در این مطلب، ویدئو تشخیص سرطان سینه با استفاده از پایتون و یادگیری ماشینی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 1:02:54
تصاویر این ویدئو:

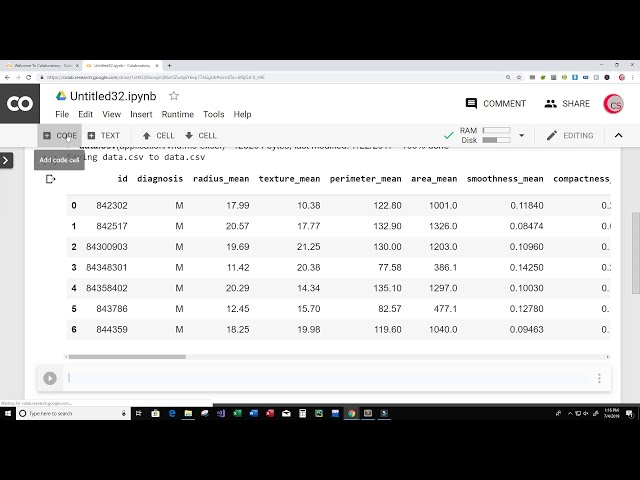
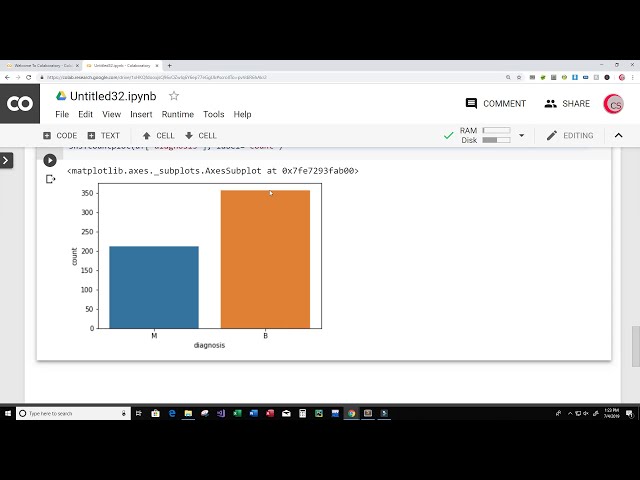
قسمتی از زیرنویس این فیلم:
00:00:00,469 –> 00:00:03,179
سلام بچه ها و به این ویدیو در
2
00:00:03,179 –> 00:00:04,859
مورد زبان برنامه نویسی پایتون و
3
00:00:04,859 –> 00:00:07,319
یادگیری ماشین خوش آمدید، بنابراین در این
4
00:00:07,319 –> 00:00:09,480
ویدیو به شما بچه ها نشان می دهم که چگونه
5
00:00:09,480 –> 00:00:12,509
برنامه ای بنویسید که سرطان سینه را بر اساس داده ها تشخیص دهد،
6
00:00:12,509 –> 00:00:14,880
اکنون سرطان سینه یک
7
00:00:14,880 –> 00:00:16,980
سرطان رایج برای زنان در اطراف است. جهان
8
00:00:16,980 –> 00:00:19,740
و تشخیص زودهنگام سرطان سینه می تواند
9
00:00:19,740 –> 00:00:23,070
10
00:00:23,070 –> 00:00:25,439
با ترویج درمان بالینی
11
00:00:25,439 –> 00:00:27,810
بیماران در اسرع وقت، پیش آگهی و شانس بقا را تا حد زیادی بهبود بخشد، بنابراین من
12
00:00:27,810 –> 00:00:29,130
فکر می کنم واقعاً جالب است که شما
13
00:00:29,130 –> 00:00:32,509
احتمالاً می توانید جان یک نفر را از داده ها
14
00:00:32,509 –> 00:00:36,300
نجات دهید، بنابراین در حال حاضر در وب سایت Google به
15
00:00:36,300 –> 00:00:39,149
نام تحقیقات collab google.com
16
00:00:39,149 –> 00:00:40,890
و دلیل حضور من در این وب سایت این است
17
00:00:40,890 –> 00:00:42,390
که شروع برنامه نویسی در پایتون را بسیار آسان می کند،
18
00:00:42,390 –> 00:00:44,940
بنابراین
19
00:00:44,940 –> 00:00:47,670
لازم نیست پایتون را روی
20
00:00:47,670 –> 00:00:51,510
لپ تاپ یا رایانه رومیزی خود نصب کنید،
21
00:00:51,510 –> 00:00:54,809
فقط می توانید به این آدرس بروید. در مرورگر خود یا
22
00:00:54,809 –> 00:00:57,899
در مرورگر خود پیوند دهید و سپس وارد
23
00:00:57,899 –> 00:00:59,579
حساب Google خود شوید تا به یک حساب Google نیاز داشته
24
00:00:59,579 –> 00:01:01,170
باشید و بتوانید
25
00:01:01,170 –> 00:01:03,239
بلافاصله برنامه نویسی در پایتون را شروع کنید، بنابراین
26
00:01:03,239 –> 00:01:06,780
واقعاً آسان است. و خیلی سریع، خوب، پس
27
00:01:06,780 –> 00:01:08,040
بیایید ادامه دهیم و نوشتن
28
00:01:08,040 –> 00:01:11,640
برنامه پایتون یادگیری ماشینی خود را شروع کنیم، بنابراین
29
00:01:11,640 –> 00:01:12,510
کاری که میخواهم انجام دهم این است که از
30
00:01:12,510 –> 00:01:14,549
اینجا بالا میروم،
31
00:01:14,549 –> 00:01:17,009
یک فایل کلیکی را کمی بیشتر زوم میکنم و سپس کلیک میکنم.
32
00:01:17,009 –> 00:01:19,979
نوت بوک جدید پایتون 3 و چیزی که خواهیم دید
33
00:01:19,979 –> 00:01:23,549
این است که یک برگه جدید برای ما باز می شود و یک
34
00:01:23,549 –> 00:01:28,259
سلول جدید نیز برای ما ایجاد می شود بنابراین برای شروع
35
00:01:28,259 –> 00:01:30,509
نوشتن در پایتون می توانید فقط
36
00:01:30,509 –> 00:01:33,030
در داخل این سلول شروع به نوشتن کد خود کنید
37
00:01:33,030 –> 00:01:35,759
تا من یک کار کوچک انجام دهم.
38
00:01:35,759 –> 00:01:38,310
عبارت hello را چاپ کنید و سپس می توانید با
39
00:01:38,310 –> 00:01:39,720
کلیک کردن روی این دکمه در سمت چپ
40
00:01:39,720 –> 00:01:41,579
آن را اجرا کنید و سپس خواهیم دید که Hello در
41
00:01:41,579 –> 00:01:43,740
زیر نمایش داده می شود.
42
00:01:43,740 –> 00:01:45,750
43
00:01:45,750 –> 00:01:48,060
دوباره در داخل
44
00:01:48,060 –> 00:01:51,360
سلول کلیک کنید و روی این دکمه کد کلیک کنید تا
45
00:01:51,360 –> 00:01:54,390
یک سلول جدید اضافه کنید، بنابراین اکنون
46
00:01:54,390 –> 00:01:56,820
یک عبارت دیگر را چاپ می کنم و
47
00:01:56,820 –> 00:02:02,880
Python را یک علامت تعجب شگفت انگیز قرار می
48
00:02:02,880 –> 00:02:06,030
دهم و من این سلول را به تنهایی اجرا می کنم و
49
00:02:06,030 –> 00:02:07,350
می توانیم ببینیم آن پایتون شگفت انگیز است، در
50
00:02:07,350 –> 00:02:09,840
زیر نمایش داده می شود، بنابراین بیایید از آن خارج شویم و
51
00:02:09,840 –> 00:02:13,269
اکنون می خواهم همه را اجرا کنم از این،
52
00:02:13,269 –> 00:02:15,849
من هر دو عبارت چاپی را اجرا می کنم، بنابراین می
53
00:02:15,849 –> 00:02:18,459
خواهم هر دوی این سلول ها را اجرا کنم، بنابراین
54
00:02:18,459 –> 00:02:20,349
روی run time و روی run all کلیک می کنم
55
00:02:20,349 –> 00:02:24,370
و سپس می بینیم که hello و python هر دو
56
00:02:24,370 –> 00:02:27,879
شگفت انگیز هستند، به خوبی نمایش داده می
57
00:02:27,879 –> 00:02:30,189
شوند، بنابراین کارم تمام است با این سلول دوم،
58
00:02:30,189 –> 00:02:32,170
بنابراین من داخل آن را کلیک می کنم، به
59
00:02:32,170 –> 00:02:34,989
سمت راست بروید و روی این سه نقطه
60
00:02:34,989 –> 00:02:37,569
کلیک کنید و سپس روی حذف سلول کلیک کنید تا از
61
00:02:37,569 –> 00:02:39,849
شر سلول خلاص شوید و البته
62
00:02:39,849 –> 00:02:42,519
من از شر این عبارت چاپی یا این خلاص می شوم.
63
00:02:42,519 –> 00:02:45,189
این عبارت hello print در اینجا و
64
00:02:45,189 –> 00:02:46,480
آنها می خواهند از شر این
65
00:02:46,480 –> 00:02:50,560
عبارت چاپی در خود سلول خلاص
66
00:02:50,560 –> 00:02:53,769
شوند، بنابراین حالا بیایید جلو برویم و
67
00:02:53,769 –> 00:02:55,510
برنامه خود را بنویسیم حالا که کمی
68
00:02:55,510 –> 00:02:58,359
با این ابزار آشنا هستیم، بنابراین اولین
69
00:02:58,359 –> 00:02:59,799
کاری که من دوست دارم انجام دهم این است.
70
00:02:59,799 –> 00:03:03,359
توضیحی درباره کارهایی که برنامه من انجام می دهد ایجاد
71
00:03:03,359 –> 00:03:10,439
کنید، بنابراین دوباره این برنامه سرطان سینه را
72
00:03:10,439 –> 00:03:16,299
بر اساس داده ها تشخیص می دهد، اکنون بلافاصله وقتی
73
00:03:16,299 –> 00:03:20,739
کلمه detect را می بینید، می توانید
74
00:03:20,739 –> 00:03:24,069
به کلاس یادگیری ماشینی یک
75
00:03:24,069 –> 00:03:25,930
طبقه بندی کننده یادگیری ماشین فکر کنید، بنابراین ما می خواهیم
76
00:03:25,930 –> 00:03:29,079
اساساً داده ها را به عنوان سرطان طبقه بندی کنیم.
77
00:03:29,079 –> 00:03:32,260
s یا غیر سرطانی بسیار خوب است،
78
00:03:32,260 –> 00:03:33,909
بنابراین ما میخواهیم سرطان را
79
00:03:33,909 –> 00:03:36,189
در دادهها تشخیص دهیم، سلولهای سرطانی را
80
00:03:36,189 –> 00:03:40,030
در دادههایمان شناسایی کنیم، بنابراین بیایید ادامه دهیم
81
00:03:40,030 –> 00:03:42,189
و با کلیک روی
82
00:03:42,189 –> 00:03:45,699
آن دکمه کد، یک سلول جدید ایجاد کنیم و در اینجا
83
00:03:45,699 –> 00:03:50,590
میخواهیم وارد کنیم. کتابخانهها خوب هستند، بنابراین
84
00:03:50,590 –> 00:03:54,220
من numpy را وارد میکنم، به
85
00:03:54,220 –> 00:03:57,909
آن یک نام مستعار میدهم، بنابراین آن را MP بنامیم،
86
00:03:57,909 –> 00:04:02,500
پانداها را نیز وارد میکنم و
87
00:04:02,500 –> 00:04:05,799
به آن نام مستعار میدهم که آن را PD کنید و
88
00:04:05,799 –> 00:04:08,620
سپس من می خواهم mat plot live
89
00:04:08,620 –> 00:04:13,540
dot pi plot s PLT را وارد کنم و
90
00:04:13,540 –> 00:04:18,459
C را که به صورت S متولد شده است وارد کنم اکنون این ممکن
91
00:04:18,459 –> 00:04:20,589
است تمام کتابخانه های مورد نیاز ما نباشد، اما می
92
00:04:20,589 –> 00:04:21,760
دانم که اینها همان هایی هستند که من
93
00:04:21,760 –> 00:04:24,219
قطعاً آنها را دارم. فوراً استفاده میشود،
94
00:04:24,219 –> 00:04:25,570
بنابراین من میروم و
95
00:04:25,570 –> 00:04:26,800
این سلول را اجرا
96
00:04:26,800 –> 00:04:27,520
میکنم و مطمئن میشوم که هیچ
97
00:04:27,520 –> 00:04:29,680
غلط املایی ندارم و همه چیز
98
00:04:29,680 –> 00:04:31,660
اینجا خوب به نظر میرسد، به نظر میرسد بررسی شود، بنابراین من میخواهم
99
00:04:31,660 –> 00:04:34,870
یک سلول جدید اینجا و اینجا ایجاد کنم. ما
100
00:04:34,870 –> 00:04:40,180
قرار است داده ها را بارگیری کنیم، بنابراین از آنجایی که من در
101
00:04:40,180 –> 00:04:43,150
وب سایت Google هستم، باید از
102
00:04:43,150 –> 00:04:45,250
کتابخانه Google برای بارگیری داده ها از
103
00:04:45,250 –> 00:04:48,190
رایانه خود استفاده کنم و برای انجام این کار، کافیست
104
00:04:48,190 –> 00:04:56,440
فایلهای وارد کردن را از طریق آزمایشگاه کد گوگل تایپ کنید
105
00:04:56,440 –> 00:04:57,909
و سپس متغیری به نام
106
00:04:57,909 –> 00:05:02,229
آپلود آن ایجاد کنید و آن را برابر با فایلهای نقطه
107
00:05:02,229 –> 00:05:07,030
آپلود قرار دهید و سپس متغیری
108
00:05:07,030 –> 00:05:08,889
به نام D F ایجاد میکنیم که مخفف یک
109
00:05:08,889 –> 00:05:13,300
قاب داده است و آن را برابر با پانداهای ما
110
00:05:13,300 –> 00:05:17,259
روش یا تابع زیرخط CSV را می خوانند
111
00:05:17,259 –> 00:05:21,759
و سپس
112
00:05:21,759 –> 00:05:25,750
نام فایلی را می گیریم که CSV نقطه داده است،
113
00:05:25,750 –> 00:05:28,599
پس از اینکه آن داده ها را در قاب داده خود
114
00:05:28,599 –> 00:05:32,020
داشتیم، می خواهیم هفت
115
00:05:32,020 –> 00:05:34,539
ردیف اول داده را چاپ کنیم تا این کار را انجام دهید، من
116
00:05:34,539 –> 00:05:38,500
فقط D F dot head را تایپ می کنم و سپس
117
00:05:38,500 –> 00:05:41,409
مقدار هفت را به عنوان پارامتر وارد می
118
00:05:41,409 –> 00:05:43,779
کنم تا هفت ردیف اول داده را به دست بیاورم، بنابراین اجازه دهید
119
00:05:43,779 –> 00:05:46,630
من ادامه دهم و این سلول را اجرا کنم و می
120
00:05:46,630 –> 00:05:48,610
بینیم که این گزینه برای انتخاب فایل داریم.
121
00:05:48,610 –> 00:05:51,940
“من روی آن گزینه کلیک می کنم و به مکانی می روم
122
00:05:51,940 –> 00:05:54,159
که داده های من در آن قرار دارد
123
00:05:54,159 –> 00:05:57,880
و به داده ها داده
124
00:05:57,880 –> 00:06:00,069
CSV می گویند، بنابراین من روی آن کلیک می کنم و سپس
125
00:06:00,069 –> 00:06:00,759
روی open کلیک می کنم
126
00:06:00,759 –> 00:06:05,830
و اکنون در حال بارگیری فایل هستیم و ما”
127
00:06:05,830 –> 00:06:08,949
همچنین هفت ردیف اول داده را دوباره چاپ می
128
00:06:08,949 –> 00:06:12,940
کنیم، بنابراین به این مجموعه داده نگاه می کنیم و می
129
00:06:12,940 –> 00:06:16,300
توانیم c را ببینیم ستونی به نام ID که
130
00:06:16,300 –> 00:06:18,639
شناسه بیمار است، ستونی به نام
131
00:06:18,639 –> 00:06:23,590
تشخیص می بینیم که به ما می گوید کدام بیمار
132
00:06:23,590 –> 00:06:28,690
سرطان دارد و کدام یک نه،
133
00:06:28,690 –> 00:06:32,830
بنابراین تشخیص M مخفف بدخیم است، به
134
00:06:32,830 –> 00:06:34,300
این معنی که سلول آنها بدخیم
135
00:06:34,300 –> 00:06:36,610
یا مضر است و این یک سلول سرطانی
136
00:06:36,610 –> 00:06:40,599
و سپس ما در اینجا هیچ نمونه ای از
137
00:06:40,599 –> 00:06:43,389
خوش خیم نداریم اما خوش خیم
138
00:06:43,389 –> 00:06:47,229
با حرف B در این ستون تشخیص داده می شود
139
00:06:47,229 –> 00:06:49,569
و این بدان معنی است که سلول D
140
00:06:49,569 –> 00:06:53,319
مضر نیست بنابراین غیر سرطانی است
141
00:06:53,319 –> 00:06:54,729
و همچنین ستون های دیگری به نام
142
00:06:54,729 –> 00:06:56,559
زیرخط رادیوس را می بینیم. بافت
143
00:06:56,559 –> 00:07:00,939
زیرخط متوسط صافی زیرخط مت
144
00:07:00,939 –> 00:07:02,679
سط مساحت زیرخط متوسط محیطی زیرخط متو
145
00:07:02,679 –> 00:07:04,599
ط متراکم بودن زیرخط یعنی فکر می ک
146
00:07:04,599 –> 00:07:07,270
م می توانید خودتان آن را بخوانید اما نکته اصل
147
00:07:07,270 –> 00:07:11,979
اینجاست که ما این نام
148
00:07:11,979 –> 00:07:16,449
ستون ها را داریم و سپس ی
149
00:07:16,449 –> 00:07:19,300
زیرخط و سپس یک نام دیگر د
150
00:07:19,300 –> 00:07:21,639
اینجا داریم. اگر اینجا
151
00:07:21,639 –> 00:07:25,749
نجا را در سمت راست داده ها ادامه دهم، خواهید دید
152
00:07:25,749 –> 00:07:28,509
که برخی از نام ستون ها را
153
00:07:28,509 –> 00:07:31,539
حداقل برای اولین کلمه تکرار می کند، مانند
154
00:07:31,539 –> 00:07:34,360
شعاع اینجا شعاع زیر امتیاز را این بار ببینید،
155
00:07:34,360 –> 00:07:37,139
بنابراین اکنون ما زیرخط را پین می
156
00:07:37,139 –> 00:07:39,819
کنیم، ما دوباره بافت داریم، اما این بار
157
00:07:39,819 –> 00:07:41,860
زیرخط s e است و مخفف
158
00:07:41,860 –> 00:07:43,659
خطای استاندارد است و وقتی به پیمایش ادامه می
159
00:07:43,659 –> 00:07:46,089
دهیم، خواهیم دید که
160
00:07:46,089 –> 00:07:50,379
کلمه متفاوتی با پین به این ستون ها دریافت می کنیم.
161
00:07:50,379 –> 00:07:51,969
نام هایی مانند شعاع و بافت و
162
00:07:51,969 –> 00:07:53,589
این بار ما زیرخط بدتر را اضافه می کنیم،
163
00:07:53,589 –> 00:07:57,759
خوب است، بنابراین این برخی از داده ها است
164
00:07:57,759 –> 00:08:00,490
که فقط باید به آنها توجه کرد و سپس ما
165
00:08:00,490 –> 00:08:03,159
در اینجا ستونی به نام بی نام 32 داریم
166
00:08:03,159 –> 00:08:05,219
و به نظر می رسد که دارای یک دسته
167
00:08:05,219 –> 00:08:10,949
مقادیر خالی است یا در یک n مقادیر کاملاً درست است،
168
00:08:10,949 –> 00:08:14,079
بنابراین بیایید اینجا را ادامه دهیم، من
169
00:08:14,079 –> 00:08:16,860
دوباره به سلول خود در اینجا کلیک می کنم و سپس روی یک
170
00:08:16,860 –> 00:08:20,860
کد کلیک کنید تا یک سلول جدید دریافت کنید و
171
00:08:20,860 –> 00:08:24,459
من به سمت بالا حرکت می کنم و می خواهم
172
00:08:24,459 –> 00:08:28,959
تعداد ردیف ها را بشمارم و ستونها در
173
00:08:28,959 –> 00:08:34,120
مجموعه دادهها خوب است، بنابراین من فقط
174
00:08:34,120 –> 00:08:37,630
شکل نقطهای DF را تایپ میکنم و
175
00:08:37,630 –> 00:08:40,779
این تعداد ردیفها و تعداد
176
00:08:40,779 –> 00:08:43,509
ستونها را به ما میدهد، بنابراین میتوانم ببینم که ما 569
177
00:08:43,509 –> 00:08:45,970
ردیف داریم و به یاد داشته باشید که هر ردیف نشان دهنده یک
178
00:08:45,970 –> 00:08:48,550
بیمار است، بنابراین این 500 است. و این داده ها
179
00:08:48,550 –> 00:08:52,290
در مورد 569 بیمار است و پس از آن ما داریم e 33
180
00:08:52,290 –> 00:08:54,490
ستون به این معنی که
181
00:08:54,490 –> 00:08:58,990
در حال حاضر 3333 ویژگی یا نقطه داده های مختلف
182
00:08:58,990 –> 00:09:03,750
در این 569 بیمار وجود دارد،
183
00:09:03,750 –> 00:09:07,060
زیرا آنچه قبلاً دیدیم ستون آخر به
184
00:09:07,060 –> 00:09:09,550
نظر می رسد اطلاعات زیادی به ما نمی دهد،
185
00:09:09,550 –> 00:09:14,490
بنابراین ممکن است کمتر از 33 نقطه داده ارزشمند وجود داشته باشد.
186
00:09:14,490 –> 00:09:17,260
187
00:09:17,260 –> 00:09:23,440
بنابراین بیایید یک سلول جدید ایجاد کنیم و این بار
188
00:09:23,440 –> 00:09:29,070
میخواهم تعداد
189
00:09:29,820 –> 00:09:39,700
خالی مقادیر خالی در هر ستون را
190
00:09:39,700 –> 00:09:45,730
به دست بیاورم و به یاد داشته باشید خالی است خالی است با N یا
191
00:09:45,730 –> 00:09:50,410
بزرگ na در شما همه حروف را میدانید یا فقط
192
00:09:50,410 –> 00:09:55,150
na خوب است بنابراین همه آنها مقادیر به من
193
00:09:55,150 –> 00:09:57,700
می گویند که آن مقداری که آن
194
00:09:57,700 –> 00:10:02,560
ستون خالی است، بسیار خوب است، بنابراین برای بدست آوردن این
195
00:10:02,560 –> 00:10:07,710
تعداد نیز باید نوع DF dot یک A است و
196
00:10:07,710 –> 00:10:12,550
سپس جمع نقطه و سپس من این سلول را
197
00:10:12,550 –> 00:10:15,880
در اینجا اجرا می کنم و اکنون همه ستون ها را
198
00:10:15,880 –> 00:10:19,900
در داده های خود دریافت می کنیم. تنظیم کنید و مجموعی از
199
00:10:19,900 –> 00:10:24,820
تعداد مقادیر خالی برای هر ستون را دریافت می کنیم، بنابراین
200
00:10:24,820 –> 00:10:26,140
در حال حاضر به نظر می رسد که همه این ستون
201
00:10:26,140 –> 00:10:30,840
ها مقادیر خالی ندارند که شگفت انگیز است
202
00:10:30,840 –> 00:10:33,160
به جز آخرین ستونی که
203
00:10:33,160 –> 00:10:35,200
قبلاً دیدیم به نام بی نام 32 نامیده
204
00:10:35,200 –> 00:10:41,260
می شود و دارای 569 مقدار خالی است بنابراین من فکر می کنم
205
00:10:41,260 –> 00:10:42,760
می توان گفت که ما ج از شر این ستون خلاص شوید
206
00:10:42,760 –> 00:10:47,320
زیرا فقط 569 ردیف
207
00:10:47,320 –> 00:10:51,040
داده وجود دارد، به این معنی که
208
00:10:51,040 –> 00:10:54,820
به معنای واقعی کلمه هیچ داده ای در آن
209
00:10:54,820 –> 00:10:59,110
ستون وجود ندارد، بنابراین من به اینجا برمی گردم
210
00:10:59,110 –> 00:11:01,150
داخل سلول کلیک کنید و
211
00:11:01,150 –> 00:11:03,810
یک سلول جدید ایجاد می کنم.
212
00:11:03,810 –> 00:11:08,339
و میخواهم بگیرم، میخواهم از شر آن ستون خلاص شوم،
213
00:11:08,339 –> 00:11:11,189
بنابراین ستون را رها
214
00:11:11,189 –> 00:11:13,999
میکنیم و آن را اینجا در نظرات تایپ میکنم،
215
00:11:13,999 –> 00:11:16,620
بنابراین
216
00:11:16,620 –> 00:11:23,220
ستون را با تمام مقادیر از دست رفته
217
00:11:23,220 –> 00:11:25,860
رها میکنیم و واقعاً در حال رها شدن هستیم. همه ستونها با
218
00:11:25,860 –> 00:11:28,740
مقادیر از دست رفته که میخواهم به
219
00:11:28,740 –> 00:11:31,230
شما نشان دهم که چگونه این کار را انجام دهید، اما چون ما
220
00:11:31,230 –> 00:11:34,139
فقط یک ستون با تمام مقادیر از دست رفته
221
00:11:34,139 –> 00:11:39,420
داریم، متأسفم چون فقط
222
00:11:39,420 –> 00:11:40,980
یک ستون با مقادیر از دست رفته
223
00:11:40,980 –> 00:11:44,749
داریم، فقط آن یک ستون را حذف میکنیم.
224
00:11:44,749 –> 00:11:50,399
خوب است، بنابراین برای رها کردن این ستونها،
225
00:11:50,399 –> 00:11:54,540
فقط DF dot drop و a را تایپ کنید و ما میخواهیم
226
00:11:54,540 –> 00:11:57,540
روی ستون رها کنیم تا محور
227
00:11:57,540 –> 00:12:02,160
برابر با یک شود و این به ما یک
228
00:12:02,160 –> 00:12:06,839
مجموعه داده جدید بدون آن ستون خالی میدهد، بنابراین من
229
00:12:06,839 –> 00:12:08,579
میخواهم آن را دوباره در آن ذخیره کنم.
230
00:12:08,579 –> 00:12:11,639
قاب داده اصلی ما، بنابراین من فقط تایپ می کنم DF
231
00:12:11,639 –> 00:12:16,139
برابر است با DF drop n/a، بنابراین اکنون این است
232
00:12:16,139 –> 00:12:18,629
همه ستونها را با مقادیر خالی حذف میکند و
233
00:12:18,629 –> 00:12:23,430
در این مورد فقط یک ok داریم، بنابراین
234
00:12:23,430 –> 00:12:28,649
من میخواهم این را درست اجرا کنم
235
00:12:28,649 –> 00:12:33,029
و حالا بیایید یک سلول جدید ایجاد کنیم و
236
00:12:33,029 –> 00:12:38,279
تعداد سطرها و
237
00:12:38,279 –> 00:12:40,519
ستونها
238
00:12:40,519 –> 00:12:43,170
را دوباره به دست آوریم. برای انجام این کار فقط شکل نقطه DF را تایپ می کنیم
239
00:12:43,170 –> 00:12:45,600
و من می خواهم این را اجرا کنم و
240
00:12:45,600 –> 00:12:48,689
اکنون می بینیم که ما هنوز 569
241
00:12:48,689 –> 00:12:50,370
ردیف داده داریم اما این بار فقط 32
242
00:12:50,370 –> 00:12:52,139
ستون داریم و دلیل آن
243
00:12:52,139 –> 00:12:55,589
این است که آخرین ستون به نام unnamed 32 را کاملاً حذف کردیم.
244
00:12:55,589 –> 00:12:58,160
بنابراین بیایید یک سلول جدید در اینجا ایجاد
245
00:12:58,160 –> 00:13:00,269
کنیم زیرا ما فقط در حال کاوش در
246
00:13:00,269 –> 00:13:02,550
داده های خود و پاکسازی آنها هستیم قبل از اینکه
247
00:13:02,550 –> 00:13:04,949
مدل خود را ایجاد کنیم که قرار
248
00:13:04,949 –> 00:13:07,889
است طبقه بندی یا تشخیص
249
00:13:07,889 –> 00:13:12,269
سلول های سرطانی را به درستی انجام دهد، بنابراین اکنون می
250
00:13:12,269 –> 00:13:16,399
خواهم به آن دست پیدا کنم. شمارش تعداد
251
00:13:16,399 –> 00:13:17,910
بدخیم
252
00:13:17,910 –> 00:13:21,750
که با حرف M یا
253
00:13:21,750 –> 00:13:25,050
b9 نشان داده می شود که با سلول های حرف B نشان داده می
254
00:13:25,050 –> 00:13:30,990
شود، بسیار خوب است، بنابراین تمام کاری که باید انجام داد این است که
255
00:13:30,990 –> 00:13:35,340
DF را تایپ کنید و سپس من اطلاعاتی را از
256
00:13:35,340 –> 00:13:42,000
ستون تشخیص می خواهم و
257
00:13:42,000 –> 00:13:45,240
تعداد آن ها را می خواهم. مقادیر، بنابراین من فقط مقدار un را تایپ می کنم
258
00:13:45,240 –> 00:13:49,590
derscore شمارش می شود و این
259
00:13:49,590 –> 00:13:53,100
باید تعداد هر مقدار را به ما اطلاع دهد، بنابراین به
260
00:13:53,100 –> 00:13:59,610
نظر می رسد که ما 357 ردیف مختلف یا 357
261
00:13:59,610 –> 00:14:03,900
ردیف داده داریم که در آن سلول های بیمار
262
00:14:03,900 –> 00:14:06,540
خوش خیم هستند، بنابراین سرطان ندارند و
263
00:14:06,540 –> 00:14:09,930
سپس ما 212 ردیف داده داریم که در آن
264
00:14:09,930 –> 00:14:12,690
بیمار است. سلول ها بدخیم هستند و من
265
00:14:12,690 –> 00:14:15,300
در اینجا بدخیم را اشتباه نوشتم پای من
266
00:14:15,300 –> 00:14:17,240
267
00:14:17,240 –> 00:14:21,900
212 ردیف داده را به درستی گره زد، بنابراین 212 بیمار
268
00:14:21,900 –> 00:14:25,170
که متاسفانه سرطان دارند، این بدان معنا نیست
269
00:14:25,170 –> 00:14:27,180
که شما می دانید که هر چیزی از دنیا خواهند رفت،
270
00:14:27,180 –> 00:14:29,250
بلکه فقط به این معنی است که آنها
271
00:14:29,250 –> 00:14:32,220
سرطان دارند، بنابراین این بر
272
00:14:32,220 –> 00:14:34,620
اساس مجموعه دادههای خود، اکنون میتوانیم کمی
273
00:14:34,620 –> 00:14:38,070
بهتر انجام دهیم و میتوانیم تصویری از این داشته باشیم،
274
00:14:38,070 –> 00:14:42,660
بنابراین من یک سلول جدید ایجاد میکنم و در اینجا
275
00:14:42,660 –> 00:14:47,550
میخواهیم تعداد را تجسم کنیم تا برای
276
00:14:47,550 –> 00:14:49,740
انجام این کار از آن استفاده کنم. کتابخانه Seabourn
277
00:14:49,740 –> 00:14:53,040
بنابراین من فقط SN s dot count نمودار را تایپ می کنم
278
00:14:53,040 –> 00:14:57,230
و آنها باید به آن بگویند که
279
00:14:57,230 –> 00:14:59,940
کدام ستون را می خواهم تعداد آن را دریافت کنم، بنابراین
280
00:14:59,940 –> 00:15:02,820
آن ستونی در چارچوب داده ما
281
00:15:02,820 –> 00:15:05,550
به نام تشخیص است، بنابراین من فقط DF را تایپ می
282
00:15:05,550 –> 00:15:09,270
کنم سپس براکت ها را تایپ می کنم و سپس می گذارم در n نقل قول
283
00:15:09,270 –> 00:15:13,160
در اینجا نام ستون
284
00:15:13,160 –> 00:15:14,340
o را تشخیص دهید kay
285
00:15:14,340 –> 00:15:19,790
و من یک برچسب روی محور y
286
00:15:19,790 –> 00:15:23,910
به آن میدهم و آن را count oky مینامم، پس بیایید این را اجرا
287
00:15:23,910 –> 00:15:29,160
کنیم، بنابراین اکنون میبینیم که در محور y
288
00:15:29,160 –> 00:15:31,210
289
00:15:31,210 –> 00:15:38,590
مقادیر بدخیم و خوشخیم در
290
00:15:38,590 –> 00:15:41,800
ستون تشخیص وجود دارد و اکنون میتوانیم
291
00:15:41,800 –> 00:15:44,320
کمی بیشتر به صورت بصری ببینید که
292
00:15:44,320 –> 00:15:48,040
تعداد بیشتری از بیماران با سلول های خوش خیم وجود دارد، بنابراین
293
00:15:48,040 –> 00:15:49,870
بیمارانی که سرطان ندارند، سپس
294
00:15:49,870 –> 00:15:54,730
بیمارانی هستند که سرطان دارند، بنابراین این فقط یک
295
00:15:54,730 –> 00:15:57,160
تجسم است، اما در اینجا ما
296
00:15:57,160 –> 00:16:01,240
اعداد واقعی را در بالا داریم و این به نظر من از
297
00:16:01,240 –> 00:16:05,080
نظر بصری جذاب تر از صرف است. به سادگی
298
00:16:05,080 –> 00:16:07,660
میتوانم اعداد را ببینم، اما واقعاً ترجیح میدهم
299
00:16:07,660 –> 00:16:09,700
هر دو را خوب ببینم، بنابراین بیایید پیش برویم و
300
00:16:09,700 –> 00:16:16,390
یک سلول جدید ایجاد کنیم و بیایید به انواع دادهها نگاه کنیم،
301
00:16:16,390 –> 00:16:18,910
بنابراین در اینجا نوع من
302
00:16:18,910 –> 00:16:25,720
به انواع دادهها نگاه کنید تا ببینید کدام ستونها
303
00:16:25,720 –> 00:16:30,130
باید کدگذاری شوند، بنابراین اینها ستونهایی هستند
304
00:16:30,130 –> 00:16:33,850
که من باید به یک
305
00:16:33,850 –> 00:16:36,850
مقدار عددی مانند یک عدد صحیح یا یک
306
00:16:36,850 –> 00:16:41,110
شناور تبدیل کنم، بنابراین من واقعاً به دنبال
307
00:16:41,110 –> 00:16:44,710
داده های طبقه بندی شده یا انواع داده های شی در
308
00:16:44,710 –> 00:16:49,030
پایتون در اینجا هستم، بنابراین برای انجام این کار فقط نوع D
309
00:16:49,030 –> 00:16:54,160
F نقطه d را تایپ می کنم و این سلول را اجرا می کنم اوه من
310
00:16:54,160 –> 00:16:58,090
انواع s را قرار دادم پس بیایید D را قرار دهیم تایپ کنید سپس
311
00:16:58,090 –> 00:17:00,910
سلول را اجرا می کنم و همه
312
00:17:00,910 –> 00:17:03,220
ستون ها و نوع داده آنها را در اینجا به
313
00:17:03,220 –> 00:17:06,400
سمت راست برمی گردانیم، بنابراین به نظر می رسد ID یک
314
00:17:06,400 –> 00:17:10,119
مقدار صحیح است و حالا که به آن فکر
315
00:17:10,119 –> 00:17:14,170
کنید ID واقعاً اطلاعات زیادی
316
00:17:14,170 –> 00:17:15,670
برای بیمار نمی دهد.
317
00:17:15,670 –> 00:17:18,849
فقط بیمار را به درستی شناسایی می کند، بنابراین ما احتمالاً می
318
00:17:18,849 –> 00:17:21,880
توانیم از شر آن ستون نیز خلاص شویم،
319
00:17:21,880 –> 00:17:24,579
احتمالاً ضروری نیست، ستون تشخیص
320
00:17:24,579 –> 00:17:27,579
یک شی خوب است و ما می دانیم
321
00:17:27,579 –> 00:17:29,940
که آن یک شی است زیرا a
322
00:17:29,940 –> 00:17:33,460
حاوی حروف m و B است که این موارد
323
00:17:33,460 –> 00:17:36,100
هستند. مقادیر در آن ستون، بنابراین یک
324
00:17:36,100 –> 00:17:38,980
شی است، یک رشته یا داده های طبقه بندی شده است
325
00:17:38,980 –> 00:17:41,650
و سپس همه چیزهای دیگر همه مقادیر دیگر
326
00:17:41,650 –> 00:17:44,280
شناور به نظر می رسند
327
00:17:44,280 –> 00:17:46,500
و می بینیم که ما دیگر آن
328
00:17:46,500 –> 00:17:49,770
ستونی به نام آنچه که آن را بدون نام 32 نامیده می شد
329
00:17:49,770 –> 00:17:52,950
نداریم، بنابراین آن ستون
330
00:17:52,950 –> 00:17:57,960
واقعاً از مجموعه داده ما خوب است، بنابراین
331
00:17:57,960 –> 00:18:00,299
من دوباره در سلول اینجا کلیک می کنم اینجا را
332
00:18:00,299 –> 00:18:05,630
کلیک کنید تا یک سلول جدید اضافه شود بسیار خوب و
333
00:18:05,630 –> 00:18:09,870
اکنون می خواهم مقادیر داده های طبقه بندی را رمزگذاری کنم،
334
00:18:09,870 –> 00:18:12,870
بنابراین در اینجا در نظر بسیاری
335
00:18:12,870 –> 00:18:18,260
از put مقادیر داده های دسته بندی را رمزگذاری می
336
00:18:18,260 –> 00:18:21,720
کنند تا به d o که من
337
00:18:21,720 –> 00:18:26,179
باید از یک کتابخانه استفاده کنم، بنابراین از SK یادگیری
338
00:18:26,179 –> 00:18:31,370
مجدد پردازش، من می خواهم رمزگذار برچسب را وارد
339
00:18:31,370 –> 00:18:35,010
کنم و سپس
340
00:18:35,010 –> 00:18:37,909
یک متغیر به نام رمزگذار برچسب
341
00:18:37,909 –> 00:18:41,400
زیر خط Y به جای برابر با رمزگذار برچسب ایجاد می کنم
342
00:18:41,400 –> 00:18:43,309
343
00:18:43,309 –> 00:18:48,210
و اکنون می خواهیم برای تبدیل
344
00:18:48,210 –> 00:18:51,510
دادههای طبقهبندی ما به تعداد کافی به
345
00:18:51,510 –> 00:18:56,840
اعداد، بنابراین من میخواهم برچسب
346
00:18:56,840 –> 00:19:03,260
رمزگذار زیرخط Y نقطه متناسب تبدیل
347
00:19:03,260 –> 00:19:08,970
تناسب زیرخط تبدیل را تایپ کنم و اکنون
348
00:19:08,970 –> 00:19:10,980
آن را میخواهم، باید به آن بگویم چه دادههایی را
349
00:19:10,980 –> 00:19:13,679
میخواهم تبدیل کند و این دادههای موجود در دادههای ما هستند.
350
00:19:13,679 –> 00:19:20,159
فریمی که در موقعیت یک
351
00:19:20,159 –> 00:19:26,130
سمت راست است، بنابراین شاخصی که در
352
00:19:26,130 –> 00:19:29,549
قاب داده ما برای تشخیص در شاخص یک
353
00:19:29,549 –> 00:19:32,340
است، شعاع شعاع صفر است،
354
00:19:32,340 –> 00:19:36,990
میانگین در شاخص دو خوب است و همچنین
355
00:19:36,990 –> 00:19:40,830
میخواهم به آن بگویم که همه ردیفها را دریافت کند.
356
00:19:40,830 –> 00:19:43,289
بنابراین برای انجام این کار، من فقط یک دونقطه را در اینجا تایپ می کنم،
357
00:19:43,289 –> 00:19:46,159
بنابراین به شما می گویم که تمام سطرها را
358
00:19:46,159 –> 00:19:51,620
دریافت کنید و داده ها را از نمایه از تشخیص ستون دریافت کنید
359
00:19:51,620 –> 00:19:55,960
که در شاخص یک خوب است
360
00:19:55,960 –> 00:19:58,210
و به طور خاص اجازه دهید مقادیر را به آن بگویم
361
00:19:58,210 –> 00:20:05,669
کاملاً خوب است. دوباره
362
00:20:05,669 –> 00:20:09,820
مقادیر را در اینجا وارد کنید ما ba از لحاظ ظاهری
363
00:20:09,820 –> 00:20:12,340
آن را به یک آرایه تبدیل می کنیم، ما یک آرایه را
364
00:20:12,340 –> 00:20:16,690
در داخل این در داخل این تابع
365
00:20:16,690 –> 00:20:19,960
یا روش وارد می کنیم، خوب است و در واقع شما می دانید
366
00:20:19,960 –> 00:20:22,749
چه چیزی به من اجازه می دهد فقط این را اینجا کپی کنم و
367
00:20:22,749 –> 00:20:25,450
منظورم را به شما نشان دهم، بنابراین من ادامه می دهم
368
00:20:25,450 –> 00:20:35,980
و این نقطه DF را اجرا می کنم. بسیاری از نقاط که من
369
00:20:35,980 –> 00:20:40,119
مقادیر را اشتباه بیان کردم خوب است، بنابراین باید
370
00:20:40,119 –> 00:20:44,769
اینجا را نیز تغییر دهم، بنابراین اجازه دهید
371
00:20:44,769 –> 00:20:47,889
دوباره این را اجرا کنم و اکنون می توانید ببینید
372
00:20:47,889 –> 00:20:51,129
که ما مقادیر قاب داده خود را نشان می دهیم
373
00:20:51,129 –> 00:20:54,399
و این یک آرایه است، بنابراین من من
374
00:20:54,399 –> 00:20:56,409
دقیقاً اینجا را وارد میکنم و این تمام
375
00:20:56,409 –> 00:20:58,960
چیزی است که میخواهم به شما نشان دهم خوب است،
376
00:20:58,960 –> 00:21:01,389
بنابراین اگر این را اجرا کنم، همه
377
00:21:01,389 –> 00:21:04,389
چیز خوب است بله عالی است، بنابراین هنوز در حال
378
00:21:04,389 –> 00:21:08,169
چاپ است، اکنون
379
00:21:08,169 –> 00:21:10,539
مقدار رمزگذاری شده را چاپ میکند، بنابراین اجازه دهید کنترل Z
380
00:21:10,539 –> 00:21:12,159
را در اینجا انجام دهم. قبلاً چه شکلی بود،
381
00:21:12,159 –> 00:21:12,759
382
00:21:12,759 –> 00:21:16,169
بنابراین در اینجا ما مقادیر M و B را داریم و
383
00:21:16,169 –> 00:21:18,999
اکنون مقدار M
384
00:21:18,999 –> 00:21:20,499
با عدد یک و
385
00:21:20,499 –> 00:21:22,629
مقدار B با
386
00:21:22,629 –> 00:21:25,539
عدد صفر نشان داده می شود، بنابراین اگر دوباره از شر آن خلاص
387
00:21:25,539 –> 00:21:28,960
شوم و اجرا کنم. می توانید ببینید که ما
388
00:21:28,960 –> 00:21:31,090
یک دسته از یک ها و صفرها را از رمزگذاری برچسب خود دریافت می کنیم
389
00:21:31,090 –> 00:21:34,210
r در اینجا کاملاً بر روی Y تأکید کنید.
390
00:21:34,210 –> 00:21:37,119
من میخواهم این دادهها را دوباره در قاب دادهام قرار دهم،
391
00:21:37,119 –> 00:21:40,139
بنابراین فقط DF
392
00:21:40,139 –> 00:21:45,509
dot I lock را تایپ میکنم و میخواهم تمام ردیفهای
393
00:21:45,509 –> 00:21:50,350
ستون تشخیص برابر با این
394
00:21:50,350 –> 00:21:52,749
تبدیل جدید باشند، بنابراین اجازه دهید این را اجرا کنیم.
395
00:21:52,749 –> 00:21:55,720
اینجا و به نظر می رسد همه چیز اوکی است و
396
00:21:55,720 –> 00:21:59,590
حالا اگر این را هایلایت کنم و آن را کپی کنم
397
00:21:59,590 –> 00:22:03,009
و سپس آن را اینجا بچسبانم و این را اجرا کنم،
398
00:22:03,009 –> 00:22:06,369
خواهیم دید که اکنون همه یک ها و
399
00:22:06,369 –> 00:22:08,159
صفرها
400
00:22:08,159 –> 00:22:11,830
اوکی هستند و می دانم که یکی
401
00:22:11,830 –> 00:22:17,649
با رشته em مطابقت دارد من می دانم که
402
00:22:17,649 –> 00:22:21,580
به دلیل داده های ما، صفر با رشته B مطابقت دارد،
403
00:22:21,580 –> 00:22:25,860
بنابراین می توانیم دقیقاً از زمانی
404
00:22:25,860 –> 00:22:28,869
که هفت ردیف اول داده ها را فهرست کرده ایم، ببینیم
405
00:22:28,869 –> 00:22:32,519
که تشخیص M بوده است، بنابراین برای
406
00:22:32,519 –> 00:22:38,080
هفت ردیف اول در اینجا، آن مقدار همچنان
407
00:22:38,080 –> 00:22:40,809
M است، اما اکنون این مقدار است. به یک تبدیل می شود
408
00:22:40,809 –> 00:22:42,970
تا بتوانیم ببینیم که هفت سطر اول
409
00:22:42,970 –> 00:22:45,429
باید همه یک باشند و سپس اگر بخواهیم به
410
00:22:45,429 –> 00:22:49,269
دنبال جایی باشیم که رشته در آن ضرب شده است،
411
00:22:49,269 –> 00:22:53,619
در ردیف ردیف نوزدهم را می بینیم، حدس می زنم
412
00:22:53,619 –> 00:22:57,100
ردیف در شاخص نوزده، یک B
413
00:22:57,100 –> 00:23:01,149
در داده های اصلی وجود داشته باشد. باشه پس
414
00:23:01,149 –> 00:23:02,950
من فقط از شر آن خلاص می شوم، بیایید
415
00:23:02,950 –> 00:23:06,879
سلول خود را دوباره اجرا کنیم خوب است و من
416
00:23:06,879 –> 00:23:11,580
یک سلول جدید ایجاد می کنم و در اینجا می خواهم
417
00:23:11,580 –> 00:23:19,869
یک نمودار ایجاد یک جفت درست کنم بنابراین برای
418
00:23:19,869 –> 00:23:22,330
انجام این کار از C متولد دوباره استفاده می کنم و
419
00:23:22,330 –> 00:23:28,809
S&S pair plot را تایپ می کنم و باید به آن بگویم
420
00:23:28,809 –> 00:23:34,629
چه دادههایی را میخواهم با
421
00:23:34,629 –> 00:23:37,210
ستونهایی که میخواهم جفت شود یا با آنها مطابقت
422
00:23:37,210 –> 00:23:42,039
داشته باشد، برای این کار تمام کاری که باید انجام دهیم این است که
423
00:23:42,039 –> 00:23:48,460
در اینجا DF را تایپ کنیم و اگر بخواهم فقط نمونهای از آن را دریافت کنم، میتوانم DF dot را انجام دهم.
424
00:23:48,460 –> 00:23:50,679
425
00:23:50,679 –> 00:23:53,759
دادههای من در اینجا است، بنابراین من همه ردیفها را
426
00:23:53,759 –> 00:24:00,929
میخواهم و همه ردیفها را از شاخص 1 تا
427
00:24:00,929 –> 00:24:07,409
نمایه 6 میخواهم، اما شاخص 6 را شامل نمیشود،
428
00:24:07,409 –> 00:24:12,429
بنابراین ما شاخص 6 را در اینجا
429
00:24:12,429 –> 00:24:16,690
در برنامه وارد نمیکنیم، بنابراین اجازه دهید این را اجرا کنیم و ممکن
430
00:24:16,690 –> 00:24:19,140
است کمی طول بکشد. زمان
431
00:24:19,140 –> 00:24:23,560
و بنابراین اکنون میتوانیم ستون را ببینیم، بنابراین
432
00:24:23,560 –> 00:24:25,960
ستونهای یک دو پنج را میبینیم که دوباره تشخیص را میبینیم
433
00:24:25,960 –> 00:24:29,650
که دوباره این است که شاخص 1
434
00:24:29,650 –> 00:24:32,800
میانگین شعاع را میبینیم که در شاخص 2 است،
435
00:24:32,800 –> 00:24:35,110
بافت من را میبینیم که در شاخص 3 است،
436
00:24:35,110 –> 00:24:37,630
پارامتر من را میبینیم. که در نمایه 4 است،
437
00:24:37,630 –> 00:24:39,580
ناحیه من را می بینید که در شاخص 5 است و
438
00:24:39,580 –> 00:24:41,260
سپس ما دیگر ستون ها را نمی بینیم، بنابراین می
439
00:24:41,260 –> 00:24:47,500
بینیم که ما در حال مقایسه 1 2 3 4
440
00:24:47,500 –> 00:24:56,950
5 ستون ها هستیم ok اکنون به نظر می رسد خوب است، می توانم ببینم
441
00:24:56,950 –> 00:24:58,960
که یکی از این نمودارها در
442
00:24:58,960 –> 00:25:01,330
اینجا از صفحه خارج می شوند، بنابراین من فقط
443
00:25:01,330 –> 00:25:05,220
این را به 5 تغییر می دهم تا
444
00:25:05,220 –> 00:25:07,930
این بار فقط چهار ستون داشته باشیم و
445
00:25:07,930 –> 00:25:11,200
امیدوارم همه آنها بر روی صفحه نمایش خوب باشند.
446
00:25:11,200 –> 00:25:15,160
خوب به نظر می رسد و بیایید
447
00:25:15,160 –> 00:25:17,770
بهتر به نظر برسد، ما می توانیم درست انجام دهیم، بنابراین
448
00:25:17,770 –> 00:25:22,060
من می خواهم نقاط تشخیص را در
449
00:25:22,060 –> 00:25:25,330
این نمودارها ببینم تا این کار را انجام دهم که فقط u
450
00:25:25,330 –> 00:25:29,290
برابر تشخیص را تایپ می کنم و اجازه دهید دوباره این کار را اجرا کنیم
451
00:25:29,290 –> 00:25:35,620
و حالا که خیلی بهتر به نظر می رسد می
452
00:25:35,620 –> 00:25:38,740
توانیم ببینیم سلول های مهره 9 که
453
00:25:38,740 –> 00:25:41,230
آبی هستند با عدد 0 نشان داده می شوند و ما
454
00:25:41,230 –> 00:25:42,790
سلول های بدخیم را می بینیم که سلول های
455
00:25:42,790 –> 00:25:45,880
سرطانی هستند که با عدد 1 نشان داده شده اند
456
00:25:45,880 –> 00:25:49,260
و آنها نارنجی هستند و مشکلی ندارند
457
00:25:49,260 –> 00:25:54,400
و وقتی کدگذاری این کار را تمام کردم
458
00:25:54,400 –> 00:25:57,700
احتمالاً همه موارد را قرار خواهم داد.
459
00:25:57,700 –> 00:26:02,640
ستونهای اینجا با برچسبهای تشخیص
460
00:26:02,640 –> 00:26:05,470
و من فقط برای اینکه بدانید میتوانید
461
00:26:05,470 –> 00:26:07,360
همه دادهها را داشته باشید، همه ستونها
462
00:26:07,360 –> 00:26:11,200
را با هم جفت میکنید، اما برای این
463
00:26:11,200 –> 00:26:13,330
ویدیوی کوچک در اینجا یا این مثال کوچک برای
464
00:26:13,330 –> 00:26:15,940
این ویدیو، تولید اینها بسیار سریع است.
465
00:26:15,940 –> 00:26:18,010
نمودارهایی که می گیرد
466
00:26:18,010 –> 00:26:20,890
مدتی است که برای
467
00:26:20,890 –> 00:26:22,540
تمام ستونهایی که در آن
468
00:26:22,540 –> 00:26:25,780
مجموعه داده داریم یک نمودار ایجاد کند، بنابراین فکر میکنم عالی به نظر میرسد
469
00:26:25,780 –> 00:26:26,500
،
470
00:26:26,500 –> 00:26:30,409
اجازه دهید پیش برویم و یک سلول جدید اضافه
471
00:26:30,409 –> 00:26:35,610
کنیم و حالا پنج ردیف
472
00:26:35,610 –> 00:26:41,279
اول مجموعه داده جدیدمان را چاپ کنیم.
473
00:26:41,279 –> 00:26:46,259
پنج سطر اول داده های جدید را چاپ کنید و برای انجام این کار
474
00:26:46,259 –> 00:26:52,080
من فقط D F dot head را درست تایپ می کنم، بنابراین
475
00:26:52,080 –> 00:26:56,909
اکنون تشخیص داریم که همه یک
476
00:26:56,909 –> 00:26:59,220
و صفر هستند و دیگر
477
00:26:59,220 –> 00:27:02,909
ستون خود را با تمام مقادیر خالی
478
00:27:02,909 –> 00:27:08,029
در پایان نداریم، بنابراین این دوباره دادههای پاککننده جدید ما است،
479
00:27:08,029 –> 00:27:10,049
فکر نمیکنم به آن ستون ID نیاز داشته باشیم،
480
00:27:10,049 –> 00:27:12,330
اما نمیخواهم آن را رها کنم
481
00:27:12,330 –> 00:27:14,759
، به
482
00:27:14,759 –> 00:27:19,230
روشی متفاوت از استفاده از روش drop یا
483
00:27:19,230 –> 00:27:21,899
تابع خلاص میشویم، بنابراین ما
484
00:27:21,899 –> 00:27:24,149
وقتی در واقع
485
00:27:24,149 –> 00:27:29,610
به مدل خود برای تشخیص سرطان آموزش میدهیم، از شر آن ستون خلاص میشویم، بسیار خوب،
486
00:27:29,610 –> 00:27:32,940
پس بیایید کمی بیشتر به کاوش در دادههایمان ادامه دهیم
487
00:27:32,940 –> 00:27:36,409
، اجازه دهید به همبستگیها نگاه کنیم،
488
00:27:36,409 –> 00:27:39,840
بنابراین در اینجا
489
00:27:39,840 –> 00:27:45,240
میخواهم همبستگی ستونهای D را به دست بیاورم و برای
490
00:27:45,240 –> 00:27:50,129
انجام این کار می توانم D F dot cor را تایپ کنم اما
491
00:27:50,129 –> 00:27:53,820
فقط می خواهم نمونه ای از آن را دریافت کنم
492
00:27:53,820 –> 00:27:56,279
برای انجام این کار،
493
00:27:56,279 –> 00:28:00,179
DF dot را تایپ میکنم، قفل میکنم و همه سطرها
494
00:28:00,179 –> 00:28:04,769
از ستونهای یک تا دوازده را میخواهم، اما ستون دوازده را شامل نمیشود
495
00:28:04,769 –> 00:28:09,440
496
00:28:09,440 –> 00:28:11,789
و وقتی میگویم یک در دوازده، منظورم
497
00:28:11,789 –> 00:28:14,610
ایندکسها است که خیلی خوب است. ما میتوانیم
498
00:28:14,610 –> 00:28:18,679
شاخص نمایه ستون در دوازده
499
00:28:18,679 –> 00:28:22,379
باشیم و فقط از تشخیص ستون شروع میکنیم،
500
00:28:22,379 –> 00:28:25,289
اکنون اولین ستون واقعی،
501
00:28:25,289 –> 00:28:28,679
ستون ID است و در
502
00:28:28,679 –> 00:28:30,720
شاخص صفر است، بنابراین من فقط میخواهم مطمئن شوم
503
00:28:30,720 –> 00:28:33,690
که بسیار واضح است، درست است و سپس
504
00:28:33,690 –> 00:28:36,330
من همبستگیها را میخواهم، بنابراین
505
00:28:36,330 –> 00:28:42,970
هسته نقطهای را تایپ میکنم و حالا اگر این را اجرا کنم،
506
00:28:42,970 –> 00:28:47,470
میتوانیم همبستگی بین همبستگیهای خود
507
00:28:47,470 –> 00:28:50,800
را بین هر ستون
508
00:28:50,800 –> 00:28:52,870
ببینیم، بنابراین میتوانیم ببینیم چگونه یک ستون میتواند روی
509
00:28:52,870 –> 00:28:56,350
دیگری تأثیر بگذارد و بنابراین به نظر میرسد که شعاع
510
00:28:56,350 –> 00:29:00,390
میانگین و شعاع آرام است. میانگین
511
00:29:00,390 –> 00:29:03,820
بر ستون تشخیص تأثیر دارد و
512
00:29:03,820 –> 00:29:07,210
به نظر می رسد میانگین محیطی نیز
513
00:29:07,210 –> 00:29:09,970
بر ستون تشخیص تأثیر مثبت داشته
514
00:29:09,970 –> 00:29:14,100
باشد و میانگین نقاط مقعر
515
00:29:14,100 –> 00:29:18,790
تأثیر مثبت داشته باشد و میانگین بعد فراکتال
516
00:29:18,790 –> 00:29:21,610
517
00:29:21,610 –> 00:29:23,530
همبستگی یا تأثیر منفی بر آن داشته باشد.
518
00:29:23,530 –> 00:29:25,630
ستون تشخیص e و البته اگر
519
00:29:25,630 –> 00:29:27,070
مقدار صفر داشته باشیم به این معنی است که
520
00:29:27,070 –> 00:29:30,040
آن ستون هیچ تاثیری روی
521
00:29:30,040 –> 00:29:35,020
ستون دیگر ندارد، بسیار خوب است، بنابراین اجازه دهید
522
00:29:35,020 –> 00:29:36,760
به بالا برگردم اینجا، داخل این سلول کلیک کنید و
523
00:29:36,760 –> 00:29:44,260
اجازه دهید یک سلول جدید ایجاد کنیم، خوب حالا
524
00:29:44,260 –> 00:29:48,430
میخواهم آن همبستگی را
525
00:29:48,430 –> 00:29:51,630
تجسم کنید، بنابراین همبستگی را تجسم کنید،
526
00:29:51,630 –> 00:29:56,290
متأسفم، بنابراین ما
527
00:29:56,290 –> 00:30:01,170
اکنون میخواهیم همبستگی را تجسم کنیم تا این کار را انجام دهیم،
528
00:30:01,170 –> 00:30:04,830
من دوباره از کتابخانه Seabourn استفاده میکنم،
529
00:30:04,830 –> 00:30:11,500
بنابراین فقط نقشه حرارتی نقطهای SNS را تایپ کنید و باید
530
00:30:11,500 –> 00:30:15,730
به آن بگویم چه ستونهایی را میخواهم.
531
00:30:15,730 –> 00:30:18,370
برای انجام این کار، فقط DF dot
532
00:30:18,370 –> 00:30:21,910
را زیاد تایپ میکنم و میخواهم هر سطر
5