در این مطلب، ویدئو آموزش 46- مدیریت مجموعه داده های نامتعادل با استفاده از پایتون- قسمت 2 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:58
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,800 –> 00:00:04,110
سلام به همه ما قسمت
2
00:00:04,110 –> 00:00:06,839
دوم رفع مجموعه داده های عدم تعادل را ادامه خواهیم داد و
3
00:00:06,839 –> 00:00:08,490
این تکنیک خاص با استفاده
4
00:00:08,490 –> 00:00:11,250
از نمونه برداری بیش از حد مثال قبلی است که
5
00:00:11,250 –> 00:00:13,110
قبلاً در مورد نمونه گیری زیر نشان داده ام اما
6
00:00:13,110 –> 00:00:15,389
این بار با پایه
7
00:00:15,389 –> 00:00:19,199
نمونه برداری بیش از حد در حال حاضر خواهد بود. قبلاً توضیح دادهام
8
00:00:19,199 –> 00:00:20,850
که چه چیزی بیش از نمونهگیری است، اما اجازه دهید
9
00:00:20,850 –> 00:00:22,980
تکرار کنم آنچه اتفاق میافتد این است که در
10
00:00:22,980 –> 00:00:25,260
نمونهگیری ما فرض کنید من یک مجموعه داده دارم
11
00:00:25,260 –> 00:00:27,449
، من یک مجموعه داده نامتعادل دارم که
12
00:00:27,449 –> 00:00:29,789
چیزی شبیه به این است، زیرا من
13
00:00:29,789 –> 00:00:32,340
در اینجا امتیاز بیشتری دارم، در اینجا نقاط بیشتری دارم
14
00:00:32,340 –> 00:00:33,920
15
00:00:33,920 –> 00:00:37,280
و فرض کنید تعداد
16
00:00:37,280 –> 00:00:40,399
امتیازهای من در اینجا از یک دسته
17
00:00:40,399 –> 00:00:42,680
در حال حاضر کمتر است، می توانید ببینید که فرض کنید
18
00:00:42,680 –> 00:00:44,780
این امتیاز خاص است، تعداد کل
19
00:00:44,780 –> 00:00:46,550
حدود 900 است و این
20
00:00:46,550 –> 00:00:48,500
نقطه خاص، تعداد کل 100
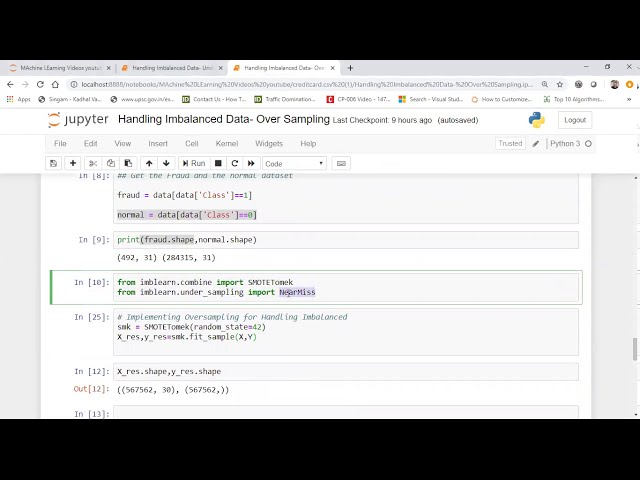
21
00:00:48,500 –> 00:00:51,290
است در نمونه برداری بیش از آنچه انجام می دهیم این است که
22
00:00:51,290 –> 00:00:53,150
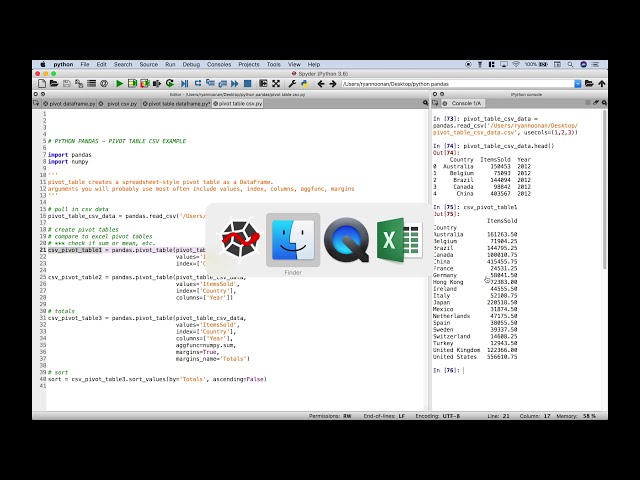
ما تحت چیزی با
23
00:00:53,150 –> 00:00:55,550
عدم کاهش نقاط کار نمی کنیم، در عوض، کاری که انجام می دهیم این
24
00:00:55,550 –> 00:00:58,760
است که اکنون یک مجموعه داده جدید ایجاد می کنیم
25
00:00:58,760 –> 00:01:00,739
که چیزی شبیه به این خواهد بود و
26
00:01:00,739 –> 00:01:04,069
همه نقاط، همه آنها خواهند بود.
27
00:01:04,069 –> 00:01:05,810
نقاط انحلال فقط جایگزین می شوند تا اینجا باشند
28
00:01:05,810 –> 00:01:08,840
فقط به عنوان شمارش
29
00:01:08,840 –> 00:01:11,450
برای ما در اینجا در نظر گرفته می شود، اما برای این نقاط
30
00:01:11,450 –> 00:01:14,660
کاری که ما انجام می دهیم این است که ما هنوز
31
00:01:14,660 –> 00:01:18,110
چند امتیاز دیگر را در همان ابعاد بیهوده اضافه می کنیم،
32
00:01:18,110 –> 00:01:20,899
منظورم در همان بعد است که سعی می کنیم
33
00:01:20,899 –> 00:01:22,759
امتیاز را افزایش دهید، فرض کنید یک
34
00:01:22,759 –> 00:01:24,850
فاصله بود، سعی می کنیم آن عدد را افزایش دهیم،
35
00:01:24,850 –> 00:01:27,500
فرض کنید این اساساً منهای دو یک
36
00:01:27,500 –> 00:01:29,210
است برای هر امتیاز، سعی می کنیم
37
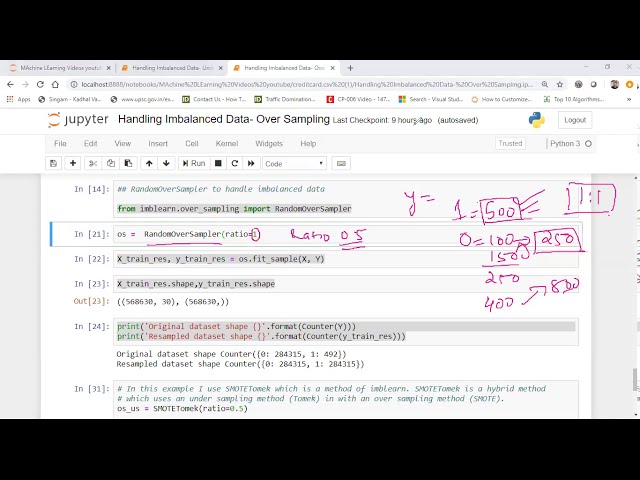
00:01:29,210 –> 00:01:32,060
9 برابر افزایش دهیم، می دانید که ما
38
00:01:32,060 –> 00:01:35,000
9 نقطه جدید در بالای
39
00:01:35,000 –> 00:01:37,039
آن نقاط ایجاد خواهیم کرد. زانو در واقع
40
00:01:37,039 –> 00:01:40,610
وجود داشت و تا این
41
00:01:40,610 –> 00:01:43,150
لحظه نسبت شما 1 به 1 خواهد بود یا تقریباً
42
00:01:43,150 –> 00:01:46,430
برابر با 1 به 1 خواهد بود، بنابراین این روشی است
43
00:01:46,430 –> 00:01:49,220
که شما با نمونهبرداری انجام میدهید و در اینجا
44
00:01:49,220 –> 00:01:52,460
در نمونهبرداری بیشازحد بسیاری از
45
00:01:52,460 –> 00:01:54,170
بیانهای مسئله را انجام میدهید. نمونه برداری بیش از حد
46
00:01:54,170 –> 00:01:56,720
به جای انجام زیر نمونه برداری
47
00:01:56,720 –> 00:01:59,360
و بسیار کارآمدتر از نمونه گیری زیر است
48
00:01:59,360 –> 00:02:01,040
زیرا در درک
49
00:02:01,040 –> 00:02:02,869
مقداری از داده ها را از دست می دهیم اما در صورت
50
00:02:02,869 –> 00:02:05,090
نمونه گیری ما این نیست که
51
00:02:05,090 –> 00:02:06,860
سعی کنیم داده های بیشتری را برای
52
00:02:06,860 –> 00:02:08,299
حضور در خود ایجاد کنیم. در حال تلاش برای ایجاد این
53
00:02:08,299 –> 00:02:10,610
مجموعه دادههای عدم تعادل در تلاش برای رفع این
54
00:02:10,610 –> 00:02:13,400
قاره آمریکا هستیم، اکنون ادامه میدهیم و میبینیم که چگونه
55
00:02:13,400 –> 00:02:16,070
میتوانیم با کمک کد پایتون
56
00:02:16,070 –> 00:02:19,100
و به عنوان کتابخانهای که در بخش قبلی به شما گفتم
57
00:02:19,100 –> 00:02:20,810
که به نام
58
00:02:20,810 –> 00:02:24,350
من متعادل میکنم این کار را انجام دهیم. از آن
59
00:02:24,350 –> 00:02:27,799
کتابخانه خاصی که من استفاده خواهم کرد، بنابراین برای شروع
60
00:02:27,799 –> 00:02:29,959
، از همان مجموعه داده استفاده
61
00:02:29,959 –> 00:02:34,760
می کنم که کارت اعتباری کارت من است و این از
62
00:02:34,760 –> 00:02:36,530
مسابقه Carroll است که این
63
00:02:36,530 –> 00:02:38,239
مجموعه داده خاص را گرفته است، فکر می کنم همه
64
00:02:38,239 –> 00:02:39,320
تا اینجا آشنا هستند
65
00:02:39,320 –> 00:02:42,920
زیرا در تراکنش به من اجازه می دهد
66
00:02:42,920 –> 00:02:45,110
کمی بزرگنمایی کنم، بنابراین در اینجا
67
00:02:45,110 –> 00:02:47,209
توزیع کلاس تراکنش من است، می توانید
68
00:02:47,209 –> 00:02:47,660
ببینید که
69
00:02:47,660 –> 00:02:50,240
من بیش از دو مورد مانند 50000 دارم، زیرا
70
00:02:50,240 –> 00:02:52,700
این تراکنش ها عادی هستند، اما
71
00:02:52,700 –> 00:02:54,530
تعداد رکوردهایی که مانند تراکنش کلاهبرداری هستند بسیار کمتر است.
72
00:02:54,530 –> 00:02:58,040
بنابراین
73
00:02:58,040 –> 00:03:00,050
اکنون این کاملاً یک مجموعه داده عدم تعادل است،
74
00:03:00,050 –> 00:03:02,030
ما باید آن را برطرف کنیم، اکنون در
75
00:03:02,030 –> 00:03:05,090
حال تلاش برای رفع این مشکل با استفاده از OERها هستیم و
76
00:03:05,090 –> 00:03:06,980
هیچ داده ای را از دست نمی دهیم در عوض ما
77
00:03:06,980 –> 00:03:10,070
در حال ایجاد مقداری داده بیشتر با
78
00:03:10,070 –> 00:03:12,800
کاری که من انجام می دهم هستیم. یک
79
00:03:12,800 –> 00:03:15,440
متغیر fraud که در آن من تمام تقلب های خود را انتخاب می کنم
80
00:03:15,440 –> 00:03:18,020
این برای مقادیر تقلب همه در این
81
00:03:18,020 –> 00:03:20,150
متغیر تقلب سوابق کلاهبرداری اساساً
82
00:03:20,150 –> 00:03:22,730
سونی عادی در اینجا قرار می گیرد اکنون
83
00:03:22,730 –> 00:03:24,710
می توانید شکل را در اینجا ببینید در تقلب
84
00:03:24,710 –> 00:03:27,650
من 492 مشترک دارم 31 در عادی من
85
00:03:27,650 –> 00:03:30,440
دو دارم هشت چهار سه یک پنج کاما 31
86
00:03:30,440 –> 00:03:34,880
خوب حالا در دفعه قبل که زیر نمونه برداری
87
00:03:34,880 –> 00:03:36,590
انجام می دادم از این
88
00:03:36,590 –> 00:03:38,180
کتابخانه خاص استفاده کردم که به آن
89
00:03:38,180 –> 00:03:41,540
نزدیک می شود و داخل آن وجود دارد.
90
00:03:41,540 –> 00:03:44,870
91
00:03:44,870 –> 00:03:46,970
چیزی به نام دود
92
00:03:46,970 –> 00:03:50,990
به آمچه خوب دود اجاق گاز برای
93
00:03:50,990 –> 00:03:53,209
94
00:03:53,209 –> 00:03:55,160
صاف تر کردن آن.
95
00:03:55,160 –> 00:03:57,170
96
00:03:57,170 –> 00:03:59,090
97
00:03:59,090 –> 00:04:01,580
98
00:04:01,580 –> 00:04:03,950
برای درست کردن
99
00:04:03,950 –> 00:04:06,530
تومک نرم و صاف در این سنگ
100
00:04:06,530 –> 00:04:08,990
تومک یک مقدار حالت تصادفی می دهم و بعد از
101
00:04:08,990 –> 00:04:11,360
آن فقط همان روشی را انجام
102
00:04:11,360 –> 00:04:12,950
می دهم که برای نمونه برداری زیر در
103
00:04:12,950 –> 00:04:15,440
نمونه برداری سختی انجام دادم، می توانید ببینید که من همین جا را به
104
00:04:15,440 –> 00:04:18,500
اینجا رساندم. من فقط این
105
00:04:18,500 –> 00:04:20,750
106
00:04:20,750 –> 00:04:24,140
107
00:04:24,140 –> 00:04:27,530
108
00:04:27,530 –> 00:04:29,240
کار
109
00:04:29,240 –> 00:04:31,520
110
00:04:31,520 –> 00:04:33,560
را انجام دادم. این کار را اکنون انجام دهید این دو
111
00:04:33,560 –> 00:04:35,060
متغیری که در اینجا ایجاد شدهاند،
112
00:04:35,060 –> 00:04:37,220
میتوانید ببینید که زیرخط X من
113
00:04:37,220 –> 00:04:39,230
در اینجا شکل شروع میشود و شکل زیرخط U من
114
00:04:39,230 –> 00:04:42,320
اکنون به 5 6 7 تبدیل میشود
115
00:04:42,320 –> 00:04:46,310
که چیزی نیست جز v بعدی 67,000 562 حالا
116
00:04:46,310 –> 00:04:49,610
چطور در ابتدا شما یک رکورد داشتید. از
117
00:04:49,610 –> 00:04:53,600
حدود 222 لات 84000 چگونه به
118
00:04:53,600 –> 00:04:57,380
فی مانند 67000 تبدیل شده است بچه ها اکنون
119
00:04:57,380 –> 00:05:00,449
اینجا می توانید ببینید که
120
00:05:00,449 –> 00:05:02,580
داده های کلاهبرداری من دقیقاً اطلاعات کلاهبرداری من
121
00:05:02,580 –> 00:05:04,830
جایی در اطراف افراد معدن بوده است، اما اکنون
122
00:05:04,830 –> 00:05:06,749
اگر بخواهم امتیازهای اضافی بیشتری ایجاد
123
00:05:06,749 –> 00:05:08,939
کنم، من این را دارم. برای
124
00:05:08,939 –> 00:05:11,430
تطبیق این عدد خاص در حال حاضر وقتی
125
00:05:11,430 –> 00:05:13,589
میخواهم آن را اضافه کنم این برای شمارش برابر خواهد بود،
126
00:05:13,589 –> 00:05:17,490
بنابراین این دو یا دو مانند
127
00:05:17,490 –> 00:05:19,139
هشتاد و چهار هزار و سیصد و
128
00:05:19,139 –> 00:05:21,029
پانزده دو برابر می شود، می دانید و
129
00:05:21,029 –> 00:05:23,189
زمانی که به سرعت دو برابر می شود، ما با آن روبرو خواهیم شد.
130
00:05:23,189 –> 00:05:24,689
تعداد کل
131
00:05:24,689 –> 00:05:29,069
خلبان ها 67,000 562 خواهد بود اکنون می توانید از
132
00:05:29,069 –> 00:05:30,870
این تعداد کتابخانه بررسی
133
00:05:30,870 –> 00:05:33,240
کنید و بگویید که ویژگی وابسته به y شما در ابتدا
134
00:05:33,240 –> 00:05:36,539
چند شکل بود، بنابراین
135
00:05:36,539 –> 00:05:38,430
در اینجا می توانید اساساً تعداد
136
00:05:38,430 –> 00:05:40,409
م


![فیلم آموزشی: نحوه اجرای پایتون در کد ویژوال استودیو در ویندوز 10 [2022] | نمونه برنامه پایتون را اجرا کنید با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/zk5qOQBvuK4image2.jpg)