در این مطلب، ویدئو تجزیه و تحلیل احساسات با TensorFlow 2 و Keras با استفاده از پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:48:10
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,399
سلام بچه ها، امیدوارم تا اینجا از تعطیلات خود لذت برده باشید
2
00:00:02,399 –> 00:00:05,069
و امروز می خواهیم در
3
00:00:05,069 –> 00:00:07,950
مورد اینکه چگونه می توانید تحلیل احساسات را
4
00:00:07,950 –> 00:00:10,260
5
00:00:10,260 –> 00:00:13,650
6
00:00:13,650 –> 00:00:16,710
با استفاده از جمله مراقبت انجام دهید، بررسی کنیم.
7
00:00:16,710 –> 00:00:18,600
.com
8
00:00:18,600 –> 00:00:21,720
و در Keagle میزبانی
9
00:00:21,720 –> 00:00:25,740
می شود، بنابراین خود مجموعه داده را می توان در Ko یافت البته
10
00:00:25,740 –> 00:00:29,310
ما پنج داده 15 هزار بررسی هتل برای
11
00:00:29,310 –> 00:00:32,820
برخی از هتل های اروپایی داریم، بنابراین این داده
12
00:00:32,820 –> 00:00:36,570
ها با استفاده از scraping booking.com جمع آوری شده است
13
00:00:36,570 –> 00:00:39,510
و همانطور که می بینید قسمت بیرونی مجموعه داده
14
00:00:39,510 –> 00:00:43,020
توضیح می دهد. که این
15
00:00:43,020 –> 00:00:48,210
مقدار نظرات مشتریان است و حدود 11.5 هزار
16
00:00:48,210 –> 00:00:53,879
هتل در سراسر اروپا است، بنابراین میتوانید ببینید
17
00:00:53,879 –> 00:00:56,789
که مجموعه دادهها دارای
18
00:00:56,789 –> 00:00:58,739
ویژگیهای زیادی مانند آدرس
19
00:00:58,739 –> 00:01:02,129
هتل، میانگین امتیاز تاریخ است، اما
20
00:01:02,129 –> 00:01:04,920
ما بیشتر به
21
00:01:04,920 –> 00:01:09,240
خود متن را مرور کنید و اینکه آیا
22
00:01:09,240 –> 00:01:13,320
نمره مثبت یا منفی است یا خیر، بنابراین
23
00:01:13,320 –> 00:01:16,560
نمره نقد در واقع بر اساس تجربه شخص
24
00:01:16,560 –> 00:01:18,750
است و من معتقدم که عددی
25
00:01:18,750 –> 00:01:21,720
بین 1 تا 10 است بنابراین 10 دقیقه مانند
26
00:01:21,720 –> 00:01:23,909
شگفت انگیزترین هتل است. r و one به
27
00:01:23,909 –> 00:01:28,170
این معنی است که شما می دانید چه مشکلی ندارد، بنابراین اجازه
28
00:01:28,170 –> 00:01:31,740
دهید ابتدا
29
00:01:31,740 –> 00:01:35,280
دفترچه یادداشت فعلی را که در اینجا دارم به شما نشان دهم، بنابراین
30
00:01:35,280 –> 00:01:37,680
این بار در ابتدا می خواهم بزرگنمایی
31
00:01:37,680 –> 00:01:40,799
کنم، بنابراین اساساً
32
00:01:40,799 –> 00:01:44,670
با این دفترچه خالی شروع می کنم. و من فقط
33
00:01:44,670 –> 00:01:49,409
پردازنده گرافیکی که به من داده شده را بررسی می کنم،
34
00:01:49,409 –> 00:01:52,200
بنابراین کلمه آزمایشی p4 را دارم که بد نیست،
35
00:01:52,200 –> 00:01:55,890
اما عالی هم نیست، بنابراین کار بعدی
36
00:01:55,890 –> 00:01:58,079
که می خواهم انجام دهم این است که
37
00:01:58,079 –> 00:02:02,670
برخی از نصب ها را در برخی از کتابخانه ها کپی و پیست کنم.
38
00:02:02,670 –> 00:02:05,640
برای این آموزش
39
00:02:05,640 –> 00:02:08,788
از رمزگذار جملات یا
40
00:02:08,788 –> 00:02:11,038
مهمتر از آن رمزگذار جملات جهانی استفاده می کنیم
41
00:02:11,038 –> 00:02:13,380
و این
42
00:02:13,380 –> 00:02:16,860
مدل توسط هوک 1004 ارائه شده است بنابراین مدل
43
00:02:16,860 –> 00:02:19,860
بر روی تانسور برای هاب موجود است و در آنجا
44
00:02:19,860 –> 00:02:23,910
می خواهیم
45
00:02:23,910 –> 00:02:25,920
مدل مورد استفاده را دانلود کنیم.
46
00:02:25,920 –> 00:02:28,140
تجزیه و تحلیل احساسات ما و علاوه بر آن، ما قصد
47
00:02:28,140 –> 00:02:30,140
داریم یک شبکه عصبی عمیق بسازیم که
48
00:02:30,140 –> 00:02:33,120
متن را به یک نمره مثبت یا منفی طبقه بندی می کند،
49
00:02:33,120 –> 00:02:36,660
بنابراین شما مانند
50
00:02:36,660 –> 00:02:40,010
طبقه بندی باینری برای این مشکل
51
00:02:40,010 –> 00:02:42,930
و دو طبقه بندی برای همه چیز دارید که باید
52
00:02:42,930 –> 00:02:45,480
تانسور را نصب کنیم. متن خطا و اگر
53
00:02:45,480 –> 00:02:47,880
در مورد آن اطلاعی ندارید کتابخانه تمام متنی تانسور
54
00:02:47,880 –> 00:02:51,960
اجازه دهید آن را در github
55
00:02:51,960 –> 00:02:58,620
برای شما باز کنم okay II و شعار یا
56
00:02:58,620 –> 00:03:00,960
ضرب المثل کتابخانه این است که متن
57
00:03:00,960 –> 00:03:02,760
شهروند درجه یک را شدید یا سقوط کند
58
00:03:02,760 –> 00:03:05,850
و شما می توانید از دو قسمت
59
00:03:05,850 –> 00:03:08,040
بیشتر کتابخانه عبور کنید و می توانید ببینید که در این کتابخانه
60
00:03:08,040 –> 00:03:11,340
یک ساختمان نرمال سازی وجود دارد که
61
00:03:11,340 –> 00:03:15,900
62
00:03:15,900 –> 00:03:19,560
با اضافه کردن افست ها و تبدیل تمام
63
00:03:19,560 –> 00:03:24,990
متن به نوعی فرمت داده یا
64
00:03:24,990 –> 00:03:28,920
عمدتاً بردارهایی از نوعی و استفاده شده از UN
65
00:03:28,920 –> 00:03:31,830
شما استفاده می شود. اساساً میتوانید از آنها در
66
00:03:31,830 –> 00:03:34,020
شبکههای عصبی عمیق خود یا هر مدلی که در
67
00:03:34,020 –> 00:03:38,040
حال حاضر استفاده میکنید استفاده کنید، بنابراین اساساً
68
00:03:38,040 –> 00:03:41,550
ما این جمله جهانی را در
69
00:03:41,550 –> 00:03:44,280
رنگها داریم که از تبدیل
70
00:03:44,280 –> 00:03:46,620
متن به اعداد مراقبت میکند و سپس
71
00:03:46,620 –> 00:03:49,650
از آن اعداد استفاده میکنیم و خودمان را آموزش میدهیم.
72
00:03:49,650 –> 00:03:52,320
بر اساس آن اعداد مدل کنید، بنابراین من
73
00:03:52,320 –> 00:03:55,200
می خواهم اعداد جمع آوری
74
00:03:55,200 –> 00:03:57,510
و نحوه استفاده از مراکز جهانی را به صورت
75
00:03:57,510 –> 00:04:01,410
رنگی به شما نشان دهم، اما ابتدا اجازه دهید با
76
00:04:01,410 –> 00:04:05,060
نصب تانسور کامل متن mg پایین و
77
00:04:05,060 –> 00:04:07,500
مورد بعدی شروع کنم. کاری که میخواهم انجام دهم این است
78
00:04:07,500 –> 00:04:13,250
که Quad را نصب کنم، بنابراین میبینید که چرا ما
79
00:04:13,250 –> 00:04:16,140
از این کتابخانه استفاده میکنیم
80
00:04:16,140 –> 00:04:20,100
و سپس کتابخانه نهایی که
81
00:04:20,100 –> 00:04:22,108
قرار است استفاده کنیم پترا 4 خواهد بود و
82
00:04:22,108 –> 00:04:25,169
در حال حاضر آخرین نسخه آزمایشی
83
00:04:25,169 –> 00:04:26,500
برای GP است. یا تست
84
00:04:26,500 –> 00:04:31,600
برای 2.0 2.1 rc2 است من فکر می کنم در راه
85
00:04:31,600 –> 00:04:34,090
است اجازه دهید نسخه های آن
86
00:04:34,090 –> 00:04:37,500
بله RC را بررسی کنم – پنج روز پیش منتشر شد
87
00:04:37,500 –> 00:04:41,740
بنابراین شاید در اوایل ژانویه بتوانیم
88
00:04:41,740 –> 00:04:45,910
مداد را برای دو نقطه یک انتظار داشته باشیم و من
89
00:04:45,910 –> 00:04:48,850
معتقدم که همه آن آموزش ها که
90
00:04:48,850 –> 00:04:51,970
ما به دنبال آن بودیم که ما
91
00:04:51,970 –> 00:04:55,390
برای دو نقطه یک به صورت فشرده کار می کنیم
92
00:04:55,390 –> 00:04:58,960
اما باید توجه داشته باشید که tensorflow دو
93
00:04:58,960 –> 00:05:02,790
نقطه دو پایتون 2 را پشتیبانی نمی کند، بنابراین
94
00:05:02,790 –> 00:05:05,919
مناقصه برای دو نقطه یک اولین
95
00:05:05,919 –> 00:05:08,669
نسخه ای است که پایتون 2 را پشتیبانی می کند و
96
00:05:08,669 –> 00:05:12,580
در واقع بله شما شما هستید. باید قبلاً به پایتون 3 مهاجرت کنید،
97
00:05:12,580 –> 00:05:15,490
بنابراین اگر قبلاً این کار را انجام نداده اید،
98
00:05:15,490 –> 00:05:20,200
لطفاً فقط خوب مهاجرت کنید تا
99
00:05:20,200 –> 00:05:22,540
ما کاملاً پنبه ای کار کرده ایم و من می
100
00:05:22,540 –> 00:05:25,919
خواهم GPU tensorflow را در اینجا نصب کنم.
101
00:05:25,919 –> 00:05:28,540
کار بعدی که می خواهم انجام دهم این است
102
00:05:28,540 –> 00:05:33,419
که اساساً یک دسته وارداتی بردارید و
103
00:05:33,419 –> 00:05:35,890
آنها را در اینجا بچسبانید بعد از
104
00:05:35,890 –> 00:05:39,960
نصب همه اینها انجام شد و
105
00:05:39,960 –> 00:05:43,210
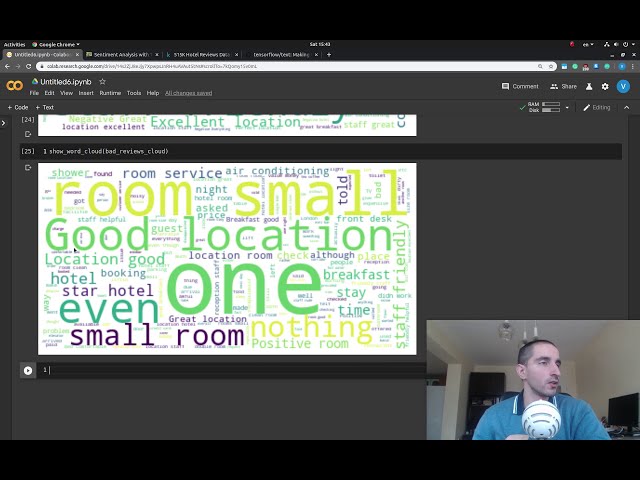
شاید چیزی متفاوت در اینجا این
106
00:05:43,210 –> 00:05:45,190
واقعیت است که من از یک پالت رنگ سفارشی
107
00:05:45,190 –> 00:05:49,979
برای Seabourn استفاده می کنم، بنابراین باید
108
00:05:49,979 –> 00:05:54,910
درک کنید که این رنگ
109
00:05:54,910 –> 00:05:59,800
ها زمانی که ما از بسته sea-bottom در استفاده می کنیم نشان داده می شود.
110
00:05:59,800 –> 00:06:03,160
خوب است، بنابراین کار بعدی
111
00:06:03,160 –> 00:06:06,940
که می خواهم انجام دهم این است که البته بعد از
112
00:06:06,940 –> 00:06:08,830
اتمام نصب،
113
00:06:08,830 –> 00:06:12,070
فقط می خواهم بررسی کنم که آیا GPU در
114
00:06:12,070 –> 00:06:14,860
دسترس است یا نه، بنابراین می خواهم این کار را انجام دهم
115
00:06:14,860 –> 00:06:16,840
که آیا GPU از طریق تست موجود است یا خیر.
116
00:06:16,840 –> 00:06:20,640
تستر برای بسته و در نهایت و ما
117
00:06:20,640 –> 00:06:23,260
باید برای ادامه
118
00:06:23,260 –> 00:06:26,020
آموزش آماده باشیم، اما بله، باید منتظر
119
00:06:26,020 –> 00:06:28,169
بمانیم تا tensorflow GPO نصب شود، حدس میزنم
120
00:06:28,169 –> 00:06:31,660
خوب است، اکنون که این کار انجام شد، واردات ما در
121
00:06:31,660 –> 00:06:34,210
حال اجرا است و پیکربندی
122
00:06:34,210 –> 00:06:37,260
کتابخانههای رسم انجام میشود، بنابراین بله ما
123
00:06:37,260 –> 00:06:40,449
پردازنده گرافیکی داریم که عالی است
124
00:06:40,449 –> 00:06:43,809
و سپس من میخواهم دادههای بررسیها را دانلود کنم،
125
00:06:43,809 –> 00:06:46,749
این فقط یک فایل فشرده
126
00:06:46,749 –> 00:06:51,599
از مجموعه دادههای Kegel است، بنابراین این
127
00:06:51,599 –> 00:06:56,020
تقریباً 15 50 مگابایت است و بعد از آن
128
00:06:56,020 –> 00:07:03,460
میخواهم آن را از حالت فشرده خارج کنم و میخواهم آن را از حالت فشرده خارج
129
00:07:03,460 –> 00:07:12,069
کنم. بی سر و صدا بعد از انجام همه این کارها ما
130
00:07:12,069 –> 00:07:15,759
باید یک پوشه یا دایرکتوری داشته باشد که
131
00:07:15,759 –> 00:07:19,810
حاوی اوه نه ما فقط فایل csv
132
00:07:19,810 –> 00:07:21,789
را در اینجا داریم که به آن نظرات هتل می گویند
133
00:07:21,789 –> 00:07:26,259
البته خوب است، بنابراین اجازه دهید من فقط از پانداها استفاده کنم که
134
00:07:26,259 –> 00:07:30,370
این فایل CSV را در اینجا
135
00:07:30,370 –> 00:07:38,319
و خوب است و سپس ما یک
136
00:07:38,319 –> 00:07:42,849
نگاه کنید اجازه دهید فقط چیزی را به شما نشان دهم
137
00:07:42,849 –> 00:07:45,339
که فقط دو
138
00:07:45,339 –> 00:07:51,279
شراب اول این فایل را با استفاده از دستور head
139
00:07:51,279 –> 00:07:54,399
در لینوکس می گیرم و همانطور که می بینید ما
140
00:07:54,399 –> 00:07:58,930
داده های زیادی داریم و همانطور که
141
00:07:58,930 –> 00:08:03,580
قبلاً در مورد برخی از آنها بحث کرده ایم. خواهد
142
00:08:03,580 –> 00:08:07,300
بیشتر به نمره و متن بررسی علاقه مند خواهد شد
143
00:08:07,300 –> 00:08:10,300
، اما مورد بعدی که
144
00:08:10,300 –> 00:08:13,300
ما به آن علاقه مندیم
145
00:08:13,300 –> 00:08:16,659
تاریخ بررسی است و
146
00:08:16,659 –> 00:08:18,570
147
00:08:18,570 –> 00:08:24,810
با استفاده از تاریخ های تجزیه شده آن را تجزیه می کنیم و سپس دوباره
148
00:08:24,810 –> 00:08:28,710
بررسی می کنم شکل این
149
00:08:28,710 –> 00:08:34,770
قاب داده، بنابراین من اشتباه تایپی کردم
150
00:08:34,770 –> 00:08:37,049
تاریخ بررسی که باید
151
00:08:37,049 –> 00:08:41,850
نام ستون باشد و بله، ما تقریباً
152
00:08:41,850 –> 00:08:45,410
مقدار بیرونی را همانطور که وعده داده بود داریم،
153
00:08:45,410 –> 00:08:50,010
بنابراین اجازه دهید فقط با نگاهی
154
00:08:50,010 –> 00:08:54,330
به سر بعد از این داده شروع کنیم. قاب بنابراین
155
00:08:54,330 –> 00:08:56,420
بله ما بررسی آدرس d را داریم
156
00:08:56,420 –> 00:08:59,730
میانگین امتیاز هتل را خوردم هر
157
00:08:59,730 –> 00:09:02,880
تعداد کل نظرات برای شاید
158
00:09:02,880 –> 00:09:05,190
برای پیشنمایش یا نمیدانم
159
00:09:05,190 –> 00:09:08,010
مقداری مالیات داریم اما اینجا بخش
160
00:09:08,010 –> 00:09:11,640
مهم امتیاز بررسی است و مهمترین
161
00:09:11,640 –> 00:09:15,450
نکته بعدی بررسی مثبت است در واقع
162
00:09:15,450 –> 00:09:18,960
ما یک جدایی داریم در اینجا که مانند
163
00:09:18,960 –> 00:09:23,580
حسابی است که به عنوان بررسی مثبت و
164
00:09:23,580 –> 00:09:28,350
آرام شناخته شده به عنوان بررسی منفی شناخته می شود، بنابراین می دانم که
165
00:09:28,350 –> 00:09:32,220
این کمی گیج کننده است، اما من به شما کمک
166
00:09:32,220 –> 00:09:35,430
می کنم در واقع همه اینها را به یک
167
00:09:35,430 –> 00:09:39,930
مجموعه داده ساده تر تبدیل کنید، بنابراین
168
00:09:39,930 –> 00:09:43,470
اجازه دهید به این کار ادامه دهیم و من قصد دارم
169
00:09:43,470 –> 00:09:45,870
در واقع همین الان یک
170
00:09:45,870 –> 00:09:49,290
بررسی معمولی مخروطی ایجاد کنم و این شانه
171
00:09:49,290 –> 00:09:51,120
حاوی تمام نظرات منفی و
172
00:09:51,120 –> 00:09:53,700
همه نظرات مثبت است، بنابراین اجازه دهید بررسی کنم
173
00:09:53,700 –> 00:09:59,130
که خوب است، بنابراین این خانه جدید شانه
174
00:09:59,130 –> 00:10:02,250
نامیده می شود فقط مرور کنید این فقط شامل
175
00:10:02,250 –> 00:10:06,350
برخی از متنها و این قرار است
176
00:10:06,350 –> 00:10:09,090
نظرات منفی و
177
00:10:09,090 –> 00:10:15,870
نظرات مثبت را یکی کند، در ادامه به اینجا میروم به
178
00:10:15,870 –> 00:10:19,110
من اجازه دهید این کار را انجام دهم و من میخواهم این کار را انجام
179
00:10:19,110 –> 00:10:21,900
دهم تا بررسی کنم آیا
180
00:10:21,900 –> 00:10:24,840
متنی داریم یا خیر، بله، ما داریم
181
00:10:24,840 –> 00:10:27,750
تی xt در اینجا، بنابراین حدس میزنم خیلی خوب به نظر میرسد
182
00:10:27,750 –> 00:10:32,280
و سپس برای هر ردیف،
183
00:10:32,280 –> 00:10:35,220
یک ستون جدید ایجاد میکنم که
184
00:10:35,220 –> 00:10:37,770
میگوید اگر بررسی مثبت است یا
185
00:10:37,770 –> 00:10:39,840
یک بررسی خوب یا یک بررسی بد،
186
00:10:39,840 –> 00:10:42,330
بنابراین من این جدید را ایجاد میکنم.
187
00:10:42,330 –> 00:10:46,140
نوع بررسی Norma را فراخوانی میکنم و من
188
00:10:46,140 –> 00:10:50,750
میخواهم آن خلیج را بر اساس امتیاز
189
00:10:50,750 –> 00:10:54,630
بازبینی کننده امتیاز بررسی قرار دهم، بنابراین پسری که فقط دختر ما،
190
00:10:54,630 –> 00:11:00,210
بله، یک بررسی گذاشته است و در
191
00:11:00,210 –> 00:11:03,570
اینجا برای هر مقدار من از تابع 1 استفاده میکنم
192
00:11:03,570 –> 00:11:06,450
که میگوید که
193
00:11:06,450 –> 00:11:11,100
اگر نمره زیر 7 و 7 باشد، اگر نمره زیر 7 و 7
194
00:11:11,100 –> 00:11:13,830
نباشد و مانند 5 یا چیزی شبیه
195
00:11:13,830 –> 00:11:17,580
به آن خوب باشد، بررسی بد است، خوب به
196
00:11:17,580 –> 00:11:25,470
شما نشان دهم که آیا ما چه چیزی به من اجازه داد فقط فکر کنم که
197
00:11:25,470 –> 00:11:28,920
برای شما نمره بازبین را
198
00:11:28,920 –> 00:11:32,760
امتحان نکردهام این اما امیدوارم
199
00:11:32,760 –> 00:11:36,440
شهود من را در مورد آن
200
00:11:36,440 –> 00:11:41,070
تایید کند، بله، عالی است، خوب به نظر می رسد، زیرا
201
00:11:41,070 –> 00:11:44,730
می توانید اکثر نظراتی را که
202
00:11:44,730 –> 00:11:46,650
در اینجا داریم و ما یک هیئت بررسی داریم
203
00:11:46,650 –> 00:11:50,850
و خوب ما دنیایی از هتل های لوکس داریم،
204
00:11:50,850 –> 00:11:53,280
بنابراین شاید بله، شاید هتل های لوکس
205
00:11:53,280 –> 00:11:57,270
در واقع بسیار خوب هستند، بنابراین حتی
206
00:11:57,270 –> 00:12:00,030
اگر مهمانان ممکن است در مورد آنها بسیار حساس باشند
207
00:12:00,030 –> 00:12:02,460
ممکن است باز هم نظرات مثبت زیادی از خود به جای بگذارند،
208
00:12:02,460 –> 00:12:05,790
بنابراین همانطور که میبینید،
209
00:12:05,790 –> 00:12:08,310
ما در اینجا دنیایی از نظرات مثبت
210
00:12:08,310 –> 00:12:13,350
داریم، مانند 65 تا 70 درصد دادهها
211
00:12:13,350 –> 00:12:18,750
یا تراکم این نمودار بالای 7
212
00:12:18,750 –> 00:12:24,270
نمره است، بنابراین اگر فقط یک امتیاز را در نظر بگیریم. 5 که
213
00:12:24,270 –> 00:12:27,270
ما را فقط با آن بررسی ها باقی می گذارد، اما من
214
00:12:27,270 –> 00:12:32,100
می خواهم مانند 7 را انتخاب کنم، بنابراین ما
215
00:12:32,100 –> 00:12:35,220
نظرات را کمی بیشتر تقسیم می کنیم و به این ترتیب
216
00:12:35,220 –> 00:12:37,560
می خواهیم بگوییم که همه
217
00:12:37,560 –> 00:12:41,550
بررسی هایی که زیر 7 هستند بد هستند، بنابراین اجازه دهید
218
00:12:41,550 –> 00:12:44,400
من فقط به شما نشان میدهم که چگونه این کار را انجام دهید، من میخواهم امتیاز
219
00:12:44,400 –> 00:12:46,080
220
00:12:46,080 –> 00:12:49,950
مبتنی بر X یا امتیاز بررسی را
221
00:12:49,950 –> 00:12:53,070
در اینجا پایهگذاری کنم و به عنوان جبران،
222
00:12:53,070 –> 00:12:56,070
اگر امتیاز زیر
223
00:12:56,070 –> 00:12:59,580
هفت به شدت زیر هفت باشد یا در غیر
224
00:12:59,580 –> 00:13:04,560
این صورت نتیجه را به عنوان بد عنوان میکنم. نوع خوب خواهد بود، بنابراین
225
00:13:04,560 –> 00:13:07,830
ممکن است قبلاً حدس زده باشید که اگر من
226
00:13:07,830 –> 00:13:10,710
همین الان این را ترسیم کنم، توزیع
227
00:13:10,710 –> 00:13:14,970
واقعاً متعادل نخواهد بود، بنابراین اجازه دهید این کار را انجام
228
00:13:14,970 –> 00:13:29,160
دهم و بیایید نگاهی بیندازیم، بله،
229
00:13:29,160 –> 00:13:30,630
ممکن است درست حدس زده باشید،
230
00:13:30,630 –> 00:13:33,900
بنابراین ما کارمان را بیشتر از چهار مورد داریم.
231
00:13:33,900 –> 00:13:36,540
نقدهای خوب پنج برابر بیشتر از نقدهای بد است،
232
00:13:36,540 –> 00:13:40,970
بنابراین ما یک تلاقی نامتعادل داریم
233
00:13:40,970 –> 00:13:44,850
مشکل طبقهبندی، بنابراین من میخواهم
234
00:13:44,850 –> 00:13:46,290
235
00:13:46,290 –> 00:13:49,710
برخی از راههای رسیدگی به این
236
00:13:49,710 –> 00:13:53,100
موضوع را در زیر در توضیحات پیوند دهم، اما در مورد ما میخواهیم
237
00:13:53,100 –> 00:13:55,260
کاری بسیار ساده انجام دهیم و
238
00:13:55,260 –> 00:14:00,240
حداقل فعلاً به تجزیه و تحلیل
239
00:14:00,240 –> 00:14:02,340
ادامه دهیم. کاری که باید انجام دهم این است
240
00:14:02,340 –> 00:14:04,530
که مرورهای خوب و بد را پشت سر
241
00:14:04,530 –> 00:14:09,410
بگذارم و من از
242
00:14:09,410 –> 00:14:14,820
گزینه فیلتر کردن پانداها برای انجام این کار استفاده میکنم که ابتدا
243
00:14:14,820 –> 00:14:18,590
بررسیهای خوب و سپس بررسیهای بد
244
00:14:20,850 –> 00:14:25,350
خوب است، بنابراین ما دو فریم داده داریم و
245
00:14:25,350 –> 00:14:27,749
توزیع همچنان یکسان است. بنابراین
246
00:14:27,749 –> 00:14:29,839
نکته بعدی که آنها می خواهند به شما نشان دهند
247
00:14:29,839 –> 00:14:32,999
کلماتی هستند که
248
00:14:32,999 –> 00:14:36,089
معمولاً مرتبط هستند یا بیشتر در بررسی های خوب یافت می شوند
249
00:14:36,089 –> 00:14:39,179
و آنهایی که
250
00:14:39,179 –> 00:14:42,689
معمولاً در بررسی های بد یافت می شوند اما اگر
251
00:14:42,689 –> 00:14:46,619
همه کلمات را به خوبی دریافت کنیم
252
00:14:46,619 –> 00:14:49,410
بیشتر کلمات مانند N و a خواهد بود
253
00:14:49,410 –> 00:14:51,629
و می دانید من در مورد رایج ترین کلماتی صحبت می کنم
254
00:14:51,629 –> 00:14:54,259
که در
255
00:14:54,259 –> 00:14:57,859
هنگام نوشتن چیزی
256
00:14:57,859 –> 00:15:01,319
معنی ندارند، بنابراین ما از چیزی به نام کلمات توقف استفاده می کنیم
257
00:15:01,319 –> 00:15:04,559
و آن ها را از
258
00:15:04,559 –> 00:15:06,539
بررسی ها حذف می کنیم و بعد از آن
259
00:15:06,539 –> 00:15:09,269
میخواهم به نتیجه نگاهی بیندازم
260
00:15:09,269 –> 00:15:12,539
که عمدتاً کلمات یا
261
00:15:12,539 –> 00:15:15,509
عبارات معنیداری است که هنگام بررسی
262
00:15:15,509 –> 00:15:19,799
هتلها استفاده میشود، بنابراین اجازه دهید همه
263
00:15:19,799 –> 00:15:22,109
متن را از نظرات خوب و همه
264
00:15:22,109 –> 00:15:23,970
متن را از نظرات بد دریافت کنم. فقط
265
00:15:23,970 –> 00:15:29,009
266
00:15:29,009 –> 00:15:31,049
با استفاده از تابع مشترک مانند پایتون معمولی به این لیست ملحق
267
00:15:31,049 –> 00:15:36,049
268
00:15:36,049 –> 00:15:39,769
می شوم، بنابراین فقط متن نظرات خوب را
269
00:15:39,769 –> 00:15:49,199
با استفاده از فضا به آن متصل می کنم یا به آن می پیوندم و
270
00:15:49,199 –> 00:15:52,019
متن بررسی را از اینجا می گیرم که آن را به داور تبدیل می کنم.
271
00:15:52,019 –> 00:15:56,909
امتیاز دهید و سپس دو لیست و من
272
00:15:56,909 –> 00:15:59,249
همین کار را برای بررسی های بد انجام می دهم بسیار
273
00:15:59,249 –> 00:16:01,579
274
00:16:03,259 –> 00:16:07,050
خوب و کار بعدی که می
275
00:16:07,050 –> 00:16:10,230
خواهم برای شما انجام دهم این است که چهار کلمه ای دو کلمه ای ایجاد
276
00:16:10,230 –> 00:16:12,569
کنم و اگر ندیده اید آنها Coops
277
00:16:12,569 –> 00:16:15,899
هستند. آنها را قبلاً می توانید در نظر بگیرید
278
00:16:15,899 –> 00:16:17,999
مانند اوه کوپ یا هر چیز دیگری که
279
00:16:17,999 –> 00:16:20,699
من فقط به شما نشان خواهم داد که
280
00:16:20,699 –> 00:16:25,740
چگونه به نظر می رسند
281
00:16:25,740 –> 00:16:31,699
، اولین مورد را برای بررسی های خوب ایجاد خواهم کرد و
282
00:16:31,699 –> 00:16:33,990
دوباره این از کلمه
283
00:16:33,990 –> 00:16:37,649
کتابخانه ابری I استفاده می کند. m قرار است کلمات توقف را مشخص کنیم،
284
00:16:37,649 –> 00:16:40,199
آن کلماتی هستند که فیلتر خواهند شد
285
00:16:40,199 –> 00:16:44,279
و این مجموعه ای از
286
00:16:44,279 –> 00:16:46,350
کلمات برتر انگلیسی است که توسط کتابخانه ها ارائه می شوند
287
00:16:46,350 –> 00:16:48,959
و در واقع
288
00:16:48,959 –> 00:16:51,209
وقتی وارد می شوند که کل مجموعه کتابخانه ها
289
00:16:51,209 –> 00:16:54,240
را در بالا وارد می کنیم و من رنگ پس زمینه را مشخص می کنم
290
00:16:54,240 –> 00:16:56,910
و این سفید خواهد بود
291
00:16:56,910 –> 00:17:01,800
و I’m با من تماس میگیرم تا
292
00:17:01,800 –> 00:17:04,529
تولید
293
00:17:04,529 –> 00:17:07,730
کنم و میخواهم متن نظرات خوب را بگذرانم و
294
00:17:07,730 –> 00:17:12,659
نظرات بد را در اینجا با همان
295
00:17:12,659 –> 00:17:17,959
پارامترها انجام میدهم، در واقع خوب است، بنابراین اکنون
296
00:17:17,959 –> 00:17:22,289
دو جمعیت داریم و به خصوص متنهای زیادی داریم.
297
00:17:22,289 –> 00:17:24,390
ما نظرات خوب زیادی داریم،
298
00:17:24,390 –> 00:17:28,319
بنابراین این باید کمی زمان ببرد و
299
00:17:28,319 –> 00:17:30,750
در این مدت من یک
300
00:17:30,750 –> 00:17:33,360
تابع به نام short word crowd تعریف
301
00:17:33,360 –> 00:17:36,390
می کنم و به عنوان پارامتر یک
302
00:17:36,390 –> 00:17:40,110
لحاف و عنوان را در نظر می گیرد، اما من می روم فقط
303
00:17:40,110 –> 00:17:43,350
از عنوان فعلا صرف نظر کنید و در اینجا من
304
00:17:43,350 –> 00:17:46,740
یک شکل ایجاد می کنم و
305
00:17:46,740 –> 00:17:49,169
اندازه شکل را مشخص می کنم زیرا می خواهم
306
00:17:49,169 –> 00:17:52,320
این چیز با حروف بزرگ باشد که همان است
307
00:17:52,320 –> 00:17:58,500
و سپس می خواهم تصویری را نشان دهم که
308
00:17:58,500 –> 00:18:01,529
در حال رفتن است to be the crowd و من قصد دارم
309
00:18:01,529 –> 00:18:04,130
از درون یابی خطی بودن استفاده
310
00:18:04,130 –> 00:18:08,130
کنم که به نظر می رسد p احتمالاً به نظر من بهترین
311
00:18:08,130 –> 00:18:10,889
است و من
312
00:18:10,889 –> 00:18:13,340
محور
313
00:18:13,369 –> 00:18:18,049
را خاموش می کنم و فقط این مورد
314
00:18:18,049 –> 00:18:21,749
را نشان می دهم خوب است ، بنابراین اگر با تیم بازبینی خوب به show word quad زنگ بزنم
315
00:18:21,749 –> 00:18:24,779
و به سمت
316
00:18:24,779 –> 00:18:28,110
خودت بروم که اینجا رقابت می کند ، ما
317
00:18:28,110 –> 00:18:31,799
منتظر خواهیم بود و ازدحام کلماتی را
318
00:18:31,799 –> 00:18:33,389
که بیشتر در نقدهای خوب استفاده می شود ببینید،
319
00:18:33,389 –> 00:18:37,080
بنابراین آنچه که ما در اینجا داریم،
320
00:18:37,080 –> 00:18:39,389
موقعیت عالی داریم، بنابراین وقتی در حال صحبت درباره
321
00:18:39,389 –> 00:18:42,029
گردشگری هستیم، ممکن است
322
00:18:42,029 –> 00:18:46,499
عبارتی مانند موقعیت مکانی
323
00:18:46,499 –> 00:18:48,779
موقعیت مکانی را شنیده باشید، بنابراین موقعیت، بله، واقعاً چنین است.
324
00:18:48,779 –> 00:18:51,330
هنگامی که شما در حال بازدید از یک هتل هستید مهم است
325
00:18:51,330 –> 00:18:54,659
و پس از آن چیزی که واقعاً مورد
326
00:18:54,659 –> 00:18:57,509
توجه قرار میگیرد این است که کارکنان دوستانه و
327
00:18:57,509 –> 00:18:59,809
دوستانه کارکنان
328
00:18:59,809 –> 00:19:05,009
مفید و مفید
329
00:19:05,009 –> 00:19:08,990
330
00:19:08,990 –> 00:19:12,690
به خوبی متوقف میشوند.
331
00:19:12,690 –> 00:19:14,970
در بررسی ذکر شده باشد و
332
00:19:14,970 –> 00:19:18,470
حداقل از هر دو متن به نظر می رسد که
333
00:19:18,470 –> 00:19:22,950
کارکنان خوش برخورد واقعاً مهم
334
00:19:22,950 –> 00:19:25,320
بوده اند، بیایید نگاهی به نظرات بد بیندازیم
335
00:19:25,320 –> 00:19:27,899
و ببینیم
336
00:19:27,899 –> 00:19:32,100
رایج ترین کلمات مورد استفاده در آنجا چیست، پس
337
00:19:32,100 –> 00:19:37,200
yo را انتخاب کنید میهمان شما حدس شما را انتخاب کنید من حدس میزنم
338
00:19:37,200 –> 00:19:41,460
اتاق خیلی کوچک موقعیت مکانی خوبی داشته باشد و فکر
339
00:19:41,460 –> 00:19:44,779
میکنم اگر موقعیت مکانی بد باشد در واقع
340
00:19:44,779 –> 00:19:47,490
آنها از موقعیت مکانی شکایت خواهند کرد،
341
00:19:47,490 –> 00:19:53,850
البته اتاق کوچک، بله،
342
00:19:53,850 –> 00:19:59,369
اتاق کوچک اتاق موقعیت اتاق مثبت، بنابراین وقتی
343
00:19:59,369 –> 00:20:03,840
مردم عصبانی هستند، عصبانی میشوند.
344
00:20:03,840 –> 00:20:06,950
بیشتر در مورد تعطیلات البته
345
00:20:06,950 –> 00:20:14,399
و خود اتاق، می توانید ببینید که ما
346
00:20:14,399 –> 00:20:19,740
347
00:20:19,740 –> 00:20:22,830
بر اساس چیزهای موجود در اینجا چیز خیلی مهمی نداریم، بنابراین به
348
00:20:22,830 –> 00:20:25,070
نظر می رسد که چیزهای شما
349
00:20:25,070 –> 00:20:28,429
دوستانه باشند، ممکن است عالی باشد، اما اگر
350
00:20:28,429 –> 00:20:29,659
مردم اتاق یا
351
00:20:29,659 –> 00:20:32,960
حرفه ای را دوست ندارند که ممکن است آن را از بین
352
00:20:32,960 –> 00:20:36,919
نبرد، اگر می خواهید یک بررسی خوب داشته باشید، بنابراین
353
00:20:36,919 –> 00:20:40,149
امیدوارم که شهود بیشتری در مورد
354
00:20:40,149 –> 00:20:44,929
آنچه مهم است و آنچه
355
00:20:44,929 –> 00:20:47,000
واقعاً مهم است در هنگام نوشتن یک نظر
356
00:20:47,000 –> 00:20:49,460
و برای مشتریان آن هتلها
357
00:20:49,460 –> 00:20:53,299
حداقل از آن نوع هتلهای لوکس،
358
00:20:53,299 –> 00:20:55,460
بنابراین کار بعدی که میخواهیم انجام دهیم
359
00:20:55,460 –> 00:21:00,500
این است که مشکل را با
360
00:21:00,500 –> 00:21:03,620
مقادیر کاملاً متفاوت نظرات مثبت یا خوب و
361
00:21:03,620 –> 00:21:06,409
بد و روشی که قرار است انجام دهیم،
362
00:21:06,409 –> 00:21:08,750
حل کنیم. او در اصل این است که ما
363
00:21:08,750 –> 00:21:11,029
تعداد بررسی های بدی را
364
00:21:11,029 –> 00:21:14,389
که در اینجا داریم در نظر می گیریم و سپس
365
00:21:14,389 –> 00:21:17,269
من فقط یک نمونه تصادفی
366
00:21:17,269 –> 00:21:19,580
از اینجا می گیرم و نمونه تصادفی
367
00:21:19,580 –> 00:21:25,429
به عنوان آگهی به عنوان همان
368
00:21:25,429 –> 00:21:28,070
تعداد بد محاسبه می شود. بررسیهایی که در اینجا خواهند بود، بنابراین
369
00:21:28,070 –> 00:21:31,700
بیایید بگوییم که ما داریم، فرض کنیم با
370
00:21:31,700 –> 00:21:35,360
این که شاید چیزی در حدود 90 هزار
371
00:21:35,360 –> 00:21:38,600
بررسی بد داشته باشیم، میخواهیم فقط 90
372
00:21:38,600 –> 00:21:43,580
هزار بررسی تصادفی را از نوع خوب دریافت کنیم، بنابراین
373
00:21:43,580 –> 00:21:46,970
چگونه میتوانیم ابتدا با استفاده از پاندا این کار را انجام دهیم
374
00:21:46,970 –> 00:21:52,009
. نمونهبرداری را انجام میدهم
375
00:21:52,009 –> 00:21:55,789
، بررسیهای
376
00:21:55,789 –> 00:22:00,049
خوب را میگیرم و از بین آنها بهطور تصادفی از
377
00:22:00,049 –> 00:22:03,919
تعداد بررسیهای بد نمونهبرداری میکنم و
378
00:22:03,919 –> 00:22:06,440
در اینجا در حالت تصادفی عبور میکنم، زیرا میخواهم
379
00:22:06,440 –> 00:22:10,669
این چیز باشد. قابل تکرار و
380
00:22:10,669 –> 00:22:13,460
DF بد قرار است حاوی
381
00:22:13,460 –> 00:22:15,950
قاب داده ما باشد، شامل تمام بررسی های بد است،
382
00:22:15,950 –> 00:22:23,120
بنابراین اگر اکنون نگاهی به
383
00:22:23,120 –> 00:22:25,870
شکل
384
00:22:26,190 –> 00:22:33,630
های خوب و بد DF بیاندازیم،
385
00:22:33,630 –> 00:22:40,020
من یک اشتباه تایپی انجام دادم، می توانیم ببینیم که داریم.
386
00:22:40,020 –> 00:22:42,840
اساساً همان مقدار بررسی در
387
00:22:42,840 –> 00:22:45,540
هر دوی آنها، بنابراین مورد بعدی که من
388
00:22:45,540 –> 00:22:47,850
میروم کاری که باید انجام داد ایجاد یک
389
00:22:47,850 –> 00:22:50,430
قاب کلان داده است که شامل تمام نظرات خوب و بدی است
390
00:22:50,430 –> 00:22:54,300
که ما ایجاد کردهایم و من میخواهم این
391
00:22:54,300 –> 00:22:57,840
کار را با اضافه کردن bat DF
392
00:22:57,840 –> 00:23:00,810
به DF خوب انجام دهم و
393
00:23:00,810 –> 00:23:03,300
ایندکس را بازنشانی کنم. بنابراین همه چیز تمیز و
394
00:23:03,300 –> 00:23:07,560
مرتب است و کار بعدی که می
395
00:23:07,560 –> 00:23:12,530
خواهم انجام دهم این است که نگاهی به بررسی DF بیندازم
396
00:23:13,760 –> 00:23:19,350
و بله



![فیلم آموزشی: آموزش یادگیری عمیق با پایتون | یادگیری ماشین با شبکه های عصبی [مدرس برتر Udemy] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/7x2YZhEj9Dwimage2.jpg)