در این مطلب، ویدئو رگرسیون در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:51
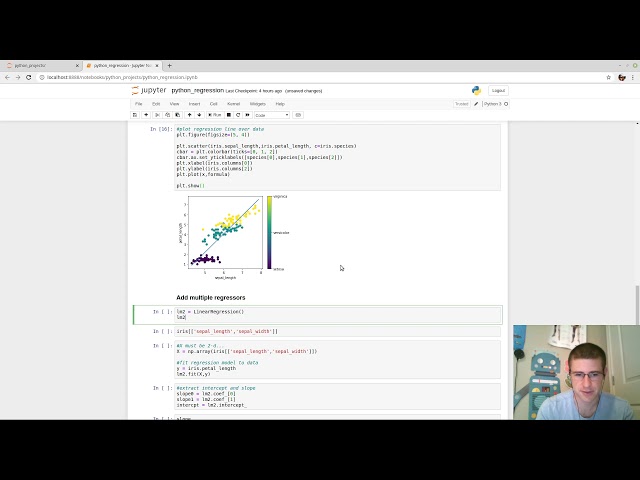
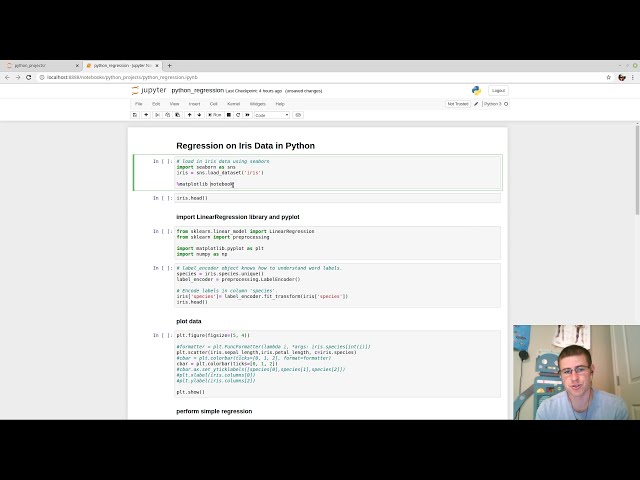
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,230 –> 00:00:02,730
سلام به همه، این یک ویدیو در مورد نحوه
2
00:00:02,730 –> 00:00:05,970
انجام رگرسیون اولیه در پایتون است، من
3
00:00:05,970 –> 00:00:08,280
اخیراً یکی از آن ها را در مورد نحوه
4
00:00:08,280 –> 00:00:10,950
انجام همین کار در MATLAB به پایان رساندم و اکنون جابجایی
5
00:00:10,950 –> 00:00:13,799
پایتون بعدی در R خواهد بود، بنابراین
6
00:00:13,799 –> 00:00:15,360
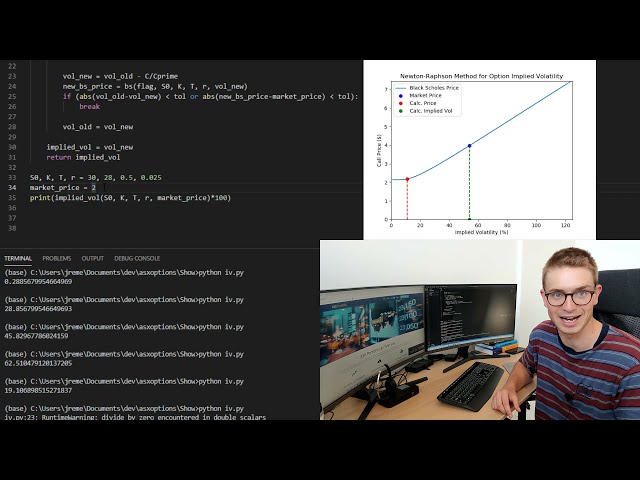
ما همچنان با مجموعه داده های iris کار می کنیم.
7
00:00:15,360 –> 00:00:17,520
فقط به خاطر سادگی،
8
00:00:17,520 –> 00:00:20,189
فکر می کنم همه تقریباً با
9
00:00:20,189 –> 00:00:21,869
این مجموعه داده آشنا هستند آنچه را که من در آنجا بارگذاری کردم،
10
00:00:21,869 –> 00:00:23,850
سؤالات زیادی در
11
00:00:23,850 –> 00:00:26,880
مورد چیستی داده ها وجود
12
00:00:26,880 –> 00:00:28,800
نخواهد داشت، اگر بخواهید بارگذاری در آن داده ها مشکلی نخواهد داشت.
13
00:00:28,800 –> 00:00:31,500
برای اجرای این مجموعه خودتان به
14
00:00:31,500 –> 00:00:33,660
مجموعه دادههای تعبیهشده در پایتون یا
15
00:00:33,660 –> 00:00:35,489
تعبیهشده در MATLAB یا تعبیهشده در R دسترسی داشته باشید تا
16
00:00:35,489 –> 00:00:37,739
بتوانیم با این مجموعه
17
00:00:37,739 –> 00:00:39,719
18
00:00:39,719 –> 00:00:43,320
داده تا جایی که میخواهیم بازی
19
00:00:43,320 –> 00:00:44,370
کنیم. در واقع از
20
00:00:44,370 –> 00:00:46,680
Seabourn برای بارگذاری در مجموعه داده استفاده خواهم کرد، من
21
00:00:46,680 –> 00:00:48,120
یک ویدیوی دیگر در مورد نحوه بارگیری آن دارم
22
00:00:48,120 –> 00:00:49,500
و در واقع دو گزینه در دسترس وجود دارد که
23
00:00:49,500 –> 00:00:50,910
یکی Seabourn است و من معتقدم یکی از آنها
24
00:00:50,910 –> 00:00:53,879
scikit-learn است.
25
00:00:53,879 –> 00:00:55,800
26
00:00:55,800 –> 00:01:00,059
به عنوان یک چارچوب داده که نوعی
27
00:01:00,059 –> 00:01:04,650
جدول سبک جدولی به سبک CSV شما است، در حالی
28
00:01:04,650 –> 00:01:06,780
که وقتی یک Sikit-Learn انجام می دهید، در
29
00:01:06,780 –> 00:01:08,610
واقع چیزی دارید که به آن یک دسته می گویند و
30
00:01:08,610 –> 00:01:12,479
ویژگی های متفاوتی دارد، علاوه بر
31
00:01:12,479 –> 00:01:15,650
این، من این نوت بوک فاصله دار %matplotlib را نیز انجام می دهم
32
00:01:15,650 –> 00:01:18,659
آنچه به شما می دهد در
33
00:01:18,659 –> 00:01:21,299
واقع این است. میتوانیم چیزهای خاصی را
34
00:01:21,299 –> 00:01:24,869
در یک دفترچه یادداشت مشتری در یک خط یک matplotlib بنامیم،
35
00:01:24,869 –> 00:01:27,509
بنابراین وقتی به نموداری در پایین میرسیم،
36
00:01:27,509 –> 00:01:30,960
وقتی آن را صدا میزنیم، اگر این کار را انجام
37
00:01:30,960 –> 00:01:33,810
نمیدادیم matplotlib، تعاملی نبود، بنابراین
38
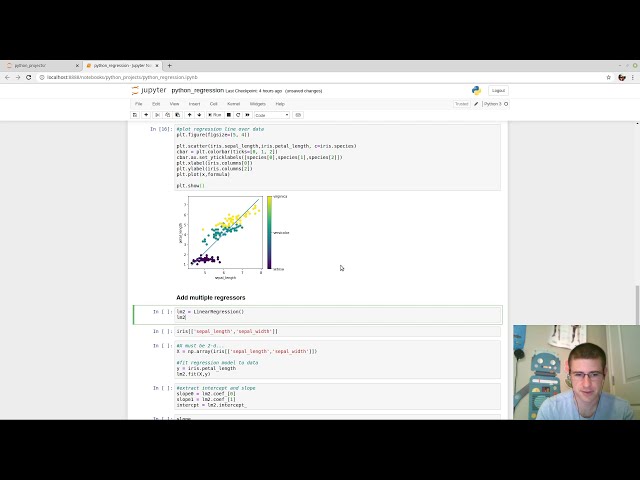
00:01:33,810 –> 00:01:35,640
نوعی تعامل با نمودارها و موارد دیگر را ممکن میسازد.
39
00:01:35,640 –> 00:01:38,130
بنابراین من خط به خط
40
00:01:38,130 –> 00:01:39,869
میروم و توضیح میدهم که در هر مرحله چه کاری انجام میدهم،
41
00:01:39,869 –> 00:01:42,150
در واقع Seabourn را وارد
42
00:01:42,150 –> 00:01:44,970
میکنیم و آن را به SNS تغییر نام دادهایم و
43
00:01:44,970 –> 00:01:47,189
یک تابع فراخوانی به نام load data مجموعه وجود دارد و
44
00:01:47,189 –> 00:01:49,409
ما در حال بارگیری در iris هستیم. من آن را در
45
00:01:49,409 –> 00:01:50,729
یک متغیر عنبیه ذخیره کردهام و سپس
46
00:01:50,729 –> 00:01:53,250
این طرح % mat را به صورت زنده فراخوانی میکنم که
47
00:01:53,250 –> 00:01:56,100
امکان تعامل طرحهای ما را
48
00:01:56,100 –> 00:01:58,290
پس از بارگذاری در آن فراهم میکند، فقط میخواهم به آن نگاه
49
00:01:58,290 –> 00:02:01,049
کنم تا یک قاب داده به شما اجازه دهد سر نقطه را انجام دهید.
50
00:02:01,049 –> 00:02:03,149
و 5 ردیف اول داده را به شما می
51
00:02:03,149 –> 00:02:04,979
دهد بنابراین خواهید دید که ما
52
00:02:04,979 –> 00:02:07,079
طول کاسبرگ داریم عرض کاسبرگ طول
53
00:02:07,079 –> 00:02:09,199
عرض گلبرگ و سپس گونه
54
00:02:09,199 –> 00:02:12,170
هایی را نیز داریم که در اینجا فهرستی
55
00:02:12,170 –> 00:02:14,910
از آنجا داریم که در چند
56
00:02:14,910 –> 00:02:16,170
کتابخانه اضافی بارگذاری می کنیم که بعدا از آنها استفاده خواهیم کرد،
57
00:02:16,170 –> 00:02:20,099
اما یکی از آنها SK است که
58
00:02:20,099 –> 00:02:22,110
scikit-learn است و در کتابخانه مدل خطی قرار
59
00:02:22,110 –> 00:02:24,599
دارد که در رگرسیون خطی بارگذاری
60
00:02:24,599 –> 00:02:25,860
میکنیم، زیرا در
61
00:02:25,860 –> 00:02:28,590
اینجا رگرسیون
62
00:02:28,590 –> 00:02:30,290
63
00:02:30,290 –> 00:02:32,340
انجام میدهیم. بارگیری چند
64
00:02:32,340 –> 00:02:34,620
چیز از SK یاد بگیرید ما همچنین
65
00:02:34,620 –> 00:02:36,450
در matplotlib بارگذاری خواهیم کرد، این به ما امکان می دهد
66
00:02:36,450 –> 00:02:38,069
چیزهایی را رسم کنیم و ما آنها
67
00:02:38,069 –> 00:02:39,959
را به خاطر استفاده از آرایه ها
68
00:02:39,959 –> 00:02:42,540
به صورت numpy بارگذاری می کنیم، در واقع من فکر می کنم که این جنبه را حذف کردم،
69
00:02:42,540 –> 00:02:44,910
نه. من آن را دقیقاً در اینجا می بینم،
70
00:02:44,910 –> 00:02:46,410
بنابراین باید از numpy نیز استفاده کنیم تا این
71
00:02:46,410 –> 00:02:48,330
کتابخانه ها بارگیری شوند، بیایید
72
00:02:48,330 –> 00:02:51,150
ادامه دهیم و این کار را درست
73
00:02:51,150 –> 00:02:53,850
انجام دهیم.
74
00:02:53,850 –> 00:02:56,760
بر اساس
75
00:02:56,760 –> 00:02:59,910
گونه بنابراین هر نوع گل که
76
00:02:59,910 –> 00:03:03,420
رنگ توسا برعکس و ویرجینیکا است من
77
00:03:03,420 –> 00:03:05,819
آن را باور دارم قرار است کدگذاری رنگی خود را
78
00:03:05,819 –> 00:03:11,030
روی طرح داشته باشد، به همین دلیل
79
00:03:11,030 –> 00:03:13,920
تابع نموداری که من از آن استفاده
80
00:03:13,920 –> 00:03:17,100
خواهم کرد، دوست ندارد چیزها را بر اساس
81
00:03:17,100 –> 00:03:18,900
نام رمزگذاری کند، بلکه دوست دارد چیزها را بر اساس اعداد رمزگذاری کند،
82
00:03:18,900 –> 00:03:21,120
بنابراین برای انجام این کار من از
83
00:03:21,120 –> 00:03:24,239
این رمزگذار برچسب استفاده کنید و اولین کاری که انجام می دهم این
84
00:03:24,239 –> 00:03:28,319
است که نام گونه منحصر به فرد را استخراج کنم،
85
00:03:28,319 –> 00:03:29,910
بنابراین اساساً چند گروه
86
00:03:29,910 –> 00:03:32,100
دارم و آن را به عنوان متغیر ذخیره می کنم، آن
87
00:03:32,100 –> 00:03:33,750
را به عنوان یک متغیر ذخیره می کنم فقط به این دلیل که
88
00:03:33,750 –> 00:03:35,790
می خواهم این مقادیر را ذخیره کنم و زمانی که می خواهم
89
00:03:35,790 –> 00:03:37,560
این رمزگذار برچسب را انجام دهید
90
00:03:37,560 –> 00:03:41,340
، مقادیر را با اعداد جایگزین میکند، بنابراین
91
00:03:41,340 –> 00:03:43,230
ابتدا آن را بیرون میآورم و فقط در صورت نیاز آن را کنار میگذارم
92
00:03:43,230 –> 00:03:45,540
، سپس یک رمزگذار برچسب را ذخیره
93
00:03:45,540 –> 00:03:49,440
میکنم که در واقع
94
00:03:49,440 –> 00:03:52,200
این سیستم شمارهگذاری را ایجاد میکند و
95
00:03:52,200 –> 00:03:54,750
میخواهم گونه عنبیه را با آن مناسب کنید و من
96
00:03:54,750 –> 00:03:56,970
آن را دوباره به عنوان گونه بیرونی ذخیره می کنم، بنابراین وقتی این
97
00:03:56,970 –> 00:03:58,200
کار را انجام دادم، آن را نیز خاموش
98
00:03:58,200 –> 00:04:00,120
می کنم، Satou را می بینید، بنابراین چیزی که ما در اینجا داشتیم
99
00:04:00,120 –> 00:04:02,130
، به صفر تبدیل شد، بنابراین شما صفر یک دارید
100
00:04:02,130 –> 00:04:05,489
و دو نفر بعدی واقعاً میخواهند دادهها را رسم کنند،
101
00:04:05,489 –> 00:04:07,530
بنابراین اکنون من دادههایی را که به نوعی پیدا کردهام دیدهام
102
00:04:07,530 –> 00:04:09,870
اکنون آن را به درستی قالب بندی کرده ام، من می خواهم
103
00:04:09,870 –> 00:04:11,519
به آن نگاه کنم و
104
00:04:11,519 –> 00:04:14,989
به طور خاص در مورد بسیاری از این موارد نظر
105
00:04:14,989 –> 00:04:17,070
داده ام زیرا در واقع فکر نمی کنم دیگر مجبور
106
00:04:17,070 –> 00:04:18,389
باشم از فرمت کننده استفاده
107
00:04:18,389 –> 00:04:19,798
کنم و بعداً دوباره با آن تماس خواهم گرفت و من
108
00:04:19,798 –> 00:04:21,690
در واقع آن را حذف کرد، اما فقط در
109
00:04:21,690 –> 00:04:24,540
صورتی که شما اینگونه آن را برای
110
00:04:24,540 –> 00:04:27,750
ورودی ماده صدا کنید و برای نوار رنگی استفاده می
111
00:04:27,750 –> 00:04:30,930
شود که می گوید ما آن را بدون آن صدا می زنیم،
112
00:04:30,930 –> 00:04:32,370
بسیار خوب است،
113
00:04:32,370 –> 00:04:35,790
بنابراین برای ترسیم نمودار پراکندگی داده هایی که می
114
00:04:35,790 –> 00:04:37,230
خواهم از PLT استفاده کنید که تابع matplotlib
115
00:04:37,230 –> 00:04:40,800
است و من پراکنده هستم اولین
116
00:04:40,800 –> 00:04:43,320
تبدیل محور x طول کاسبرگ عنبیه است
117
00:04:43,320 –> 00:04:44,790
و کاری که میخواهم انجام دهم این است که از
118
00:04:44,790 –> 00:04:47,370
تامین برای پیشبینی طول گلبرگ استفاده کنم
119
00:04:47,370 –> 00:04:49,890
نه گونهها دلیلی که انجام میدهم. این
120
00:04:49,890 –> 00:04:51,930
به این دلیل است که من رگرسیون پایه را انجام می دهم
121
00:04:51,930 –> 00:04:53,790
که در آن یک متغیر پیوسته به عنوان
122
00:04:53,790 –> 00:04:55,920
ورودی دارم و خروجی متغیرهای پیوسته را پیش بینی می کنم
123
00:04:55,920 –> 00:04:58,650
زمانی که با گونه
124
00:04:58,650 –> 00:05:00,930
ها یک متغیر کلاس یا یک متغیر طبقه بندی
125
00:05:00,930 –> 00:05:03,030
داریم و این کار کمی
126
00:05:03,030 –> 00:05:04,470
پیچیده تر می شود، بنابراین می خواستم آن را
127
00:05:04,470 –> 00:05:07,350
در اینجا بسیار ساده نگه دارید اما آنچه که من هستم
128
00:05:07,350 –> 00:05:09,810
کد رنگ بر اساس گونهها، این همان چیزی است که C
129
00:05:09,810 –> 00:05:12,150
مخفف آن است، بنابراین وقتی این را
130
00:05:12,150 –> 00:05:15,780
اجرا میکنم، ابتدا آن را با تمام این کامنتگذاریها اجرا
131
00:05:15,780 –> 00:05:18,420
میکنم، خواهید دید که محور x خود، محور y من
132
00:05:18,420 –> 00:05:20,190
هیچ برچسبی ندارم اما من نقشه حرارتی دارم
133
00:05:20,190 –> 00:05:22,380
و شما سه گروه را می بینید، بنابراین واضح است که
134
00:05:22,380 –> 00:05:23,550
می توانید ببینید سه گروه مختلف عالی وجود دارد،
135
00:05:23,550 –> 00:05:27,600
اما کاری که من می خواهم انجام دهم این است که
136
00:05:27,600 –> 00:05:30,180
در واقع این خط را نظر خواهم داد
137
00:05:30,180 –> 00:05:33,750
و بنابراین آنچه انجام دادم در
138
00:05:33,750 –> 00:05:37,680
تابع نمودار matplotlib است. کتابخانه نمودار
139
00:05:37,680 –> 00:05:41,370
یک تابع نوار رنگی وجود دارد که
140
00:05:41,370 –> 00:05:43,380
شما تیک ها را ایجاد می کنید و تیک ها را دقیقاً
141
00:05:43,380 –> 00:05:46,200
در اینجا با 0 1 و 2 می بینید، بنابراین من سه
142
00:05:46,200 –> 00:05:47,400
تیک در نوار رنگ ایجاد کردم که فاصله آنها به
143
00:05:47,400 –> 00:05:49,290
طور مساوی است و به همین دلیل است که شما
144
00:05:49,290 –> 00:05:51,060
این سه رنگ را در اینجا دریافت می کنید، اما من
145
00:05:51,060 –> 00:05:53,040
واقعاً می خواهم این کار را انجام دهم این است که آنها را نام
146
00:05:53,040 –> 00:05:54,810
ببرم و بنابراین کاری که می خواهم انجام دهم این است که ببینم بارت نه
147
00:05:54,810 –> 00:05:58,170
تبر و تبرها تیک گسترده ای را تنظیم می کند که
148
00:05:58,170 –> 00:05:59,820
به این معنی است
149
00:05:59,820 –> 00:06:02,070
که اگر x2 را انجام دهم نوار رنگ را در اینجا خواهم داشت.
150
00:06:02,070 –> 00:06:05,490
محور x سپس من قصد دارم گونه ها
151
00:06:05,490 –> 00:06:08,880
را شاخص اول یا شاخص 0 شاخص
152
00:06:08,880 –> 00:06:11,630
دوم یا شاخص اول را ادعا کنم و من در
153
00:06:11,630 –> 00:06:15,480
برنامه نویسی ایندکس ها را ایندکس می کنم و در
154
00:06:15,480 –> 00:06:18,210
آخرین ایندکس وقتی اجرا می
155
00:06:18,210 –> 00:06:20,010
کنم 0 1 و 2 خواننده را می بینید، بنابراین من ادامه می دهم
156
00:06:20,010 –> 00:06:22,140
و آن را اجرا می کنم و اکنون در
157
00:06:22,140 –> 00:06:24,840
واقع گونه ها را داریم و به یاد می آوریم که من خروجی گونه ها را ذخیره کرده ام.
158
00:06:24,840 –> 00:06:27,300
در اینجا من این کار را به
159
00:06:27,300 –> 00:06:29,700
طور خاص انجام دادم تا بتوانم مستقیماً از آن نام ببرم
160
00:06:29,700 –> 00:06:31,110
، کمی قابل درک تر بود،
161
00:06:31,110 –> 00:06:33,150
خوب، دو مورد
162
00:06:33,150 –> 00:06:34,630
آخری که در
163
00:06:34,630 –> 00:06:37,430
اینجا نظر خواهم داد، برچسب X
164
00:06:37,430 –> 00:06:39,470
و برچسب y خواهند بود و دوباره این فقط
165
00:06:39,470 –> 00:06:43,190
برای این را
166
00:06:43,190 –> 00:06:44,870
قابل درک تر کنم و کاری که من کردم این بود که ستون عنبیه را گرفتم،
167
00:06:44,870 –> 00:06:47,330
بنابراین تمام ستون ها را مرتب می کند
168
00:06:47,330 –> 00:06:49,310
و شما آنها را در اینجا دارید و
169
00:06:49,310 –> 00:06:51,170
من ستون 0 را که
170
00:06:51,170 –> 00:06:52,970
طول کاسبرگ است و
171
00:06:52,970 –> 00:06:55,010
ستون دوم را که گلبرگ است را انتخاب می کنم. طول و وقتی
172
00:06:55,010 –> 00:06:57,830
اجرا می کنم می بینید که محور x من
173
00:06:57,830 –> 00:07:00,500
اکنون طول کاسبرگ
174
00:07:00,500 –> 00:07:02,510
175
00:07:02,510 –> 00:07:04,340
است.
176
00:07:04,340 –> 00:07:06,170
177
00:07:06,170 –> 00:07:08,360
رگرسیون را روی آن انجام دهید بنابراین
178
00:07:08,360 –> 00:07:09,680
اولین رگرسیونی که می خواهیم اجرا کنیم فقط
179
00:07:09,680 –> 00:07:11,990
کاسبرگ است طول پیشبینی طول گلبرگ و
180
00:07:11,990 –> 00:07:13,160
کاری که من میخواهم انجام دهم این است که یک
181
00:07:13,160 –> 00:07:14,930
مدل رگرسیون خطی ایجاد کنم و آن را
182
00:07:14,930 –> 00:07:17,540
مدل خطی 1 LM 1 مینامم، بنابراین وقتی اجرا میکنم،
183
00:07:17,540 –> 00:07:20,030
رگرسیون خطی را کپی میکنم،
184
00:07:20,030 –> 00:07:22,190
وقفه برازش واقعی X است،
185
00:07:22,190 –> 00:07:23,360
جالب است زیرا به شما یک
186
00:07:23,360 –> 00:07:25,970
قطع y می دهد یا نه و سپس
187
00:07:25,970 –> 00:07:28,880
مجموعه را به false عادی می کند، بنابراین ما موب خود را
188
00:07:28,880 –> 00:07:30,860
داریم، ما هیچ کاری با آن انجام نداده ایم، بنابراین اکنون
189
00:07:30,860 –> 00:07:32,840
می خواهم از متغیرهای پیش بینی خود استفاده کنم
190
00:07:32,840 –> 00:07:36,080
که X خواهد بود و متغیر هدف من
191
00:07:36,080 –> 00:07:39,500
که خواهد بود. be Y باید X را تنظیم
192
00:07:39,500 –> 00:07:40,490
کنم کمی پیچ شده است
193
00:07:40,490 –> 00:07:42,100
زیرا انتظار دارد دوبعدی باشد و
194
00:07:42,100 –> 00:07:44,450
در حال حاضر عنبیه که طول پله
195
00:07:44,450 –> 00:07:46,790
یک بعدی است، بنابراین برای انجام این کار
196
00:07:46,790 –> 00:07:50,390
فقط آن را MP numpy آرایه حول
197
00:07:50,390 –> 00:07:51,830
طول ساده بنامید و سپس یک
198
00:07:51,830 –> 00:07:56,000
اگر
199
00:07:56,000 –> 00:07:59,300
من کمی گیج هستم که
200
00:07:59,300 –> 00:08:01,100
چرا منفی 1 1 است، تابع را برای تغییر شکل اخیر فراخوانی می کند، اما اگر این کار را انجام دهید
201
00:08:01,100 –> 00:08:02,270
در واقع کار می کند و من ابعاد مناسب را به شما می دهم
202
00:08:02,270 –> 00:08:04,490
و پس از آن Y
203
00:08:04,490 –> 00:08:06,770
فقط به طول گلبرگ تبدیل می شود.
204
00:08:06,770 –> 00:08:08,960
آن مجموعه ای که من می خواهم به آنها زنگ بزنم
205
00:08:08,960 –> 00:08:10,880
مدل خطی و من مقادیر x خود را به
206
00:08:10,880 –> 00:08:13,630
چشم همسرم تطبیق می دهم، بنابراین
207
00:08:13,630 –> 00:08:18,470
LM 1 من مقداری خروجی دارد که همه چیز
208
00:08:18,470 –> 00:08:21,620
خوب است و در واقع فکر می کنم فقط به خاطر
209
00:08:21,620 –> 00:08:23,990
اینجا می خواهم دوباره LM 1
210
00:08:23,990 –> 00:08:26,540
را صدا کنم، بله. هنوز هیچ اطلاعاتی در اختیار ما قرار نمی دهد
211
00:08:26,540 –> 00:08:30,800
، پارامترهای زیادی در داخل آن وجود دارد،
212
00:08:30,800 –> 00:08:33,080
بنابراین می توانید آنها را فراخوانی کنید
213
00:08:33,080 –> 00:08:34,490
اولین مواردی که قرار است آنها را فراخوانی کنیم ضرایب هستند،
214
00:08:34,490 –> 00:08:37,490
بنابراین شیب برابر است با ضریب LM 1
215
00:08:37,490 –> 00:08:40,370
، این شیب
216
00:08:40,370 –> 00:08:43,039
متغیرهای پیش بینی است، بنابراین چه تاثیری دارند.
217
00:08:43,039 –> 00:08:44,900
روی متغیر هدف وجود داشت،
218
00:08:44,900 –> 00:08:46,850
سپس شما رهگیری را دارید و آن
219
00:08:46,850 –> 00:08:49,760
دقیقاً کمتر از lm-1 است، بنابراین وقتی
220
00:08:49,760 –> 00:08:52,160
اینها را چاپ میکنم اجازه دهید در واقع ادامه دهم و
221
00:08:52,160 –> 00:08:54,350
این را اجرا کنم و سپس به شما نشان خواهم داد که ما
222
00:08:54,350 –> 00:08:57,020
فقط شیب را در انتهای اینجا انجام خواهیم داد.
223
00:08:57,020 –> 00:08:58,640
بروید و خواهید دید که یک آرایه است
224
00:08:58,640 –> 00:09:00,470
و یک مقدار دارد که شیب متصل
225
00:09:00,470 –> 00:09:03,380
به متغیرهای پیشبینی X من است، اگر
226
00:09:03,380 –> 00:09:05,690
رهگیری کنم، بیایید اینجا ببینیم که
227
00:09:05,690 –> 00:09:08,210
املای آن درست است،
228
00:09:08,210 –> 00:09:10,280
اگر ویدیوی متلب من را ببینید هفت نقطه منفی داریم،
229
00:09:10,280 –> 00:09:11,150
فکر میکنم اینها هستند. در واقع
230
00:09:11,150 –> 00:09:13,790
متغیرهای یکسان یا خروجی یکسان با آنچه
231
00:09:13,790 –> 00:09:16,070
MATLAB هستند مسیری که انتظار میرود
232
00:09:16,070 –> 00:09:17,690
همان داده باشد، بنابراین تا زمانی که
233
00:09:17,690 –> 00:09:19,100
همه کارها را درست انجام میدهم، باید دادههای بسیار مشابهی دریافت کنیم، بدون اینکه
234
00:09:19,100 –> 00:09:20,290
235
00:09:20,290 –> 00:09:22,990
خطاهای گرد کردن عجیب و غریب وجود داشته باشد، اشکالی ندارد.
236
00:09:22,990 –> 00:09:25,460
237
00:09:25,460 –> 00:09:27,110
238
00:09:27,110 –> 00:09:28,850
برای ترسیم خط رگرسیون خود، بنابراین من اکنون
239
00:09:28,850 –> 00:09:32,390
نقطه قطع و شیب را دارم که
240
00:09:32,390 –> 00:09:34,670
اساساً یک فرمول Y به من می دهد،
241
00:09:34,670 –> 00:09:36,770
من یک فرمول خط دریافت می کنم، اما کاری که
242
00:09:36,770 –> 00:09:38,960
باید برای مقادیر X انجام دهم، باید آنها را به
243
00:09:38,960 –> 00:09:41,210
نوعی افزایش دهم تا بتوانم
244
00:09:41,210 –> 00:09:44,210
من از حداقل مقدار خود شروع میکنم و به
245
00:09:44,210 –> 00:09:46,460
حداکثر مقدار خود پایان میدهم و
246
00:09:46,460 –> 00:09:49,340
در فواصل زمانی گامهایی را انجام میدهم، اگر این کار را نکنم
247
00:09:49,340 –> 00:09:51,440
مشکل این است که مقدار x از
248
00:09:51,440 –> 00:09:54,560
0 تا 150 خواهم داشت زیرا من 150 اندازهگیری
249
00:09:54,560 –> 00:09:56,210
دارم. این
250
00:09:56,210 –> 00:09:58,100
مقدارها فقط به 0 150 میرسند، بنابراین باید
251
00:09:58,100 –> 00:10:01,430
کمی آن را بازی کنم، بنابراین کاری که میکنم این است
252
00:10:01,430 –> 00:10:03,620
که محدوده حداکثر مقدار X
253
00:10:03,620 –> 00:10:05,780
منهای حداقل مقدار X را برمیدارم و
254
00:10:05,780 –> 00:10:08,450
آن را بر تقسیم میکنم. تعداد کل
255
00:10:08,450 –> 00:10:11,210
اندازه گیری هایی که به من می
256
00:10:11,210 –> 00:10:13,640
دهد افزایش من است که فاصله من چند است
257
00:10:13,640 –> 00:10:16,490
باید انجام شود تا اساساً 150
258
00:10:16,490 –> 00:10:19,490
اندازه گیری مختلف ایجاد شود، سپس من می خواهم
259
00:10:19,490 –> 00:10:22,910
در آرایه ای از آن یک عدد ایجاد کنم و تنها کاری
260
00:10:22,910 –> 00:10:25,220
که باید انجام دهم این است که یک نقطه ناقص تصادفی را صدا بزنم
261
00:10:25,220 –> 00:10:27,530
ترتیب دهید که شما مقدار شروع
262
00:10:27,530 –> 00:10:29,870
خود را مقدار پایانی خود انجام دهید و مرحله شما را که
263
00:10:29,870 –> 00:10:32,930
آیا فاصله ما در اینجا خوب است، سپس
264
00:10:32,930 –> 00:10:34,850
من فرمول خود را ایجاد می کنم و فرمول
265
00:10:34,850 –> 00:10:37,460
دوباره فقط یک فرمول خط است و
266
00:10:37,460 –> 00:10:38,870
267
00:10:38,870 –> 00:10:41,390
به جای اینکه بگویم MX به اضافه B، من می
268
00:10:4


![فیلم آموزشی: چگونه صفحه نمایش خود را در Pygame محو کنید [کد در توضیحات] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/H2r2N7D56Uwimage2.jpg)