در این مطلب، ویدئو طبقه بندی علائم راهنمایی و رانندگی با استفاده از شبکه های عصبی پیچشی CNN | OPENCV پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:58
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:02,210 –> 00:00:05,339
سلام همه به کانال من خوش آمدید امروز
2
00:00:05,339 –> 00:00:07,710
قصد داریم
3
00:00:07,710 –> 00:00:10,019
علائم راهنمایی و رانندگی را با استفاده از
4
00:00:10,019 –> 00:00:12,900
شبکه های عصبی کانولوشن آموزش و طبقه بندی کنیم این کار با استفاده از CV باز
5
00:00:12,900 –> 00:00:15,870
در زمان واقعی با استفاده از وب
6
00:00:15,870 –> 00:00:17,940
کم ما انجام می شود.
7
00:00:17,940 –> 00:00:21,240
8
00:00:21,240 –> 00:00:23,880
با کمک تنسورفلو و
9
00:00:23,880 –> 00:00:27,240
کیرا تا پایان ویدیو،
10
00:00:27,240 –> 00:00:28,890
اطلاعاتی را به اشتراک میگذارم که به شما کمک میکند
11
00:00:28,890 –> 00:00:30,830
اطلاعات مجموعه دادههای خود را طبقهبندی کنید،
12
00:00:30,830 –> 00:00:33,180
مثلاً چقدر طول
13
00:00:33,180 –> 00:00:36,090
میکشد تا میزان دادهای از هر
14
00:00:36,090 –> 00:00:37,829
کلاس برای داشتن یک طبقهبندی خوب را آموزش دهید.
15
00:00:37,829 –> 00:00:40,829
مدل پس
16
00:00:40,829 –> 00:00:43,800
اگر میخواهید درباره مدلهای پرطرفدار
17
00:00:43,800 –> 00:00:46,020
هوش مصنوعی و برنامههای کاربردی آن اطلاعات بیشتری کسب کنید، با ما همراه
18
00:00:46,020 –> 00:00:47,910
باشید زیرا من
19
00:00:47,910 –> 00:00:52,079
به صورت هفتگی ویدیوها را آپلود خواهم کرد، بنابراین
20
00:00:52,079 –> 00:00:54,820
بیایید
21
00:00:54,820 –> 00:01:01,270
[Music] را شروع کنیم
22
00:01:01,270 –> 00:01:04,099
تا پس از دانلود مخزن github
23
00:01:04,099 –> 00:01:06,890
، آن را مشاهده کنید. چیزی شبیه به
24
00:01:06,890 –> 00:01:10,430
این اکنون ما داده های من را داریم که
25
00:01:10,430 –> 00:01:13,040
در پیوند دیگری در دسترس خواهد بود، بنابراین اگر
26
00:01:13,040 –> 00:01:16,400
به داده های خود نگاه کنیم می توانیم ببینیم که 43
27
00:01:16,400 –> 00:01:18,410
پوشه مختلف داریم که از 0 شروع می شود و
28
00:01:18,410 –> 00:01:21,830
به پایان می رسد. به 42 بنابراین در هر پوشه
29
00:01:21,830 –> 00:01:24,410
تصاویر کلاس های مربوطه را داریم به
30
00:01:24,410 –> 00:01:26,630
عنوان مثال این 20 محدودیت سرعت است و
31
00:01:26,630 –> 00:01:31,460
سپس 30 داریم و سپس همه
32
00:01:31,460 –> 00:01:37,090
این علائم مختلف را داریم همانطور که در
33
00:01:37,090 –> 00:01:41,630
یک پوشه می بینید اکنون در برچسب ها
34
00:01:41,630 –> 00:01:44,840
نام ها را داریم. از این کلاسها، بنابراین آنچه که در گذشته
35
00:01:44,840 –> 00:01:47,450
دیدهایم، شناسههای
36
00:01:47,450 –> 00:01:53,320
0 1 2 تا 42 است، اما در برچسبهای
37
00:01:53,320 –> 00:01:57,740
خود نام هر شناسه را داریم، بنابراین 0 نشاندهنده
38
00:01:57,740 –> 00:01:59,060
محدودیت سرعت 20 است
39
00:01:59,060 –> 00:02:03,910
در حالی که 14 نشاندهنده توقف است و به همین ترتیب
40
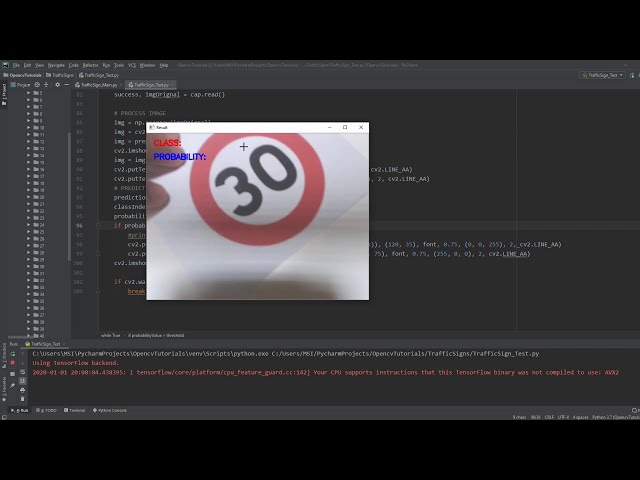
00:02:05,440 –> 00:02:08,780
اکنون مدل آموزشدیده شده اساساً
41
00:02:08,780 –> 00:02:11,080
در فایلی که تمام
42
00:02:11,080 –> 00:02:13,819
اطلاعات طبقه بندی را دارد، بنابراین وقتی
43
00:02:13,819 –> 00:02:15,920
مدل خود را آموزش دادید، یک
44
00:02:15,920 –> 00:02:18,710
فایل اکسپورت شده دریافت خواهید کرد که به صورت Model
45
00:02:18,710 –> 00:02:21,530
Trained Dot P است.
46
00:02:21,530 –> 00:02:24,740
47
00:02:24,740 –> 00:02:29,209
بیایید
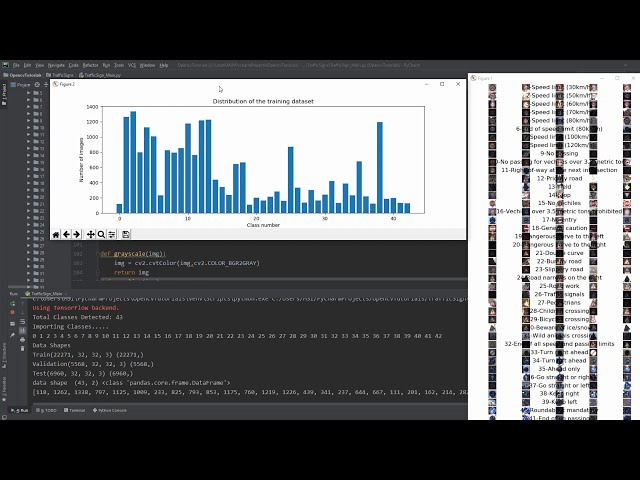
48
00:02:29,209 –> 00:02:32,150
اکنون به کد نگاه کنیم آنچه در ابتدا داریم تمام
49
00:02:32,150 –> 00:02:34,790
کتابخانه های ما است، بنابراین ما هیچ لوله ای نداریم
50
00:02:34,790 –> 00:02:38,420
matplotlib Kiera’s etc. بنابراین یکی از مواردی که
51
00:02:38,420 –> 00:02:42,890
در اینجا ذکر نشده است جریان تانسور است
52
00:02:42,890 –> 00:02:45,800
که باید آن را نیز نصب کنید، بنابراین
53
00:02:45,800 –> 00:02:48,170
اگر فقط Kiera را نصب کنید و سعی کنید
54
00:02:48,170 –> 00:02:49,700
آن را اجرا کنید به شما یک خطا می دهد و
55
00:02:49,700 –> 00:02:52,190
به شما می گوید که باید tensor flow را نصب کنید،
56
00:02:52,190 –> 00:02:54,350
پس چگونه نصب می کنید، به فایل
57
00:02:54,350 –> 00:02:57,440
بروید و به تنظیمات بروید و در پروژه می روید
58
00:02:57,440 –> 00:03:00,200
تا اضافه کنید تا هر چیزی که از دست رفته است،
59
00:03:00,200 –> 00:03:02,599
هر زمان که خط قرمز دریافت کردید به این معنی است.
60
00:03:02,599 –> 00:03:04,730
وجود ندارد، می توانید اینجا را تایپ کنید، به
61
00:03:04,730 –> 00:03:08,030
عنوان مثال Kira’s و می توانید بسته نصب را فشار دهید،
62
00:03:08,030 –> 00:03:10,220
بنابراین به این صورت است که
63
00:03:10,220 –> 00:03:12,060
هر یک از بسته ها را نصب می کنید،
64
00:03:12,060 –> 00:03:14,580
بنابراین وقتی این کار تمام شد،
65
00:03:14,580 –> 00:03:16,680
اکنون پارامترهای خود را در پارامترها داریم،
66
00:03:16,680 –> 00:03:20,040
اولین مورد جایی است که داده های شما قرار دارد.
67
00:03:20,040 –> 00:03:22,620
پوشه ای را که در آن ذخیره می شود ذخیره کرد، بنابراین در
68
00:03:22,620 –> 00:03:26,010
مورد ما داده های من را به عنوان نام پوشه داریم
69
00:03:26,010 –> 00:03:28,349
و سپس باید
70
00:03:28,349 –> 00:03:30,540
فایل برچسب های خود را تعریف کنیم که در آن همه
71
00:03:30,540 –> 00:03:33,900
نام ها وجود داشته باشد، بنابراین برچسب ها نقطه CSV هستند
72
00:03:33,900 –> 00:03:36,090
بقیه پارامترها را توصیه نمی کنم شما باید
73
00:03:36,090 –> 00:03:37,950
تغییر کنید مگر اینکه بدانید دارید چه کار می کنید،
74
00:03:37,950 –> 00:03:40,200
بنابراین تنها چیزی که ممکن است بخواهید
75
00:03:40,200 –> 00:03:43,620
تغییر دهید این است که باکس الکترونیکی چند
76
00:03:43,620 –> 00:03:45,660
بار تکرار خواهد شد، بنابراین
77
00:03:45,660 –> 00:03:49,500
چیزی شبیه به 10 برای شروع خوب است
78
00:03:49,500 –> 00:03:52,980
اما تا 20 تا 30 آن را افزایش دهید.
79
00:03:52,980 –> 00:03:55,019
شاید سه چهار ساعت بیشتر طول بکشد، اما آن
80
00:03:55,019 –> 00:03:58,410
را حالا نتایج بهتری به شما میدهم
81
00:03:58,410 –> 00:04:00,989
، نسبت تست اساساً این است که چند
82
00:04:00,989 –> 00:04:03,989
تصویر برای آموزش
83
00:04:03,989 –> 00:04:05,640
میگیرید و چند عکس برای
84
00:04:05,640 –> 00:04:07,890
آزمایش میگیرید، بنابراین اگر
85
00:04:07,890 –> 00:04:11,430
مثلاً 1000 تصویر داشته باشید اگر 0.2 قرار دهید
86
00:04:11,430 –> 00:04:15,109
، 200 تصویر برای آزمایش تقسیم میشود. و
87
00:04:15,109 –> 00:04:19,410
سپس تصاویر باقیمانده شما 800
88
00:04:19,410 –> 00:04:22,650
از این 800 خواهد بود، اگر 0.2 را برای
89
00:04:22,650 –> 00:04:25,950
اعتبار سنجی قرار دهید، 160 تصویر برای اعتبار سنجی طول می کشد،
90
00:04:25,950 –> 00:04:30,419
بنابراین در ادامه ما یک کد
91
00:04:30,419 –> 00:04:32,370
برای وارد کردن تصاویر داریم، بنابراین
92
00:04:32,370 –> 00:04:35,789
نگران پوشه ها و چگونگی آن نباشید.
93
00:04:35,789 –> 00:04:37,440
پوشه های زیادی وجود دارد که چند کلاس
94
00:04:37,440 –> 00:04:39,750
وجود دارد وقتی همه چیز را در داده های من قرار دهید
95
00:04:39,750 –> 00:04:42,479
، کد به طور خودکار
96
00:04:42,479 –> 00:04:44,570
تعداد کلاس ها را تشخیص می
97
00:04:44,570 –> 00:04:48,690
دهد و همه آنها را در یک ماتریس قرار می دهد، بنابراین بیایید ببینیم
98
00:04:48,690 –> 00:04:51,570
اگر این را اجرا کنیم چه اتفاقی می افتد، پس وقتی
99
00:04:51,570 –> 00:04:54,840
آن را اجرا کنیم. تعداد
100
00:04:54,840 –> 00:04:58,889
کلاسها را شناسایی میکند، بنابراین کل کلاسهای شناسایی شده 43 است
101
00:04:58,889 –> 00:05:01,800
و سپس هر پوشه
102
00:05:01,800 –> 00:05:04,260
را یکی یکی وارد میکند، بنابراین در حال حاضر هر
103
00:05:04,260 –> 00:05:06,660
پوشه و تصاویر موجود در این پوشهها را وارد میکند
104
00:05:06,660 –> 00:05:09,330
و همه اینها را در یک
105
00:05:09,330 –> 00:05:12,389
ماتریس قرار میدهد و آن ماتریس
106
00:05:12,389 –> 00:05:15,870
تصاویری برای خود تصاویر خواهد بود و
107
00:05:15,870 –> 00:05:18,810
شماره شناسه کلاس در شماره کلاس ذخیره میشود،
108
00:05:18,810 –> 00:05:21,870
بنابراین هر تصویر یک
109
00:05:21,870 –> 00:05:24,270
شناسه مربوطه خواهد داشت که در کلاس ذخیره میشود،
110
00:05:24,270 –> 00:05:25,500
111
00:05:25,500 –> 00:05:29,650
بنابراین در حال حرکت، زمانی که اجازه دادیم دادههای خود را تقسیم کنیم.
112
00:05:29,650 –> 00:05:33,130
من این کار را متوقف میکنم تا وقتی دادههایمان را داشتیم،
113
00:05:33,130 –> 00:05:36,520
میتوانیم آنها را
114
00:05:36,520 –> 00:05:39,940
با استفاده از پارامترهایی
115
00:05:39,940 –> 00:05:43,210
که قبلاً تعریف کردهایم به آزمایش و اعتبار خود تقسیم کنیم، بنابراین یک نکته
116
00:05:43,210 –> 00:05:46,480
قابل توجه این است که دادههای شما در X
117
00:05:46,480 –> 00:05:49,690
train X test و X file نسخه ذخیره میشوند، بنابراین
118
00:05:49,690 –> 00:05:52,320
همه اینها اساساً آرایهای از تصاویر هستند
119
00:05:52,320 –> 00:05:56,290
که بعداً از آنها استفاده خواهیم کرد و همه
120
00:05:56,290 –> 00:06:00,910
شناسههای مربوطه در آزمون Y so
121
00:06:00,910 –> 00:06:06,550
Y train Y و اعتبارسنجی Y ذخیره میشوند، بنابراین
122
00:06:06,550 –> 00:06:08,920
قبل از اینکه جلوتر برویم، باید
123
00:06:08,920 –> 00:06:12,940
مطمئن شویم که اندازههای قطار X
124
00:06:12,940 –> 00:06:15,940
را داریم. به عنوان مثال و قطار y
125
00:06:15,940 –> 00:06:18,400
مشابه هستند زیرا اگر
126
00:06:18,400 –> 00:06:20,140
هزار تصویر داشته باشیم باید
127
00:06:20,140 –> 00:06:22,600
هزار شناسه داشته باشیم، بنابراین همه اینها فقط
128
00:06:22,600 –> 00:06:26,710
آزمایش است اگر تصاویر
129
00:06:26,710 –> 00:06:29,200
آموزشی و شناسه های آموزشی همه
130
00:06:29,200 –> 00:06:31,180
مشابه آزمایش و
131
00:06:31,180 –> 00:06:33,370
اعتبارسنجی باشند. همه مشابه هستند اگر
132
00:06:33,370 –> 00:06:35,760
در اینجا با خطا مواجه شدید، باید ببینید که
133
00:06:35,760 –> 00:06:41,680
شکل داده شما دقیق نیست، بنابراین
134
00:06:41,680 –> 00:06:44,490
ما فایل CSV خود را می خوانیم و
135
00:06:44,490 –> 00:06:47,860
از آنجا می خواهیم داده های خود را رسم
136
00:06:47,860 –> 00:06:50,980
کنیم تا بتوانیم تجسم کنیم و ببینیم که آیا ما
137
00:06:50,980 –> 00:06:54,040
در حال جمعآوری دادههای صحیح هستند و
138
00:06:54,040 –> 00:06:56,680
قبل از شروع فرآیند آموزشی آنها را بهدرستی طبقهبندی میکنیم
139
00:06:56,680 –> 00:06:59,080
، بنابراین اگر
140
00:06:59,080 –> 00:07:02,640
دوباره آن را اجرا کنیم، ببینیم چه اتفاقی میافتد،
141
00:07:02,700 –> 00:07:05,950
بنابراین اگر دوباره آن را اجرا کنیم، میتوانیم ببینیم
142
00:07:05,950 –> 00:07:08,080
که توزیع
143
00:07:08,080 –> 00:07:10,630
مجموعه دادههای آموزشی را به ما میگوید و همچنین به
144
00:07:10,630 –> 00:07:15,340
ما بگویید هر کلاس را با برچسب مربوطه به ما نشان می دهد
145
00:07:15,340 –> 00:07:18,550
اکنون در پایین
146
00:07:18,550 –> 00:07:20,790
اینجا می توانید ببینید که ما حدود
147
00:07:20,790 –> 00:07:25,600
22000 تصویر برای آموزش حدود 5500
148
00:07:25,600 –> 00:07:28,030
تصویر برای اعتبار سنجی و حدود 7000
149
00:07:28,030 –> 00:07:31,570
تصویر برای آزمایش داریم و شکل داده ها
150
00:07:31,570 –> 00:07:35,200
باید همان 32 در 32 باشد. 3 که به معنای
151
00:07:35,200 –> 00:07:36,760
3 کانال است
152
00:07:36,760 –> 00:07:40,570
و به همین دلیل است که برچسبها نه
153
00:07:40,570 –> 00:07:43,210
برچسبها، شناسهها و مربوط به
154
00:07:43,210 –> 00:07:46,540
هر تصویر است، بنابراین اگر ما 22000 تصویر داشته
155
00:07:46,540 –> 00:07:49,870
باشیم باید 22000 شناسه داشته باشیم که
156
00:07:49,870 –> 00:07:53,440
مطابق با جایی است که در اینجا به آن تعلق دارد
157
00:07:53,440 –> 00:07:55,990
، دیدن آن مهم است. در ما نداریم
158
00:07:55,990 –> 00:07:58,660
تعداد تصاویر یکسان برای هر
159
00:07:58,660 –> 00:08:01,120
کلاس است، بنابراین در اینجا می توانید ببینید که ما
160
00:08:01,120 –> 00:08:03,550
حدود صد تصویر برای کلاس اول داریم و
161
00:08:03,550 –> 00:08:07,600
سپس حدود 1300 تصویر برای
162
00:08:07,600 –> 00:08:10,810
کلاس دیگر داریم، بنابراین توزیع یکسان
163
00:08:10,810 –> 00:08:13,870
نیست بنابراین ممکن است خوب به دست آوریم. طبقه بندی
164
00:08:13,870 –> 00:08:16,240
برای یک کلاس و طبقه بندی بد
165
00:08:16,240 –> 00:08:18,340
برای کلاس دیگر، زیرا مجموعه داده ها به
166
00:08:18,340 –> 00:08:20,410
طور مساوی توزیع نشده است، ما به
167
00:08:20,410 –> 00:08:23,380
اندازه کافی از هر کلاس نداریم، بنابراین
168
00:08:23,380 –> 00:08:25,560
در پایان این ویدیو می خواهیم یاد بگیریم
169
00:08:25,560 –> 00:08:28,950
که برای داشتن یک طبقه بندی خوب چه مقدار مجموعه داده لازم است.
170
00:08:28,950 –> 00:08:32,440
بنابراین، در حال پیشبرد
171
00:08:32,440 –> 00:08:35,229
پردازش تصاویر خود هستیم، ابتدا
172
00:08:35,229 –> 00:08:37,419
آن را به مقیاس خاکستری تبدیل می کنیم و سپس
173
00:08:37,419 –> 00:08:40,929
تصاویر خود را یکسان می کنیم تا برای
174
00:08:40,929 –> 00:08:43,450
هر تصویر یک نور استاندارد استاندارد داشته باشیم
175
00:08:43,450 –> 00:08:45,790
و سپس
176
00:08:45,790 –> 00:08:49,420
مقادیر را نرمال می کنیم، بنابراین به جای
177
00:08:49,420 –> 00:08:53,250
0 تا 255، این کار را انجام می دهیم. دارا





![فیلم آموزشی: [پروژه پایتون] ML FastAPI Skill Rating Calculator ... توسط Ian aka. \ با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/s61QFJkEaQUimage2.jpg)