در این مطلب، ویدئو نحوه ناشناس کردن داده ها با پایتون – انطباق با GDPR برای پروژه های علم داده با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:04:30
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:17,539 –> 00:00:19,949
سلام به همه در این ویدیو، من به
2
00:00:19,949 –> 00:00:22,910
شما دوستان نشان خواهم داد که چگونه می توانید داده ها را
3
00:00:22,910 –> 00:00:26,220
از مجموعه داده های موجود ناشناس کنید و
4
00:00:26,220 –> 00:00:29,550
این بسیار مفید است زیرا در این
5
00:00:29,550 –> 00:00:32,130
دنیا وقتی صحبت از Gdpr و همه
6
00:00:32,130 –> 00:00:33,360
چیزها می شود، نمی خواهید هیچ
7
00:00:33,360 –> 00:00:36,239
مشکلی داشته باشید. وقتی دادهها را تجزیه و تحلیل میکنید، اگر
8
00:00:36,239 –> 00:00:38,370
برخی از اطلاعات حساس مشتری
9
00:00:38,370 –> 00:00:40,770
مانند نام یا ایمیل را استخراج کنیم،
10
00:00:40,770 –> 00:00:42,750
نمیخواهید بعداً وقتی
11
00:00:42,750 –> 00:00:45,149
آن اطلاعات را با سایر طرفها به اشتراک میگذارید با مشکلی مواجه شوید
12
00:00:45,149 –> 00:00:46,920
و به همین دلیل است که
13
00:00:46,920 –> 00:00:48,899
دادههای mmm isaac
14
00:00:48,899 –> 00:00:51,390
برای محافظت از شما واقعاً مهم است.
15
00:00:51,390 –> 00:00:54,000
و همچنین حفاظت از مشتریان شما، بنابراین برای
16
00:00:54,000 –> 00:00:55,860
این دیدگاه، من به شما دوستان نشان خواهم داد
17
00:00:55,860 –> 00:00:58,170
که چگونه می توانید این کار را انجام دهید، بنابراین بیایید
18
00:00:58,170 –> 00:01:00,379
جلوتر برویم،
19
00:01:04,170 –> 00:01:07,570
بنابراین ما باید برخی از داده ها را ناشناس
20
00:01:07,570 –> 00:01:09,760
کنیم، خب ما ابتدا CSV را در
21
00:01:09,760 –> 00:01:12,460
مجموعه ها وارد می کنیم، بنابراین این تابعی است که
22
00:01:12,460 –> 00:01:14,290
will uh naanum داده است بنابراین
23
00:01:14,290 –> 00:01:16,510
اساساً نگاشتهایی از فیلدهایی ایجاد می کند
24
00:01:16,510 –> 00:01:19,330
که باید ناشناس شوند و در
25
00:01:19,330 –> 00:01:22,300
مورد ما از آنجایی که ما یک مجموعه داده جعلی
26
00:01:22,300 –> 00:01:24,250
داریم که ایجاد کرده ایم اگر می خواهید ببینید که
27
00:01:24,250 –> 00:01:26,260
چگونه یک مجموعه داده جعلی ایجاد می کنید.
28
00:01:26,260 –> 00:01:28,690
ویدیوی دیگری برای آن دارم و
29
00:01:28,690 –> 00:01:30,340
من پیوند را در توضیحات قرار
30
00:01:30,340 –> 00:01:32,950
می دهم تا بتوانید ببینید چگونه به این مجموعه داده های جعلی رسیدیم،
31
00:01:32,950 –> 00:01:35,110
32
00:01:35,110 –> 00:01:37,450
بنابراین ما فقط
33
00:01:37,450 –> 00:01:39,820
نام خانوادگی و ایمیل رایگان داریم که
34
00:01:39,820 –> 00:01:42,190
ستون های آن هستند. مجموعه دادهها بیایید در واقع
35
00:01:42,190 –> 00:01:48,790
به آن نگاه کنیم و آن را به دست آوریم، بنابراین
36
00:01:48,790 –> 00:01:50,740
میبینید که ما نام و ایمیلی
37
00:01:50,740 –> 00:01:54,940
داریم که باید نام و ایمیل این افراد را ناشناس کنیم،
38
00:01:54,940 –> 00:01:59,770
بسیار خوب، بنابراین
39
00:01:59,770 –> 00:02:01,450
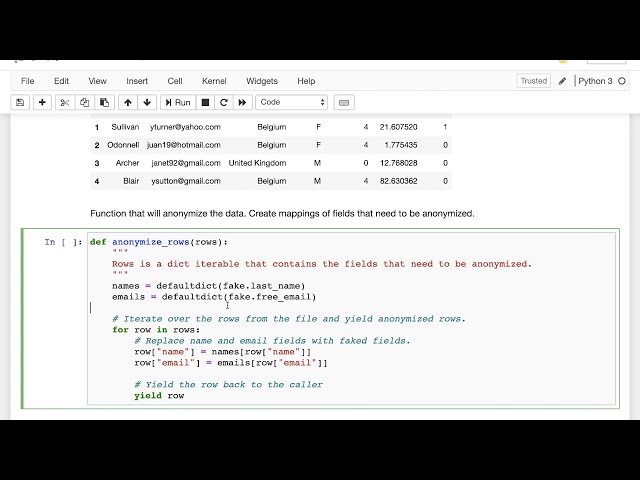
این تابعی است که برای ناشناس کردن باید اجرا کنیم.
40
00:02:01,450 –> 00:02:07,479
ردیفها خوب است، بنابراین همانطور که
41
00:02:07,479 –> 00:02:09,758
در اینجا میبینید روی همه ردیفها تکرار میشود و
42
00:02:09,758 –> 00:02:16,140
سپس آن را با دادههای جعلی جدید جایگزین میکند، بسیار
43
00:02:16,140 –> 00:02:19,569
خو




![فیلم آموزشی: [آموزش سالومه] بیایید یک بلوک بتنی با مصالح با پایتون در سالومه بسازیم! با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/MwHQIvgH5xUimage2.jpg)