22,089 –> 00:04:23,620
ندارد. چیزی که واقعاً باید آنها را با سایر مجموعههای داده مقایسه کرد،
130
00:04:23,620 –> 00:04:25,970
131
00:04:25,970 –> 00:04:27,320
امیدوارم که این منطقی باشد، اما
132
00:04:27,320 –> 00:04:28,640
این خیلی مهم نیست، ما بیحس میشویم
133
00:04:28,640 –> 00:04:31,280
کلمات برابر با 10000، همچنین
134
00:04:31,280 –> 00:04:32,780
پدرمان را کمی کوچک میکند و همین باعث میشود
135
00:04:32,780 –> 00:04:34,850
که اکنون آن چیزی که ما داریم کمی زیباتر شود. کار
136
00:04:34,850 –> 00:04:37,160
بعدی این است که ما در واقع نشان خواهیم داد که چگونه
137
00:04:37,160 –> 00:04:40,640
میتوانیم این دادهها را اکنون نمایش دهیم، اگر من
138
00:04:40,640 –> 00:04:42,350
با نشان دادن دادههای زیرخط قطار به شما شروع کنم
139
00:04:42,350 –> 00:04:44,390
و بیایید مانند صفر با یک را انتخاب کنیم،
140
00:04:44,390 –> 00:04:45,920
بنابراین حدس میزنم اولی را انتخاب
141
00:04:45,920 –> 00:04:47,930
کنم و آن را چاپ کنم. به صفحه نمایش، بنابراین
142
00:04:47,930 –> 00:04:51,590
اگر من توانستم پایتون 2pi را دریافت کنم، بیایید برویم و فکر می
143
00:04:51,590 –> 00:04:52,820
کنم در این مورد باید این
144
00:04:52,820 –> 00:04:54,530
کار را انجام دهیم، احتمالاً فقط باید این را تایپ کنم تا
145
00:04:54,530 –> 00:04:59,990
آموزش شروع شود تا زمانی که واقعاً
146
00:04:59,990 –> 00:05:01,430
چاپ می شود، احتمالاً یک ثانیه طول می کشد
147
00:05:01,430 –> 00:05:02,960
اینجا فقط برای شروع مجموعه دادهها را دانلود
148
00:05:02,960 –> 00:05:05,690
کنید، میتوانید ببینید که آنچه ما داریم در
149
00:05:05,690 –> 00:05:08,210
واقع فقط یک دسته از اعداد است، حالا
150
00:05:08,210 –> 00:05:09,440
این واقعاً شبیه یک
151
00:05:09,440 –> 00:05:11,480
نقد فیلم به نظر نمیرسد.
152
00:05:11,480 –> 00:05:15,290
153
00:05:15,290 –> 00:05:17,510
154
00:05:17,510 –> 00:05:19,730
یک کلمه خاص و آنچه ما این کار را انجام
155
00:05:19,730 –> 00:05:22,430
دادیم
156
00:05:22,430 –> 00:05:24,230
تا طبقه بندی واقعی اینها و کار با
157
00:05:24,230 –> 00:05:26,180
آنها را برای مدل ما آسانتر کنیم، به هر کلمه یک
158
00:05:26,180 –> 00:05:27,830
عدد صحیح داده ایم، بنابراین در این مورد ممکن است مانند
159
00:05:27,830 –> 00:05:29,780
کلمه عدد صحیح یک یا چیزی
160
00:05:29,780 –> 00:05:31,130
که عدد صحیح چهارده مخفف
161
00:05:31,130 –> 00:05:32,660
چیزی و همه باشد. ما انجام دادیم،
162
00:05:32,660 –> 00:05:35,120
فقط آن اعداد صحیح را به لیستی اضافه کردیم که
163
00:05:35,120 –> 00:05:37,400
نشان دهنده مکان این کلمات
164
00:05:37,400 –> 00:05:40,130
در بررسی فیلم است، اکنون برای رایانه خوب است
165
00:05:40,130 –> 00:05:41,570
، اما
166
00:05:41,570 –> 00:05:42,770
اگر واقعاً بخواهیم این کلمات را بخوانیم برای
167
00:05:42,770 –> 00:05:44,990
ما خیلی خوب نیست، بنابراین باید این کار را انجام دهیم. این است که
168
00:05:44,990 –> 00:05:46,820
نگاشت این کلمات را پیدا کنید و سپس
169
00:05:46,820 –> 00:05:48,860
راهی برای نمایش واقعی آن پیدا کنید تا
170
00:05:48,860 –> 00:05:50,300
بدانید که اکنون می توانیم به آن نگاهی بیندازیم،
171
00:05:50,300 –> 00:05:52,010
صادقانه می گویم اینجا فقط می
172
00:05:52,010 –> 00:05:53,420
خواهم این را از آنچه آنها در
173
00:05:53,420 –> 00:05:54,950
وب سایت تنسورفلو دارند در نظر بگیرم. چگونه می توان این کار را انجام داد
174
00:05:54,950 –> 00:05:56,570
معمولاً شما
175
00:05:56,570 –> 00:05:58,310
نگاشت خود را برای کلمات با
176
00:05:58,310 –> 00:05:59,630
فرهنگ لغت خود ایجاد می کنید و فقط قبلاً
177
00:05:59,630 –> 00:06:01,550
آن اطلاعات را دارید، اما خوشبختانه برای ما
178
00:06:01,550 –> 00:06:03,260
tensorflow قبلاً این کار را انجام می دهد بنابراین برای انجام
179
00:06:03,260 –> 00:06:04,760
این کار می خواهم بگویم شاخص زیر خط کلمه
180
00:06:04,760 –> 00:06:07,540
در این برابر است. مورد
181
00:06:07,540 –> 00:06:10,520
زیرخط زیرخط زیرخط IMDB، نمایه زیرخط کلمه مانند
182
00:06:10,520 –> 00:06:12,440
این، حالا کاری که این کار انجام میدهد، در
183
00:06:12,440 –> 00:06:14,000
واقع به ما یک فرهنگ لغت میدهد که
184
00:06:14,000 –> 00:06:16,970
آن کلیدها و آن نقشهبرداریها را دارد، به طوری که
185
00:06:16,970 –> 00:06:19,610
کاری که ما میتوانیم انجام دهیم این است که به خوبی
186
00:06:19,610 –> 00:06:21,440
بفهمیم که این اعداد صحیح واقعاً چه
187
00:06:21,440 –> 00:06:22,670
معنایی دارند، بنابراین وقتی میخواهیم. برای چاپ
188
00:06:22,670 –> 00:06:25,040
بعداً میتوانیم به آنها نگاهی بیندازیم، بنابراین من میخواهم
189
00:06:25,040 –> 00:06:27,830
بگویم که آیا شاخص زیرخط کلمه
190
00:06:27,830 –> 00:06:32,510
در این مورد برابر است با K: و سپس میخواهیم
191
00:06:32,510 –> 00:06:35,960
بگوییم چه چیزی میتواند به اضافه سه
192
00:06:35,960 –> 00:06:38,230
برای K باشد.
193
00:06:38,230 –> 00:06:41,920
194
00:06:41,920 –> 00:06:44,680
مواردی که ممکن است در اینجا نادرست بوده باشم،
195
00:06:44,680 –> 00:06:45,640
این در واقع یک فرهنگ لغت
196
00:06:45,640 –> 00:06:47,620
به ما نمی دهد، بلکه فقط به ما مانند تاپل هایی می دهد
197
00:06:47,620 –> 00:06:51,130
که رشته و کلمه در آنها وجود دارد، من
198
00:06:51,130 –> 00:06:52,960
معتقدم و سپس آنچه ما در اینجا انجام می دهیم این
199
00:06:52,960 –> 00:06:54,970
است که به جای آن می گوییم ج متاسفم
200
00:06:54,970 –> 00:06:56,980
این باید B باشد، عذرخواهی من این است که ما
201
00:06:56,980 –> 00:06:58,570
میخواهیم دریافت کنیم، فقط آن دسته
202
00:06:58,570 –> 00:07:00,460
را به K و V میشکنیم که مخفف کلید و
203
00:07:00,460 –> 00:07:02,080
مقدار است و کلید کلمه کلمه
204
00:07:02,080 –> 00:07:05,500
خواهد بود. مقدار مشخصاً عدد صحیح خواهد بود
205
00:07:05,500 –> 00:07:07,060
بله خواهد بود و ما
206
00:07:07,060 –> 00:07:09,040
برای اقلام کلمه an d ایندکس آن را تجزیه میکند
207
00:07:09,040 –> 00:07:10,150
و سپس ما فقط میخواهیم
208
00:07:10,150 –> 00:07:11,830
دستهای از کلیدهای مختلف را به مجموعه دادههای خود اضافه کنیم
209
00:07:11,830 –> 00:07:13,720
، دلیل اینکه از
210
00:07:13,720 –> 00:07:16,060
+3 شروع میکنیم این است که در واقع
211
00:07:16,060 –> 00:07:18,640
یک یا سه کلید خواهیم داشت.
212
00:07:18,640 –> 00:07:20,800
مانند کاراکترهای ویژه برای نگاشت کلمه ما باشید
213
00:07:20,800 –> 00:07:22,000
و شما بچه ها خواهید دید که آنها
214
00:07:22,000 –> 00:07:23,860
در یک ثانیه چگونه کار می کنند، بنابراین من
215
00:07:23,860 –> 00:07:25,900
فقط با گفتن فهرست کلمات شروع می کنم و در این مورد
216
00:07:25,900 –> 00:07:29,800
من در اینجا صفحه قرار می دهم
217
00:07:29,800 –> 00:07:30,880
که در مورد آن صحبت می کنیم. یک ثانیه پس
218
00:07:30,880 –> 00:07:31,900
نگران نباشید اگر شما بچهها شبیه کاری هستید که
219
00:07:31,900 –> 00:07:33,550
الان انجام میدهید، من میخواهم
220
00:07:33,550 –> 00:07:38,130
نمایه کلمه را بگویم و در این مورد
221
00:07:38,130 –> 00:07:39,550
برابر با 1 است.
222
00:07:39,550 –> 00:07:42,550
223
00:07:42,550 –> 00:07:45,250
224
00:07:45,250 –> 00:07:47,350
وقتی میگویم UNK برابر 2 است،
225
00:07:47,350 –> 00:07:50,350
اکنون UNK فقط مخفف ناشناخته است و
226
00:07:50,350 –> 00:07:51,580
من همه اینها را در یک ثانیه توضیح میدهم،
227
00:07:51,580 –> 00:07:52,900
اما سادهتر است که ابتدا آن را تایپ کنید
228
00:07:52,900 –> 00:07:55,120
و در این مورد نمایه کلمه را در
229
00:07:55,120 –> 00:07:58,750
داخل این برچسب استفاده میکنیم.
230
00:07:58,750 –> 00:08:01,420
ما میخواهیم بگوییم برابر با 3 است، بنابراین کاری که من انجام میدهم
231
00:08:01,420 –> 00:08:03,160
اساساً همه کلمات در
232
00:08:03,160 –> 00:08:07,420
آموزش و آزمایش ما هستند. مجموعهای مانند
233
00:08:07,420 –> 00:08:09,070
کلیدها و مقادیر مرتبط با آنها هستند
234
00:08:09,070 –> 00:08:11,200
که از 1 شروع میشوند، بنابراین کاری که من انجام میدهم این است که
235
00:08:11,200 –> 00:08:13,870
من فقط 3 را به همه این مقادیر اضافه
236
00:08:13,870 –> 00:08:16,090
میکنم تا در واقع کاری که میتوانم انجام دهم این است
237
00:08:16,090 –> 00:08:18,490
که نوع خود مقادیری را که میخواهند انجام دهم اختصاص دهم.
238
00:08:18,490 –> 00:08:21,610
برای padding شروع ناشناخته و
239
00:08:21,610 –> 00:08:24,460
استفاده نشده است، به طوری که اگر مقادیری را دریافت کنیم که
240
00:08:24,460 –> 00:08:26,530
معتبر نیستند، می توانیم آنها
241
00:08:26,530 –> 00:08:28,300
را اساساً در فرهنگ لغت به آن اختصاص دهیم، اکنون
242
00:08:28,300 –> 00:08:29,740
آنچه من برای padding استفاده می کنم، شما بچه ها
243
00:08:29,740 –> 00:08:31,270
فقط در عرض یک ثانیه خواهید دید که اساساً
244
00:08:31,270 –> 00:08:32,679
ما می توانیم
245
00:08:32,679 –> 00:08:34,990
طول مجموعههای فیلمهایمان را یکسان کنیم، بنابراین
246
00:08:34,990 –> 00:08:37,240
این چیزی که به عنوان تگ پد شناخته میشود را اضافه میکنیم و این
247
00:08:37,240 –> 00:08:39,849
کار را با اضافه کردن ۰ به فهرست نقد واقعی فیلممان انجام میدهیم،
248
00:08:39,849 –> 00:08:41,679
بهطوریکه
249
00:08:41,679 –> 00:08:43,659
میخواهیم مرور هر فیلم را با طول و طول یکسان انجام
250
00:08:43,659 –> 00:08:45,460
دهیم. روشی که ما این کار را انجام می دهیم اساساً این است که اگر
251
00:08:45,460 –> 00:08:46,660
طول آنها یکسان نباشد، بنابراین شاید
252
00:08:46,660 –> 00:08:48,580
یک صد یا شاید یک 200 می خواهیم
253
00:08:48,580 –> 00:08:50,240
همه آنها 200
254
00:08:50,240 –> 00:08:53,810
لیست فیلم های صد طولی باشند، کاری که
255
00:08:53,810 –> 00:08:55,370
ما انجام خواهیم داد این است که ما فقط یک دسته از فیلم ها را اضافه می کنیم.
256
00:08:55,370 –> 00:08:56,810
تا انتهای آن بالشتک بزنید تا
257
00:08:56,810 –> 00:09:00,230
طول آن 200 شود و سپس بدیهی است که مدل ما
258
00:09:00,230 –> 00:09:01,760
امیدوار خواهد بود اولی بتوانیم
259
00:09:01,760 –> 00:09:04,100
این واقعیت را متمایز کنیم که این بالشتک است و بعد
260
00:09:04,100 –> 00:09:05,390
ما به بالشتک اهمیتی نمی دهیم و اینکه
261
00:09:05,390 –> 00:09:06,589
ما حتی نباید زحمت این را داشته باشیم
262
00:09:06,589 –> 00:09:09,230
که به درستی نگاه کنیم، بنابراین اکنون
263
00:09:09,230 –> 00:09:11,270
کاری که من می خواهم انجام دهم این است که این نوع پیچیده را اضافه کنم.
264
00:09:11,270 –> 00:09:14,120
اینجا را خط بکشید، من حتی نمی
265
00:09:14,120 –> 00:09:15,680
دانم چرا آنها این را دارند،
266
00:09:15,680 –> 00:09:17,089
صادقانه بگویم، این راهی است که
267
00:09:17,089 –> 00:09:18,980
تانسور تصمیم گرفته است آنها را مانند نگاشت کلمات انجام دهد،
268
00:09:18,980 –> 00:09:20,870
اما ظاهراً باید
269
00:09:20,870 –> 00:09:24,860
این فهرست زیرخط زیرخط معکوس
270
00:09:24,860 –> 00:09:27,459
را اضافه کنید. برابر با
271
00:09:27,459 –> 00:09:29,690
فرهنگ لغت و سپس در اینجا ما می
272
00:09:29,690 –> 00:09:38,740
گوییم مقدار کلید کاما برای مقدار کاما کلیدی
273
00:09:38,740 –> 00:09:43,279
در فهرست زیرخط کلمه من فکر می
274
00:09:43,279 –> 00:09:44,959
کنم این درست است و کاری که این کار انجام می دهد
275
00:09:44,959 –> 00:09:47,000
در واقع متأسفم نه فهرست کلمه فهرست
276
00:09:47,000 –> 00:09:50,180
موارد نقطه شاخص کلمه آنچه که این کار انجام می دهد اشکالی ندارد.
277
00:09:50,180 –> 00:09:52,399
اکنون متوجه شوید که من آن را تایپ
278
00:09:52,399 –> 00:09:53,990
کردم، شما فقط تمام مقادیر
279
00:09:53,990 –> 00:09:55,760
کلیدها را عوض کنید تا در حال حاضر
280
00:09:55,760 –> 00:09:59,930
یک فرهنگ لغت داشته باشیم که همه
281
00:09:59,930 –> 00:10:01,220
کلیدهای مشابه را دارد که ابتدا
282
00:10:01,220 –> 00:10:03,740
کلمه خواهد بود و سپس مقادیری که در واقع ما در آن قرار می گیرند.
283
00:10:03,740 –> 00:10:05,209
خواستن آن برعکس، بنابراین
284
00:10:05,209 –> 00:10:06,980
ما مانند عدد صحیح به کلمه اشاره می
285
00:10:06,980 –> 00:10:08,750
کنیم، زیرا مجموعه داده های خود را خواهیم داشت
286
00:10:08,750 –> 00:10:10,790
که فقط شامل اعداد صحیحی
287
00:10:10,790 –> 00:10:12,770
است که در اینجا دیدیم و می خواهیم این
288
00:10:12,770 –> 00:10:14,660
اعداد صحیح بتوانند به یک کلمه
289
00:10:14,660 –> 00:10:16,520
در مقابل اشاره کنند. برعکس، بنابراین
290
00:10:16,520 –> 00:10:18,290
کاری که ما انجام میدهیم این است که این کار را
291
00:10:18,290 –> 00:10:22,250
با فهرست فهرست معکوس کلمه معکوس کنیم، فقط
292
00:10:22,250 –> 00:10:23,630
فرهنگ لغت ما متأسفم، اساساً
293
00:10:23,630 –> 00:10:26,240
این همان کاری است که اینجا انجام میدهد در حال حاضر که
294
00:10:26,240 –> 00:10:27,950
ما انجام دادیم که آخرین مرحله فقط
295
00:10:27,950 –> 00:10:29,810
اضافه کردن یک تابع است. و کاری که این تابع
296
00:10:29,810 –> 00:10:33,560
انجام خواهد داد این است که اساساً
297
00:10:33,560 –> 00:10:35,120
تمام این داده های آموزشی و آزمایشی را
298
00:10:35,120 –> 00:10:38,180
به کلمات قابل خواندن توسط انسان رمزگشایی می کند، بنابراین
299
00:10:38,180 –> 00:10:40,040
راه های مختلفی برای انجام دوباره این کار وجود دارد، من فقط
300
00:10:40,040 –> 00:10:41,149
این را از
301
00:10:41,149 –> 00:10:42,740
وب سایت tensorflow ح