در این مطلب، ویدئو رگرسیون رج چگونه کار می کند؟ | الگوریتم رگرسیون ریج در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:20:44
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,190
سلام و خوش آمدید به ویدیوی جدید و
2
00:00:02,190 –> 00:00:04,980
در این ویدیو ما به رگرسیون غنی نگاه خواهیم کرد،
3
00:00:04,980 –> 00:00:08,250
بنابراین رگرسیون غنی
4
00:00:08,250 –> 00:00:11,400
شکل دیگری از رگرسیون خطی است که به ما کمک می کند تا
5
00:00:11,400 –> 00:00:14,429
در
6
00:00:14,429 –> 00:00:17,760
صورت وجود تتای نادیده جدید
7
00:00:17,760 –> 00:00:21,240
که مدل آن را ندیده باشد، معادله خطی نرمال را بهبود ببخشیم. شما می خواهید
8
00:00:21,240 –> 00:00:23,640
نتایج را بر اساس
9
00:00:23,640 –> 00:00:25,590
داده های جدیدی که می بینید بهبود ببخشید، بنابراین در این
10
00:00:25,590 –> 00:00:27,330
ویدیو توضیح و
11
00:00:27,330 –> 00:00:30,390
پیاده سازی پایتون را خواهیم دید، بنابراین اول از همه
12
00:00:30,390 –> 00:00:32,250
رگرسیون غنی چیست، بنابراین همین الان
13
00:00:32,250 –> 00:00:34,850
یک تعریف کوچک به شما ارائه دادم که
14
00:00:34,850 –> 00:00:36,930
رگرسیون Ridge یک
15
00:00:36,930 –> 00:00:39,390
تکنیک های منظم سازی که به ما کمک می کند اساساً
16
00:00:39,390 –> 00:00:41,760
مدل را برای مدل رگرسیون خطی بهبود
17
00:00:41,760 –> 00:00:44,610
دهیم تا در سناریوهایی که
18
00:00:44,610 –> 00:00:47,129
در آن واریانس بالایی وجود دارد در مقایسه
19
00:00:47,129 –> 00:00:49,800
با داده هایی که در درخت استفاده می شود برای
20
00:00:49,800 –> 00:00:52,920
آموزش مدل استفاده می شود خوب عمل کند،
21
00:00:52,920 –> 00:00:54,629
بنابراین این نقاط داده وجود دارد.
22
00:00:54,629 –> 00:00:57,629
زمانی که شما مدل را ایجاد کردید از آن استفاده می کردیم، اما
23
00:00:57,629 –> 00:01:00,239
وقتی مدل خود را در سناریویی
24
00:01:00,239 –> 00:01:02,940
قرار می دهید که نقاط داده را ندیده باشد،
25
00:01:02,940 –> 00:01:05,640
اکنون این نقاط داده می توانند دارای تنوع بالایی باشند.
26
00:01:05,640 –> 00:01:07,740
این به معنای دور بودن از خط است
27
00:01:07,740 –> 00:01:10,260
و در آن صورت رگرسیون خطی معمولی
28
00:01:10,260 –> 00:01:13,619
ممکن است خروجی خوبی به ما ندهد،
29
00:01:13,619 –> 00:01:16,710
بنابراین چه رگرسیون غنی اساساً
30
00:01:16,710 –> 00:01:19,619
از تکنیک منظم سازی استفاده می کند که
31
00:01:19,619 –> 00:01:23,250
اساساً مدل را برای این واریانس بالا جریمه می کند
32
00:01:23,250 –> 00:01:26,670
و سپس یک خط جدید
33
00:01:26,670 –> 00:01:29,700
یا یک ساختار جدید ایجاد می کند. در جریان است و
34
00:01:29,700 –> 00:01:32,729
با کاهش واریانس خروجی بهتری
35
00:01:32,729 –> 00:01:35,040
به شما می دهد و در
36
00:01:35,040 –> 00:01:37,950
عرض چند دقیقه خواهید دید که چگونه این کار را گام به گام
37
00:01:37,950 –> 00:01:41,610
انجام می دهد، بنابراین فقط یک تعریف سریع از
38
00:01:41,610 –> 00:01:45,509
منظم سازی است، بنابراین تکنیکی برای
39
00:01:45,509 –> 00:01:48,390
تجزیه و تحلیل مدل برای برازش بیش از حد است.
40
00:01:48,390 –> 00:01:50,939
داده ها و افزودن پارامتری که
41
00:01:50,939 –> 00:01:53,820
مدل madoff را برای نتیجه بهتر تنظیم می کند، همانطور
42
00:01:53,820 –> 00:01:56,880
که وقتی اینجا بودم گفتم که ایجاد می کند
43
00:01:56,880 –> 00:01:59,700
یا مدل را با اضافه کردن یک بایاس جریمه می
44
00:01:59,700 –> 00:02:03,750
کند و سپس جریان واریانس
45
00:02:03,750 –> 00:02:06,659
را از نقاط داده جدید کاهش می دهد، خوب
46
00:02:06,659 –> 00:02:10,800
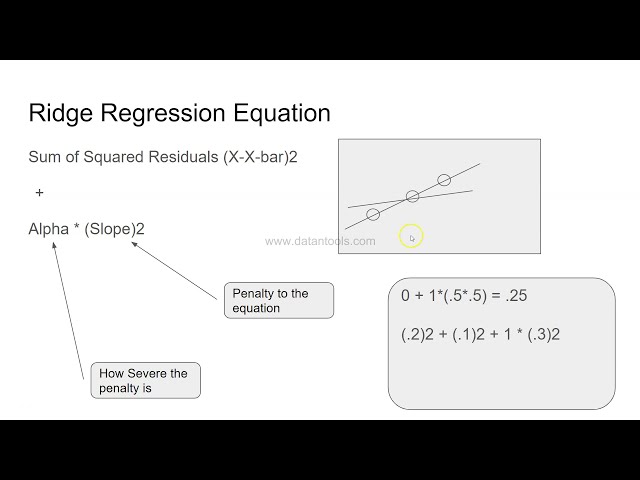
اجازه دهید آن را در ادامه ببینیم. نمونه عملی از
47
00:02:10,800 –> 00:02:12,780
رگرسیون خطی حتما ویدیوهای قبلی من را دیده
48
00:02:12,780 –> 00:02:13,090
49
00:02:13,090 –> 00:02:15,640
اید که در آن در مورد رگرسیون خطی توضیح داده ام
50
00:02:15,640 –> 00:02:17,739
و در اینجا یک
51
00:02:17,739 –> 00:02:19,120
معادله رگرسیون خطی ساده است که من
52
00:02:19,120 –> 00:02:22,239
فروش s برابر با 1 1 است که اساساً نقطه
53
00:02:22,239 –> 00:02:25,120
قطع به اضافه 0.5 است که یک شیب
54
00:02:25,120 –> 00:02:28,330
ضرب شده با بازاریابی است، بنابراین آنچه که
55
00:02:28,330 –> 00:02:31,090
ما انجام می دهیم این است که فرض می کنیم
56
00:02:31,090 –> 00:02:33,790
ارزش بازاریابی را که 10 است به
57
00:02:33,790 –> 00:02:36,670
شیب اضافه می کنیم و فروش به 6 می رسد،
58
00:02:36,670 –> 00:02:38,920
شاید اگر 6000 دلار باشد. شما در حال اضافه کردن
59
00:02:38,920 –> 00:02:41,920
مدل 10000 دلاری دیگر هستید 10000 دلار دیگر را به بازاریابی اضافه می
60
00:02:41,920 –> 00:02:45,040
کنید، فروش با 6000 دلار افزایش می یابد،
61
00:02:45,040 –> 00:02:47,170
بنابراین مواردی مانند این را
62
00:02:47,170 –> 00:02:49,989
توضیح خواهیم داد که اساساً توضیح می دهیم که آنها
63
00:02:49,989 –> 00:02:52,810
برای این مدل هستند یا مدل رگرسیون خطی واقعی
64
00:02:52,810 –> 00:02:54,910
اساساً به ما کمک می کند
65
00:02:54,910 –> 00:02:57,549
به این خروجی های ساده دست یابیم و این
66
00:02:57,549 –> 00:02:59,920
همان چیزی است که من آن را در اینجا
67
00:02:59,920 –> 00:03:03,010
با کمک خط خطی با
68
00:03:03,010 –> 00:03:04,900
کمک نمودار توضیح داده ام، بنابراین در اینجا فقط
69
00:03:04,900 –> 00:03:07,180
فرض کنید که فروش است و این بازاریابی است
70
00:03:07,180 –> 00:03:09,010
، هرچه بیشتر برای
71
00:03:09,010 –> 00:03:11,950
بازاریابی هزینه کنید، فروش به درستی بالا می رود
72
00:03:11,950 –> 00:03:13,569
و این چیزی است که دارد.
73
00:03:13,569 –> 00:03:16,120
با کمک یک روند خطی مثبت با
74
00:03:16,120 –> 00:03:20,079
شیب مثبت به سمت
75
00:03:20,079 –> 00:03:22,709
76
00:03:22,709 –> 00:03:27,370
راست نشان
77
00:03:27,370 –> 00:03:29,709
داده شده است. خط اصلی ماست،
78
00:03:29,709 –> 00:03:32,440
اما بیایید بگوییم که اگر نقاط داده جدیدی وجود دارد
79
00:03:32,440 –> 00:03:34,540
که به این صورت اضافه شده است،
80
00:03:34,540 –> 00:03:38,950
این و این و آن در سناریوهایی
81
00:03:38,950 –> 00:03:41,590
مانند این، زمانی که مدل خود را آزمایش می کنید
82
00:03:41,590 –> 00:03:45,310
که این است، خروجی دقیق درستی به دست نمی دهد
83
00:03:45,310 –> 00:03:49,599
زیرا این خط
84
00:03:49,599 –> 00:03:52,120
بهترین نیست. نمایش این
85
00:03:52,120 –> 00:03:54,730
نقاط داده و این نقاط داده را
86
00:03:54,730 –> 00:03:58,269
ندیده است و به این سناریو خاص
87
00:03:58,269 –> 00:04:01,599
می گویند که در آن شما
88
00:04:01,599 –> 00:04:04,630
مدل
89
00:04:04,630 –> 00:04:06,549
90
00:04:06,549 –> 00:04:09,130
را آموزش داده اید.
91
00:04:09,130 –> 00:04:11,889
شما
92
00:04:11,889 –> 00:04:14,530
آن را در معرض نقاط داده نادیده مانند
93
00:04:14,530 –> 00:04:17,738
این یا این قرار می دهید، خروجی دقیقی به شما نمی دهد،
94
00:04:17,738 –> 00:04:19,750
بنابراین آنچه ممکن است لازم باشد
95
00:04:19,750 –> 00:04:22,840
انجام دهید این است که مدل را بر اساس مقادیر جدید دوباره آموزش دهید
96
00:04:22,840 –> 00:04:25,510
و احتمالاً
97
00:04:25,510 –> 00:04:26,690
خط دومی
98
00:04:26,690 –> 00:04:28,940
مانند این دریافت خواهید کرد که اینطور نیست. یک تناسب استاندارد
99
00:04:28,940 –> 00:04:30,830
مانند این، اما یک خط مانند این و
100
00:04:30,830 –> 00:04:32,510
آن چیزی است که تفریحات غنی اساسا
101
00:04:32,510 –> 00:04:35,150
به ما کمک می کند، بنابراین با جریمه کردن مدل، یک سوگیری مانند
102
00:04:35,150 –> 00:04:37,820
از این معادله به این معادله ایجاد
103
00:04:37,820 –> 00:04:40,190
می کند. و با این
104
00:04:40,190 –> 00:04:42,680
کمی سوگیری کاری که انجام
105
00:04:42,680 –> 00:04:46,130
می دهد این است که به کاهش واریانس بین
106
00:04:46,130 –> 00:04:49,760
واقعی و پیش بینی واقعی و
107
00:04:49,760 –> 00:04:51,860
باقی مانده کمک می کند، به عنوان مثال
108
00:04:51,860 –> 00:04:54,020
مقدار واقعی شما این است و مقدار پیش بینی شده شما
109
00:04:54,020 –> 00:04:56,150
این است و تفاوت بین
110
00:04:56,150 –> 00:04:58,970
این باقیمانده است، بنابراین اساسا
111
00:04:58,970 –> 00:05:01,010
باقیمانده بین این دو مقدار
112
00:05:01,010 –> 00:05:04,220
یا واریانس را کاهش داد، بنابراین اگر
113
00:05:04,220 –> 00:05:07,040
بتوانید واریانس بین این خط و این
114
00:05:07,040 –> 00:05:09,320
نقطه داده را ببینید از این خط و این نقطه داده بالاتر خواهد بود
115
00:05:09,320 –> 00:05:11,750
و زمانی که
116
00:05:11,750 –> 00:05:14,060
واریانس کاهش یافته را داشته باشید خروجی بهتری خواهید داشت
117
00:05:14,060 –> 00:05:17,630
که شما می توانید برای
118
00:05:17,630 –> 00:05:19,250
اقدامات بعدی مصرف کنید و این همان چیزی است که من
119
00:05:19,250 –> 00:05:22,280
در اینجا توضیح داده ام، ما
120
00:05:22,280 –> 00:05:25,070
مقدار کمی از پای ها را معرفی می کنیم تا بیش از حد با
121
00:05:25,070 –> 00:05:27,020
داده های آموزشی تناسب نداشته باشند، به این معنی که با اضافه
122
00:05:27,020 –> 00:05:28,970
کردن مقدار کمی پای،
123
00:05:28,970 –> 00:05:32,110
از اینجا به اینجا منتقل شده ایم و این پای است. سپس
124
00:05:32,110 –> 00:05:35,000
منجر به کاهش واریانس در
125
00:05:35,000 –> 00:05:38,030
داده های نادیده می شود، بنابراین واریانس بین این
126
00:05:38,030 –> 00:05:40,250
خط و این خط، این نقطه داده
127
00:05:40,250 –> 00:05:43,370
کاهش می یابد و سپس بر
128
00:05:43,370 –> 00:05:46,850
مشکل بیش از حد برازش نیز غلبه می شود. بنابراین
129
00:05:46,850 –> 00:05:49,610
حتی می توانید در مصاحبه توضیح دهید
130
00:05:49,610 –> 00:05:52,520
که اگر کسی از شما می پرسد که چگونه
131
00:05:52,520 –> 00:05:55,370
مشکل بیش از حد برازش را کاهش
132
00:05:55,370 –> 00:05:57,860
می دهید، می توانید این مثال
133
00:05:57,860 –> 00:05:59,810
را بزنید و اساساً به او کمک کنید یا اگر
134
00:05:59,810 –> 00:06:01,970
به شما کاغذ طرح دار داده است، می دانید
135
00:06:01,970 –> 00:06:03,890
فقط کافی است این ها را بنویسید. دادهها در
136
00:06:03,890 –> 00:06:05,840
آنجا وجود دارد و شما میتوانید آن را توضیح
137
00:06:05,840 –> 00:06:09,470
دهید حالا بیایید با قرار دادن
138
00:06:09,470 –> 00:06:10,310
مقادیر،
139
00:06:10,310 –> 00:06:13,250
اول از همه معادله
140
00:06:13,250 –> 00:06:15,860
رگرسیون پشته را ببینیم، بنابراین معادله رگرسیون غنی
141
00:06:15,860 –> 00:06:18,380
اساساً مجموع مجذور
142
00:06:18,380 –> 00:06:21,950
باقیمانده است که به معنی X منهای X
143
00:06:21,950 –> 00:06:24,410
نوار میانگین است. ارزش، بنابراین چیزی که دارد
144
00:06:24,410 –> 00:06:27,080
اساساً این است که X است و این
145
00:06:27,080 –> 00:06:29,000
نوار X است و سپس شما یک مربع
146
00:06:29,000 –> 00:06:32,720
از آن را می گیرید و سپس آلفا آلفا را اضافه می کنید
147
00:06:32,720 –> 00:06:36,460
اساساً جریمه است که چقدر
148
00:06:36,460 –> 00:06:39,560
متاسفم که سوگیری بنابراین تعصب اساساً
149
00:06:39,560 –> 00:06:40,460
از
150
00:06:40,460 –> 00:06:42,770
بنابراین صفر مطلقاً بدون تعصب است و
151
00:06:42,770 –> 00:06:44,600
پس از آن می توانید مقدار یک داشته باشید، می
152
00:06:44,600 –> 00:06:47,360
توانید ارزش دو را داشته باشید سه بر اساس جایی که
153
00:06:47,360 –> 00:06:49,849
می دانید چقدر می خواهید بخرید و
154
00:06:49,849 –> 00:06:52,819
بر این اساس شیب اساساً یک
155
00:06:52,819 –> 00:06:56,060
جریمه است که یا پین که
156
00:06:56,060 –> 00:06:58,550
میدانید تنبیه مدل است که در حال
157
00:06:58,550 –> 00:07:01,280
انحراف است، پس این اساساً این
158
00:07:01,280 –> 00:07:05,120
جریمهسازی تبلیغاتی به مدل است، بنابراین فقط برای
159
00:07:05,120 –> 00:07:07,250
اینکه ببینید این کل این چیز اساسا چگونه
160
00:07:07,250 –> 00:07:10,370
کار میکند، بنابراین در اینجا یک جریمه برای
161
00:07:10,370 –> 00:07:13,039
معادله و مجازات شدید است
162
00:07:13,039 –> 00:07:18,680
و این اساساً نموداری را
163
00:07:18,680 –> 00:07:21,650
که در اسلاید قبلی دیدهایم نشان میدهد که در
164
00:07:21,650 –> 00:07:24,050
آن معادله استاندارد ما است، اما
165
00:07:24,050 –> 00:07:26,270
فرض کنید پس از اضافه کردن جریمه
166
00:07:26,270 –> 00:07:29,750
یک، خط از اینجا به اینجا منتقل
167
00:07:29,750 –> 00:07:32,990
شده است و اکنون یک خط جدید مانند این است
168
00:07:32,990 –> 00:07:35,539
که باعث کاهش مقدار میشود. واریانس
169
00:07:35,539 –> 00:07:38,060
نقاط داده نادیده پس اگر معادله جدید را مشاهده کردید،
170
00:07:38,060 –> 00:07:42,259
اول از همه مجموع
171
00:07:42,259 –> 00:07:45,229
مجذور باقیمانده در یک نمودار خطی استاندارد
172
00:07:45,229 –> 00:07:48,500
صفر خواهد شد زیرا تمام
173
00:07:48,500 –> 00:07:51,080
نقاط داده از روی خط می آیند و
174
00:07:51,080 –> 00:07:53,509
به همین دلیل است که این صفر است. مجموع باقیمانده مربع
175
00:07:53,509 –> 00:07:57,969
0 به اضافه 1 ضرب در
176
00:07:57,969 –> 00:08:01,849
مربع شیب است، بنابراین
177
00:08:01,849 –> 00:08:04,969
اگر از معادله قبلی به یاد داشته باشید
178
00:08:04,969 –> 00:08:08,570
که فروش برابر با 1
179
00:08:08,570 –> 00:08:11,270
به علاوه 0.5 بازاریابی است، اگر آن را
180
00:08:11,270 –> 00:08:12,710
درست به خاطر بسپارم، مربع شیب اساساً 0.5 است. معادله چیست
181
00:08:12,710 –> 00:08:16,969
و 0.5 مربع همان چیزی است که ما باید
182
00:08:16,969 –> 00:08:19,789
طبق معادله رگرسیون بگیریم زیرا
183
00:08:19,789 –> 00:08:21,830
این همان شیب مربع است و ما
184
00:08:21,830 –> 00:08:25,310
شیب 0.5 داشتیم، بنابراین 0.5 ضرب در 0.5
185
00:08:25,310 –> 00:08:27,169
ضرب در 1 اساساً
186
00:08:27,169 –> 00:08:31,340
نقطه شما 2 5 است، یعنی زمانی که شما آنجا هستید.
187
00:08:31,340 –> 00:08:33,589
نقاط داده را در واقع روی
188
00:08:33,589 –> 00:08:37,610
خط داشته باشید، اما وقتی نقطه داده جدید را دارید
189
00:08:37,610 –> 00:08:40,969
و بر اساس تاریخ جدید و
190
00:08:40,969 –> 00:08:43,429
نقاط داده جدید برای آنها، می دانید که اگر
191
00:08:43,429 –> 00:08:48,740
d pi را اضافه کنیم، سپس i و شیب جدید
192
00:08:48,740 –> 00:08:50,810
را اضافه می کنیم و می آید، چه اتفاقی می افتد بنابراین
193
00:08:50,810 –> 00:08:53,000
فرض کنید که ما
194
00:08:53,000 –> 00:08:56,089
به این خط و تفاوت بین
195
00:08:56,089 –> 00:08:58,610
نقطه داده واقعی منتقل شده ایم و سپس این
196
00:08:58,610 –> 00:09:02,180
خط اساساً نقطه دو است، سپس
197
00:09:02,180 –> 00:09:03,649
یک مربع می گیرد زیرا ما باید یک مربع بگیریم
198
00:09:03,649 –> 00:09:06,920
زیرا برای این جمع آلفا
199
00:09:06,920 –> 00:09:09,920
آلفا فرض کنید 0.1 اینچ است. در این حالت شما
200
00:09:09,920 –> 00:09:13,610
می توانید نور را از 1/2 تا 2/3 یا 0.1 داشته
201
00:09:13,610 –> 00:09:15,170
باشید، همچنین می توانید آن را داشته باشید، اما این مانند این است که
202
00:09:15,170 –> 00:09:16,910
فقط برای نمایش در اینجا
203
00:09:16,910 –> 00:09:19,910
می توانید حتی یک را نیز داشته باشید، بنابراین 0.1
204
00:09:19,910 –> 00:09:23,569
ضرب در 2 به علاوه مربع شیب 1
205
00:09:23,569 –> 00:09:26,959
ضرب در 0.3 می شود. مربع پس اگر انجام دهید
206
00:09:26,959 –> 00:09:30,500
در ریاضیات شما نقطه 0 4 به اضافه
207
00:09:30,500 –> 00:09:33,980
نقطه صفر 1 به علاوه نقطه صفر 9 برابر با
208
00:09:33,980 –> 00:09:37,730
0.1 3 است بنابراین در صورت وجود نقاط داده جدید هنگامی
209
00:09:37,730 –> 00:09:40,550
که شیب جدید را بدست می آوریم و
210
00:09:40,550 –> 00:09:43,040
مجموع مجذور باقیمانده ها را به
211
00:09:43,040 –> 00:09:45,980
معادله اضافه می کنیم، نرخ خطای جدید را دریافت می کنیم.
212
00:09:45,980 –> 00:09:51,560
که مانند 0.13 است، بنابراین در مورد
213
00:09:51,560 –> 00:09:54,980
خط استاندارد معمولی، مجموع باقیمانده مربع
214
00:09:54,980 –> 00:09:58,850
به اضافه جریمه 0.25 بود، اما اگر
215
00:09:58,850 –> 00:10:00,769
زمانی که
216
00:10:00,769 –> 00:10:03,800
رگرسیون غنی را اعمال کردید و بایاس را اعمال کردید
217
00:10:03,800 –> 00:10:07,639
،