در این مطلب، ویدئو پایتون: NLTK قسمت 2/3 | کیت ابزار زبان طبیعی – stemmer، tokenizer، POS tagger با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:07:49
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,240 –> 00:00:01,469
قبلاً اشاره کردم که
2
00:00:01,469 –> 00:00:03,689
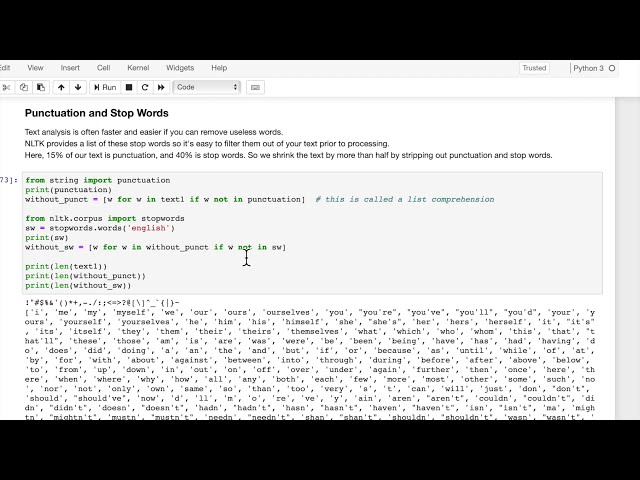
برای حذف علائم نگارشی و برخی از این
3
00:00:03,689 –> 00:00:05,430
کلمات بیهوده که ما آنها را کلمات توقف می نامیم
4
00:00:05,430 –> 00:00:07,890
از متن خود قبل از شروع هر
5
00:00:07,890 –> 00:00:10,139
تحلیلی مفید خواهد بود زیرا کلماتی مانند the
6
00:00:10,139 –> 00:00:13,320
and we and me و مواردی از این قبیل
7
00:00:13,320 –> 00:00:16,170
واقعاً هیچ تمایزی اضافه نمی کنند.
8
00:00:16,170 –> 00:00:18,630
ارزش متن از نظر تمایز
9
00:00:18,630 –> 00:00:21,000
از سایر متون، بنابراین اولین کاری که
10
00:00:21,000 –> 00:00:24,090
معمولاً میخواهیم در تجزیه و تحلیل حملات
11
00:00:24,090 –> 00:00:26,580
انجام دهیم این است که نشانههای نقطهگذاری را حذف کنیم، بنابراین این کار
12
00:00:26,580 –> 00:00:28,980
را با انجام علامتگذاری واردات رشته انجام
13
00:00:28,980 –> 00:00:31,140
میدهیم که این
14
00:00:31,140 –> 00:00:33,020
رشته کوچک زیبا از علائم نگارشی را در اینجا
15
00:00:33,020 –> 00:00:36,809
به ما میدهد. ما میتوانیم از درک فهرست w4w
16
00:00:36,809 –> 00:00:39,660
در متن 1 استفاده کنیم، اگر w در نشانهگذاری نباشد،
17
00:00:39,660 –> 00:00:42,059
درک فهرست در پایتون نامیده میشود، بنابراین
18
00:00:42,059 –> 00:00:43,950
ما اساساً به عبارت دیگر در حال
19
00:00:43,950 –> 00:00:47,010
تکرار در کل متن خود هستیم
20
00:00:47,010 –> 00:00:49,739
که یک لیست است و
21
00:00:49,739 –> 00:00:51,660
کلماتی را که در این هستند فیلتر میکنیم. لیست علائم نگارشی
22
00:00:51,660 –> 00:00:54,239
و ما آنها را حذف می کنیم و
23
00:00:54,239 –> 00:00:56,070
سپس این لیست جدید را
24
00:00:56,070 –> 00:00:59,100
به متغیری به نام بدون
25
00:00:59,100 –> 00:01:02,520
علامت گذاری تخصیص می دهیم، بنابراین اکنون بدون
26
00:01:02,520 –> 00:01:03,510
علامت گذاری
27
00:01:03,510 –> 00:01:06,090
داریم که al آماده حذف شد تمام
28
00:01:06,090 –> 00:01:07,439
کارهای بعدی که می خواهیم انجام دهیم این است که تمام
29
00:01:07,439 –> 00:01:10,920
کلمات توقف را از شما حذف
30
00:01:10,920 –> 00:01:13,740
31
00:01:13,740 –> 00:01:15,810
32
00:01:15,810 –> 00:01:17,369
کنیم.
33
00:01:17,369 –> 00:01:18,840
چندین
34
00:01:18,840 –> 00:01:21,689
زبان، بنابراین ما باید SW کلمات توقف برابر با
35
00:01:21,689 –> 00:01:24,390
کلمات نقطه را انجام دهیم و سپس به
36
00:01:24,390 –> 00:01:25,830
عنوان آرگومان زبان انتخابی ما را
37
00:01:25,830 –> 00:01:29,970
که در این مورد انگلیسی است، ارسال می کنیم، بنابراین در اینجا
38
00:01:29,970 –> 00:01:31,470
ما لیستی را برای توقف کار چاپ کرده ایم تا
39
00:01:31,470 –> 00:01:33,180
بتوانید ببینید چه چیزی است. در
40
00:01:33,180 –> 00:01:35,220
اینجا یکسری کلمات وجود دارد، اینها همه کلمات توقف هستند
41
00:01:35,220 –> 00:01:37,799
و اساساً
42
00:01:37,799 –> 00:01:39,930
همه اینها را از متن ما حذف می کند زیرا ما به آنها
43
00:01:39,930 –> 00:01:42,390
اهمیت نمی دهیم کلماتی مانند داخل و خارج
44
00:01:42,390 –> 00:01:45,299
و روشن و خاموش کردن این
45
00:01:45,299 –> 00:01:47,640
متن را از متن های دیگر متمایز نمی کنند.
46
00:01:47,640 –> 00:01:49,409
اگر میخواهیم سندی را تجزیه و تحلیل کنیم، میتوانیم با خیال راحت آنها را حذف کنیم،
47
00:01:49,409 –> 00:01:52,860
بنابراین دقیقاً همان کاری را انجام
48
00:01:52,860 –> 00:01:55,049
میدهیم که از درک فهرست استفاده میکنیم و اکنون در حال
49
00:01:55,049 –> 00:01:56,640
بررسی کلمات در این فهرست کلمات توقف هستیم،
50
00:01:56,640 –> 00:02:00,030
بنابراین من طول متن را
51
00:02:00,030 –> 00:02:02,909
قبل از برداشتن چیزی چاپ میکنم و سپس من
52
00:02:02,909 –> 00:02:04,890
یک لینک را چاپ کرد xt بدون
53
00:02:04,890 –> 00:02:06,719
علامت نقطه گذاری و سپس بدون
54
00:02:06,719 –> 00:02:08,910
کلمات توقف و می بینید که
55
00:02:08,910 –> 00:02:10,440
ما با یک متن دویست و شصت هزار
56
00:02:10,440 –> 00:02:12,959
کلمه ای شروع کردیم که بدون علامت
57
00:02:12,959 –> 00:02:13,790
گذاری به دو عدد
58
00:02:13,790 –> 00:02:15,990
21000 رسید و سپس وقتی کلمات توقف را
59
00:02:15,990 –> 00:02:18,510
خارج کردیم به 120 میلی متر رسید. بنابراین ما
60
00:02:18,510 –> 00:02:21,360
61
00:02:21,360 –> 00:02:24,750
با حذف همه
62
00:02:24,750 –> 00:02:27,630
کلمات بیهوده و علائم نگارشی، اندازه متن خود را حدود 60 درصد کاهش دادیم، اکنون یک
63
00:02:27,630 –> 00:02:30,420
سند بسیار کوچکتر داریم تا
64
00:02:30,420 –> 00:02:32,700
بتوانیم آن را با سرعت بیشتری تجزیه و تحلیل کنیم و خواهید
65
00:02:32,700 –> 00:02:34,620
دید که همانطور که دارید مجموعه بسیار بزرگ
66
00:02:34,620 –> 00:02:36,840
یا سند بسیار بزرگی که در حال
67
00:02:36,840 –> 00:02:39,900
تجزیه و تحلیل آن هستید، برخی از این
68
00:02:39,900 –> 00:02:41,430
الگوریتمها به کندی اجرا میشوند، بنابراین میخواهید
69
00:02:41,430 –> 00:02:43,380
تا جایی که میتوانید چیزهای بیفایده
70
00:02:43,380 –> 00:02:45,630
را حذف کنید، سرعت اجرای
71
00:02:45,630 –> 00:02:50,400
الگوریتمهای شما را افزایش میدهد.
72
00:02:50,400 –> 00:02:52,560
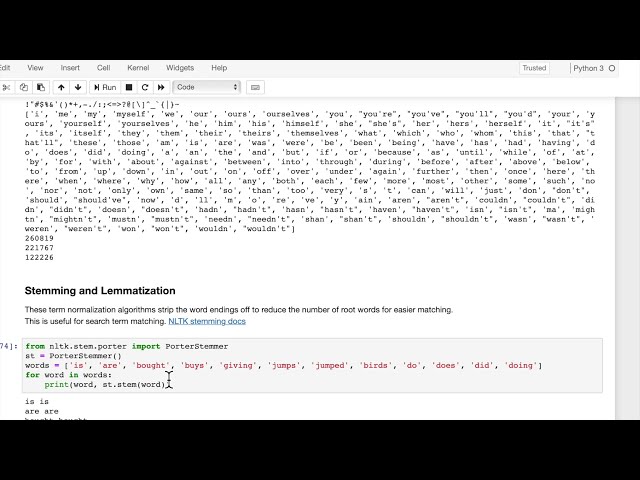
ریشه یابی enix و محدود سازی، بنابراین بیایید
73
00:02:52,560 –> 00:02:55,500
چند کاربرد خاص داشته باشیم، به
74
00:02:55,500 –> 00:02:57,300
نظر من مخصوصا برای موتورهای جستجو مفید است،
75
00:02:57,300 –> 00:02:59,100
زیرا شما
76
00:02:59,100 –> 00:03:02,010
اشکال مختلفی از کلمات دارید، بنابراین بیایید ابتدا ببینیم که چگونه
77
00:03:02,010 –> 00:03:04,800
کار می کند.
78
00:03:04,800 –> 00:03:06,960
79
00:03:06,960 –> 00:03:08,400
لکنت زبانهای مختلف که میتوانید با آنها بازی کنید، من فکر میکنم
80
00:03:08,400 –> 00:03:11,280
به هر حال یک استنفورد وجود دارد، من
81
00:03:11,280 –> 00:03:12,870
پیوندی به مستندات را در اینجا قرار دادم، میتوانید به
82
00:03:12,870 –> 00:03:14,100
اسناد پایه نگاه کنید و میتوانید
83
00:03:14,100 –> 00:03:15,630
موارد مختلف را امتحان کنید.
84
00:03:15,630 –> 00:03:17,250
85
00:03:17,250 –> 00:03:19,500
قبل و اینجا من فقط میخواهم
86
00:03:19,500 –> 00:03:22,709
فهرستی از کلمات ایجاد کنم خریدهای خرید شده ما هستند
87
00:03:22,709 –> 00:03:25,440
و چیزی که میخواهیم ببینیم این است که چگونه
88
00:03:25,440 –> 00:03:27,360
این کلمات را عادی میکند و
89
00:03:27,360 –> 00:03:29,370
اساساً با حذف اشکال جمع
90
00:03:29,370 –> 00:03:31,800
فعل یا گذشته از زمان حال آنها
91
00:03:31,800 –> 00:03:34,350
از یک فعل، آنها را عادی میکند. برای دادن
92
00:03:34,350 –> 00:03:36,810
یک کلمه به جای پنج
93
00:03:36,810 –> 00:03:39,270
شکل مختلف از یک کلمه، بنابراین ما برای هر یک از
94
00:03:39,270 –> 00:03:40,260
آنها کلمه را چاپ میکنیم
95
00:03:40,260 –> 00:03:44,550
و سپس نسخه اصلی کلمه so
96
00:03:44,550 –> 00:03:46,530
is تغییر نمیکند. تغییر
97
00:03:46,530 –> 00:03:49,110
خرید تغییر ن