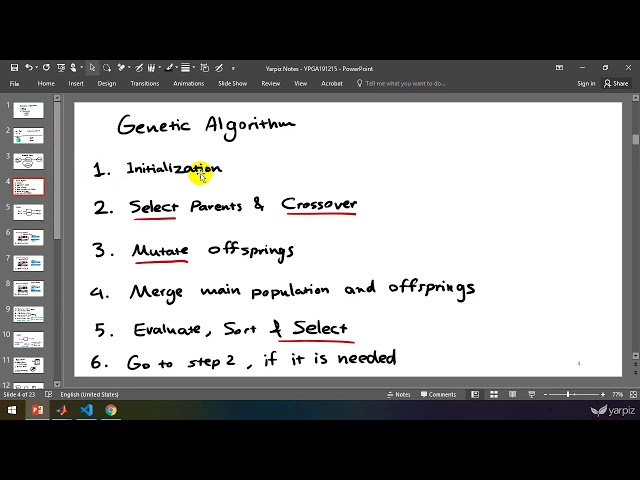
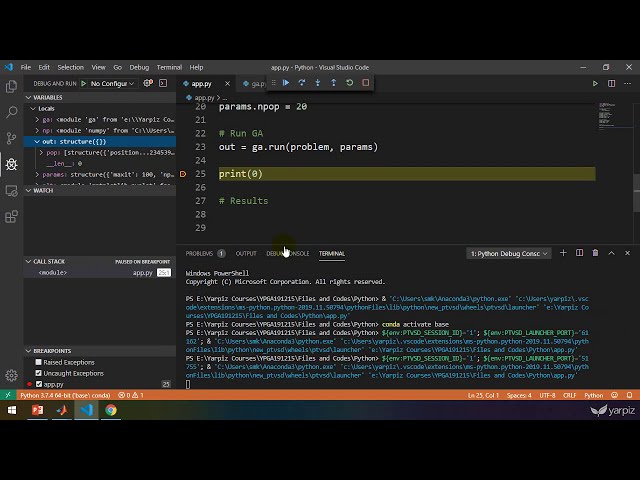
در این مطلب، ویدئو الگوریتم ژنتیک در پایتون – قسمت الف – سری الگوریتم های ژنتیک عملی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:42:40
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:03,890 –> 00:00:06,540
در این بخش قصد دارم
2
00:00:06,540 –> 00:00:10,950
GA را از ابتدا در پایتون پیاده سازی کنم و فقط
3
00:00:10,950 –> 00:00:12,780
4
00:00:12,780 –> 00:00:15,599
الگوریتم ژنتیک کدگذاری شده واقعی را پیاده سازی می کنم و شما می توانید
5
00:00:15,599 –> 00:00:18,359
الگوریتم ژنتیک باینری را به
6
00:00:18,359 –> 00:00:21,330
روشی مشابه پیاده سازی کنید
7
00:00:21,330 –> 00:00:23,640
که برای الگوریتم ژنتیک کدگذاری شده واقعی در برنامه داریم.
8
00:00:23,640 –> 00:00:25,470
MATLAB در قسمت های قبلی این فیلم
9
00:00:25,470 –> 00:00:28,289
آموزشی قصد دارم این مشکل را حل
10
00:00:28,289 –> 00:00:30,570
کنم تابع asphere که یک
11
00:00:30,570 –> 00:00:32,308
تابع معیار شناخته شده در
12
00:00:32,308 –> 00:00:35,610
بهینه سازی است و اجازه دهید این تابع را پیاده سازی
13
00:00:35,610 –> 00:00:37,829
کنیم و سپس
14
00:00:37,829 –> 00:00:39,930
الگوریتم ژنتیک ژنتیک کد شده واقعی را پیاده سازی کنیم.
15
00:00:39,930 –> 00:00:41,910
الگوریتمی برای حل این
16
00:00:41,910 –> 00:00:45,120
مسائل بهینه سازی و یافتن n
17
00:00:45,120 –> 00:00:47,370
عدد واقعی که مقدار of را به حداقل می رساند
18
00:00:47,370 –> 00:00:48,809
تابع واقعی است و می دانیم که
19
00:00:48,809 –> 00:00:51,030
پاسخ منشا فضای جستجو است
20
00:00:51,030 –> 00:00:54,289
ok اجازه دهید با پیاده سازی شروع
21
00:00:54,289 –> 00:00:59,579
کنیم اجازه دهید یک فایل پایتون را درمان کنیم و یک نقطه PP
22
00:00:59,579 –> 00:01:02,430
PI خواهد بود. نام فایلی که قرار است
23
00:01:02,430 –> 00:01:03,510
استفاده کنیم خوب است،
24
00:01:03,510 –> 00:01:06,869
اجازه دهید تعدادی از کتابخانه ها را وارد کنیم numpy را
25
00:01:06,869 –> 00:01:14,250
به عنوان NP و matplotlib dot pi plus را
26
00:01:14,250 –> 00:01:20,280
به عنوان PLT وارد کنیم و همچنین اجازه دهید تابع هزینه را پیاده سازی کنیم.
27
00:01:20,280 –> 00:01:23,460
در اینجا یک تابع
28
00:01:23,460 –> 00:01:28,470
به نام کره تعریف کنید یا می توانید از حروف کوچک و
29
00:01:28,470 –> 00:01:31,560
حروف کوچک به عنوان
30
00:01:31,560 –> 00:01:33,650
نام توابع استفاده کنید و این به شما بستگی دارد و
31
00:01:33,650 –> 00:01:36,990
این تابع یک Panter منفرد
32
00:01:36,990 –> 00:01:40,770
به نام X را می پذیرد و این
33
00:01:40,770 –> 00:01:45,479
مجموع مربع های همه اعضا همه
34
00:01:45,479 –> 00:01:48,750
عناصر را برمی گرداند. از این آرایه، بنابراین
35
00:01:48,750 –> 00:01:55,079
این مجموع X ^ را به مجموع x مربع برمی گرداند
36
00:01:55,079 –> 00:01:59,549
و این تابع هزینه ما خواهد بود، بنابراین
37
00:01:59,549 –> 00:02:02,310
این تابع هزینه یا یک
38
00:02:02,310 –> 00:02:06,840
تابع تست کره ای خواهد بود و اجازه دهید مشکل را تعریف کنیم
39
00:02:06,840 –> 00:02:09,628
که کد بسیار شبیه
40
00:02:09,628 –> 00:02:11,910
به پیاده سازی ما است. در
41
00:02:11,910 –> 00:02:12,890
متلب یک قسمت
42
00:02:12,890 –> 00:02:15,950
در کد خود داریم که اول تعریف مشکل است
43
00:02:15,950 –> 00:02:20,780
و بعد از
44
00:02:20,780 –> 00:02:22,670
آن پارامترهای الگوریتم ژنتیک پارامترهای
45
00:02:22,670 –> 00:02:25,150
OTA را تنظیم
46
00:02:25,150 –> 00:02:29,540
می کنیم و سپس
47
00:02:29,540 –> 00:02:32,900
الگوریتم ژنتیک اجرای GA را اجرا می کنیم و
48
00:02:32,900 –> 00:02:36,020
به نتیجه می رسیم. خوب،
49
00:02:36,020 –> 00:02:39,020
بیایید مشکل را اینجا تعریف کنیم، من
50
00:02:39,020 –> 00:02:42,050
کتابخانه دیگری را وارد می کنم که یکی
51
00:02:42,050 –> 00:02:45,670
از کتابخانه های توسعه یافته توسط هنرمندان است و
52
00:02:45,670 –> 00:02:49,760
به همین دلیل است که PA شروع می شود، بنابراین می خواهم ساختار
53
00:02:49,760 –> 00:02:55,970
نام کلاس را از YP وارد کنم
54
00:02:55,970 –> 00:03:00,620
و شروع کنم. اگر
55
00:03:00,620 –> 00:03:04,370
این کتابخانه را در پایتون خود نصب نکرده اید، می توانید
56
00:03:04,370 –> 00:03:08,120
از pip install wipe a start برای نصب
57
00:03:08,120 –> 00:03:11,990
این بسته بر روی دستگاه خود استفاده کنید و
58
00:03:11,990 –> 00:03:14,630
این کتابخانه ای است که توسط AR place ایجاد شده است و
59
00:03:14,630 –> 00:03:17,720
ساختاری به نام کلاس ارائه می دهد
60
00:03:17,720 –> 00:03:20,540
که بسیار شبیه به مختل کننده ها است.
61
00:03:20,540 –> 00:03:23,540
زبان های دیگر به نوع ساختار به
62
00:03:23,540 –> 00:03:27,470
عنوان مثال C ++ C شارپ یا متلب و
63
00:03:27,470 –> 00:03:32,120
زبان های دیگر و در واقع
64
00:03:32,120 –> 00:03:34,700
نسخه تغییر یافته ای از نوع tked یا
65
00:03:34,700 –> 00:03:37,880
دیکشنری در پایتون است و
66
00:03:37,880 –> 00:03:40,940
به شما کمک می کند تا از نماد نقطه برای افزودن
67
00:03:40,940 –> 00:03:46,010
فیلدها یا اعضا به فرهنگ لغت استفاده کنید اما
68
00:03:46,010 –> 00:03:48,860
از این به بعد میخواهیم به این
69
00:03:48,860 –> 00:03:51,320
نوع به عنوان ساختار
70
00:03:51,320 –> 00:03:54,709
اشاره کنیم خوب بیایید مشکل را تعریف کنیم مشکل
71
00:03:54,709 –> 00:03:58,220
یک ساختار خواهد بود بنابراین من
72
00:03:58,220 –> 00:04:01,190
در اینجا یک ساختار خالی ایجاد می کنم و می خواهم
73
00:04:01,190 –> 00:04:06,500
تابع هزینه نقطه مشکل هزینه
74
00:04:06,500 –> 00:04:07,160
75
00:04:07,160 –> 00:04:12,310
funk را تعریف کنم. Tool Sphere و
76
00:04:12,310 –> 00:04:17,000
ما قصد داریم یک ساختار را در این ساختار تعریف کنیم که یک فیلد
77
00:04:17,000 –> 00:04:19,070
به نام تابع cost
78
00:04:19,070 –> 00:04:21,680
و مقدار فیلد sphere است
79
00:04:21,680 –> 00:04:25,669
که به اختلال عملکرد okay اشاره دارد و برای
80
00:04:25,669 –> 00:04:26,780
تعریف
81
00:04:26,780 –> 00:04:29,510
فضای جستجو باید num را تعریف کنیم. تعدادی از
82
00:04:29,510 –> 00:04:33,350
متغیرها بنابراین نقطه مشکل به این صورت که
83
00:04:33,350 –> 00:04:36,050
تعداد متغیرها برابر است
84
00:04:36,050 –> 00:04:39,169
مثلاً با پنج متغیر تصمیم و
85
00:04:39,169 –> 00:04:42,530
نقطه مشکل که در آن میانگین
86
00:04:42,530 –> 00:04:46,070
کران پایینی این متغیرها است، بنابراین برای مثال
87
00:04:46,070 –> 00:04:48,830
منفی ده و بیایید
88
00:04:48,830 –> 00:04:53,360
نقطه مشکل را در جایی که حداکثر و این ده خواهد بود تعریف کنیم به
89
00:04:53,360 –> 00:04:56,810
یاد داشته باشید. که این ساختار
90
00:04:56,810 –> 00:05:00,910
ما را قادر میسازد از این نمادهای نقطهای استفاده کنیم و
91
00:05:00,910 –> 00:05:04,820
این فیلدها را
92
00:05:04,820 –> 00:05:07,850
به نام متغیرها در داخل
93
00:05:07,850 –> 00:05:11,270
یک متغیر با ساختار نوع جمعآوری و جمعآوری کنیم،
94
00:05:11,270 –> 00:05:15,800
بنابراین روشی بسیار کارآمد برای مقابله با
95
00:05:15,800 –> 00:05:19,340
این نوع دادههای ساختاریافته است و برای استفاده از
96
00:05:19,340 –> 00:05:22,550
آن باید وارد ساختار از
97
00:05:22,550 –> 00:05:26,570
wipe a struct library خوب
98
00:05:26,570 –> 00:05:28,639
ما مشکل خود را تعریف کردیم و تعریف
99
00:05:28,639 –> 00:05:31,520
مشکل شامل تعریف
100
00:05:31,520 –> 00:05:33,530
تابع هزینه تابعی هدف
101
00:05:33,530 –> 00:05:37,669
و تعریف چنین فضایی خوب است بعد
102
00:05:37,669 –> 00:05:40,010
باید پارامترها را برای
103
00:05:40,010 –> 00:05:44,900
الگوریتم ژنتیک تعریف کنیم پارامتر نیز یک
104
00:05:44,900 –> 00:05:47,240
ساختار خالی است و I’ m این را مقداردهی اولیه می
105
00:05:47,240 –> 00:05:52,910
کند و نقطه والد max
106
00:05:52,910 –> 00:05:54,979
حداکثر تعداد تکرارهای
107
00:05:54,979 –> 00:05:57,530
الگوریتم خواهد بود که p معمولی است. پارامتر در بین
108
00:05:57,530 –> 00:05:59,570
الگوریتم های تکاملی و متا
109
00:05:59,570 –> 00:06:02,990
اکتشافی ها، بنابراین پارامتر این است که حداکثر
110
00:06:02,990 –> 00:06:05,720
برای مثال صد خواهد بود
111
00:06:05,720 –> 00:06:09,710
که برای شروع کافی خواهد بود و پرینز
112
00:06:09,710 –> 00:06:12,590
به اندازه جمعیت یا در واقع
113
00:06:12,590 –> 00:06:15,470
اندازه اولیه جمعیت را نقطه و پاپ می کند و به عنوان
114
00:06:15,470 –> 00:06:19,190
مثال فعلاً از 20 کروموزوم استفاده می کنیم و
115
00:06:19,190 –> 00:06:21,830
خواهیم کرد. پارامترهای دیگر را اضافه کنید و به
116
00:06:21,830 –> 00:06:26,690
جلو می رویم و اجازه دهید GA را اجرا کنیم، GA
117
00:06:26,690 –> 00:06:29,660
یک تابع خواهد بود به عنوان مثال تابعی به
118
00:06:29,660 –> 00:06:32,630
نام حل از هر چیزی که می
119
00:06:32,630 –> 00:06:35,780
خواهید نامش را بگذارید و ما
120
00:06:35,780 –> 00:06:40,190
دو مشکل آرگومان را می پذیریم و این به شما می گوید
121
00:06:40,190 –> 00:06:40,460
122
00:06:40,460 –> 00:06:43,010
که کدام مشکل را داریم. ‘میخواهد حل کند و پارامترها را حل کند
123
00:06:43,010 –> 00:06:46,310
و به الگوریتم میگوید
124
00:06:46,310 –> 00:06:49,610
که کدام مقادیر پارامتر باید
125
00:06:49,610 –> 00:06:53,480
در ساختار الگوریتم ژنتیک استفاده شود، خوب است،
126
00:06:53,480 –> 00:06:57,830
برای مثال بیایید یک مبارزه جدید در اینجا اضافه کنیم
127
00:06:57,830 –> 00:07:03,530
و بگذارید نام آن را به عنوان ga ga بگذاریم،
128
00:07:03,530 –> 00:07:06,470
خوب است و اگر میتوانید از نامهای دیگر استفاده کنید. به
129
00:07:06,470 –> 00:07:10,430
عنوان مثال YPG a یا GA من می خواهم از نام های
130
00:07:10,430 –> 00:07:14,690
ساده و کوتاه استفاده کنم و
131
00:07:14,690 –> 00:07:19,460
تابعی به نام Bron تعریف کنم که
132
00:07:19,460 –> 00:07:23,240
مشکل و parms را می پذیرد
133
00:07:23,240 –> 00:07:29,930
و در حال حاضر هیچ کدام را بر نمی گرداند.
134
00:07:29,930 –> 00:07:33,590
من تابعی به نام run در GA تعریف
135
00:07:33,590 –> 00:07:38,920
کردم، بنابراین قصد دارم GA را نیز وارد
136
00:07:38,920 –> 00:07:43,730
کنم و در اینجا میتوانیم GA dot drawn را اجرا کنیم، میتوانیم
137
00:07:43,730 –> 00:07:47,450
این تابع را فراخوانی کنیم و مشکل و فارمها
138
00:07:47,450 –> 00:07:50,000
را به تابع منتقل کنیم تا نتایج آنها را داشته باشیم
139
00:07:50,000 –> 00:07:54,770
.
140
00:07:54,770 –> 00:07:59,030
خروجی این تابع را به عنوان خروجی داشته باشیم و در نهایت
141
00:07:59,030 –> 00:08:02,720
نتایج را رسم می کنیم و مقداری از خروجی متن را چاپ می کنیم
142
00:08:02,720 –> 00:08:06,430
تا در مورد نتیجه
143
00:08:06,430 –> 00:08:10,670
بهینه سازی بگوییم اکنون
144
00:08:10,670 –> 00:08:13,160
پیاده سازی این تابع را
145
00:08:13,160 –> 00:08:16,460
که در اینجا تعریف شده است کامل می کنیم و
146
00:08:16,460 –> 00:08:19,340
عناصر دیگر الگوریتم ژنتیک را
147
00:08:19,340 –> 00:08:22,490
دقیقاً در اینجا در این فایل اضافه کنید در اینجا آماده ایم
148
00:08:22,490 –> 00:08:25,340
الگوریتم ژنتیک را در
149
00:08:25,340 –> 00:08:29,530
داخل تابع اجرا شده در فایل PI th پیاده سازی
150
00:08:29,530 –> 00:08:33,169
کنیم و اجازه دهید این خط را حذف
151
00:08:33,169 –> 00:08:35,720
کنیم و ابتدا اطلاعات را
152
00:08:35,720 –> 00:08:38,480
از ساختار مسئله استخراج کنیم و
153
00:08:38,480 –> 00:08:41,960
ساختار پارامتر بنابراین من می خواهم
154
00:08:41,960 –> 00:08:46,220
اطلاعات مشکل را در اینجا داشته باشم و ما یک
155
00:08:46,220 –> 00:08:49,220
تابع هزینه داریم هزینه funk که برابر است با
156
00:08:49,220 –> 00:08:50,370
یک مشکل
157
00:08:50,370 –> 00:08:54,150
first funk ما یک فیلد به نام cost
158
00:08:54,150 –> 00:08:56,850
funk در ساختار مشکل داریم و جایی که
159
00:08:56,850 –> 00:09:01,820
Coolidge به مشکل می رسد. نقطه و آن و
160
00:09:01,820 –> 00:09:07,410
ما متوسط برابر با مشکل نقطه بسیار مت
161
00:09:07,410 –> 00:09:11,490
سط هستیم که در آن حداکثر نزدیک به نقطه مشکل است که حدا
162
00:09:11,490 –> 00:09:15,810
ثر ارائه این پارامترها به عنوان ساختا
163
00:09:15,810 –> 00:09:19,380
به ما کمک می کند تا پیاده
164
00:09:19,380 –> 00:09:22,110
ازی را تا حد امکان ساده نگه داریم و به عنو
165
00:09:22,110 –> 00:09:24,839
166
00:09:24,839 –> 00:09:27,690
ن مثال به جای چهار با یک پارامتر سر و کار داریم. در ای
167
00:09:27,690 –> 00:09:30,360
ما با یک پارامتر سر و کار داریم و
168
00:09:30,360 –> 00:09:33,630
اگر بخواهیم چند پارامتر دیگر یا اضافی اضافه
169
00:09:33,630 –> 00:09:36,510
کنیم، امضای کلی
170
00:09:36,510 –> 00:09:39,540
این تابع در مورد پارامترها تغییر نمی کند،
171
00:09:39,540 –> 00:09:43,320
من حداکثر
172
00:09:43,320 –> 00:09:46,800
آن را از این استخراج می کنم و نقطه حداکثر تالار گفتگو را داریم.
173
00:09:46,800 –> 00:09:49,650
اینجا و سپس من
174
00:09:49,650 –> 00:09:52,500
IMP را استخراج می کنم که برابر است با farms
175
00:09:52,500 –> 00:09:56,970
dot n pop و در اینجا
176
00:09:56,970 –> 00:09:58,920
مرحله اولیه سازی
177
00:09:58,920 –> 00:10:01,020
الگوریتم را انجام می دهیم
178
00:10:01,020 –> 00:10:03,570
بیایید ببینیم فاز اولیه چیست، اولین
179
00:10:03,570 –> 00:10:05,550
ساختار کلی الگوریتم ژنتیک است.
180
00:10:05,550 –> 00:10:07,589
مرحله اولیه سازی است، بنابراین
181
00:10:07,589 –> 00:10:09,450
ما یک جمعیت اولیه ایجاد می کنیم
182
00:10:09,450 –> 00:10:12,500
و آنها را ارزیابی می کنیم و
183
00:10:12,500 –> 00:10:16,410
همه چیز را برای ورود به این حلقه تکامل مقداردهی اولیه می کنیم،
184
00:10:16,410 –> 00:10:19,830
بنابراین من یک po اولیه ایجاد می کنم.
185
00:10:19,830 –> 00:10:22,620
در اینجا بیایید یک
186
00:10:22,620 –> 00:10:25,800
الگو برای فرد خالی داشته باشیم و یک
187
00:10:25,800 –> 00:10:29,040
راه حل واحد این ساختار
188
00:10:29,040 –> 00:10:32,730
را داشته باشد، این تعریف را خواهد داشت و
189
00:10:32,730 –> 00:10:35,550
اگر باید یک الگو برای
190
00:10:35,550 –> 00:10:39,680
این کار تعریف کنیم و قالب فردی خالی داریم
191
00:10:39,680 –> 00:10:43,760
و بیایید فردی خالی را
192
00:10:43,760 –> 00:10:47,940
به عنوان یک ساختار تعریف کنیم.
193
00:10:47,940 –> 00:10:53,339
ساختار ساختار خالی و ما باید
194
00:10:53,339 –> 00:10:57,570
این ابزار مشابه را این خط را از
195
00:10:57,570 –> 00:11:00,450
ساختار واردات ساختار YP وارد کنیم، خوب اجازه دهید این را اضافه
196
00:11:00,450 –> 00:11:01,860
کنیم
197
00:11:01,860 –> 00:11:07,019
و همچنین من numpy را نیز خالی وارد میکنم
198
00:11:07,019 –> 00:11:11,760
و در اینجا
199
00:11:11,760 –> 00:11:14,490
ساختار خالی داریم، یک مربی
200
00:11:14,490 –> 00:11:17,910
خالی به نام فردی خالی داریم و همچنین من
201
00:11:17,910 –> 00:11:20,510
قصد دارم چند فیلد را به این
202
00:11:20,510 –> 00:11:24,720
موقعیت نقطه فردی خالی اضافه کنم که فعلاً برابر با
203
00:11:24,720 –> 00:11:28,680
هیچ خواهد بود و هزینه نقطه فردی خالی
204
00:11:28,680 –> 00:11:32,579
ارزش هزینه نیز هیچ خواهد بود
205
00:11:32,579 –> 00:11:38,040
و همین است که ما یک الگو
206
00:11:38,040 –> 00:11:42,000
برای افراد خالی خود ایجاد کردیم. قرار است
207
00:11:42,000 –> 00:11:45,690
آرایه ای از افراد خالی ایجاد کنیم
208
00:11:45,690 –> 00:11:48,660
که به معنای جمعیت اولیه ما هستند،
209
00:11:48,660 –> 00:11:52,079
بنابراین من این
210
00:11:52,079 –> 00:11:57,029
ساختار را به عنوان عناصر یک آرایه که
211
00:11:57,029 –> 00:11:59,160
اولین مورد ما خواهد بود تکرار می کنم. جمعیت
212
00:11:59,160 –> 00:12:02,180
نسل اول بنابراین برای انجام این کار اجازه دهید
213
00:12:02,180 –> 00:12:05,100
از طریق این بخش جمعیت مقداردهی اولیه ایجاد کنیم
214
00:12:05,100 –> 00:12:10,320
215
00:12:10,320 –> 00:12:14,070
و من یک متغیر pop ایجاد می کنم و یک
216
00:12:14,070 –> 00:12:17,970
تابع را از فردی خالی فراخوانی می کنم و
217
00:12:17,970 –> 00:12:21,019
ما یک تابع به نام تکرار در اینجا داریم و
218
00:12:21,019 –> 00:12:24,600
این تعداد را می پذیرد. تکرارها
219
00:12:24,600 –> 00:12:27,300
و ما می دانیم که باید این را برای
220
00:12:27,300 –> 00:12:30,149
بارهای M پاپ تکرار کنیم این تابع تابع تکرار
221
00:12:30,149 –> 00:12:33,029
کلاس ساختار
222
00:12:33,029 –> 00:12:36,930
آرایه ای از ساختارها را برمی گرداند و همه آنها
223
00:12:36,930 –> 00:12:40,860
مشابه هستند و از این رو ما pop را به عنوان
224
00:12:40,860 –> 00:12:44,640
آرایه ای از افراد خالی M pop داریم در اینجا
225
00:12:44,640 –> 00:12:47,430
این اولیه ما است. جمعیت، بنابراین ما میخواهیم
226
00:12:47,430 –> 00:12:50,130
موقعیتهای تصادفی را برای
227
00:12:50,130 –> 00:12:52,829
این اعضا برای همه اعضای پاپ به
228
00:12:52,829 –> 00:12:55,079
عنوان جمعیت اولیه ایجاد کنیم و سپس
229
00:12:55,079 –> 00:12:58,649
آن راهحلها را برای
230
00:12:58,649 –> 00:13:01,560
مقداردهی اولیه جمعیت ارزیابی
231
00:13:01,560 –> 00:13:04,230
میکنیم و جاهای خالی را پر میکنیم که یک حلقه for خواهیم داشت.
232
00:13:04,230 –> 00:13:10,110
برای هر I در محدوده 0 تا M
233
00:13:10,110 –> 00:13:11,260
پاپ
234
00:13:11,260 –> 00:13:13,720
برای ایجاد موقعیت های تصادفی برای
235
00:13:13,720 –> 00:13:15,880
اعضای جمعیت، بنابراین عضو i را باز کنید
236
00:13:15,880 –> 00:13:18,820
و این تقسیم بندی
237
00:13:18,820 –> 00:13:21,840
در جمعیت و موقعیت این
238
00:13:21,840 –> 00:13:25,270
ind است. اگر در فضای جستجوی ما تا یک نقطه تصادفی خنک می شود تا یک نقطه
239
00:13:25,270 –> 00:13:28,300
تصادفی ایجاد
240
00:13:28,300 –> 00:13:32,940
کنیم، ما از نقطه MP یکنواخت نقطه تصادفی استفاده
241
00:13:32,940 –> 00:13:37,360
می کنیم و می دانیم که این
242
00:13:37,360 –> 00:13:40,270
تابع یک کران پایین و یک کران بالاتر را می پذیرد
243
00:13:40,270 –> 00:13:43,930
و اندازه به سمت
244
00:13:43,930 –> 00:13:46,300
بالا رفته است. محدود شده است که آنها
245
00:13:46,300 –> 00:13:48,850
حداکثر هستند و اندازه ای را که در
246
00:13:48,850 –> 00:13:51,700
آن ایجاد می شود عبور می دهیم.
247
00:13:51,700 –> 00:13:53,620
248
00:13:53,620 –> 00:13:56,050
249
00:13:56,050 –> 00:14:00,400
250
00:14:00,400 –> 00:14:02,620
از این مقدار
251
00:14:02,620 –> 00:14:05,050
تابع هزینه خروجی
252
00:14:05,050 –> 00:14:10,960
تابع هزینه برای پوپ I نقطه
253
00:14:10,960 –> 00:14:13,990
خواهد بود و این موقعیت را به تابع هزینه منتقل می کند
254
00:14:13,990 –> 00:14:15,760
و تابع هزینه مشکلی است که
255
00:14:15,760 –> 00:14:19,960
هزینه فانک و هزینه فانک یک کره است و
256
00:14:19,960 –> 00:14:22,480
یک کره این است و موقعیت در واقع X است
257
00:14:22,480 –> 00:14:25,450
و این
258
00:14:25,450 –> 00:14:29,470
مجموع مربعات عناصر X را محاسبه می کند و
259
00:14:29,470 –> 00:14:31,690
این را به عنوان خروجی برمی گرداند و
260
00:14:31,690 –> 00:14:34,510
ما فیلد هزینه برابر با
261
00:14:34,510 –> 00:14:36,880
خروجی تابع هزینه خواهیم داشت و این
262
00:14:36,880 –> 00:14:40,120
تابع کره است و در اینجا
263
00:14:40,120 –> 00:14:44,380
راه حل ها را به صورت ارزیابی می کنیم. خوب الف و اجازه دهید یک
264
00:14:44,380 –> 00:14:47,620
متغیر برای حفظ نتایج
265
00:14:47,620 –> 00:14:50,800
الگوریتمی که قرار است از آن استفاده کنم ایجاد کنیم که
266
00:14:50,800 –> 00:14:54,670
برابر با یک ساختار خالی است و از نقطهای بیرون میآید،
267
00:14:54,670 –> 00:14:58,180
قسمت بالای این
268
00:14:58,180 –> 00:15:01,030
ساختار سرد و باز میشود و در نهایت من میخواهم
269
00:15:01,030 –> 00:15:05,260
به بیرون برگردم. یک نتیجه را به عنوان
270
00:15:05,260 –> 00:15:10,210
خروجی در اینجا داشته باشید و در نهایت اجازه دهید
271
00:15:10,210 –> 00:15:14,230
کد را در اینجا اجرا کنیم و نتایج را داشته باشیم تا نتایج را
272
00:15:14,230 –> 00:15:15,160
ببینیم به
273
00:15:15,160 –> 00:15:20,970
عنوان مثال بیایید یک خط ساختگی در اینجا داشته باشیم
274
00:15:21,090 –> 00:15:24,550
من می خواهم این کد را با داشتن
275
00:15:24,550 –> 00:15:29,100
یک نقطه شکست در اینجا f5 حذف کنم و کد را
276
00:15:29,100 –> 00:15:32,650
در اینجا اجرا کنید. ببینید ما در اینجا ساختاری داریم
277
00:15:32,650 –> 00:15:37,330
با پاپ ناموفق و اگر به
278
00:15:37,330 –> 00:15:42,250
کنترل نقطهای از بالا پاپ بروید، این را بیاورید و
279
00:15:42,250 –> 00:15:45,130
آن صفر را بیرون بیاورید، این اولین
280
00:15:45,130 –> 00:15:48,460
عنصر جمعیت است و هزینه این است
281
00:15:48,460 –> 00:15:52,180
و مقادیر کروموزوم،
282
00:15:52,180 –> 00:15:56,280
راه حل این است. این و همچنین به عنوان
283
00:15:56,280 –> 00:16:01,720
مثال که پاپ یک این است و می بینید
284
00:16:01,720 –> 00:16:04,810
که ارزش هزینه است و
285
00:16:04,810 –> 00:16:06,610
این مقادیر متغیرهای تصمیم هستند و
286
00:16:06,610 –> 00:16:07,330
از بین
287
00:16:07,330 –> 00:16:09,550
پاپ 0 در بالای یک، اعضای اول و دوم
288
00:16:09,550 –> 00:16:12,160
جمعیت بدیهی است که نفر
289
00:16:12,160 –> 00:16:15,070
برتر بهتر است و در مورد
290
00:16:15,070 –> 00:16:19,330
دو نفر برتر شما چطور؟ ببینید که ارزش هزینه 82
291
00:16:19,330 –> 00:16:22,660
واقعی است و این حتی بهتر است و
292
00:16:22,660 –> 00:16:25,860
بیایید پاپ 3 را بررسی کنیم و ارزش هزینه
293
00:16:25,860 –> 00:16:30,730
182 است و این راه حل خوبی نیست
294
00:16:30,730 –> 00:16:33,880
تا اینجا خروجی پاپ به این بهترین
295
00:16:33,880 –> 00:16:36,250
مقدار راه حل برای عضو اول است
296
00:16:36,250 –> 00:16:40,000
. جمعیت، بنابراین در اینجا می بینید که
297
00:16:40,000 –> 00:16:43,600
ما خارج هستیم و حاوی مقادیر
298
00:16:43,600 –> 00:16:46,570
اعضای جمعیت در اینجا است، خوب،
299
00:16:46,570 –> 00:16:51,190
بیایید این خط را حذف کنیم و ما آماده هستیم
300
00:16:51,190 –> 00:16:55,330
تا قسمت های دیگر را به این کد اضافه کنیم، بسیار خوب،
301
00:16:55,330 –> 00:16:57,820
باید رکوردی از بهترین
302
00:16:57,820 –> 00:17:00,790
راه حلی که تاکنون پیدا شده است داشته باشیم. من قصد دارم
303
00:17:00,790 –> 00:17:04,470
راه حل دیگری ایجاد کنم بهترین
304
00:17:04,470 –> 00:17:09,250
راه حلی که آنها پیدا شده اند و من
305
00:17:09,250 –> 00:17:13,900
این بهترین روح را نام می برم و این یک
306
00:17:13,900 –> 00:17:17,380
بخش فردی جالب و خالی است در اینجا
307
00:17:17,380 –> 00:17:21,670
ساختار یک نوع مرجع است و اگر بهترین
308
00:17:21,670 –> 00:17:24,099
روح را برابر با فرد خالی قرار دهیم، هر
309
00:17:24,099 –> 00:17:26,170
تغییر در بهترین روح بر روی فرد خالی تأثیر می گذارد
310
00:17:26,170 –> 00:17:28,480
و برعکس، بنابراین من
311
00:17:28,480 –> 00:17:31,090
یک کپی عمیق از
312
00:17:31,090 –> 00:17:34,169
آن خواهم داشت و این یک کپی عمیق از آن ایجاد می کند و
313
00:17:34,169 –> 00:17:36,359
تغییرات در بهترین فرد خالی خورشیدی
314
00:17:36,359 –> 00:17:39,509
تأثیری بر دیگری نخواهد
315
00:17:39,509 –> 00:17:41,909
داشت. من یک کپی دارم o اگر
316
00:17:41,909 –> 00:17:44,519
فرد خالی به این صورت باشد و ما می دانیم که اگر
317
00:17:44,519 –> 00:17:48,749
بهترین روح مسئول
318
00:17:48,749 –> 00:17:51,629
ثبت بهترین راه حلی است که تاکنون پیدا شده است،
319
00:17:51,629 –> 00:17:54,869
قبل از اینکه ما اجرای
320
00:17:54,869 –> 00:17:57,359
الگوریتم را شروع کنیم و اصلاً چیزی را ارزیابی
321
00:17:57,359 –> 00:18:00,809
نکرده باشیم، باید
322
00:18:00,809 –> 00:18:05,039
با بدترین چیز ممکن برابری کند. بنابراین بیایید
323
00:18:05,039 –> 00:18:08,129
مقدار هزینه این را به عنوان بدترین
324
00:18:08,129 –> 00:18:12,090
مقدار تابع هزینه تعریف کنیم و برای یک
325
00:18:12,090 –> 00:18:15,210
مشکل کمینه سازی مقدار جدا شده
326
00:18:15,210 –> 00:18:17,779
تابع هدف بی نهایت است و
327
00:18:17,779 –> 00:18:22,980
برای تعریف بی نهایت باید از MP dot MF استفاده کنیم
328
00:18:22,980 –> 00:18:26,159
و این می گوید که ما یک
329
00:18:26,159 –> 00:18:29,460
راه حل با مقدار هزینه بی نهایت
330
00:18:29,460 –> 00:18:31,859
در ابتدای الگوریتم و در اینجا
331
00:18:31,859 –> 00:18:35,309
پس از ارزیابی راه حل، می
332
00:18:35,309 –> 00:18:39,330
توانیم top I را با بهترین روح مقایسه کنیم، بنابراین می خواهم این
333
00:18:39,330 –> 00:18:44,850
را مقایسه کنم اگر هزینه top I dot
334
00:18:44,850 –> 00:18:50,340
کمتر از بهترین هزینه کامل نقطه باشد،
335
00:18:50,340 –> 00:18:55,379
این روح باید باشد. در جایی که سلام جایگزین شد، اما
336
00:18:55,379 –> 00:18:58,799
دوباره به یاد داشته باشید که نوع ساختار ما
337
00:18:58,799 –> 00:19:02,639
در ساختار YP یک مقدار مرجع است، بنابراین من
338
00:19:02,639 –> 00:19:07,139
بهترین را به عنوان یک
339
00:19:07,139 –> 00:19:12,059
کپی مهره ای از popeye اختصاص می دهم و این به این دلیل است که اگر
340
00:19:12,059 –> 00:19:14,519
ID پاپ را تغییر دهید و بهترین روح، chan خواهد بود.
341
00:19:14,519 –> 00:19:17,039
ge و این منطقی نیست و
342
00:19:17,039 –> 00:19:20,549
اشتباه است و بنابراین ما قصد داریم یک
343
00:19:20,549 –> 00:19:24,299
کپی عمیق ایجاد کنیم تا به بهترین
344
00:19:24,299 –> 00:19:28,289
روح مقدار جدیدی که به عنوان pop شناخته
345
00:19:28,289 –> 00:19:31,019
می شود اختصاص
346
00:19:31,019 –> 00:19:34,769
347
00:19:34,769 –> 00:19:38,309
دهیم. و بنابراین بهترین نقش باید
348
00:19:38,309 –> 00:19:43,529
با Popeye جایگزین شود و همچنین باید
349
00:19:43,529 –> 00:19:46,470
بهترین هزینه را در پایان n
350
00:19:46,470 –> 00:19:47,730
تکرار
351
00:19:47,730 –> 00:19:51,720
پیگیری کنیم.
352
00:19:51,720 –> 00:19:55,440
353
00:19:55,440 –> 00:20:02,610
بهترین
354
00:20:02,610 –> 00:20:06,600
هزینه یک ماتریس خالی است، بنابراین من قصد دارم
355
00:20:06,600 –> 00:20:11,820
از MP نقطه M T استفاده کنم و این شامل حداکثر
356
00:20:11,820 –> 00:20:16,140
عناصر نوک حداکثر فضاهای خالی آن
357
00:20:16,140 –> 00:20:21,090
برای ذخیره حداکثر مقادیر بهترین هزینه
358
00:20:21,090 –> 00:20:25,260
در پایان هر تکرار خواهد بود و در اینجا تا
359
00:20:25,260 –> 00:20:28,260
این زمان ما به پایان رسیدیم. مرحله اولیه سازی
360
00:20:28,260 –> 00:20:30,600
ما یک الگوی فردی خالی
361
00:20:30,600 –> 00:20:33,300
ایجاد کردیم، بهترین راه حل را ایجاد کردیم
362
00:20:33,300 –> 00:20:35,760
و تست هایی را که ایجاد
363
00:20:35,760 –> 00:20:38,160
کردیم و جمعیت اولیه را به روز کردیم و
364
00:20:38,160 –> 00:20:41,460
یک ماتریس جدید و
365
00:20:41,460 –> 00:20:45,150
ماتریس خالی با حداکثر اسلات خالی آن مقداردهی اولیه ایجاد
366
00:20:45,150 –> 00:20:49,620
کردیم و آماده ورود به قسمت اصلی هستیم.
367
00:20:49,620 –> 00:20:52,010
حلقه تکامل الگوریتم ژنتیک را حلقه
368
00:20:52,010 –> 00:20:55,350
کنید خوب بیایید حلقه اصلی الگوریتم را شروع
369
00:20:55,350 –> 00:20:58,680
کنیم و این یک پوشه یا هر
370
00:20:58,680 –> 00:21:03,900
تکرار در محدوده صفر تا حداکثر آن است
371
00:21:03,900 –> 00:21:09,840
و می توانید 0 5 را نادیده بگیرید تا قدیمی را
372
00:21:09,840 –> 00:21:13,980
کوتاهتر کنید و این حلقه for ما است.
373
00:21:13,980 –> 00:21:16,860
داریم و