

در این مطلب، ویدئو آموزش یادگیری ماشین پایتون در دنیای واقعی با یادگیری Scikit (اصول اسکلارن، NLP، طبقهبندیکنندهها و غیره) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 1:40:48
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:01,740
سلام بچه ها و دختران چه خبر و
2
00:00:01,740 –> 00:00:03,899
به یک ویدیوی دیگر خوش آمدید که برای این ویدیو بسیار هیجان زده هستم،
3
00:00:03,899 –> 00:00:05,220
امروز ما
4
00:00:05,220 –> 00:00:07,049
کتابخانه یادگیری اسکییت
5
00:00:07,049 –> 00:00:09,990
پایتون را مرور خواهیم کرد که یک کتابخانه بسیار مهم
6
00:00:09,990 –> 00:00:12,349
برای یادگیری ماشینی در پایتون است و
7
00:00:12,349 –> 00:00:14,549
قطعا این ویدیو بسیار عالی بود.
8
00:00:14,549 –> 00:00:16,470
درخواست شد، بنابراین من هیجان زده هستم که بالاخره
9
00:00:16,470 –> 00:00:18,930
به آن برسم، بنابراین کاری که به طور خاص
10
00:00:18,930 –> 00:00:21,300
در این ویدیو انجام می شود این است که روبی به آرامی
11
00:00:21,300 –> 00:00:22,680
راه ما را در کتابخانه یادگیری چرخه طی می کند
12
00:00:22,680 –> 00:00:24,180
و دوست دارد
13
00:00:24,180 –> 00:00:25,710
همه راه های مختلفی را که
14
00:00:25,710 –> 00:00:28,080
می توانید بروید نشان دهد، اما وظیفه نهایی ما این است که ما
15
00:00:28,080 –> 00:00:30,630
در این ویدیو خواهیم ساخت که
16
00:00:30,630 –> 00:00:32,340
دو مدل مختلف یادگیری ماشینی خواهد بود،
17
00:00:32,340 –> 00:00:33,930
مدل اول به
18
00:00:33,930 –> 00:00:36,360
طور خودکار متنی را که قرار داده ایم
19
00:00:36,360 –> 00:00:39,629
به عنوان مثبت یا منفی طبقه بندی
20
00:00:39,629 –> 00:00:42,090
می کند، بنابراین اگر من این خط کد را
21
00:00:42,090 –> 00:00:42,750
درست در اینجا اجرا
22
00:00:42,750 –> 00:00:44,460
کردم، می دانید از این پنج ستاره کاملاً لذت بردم
23
00:00:44,460 –> 00:00:47,280
که کتاب بدی مثبت است
24
00:00:47,280 –> 00:00:49,890
نخرید که یک مثال منفی باشد
25
00:00:49,890 –> 00:00:52,020
چیزهای بسیار جالبی است متشکرم که
26
00:00:52,020 –> 00:00:53,460
مثبت است و همانطور که می بینید
27
00:00:53,460 –> 00:00:55,340
خروجی مدل یادگیری ماشین c مقادیر مربوطه
28
00:00:55,340 –> 00:00:57,930
را می توانم این را به چیزی
29
00:00:57,930 –> 00:01:02,340
مانند وحشتناک تغییر دهم، او را نخرید،
30
00:01:02,340 –> 00:01:06,119
قبلاً گفتم اتلاف وقت وحشتناک نخرید
31
00:01:06,119 –> 00:01:07,409
32
00:01:07,409 –> 00:01:09,780
و اکنون ما این تغییر را
33
00:01:09,780 –> 00:01:12,600
به منفی خواهیم دید تا خنک شود، بنابراین به
34
00:01:12,600 –> 00:01:14,310
طور خودکار می داند که آیا این
35
00:01:14,310 –> 00:01:16,920
موارد مثبت هستند یا خیر. یا منفی و این می
36
00:01:16,920 –> 00:01:18,060
تواند برای همه چیزهای جالب اعمال شود،
37
00:01:18,060 –> 00:01:20,130
مانند من می توانم بدانید که این
38
00:01:20,130 –> 00:01:22,680
مدل را در نظرات YouTube من بگنجانید و ببینید
39
00:01:22,680 –> 00:01:24,180
چقدر چیزهای منفی مثبت دریافت
40
00:01:24,180 –> 00:01:26,580
می کنم، بنابراین
41
00:01:26,580 –> 00:01:28,350
بازی کردن با داده های متن واقعی واقعاً سرگرم کننده است
42
00:01:28,350 –> 00:01:30,600
و ایجاد یک مدل یادگیری ماشینی با
43
00:01:30,600 –> 00:01:33,270
یادگیری scikit و من حدس میزنم که این را
44
00:01:33,270 –> 00:01:36,119
به عنوان خروجی دریافت کنیم، سپس یک کار دیگر انجام میدهیم
45
00:01:36,119 –> 00:01:39,930
که بسیار مشابه است، مدل
46
00:01:39,930 –> 00:01:41,159
خیلی تغییر نمیکند، اما
47
00:01:41,159 –> 00:01:42,630
دیدن کمی بیشتر
48
00:01:42,630 –> 00:01:45,119
آنچه شما دارید بسیار جالب است. می تواند با همان نوع
49
00:01:45,119 –> 00:01:47,100
مطالب یادگیری SK انجام دهد، بنابراین این نیز یک
50
00:01:47,100 –> 00:01:49,079
مدل پردازش زبان طبیعی NLP است و
51
00:01:49,079 –> 00:01:51,869
این مدل به جای مثبت یا منفی
52
00:01:51,869 –> 00:01:54,149
، چندین دسته مختلف داریم
53
00:01:54,149 –> 00:01:55,770
که به نوعی
54
00:01:55,770 –> 00:01:58,799
کام ما را گروه بندی می کردند. روشی که
55
00:01:58,799 –> 00:02:00,780
می توانید در مورد این موضوع فکر کنید این است که تصور
56
00:02:00,780 –> 00:02:03,299
کنید مانند منابع انسانی مسئول توییتر
57
00:02:03,299 –> 00:02:05,790
هستید و می دانید که همه این
58
00:02:05,790 –> 00:02:08,459
بازخوردهای مثبت و منفی را به حساب توییتر خود دریافت می
59
00:02:08,459 –> 00:02:10,440
کنید، اما نمی دانید چه
60
00:02:10,440 –> 00:02:12,330
محصولاتی آنها در مورد این مدل یادگیری ماشینی صحبت می کنند،
61
00:02:12,330 –> 00:02:13,980
62
00:02:13,980 –> 00:02:17,250
متن را از نظر پزشکی به عنوان یک
63
00:02:17,250 –> 00:02:18,930
دسته بندی خاص طبقه بندی می کند، بنابراین اگر برای عروسی من عالی است
64
00:02:18,930 –> 00:02:21,989
، به دسته لباسی که من آن را در باغم دوست داشتم نگاشت می کند،
65
00:02:21,989 –> 00:02:24,900
دسته پاسیو
66
00:02:24,900 –> 00:02:27,480
و کامپیوتر خوب الکترونیکی است
67
00:02:27,480 –> 00:02:29,340
و همانطور که می بینید Maps به درستی به
68
00:02:29,340 –> 00:02:30,810
این چیزها می پردازم، بنابراین این دو مدل
69
00:02:30,810 –> 00:02:32,489
ساخته خواهند شد، به سرعت در میان
70
00:02:32,489 –> 00:02:34,019
انواع چیزهای جالب با
71
00:02:34,019 –> 00:02:36,150
scikit-learn قدم می زنند، اجازه دهید من فقط
72
00:02:36,150 –> 00:02:38,519
جدول زمانی این ویدیو را پوشش دهم و این
73
00:02:38,519 –> 00:02:40,079
در نظرات خواهد بود، پس حتما آن را
74
00:02:40,079 –> 00:02:41,640
بررسی کنید ما
75
00:02:41,640 –> 00:02:43,379
با یک نمای کلی از اینکه چرا از SK Larian استفاده می کنید شروع می کنیم
76
00:02:43,379 –> 00:02:46,319
چه هدفی دارد چه زمانی
77
00:02:46,319 –> 00:02:47,640
باید از آن استفاده کنید در حالی که نباید از آن استفاده کنید،
78
00:02:47,640 –> 00:02:50,150
سپس به بارگیری داده ها
79
00:02:50,150 –> 00:02:53,190
در SK Learn و آنچه SK می شود می پردازیم. یادگیری می تواند
80
00:02:53,190 –> 00:02:54,989
برای کمک به ما در این زمینه انجام دهد و ما به
81
00:02:54,989 –> 00:02:57,660
محض
82
00:02:57,660 –> 00:02:59,549
انتخاب طبقه بندی کننده خود، طبقه بندی کننده خود
83
00:02:59,549 –> 00:03:01,049
84
00:03:01,049 –> 00:03:02,549
85
00:03:02,549 –> 00:03:04,440
را انتخاب
86
00:03:04,440 –> 00:03:07,680
خواهیم کرد. برای فکر کردن اگر
87
00:03:07,680 –> 00:03:10,829
چیز دیگری وجود دارد، ما نیز
88
00:03:10,829 –> 00:03:12,239
مدل خود را ذخیره خواهیم کرد، بنابراین
89
00:03:12,239 –> 00:03:13,739
اگر میخواهید از آن در تولید استفاده کنید، مجبور نباشید هر بار آن را دوباره آموزش دهید
90
00:03:13,739 –> 00:03:16,620
و همچنین من فقط میخواهم
91
00:03:16,620 –> 00:03:18,540
سریع بگویم این یک ویدیو نسبتا طولانی است،
92
00:03:18,540 –> 00:03:20,609
بنابراین اگر میخواهید برای تقسیم کردن این
93
00:03:20,609 –> 00:03:23,040
به 15 دقیقه، سعی می کنم
94
00:03:23,040 –> 00:03:24,540
ساختارش را بسازم، بنابراین انجام این کار بسیار آسان است،
95
00:03:24,540 –> 00:03:25,560
بنابراین احساس نکنید که مجبور هستید
96
00:03:25,560 –> 00:03:27,030
این ویدیو را یکباره تماشا کنید،
97
00:03:27,030 –> 00:03:29,160
یک قسمت را تماشا کنید و بعداً به قسمت دوم برگردید،
98
00:03:29,160 –> 00:03:31,560
اما من تا حدودی میخواهم همه آنها را
99
00:03:31,560 –> 00:03:32,790
با هم نگه دارم، زیرا فکر
100
00:03:32,790 –> 00:03:35,340
میکنم دیدن کامل از ابتدا از
101
00:03:35,340 –> 00:03:40,560
دادهها تا مدل نهایی Avenue خوب است، بنابراین
102
00:03:40,560 –> 00:03:42,299
کمی اطلاعات پیشزمینه در مورد
103
00:03:42,299 –> 00:03:44,099
یادگیری SK و یادگیری ماشینی
104
00:03:44,099 –> 00:03:45,780
به طور کلی این است که میگویم
105
00:03:45,780 –> 00:03:47,760
تقریباً هر یادگیری ماشین تا sk
106
00:03:47,760 –> 00:03:51,569
چندین مرحله مرتبط با آن دارد، بنابراین
107
00:03:51,569 –> 00:03:53,730
منظور من در هسته آن هر نوع
108
00:03:53,730 –> 00:03:54,780
یادگیری ماشینی است که می خواهید انجام دهید
109
00:03:54,780 –> 00:03:55,980
، یک نوع سؤال
110
00:03:55,980 –> 00:03:57,870
دارید که می خواهید به آن پاسخ دهید، بنابراین همیشه
111
00:03:57,870 –> 00:03:58,950
اولین چیزی است که می دانید این
112
00:03:58,950 –> 00:04:00,959
سؤال را دارید. که میخواهید به آن پاسخ دهید و
113
00:04:00,959 –> 00:04:02,250
سپس باید دادههایی پیدا کنید که
114
00:04:02,250 –> 00:04:03,900
به شما در پاسخ به این سؤال کمک میکند، میتوانید پس از یافتن
115
00:04:03,900 –> 00:04:06,180
116
00:04:06,180 –> 00:04:07,799
آن دادهها و درخواست، مدلی را حول آن دادهها بسازید و
117
00:04:07,799 –> 00:04:09,900
باید برخی از دادهها را به
118
00:04:09,900 –> 00:04:11,430
نوعی پردازش کنید.
119
00:04:11,430 –> 00:04:14,220
فیلتر کردن، زمانی که دادههای خود را
120
00:04:14,220 –> 00:04:15,599
آماده کردید، میخواهید
121
00:04:15,599 –> 00:04:18,570
مدلی را پیرامون دادهها بسازید، زمانی
122
00:04:18,570 –> 00:04:20,160
که یک مدل دارید،
123
00:04:20,160 –> 00:04:22,079
میخواهید ارزیابی
124
00:04:22,079 –> 00:04:23,850
کنید که مدل شما چقدر خوب عمل میکند
125
00:04:23,850 –> 00:04:27,240
و به نوعی پس از آن، بهبودهایی را ایجاد
126
00:04:27,240 –> 00:04:28,740
می کنید، مدل را تنظیم می
127
00:04:28,740 –> 00:04:30,660
کنید، آنها پارامترهای مختلفی را پیدا می کنند، می
128
00:04:30,660 –> 00:04:31,890
دانید شاید تاریخ خود را کمی بیشتر تنظیم کنید
129
00:04:31,890 –> 00:04:33,990
و فقط سعی کنید تا حد امکان مدل خود را بهبود ببخشید.
130
00:04:33,990 –> 00:04:37,430
یادگیری SK به
131
00:04:37,430 –> 00:04:40,230
ساده سازی کل خط لوله کمک می کند.
132
00:04:40,230 –> 00:04:42,780
آنها کمک آنها برای کمک به بسیاری از
133
00:04:42,780 –> 00:04:44,280
چیزهای معمولی هستند که می خواهید انجام دهید تا مدل خود را بهبود بخشید
134
00:04:44,280 –> 00:04:46,710
و مدل خود را آماده
135
00:04:46,710 –> 00:04:49,470
ساخت کنید یا من در واقع از یک
136
00:04:49,470 –> 00:04:52,020
الگوریتم خاص برای مدل بسته های آموخته شده SK
137
00:04:52,020 –> 00:04:54,840
استفاده می کنم که همه را بسته بندی می کند. که
138
00:04:54,840 –> 00:04:58,140
به یک کتابخانه خوب برای شما تبدیل شده است، بنابراین
139
00:04:58,140 –> 00:04:59,790
کمی جزئیات بیشتر مانند من اینجا هستم که به
140
00:04:59,790 –> 00:05:02,400
سایت یادگیری SK نگاه می کنم، انواع
141
00:05:02,400 –> 00:05:04,230
الگوریتم های طبقه بندی
142
00:05:04,230 –> 00:05:07,800
وجود دارد و می دانید که در اینجا کدی برای
143
00:05:07,800 –> 00:05:11,990
یک الگوریتم طبقه بندی خاص به این
144
00:05:11,990 –> 00:05:15,960
طولانی وجود دارد. پیچیده است اما با یادگیری SK
145
00:05:15,960 –> 00:05:18,630
می توانید از همان الگوریتم استفاده کنید زیرا می
146
00:05:18,630 –> 00:05:21,930
دانید چند خط یکسان را با
147
00:05:21,930 –> 00:05:25,160
رگرسیون خود خوشه بندی می کنید که
148
00:05:25,160 –> 00:05:28,140
ممکن است مقدار زیادی از کدهای خود را برای انجام
149
00:05:28,140 –> 00:05:30,000
150
00:05:30,000 –> 00:05:31,440
آن
151
00:05:31,440 –> 00:05:33,930
نیاز داشته باشد. استفاده از خود آسان است،
152
00:05:33,930 –> 00:05:36,780
جدایی دیگری که میخواهم
153
00:05:36,780 –> 00:05:38,730
خیلی سریع انجام دهم این است که میتوانم بگویم
154
00:05:38,730 –> 00:05:41,310
دو نوع مدل وجود دارد که
155
00:05:41,310 –> 00:05:43,770
میتوانید در یادگیری ماشین بسازید، بنابراین
156
00:05:43,770 –> 00:05:45,780
این بسیار کلی است. از یک
157
00:05:45,780 –> 00:05:48,060
طرف شما
158
00:05:48,060 –> 00:05:50,790
مدل های یادگیری عمیق را در شبکه عصبی دارید و از
159
00:05:50,790 –> 00:05:52,290
طرف دیگر این
160
00:05:52,290 –> 00:05:55,610
مدل های یادگیری ماشینی از نوع الگوریتمی سنتی را دارید.
161
00:05:55,610 –> 00:05:59,940
SK یادگیری واقعاً در
162
00:05:59,940 –> 00:06:04,020
این مدل های الگوریتمی سنتی مفید
163
00:06:04,020 –> 00:06:06,330
164
00:06:06,330 –> 00:06:09,060
است. برای استفاده از سمت الگوریتم
165
00:06:09,060 –> 00:06:11,280
برای مواردی از نوع شبکه عصبی،
166
00:06:11,280 –> 00:06:12,930
در این ویدیو قرار نیست آن را پوشش دهیم
167
00:06:12,930 –> 00:06:15,600
و نمیدانم من دیدم به مواردی در مستندات نگاه کردم.
168
00:06:15,600 –> 00:06:17,070
169
00:06:17,070 –> 00:06:19,020
170
00:06:19,020 –> 00:06:20,820
به نظر یک یادگیری SK است، اما
171
00:06:20,820 –> 00:06:22,170
اگر میخواهید تجربه
172
00:06:22,170 –> 00:06:23,730
یادگیری ماشین شبکههای عصبی را کسب کنید، من واقعاً توصیه
173
00:06:23,730 –> 00:06:26,940
میکنم که تنسورفلو را بررسی کنید، من
174
00:06:26,940 –> 00:06:30,300
شخصاً از مشعل پی استفاده میکنم.
175
00:06:30,300 –> 00:06:32,130
176
00:06:32,130 –> 00:06:34,620
177
00:06:34,620 –> 00:06:36,129
178
00:06:36,129 –> 00:06:38,589
خوب است، پس اکنون
179
00:06:38,589 –> 00:06:40,029
که کمی در مورد ska iron مرور کردیم،
180
00:06:40,029 –> 00:06:42,309
اجازه دهید به سوالی
181
00:06:42,309 –> 00:06:43,629
که در ابتدا سعی در پاسخگویی به آن داشتیم برگردیم و
182
00:06:43,629 –> 00:06:45,369
این به طور خودکار c نادیده گرفتن
183
00:06:45,369 –> 00:06:48,219
نظرات به عنوان مثبت یا منفی و برای
184
00:06:48,219 –> 00:06:50,139
انجام این کار، ابتدا به داده هایی نیاز داریم تا
185
00:06:50,139 –> 00:06:53,080
مدل خود را آموزش دهیم.
186
00:06:53,080 –> 00:06:54,879
187
00:06:54,879 –> 00:06:57,999
188
00:06:57,999 –> 00:07:05,349
189
00:07:05,349 –> 00:07:13,389
آیا
190
00:07:13,389 –> 00:07:17,529
او بهترین کاری است که میتوانم
191
00:07:17,529 –> 00:07:19,809
این کار را انجام دهم، اما من سالها اینجا هستم که
192
00:07:19,809 –> 00:07:23,110
اساساً دادههای کافی برای
193
00:07:23,110 –> 00:07:24,550
نیازهای این ویدیو ایجاد کنم و یک مدل خوب بسازم،
194
00:07:24,550 –> 00:07:26,769
بنابراین بله، ایجاد دادهها
195
00:07:26,769 –> 00:07:28,379
احتمالاً بهترین رویکردی نیست که میتوانید انجام دهید.
196
00:07:28,379 –> 00:07:31,059
جمعسپاری و مانند اینکه افراد زیادی را
197
00:07:31,059 –> 00:07:32,679
وادار کنید تا دادههایی را که به صورت بالقوه کمی بهتر کار میکنند، به صورت دستی برش
198
00:07:32,679 –> 00:07:34,709
دهند، اما همچنان
199
00:07:34,709 –> 00:07:37,749
زمانبر احتمالاً
200
00:07:37,749 –> 00:07:40,300
بهترین نیست، بنابراین بهترین رویکرد برای دریافت
201
00:07:40,300 –> 00:07:42,189
دادههای مورد نیاز این است که سعی کنید خلاق باشید چگونه
202
00:07:42,189 –> 00:07:43,959
میتوانیم دادههایی را پیدا کنیم که به ما کمک خواهد کرد
203
00:07:43,959 –> 00:07:46,809
آنچه را که از قبل برای
204
00:07:46,809 –> 00:07:50,699
این مدل بازخورد منفی مثبت وجود دارد انجام دهیم
205
00:07:50,699 –> 00:07:56,009
، جایی که من تصمیم گرفتم بروم
206
00:07:56,009 –> 00:07:58,329
amazon.com است، بنابراین منظورم این است که ما روی
207
00:07:58,329 –> 00:08:00,789
هر چیزی شبیه به این کوچولوی زیبا کلیک کنیم.
208
00:08:00,789 –> 00:08:04,419
خدای من، این لباس کوچک زیبا بسیار دوست داشتنی است
209
00:08:04,419 –> 00:08:07,479
و ما می توانیم به
210
00:08:07,479 –> 00:08:09,610
بررسی ها و نظرات برویم.
211
00:08:09,610 –> 00:08:13,149
212
00:08:13,149 –> 00:08:15,699
213
00:08:15,699 –> 00:08:18,639
214
00:08:18,639 –> 00:08:21,969
215
00:08:21,969 –> 00:08:23,860
از طرف دیگر، بیایید ببینیم آیا می توانیم یک
216
00:08:23,860 –> 00:08:26,229
ستاره یک ستاره پیدا کنیم، نمی دانم آیا آن را پیدا خواهم کرد
217
00:08:26,229 –> 00:08:28,389
با این لباس چقدر دوست داشتنی است،
218
00:08:28,389 –> 00:08:30,189
بله، ما یک بررسی یک ستاره
219
00:08:30,189 –> 00:08:34,380
در اینجا داریم، شاید این را کمی بزرگتر کنیم،
220
00:08:35,279 –> 00:08:39,399
مثل این که کیفیت ندارد اصلاً مانند
221
00:08:39,399 –> 00:08:41,559
این بررسی یک ستاره، ما یک
222
00:08:41,559 –> 00:08:42,698
بازخورد منفی داریم، ما چیزهای منفی داریم که
223
00:08:42,698 –> 00:08:45,009
مردم می گویند، بنابراین اگر
224
00:08:45,009 –> 00:08:46,510
225
00:08:46,510 –> 00:08:49,480
بتوانیم بازدیدهای زیادی از آمازون داشته باشیم، می توانیم از آن به عنوان داده های آموزشی خود استفاده کنیم،
226
00:08:49,480 –> 00:08:51,160
بنابراین این دقیقاً همان کاری است که ما می خواهیم
227
00:08:51,160 –> 00:08:54,280
انجام دهیم. من این کار را به پایان رساندم و کار
228
00:08:54,280 –> 00:08:55,900
را برای شما کمی سادهتر کردم این است که
229
00:08:55,900 –> 00:09:00,910
این مرد JM Colley در USC D کارهای زیادی
230
00:09:00,910 –> 00:09:02,170
برای ما انجام داد که در واقع
231
00:09:02,170 –> 00:09:05,980
از آمازون عبور نمیکنید، اما از سال 1996 تا
232
00:09:05,980 –> 00:09:09,490
ژوئیه 2014 او انواع مختلفی را جمعآوری کرد.
233
00:09:09,490 –> 00:09:12,730
داده های بررسی آمازون بنابراین من پیش رفتم و
234
00:09:12,730 –> 00:09:15,370
برخی از آنها را برداشتم و آنها را تجزیه کردم،
235
00:09:15,370 –> 00:09:17,740
من فیلمنامهای دارم که دقیقاً نشان میدهد چگونه این
236
00:09:17,740 –> 00:09:18,400
کار را انجام دادهام
237
00:09:18,400 –> 00:09:21,820
که به شما نشان میدهد، اما من فقط
238
00:09:21,820 –> 00:09:23,440
آن را به مقدار قابل کنترلتری
239
00:09:23,440 –> 00:09:26,260
از بررسیها برای چندین مورد از این
240
00:09:26,260 –> 00:09:29,980
دستهها در اینجا از سال 2014 تقسیم کردم.
241
00:09:29,980 –> 00:09:31,480
این همان چیزی است که ما به عنوان داده های خود
242
00:09:31,480 –> 00:09:33,460
به عنوان داده های آموزشی خود استفاده خواهیم کرد، برای دریافت آن
243
00:09:33,460 –> 00:09:35,500
داده ها و شروع به نوشتن کد
244
00:09:35,500 –> 00:09:39,580
ما باید به صفحه github من بروید Keith
245
00:09:39,580 –> 00:09:41,050
galley این نیز در توضیحات به آن پیوند داده خواهد شد
246
00:09:41,050 –> 00:09:43,420
و بله کیث یک
247
00:09:43,420 –> 00:09:44,980
اسلش تازه اومده هیوئون و در حالی که شما در اون هستید
248
00:09:44,980 –> 00:09:45,280
249
00:09:45,280 –> 00:09:47,410
github من رو دنبال کنید چون هر چه
250
00:09:47,410 –> 00:09:49,420
نقاط عطف بیشتر عکس های سرگرم کننده تری مثل
251
00:09:49,420 –> 00:09:53,110
این بگیرم، یک پست خوب دریافت کردم و بنابراین
252
00:09:53,110 –> 00:09:54,910
وقتی در صفحه github قرار گرفتید می
253
00:09:54,910 –> 00:09:57,550
خواهید به داده ها بروید. و برای شروع، من
254
00:09:57,550 –> 00:09:59,710
فقط می روم، توصیه می کنم فقط به سمت
255
00:09:59,710 –> 00:10:01,480
احساسات بروید و این فایل را دانلود کنید که من
256
00:10:01,480 –> 00:10:04,330
نام کتاب را کوچک گذاشتم، بنابراین این 1000
257
00:10:04,330 –> 00:10:07,090
بررسی آمازون از سال 2014 به طور خاص در مورد
258
00:10:07,090 –> 00:10:11,370
کتاب های الکترونیکی است، بنابراین ادامه دهید، می توانید روی آن کلیک کنید
259
00:10:11,370 –> 00:10:13,960
و اگر روی آن کلیک کنید، جایی وجود دارد
260
00:10:13,960 –> 00:10:15,310
– بله فقط دانلود فایل خام
261
00:10:15,310 –> 00:10:18,280
he دوباره یا خام را کلیک کنید و سپس می
262
00:10:18,280 –> 00:10:22,330
توانید ذخیره کنید زیرا کتاب ها کوچک و
263
00:10:22,330 –> 00:10:26,470
سند متنی باید خوب باشد یا
264
00:10:26,470 –> 00:10:31,050
شاید فقط همه فایل ها را انجام دهید سپس فقط JSON را
265
00:10:32,790 –> 00:10:36,269
انجام دهید مهم نیست ما آن را ذخیره می کنیم بله بنابراین
266
00:10:36,269 –> 00:10:38,220
من فقط با صرفه جویی در ذخیره شده که قبلاً آن را
267
00:10:38,220 –> 00:10:40,050
ذخیره کرده ام، اما بله، آن را در جایی ذخیره کنید که
268
00:10:40,050 –> 00:10:41,540
نزدیک به جایی است که کد خود را می نویسید،
269
00:10:41,540 –> 00:10:44,010
خوب ویرایشگر کد مورد علاقه خود را باز کنید، من
270
00:10:44,010 –> 00:10:46,139
شخصاً نوت بوک های Jupiter را برای
271
00:10:46,139 –> 00:10:48,029
هر چیزی که مربوط به علم داده های رژیم غذایی است دوست
272
00:10:48,029 –> 00:10:50,430
دارم و در واقع شروع به فرو رفتن در
273
00:10:50,430 –> 00:10:53,880
وظایف یادگیری ماشینی کرده است. بنابراین برای شروع
274
00:10:53,880 –> 00:10:55,680
قبل از نوشتن حتی هر کدی که فقط
275
00:10:55,680 –> 00:11:00,329
دوباره به داده های ما نگاه می کند و من برای اولین بار حدس می زنم
276
00:11:00,329 –> 00:11:02,040
این چیزی است که داده های ما به
277
00:11:02,040 –> 00:11:03,810
نظر می رسد این کتاب کوچک است که به
278
00:11:03,810 –> 00:11:06,630
شما گفتم آن را دانلود کنید به این شکل است بنابراین
279
00:11:06,630 –> 00:11:10,829
حدس می زنم یک فایل JSON است. و هر
280
00:11:10,829 –> 00:11:13,410
خط یک شی JSON دیگر است، بنابراین
281
00:11:13,410 –> 00:11:15,089
اگر بخواهیم این
282
00:11:15,089 –> 00:11:16,529
را به روشی منطقی بارگذاری کنیم، باید
283
00:11:16,529 –> 00:11:19,769
در این فایل خط به خط بارگذاری کنیم و
284
00:11:19,769 –> 00:11:21,720
سپس آب فیلدهای مهمی در اینجا هستند. در
285
00:11:21,720 –> 00:11:25,079
این JSON بنابراین من می بینم که ما این
286
00:11:25,079 –> 00:11:28,110
متن بررسی و این در واقع
287
00:11:28,110 –> 00:11:29,579
محتوای متن در بررسی است، بنابراین
288
00:11:29,579 –> 00:11:30,750
مهم است، بنابراین ما آن را می خواهیم
289
00:11:30,750 –> 00:11:32,790
و سپس چیز دیگری که
290
00:11:32,790 –> 00:11:34,350
مهم خواهد بود، خدای من، این متن
291
00:11:34,350 –> 00:11:36,690
طولانی است، در کل
292
00:11:36,690 –> 00:11:40,500
به این اندازه خواهد بود. از رتبه 5 ستاره، بنابراین
293
00:11:40,500 –> 00:11:41,940
این دو فیلد هستند که من واقعاً به آنها
294
00:11:41,940 –> 00:11:44,069
اهمیت میدهم و سپس میتوانیم
295
00:11:44,069 –> 00:11:46,560
کارهای دیگری را با آن انجام دهیم، بنابراین این یک
296
00:11:46,560 –> 00:11:50,600
فایل است و بیایید پردازش آن را شروع کنیم، بنابراین
297
00:11:50,600 –> 00:11:54,449
یکی از مواردی که توصیه میکنم این است که ابتدا
298
00:11:54,449 –> 00:11:57,839
کتابخانه JSON را وارد کنیم. فقط
299
00:11:57,839 –> 00:12:01,620
به ما اجازه دهید آن فایل را پردازش کنیم و سپس
300
00:12:01,620 –> 00:12:03,779
اگر میخواهیم این فایل را خط به خط بارگذاری کنیم،
301
00:12:03,779 –> 00:12:06,630
این کاری است که میتوانیم انجام دهیم، بنابراین
302
00:12:06,630 –> 00:12:09,089
ابتدا به خوبی پیش میرویم، باید
303
00:12:09,089 –> 00:12:13,620
نام فایل خود را بدانیم و فایل ما
304
00:12:13,620 –> 00:12:16,290
نامیده میشود. مسیری که گذاشتم مسیر من را در آن ذخیره
305
00:12:16,290 –> 00:12:20,339
کرد و این نسبت به کدی است که
306
00:12:20,339 –> 00:12:22,440
می نویسم در پوشه داده است
307
00:12:22,440 –> 00:12:25,920
و سپس در قسمت احساسات قرار داشت
308
00:12:25,920 –> 00:12:29,000
و به آن کتابها کوچک
309
00:12:29,000 –> 00:12:31,740
لمسی JSON می گفتند بنابراین ممکن است نام فایل من
310
00:12:31,740 –> 00:12:33,170
این باشد. چیز متفاوتی
311
00:12:33,170 –> 00:12:35,639
خوب حالا ما می خواهیم O آن فایل را بنویسید
312
00:12:35,639 –> 00:12:41,430
تا بتوانیم با نام فایل باز تایپ
313
00:12:41,430 –> 00:12:46,240
کنیم که آن شخص f چیست، بنابراین ما این
314
00:12:46,240 –> 00:12:49,180
نام فایل را به عنوان برنامه باز می کنیم که فایل F نامیده می شود
315
00:12:49,180 –> 00:12:52,120
و سپس کاری که می توانیم انجام دهیم برای خط و
316
00:12:52,120 –> 00:12:54,490
F است و فقط برای اینکه ببینیم چه چیزی داریم. در حال حاضر
317
00:12:54,490 –> 00:12:57,940
من فقط می خواهم یک خط چاپی انجام دهم و
318
00:12:57,940 –> 00:12:59,650
این پایتون 3 است فقط یک سر بالا، بنابراین من
319
00:12:59,650 –> 00:13:00,430
کسانی که آن را با پرانتز در اطراف آن قرار
320
00:13:00,430 –> 00:13:01,810
می دهند و
321
00:13:01,810 –> 00:13:02,680
کمی از کار می افتم زیرا نمی خواهم
322
00:13:02,680 –> 00:13:04,930
همه چیز را فعلا اجرا کنم بسیار خوب، بنابراین
323
00:13:04,930 –> 00:13:09,130
من چیزی از آن به دست آوردم و اکنون کاری که
324
00:13:09,130 –> 00:13:13,510
می خواهم انجام دهم این است که می خواهم سریع انجام دهم، می
325
00:13:13,510 –> 00:13:15,550
خواهم سریع چه چیزی را می خواهم انجام
326
00:13:15,550 –> 00:13:20,830
دهم، می خواهم متن نقد را دریافت کنم بنابراین می
327
00:13:20,830 –> 00:13:25,770
خواهیم به کلیتی
328
00:13:29,410 –> 00:13:33,490
که می خواهیم برسیم دریافت متن نقد در اینجا و
329
00:13:33,490 –> 00:13:35,410
مانند این قطعاً یک چیز مثبت است.
330
00:13:35,410 –> 00:13:38,860
در مجموع چهار ستاره است مانند الهی توسط
331
00:13:38,860 –> 00:13:41,380
طوفان با رمان جدید منحصر به فرد خود، او
332
00:13:41,380 –> 00:13:43,540
دنیایی را ایجاد می کند که شبیه سایرین
333
00:13:43,540 –> 00:13:45,220
نیست، بنابراین همه اینها خوب به نظر می رسد و این در
334
00:13:45,220 –> 00:13:47,350
مورد کتاب است، بنابراین بیایید سعی کنیم آن را بدست آوریم. که
335
00:13:47,350 –> 00:13:52,810
متن را مرور می کنیم تا به طور معمول خط چاپ شود اگر
336
00:13:52,810 –> 00:13:54,640
این مانند در یک فرهنگ لغت بارگذاری شده باشد،
337
00:13:54,640 –> 00:13:57,330
باید فقط بتوانید خط را انجام دهید و
338
00:13:57,330 –> 00:14:00,550
سپس متونی مانند این را مرور کنید، بنابراین بیایید ببینیم
339
00:14:00,550 –> 00:14:01,060
که آیا کار می کند یا
340
00:14:01,060 –> 00:14:04,000
خیر، ما داریم به آنجا می رسیم و بنابراین
341
00:14:04,000 –> 00:14:05,260
دلیل دریافت خطا این است که در حال حاضر
342
00:14:05,260 –> 00:14:08,170
این فقط متن خام است، بنابراین باید از
343
00:14:08,170 –> 00:14:10,510
این کتابخانه JSON استفاده کنیم تا در واقع آن را به
344
00:14:10,510 –> 00:14:16,210
عنوان یک بررسی مانند فرهنگ لغت بارگذاری کنید تا
345
00:14:16,210 –> 00:14:18,640
بتوانیم چیزی بگوییم مانند بررسی
346
00:14:18,640 –> 00:14:36,580
برابر با json dot loads line و حالا اگر
347
00:14:36,580 –> 00:14:41,230
بررسی متن نقد را چاپ کنم،
348
00:14:41,230 –> 00:14:44,760
باید آنچه را که به دنبالش هستیم در اینجا دریافت کنیم،
349
00:14:44,760 –> 00:14:49,120
بدانیم چه نوع در ما جالب است.
350
00:14:49,120 –> 00:14:52,230
فقط آن متن را دریافت کنید و اگر من فقط آن
351
00:14:52,230 –> 00:14:55,950
نمره کلی را می خواستم، می توانستم به طور کلی مرور
352
00:14:55,950 –> 00:15:00,370
کنم، این کلید JSON بود که مقدار مناسبی را تولید می
353
00:15:00,370 –> 00:15:03,390
کرد که چه کاری انجام دادم تا به آن
354
00:15:03,390 –> 00:15:06,310
اشاره کنم جالب است، به طوری که چهار
355
00:15:06,310 –> 00:15:08,110
ستاره بود، بنابراین هر دو مورد را دریافت کردیم. ما
356
00:15:08,110 –> 00:15:09,910
می خواستیم پس اکنون آنچه واقعاً باید انجام دهیم این
357
00:15:09,910 –> 00:15:13,050
است که همه اینها را به روشی خوب جمع آوری کنیم تا
358
00:15:13,050 –> 00:15:19,080
از شر این
359
00:15:21,030 –> 00:15:23,230
بیانیه نقض خلاص شوم و می خواهم مرورهایی را
360
00:15:23,230 –> 00:15:25,240
بگویم که به عنوان یک لیست خالی شروع می شوند
361
00:15:25,240 –> 00:15:27,820
و آنچه را که ما انجام می دهیم قرار است انجام دهیم این است
362
00:15:27,820 –> 00:15:32,200
که ما فقط بررسی هایی را انجام می
363
00:15:32,200 –> 00:15:35,680
دهیم و شاید ما یک
364
00:15:35,680 –> 00:15:41,610
شیء چندگانه از متن بررسی مرور و یک امتیاز
365
00:15:45,120 –> 00:15:50,370
و مربع
366
00:15:51,880 –> 00:15:54,670
367
00:15:54,670 –> 00:15:56,170
368
00:15:56,170 –> 00:15:59,350
369
00:15:59,350 –> 00:16:01,690
را اضافه کنیم. کار می کند بیایید مانند
370
00:16:01,690 –> 00:16:03,970
یک شی تصادفی چاپ کنیم، بنابراین من می
371
00:16:03,970 –> 00:16:08,550
خواهم فقط با نقد شماره پنج
372
00:16:08,550 –> 00:16:11,500
ادامه دهم عشق کتاب داستان عالی شما
373
00:16:11,500 –> 00:16:13,209
را برای اولین رمان از این
374
00:16:13,209 –> 00:16:14,949
پیشنهاد سرگرم می کند. او کار فوق العاده ای
375
00:16:14,949 –> 00:16:16,420
انجام داده است. یک
376
00:16:16,420 –> 00:16:18,399
بررسی بسیار مثبت من تعجب کردم که آنها
377
00:16:18,399 –> 00:16:20,589
فقط چهار ستاره به آن دادند، زیرا می
378
00:16:20,589 –> 00:16:22,600
توانستند آن را در پنج ستاره بگذارند، اما بله،
379
00:16:22,600 –> 00:16:24,970
اما بله، به نظر می رسد که
380
00:16:24,970 –> 00:16:27,550
به درستی بارگیری شده است و اکنون اگر ما فقط
381
00:16:27,550 –> 00:16:32,259
می خواستیم مانند بررسی دسترسی داشته باشیم،
382
00:16:32,259 –> 00:16:35,759
فقط مات و مبهوت بودیم. ردیف و ما میخواهیم
383
00:16:35,759 –> 00:16:39,670
متن یا امتیاز را بخوبی انجام دهیم، این
384
00:16:39,670 –> 00:16:41,920
کار با کل این نمایهسازی کار میکند تا
385
00:16:41,920 –> 00:16:46,000
نمره را دوست داشته باشد و متن
386
00:16:46,000 –> 00:16:47,920
این تمیزترین راه نیست و من فکر میکنم مشکلی
387
00:16:47,920 –> 00:16:49,959
را با بسیاری از دانشمندان دادهای مشابه میبینم.
388
00:16:49,959 –> 00:16:52,720
و مهندسین یادگیری ماشینی است که به
389
00:16:52,720 –> 00:16:55,569
هم ریخته می شود داده های آنها به هم ریخته
390
00:16:55,569 –> 00:16:58,420
می شود تجزیه کدهای شخصی سخت می شود،
391
00:16:58,420 –> 00:17:00,759
بنابراین کاری که ما می خواهیم به سرعت انجام دهیم این
392
00:17:00,759 –> 00:17:05,049
است که یک کلاس داده برای آن ها همه
393
00:17:05,049 –> 00:17:06,849
داده هایی هستند که بارگذاری می کنیم، بنابراین من این کار را در بالا انجام خواهم داد.
394
00:17:06,849 –> 00:17:08,770
ما این کلاس را
395
00:17:08,770 –> 00:17:16,929
مرور مینامیم و میخواهیم آن را با شما مقداردهی اولیه کنیم.
396
00:17:16,929 –> 00:17:20,319
همیشه مقداردهی اولیه را
397
00:17:20,319 –> 00:17:26,669
با
398
00:17:30,500 –> 00:17:37,680
متنها و امتیازات خود داشته باشید و اساساً
399
00:17:37,680 –> 00:17:43,040
متن خود نقطهای برابر با متن است و امتیاز خود نقطهای
400
00:17:43,040 –> 00:17:45,420
که امتیاز شروع آن مانند
401
00:17:45,420 –> 00:17:46,800
عدد است. از ستاره ها چیزی که من با آن می گویم در حالی
402
00:17:46,800 –> 00:17:50,370
که شما برای گلزنی می روید و سپس ما
403
00:17:50,370 –> 00:17:51,750
کارهای دیگری را در این کلاس انجام می دهیم
404
00:17:51,750 –> 00:17:53,250
تا
405
00:17:53,250 –> 00:17:55,350
این امتیاز را به یک احساس تبدیل
406
00:17:55,350 –> 00:17:57,540
کنیم و در نهایت داشتن این کلاس
407
00:17:57,540 –> 00:18:01,290
همه چیز را مرتب تر می کند، بنابراین اکنون آنچه را که می
408
00:18:01,290 –> 00:18:03,360
کنیم. به جای ضمیمه کردن
409
00:18:03,360 –> 00:18:07,220
این تاپل، میرویم و
410
00:18:07,220 –> 00:18:13,170
یک شی بررسی ایجاد میکنیم، بنابراین مرور کنید و
411
00:18:13,170 –> 00:18:16,470
سپس متن
412
00:18:16,470 –> 00:18:18,210
و نمره را پاس میکنیم تا در واقع
413
00:18:18,210 –> 00:18:23,880
آن متن را در اینجا داشته باشیم و به
414
00:18:23,880 –> 00:18:28,440
جای انجام یک شاخص برای به دست آوردن نمره
415
00:18:28,440 –> 00:18:30,450
من می توانم بررسی پنج نمره e dot و همانطور
416
00:18:30,450 –> 00:18:32,340
که می بینید ثابت می ماند و اگر
417
00:18:32,340 –> 00:18:35,400
من اکنون متن متن را انجام دهم به راحتی می توانم
418
00:18:35,400 –> 00:18:38,100
متن را کمی دقیق تر دریافت کنم و به
419
00:18:38,100 –> 00:18:39,750
شما کمک می کند تا چیزها را پیگیری کنید و
420
00:18:39,750 –> 00:18:41,280
ما کمی بیشتر انجام خواهیم داد.
421
00:18:41,280 –> 00:18:43,680
در این کلاس، بنابراین یک کاری که میخواهم
422
00:18:43,680 –> 00:18:46,190
انجام دهم این است که نوعی احساس را مقداردهی اولیه کنم،
423
00:18:46,190 –> 00:18:49,440
بنابراین یک احساس جدید خودآموخته و برای
424
00:18:49,440 –> 00:18:51,600
احساسات چهار یا پنج ستاره به معنای
425
00:18:51,600 –> 00:18:54,540
مثبت یک یا دو ستاره به معنای منفی است
426
00:18:54,540 –> 00:18:56,820
و سپس حدس میزنم میتوانیم از سه به عنوان
427
00:18:56,820 –> 00:18:59,460
مثل خنثی استفاده کنیم. من یک تابع
428
00:18:59,460 –> 00:19:01,790
در کلاس بررسی ایجاد خواهم کرد به نام get
429
00:19:01,790 –> 00:19:05,190
sentiment همه توابع در یک کلاس
430
00:19:05,190 –> 00:19:09,140
پاس به خودی خود و بنابراین کاری که ما انجام خواهیم داد این است که
431
00:19:09,140 –> 00:19:16,510
و این را روی self get sentiment تنظیم میکنم،
432
00:19:16,510 –> 00:19:19,120
بنابراین وقتی این پاسخ را پر کردیم، برمیگردد.
433
00:19:19,120 –> 00:19:21,309
هر کاری که این تابع انجام می دهد
434
00:19:21,309 –> 00:19:27,220
و خوب است، بنابراین اگر سه یا چهار یا
435
00:19:27,220 –> 00:19:29,710
پنج ستاره باشد باید مثبت باشد اگر
436
00:19:29,710 –> 00:19:30,790
یک یا دو ستاره باشد باید منفی باشد
437
00:19:30,790 –> 00:19:34,510
بنابراین اگر
438
00:19:34,510 –> 00:19:37,600
امتیاز خود نقطه کمتر یا مساوی دو باشد با منفی شروع
439
00:19:37,600 –> 00:19:40,960
می کنم. می خواهید آن را تنظیم کنید یا می خواهیم
440
00:19:40,960 –> 00:19:46,419
منفی را برگردانیم و من درست می کنم فعلاً از
441
00:19:46,419 –> 00:19:51,000
رشته ها استفاده کنید L اگر امتیاز خود نقطه
442
00:19:51,000 –> 00:19:53,559
برابر با سه باشد، این
443
00:19:53,559 –> 00:19:54,520
حالت خنثی خواهد بود، نمی دانم آیا ما
444
00:19:54,520 –> 00:19:55,690
واقعاً از آن استفاده خواهیم کرد یا خیر،
445
00:19:55,690 –> 00:19:57,790
اما من فقط می خواهم تمام
446
00:19:57,790 –> 00:19:59,950
امتیازهای ممکن ما پوشش داده شود تا خنثی باشد.
447
00:19:59,950 –> 00:20:04,110
و در نهایت، این
448
00:20:04,110 –> 00:20:08,650
امتیاز چهار یا پنج خواهد
449
00:20:08,650 –> 00:20:13,150
بود که مثبت برگردانده می شود و یک کار کوچک دیگر
450
00:20:13,150 –> 00:20:15,520
که دوست دارم هر زمان
451
00:20:15,520 –> 00:20:17,320
که ممکن است انجام دهم این است که دوست ندارم فقط
452
00:20:17,320 –> 00:20:18,880
رشته هایی در اطراف شناور باشند، دوست دارم با آن ها
453
00:20:18,880 –> 00:20:21,190
بسیار سازگار باشم. رشتهها، بنابراین
454
00:20:21,190 –> 00:20:22,929
من بهطور تصادفی دوست
455
00:20:22,929 –> 00:20:24,940
ندارم چیز اشتباهی را انتخاب کنم، بنابراین من
456
00:20:24,940 –> 00:20:26,679
در واقع یک کلاس enum ایجاد میکنم که
457
00:20:26,679 –> 00:20:29,230
فقط یک کلاس معمولی است، اما شما به
458
00:20:29,230 –> 00:20:32,410
نوعی آنها را enums و برنامهنویسی صحبت میکنید
459
00:20:32,410 –> 00:20:34,450
و من این احساس را صدا میکنم و
460
00:20:34,450 –> 00:20:36,820
که چند
461
00:20:36,820 –> 00:20:39,960
ویژگی متفاوت خواهد داشت، یک منفی
462
00:20:39,960 –> 00:20:42,460
برابر با منفی خواهد داشت
463
00:20:42,460 –> 00:20:44,259
و خواهید دید که چرا من این کار را در یک ثانیه انجام می دهم
464
00:20:44,259 –> 00:20:52,590
خنثی برابر خنثی و مثبت
465
00:20:52,590 –> 00:20:57,610
برابر با مثبت است، بنابراین دلیلی که من این کار را انجام
466
00:20:57,610 –> 00:21:05,879
دادم دلیل این بود که این کار را انجام دادم حالا
467
00:21:05,879 –> 00:21:11,110
بیایید من باشم این را دوباره اجرا می کنم و
468
00:21:11,110 –> 00:21:13,659
دوباره این را اجرا می کنم، اکنون می توانم
469
00:21:13,659 –> 00:21:16,720
کاری انجام دهم مانند نظرات نقطه نظر، بنابراین
470
00:21:16,720 –> 00:21:19,029
به یاد داشته باشید که این یک بررسی چهار ستاره است
471
00:21:19,029 –> 00:21:21,129
بنابراین باید مثبت باشد و می گوید
472
00:21:21,129 –> 00:21:23,019
مثبت است، درست است که خوب است که ما
473
00:21:23,019 –> 00:21:24,999
اینجا گفتیم اما اکنون اساسا به جای همیشه
474
00:21:24,999 –> 00:21:26,830
رشتههای منفی و خنثی را تایپ میکنیم
475
00:21:26,830 –> 00:21:28,899
و شاید فراموش میکنیم
476
00:21:28,899 –> 00:21:30,399
که کل مطلب را با حروف بزرگ نوشتهایم یا
477
00:21:30,399 –> 00:21:32,950
غلط املایی میکنیم، به این موارد به عنوان
478
00:21:32,950 –> 00:21:36,610
کلاس احساسات اشاره میکنیم و
479
00:21:36,610 –> 00:21:43,869
احساسات منفی یا نقطه احساس را مکث میکنیم.
480
00:21:43,869 –> 00:21:46,389
481
00:21:46,389 –> 00:21:54,820
482
00:21:54,820 –> 00:21:57,490
این فقط برای اطمینان از این است که
483
00:21:57,490 –> 00:21:59,650
ما ثابت قدم هستیم، همچنین به نوعی خوب است
484
00:21:59,650 –> 00:22:03,370
زیرا بسیاری از عوامل eTCO ما
485
00:22:03,370 –> 00:22:09,280
می توانند این را به طور خودکار به ما توصیه کنند، اما اکنون اگر
486
00:22:09,280 –> 00:22:12,130
این را اجرا کنیم و به اینجا
487
00:22:12,130 –> 00:22:13,600
برگردیم، باز هم مثبت است.
488
00:22:13,600 –> 00:22:15,700
با داشتن
489
00:22:15,700 –> 00:22:17,410
این نوع کارها کمی تمیزتر است، شما مجبور نیستید آن کار را انجام دهید،
490
00:22:17,410 –> 00:22:19,090
اما فقط کاری را که من دوست دارم
491
00:22:19,090 –> 00:22:21,370
انجام دهم خوب است، بنابراین ما اکنون این کلاس بررسی داریم
492
00:22:21,370 –> 00:22:22,810
که به طور خودکار موارد مثبت را پر می کند.
493
00:22:22,810 –> 00:22:24,430
احساسات منفی یا منفی، بنابراین ما در حال
494
00:22:24,430 –> 00:22:24,970
رسیدن به آنجا
495
00:22:24,970 –> 00:22:26,500
هستیم، بیایید
496
00:22:26,500 –> 00:22:27,910
ادامه دهیم و اطلاعات خود را آماده کنیم و
497
00:22:27,910 –> 00:22:29,350
اساساً کاری که بعداً انجام خواهیم داد این
498
00:22:29,350 –> 00:22:33,510
است که دوباره این متن را
499
00:22:33,870 –> 00:22:36,280
بپذیریم.
500
00:22:36,280 –> 00:22:39,040
با دادههای متنی،
501
00:22:39,040 –> 00:22:41,080
ساختن مدلهای یادگیری ماشینی
502
00:22:41,080 –> 00:22:43,570
در اطراف مدلهای یادگیری ماشینی دادههای متنی واقعاً سخت
503
00:22:43,570 –> 00:22:46,870
است و شما
504
00:22:46,870 –> 00:22:49,960
دادههای عددی را بهعنوان بردارهای عددی ورودی میشناسید،
505
00:22:49,960 –> 00:22:52,030
بنابراین ما در مورد
506
00:22:52,030 –> 00:22:56,920
روشهایی برای تبدیل متن به
507
00:22:56,920 –> 00:22:59,350
بردار کمی صحبت خواهیم کرد.
508
00:22:59,350 –> 00:23:01,960
509
00:23:01,960 –> 00:23:03,910
اگر
510
00:23:03,910 –> 00:23:05,920
از قبل نمیدانید تصور کنید که ما این
511
00:23:05,920 –> 00:23:09,880
دو عبارت را داریم، این کتاب عالی است و این
512
00:23:09,880 –> 00:23:12,370
کتاب بسیار بد بود، بنابراین نحوه کار ما با استفاده از
513
00:23:12,370 –> 00:23:14,440
کیسهی کلمات بسیار سریع است تا بفهمید که مجموعه کلمات چگونه کار میکند. از کلمات این است که ما ابتدا این را
514
00:23:14,440 –> 00:23:16,750
به فرهنگ لغت نشانه ها یا
515
00:23:16,750 –> 00:23:19,870
کلمات تقسیم می کنیم، در این مورد ما unigram را انجام می دهیم، بنابراین
516
00:23:19,870 –> 00:23:23,230
فقط کلمات را به عنوان فرهنگ لغت خود تقسیم می کنیم،
517
00:23:23,230 –> 00:23:26,110
بنابراین ما آن را تقسیم می کنیم، بنابراین این
518
00:23:26,110 –> 00:23:31,060
کتاب عالی است، گاهی اوقات ممکن است به صورت اختیاری
519
00:23:31,060 –> 00:23:33,370
شامل این توضیح به غیر از
520
00:23:33,370 –> 00:23:35,470
علامت لمیت اما بستگی به این دارد که چگونه
521
00:23:35,470 –> 00:23:38,050
بردار کردن این موضوع
522
00:23:38,050 –> 00:23:42,490
از بحث دوم بسیار بد بود،
523
00:23:42,490 –> 00:23:44,770
بنابراین اگر در حال آموزش مدل کیسه ای از کلمات
524
00:23:44,770 –> 00:23:47,800
بودیم، از همه این کلمات برای
525
00:23:47,800 –> 00:23:51,370
ایجاد این نوع فرهنگ لغت استفاده می کردیم و
526
00:23:51,370 –> 00:23:55,350
سپس در واقع این کلمه را به یک
527
00:23:55,350 –> 00:23:58,060
بردار عددی تبدیل می کنیم، تنها کاری که باید انجام دهیم این
528
00:23:58,060 –> 00:24:02,650
است که یک ها و صفرها را با عبارت های اینجا ترسیم کنیم،
529
00:24:02,650 –> 00:24:05,680
بنابراین این کتاب عالی است که یک ها
530
00:24:05,680 –> 00:24:07,240
را
531
00:24:07,240 –> 00:24:09,580
به چهار کلمه اول نگاشت اما
532
00:24:09,580 –> 00:24:11,800
ندارد، ندارد، بنابراین ندارد.
533
00:24:11,800 –> 00:24:15,370
در آن بد نیست، بنابراین آنها صفر میشوند، یکها هستند
534
00:24:15,370 –> 00:24:18,640
، کلمه صفر است، این
535
00:24:18,640 –> 00:24:20,410
کتاب آنقدر بد بود که
536
00:24:20,410 –> 00:24:22,750
چیزی شبیه به این میشد، شما این کتاب
537
00:24:22,750 –> 00:24:26,350
را داشته باشید، هر دو وجود دارند، در این
538
00:24:26,350 –> 00:24:28,750
جمله نیستند عالی هستند، در این نیستند
539
00:24:28,750 –> 00:24:31,300
جمله خیلی بد بود، همه آنها در جمله هستند،
540
00:24:31,300 –> 00:24:33,370
بنابراین این یک فرآیند تبدیل متناسب با
541
00:24:33,370 –> 00:24:37,120
کلمات چهار کیسه ای بود،
542
00:24:37,120 –> 00:24:42,820
بردار شمارش در همه اینها آخرین
543
00:24:42,820 –> 00:24:46,510
مورد این است که اگر می خواستید اکنون
544
00:24:46,510 –> 00:24:51,250
کلمه یا جمله ای را تبدیل کنید که تا به حال نکرده بودید.
545
00:24:51,250 –> 00:24:54,070
پیش از این دیده شده است، بنابراین تصور کنید که کتاب بسیار
546
00:24:54,070 –> 00:24:57,820
خوبی بود جزئیات کوچکی در مورد
547
00:24:57,820 –> 00:25:00,340
این موضوع در مجموعه آموزشی اصلی وجود نداشت
548
00:25:00,340 –> 00:25:03,130
، بنابراین ما واقعاً دوست داریم
549
00:25:03,130 –> 00:25:05,200
این اصطلاحات را کنار بگذاریم و نمی
550
00:25:05,200 –> 00:25:06,190
دانیم با آنها چه کنیم زیرا
551
00:25:06,190 –> 00:25:07,870
زمانی که در حال تطبیق خود بودیم آنها را ندیدیم.
552
00:25:07,870 –> 00:25:10,600
vectorizer اما با کیسه کلمات برای
553
00:25:10,600 –> 00:25:12,820
این اگر ما این را در زمان آزمایش می دیدیم
554
00:25:12,820 –> 00:25:15,790
که من به 0 تبدیل می شدم برای این
555
00:25:15,790 –> 00:25:21,190
یکی برای سلام کتاب یک بود یک بود
556
00:25:21,190 –> 00:25:23,350
و هر چیز دیگری یک صفر است که وجود ندارد
557
00:25:23,350 –> 00:25:25,240
و سپس ما نمیتوانیم از عهده این موضوع برآییم
558
00:25:25,240 –> 00:25:26,620
، زیرا او را در
559
00:25:26,620 –> 00:25:29,830
زمان تمرین ندیدهایم، بنابراین این در سطح بالایی است
560
00:25:29,830 –> 00:25:33,250
که چگونه مجموعهای از کلمات کار میکنند
561
00:25:33,250 –> 00:25:35,470
قبل از اینکه واقعاً از
562
00:25:35,470 –> 00:25:38,050
کلمات بهتر و تقریباً هر
563
00:25:38,050 –> 00:25:39,700
کار یادگیری ماشینی که میخواهید انجام دهید استفاده کنیم.
564
00:25:39,700 –> 00:25:41,620
شما مجموعه ای از داده ها دارید و بنابراین در حال حاضر
565
00:25:41,620 –> 00:25:47,530
ما همه این بررسی ها را داریم و در
566
00:25:47,530 –> 00:25:50,110
مجموع در حال حاضر هزار بررسی داریم، اگر
567
00:25:50,110 –> 00:25:53,550
اشتباه نکنم، می توانم دوباره بررسی کنم که
568
00:25:54,279 –> 00:25:56,480
بله، اوه، ما در حال حاضر هزاران نظر
569
00:25:56,480 –> 00:25:58,460
داریم، اما هر زمان که ساختن
570
00:25:58,460 –> 00:25:59,899
مدلهای یادگیری ماشینی میدانید که میخواهیم برخی از
571
00:25:59,899 –> 00:26:01,549
زیر مجموعههای آن tr باشد دادههای موجود در
572
00:26:01,549 –> 00:26:05,330
برخی از تستهای زیرمجموعه گفته شده و اساساً با
573
00:26:05,330 –> 00:26:06,980
الگوی رایج به جای یادگیری SK این است
574
00:26:06,980 –> 00:26:08,840
که آنها روشهای خوبی برای انجام تقریباً
575
00:26:08,840 –> 00:26:10,760
بیشتر کارهایی دارند که فکر میکنید مردم
576
00:26:10,760 –> 00:26:12,980
میخواهند مکرراً با
577
00:26:12,980 –> 00:26:14,720
یادگیری ماشینی انجام دهند، بنابراین در این مورد میخواهیم
578
00:26:14,720 –> 00:26:17,029
این هزار مورد را تقسیم کنیم. در یک
579
00:26:17,029 –> 00:26:20,120
مجموعه آموزشی و یک مجموعه آزمایشی، بنابراین
580
00:26:20,120 –> 00:26:22,100
وقتی میخواهم این کار را به تنهایی انجام دهم، چه کاری انجام میدهم این است
581
00:26:22,100 –> 00:26:24,519
که به معنای واقعی کلمه به دنبال
582
00:26:24,519 –> 00:26:28,490
تقسیم نام آزمون SK Learn Train یا چیزی شبیه به
583
00:26:28,490 –> 00:26:32,210
آن میگردم و میدانید که چند
584
00:26:32,210 –> 00:26:33,769
گزینه مختلف وجود دارد که ظاهر میشوند. همین جا بالاست،
585
00:26:33,769 –> 00:26:36,080
اما معمولاً اولین نتیجه شما اگر
586
00:26:36,080 –> 00:26:38,720
چیزی خیلی ساده را در گوگل جستجو کنید همان چیزی
587
00:26:38,720 –> 00:26:41,360
خواهد بود که به دنبال آن هستید، بنابراین
588
00:26:41,360 –> 00:26:45,470
ما این آزمایش قطار را داریم که آن را تقسیم کنیم، همه
589
00:26:45,470 –> 00:26:47,899
نوع اطلاعات در مورد آن دارد.
590
00:26:47,899 –> 00:26:49,130
591
00:26:49,130 –> 00:26:50,779
به این روز دیگر
592
00:26:50,779 –> 00:26:53,029
اشکالی ندارد، پس چگونه این را وارد
593
00:26:53,029 –> 00:26:57,860
کنیم، بیایید مقداری از کاربرد را ببینیم، شما می توانید این کار را خوب انجام دهید،
594
00:26:57,860 –> 00:27:02,659
بنابراین ما سعی می کنیم نظرات خود را
595
00:27:02,659 –> 00:27:04,460
هزاران مرور به یک
596
00:27:04,460 –> 00:27:08,659
مجموعه آموزشی و مجموعه تست تقسیم کنیم، بنابراین من من
597
00:27:08,659 –> 00:27:10,760
فقط مستندات را به شما نشان دادم، اما
598
00:27:10,760 –> 00:27:12,169
آنچه در واقع بسیار جالب است این است که
599
00:27:12,169 –> 00:27:14,179
اگر از یک نوت بوک مشتری مانند من استفاده می کنید،
600
00:27:14,179 –> 00:27:20,720
اگر Shift + tab را روی آن تابع انجام دهید،
601
00:27:20,720 –> 00:27:27,309
بنابراین من همان اسناد میزبان را به من می دهد که
602
00:27:27,309 –> 00:27:29,809
اساساً دقیقاً همین جا
603
00:27:29,809 –> 00:27:31,429
دفترچه یادداشت Jupiter من که زیباست.
604
00:27:31,429 –> 00:27:34,399
بسیار منظم، تقسیم و بالا بردن یا ماتریس ها به
605
00:27:34,399 –> 00:27:35,899
زیر مجموعه های تصادفی قطار و آزمایش به طوری که
606
00:27:35,899 –> 00:27:38,090
دقیقا همان چیزی است که من می خواهم.
607
00:27:38,090 –> 00:27:42,919
608
00:27:42,919 –> 00:27:46,700
609
00:27:46,700 –> 00:27:48,980
610
00:27:48,980 –> 00:27:51,860
و نشان دهنده نسبت مجموعه داده هایی است که باید
611
00:27:51,860 –> 00:27:53,929
در تقسیم آزمایشی گنجانده شود، بنابراین
612
00:27:53,929 –> 00:27:55,429
اولین چیزی که متوجه شدم
613
00:27:55,429 –> 00:27:58,460
مهم است اندازه تست است، همچنین می توانیم
614
00:27:58,460 –> 00:28:01,429
هر نوع آرایه ای را پاس کنیم و
615
00:28:01,429 –> 00:28:03,770
از آن مراقبت می کند، ببینیم، شما
616
00:28:03,770 –> 00:28:06,590
همچنین می توانید مشخص کنید.
617
00:28:06,590 –> 00:28:08,269
حالت تصادفی اندازه قطار یکی دیگر از موارد مهم است
618
00:28:08,269 –> 00:28:11,510
که اساساً به شما این امکان را میدهد که
619
00:28:11,510 –> 00:28:13,669
تقسیم تصادفی خود را تخمین بزنید، بنابراین اگر میخواهید
620
00:28:13,669 –> 00:28:15,409
همان تقسیم دقیق را در چند نمونه تکرار کنید،
621
00:28:15,409 –> 00:28:18,590
اگر
622
00:28:18,590 –> 00:28:21,230
هر زمانی که تنظیم میکنید این مقدار را روی مقداری تنظیم کنید. با همان
623
00:28:21,230 –> 00:28:24,010
مقدار شما دقیقاً همان طبقه بندی تقسیم را دریافت خواهید کرد
624
00:28:24,010 –> 00:28:26,840
همچنین می تواند
625
00:28:26,840 –> 00:28:30,649
اساساً مهم باشد که نسبت برچسب های کلاس را حفظ می کند
626
00:28:30,649 –> 00:28:32,960
بنابراین در مورد ما
627
00:28:32,960 –> 00:28:35,240
احساس نقطه منفی
628
00:28:35,240 –> 00:28:37,760
مثبت در هر دو تقسیم یکسان است یا نسبتاً مساوی
629
00:28:37,760 –> 00:28:39,590
است بنابراین دقیقاً مانند همه موارد
630
00:28:39,590 –> 00:28:41,480
مثبت در یک مجموعه و همه
631
00:28:41,480 –> 00:28:47,149
منفی ها و دیگری به طور تصادفی خوب است،
632
00:28:47,149 –> 00:28:48,950
بنابراین بیایید آنها را یک N پاس کنیم، بنابراین می
633
00:28:48,950 –> 00:28:54,679
خواهیم در بررسی های خود قبول کنیم، می خواهیم به آن یک
634
00:28:54,679 –> 00:28:57,110
اندازه تست بدهیم، بنابراین فرض کنید اندازه آزمون ما
635
00:28:57,110 –> 00:29:02,960
قرار است باشد 0.33 33% از بررسی ها
636
00:29:02,960 –> 00:29:04,880
همان چیزی خواهد بود که می توانیم در تست استفاده کنیم،
637
00:29:04,880 –> 00:29:09,860
یعنی 66% مربوط به آموزش است و همچنین به آن
638
00:29:09,860 –> 00:29:12,169
حالت تصادفی می دهیم تا
639
00:29:12,169 –> 00:29:16,399
هر بار همان چیزی را دریافت
640
00:29:16,399 –> 00:29:17,960
کنیم و این آخرین چیزی است که من می خواهم به آن نگاه کنید،
641
00:29:17,960 –> 00:29:19,010
بنابراین من می خواهم دوباره این
642
00:29:19,010 –> 00:29:20,440
برگه shift را برجسته کنم،
643
00:29:20,440 –> 00:29:28,360
جایی که لیست های بازگشتی در آن قرار دارند و
644
00:29:33,069 –> 00:29:38,889
خوب است، بنابراین یک X&Y به نظر
645
00:29:39,639 –> 00:29:43,549
خوب است، مهم نیست که چقدر متاسفم که داشتم آن را می
646
00:29:43,549 –> 00:29:45,259
خواندم و کمی
647
00:29:45,259 –> 00:29:47,089
گیج شدم. مهم نیست
648
00:29:47,089 –> 00:29:48,859
از چند لیست عبور کنید آن را ویرایش کنید و چند
649
00:29:48,859 –> 00:29:51,079
آرایه را در خروجی آن ارسال کردید
650
00:29:51,079 –> 00:29:52,849
دو بار به این ترتیب که در مورد ما
651
00:29:52,849 –> 00:29:56,089
فقط یک لیست بررسی واحد را ارسال می
652
00:29:56,089 –> 00:30:04,459
کنیم تا یک x و یک نسخه y پشتیبان دریافت کنیم که در
653
00:30:04,459 –> 00:30:05,749
واقع اینطور نیست که من حدس می زنم این
654
00:30:05,749 –> 00:30:10,479
مناسب تر باشد. آموزش و تست
655
00:30:10,479 –> 00:30:14,329
بیایید آن را اجرا کنیم، بنابراین اگر به
656
00:30:14,329 –> 00:30:16,639
طول تمرین نگاه کنیم، شصت و شش
657
00:30:16,639 –> 00:30:20,359
درصد چیزها را گرفتیم، بنابراین این باید 666 باشد.
658
00:30:20,359 –> 00:30:23,059
659
00:30:23,059 –> 00:30:30,559
660
00:30:30,559 –> 00:30:32,690
درصد دقیقاً
661
00:30:32,690 –> 00:30:36,169
یک سوم را دقیقاً مشخص نکردیم و سپس تست
662
00:30:36,169 –> 00:30:39,469
باید 330 باشد، بنابراین می بینید که چگونه به خوبی
663
00:30:39,469 –> 00:30:42,069
آن را به یک آموزش و آزمایش تقسیم کردیم،
664
00:30:42,069 –> 00:30:44,869
بنابراین اکنون کاری که می خواهیم انجام دهیم این است که
665
00:30:44,869 –> 00:30:49,639
مدل کیسه کلمات خود را با مجموعه آموزشی خود مطابقت
666
00:30:49,639 –> 00:30:51,979
دهیم. یک طبقهبندی کننده روی آن
667
00:30:51,979 –> 00:30:54,319
مجموعه آموزشی میسازیم و سپس هر کاری را انجام میدهیم
668
00:30:54,319 –> 00:30:55,819
تا همه چیز را روی دادههای آزمایشی خود آزمایش
669
00:30:55,819 –> 00:30:57,440
کنیم، بنابراین میخواهیم
670
00:30:57,440 –> 00:30:58,969
مجموعه آموزشی خود را در بسته کلمات
671
00:30:58,969 –> 00:30:59,929
برداری منتقل
672
00:30:59,929 –> 00:31:04,099
کنیم، فقط به این نگاه کنیم که مانند چاپ
673
00:31:04,099 –> 00:31:08,049
ردیف اول است. از آموزش ما اولین
674
00:31:08,049 –> 00:31:10,309
بررسی آموزشی ما همه اینها هستند او
675
00:31:10,309 –> 00:31:13,099
بررسی می کند خوب است و این هنوز هم
676
00:31:13,099 –> 00:31:15,849
موضوع است، بنابراین اگر می خواستم اولین متن را چاپ کنم به
677
00:31:15,849 –> 00:31:23,349
یاد داشته باشید که می توانیم این کار را انجام دهیم،
678
00:31:23,779 –> 00:31:27,499
بسیار خوب، بنابراین این یک بررسی مثبت است، بگذارید
679
00:31:27,499 –> 00:31:28,940
فقط بررسی کنیم، بنابراین به یاد داشته باشید که ما می توانیم احساسات را انجام دهیم،
680
00:31:28,940 –> 00:31:31,820
فقط داده ها را به خود یادآوری کنید
681
00:31:31,820 –> 00:31:32,779
خوب عالی است،
682
00:31:32,779 –> 00:31:35,710
بنابراین میخواهیم
683
00:31:35,710 –> 00:31:38,419
بردار کلمات را وارد کنیم
684
00:31:38,419 –> 00:31:43,899
و یا شاید بهطور کلیتر فکر
685
00:31:43,899 –> 00:31:47,840
کنیم، میخواهیم متنی بگیریم و بتوانیم
686
00:31:47,840 –> 00:31:50,119
مثبت یا منفی بودن آن را پیشبینی کنیم،
687
00:31:50,119 –> 00:31:53,090
بنابراین X ما چیزی که در حال
688
00:31:53,090 –> 00:31:55,309
عبور است در مدل ما
689
00:31:55,309 –> 00:31:59,119
متن خواهد بود و Y ما مقوله
690
00:31:59,119 –> 00:32:00,710
یا احساس است، بنابراین مثبت یا
691
00:32:00,710 –> 00:32:02,259
منفی است، بنابراین احتمالاً ارزش آن را دارد
692
00:32:02,259 –> 00:32:04,969
که داده های آموزشی خود را به مانند
693
00:32:04,969 –> 00:32:06,739
آموزش X تقسیم کنیم یا شاید بتوانیم این
694
00:32:06,739 –> 00:32:12,859
قطار را X و آموزش Y را بنامیم تا به نتیجه برسیم.
695
00:32:12,859 –> 00:32:15,529
فقط متن X را می توانیم کمی
696
00:32:15,529 –> 00:32:19,249
درک لیست انجام دهیم تا بتوانیم متن X نقطه را
697
00:32:19,249 –> 00:32:25,369
برای X در آموزش انجام دهیم و برای قطار Y
698
00:32:25,369 –> 00:32:29,749
به راحتی می توانیم احساس X نقطه را برای X
699
00:32:29,749 –> 00:32:35,619
و آموزش انجام دهیم، بنابراین اکنون به
700
00:32:35,619 –> 00:32:38,509
کاری که در حال انجام بودیم برگردیم. با متن اگر
701
00:32:38,509 –> 00:32:41,450
من آیا Train X 0 را انجام دادم اکنون لازم نیست که txt را انجام دهم
702
00:32:41,450 –> 00:32:44,479
و می بینید که متنی که
703
00:32:44,479 –> 00:32:46,149
قبلاً دیده بودیم وجود دارد
704
00:32:46,149 –> 00:32:49,609
به طور مشابه قطار Y باید به ما بگوید که
705
00:32:49,609 –> 00:32:52,789
احساسات مثبت همانطور که می بینید
706
00:32:52,789 –> 00:32:56,389
مثبت است، بنابراین اکنون آن را تقسیم کرده ایم تا
707
00:32:56,389 –> 00:32:58,969
واقعاً باشد. X ما X همان چیزی است که ما
708
00:32:58,969 –> 00:33:00,469
در آن قبول می کنیم و سپس Y چیزی است که ما سعی می کنیم
709
00:33:00,469 –> 00:33:03,109
پیش بینی کنیم، بنابراین برای آموزش از x و
710
00:33:03,109 –> 00:33:07,249
y با هم استفاده می کنیم تا دوست داشته باشیم که چگونه مدل خود را بسازیم
711
00:33:07,249 –> 00:33:10,369
و سپس وقتی در حال آزمایش هستیم،
712
00:33:10,369 –> 00:33:15,639
فقط روی تست آزمایش می کنیم. X که قرار است به صورت
713
00:33:15,639 –> 00:33:19,599
X نقطه متن باشد
714
00:33:20,340 –> 00:33:25,780
4xn تست و تست چرا
715
00:33:25,780 –> 00:33:30,280
همان احساس نقطه Y X برای X
716
00:33:30,280 –> 00:33:35,340
و تست خواهد بود، پس بله، بنابراین وقتی
717
00:33:35,340 –> 00:33:38,170
میخواهیم مدل خود را آزمایش کنیم، آیا فقط
718
00:33:38,170 –> 00:33:40,960
X را تست میکنیم و ببینیم آیا آن را آزمایش میکنیم؟ دقیقاً با
719
00:33:40,960 –> 00:33:43,060
تست y مطابقت دارد، اما در یک ثانیه مشکلی
720
00:33:43,060 –> 00:33:45,490
نیست، بنابراین متاسفم که منحرف شدم، اما
721
00:33:45,490 –> 00:33:48,390
بردارسازی کلمات در این مورد، بنابراین
722
00:33:48,390 –> 00:33:51,340
یک بار دیگر این موضوع رایج است، شما می
723
00:33:51,340 –> 00:33:53,530
دانید که ما این روش کیسه ای از urns را
724
00:33:53,530 –> 00:33:55,510
داریم که می خواهیم انجام دهیم انجام دهید، اما چگونه میتوانیم
725
00:33:55,510 –> 00:33:57,700
آن را با SK انجام دهیم خوب یاد بگیرید،
726
00:33:57,700 –> 00:33:59,650
اجازه دهید یک جستجوی سریع دیگر در گوگل انجام
727
00:33:59,650 –> 00:34:01,690
دهیم. احتمالاً یک شرط مطمئن است
728
00:34:01,690 –> 00:34:04,660
که چه اتفاقی میافتد، بنابراین ما مجموعهای از
729
00:34:04,660 –> 00:34:07,630
این پاسخها را دریافت میکنیم و بار دیگر ابتدا
730
00:34:07,630 –> 00:34:09,880
احتمالاً اینها
731
00:34:09,880 –> 00:34:11,440
گزینههای خوبی خواهند بود، من فقط
732
00:34:11,440 –> 00:34:14,830
روی کار با دادههای متنی اینجا کلیک میکنم، به نظر
733
00:34:14,830 –> 00:34:16,690
میرسد کمی وجود دارد.
734
00:34:16,690 –> 00:34:20,290
735
00:34:20,290 –> 00:34:26,530
736
00:34:26,530 –> 00:34:27,130
737
00:34:27,130 –> 00:34:31,750
برای انجام
738
00:34:31,750 –> 00:34:33,310
یادگیری ماشینی بر روی اسناد متنی،
739
00:34:33,310 –> 00:34:35,440
ابتدا باید محتوای متن را به
740
00:34:35,440 –> 00:34:36,880
بردارهای عددی تبدیل
741
00:34:36,880 –> 00:34:38,050
کنیم. در این
742
00:34:38,050 –> 00:34:40,449
آموزش تاکنون در مورد شهودی ترین راه برای انجام
743
00:34:40,449 –> 00:34:42,909
این کار صحبت کرده ام، بنابراین نمایش معکوس است، بنابراین
744
00:34:42,909 –> 00:34:44,679
آنها توضیحات کمی در اینجا دارند
745
00:34:44,679 –> 00:34:47,739
و سپس همانطور که در اینجا می بینیم به نظر می رسد
746
00:34:47,739 –> 00:34:49,330
که آنها در واقع این کار را با SK Learn انجام می دهند،
747
00:34:49,330 –> 00:34:51,580
بنابراین این فوق العاده به نظر می رسد. به راحتی
748
00:34:51,580 –> 00:34:53,290
میتوانیم فقط این خطوط را کپی کنیم، بنابراین من
749
00:34:53,290 –> 00:34:57,340
این خط را همینجا کپی میکنم و بعد
750
00:34:57,340 –> 00:35:00,280
شمارش میکنم خیلی خوب است و ممکن است
751
00:35:00,280 –> 00:35:01,660
در واقع چیزی که مفید است جستجوی
752
00:35:01,660 –> 00:35:03,390
بردار شمارش باشد،
753
00:35:03,390 –> 00:35:05,140
زیرا واقعاً به همین شکل است. nna
754
00:35:05,140 –> 00:35:11,770
می خواهم این کار را انجام دهم زیرا فقط
755
00:35:11,770 –> 00:35:14,440
یک مثال خوب به آن نشان می دهد و اگر به
756
00:35:14,440 –> 00:35:17,770
اینجا برویم چیزی که اغلب حتی
757
00:35:17,770 –> 00:35:19,060
مفیدترین است و من سعی می کنم
758
00:35:19,060 –> 00:35:21,580
با یک
759
00:35:21,580 –> 00:35:24,400
کتابخانه یا ابزار یا روش SK larren آشنا شوم پیدا کردن آن است.
760
00:35:24,400 –> 00:35:26,080
به عنوان مثال، آنها همیشه نمونه هایی را در مستندات ارائه می دهند
761
00:35:26,080 –> 00:35:26,850
762
00:35:26,850 –> 00:35:29,640
و بنابراین اگر من به این مثال نگاه کنم،
763
00:35:29,640 –> 00:35:33,230
این چهار سند را در مجموعه خود دارد و
764
00:35:33,230 –> 00:35:37,200
همانطور که می بینید، این
765
00:35:37,200 –> 00:35:38,850
ویژگی ها را در اینجا استخراج می کند و اگر مجموعه ای از کلمات را به خاطر دارید
766
00:35:38,850 –> 00:35:41,280
که ما به تازگی مرور کردیم، این است
767
00:35:41,280 –> 00:35:43,980
آخرین ویژگی بنابراین برای اولین
768
00:35:43,980 –> 00:35:46,320
سند کلمه this ظاهر می شود بنابراین باید
769
00:35:46,320 –> 00:35:48,060
یک مورد در آخرین نقطه برای سند اول
770
00:35:48,060 –> 00:35:50,640
771
00:35:50,640 –> 00:35:53,670
772
00:35:53,670 –> 00:35:56,160
وجود داشته
773
00:35:56,160 –> 00:35:57,990
باشد. نکته ای که باید به آن توجه کرد که
774
00:35:57,990 –> 00:35:59,610
کمی متفاوت است این است
775
00:35:59,610 –> 00:36:01,830
که با این فشرده ساز یک چیز باینری نیست.
776
00:36:01,830 –> 00:36:05,190
777
00:36:05,190 –> 00:36:08,460
778
00:36:08,460 –> 00:36:12,090
779
00:36:12,090 –> 00:36:13,490
این
780
00:36:13,490 –> 00:36:17,240
باینری را بزنید تا بتوانید فقط یک یا صفر
781
00:36:17,240 –> 00:36:19,770
را انجام دهید، باید دوبار بررسی کنم که
782
00:36:19,770 –> 00:36:22,530
واقعاً در اینجا باینری هستید تا
783
00:36:22,530 –> 00:36:23,790
تعداد غیر صفر فقط روی یک تنظیم شود در
784
00:36:23,790 –> 00:36:25,260
مقابل دو تا بتوانید بازی
785
00:36:25,260 –> 00:36:27,060
کنید و ببینید چه چیزی برای شما بهتر است. مدل،
786
00:36:27,060 –> 00:36:29,100
اما بیایید ادامه دهیم و در واقع این کار را
787
00:36:29,100 –> 00:36:33,060
اکنون با چیز خود انجام دهیم، بنابراین من آن را کپی می کنم، یکی از
788
00:36:33,060 –> 00:36:34,710
موارد قابل توجه این است که اگر می خواهید از
789
00:36:34,710 –> 00:36:38,250
روش شیفت تب برای دیدن اسناد
790
00:36:38,250 –> 00:36:40,110
استفاده کنید، ابتدا باید سلول خود را اجرا کنید، آن را نمی
791
00:36:40,110 –> 00:36:42,510
شناسد. به دنبال چه چیزی است مگر اینکه شما انجام دهید
792
00:36:42,510 –> 00:36:44,730
که من مدتی پیش خودم را به زمین انداختم
793
00:36:44,730 –> 00:36:46,770
اما این کار را درست انجام ندادم، بنابراین آنچه در
794
00:36:46,770 –> 00:36:49,230
آن مثال بردار برابر با بردار شمارنده است،
795
00:36:49,230 –> 00:36:51,150
ما فقط آن را در سلول خود کپی می
796
00:36:51,150 –> 00:36:56,790
کنیم و بله از اینجا ظاهر می شد
797
00:36:56,790 –> 00:36:58,970
.
798
00:37:03,760 –> 00:37:06,820
او یک پیمانکار است و
799
00:37:06,820 –> 00:37:17,320
پس از آن، پیکره را تبدیل میکند خوب
800
00:37:17,320 –> 00:37:25,030
و بردار، تبدیل به نقطه تناسب میشود و حالا
801
00:37:25,030 –> 00:37:27,790
پیکره ما بهجای اینکه مجموعه مروری کوچکی باشد
802
00:37:27,790 –> 00:37:30,520
که در اینجا به ما نشان دادهاند،
803
00:37:30,520 –> 00:37:32,170
در واقع فقط تمام بررسیهای آموزشی ما است،
804
00:37:32,170 –> 00:37:36,970
بنابراین آموزشدیده باشید و پس
805
00:37:36,970 –> 00:37:39,820
چه میگیریم وقتی ما Ru n که آه یک
806
00:37:39,820 –> 00:37:42,190
ماتریس واقعاً بزرگ است، بنابراین ششصد و
807
00:37:42,190 –> 00:37:44,070
هفتاد است، بنابراین هر یک از
808
00:37:44,070 –> 00:37:48,400
مقادیر آموزشی ما هستند، بنابراین همه
809
00:37:48,400 –> 00:37:50,710
آنها ردیف خود را دارند و هر یک از آن
810
00:37:50,710 –> 00:37:52,359
ردیفها هفت هزار و سیصد و
811
00:37:52,359 –> 00:37:54,369
هفتاد و دو ستون دارند، بنابراین این واقعاً یک
812
00:37:54,369 –> 00:37:56,140
ماتریس واقعاً عظیم، بسیار بزرگتر
813
00:37:56,140 –> 00:37:58,450
از این ماتریس نمونه کوچک است، اما
814
00:37:58,450 –> 00:38:00,220
دوباره اگر به این ماتریس فکر کنیم،
815
00:38:00,220 –> 00:38:04,810
منطقی است که چرا بزرگتر است، زیرا ما
816
00:38:04,810 –> 00:38:06,609
اکنون ششصد و هفتاد سند داریم
817
00:38:06,609 –> 00:38:09,220
که همگی طولانی تر از این تکه های
818
00:38:09,220 –> 00:38:11,980
متن هستند، بنابراین ماتریس ما زیبا است.
819
00:38:11,980 –> 00:38:14,440
خیلی بزرگ است، اما برای کامپیوتر ما آنقدرها هم مشکل نیست
820
00:38:14,440 –> 00:38:15,790
، بنابراین ما با این وکتورایزر کاملاً خوب خواهیم بود،
821
00:38:15,790 –> 00:38:18,369
822
00:38:18,369 –> 00:38:22,150
خوب حالا که این وکتوریزر را داریم، میتوانیم ادامه دهیم
823
00:38:22,150 –> 00:38:23,770
و شروع به آماده شدن
824
00:38:23,770 –> 00:38:26,109
برای ساختن یک مدل در اطراف آن کنیم، بنابراین
825
00:38:26,109 –> 00:38:30,430
اساساً خروجی و آنچه
826
00:38:30,430 –> 00:38:33,100
ما در اینجا می بینیم چیزی است که در واقع
827
00:38:33,100 –> 00:38:36,880
می خواهیم از آن به عنوان ورودی آموزشی خود استفاده کنیم
828
00:38:36,880 –> 00:38:42,580
، مانند قبل از اینکه قطار X داشته باشیم
829
00:38:42,580 –> 00:38:45,280
که برابر است.
830
00:38:45,280 –> 00:38:50,230
831
00:38:50,230 –> 00:38:53,020
این سریع واقعی دقیقاً مانند
832
00:38:53,020 –> 00:38:56,859
یک متن بود که اکنون خروجی آن
833
00:38:56,859 –> 00:39:02,560
مانند قطار X بردارها برابر است با آن و اکنون
834
00:39:02,560 –> 00:39:09,820
اگر ما بردارهای X را آموزش دهیم ماتریسی دریافت می
835
00:39:09,820 –> 00:39:13,750
کنیم که نشان دهنده آن است، من فقط
836
00:39:13,750 –> 00:39:16,830
هر دوی این موارد را
837
00:39:19,410 –> 00:39:22,390
چاپ می کنم. این متن را داشته باشید و اکنون
838
00:39:22,390 –> 00:39:25,300
این بردارهای قطار X در اینجا ماتریسی است
839
00:39:25,300 –> 00:39:28,630
که این متن را نشان میدهد، بنابراین
840
00:39:28,630 –> 00:39:31,150
همانطور که در اینجا میبینید دارای یکی است و همه
841
00:39:31,150 –> 00:39:33,430
موقعیتها در واقع
842
00:39:33,430 –> 00:39:36,369
برای یک کلمه خاص همه
843
00:39:36,369 –> 00:39:39,280
موقعیتهایی را که در ماتریس ما غیر صفر هستند، دو میشمرد.
844
00:39:39,280 –> 00:39:40,660
و اگر میخواستید روش سنتیتری را ببینید،
845
00:39:40,660 –> 00:39:42,520
من فکر میکنم خوب است که
846
00:39:42,520 –> 00:39:46,510
آرایه کنید و این کل ماتریس است، اما
847
00:39:46,510 –> 00:39:47,950
چون هفت هزار و
848
00:39:47,950 –> 00:39:49,240
سیصد و هفتاد و دو بود، نمیتوانیم
849
00:39:49,240 –> 00:39:50,860
کل چیز را ببینیم، اما فقط میدانیم که
850
00:39:50,860 –> 00:39:53,940
در داخل این یک مورد وجود دارد هر جا که
851
00:39:53,940 –> 00:39:56,740
این قطعه متن چیزی را
852
00:39:56,740 –> 00:39:58,260
در وکتوریزر ما راهاندازی کرده
853
00:39:58,260 –> 00:40:02,619
باشد، اگر امیدوارم درست باشد،
854
00:40:02,619 –> 00:40:04,930
و یک چیز که دانستن آن نیز
855
00:40:04,930 –> 00:40:08,770
مفید میدانم این است که در این مرحله
856
00:40:08,770 –> 00:40:10,660
دقیقاً در اینجا ما بهطور همزمان دو مرحله
857
00:40:10,660 –> 00:40:14,890
را انجام دادیم. وکتورایزر به این
858
00:40:14,890 –> 00:40:16,210
داده های آموزشی و سپس ما نیز
859
00:40:16,210 –> 00:40:18,490
داده های آموزشی خود را تغییر دادیم تا
860
00:40:18,490 –> 00:40:21,970
این بردارهای X آموزش دیده را به ما ارائه دهیم، شما
861
00:40:21,970 –> 00:40:24,210
می توانید این کار را به همین روش در دو مرحله انجام دهید
862
00:40:24,210 –> 00:40:27,190
، اساساً دو تابع جداگانه وجود دارد
863
00:40:27,190 –> 00:40:29,020
که می توانید استفاده کنید تا بتوانید اولین
864
00:40:29,020 –> 00:40:34,480
نقطه بردار را با قطار X انجام دهید. و
865
00:40:34,480 –> 00:40:37,960
هر کاری را انجام میدهد که فقط با
866
00:40:37,960 –> 00:40:43,119
دادههای آموزشی مطابقت داشته باشد و سپس اگر آموزش
867
00:40:43,119 –> 00:40:47,980
بردار X برابر با
868
00:40:47,980 –> 00:40:53,560
قطار تبدیل نقطهای بردار X باشد،
869
00:40:53,560 –> 00:40:57,310
همان نتیجه نهایی را میگیرید، بنابراین چیزی که من میگویم این است
870
00:40:57,310 –> 00:40:59,920
که این دو مرحله در این جا متناسب و تبدیل میشوند
871
00:40:59,920 –> 00:41:03,070
. تبدیل تابع تناسب
872
00:41:03,070 –> 00:41:06,160
آنها دقیقاً همان چیزی هستند که آن را به صورت یکپارچه در آن قرار دادند
873
00:41:06,160 –> 00:41:07,780
زیرا شما اغلب می خواهید یک
874
00:41:07,780 –> 00:41:09,609
مدل را جابجا کنید سپس چیزهایی را که آنها
875
00:41:09,609 –> 00:41:11,859
نیز چنین کمکی برای آنها دارند در یک
876
00:41:11,859 –> 00:41:15,280
تابع تبدیل کنید، اما انجام آن در دو
877
00:41:15,280 –> 00:41:17,980
مرحله یکسان بود.
878
00:41:17,980 –> 00:41:20,170
دانستن آن بسیار مفید است زیرا
879
00:41:20,170 –> 00:41:22,060
من فکر میکنم اکثر خطوط SK مانند یک فیت تبدیل
880
00:41:22,060 –> 00:41:25,300
مناسب و تبدیل است و معمولاً شما
881
00:41:25,300 –> 00:41:26,470
میخواهید
882
00:41:26,470 –> 00:41:28,569
ابتدا آن را جابجا کنید و تبدیل کنید، اما اکنون در واقع
883
00:41:28,569 –> 00:41:29,980
زمانی که ما دوست داریم با wi بازی کنیم. با
884
00:41:29,980 –> 00:41:33,069
دریافت بردارهای X آزمون خود، نمایشهای عددی
885
00:41:33,069 –> 00:41:36,730
886
00:41:36,730 –> 00:41:39,720
متن مجموعه آزمایشی خود را درست میکنیم، ما فقط میتوانیم
887
00:41:39,720 –> 00:41:43,569
تبدیل نقطهای بردار را انجام دهیم،
888
00:41:43,569 –> 00:41:45,430
زیرا نمیخواهیم مدل جدیدی را متناسب کنیم،
889
00:41:45,430 –> 00:41:49,690
بنابراین شما فقط آن را به متن X تبدیل کنید.
890
00:41:49,690 –> 00:41:54,460
این قطار X بردارها را اکنون
891
00:41:54,460 –> 00:41:57,430
دادههای نهایی ما اساساً بردارهای قطار X
892
00:41:57,430 –> 00:42:02,050
و قطار Y هستند و اساساً
893
00:42:02,050 –> 00:42:04,000
میخواهیم مدلی را در اطراف آنها قرار
894
00:42:04,000 –> 00:42:05,829
دهیم، بنابراین بیایید شروع به انتخاب
895
00:42:05,829 –> 00:42:08,800
مدل مناسب کنیم، خوب ما X خودمان را داریم و
896
00:42:08,800 –> 00:42:10,270
حالا بیایید در واقع برخی از آنها را انجام دهیم.
897
00:42:10,270 –> 00:42:13,869
طبقهبندی و SK Learn
898
00:42:13,869 –> 00:42:16,720
تعداد زیادی طبقهبندیکننده مختلف را ارائه میدهد، بنابراین من
899
00:42:16,720 –> 00:42:18,250
میخواهم برخی از
900
00:42:18,250 –> 00:42:20,760
گزینهها را مرور کنم و این بخش بزرگی از
901
00:42:20,760 –> 00:42:22,540
این است که همه این گزینهها برای
902
00:42:22,540 –> 00:42:24,670
طبقهبندیکنندهها وجود دارد، اما مگر اینکه شما به نوعی
903
00:42:24,670 –> 00:42:26,770
روی این طبقهبندیکنندهها مطالعه کنید و
904
00:42:26,770 –> 00:42:28,569
کمی شبیه به درک نظری تر
905
00:42:28,569 –> 00:42:30,190
از آنها باشید،
906
00:42:30,190 –> 00:42:34,720
گاهی اوقات تصمیم گیری دشوار است، بنابراین مانند اینجا
907
00:42:34,720 –> 00:42:37,359
یک مثال مقایسه طبقه بندی کننده است و می
908
00:42:37,359 –> 00:42:40,420
توانید تمام این انواع مختلف
909
00:42:40,420 –> 00:42:42,550
طبقه بندی کننده ها را ببینید که همه ساخته شده اند.
910
00:42:42,550 –> 00:42:45,609
به راحتی از طریق یادگیری SK و آنچه من توصیه می کنم این
911
00:42:45,609 –> 00:42:46,990
است که اگر می خواهید
912
00:42:46,990 –> 00:42:49,990
بفهمید کدام طبقه بندی درست است، می
913
00:42:49,990 –> 00:42:52,119
دانید که جستجوی اضافی در گوگل انجام دهید
914
00:42:52,119 –> 00:42:54,480
برخی از ویدیوهای یوتیوب را در این موارد تماشا کنید، من
915
00:42:54,480 –> 00:42:57,490
می دانم مانند MIT OpenCourseWare
916
00:42:57,490 –> 00:42:59,260
استاد واقعی که در زمان من داشتم. داشتم
917
00:42:59,260 –> 00:43:01,420
در کلاس هوش مصنوعی در MIT شرکت
918
00:43:01,420 –> 00:43:04,150
میکردم که متأسفانه درگذشت، اما اگر من مانند
919
00:43:04,150 –> 00:43:09,490
SVM MIT خطی نگاه میکردم، میدانید که همه
920
00:43:09,490 –> 00:43:11,410
این سخنرانیها را میگیرید که اطلاعات خوبی را
921
00:43:11,410 –> 00:43:14,109
دریافت میکنید و درک نظری بیشتری به دست میآورید تا
922
00:43:14,109 –> 00:43:16,060
بتوانید به نوعی از آن عبور کنید و شکل را دوست داشته باشید.
923
00:43:16,060 –> 00:43:18,579
آنچه را که میدانید برای
924
00:43:18,579 –> 00:43:20,890
این مدلهای مختلف احساس کنید و شاید
925
00:43:20,890 –> 00:43:23,230
احساس کنید که کدام یک بهتر است،
926
00:43:23,230 –> 00:43:26,609
بخش دیگر این است که میدانید
927
00:43:26,609 –> 00:43:29,349
بخشی از آن فقط آزمایش است، فقط
928
00:43:29,349 –> 00:43:31,150
مدل خود را آموزش دهید که آن را روی دادههای تست
929
00:43:31,150 –> 00:43:32,890
اجرا کند و ببینید چه عملکردی دارد. بهتر است که
930
00:43:32,890 –> 00:43:34,210
ما یک جفت از اینها را متناسب با چند
931
00:43:34,210 –> 00:43:35,560
مدل مختلف انتخاب کنیم و عملکرد
932
00:43:35,560 –> 00:43:36,089
آنها
933
00:43:36,089 –> 00:43:39,749
را ببینیم، بنابراین اگر
934
00:43:39,749 –> 00:43:43,650
من هر دوی اینها را هسته خطی
935
00:43:43,650 –> 00:43:48,289
بگیرم، یک SVM می گیریم. احتمالاً
936
00:43:48,289 –> 00:43:51,269
نوعی درخت تصمیم را انجام میدهم،
937
00:43:51,269 –> 00:43:54,269
بیز سادهلوح را وارد میکنم، شاید ما
938
00:43:54,269 –> 00:43:56,430
نیز انجام دهیم، فکر میکنم رگرسیون رگرسیون لجستیک
939
00:43:56,430 –> 00:44:00,449
که اینجا نیست، اما مشکلی ندارد، بنابراین
940
00:44:00,449 –> 00:44:03,709
ما SVM را وارد میکنیم تا خوب شروع شود،
941
00:44:03,709 –> 00:44:07,759
بنابراین
942
00:44:12,560 –> 00:44:21,450
طبقهبندی با یک SVM خطی شروع شود. و استفاده از آن بسیار
943
00:44:21,450 –> 00:44:25,800
ساده است، ما فقط می
944
00:44:25,800 –> 00:44:28,830
توانیم طبقه بندی کننده را انجام دهیم و من فقط می گویم
945
00:44:28,830 –> 00:44:32,790
طبقه بندی کننده SVM SVC طبقه بندی کننده بردار پشتیبان،
946
00:44:32,790 –> 00:44:34,460
فکر می کنم مخفف آن است که
947
00:44:34,460 –> 00:44:36,840
اغلب اوقات شما نیز SVM ماشین بردار پشتیبانی را می بینید،
948
00:44:36,840 –> 00:44:42,330
بنابراین ما در واقع فکر می کنم
949
00:44:42,330 –> 00:44:44,510
به طور کلی می توانید این کار را انجام دهید. از SK یاد بگیرید
950
00:44:44,510 –> 00:44:55,100
import SVM را انجام دهید و ما می توانیم sv m dot SVC را انجام دهیم
951
00:44:55,100 –> 00:44:58,440
و اگر من نگاه کنم این را اجرا کنید و
952
00:44:58,440 –> 00:45:01,680
فقط مستندات را در اینجا جستجو کنم چند
953
00:45:01,680 –> 00:45:10,400
چیز وجود دارد که در مقدار هسته C ارسال می
954
00:45:10,400 –> 00:45:13,530
کنیم و بله با خواندن مستندات
955
00:45:13,530 –> 00:45:15,270
پارامتر جریمه C از عبارت خطا را
956
00:45:15,270 –> 00:45:17,130
می خوانیم. میدانید که نظریه را بخوانید،
957
00:45:17,130 –> 00:45:18,300
کمی بیشتر از
958
00:45:18,300 –> 00:45:20,190
این پارامترهای مختلف ایده خواهید داشت، خوب است
959
00:45:20,190 –> 00:45:23,250
بدانید با چه چیزی میتوانید بازی کنید، بنابراین
960
00:45:23,250 –> 00:45:26,130
برای شروع این تئوری را خطی
961
00:45:26,130 –> 00:45:30,950
میکنیم، بنابراین میخواهیم بگوییم که هسته برابر با خط است. ar
962
00:45:30,950 –> 00:45:32,970
اما ما میتوانیم به همه گزینههای مختلف
963
00:45:32,970 –> 00:45:36,480
مانند هستهها نگاه کنیم، یک گزینه C
964
00:45:36,480 –> 00:45:39,170
پارامتر دیگری است که میتوانید با گاما بازی
965
00:45:39,170 –> 00:45:42,060
966
00:45:42,060 –> 00:45:47,850
967
00:45:47,850 –> 00:45:51,000
968
00:45:51,000 –> 00:45:53,430
کنید. طبقهبندیکننده برای
969
00:45:53,430 –> 00:45:55,610
X و Y که در اینجا تعریف
970
00:45:55,610 –> 00:46:01,740
کردیم، میتوانیم Co چپ SVM را انجام دهیم و این
971
00:46:01,740 –> 00:46:03,950
باید یک دستور آشنا باشد تا شما
972
00:46:03,950 –> 00:46:07,700
بردارهای قطار X را متناسب کنید
973
00:46:07,700 –> 00:46:11,839
و چرایی را آموزش دهید، بنابراین ما در یک X و Y عبور میدهیم تا
974
00:46:11,839 –> 00:46:15,589
این طبقهبندی کننده را با دادههایمان در آنجا جا دهیم. ما
975
00:46:15,589 –> 00:46:18,710
می رویم و بعد چه جالب این است که می توانیم
976
00:46:18,710 –> 00:46:20,869
جلو برویم و من چیزی را پیش بینی می کنم، بنابراین بر
977
00:46:20,869 –> 00:46:23,510
اساس تمام بررسی های آموزشی که داشتیم،
978
00:46:23,510 –> 00:46:27,920
می توانیم جلو برویم و CL f sv m dot را
979
00:46:27,920 –> 00:46:31,010
پیش بینی کنیم و خیلی سریع باید
980
00:46:31,010 –> 00:46:33,349
چیزی برای پیش بینی به دست آوریم، بنابراین شاید ما فقط
981
00:46:33,349 –> 00:46:38,839
به بالا نگاه کنید، من می خواهم نسخه را کپی کنم،
982
00:46:38,839 –> 00:46:42,400
آزمایش ما را به سرعت چاپ کنم X 0
983
00:46:42,400 –> 00:46:47,349
ببینیم، بنابراین این یک آشکارسازی مثبت است، به
984
00:46:47,349 –> 00:46:51,680
نظر می رسد که ما می توانیم
985
00:46:51,680 –> 00:47:02,900
بردار آن را نیز مانند بردارها دریافت کنیم. فکر می کنم
986
00:47:02,900 –> 00:47:07,900
من تعریف کردم. که شاید آموزش نباشد – بردارها
987
00:47:07,900 –> 00:47:12,650
تا آزمون X حقیقت را بدست آوریم یا میتوانیم به
988
00:47:12,650 –> 00:47:14,000
نوعی انجام دهیم تا بفهمیم که
989
00:47:14,000 –> 00:47:22,430
تست خطا X بردار برابر با بردار است و
990
00:47:22,430 –> 00:47:24,230
نمیخواهیم دوباره جاسازی کنیم، فقط میخواهیم
991
00:47:24,230 –> 00:47:26,559
تبدیل کنیم زیرا این دادههای آزمایشی ما است
992
00:47:26,559 –> 00:47:29,980
فقط X
9


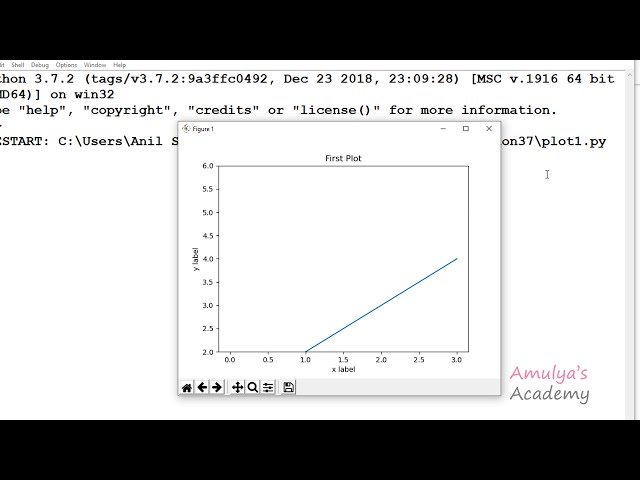

![فیلم آموزشی: [اپریل Fools 2021] Python 4.0! چاپ قدیمی جدید، تایپ استاتیک اجباری، ادغام StackOverflow با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/lC6JtoSN-KQimage2.jpg)



![فیلم آموزشی: دوره سقوط پایتون [TAGALOG]](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/LQA4WSg011kimage2.jpg)


