در این مطلب، ویدئو 5. تقسیم داده ها به مجموعه آموزشی و آزمایشی در Data Science (Python) | تابع تقسیم تست قطار در ML با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:12:49
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,700
سلام دوستان، بنابراین در این آموزش من
2
00:00:02,700 –> 00:00:04,799
قصد دارم در مورد یکی از
3
00:00:04,799 –> 00:00:06,390
جنبه های مهم یادگیری ماشین به نام
4
00:00:06,390 –> 00:00:09,210
تقسیم مجموعه داده ها به مجموعه آموزشی
5
00:00:09,210 –> 00:00:13,740
و تست صحبت کنم، خوب، همچنین می خواهم در
6
00:00:13,740 –> 00:00:16,830
مورد اینکه چرا دقیقاً باید این کار را انجام دهیم صحبت خواهم کرد.
7
00:00:16,830 –> 00:00:19,109
دیدگاه یادگیری ماشین
8
00:00:19,109 –> 00:00:21,420
و همچنین اندازه ایدهآل
9
00:00:21,420 –> 00:00:23,850
برای یک مجموعه آزمایشی در حین انجام این نوع
10
00:00:23,850 –> 00:00:25,230
تقسیمبندیها خوب است،
11
00:00:25,230 –> 00:00:27,570
بنابراین این ناتان است که مصمم است
12
00:00:27,570 –> 00:00:29,760
13
00:00:29,760 –> 00:00:32,070
هوش مصنوعی Big Data Hadoop و
14
00:00:32,070 –> 00:00:34,620
رایانش ابری را در جهان و با این هدف دموکراتیزه کند.
15
00:00:34,620 –> 00:00:36,750
یا من محتوای Associated را ایجاد
16
00:00:36,750 –> 00:00:39,570
خواهم کرد و آن
17
00:00:39,570 –> 00:00:42,780
محتوا را به صورت دوره ای منتشر خواهم کرد و آن
18
00:00:42,780 –> 00:00:44,850
را برای شما در دسترس قرار خواهیم داد تا بتوانید
19
00:00:44,850 –> 00:00:47,219
برای دریافت آخرین به روز رسانی ها
20
00:00:47,219 –> 00:00:49,950
یا در مورد داغ ترین فناوری های
21
00:00:49,950 –> 00:00:55,110
قرن بیست و یکم در کانال من مشترک شوید، بنابراین برای این آموزش می
22
00:00:55,110 –> 00:00:58,670
رویم. برای استفاده از مجموعه داده مسکن کالیفرنیا
23
00:00:58,670 –> 00:01:01,559
که ما می خواهیم برای
24
00:01:01,559 –> 00:01:04,019
تقسیم مجموعه داده ها به دو مجموعه جداگانه
25
00:01:04,019 –> 00:01:10,350
برای آموزش و آزمایش استفاده کنیم و این
26
00:01:10,350 –> 00:01:13,380
مجموعه داده من است که کالیفرنیا است
27
00:01:13,380 –> 00:01:17,880
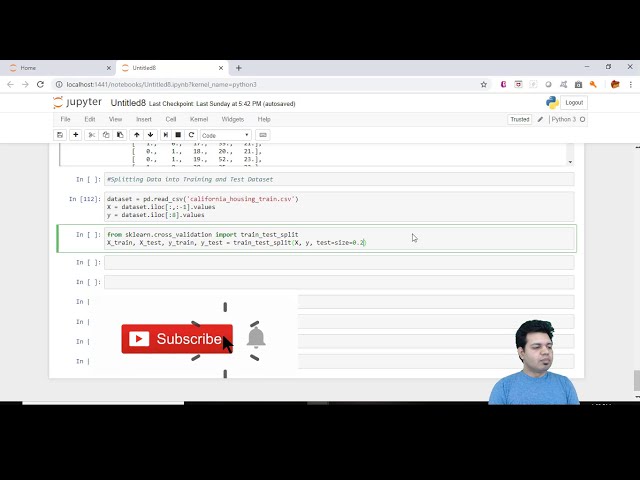
قرار دادن مجموعه داده ها خوب است و این همان
28
00:01:17,880 –> 00:01:21,060
چیزی است که ما اساساً
29
00:01:21,060 –> 00:01:24,540
به آموزش و همچنین مجموعه آزمایشی خود تقسیم می کنیم،
30
00:01:24,540 –> 00:01:28,020
بنابراین
31
00:01:28,020 –> 00:01:31,110
اکنون سؤال این است که چرا باید
32
00:01:31,110 –> 00:01:33,689
مجموعه داده ها را به خوبی تقسیم کنیم، پاسخ این است
33
00:01:33,689 –> 00:01:37,439
که اگر می خواهیم یادگیری ماشین ما و
34
00:01:37,439 –> 00:01:41,280
در زمینه یا الگوریتم ما
35
00:01:41,280 –> 00:01:43,560
برای یادگیری چیزی، سپس باید ابتدا
36
00:01:43,560 –> 00:01:46,350
از برخی داده های تاریخی یاد بگیرد تا
37
00:01:46,350 –> 00:01:48,750
بتواند پیش بینی کند، بنابراین مدل یادگیری ماشینی
38
00:01:48,750 –> 00:01:50,970
39
00:01:50,970 –> 00:01:53,610
قرار است با درک برخی از همبستگی هایی که در مجموعه داده های شما وجود دارد چیزی را در مجموعه داده های شما بیاموزد.
40
00:01:53,610 –> 00:01:56,310
41
00:01:56,310 –> 00:01:58,350
اگر
42
00:01:58,350 –> 00:02:00,899
مدل یادگیری ماشین شما بیش از حد از
43
00:02:00,899 –> 00:02:03,600
مجموعه دادههای شما میداند که در حال یادگیری بیش از حد برای
44
00:02:03,600 –> 00:02:08,098
همبستگی مقدار است، منظورم این است که در بین
45
00:02:08,098 –> 00:02:10,560
ستونها یا ویژگیهای مجموعه دادههای شما، به
46
00:02:10,560 –> 00:02:13,140
این حالت
47
00:02:13,140 –> 00:02:15,660
overfitting گفته میشود که بعداً به آن میپردازم، بنابراین
48
00:02:15,660 –> 00:02:18,120
عملکرد ممکن است
49
00:02:18,120 –> 00:02:22,440
در چنین مواردی عالی نباشید، خوب و
50
00:02:22,440 –> 00:02:24,780
مثالی را در نظر بگیرید که دانش آموزی که
51
00:02:24,780 –> 00:02:28,530
درسش را از روی قلب می آموزد، در امتحان می نشیند و
52
00:02:28,530 –> 00:02:31,110
به
53
00:02:31,110 –> 00:02:33,690
دلیل اینکه یاد گرفته است، به مشکل می خورد. خیلی درسته و
54
00:02:33,690 –> 00:02:37,730
درسش خیلی زیاد یاد گرفته با در واقع
55
00:02:37,730 –> 00:02:41,220
خیلی از درس هایش رو از زبان یاد میگیره
56
00:02:41,220 –> 00:02:43,620
و نمیتونه
57
00:02:43,620 –> 00:02:46,709
بین چیزی که یادگرفته و اون
58
00:02:46,709 –> 00:02:50,010
چیزی که تو امتحان اومده ارتباط برقرار کنه خوبه، پس
59
00:02:50,010 –> 00:02:52,500
الان در مورد ماشین هم همینطوره. یادگیری
60
00:02:52,500 –> 00:02:55,290
یعنی ما میخواهیم
61
00:02:55,290 –> 00:02:57,530
مدل یادگیری ماشین خود را بر روی مجموعه دادهای
62
00:02:57,530 –> 00:03:01,650
بسازیم که آن را به عنوان مجموعه آموزشی مینامیم okay و
63
00:03:01,650 –> 00:03:04,860
سپس باید آن مدل را روی مجموعه جدیدی
64
00:03:04,860 –> 00:03:12,239
به نام مجموعه تست okay آزمایش
65
00:03:12,239 –> 00:03:15,180
کنیم که کمی با مجموعه داده متفاوت است.
66
00:03:15,180 –> 00:03:17,310
67
00:03:17,310 –> 00:03:21,030
ما معمولاً عملکرد
68
00:03:21,030 –> 00:03:23,519
مدل یادگیری ماشینی خود را روی مجموعه دادههای آزمایشی آزمایش
69
00:03:23,519 –> 00:03:27,060
میکنیم که در اینجا باید به آن توجه کرد این است که
70
00:03:27,060 –> 00:03:29,310
عملکرد مجموعه آزمایشی نباید
71
00:03:29,310 –> 00:03:31,830
آنقدر متفاوت از عملکرد
72
00:03:31,830 –> 00:03:34,739
مجموعه آموزشی باشد، زیرا در این صورت این بدان معناست
73
00:03:34,739 –> 00:03:36,510
که مدلهای یادگیری ماشینی
74
00:03:36,510 –> 00:03:39,920
همبستگیها را به خوبی درک کردهاند و
75
00:03:39,920 –> 00:03:43,620
آنها را از روی یاد نگرفتهاند
76
00:03:43,620 –> 00:03:45,810
تا بتواند به مجموعههای جدید و موقعیتهای جدید اضافه
77
00:03:45,810 –> 00:03:48,420
شود، بنابراین این دلیلی است
78
00:03:48,420 –> 00:03:50,790
که ما مجموعه دادهها را به دو دسته تقسیم میکنیم. o آموزش و
79
00:03:50,790 –> 00:03:55,080
همچنین یک مجموعه آزمایشی، بنابراین اجازه دهید مقداری
80
00:03:55,080 –> 00:03:57,540
کدنویسی را در پایتون شروع کنیم تا انجام دهیم، میدانید
81
00:03:57,540 –> 00:04:00,239
که مراحل مربوطه قبل از
82
00:04:00,239 –> 00:04:03,269
تقسیم دادهها هستند، بیایید با خواندن مجموعه دادههای مسکن کالیفرنیا چارچوب داده را ایجاد کنیم،
83
00:04:03,269 –> 00:04:05,790
84
00:04:05,790 –> 00:04:06,390
85
00:04:06,390 –> 00:04:10,880
بنابراین بیایید آن مراحل را انجام دهیم،
86
00:04:12,550 –> 00:04:18,760
بنابراین این کار من است. نوت بوک مفسر
87
00:04:20,440 –> 00:04:24,830
بسیار خوب است، پس اجازه دهید
88
00:04:24,830 –> 00:04:25,970
مجموعه داده های مسکن کالیفرنیا را بخوانم
89
00:04:25,970 –> 00:04:29,240
خوب است، بنابراین من این
90
00:04:29,240 –> 00:04:33,860
مجموعه داده مسکن کالیفرنیا را نام می برم همانطور که منظورم
91
00:04:33,860 –> 00:04:38,180
نام قاب داده است زیرا مجموعه داده برابر است با P D
92
00:04:38,180 –> 00:04:44,300
dot read CSV و سپس آن را به عنوان کلی نام می برم
93
00:04:44,300 –> 00:04:47,480
متاسفم نیست در
94
00:04:47,480 –> 00:04:50,320
وسط نام فایل CSV
95
00:04:50,320 –> 00:04:55,970
California underscore مسکن و نرخ نقطه
96
00:04:55,970 –> 00:05:01,610
با پسوند قطار اشتباه نشود،
97
00:05:01,610 –> 00:05:07,010
این فقط یکی است فقط
98
00:05:07,010 –> 00:05:11,810
نام فایل است که اشکالی ندارد،
99
00:05:11,810 –> 00:05:18,110
پس این است و حالا چه چیز دیگری کاری که ما میتوانیم
100
00:05:18,110 –> 00:05:20,240
انجام دهیم این است که میتوانیم ماتریس ویژگی
101
00:05:20,240 –> 00:05:23,419
X و بردار وابسته Y را نیز
102
00:05:23,419 –> 00:05:25,820
از آن مجموعه داده ایجاد کنیم، زیرا شما
103
00:05:25,820 –> 00:05:29,240
در زندگی واقعی میدانید که اساساً کاری که انجام میدهید
104
00:05:29,240 –> 00:05:32,240
قبل از هر چیز زمانی است که
105
00:05:32,240 –> 00:05:34,850
دادههایی را که میدانید دریافت کنید. cr
106
00:05:34,850 –> 00:05:38,750
ماتریس ویژگی و همچنین بردار وابسته خود را
107
00:05:38,750 –> 00:05:40,880
که میدانید بخورید و بعد از آن
108
00:05:40,880 –> 00:05:43,400
همه این تقسیمبندیها
109
00:05:43,400 –> 00:05:46,580
را انجام میدهید، بنابراین بیایید این کار را انجام دهیم
110
00:05:46,580 –> 00:05:53,110
تا x برابر با دو نقطه مجموعه دادهها باشد، من قفل
111
00:05:53,110 –> 00:05:56,660
میکنیم و کاری که میخواهیم انجام دهیم
112
00:05:56,660 –> 00:05:59,330
میخواهم همه ستونها را به جز
113
00:05:59,330 –> 00:06:00,350
آخرین ستون در نظر
114
00:06:00,350 –> 00:06:03,620
بگیرم، بنابراین مشکل آخر این
115
00:06:03,620 –> 00:06:06,169
مقدار خانه میانه است و این
116
00:06:06,169 –> 00:06:09,970
متغیر هدف یا وابسته ما خواهد
117
00:06:09,970 –> 00: