در این مطلب، ویدئو دوره کامل TensorFlow 2.0 – آموزش شبکه های عصبی پایتون برای مبتدیان با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 6:52:08
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,290 –> 00:00:05,490
سلام، به همه، و به یک یادگیری ماشینی
کاملاً عظیم TensorFlow خوش آمدید
2
00:00:05,490 –> 00:00:09,940
دوره هوش مصنوعی اسلش اکنون، لطفاً برای
این مقدمه کوتاه با من همراه باشید،
3
00:00:09,940 –> 00:00:14,210
از آنجایی که من قصد دارم اطلاعات مهم زیادی
در مورد محتوای دوره به شما بدهم،
4
00:00:14,210 –> 00:00:18,700
منابع دوره، و آنچه می توانید پس از گذراندن
آن انتظار داشته باشید. اکنون،
5
00:00:18,700 –> 00:00:23,540
ابتدا به شما خواهم گفت که این دوره برای چه کسانی طراحی
شده است. بنابراین این دوره برای افراد در نظر گرفته شده است
6
00:00:23,540 –> 00:00:27,710
که در یادگیری ماشین و هوش مصنوعی مبتدی
هستند یا شاید کمی داشته باشند
7
00:00:27,710 –> 00:00:32,149
کمی درک می کنند، اما سعی می کنند بهتر
شوند، اما دانش اساسی اساسی دارند
8
00:00:32,149 –> 00:00:36,500
برنامه نویسی و پایتون بنابراین اگر این
کار را نکرده اید، این دوره آموزشی نیست
9
00:00:36,500 –> 00:00:41,050
قبلاً هر گونه برنامه نویسی انجام داده اید، یا اگر به طور
کلی دستور زبان پایتون را نمی دانید، این کار انجام می شود.
10
00:00:41,050 –> 00:00:45,220
به شدت توصیه می شود که سینتکس اساسی پشت
پایتون را درک کنید، زیرا من قصد ندارم
11
00:00:45,220 –> 00:00:48,900
تا در طول این دوره توضیح داده شود. در حال
حاضر، از نظر مربی خود را برای این
12
00:00:48,900 –> 00:00:53,290
البته، این من خواهم بود، نام من تیم است، ممکن است برخی
از شما من را به عنوان یک متخصص فناوری بشناسید
13
00:00:53,290 –> 00:00:56,880
تیم، از کانال یوتیوب من، انواع موضوعات
مختلف برنامه نویسی را آموزش می دهد.
14
00:00:56,880 –> 00:01:00,480
و من در واقع با Free Code Camp کار کردهام و برخی
از سریالهایم را در آنها پست کردهام
15
00:01:00,480 –> 00:01:04,729
کانال نیز حالا بیایید وارد دوره آموزشی بشویم
و دقیقاً در مورد آنچه هستید صحبت کنیم
16
00:01:04,729 –> 00:01:08,510
قرار است یاد بگیرید و چه انتظاراتی از این دوره
دارید. بنابراین همانطور که این دوره به سمت
17
00:01:08,510 –> 00:01:12,390
مبتدیان، و افرادی که تازه در دنیای یادگیری ماشینی
و هوش مصنوعی شروع کرده اند، ما هستیم
18
00:01:12,390 –> 00:01:16,170
با تجزیه و تحلیل دقیق یادگیری ماشین
و هوش مصنوعی شروع می کنیم
19
00:01:16,170 –> 00:01:20,100
است. بنابراین صحبت در مورد اینکه چه تفاوت هایی
بین آنها وجود دارد، انواع مختلف آنها
20
00:01:20,100 –> 00:01:24,450
یادگیری ماشین، یادگیری تقویتی، به عنوان
مثال، در مقابل شبکه های عصبی در مقابل
21
00:01:24,450 –> 00:01:29,210
یادگیری ماشینی ساده، ما با تمام آن تفاوتهای
مختلف روبرو خواهیم شد. و سپس
22
00:01:29,210 –> 00:01:33,090
ما قصد داریم به معرفی کلی TensorFlow بپردازیم.
در حال حاضر، برای کسانی از شما که
23
00:01:33,090 –> 00:01:37,440
نمی دانم، TensorFlow یک ماژول است که توسط گوگل توسعه یافته
و نگهداری می شود و می توان از آن استفاده کرد
24
00:01:37,440 –> 00:01:41,880
در پایتون به انجام یک تن از محاسبات علمی
مختلف، یادگیری ماشین و مصنوعی
25
00:01:41,880 –> 00:01:45,510
کاربردهای هوش ما در کل آموزش
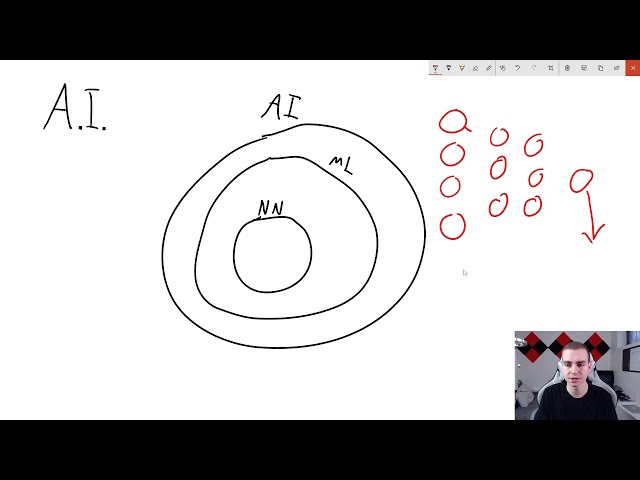
با آن کار خواهیم کرد
26
00:01:45,510 –> 00:01:49,450
سلسله. و پس از انجام این مقدمه کلی برای TensorFlow،
میخواهیم وارد برنامه خود شویم
27
00:01:49,450 –> 00:01:53,340
الگوریتم های اصلی یادگیری اکنون، اینها الگوریتم
های یادگیری هستند که باید بدانید
28
00:01:53,340 –> 00:01:58,160
قبل از اینکه بتوانیم بیشتر به یادگیری ماشین برویم،
آنها یک پایه واقعا قوی ایجاد می کنند، آنها هستند
29
00:01:58,160 –> 00:02:02,650
درک و پیاده سازی بسیار آسان است. و آنها فوق العاده
قدرتمند هستند. بعد از انجام این کار،
30
00:02:02,650 –> 00:02:06,070
ما قصد داریم وارد شبکههای
عصبی شویم
31
00:02:06,070 –> 00:02:09,449
شبکههای عصبی کار میکنند، چگونه میتوانیم از آنها استفاده
کنیم، و سپس مجموعهای از نمونههای مختلف را انجام دهیم.
32
00:02:09,449 –> 00:02:13,269
و سپس به برخی از جنبه های پیچیده تر
یادگیری ماشینی و مصنوعی می پردازیم
33
00:02:13,269 –> 00:02:17,760
هوش و رسیدن به شبکه های عصبی کانولوشن، که
می توانند کارهایی مانند تشخیص تصویر را انجام دهند
34
00:02:17,760 –> 00:02:20,989
و تشخیص و سپس وارد شبکه های عصبی
تکراری خواهیم شد، که هستند
35
00:02:20,989 –> 00:02:26,590
کارهایی مانند پردازش زبان طبیعی، رباتهای گفتگو،
پردازش متن، و همه اینها متفاوت است
36
00:02:26,590 –> 00:02:31,279
انواع چیزها، و در نهایت با یادگیری
تقویتی به پایان رسید. حالا از نظر منابع
37
00:02:31,279 –> 00:02:35,090
برای این دوره، تعداد زیادی وجود دارد، و کاری که ما
قصد داریم انجام دهیم تا این را واقعاً انجام دهیم
38
00:02:35,090 –> 00:02:39,799
آسان برای شما و برای من، انجام همه کارها از
طریق Google Collaboratory است. حالا اگر شما
39
00:02:39,799 –> 00:02:43,879
در مورد Google Collaboratory چیزی نشنیدهام، اساساً این
یک محیط برنامهنویسی مشترک است که
40
00:02:43,879 –> 00:02:49,120
یک نوت بوک iPython را در فضای ابری، روی یک دستگاه Google اجرا
می کند که در آن می توانید همه کارهای خود را انجام دهید
41
00:02:49,120 –> 00:02:53,080
یادگیری ماشینی به صورت رایگان بنابراین شما نیازی
به نصب هیچ بسته ای ندارید، نیازی به نصب ندارید
42
00:02:53,080 –> 00:02:57,183
از Pip استفاده کنید، نیازی به تنظیم محیط خود ندارید، تنها
کاری که باید انجام دهید این است که یک Google جدید باز کنید
43
00:02:57,183 –> 00:03:00,930
پنجره همکاری، و می توانید شروع به نوشتن کد کنید.
و این کاری است که ما انجام خواهیم داد
44
00:03:00,930 –> 00:03:04,890
در این سریال اگر همین الان به توضیحات نگاه کنید،
پیوندهایی به همه موارد را خواهید دید
45
00:03:04,890 –> 00:03:09,170
نوت بوک هایی که در این راهنما استفاده می کنم. بنابراین
اگر چیزی وجود دارد که می خواهید پاک کنید
46
00:03:09,170 –> 00:03:12,840
بالا، اگر کد را برای خود میخواهید، اگر میخواهید
فقط توضیحات مبتنی بر متن را داشته باشید
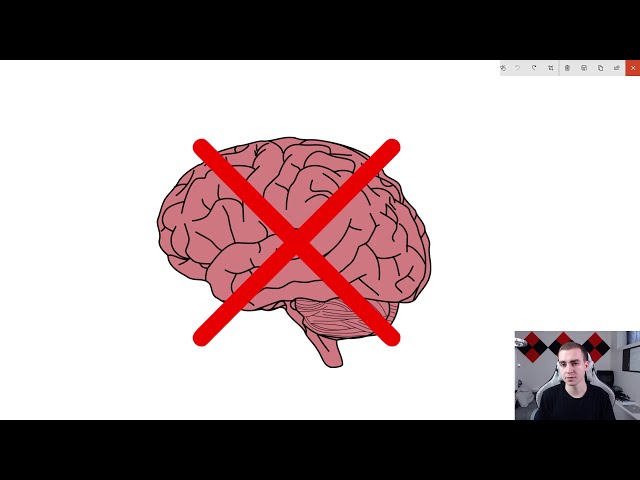
47
00:03:12,840 –> 00:03:16,579
چیزهایی که من می گویم، می توانید روی آن پیوندها
کلیک کنید و به آنها دسترسی پیدا کنید. پس با آن
48
00:03:16,579 –> 00:03:20,849
گفته می شود، من برای شروع بسیار هیجان زده هستم، امیدوارم
شما بچه ها نیز همینطور باشید. و بریم
49
00:03:20,849 –> 00:03:27,200
پیش بروید و وارد محتوا شوید.
50
00:03:27,200 –> 00:03:30,599
بنابراین در این بخش اول، من قصد دارم چند دقیقه
ای را صرف بحث در مورد تفاوت بین آنها کنم
51
00:03:30,599 –> 00:03:35,349
هوش مصنوعی، شبکه های عصبی و یادگیری
ماشینی. و دلیلی که ما نیاز داریم
52
00:03:35,349 –> 00:03:38,359
به این دلیل است که ما همه این موضوعات
را در طول این پوشش خواهیم داد
53
00:03:38,359 –> 00:03:42,409
دوره. بنابراین بسیار مهم است که شما بچه ها بفهمید که اینها در
واقع چه معنایی دارند. و شما می توانید مهربانی کنید
54
00:03:42,409 –> 00:03:46,540
از تمایز بین آنها بنابراین این چیزی است که ما اکنون
روی آن تمرکز خواهیم کرد. اکنون، سلب مسئولیت سریع
55
00:03:46,540 –> 00:03:50,390
در اینجا، فقط برای اینکه همه بدانند، من از چیزی
به نام Windows Inc استفاده می کنم. این فقط پیش فرض است
56
00:03:50,390 –> 00:03:53,599
همراه با ویندوز است، من یک تبلت طراحی
دارم. و این چیزی است که من خواهم شد
57
00:03:53,599 –> 00:03:58,499
برای برخی از بخش های توضیحی استفاده می شود، اما
هیچ کدنویسی واقعی وجود ندارد، فقط برای نشان دادن
58
00:03:58,499 –> 00:04:03,489
برخی از مفاهیم و موضوعات به شما. الان دستخط
خیلی وحشتناکی دارم، اهل هنر نیستم
59
00:04:03,489 –> 00:04:08,360
به هر حال، برنامه نویسی قطعاً بیشتر
از آنچه که می دانید، طراحی و
60
00:04:08,360 –> 00:04:11,769
انجام نمودارها و چیزهای دیگر اما من تمام
تلاشم را خواهم کرد. و این فقط راه آن است
61
00:04:11,769 –> 00:04:16,140
من متوجه شدم که می توانم بهترین اطلاعات را به شما عزیزان
منتقل کنم. بنابراین به هر حال، بیایید شروع کنیم و
62
00:04:16,140 –> 00:04:20,820
اولین موضوع را اینجا مطرح کنید که هوش
مصنوعی است. حالا هوش مصنوعی
63
00:04:20,820 –> 00:04:25,070
این روزها یک تبلیغات بزرگ است. و خنده دار است زیرا
بسیاری از مردم واقعاً نمی دانند این چیست
64
00:04:25,070 –> 00:04:29,890
به معنای. یا سعی کردند به مردم بگویند
آنچه ساخته اند هوش مصنوعی نیست،
65
00:04:29,890 –> 00:04:35,090
در حالی که در واقعیت، در واقع اینطور است. در حال
حاضر نوعی تعریف رسمی از AI و من فقط می خواهم
66
00:04:35,090 –> 00:04:38,690
آن را از اسلاید من در اینجا بخوانید تا مطمئن
شوید که این کار را خراب نمی کنم، این تلاش است
67
00:04:38,690 –> 00:04:45,080
برای خودکار کردن وظایف فکری که معمولاً توسط انسان انجام
می شود. حالا، این یک تعریف نسبتا بزرگ است،
68
00:04:45,080 –> 00:04:50,130
درست؟ کاری که یک وظیفه فکری تلقی می
شود و، می دانید، واقعاً کمکی نمی کند
69
00:04:50,130 –> 00:04:54,560
ما بیش از حد بنابراین کاری که می خواهم انجام دهم این است که ما را به زمانی
برگردانم که هوش مصنوعی برای اولین بار برای مهربانی ایجاد شد
70
00:04:54,560 –> 00:04:59,810
برای شما توضیح دهد که هوش مصنوعی چگونه تکامل یافته
است و واقعاً چه چیزی در سال 1950 شروع شد
71
00:04:59,810 –> 00:05:05,000
یک نوع سوال توسط دانشمندان و محققین
پرسیده می شد، کامپیوترها
72
00:05:05,000 –> 00:05:09,520
فکر کنید، آیا می توانیم آنها را وادار کنیم تا مسائل را بفهمند؟
آیا می توانیم از کدنویسی سخت دور شویم؟ و شما
73
00:05:09,520 –> 00:05:13,780
آیا میدانیم، آیا میتوانیم رایانهای را وادار کنیم که فکر
کند آیا میتواند کار خودش را انجام دهد؟ پس همین بود
74
00:05:13,780 –> 00:05:17,590
نوعی سوالی که پرسیده شد و این زمانی
بود که اصطلاح هوش مصنوعی بود
75
00:05:17,590 –> 00:05:23,670
نوعی ابداع و خلق شده است. در آن زمان هوش مصنوعی صرفاً
مجموعه ای از قوانین از پیش تعریف شده بود. بنابراین
76
00:05:23,670 –> 00:05:28,420
اگر به هوش مصنوعی فکر می کنید، شاید مانند تیک تاک
پا، یا هوش مصنوعی برای شطرنج، همه آنها
77
00:05:28,420 –> 00:05:32,980
در آن زمان قوانین از پیش تعریف شده ای وجود دارد
که انسان ها به وجود آورده و تایپ کرده اند
78
00:05:32,980 –> 00:05:37,260
کامپیوتر در کد و کامپیوتر به سادگی آن مجموعه
قوانین را اجرا می کند و از آنها پیروی می کند
79
00:05:37,260 –> 00:05:42,150
آن دستورالعمل ها بنابراین هیچ الگوریتم دیوانه وار
یادگیری ماشینی یادگیری عمیق وجود نداشت،
80
00:05:42,150 –> 00:05:46,560
به سادگی اگر میخواهید رایانه کاری
انجام دهد، باید از قبل به آن بگویید،
81
00:05:46,560 –> 00:05:51,420
بگو تو در این موقعیت هستی و این اتفاق می افتد، این کار را انجام
دهید. و این همان چیزی بود که هوش مصنوعی بود. و خیلی
82
00:05:51,420 –> 00:05:56,470
هوش مصنوعی خوب صرفاً مجموعهای از قوانین بسیار خوب بود که تعداد
زیادی از قوانین متفاوتی را که انسانها داشت، تشکیل میداد
83
00:05:56,470 –> 00:06:00,510
در برخی از برنامه ها پیاده سازی شده بود، شما می توانید برنامه
های هوش مصنوعی داشته باشید که در حال گسترش هستند
84
00:06:00,510 –> 00:06:04,930
بدانید، نیم میلیون خط کد، فقط با
تن و تن و تن از قوانین مختلف
85
00:06:04,930 –> 00:06:10,700
که برای آن هوش مصنوعی ایجاد شده اند. بنابراین فقط حواستان
باشد که هوش مصنوعی لزوماً به این معنا نیست
86
00:06:10,700 –> 00:06:15,830
هر چیز دیوانه کننده، پیچیده یا فوق العاده پیچیده.
اما اساساً، اگر میخواهید شبیهسازی کنید
87
00:06:15,830 –> 00:06:20,660
یک کار فکری، مانند انجام یک بازی که یک
انسان با کامپیوتر انجام می دهد، آن
88
00:06:20,660 –> 00:06:25,970
هوش مصنوعی در نظر گرفته شده است، بنابراین حتی یک هوش مصنوعی بسیار
ابتدایی برای بازی تیک تاک پا که در آن وجود دارد
89
00:06:25,970 –> 00:06:29,950
علیه شما بازی می کند، که هنوز هوش مصنوعی محسوب
می شود. و اگر به چیزی شبیه Pac فکر کنیم
90
00:06:29,950 –> 00:06:33,780
مرد، درست است، جایی که ما، می دانید، روح کوچکمان
را داریم، و این طرح اولیه من خواهد بود
91
00:06:33,780 –> 00:06:38,360
یک روح، ما پسر Pac Man خود را داریم که فقط همین
خواهد بود. خوب، وقتی این را در نظر می گیریم
92
00:06:38,360 –> 00:06:45,410
هوش مصنوعی شبح، کاری که انجام می دهد این است که تلاش می
کند نحوه رسیدن به Pac Man را بیابد و شبیه سازی کند،
93
00:06:45,410 –> 00:06:49,630
درست. و نحوه کار این فقط با استفاده از یک الگوریتم
مسیریابی بسیار ابتدایی است. این دارد
94
00:06:49,630 –> 00:06:53,310
هیچ ربطی به یادگیری عمیق، یا یادگیری ماشینی یا
هر چیز دیوانه کننده ای ندارد. اما این هنوز است
95
00:06:53,310 –> 00:06:58,200
در نظر گرفته شده هوش مصنوعی، کامپیوتر در حال کشف کردن
است که چگونه می تواند به نوعی بازی کند و
96
00:06:58,200 –> 00:07:02,170
با پیروی از یک الگوریتم کاری انجام دهید. بنابراین
لزوماً نیازی به داشتن چیزی نداریم
97
00:07:02,170 –> 00:07:07,510
پیچیده احمقانه و احمقانه که باید هوش مصنوعی در نظر
گرفته شود، فقط باید برخی از آن ها را شبیه سازی کند
98
00:07:07,510 –> 00:07:12,180
رفتار عقلانی انسان این نوعی
تعریف هوش مصنوعی است.
99
00:07:12,180 –> 00:07:16,900
اکنون، بدیهی است، امروز، هوش مصنوعی به حوزه بسیار پیچیدهتری
تبدیل شده است که در حال حاضر آن را داریم
100
00:07:16,900 –> 00:07:20,020
یادگیری ماشین و یادگیری عمیق و همه این
تکنیک های دیگر، چیزی که ما هستیم
101
00:07:20,020 –> 00:07:24,170
الان در موردش صحبت می کنیم بنابراین کاری که میخواهم
با انجام آن شروع کنم، کشیدن یک دایره در اینجا است.
102
00:07:24,170 –> 00:07:29,660
و من می خواهم به این دایره برچسب بزنم و بگویم، A، من
آن را دوست دارم. بنابراین این AI را تعریف می کند،
103
00:07:29,660 –> 00:07:34,360
زیرا هر چیزی که می خواهم در اینجا
قرار دهم، هوش مصنوعی محسوب می شود.
104
00:07:34,360 –> 00:07:38,230
خب حالا بیایید به یادگیری ماشین بپردازیم. بنابراین کاری
که من می خواهم انجام دهم این است که یک دایره دیگر بکشم
105
00:07:38,230 –> 00:07:44,050
داخل اینجا و ما این دایره را برای یادگیری ماشین
برچسب گذاری می کنیم. حالا توجه کنید
106
00:07:44,050 –> 00:07:48,480
من این را در دایره هوش مصنوعی قرار دادم. این
به این دلیل است که یادگیری ماشینی است
107
00:07:48,480 –> 00:07:54,210
بخشی از هوش مصنوعی حال، یادگیری ماشین
چیست؟ خوب، چیزی که ما صحبت کردیم
108
00:07:54,210 –> 00:08:00,050
قبلاً، نوعی این ایده بود که هوش مصنوعی فقط
مجموعه ای از قوانین از پیش تعریف شده بود،
109
00:08:00,050 –> 00:08:04,790
درست؟ جایی که اتفاقی می افتد، ما مقداری داده
را تغذیه می کنیم، قوانین را دنبال می کنیم
110
00:08:04,790 –> 00:08:08,450
توسط و سپس داده ها را با قوانین تجزیه و تحلیل کنید.
و سپس مقداری خروجی را بیرون می آوریم که
111
00:08:08,450 –> 00:08:12,310
آیا می دانید، ما قرار است چه کار کنیم. بنابراین
در مثال کلاسیک شطرنج، بگویید، ما هستیم
112
00:08:12,310 –> 00:08:17,240
در بررسی، آنچه که ما اطلاعات آن برد را به رایانه ارسال
می کنیم، مجموعه قوانین آن را بررسی می کند،
113
00:08:17,240 –> 00:08:21,500
آن را مشخص می کند که ما تحت کنترل هستیم، و سپس
ما را به جای دیگری منتقل می کند. حالا ماشین چیه
114
00:08:21,500 –> 00:08:26,310
یادگیری در مقابل آن؟ خوب، یادگیری
ماشین اولین زمینه ای است که در واقع
115
00:08:26,310 –> 00:08:31,650
قوانین را برای ما تعیین می کند بنابراین به جای اینکه
ما قوانین را به سختی در رایانه کدنویسی کنیم،
116
00:08:31,650 –> 00:08:36,479
کاری که یادگیری ماشین انجام میدهد این است
که دادهها را بگیرد و خروجی را بگیرد،
117
00:08:36,479 –> 00:08:38,360
و قوانین را برای ما مشخص کنید.
118
00:08:38,360 –> 00:08:39,360
بنابراین شما اغلب
119
00:08:39,360 –> 00:08:43,070
بشنوید که، می دانید، یادگیری ماشینی به داده های زیادی
نیاز دارد. و شما به نمونه های زیادی نیاز دارید
120
00:08:43,070 –> 00:08:48,430
و می دانید، داده های ورودی را برای آموزش واقعاً
یک مدل خوب وارد کنید. خوب، دلیل آن است
121
00:08:48,430 –> 00:08:52,809
زیرا روشی که یادگیری ماشینی کار می کند این است که
قوانین را برای ما ایجاد می کند. ما می دهیم
122
00:08:52,809 –> 00:08:57,471
مقداری از داده های ورودی به آن داده می شود که داده های
خروجی باید چه باشد. و سپس به آن نگاه می کند
123
00:08:57,471 –> 00:09:02,640
اطلاعات و کشف می کند که چه قوانینی را می توانیم ایجاد
کنیم، به طوری که وقتی به داده های جدید نگاه می کنیم،
124
00:09:02,640 –> 00:09:07,190
ما می توانیم بهترین خروجی ممکن را برای آن داشته باشیم.
در حال حاضر، به همین دلیل است که بسیاری از مواقع، ماشین
125
00:09:07,190 –> 00:09:12,209
مدل های یادگیری دقت 100% ندارند، به این
معنی که ممکن است لزوماً نباشند
126
00:09:12,209 –> 00:09:16,870
هر بار پاسخ صحیح را دریافت کنید و
هدف ما از ایجاد یادگیری ماشینی است
127
00:09:16,870 –> 00:09:20,870
مدلها این است که دقت ما را تا حد امکان بالا ببرند،
که به این معنی است که این کار را انجام میدهد
128
00:09:20,870 –> 00:09:25,269
کمترین اشتباه ممکن از آنجا که دقیقاً مانند یک
انسان، می دانید، مدل های یادگیری ماشینی ما،
129
00:09:25,269 –> 00:09:29,839
که در تلاش برای شبیه سازی هستند، می دانید، رفتار
انسان ممکن است اشتباه کند. اما به طور خلاصه
130
00:09:29,839 –> 00:09:35,069
که اساساً یادگیری ماشینی تفاوت بین آن
و نوع الگوریتمها را میدانید
131
00:09:35,069 –> 00:09:40,399
و هوش مصنوعی پایه این واقعیت است که به
جای ما برنامه نویس، آن را دریافت می کنیم
132
00:09:40,399 –> 00:09:45,279
قوانین را به آن می دهد. قوانین را برای ما مشخص
می کند. و ما ممکن است لزوماً ندانیم
133
00:09:45,279 –> 00:09:49,700
وقتی به یادگیری ماشین نگاه می کنیم و یادگیری
ماشین را ایجاد می کنیم، به صراحت قوانین چیست
134
00:09:49,700 –> 00:09:54,390
مدل ها. اما می دانیم که داده های ورودی را ارائه
می دهیم، خروجی مورد انتظار را ارائه می دهیم
135
00:09:54,390 –> 00:09:58,410
دادهها، و سپس به همه این اطلاعات نگاه میکند که الگوریتمهایی
را انجام میدهند که در مورد آنها صحبت خواهیم کرد
136
00:09:58,410 –> 00:10:03,339
بعداً و قوانین را برای ما مشخص می کند. به طوری
که بعداً وقتی به آن مقداری ورودی می دهیم
137
00:10:03,339 –> 00:10:07,350
دادهها، و ما دادههای خروجی را نمیدانیم، میتواند
از قوانینی که مشخص شده است استفاده کند
138
00:10:07,350 –> 00:10:11,920
از مثالهای ما و تمام دادههای آموزشی که
برای تولید خروجی به آن دادهایم. باشه،
139
00:10:11,920 –> 00:10:16,709
بنابراین این یادگیری ماشینی است. اکنون به هوش مصنوعی و یادگیری
ماشینی پرداخته ایم. و اکنون زمان آن فرا رسیده است
140
00:10:16,709 –> 00:10:21,639
برای پوشش شبکه های عصبی یا یادگیری عمیق. اکنون،
این دایره باید دقیقاً به داخل آن برود
141
00:10:21,639 –> 00:10:25,550
یادگیری ماشین دقیقاً در اینجا، من فقط می خواهم
به این یک و n که مخفف آن است برچسب بزنم
142
00:10:25,550 –> 00:10:30,480
شبکه های عصبی. در حال حاضر، شبکه های عصبی تبلیغات بزرگی
دریافت می کنند، آنها معمولا اولین چیزی هستند،
143
00:10:30,480 –> 00:10:33,680
می دانید، وقتی وارد یادگیری ماشینی می شوید، می خواهید
یاد بگیرید که شبکه های عصبی مهربان هستند
144
00:10:33,680 –> 00:10:37,709
مانند شبکه های عصبی جالب هستند، آنها قادر به کارهای
زیادی هستند. اما بیایید بحث کنیم که اینها چیست
145
00:10:37,709 –> 00:10:42,380
واقعا هستند بنابراین ساده ترین راه برای تعریف
یک شبکه عصبی آن به عنوان یک ماشین است
146
00:10:42,380 –> 00:10:47,699
یادگیری که از نمایش لایه ای داده ها استفاده
می کند. در حال حاضر، ما واقعا نمی فهمیم
147
00:10:47,699 –> 00:10:51,800
این کاملا در حال حاضر اما هرچه به جلوتر میرویم،
این موضوع باید حس بیشتری پیدا کند
148
00:10:51,800 –> 00:10:56,709
یک تعریف اما چیزی که باید به نوعی برای شما توضیح
دهم این است که در مثال قبلی، کجا
149
00:10:56,709 –> 00:11:00,399
ما فقط در مورد یادگیری ماشین صحبت کردیم، در اصل چیزی که
داشتیم این بود که حباب های ورودی داشتیم،
150
00:11:00,399 –> 00:11:04,569
که من می خواهم این را تعریف کنم، ما مجموعه ای
از قوانین داشتیم که در این بین قرار می گیرند
151
00:11:04,569 –> 00:11:08,519
در اینجا، و سپس ما مقداری خروجی داشتیم. و چه اتفاقی می
افتد این است که ما این ورودی را به این تغذیه کنیم
152
00:11:08,519 –> 00:11:14,019
مجموعه ای از قوانین، چیزی در اینجا اتفاق می افتد، و سپس
ما مقداری خروجی دریافت می کنیم. و سپس آن است
153
00:11:14,019 –> 00:11:17,579
آنچه می دانید، برنامه ما انجام می دهد، این چیزی است
که ما از مدل دریافت می کنیم، ما تقریباً فقط
154
00:11:17,579 –> 00:11:22,389
دارای دو لایه، یک نوع لایه ورودی،
لایه خروجی، و قوانین هستند
155
00:11:22,389 –> 00:11:27,129
چیزی که این دو لایه را به هم متصل می کند.
در حال حاضر در شبکه های عصبی، و چه
156
00:11:27,129 –> 00:11:31,560
ما یادگیری عمیق می نامیم، ما بیش از دو لایه داریم. در
حال حاضر، من فقط سعی می کنم همه چیز را پاک کنم
157
00:11:31,560 –> 00:11:36,019
این به سرعت بنابراین من می توانم آن را به شما نشان دهم. پس بیایید
بگوییم و همه روزنامه نگاران رنگ دیگری می خواهند،
158
00:11:36,019 –> 00:11:40,800
چرا که نه اگر ما در مورد شبکه های عصبی صحبت می کنیم،
آنچه ممکن است داشته باشیم، و این خواهد شد
159
00:11:40,800 –> 00:11:44,779
متفاوت است، و من در یک ثانیه در مورد این صحبت خواهم
کرد این واقعیت است که ما یک لایه ورودی داریم که
160
00:11:44,779 –> 00:11:49,620
اولین لایه داده ما خواهد بود، ما می توانیم
چند لایه در بین این لایه داشته باشیم
161
00:11:49,620 –> 00:11:54,990
همه به هم متصل هستند و سپس می توانیم مقداری لایه
خروجی داشته باشیم. بنابراین اساسا، چه
162
00:11:54,990 –> 00:12:00,980
اتفاق می افتد این است که داده های ما از طریق لایه
های مختلف و چیزهای مختلف تبدیل می شوند
163
00:12:00,980 –> 00:12:05,379
قرار است اتفاق بیفتد، ارتباطات مختلفی بین
این لایه ها وجود خواهد داشت. و سپس
164
00:12:05,379 –> 00:12:09,360
در نهایت به یک خروجی خواهیم رسید. اکنون توضیح
شبکه های عصبی بسیار دشوار است
165
00:12:09,360 –> 00:12:14,740
بدون اینکه به طور کامل عمیق شود. بنابراین ما چند
یادداشت دیگر را که در اینجا دارم پوشش خواهیم داد. اساسا،
166
00:12:14,740 –> 00:12:18,450
در شبکه های عصبی، ما فقط چندین لایه داریم،
این راهی است که باید به آن فکر کرد
167
00:12:18,450 –> 00:12:22,910
آنها و همانطور که ما یادگیری ماشین را می بینیم،
شما بچه ها باید این را بیشتر درک کنید.
168
00:12:22,910 –> 00:12:26,480
اما فقط درک کنید که ما با چندین لایه سروکار
داریم. و بسیاری از مردم در واقع
169
00:12:26,480 –> 00:12:31,850
این را فرآیند استخراج اطلاعات چند مرحله ای
می نامید. حالا من به این فکر نکردم
170
00:12:31,850 –> 00:12:35,889
مدت، اصطلاح. من فکر می کنم از یک کتاب یا چیزی است. اما
اساساً آنچه در نهایت اتفاق می افتد این است
171
00:12:35,889 –> 00:12:39,500
ما داده های خود را در این لایه اول داریم،
که همان اطلاعات ورودی است که می رویم
172
00:12:39,500 –> 00:12:43,709
برای انتقال به مدلی که قرار است کاری با
آن انجام دهیم، سپس به مدل دیگری می رود
173
00:12:43,709 –> 00:12:48,990
لایه، جایی که تبدیل خواهد شد، با استفاده از یک لایه
از پیش تعریف شده، به چیز دیگری تغییر خواهد کرد
174
00:12:48,990 –> 00:12:54,319
مجموعهای از قوانین و وزنها که بعداً در مورد
آن صحبت خواهیم کرد، سپس از آن عبور خواهد کرد
175
00:12:54,319 –> 00:12:58,360
همه این لایههای مختلف ویژگیهای متفاوتی
از دادهها بودند که باز هم،
176
00:12:58,360 –> 00:13:03,630
ما در یک ثانیه بحث خواهیم کرد استخراج
خواهد شد مشخص خواهد شد تا در نهایت
177
00:13:03,630 –> 00:13:07,649
ما به یک لایه خروجی می رسیم که در آن می توانیم هر
چیزی را که در مورد آن کشف کرده ایم ترکیب کنیم
178
00:13:07,649 –> 00:13:12,629
داده ها را به نوعی خروجی تبدیل می کند که برای برنامه ما
معنادار است. بنابراین این یک نوع بهترین است
179
00:13:12,629 –> 00:13:16,800
کاری که میتوانم برای توضیح شبکههای عصبی بدون رفتن
به سطح عمیقتر انجام دهم، این را میدانم
180
00:13:16,800 –> 00:13:20,639
احتمالاً بسیاری از شما در حال حاضر نمیدانید
که آنها چه هستند. و این کاملاً خوب است.
181
00:13:20,639 –> 00:13:26,459
اما فقط بدانید که نمایش لایه ای از داده ها وجود
دارد، ما چندین لایه اطلاعات داریم.
182
00:13:26,459 –> 00:13:30,980
در حالی که در یادگیری ماشینی استاندارد، ما
فقط یک یا دو لایه و سپس شما را می شناسیم
183
00:13:30,980 –> 00:13:35,490
هوش مصنوعی به طور کلی، ما لزوما نباید مانند
یک از پیش تعریف شده داشته باشیم
184
00:13:35,490 –> 00:13:36,959
مجموعه ای از لایه ها
185
00:13:36,959 –> 00:13:38,399
باشه پس
186
00:13:38,399 –> 00:13:42,529
تقریباً برای شبکه های عصبی است، آخرین چیزی
که در مورد آنها خواهم گفت این است
187
00:13:42,529 –> 00:13:46,749
آنها در واقع از مغز الگوبرداری نشده اند. بنابراین
به نظر می رسد بسیاری از مردم چنین فکر می کنند
188
00:13:46,749 –> 00:13:50,889
شبکهها بر اساس مغز و این واقعیت که نورونهایی
در بدن شما شلیک میکنند، مدلسازی میشوند
189
00:13:50,889 –> 00:13:55,610
مغز و این می تواند به شبکه های عصبی مربوط شود. در حال
حاضر، یک الهام بیولوژیکی برای وجود دارد
190
00:13:55,610 –> 00:14:00,660
شبکه های عصبی را به روشی که از زیست شناسی انسان
کار می کنند نام ببرید، اما همینطور است
191
00:14:00,660 –> 00:14:04,329
لزوماً در مورد نحوه عملکرد مغز ما مدل
سازی نشده است. و در واقع، ما در واقع
192
00:14:04,329 –> 00:14:08,371
واقعاً نمیدانم بسیاری از چیزهای مغز ما چگونه
عمل میکنند و چگونه کار میکنند. پس می شود
193
00:14:08,371 –> 00:14:12,600
برای ما غیرممکن است که بگوییم شبکه های عصبی
بر اساس مغز مدل شده اند، زیرا ما در واقع
194
00:14:12,600 –> 00:14:17,660
نمی دانم اطلاعات چگونه اتفاق می افتد و رخ
می دهد و از طریق مغز ما منتقل می شود.
195
00:14:17,660 –> 00:14:22,209
یا حداقل ما به اندازه کافی نمی دانیم که بتوانیم
بگوییم این دقیقا همان چیزی است که یک عصبی است
196
00:14:22,209 –> 00:14:25,550
شبکه. بنابراین به هر حال، این آخرین نکته
در آنجا بود. خوب، حالا ما نیاز داریم
197
00:14:25,550 –> 00:14:31,329
در مورد داده ها صحبت کنید اکنون داده ها مهمترین
بخش یادگیری ماشین و هوش مصنوعی است.
198
00:14:31,329 –> 00:14:36,939
شبکه های عصبی نیز و بسیار مهم است که
بفهمیم داده ها چقدر مهم هستند و
199
00:14:36,939 –> 00:14:40,149
انواع مختلف قطعات آن چیست، زیرا قرار
است به آنها ارجاع زیادی شود
200
00:14:40,149 –> 00:14:44,529
در هر یک از منابعی که ما استفاده می کنیم. اکنون کاری
که من می خواهم انجام دهم این است که فقط یک مثال ایجاد کنم
201
00:14:44,529 –> 00:14:49,699
در اینجا، من قصد دارم یک مجموعه داده درست کنم که در
مورد نمرات نهایی دانش آموزان مانند یک مدرسه باشد
202
00:14:49,699 –> 00:14:53,689
سیستم. بنابراین اساسا، ما این را به یک مثال بسیار آسان
تبدیل خواهیم کرد. ما تمام چیزی هستیم که می خواهیم
203
00:14:53,689 –> 00:14:57,329
دارای برای این مجموعه داده است که ما اطلاعاتی در مورد
دانش آموزان خواهیم داشت. بنابراین ما می خواهیم
204
00:14:57,329 –> 00:15:01,920
نمره میان ترم خود را یک، میان ترم به نمره،
و سپس ما آنها را خواهیم داشت
205
00:15:01,920 –> 00:15:08,811
نمرهی نهایی. بنابراین من فقط می خواهم بگویم میان
ترم، یک. و باز هم دست خط من را در اینجا ببخشید
206
00:15:08,811 –> 00:15:14,079
نوشتن با این تبلت طراحی ساده ترین کار نیست.
و بعد من فقط فینال را انجام می دهم.
207
00:15:14,079 –> 00:15:18,019
بنابراین این مجموعه داده ما خواهد بود. و ما در واقع
تعدادی مجموعه داده مشابه با این را خواهیم دید
208
00:15:18,019 –> 00:15:22,959
همانطور که در ادامه می گذریم و نمونه هایی را انجام می
دهیم. بنابراین برای دانش آموز، که ما فقط قرار می دهیم
209
00:15:22,959 –> 00:15:27,639
برخی از دانشآموزان اینجا، ما میخواهیم نمره میان
ترم آنها را بگیریم، شاید این نمره 70 باشد.
210
00:15:27,639 –> 00:15:32,129
میان ترم تا نمره، شاید 80 بود. و بعد فرض
کنید فینال آنها مانند آنها بود
211
00:15:32,129 –> 00:15:37,839
نمره ترم آخر، نه فقط نمره امتحان نهایی،
بیایید به آنها نمره 77 بدهیم
212
00:15:37,839 –> 00:15:41,999
میان ترم می توان به کسی 60 داد، شاید ما به
او 90 بدهیم، و سپس آن را تعیین می کنیم
213
00:15:41,999 –> 00:15:47,720
نمره نهایی در امتحان آنها، فرض کنید، 84 بود.
و سپس ما می توانیم با شاید کاری انجام دهیم
214
00:15:47,720 –> 00:15:55,670
در اینجا یک نمره پایین تر، بنابراین 4050، و سپس
شاید آنها 38، یا چیزی در نمره نهایی گرفته اند.
215
00:15:55,670 –> 00:15:59,259
اکنون، بدیهی است که ما میتوانیم اطلاعات دیگری را در اینجا
داشته باشیم که شاید در آنجا اعتراف میکنیم
216
00:15:59,259 –> 00:16:02,879
برخی از امتحانات، برخی تکالیف، هر
کار دیگری که انجام دادند کمک کرد
217
00:16:02,879 –> 00:16:07,470
به درجه آنها اما مشکلی که من می خواهم در اینجا
در نظر بگیرم این واقعیت است که با توجه به ما
218
00:16:07,470 –> 00:16:12,009
میان ترم، یک نمره و میان ترم به نمره و نمره نهایی
ما، چگونه می توانم از این اطلاعات استفاده کنم
219
00:16:12,009 –> 00:16:17,439
برای پیش بینی هر یک از این سه ستون. پس اگر
میان ترم دانشجویی به من داده شود، یک
220
00:16:17,439 –> 00:16:21,790
نمره، و نمره نهایی یک دانش آموز به من داده شد،
چگونه می توانم میان ترم آنها را پیش بینی کنم
221
00:16:21,790 –> 00:16:28,129
مقطع تحصیلی. بنابراین اینجا جایی است که ما در مورد ویژگی
ها و برچسب ها صحبت خواهیم کرد. حالا هر اطلاعاتی که باشه
222
00:16:28,129 –> 00:16:32,379
ما داریم که اطلاعات ورودی است، که اطلاعاتی
است که ما همیشه آن را خواهیم داشت
223
00:16:32,379 –> 00:16:37,360
ما باید به مدل بدهیم تا مقداری خروجی بگیریم چیزی که
ما آن را ویژگی های خود می نامیم. بنابراین در مثال
224
00:16:37,360 –> 00:16:41,279
جایی که ما سعی می کنیم میان ترم دو را پیش بینی کنیم، و
بیایید این کار را انجام دهیم و این را برجسته کنیم
225
00:16:41,279 –> 00:16:46,740
به رنگ قرمز، بنابراین ما متوجه می شویم که چه
ویژگی هایی داریم، اطلاعات ورودی ما چیست
226
00:16:46,740 –> 00:16:51,879
میان ترم خواهد بود و در نهایت، زیرا این اطلاعاتی
است که ما از آن استفاده خواهیم کرد
227
00:16:51,879 –> 00:16:56,480
برای پیشبینی چیزی، ورودی است، آن چیزی است
که باید مدل را ارائه کنیم. و اگر ما هستیم
228
00:16:56,480 –> 00:17:00,389
آموزش یک مدل برای نگاه کردن به نمره میان ترم
یک و آخر، هر زمان که بخواهیم جدید بسازیم
229
00:17:00,389 –> 00:17:04,849
پیش بینی، برای انجام این کار باید آن اطلاعات را داشته
باشیم. اکنون، آنچه با رنگ قرمز مشخص شده است،
230
00:17:04,849 –> 00:17:11,078
بنابراین این میان ترم دو در اینجا چیزی است که
ما آن را برچسب یا خروجی می نامیم. حالا، برچسب
231
00:17:11,079 –> 00:17:16,200
چیزی است که ما سعی می کنیم به دنبال آن باشیم یا پیش بینی
کنیم. بنابراین وقتی در مورد ویژگی ها در مقابل صحبت می کنیم
232
00:17:16,200 –> 00:17:20,030
برچسبها، ویژگیها اطلاعات ورودی ما هستند،
اطلاعاتی که ما به آن نیاز داریم
233
00:17:20,030 –> 00:17:25,010
برای پیش بینی استفاده کنید. و برچسب
ما آن اطلاعات خروجی است که فقط نشان می دهد
234
00:17:25,010 –> 00:17:30,050
شما می دانید ما به دنبال چه هستیم بنابراین وقتی ویژگی
های خود را به یک مدل تغذیه می کنیم، او خواهد داد
235
00:17:30,050 –> 00:17:34,000
برای ما یک برچسب و این نکته ای است که
ما باید آن را درک کنیم. پس این بود
236
00:17:34,000 –> 00:17:38,270
اساسی در اینجا و اکنون من فقط می خواهم کمی بیشتر در
مورد داده ها صحبت کنم، زیرا ما این کار را خواهیم کرد
237
00:17:38,270 –> 00:17:41,920
با ادامه کار و اهمیت آن بیشتر به این
موضوع بپردازید.
238
00:17:41,920 –> 00:17:42,920
پس دلیل آن
239
00:17:42,920 –> 00:17:48,550
داده ها بسیار مهم هستند، این چیزی است که ما برای
ایجاد مدل ها از آن استفاده می کنیم. بنابراین
240
00:17:48,550 –> 00:17:52,970
هر زمان که در حال انجام هوش مصنوعی و یادگیری ماشینی هستیم، تقریباً
به داده نیاز داریم، مگر اینکه شما این کار را انجام دهید
241
00:17:52,970 –> 00:17:56,680
یک نوع بسیار خاص از یادگیری ماشینی و هوش مصنوعی،
که ما در مورد آن صحبت خواهیم کرد
242
00:17:56,680 –> 00:18:00,880
در مورد بعد اکنون برای اکثر این مدل ها،
ما به هزاران داده مختلف نیاز داریم
243
00:18:00,880 –> 00:18:04,760
از نمونه های مختلف و این به این دلیل است که ما می
دانیم یادگیری ماشین در حال حاضر چگونه کار می کند
244
00:18:04,760 –> 00:18:10,400
اساساً، ما سعی میکنیم قوانینی را برای یک مجموعه
داده ارائه کنیم، ما مقداری اطلاعات ورودی داریم،
245
00:18:10,400 –> 00:18:14,920
ما برخی از اطلاعات خروجی یا برخی ویژگی ها و برخی برچسب
ها را داریم، می توانیم آن را به یک مدل بدهیم
246
00:18:14,920 –> 00:18:19,470
و به آن بگویید که آموزش را شروع کند. و کاری که انجام
خواهد داد این است که قوانینی را ارائه کند که ما
247
00:18:19,470 –> 00:18:22,980
فقط می تواند برخی از ویژگی ها را در آینده
به مدل بدهد. و سپس باید بتواند
248
00:18:22,980 –> 00:18:28,360
یک تخمین خوب از اینکه خروجی باید چقدر باشد به
ما بدهید. بنابراین وقتی در حال تمرین هستیم،
249
00:18:28,360 –> 00:18:33,700
ما مجموعه ای از داده های آموزشی داریم. و این
داده هایی است که در آن ما همه ویژگی ها و
250
00:18:33,700 –> 00:18:37,970
همه برچسب ها بنابراین ما همه این اطلاعات را
داریم، پس زمانی که می خواهیم آزمایش کنیم
251
00:18:37,970 –> 00:18:42,760
مدل یا بعداً از مدل استفاده کنید، ما
این اطلاعات میان ترم را نداریم
252
00:18:42,760 –> 00:18:46,820
این را در مدل پاس نمیکنیم، ما فقط ویژگیهایمان
را پاس میکنیم، که میانترم است
253
00:18:46,820 –> 00:18:51,420
و نهایی و سپس خروجی میان ترم دو را می گیریم.
بنابراین امیدوارم که منطقی باشد.
254
00:18:51,420 –> 00:18:56,060
این فقط به این معنی است که داده ها بسیار مهم هستند.
اگر داده ها یا داده های نادرستی را تغذیه می کنیم
255
00:18:56,060 –> 00:19:00,280
ما نباید از مدلی استفاده کنیم که قطعاً می
تواند منجر به اشتباهات زیادی شود. و
256
00:19:00,280 –> 00:19:04,100
اگر اطلاعات خروجی نادرست یا اطلاعات
ورودی نادرست داریم
257
00:19:04,100 –> 00:19:07,730
همچنین باعث اشتباهات زیادی شود، زیرا اساساً این
همان چیزی است که مدل از آن استفاده می کند
258
00:19:07,730 –> 00:19:12,690
یاد بگیرند و به نوعی توسعه دهند و بفهمند که
قرار است با اطلاعات ورودی جدید چه کاری انجام دهد.
259
00:19:12,690 –> 00:19:16,650
بنابراین به هر حال، این اطلاعات کافی است. حالا بیایید
در مورد انواع مختلف ماشین صحبت کنیم
260
00:19:16,650 –> 00:19:20,830
یادگیری. خوب، حالا که تفاوت بین هوش
مصنوعی را مورد بحث قرار دادیم،
261
00:19:20,830 –> 00:19:25,050
یادگیری ماشین و شبکه های عصبی، ما نوعی ایده مناسب
در مورد اینکه داده ها در آن قرار دارند، داریم
262
00:19:25,050 –> 00:19:29,470
تفاوت بین ویژگی ها و برچسب ها وقت آن است
که در مورد انواع مختلف صحبت کنیم
263
00:19:29,470 –> 00:19:35,000
یادگیری ماشین به طور خاص، که یادگیری
بدون نظارت، یادگیری نظارت شده است
264
00:19:35,000 –> 00:19:39,270
و یادگیری تقویتی اکنون، اینها
فقط انواع مختلف یادگیری هستند
265
00:19:39,270 –> 00:19:43,910
انواع فهمیدن چیزها اکنون، انواع مختلف الگوریتمها
در این الگوریتمهای متفاوت قرار میگیرند
266
00:19:43,910 –> 00:19:48,230
مقولههایی از درون هوش مصنوعی در
یادگیری ماشینی و درون عصبی
267
00:19:48,230 –> 00:19:52,050
شبکه های. بنابراین اولین موردی که قرار است
در مورد آن صحبت کنیم، یادگیری تحت نظارت است
268
00:19:52,050 –> 00:19:57,610
چیزی که قبلاً بحث کردیم. بنابراین من فقط
با نظارت اینجا می نویسم. باز هم بهانه
269
00:19:57,610 –> 00:20:02,130
دست خط بنابراین تحت نظارت یادگیری. حالا
این چیه؟
270
00:20:02,130 –> 00:20:03,130
خوب، تحت نظارت
271
00:20:03,130 –> 00:20:07,680
یادگیری نوعی از همه چیزهایی است که قبلاً آموخته ایم،
که این است که ما برخی ویژگی ها را داریم. بنابراین
272
00:20:07,680 –> 00:20:12,170
ما ویژگی های خود را اینگونه می نویسیم، درست است،
ما برخی از ویژگی ها را داریم. و آن ویژگی ها
273
00:20:12,170 –> 00:20:18,340
با برخی از برچسب ها یا برچسب های بالقوه مطابقت دارد،
گاهی اوقات ممکن است بیش از یک اطلاعات را پیش بینی کنیم.
274
00:20:18,340 –> 00:20:22,340
بنابراین وقتی این اطلاعات را داریم، ویژگیها
را داریم، و برچسبهایی را داریم که چه
275
00:20:22,340 –> 00:20:26,570
ما انجام می دهیم این است که این اطلاعات را به برخی از مدل
های یادگیری ماشینی منتقل می کنیم، آن را تشخیص می دهد
276
00:20:26,570 –> 00:20:30,630
قوانین برای ما و بعداً، تنها چیزی که نیاز داریم
ویژگیهاست. و مقداری به ما خواهد داد
277
00:20:30,630 –> 00:20:35,040
برچسب هایی که از آن قوانین استفاده می کنند. اما اساساً
آنچه یادگیری تحت نظارت است، زمانی است که داریم
278
00:20:35,040 –> 00:20:39,540
هر دوی این اطلاعات، دلیلی که تحت نظارت نامیده
می شود این است که چه چیزی به پایان می رسد
279
00:20:39,540 –> 00:20:44,840
زمانی که مدل یادگیری ماشین خود را آموزش میدهیم
این است که اطلاعات ورودی را ارسال میکنیم
280
00:20:44,840 –> 00:20:49,320
با استفاده از قوانینی که از قبل می داند، برخی پیش
بینی های دلخواه انجام می دهد. و سپس مقایسه می کند
281
00:20:49,320 –> 00:20:54,540
پیشبینیای که انجام داد تا پیشبینی واقعی
چیست، که این برچسب است. پس ما
282
00:20:54,540 –> 00:20:59,500
بر مدل نظارت کنید و ما می گوییم، خوب، پس شما
پیش بینی کردید که رنگ قرمز است، اما واقعا،
283
00:20:59,500 –> 00:21:03,180
رنگ هر چیزی که می گذشتیم باید آبی می بود.
بنابراین ما فقط باید شما را اصلاح کنیم
284
00:21:03,180 –> 00:21:07,110
کمی تا کمی بهتر شوید و
در مسیر درست حرکت کنید.
285
00:21:07,110 –> 00:21:10,920
و این به نوعی کار می کند. به عنوان مثال، بگویید
ما در حال پیش بینی هستیم، می دانید،
286
00:21:10,920 –> 00:21:15,670
نمره نهایی دانش آموز، خوب، اگر پیش بینی
کنیم که نمره نهایی 76 باشد، اما واقعی
287
00:21:15,670 –> 00:21:20,940
بهترین 77، ما خیلی نزدیک بودیم، اما کاملاً آنجا
نیستیم. بنابراین ما بر مدل نظارت می کنیم
288
00:21:20,940 –> 00:21:24,990
و ما می گوییم، هی، ما شما را کمی تغییر می
دهیم، شما را در مسیر درست حرکت می دهیم.
289
00:21:24,990 –> 00:21:29,830
و امیدواریم شما را به 77 برسانیم. و این راهی
برای توضیح این موضوع است، درست است، شما
290
00:21:29,830 –> 00:21:33,770
ویژگی ها را دارند بنابراین شما برچسبها را دارید،
وقتی ویژگیها را پاس میکنید، مدل دارای آن است
291
00:21:33,770 –> 00:21:38,050
برخی از قوانین، و از قبل ساخته شده است، پیش
بینی می کند. و سپس آن پیش بینی را مقایسه می کند
292
00:21:38,050 –> 00:21:43,500
به برچسب، و سپس دوباره مدل را تغییر دهید
و این کار را با 1000s روی 1000s ادامه دهید
293
00:21:43,500 –> 00:21:48,500
بر روی 1000 قطعه داده تا زمانی که در نهایت آنقدر
خوب شود که بتوانیم آموزش را متوقف کنیم.
294
00:21:48,500 –> 00:21:52,990
و این همان چیزی است که یادگیری تحت نظارت است، این
رایج ترین نوع یادگیری است، قطعاً همینطور است
295
00:21:52,990 –> 00:21:57,630
بیشترین کاربرد در بسیاری از موارد. و اکثر
الگوریتم های یادگیری ماشین که
296
00:21:57,630 –> 00:22:02,130
در واقع از نوعی یادگیری ماشینی نظارت شده استفاده
می شود. بسیاری از مردم به نظر می رسد
297
00:22:02,130 –> 00:22:06,590
فکر کنید که این یک روش کمتر پیچیده و کمتر پیشرفته
برای انجام کارها است. به این معنا که
298
00:22:06,590 –> 00:22:09,860
قطعا درست نیست همه روشهای مختلف، میخواهم
به شما بگویم که متفاوت هستند
299
00:22:09,860 –> 00:22:14,930
مزایا و معایب. و این مزیت بزرگی دارد که
شما تعداد زیادی از آن را داشته باشید
300
00:22:14,930 –> 00:22:19,440
اطلاعات و شما خروجی آن اطلاعات را نیز دارید.
اما گاهی اوقات ما این کار را نمی کنیم
301
00:22:19,440 –> 00:22:23,270
لوکس این کار را داشته باشید و اینجاست که ما
در مورد یادگیری بدون نظارت صحبت می کنیم.
302
00:22:23,270 –> 00:22:27,870
بنابراین امیدوارم که برای یادگیری نظارت شده منطقی
باشد، تمام تلاشم را کردم تا آن را توضیح دهم. و
303
00:22:27,870 –> 00:22:33,380
اکنون برای یادگیری نظارت شده وارد یا متأسفیم.
حالا بیایید به یادگیری بدون نظارت برویم.
304
00:22:33,380 –> 00:22:37,690
بنابراین اگر تعریف یادگیری تحت نظارت
را بدانیم، امیدواریم بتوانیم بیایم
305
00:22:37,690 –> 00:22:43,710
با تعریفی از یادگیری بدون نظارت، یعنی زمانی که ما
فقط ویژگی ها را داریم. بنابراین داده شده است
306
00:22:43,710 –> 00:22:50,170
مجموعه ای از ویژگی های مانند این، و مطلقا بدون
برچسب، هیچ خروجی برای این ویژگی ها. چی
307
00:22:50,170 –> 00:22:55,290
ما می خواهیم انجام دهیم این است که مدلی با آن برچسب ها
برای ما ارائه دهد. در حال حاضر، این یک نوع است
308
00:22:55,290 –> 00:22:59,350
عجیب و غریب. شما یک جورهایی شبیه ویت هستید، چطور کار
می کند؟ اصلاً چرا می خواهیم این کار را انجام دهیم؟
309
00:22:59,350 –> 00:23:05,231
خوب، بیایید این را به عنوان مثال در نظر بگیریم. ما برخی
از محورها و محورهای داده داریم، بسیار خوب. و ما
310
00:23:05,231 –> 00:23:09,870
مانند یک نقطه داده دو بعدی است. بنابراین من
فقط می خواهم این را صدا کنم، فرض کنید x، و
311
00:23:09,870 –> 00:23:14,390
بیایید بگوییم y، بسیار خوب، و من فقط می خواهم
یک دسته از نقطه ها را روی صفحه نمایش بگذارم.
312
00:23:14,390 –> 00:23:18,700
شاید یک نمودار پراکنده از برخی از داده های
مختلف ما را نشان دهد. و من فقط می روم
313
00:23:18,700 –> 00:23:21,760
برای قرار دادن برخی نقاط به طور خاص به نقاط دیگر،
314
00:23:21,760 –> 00:23:25,760
فقط به این دلیل که شما بچه ها به نوعی هدف کاری که ما در اینجا
می خواهیم انجام دهیم را متوجه شوید. پس بیایید انجام دهیم
315
00:23:25,760 –> 00:23:30,810
که خوب، پس فرض کنید من این مجموعه داده را دارم،
این چیزی است که ما با آن کار می کنیم.
316
00:23:30,810 –> 00:23:36,190
و ما این ویژگی ها را داریم، ویژگی های
این نمونه، x و y خواهند بود، درست است؟
317
00:23:36,190 –> 00:23:41,490
بنابراین X و Y ویژگی های من هستند. اکنون ما
هیچ خروجی خاصی برای این داده ها نداریم
318
00:23:41,490 –> 00:23:46,630
نکته، آنچه ما در واقع می خواهیم انجام دهیم این
است که می خواهیم نوعی مدل ایجاد کنیم که بتواند
319
00:23:46,630 –> 00:23:52,140
این نقاط داده را خوشه بندی کنید، به این معنی که
گروه های منحصر به فردی از داده ها را دریابید
320
00:23:52,140 –> 00:23:55,860
و بگویید، خوب، پس شما در گروه یک، در گروه
دو هستید، در گروه سه هستید، و شما
321
00:23:55,860 –> 00:24:01,020
در گروه چهار، ممکن است لزوماً ندانیم
چند گروه داریم، هرچند گاهی اوقات
322
00:24:01,020 –> 00:24:05,610
ما انجام می دهیم. اما کاری که ما می خواهیم انجام دهیم این است که فقط
آنها را گروه بندی کنیم و به نوعی بگوییم، خوب، می خواهیم بفهمیم
323
00:24:05,610 –> 00:24:09,900
مشخص کنید که کدام یک شبیه هستند و ما می خواهیم
آنها را با هم ترکیب کنیم. پس امیدوارم، چه
324
00:24:09,900 –> 00:24:14,280
ما میتوانیم با یک مدل یادگیری ماشینی بدون نظارت انجام
دهیم، همه این ویژگیها را پاس کنیم و سپس
325
00:24:14,280 –> 00:24:19,630
مدلی از این گروه بندی ها را ایجاد کند. پس مثل
اینکه شاید این یک گروه باشد، شاید این
326
00:24:19,630 –> 00:24:24,020
یک گروه است، شاید اگر ما چهار گروه داشتیم
این یک گروه باشد و شاید اگر داشتیم
327
00:24:24,020 –> 00:24:28,550
دو گروه بندی، ممکن است گروه بندی هایی دریافت کنیم
که چیزی شبیه به این هستند، درست است. و سپس
328
00:24:28,550 –> 00:24:33,320
هنگامی که ما یک نقطه داده جدید را به آن منتقل می
کنیم، می توانیم بفهمیم که کدام گروه یک است
329
00:24:33,320 –> 00:24:38,550
بخشی از با تعیین، می دانید که به کدام یک
نزدیکتر است. حالا این یک نوع خشن است
330
00:24:38,550 –> 00:24:42,270
مثال. باز هم توضیح دادن همه اینها بدون
پرداختن به عمق زیاد دشوار است
331
00:24:42,270 –> 00:24:46,810
الگوریتم های خاص اما یادگیری ماشینی بدون نظارت
یا به طور کلی فقط یادگیری زمانی است
332
00:24:46,810 –> 00:24:51,500
اطلاعات خروجی ندارید شما در واقع
می خواهید مدل آن را بفهمد
333
00:24:51,500 –> 00:24:55,430
خروجی برای شما و واقعاً برایتان مهم نیست که چگونه
به آنجا می رسد. شما فقط می خواهید آن را دریافت کنید
334
00:24:55,430 –> 00:25:00,010
آنجا. و دوباره، یک مثال خوب، خوشه بندی نقاط داده
است، و ما در مورد برخی موارد خاص صحبت خواهیم کرد
335
00:25:00,010 –> 00:25:04,410
کاربردهایی که ممکن است بعداً بخواهیم از آن
استفاده کنیم، فقط متوجه شوید که دارید
336
00:25:04,410 –> 00:25:09,040
ویژگیها، برچسبها را ندارید و مدل بدون
نظارت را به نوعی دریافت میکنید
337
00:25:09,040 –> 00:25:10,690
آن را برای شما رقم بزنید باشه پس
338
00:25:10,690 –> 00:25:14,650
اکنون آخرین نوع ما که با دو نوع که توضیح
دادم بسیار متفاوت است، نامیده می شود
339
00:25:14,650 –> 00:25:19,160
یادگیری تقویتی الان شخصاً یادگیری را تقویت می
کنم و حتی نمی دانم که بخواهم یا نه
340
00:25:19,160 –> 00:25:25,430
این را املا کنم زیرا احساس می کنم دارم
آن را خراب می کنم. یادگیری تقویتی است
341
00:25:25,430 –> 00:25:30,030
جالب ترین نوع یادگیری ماشینی به نظر من. و این زمانی
است که شما در واقع هیچ کدام را ندارید
342
00:25:30,030 –> 00:25:35,580
داده ها، شما چیزی را دارید که به آن یک عامل می
گویید، و محیط و یک پاداش. من می خواهم توضیح دهم
343
00:25:35,580 –> 00:25:40,471
این به طور خلاصه با یک مثال بسیار بسیار بسیار
ساده، زیرا بدست آوردن آن نیز سخت است
344
00:25:40,471 –> 00:25:44,880
دور پس فرض کنید ما یک بازی بسیار ابتدایی داریم،
می دانید، شاید این بازی را خودمان ساخته ایم.
345
00:25:44,880 –> 00:25:49,480
و اساساً هدف بازی رسیدن به
جریان است. باشه، همین
346
00:25:49,480 –> 00:25:54,430
است، ما مقداری زمین داریم، شما می توانید از چپ به
راست حرکت کنید، و ما می خواهیم به این پرچم برسیم.
347
00:25:54,430 –> 00:25:59,290
خوب، ما می خواهیم چند هوش مصنوعی، یک مدل یادگیری ماشینی
را آموزش دهیم که بتواند شکل بگیرد
348
00:25:59,290 –> 00:26:06,840
نحوه انجام این کار بنابراین کاری که ما انجام میدهیم این است
که این را عامل خود مینامیم، ما آن را کل مینامیم.
349
00:26:06,840 –> 00:26:12,370
بنابراین کل این موضوع اینجاست، محیط زیست. بنابراین حدس
میزنم میتوانم آن را اینجا بنویسم. بنابراین و
350
00:26:12,370 –> 00:26:18,050
منظور ما، فکر کنید من آن را درست نوشتم.
و سپس چیزی به نام پاداش داریم.
351
00:26:18,050 –> 00:26:22,920
و پاداش اساساً همان چیزی است که عامل وقتی کاری را
به درستی انجام می دهد، دریافت می کند. بنابراین
352
00:26:22,920 –> 00:26:27,000
فرض کنید نماینده یک گام در این راه برمی دارد. بنابراین
بیایید بگوییم که او یک موقعیت جدید است،
353
00:26:27,000 –> 00:26:31,210
من فقط می خواهم به کشیدن او ادامه دهم. بنابراین من فقط
از یک نقطه استفاده می کنم. خوب، او به آن نزدیکتر شد
354
00:26:31,210 –> 00:26:36,810
پرچم. بنابراین کاری که من در واقع انجام خواهم داد این است
که به او یک جایزه بعلاوه دو بدهم. پس بیایید بگوییم او
355
00:26:36,810 –> 00:26:42,940
دوباره حرکت میکند، به پرچم نزدیکتر میشود، شاید
الان به او بعلاوه یک بدهم، این بار، او حتی نزدیکتر شد.
356
00:26:42,940 –> 00:26:48,070
و هر چه نزدیکتر می شود، من به او پاداش بیشتری
می دهم. حالا اگر حرکت کند چه اتفاقی می افتد
357
00:26:48,070 –> 00:26:52,600
به عقب؟ پس بیایید این را پاک کنیم. و بیایید
بگوییم که در مقطعی از زمان، به جای
358
00:26:52,600 –> 00:26:58,940
با نزدیک شدن به پرچم، او به سمت عقب حرکت می
کند، خوب، ممکن است یک جایزه منفی دریافت کند.
359
00:26:58,940 –> 00:27:05,240
اکنون، اساساً هدف این عامل این است که
پاداش خود را به حداکثر برساند.
360
00:27:05,240 –> 00:27:09,860
بنابراین اگر برای حرکت رو به عقب به آن جایزه منفی
بدهید، به یاد میآورد که همینطور است
361
00:27:09,860 –> 00:27:14,750
می خواهم بگویم، خوب، در این موقعیت اینجا، جایی
که ایستاده بودم، وقتی به عقب حرکت کردم،
362
00:27:14,750 –> 00:27:19,720
جایزه منفی گرفتم بنابراین اگر به این موقعیت
برسم، باز هم نمیخواهم به عقب برگردم
363
00:27:19,720 –> 00:27:25,530
دیگر، من می خواهم به جلو بروم، زیرا این
باید یک پاداش مثبت به من بدهد. و
364
00:27:25,530 –> 00:27:31,100
نکته اصلی این است که ما این نماینده را داریم
که بدون هیچ ایده ای شروع می کند، نه
365
00:27:31,100 –> 00:27:36,360
می دانید، نوعی دانش از محیط زیست است. و کاری که انجام
می دهد این است که شروع به کاوش می کند، و
366
00:27:36,360 –> 00:27:40,880
این ترکیبی از کاوش تصادفی و کاوش با استفاده از
نوعی از چیزهایی است که به دست آمده است
367
00:27:40,880 –> 00:27:46,510
تا کنون، سعی کنید پاداش خود را به حداکثر برسانید.
بنابراین در نهایت، زمانی که عامل به
368
00:27:46,510 –> 00:27:51,970
پرچم، بیشترین پاداش ممکن را
خواهد داشت. و دفعه بعد
369
00:27:51,970 –> 00:27:57,190
اگر این عامل را به محیط وصل کنیم، میداند
چگونه فوراً به پرچم برسد،
370
00:27:57,190 –> 00:28:00,960
چون به نوعی متوجه شده است، مشخص شده
است که در تمام این موقعیت های مختلف،
371
00:28:00,960 –> 00:28:06,220
اگر من به اینجا نقل مکان کنم، اینجا بهترین مکان برای نقل
مکان است. بنابراین اگر در این موقعیت قرار گرفتم، به آنجا بروید.
372
00:28:06,220 –> 00:28:10,360
اکنون باز هم توضیح این موضوع بدون مثالهای
دقیقتر و ریاضیات بیشتر دشوار است
373
00:28:10,360 –> 00:28:14,850
و همه اینها، اما اساساً، فقط میدانیم که ما
عامل را داریم، که به نوعی همان چیزی است
374
00:28:14,850 –> 00:28:19,771
مسئله این است که در محیط ما در حال حرکت است، ما
این جادوگر محیط را داریم، که این است
375
00:28:19,771 –> 00:28:24,340
فقط چیزی که نماینده می تواند در آن جابجا شود.
و سپس ما یک جایزه داریم. و ثواب همین است
376
00:28:24,340 –> 00:28:28,690
ما باید به عنوان برنامه نویس راهی برای پاداش
صحیح به عامل پیدا کنیم تا بتوانیم
377
00:28:28,690 –> 00:28:35,150
به بهترین شکل ممکن به هدف می رسد. اما عامل
به سادگی آن پاداش را به حداکثر می رساند.
378
00:28:35,150 –> 00:28:38,810
بنابراین فقط متوجه می شود که برای به حداکثر رساندن آن
پاداش باید به کجا بروم، از همان زمان شروع می شود
379
00:28:38,810 –> 00:28:42,340
شروع، به نوعی به طور تصادفی محیط را کاوش
می کند، زیرا هیچ یک از آنها را نمی شناسد
380
00:28:42,340 –> 00:28:45,970
پاداش هایی که در هر یک از موقعیت ها دریافت می کند. و
سپس به عنوان آن را به بررسی برخی از متفاوت تر است
381
00:28:45,970 –> 00:28:50,660
به نوعی قوانین و روشی که محیط کار
می کند را مشخص می کند. و سپس
382
00:28:50,660 –> 00:28:55,170
ما تعیین خواهیم کرد که چگونه به هدف برسیم،
یعنی هر چیزی که باشد، این بسیار است
383
00:28:55,170 –> 00:28:58,740
به عنوان مثال ساده، می توانید یک مدل تقویت کننده برای
این کار آموزش دهید. و میدونی، مثل نصف
384
00:28:58,740 –> 00:29:03,460
یک ثانیه، درست است اما نمونه های بسیار پیشرفته
تری وجود دارد. و نمونه هایی از تقویت وجود دارد
385
00:29:03,460 –> 00:29:08,330
یادگیری، مانند هوش مصنوعی تقریباً فهمیدن
اینکه چگونه با هم بازی کنیم چگونه است
386
00:29:08,330 –> 00:29:11,740
در واقع برخی از کارهایی که یادگیری تقویتی
انجام می دهد بسیار جالب است. و
387
00:29:11,740 –> 00:29:15,210
این یک نوع پیشرفت واقعاً عالی در این زمینه
است زیرا به این معنی است که ما نیازی نداریم
388
00:29:15,210 –> 00:29:19,620
همه این داده ها دیگر ما فقط می توانیم این را به
نوعی بفهمیم که چگونه کارها را انجام دهیم
389
00:29:19,620 –> 00:29:23,950
ما و محیط را کاوش کرده و خود به خود یاد بگیرید.
حالا این می تواند خیلی طول بکشد،
390
00:29:23,950 –> 00:29:27,700
این می تواند مدت زمان بسیار کمی طول بکشد
که واقعاً به محیط بستگی دارد. اما واقعی
391
00:29:27,700 –> 00:29:31,690
استفاده از این آموزش هوش مصنوعی برای بازی کردن است،
همانطور که ممکن است بتوانید از نوع خود بگویید
392
00:29:31,690 –> 00:29:35,810
از چیزی که اینجا توضیح می دادم و بله،
پس این نوعی تفاوت اساسی است
393
00:29:35,810 –> 00:29:40,350
بین یادگیری تحت نظارت، بدون نظارت و تقویتی،
ما هر سه مورد را پوشش خواهیم داد
394
00:29:40,350 –> 00:29:44,550
این موضوعات در طول این دوره و دیدن
برخی از برنامه ها واقعا جالب است
395
00:29:44,550 –> 00:29:47,570
ما در واقع می توانیم با این کار انجام دهیم. بنابراین با
این گفته، من قصد دارم به نوعی به چه چیزی پایان دهم
396
00:29:47,570 –> 00:29:52,470
من ماژول یک را می نامم، که فقط یک
نمای کلی از موضوعات مختلف است،
397
00:29:52,470 –> 00:29:56,270
برخی از تعاریف و کسب دانش اساسی.
و در مورد بعدی، آنچه ما هستیم
398
00:29:56,270 –> 00:30:00,320
قرار است در مورد آن صحبت کنیم که TensorFlow
چیست، ما کمی بعد وارد کد خواهیم شد
399
00:30:00,320 –> 00:30:04,321
کمی، و ما قصد داریم در مورد برخی از جنبه های مختلف
TensorFlow و چیزهایی که نیاز داریم بحث کنیم
400
00:30:04,321 –> 00:30:10,000
بدانید که می توانید به جلو حرکت کنید و کارهای پیشرفته
تری انجام دهید.
401
00:30:10,000 –> 00:30:13,480
بنابراین اکنون در ماژول دو این دوره، کاری که
میخواهیم انجام دهیم، دریافت یک کلیات است
402
00:30:13,480 –> 00:30:18,230
مقدمه ای بر TensorFlow، درک اینکه
تانسور چیست درک اشکال و
403
00:30:18,230 –> 00:30:23,370
نمایش داده ها، و سپس نحوه عملکرد
TensorFlow در سطح کمی پایین تر،
404
00:30:23,370 –> 00:30:27,240
این بسیار مهم است، زیرا مطمئناً می توانید از طریق
یادگیری ماشینی یاد بگیرید و یاد بگیرید
405
00:30:27,240 –> 00:30:31,450
بدون به دست آوردن این اطلاعات و دانش.
اما این کار را بسیار دشوارتر می کند
406
00:30:31,450 –> 00:30:35,280
مدل های خود را تغییر دهید و واقعا بفهمید که چه اتفاقی
می افتد، اگر این کار را نکنید، می دانید، دارید
407
00:30:35,280 –> 00:30:39,900
دانش سطح پایین تر در مورد نحوه
عملکرد و عملکرد TensorFlow.
408
00:30:39,900 –> 00:30:43,590
بنابراین این دقیقاً همان چیزی است که ما در اینجا به آن می
پردازیم. حالا، برای کسانی از شما که نمیدانید چیست
409
00:30:43,590 –> 00:30:47,850
TensorFlow اساساً یک کتابخانه یادگیری
ماشین منبع باز است. این یکی است
410
00:30:47,850 –> 00:30:51,980
یکی از بزرگترین آنها در جهان، یکی از شناخته
شده ترین ها است و از آن نگهداری می شود
411
00:30:51,980 –> 00:30:57,690
و توسط گوگل پشتیبانی می شود. اکنون، TensorFlow، اساساً
به ما اجازه می دهد تا ماشین را انجام دهیم و ایجاد کنیم
412
00:30:57,690 –> 00:31:01,640
مدلهای یادگیری و شبکههای عصبی، و همه اینها
بدون نیاز به داشتن یک چیز بسیار پیچیده
413
00:31:01,640 –> 00:31:05,980
پس زمینه ریاضی اکنون، همانطور که بیشتر وارد میشویم،
شروع میکنیم به بحث مفصلتر در مورد چگونگی
414
00:31:05,980 –> 00:31:09,740
متوجه خواهید شد که شبکه های عصبی کار می کنند و
الگوریتم های یادگیری ماشین در واقع کار می کنند
415
00:31:09,740 –> 00:31:14,390
ریاضیات زیادی در این مورد وجود
دارد. اکنون، بسیار اساسی است،
416
00:31:14,390 –> 00:31:19,330
مانند حساب پایه و جبر خطی پایه. و سپس
در مسائل بسیار پیشرفته تر می شود
417
00:31:19,330 –> 00:31:24,440
مانند نزول گرادیان، و برخی تکنیک های
رگرسیون و طبقه بندی بیشتر. و در اصل،
418
00:31:24,440 –> 00:31:29,030
می دانید، بسیاری از ما نمی دانیم که واقعاً نیازی
به دانستن آن نداریم، تا زمانی که بدانیم
419
00:31:29,030 –> 00:31:33,710
یک درک اولیه از آن، سپس می توانیم از ابزارهایی
که TensorFlow برای ما فراهم می کند استفاده کنیم
420
00:31:33,710 –> 00:31:38,380
برای ایجاد مدل ها و این دقیقاً همان کاری است که تنسورفلو
انجام می دهد. در حال حاضر، آنچه در حال حاضر در آن هستم
421
00:31:38,380 –> 00:31:42,230
چیزی است که من آن را Google Collaboratory می نامم. من در
یک ثانیه در این مورد عمیق تر صحبت خواهم کرد.
422
00:31:42,230 –> 00:31:47,540
اما کاری که من برای کل این دوره انجام داده ام، این
است که همه چیز را با جزئیات کامل رونویسی کرده ام
423
00:31:47,540 –> 00:31:51,590
که من قصد دارم از طریق هر ماژول پوشش
دهم. بنابراین این یک نوع رونویسی است
424
00:31:51,590 –> 00:31:56,680
ماژول یک، که مقدمه ای برای TensorFlow است،
می توانید ببینید که طولانی نیست.
425
00:31:56,680 –> 00:32:01,040
اما من می خواستم این کار را انجام دهم تا هر کدام
از شما بتوانید با نوعی از پایه متن دنبال کنید
426
00:32:01,040 –> 00:32:04,660
و از نوع یادداشتهای سخنرانی من، تقریباً میخواهم
آنها را در حین گذراندن موارد مختلف صدا بزنم
427
00:32:04,660 –> 00:32:08,960
محتوا. بنابراین در توضیحات، پیوندهایی به
تمام این نوت بوک های مختلف وجود خواهد داشت.
428
00:32:08,960 –> 00:32:12,560
این در چیزی به نام Google Collaboratory است، که مجدداً
در یک ثانیه به آن خواهیم پرداخت.
429
00:32:12,560 –> 00:32:16,440
اما در اینجا می توانید ببینید که من یک دسته
از متن دارم، و سپس به مقداری متفاوت می رسد
430
00:32:16,440 –> 00:32:20,340
جنبه های کدگذاری و کاری که قرار است انجام دهم تا
مطمئن شوم در مسیر باقی میمانم، ساده است
431
00:32:20,340 –> 00:32:24,900
در ادامه این مطلب، ممکن است کمی منحرف شوم،
ممکن است به چند نمونه دیگر بپردازم.
432
00:32:24,900 –> 00:32:29,200
این همه چیزهایی است که من در هر
ماژول پوشش خواهم داد. پس دوباره،
433
00:32:29,200 –> 00:32:35,190
برای پیگیری، روی لینک در توضیحات کلیک کنید. خوب، پس
با TensorFlow چه کاری می توانیم انجام دهیم؟
434
00:32:35,190 –> 00:32:39,150
خوب، اینها برخی از چیزهای مختلفی هستند که من آنها
را در اینجا فهرست کرده ام. پس فراموش نمی کنم،
435
00:32:39,150 –> 00:32:44,500
می توانیم طبقه بندی تصویر، خوشه بندی داده ها، رگرسیون،
یادگیری تقویتی، طبیعی را انجام دهیم
436
00:32:44,500 –> 00:32:49,080
پردازش زبان و تقریباً هر چیزی که با یادگیری
ماشینی می توانید تصور کنید.
437
00:32:49,080 –> 00:32:54,000
اساساً کاری که TensorFlow انجام می دهد این است که کتابخانه
ای از ابزارها را به ما می دهد که به ما امکان حذف
438
00:32:54,000 –> 00:32:59,280
باید این عملیات ریاضی بسیار پیچیده را انجام دهد. فقط آنها را
برای ما انجام می دهد. در حال حاضر، وجود دارد
439
00:32:59,280 –> 00:33:04,280
کمی که ما باید در مورد آنها بدانیم، اما هیچ چیز خیلی پیچیده
نیست. حالا بیایید در مورد چگونگی TensorFlow صحبت کنیم
440
00:33:04,280 –> 00:33:10,080
در واقع کار می کند بنابراین TensorFlow دو مؤلفه
اصلی دارد که باید آنها را درک کنیم
441
00:33:10,080 –> 00:33:14,650
نحوه انجام عملیات و ریاضیات را دریابید.
اکنون چیزی به نام نمودار داریم
442
00:33:14,650 –> 00:33:21,720
و جلسات اکنون، روشی که جریان تانسور کار می کند،
این است که نموداری از محاسبات جزئی ایجاد می کند.
443
00:33:21,720 –> 00:33:25,240
حالا، من می دانم که این کمی پیچیده به نظر می
رسد، برخی از شما بچه ها فقط سعی کنید
444
00:33:25,240 –> 00:33:30,240
واژگان پیچیده را فراموش کنید و دنبال
کنید. اما اساسا، آنچه ما
445
00:33:30,240 –> 00:33:35,210
وقتی کدی را در TensorFlow می نویسیم، یک نمودار ایجاد
می کنیم. بنابراین اگر بخواهم برخی را ایجاد کنم
446
00:33:35,210 –> 00:33:40,360
متغیر، آن متغیر به نمودار اضافه می
شود و شاید آن متغیر مجموع باشد
447
00:33:40,360 –> 00:33:45,380
یا جمع دو متغیر دیگر. آنچه که نمودار اکنون تعریف
می کند این است که بگوید، می دانید،
448
00:33:45,380 –> 00:33:51,870
متغیر یک داریم که برابر با مجموع
متغیر دو و متغیر سه است. ولی
449
00:33:51,870 –> 00:33:57,059
چیزی که ما باید بدانیم این است که در واقع ارزیابی
نمی کند که به سادگی آن را بیان می کند
450
00:33:57,059 –> 00:34:02,180
این محاسباتی است که ما تعریف کرده ایم. بنابراین
تقریباً مانند نوشتن یک معادله است
451
00:34:02,180 –> 00:34:07,390
بدون انجام هیچ گونه ریاضی، ما به نوعی،
می دانید، آن معادله را در آنجا داریم.
452
00:34:07,390 –> 00:34:12,070
ما می دانیم که این ارزش است، اما آن را ارزیابی
نکرده ایم. بنابراین ما این ارزش را نمی دانیم
453
00:34:12,070 –> 00:34:17,500
مانند 7٪ است، ما فقط می دانیم که این مجموع،
می دانید، بردار یک و بردار دو است، یا
454
00:34:17,500 –> 00:34:22,139
این مجموع این است یا حاصل ضرب متقاطع یا حاصل ضرب
نقطه ای است، ما فقط همه را تعریف کردیم
455
00:34:22,139 –> 00:34:27,070
محاسبات جزئی مختلف، زیرا ما هنوز
آن محاسبات را ارزیابی نکرده ایم.
456
00:34:27,070 –> 00:34:31,960
و این همان چیزی است که در نمودار ذخیره می شود.
و دلیلی که به آن گراف می گویند این است که
457
00:34:31,960 –> 00:34:36,899
محاسبات مختلف را می توان به یکدیگر مرتبط
کرد. مثلاً اگر بخواهم بفهمم
458
00:34:36,899 –> 00:34:42,690
مقدار بردار یک، اما بردار یک برابر
با مقدار بردار سه به علاوه بردار است
459
00:34:42,690 –> 00:34:47,050
چهار، من باید مقدار بردار سه و بردار چهار
را تعیین کنم، زیرا قبل از اینکه بتوانم
460
00:34:47,050 –> 00:34:51,300
این محاسبات را انجام دهید، بنابراین آنها به نوعی
به هم مرتبط هستند و امیدوارم که کمی کمک کند
461
00:34:51,300 –> 00:34:57,990
از حس حالا جلسه چیست؟ Well session اساسا
راهی برای اجرای قسمت یا قسمت است
462
00:34:57,990 –> 00:35:03,330
کل نمودار بنابراین وقتی در یک جلسه شروع می کنیم، کاری که
انجام می دهیم این است که شروع به اجرای متفاوت می کنیم
463
00:35:03,330 –> 00:35:08,170
جنبه های نمودار بنابراین از پایین ترین سطح نمودار
شروع می کنیم، جایی که هیچ چیز وابسته نیست
464
00:35:08,170 –> 00:35:12,930
در مورد هر چیز دیگری، ما ممکن است مقادیر ثابت یا چیزی
شبیه به آن داشته باشیم. و سپس ما را حرکت می دهیم
465
00:35:12,930 –> 00:35:17,150
از نمودار عبور کرده و شروع به انجام
تمام محاسبات جزئی مختلف کنید
466
00:35:17,150 –> 00:35:21,020
ما تعریف کرده ایم حالا، امیدوارم که این خیلی گیج
کننده نباشد. من می دانم که این مقدار زیادی است
467
00:35:21,020 –> 00:35:24,910
شما بچه ها باید این را در حالی که ما از طریق آن عبور می کنیم،
درک خواهید کرد. و دوباره می توانید بخوانید
468
00:35:24,910 –> 00:35:28,530
از طریق برخی از این مؤلفهها در اینجا که
من در Collaboratory دارم، اگر به نوعی از آن بگذرم
469
00:35:28,530 –> 00:35:33,050
از طریق هر چیزی که واقعاً درک نمی کنید. اما این
روشی است که نمودارها و جلسات را نشان می دهد
470
00:35:33,050 –> 00:35:37,290
کار، ما خیلی با آنها عمیق نخواهیم
شد، ما باید درک کنیم که همین است
471
00:35:37,290 –> 00:35:41,880
روشی که TensorFlow کار می کند. و برخی مواقع وجود دارد که ما
نمی توانیم از یک مقدار خاص در خود استفاده کنیم
472
00:35:41,880 –> 00:35:46,820
هنوز کد، چون ما نمودار را ارزیابی نکرده ایم،
جلسه ای ایجاد نکرده ایم و دریافت نکرده ایم
473
00:35:46,820 –> 00:35:50,921
مقادیر هنوز، که ممکن است لازم باشد قبل از اینکه واقعاً
بتوانیم از برخی استفاده کنیم، انجام دهیم
474
00:35:50,921 –> 00:35:53,460
ارزش خاص بنابراین این فقط چیزی است که باید در نظر
گرفت.
475
00:35:53,460 –> 00:35:54,460
بسیار خوب،
476
00:35:54,460 –> 00:35:59,340
بنابراین اکنون ما در واقع وارد کدنویسی،
نصب TensorFlow می شویم. حالا این
477
00:35:59,340 –> 00:36:02,890
جایی است که من قصد دارم شما را با Google Collaboratory
آشنا کنم و توضیح دهم که چگونه می توانید
478
00:36:02,890 –> 00:36:07,430
بدون نیاز به نصب چیزی بر روی کامپیوتر
خود را دنبال کنید. و مهم نیست که
479
00:36:07,430 –> 00:36:11,560
شما مانند یک کامپیوتر واقعاً مزخرف دارید، یا حتی
اگر مانند یک آیفون روشن هستید، به خودی خود،
480
00:36:11,560 –> 00:36:17,560
شما در واقع می توانید این کار را انجام دهید، که شگفت انگیز
است. بنابراین تنها کاری که باید انجام دهید Google Google Collaboratory است،
481
00:36:17,560 –> 00:36:23,240
و یک نوت بوک جدید بسازید. اکنون آنچه Google
Collaboratory است، اساساً یک Jupyter رایگان است
482
00:36:23,240 –> 00:36:28,150
نوت بوک در ابر برای شما. روش کار این است که
شما می توانید این نوت بوک را باز کنید
483
00:36:28,150 –> 00:36:33,590
می توانم ببینم این به نام I، py و B است، بله،
آن چیزی است که من py و B، که فکر می کنم فقط
484
00:36:33,590 –> 00:36:38,619
مخفف عبارت IPython notebook است. و کاری که میتوانید
در اینجا انجام دهید، نوشتن کد و
485
00:36:38,619 –> 00:36:43,400
متن هم بنویس بنابراین، این همان چیزی
است که به آن میگویند، Google Collaboratory
486
00:36:43,400 –> 00:36:47,540
نوت بوک. و اساساً چرا به آن نوت بوک می گویند به
این دلیل است که نه تنها می توانید قرار دهید
487
00:36:47,540 –> 00:36:52,790
کد اما شما همچنین می توانید یادداشت قرار دهید،
کاری که من در اینجا با این عناوین خاص انجام داده ام.
488
00:36:52,790 –> 00:36:56,700
بنابراین می توانید در واقع از علامت گذاری در داخل این استفاده
کنید. بنابراین اگر من یکی از اینها را باز کنم، می توانید
489
00:36:56,700 –> 00:37:02,540
ببینید که من از متن علامت گذاری برای ایجاد
این بخش ها استفاده کرده ام. و بله، آن
490
00:37:02,540 –> 00:37:07,690
نوعی نحوه کار Collaboratory است. اما کاری که می توانید
در Collaboratory انجام دهید فراموش کردن آن است
491
00:37:07,690 –> 00:37:12,490
باید همه این ماژول ها را نصب کنید. آنها قبلاً
برای شما نصب شده اند. پس همینی که هستی
492
00:37:12,490 –> 00:37:17,190
در واقع وقتی یک پنجره مشارکتی را باز می کنید،
گوگل به طور خودکار انجام می دهد
493
00:37:17,190 –> 00:37:21,430
شما را به یکی از سرورهای آنها یا یکی از ماشین
های آنها که همه این موارد را دارد وصل کنید
494
00:37:21,430 –> 00:37:26,230
انجام شد و برای شما تنظیم شد. و می توانید شروع
به نوشتن کد و اجرای آن در دستگاه خود کنید
495
00:37:26,230 –> 00:37:31,680
و دیدن نتیجه به عنوان مثال، اگر میخواهم
hello را چاپ کنید، مانند این، و
496
00:37:31,680 –> 00:37:36,020
من کمی بزرگنمایی می کنم، تا بچه ها بتوانید این را بخوانید،
تمام کاری که انجام می دهم این است که یک کد جدید ایجاد کنم
497
00:37:36,020 –> 00:37:41,030
مسدود کردن، که من می توانم با کلیک کردن روی کد انجام
دهم. اینطوری میتونم یکی مثل اون رو هم حذف کنم. و
498
00:37:41,030 –> 00:37:45,970
زدم فرار. حالا توجه کنید، یک ثانیه به آن زمان بدهید،
بیشتر از زمانی که به تنهایی طول می کشد
499
00:37:45,970 –> 00:37:50,720
دستگاه، و ما Hello را در اینجا ظاهر می کنیم. بنابراین
نکته مهم در مورد Collaboratory این است
500
00:37:50,720 –> 00:37:55,310
این واقعیت که ما میتوانیم چندین بلوک کد داشته باشیم،
و میتوانیم آنها را در هر دنبالهای اجرا کنیم
501
00:37:55,310 –> 00:37:59,369
خواستن بنابراین برای ایجاد یک بلوک کد دیگر، فقط
می توانید بدانید، یک بلوک کد دیگر را انجام دهید
502
00:37:59,369 –> 00:38:03,620
در اینجا یا فقط با نگاه کردن به اینجا، کد دریافت
می کنید و متن دریافت می کنید. و من میتونم بدوم
503
00:38:03,620 –> 00:38:09,400
این به هر ترتیبی که من می خواهم بنابراین من می توانم مانند
چاپ انجام دهم. بله، برای مثال، می توانم Yes را اجرا کنم،
504
00:38:09,400 –> 00:38:13,410
و ما خروجی Yes را خواهیم دید و سپس می توانم
یک بار دیگر hello را چاپ کنم. و توجه کنید
505
00:38:13,410 –> 00:38:17,830
که این شماره را در سمت چپ در اینجا به من نشان
می دهد که در آن این نوع کدها وجود دارد
506
00:38:17,830 –> 00:38:23,330
بلوک ها اجرا شد. اکنون همه این بلوک های کد می توانند به
نوعی به یکدیگر دسترسی داشته باشند. بنابراین برای مثال،
507
00:38:23,330 –> 00:38:28,010
من فانک را تعریف میکنم، و فقط مقداری پارامتر H را میگیریم
و تمام کاری که انجام میدهیم این است که فقط چاپ کنیم
508
00:38:28,010 –> 00:38:33,780
H، خوب، اگر من یک بلوک کد دیگر را در اینجا ایجاد کنم، پس بیایید
به کدنویسی برویم. من می توانم با فانک تماس بگیرم
509
00:38:33,780 –> 00:38:39,980
بگویید، سلام، مطمئن شوید که ابتدا این بلوک را اجرا می کنم. بنابراین
ما تابع را تعریف می کنیم. حالا ما فانک اجرا می کنیم
510
00:38:39,980 –> 00:38:44,660
و توجه کنید که خروجی Hello را دریافت می کنیم. بنابراین
ما می توانیم به همه متغیرها، همه توابع دسترسی داشته باشیم،
511
00:38:44,660 –> 00:38:48,420
هر چیزی که در بلوکهای کد دیگر از بلوکهای
کد زیر آن یا کد تعریف کردهایم
512
00:38:48,420 –> 00:38:52,310
بلوک هایی که بعد از آن اجرا می شوند. حالا چیز دیگری
که در مورد Collaboratory عالی است این است
513
00:38:52,310 –> 00:38:56,330
این واقعیت که ما می توانیم تقریباً هر ماژولی
را که تصور کنیم وارد کنیم. و ما نیازی نداریم
514
00:38:56,330 –> 00:39:01,060
آن را نصب کنید. بنابراین من در واقع نحوه
نصب TensorFlow را به طور کامل بررسی نمی کنم.
515
00:39:01,060 –> 00:39:06,220
کمی در مورد نحوه نصب TensorFlow در دستگاه محلی
خود در داخل این نوت بوک وجود دارد.
516
00:39:06,220 –> 00:39:09,790
که من شما را به آن ارجاع خواهم داد. اما اساساً،
اگر می دانید چگونه از Pip استفاده کنید، بسیار ساده است.
517
00:39:09,790 –> 00:39:15,300
اگر یک GPU سازگار دارید، میتوانید TensorFlow
را با نصب Pip یا GPU TensorFlow نصب Pip کنید.
518
00:39:15,300 –> 00:39:20,140
که می توانید از لینکی که در این دفترچه است
بررسی کنید. حالا اگر بخواهم چیزی وارد کنم،
519
00:39:20,140 –> 00:39:24,119
کاری که من می توانم انجام دهم این است که به معنای واقعی کلمه واردات
را بنویسم. بنابراین می توانم بگویم NumPy را مانند این وارد کنید.
520
00:39:24,119 –> 00:39:28,270
و معمولا NumPy ماژولی است که باید نصب کنید. اما
ما نیازی به انجام این کار در اینجا نداریم.
521
00:39:28,270 –> 00:39:32,100
قبلاً روی دستگاه نصب شده است. بنابراین دوباره،
ما به آن سرورهای Google متصل می شویم،
522
00:39:32,100 –> 00:39:36,510
ما می توانیم از سخت افزار آنها برای انجام یادگیری ماشین
استفاده کنیم. و این فوق العاده است. این شگفت انگیز است.
523
00:39:36,510 –> 00:39:40,680
و زمانی که در حال دویدن هستید، مانند یک
نوع بدتر، مزایای عملکردی به شما می دهد
524
00:39:40,680 –> 00:39:44,670
ماشین، درست است بنابراین ما میتوانیم نگاهی
به RAM و فضای دیسک کامپیوتر خود بیندازیم
525
00:39:44,670 –> 00:39:49,750
می توانید ببینید که ما 12 گیگ رم داریم. ما با 107
گیگابایت داده در فضای دیسک خود سروکار داریم.
526
00:39:49,750 –> 00:39:53,690
و واضح است که میدانید، اگر بخواهیم،
میتوانیم به آن وصل شویم
527
00:39:53,690 –> 00:39:56,900
زمان اجرا محلی، که به اعتقاد من به دستگاه محلی
شما متصل می شود، اما من قصد ندارم بروم
528
00:39:56,900 –> 00:40:01,190
از طریق همه آن من فقط می خواهم برخی از اجزای
اساسی Have Collaboratory را به شما عزیزان نشان دهم.
529
00:40:01,190 –> 00:40:04,910
در حال حاضر، برخی از چیزهای دیگر که برای
درک مهم است، این تب زمان اجرا است، که شما
530
00:40:04,910 –> 00:40:10,920
ممکن است ببیند من استفاده می کنم. بنابراین راه اندازی مجدد زمان اجرا اساساً
تمام خروجی های شما را پاک می کند و فقط راه اندازی مجدد می شود
531
00:40:10,920 –> 00:40:15,320
هر اتفاقی افتاده از آنجا که چیز بزرگ با Collaboratory
این است که من می توانم به طور خاص اجرا کنم
532
00:40:15,320 –> 00:40:20,900
بلوک های کد، لازم نیست هر بار که می خواهم
چیزی را اجرا کنم کل کد را اجرا کنم،
533
00:40:20,900 –> 00:40:25,450
اگر فقط یک تغییر جزئی در یک بلوک کد ایجاد کرده باشم،
فقط می توانم آن کد را اجرا کنم. متاسفم، من
534
00:40:25,450 –> 00:40:29,540
فقط می تواند آن بلوک کد را اجرا کند. لازم نیست
همه چیز را قبل از آن اجرا کنم یا حتی همه چیز را
535
00:40:29,540 –> 00:40:34,650
بعد از آن درست اما گاهی اوقات می خواهید همه چیز را دوباره
راه اندازی کنید و فقط همه چیز را دوباره اجرا کنید.
536
00:40:34,650 –> 00:40:38,400
بنابراین برای انجام این کار، روی Restart Runtime کلیک کنید، این
کار فقط همه چیزهایی را که شما پاک میکنید پاک میکند
537
00:40:38,400 –> 00:40:43,560
دارند. و سپس راه اندازی مجدد و اجرای همه، زمان اجرا و همچنین
اجرای هر بلوک منفرد را مجدداً راه اندازی می کند
538
00:40:43,560 –> 00:40:49,321
کدی که دارید به ترتیبی که در آن چیز نشان داده
می شود. بنابراین من به شما توصیه می کنم
539
00:40:49,321 –> 00:40:52,690
بچه ها یکی از این پنجره ها را باز کنید، بدیهی
است که می توانید با این دفترچه همراه باشید
540
00:40:52,690 –> 00:40:56,050
اگر می خواهید اما اگر می خواهید آن را به تنهایی تایپ
کنید و به نوعی با آن مشکل دارید، باز کنید
541
00:40:56,050 –> 00:41:01,010
یک دفترچه یادداشت بردارید، آن را ذخیره کنید، بسیار
آسان است. و اینها دوباره بسیار شبیه ژوپیتر هستند
542
00:41:01,010 –> 00:41:07,840
نوت بوک یا نوت بوک Jupyter. آنها تقریباً یکسان
هستند. خوب، پس این یک نوع است
543
00:41:07,840 –> 00:41:11,970
جنبه مشارکتی Google نحوه استفاده از آن. بیایید
وارد وارد کردن TensorFlow شویم. اکنون،
544
00:41:11,970 –> 00:41:16,150
این به نوعی مختص Google Collaboratory خواهد بود. بنابراین
می توانید اینها را اینجا ببینید
545
00:41:16,150 –> 00:41:20,450
نوعی از مراحلی است که باید برای وارد کردن TensorFlow دنبال
کنیم. بنابراین از آنجایی که ما در حال کار هستیم
546
00:41:20,450 –> 00:41:24,670
در Google Collaboratory، آنها چندین نسخه از TensorFlow
دارند، آنها نسخه اصلی را دارند
547
00:41:24,670 –> 00:41:30,030
نسخه TensorFlow که 1.0 است و نسخه 2.0. حال
برای تعریف این واقعیت که ما
548
00:41:30,030 –> 00:41:31,930
می خواهید از TensorFlow 2.0 استفاده کنید.
549
00:41:31,930 –> 00:41:32,930
فقط
550
00:41:32,930 –> 00:41:36,430
از آنجایی که ما در این نوت بوک هستیم، باید
این خط کد را در همان ابتدا بنویسیم
551
00:41:36,430 –> 00:41:42,290
از تمام نوت بوک های ما بنابراین درصد، TensorFlow بر
نسخه دو نقطه x تأکید دارد. حالا این است
552
00:41:42,290 –> 00:41:46,730
به سادگی گفتن، باید از TensorFlow دو نقطه ای x استفاده
کنیم. بنابراین هر نسخه ای که باشد،
553
00:41:46,730 –> 00:41:50,041
و این فقط در یک نوت بوک مورد نیاز است، اگر این
کار را در دستگاه محلی خود انجام می دهید
554
00:41:50,041 –> 00:41:54,619
یک ویرایشگر متن، شما نیازی به نوشتن این ندارید.
حالا وقتی این کار را انجام می دهیم، معمولاً
555
00:41:54,619 –> 00:42:00,500
TensorFlow را به عنوان نام مستعار TF وارد کنید. اکنون
برای انجام این کار، به سادگی TensorFlow را وارد می کنیم
556
00:42:00,500 –> 00:42:04,570
ماژول و سپس به صورت TF می نویسیم. اگر روی دستگاه
محلی خود کار می کنید، دوباره می روید
557
00:42:04,570 –> 00:42:08,420
باید ابتدا TensorFlow را نصب کنید تا مطمئن شوید که قادر
به انجام این کار هستید، اما از آنجایی که
558
00:42:08,420 –> 00:42:12,430
ما در Collaboratory هستیم، نیازی به انجام این کار نداریم. در
حال حاضر، از آنجایی که ما این واقعیت را تعریف کرده ایم
559
00:42:12,430 –> 00:42:17,941
با استفاده از نسخه دو نقطه x، زمانی که نسخه TensorFlow را
چاپ می کنیم، در اینجا می توانیم ببینیم که آن را
560
00:42:17,941 –> 00:42:21,860
می گوید نسخه دو، که دقیقا همان چیزی است که ما
به دنبال آن هستیم. و سپس این TensorFlow است.
561
00:42:21,860 –> 00:42:26,710
2.1. نقطه اوه بنابراین مطمئن شوید که نسخه خود را
که از نسخه 2.0 استفاده می کنید چاپ می کنید. زیرا
562
00:42:26,710 –> 00:42:32,260
بسیاری از چیزهایی که من در این سری استفاده می کنم وجود
دارد که اگر در TensorFlow 1.0 هستید، به نوعی می باشد.
563
00:42:32,260 –> 00:42:36,970
این کار نمی کند. بنابراین در TensorFlow 2.0
جدید است. یا آن را refactored و نام
564
00:42:36,970 –> 00:42:41,190
تغییر کرده اند. خوب، حالا که این کار را انجام دادیم،
TensorFlow را وارد کردیم، این کار را انجام دادیم
565
00:42:41,190 –> 00:42:44,420
اینو اینجا گرفتم و من در واقع می خواهم به دفترچه یادداشت
تازه ام بروم و فقط این کار را انجام دهم. بنابراین
566
00:42:44,420 –> 00:42:47,980
ما فقط این خطوط را کپی می کنیم تا مقداری
کد جدید داشته باشیم، و من همه را ندارم
567
00:42:47,980 –> 00:42:54,070
این متنی که باید به آن بپردازیم. پس بیایید این TensorFlow
را انجام دهیم، اجازه دهید TensorFlow را وارد کنیم
568
00:42:54,070 –> 00:43:01,750
به عنوان TF. و سپس می توانیم نسخه TF dot را چاپ کنیم و
نگاهی به آن بیندازیم. بنابراین نسخه. باشه،
569
00:43:01,750 –> 00:43:06,250
پس بیایید کد خود را اجرا کنیم. اینجا. میتوانیم ببینیم که TensorFlow
قبلاً بارگذاری شده است. اوه میگه 1.0 بنابراین اگر
570
00:43:06,250 –> 00:43:09,900
شما این خطا را دریافت می کنید، در واقع خوب است. من
به این جایی که TensorFlow در حال حاضر است برخورد کردم
571
00:43:09,900 –> 00:43:13,250
بارگذاری شده است، تنها کاری که باید انجام دهید این است که زمان اجرا خود را مجدداً
راه اندازی کنید. بنابراین من می خواهم به راه اندازی مجدد و
572
00:43:13,250 –> 00:43:17,840
اجرای همه فقط روی Yes کلیک کنید. و اکنون باید ببینیم
که آن نسخه 2.0 را دریافت می کنیم. یک بار این
573
00:43:17,840 –> 00:43:24,760
شروع به اجرا می کند، یک ثانیه به آن بدهید، TensorFlow
2.0 انتخاب شده است، ما آن ماژول را وارد می کنیم.
574
00:43:24,760 –> 00:43:29,990
و در آنجا می رویم، نسخه 2.0 را دریافت می کنیم. خوب، پس اکنون
وقت آن است که در مورد تانسورها صحبت کنیم. اکنون،
575
00:43:29,990 –> 00:43:34,650
تانسور چیست؟ اکنون تانسور بلافاصله به نوعی مانند
یک نام پیچیده به نظر می رسد. شما هستید
576
00:43:34,650 –> 00:43:39,210
مانند، بسیار خوب، تانسور مانند این گیج کننده است. اما
آنچه خوب است، بدیهی است که این اتفاق می افتد
577
00:43:39,210 –> 00:43:44,350
با توجه به شباهت های نام، جنبه اصلی
TensorFlow باشد. و در اصل، همه
578
00:43:44,350 –> 00:43:50,900
آن است، بردار تعمیم یافته به ابعاد بالاتر است. حال،
بردار چیست؟ خوب، اگر شما تا به حال
579
00:43:50,900 –> 00:43:55,100
هر جبر خطی یا حتی نوعی حساب برداری اساسی
را انجام دهید، امیدواریم باید
580
00:43:55,100 –> 00:43:59,910
بدانید آن چیست اما در اصل، این یک
نوع نقطه داده است که به نوعی آن است
581
00:43:59,910 –> 00:44:04,640
دوست دارم توصیفش کنم و دلیل اینکه ما آن را بردار
می نامیم این است که لزوماً اینطور نیست
582
00:44:04,640 –> 00:44:09,990
مختصات خاصی داشته باشد بنابراین، اگر در مورد
یک نقطه داده دو بعدی صحبت می کنید،
583
00:44:09,990 –> 00:44:15,060
شما می دانید، شاید یک مقدار x و یک مقدار y، یا
مانند یک مقدار x یک و یک مقدار x دو دارید.
584
00:44:15,060 –> 00:44:19,970
حالا یک بردار می تواند هر مقداری از ابعاد را در خود
داشته باشد، می تواند یک بعد داشته باشد، که
585
00:44:19,970 –> 00:44:24,190
به سادگی به این معنی است که فقط یک عدد می تواند
دو بعد داشته باشد، یعنی ما دو بعد داریم
586
00:44:24,190 –> 00:44:29,090
اعداد، بنابراین مانند یک مقدار x و یک y. اگر به یک
نمودار دو بعدی فکر می کنیم، این کار را می کنیم
587
00:44:29,090 –> 00:44:32,900
اگر به یک نمودار سه بعدی فکر می کنیم، سه
بعد داشته باشیم، پس اینطور خواهد بود
588
00:44:32,900 –> 00:44:37,450
سه نقطه داده، اگر در مورد بعضی اوقات تصویر
صحبت می کنیم، یک چهار بعد دریافت می کنیم
589
00:44:37,450 –> 00:44:43,150
داده ها و برخی داده های ویدئویی، پنج بعدی،
و ما می توانیم با بردارها ادامه دهیم.
590
00:44:43,150 –> 00:44:47,180
بنابراین اساساً تانسور چیست و من فقط این
تعریف رسمی را می خوانم تا مطمئن شوم
591
00:44:47,180 –> 00:44:52,030
من چیزی که از وبسایت واقعی تنسورفلو
باشد را نخریدهام. تانسور یک تعمیم است
592
00:44:52,030 –> 00:44:56,890
از بردارها و ماتریس ها به ابعاد بالقوه بالاتر.
در داخل، TensorFlow نشان داده شده است
593
00:44:56,890 –> 00:45:01,470
تانسورها به عنوان آرایه های بعدی n از انواع داده های پایه.
حالا ما متوجه خواهیم شد که این به چه معناست
594
00:45:01,470 –> 00:45:07,650
دومین. اما امیدوارم که منطقی باشد. اکنون، از آنجایی
که تانسورها برای TensorFlow بسیار مهم هستند،
595
00:45:07,650 –> 00:45:11,650
آنها به نوعی شی اصلی هستند که ما با دستکاری
و دستکاری آنها کار خواهیم کرد
596
00:45:11,650 –> 00:45:16,910
مشاهده و این شیء اصلی است که از طریق برنامه
ما منتقل شده است. حالا آنچه می توانیم
597
00:45:16,910 –> 00:45:21,960
در اینجا ببینید هر تانسور یک محاسبات تا حدی تعریف
شده را نشان می دهد که در نهایت تولید خواهد شد
598
00:45:21,960 –> 00:45:26,369
یک ارزش بنابراین همانطور که در نمودارها و جلسات در
مورد آن صحبت کردیم، قرار است چه کاری انجام دهیم
599
00:45:26,369 –> 00:45:30,770
زمانی که ما برنامه خود را ایجاد می کنیم، دسته
ای از تانسورها را ایجاد می کنیم. و تنسورفلو
600
00:45:30,770 –> 00:45:35,360
قرار است آنها را نیز ایجاد کند. و آنهایی
که تا حدی تعریف شده ذخیره می شوند
601
00:45:35,360 –> 00:45:40,370
محاسبات در نمودار بعداً، زمانی که ما واقعاً
نمودار را می سازیم و جلسه را برگزار می کنیم
602
00:45:40,370 –> 00:45:43,640
در حال اجرا، بخش های مختلفی از نمودار را اجرا خواهیم
کرد، به این معنی که ما متفاوت را اجرا خواهیم کرد
603
00:45:43,640 –> 00:45:48,290
تانسورها و بتوانیم نتایج متفاوتی از تانسورهای
خود بگیریم. حالا هر تانسوری چه چیزی دارد
604
00:45:48,290 –> 00:45:53,410
ما یک نوع داده و یک شکل می نامیم. و این چیزی است که
ما اکنون به آن خواهیم پرداخت. بنابراین یک داده
605
00:45:53,410 –> 00:45:57,470
نوع به سادگی نوع اطلاعاتی است که در تانسور
ذخیره می شود. الان خیلی نادره
606
00:45:57,470 –> 00:46:01,600
که ما هر نوع داده ای را متفاوت از اعداد
می بینیم، اگرچه نوع داده ای وجود دارد
607
00:46:01,600 –> 00:46:04,911
رشته ها و چند تای دیگر نیز. اما من همه آنها را
در اینجا گنجانده ام، زیرا آنها هستند
608
00:46:04,911 –> 00:46:10,590
آنقدر مهم نیست اما برخی از نمونه هایی که می توانیم
ببینیم عبارتند از float، 32، و 32، رشته و موارد دیگر.
609
00:46:10,590 –> 00:46:16,560
حال، شکل صرفاً نمایش تانسور
از نظر ابعاد آن است
610
00:46:16,560 –> 00:46:20,150
است. و ما به چند مثال می رسیم، زیرا تا زمانی
که ما نمی خواهیم شکل را توضیح دهم
611
00:46:20,150 –> 00:46:24,880
میتوان نمونههایی را مشاهده کرد که واقعاً میتوانند وارد
شوند. اما در اینجا چند نمونه از نحوه ایجاد وجود دارد
612
00:46:24,880 –> 00:46:31,050
تانسورهای مختلف بنابراین کاری که می توانید انجام دهید این است
که به سادگی می توانید متغیر TF dot را انجام دهید و سپس شما
613
00:46:31,050 –> 00:46:36,260
می تواند مقدار و نوع داده ای را که تانسور شما است انجام
دهد. بنابراین در این مورد، ما ایجاد کرده ایم
614
00:46:36,260 –> 00:46:41,630
یک تانسور رشته ای که یک رشته را ذخیره می کند و آن
رشته های نقطه ای TF است، داده ها را تعریف می کنیم
615
00:46:41,630 –> 00:46:47,380
نوع دوم، یک تانسور عددی داریم که مقداری
عدد صحیح را ذخیره می کند. و سپس آن است
616
00:46:47,380 –> 00:46:53,190
از نوع TF، int 16. و ما یک تانسور ممیز شناور
داریم که یک شناور ساده را ذخیره می کند.
617
00:46:53,190 –> 00:46:59,700
نقطه. حالا این تانسورها شکلی دارند، من
معتقدم که یکی خواهد بود، که به سادگی
618
00:46:59,700 –> 00:47:04,800
یعنی اسکالر هستند. حالا یک مقدار اسکالر. و ممکن
است بشنوید که من این را خیلی ساده می گویم
619
00:47:04,800 –> 00:47:10,660
یعنی فقط یک مقدار معنیش همینه هنگامی که ما در
مورد مقادیر مشابه بردار صحبت می کنیم، آن
620
00:47:10,660 –> 00:47:14,830
معمولاً به معنای بیش از یک مقدار است. و ما در
مورد ماتریس ها صحبت کردیم، ما متفاوت هستیم
621
00:47:14,830 –> 00:47:21,570
فقط بالا میره اما اسکالار به سادگی به معنای یک عدد است.
بنابراین بله، این چیزی است که ما برای آن دریافت می کنیم
622
00:47:21,570 –> 00:47:25,050
انواع داده های مختلف و ایجاد تانسورها،
ما واقعاً این کار را انجام نمی دهیم
623
00:47:25,050 –> 00:47:29,610
در برنامه ما اما فقط برای نمونه هایی در اینجا، این کار
را به این صورت انجام می دهیم. بنابراین ما وارد کرده ایم
624
00:47:29,610 –> 00:47:32,540
آنها بنابراین من واقعاً می توانم اینها را اجرا کنم. و منظورم
این است که ما واقعاً هیچ خروجی ای دریافت نمی کنیم
625
00:47:32,540 –> 00:47:36,820
اجرای این کد، زیرا خوب، چیزی برای دیدن وجود ندارد.
اما اکنون در مورد آن صحبت می کنیم
626
00:47:36,820 –> 00:47:42,990
درجه اسلش رتبه تانسورها. پس کلمه دیگر
برای رتبه مدرک است. پس اینها به جای هم هستند.
627
00:47:42,990 –> 00:47:47,820
و باز هم، این به سادگی به معنی عدد،
تعداد ابعاد درگیر در تانسور است.
628
00:47:47,820 –> 00:47:53,050
بنابراین وقتی یک تانسور از رتبه صفر ایجاد می کنیم، کاری
که در اینجا انجام داده ایم، آن را a می نامیم
629
00:47:53,050 –> 00:47:58,690
اسکالر حالا دلیل اینکه این رتبه صفر دارد این
است که به سادگی یک چیز است، ما نداریم
630
00:47:58,690 –> 00:48:03,880
هر بُعدی برای این داشته باشید، مانند ابعاد صفر
وجود دارد، اگر حتی یک کلمه بود، آن را
631
00:48:03,880 –> 00:48:10,849
فقط یک مقدار در حالی که در اینجا، ما یک آرایه داریم.
حالا وقتی یک آرایه یا یک لیست داریم، بلافاصله
632
00:48:10,849 –> 00:48:16,369
حداقل رتبه یک را داشته باشد. اکنون دلیل آن این است
که این آرایه می تواند موارد بیشتری را ذخیره کند
633
00:48:16,369 –> 00:48:22,390
بیش از یک مقدار در یک بعد، درست است؟ بنابراین من می توانم
کاری مانند تست انجام دهم، می توانم خوب انجام دهم،
634
00:48:22,390 –> 00:48:26,550
من می توانم انجام دهم، تیم، که نام من است. و ما می
توانیم این را اجرا کنیم، و هیچ کدام را نخواهیم گرفت
635
00:48:26,550 –> 00:48:31,640
خروجی بدیهی است در اینجا اما این چیزی است که
ما آن را تانسور رتبه یک می نامیم. چون هست
636
00:48:31,640 –> 00:48:36,960
به سادگی یک لیست یک آرایه، که به معنای یک
بعد است، و دوباره، می دانید، این نیز است
637
00:48:36,960 –> 00:48:42,640
مانند بردار اکنون، این چیزی که ما در اینجا به
آن نگاه می کنیم یک تانسور رتبه دو است. دلیل این
638
00:48:42,640 –> 00:48:48,150
یک تانسور رتبه دو به این دلیل است که ما یک لیست
در داخل یک لیست یا در این مورد چندگانه داریم
639
00:48:48,150 –> 00:48:53,290
لیست های داخل یک لیست بنابراین راهی که در واقع
می توانید رتبه یک تانسور را تعیین کنید
640
00:48:53,290 –> 00:48:59,040
عمیق ترین سطح لیست های تودرتو است، حداقل
در پایتون با نمایش ما. یعنی
641
00:48:59,040 –> 00:49:03,980
آن چیست بنابراین در اینجا، میتوانیم ببینیم که
یک لیست در داخل یک لیست داریم و سپس یک لیست دیگر
642
00:49:03,980 –> 00:49:08,440
لیست داخل این لیست بالایی بنابراین این به ما رتبه
دو می دهد. و این چیزی است که ما به طور معمول
643
00:49:08,440 –> 00:49:14,160
یک ماتریس تماس بگیرید و این دوباره از رشته های
نقطه ای TF خواهد بود. بنابراین این نوع داده است
644
00:49:14,160 –> 00:49:19,010
برای این متغیر تانسور بنابراین همه اینهایی که ما
ایجاد کردهایم تانسور هستند. آنها یک داده دارند
645
00:49:19,010 –> 00:49:22,359
نوع، و آنها برخی از رتبه و برخی
از شکل. و ما در مورد شکل و
646
00:49:22,359 –> 00:49:28,060
دومین. بنابراین برای تعیین رتبه یک تانسور،
می توانیم به سادگی از روش TF dot استفاده کنیم
647
00:49:28,060 –> 00:49:34,070
رتبه بنابراین توجه کنید، وقتی این را اجرا می کنم، شکلی
را می گیریم که خالی از تانسور رتبه دو است.
648
00:49:34,070 –> 00:49:39,570
خوبه. و سپس NumPy دو را دریافت می کنیم، که به سادگی
به این معنی است که این رتبه دو است. اکنون،
649
00:49:39,570 –> 00:49:44,540
اگر من آن رتبه یک تانسور را انتخاب کنم و آن را چاپ کنم.
پس بیایید نگاهی به آن بیندازیم، متوجه می شویم
650
00:49:44,540 –> 00:49:50,619
NumPy یک در اینجا، که به ما می گوید که این به سادگی
در رتبه یک است. حالا اگه بخوام استفاده کنم
651
00:49:50,619 –> 00:49:54,720
یکی از این موارد بالا و ببینید چیست، پس بیایید آن را امتحان
کنیم. ما می توانیم اعداد را انجام دهیم، بنابراین
652
00:49:54,720 –> 00:49:59,110
شماره رتبه نقطه TF، بنابراین ما آن را در اینجا چاپ می
کنیم و NumPy صفر دریافت می کنیم زیرا این رتبه است
653
00:49:59,110 –> 00:50:02,760
صفر، درست است؟ بنابراین به چیزی که داشتیم برمی
گردیم که تانسور رتبه دو بود. اما باز هم آن ها
654
00:50:02,760 –> 00:50:07,320
نمونه هایی هستند که می خواهیم به آنها نگاه کنیم.
خوب، پس اشکال یک تانسور. بنابراین این یک است
655
00:50:07,320 –> 00:50:12,430
اکنون کمی متفاوت است، چیزی که یک شکل به سادگی به ما
می گوید این است که در هر کدام چند آیتم داریم
656
00:50:12,430 –> 00:50:18,650
بعد، ابعاد، اندازه. بنابراین در این مورد، وقتی به رتبه دو
نگاه می کنیم، شکل نقطه تانسور، بنابراین داریم
657
00:50:18,650 –> 00:50:23,109
شکل نقطه در اینجا، این ویژگی همه تانسورهای
ما است، به دو میرسیم. حالا بیایید نگاه کنیم
658
00:50:23,109 –> 00:50:28,980
در اینجا، چیزی که ما داریم هوآ است، به این دو و
دو نگاه کنید، بنابراین ما دو عنصر در آن داریم
659
00:50:28,980 –> 00:50:32,430
بعد اول، سمت راست و سپس دو عنصر در
بعد دوم. این تقریباً زیاد است
660
00:50:32,430 –> 00:50:37,530
این چه چیزی به ما می گوید حالا بیایید به
رتبه یا شکل تانسور رتبه یک نگاه کنیم،
661
00:50:37,530 –> 00:50:44,010
سه می گیریم بنابراین چون ما فقط رتبه یک داریم،
توجه کنید که فقط یک عدد می گیریم، در حالی که
662
00:50:44,010 –> 00:50:48,859
وقتی رتبه دو را داشتیم، دو عدد به دست آوردیم.
و به ما گفت که در هر کدام چند عنصر وجود دارد
663
00:50:48,859 –> 00:50:53,200
از این لیست ها، درست است؟ بنابراین اگر من بروم و یکی
دیگر را در اینجا اضافه کنم، مانند آن، و ما یک
664
00:50:53,200 –> 00:50:58,380
حالا به شکل نگاه کنید، اوه، اول باید این را اجرا کنم.
پس این چیزی است که اوه، نمی توان آن را تبدیل کرد
665
00:50:58,380 –> 00:51:04,150
غیر مربع به تانسور متأسفم، بنابراین من باید مقدار
یکنواخت عناصر را در هر کدام داشته باشم
666
00:51:04,150 –> 00:51:08,490
یکی اینجا، من نمی توانم کاری را که آنجا انجام دادم انجام دهم.
بنابراین ما یک عنصر سوم را در اینجا اضافه می کنیم. حالا چی
667
00:51:08,490 –> 00:51:14,430
ما می توانیم انجام دهیم این است که نباید هیچ مشکلی ایجاد شود،
اجازه دهید نگاهی به شکل بیندازیم. و توجه کنید
668
00:51:14,430 –> 00:51:20,780
اکنون دو، سه می گیریم. بنابراین ما دو لیست داریم.
و هر یک از آن لیست ها دارای سه عنصر هستند
669
00:51:20,780 –> 00:51:25,380
داخل آنها بنابراین شکل کار به این صورت است. اکنون،
می توانم ادامه دهم و لیست دیگری اضافه کنم
670
00:51:25,380 –> 00:51:30,550
اگر من می خواستم در اینجا و میتوانم بگویم، باشه،
باشه.
671
00:51:30,550 –> 00:51:35,661
خوب، پس بیایید این را اجرا کنیم، امیدوارم هیچ خطایی به
نظر نمی رسد که ما خوب هستیم. حالا بیایید نگاه کنیم
672
00:51:35,661 –> 00:51:39,710
دوباره شکل بده و اکنون شکل سه، سه به دست
می آوریم، زیرا ما سه لیست داخلی داریم.
673
00:51:39,710 –> 00:51:44,190
و در هر یک از آن لیست ها، ما سه عنصر
داریم. و تقریباً همینطور است
674
00:51:44,190 –> 00:51:48,480
آثار. حالا، دوباره، میتوانیم حتی بیشتر از اینجا پیش برویم،
میتوانیم فهرست دیگری را در داخل قرار دهیم
675
00:51:48,480 –> 00:51:52,640
در اینجا، این یک تانسور رتبه سه به ما می دهد. و
ما باید این کار را در داخل همه انجام دهیم
676
00:51:52,640 –> 00:51:56,950
این لیست ها و سپس آنچه که اکنون
به ما می دهد، سه عدد خواهد بود
677
00:51:56,950 –> 00:52:03,660
چند عنصر در هر یک از آن ابعاد مختلف
داریم. خوب، پس تغییر شکل.
678
00:52:03,660 –> 00:52:07,760
بسیار خوب، پس این همان کاری است که در بسیاری از مواقع
وقتی با تانسورها سروکار داریم، باید انجام دهیم
679
00:52:07,760 –> 00:52:13,140
TensorFlow. بنابراین اساساً، بسیاری از اشکال مختلف
وجود دارد که می توانند یکسان را نشان دهند
680
00:52:13,140 –> 00:52:19,490
تعداد عناصر بنابراین تا اینجا، ما سه عنصر
در یک تانسور رتبه یک داریم. و سپس اینجا،
681
00:52:19,490 –> 00:52:25,160
ما نه عنصر در یک تانسور رتبه دو داریم. اکنون، راههایی
وجود دارد که میتوانیم این را دوباره شکل دهیم
682
00:52:25,160 –> 00:52:30,060
داده ها به طوری که تعداد عناصر یکسانی داشته باشیم
اما به شکلی متفاوت. مثلا من می توانستم
683
00:52:30,060 –> 00:52:35,920
این را صاف کنید، درست است، همه این عناصر را بردارید
و آنها را در یک تانسور رتبه یک بیندازید. که
684
00:52:35,920 –> 00:52:40,609
به سادگی طولی از نه عنصر است. خب چطور باید انجامش
بدیم؟ خوب، اجازه دهید من فقط این را اجرا کنم
685
00:52:40,609 –> 00:52:43,870
برای ما در اینجا کد کنید و به این نگاه کنید. بنابراین کاری
که ما انجام داده ایم این است که تانسور ایجاد کرده ایم
686
00:52:43,870 –> 00:52:44,870
یک، یعنی
687
00:52:44,870 –> 00:52:46,369
نقطه های TF،
688
00:52:46,369 –> 00:52:51,800
منظور این است که ما یک تانسور ایجاد می
کنیم که به سادگی کاملاً پر شده است
689
00:52:51,800 –> 00:52:58,060
با یکی از این شکل بنابراین شکل 123، یعنی
می دانید، این شکلی است که ما می رویم
690
00:52:58,060 –> 00:53:02,180
برای بدست آوردن پس بیایید این را چاپ کنیم و به
تانسور یک نگاه کنیم تا بتوانم بهتر توضیح دهم
691
00:53:02,180 –> 00:53:10,180
این. بنابراین تانسور یک، به شکلی نگاه کنید که
123 داریم، درست است، بنابراین یک داخلی داریم
692
00:53:10,180 –> 00:53:14,560
لیستی که ما در اینجا به آن نگاه می کنیم. و
سپس ما دو لیست در داخل آن لیست داریم. و
693
00:53:14,560 –> 00:53:19,230
سپس هر یک از آن لیست ها، ما سه عنصر داریم. بنابراین
این شکلی است که ما تعریف کردیم. اکنون،
694
00:53:19,230 –> 00:53:24,420
ما شش عنصر در داخل اینجا داریم. بنابراین باید راهی وجود
داشته باشد که بتوانیم این داده ها را تغییر شکل دهیم
695
00:53:24,420 –> 00:53:29,460
دارای شش عنصر، اما به شکلی متفاوت. در واقع، کاری که ما میتوانیم
انجام دهیم این است که این را به شکلی دوباره شکل دهیم
696
00:53:29,460 –> 00:53:34,630
یک شکل 231، ما دو لیست خواهیم داشت، درست است؟
ما قصد داریم سه تا در داخل داشته باشیم
697
00:53:34,630 –> 00:53:38,310
آن ها و سپس در داخل هر یک از آنها، ما یک
عنصر خواهیم داشت. پس بیایید یک
698
00:53:38,310 –> 00:53:41,880
به اون یکی نگاه کن پس بیایید نگاهی به تانسور
دو بیندازیم، در واقع، ما چه کار میکنم
699
00:53:41,880 –> 00:53:44,960
تمام آنچه را که می توانیم همه آنها را اینجا چاپ کنیم چاپ کنید.
پس بیایید فقط آنها را چاپ کنیم و نگاهی به آنها بیندازیم.
700
00:53:44,960 –> 00:53:49,100
بنابراین وقتی به تانسور یک نگاه می کنیم، دیدیم که
این یک شکل است. و اکنون به این تانسور نگاه می کنیم
701
00:53:49,100 –> 00:53:54,040
دو و ما می توانیم ببینیم که ما دو لیست داریم، درست
است؟ در داخل هر یک از آن لیست ها، ما داریم
702
00:53:54,040 –> 00:53:59,620
سه لیست و در داخل هر یک از آن لیست ها، ما یک
عنصر داریم. حالا بالاخره تانسور ما
703
00:53:59,620 –> 00:54:06,090
سه شکل سه است، یک منفی، چه منفی
است، وقتی یک منفی می گذاریم
704
00:54:06,090 –> 00:54:11,680
در اینجا، کاری که این کار انجام می دهد این است که استنباط کند که این
عدد واقعاً باید چه باشد. بنابراین اگر یک حرف اول را تعریف کنیم
705
00:54:11,680 –> 00:54:16,840
شکل سه، کاری که این کار انجام می دهد این است که می گوید،
بسیار خوب، ما سه لیست خواهیم داشت. این مال ماست
706
00:54:16,840 –> 00:54:21,680
سطح اول. و سپس ما باید بر اساس تعداد عناصر
موجود در این موضوع مشخص کنیم
707
00:54:21,680 –> 00:54:25,100
تغییر شکل، که روشی است که ما استفاده می کنیم،
که من حتی در مورد آن صحبت نکردم، که خواهد شد
708
00:54:25,100 –> 00:54:29,420
به یک ثانیه بروید، این بعد بعدی باید چه باشد.
در حال حاضر، بدیهی است، این قرار است
709
00:54:29,420 –> 00:54:33,470
باید سه باشد پس سه، سه، درست است؟ زیرا
ما سه لیست در داخل خواهیم داشت
710
00:54:33,470 –> 00:54:36,760
از هر یک از آن لیست هایی که باید داشته باشیم
واقعاً درست است؟ بیایید ببینیم که آیا این است
711
00:54:36,760 –> 00:54:41,620
حتی شکل سه به خفاش من. بنابراین این در واقع
باید به سه، دو تغییر کند، من نمی دانم
712
00:54:41,620 –> 00:54:45,631
چرا اونجا سه سه نوشتم اما نکته را متوجه شدید.
درست است، پس چه کاری انجام می دهد، ما داریم
713
00:54:45,631 –> 00:54:49,840
سه لیست، ما شش عنصر داریم. این عدد بدیهی
است که باید دو باشد زیرا خوب، سه
714
00:54:49,840 –> 00:54:53,510
ضربدر 2 به ما 6 می دهد و این اساساً
نحوه تعیین تعداد است
715
00:54:53,510 –> 00:54:58,240
عناصر در واقع با نگاه کردن به شکل آن در یک
تانسور قرار دارند. حالا این تغییر شکل است
716
00:54:58,240 –> 00:55:02,661
روشی که در آن تنها کاری که باید انجام دهیم تغییر شکل نقطه
TF نامیده می شود، تانسور را می دهیم و عدد را می دهیم
717
00:55:02,661 –> 00:55:08,010
شکل ما می خواهیم آن را تا زمانی که یک شکل معتبر
است تغییر دهیم. و وقتی همه را ضرب کنیم
718
00:55:08,010 –> 00:55:11,880
اعداد در اینجا، برابر است با تعداد عناصر
این تانسور که تغییر شکل میدهند
719
00:55:11,880 –> 00:55:16,650
آن را برای ما و آن داده های شکل جدید را به ما می دهد. این
بسیار مفید است. ما در واقع از این استفاده خواهیم کرد
720
00:55:16,650 –> 00:55:20,540
زمانی که از TensorFlow عبور می کنیم. بنابراین مطمئن
شوید که به نوعی با این روش آشنا هستید
721
00:55:20,540 –> 00:55:25,380
آثار. خوب، پس اکنون به سراغ انواع تانسورها
می رویم.
722
00:55:25,380 –> 00:55:26,510
بنابراین وجود دارد
723
00:55:26,510 –> 00:55:30,119
دسته ای از انواع مختلف تانسور که می توانیم استفاده
کنیم. تا اینجای کار، تنها موردی که نگاه کردیم
724
00:55:30,119 –> 00:55:36,150
در متغیر است. بنابراین، ما متغیرهای نقطه TF را ایجاد کردهایم
و تانسورهای خود را به نوعی سخت کدگذاری کردهایم.
725
00:55:36,150 –> 00:55:40,610
ما واقعاً این کار را انجام نمی دهیم. اما
فقط برای آن مثال. پس ما اینها را داریم
726
00:55:40,610 –> 00:55:45,651
انواع مختلف، متغیر sparsetensor متغیر متغیر
ثابت داریم، در واقع یک وجود دارد
727
00:55:45,651 –> 00:55:51,250
چند مورد دیگر نیز حالا، ما واقعاً در مورد
این دو تا آنقدر صحبت نمی کنیم،
728
00:55:51,250 –> 00:55:55,710
اگرچه ثابت و متغیر برای درک تفاوت
بین بنابراین ما مهم هستند
729
00:55:55,710 –> 00:55:59,580
می تواند این را بخواند، به استثنای متغیر، همه این
تانسورها غیر قابل تغییر هستند، به این معنی
730
00:55:59,580 –> 00:56:04,420
مقدار آنها ممکن است در طول اجرا تغییر نکند. بنابراین
اساسا، همه اینها، زمانی که ما ایجاد می کنیم
731
00:56:04,420 –> 00:56:09,200
یک میانگین تانسور، مقداری ثابت داریم، به این
معنی که هر آنچه را که در اینجا تعریف کرده ایم،
732
00:56:09,200 –> 00:56:14,480
تغییر نمی کند، در حالی که تانسور متغیر می
تواند تغییر کند. پس این فقط چیزی است
733
00:56:14,480 –> 00:56:18,310
زمانی که از متغیر استفاده می کنیم به خاطر داشته باشیم. این به این
دلیل است که ما فکر می کنیم ممکن است نیاز به تغییر آن داشته باشیم
734
00:56:18,310 –> 00:56:22,619
مقدار آن تانسور بعدا در حالی که اگر از یک
تانسور مقدار ثابت استفاده کنیم، نمی توانیم
735
00:56:22,619 –> 00:56:25,920
تغییر دهید. بنابراین این فقط چیزی است که باید در نظر داشت،
واضح است که می توانیم آن را کپی کنیم، اما ما
736
00:56:25,920 –> 00:56:30,180
نمی تواند تغییر کند بسیار خوب، پس در حال ارزیابی
تانسورها، تقریباً در پایان این بخش هستیم، من
737
00:56:30,180 –> 00:56:34,609
دانستن و سپس وارد نوعی کد عمیق تر خواهیم شد.
بنابراین برخی اوقات وجود خواهد داشت
738
00:56:34,609 –> 00:56:38,490
برای این راهنما، ما باید یک زمان را ارزیابی کنیم، البته،
بنابراین برای ارزیابی چه کاری باید انجام دهیم
739
00:56:38,490 –> 00:56:43,910
یک تانسور ایجاد یک جلسه است. حالا، این واقعاً اینطور
نیست، ما قرار نیست این کار را انجام دهیم
740
00:56:43,910 –> 00:56:47,200
بسیار اما من فقط فکر کردم که به آن اشاره کنم تا
مطمئن شوم که شما بچه ها از چه چیزی آگاه هستید
741
00:56:47,200 –> 00:56:51,570
من دارم انجام می دهم. اگر بعداً شروع به تایپ کردن
آن کنم. اساسا، گاهی اوقات ما برخی از آنها را داریم
742
00:56:51,570 –> 00:56:56,330
شی تانسور، و در سراسر کد ما، در واقع
باید آن را ارزیابی کنیم تا بتوانیم
743
00:56:56,330 –> 00:57:02,359
کار دیگری انجام دهد بنابراین برای انجام این کار، تنها کاری که باید انجام
دهیم این است که به معنای واقعی کلمه از این نوع پیش فرض استفاده کنیم
744
00:57:02,359 –> 00:57:07,760
قالب، یک بلوک از کد، که در آن ما می گوییم
با جلسه نقطه TF، به عنوان نوعی از جلسه نیست
745
00:57:07,760 –> 00:57:13,190
واقعا مهم است که چه چیزی را در اینجا قرار می دهیم، پس می
توانیم هر کاری که نام تانسور نقطه ای باشد را انجام دهیم،
746
00:57:13,190 –> 00:57:17,250
و فراخوانی که در واقع TensorFlow خواهد داشت، فقط بفهمید
که برای پیدا کردن چه کاری باید انجام دهد
747
00:57:17,250 –> 00:57:20,859
مقدار این تانسور، آن را ارزیابی می کند،
و سپس به ما اجازه می دهد تا در واقع
748
00:57:20,859 –> 00:57:24,580
از آن مقدار استفاده کنید بنابراین من این را در اینجا
قرار دادم، شما بچه ها به وضوح می توانید این را بخوانید
749
00:57:24,580 –> 00:57:28,200
می خواهم به طور عمیق تر در مورد نحوه کار
آن درک کنم. و منبع این امر مستقیم است
750
00:57:28,200 –> 00:57:32,490
از وبسایت TensorFlow، بسیاری از این موارد مستقیماً
از آنجا کپی شدهاند. و من دارم
751
00:57:32,490 –> 00:57:35,790
فقط به نوعی چرخش خودم را به آن اضافه کردم
و درک آن را کمی آسانتر کردم. باشه،
752
00:57:35,790 –> 00:57:40,430
بنابراین ما همه این کارها را انجام داده ایم. پس بیایید
وارد اینجا شویم و چند نمونه از تغییر شکل را انجام دهیم
753
00:57:40,430 –> 00:57:43,430
مطمئن شوید که همه در یک صفحه هستند.
و سپس ما به سمت واقعی حرکت می کنیم
754
00:57:43,430 –> 00:57:47,940
صحبت در مورد چند الگوریتم یادگیری ساده بنابراین میخواهم
تانسوری بسازم که بتوانیم مهربان باشیم
755
00:57:47,940 –> 00:57:52,720
از آشفتگی و تغییر شکل، بنابراین کاری که می خواهم انجام
دهم این است که بگویم t برابر است و ما می گوییم TF
756
00:57:52,720 –> 00:57:59,190
نقطه ای ها اکنون، کاری که TF dot ones انجام میدهد این است که
دوباره همه مقادیر را ایجاد میکند تا آنهایی باشند
757
00:57:59,190 –> 00:58:03,530
ما خواهیم داشت و هر شکلی که اکنون بتوانیم صفر
و صفر را نیز انجام دهیم، در حال انجام است
758
00:58:03,530 –> 00:58:07,270
تا به ما یک دسته صفر بدهد. و بیایید شکلی شبیه
به دیوانه بسازیم و فقط این را تجسم کنیم،
759
00:58:07,270 –> 00:58:11,250
بیایید مانند پنج در پنج در پنج ببینیم. بنابراین
بدیهی است که اگر بخواهیم تعداد آنها را مشخص کنیم
760
00:58:11,250 –> 00:58:14,370
عناصر قرار است در اینجا باشند، ما باید این مقدار
را ضرب کنیم. بنابراین من این را باور دارم
761
00:58:14,370 –> 00:58:18,730
می شود 625، زیرا باید پنج به توان چهار
باشد، بنابراین پنج برابر پنج
762
00:58:18,730 –> 00:58:23,320
بار پنج برابر پنج و بیایید در واقع T را چاپ
کنیم و به آن نگاهی بیندازیم و ببینیم چه چیزی
763
00:58:23,320 –> 00:58:27,750
این هست. بنابراین اکنون این را اجرا می کنیم. و می توانید ببینید
که این خروجی است که ما دریافت می کنیم. بنابراین بدیهی است،
764
00:58:27,750 –> 00:58:31,849
این یک تانسور بسیار دیوانه کننده است. اما شما
نکته را درست متوجه شدید و به ما می گوید
765
00:58:31,849 –> 00:58:38,060
شکل 55555 است. حالا ببینید وقتی این تانسور را دوباره
شکل می دهم چه اتفاقی می افتد. پس اگر بخواهم
766
00:58:38,060 –> 00:58:42,792
همه این عناصر را بردارید و آنها را صاف کنید، کاری که من می توانم
انجام دهم این است که به سادگی بگویم، ما خواهیم کرد
767
00:58:42,792 –> 00:58:51,470
مثلاً t برابر است با تغییر شکل نقطه TF. و تانسور
t را فقط به شکل تغییر شکل می دهیم
768
00:58:51,470 –> 00:59:00,349
625. حالا، اگر این کار را انجام دهیم، و اینجا اجرا
کنیم، اوه، باید T را چاپ کنم. در پایین، بعد از
769
00:59:00,349 –> 00:59:05,680
ما این کار را انجام دادیم، اگر بتوانم عبارت چاپ را
به درستی بنویسم، اکنون می توانید آن را ببینید
770
00:59:05,680 –> 00:59:11,830
ما فقط این لیست عظیم را دریافت می کنیم که فقط 625 صفر
دارد. و دوباره، اگر میخواهیم دوباره شکل دهیم
771
00:59:11,830 –> 00:59:15,339
این به چیزی شبیه به 125، و شاید ما در ریاضیات آنقدر
خوب نبودیم و نمی توانستیم بفهمیم
772
00:59:15,339 –> 00:59:19,869
که این مقدار آخر باید پنج باشد، میتوانیم
یک عدد منفی قرار دهیم، این بدان معناست که TensorFlow
773
00:59:19,869 –> 00:59:24,589
اکنون استنباط می کند که شکل باید چه باشد. و حالا
وقتی به آن نگاه می کنیم، می توانیم آن را ببینیم
774
00:59:24,589 –> 00:59:30,820
ما می خواهیم به سادگی پنج نوع از این مجموعه
ها را دریافت کنیم. من ماتریس ها را نمی دانم،
775
00:59:30,820 –> 00:59:36,089
هر چی میخوای صداشون کن و شکل ما 125 میشه.
پنج. بنابراین اساساً اینگونه است
776
00:59:36,089 –> 00:59:41,230
آثار. پس اینطوری شکل میدیم. ما به نوعی با
تانسورها برخورد می کنیم. ایجاد متغیرها،
777
00:59:41,230 –> 00:59:44,940
چگونه از نظر جلسات و نمودارها کار می کند. و امیدوارم
با آن، این به اندازه کافی به شما می دهد
778
00:59:44,940 –> 00:59:51,190
از درک تانسورهای اشکال از یک مقدار
به طوری که زمانی که ما به حرکت در
779
00:59:51,190 –> 00:59:54,180
بخش بعدی آموزش، ما در واقع در حال نوشتن کد هستیم
و قول میدهم که این کار را انجام دهیم
780
00:59:54,180 –> 01:00:03,163
در حال نوشتن کدهای پیشرفته تر، خواهید فهمید
که چگونه کار می کند. پس با آن موجود
781
01:00:03,163 –> 01:00:04,163
گفت بیایید وارد بخش بعدی شویم.
782
01:00:04,163 –> 01:00:06,820
بنابراین به ماژول سه این دوره خوش آمدید. حالا
کاری که ما در این ماژول انجام خواهیم داد
783
01:00:06,820 –> 01:00:11,560
در حال یادگیری الگوریتم های اصلی یادگیری ماشین است که
همراه با TensorFlow ارائه می شود. حالا این الگوریتم ها
784
01:00:11,560 –> 01:00:15,470
مختص TensorFlow نیستند، اما در آنجا استفاده می شوند.
و از برخی ابزارها استفاده خواهیم کرد
785
01:00:15,470 –> 01:00:19,710
از TensorFlow تا نوعی پیاده سازی آنها. اما
در اصل، اینها بلوک های سازنده هستند.
786
01:00:19,710 –> 01:00:23,780
قبل از رفتن به چیزهایی مانند شبکه های عصبی
و تکنیک های پیشرفته تر یادگیری ماشین،
787
01:00:23,780 –> 01:00:27,930
شما واقعاً باید بدانید که اینها چگونه کار می کنند زیرا
آنها به نوعی در موارد مختلف مورد استفاده قرار می گیرند
788
01:00:27,930 –> 01:00:31,820
تکنیک ها و ترکیب با هم، و یکی از آنها اما
برای نشان دادن شما در واقع بسیار قدرتمند است
789
01:00:31,820 –> 01:00:36,160
اگر از آن به روش درست استفاده کنید، بسیاری از آنچه
در واقع یادگیری ماشینی است و بسیاری از آن
790
01:00:36,160 –> 01:00:39,910
الگوریتم های یادگیری ماشین و پیاده سازی ها
و مشاغل و برنامه ها و موارد دیگر
791
01:00:39,910 –> 01:00:45,380
مانند آن، در واقع فقط از مدل های بسیار ابتدایی
استفاده کنید. زیرا این مدل ها قادر به
792
01:00:45,380 –> 01:00:48,810
در واقع انجام کارهای بسیار قدرتمندی است.
وقتی با چیزی که هست سر و کار ندارید
793
01:00:48,810 –> 01:00:53,420
دیوانه وار پیچیده است، شما فقط به یادگیری ماشینی
اولیه و طبقه بندی اولیه نیاز دارید،
794
01:00:53,420 –> 01:00:57,720
شما می توانید از این نوع الگوریتم های اصلی یادگیری
اصلی استفاده کنید. حالا، اولین نفری هستیم که ما هستیم
795
01:00:57,720 –> 01:01:01,520
رفتن از طریق رگرسیون خطی است. اما طبقه
بندی و خوشه بندی را پوشش خواهیم داد
796
01:01:01,520 –> 01:01:06,660
در مدل های مخفی مارکوف و اینها به نوعی
به ما گسترش خوبی از موارد مختلف می دهند
797
01:01:06,660 –> 01:01:12,670
الگوریتم های اصلی اکنون هزاران هزار الگوریتم
مختلف یادگیری ماشین وجود دارد.
798
01:01:12,670 –> 01:01:16,400
اینها دسته بندی های اصلی هستند که شما پوشش
می دهید. اما در این دسته بندی ها،
799
01:01:16,400 –> 01:01:19,930
الگوریتم های خاص تری وجود دارد که می توانید وارد
آنها شوید، فقط احساس می کنم لازم است به آنها اشاره کنم
800
01:01:19,930 –> 01:01:23,800
که چون میدانم بسیاری از شما راههای
متفاوتی برای انجام کارها دیدهاید
801
01:01:23,800 –> 01:01:27,550
در این دوره ممکن است دیدگاه متفاوتی در مورد
آن به شما نشان دهد. بنابراین اجازه دهید من فقط
802
01:01:27,550 –> 01:01:31,369
به سرعت در مورد اینکه چگونه می خواهم این را پشت سر بگذارم صحبت
کنید، بسیار شبیه قبل از این است که من این را داشته باشم
803
01:01:31,369 –> 01:01:34,920
نوت بوک، همانطور که قبلاً در مورد آن صحبت کردم،
یک لینک در توضیحات وجود دارد، توصیه می کنم
804
01:01:34,920 –> 01:01:39,220
که شما بچه ها آن را بزنید و کارهای من را
دنبال کنید و از طریق دفترچه بخوانید.
805
01:01:39,220 –> 01:01:42,099
اما من فقط دفترچه یادداشت را مرور خواهم کرد. و
سپس گهگاه، آنچه را که در واقع خواهم کرد
806
01:01:42,099 –> 01:01:47,119
انجام دهم، اوه، باید اینجا را باز کنم، به این
نوع برگه بدون عنوانی که اینجا دارم بروید و
807
01:01:47,119 –> 01:01:50,930
کدی را در اینجا بنویسید، زیرا بیشتر کاری که می خواهم
انجام دهم این است که فقط کد را در آن کپی کنید
808
01:01:50,930 –> 01:01:56,200
در اینجا، بنابراین ما می توانیم همه آن را در یک نوع
بلوک ببینیم. و سپس ما خوب خواهیم بود که برویم. و
809
01:01:56,200 –> 01:01:59,580
آخرین یادداشت قبل از اینکه واقعاً وارد آن شویم،
و متاسفم، من زیاد صحبت می کنم. اما مهم است
810
01:01:59,580 –> 01:02:03,880
برای اینکه شما بچه ها از این موضوع آگاه شوید، خواهید
دید که ما از نحو پیچیده زیادی استفاده می کنیم
811
01:02:03,880 –> 01:02:07,859
در طول این نوع سریال و به طور کلی
بقیه دوره، فقط می خواهم بسازم
812
01:02:07,859 –> 01:02:13,460
بسیار واضح است که شما نباید حفظ کنید
یا حتی خود را موظف به حفظ کنید
813
01:02:13,460 –> 01:02:17,280
هر یک از نحوی که شما هر چیزی را که در اینجا
می بینید می بینید، من شخصاً حتی نمی بینم
814
01:02:17,280 –> 01:02:20,940
به خاطر بسپارم، چیزهای زیادی در اینجا
وجود دارد که من نمی توانم به آنها برسم
815
01:02:20,940 –> 01:02:26,540
از ذهن من، وقتی با نوعی کتابخانه و ماژول
آنقدر بزرگ سروکار داریم که مانند TensorFlow،
816
01:02:26,540 –> 01:02:30,099
به خاطر سپردن تمام آن اجزای مختلف سخت
است. پس فقط مطمئن شوید که متوجه شده اید
817
01:02:30,099 –> 01:02:33,320
چه اتفاقی می افتد اما اگر نیاز به استفاده
از آن دارید، نیازی به حفظ آن ندارید
818
01:02:33,320 –> 01:02:36,089
از میان این ابزارها، می خواهید آنها را جستجو
کنید، می خواهید ببینید که چه چیزی هستید
819
01:02:36,089 –> 01:02:38,810
مثل، خوب، من قبلا از این استفاده کرده ام، شما
آن را درک خواهید کرد. و سپس می توانید بروید
820
01:02:38,810 –> 01:02:42,591
پیشاپیش و می دانید، آن کد را در آن کپی کنید و به هر شکلی
که نیاز دارید از آن استفاده کنید، این کار را نمی کنید
821
01:02:42,591 –> 01:02:46,000
باید هر کاری را که اینجا انجام می دهیم حفظ کنیم.
خوب، پس بیایید جلو برویم و شروع کنیم
822
01:02:46,000 –> 01:02:51,430
با رگرسیون خطی پس رگرسیون خطی چیست؟
یکی از آن اشکال اساسی چیست
823
01:02:51,430 –> 01:02:55,750
یادگیری ماشین، و اساساً، آنچه ما سعی می کنیم انجام
دهیم این است که یک مطابقت خطی داشته باشیم
824
01:02:55,750 –> 01:02:59,850
بین نقاط داده بنابراین من فقط قصد دارم در
اینجا به یک مثال خوب پیمایش کنم. پس چی
825
01:02:59,850 –> 01:03:04,150
من این کار را انجام دادم از matplotlib، فقط برای رسم یک نمودار کوچک
در اینجا استفاده کردم. بنابراین ما می توانیم این یکی را ببینیم
826
01:03:04,150 –> 01:03:07,750
درست همین جا. و اساساً، این یک نوع مجموعه
داده ما است، ما به آن خواهیم گفت
827
01:03:07,750 –> 01:03:12,620
مجموعه داده ها، کاری که می خواهیم انجام دهیم این است که
از رگرسیون خطی برای ارائه مدلی استفاده کنیم که بتواند
828
01:03:12,620 –> 01:03:16,570
چند پیش بینی خوب برای نقاط داده ما به ما بدهید. بنابراین
در این مثال، شاید همان چیزی است که ما
829
01:03:16,570 –> 01:03:22,040
want to do مقدار x برای یک نقطه داده داده می شود،
می خواهیم مقدار y را پیش بینی کنیم. اکنون
830
01:03:22,040 –> 01:03:26,970
در این مورد، میتوانیم ببینیم که نوعی مطابقت
خطی برای این نقاط داده وجود دارد.
831
01:03:26,970 –> 01:03:31,329
حال، معنای آن این است که میتوانیم چیزی به نام خط
بهترین تناسب را از طریق این دادهها ترسیم کنیم
832
01:03:31,329 –> 01:03:36,260
نکاتی که میتوانند بهطور دقیق آنها را طبقهبندی
کنند، اگر منطقی باشد. پس من می روم
833
01:03:36,260 –> 01:03:41,030
برای اسکرول کردن اینجا و نگاه کردن به بهترین
خط ما برای این مجموعه داده در واقع چیست،
834
01:03:41,030 –> 01:03:45,950
ما می توانیم این خط آبی را ببینیم، تقریباً منظورم
این است که بهترین خط مناسب برای آن است
835
01:03:45,950 –> 01:03:50,980
این مجموعه داده و با استفاده از این خط، ما در واقع می توانیم
مقادیر آینده را در داده های خود پیش بینی کنیم
836
01:03:50,980 –> 01:03:55,430
تنظیم. بنابراین اساسا، رگرسیون خطی زمانی استفاده
میشود که نقاط دادهای داشته باشید که همبستگی دارند
837
01:03:55,430 –> 01:03:59,360
به نوعی خطی اکنون، این یک مثال بسیار اساسی
است، زیرا ما در حال انجام آن هستیم
838
01:03:59,360 –> 01:04:04,570
این در دو بعدی با x و y. اما اغلب، آنچه شما خواهید
داشت این است که نقاط داده خواهید داشت
839
01:04:04,570 –> 01:04:08,920
که می دانید، هشت یا نه نوع مقدار ورودی. بنابراین
این به ما می دهد که شما می دانید، یک
840
01:04:08,920 –> 01:04:13,350
مجموعه داده های نه بعدی و کاری که ما انجام خواهیم
داد این است که یکی از مقادیر مختلف را پیش بینی کنیم.
841
01:04:13,350 –> 01:04:17,349
بنابراین در موردی که قبلاً در مورد دانشآموزان
صحبت میکردیم، شاید دانشجویی داشته باشیم
842
01:04:17,349 –> 01:04:20,580
چه نمره میان ترم و نمره دوم میان ترم خود
را، و سپس ما می خواهیم به پیش بینی
843
01:04:20,580 –> 01:04:25,609
نمره نهایی آنها، کاری که ما می توانیم انجام دهیم این است که از رگرسیون
خطی برای انجام آن استفاده کنیم، جایی که نوع ورودی ما است
844
01:04:25,609 –> 01:04:30,050
مقادیر دو نمره میان ترم و مقدار
خروجی آن نهایی خواهد بود
845
01:04:30,050 –> 01:04:33,810
نمره ای که ما به دنبال پیش بینی آن هستیم. بنابراین اگر
قرار بود آن را طرح کنیم، آن را روی نقشه می کشیدیم
846
01:04:33,810 –> 01:04:38,400
یک نمودار سه بعدی، و ما یک خط سه بعدی
ترسیم می کنیم که نشان دهنده آن است
847
01:04:38,400 –> 01:04:42,320
خط بهترین تناسب برای آن مجموعه داده. در حال حاضر،
برای هر یک از شما که نمی دانید چه خطی دارد
848
01:04:42,320 –> 01:04:46,760
بهترین فیت مخفف آن است، می گوید خط یا این فقط
تعریفی است که من از این وب سایت دریافت کردم
849
01:04:46,760 –> 01:04:51,170
اینجا. خط بهترین تناسب به خطی از طریق نمودار پراکنده
از نقاط داده اشاره دارد که به بهترین شکل بیان می کند
850
01:04:51,170 –> 01:04:55,070
رابطه بین آن نقاط بنابراین دقیقاً
همان چیزی است که من سعی کردم توضیح دهم
851
01:04:55,070 –> 01:05:00,500
وقتی داده هایی داریم که به صورت خطی همبستگی دارند و
من همیشه آن کلمه را قصاب می کنم. آنچه ما می توانیم
852
01:05:00,500 –> 01:05:04,859
انجام این است که یک خط از آن بکشید. و سپس می توانیم
از آن خط برای پیش بینی نقاط داده جدید استفاده کنیم.
853
01:05:04,859 –> 01:05:09,839
زیرا اگر آن خط خوب باشد، بهترین خط مناسب
برای مجموعه داده است، پس امیدوارم،
854
01:05:09,839 –> 01:05:14,089
ما فرض میکنیم که میتوانیم، میدانی، نقطهای
را انتخاب کنیم، پیدا کنیم که در کجا قرار دارد
855
01:05:14,089 –> 01:05:18,470
آن خط و این به نوعی ارزش پیش بینی شده ما خواهد بود.
بنابراین من قصد دارم به یک مثال بپردازم
856
01:05:18,470 –> 01:05:21,920
حالا جایی که من شروع به کشیدن می کنم و کمی به ریاضیات
می پردازم. بنابراین ما درک می کنیم که چگونه این
857
01:05:21,920 –> 01:05:25,450
در سطح عمیق تری کار می کند. اما این باید
به شما درک سطحی بدهد. بنابراین در واقع،
858
01:05:25,450 –> 01:05:30,220
من این را رها می کنم زیرا از قبل با این موضوع
درگیر بودم. این یک نوع مجموعه داده است
859
01:05:30,220 –> 01:05:34,410
که من در اینجا ترسیم کرده ام بنابراین ما x خود
را داریم و y خود را داریم و خط خود را داریم
860
01:05:34,410 –> 01:05:35,839
بهترین تناسب.
861
01:05:35,839 –> 01:05:36,839
حالا چی
862
01:05:36,839 –> 01:05:40,500
میخواهم انجام دهم این است که میخواهم از این خط بهترین
تناسب برای پیشبینی نقطه داده جدید استفاده کنم. پس همه
863
01:05:40,500 –> 01:05:44,360
این نقاط داده قرمز رنگی هستند که ما مدل خود
را با اطلاعاتی که در آن آموزش داده ایم
864
01:05:44,360 –> 01:05:48,440
ما به مدل دادیم تا بتواند این خط بهترین
تناسب را ایجاد کند، زیرا اساساً
865
01:05:48,440 –> 01:05:53,390
تنها کاری که رگرسیون خطی انجام می دهد این است که
به تمام این نقاط داده نگاه کرده و یک خط ایجاد کند
866
01:05:53,390 –> 01:05:58,109
بهترین مناسب برای آنها تمام کاری که می کند
همین است. زیباست، کلمهی آن را نمیدانم
867
01:05:58,109 –> 01:06:02,610
انجام این کار بسیار آسان است، این الگوریتم آنقدرها
هم پیچیده نیست و آنقدرها هم پیشرفته نیست.
868
01:06:02,610 –> 01:06:06,230
و به همین دلیل است که ما با آن در اینجا شروع می
کنیم زیرا توضیح آن منطقی است. پس من
869
01:06:06,230 –> 01:06:11,260
امیدوارم که بسیاری از شما در دو بعد، یک خط را
به صورت زیر تعریف کنید. بنابراین با
870
01:06:11,260 –> 01:06:18,060
معادله y برابر است با mx بعلاوه b، اکنون B
مخفف نقطه ی y است که به معنی جایی است
871
01:06:18,060 –> 01:06:23,390
در این خط، بنابراین اساساً از جایی که خط شروع
می شود. بنابراین در این مثال، مقدار b ما است
872
01:06:23,390 –> 01:06:28,400
همین جا خواهد بود بنابراین این B خواهد
بود زیرا این وقفه y است. پس ما
873
01:06:28,400 –> 01:06:33,320
می توان گفت که شاید شما بدانید، ما ادامه می دهیم، ما
این کار را انجام می دهیم، ما می گوییم این شبیه است
874
01:06:33,320 –> 01:06:40,300
123، ممکن است بگوییم B چیزی شبیه به 0.4 است، درست است؟
بنابراین من فقط می توانم آن را در 0.4 مداد کنم. و
875
01:06:40,300 –> 01:06:45,840
پس m x و y چیست؟ خوب، X و Y مخفف مختصات
این نقطه داده است. بنابراین
876
01:06:45,840 –> 01:06:51,329
می دانید که این مقدار x y دارد. در این مورد،
ما ممکن است آن را می دانید، چیزی بنامیم
877
01:06:51,329 –> 01:06:56,800
مثلاً، چه چیزی می خواهید به 2.7 بگویید که ممکن
است مقدار این نقطه داده باشد. بنابراین
878
01:06:56,800 –> 01:07:02,150
این x و y ما است. و سپس M ما مخفف شیب
است که احتمالاً بیشترین است
879
01:07:02,150 –> 01:07:07,820
بخش مهم. اکنون شیب به سادگی شیب این
خط بهترین تناسب را مشخص می کند
880
01:07:07,820 –> 01:07:13,630
اینجا انجام شد اکنون روشی که ما شیب را محاسبه میکنیم، از
افزایش بیش از اجرا استفاده میکند، اساساً بدون افزایش بیش از اجرا
881
01:07:13,630 –> 01:07:17,930
فقط به این معنی است که چقدر بالا رفتیم در
مقابل چقدر رفتیم. پس اگر می خواهید محاسبه کنید
882
01:07:17,930 –> 01:07:22,140
شیب یک خط، کاری که در واقع می توانید انجام دهید
این است که فقط یک مثلث بکشید. خیلی راست زاویه
883
01:07:22,140 –> 01:07:26,940
مثلث در هر نقطه از خط، بنابراین فقط دو نقطه داده را
انتخاب کنید. و کاری که می توانید انجام دهید محاسبه است
884
01:07:26,940 –> 01:07:32,170
این فاصله و این فاصله، و سپس می توانید
به سادگی فاصله را بر تقسیم کنید
885
01:07:32,170 –> 01:07:35,920
فاصله در عرض، و این به شما شیب می دهد. حالا،
من قصد ندارم زیاد به سمت شیب بروم،
886
01:07:35,920 –> 01:07:39,500
چون احساس میکنم شما بچهها احتمالاً متوجه میشوید که
چیست. اما بیایید فقط برخی از مقادیر را انتخاب کنیم
887
01:07:39,500 –> 01:07:43,040
برای این خط و من میخواهم چند نمونه واقعی
از ریاضیات و وضعیت ما را به شما نشان دهم
888
01:07:43,040 –> 01:07:46,950
قرار است این کار را انجام دهد بنابراین بیایید بگوییم که
الگوریتم رگرسیون خطی ما، میدانید، به دست میآید
889
01:07:46,950 –> 01:07:50,230
در این خط، من قصد ندارم در مورد چگونگی انجام
این کار صحبت کنم، اگرچه بسیار زیباست
890
01:07:50,230 –> 01:07:55,290
خیلی به همه این نقاط داده نگاه می کند، و خطی را که می
شناسید پیدا می کند، می رود، این ها را تقسیم می کند
891
01:07:55,290 –> 01:08:00,230
داده ها به طور مساوی نشان می دهند. بنابراین اساساً،
شما می خواهید تا حد امکان به هر نقطه داده نزدیک شوید.
892
01:08:00,230 –> 01:08:04,270
و شما می خواهید به همان تعداد نقاط داده داشته باشید،
می خواهید به همان میزان نقاط داده داشته باشید
893
01:08:04,270 –> 01:08:07,890
در سمت چپ و سمت راست خط. بنابراین
در این مثال، ما میدانیم که
894
01:08:07,890 –> 01:08:11,550
یک نقطه داده در سمت چپ یک نقطه داده در سمت
چپ، ما یک دو داریم که تقریباً هستند
895
01:08:11,550 –> 01:08:15,010
روی خط. و سپس ما دو نفر داریم که در سمت راست
هستند. بنابراین این یک خط بسیار خوب است
896
01:08:15,010 –> 01:08:20,089
بهترین تناسب است، زیرا همه نقاط بسیار نزدیک
به خط هستند و آنها را تقسیم می کنند
897
01:08:20,089 –> 01:08:24,170
به طور مساوی بنابراین این گونه است که شما یک خط بهترین
تناسب را پیدا می کنید. پس بیایید این را بگوییم
898
01:08:24,170 –> 01:08:32,149
معادله این خط چیزی شبیه به y برابر است،
اجازه دهید آن را 1.5 و x به علاوه بدهیم،
899
01:08:32,149 –> 01:08:36,499
و بیایید بگوییم که مقدار آن فقط 0.5 است تا
آسان شود. بنابراین این معادله خواهد بود
900
01:08:36,500 –> 01:08:41,210
از خط ما حالا توجه کنید که X و Y مقداری
ندارند، به این دلیل است که باید بدهیم
901
01:08:41,210 –> 01:08:45,770
ارزش به دست آوردن یکی از آنهایی که دیگر. پس کاری که ما می
توانیم انجام دهیم این است که اگر ما می توانیم بگوییم
902
01:08:45,770 –> 01:08:50,620
یا مقدار y را داشته باشیم، یا مقدار x نقطه
ای را داریم و می خواهیم رقم بزنیم
903
01:08:50,620 –> 01:08:55,969
بیرون، میدانید کجای خط است، کاری که ما میتوانیم
انجام دهیم این است که یک نفر را وارد یک محاسبه کنیم،
904
01:08:55,969 –> 01:08:59,609
و این در واقع ارزش دیگری را به ما می دهد. بنابراین
در این مثال، بیایید بگوییم که، می دانید،
905
01:08:59,609 –> 01:09:04,988
من سعی می کنم چیزی را پیش بینی کنم و با توجه به این
واقعیت که x برابر با دو است، این را می دانم
906
01:09:04,988 –> 01:09:10,258
x مساوی دو است، و من میخواهم بفهمم اگر x برابر
دو باشد، y چیست، خوب، میتوانم استفاده کنم
907
01:09:10,259 –> 01:09:17,100
این خط برای انجام این کار. بنابراین کاری که من انجام می
دهم این است که بگویم y برابر با 1.5 برابر دو به اضافه است
908
01:09:17,100 –> 01:09:23,729
0.5. حالا همه شما که در رشته های ریاضی سریع
هستید، ارزش 3.5 را به من بدهید. یعنی
909
01:09:23,729 –> 01:09:29,169
که اگر x در دو بود، آنگاه نقطه دادهام را به
عنوان پیشبینی اینجا در این خط خواهم داشت.
910
01:09:29,170 –> 01:09:33,250
و من می گویم باشه، پس شما به من می گویید دسترسی
به پیش بینی من این است که y می رود
911
01:09:33,250 –> 01:09:37,500
برابر با 3.5 باشد. زیرا با توجه به خط بهترین
تناسب برای این مجموعه داده، اینجاست
912
01:09:37,500 –> 01:09:42,819
این نقطه روی آن خط قرار خواهد گرفت. بنابراین امیدوارم که منطقی
باشد. شما در واقع می توانید این کار را انجام دهید
913
01:09:42,819 –> 01:09:47,488
راه معکوس نیز بنابراین اگر مقداری مقدار y به من داده می
شود، بگویید می دانم که شما ارزش من را می شناسید
914
01:09:47,488 –> 01:09:53,029
مقدار y برابر با 2.7 یا چیزی مشابه است. من می توانم
آن را وصل کنم فقط اعداد را مرتب کنم
915
01:09:53,029 –> 01:09:57,641
این معادله و سپس برای x حل کنید. اکنون بدیهی است که این
یک مثال بسیار اساسی است، زیرا ما هستیم
916
01:09:57,641 –> 01:10:01,930
فقط همه این کارها را در دو بعد انجام دهید، اما
می توانید این کار را در ابعاد بالاتر انجام دهید
917
01:10:01,930 –> 01:10:05,430
خوب. بنابراین در واقع، اغلب اوقات، چیزی که قرار است در
نهایت اتفاق بیفتد این است که شما خواهید داشت، شما
918
01:10:05,430 –> 01:10:09,010
بدانید، مانند هشت یا نه متغیر ورودی،
و سپس یک متغیر خروجی خواهید داشت.
919
01:10:09,010 –> 01:10:14,160
که شما پیش بینی می کنید اکنون، تا زمانی که نقاط
داده ما به صورت خطی همبستگی داشته باشند، در سه
920
01:10:14,160 –> 01:10:18,320
ابعاد، ما هنوز هم می توانیم این کار را انجام دهیم. بنابراین
من سعی خواهم کرد این را در سه مورد به شما نشان دهم
921
01:10:18,320 –> 01:10:22,080
ابعاد، فقط امیدواریم که برخی چیزها را
روشن کنیم، زیرا به نوعی مهم است
922
01:10:22,080 –> 01:10:28,440
درک و چشم اندازی از ابعاد مختلف. بنابراین بیایید
بگوییم که ما یکسری نقاط داده داریم
923
01:10:28,440 –> 01:10:33,540
که به نوعی شبیه این هستند و من تمام تلاشم را
می کنم تا آنها را به صورت خطی ترسیم کنم
924
01:10:33,540 –> 01:10:39,090
مد با استفاده از تمام ابعاد اینجا.
اما به دلیل ترسیم سه بعدی سخت است
925
01:10:39,090 –> 01:10:42,830
در یک صفحه نمایش دو بعدی آسان نیست. باشه. بنابراین بیایید
بگوییم که این به نوعی شبیه آنچه ما است
926
01:10:42,830 –> 01:10:48,000
نقاط داده شبیه به حالا، من میتوانم بگویم که اینها
به صورت خطی مرتبط هستند، مانند زیبا بودن
927
01:10:48,000 –> 01:10:49,000
خوب،
928
01:10:49,000 –> 01:10:52,490
آنها به نوعی به یک شکل بالا می روند. و ما
مقیاس این را نمی دانیم. پس احتمالاً این است
929
01:10:52,490 –> 01:10:57,060
سرگرم کننده بنابراین خط بهترین تناسب برای این مجموعه
داده، و من فقط نوع ضخامت خود را قرار می دهم
930
01:10:57,060 –> 01:11:03,140
بالا ممکن است چیزی شبیه به این باشد درست
است؟ حال توجه کنید که این خط سه بعدی است،
931
01:11:03,140 –> 01:11:08,660
درست؟ حدس میزنم این محورهای
x، y و Zed ما باشد. پس ما داریم
932
01:11:08,660 –> 01:11:12,130
یک خط سه بعدی حالا، معادله
این خط کمی پیچیده تر است،
933
01:11:12,130 –> 01:11:16,760
من قصد ندارم در مورد اینکه دقیقاً چیست صحبت کنم. اما اساساً
کاری که ما انجام می دهیم این است که می سازیم
934
01:11:16,760 –> 01:11:20,239
این خط و سپس می گوییم، خوب، چه مقداری را می خواهم
پیش بینی کنم؟ آیا می خواهم پیش بینی کنم
935
01:11:20,239 –> 01:11:27,400
y x y زد. حالا، تا زمانی که من دو مقدار داشته باشم، بنابراین
دو مقدار، همیشه می توانم دیگری را پیش بینی کنم
936
01:11:27,400 –> 01:11:32,090
یکی بنابراین اگر من x y یک نقطه داده
را داشته باشم، Zed را به من می دهد. و
937
01:11:32,090 –> 01:11:38,550
اگر Zed y را داشته باشم، x را به من می دهد. بنابراین
تا زمانی که شما دارید، همه را می دانید
938
01:11:38,550 –> 01:11:43,570
نقاط داده، به جز یکی، همیشه می توانید بر
اساس این واقعیت، آن نقطه را پیدا کنید
939
01:11:43,570 –> 01:11:47,020
که، می دانید، ما این خط را داریم، و از آن برای پیش بینی
استفاده می کنیم. بنابراین فکر می کنم دارم می روم
940
01:11:47,020 –> 01:11:52,320
برای توضیح آن را کنار بگذارم. امیدوارم
منطقی باشد. باز هم، فقط درک کنید
941
01:11:52,320 –> 01:11:56,190
زمانی که نقاط داده ما به صورت خطی همبستگی دارند
از رگرسیون خطی استفاده می کنیم. حالا بعضی ها
942
01:11:56,190 –> 01:12:00,090
نمونه های خوب رگرسیون خطی، می دانید، آن نوع
دانش آموزی بود که پیش بینی می کرد
943
01:12:00,090 –> 01:12:05,200
یک نوع نمره، شما فرض می کنید که اگر
کسی نمره پایینی داشته باشد، پس
944
01:12:05,200 –> 01:12:08,480
آنها با نمره پایین تر به پایان می رسند، و شما
فرض می کنید که آنها نمره بالاتری داشته باشند،
945
01:12:08,480 –> 01:12:12,480
آنها با نمره بالاتر تمام می کردند. اکنون، شما همچنین
می توانید کاری مانند پیش بینی انجام دهید،
946
01:12:12,480 –> 01:12:17,270
می دانید، امید به زندگی در آینده اکنون،
این یک نمونه تاریک تر است. اما در اصل،
947
01:12:17,270 –> 01:12:21,500
چیزی که می توانید در اینجا به آن فکر کنید این است که
اگر فردی مسن تر باشد، انتظار می رود که زندگی کند،
948
01:12:21,500 –> 01:12:25,770
مانند، نه به مدت طولانی یا اگر فردی در بیماری وخیم
است، می توانید به وضعیت سلامتی نگاه کنید
949
01:12:25,770 –> 01:12:29,990
شرایط، و آنها یک بیماری بحرانی دارند، پس
به احتمال زیاد امید به زندگی آنها است
950
01:12:29,990 –> 01:12:33,671
پایین تر بنابراین این مثالی از چیزی است
که به طور خطی، اساساً، چیزی مرتبط است
951
01:12:33,671 –> 01:12:37,260
بالا می رود و چیزی پایین می آید یا چیزی بالا
می رود، چیز دیگر بالا می رود. این مهربان است
952
01:12:37,260 –> 01:12:41,280
وقتی به یک همبستگی خطی فکر می کنید
باید به آن چه فکر کنید. حالا قدر
953
01:12:41,280 –> 01:12:45,130
از این همبستگی، بنابراین می دانید، یک نفر
چقدر بالا می رود در مقابل چقدر پایین می آید،
954
01:12:45,130 –> 01:12:48,890
دقیقاً همان چیزی است که الگوریتم ما برای ما رقم
می زند، فقط باید بدانیم که خطی را انتخاب کنیم
955
01:12:48,890 –> 01:12:52,950
رگرسیون زمانی که فکر می کنیم چیزها
از این نظر با هم مرتبط هستند. باشه پس
956
01:12:52,950 –> 01:12:56,770
برای توضیح رگرسیون خطی کافی است. در حال حاضر،
ما قصد داریم به کدنویسی واقعی بپردازیم
957
01:12:56,770 –> 01:13:00,100
و ایجاد یک مدل اما ابتدا باید در مورد مجموعه
داده هایی که قرار است صحبت کنیم
958
01:13:00,100 –> 01:13:03,850
در مثالی که قصد داریم به نوعی رگرسیون خطی
را با آن نشان دهیم استفاده کنید. باشه پس
959
01:13:03,850 –> 01:13:07,540
من اینجا هستم و دوباره در دفترچه یادداشت هستم. اکنون،
اینها ورودیها هستند، باید با آن شروع کنیم
960
01:13:07,540 –> 01:13:11,100
برای شروع برنامه نویسی و انجام برخی کارها.
در حال حاضر، اولین چیزی که ما نیاز داریم
961
01:13:11,100 –> 01:13:15,661
در واقع باید SK Learn را نصب کنید. در حال حاضر، حتی اگر
شما در یک نوت بوک هستید، در واقع نیاز دارید
962
01:13:15,661 –> 01:13:19,420
این کار را انجام دهید زیرا بنا به دلایلی به صورت پیش
فرض همراه نوت بوک نیست. بنابراین برای انجام
963
01:13:19,420 –> 01:13:24,210
این، ما فقط یک علامت تعجب انجام دادیم،
خط تیره نصب pip، Q، sk Learn. حالا اگر هستی
964
01:13:24,210 –> 01:13:27,880
قرار است روی دستگاه خود کار کنید. باز هم می توانید
از PIP برای نصب آن استفاده کنید. و من فرض می کنم
965
01:13:27,880 –> 01:13:31,210
اگر میخواهید در این مسیر حرکت کنید، میدانید
که از PIP استفاده کنید. در حال حاضر، به عنوان
966
01:13:31,210 –> 01:13:34,910
قبل از اینکه ما در نوت بوک هستیم، باید تعریف
کنیم که از نسخه TensorFlow استفاده خواهیم کرد.
967
01:13:34,910 –> 01:13:39,790
دو نقطه x بنابراین برای انجام این کار، فقط میدانید،
این کار را تا اینجا با درصد انجام میدهیم
968
01:13:39,790 –> 01:13:43,150
امضاء کردن. و سپس ما همه این واردات را داریم
که در اینجا از آنها استفاده خواهیم کرد.
969
01:13:43,150 –> 01:13:47,739
بنابراین از واردات آینده، بخش کاملاً
مهم، تابع چاپ، حروف یونیکد.
970
01:13:47,739 –> 01:13:52,750
و سپس بدیهی است که بزرگها. بنابراین NumPy، پانداها
matplotlib. وقتی از ipython استفاده می کنیم،
971
01:13:52,750 –> 01:13:57,480
ما از TensorFlow استفاده خواهیم کرد. و بله، بنابراین
من در واقع فقط می خواهم آنچه را توضیح دهم
972
01:13:57,480 –> 01:14:01,540
از این ماژول ها هستند. چون احساس می کنم ممکن
است برخی از شما واقعاً ندانید. NumPy است
973
01:14:01,540 –> 01:14:08,300
در اصل نسخه ای بسیار بهینه از آرایه ها در پایتون است. بنابراین
آنچه که این به ما امکان می دهد انجام دهیم این است
974
01:14:08,300 –> 01:14:13,380
بسیاری از انواع محاسبات چند بعدی بنابراین
اساسا، اگر شما یک چند بعدی دارید
975
01:14:13,380 –> 01:14:16,730
آرایه ای که قبلاً در مورد آن صحبت کرده ایم، درست
زمانی که آن اشکال دیوانه را داشتیم،
976
01:14:16,730 –> 01:14:22,320
مانند 5555 NumPy، به ما این امکان را می دهد که داده ها را
در آن شکل نمایش دهیم و سپس خیلی سریع دستکاری کنیم
977
01:14:22,320 –> 01:14:27,100
و بر روی آن عملیات انجام دهید. بنابراین ما می توانیم کارهایی
مانند محصول نقطه ای متقاطع، ماتریس را انجام دهیم
978
01:14:27,100 –> 01:14:32,969
جمع، تفریق ماتریس، عنصر عاقلانه،
جمع، تفریق، می دانید، عملیات برداری،
979
01:14:32,969 –> 01:14:36,070
این کاری است که انجام می دهد. برای ما. این بسیار
پیچیده است، اما ما از آن استفاده خواهیم کرد
980
01:14:36,070 –> 01:14:41,880
مقدار منصفانه. پانداها حالا کاری که پانداها انجام می دهند
این است که به نوعی یک ابزار تجزیه و تحلیل داده است. من تقریبا
981
01:14:41,880 –> 01:14:46,430
میخواهم بگویم، من تعریف رسمی پانداها را نمیدانم،
اما به ما این امکان را میدهد
982
01:14:46,430 –> 01:14:52,280
به راحتی داده ها را دستکاری کنید تا بدانید، بارگیری مجموعه
داده ها، مشاهده مجموعه داده ها، قطع کردن خاص
983
01:14:52,280 –> 01:14:56,719
ستونها، یا برش ردیفهایی از مجموعه دادههای ما،
مجموعه دادهها را تجسم کنید. پانداها همین هستند
984
01:14:56,719 –> 01:15:02,050
برای ما انجام می دهد حال، matplotlib در واقع یک تجسم
است که دارای انواع نمودارها و نمودارها است.
985
01:15:02,050 –> 01:15:06,030
بنابراین زمانی که من واقعاً برخی از جنبه های مختلف
را نمودار می کنم، از آن کمی کمتر استفاده می کنیم
986
01:15:06,030 –> 01:15:10,920
مجموعه داده ما، نمایشگر ipython. این
فقط مختص این نوت بوک است. این فقط
987
01:15:10,920 –> 01:15:14,480
برای پاک کردن خروجی هیچ چیز دیوانه کننده ای با آن
وجود ندارد. و بعد بدیهی است که می دانیم چه چیزی
988
01:15:14,480 –> 01:15:20,150
TensorFlow این واردات دیوانه کننده برای TensorFlow در اینجا است.
بنابراین ستون ویژگی فشرده v2 را به عنوان FC خواهیم کرد
989
01:15:20,150 –> 01:15:25,330
در مورد بعد صحبت کنید اما وقتی یک رگرسیون خطی ایجاد
می کنیم به چیزی به نام ستون ویژگی نیاز داریم
990
01:15:25,330 –> 01:15:30,120
الگوریتم یا مدل در TensorFlow، بنابراین ما از آن
استفاده خواهیم کرد. باشه. پس حالا که داریم
991
01:15:30,120 –> 01:15:33,230
با گذشتن از همه اینها، باید در مورد مجموعه داده
ای که قرار است استفاده کنیم صحبت کنیم
992
01:15:33,230 –> 01:15:36,219
برای رگرسیون خطی و برای این مثال، چون کاری
که ما می خواهیم انجام دهیم این است که،
993
01:15:36,219 –> 01:15:40,580
در واقع این مدل را ایجاد کنید و شروع به استفاده از آن برای
پیش بینی مقادیر کنید. بنابراین داده ها
994
01:15:40,580 –> 01:15:43,980
مجموعه ای که قرار است از آن استفاده کنیم، در واقع، من باید
این را بخوانم زیرا دقیقاً فراموش کرده ام که چه چیزی
995
01:15:43,980 –> 01:15:48,480
نام آن مجموعه داده تایتانیک است، این همان چیزی
است که هست. بنابراین اساسا، این چه چیزی است
996
01:15:48,480 –> 01:15:53,530
انجام می دهد با هدف پیش بینی اینکه چه کسی زنده
می ماند، یا احتمال زنده ماندن کسی است
997
01:15:53,530 –> 01:15:58,590
حضور در تایتانیک مجموعه ای از اطلاعات داده شده است. بنابراین کاری که
ما باید انجام دهیم این است که در این داده ها بارگذاری کنیم
998
01:15:58,590 –> 01:16:01,620
تنظیم. حالا میدانم که به نظر میرسد این یک دسته حرفهای
بیمعنی است، اما اینگونه باید بارگذاری کنیم
999
01:16:01,620 –> 01:16:08,310
آی تی. بنابراین ما از پانداها استفاده خواهیم کرد، بنابراین
نقطه PD CSV را از این URL بخواند. پس این چه می شود
1000
01:16:08,310 –> 01:16:13,460
برای انجام این کار این است که این فایل CSV را که مخفف
مقادیر جدا شده با کاما است، برداریم و در واقع می توانیم
1001
01:16:13,460 –> 01:16:17,910
اگر خواستیم به این نگاه کنید، فکر می کنم، بنابراین
گفتم Ctrl، کلیک کنید، ببینیم این ظاهر می شود یا نه
1002
01:16:17,910 –> 01:16:22,030
بالا بنابراین بیایید در واقع این را دانلود کنیم. و بیایید
خودمان این را باز کنیم و نگاهی به آن بیندازیم
1003
01:16:22,030 –> 01:16:26,430
آنچه در اکسل است. بنابراین من می خواهم این را در اینجا
مطرح کنم، شما می توانید آن لینک را ببینید. و این
1004
01:16:26,430 –> 01:16:32,030
مجموعه داده های ما همان است. بنابراین ما ستونهای خود را
داریم که فقط نشان میدهند، میدانید که چیست
1005
01:16:32,030 –> 01:16:35,410
ویژگی های مختلف در مجموعه داده های ما از
ویژگی ها و برچسب های مختلف داده های ما
1006
01:16:35,410 –> 01:16:39,520
مجموعه، ما زنده مانده ایم. بنابراین این همان چیزی است
که ما در واقع قصد پیشبینی آن را داریم. بنابراین
1007
01:16:39,520 –> 01:16:45,310
ما می خواهیم این برچسب را دقیقاً جایی که اطلاعات خروجی ما
قرار دارد، بنامیم. بنابراین در اینجا، یک صفر می ایستد
1008
01:16:45,310 –> 01:16:49,469
برای این واقعیت که کسی زنده نمانده است، و یکی
از این واقعیت است که کسی زنده مانده است
1009
01:16:49,469 –> 01:16:53,740
زنده ماندن. حالا فقط یک ثانیه به تنهایی به
آن فکر کنید و به برخی از آنها نگاه کنید
1010
01:16:53,740 –> 01:16:58,480
دسته بندی هایی که ما در اینجا داریم، می توانید
به این فکر کنید که چرا رگرسیون خطی خوب است
1011
01:16:58,480 –> 01:17:03,390
الگوریتم برای چیزی شبیه به این؟ خوب، مثلاً
اگر یک نفر زن باشد، می توانیم مهربانی کنیم
1012
01:17:03,390 –> 01:17:07,690
فرض کنید که آنها شانس بیشتری برای زنده ماندن
در تایتانیک خواهند داشت، فقط به این دلیل
1013
01:17:07,690 –> 01:17:10,740
از شما می دانید، نوع روشی که فرهنگ
ما کار می کند، می دانید، نجات زن و
1014
01:17:10,740 –> 01:17:14,550
اول بچه ها درسته و اگر از طریق این مجموعه داده نگاه
کنیم، زمانی که ببینیم آن را خواهیم دید
1015
01:17:14,550 –> 01:17:18,910
خانمها، بسیار نادر است که زنده نمانند،
اگرچه همانطور که من میگذرم، وجود دارد
1016
01:17:18,910 –> 01:17:22,380
تعداد زیادی که زنده نماندند. اما اگر به آن نگاه
کنیم، در مقایسه با مردان، می دانید، وجود دارد
1017
01:17:22,380 –> 01:17:26,400
قطعاً یک همبستگی قوی وجود دارد که زن
بودن منجر به نرخ بقای قویتر میشود.
1018
01:17:26,400 –> 01:17:30,211
حالا، اگر به سن نگاه کنیم، درست است، آیا میتوانیم به این
فکر کنیم که سن چه تأثیری بر این موضوع دارد؟ خوب، من
1019
01:17:30,211 –> 01:17:34,520
فرض کنید اگر فردی جوانتر است، احتمالاً شانس
بیشتری برای زنده ماندن دارد، زیرا
1020
01:17:34,520 –> 01:17:39,150
آنها میدانند، از نظر قایقهای نجات یا هر
چیز دیگری اولویتبندی شدهاند، نمیدانم
1021
01:17:39,150 –> 01:17:42,210
چیزهای زیادی در مورد تایتانیک بنابراین من نمی توانم به
طور خاص در مورد آن صحبت کنم. اما من فقط سعی می کنم
1022
01:17:42,210 –> 01:17:46,000
دسته ها را مرور کنید و به شما توضیح دهیم که چرا این
الگوریتم را انتخاب می کنیم. در حال حاضر، تعداد
1023
01:17:46,000 –> 01:17:50,449
خواهر و برادرهایی که ممکن است یکی آنطور که می دانید، تأثیرگذار
نباشد، به نظر من، parche. من این کار را نمی کنم
1024
01:17:50,449 –> 01:17:56,790
در واقع به یاد داشته باشید که parche مخفف چیست،
فکر می کنم مانند کدام قسمت است، نمی دانم
1025
01:17:56,790 –> 01:18:00,880
دقیقا همان چیزی است که این ستون مخفف آن است. بنابراین، متأسفانه،
من نمی توانم آن را به شما بگویم. اما خب
1026
01:18:00,880 –> 01:18:06,020
در مورد کرایه دوم بیشتر صحبت کنید، دوباره، دقیقاً
مطمئن نیستم که کرایه چیست، من هستم
1027
01:18:06,020 –> 01:18:09,489
بعد از این به وب سایت TensorFlow نگاه می کنم
و به شما دوستان باز می گردم. و داریم
1028
01:18:09,489 –> 01:18:13,560
یک کلاس. بنابراین کلاس آن کلاسی است که آنها در
قایق بودند، درست است؟ بنابراین درجه اول، دوم
1029
01:18:13,560 –> 01:18:17,000
کلاس، کلاس سوم بنابراین ممکن است فکر کنید فردی که در
یک کلاس بالاتر است ممکن است دارای بالاتر باشد
1030
01:18:17,000 –> 01:18:21,690
شانس زنده ماندن، ما عرشه داریم. بنابراین این همان
عرشه ای است که آنها هنگام سقوط آن روی آن بودند.
1031
01:18:21,690 –> 01:18:26,150
بنابراین ناشناخته بسیار رایج است. و سپس ما همه
این عرشه های دیگر را داریم، اگر کسی باشد
1032
01:18:26,150 –> 01:18:30,770
ضربه خورد، اگر کسی روی عرشه ایستاده بود که
ضربه اولیه را داشت، ممکن است فرض کنیم
1033
01:18:30,770 –> 01:18:34,949
که آنها شانس کمتری برای بقا دارند،
جایی که میرفتند، و سپس
1034
01:18:34,949 –> 01:18:38,040
آیا آنها تنها هستند؟ آره یا نه. و این یکی،
می دانید، جالب است، ما می خواهیم
1035
01:18:38,040 –> 01:18:41,960
ببینید آیا این تاثیری دارد، اگر کسی وام داشته
باشد شانس زنده ماندن آن بیشتر است؟
1036
01:18:41,960 –> 01:18:45,180
آیا این شانس کمتری برای زنده ماندن است؟ بنابراین
این یک نوع جالب است. و این چیزی است که من
1037
01:18:45,180 –> 01:18:48,780
میخواهم شما بچهها به این فکر کنید این است که وقتی
ما اطلاعات و دادههایی مانند این داریم، ما
1038
01:18:48,780 –> 01:18:53,150
لزوما نمی دانم چه همبستگی هایی ممکن است وجود داشته باشد.
اما می توانیم به نوعی فرض کنیم که وجود دارد
1039
01:18:53,150 –> 01:18:57,810
یک چیز خطی است که ما به دنبال نوعی الگو
هستیم، درست است. در حالی که اگر چیزی
1040
01:18:57,810 –> 01:19:02,190
درست است، پس می دانید، شاید احتمال بیشتری وجود دارد
که کسی زنده بماند. در حالی که مانند، اگر آنها هستند
1041
01:19:02,190 –> 01:19:06,620
تنها نیست، شاید کمتر باشد. و شاید هیچ ارتباطی
وجود نداشته باشد. اما همین است
1042
01:19:06,620 –> 01:19:10,810
جایی که ما در حین انجام این مدل متوجه خواهیم شد. بنابراین
اجازه دهید من در واقع به TensorFlow نگاه کنم
1043
01:19:10,810 –> 01:19:15,530
وب سایت و ببینید که آیا می توانم به یاد داشته باشم که چه
parche و من حدس می زنم چه نمایشگاهی بود. پس بریم بالا
1044
01:19:15,530 –> 01:19:19,420
به بالای اینجا. باز هم، بسیاری از این
موارد مستقیماً از TensorFlow کپی شده اند
1045
01:19:19,420 –> 01:19:23,170
سایت اینترنتی. من فقط چیزهای خودم را به آن اضافه کردم.
می توانید ببینید، من فقط همه اینها را کپی کردم.
1046
01:19:23,170 –> 01:19:27,750
ما فقط آن را وارد می کنیم. بیایید ببینیم
در مورد ستون های مختلف if چه می گوید
1047
01:19:27,750 –> 01:19:33,920
هر توضیح دقیقی به ما می دهد. خوب، بنابراین من نتوانستم
پیدا کنم که چه بخش هایی دارای موضع منصفانه هستند
1048
01:19:33,920 –> 01:19:37,110
جایی که بنا به دلایلی در وب سایت تنسورفلو وجود
دارد، یا من واقعاً نتوانستم آن را پیدا کنم
1049
01:19:37,110 –> 01:19:40,520
اطلاعات در مورد آن چون نه، می دانید،
یک نظر در زیر بنویسید. اما این نیست
1050
01:19:40,520 –> 01:19:45,170
مهم. ما فقط می خواهیم از این داده ها برای انجام آزمایش استفاده
کنیم. بنابراین کاری که من اینجا انجام داده ام، انجام داده ایم
1051
01:19:45,170 –> 01:19:50,000
در مجموعه داده های من بارگذاری شده است، و توجه کنید که من یک
مجموعه داده آموزشی را در یک داده آزمایشی بارگذاری کرده ام
1052
01:19:50,000 –> 01:19:54,420
تنظیم. حالا بعداً در این مورد بیشتر صحبت خواهیم
کرد. این مهم است، من دو داده متفاوت دارم
1053
01:19:54,420 –> 01:19:58,980
مجموعه ها، یکی برای آموزش مدل، و دیگری
برای تست مدل بدون هیچ نوع پایه
1054
01:19:58,980 –> 01:20:02,969
دلیل این است که ما این کار را انجام می دهیم زیرا وقتی مدل
خود را برای دقت آزمایش می کنیم تا ببینیم چقدر خوب است
1055
01:20:02,969 –> 01:20:07,470
با انجام دادن، آزمایش آن بر روی داده هایی که قبلاً
دیده شده است، منطقی نیست، باید تازه ببیند
1056
01:20:07,470 –> 01:20:12,510
دادهها تا بتوانیم مطمئن شویم که سوگیری وجود
ندارد و صرفاً دادهها را حفظ نکرده است،
1057
01:20:12,510 –> 01:20:17,300
میدونی که داشتیم حالا، کاری که من اینجا
در پایین با این قطار y انجام می دهم، و
1058
01:20:17,300 –> 01:20:23,560
این y ارزش این است که من اساساً یک ستون از این مجموعه داده
را بیرون میآورم. بنابراین اگر من آن را چاپ کنم
1059
01:20:23,560 –> 01:20:26,621
داده ها را در اینجا تنظیم کنید، و من در واقع می خواهم
یک ترفند جالب با پانداها را به شما نشان دهم
1060
01:20:26,621 –> 01:20:33,780
ما می توانیم برای بررسی این مورد استفاده کنیم. بنابراین می
توانم بگویم df train.so، با نگاه کردن به این فقط با نگاه کردن
1061
01:20:33,780 –> 01:20:38,350
در راس، و ما این را چاپ خواهیم کرد، ممکن است لازم باشد
برخی از موارد را در بالا وارد کنم. خواهیم دید
1062
01:20:38,350 –> 01:20:43,330
اگر این کار کند یا نه، بنابراین من فقط باید این واردات
را انجام دهم. پس بیایید نصب کنیم. و اجازه دهید
1063
01:20:43,330 –> 01:20:47,400
این واردات را برای سرانا انجام دهید. خوب، بنابراین
من به تازگی TensorFlow 2.0 را انتخاب کرده ام. بود
1064
01:20:47,400 –> 01:20:51,480
فقط وارد کردن این در حال حاضر باید در یک ثانیه انجام شود.
و حالا کاری که ما انجام خواهیم داد این است که خواهیم کرد
1065
01:20:51,480 –> 01:20:57,020
چارچوب داده را در اینجا چاپ کنید. بنابراین، اساساً کاری که این کار
انجام می دهد این است که آن را در یک پاندا بارگذاری می کند
1066
01:20:57,020 –> 01:21:01,940
چارچوب داده این یک نوع خاص از شی است. اکنون،
ما به طور خاص وارد این موضوع نمی شویم.
1067
01:21:01,940 –> 01:21:06,110
اما یک چارچوب داده به ما اجازه می دهد تا جنبه های مختلف
زیادی را در مورد داده ها و نوع آن مشاهده کنیم
1068
01:21:06,110 –> 01:21:09,890
آن را به شکلی زیبا ذخیره کنید، برخلاف
بارگیری و ذخیره آن به شکل مشابه
1069
01:21:09,890 –> 01:21:14,710
یک لیست یا یک آرایه NumPy، که اگر نمی دانستیم چگونه از پانداها
استفاده کنیم، ممکن است این کار را انجام دهیم.
1070
01:21:14,710 –> 01:21:19,380
روش بسیار خوبی برای خواندن CSV بارگذاری شده در
یک شی قاب داده است که در واقع به این معنی است
1071
01:21:19,380 –> 01:21:23,770
میتوانیم به ستونها و ردیفهای خاص در چارچوب داده
ارجاع دهیم. پس بیایید این را اجرا کنیم
1072
01:21:23,770 –> 01:21:31,590
و فقط نگاهی به آن بیندازید بله، من باید سر نقطه قطار
df را چاپ کنم. پس بیایید این کار را انجام دهیم.
1073
01:21:31,590 –> 01:21:36,311
و ما به آنجا می رویم. بنابراین این همان چیزی است
که سر قاب داده ما به نظر می رسد. حالا سر، آن چه
1074
01:21:36,311 –> 01:21:41,440
انجام می دهد این است که پنج ورودی اول در مجموعه داده های ما را به
ما نشان می دهد و همچنین تعداد زیادی از آنها را به ما نشان می دهد
1075
01:21:41,440 –> 01:21:45,460
ستون های مختلفی که در آن قرار دارند. حالا از آنجایی
که ما بیشتر از آنچه شما می دانید داریم، داریم
1076
01:21:45,460 –> 01:21:48,380
چند ستون مختلف، همه آنها را به ما نشان
نمی دهد، فقط نقطه را به ما می دهد
1077
01:21:48,380 –> 01:21:52,200
نقطه نقطه اما میتوانیم ببینیم که قاب داده
به این شکل است. و این یک نوع است
1078
01:21:52,200 –> 01:21:57,931
نمایندگی داخلی بنابراین ما ورودی هایی داریم
که صفر باقی مانده است. یکی، ما داریم
1079
01:21:57,931 –> 01:22:03,160
مرد، زن، همه اینها حالا توجه کنید که این
ستون باقی مانده است، خوب؟ به چه دلیل
1080
01:22:03,160 –> 01:22:09,920
من قصد دارم انجام دهم این است که دوباره سر قاب
داده را چاپ کنم. بنابراین قطار df، سر نقطه،
1081
01:22:09,920 –> 01:22:15,540
بعد از اینکه این دو خط را اجرا کردیم. حالا کاری که این
خط انجام می دهد این است که کل ستون باقی مانده را می گیرد،
1082
01:22:15,540 –> 01:22:21,090
بنابراین تمام این صفرها و یک ها، و آن را از این
قاب داده حذف می کند، بنابراین قاب داده سر،
1083
01:22:21,090 –> 01:22:25,220
و آن را در متغیر y train ذخیره می کند. دلیل اینکه ما
باید این کار را انجام دهیم این است که نیاز داریم
1084
01:22:25,220 –> 01:22:29,450
برای جدا کردن داده ها، از داده هایی که نوعی
اطلاعات ورودی ما هستند، دسته بندی می کنیم
1085
01:22:29,450 –> 01:22:34,300
یا مجموعه داده های اولیه ما. درست. بنابراین از آنجایی
که ما به دنبال اطلاعات باقیمانده هستیم، هستیم
1086
01:22:34,300 –> 01:22:38,880
میدانید، آن را در یک نوع ذخیره متغیر در اینجا
قرار خواهم داد. حالا ما همین کار را خواهیم کرد
1087
01:22:38,880 –> 01:22:44,260
چیزی برای مجموعه داده های ارزیابی، که داده
های ارزیابی یا آزمایش df است. و توجه کنید
1088
01:22:44,260 –> 01:22:49,330
که در اینجا، این به عنوان CSV آموزش داده شد،
و این یکی eval dot CSV بود. حالا اینها دقیق هستند
1089
01:22:49,330 –> 01:22:54,350
به همان شکل، ظاهر آنها کاملاً یکسان است. فقط این است
که، می دانید، برخی از ورودی ها، ما داریم
1090
01:22:54,350 –> 01:22:58,179
فقط به نوعی خودسرانه آنها را تقسیم کرد. بنابراین
ما در این آموزش ورودی های زیادی خواهیم داشت
1091
01:22:58,179 –> 01:23:01,350
تنظیم. و ما تعدادی در مجموعه آزمایشی خواهیم داشت
که فقط از آنها برای ارزیابی استفاده خواهیم کرد
1092
01:23:01,350 –> 01:23:07,240
مدل بعدا بنابراین ما آنها را با این کار
حذف می کنیم و این ستون را برمی گرداند.
1093
01:23:07,240 –> 01:23:11,050
بنابراین، اگر من y train را چاپ کنم، که در واقع هستند، اجازه
دهید ابتدا به این یکی نگاه کنیم، فقط برای نشان دادن
1094
01:23:11,050 –> 01:23:15,810
شما چگونه حذف شده است، ما می توانیم ببینیم که ما
ستون باقی مانده را در اینجا داریم، ما ظاهر شدیم،
1095
01:23:15,810 –> 01:23:20,030
و اکنون ستون باقی مانده از آن مجموعه داده
حذف می شود. بنابراین فقط مهم است که بفهمیم.
1096
01:23:20,030 –> 01:23:24,130
اکنون می توانیم موارد دیگر را نیز چاپ کنیم. بنابراین
ما می توانیم به قطار Y نگاه کنیم، ببینیم آن چیست
1097
01:23:24,130 –> 01:23:28,561
فقط برای این است که مطمئن شویم واقعاً این داده ها را
درک می کنیم. بنابراین بیایید به قطار y نگاه کنیم. و شما
1098
01:23:28,561 –> 01:23:34,679
می توانید ببینید که ما 626 یا 627 ورودی داریم، و
فقط شما می دانید، صفر یا یک نشان دهنده
1099
01:23:34,679 –> 01:23:39,840
چه کسی زنده بماند یا نه. در حال
حاضر شاخص های مربوطه در این
1100
01:23:39,840 –> 01:23:45,550
نوع فهرست یا چارچوب داده با شاخص های موجود
در چارچوب داده های تست و آموزش مطابقت دارد.
1101
01:23:45,550 –> 01:23:51,080
منظور من از آن این است که، می دانید، ورودی صفر
در این چارچوب داده خاص، با آن مطابقت دارد
1102
01:23:51,080 –> 01:23:56,510
ورودی صفر در متغیر y train ما. بنابراین اگر
کسی زنده ماند، می دانید، در ورودی صفر،
1103
01:23:56,510 –> 01:24:01,780
در اینجا می گویند یک، درست است، یا در این مورد، ورودی
صفر زنده نمی ماند. حالا، امیدوارم که اینطور باشد
1104
01:24:01,780 –> 01:24:05,290
روشن امیدوارم شما را با آن اشتباه نگیرم. اما
من فقط می خواهم یک مثال دیگر را نشان دهم
1105
01:24:05,290 –> 01:24:09,430
مطمئن شوید. بنابراین ما می گوییم df train
zero، من آن را چاپ می کنم و سپس می رویم
1106
01:24:09,430 –> 01:24:15,000
چاپ y با شاخص صفر، اوه، اگر براکت هایم را خراب
نکردم، و ما نگاهی خواهیم انداخت
1107
01:24:15,000 –> 01:24:19,110
در آن. خوب، پس من فقط اسناد را جستجو کردم، زیرا کاملاً فراموش
کرده بودم که نمی توانم این کار را انجام دهم
1108
01:24:19,110 –> 01:24:24,179
که اگر بخواهم یک ردیف خاص در قاب داده خود پیدا کنم،
کاری که می توانم انجام دهم چاپ نقطه است
1109
01:24:24,179 –> 01:24:29,110
نگاه کن بنابراین فریم دادهام را انجام میدهم، سپس نگاه نقطهای،
و سپس هر شاخصی را که میخواهم انجام میدهم. بنابراین در
1110
01:24:29,110 –> 01:24:34,130
در این مورد، من ردیف صفر را پیدا می کنم، که این
است. و سپس در قطار Y، من این کار را انجام می دهم
1111
01:24:34,130 –> 01:24:39,120
همان چیز من ردیف صفر را پیدا می کنم. حالا آنچه قبلا
داشتم، درست است، اگر df train انجام می دادم، و
1112
01:24:39,120 –> 01:24:43,810
من براکت های مربع را در اینجا قرار دادم، کاری
که می توانم انجام دهم ارجاع به یک ستون خاص است.
1113
01:24:43,810 –> 01:24:48,520
بنابراین اگر می خواستم نگاه کنم، می دانید، ستون را برای
سن بگویید، درست است، بنابراین ما یک ستون داریم
1114
01:24:48,520 –> 01:24:53,739
برای سن، کاری که می توانم انجام دهم این است که df train age را
انجام دهم. و سپس من می توانم این را به این شکل چاپ کنم، و
1115
01:24:53,739 –> 01:24:57,600
این همه ارزش های سنی مختلف را به من می دهد. بنابراین
به نوعی از یک قاب داده استفاده می کنیم.
1116
01:24:57,600 –> 01:25:00,970
همانطور که جلوتر می رویم آن را خواهیم دید. اکنون.
بیایید به مثال دیگری که داشتم برگردیم، زیرا
1117
01:25:00,970 –> 01:25:07,019
من فقط آن را پاک کردم، جایی که می خواستم ردیف های
صفر را در قاب داده به شما نشان دهم. این آموزش است.
1118
01:25:07,019 –> 01:25:11,990
و سپس در قطار y، می دانید، خروجی،
هر چه که باشد. پس بقا. پس تو
1119
01:25:11,990 –> 01:25:17,160
در اینجا می توانید ببینید که این همان چیزی است که
از چاپ df train dot loke، صفر به دست می آوریم. پس ردیف صفر،
1120
01:25:17,160 –> 01:25:21,001
این همه اطلاعات است و سپس در اینجا، این با
واقعیتی که آنها انجام دادند مطابقت دارد
1121
01:25:21,001 –> 01:25:25,670
در ردیف صفر زنده نمانید زیرا به سادگی خروجی
مقدار صفر است. من این را می دانم
1122
01:25:25,670 –> 01:25:30,410
عجیب است که می گویید مانند نام صفر D تایپ کنید
شی صفر، نگران این نباشید. فقط به این دلیل است
1123
01:25:30,410 –> 01:25:34,130
سعی دارد آن را با اطلاعاتی چاپ کند. اما
در اصل، این فقط به معنای این شخص است
1124
01:25:34,130 –> 01:25:37,360
که مرد 22 ساله بود و یک خواهر و برادر داشت زنده
نماند.
1125
01:25:37,360 –> 01:25:38,360
باشه،
1126
01:25:38,360 –> 01:25:42,630
پس بیایید از این وضعیت خارج شویم حالا میتوانیم
این را ببندیم، و بیایید به اوه، تقریباً زیاد
1127
01:25:42,630 –> 01:25:47,280
قبلاً کاری را که من در اینجا انجام دادهام انجام دادهایم،
میتوانیم به سر قاب داده نگاه کنیم، این است
1128
01:25:47,280 –> 01:25:51,440
کمی خروجی بهتر، زمانی که ما فقط سر نقطه قطار
df داشته باشیم، می توانیم ببینیم که ما
1129
01:25:51,440 –> 01:25:55,090
یک نمودار کوچک خروجی خوب دریافت کنید، ما
قبلاً به این اطلاعات نگاه کرده ایم.
1130
01:25:55,090 –> 01:25:59,130
بنابراین ما برخی از ویژگی های مجموعه داده را
می دانیم. حال می خواهیم به شرح آن بپردازیم
1131
01:25:59,130 –> 01:26:03,590
مجموعه دادهها، گاهی اوقات آنچه توصیف میکند این
است که اطلاعات کلی را به ما میدهد. بنابراین
1132
01:26:03,590 –> 01:26:09,460
بیایید اینجا نگاهی به آن بیندازیم، میتوانیم ببینیم
که 627 ورودی داریم، میانگین سنی 29 سال است.
1133
01:26:09,460 –> 01:26:14,160
انحراف معیار این است که می دانید، 12، نقطه، هر چه
باشد. و سپس همان اطلاعات را به دست می آوریم
1134
01:26:14,160 –> 01:26:18,080
در مورد تمام این ویژگی های مختلف دیگر. بنابراین به
عنوان مثال، به ما میدهد که میدانید،
1135
01:26:18,080 –> 01:26:21,640
به معنای عادلانه، حداقل عادلانه، و فقط
برخی از آمار. چون این عالی را درک کنید،
1136
01:26:21,640 –> 01:26:25,120
اگر واقعاً مهم نیست، نکته مهمی که معمولاً باید به
آن نگاه کنید این است که تعداد آنها چقدر است
1137
01:26:25,120 –> 01:26:29,480
ورودی هایی که داریم، گاهی اوقات به آن اطلاعات نیاز داریم.
و گاهی اوقات میانگین نیز می تواند مفید باشد،
1138
01:26:29,480 –> 01:26:33,910
زیرا می توانید به نوعی میانگینی از
مقدار میانگین داده ها بدست آورید
1139
01:26:33,910 –> 01:26:37,540
تنظیم. بنابراین اگر بعداً سوگیری وجود داشت،
می توانید آن را کشف کنید. اما دیوانه وار مهم نیست.
1140
01:26:37,540 –> 01:26:41,840
خوب، پس بیایید به شکل نگاهی بیندازیم. بنابراین درست
مانند آرایه های NumPy، و تانسورها دارای یک هستند
1141
01:26:41,840 –> 01:26:45,330
ویژگی شکل فریم های داده هم همینطور. بنابراین ما می
خواهیم به شکل نگاه کنیم، می دانید، ما می توانیم
1142
01:26:45,330 –> 01:26:51,340
فقط یک شکل نقطه قطار df را چاپ کنید، 627 در 9 می
گیریم، که در اصل به این معنی است که 627 داریم.
1143
01:26:51,340 –> 01:26:57,929
سطرها و نه ستون یا نه ویژگی. پس بله، این
چیزی است که اینجا می گوید، می دانید،
1144
01:26:57,929 –> 01:27:02,489
627 ورودی، نه ویژگی، ما می توانیم ویژگی ها و ویژگی
ها را با هم عوض کنیم. و ما می توانیم نگاه کنیم
1145
01:27:02,489 –> 01:27:05,699
اطلاعات سر برای y. بنابراین ما می توانیم آن
را در اینجا ببینیم، که قبلاً به آن نگاه کرده ایم.
1146
01:27:05,699 –> 01:27:11,170
و این به ما نامی می دهد که از آن باقی مانده است. خوب، حالا
کاری که می توانیم انجام دهیم این است که بسازیم
1147
01:27:11,170 –> 01:27:14,360
نوعی نمودار در مورد این داده ها. حالا من این
کد را دزدیده ام، می دانید، مستقیم
1148
01:27:14,360 –> 01:27:18,690
از وب سایت تنسورفلو، من از شما بچه ها انتظار ندارم
که هیچ کدام از این کارها را انجام دهید، می دانید،
1149
01:27:18,690 –> 01:27:22,500
مانند خروجی هر یک از این مقادیر، کاری که ما می خواهیم
انجام دهیم این است که چند هیستوگرام و
1150
01:27:22,500 –> 01:27:26,280
برخی نمودارها فقط برای نگاه کردن به نوعی همبستگی در داده
ها به طوری که وقتی شروع به ایجاد کنیم
1151
01:27:26,280 –> 01:27:31,710
در این مدل، ما مقداری شهود در مورد آنچه ممکن است انتظار داشته
باشیم، داریم. پس بیایید به سن نگاه کنیم. بنابراین
1152
01:27:31,710 –> 01:27:36,179
این یک هیستوگرام از سن به ما می دهد. بنابراین میتوانیم
ببینیم که حدود 25 نفر هستند، افرادی که این تعداد هستند
1153
01:27:36,179 –> 01:27:41,790
به نوعی بین صفر تا پنج هستند، می
دانید، شاید پنج نفر باشند
1154
01:27:41,790 –> 01:27:46,010
بین پنج تا 10. و سپس بیشترین تعداد افراد
به نوعی در بین آنها قرار می گیرند
1155
01:27:46,010 –> 01:27:50,850
دهه 20 و 30 بنابراین در اواسط دهه 20، این اطلاعات خوبی
برای دانستن است، زیرا در حال انجام است
1156
01:27:50,850 –> 01:27:55,641
برای وارد کردن کمی تعصب به نوعی نمودار
همبستگی خطی ما، درست است. بنابراین
1157
01:27:55,641 –> 01:27:59,890
فقط با درک اینکه می دانید که ما یک زیرمجموعه بزرگ
داریم، در اینجا برخی موارد پرت وجود دارد،
1158
01:27:59,890 –> 01:28:04,220
مثل اینکه یک نفر اینجا تبلیغ می
کند، چند نفر 70 ساله، لاغر و مهم
1159
01:28:04,220 –> 01:28:08,130
قبل از اینکه به سراغ الگوریتم برویم، چیزهایی
را باید درک کنیم. پس بیایید نگاه کنیم
1160
01:28:08,130 –> 01:28:12,679
ارزش های جنسی در حال حاضر بنابراین این تعداد ماده
و چند مرد است، ما می توانیم ببینیم که وجود دارد
1161
01:28:12,679 –> 01:28:16,960
تعداد بسیار زیادی از مردان در آنجا به عنوان زن، ما می
توانیم نگاهی به کلاس بیندازیم. بنابراین می توانیم
1162
01:28:16,960 –> 01:28:22,030
ببینید آیا آنها در کلاس اول، دوم یا سوم هستند یا خیر، اکثر افراد
در رتبه سوم قرار دارند و سپس به دنبال آنها قرار می گیرند
1163
01:28:22,030 –> 01:28:26,380
اول و بعد دوم و در نهایت، میتوانیم ببینیم
این چه کاری است که انجام میدهیم
1164
01:28:26,380 –> 01:28:31,750
اوه، درصد بقا بر اساس جنسیت. بنابراین ما می
توانیم ببینیم که یک فرد خاص یا خاص چقدر محتمل است
1165
01:28:31,750 –> 01:28:36,920
رابطه جنسی فقط با طرح این موضوع زنده ماندن است. بنابراین
می توانیم ببینیم که مردان حدود 20 درصد بقا دارند
1166
01:28:36,920 –> 01:28:41,739
نرخ، در حالی که زنان تا حدود 78 درصد
هستند. بنابراین درک آن مهم است،
1167
01:28:41,739 –> 01:28:45,760
آن چیزی که قبلاً در مجموعه دادهها در هنگام
کاوش به آن نگاه میکردیم، تأیید میکند
1168
01:28:45,760 –> 01:28:49,220
آن را انجام دهید، و لازم نیست هر بار که به یک مجموعه داده نگاه
می کنید این کار را انجام دهید، اما این کار را انجام دهید
1169
01:28:49,220 –> 01:28:52,660
خوب است که به نوعی شهود در مورد آن به دست آوریم. بنابراین
این چیزی است که ما یاد گرفته ایم. تا حالا،
1170
01:28:52,660 –> 01:28:56,551
اکثر مسافران 20 یا 30 ساله هستند، اکثر
مسافران مرد هستند، آنها
1171
01:28:56,551 –> 01:29:00,950
در کلاس سوم و زنان شانس بیشتری برای زنده ماندن
دارند که قبلاً این را می دانستند.
1172
01:29:00,950 –> 01:29:03,739
بسیار خوب، پس آموزش و آزمایش مجموعه داده ها.
حالا، ما قبلاً به نوعی این را گذرانده ایم،
1173
01:29:03,739 –> 01:29:08,110
بنابراین من سریع آن را مرور می کنم. کاری که در بالا انجام
دادیم این است که در دو بار مختلف بارگذاری می شود
1174
01:29:08,110 –> 01:29:14,390
مجموعه های داده اولین مجموعه داده آن مجموعه
داده آموزشی بود که شکل 627 در 9 داشت.
1175
01:29:14,390 –> 01:29:18,070
کاری که من واقعاً میخواهم انجام دهم این است که یک بلوک
کد در اینجا ایجاد کنم، و فقط نگاهی به چه چیزی داشته باشم
1176
01:29:18,070 –> 01:29:24,150
این شکل نقطه معادل df برای نشان دادن تعداد ورودی
های ما در اینجا بود. بنابراین در اینجا در ما
1177
01:29:24,150 –> 01:29:29,949
در حال آزمایش مجموعه دادهها، میتوانید ببینید که ما در 264 ورودی یا
ردیف، هرچه که هستید، به میزان قابل توجهی کمتر داریم.
1178
01:29:29,949 –> 01:29:34,841
می خواهم با آنها تماس بگیرم بنابراین این تعداد چیزهایی
است که ما باید واقعاً مدل خود را آزمایش کنیم. پس چی
1179
01:29:34,841 –> 01:29:38,720
ما از آن داده های آموزشی برای ایجاد مدل و سپس
داده های آزمایشی برای ارزیابی استفاده می کنیم
1180
01:29:38,720 –> 01:29:42,449
و مطمئن شوید که به درستی کار می کند. پس
این موارد مهم است. هر وقت که هستیم
1181
01:29:42,449 –> 01:29:47,320
با انجام مدلهای یادگیری ماشین، معمولاً
دادههای آزمایش و آموزش داریم. و بله،
1182
01:29:47,320 –> 01:29:51,190
تقریباً همین است. حالا من فقط یک ثانیه وقت
می گذارم تا بسیاری از این ها را کپی کنم
1183
01:29:51,190 –> 01:29:55,489
به نوت بوک دیگری که من دارم کد بزنید تا
بتوانیم همه آن را یکجا ببینیم. و
1184
01:29:55,489 –> 01:29:57,620
سپس ما برمی گردیم و در واقع به ساخت مدل
می پردازیم.
1185
01:29:57,620 –> 01:30:01,000
خوب، بنابراین من در برخی از کدهای اینجا کپی کردم.
من می دانم که این به نظر می رسد یک نوع چرندیات است
1186
01:30:01,000 –> 01:30:04,580
در حال حاضر، اما من خط به خط می نویسم
که همه اینها چه می کنند و چرا داریم
1187
01:30:04,580 –> 01:30:08,600
این اینجا اما ابتدا باید در مورد چیزی به
نام ستون های ویژگی بحث کنیم. و تفاوت
1188
01:30:08,600 –> 01:30:14,880
بین داده های مقوله ای و عددی بنابراین دریافت داده
های طبقه بندی شده در واقع نسبتاً رایج است.
1189
01:30:14,880 –> 01:30:17,989
حالا وقتی به مجموعه دادههایمان نگاه میکنیم،
و در واقع میتوانم باز کنم، آن را باز نمیکنم
1190
01:30:17,989 –> 01:30:23,270
اکسل دیگر. اما بیایید این را از دانلودهای من
باز کنیم. پس بیایید دانلود کنیم این کجاست
1191
01:30:23,270 –> 01:30:29,870
قطار – تعلیم دادن؟ باشه عالیه بنابراین ما این برگه داده
اکسل را در اینجا داریم. و ما می توانیم ببینیم که چه قاطعانه است
1192
01:30:29,870 –> 01:30:34,990
داده ها یا داده های طبقه ای است، چیزی است
که عددی نیست. به عنوان مثال، ناشناخته
1193
01:30:34,990 –> 01:30:41,550
ببینید، سوم اول، شهر و چرا درست است، بنابراین هر چیزی
که دسته بندی های مختلف داشته باشد، وجود دارد
1194
01:30:41,550 –> 01:30:46,261
برای اینکه مانند یک مجموعه خاص از دسته های مختلف باشد،
می تواند برای مثال، برای سن، نوع باشد
1195
01:30:46,261 –> 01:30:50,100
مجموعه مقادیری که میتوانیم برای سن داشته باشیم
عددی است، بنابراین متفاوت است. اما برای
1196
01:30:50,100 –> 01:30:53,800
به طور قطعی، ما می توانیم مرد یا زن داشته باشیم، و من
فکر می کنم می توانیم غیر از این داشته باشیم
1197
01:30:53,800 –> 01:30:58,150
مجموعه داده، ما فقط نامه داریم و فقط زن داریم.
برای کلاس، ابتدا باید داشته باشیم،
1198
01:30:58,150 –> 01:31:02,390
سومین سوم برای عرشه، ما می توانیم CA ناشناخته
داشته باشیم، مطمئنم از طریق تمام حروف
1199
01:31:02,390 –> 01:31:07,360
حروف الفبا، اما هنوز هم به صورت طبقه بندی شده در نظر گرفته می
شود. حال، با داده های طبقه بندی شده چه کنیم؟
1200
01:31:07,360 –> 01:31:12,410
خوب، ما همیشه باید این داده ها را به نحوی به اعداد
تبدیل کنیم. بنابراین آنچه ما در واقع
1201
01:31:12,410 –> 01:31:17,590
در پایان کار این است که این داده ها را با استفاده از مقادیر
صحیح رمزگذاری می کنیم. بنابراین برای مثال مرد
1202
01:31:17,590 –> 01:31:21,770
و زن، چیزی که ممکن است بگوییم، و این کاری است
که در یک ثانیه انجام خواهیم داد، آن زن است
1203
01:31:21,770 –> 01:31:27,160
با صفر و نر با یک نشان داده می شود، ما این
کار را انجام می دهیم زیرا اگرچه جالب است
1204
01:31:27,160 –> 01:31:31,960
برای اینکه بدانیم کلاس واقعی چیست، مدل اهمیتی
نمیدهد، درست زن و مرد، آن را ندارد
1205
01:31:31,960 –> 01:31:35,541
برای آن تفاوت ایجاد کند، فقط باید بداند
که آن مقادیر متفاوت یا متفاوت هستند،
1206
01:31:35,541 –> 01:31:39,429
یا آن مقادیر یکسان هستند. بنابراین به جای استفاده
از رشته ها و تلاش برای یافتن راهی
1207
01:31:39,429 –> 01:31:43,429
برای قبول کردن آن و انجام ریاضی با آن، باید
آنها را به اعداد صحیح تبدیل کنیم
1208
01:31:43,429 –> 01:31:48,470
آنها در حال حاضر برای کلاس صفر و یک هستند، درست
است، بنابراین اول، دوم، سوم، می دانید،
1209
01:31:48,470 –> 01:31:51,140
شما بچه ها احتمالاً می توانید فرض کنید که ما قصد داریم این
را رمزگذاری کنیم با ما آن را رمزگذاری خواهیم کرد
1210
01:31:51,140 –> 01:31:56,960
با 012. اکنون، دوباره، این لزوماً نیازی به سفارش
ندارد. بنابراین یک سوم می تواند نماینده باشد
1211
01:31:56,960 –> 01:32:01,420
توسط یک و اولین را می توان با دو نشان داد، درست
است؟ این نیازی به سفارش نیست، این است
1212
01:32:01,420 –> 01:32:05,179
مهم نیست تا زمانی که هر سوم عدد یکسانی
داشته باشد، هر اولی یکسان است
1213
01:32:05,179 –> 01:32:08,610
عدد، و هر ثانیه همان عدد را دارد. و سپس
همان چیز با عرشه. همین مورد
1214
01:32:08,610 –> 01:32:12,760
با embark و همین مورد با وام. اکنون، میتوانیم
نمونهای داشته باشیم که شما بدانید،
1215
01:32:12,760 –> 01:32:17,170
ما هر یک از این مقادیر را با مقدار متفاوتی رمزگذاری
کرده ایم. بنابراین در، شما می دانید،
1216
01:32:17,170 –> 01:32:21,540
موقعیت نادری که در آن یک دسته وجود
دارد، آن دسته بندی، و هر ارزش واحد
1217
01:32:21,540 –> 01:32:27,850
در آن دسته با چیزی که ما خواهیم داشت متفاوت
است، می دانید، 627، در این مثال، متفاوت است
1218
01:32:27,850 –> 01:32:31,449
رمزگذاری برچسب هایی که قرار است اعداد باشند، خوب است،
ما می توانیم این کار را انجام دهیم. و در واقع،
1219
01:32:31,449 –> 01:32:35,429
ما واقعاً نیازی به انجام این کار نداریم، زیرا میخواهید ببینید
که چگونه TensorFlow میتواند این کار را انجام دهد
1220
01:32:35,429 –> 01:32:40,100
برای ما. بنابراین آن داده های طبقه بندی شده،
ستون های عددی بسیار ساده هستند. آنها هستند
1221
01:32:40,100 –> 01:32:45,111
هر چیزی که فقط دارای مقادیر صحیح یا شناور است.
بنابراین در این مورد، سن و منصفانه. و
1222
01:32:45,111 –> 01:32:48,980
بله، پس این کاری است که ما انجام داده ایم. ما فقط ستون
های دسته بندی خود را در اینجا تعریف کرده ایم، و
1223
01:32:48,980 –> 01:32:52,510
ستون های عددی ما در اینجا. این مهم است، زیرا
ما می خواهیم از طریق آنها حلقه بزنیم،
1224
01:32:52,510 –> 01:32:55,850
که ما در اینجا برای ایجاد چیزی به نام ستون های
ویژگی انجام می دهیم. ستون های ویژگی هستند
1225
01:32:55,850 –> 01:32:59,800
چیز خاصی نیست، آنها فقط همان چیزی هستند که ما
باید به برآوردگر خطی یا خطی خود تغذیه کنیم
1226
01:32:59,800 –> 01:33:04,000
مدلی برای پیش بینی واقعی به قدری گام
های ما در اینجاست که طی کرده ایم
1227
01:33:04,000 –> 01:33:10,550
تا کنون، وارد میشود، مجموعه داده را بارگیری میکند، مجموعه
داده را کاوش میکند، مطمئن شوید که آن را درک کردهایم،
1228
01:33:10,550 –> 01:33:14,180
ستون های دسته بندی و ستون های عددی ما را ایجاد کنید.
بنابراین من فقط اینها را سخت کدگذاری کردم
1229
01:33:14,180 –> 01:33:20,060
درست است، مانند عرشه کلاس پارچ جنسی به تنهایی،
همه اینها. و سپس همان چیز با عدد
1230
01:33:20,060 –> 01:33:23,640
ستون ها. و سپس برای یک برآوردگر خطی، باید اینها
را به عنوان ستون های ویژگی ایجاد کنیم
1231
01:33:23,640 –> 01:33:27,401
با استفاده از نوعی نحو پیشرفته، که در اینجا به بررسی
آن خواهیم پرداخت. بنابراین ما ایجاد می کنیم
1232
01:33:27,401 –> 01:33:30,989
یک لیست خالی، که ستون های ویژگی ما است، که
فقط ویژگی های مختلف ما را ذخیره می کند
1233
01:33:30,989 –> 01:33:36,800
ستونها، نام هر ویژگی را در ستونهای دستهبندی
حلقه میزنیم. و کاری که ما انجام می دهیم
1234
01:33:36,800 –> 01:33:41,950
ما یک واژگان تعریف می کنیم که برابر با چارچوب
داده در نام ویژگی است. بنابراین
1235
01:33:41,950 –> 01:33:45,480
اول با سکس شروع میکردیم، بعد میرفتیم و خواهر
و برادر، بعد خشک میشویم، بعد میرویم
1236
01:33:45,480 –> 01:33:50,350
برو کلاس و ما همه مقادیر منحصر به فرد مختلف را دریافت
می کنیم. بنابراین در واقع این چیزی است که این
1237
01:33:50,350 –> 01:33:55,429
dot unique لیستی از تمام مقادیر منحصر به فرد را از
کد ویژگی دریافت می کند. و من می توانم چاپ کنم
1238
01:33:55,429 –> 01:33:59,750
این، او این را در یک خط متفاوت قرار می دهد، ما فقط
این مقدار را می گیریم و نگاهی می اندازیم
1239
01:33:59,750 –> 01:34:05,310
در واقع این چه چیزی است، درست است. بنابراین اگر من
بدوم، فقط باید همه اینها را به ترتیب اجرا کنم.
1240
01:34:05,310 –> 01:34:10,880
و سپس ما یک بلوک کد جدید ایجاد می کنیم در حالی که
منتظریم تا این اتفاق بیفتد. ببینیم آیا ما
1241
01:34:10,880 –> 01:34:14,980
می توانید این نصب را به اندازه کافی سریع انجام دهید.
1242
01:34:14,980 –> 01:34:17,940
بدو بدو بدو.
1243
01:34:17,940 –> 01:34:25,199
خوب، اکنون به قطار df می رویم، و می توانیم ببینیم که
این چیزی است که به نظر می رسد. پس اینها هستند
1244
01:34:25,199 –> 01:34:29,200
تمام مقادیر منحصر به فرد متفاوتی که در
نام ویژگی خاص داشتیم. اکنون آن ویژگی
1245
01:34:29,200 –> 01:34:34,590
اسم چی بود ستون های طبقه بندی شده اوه، کاری که من انجام
می دهم، نام ویژگی متأسفانه، همین خواهد بود
1246
01:34:34,590 –> 01:34:39,260
منحصر به فرد اجازه دهید فقط به جای نام ویژگی،
جنسیت را درست قرار دهیم و اجازه دهید
1247
01:34:39,260 –> 01:34:44,050
ببین این چیه بنابراین ما می توانیم ببینیم
که دو ارزش منحصر به فرد مرد و زن هستند.
1248
01:34:44,050 –> 01:34:48,510
حالا من واقعاً میخواهم کاری را انجام دهم که embark
town است و میخواهم ببینم این یکی چیست. بنابراین
1249
01:34:48,510 –> 01:34:53,690
ما چقدر مقادیر مختلف داریم، بنابراین آن را در آن
کپی می کنیم و می توانیم ببینیم که ساوتهمپتون داریم
1250
01:34:53,690 –> 01:34:57,590
نمیتوانیم آن و سپس شهرهای دیگر و مجهول را تلفظ
کنیم، و به نوعی به این نتیجه میرسیم
1251
01:34:57,590 –> 01:35:00,949
ارزش منحصر به فرد پس این کاری است که آن روش انجام
می دهد. آنجا. بیایید در واقع این را حذف کنیم
1252
01:35:00,949 –> 01:35:03,090
بلوک کد چون دیگر نیازی نداریم.
1253
01:35:03,090 –> 01:35:04,290
خوب، پس همین است
1254
01:35:04,290 –> 01:35:07,719
کاری که ما انجام می دهیم و سپس وقتی اینجا را انجام می دهیم،
می گوییم ستون های ویژگی نقطه اضافه می شوند. بنابراین فقط
1255
01:35:07,719 –> 01:35:14,179
به این لیست، ستون مشخصه TensorFlow را با لیست
واژگان نقطه نقطه اضافه کنید.
1256
01:35:14,179 –> 01:35:17,390
حالا، من می دانم که این یک لقمه است، اما
این یک چیزی است، شما فقط می روید
1257
01:35:17,390 –> 01:35:20,410
برای جستجو در زمانی که نیاز به استفاده از آن دارید، درست
است. بنابراین درک کنید که باید ویژگی ایجاد کنید
1258
01:35:20,410 –> 01:35:24,270
ستونهای رگرسیون خطی، شما واقعاً نیازی به درک
کامل نحوه انجام آن ندارید، اما شما
1259
01:35:24,270 –> 01:35:27,870
فقط باید بدانید که این کاری است که باید انجام
دهید. و سپس می توانید نحو را جستجو کنید
1260
01:35:27,870 –> 01:35:32,370
و درک کنید. بنابراین این کاری است که این کار انجام
می دهد، این در واقع برای ما ایجاد می کند
1261
01:35:32,370 –> 01:35:37,199
ستون، به شکل یک آرایه NumPy مانند خواهد
بود، نوعی که دارای این ویژگی است
1262
01:35:37,199 –> 01:35:41,510
نام، بنابراین هر کدام را که از طریق حلقه
بررسی کرده ایم، و سپس همه واژگان مختلف مرتبط
1263
01:35:41,510 –> 01:35:46,340
با آن. اکنون ما به این نیاز داریم زیرا فقط
باید این ستون را ایجاد کنیم تا بتوانیم
1264
01:35:46,340 –> 01:35:50,490
مدل ما را با استفاده از آن ستون های مختلف ایجاد کنید،
اگر این کار منطقی است. بنابراین مدل خطی ما
1265
01:35:50,490 –> 01:35:53,800
باید شما را بشناسد، تمام ستون های مختلفی
که قرار است استفاده کنیم، باید بداند
1266
01:35:53,800 –> 01:35:56,949
تمام ورودی های مختلف که می تواند در
آن ستون باشد، و باید بداند که آیا
1267
01:35:56,949 –> 01:36:01,550
این یک ستون طبقه بندی یا یک ستون عددی
است. در مثال های قبلی، آنچه ممکن است
1268
01:36:01,550 –> 01:36:06,000
در واقع مجموعه داده ها را به صورت دستی تغییر داده اید،
بنابراین آن را به صورت دستی، TensorFlow، رمزگذاری کنید
1269
01:36:06,000 –> 01:36:10,950
فقط می توانید این کار را برای ما در حال حاضر در تماس برای 2.0 انجام دهید.
بنابراین ما فقط از آن نیز استفاده خواهیم کرد. خوب، پس همین است
1270
01:36:10,950 –> 01:36:14,570
کاری که ما با این ستون های ویژگی انجام دادیم.
اکنون، برای ستون های عددی کمی متفاوت است،
1271
01:36:14,570 –> 01:36:18,110
در واقع ساده تر است، تنها کاری که باید انجام دهیم
این است که نام ویژگی و هر داده ای را ارائه دهیم
1272
01:36:18,110 –> 01:36:22,260
است را تایپ کنید و با آن یک ستون ایجاد کنید. بنابراین توجه
کنید، ما نمی توانیم این مقدار منحصر به فرد را حذف کنیم
1273
01:36:22,260 –> 01:36:25,140
زیرا ما می دانیم که چه زمانی عددی است، اما می دانید،
ممکن است تعداد نامحدودی وجود داشته باشد
1274
01:36:25,140 –> 01:36:28,340
ارزش های. و سپس من بهتازگی ستونهای ویژگی را چاپ
کردم، میتوانید ببینید چه چیزی به نظر میرسد
1275
01:36:28,340 –> 01:36:32,980
پسندیدن. بنابراین فهرست واژگان، ستون طبقهبندی،
تعداد خواهر و برادرها را به ما میدهد و سپس
1276
01:36:32,980 –> 01:36:37,449
لیست واژگان این است که همه مقادیر رمزگذاری متفاوتی
هستند که ایجاد می شوند. سپس همان
1277
01:36:37,449 –> 01:36:42,199
چیزی که می دانید، ما به اینجا می رویم parch، اینها رمزگذاری
های متفاوتی هستند. بنابراین آنها لزوما نیستند
1278
01:36:42,199 –> 01:36:47,390
یک سفارش مانند چیزی است که قبلاً در مورد آن صحبت
کردم. بریم سراغ یک عددی. چه کاری انجام دهید
1279
01:36:47,390 –> 01:36:53,940
ما اینجاییم؟ اوم، آره، بنابراین برای comm عددی، دقیقاً
به عنوان کلید، این شکلی است که ما انتظار داریم،
1280
01:36:53,940 –> 01:36:58,570
و این نوع داده است. بنابراین تقریباً همین است.
ما در واقع در حال بارگذاری اینها هستیم.
1281
01:36:58,570 –> 01:37:02,980
بنابراین اکنون تقریباً زمان ایجاد مدل است. بنابراین
برای ایجاد مدل چه کاری انجام می دهیم
1282
01:37:02,980 –> 01:37:08,160
اکنون در مورد فرآیند آموزش و آموزش
نوعی ماشین، می دانید، صحبت می شود
1283
01:37:08,160 –> 01:37:13,390
مدل یادگیری خوب، بنابراین روند آموزش،
اکنون، روند آموزش مدل ما است
1284
01:37:13,390 –> 01:37:17,870
در واقع نسبتاً ساده است، حداقل برای مدل خطی.
حالا روشی که ما مدل را آموزش می دهیم
1285
01:37:17,870 –> 01:37:23,510
آیا ما اطلاعات آن را تغذیه می کنیم، درست است؟ بنابراین ما آن را
تغذیه می کنیم که آن داده ها از مجموعه داده های ما اشاره کنند.
1286
01:37:23,510 –> 01:37:26,450
اما چگونه این کار را انجام دهیم؟ درست؟ مثلاً چگونه
آن را به مدل تغذیه کنیم؟ آیا ما فقط می دهیم
1287
01:37:26,450 –> 01:37:31,159
همه را به یکباره؟ خوب، در مورد ما، ما
فقط 627 ردیف داریم که واقعاً زیاد نیست
1288
01:37:31,159 –> 01:37:35,320
دادهها، مثل اینکه میتوانیم آنها را در رم رایانهمان قرار دهیم،
درست است؟ اما چه می شود اگر ما یک دیوانه را آموزش دهیم
1289
01:37:35,320 –> 01:37:39,489
مدل یادگیری ماشین، و می دانید، 25 ترابایت
داده داریم که باید انتقال دهیم
1290
01:37:39,489 –> 01:37:43,830
ما نمیتوانیم آن را در RAM بارگذاری کنیم، حداقل من
نمیدانم، هر رمی که به این بزرگی باشد. بنابراین
1291
01:37:43,830 –> 01:37:47,620
ما باید راهی پیدا کنیم که بتوانیم آن
را در دسته ای بارگذاری کنیم. پس راه
1292
01:37:47,620 –> 01:37:52,080
که ما در واقع این مدل را بارگذاری می کنیم، آن را به
صورت دسته ای بارگذاری می کنیم. حالا لازم نیست بفهمیم
1293
01:37:52,080 –> 01:37:56,739
واقعاً این که چگونه این فرآیند کار می کند و نوع دسته
بندی چگونه رخ می دهد، کاری است که ما انجام می دهیم
1294
01:37:56,739 –> 01:38:02,250
32 ورودی را همزمان به مدل بدهید. حالا دلیل
این است که ما فقط یکی یکی غذا نمی دهیم
1295
01:38:02,250 –> 01:38:07,739
به این دلیل است که
بسیار کندتر است.
1296
01:38:07,739 –> 01:38:11,681
سرعت ما را به طرز چشمگیری افزایش دهید و این
نوعی درک سطح پایین تر است. منم همین طور
1297
01:38:11,681 –> 01:38:14,800
قرار نیست خیلی در این مورد پیش برویم. حالا که فهمیدیم،
به نوعی آن را به صورت دستهای بارگذاری میکنیم،
1298
01:38:14,800 –> 01:38:19,340
درست؟ بنابراین ما آن را به طور کامل یکباره بارگذاری نمی
کنیم، فقط یک مجموعه خاص از نوع را بارگذاری می کنیم
1299
01:38:19,340 –> 01:38:26,120
عناصر در حالی که ما می رویم. آنچه ما داریم دوران
نامیده می شود. حال، دوره ها چیست؟ خوب، دوره ها
1300
01:38:26,120 –> 01:38:30,780
در اصل چند بار مدل قرار است داده های یکسانی
را ببیند. پس چه چیزی ممکن است
1301
01:38:30,780 –> 01:38:34,989
اینطور باشد، درست است، و زمانی که داده ها
را به مدل خود منتقل می کنیم، اولین بار است
1302
01:38:34,989 –> 01:38:38,810
خیلی بد است، مثل اینکه به نظر می رسد مدل بهترین
تناسب را ایجاد می کند، اما عالی نیست،
1303
01:38:38,810 –> 01:38:42,750
کامل کار نمی کند بنابراین ما باید از چیزی به نام دوره
استفاده کنیم، به این معنی که ما داریم می رویم
1304
01:38:42,750 –> 01:38:47,600
برای تغذیه مدل دوباره داده ها را تغذیه می کند، اما به ترتیبی
متفاوت. بنابراین ما این چندگانه را انجام می دهیم
1305
01:38:47,600 –> 01:38:51,880
بارها، به طوری که مدل به داده ها نگاه کند،
به روشی متفاوت به داده ها نگاه کند،
1306
01:38:51,880 –> 01:38:55,500
و سپس نوعی فرم متفاوت است و در چند بار
انتخاب، همان داده ها را می بینید
1307
01:38:55,500 –> 01:38:59,500
در مورد الگوها، زیرا اولین باری که یک نقطه
داده جدید را می بیند احتمالاً نمی رود
1308
01:38:59,500 –> 01:39:03,430
تا ایده خوبی داشته باشید که چگونه می توان برای آن پیش بینی
کرد. بنابراین می توانیم بیشتر و بیشتر به آن غذا بدهیم
1309
01:39:03,430 –> 01:39:08,110
و بیشتر از آنچه شما می دانید، ما می توانیم پیش بینی بهتری داشته
باشیم. حالا اینجا جایی است که ما در مورد آن صحبت می کنیم
1310
01:39:08,110 –> 01:39:13,470
چیزی به نام overfitting، با این حال، گاهی اوقات ما می توانیم
داده ها را بیش از حد از گذشته نیز ببینیم
1311
01:39:13,470 –> 01:39:18,090
داده های زیادی به مدل ما می رسد تا جایی
که به طور مستقیم آن نقاط داده را حفظ می کند.
1312
01:39:18,090 –> 01:39:22,550
و این واقعاً در طبقهبندی برای آن نقاط داده خوب
است، اما ما آن را تا حدی جدید منتقل میکنیم
1313
01:39:22,550 –> 01:39:28,020
برای مثال، نقاط داده، مانند داده های آزمایشی
ما. این در نوع طبقه بندی وحشتناک است
1314
01:39:28,020 –> 01:39:32,900
آن ها بنابراین کاری که ما برای جلوگیری از این اتفاق
انجام میدهیم این است که فقط مطمئن شویم که داریم
1315
01:39:32,900 –> 01:39:36,880
با مقدار کمتری از دورهها شروع کنید و سپس میتوانیم
راه خود را بالا ببریم و بهصورت تدریجی
1316
01:39:36,880 –> 01:39:42,360
این را تغییر دهید اگر لازم بود، می دانید، بالاتر برویم، درست
است؟ ما به دوره های بیشتری نیاز داریم. پس بله، پس همین است
1317
01:39:42,360 –> 01:39:46,850
نوعی از آن برای دوره ها. حالا من می گویم که این
فرآیند آموزشی به نوعی برای همه صدق می کند
1318
01:39:46,850 –> 01:39:50,401
مدلهای مختلف یادگیری ماشینی که میخواهیم
بررسی کنیم چیست؟ ما داریم
1319
01:39:50,401 –> 01:39:54,610
دورهها، دستههایی داریم که اندازه دستهای
داریم و اکنون چیزی به نام ورودی داریم
1320
01:39:54,610 –> 01:40:00,490
عملکرد. در حال حاضر، این بسیار پیچیده
است. این کد تابع ورودی است. نکن
1321
01:40:00,490 –> 01:40:06,020
مانند آن ما باید این کار را انجام دهیم، اما لازم
است. بنابراین اساساً تابع ورودی چیست،
1322
01:40:06,020 –> 01:40:10,760
روشی است که ما تعریف می کنیم چگونه داده
هایمان به دوره ها و دسته ها تقسیم می شوند
1323
01:40:10,760 –> 01:40:15,610
برای تغذیه مدل ما اکنون، اینها، احتمالاً هرگز
واقعاً نیازی به کدنویسی مانند آن ندارید
1324
01:40:15,610 –> 01:40:20,060
از ابتدا توسط خودتان اما این یکی است که
من به تازگی از وب سایت ملموس دزدیده ام
1325
01:40:20,060 –> 01:40:25,440
تقریباً مانند هر چیز دیگری که در این سریال وجود دارد.
و آنچه این کار انجام می دهد، این است که طول می کشد
1326
01:40:25,440 –> 01:40:32,780
داده های ما را در یک شیء مجموعه داده TF رمزگذاری
می کند. حالا این به این دلیل است که مدل ما
1327
01:40:32,780 –> 01:40:37,810
به این شی خاص نیاز دارد تا بتواند کار کند، باید
یک شی مجموعه داده را ببیند تا بتواند کار کند
1328
01:40:37,810 –> 01:40:42,850
برای استفاده از آن داده ها برای ایجاد مدل. بنابراین کاری که ما
باید انجام دهیم این است که چارچوب داده این پاندا را بگیریم،
1329
01:40:42,850 –> 01:40:47,660
ما باید آن را به آن شی تبدیل کنیم. و روشی که ما
این کار را انجام می دهیم با تابع ورودی است.
1330
01:40:47,660 –> 01:40:51,550
بنابراین ما می توانیم ببینیم که این اینجا چه می
کند. بنابراین این تابع ورودی است، ما در واقع
1331
01:40:51,550 –> 01:40:55,470
یک تابع در داخل یک تابع دیگر تعریف شده است.
می دانم که این یک جورهایی پیچیده است
1332
01:40:55,470 –> 01:40:59,300
برای برخی از شما بچه ها، اما و آنچه که من واقعاً می خواهم
انجام دهم متأسفم، من فقط این را در آن کپی می کنم
1333
01:40:59,300 –> 01:41:02,820
صفحه دیگر، زیرا فکر میکنم بدون تمام متنهای
اطراف توضیح دادن آسانتر است. بنابراین
1334
01:41:02,820 –> 01:41:07,170
بیایید یک بلوک کد جدید ایجاد کنیم. بیایید این را
بچسبانیم. و بیایید نگاهی به این داشته باشیم
1335
01:41:07,170 –> 01:41:13,820
میکند. بنابراین در واقع، اجازه دهید من فقط ضربه بزنید. خوب،
بنابراین تابع ورودی را بسازید. ما پارامترهای خود را داریم
1336
01:41:13,820 –> 01:41:17,960
قاب دادههای داده، که قاب داده پاندا ما است،
قاب داده برچسبگذاری شده ما، که ایستاده است
1337
01:41:17,960 –> 01:41:24,130
برای آن برچسب ها بنابراین که y آموزش، یا
آن eval، y eval، درست است؟ ما چندین دوره داریم،
1338
01:41:24,130 –> 01:41:28,690
که چند دوره می خواهیم انجام دهیم، 10 shuffle
پیش فرض را تنظیم می کنیم، به این معنی
1339
01:41:28,690 –> 01:41:33,679
آیا قرار است داده هایمان را به هم بزنیم و آنها را با هم مخلوط
کنیم؟ قبل از اینکه آن را به صورت دسته ای به مدل منتقل کنیم
1340
01:41:33,679 –> 01:41:37,290
اندازه، یعنی چند عنصر به
آن مدل می دهیم؟
1341
01:41:37,290 –> 01:41:38,290
خوب، این است
1342
01:41:38,290 –> 01:41:43,780
آموزش یکباره اکنون، کاری که این کار انجام می دهد
این است که یک تابع ورودی در داخل آن تعریف شده است
1343
01:41:43,780 –> 01:41:51,710
عملکرد. و ما می گوییم مجموعه داده برابر است با مجموعه
داده نقطه نقطه قاب تانسور از برش های تانسور،
1344
01:41:51,710 –> 01:41:56,199
دادههای برچسبدار قاب داده را دیکت کنید. حالا این چه
کاری انجام می دهد، و ما می توانیم نظر را بخوانیم،
1345
01:41:56,199 –> 01:42:00,710
یک شیء مجموعه داده TF با داده ها و برچسب
آن ایجاد کنید. الان نمیتونم توضیح بدم
1346
01:42:00,710 –> 01:42:05,989
شما دوست دارید که چگونه این در سطح پایین تر کار می
کند. اما در اصل، ما یک نمایندگی فرهنگ لغت را تصویب می کنیم
1347
01:42:05,989 –> 01:42:11,679
از چارچوب داده ما، که هر چیزی است که ما در اینجا منتقل
کردیم. و سپس قاب داده برچسب را ارسال می کنیم،
1348
01:42:11,679 –> 01:42:16,360
که همه آن مقادیر y را می دانید. و ما
این شی را ایجاد می کنیم. و این است
1349
01:42:16,360 –> 01:42:21,340
این خط کد چه کاری انجام می دهد. بنابراین دادههای TF از برشهای
تانسور تنظیم میشوند، که دقیقاً همان چیزی است
1350
01:42:21,340 –> 01:42:24,870
شما قصد استفاده از آن را دارید، منظورم این است که ما می توانیم
این مستندات را بخوانیم، یک مجموعه داده ایجاد کنیم که عناصر آن
1351
01:42:24,870 –> 01:42:30,010
برش هایی از تانسورهای داده شده هستند. تانسورهای
داده شده در امتداد بعد اول بریده می شوند،
1352
01:42:30,010 –> 01:42:34,030
این عملیات ساختار تانسورهای ورودی
را حفظ می کند و بعد اول را حذف می کند
1353
01:42:34,030 –> 01:42:37,350
هر تانسور و استفاده از آن به عنوان بعد مجموعه داده. بنابراین
منظورم این است که شما بچه ها می توانید نگاه کنید
1354
01:42:37,350 –> 01:42:40,800
که، اگر می خواهید، اسناد را بخوانید.
اما اساساً کاری که انجام می دهد
1355
01:42:40,800 –> 01:42:48,489
برای این کار شی بیابان را ایجاد می کند. حال،
اگر shuffle شود، DS برابر است با DS dot shuffle 1000،
1356
01:42:48,489 –> 01:42:52,120
کاری که این کار انجام می دهد این است که مجموعه داده ها را به
هم ریخته است، شما واقعاً نیازی به درک بیشتر از آن ندارید
1357
01:42:52,120 –> 01:42:57,050
که و سپس کاری که ما انجام میدهیم این است که میبینیم مجموعه دادهها
برابر است با مجموعه نقطه مجموعه داده، اندازه دسته،
1358
01:42:57,050 –> 01:43:00,920
که قرار است 32 شود. و سپس برای تعداد دوره
ها تکرار کنید. پس این چه می شود
1359
01:43:00,920 –> 01:43:06,810
انجام این کار اساساً این است که مجموعه داده های ما را برداریم
و آن را به تعدادی از مواردی که نمی خواهم تقسیم کنیم
1360
01:43:06,810 –> 01:43:11,520
من می خواهم آن را چه بنامم، مانند بلوک هایی
که قرار است به مدل ما منتقل شوند. پس ما
1361
01:43:11,520 –> 01:43:15,040
می تواند این کار را با دانستن اندازه دسته انجام
دهد، بدیهی است که تعداد عناصر را می داند زیرا
1362
01:43:15,040 –> 01:43:19,520
این خود شی مجموعه داده است و سپس تعداد دوره ها را
تکرار کنید. بنابراین این می تواند رقم بخورد
1363
01:43:19,520 –> 01:43:24,900
شما می دانید، باید آن را به چند بلوک
تقسیم کنم تا به آن تغذیه کنم
1364
01:43:24,900 –> 01:43:30,040
مدل من، هرگز مجموعه ای را به سادگی از این تابع
در اینجا برنگرداند، ما آن را برمی گردانیم
1365
01:43:30,040 –> 01:43:35,370
شی مجموعه داده، و سپس در بازگشت خارجی، ما در
واقع این تابع را برمی گردانیم. پس چی
1366
01:43:35,370 –> 01:43:38,940
این عملکرد بیرونی انجام می دهد، و من واقعاً فقط
سعی می کنم این را تجزیه کنم. پس شما بچه ها
1367
01:43:38,940 –> 01:43:45,130
درک یک تابع ورودی است، به معنای واقعی کلمه یک
تابع می سازد و تابع را برمی گرداند
1368
01:43:45,130 –> 01:43:50,659
اعتراض به هر کجا که آن را صدا کنیم. پس اینطوری
کار میکنه اکنون ورودی قطار داریم
1369
01:43:50,659 –> 01:43:55,580
تابع و یک تابع ورودی ارزشی. و کاری که برای ایجاد
این تصاویر باید انجام دهیم از این استفاده کنیم
1370
01:43:55,580 –> 01:44:00,929
تابعی که در بالا تعریف کردیم. بنابراین می گوییم
تابع ورودی، df train، y train، بنابراین
1371
01:44:00,929 –> 01:44:05,280
چارچوب داده ما برای آموزش و چارچوب داده ما برای برچسب
های آن. بنابراین ما می توانیم ببینیم
1372
01:44:05,280 –> 01:44:09,060
نظر بدهید، می دانید، در اینجا ما تابع ورودی را صدا
می زنیم، درست است. و سپس قطار eval. که اینطور
1373
01:44:09,060 –> 01:44:13,199
به جز ارزیابی، همان چیزی خواهد بود.
ما نیازی به تغییر داده ها نداریم
1374
01:44:13,199 –> 01:44:17,010
چون ما آن را آموزش نمیدهیم، فقط به یک دوره نیاز
داریم، زیرا باز هم، ما فقط در حال آموزش هستیم
1375
01:44:17,010 –> 01:44:22,969
آی تی. و ما مجموعه داده های ارزیابی و ارزش
ارزیابی را از چرا ارسال می کنیم. باشه پس
1376
01:44:22,969 –> 01:44:27,790
این برای ساخت تابع ورودی است. حالا، من می
دانم که این پیچیده است، اما همین است
1377
01:44:27,790 –> 01:44:31,330
راهی که باید انجامش دهیم و متأسفانه، اگر
بعد از آن متوجه نشدید، وجود ندارد
1378
01:44:31,330 –> 01:44:34,800
خیلی بیشتر از این که می توانم انجام دهم، ممکن
است مجبور شوید برخی از اسناد را بخوانید.
1379
01:44:34,800 –> 01:44:38,870
خوب، ایجاد مدل. بالاخره رسیدیم
می دانم که مدتی است، اما من
1380
01:44:38,870 –> 01:44:42,360
باید از همه چیز عبور کرد بنابراین تخمین های
خطی، ما این را کپی می کنیم و من فقط هستم
1381
01:44:42,360 –> 01:44:47,469
قرار است آن را در اینجا بگذارم و ما در مورد اینکه این چه کاری
انجام می دهد صحبت خواهیم کرد. بنابراین خطی خطی، st برابر است
1382
01:44:47,469 –> 01:44:53,219
طبقهبندیکننده خطی نقطه برآوردگر TF،
و ما ستونهای ویژگی را به آن میدهیم
1383
01:44:53,219 –> 01:44:56,810
در اینجا ایجاد شده است. پس این کار بیهوده
نبود. ما این ستون ویژگی را داریم که
1384
01:44:56,810 –> 01:45:02,530
تعریف می کند شما می دانید، آنچه در هر راه است. برای
داده های ورودی خود چه انتظاری باید داشته باشیم،
1385
01:45:02,530 –> 01:45:07,790
ما آن را به یک شی طبقهبندی خطی از ماژول
تخمینگر از TensorFlow منتقل میکنیم.
1386
01:45:07,790 –> 01:45:11,940
و سپس این مدل را برای ما ایجاد می کند. اکنون،
این، دوباره، نحو است. پس نیازی نداری
1387
01:45:11,940 –> 01:45:15,420
برای حفظ کردن، فقط باید بدانید که چگونه کار می
کند، کاری که ما انجام می دهیم ایجاد یک است
1388
01:45:15,420 –> 01:45:19,680
برآوردگر، همه این نوع الگوریتم های یادگیری اصلی از
چیزی استفاده می کنند که برآوردگر نامیده می شود.
1389
01:45:19,680 –> 01:45:24,300
فقط پیاده سازی اولیه الگوریتم ها در TensorFlow
هستند. و دوباره، ویژگی را پاس کنید
1390
01:45:24,300 –> 01:45:25,940
ستون ها. اینطوری کار میکنه
1391
01:45:25,940 –> 01:45:26,940
بسیار خوب،
1392
01:45:26,940 –> 01:45:30,180
خب حالا بریم سراغ آموزش مدل. خوب، پس من فقط
می خواهم دوباره این را کپی کنم، می دانم
1393
01:45:30,180 –> 01:45:33,560
شما بچه ها فکر می کنید من فقط این کد را پشت سر هم
کپی می کنم. اما من قصد ندارم آن را حفظ کنم
1394
01:45:33,560 –> 01:45:36,980
نحو، من فقط می خواهم برای شما توضیح دهم که چگونه همه
اینها کار می کند. و دوباره، شما بچه ها خواهید داشت
1395
01:45:36,980 –> 01:45:41,270
همه این کدها، شما می توانید آن را به هم بزنید، با
آن بازی کنید، و به تنهایی یاد بگیرید. بنابراین
1396
01:45:41,270 –> 01:45:46,140
آموزش واقعا آسان است. تنها کاری که باید انجام دهیم،
میگویم، قطار نقطهای ESP خطی، و سپس فقط
1397
01:45:46,140 –> 01:45:50,740
آن تابع ورودی را بدهید. بنابراین تابع ورودی
که ما در اینجا ایجاد کردیم، درست است
1398
01:45:50,740 –> 01:45:56,010
از تابع make input برگردانده شده است، مانند این تابع
ورودی قطار در اینجا در واقع برابر است
1399
01:45:56,010 –> 01:46:02,580
برای یک تابع، برابر است با یک شی تابع.
اگر بخواهم خط خط قطار را صدا کنم
1400
01:46:02,580 –> 01:46:07,680
تابع ورودی مانند این، در واقع این تابع را
فراخوانی می کند. اینطوری کار میکنه
1401
01:46:07,680 –> 01:46:12,540
در پایتون، این یک نحو کمی پیچیده است، اما
نحوه کار آن است، ما آن را پاس می کنیم
1402
01:46:12,540 –> 01:46:16,910
در اینجا عملکرد کنید. و سپس از این تابع برای
گرفتن تمام ورودی های ما استفاده می کند
1403
01:46:16,910 –> 01:46:21,510
نیاز و آموزش مدل. در حال حاضر، نتیجه
به جای آموزش دیده می شود، ما هستیم
1404
01:46:21,510 –> 01:46:25,510
درست ارزیابی می کنیم و متوجه می شویم که ما این
مورد را در یک متغیر ذخیره نکرده ایم، اما داریم
1405
01:46:25,510 –> 01:46:29,570
نتیجه را در یک متغیر ذخیره می کنیم تا بتوانیم
به آن نگاه کنیم. اکنون خروجی روشن است
1406
01:46:29,570 –> 01:46:33,020
از آنچه در بالا وارد می کنیم، فقط خروجی کنسول
را پاک می کنیم، زیرا وجود خواهد داشت
1407
01:46:33,020 –> 01:46:38,460
برخی از خروجی ها در حین آموزش، که می توانیم
دقت این مدل را چاپ کنیم. پس بیایید
1408
01:46:38,460 –> 01:46:42,310
در واقع این را اجرا کنید و ببینید چگونه کار می کند.
این یک ثانیه طول می کشد. پس من یک بار برمی گردم
1409
01:46:42,310 –> 01:46:49,150
این کار انجام می شود. خوب، پس ما برگشتیم، دقت 73.8
درصدی داریم. بنابراین اساسا، آنچه ما داریم
1410
01:46:49,150 –> 01:46:52,449
درست انجام شد این است که ما مدل را آموزش دادهایم،
ممکن است در حین شما تعداد زیادی خروجی دیده باشید
1411
01:46:52,449 –> 01:46:56,550
این کار را روی صفحه نمایش شما انجام می دادند.
و سپس دقت را چاپ کردیم. پس از ارزیابی
1412
01:46:56,550 –> 01:47:01,230
مدل. این دقت خیلی خوب نیست، اما برای اولین
شلیک ما این خوب است، و ما هم هستیم
1413
01:47:01,230 –> 01:47:05,530
در یک ثانیه در مورد چگونگی بهبود این موضوع صحبت خواهم
کرد. خوب، پس ما داده ها را ارزیابی کرده ایم
1414
01:47:05,530 –> 01:47:09,969
مجموعه، ما آن را ذخیره کردیم، در نتیجه، من واقعاً میخواهم
ببینم نتیجه چیست زیرا بدیهی است،
1415
01:47:09,969 –> 01:47:14,610
میتوانید ببینید که ما به بخش دقت اشاره کردهایم،
مثل اینکه میدانید این یک پایتون است
1416
01:47:14,610 –> 01:47:18,051
فرهنگ لغت. پس بیایید این را یک بار دیگر اجرا کنیم. من فقط
می خواهم دوباره یک ثانیه وقت بگذارم. بنابراین
1417
01:47:18,051 –> 01:47:21,290
خوب، بنابراین ما نتایج را در اینجا چاپ کردیم.
و ما می توانیم ببینیم که ما در واقع یک دسته از
1418
01:47:21,290 –> 01:47:26,890
مقادیر مختلف، ما دقت، دقت، خط مبنا،
AUC و همه این انواع مختلف را داریم
1419
01:47:26,890 –> 01:47:30,420
از مقادیر آماری حالا، اینها واقعاً
برای شما مهم نیستند. اما من فقط
1420
01:47:30,420 –> 01:47:34,850
می خواهم به شما نشان دهم که ما آن آمار را داریم. و
برای دسترسی به هر مورد خاص، این واقعاً است
1421
01:47:34,850 –> 01:47:38,390
فقط یک شی دیکشنری بنابراین ما فقط می توانیم به کلیدی که می
خواهیم اشاره کنیم، همان کاری که ما انجام دادیم
1422
01:47:38,390 –> 01:47:44,871
با دقت حالا توجه کنید، دقت ما در اینجا تغییر
کرد، ما به 76 رفتیم. و دلیل آن
1423
01:47:44,871 –> 01:47:48,191
زیرا همانطور که گفتم، می دانید، داده های ما در
حال به هم ریختگی است، در حال وارد شدن است
1424
01:47:48,191 –> 01:47:52,280
یک نظم متفاوت و بر اساس ترتیبی که ما داده
ها را می بینیم، مدل ما، شما را خواهد دید
1425
01:47:52,280 –> 01:47:57,180
بدانید، پیشبینیهای متفاوتی انجام دهید و متفاوت
آموزش دهید. پس اگر داشتیم، می دانید، دیگری
1426
01:47:57,180 –> 01:48:02,110
دوران، درست است، اگر دوره ها را به 11 یا 15 تغییر
دهم، دقت ما تغییر می کند. حالا ممکنه
1427
01:48:02,110 –> 01:48:06,240
برو بالا، ممکن است پایین بیاید، این چیزی است که
ما باید با دستگاه خود بازی کنیم، همانطور که می دانید
1428
01:48:06,240 –> 01:48:09,860
توسعه دهنده یادگیری، درست است، هدف شما
این است که دقیق ترین مدل را بدست آورید.
1429
01:48:09,860 –> 01:48:13,830
خوب، پس اکنون زمان آن رسیده است که در واقع از مدل
برای پیش بینی استفاده کنیم. پس تا این زمان
1430
01:48:13,830 –> 01:48:17,630
نکته، ما به تازگی کار زیادی انجام داده ایم تا
بفهمیم چگونه می توان مدل را ایجاد کرد، شما
1431
01:48:17,630 –> 01:48:21,631
می دانم که مدل چگونه است که یک تابع ورودی، آموزش،
آزمایش داده ها را می سازیم، می دانم a
1432
01:48:21,631 –> 01:48:27,239
خیلی، خیلی، خیلی چیزها حالا برای استفاده
از این مدل و لایک پیش بینی های دقیق انجام دهید
1433
01:48:27,239 –> 01:48:32,440
با آن تا حدودی دشوار است، اما من به شما نشان
خواهم داد که چگونه. بنابراین اساسا، TensorFlow
1434
01:48:32,440 –> 01:48:37,130
مدلها برای پیشبینی در مورد بسیاری از چیزها
ساخته شدهاند که در آنها عالی نیستند
1435
01:48:37,130 –> 01:48:41,590
با انجام پیشبینیهایی مانند یک داده، شما فقط میخواهید
مانند یک مسافر یک داده را انجام دهد
1436
01:48:41,590 –> 01:48:46,020
پیش بینی برای، آنها در کار در دسته های بزرگی از
داده ها، که شما می توانید بسیار بهتر هستند
1437
01:48:46,020 –> 01:48:49,780
قطعاً این کار را با یکی انجام دهید، اما من به شما نشان خواهم
داد که چگونه میتوانیم برای آن پیشبینی کنیم
1438
01:48:49,780 –> 01:48:55,199
هر نقطه ای که در مجموعه داده های ارزیابی وجود
دارد. بنابراین در حال حاضر به دقت نگاه کردیم.
1439
01:48:55,199 –> 01:48:59,590
و روشی که ما دقت را تعیین می کنیم
اساساً با مقایسه نتایج بود
1440
01:48:59,590 –> 01:49:04,929
پیشبینیهایی که از مدل ما در مقابل
نتایج واقعی برای هر یک ارائه شد
1441
01:49:04,929 –> 01:49:09,080
یکی از آن مسافران و اینگونه بود که
به دقت 76 درصد رسیدیم. حالا اگر ما
1442
01:49:09,080 –> 01:49:13,780
می خواهید در واقع بررسی کنید و پیش بینی هایی را
از مدل دریافت کنید و ببینید که آن پیش بینی های واقعی چیست
1443
01:49:13,780 –> 01:49:18,490
هستند، کاری که می توانیم انجام دهیم استفاده از روشی به نام پیش بینی
نقطه است. بنابراین کاری که می خواهم انجام دهم این است که هستم
1444
01:49:18,490 –> 01:49:25,389
میخواهم بگویم، حدس میزنم نتایجی مانند این برابر
است و در این مورد، ما مدل را انجام میدهیم
1445
01:49:25,389 –> 01:49:32,070
نام، که خطی ESD نقطه پیش بینی است. و سپس در داخل
اینجا، چیزی که ما قرار است عبور کنیم
1446
01:49:32,070 –> 01:49:37,120
تابع ورودی است که برای ارزیابی استفاده می کنیم. بنابراین
همانطور که می دانید، ما باید یک را پاس کنیم
1447
01:49:37,120 –> 01:49:41,470
تابع ورودی برای آموزش واقعی مدل، باید یک
تابع ورودی را نیز به آن منتقل کنیم
1448
01:49:41,470 –> 01:49:45,170
یک پیش بینی انجام دهید حالا این تابع ورودی می
تواند کمی متفاوت باشد. ما می توانیم اصلاح کنیم
1449
01:49:45,170 –> 01:49:49,210
این کمی اگر بخواهیم اما برای ساده نگه داشتن همه
چیز، فعلاً از همان یکی استفاده می کنیم. پس چی
1450
01:49:49,210 –> 01:49:52,830
من قصد دارم این کار را انجام دهم این است که فقط از این توابع
ورودی eval استفاده کنم، توابعی که قبلاً در آنجا ایجاد کرده ایم
1451
01:49:52,830 –> 01:49:56,930
می دانید، ما یک دوره ای را انجام دادیم که
نیازی به آن نداریم زیرا فقط ارزیابی است
1452
01:49:56,930 –> 01:50:02,060
تنظیم. بنابراین در اینجا rindu eval input funk. اکنون
آنچه باید انجام دهیم تبدیل است
1453
01:50:02,060 –> 01:50:05,909
این به یک لیست، فقط به این دلیل که ما می خواهیم
از طریق آن حلقه بزنیم. و من در واقع می روم
1454
01:50:05,909 –> 01:50:09,650
این مقدار را چاپ کنید بنابراین، قبل از اینکه به مرحله
بعدی برسیم، میتوانیم ببینیم آن چیست. پس بیایید
1455
01:50:09,650 –> 01:50:16,130
این را اجرا کنید و به آنچه به دست می آوریم نگاهی بیندازیم. خوب، پس
آرایه تدارکات را دریافت می کنیم، می توانیم همه را ببینیم
1456
01:50:16,130 –> 01:50:22,199
این ارزش های مختلف بنابراین، می دانید، این آرایه
با این مقدار را داریم، ما احتمالاتی داریم،
1457
01:50:22,199 –> 01:50:26,340
این مقدار و این چیزی است که ما به دست می آوریم. ما
داریم تدارکات را دریافت می کنیم، همه کلاس ها،
1458
01:50:26,340 –> 01:50:29,840
مثل اینکه همه این چیزهای تصادفی وجود دارد. چیزی که امیدوارم
باید به آن توجه کنید، و من می دانم که من فقط هستم
1459
01:50:29,840 –> 01:50:34,440
مانند ویز کردن این است که ما یک فرهنگ لغت داریم که
پیش بینی ها را نشان می دهد. و من خواهم
1460
01:50:34,440 –> 01:50:39,679
ببینید آیا می توانم انتهای فرهنگ لغت را اینجا
پیدا کنم. برای هر تک، چه پیش بینی است.
1461
01:50:39,679 –> 01:50:46,320
بنابراین از زمانی که ما 267 داده ورودی را
از این تابع ورودی eval ارسال کردیم،
1462
01:50:46,320 –> 01:50:50,460
آنچه به ما بازگردانده شد فهرستی از همه این
فرهنگ لغت های مختلف است که نشان می دهد
1463
01:50:50,460 –> 01:50:55,820
هر پیش بینی بنابراین کاری که ما باید انجام دهیم این
است که به هر فرهنگ لغت نگاه کنیم تا بتوانیم تعیین کنیم
1464
01:50:55,820 –> 01:51:01,710
آنچه که پیشبینی واقعی بود، این است که کاری که من میخواهم
انجام دهم این است که در واقع فقط نتیجه انجام کار را ارائه کنم
1465
01:51:01,710 –> 01:51:05,710
سرگردان به نتیجه صفر، زیرا این یک لیست است. پس این
بدان معناست که ما می توانیم آن را ایندکس کنیم.
1466
01:51:05,710 –> 01:51:11,460
بنابراین ما در واقع به یک پیش بینی نگاه می کنیم.
خوب، پس این فرهنگ لغت یک پیش بینی است.
1467
01:51:11,460 –> 01:51:14,980
بنابراین می دانم که این خیلی زیاد به نظر می رسد. اما
این چیزی است که ما داریم. این پیش بینی ماست بنابراین
1468
01:51:14,980 –> 01:51:19,691
تدارکات، ما مقداری آرایه دریافت می کنیم، در اینجا
در این فرهنگ لغت لجستیک داریم، و سپس داریم
1469
01:51:19,691 –> 01:51:25,760
احتمالات بنابراین آنچه من در واقع می خواهم احتمال
است. در حال حاضر از آنچه که ما به پایان رسید
1470
01:51:25,760 –> 01:51:30,350
یک پیشبینی از دو کلاس بود، درست است، یا صفر
یا یک، ما یکی را پیشبینی میکنیم
1471
01:51:30,350 –> 01:51:34,400
زنده ماندند، یا زنده نماندند، یا درصدشان
چقدر باید باشد، ما می توانیم این را ببینیم
1472
01:51:34,400 –> 01:51:40,001
درصد زنده ماندن در اینجا در واقع
96٪ است. و درصدی که فکر می کند
1473
01:51:40,001 –> 01:51:46,469
زنده نمی ماند، می دانید، 3.3٪ است. بنابراین اگر می خواهیم
به این دسترسی داشته باشیم، باید چه کاری انجام دهیم
1474
01:51:46,469 –> 01:51:52,000
در برخی از فهرستها روی نتیجه کلیک کنید، بنابراین هر چیزی که میدانید،
یکی از مواردی است که ما میخواهیم. پس ما می گوییم
1475
01:51:52,000 –> 01:51:55,290
نتیجه و سپس در اینجا، ما احتمالات را قرار می
دهیم، بنابراین من فقط می خواهم چاپ کنم
1476
01:51:55,290 –> 01:52:00,480
که مثل آن و سپس می توانیم احتمالات را ببینیم. پس بیایید این
را اجرا کنیم. و اکنون ما احتمالات خود را می بینیم
1477
01:52:00,480 –> 01:52:07,540
96 و 33 هستند. حالا اگر احتمال زنده ماندن را بخواهیم،
پس فکر می کنم واقعاً ممکن است داشته باشم
1478
01:52:07,540 –> 01:52:11,861
این را به هم ریخته است، من تقریباً مطمئن هستم که
احتمال بقا در واقع آخرین مورد است. در حالیکه
1479
01:52:11,861 –> 01:52:16,100
مانند non survival اولین مورد است زیرا صفر به
معنای زنده ماندن نیست و یک به معنای
1480
01:52:16,100 –> 01:52:19,860
تو زنده ماندی پس این بد من است، من آن را به هم ریختم.
بنابراین من واقعاً شانس آنها را می خواهم
1481
01:52:19,860 –> 01:52:26,230
بقا یا شاخص یک. بنابراین، اگر من یک را ایندکس کنم، می
بینید که 3.3 درصد می گیریم. اما اگر آنها را می خواستم
1482
01:52:26,230 –> 01:52:31,239
احتمال زنده ماندن، من صفر را ایندکس می کنم.
و این منطقی است، زیرا صفر، شما است
1483
01:52:31,239 –> 01:52:35,010
بدانید، چیزی که ما به آن نگاه می کنیم، مانند صفر نشان دهنده آن است،
آنها زنده نمانند، در حالی که یک نشان دهنده آن است
1484
01:52:35,010 –> 01:52:39,770
آنها زنده ماندند بنابراین به نوعی ما این کار را انجام
می دهیم. بنابراین اینگونه به دست می آوریم. حالا اگر خواستیم
1485
01:52:39,770 –> 01:52:43,410
برای بررسی همه اینها، میتوانیم از طریق
هر فرهنگ لغت، حلقه بزنیم، میتوانیم
1486
01:52:43,410 –> 01:52:48,010
تک تک احتمالات هر فرد را چاپ کنیم، همچنین
می توانیم به آمار آن شخص نگاه کنیم و
1487
01:52:48,010 –> 01:52:52,980
سپس به احتمال آنها نگاه کنید. پس بیایید ببینیم،
احتمال زنده ماندن در این مورد است،
1488
01:52:52,980 –> 01:52:57,900
می دانید، 3٪ یا هر چیزی که 3.3٪ بود. اما بیایید
به فردی که در واقع بودیم نگاه کنیم
1489
01:52:57,900 –> 01:53:05,000
آنها را پیش بینی کنید و ببینید آیا این منطقی است یا خیر.
بنابراین اگر من بروم eval هستند چه چیزی بود DF eval نقطه
1490
01:53:05,000 –> 01:53:10,780
لوک. صفر، ما آن را چاپ می کنیم و سپس نتیجه را چاپ می
کنیم، چیزی که می توانیم ببینیم این است که برای
1491
01:53:10,780 –> 01:53:15,489
فردی که مرد و 35 ساله بود که خواهر و برادری نداشت، کرایه
آنها این بود، آنها در کلاس سوم هستند،
1492
01:53:15,489 –> 01:53:19,790
ما نمی دانیم آنها روی چه عرشه ای بودند.
و آنها تنها بودند، شانس آنها 3.3٪ است
1493
01:53:19,790 –> 01:53:24,719
بقا حال، اگر این را تغییر دهیم، میتوانیم به
دو مورد برویم، بیایید به این نگاه کنیم
1494
01:53:24,719 –> 01:53:28,620
نفر دوم و ببینید شانس زنده ماندن آنها چقدر است،
خوب، بنابراین آنها درصد شانس بیشتری دارند
1495
01:53:28,620 –> 01:53:32,780
به احتمال 38٪، آنها زن هستند، آنها کمی بزرگتر هستند.
بنابراین این ممکن است دلیلی برای آنها باشد
1496
01:53:32,780 –> 01:53:38,260
نرخ بقا کمی پایین تر است. منظورم این است که ما میتوانیم
این کار را ادامه دهیم و نگاه کنیم و ببینیم چه چیزی
1497
01:53:38,260 –> 01:53:42,600
درست است؟ اگر بخواهیم ارزش واقعی را بدست آوریم،
مثلاً این شخص زنده مانده است یا اگر
1498
01:53:42,600 –> 01:53:49,380
آنها زنده نماندند و کاری که من میتوانم انجام دهم این است
که میتوانم df eval را چاپ کنم، در واقع این کار انجام نمیشود
1499
01:53:49,380 –> 01:53:51,810
برای ارزش گذاری، آن را به y زیر خط
1500
01:53:51,810 –> 01:53:52,810
ارزیابی
1501
01:53:52,810 –> 01:53:57,500
بله و این نقطه لوک خواهد بود. سه. حالا، این
به ما می دهد اگر آنها زنده ماندند یا
1502
01:53:57,500 –> 01:54:01,590
نه بنابراین در واقع، در این مورد، آن شخص زنده
ماند، اما ما فقط 32٪ را پیش بینی می کنیم.
1503
01:54:01,590 –> 01:54:07,159
بنابراین می توانید ببینید که این در این واقعیت نشان
داده شده است که ما فقط حدود 76 درصد داریم.
1504
01:54:07,159 –> 01:54:10,550
دقت. چون این مدل کامل نیست. و در
این مورد، خیلی بد بود. این است
1505
01:54:10,550 –> 01:54:14,820
با بیان اینکه آنها 32 درصد شانس زنده ماندن دارند،
اما در واقع زنده می مانند. پس شاید همین
1506
01:54:14,820 –> 01:54:20,210
باید بالاتر باشد، درست است؟ بنابراین ما میتوانیم این
عدد را تغییر دهیم و به عدد چهار برویم. فقط دارم قاطی میکنم
1507
01:54:20,210 –> 01:54:24,180
در اطراف و نشان دادن شما بچه ها که می دانید چگونه از این
استفاده می کنیم. بنابراین در این یکی، می دانید، همان چیز،
1508
01:54:24,180 –> 01:54:30,110
این فرد جان سالم به در برد، هرچند که
تنها 14 درصد شانس زنده ماندن داشتند.
1509
01:54:30,110 –> 01:54:33,790
بنابراین به هر حال، این روش کار می کند. اینگونه
است که ما در واقع پیش بینی و نگاه می کنیم
1510
01:54:33,790 –> 01:54:37,389
در پیشبینیها، متوجه میشوید که اکنون آنچه اتفاق
میافتد این است که من این را به تبدیل کردهام
1511
01:54:37,389 –> 01:54:40,960
یک لیست فقط به این دلیل که در واقع یک شی مولد
است، به این معنی که قرار است فقط باشد
1512
01:54:40,960 –> 01:54:45,570
به جای اینکه فقط با یک لیست به آن نگاه کنید، حلقه
زد، اما خوب است. ما از یک لیست استفاده خواهیم کرد
1513
01:54:45,570 –> 01:54:49,821
و پس از آن ما فقط میتوانیم چاپ کنیم، نتیجه میگیریم
که هر چه احتمالات شاخص باشد و سپس
1514
01:54:49,821 –> 01:54:53,760
یکی برای نشان دادن شانس آنها برای بقا.
خوب، پس این برای رگرسیون خطی بوده است.
1515
01:54:53,760 –> 01:54:59,150
حالا بیایید وارد طبقه بندی شویم. و اکنون
به طبقه بندی می رویم. بنابراین اساسا
1516
01:54:59,150 –> 01:55:04,860
طبقه بندی عبارت است از تمایز بین
نقاط داده و جداسازی آنها
1517
01:55:04,860 –> 01:55:09,489
به کلاس ها بنابراین به جای پیش بینی یک
مقدار عددی، که با رگرسیون انجام دادیم
1518
01:55:09,489 –> 01:55:13,130
قبل از آن، پس رگرسیون خطی، و می دانید،
درصد شانس بقا، که یک است
1519
01:55:13,130 –> 01:55:17,690
مقدار عددی، ما در واقع می خواهیم کلاس ها را پیش بینی کنیم.
بنابراین کاری که ما قرار است در نهایت انجام دهیم
1520
01:55:17,690 –> 01:55:23,310
پیش بینی این احتمال است که یک داده خاص
یا یک ورودی خاص، یا هر چیز دیگری
1521
01:55:23,310 –> 01:55:27,380
ما می خواهیم آن را در تمام کلاس های مختلفی که
می تواند باشد بنامیم. بنابراین برای مثال،
1522
01:55:27,380 –> 01:55:32,090
در اینجا، ما از گل استفاده می کنیم. بنابراین به آن
زنبق می گویند، من فکر می کنم داده گل زنبق است
1523
01:55:32,090 –> 01:55:35,420
مجموعه یا چیزی شبیه به آن و ما از برخی
خواص مختلف گلها استفاده خواهیم کرد
1524
01:55:35,420 –> 01:55:40,050
پیش بینی کنید که چه گونه گلی است. بنابراین
این تفاوت بین طبقه بندی و رگرسیون است.
1525
01:55:40,050 –> 01:55:44,310
اکنون، من در مورد الگوریتم خاصی که در اینجا
برای طبقه بندی استفاده می کنیم صحبت نمی کنم.
1526
01:55:44,310 –> 01:55:49,870
زیرا تعداد بسیار زیادی از آنها وجود دارد که می توانید
استفاده کنید. اما بله، منظورم این است، اگر شما واقعا
1527
01:55:49,870 –> 01:55:54,040
به نحوه عملکرد آنها در سطح ریاضی پایینتر اهمیت
میدهم، من این را توضیح نمیدهم
1528
01:55:54,040 –> 01:55:57,320
زیرا وقتی که صدها الگوریتم وجود دارد
توضیح آن برای یک الگوریتم منطقی نیست،
1529
01:55:57,320 –> 01:56:01,560
و همه آنها کمی متفاوت عمل می کنند. بنابراین شما
بچه ها می توانید به نوعی به آن نگاه کنید. و
1530
01:56:01,560 –> 01:56:05,510
من به شما منابعی را می گویم و از کجا می توانید
آن را پیدا کنید. من هم قرار است سریعتر بروم
1531
01:56:05,510 –> 01:56:09,290
از طریق این مثال، فقط به این دلیل که من قبلاً
به نوعی چیزهای اساسی را پوشش داده ام
1532
01:56:09,290 –> 01:56:12,820
در رگرسیون خطی بنابراین امیدوارم، ما باید
این یکی را کمی سریعتر انجام دهیم، و
1533
01:56:12,820 –> 01:56:17,760
به جنبه های بعدی این مجموعه بروید. بسیار
خوب، پس اولین قدم ها، TensorFlow را بارگیری کنید،
1534
01:56:17,760 –> 01:56:22,090
TensorFlow را وارد کنید، ما قبلاً این کار را انجام داده ایم.
مجموعه داده ها، ما باید در مورد این صحبت کنیم. بنابراین
1535
01:56:22,090 –> 01:56:26,050
مجموعه داده ای که ما از آن استفاده می کنیم، مجموعه داده
گل های زنبق است، همانطور که در مورد آن صحبت کردم، و این خاص است
1536
01:56:26,050 –> 01:56:30,260
مجموعه داده گل ها را به سه گونه مختلف جدا می کند.
بنابراین ما این گونه های مختلف را داریم.
1537
01:56:30,260 –> 01:56:34,280
این اطلاعاتی است که ما داریم. بنابراین کاسبرگ،
طول، عرض، طول گلبرگ، عرض گلبرگ،
1538
01:56:34,280 –> 01:56:39,060
بدیهی است که ما از آن اطلاعات برای پیش بینی استفاده
خواهیم کرد. بنابراین با توجه به این اطلاعات،
1539
01:56:39,060 –> 01:56:42,710
می دانید، در مدل نهایی ما، می تواند به ما
بگوید که کدام یک از این گل ها محتمل تر است
1540
01:56:42,710 –> 01:56:48,310
بودن؟ باشه. بنابراین کاری که اکنون می خواهیم انجام دهیم
این است که نام های فراخوانی CSV و گونه ها را تعریف کنیم.
1541
01:56:48,310 –> 01:56:51,690
بنابراین نام ستونها فقط تعریف میکنند، چیزی
که ما در مجموعه دادههای خود خواهیم داشت
1542
01:56:51,690 –> 01:56:55,850
مانند سربرگ های ستون ها. گونه ها، بدیهی است
که فقط گونه ها هستند و ما خواهیم کرد
1543
01:56:55,850 –> 01:57:00,120
آنها را به آنجا پرتاب کنید بسیار خوب، پس اکنون می خواهیم مجموعه داده
های خود را بارگذاری کنیم. بنابراین این در حال رفتن است
1544
01:57:00,120 –> 01:57:03,150
هر بار که با مدل ها کار می کنید بسته
به جایی که هستید متفاوت باشید
1545
01:57:03,150 –> 01:57:06,530
گرفتن داده های خود از و مثال ما، ما آن را از
Kara’s دریافت می کنیم که دارای نوع است
1546
01:57:06,530 –> 01:57:11,420
ماژول فرعی TensorFlow مجموعه داده ها و ابزارهای
مفید زیادی دارد که ما خواهیم بود
1547
01:57:11,420 –> 01:57:16,580
استفاده در سراسر سری اما Cara که Utils dot
get file است، باز هم واقعاً تمرکز نکنید
1548
01:57:16,580 –> 01:57:20,760
در این مورد، فقط درک کنید که چه کاری قرار است
انجام دهد ذخیره این فایل در رایانه ما است
1549
01:57:20,760 –> 01:57:25,580
به عنوان نقطه آموزش Iris CSV، آن را از این لینک بگیرید.
و سپس آنچه که ما می خواهیم در اینجا انجام دهیم
1550
01:57:25,580 –> 01:57:30,500
قطار را بارگیری کنید و تست کنید و دوباره به این
آموزش توجه کنید و این تست به دو قسمت است
1551
01:57:30,500 –> 01:57:34,980
فریم های داده جداگانه بنابراین در اینجا، ما می
خواهیم از نام ستون ها به عنوان CSV استفاده کنیم
1552
01:57:34,980 –> 01:57:38,340
نام ستونها، ما از مسیر استفاده میکنیم، زیرا
هر چیزی که اینجا بارگذاری کردیم، هدر برابر است
1553
01:57:38,340 –> 01:57:43,520
صفر، که فقط به این معنی است که ردیف صفر سربرگ است. خوب، پس
اکنون، ما به سمت پایین حرکت خواهیم کرد و خواهیم رفت
1554
01:57:43,520 –> 01:57:47,620
نگاهی به مجموعه داده های ما بیندازید. بنابراین، همانطور
که قبلا انجام دادیم، اوه، من باید این کد را اجرا کنم
1555
01:57:47,620 –> 01:57:53,040
اولین. ستون csv قطع می شود، بسیار خوب، بنابراین ما فقط،
ما فقط کارها را به ترتیب اشتباهی اجرا می کنیم
1556
01:57:53,040 –> 01:57:56,271
اینجا، ظاهرا خوب، پس بیایید به سر نگاه کنیم. بنابراین
ما می توانیم ببینیم که این چیزی است که ما داریم
1557
01:57:56,271 –> 01:58:01,760
قاب داده به نظر می رسد. و توجه کنید که گونه های
ما در اینجا در واقع به صورت عددی تعریف شده اند.
1558
01:58:01,760 –> 01:58:05,840
بنابراین به جای قبل، زمانی که ما مجبور بودیم آن کار را انجام
دهیم، می دانید، ما آن ویژگی را در کجا ایجاد کردیم
1559
01:58:05,840 –> 01:58:09,480
ستونها، و ما دادههای دستهبندی را به
دادههای عددی با آن نوع تبدیل کردیم
1560
01:58:09,480 –> 01:58:14,630
ابزارهای عجیب و غریب جریان تانسور این در واقع
قبلاً برای ما رمزگذاری شده است. هیچ صفر مخفف
1561
01:58:14,630 –> 01:58:19,510
ستوزا و سپس میخواهم به ترتیب از
اینها حمایت کنم. و اینگونه است
1562
01:58:19,510 –> 01:58:25,770
که کار می کند. اکنون، من معتقدم که اینها بر حسب سانتی متر
هستند، طول کاسبرگ، طول گلبرگ، عرض گلبرگ،
1563
01:58:25,770 –> 01:58:30,720
این خیلی مهم نیست اما گاهی اوقات شما
می خواهید آن اطلاعات را بدانید. باشه،
1564
01:58:30,720 –> 01:58:34,420
بنابراین اکنون میخواهیم آن ستونها را برای
گونهها مانند قبل باز کنیم و از هم جدا کنیم
1565
01:58:34,420 –> 01:58:39,220
که به قطار y، تست y، و سپس نگاهی دوباره به
سر. پس بیایید این کار را انجام دهیم.
1566
01:58:39,220 –> 01:58:43,929
و این را اجرا کنید. توجه کنید که از بین رفته است.
باز هم در مورد نحوه کارکرد آن صحبت کرده ایم. و سپس
1567
01:58:43,929 –> 01:58:48,620
اگر بخواهیم نگاهی به آنها بیندازیم. و در واقع،
بیایید این کار را انجام دهیم، ما فقط داریم
1568
01:58:48,620 –> 01:58:57,510
یک بلوک جدید، بیایید بگوییم قطار، خط زیر، نقطه
y، چیست؟ سر نقطه؟ اگر می توانستم املا کنم
1569
01:58:57,510 –> 01:59:02,170
به درستی سر بزنید، خوب، پس سر می زنیم، و می توانیم
ببینیم، این چیزی است که به نظر می رسد چیزی نیست
1570
01:59:02,170 –> 01:59:04,510
خاص این چیزی است که ما به دست می آوریم. باشه پس
1571
01:59:04,510 –> 01:59:07,690
بیایید آن را حذف کنیم بیایید به شکل داده های آموزشی
خود نگاه کنیم. منظورم این است که ما احتمالا می توانیم
1572
01:59:07,690 –> 01:59:11,990
حدس بزنید در حال حاضر چیست اما ما شکلی
خواهیم داشت زیرا چهار ویژگی داریم.
1573
01:59:11,990 –> 01:59:16,260
و سپس چند ورودی داریم؟ خوب، من مطمئن هستم که
این به ما خواهد گفت. بنابراین 120 ورودی
1574
01:59:16,260 –> 01:59:21,030
در شکل برای عالی این شکل ماست باشه، تابع ورودی.
بنابراین ما به سرعت در اینجا حرکت می کنیم
1575
01:59:21,030 –> 01:59:24,159
در حال حاضر، ما در حال ورود به بسیاری از کدنویسی هستیم. بنابراین
کاری که من در واقع انجام خواهم داد این است که، دوباره،
1576
01:59:24,159 –> 01:59:28,040
این را در یک سند جداگانه کپی کنید. و من با
همه اینها در یک ثانیه برمی گردم. باشه،
1577
01:59:28,040 –> 01:59:32,449
بنابراین زمان تابع ورودی، ما از قبل می دانیم که تابع ورودی
چه کاری انجام می دهد، زیرا از آن استفاده کردیم
1578
01:59:32,449 –> 01:59:37,330
قبلا. اکنون، این تابع ورودی کمی
متفاوت از قبل است، فقط به این دلیل
1579
01:59:37,330 –> 01:59:42,310
ما کمی چیزها را تغییر می دهیم. بنابراین در اینجا،
ما در واقع هیچ چیزی نداریم. چه کاری انجام دهید
1580
01:59:42,310 –> 01:59:46,660
شما به آن زنگ می زنید؟ ما هیچ دوره ای نداریم و اندازه
دسته ما متفاوت است. بنابراین آنچه ما داریم
1581
01:59:46,660 –> 01:59:51,659
در اینجا انجام می شود نه در واقع، می دانید،
تعریف مانند make input تابع، ما فقط
1582
01:59:51,659 –> 01:59:56,950
تابع ورودی مانند این داشته باشید. و کاری که
ما می خواهیم انجام دهیم کمی متفاوت است
1583
01:59:56,950 –> 02:00:00,600
تابع ورودی را می گذراند. کمی پیچیده تر به شما
نشان خواهم داد. اما شما می توانید ببینید
1584
02:00:00,600 –> 02:00:04,080
که ما این را کمی تمیز کرده ایم. بنابراین، دقیقاً، ما
همان کاری را که قبلا انجام می دادیم، انجام می دهیم
1585
02:00:04,080 –> 02:00:08,400
تبدیل این داده ها، که ویژگی های ما است، که
در اینجا به یک مجموعه داده منتقل می کنیم.
1586
02:00:08,400 –> 02:00:12,450
و سپس ما آن برچسب ها را نیز منتقل می کنیم. و سپس اگر
در حال آموزش هستیم، پس اگر آموزش می دهیم
1587
02:00:12,450 –> 02:00:16,770
درست است، کاری که ما میخواهیم انجام دهیم این است که بگوییم
مجموعه دادهها برابر است با مجموعه دادهها به هم ریخته.
1588
02:00:16,770 –> 02:00:21,490
بنابراین اطلاعات را به هم می زنیم و سپس آن را تکرار
می کنیم. و این تمام چیزی است که ما واقعا داریم
1589
02:00:21,490 –> 02:00:26,580
باید انجام دهیم، میتوانیم دستهای نقطهای مجموعه داده
را در اندازه دسته 256 انجام دهیم، آن را برگردانیم، و ما
1590
02:00:26,580 –> 02:00:30,820
خوب برای رفتن بنابراین این تابع ورودی ما است.
باز هم، اینها به نوعی پیچیده هستند، شما
1591
02:00:30,820 –> 02:00:34,250
برای درک چگونگی انجام این کار، باید فقط از
دیدن یک سری موارد مختلف تجربه کسب کنید
1592
02:00:34,250 –> 02:00:38,250
در واقع یکی را به تنهایی بسازید. از این
به بعد زیاد نگران نباشید، می توانید
1593
02:00:38,250 –> 02:00:42,159
تقریباً فقط توابع ورودی را که قبلاً ایجاد کرده
اید کپی کنید و آنها را بسیار تغییر دهید
1594
02:00:42,159 –> 02:00:45,430
اگر می خواهید مدل های خود را انجام دهید،
اندکی. اما در پایان این، شما باید
1595
02:00:45,430 –> 02:00:48,890
ایده خوبی از نحوه عملکرد این توابع ورودی داشته باشید،
ما شاهد چهار یا پنج مورد خواهیم بود
1596
02:00:48,890 –> 02:00:52,090
مختلف و سپس می دانید، ما می توانیم به نوعی با آنها سر
و کار داشته باشیم و آنها را مانند خودمان تغییر دهیم
1597
02:00:52,090 –> 02:00:56,670
ادامه دادن. اما زیاد روی آن تمرکز نکنید. خوب،
بنابراین تابع ورودی، این تابع ورودی ما است،
1598
02:00:56,670 –> 02:01:01,530
من واقعاً قصد ندارم به جزئیات بیشتری در
مورد آن بپردازم. و اکنون ستون های ویژگی ما.
1599
02:01:01,530 –> 02:01:04,469
بنابراین، این دوباره، بسیار ساده است. برای ستون
های ویژگی، تمام کاری که باید انجام دهیم
1600
02:01:04,469 –> 02:01:08,030
زیرا این به این دلیل است که همه آنها ستون های
ویژگی عددی هستند به جای حلقه های برای،
1601
02:01:08,030 –> 02:01:13,620
در جایی که قبلاً ستونهای ویژگی عددی و طبقهای را از هم جدا
میکردیم، میتوانیم فقط از طریق حلقه حلقه بزنیم
1602
02:01:13,620 –> 02:01:18,719
همه کلیدهای مجموعه داده آموزشی ما. و سپس
می توانیم به ستون های ویژگی من اضافه کنیم
1603
02:01:18,719 –> 02:01:24,120
لیست خالی، ستون ویژگی نقطه ستون عددی،
در کلید برابر با هر کلید است
1604
02:01:24,120 –> 02:01:28,030
ما از اینجا حلقه زده ایم. اجازه دهید اگر کسی گیج
شده است به شما نشان دهم این به چه معناست.
1605
02:01:28,030 –> 02:01:32,830
دوباره، میتوانید ببینید وقتی ستونهای ویژگیهایم را
چاپ میکنم، کلیدی برابر با طول کاسبرگ دریافت میکنیم
1606
02:01:32,830 –> 02:01:36,909
شکل خود را بدست آوریم، و ما همه آن اطلاعات خوب دیگر را
دریافت می کنیم. پس بیایید این را در آن کپی کنیم
1607
02:01:36,909 –> 02:01:42,500
یکی دیگر، نگاهی به خروجی ما بعد از این بیندازید. بسیار
خوب، بنابراین ستون های ویژگی من برای کلید
1608
02:01:42,500 –> 02:01:49,060
و کلید قطار بنابراین به مربیهای اینجا توجه کنید، کلیدهای
قطار، کاری که انجام میدهد در واقع به همه ما میدهد
1609
02:01:49,060 –> 02:01:53,480
ستون ها بنابراین این یک راه واقعاً سریع
و آسان برای حلقه زدن همه چیزهای مختلف بود
1610
02:01:53,480 –> 02:01:58,030
ستونها، اگرچه میتوانستم نام ستونهای
CSV را مرور کنم و فقط گونهها را حذف کنم
1611
02:01:58,030 –> 02:02:03,179
ستون برای انجام این کار، اما باز هم، ما واقعاً نیازی به این کار
نداریم. بنابراین برای کلیدهای کلیدی و تجاری، من مشخص شده است
1612
02:02:03,179 –> 02:02:06,650
ستونها به TF نقطه اضافه میکنند، ستون ویژگی، کلید ستون
عددی برابر با کلید،
1613
02:02:06,650 –> 02:02:10,110
این فقط میخواهد آن ستونهای ویژگی را ایجاد کند،
ما نیازی به انجام آن کار واژگان نداریم.
1614
02:02:10,110 –> 02:02:14,560
و این نقطه منحصر به فرد است زیرا دوباره، همه اینها
قبلاً برای ما کدگذاری شده اند. باشه عالیه
1615
02:02:14,560 –> 02:02:18,469
پس این مرحله بعدی بود. پس بیایید به اینجا برگردیم
و مدل را بسازیم. باشه. بنابراین این است
1616
02:02:18,469 –> 02:02:21,790
جایی که ما باید کمی عمیق تر در مورد آنچه که در
واقع قرار است بسازیم صحبت کنیم. بنابراین
1617
02:02:21,790 –> 02:02:26,890
مدل برای این یک مدل طبقه بندی است. اکنون
مانند صدها طبقه بندی مختلف وجود دارد
1618
02:02:26,890 –> 02:02:31,480
مدل هایی که می توانیم از قبل در TensorFlow ساخته شده اند استفاده
کنیم. و تا کنون، آنچه ما با آن خطی انجام داده ایم
1619
02:02:31,480 –> 02:02:36,199
طبقه بندی کننده این است که یک مدل از پیش ساخته
شده است که ما فقط کمی از اطلاعات را تغذیه می کنیم
1620
02:02:36,199 –> 02:02:41,320
به، و فقط برای ما کار می کند. اکنون در اینجا،
ما دو نوع انتخاب اصلی داریم که می توانیم
1621
02:02:41,320 –> 02:02:45,180
برای این نوع وظایف طبقه بندی که از قبل در
TensorFlow ساخته شده اند، استفاده می کنیم
1622
02:02:45,180 –> 02:02:49,199
یک طبقهبندیکننده dnn که مخفف یک شبکه عصبی
عمیق است که ما در مورد آن بسیار صحبت کردهایم
1623
02:02:49,199 –> 02:02:53,820
به طور مبهم، بسیار مختصر، و ما یک طبقه بندی خطی داریم.
در حال حاضر، یک طبقه بندی خطی کار می کند
1624
02:02:53,820 –> 02:02:58,820
بسیار شبیه به رگرسیون خطی است، با این تفاوت
که طبقه بندی را انجام می دهد. به جای پسرفت،
1625
02:02:58,820 –> 02:03:03,630
ما در واقع مقدار عددی را دریافت می کنیم، یا متأسفیم،
می دانید، برچسب هایی مانند احتمال وجود
1626
02:03:03,630 –> 02:03:08,540
یک برچسب خاص، به جای یک مقدار عددی. اما
در این مثال، ما در واقع می رویم
1627
02:03:08,540 –> 02:03:13,150
برای رفتن با شبکه عصبی عمیق اکنون، این فقط به این
دلیل است که تانسور در وب سایت آنها جریان دارد
1628
02:03:13,150 –> 02:03:16,929
مانند این همه اینها به نوعی ساختن
وب سایت TensorFlow است، زیرا همه
1629
02:03:16,929 –> 02:03:21,389
کد بسیار شبیه است و من فقط چرخش خودم را اضافه
کردم و چیزها را بسیار عمیق توضیح دادم،
1630
02:03:21,389 –> 02:03:26,330
آنها استفاده از شبکه عصبی عمیق را برای این
انتخاب بهتر توصیه می کنند. اما به طور معمول،
1631
02:03:26,330 –> 02:03:29,489
هنگامی که شما در حال ایجاد برنامه های یادگیری
ماشینی هستید، با مدل های مختلف و
1632
02:03:29,489 –> 02:03:33,390
آنها را به نوعی تغییر دهید و متوجه خواهید
شد که تغییر مدل چندان دشوار نیست،
1633
02:03:33,390 –> 02:03:37,320
زیرا بیشتر کار از بارگیری و نوعی پیش پردازش
داده های ما حاصل می شود. باشه،
1634
02:03:37,320 –> 02:03:42,740
بنابراین کاری که ما باید انجام دهیم این است که یک شبکه عصبی عمیق
بسازیم که دو تای آن ها بعداً، دو تای دیگر مخفی هستند
1635
02:03:42,740 –> 02:03:47,449
لایه هایی با 30 گره و هر کدام 10 گره پنهان.
اکنون می خواهم معماری را ترسیم کنم
1636
02:03:47,449 –> 02:03:50,290
این شبکه عصبی تنها در یک ثانیه، اما من میخواهم
به شما نشان دهم که در اینجا چه کردهایم.
1637
02:03:50,290 –> 02:03:56,409
بنابراین گفتیم طبقه بندی کننده برابر است با برآوردگر نقطه TF.
بنابراین این ماژول برآوردگر فقط یک دسته را ذخیره می کند
1638
02:03:56,409 –> 02:04:00,840
مدل های از پیش ساخته شده از TensorFlow. بنابراین در این
مورد، طبقهبندیکننده dnn یکی از این موارد است.
1639
02:04:00,840 –> 02:04:05,179
کاری که ما باید انجام دهیم این است که ستون های ویژگی خود را ارسال کنیم،
درست مانند کاری که به طبقه بندی کننده خطی خود انجام دادیم.
1640
02:04:05,179 –> 02:04:10,080
و اکنون باید واحدهای پنهان را تعریف کنیم. اکنون
واحدهای پنهان اساساً ما یک ساختمان هستند
1641
02:04:10,080 –> 02:04:14,710
معماری شبکه عصبی بنابراین همانطور که
قبلا دیدید، ما یک لایه ورودی داشتیم،
1642
02:04:14,710 –> 02:04:17,830
ما برخی از لایههای میانی داشتیم که به آنها لایههای
پنهان در شبکه عصبی میگویند. و سپس
1643
02:04:17,830 –> 02:04:21,909
ما لایه خروجی خود را داشتیم، من قصد دارم در ماژول
بعدی شبکه های عصبی را توضیح دهم. پس این
1644
02:04:21,909 –> 02:04:26,120
همه نوع کلیک و منطقی در حال حاضر ما به طور
خودسرانه 30 گره در آن تصمیم گرفته ایم
1645
02:04:26,120 –> 02:04:31,310
اولین لایه مخفی 10 در لایه دوم، و تعداد
کلاس ها قرار است سه باشد.
1646
02:04:31,310 –> 02:04:34,949
اکنون این چیزی است که باید تصمیم بگیریم
که می دانیم سه کلاس برای گل ها وجود دارد.
1647
02:04:34,949 –> 02:04:40,330
بنابراین این چیزی است که ما تعریف کرده ایم. خوب، پس بیایید
این را کپی کنیم و به صفحه دیگر اینجا برگردیم.
1648
02:04:40,330 –> 02:04:44,690
و این الان مدل ماست. و اکنون زمان آن رسیده است که در مورد اینکه
چگونه میتوانیم واقعاً آن را آموزش دهیم صحبت کنیم
1649
02:04:44,690 –> 02:04:48,500
مدلی که اینجا پایین میاد خوب، پس من
این را کپی می کنم. من می روم چسباندن
1650
02:04:48,500 –> 02:04:52,139
اینجاست و بیایید این را بررسی کنیم
زیرا این کمی پیچیده تر است
1651
02:04:52,139 –> 02:04:56,000
کدی که معمولاً برای کار با آن استفاده می
کنیم. من هم قصد دارم این نظرات را حذف کنم
1652
02:04:56,000 –> 02:05:00,590
فقط برای تمیز کردن همه چیز در اینجا بنابراین ما
طبقه بندی کننده را تعریف کرده ایم که عصبی عمیق است
1653
02:05:00,590 –> 02:05:05,970
طبقهبندیکننده شبکه، ما ستونهای ویژگی، کلاسهای واحدهای
پنهان را داریم. اکنون برای آموزش طبقه بندی کننده،
1654
02:05:05,970 –> 02:05:10,510
بنابراین ما این تابع ورودی را در اینجا داریم،
این تابع ورودی با تابعی که ما داریم متفاوت است
1655
02:05:10,510 –> 02:05:14,929
ایجاد شده قبلا، به یاد داشته باشید زمانی
که ما قبلا مانند ایجاد ورودی هر چیزی بود
1656
02:05:14,929 –> 02:05:19,430
تابع من به تایپ کردن در داخل یک تابع دیگر
ادامه خواهم داد، در واقع آن را برگردانده است
1657
02:05:19,430 –> 02:05:24,780
که تابع از این تابع است. میدونم پیچیده اگر شما از نوع حرفه
ای پایتون نیستید، من این کار را نمی کنم
1658
02:05:24,780 –> 02:05:28,940
انتظار داشته باشید که کاملاً منطقی باشد. اما در اینجا،
ما فقط یک عملکرد داریم، درست است، ما نداریم
1659
02:05:28,940 –> 02:05:34,110
بازگرداندن یک تابع از یک تابع دیگر، فقط یک تابع.
بنابراین زمانی که می خواهیم استفاده کنیم
1660
02:05:34,110 –> 02:05:40,119
این، برای آموزش مدل خود، کاری که ما انجام می دهیم ایجاد
چیزی به نام لامبدا است. حالا یک لامبدا است
1661
02:05:40,119 –> 02:05:44,610
یک تابع ناشناس که می تواند
در یک خط تعریف شود
1662
02:05:44,610 –> 02:05:49,460
معنی اساساً این یک تابع است. بنابراین
این یک تابع است. و هر چه بعد از آن باشد
1663
02:05:49,460 –> 02:05:54,630
کولون کاری است که این تابع انجام می دهد. اکنون،
این یک تابع یک خطی است. پس مثل اگر من
1664
02:05:54,630 –> 02:06:03,050
یک لامبدا در اینجا ایجاد کنید، درست است؟ و من می گویم لامبدا،
چاپ، سلام، و گفتم، x برابر با لامبدا است. و
1665
02:06:03,050 –> 02:06:08,590
من x را همینطور صدا زدم. این کارها. این یک
خط نحو معتبر است. در واقع، من می خواهم
1666
02:06:08,590 –> 02:06:12,199
مطمئن شوید که وقتی این را می گویم، من فقط دوست
ندارم با شما درگیر شوم، و در واقع اینطور است
1667
02:06:12,199 –> 02:06:16,280
درست. بسیار خوب، متاسفم، من به طور تصادفی مدل را
آموزش دادم. بنابراین من فقط آن را نظر دادم
1668
02:06:16,280 –> 02:06:19,159
بیرون می بینید که ما در حال چاپ سلام هستیم،
درست در پایین صفحه. من می دانم، این است
1669
02:06:19,159 –> 02:06:23,120
به نوعی کوچک است، اما می گوید سلام، این
روش کار می کند. خوب، پس این چیز جالبی است.
1670
02:06:23,120 –> 02:06:26,861
اگر قبلاً این مورد را در پایتون ندیده اید، این همان کاری
است که لامبدا انجام می دهد و به شما امکان می دهد تعریف کنید
1671
02:06:26,861 –> 02:06:31,570
یک تابع در یک خط حال، چیزی که در این مورد عالی
است این است که میتوانیم بگوییم:
1672
02:06:31,570 –> 02:06:35,270
می دانید، x برابر با لامبدا است، و در اینجا یک تابع دیگر قرار
دهید، که دقیقاً همان کاری است که ما انجام داده ایم
1673
02:06:35,270 –> 02:06:39,620
با این عملکرد چاپ و این بدان معناست که وقتی x را
صدا می کنیم، می دانید، این را اجرا می کند
1674
02:06:39,620 –> 02:06:42,949
تابع، که فقط تابع دیگر را اجرا می کند. بنابراین
به نوعی مانند یک زنجیره است که در آن
1675
02:06:42,949 –> 02:06:47,500
شما x را صدا می زنید، x یک تابع است. و در داخل آن تابع،
عملکرد دیگری را انجام می دهد، درست است؟
1676
02:06:47,500 –> 02:06:50,060
درست مانند فراخوانی یک تابع از داخل
یک تابع.
1677
02:06:50,060 –> 02:06:51,170
بنابراین
1678
02:06:51,170 –> 02:06:56,909
لامبدا اینجا چه می کند؟ خوب، از آنجایی که ما به
شی تابع واقعی نیاز داریم، کاری که انجام می دهیم
1679
02:06:56,909 –> 02:07:02,270
ما تابعی را تعریف می کنیم که تابعی را به ما برمی گرداند.
بنابراین این در واقع فقط آن را دوست دارم
1680
02:07:02,270 –> 02:07:07,750
این تابع را فراخوانی می کند، وقتی این را در اینجا قرار می
دهید، اکنون، من نمی توانم وجود ندارد، بسیار دشوار است
1681
02:07:07,750 –> 02:07:12,360
برای توضیح این موضوع، اگر واقعاً مفهوم
لامبدا را درک نمی کنید. و تو نمیفهمی
1682
02:07:12,360 –> 02:07:17,219
توابع ورودی اما فقط بدانید که ما این کار را به دلیل
این واقعیت انجام می دهیم که جاسازی نکرده ایم
1683
02:07:17,219 –> 02:07:22,390
تابع دیگری را برگردانید و شی تابع را برگردانید. اگر این
کار را کرده بودیم، اگر آن کار را کرده بودیم،
1684
02:07:22,390 –> 02:07:27,369
می دانید، تابع ورودی که قبلاً در جایی که تابع
داخلی داشتیم ایجاد کردیم، سپس ما
1685
02:07:27,369 –> 02:07:29,730
نیازی به انجام این کار نیست، زیرا اتفاقی که می افتد این
است که ما انجام دهیم
1686
02:07:29,730 –> 02:07:30,800
برگشت
1687
02:07:30,800 –> 02:07:36,830
تابع ورودی، درست مثل آن، یعنی وقتی آن
را به اینجا منتقل کردیم، می تواند
1688
02:07:36,830 –> 02:07:43,630
فقط مستقیماً با آن تماس بگیرید، نیازی به داشتن لامبدا
نیست. در حالی که در اینجا، هر چند، از آن زمان
1689
02:07:43,630 –> 02:07:47,370
فقط باید یک لامبدا بگذاریم، باید تعریف کنیم
که این چیست. و بعد و بعد این کار می کند.
1690
02:07:47,370 –> 02:07:51,370
این فقط همین است، هیچ راه دیگری برای توضیح واقعی این موضوع
وجود ندارد. بنابراین بله، کاری که ما انجام می دهیم این است
1691
02:07:51,370 –> 02:07:55,820
ما این تابع ورودی را ایجاد می کنیم. پس می گذریم
قطار داریم، قطار داریم، چرا داریم
1692
02:07:55,820 –> 02:08:01,610
آموزش برابر با true است، و سپس مراحل برابر با 5000 را
انجام می دهیم. بنابراین این شبیه به یک دوره است.
1693
02:08:01,610 –> 02:08:04,780
به جز اینکه این فقط تعریف مجموعه ای از مراحلی
است که قرار است طی کنیم. بنابراین نه
1694
02:08:04,780 –> 02:08:08,240
به جای اینکه بگوییم، مثلاً 10 بار مجموعه داده را
مرور می کنیم، فقط می خواهیم بگوییم که می رویم
1695
02:08:08,240 –> 02:08:13,420
از طریق مجموعه داده تا زمانی که به 5000 عدد
مانند 5000 برسیم، چیزهایی که بررسی شده اند
1696
02:08:13,420 –> 02:08:17,230
در پس این کاری است که با آن قطار انجام می دهد. بیایید
این را اجرا کنیم و فقط به آموزش نگاه کنیم
1697
02:08:17,230 –> 02:08:21,989
خروجی از مدل ما، چیزهایی مانند، در اینجا به ما می
دهد، ما می توانیم به نوعی ببینیم که چگونه است
1698
02:08:21,989 –> 02:08:26,480
کار کردن. توجه داشته باشید که اگر بتوانم یک ثانیه
در اینجا توقف کنم، مرحله فعلی را به ما می گوید
1699
02:08:26,480 –> 02:08:32,580
به ما می گوید ضرر، کمترین، هر چه این عدد کمتر
باشد، بهتر است. و سپس به ما جهانی می گوید
1700
02:08:32,580 –> 02:08:36,699
قدم در ثانیه بنابراین در هر ثانیه چند مرحله
را تکمیل می کنیم. حالا در پایان اینجا،
1701
02:08:36,699 –> 02:08:44,119
مرحله نهایی را می گیریم، از دست دادن 39، که بسیار
زیاد است، به این معنی که بسیار بد است. ولی
1702
02:08:44,119 –> 02:08:47,960
خوبه. این اولین آزمایش ما در آموزش
شبکه عصبی است. پس این
1703
02:08:47,960 –> 02:08:51,600
فقط به ما خروجی می دهد، در حالی که در حال آموزش است تا ببینیم
چه اتفاقی در حال رخ دادن است. در حال حاضر، در ما
1704
02:08:51,600 –> 02:08:55,400
در مورد، ما واقعاً اهمیتی نمی دهیم زیرا این یک مدل
بسیار کوچک است، زمانی که شما در حال آموزش مدل هستید
1705
02:08:55,400 –> 02:09:00,250
که حجم زیادی دارند و ترابایت داده می گیرند،
شما به نوعی به پیشرفت آنها اهمیت می دهید.
1706
02:09:00,250 –> 02:09:03,560
بنابراین در آن زمان است که شما از این نوع خروجی استفاده
می کنید، درست است؟ و شما در واقع نگاه می کنید
1707
02:09:03,560 –> 02:09:06,940
در آن. خوب، حالا که مدل را آموزش دادیم، بیایید
در واقع یک ارزیابی انجام دهیم
1708
02:09:06,940 –> 02:09:11,880
مدل. بنابراین ما فقط میخواهیم بگوییم که نقطه طبقهبندی کننده ارزیابی
میشود. و کاری که ما می خواهیم انجام دهیم این است
1709
02:09:11,880 –> 02:09:16,690
یک چیز بسیار شبیه به آنچه که ما در اینجا انجام داده
ایم، فقط از این تابع ورودی گذشته است، درست، مانند
1710
02:09:16,690 –> 02:09:21,850
در اینجا با یک لامبدا یک بار دیگر، و دلیل ما اضافه
کردن لامبدا زمانی که ما این را نداریم
1711
02:09:21,850 –> 02:09:26,730
مانند، تابع دوگانه در جریان است، مانند یک تابع
تو در تو، ما به لامبدا نیاز داریم. و سپس در
1712
02:09:26,730 –> 02:09:31,600
در اینجا، کاری که ما انجام می دهیم این است که به جای
عبور از قطار و آموزش، چرا باید در آزمون قبول شویم،
1713
02:09:31,600 –> 02:09:36,640
و من فکر می کنم این است، من فقط آن را تست چرایی
می نامم. خوب، و سپس برای آموزش، بدیهی است، این
1714
02:09:36,640 –> 02:09:41,219
نادرست است بنابراین ما فقط می توانیم آن false را مانند
آن تنظیم کنیم. من فقط می خواهم به صفحه دیگر نگاه کنم
1715
02:09:41,219 –> 02:09:44,580
تا مطمئن شوم این را به هم نخوردم چون
باز هم سینتکس یادم نیست. آره
1716
02:09:44,580 –> 02:09:49,460
بنابراین طبقهبندیکننده کلاس، نقطه ارزیابی TEST
TEST چرا به نظر من خوب است. ما این چاپ را می گیریم
1717
02:09:49,460 –> 02:09:54,250
بیانیه فقط برای اینکه ما یک خروجی خوب برای دقت خود
داشته باشیم. خوب، پس بیایید به این نگاه کنیم.
1718
02:09:54,250 –> 02:09:58,719
از نو. ما باید منتظر بمانیم تا این تمرین شود. اما
من راهی را به شما نشان خواهم داد که ما نمی کنیم
1719
02:09:58,719 –> 02:10:02,989
باید هر بار و یک ثانیه منتظر این تمرین
باشم و من بلافاصله برمی گردم.
1720
02:10:02,989 –> 02:10:04,280
خوب، پس من در واقع چه هستم
1721
02:10:04,280 –> 02:10:08,720
قرار است این کار را انجام دهم، و من فقط به نوعی
مکث میکنم، مثل اجرای این کد این است
1722
02:10:08,720 –> 02:10:13,650
بلوک بعدی زیر زیرا نکته خوب در مورد Google
Collaboratory این است که می توانم اجرا کنم
1723
02:10:13,650 –> 02:10:17,460
این بلوک کد، درست است، من میتوانم همه این موارد را آموزش
دهم، این همان چیزی است که در حال حاضر اجرا خواهم کرد
1724
02:10:17,460 –> 02:10:21,610
ما داریم صحبت می کنیم تا این اتفاق بیفتد. و سپس من
می توانم یک بلوک کد دیگر به شکل زیر داشته باشم
1725
02:10:21,610 –> 02:10:26,220
آن را که من اینجا دارم. و مهم نیست، لازم نیست
هر بار آن بلوک را دوباره اجرا کنم
1726
02:10:26,220 –> 02:10:30,139
من اینجا چیزی را تغییر می دهم. بنابراین اگر چیزی را در هر
بلوک پایینی تغییر دهم، نیازی به تغییر ندارم
1727
02:10:30,139 –> 02:10:33,170
بلوک بالایی، یعنی نیازی نیست هر بار که
بخواهم منتظر این باشم تا تمرین کنم
1728
02:10:33,170 –> 02:10:37,790
برای ارزیابی آن به هر حال، پس ما این کار را انجام دادیم،
میتوانیم تست کنیم، تست y را گرفتیم، من فقط
1729
02:10:37,790 –> 02:10:44,540
باید این را به جای نتیجه ارزیابی تغییر دهید.
در واقع، من باید بگویم که نتیجه زیر خط است
1730
02:10:44,540 –> 02:10:48,119
برابر است با ارزیابی نقطه طبقهبندی کننده، به طوری که
ما میتوانیم آن را در جایی ذخیره کنیم و به دست آوریم
1731
02:10:48,119 –> 02:10:52,550
جواب. و این را چاپ میکند و متوجه میشود که خیلی سریعتر
اتفاق میافتد، ما یک آزمایش دریافت میکنیم
1732
02:10:52,550 –> 02:10:54,080
دقت 80 درصد
1733
02:10:54,080 –> 02:10:55,080
بنابراین اگر من
1734
02:10:55,080 –> 02:10:58,760
در صورت آموزش مجدد مدل، احتمال اینکه
این دقت دوباره تغییر کند، به دلیل
1735
02:10:58,760 –> 02:11:02,179
به ترتیبی که گل های مختلف را می بینیم. اما
با توجه به ما این بسیار مناسب است
1736
02:11:02,179 –> 02:11:06,659
داده های آزمایشی زیادی ندارید و ما واقعاً نمی دانیم
که چه کاری را درست انجام می دهیم؟ بود
1737
02:11:06,659 –> 02:11:10,400
یک جورهایی فقط قاطی کردن و آزمایش کردن در حال
حاضر. بنابراین گرفتن 80 درصد بسیار خوب است.
1738
02:11:10,400 –> 02:11:14,170
خوب، پس در واقع، من چه کار می کنم؟ اکنون باید
به عقب برگردیم و پیش بینی کنیم. پس چطورم
1739
02:11:14,170 –> 02:11:18,990
من این را برای گل های خاص پیش بینی می کنم. پس بیایید
به الگوریتم های اصلی یادگیری خود برگردیم.
1740
02:11:18,990 –> 02:11:24,119
و بریم سراغ پیش بینی ها. اکنون، من قبلاً یک اسکریپت
نوشته ام، فقط برای صرفه جویی در زمان
1741
02:11:24,119 –> 02:11:29,540
که به ما امکان می دهد روی هر گلی پیش بینی کنیم. بنابراین کاری
که من می خواهم انجام دهم این است که ایجاد کنم
1742
02:11:29,540 –> 02:11:34,219
یک بلوک جدید در اینجا، بلوک کد و این تابع
را کپی کنید. و حالا می خواهیم هضم کنیم
1743
02:11:34,219 –> 02:11:38,239
این و به نوعی خودمان این را طی کنیم تا
مطمئن شویم که منطقی است. اما این چیه
1744
02:11:38,239 –> 02:11:43,490
اسکریپت کوچکی که به کاربر اجازه می دهد تعدادی اعداد
را تایپ کند، بنابراین کاسبرگ، طول، عرض،
1745
02:11:43,490 –> 02:11:47,350
و حدس میزنم، طول و عرض گلبرگ، و سپس آن چیزی را
که پیشبینی میکردید، به شما خواهد گفت
1746
02:11:47,350 –> 02:11:53,530
کلاس آن گل است. بنابراین ما نمیتوانستیم
روی تک تک دادههایمان پیشبینی کنیم
1747
02:11:53,530 –> 02:11:56,449
امتیازات، مانند قبل. و ما قبلاً می دانیم که چگونه
این کار را انجام دهیم. اینو بهت نشون دادم با
1748
02:11:56,449 –> 02:12:00,369
رگرسیون خطی. اما در اینجا، من فقط می خواستم آن را
در یک ورودی انجام دهم.
1749
02:12:00,369 –> 02:12:04,719
پس چه کار کنیم؟ بنابراین من با ایجاد یک تابع ورودی
شروع می کنم، بسیار اساسی است، ما دسته ای داریم
1750
02:12:04,719 –> 02:12:10,409
اندازه 256، تنها کاری که انجام میدهیم این است که برخی از ویژگیها
را میدهیم و یک مجموعه داده از آن ویژگیها ایجاد میکنیم.
1751
02:12:10,409 –> 02:12:15,429
این یک دیکته است. و سپس دسته نقطه و اندازه دسته.
بنابراین آنچه این کار انجام می دهد توجه است
1752
02:12:15,429 –> 02:12:19,739
ما هیچ مقدار y نمی دهیم، درست است؟ ما هیچ
برچسبی نمی دهیم دلیل ما انجام نمی دهیم
1753
02:12:19,739 –> 02:12:24,199
دلیلش این است که وقتی پیشبینی میکنیم، برچسب
آن را نمیدانیم، درست است؟ مثل ما در واقع
1754
02:12:24,199 –> 02:12:28,969
می خواهیم که مدل به ما پاسخ دهد. بنابراین در اینجا،
من ویژگی ها را یادداشت کردم، من ایجاد می کنم
1755
02:12:28,969 –> 02:12:32,820
یک فرهنگ لغت پیشگو، فقط به این دلیل که می خواهم چیزهایی
را به آن اضافه کنم. و بعد من فقط درخواست کردم
1756
02:12:32,820 –> 02:12:38,410
در اینجا با یک دستور چاپ، لطفا مقادیر عددی را به عنوان
ویژگی تایپ کنید. بنابراین برای ویژگی و ویژگی،
1757
02:12:38,410 –> 02:12:43,191
valid برابر true است، خوب، Val valid برابر است با دو نقطه
از ویژگی ورودی. بنابراین این فقط به چه معناست
1758
02:12:43,191 –> 02:12:46,710
ما برای هر یک از ویژگیها انجام میدهیم، منتظر
میشویم تا پاسخ معتبری دریافت کنیم.
1759
02:12:46,710 –> 02:12:51,570
هنگامی که پاسخ معتبری دریافت کردیم، کاری که میخواهیم انجام
دهیم این است که آن را به فرهنگ لغت خود اضافه کنیم.
1760
02:12:51,570 –> 02:12:57,190
بنابراین ما می گوییم ویژگی را پیش بینی کنید. پس آن
ویژگی هر چه بود، پس کاسبرگ، طول، کاسبرگ،
1761
02:12:57,190 –> 02:13:03,630
عرض، طول گلبرگ یا پپت. عرض گلبرگ برابر
با لیستی است که در این مثال وجود دارد
1762
02:13:03,630 –> 02:13:07,661
آن ارزش هر چه بود حال، دلیل اینکه ما باید این کار
را انجام دهیم این است که دوباره، پیشبینی است
1763
02:13:07,661 –> 02:13:12,550
روش TensorFlow بر روی پیش بینی چندین چیز کار
می کند، نه فقط یک مقدار. بنابراین
1764
02:13:12,550 –> 02:13:15,989
حتی اگر فقط یک مقدار داشته باشیم، بخواهیم برای آن
پیش بینی کنیم، باید آن را در داخل آن قرار دهیم
1765
02:13:15,989 –> 02:13:20,250
یک لیست زیرا انتظار می رود که ما
بیش از یک مقدار داشته باشیم
1766
02:13:20,250 –> 02:13:24,300
که در آن ما چندین مقدار را در لیست خواهیم داشت،
درست، که هر کدام یک مقدار متفاوت را نشان می دهند
1767
02:13:24,300 –> 02:13:29,420
ردیف یا یک گل جدید برای پیش بینی کردن، خوب، حالا می
گوییم پیش بینی ها برابر است با طبقه بندی کننده
1768
02:13:29,420 –> 02:13:33,790
نقطه پیش بینی کنید و سپس در این مورد، تابع ورودی
داریم، تابع ورودی لامبدا پیش بینی می کنیم،
1769
02:13:33,790 –> 02:13:38,650
که این تابع ورودی در اینجا است. و سپس
برای لغت نامه های پیش بینی می گوییم، زیرا
1770
02:13:38,650 –> 02:13:43,460
به یاد داشته باشید، هر پیش بینی به عنوان یک فرهنگ
لغت در پیش بینی ها برمی گردد، ما می گوییم کلاس
1771
02:13:43,460 –> 02:13:49,150
ID برابر است با هر شناسه کلاس فرهنگ
لغت پیش بینی در صفر. و اینها هستند
1772
02:13:49,150 –> 02:13:55,869
به سادگی چه؟ من دقیقاً نمی دانم چگونه این را توضیح
دهم. ما در یک ثانیه نگاه می کنیم، من می گذرم
1773
02:13:55,869 –> 02:14:00,090
که و سپس احتمال برابر با احتمالات
فرهنگ لغت پیش بینی است
1774
02:14:00,090 –> 02:14:06,630
شناسه کلاس باشه؟ سپس میخواهیم بگوییم پیشبینی
چاپ این است که این کار را انجام میدهیم
1775
02:14:06,630 –> 02:14:10,989
چیز با فرمت عجیب من همین الان این را از
تنسورفلو دزدیدم. و این گونه خواهد بود
1776
02:14:10,989 –> 02:14:15,639
در شناسه کلاس و سپس 100 برابر احتمال، که
به ما مقدار صحیح واقعی می دهد. بود
1777
02:14:15,639 –> 02:14:18,910
این را هضم میکنم، اما بیایید همین الان آن را اجرا
کنیم و نگاهی بیندازیم. پس لطفا عددی را تایپ کنید
1778
02:14:18,910 –> 02:14:25,330
مقادیر مطابق خواسته طول کاسبرگ، اجازه دهید تایپ
کنید مانند 2.4 زیر عرض 2.6 عرض گلبرگ، اجازه دهید
1779
02:14:25,330 –> 02:14:31,380
فقط بگو 6.5 است. و بله، عرض گلبرگ مانند
6.3. خوب، پس این را صدا می کند
1780
02:14:31,380 –> 02:14:36,130
و می گوید پیش بینی virginica است. من حدس می زنم این
همان کلاسی است که ما با آن می رویم. و
1781
02:14:36,130 –> 02:14:42,619
می گوید 83 یا 86.3 درصد احتمال دارد که
این پیش بینی باشد. پس آره، همینطوره
1782
02:14:42,619 –> 02:14:46,630
که کار می کند. پس این کاری است که انجام می دهد. من می خواستم
یک فیلمنامه کوچک ارائه کنم که بیشتر آن را نوشتم،
1783
02:14:46,630 –> 02:14:50,560
منظورم این است که من مقداری از این را از TensorFlow دزدیدم، اما فقط
برای اینکه به شما نشان دهم واقعاً چگونه پیشبینی میکنید
1784
02:14:50,560 –> 02:14:55,860
در یک مقدار، بنابراین بیایید به این فرهنگ لغت پیش بینی
نگاه کنیم زیرا من فقط می خواهم به شما نشان دهم
1785
02:14:55,860 –> 02:15:02,230
در واقع یکی از آنها چیست بنابراین من می
خواهم بگویم چاپ پیش از خط خطی dict، و سپس
1786
02:15:02,230 –> 02:15:05,700
این به من این امکان را می دهد که در واقع به بررسی اینکه چه
شناسه های کلاسی احتمالات ما هستند و چگونه هستند، بپردازم
1787
02:15:05,700 –> 02:15:12,810
من به نوعی این کار را انجام داده ام. بنابراین بیایید
این را اجرا کنیم تا مقیاس های طول مانند 1.4 2.3 باشد.
1788
02:15:12,810 –> 02:15:18,170
من نمی دانم این ارزش ها در نهایت به چه چیزی
تبدیل می شوند. و ما پیش بینی همان است
1789
02:15:18,170 –> 02:15:23,310
یکی با 77.1٪، که منطقی است زیرا این
مقادیر از نظر تفاوت مشابه هستند
1790
02:15:23,310 –> 02:15:27,429
به کاری که قبلا انجام دادم خوب، پس این فرهنگ لغت
است. پس بیایید به دنبال آنچه بودیم بگردیم
1791
02:15:27,429 –> 02:15:32,560
به دنبال بنابراین احتمالات، توجه داشته باشید که
ما سه احتمال به دست می آوریم، یکی برای هر یک از آنها
1792
02:15:32,560 –> 02:15:38,050
کلاس ها. بنابراین ما در واقع میتوانیم بگوییم
چه درصدی برای هر یک از آنها میدانید
1793
02:15:38,050 –> 02:15:44,310
پیشبینیها، پس آنچه ما داریم شناسههای کلاس است. حالا، شناسههای
کلاس، کاری که این کار انجام میدهد به ما میگوید
1794
02:15:44,310 –> 02:15:49,960
چه شناسه کلاسی پیش بینی می کند که در واقع گل درست
است؟ بنابراین در اینجا، آن را می گوید دو، که
1795
02:15:49,960 –> 02:15:54,850
یعنی این احتمال 77 درصد است. این در شاخص دو
در این آرایه است، درست است؟ پس همین است
1796
02:15:54,850 –> 02:15:59,980
چرا این مقدار دو است بنابراین می گویند که
آن کلاس دو است، فکر می کند کلاس دو است،
1797
02:15:59,980 –> 02:16:06,850
مانند آن چیزی است که در سیستم ما کدگذاری شده است
دو است. و این روش کار می کند. پس همین است
1798
02:16:06,850 –> 02:16:12,370
چگونه می دانم کدام یک را چاپ کنم به این دلیل است
که به من می گوید کلاس دو است. و من می دانم برای
1799
02:16:12,370 –> 02:16:17,719
اگر بتوانم از شر این خروجی خلاص شوم، این
فهرست را به اینجا برگردانم. در حالیکه
1800
02:16:17,719 –> 02:16:24,110
وقتی میگویم گونهها، عدد دو ویرجینیکا است، یا حدس
میزنم اینطوری میگویید. پس همین است
1801
02:16:24,110 –> 02:16:27,639
طبقه بندی چیست پیش بینی همین است. بنابراین
من این کار را انجام می دهم. و
1802
02:16:27,639 –> 02:16:33,049
که چگونه کار می کند. خوب، پس من فکر می کنم که
در واقع تقریباً همینطور است
1803
02:16:33,049 –> 02:16:36,169
طبقه بندی. بنابراین خیلی ابتدایی است، من می روم
و می بینم که آیا چیز دیگری وجود دارد یا خیر
1804
02:16:36,170 –> 02:16:41,099
که من برای طبقه بندی در اینجا انجام دادم. خوب، بنابراین در
اینجا، من فقط چند نمونه را قرار می دهم. بنابراین اینجاست
1805
02:16:41,099 –> 02:16:45,340
چند نمونه ورودی کلاس های مورد انتظار. بنابراین شما بچه ها می
توانید در صورت تمایل این کارها را انجام دهید. بنابراین
1806
02:16:45,340 –> 02:16:53,478
به عنوان مثال، در این یکی، کاسبرگ، عرض کاسبرگ
طول. بنابراین برای 5.1 3.3 1.7 و 0.5، خروجی
1807
02:16:53,478 –> 02:17:00,129
باید ستوزا باشد. برای 5.9 3.0 4.2 1.5، باید
این یکی باشد. و سپس بدیهی است، این
1808
02:17:00,129 –> 02:17:04,799
برای این، فقط برای این که اگر می خواهید، بتوانید با آنها
سر و کله بزنید. اما این تقریباً برای آن است
1809
02:17:04,799 –> 02:17:10,799
طبقه بندی، و در حال حاضر به خوشه بندی.
خوب، پس اکنون به سمت خوشه بندی می رویم.
1810
02:17:10,799 –> 02:17:15,058
اکنون، خوشهبندی اولین الگوریتم یادگیری
بدون نظارت است که میخواهیم ببینیم
1811
02:17:15,058 –> 02:17:20,209
در این سریال و بسیار قدرتمند است. اکنون، خوشه
بندی فقط برای موارد بسیار خاص کار می کند
1812
02:17:20,209 –> 02:17:25,069
مجموعه ای از مشکلات و هنگامی که مجموعه ای از اطلاعات
ورودی یا ویژگی ها را دارید از خوشه بندی استفاده می کنید.
1813
02:17:25,070 –> 02:17:30,898
اما شما هیچ برچسب یا اطلاعات باز ندارید.
1814
02:17:30,898 –> 02:17:40,239
در اصل، کاری که خوشهبندی انجام میدهد این است که خوشههایی
از نقاط داده مشابه را پیدا میکند و به شما میگوید
1815
02:17:40,240 –> 02:17:44,429
مکان آن خوشه ها بنابراین شما یک دسته از داده های آموزشی
را می دهید، می توانید نحوه انتخاب را انتخاب کنید
1816
02:17:44,429 –> 02:17:49,070
خوشه های زیادی را که می خواهید پیدا کنید. بنابراین
شاید ما قرار است ارقام را دسته بندی کنیم، درست، دست نویس
1817
02:17:49,070 –> 02:17:52,799
ارقام، استفاده از k به معنای خوشه بندی است.
در آن نمونه، 10 خوشه مختلف خواهیم داشت
1818
02:17:52,799 –> 02:17:57,449
برای ارقام صفر تا نه، و شما تمام این
اطلاعات را ارسال می کنید. و الگوریتم
1819
02:17:57,450 –> 02:18:01,728
در واقع آن خوشهها را در مجموعه دادهها برای
شما پیدا میکند، ما یک مثال را مرور میکنیم
1820
02:18:01,728 –> 02:18:07,058
منطقی خواهد بود اما من فقط میخواهم الگوریتم پایهای
را که پشت k میانگین قرار دارد، به سرعت توضیح دهم
1821
02:18:07,058 –> 02:18:11,268
اساساً مجموعه ای از مراحل است، زیرا
من شما را از طریق آنها و با یک
1822
02:18:11,269 –> 02:18:17,709
مثال بصری بنابراین ما با انتخاب تصادفی
k نقطه برای قرار دادن یک مرکز K شروع می کنیم.
1823
02:18:17,709 –> 02:18:22,629
اکنون یک مرکز به معنای جایی است که خوشه فعلی
ما به نوعی تعریف شده است. و خواهیم دید
1824
02:18:22,629 –> 02:18:27,888
در یک ثانیه، مرحله بعدی این است که ما
تمام نقاط داده را به مرکزها اختصاص می دهیم
1825
02:18:27,888 –> 02:18:31,718
با فاصله بنابراین در واقع، اکنون که من در مورد
این صحبت می کنم، فکر می کنم که منطقی تر است
1826
02:18:31,718 –> 02:18:34,779
برای اینکه مستقیماً وارد مثال شوم، زیرا اگر من در
مورد این صحبت کنم، احتمالاً شما هم همینطور هستید
1827
02:18:34,780 –> 02:18:38,170
فقط گیج می شوم، اگرچه ممکن است فقط برای
اشاره به آن ها به این موضوع بازگردم
1828
02:18:38,170 –> 02:18:39,429
نکته ها. باشه،
1829
02:18:39,429 –> 02:18:44,309
بنابراین بیایید یک نمودار کوچک مانند این را در
دو بعدی برای مثال اصلی خود ایجاد کنیم. و
1830
02:18:44,309 –> 02:18:48,480
اجازه دهید در اینجا به برخی از داده ها اشاره کنیم. بنابراین
من فقط می خواهم همه آنها را قرمز کنم. و شما می خواهید
1831
02:18:48,481 –> 02:18:52,070
توجه داشته باشید که من با قرار دادن آنها مانند
آنها این کار را برای خودمان آسانتر می کنم
1832
02:18:52,070 –> 02:18:57,920
گروه های کوچک منحصر به فرد خود را دارید، درست است؟ بنابراین در واقع، ما
یکی را در اینجا اضافه می کنیم، سپس می توانیم مقداری اضافه کنیم
1833
02:18:57,920 –> 02:19:03,398
اینجا پایین و اینجا پایین اکنون الگوریتم برای K به
معنای خوشه بندی شروع می شود. و شما خواهید کرد
1834
02:19:03,398 –> 02:19:09,509
همانطور که با انتخاب تصادفی k مرکز ادامه می دهیم، درک
کنید که چگونه این کار را انجام می دهد. من می روم
1835
02:19:09,510 –> 02:19:15,410
یک مرکز را با کمی مثلث پر شده نشان دهید.
و اساساً اینها چه هستند،
1836
02:19:15,410 –> 02:19:20,968
جایی است که این خوشه های مختلف در حال حاضر وجود دارند.
بنابراین با انتخاب تصادفی K شروع می کنیم،
1837
02:19:20,968 –> 02:19:24,428
که ما تعریف کرده ایم. بنابراین اجازه
دهید در این مثال، ما k برابر است
1838
02:19:24,429 –> 02:19:30,638
3k، مرکز، هر کجا. بنابراین شاید ما یکی را قرار دهیم،
می دانید، جایی مانند اینجا، می دانید چیست
1839
02:19:30,638 –> 02:19:34,049
من ممکن است زحمت پر کردن اینها را نداشته باشم،
زیرا قرار است مدتی طول بکشد، شاید بگذاریم
1840
02:19:34,049 –> 02:19:38,939
یکی اینجا شاید در نهایت یکی را اینجا قرار دهیم.
حالا، من آنها را به نوعی نزدیک کرده ام
1841
02:19:38,940 –> 02:19:43,040
جایی که خوشه ها هستند. اما اینها کاملاً
تصادفی هستند. حالا چه اتفاقی می افتد
1842
02:19:43,040 –> 02:19:50,250
بعدی هر گروه یا هر نقطه داده است که بر اساس فاصله
به یک خوشه اختصاص داده می شود. بنابراین اساسا،
1843
02:19:50,250 –> 02:19:54,780
کاری که ما انجام می دهیم این است که برای هر نقطه داده
ای که داریم، آنچه را که به آن می گویند پیدا می کنیم
1844
02:19:54,780 –> 02:19:58,450
فاصله اقلیدسی، یا در واقع می تواند فاصله متفاوتی
باشد که می خواهید مانند منهتن استفاده کنید
1845
02:19:58,450 –> 02:20:02,620
اگر بچه ها می دانید که چیست. به همه سانتروئیدها
بنابراین بیایید بگوییم که در حال جستجو هستیم
1846
02:20:02,620 –> 02:20:07,750
در این نقطه داده در اینجا، کاری که ما انجام می دهیم
این است که فاصله تا همه این مرکزهای مختلف را پیدا کنیم.
1847
02:20:07,750 –> 02:20:13,060
و این نقطه داده را به نزدیکترین مرکز مرکزی اختصاص
می دهیم. بنابراین نزدیکترین از نظر فاصله،
1848
02:20:13,060 –> 02:20:16,410
در حال حاضر در این مثال به نظر می رسد
که آن را کمی از کراوات بین این مرکز
1849
02:20:16,410 –> 02:20:20,870
و این مرکز، اما من آن را به سمت چپ می دهم. بنابراین
کاری که ما انجام می دهیم این است که ما هستیم
1850
02:20:20,870 –> 02:20:25,430
میخواهم بگویم این اکنون بخشی از این مرکز است. بنابراین من
این را اینگونه صدا می کنم، بگذارید فقط این را بگوییم
1851
02:20:25,430 –> 02:20:30,160
مرکز یک است، این قرن دوم است، و این مرکز
سه است، از این که اکنون در حال رفتن است
1852
02:20:30,160 –> 02:20:34,250
بخشی از مرکز یک باشد زیرا به مرکز مرکزی
نزدیک است. و ما می توانیم از آن عبور کنیم
1853
02:20:34,250 –> 02:20:37,810
و ما این کار را برای هر نقطه داده انجام می دهیم. بنابراین
بدیهی است که ما می دانیم که همه اینها در حال انجام است
1854
02:20:37,810 –> 02:20:43,480
برای ما بودن، درست است و ما می دانیم که این
دو ما خواهند بود، بنابراین دو به دو. و سپس
1855
02:20:43,480 –> 02:20:44,480
اینها بدیهی است که خواهند بود
1856
02:20:44,480 –> 02:20:45,870
سه ما
1857
02:20:45,870 –> 02:20:49,020
اکنون، من در واقع قصد دارم چند نقطه داده دیگر
را اضافه کنم، زیرا میخواهم ایجاد کنم
1858
02:20:49,020 –> 02:20:55,220
این کمی پیچیده تر است، تقریباً، اگر منطقی باشد.
بنابراین آن داده ها را اضافه کنید
1859
02:20:55,220 –> 02:20:59,490
در اینجا یک مورد اضافه می کنیم. و این به این
برچسب ها خواهد رسید. پس اینها هستند
1860
02:20:59,490 –> 02:21:02,220
بستن. بنابراین من این را یکی به یکی می گویم،
این یکی را دو می گویم، می دانم که این است
1861
02:21:02,220 –> 02:21:06,700
نزدیکترین به آن نیست اما فقط به این دلیل که فعلاً
می خواهم این کار را انجام دهم. برای آن دو می گوییم.
1862
02:21:06,700 –> 02:21:10,740
و ما در اینجا سه می گوییم. خوب، حالا که انجام
دادیم همه این نکات را برچسب گذاری کردیم،
1863
02:21:10,740 –> 02:21:15,720
کاری که ما انجام می دهیم این است که اکنون این مرکزها
را که تعریف کرده ایم به وسط همه جابجا می کنیم
1864
02:21:15,720 –> 02:21:21,800
از نقاط داده آنها بنابراین کاری که من انجام می دهم این است که اساساً
متوجه می شوم که مرکز جرم نامیده می شود، مرکز
1865
02:21:21,800 –> 02:21:26,180
جرم بین تمام نقاط داده ای که برچسب یکسانی
دارند. پس در این مورد، اینها
1866
02:21:26,180 –> 02:21:29,330
همه آنهایی خواهند بود که برچسب یکسانی دارند.
و من این مرکز، که من هستم را انتخاب می کنم
1867
02:21:29,330 –> 02:21:33,840
باید پاکش کنم، از شرش خلاص شوم، و من
آن را درست وسط گذاشتم. پس بیایید
1868
02:21:33,840 –> 02:21:38,070
به آبی برگرد و بیایید بگوییم که
وسط این نقاط داده به جایی می رسد
1869
02:21:38,070 –> 02:21:42,680
اطراف اینجا. بنابراین ما آن را در اینجا قرار می دهیم، و این
همان چیزی است که ما به آن جرم مرکزی می گوییم. و این دوباره،
1870
02:21:42,680 –> 02:21:47,790
مرکز دو خواهد بود. پس بیایید فقط این را پاک کنیم. و
ما به آنجا می رویم. حالا ما همین کار را می کنیم
1871
02:21:47,790 –> 02:21:53,250
چیزی با مرکز دیگر. پس بیایید اینها، اینها را
حذف کنیم. بنابراین برای سه، من هستم
1872
02:21:53,250 –> 02:21:58,660
گفتن احتمالاً جایی در اینجا خواهد
بود. و سپس برای یکی، توده مرکزی ما
1873
02:21:58,660 –> 02:22:05,390
احتمالا قرار است در جایی در اینجا واقع شود. حالا کاری
که انجام می دهم این است که آن را تکرار می کنم
1874
02:22:05,390 –> 02:22:10,581
فرآیندی که من به تازگی انجام دادم، و اکنون همه نقاط
را به نزدیکترین مرکز اختصاص می دهم. پس همه
1875
02:22:10,581 –> 02:22:14,690
این نقاط دارای برچسب یک، دو هستند، همه اینها، می
دانید، ما می توانیم برچسب آنها را حذف کنیم،
1876
02:22:14,690 –> 02:22:18,620
و این خیلی خوب است که سعی کنم برچسب
ها را پاک کنم، نباید می نوشتم
1877
02:22:18,620 –> 02:22:23,000
آنها در بالا اما اساساً، کاری که ما انجام می دهیم
این است که مانند واگذاری مجدد آنها خواهیم بود.
1878
02:22:23,000 –> 02:22:26,470
بنابراین من میخواهم بگویم خوب، بنابراین این دو است،
و ما فقط همان کار قبلی را انجام میدهیم، پیدا کنید
1879
02:22:26,470 –> 02:22:30,649
نزدیک ترین فاصله بنابراین ما می گوییم می دانید، اینها
می توانند در یک خوشه باقی بمانند، شاید
1880
02:22:30,649 –> 02:22:36,280
این یکی در اینجا در واقع اکنون به یک تغییر
می کند، زیرا به مرکز مرکزی نزدیک است.
1881
02:22:36,280 –> 02:22:39,580
و ما فقط همه این نکات را دوباره اختصاص می دهیم. و
شاید شما این یکی را بدانید. حالا اگر قرار بود
1882
02:22:39,580 –> 02:22:44,181
قبل از این، بیایید بگوییم مانند این یکی، و ما فقط آنها
را تغییر می دهیم. حالا این را تکرار می کنیم
1883
02:22:44,181 –> 02:22:50,910
فرآیند یافتن نزدیکترین، یا اختصاص دادن
تمام نقاطی که نزدیکترین مرکز هستند،
1884
02:22:50,910 –> 02:22:55,500
انتقال مرکز به مرکز جرم و ما به این کار
ادامه می دهیم تا در نهایت به ما برسد
1885
02:22:55,500 –> 02:23:00,420
به نقطه ای می رسیم که هیچ یک از این نقاط تغییر نمی دهد
که کدام مرکز آنها بخشی از آن هستند. بنابراین
1886
02:23:00,420 –> 02:23:04,290
در نهایت، به نقطه ای می رسیم که من فقط این را پاک
می کنم و مانند یک نمودار جدید ترسیم می کنم،
1887
02:23:04,290 –> 02:23:07,350
چون کمی تمیزتر می شود اما چیزی که ما داریم،
می دانید، مانند یک دسته از آنهاست
1888
02:23:07,350 –> 02:23:12,979
نقاط داده بنابراین ما برخی را در اینجا داریم، برخی
را در اینجا، شاید فقط برخی را اینجا قرار دهیم.
1889
02:23:12,979 –> 02:23:17,540
و شاید ما مانند یک k برابر، به عنوان مثال، برای این یکی
انجام دهیم، و ما همه این مرکزها را داشته باشیم.
1890
02:23:17,540 –> 02:23:21,899
و من فقط این مرکزها را با رنگ آبی ترسیم می
کنم، که مستقیماً در وسط قرار دارند
1891
02:23:21,899 –> 02:23:25,270
تمام نقاط داده آنها آنها تا جایی که می توانند
در وسط هستند، هیچ کدام از ما نیستند
1892
02:23:25,270 –> 02:23:30,899
نقاط داده جابجا شده اند. و ما این را اکنون خوشه خود می
نامیم. بنابراین اکنون ما این خوشه ها را داریم،
1893
02:23:30,899 –> 02:23:34,500
ما این مرکزها را داریم، درست است، می دانیم کجا هستند.
و کاری که ما انجام می دهیم زمانی است که یک
1894
02:23:34,500 –> 02:23:38,700
نقطه داده جدیدی که میخواهیم برای آن پیشبینی
کنیم یا بفهمیم چه خوشهای بخشی است
1895
02:23:38,700 –> 02:23:43,350
از، کاری که ما انجام می دهیم این است که نقاط داده را رسم می کنیم. بنابراین
بیایید بگوییم که این نقطه داده جدید در اینجا است،
1896
02:23:43,350 –> 02:23:48,229
ما فاصله تا همه خوشه های موجود را پیدا می کنیم
و سپس آن را به نزدیکترین آنها اختصاص می دهیم
1897
02:23:48,229 –> 02:23:52,250
یکی بنابراین بدیهی است که به آن یکی اختصاص داده می شود.
و ما می توانیم این کار را برای هر داده ای انجام دهیم
1898
02:23:52,250 –> 02:23:56,150
نقطه، درست بنابراین حتی اگر یک نقطه داده را تماماً
در اینجا قرار دهم، خوب، نزدیکترین نقطه است
1899
02:23:56,150 –> 02:24:02,109
خوشه این است، بنابراین به این خوشه اختصاص داده
می شود. و خروجی من هر چه باشد خواهد بود
1900
02:24:02,109 –> 02:24:05,930
برچسب این خوشه است. و اساساً این روش کار می کند. بنابراین
شما فقط در حال خوشه بندی هستید
1901
02:24:05,930 –> 02:24:09,750
نقاط داده، تشخیص اینکه کدام یک شبیه هستند. و
یک الگوریتم بسیار ابتدایی وجود دارد،
1902
02:24:09,750 –> 02:24:13,410
مثلث کوچک خود را رسم می کنید، از هر نقطه
مثلث یا همه فاصله پیدا می کنید
1903
02:24:13,410 –> 02:24:18,740
از مثلث ها در واقع و سپس کاری که انجام می دهید این
است که به سادگی آن مقادیر را به آن اختصاص دهید
1904
02:24:18,740 –> 02:24:22,830
مرکز، شما آن مرکز را به مرکز جرم منتقل می
کنید، و این روند را دائما تکرار می کنید،
1905
02:24:22,830 –> 02:24:26,399
تا اینکه در نهایت به نقطه ای می رسید که هیچ یک از داده
های شما به شما اشاره نمی کند که در حال حرکت هستید. که
1906
02:24:26,399 –> 02:24:30,650
به این معنی است که شما در اصل بهترین خوشه هایی را که می
توانید پیدا کرده اید. در حال حاضر تنها چیزی که با
1907
02:24:30,650 –> 02:24:34,660
این است که شما باید بدانید چه تعداد خوشه برای
K می خواهید به معنای خوشه بندی است، زیرا k
1908
02:24:34,660 –> 02:24:38,700
متغیری است که شما باید آن را تعریف کنید، اگرچه الگوریتم
هایی وجود دارد که واقعاً می توانند
1909
02:24:38,700 –> 02:24:42,950
تعیین بهترین مقدار خوشه برای یک
مجموعه داده خاص. اما این کمی است
1910
02:24:42,950 –> 02:24:46,760
فراتر از چیزی که در حال حاضر بر روی آن تمرکز خواهیم
کرد. بنابراین این تقریباً خوشهبندی است.
1911
02:24:46,760 –> 02:24:51,310
واقعاً چیز زیادی برای صحبت در مورد آن وجود ندارد، به خصوص
به این دلیل که ما واقعاً نمی توانیم کدنویسی کنیم
1912
02:24:51,310 –> 02:24:56,600
هر چیزی برای آن در حال حاضر بنابراین ما به سراغ مدل
های پنهان مارکوف می رویم. اکنون مارکوف پنهان شده است
1913
02:24:56,600 –> 02:25:00,420
مدلها بسیار متفاوت از آنچه تاکنون دیدهایم هستند.
ما از نوعی الگوریتم استفاده کرده ایم
1914
02:25:00,420 –> 02:25:05,360
که بر داده ها تکیه دارند. بنابراین مانند k به معنای خوشه بندی
است، ما داده های زیادی دادیم و خوشه بندی نکردیم
1915
02:25:05,360 –> 02:25:10,290
تمام آن نقاط داده آن مرکزها را پیدا کردند. از این مرکزها
برای پیدا کردن مکان دادههای جدید استفاده کنید
1916
02:25:10,290 –> 02:25:14,979
امتیاز باید باشد. در مورد رگرسیون خطی و طبقه بندی نیز همین
موضوع وجود دارد. در حالی که مارکوف پنهان
1917
02:25:14,979 –> 02:25:19,350
مدلها، ما در واقع با توزیعهای احتمال سروکار
داریم. در حال حاضر، به عنوان مثال ما می رویم
1918
02:25:19,350 –> 02:25:23,030
به اینجا بروید و من باید مثال های زیادی برای این
کار انجام دهم، زیرا این یک کار بسیار است
1919
02:25:23,030 –> 02:25:28,040
مفهوم انتزاعی یک مدل پایه آب و هوا است. بنابراین آنچه
ما در واقع می خواهیم انجام دهیم پیش بینی است
1920
02:25:28,040 –> 02:25:35,910
آب و هوا در هر روز، با توجه به احتمال وقوع
رویدادهای مختلف. پس بیایید بگوییم
1921
02:25:35,910 –> 02:25:39,340
می دانیم، می دانید، شاید در یک محیط شبیه
سازی شده یا چیزی شبیه به آن ممکن است
1922
02:25:39,340 –> 02:25:42,050
یک برنامه کاربردی باشد،
1923
02:25:42,050 –> 02:25:45,780
که ما چیزهای خاصی در مورد محیط خود داریم،
مثلاً می دانیم، اگر هوا آفتابی است،
1924
02:25:45,780 –> 02:25:50,399
80% احتمال دارد که روز بعد دوباره
آفتابی باشد و 20% احتمال دارد
1925
02:25:50,399 –> 02:25:55,210
که باران خواهد بارید شاید اطلاعاتی در
مورد روزهای آفتابی و سرد داشته باشیم
1926
02:25:55,210 –> 02:25:59,510
روزها. و همچنین اطلاعاتی در مورد میانگین
دمای آن روزها می دانیم. استفاده كردن
1927
02:25:59,510 –> 02:26:05,070
با این اطلاعات، میتوانیم یک مدل مارکوف پنهان ایجاد
کنیم که به ما امکان پیشبینی را میدهد
1928
02:26:05,070 –> 02:26:09,479
برای آب و هوا در روزهای آینده، با توجه
به احتمالاتی که ما کشف کرده ایم.
1929
02:26:09,479 –> 02:26:13,450
حالا، ممکن است اینگونه بگویید، خوب، ما از کجا این
را بدانیم؟ مثلاً چگونه این احتمال را بدانم،
1930
02:26:13,450 –> 02:26:17,580
بسیاری از مواقع شما واقعاً احتمال وقوع
رویدادهای خاص را می دانید، یا
1931
02:26:17,580 –> 02:26:20,760
اتفاقات خاصی می افتد که این مدل ها را واقعاً
خوب می کند. اما بعضی اوقات وجود دارد
1932
02:26:20,760 –> 02:26:25,290
جایی که شما واقعاً انجام می دهید این است که مجموعه داده
های عظیمی دارید و احتمال آن را محاسبه می کنید
1933
02:26:25,290 –> 02:26:29,580
چیزهایی که بر اساس آن مجموعه داده رخ می دهند.
بنابراین ما آن بخش را انجام نمی دهیم، زیرا
1934
02:26:29,580 –> 02:26:32,550
این فقط کمی زیاده روی است.
و تمام هدف این است که
1935
02:26:32,550 –> 02:26:36,280
چند مدل مختلف را به ما معرفی کنید اما در این مثال،
کاری که ما انجام خواهیم داد استفاده از مقداری است
1936
02:26:36,280 –> 02:26:40,801
توزیع های احتمال از پیش تعریف شده بنابراین
اجازه دهید من فقط تعریف دقیق a را بخوانم
1937
02:26:40,801 –> 02:26:44,750
مدل مارکوف را پنهان کرده و عمیق تر شروع کنید.
بنابراین مدل مارکوف پنهان یک متناهی است
1938
02:26:44,750 –> 02:26:49,970
مجموعه ای از حالات، که هر کدام با
یک احتمال کلی چند بعدی همراه است
1939
02:26:49,970 –> 02:26:53,450
توزیع انتقال در بین ایالات توسط مجموعه
ای از احتمالات به نام اداره می شود
1940
02:26:53,450 –> 02:26:59,399
احتمالات انتقال بنابراین در یک مدل مارکوف پنهان،
ما یک دسته حالت داریم. در حال حاضر در
1941
02:26:59,399 –> 02:27:03,650
مثالی که من در مورد آن با این مدل آب و هوا صحبت می کردم،
حالت هایی که ما خواهیم داشت روز گرم است،
1942
02:27:03,650 –> 02:27:09,980
و روز سرد اکنون، اینها چیزی است که ما آن را پنهان می
نامیم، زیرا ما واقعاً هرگز به آن دسترسی نداریم
1943
02:27:09,980 –> 02:27:14,810
یا به این حالت ها نگاه کنید، در حالی که ما با مدل تعامل
داریم، در واقع، زمانی که ما به آن نگاه می کنیم
1944
02:27:14,810 –> 02:27:19,420
چیزی به نام مشاهدات اکنون، در هر ایالت،
ما یک مشاهده داریم، من به شما خواهم داد
1945
02:27:19,420 –> 02:27:24,630
نمونه ای از مشاهده اگر هوا گرم باشد
تیم بیرون 80 درصد شانس خوشحالی دارد.
1946
02:27:24,630 –> 02:27:30,590
اگر بیرون هوا سرد باشد، تیم 20 درصد شانس خوشحالی
دارد. این یک مشاهده است. بنابراین
1947
02:27:30,590 –> 02:27:36,610
در آن حالت، میتوانیم احتمال وقوع
چیزی در آن حالت را مشاهده کنیم
1948
02:27:36,610 –> 02:27:42,899
x، درسته؟ یا y است یا هر چه هست. بنابراین ما
واقعاً به ایالات متحده اهمیت نمی دهیم. به خصوص،
1949
02:27:42,899 –> 02:27:46,450
ما به مشاهداتی که از آن حالت می گیریم اهمیت
می دهیم. اکنون در مثال ما، آنچه هستیم
1950
02:27:46,450 –> 02:27:50,760
در واقع این کار این است که به آب و هوا به
عنوان یک مشاهده برای ایالت نگاه کنیم.
1951
02:27:50,760 –> 02:27:55,780
بنابراین، برای مثال، در یک روز آفتابی،
آب و هوا احتمال بین رفتن را دارد
1952
02:27:55,780 –> 02:28:00,790
پنج و 15 درجه سانتیگراد با میانگین
دمای 11 درجه. همینطوره
1953
02:28:00,790 –> 02:28:05,750
احتمالی که می توانیم استفاده کنیم و می دانم که
این کمی انتزاعی است، اما من فقط می خواهم صحبت کنم
1954
02:28:05,750 –> 02:28:09,390
در مورد داده هایی که در اینجا قرار است با آنها کار کنیم،
من قصد دارم یک مثال کوچک را به تصویر بکشم
1955
02:28:09,390 –> 02:28:13,521
از طریق آن، و ما در واقع وارد کد می شویم. پس
بیایید با بحث در مورد نوع داده شروع کنیم
1956
02:28:13,521 –> 02:28:17,311
ما قصد داریم استفاده کنیم. بنابراین به طور معمول، در موارد قبلی،
درست است، ما مانند صدها استفاده می کنیم، اگر نه،
1957
02:28:17,311 –> 02:28:22,460
مانند 1000 ورودی، یا ردیف ها یا نقاط داده برای مدل
های ما برای آموزش این کار. ما نمی کنیم
1958
02:28:22,460 –> 02:28:27,870
نیاز به هر یک از آن در واقع، تمام چیزی که ما نیاز
داریم فقط مقادیر ثابت برای احتمال و ماست
1959
02:28:27,870 –> 02:28:33,140
توزیع های گذار و توزیع های مشاهده ای چیست. حالا
کاری که می خواهم انجام دهم این است
1960
02:28:33,140 –> 02:28:37,190
به اینجا بروید و در مورد مشاهدات و انتقال ایالت
ها صحبت کنید. پس مقدار مشخصی داریم
1961
02:28:37,190 –> 02:28:42,670
از ایالت ها حالا ما تعریف خواهیم کرد که چند ایالت
داریم، واقعاً برای ما مهم نیست که آن حالت چیست
1962
02:28:42,670 –> 02:28:47,540
است. بنابراین میتوانیم حالتهایی داشته باشیم،
مانند گرم سرد، زیاد، کم، قرمز، سبز، آبی،
1963
02:28:47,540 –> 02:28:51,750
شما می توانید هر تعداد ایالت که ما بخواهیم داشته باشیم،
اگر چه صادق باشیم، می توانیم یک ایالت داشته باشیم
1964
02:28:51,750 –> 02:28:55,511
داشتن آن چیز عجیبی خواهد بود. و اینها را پنهان
می نامند زیرا ما این کار را نمی کنیم
1965
02:28:55,511 –> 02:29:00,390
مستقیم مشاهده کنید اکنون مشاهدات بنابراین
هر ایالت نتیجه یا مشاهده خاصی دارد
1966
02:29:00,390 –> 02:29:04,760
با آن بر اساس توزیع احتمال مرتبط است.
بنابراین می تواند این واقعیت باشد که
1967
02:29:04,760 –> 02:29:10,661
در طول یک روز گرم، 100٪ درست است که تیم خوشحال
است. اگرچه در یک روز گرم، ما می توانیم
1968
02:29:10,661 –> 02:29:16,130
توجه کنید که 80 درصد مواقع تیم خوشحال است و
20 درصد مواقع غمگین است، درست است؟ آن ها
1969
02:29:16,130 –> 02:29:20,820
مشاهداتی است که ما در مورد هر ایالت انجام
می دهیم و هر ایالت مشاهدات متفاوت خود را خواهد داشت
1970
02:29:20,820 –> 02:29:26,439
و احتمالات مختلف وقوع آن مشاهدات. بنابراین
اگر قرار بود فقط داشته باشیم
1971
02:29:26,439 –> 02:29:30,200
مانند یک نتیجه برای دولت، به این معنی که
همیشه یکسان است، هیچ احتمالی وجود ندارد
1972
02:29:30,200 –> 02:29:34,230
که اتفاقی بیفتد و در آن صورت، این
فقط یک نتیجه نامیده می شود زیرا
1973
02:29:34,230 –> 02:29:40,160
احتمال وقوع این رویداد 100 درصد خواهد بود.
خوب، پس ما انتقال داریم. بنابراین هر کدام
1974
02:29:40,160 –> 02:29:44,240
حالت احتمال انتقال به حالت
متفاوت را خواهد داشت
1975
02:29:44,240 –> 02:29:49,311
حالت. به عنوان مثال، اگر روز گرمی داشته باشیم،
درصد احتمالی وجود دارد که روز بعد
1976
02:29:49,311 –> 02:29:52,950
روز یک روز سرد خواهد بود و اگر روز سردی داشته
باشیم، درصد احتمال آن وجود خواهد داشت
1977
02:29:52,950 –> 02:29:57,399
روز بعد یا یک روز گرم است یا یک روز سرد. بنابراین
ما می خواهیم از طریق آن مانند دقیق
1978
02:29:57,399 –> 02:30:02,200
آنچه در زیر برای مدل خاص خود داریم. فقط
درک کنید که این احتمال وجود دارد
1979
02:30:02,200 –> 02:30:06,410
ما می توانیم به یک حالت متفاوت تبدیل شویم. و از
هر حالت، می توانیم به آن انتقال پیدا کنیم
1980
02:30:06,410 –> 02:30:12,271
هر حالت دیگر یا مجموعه ای از حالت های تعریف شده با
یک احتمال مشخص. بنابراین می دانم که اینطور است
1981
02:30:12,271 –> 02:30:17,500
یک لقمه، می دانم که زیاد است. اما بیایید
به یک مثال طراحی اولیه برویم. چون من فقط
1982
02:30:17,500 –> 02:30:21,470
می خواهم به صورت گرافیکی کمی نحوه عملکرد
این کار را نشان دهم. در مورد اینها
1983
02:30:21,470 –> 02:30:26,120
آیا ایده ها برای هر یک از شما کمی بیش از حد
انتزاعی هستند. خوب، من فقط می کشم بیرون
1984
02:30:26,120 –> 02:30:31,439
تبلت طراحی، فقط یک ثانیه اینجا، و بیایید این
مدل آب و هوای اولیه را انجام دهیم.
1985
02:30:31,439 –> 02:30:32,439
بنابراین
1986
02:30:32,439 –> 02:30:36,830
کاری که من می خواهم انجام دهم این است که به سادگی دو حالت را
ترسیم کنیم، در واقع، بیایید این کار را با چند رنگ انجام دهیم،
1987
02:30:36,830 –> 02:30:40,561
چرا که نه بنابراین ما از رنگ زرد استفاده می
کنیم. و این روز گرم ما خواهد بود، خوب،
1988
02:30:40,561 –> 02:30:45,540
این خورشید ما خواهد بود. و سپس من فقط قصد
دارم یک ابر بسازم، ما فقط انجام می دهیم
1989
02:30:45,540 –> 02:30:50,190
مثل یک ابر خاکستری، این ابر من خواهد بود.
و ما فقط می گوییم که باران خواهد بارید
1990
02:30:50,190 –> 02:30:55,311
اینجا. خوب، پس این دو حالت من هستند. اکنون،
در هر ایالت، احتمال انتقال وجود دارد
1991
02:30:55,311 –> 02:31:02,500
به ایالت دیگر بنابراین، برای مثال، در
یک روز گرم، فرض کنید، 20٪ احتمال انتقال داریم
1992
02:31:02,500 –> 02:31:08,780
به یک روز سرد، و ما 80 درصد شانس داریم که به
یک روز گرم دیگر مانند روز تبدیل شویم
1993
02:31:08,780 –> 02:31:14,500
روز بعد، درست است؟ حالا، در یک روز سرد، فرض
کنید، 30 درصد شانس انتقال به آن داریم
1994
02:31:14,500 –> 02:31:20,740
یک روز گرم و در این مورد، شانس
70 درصدی برای انتقال داریم
1995
02:31:20,740 –> 02:31:25,330
به یک روز سرد دیگر اکنون، در هر یک از این
روزها، فهرستی از مشاهدات داریم. پس اینها
1996
02:31:25,330 –> 02:31:29,270
آیا آن چیزی است که ما آن را دولت می نامیم، درست است؟ بنابراین
این می تواند یکی باشد. و این می تواند دو باشد، اینطور نیست
1997
02:31:29,270 –> 02:31:34,130
واقعا مهم. مثلاً اگر آنها را نام بردیم یا هر چیز دیگری،
فقط دو حالت داریم. این چیزی است که ما
1998
02:31:34,130 –> 02:31:37,580
دانستن ما احتمال انتقال را می دانیم. این چیزی است
که ما به تازگی تعریف کرده ایم. حالا ما می خواهیم
1999
02:31:37,580 –> 02:31:43,030
احتمال مشاهده یا توزیع برای آن. بنابراین
اساسا، در یک روز گرم، ما
2000
02:31:43,030 –> 02:31:50,160
مشاهده می شود که دما می تواند بین
15 تا 25 درجه سانتیگراد باشد
2001
02:31:50,160 –> 02:31:56,560
با دمای متوسط فرض کنید، 20. بنابراین می
توانیم بگوییم مشاهده، درست است، بگوییم،
2002
02:31:56,560 –> 02:32:02,080
مشاهده و ما می گوییم که میانگین، بنابراین
دمای متوسط خواهد بود
2003
02:32:02,080 –> 02:32:07,590
20. و سپس توزیع برای آن مانند
مقدار حداقل 15 خواهد بود.
2004
02:32:07,590 –> 02:32:13,220
و حداکثر 25 خواهد بود. بنابراین این چیزی است
که ما در واقع مانند انحراف معیار می نامیم.
2005
02:32:13,220 –> 02:32:16,710
من واقعاً قصد ندارم دقیقاً توضیح دهم که انحراف
معیار چیست، اگرچه می توانید لطف کنید
2006
02:32:16,710 –> 02:32:21,560
از آن به عنوان چیزی شبیه به این فکر کنید. بنابراین
اساساً یک میانگین وجود دارد که این است
2007
02:32:21,560 –> 02:32:26,540
نقطه میانی، رایج ترین رویدادی است که می تواند
رخ دهد، و در سطوح مختلف استاندارد
2008
02:32:26,540 –> 02:32:29,770
انحراف، که وارد آمار می شود، که من
واقعاً نمی خواهم به آن اشاره کنم
2009
02:32:29,770 –> 02:32:34,250
خیلی، چون من قطعاً یک متخصص نیستم، احتمال
اینکه ضربه ای متفاوت داشته باشیم داریم
2010
02:32:34,250 –> 02:32:39,149
وقتی به سمت چپ و راست این مقدار حرکت می کنیم.
بنابراین در این منحنی، در جایی،
2011
02:32:39,149 –> 02:32:43,689
ما 15 داریم. و در این منحنی سمت راست، در جایی،
25 داریم. اکنون فقط داریم تعریف می کنیم
2012
02:32:43,689 –> 02:32:47,300
این حقیقت جایی است که ما به نوعی به منحنی خود
پایان می دهیم. بنابراین ما می خواهیم بگوییم
2013
02:32:47,300 –> 02:32:52,280
که، مانند احتمال در بین این اعداد،
بین 15 تا 25 خواهد بود،
2014
02:32:52,280 –> 02:32:56,960
با میانگین 20. و سپس مدل ما به نوعی کارهایی
را برای انجام دادن مشخص خواهد کرد
2015
02:32:56,960 –> 02:33:01,080
با آن. این تا جایی است که من واقعاً می خواهم
در انحراف معیار پیش بروم. و من مطمئنم
2016
02:33:01,080 –> 02:33:04,500
این مثل یک توضیح واقعا وحشتناک است. اما
این بهترین چیزی است که قرار است بدهم
2017
02:33:04,500 –> 02:33:08,399
شما برای همین الان خوب، پس این مشاهدات
ما در اینجا است، مشاهده ما در اینجا
2018
02:33:08,399 –> 02:33:11,930
مشابه خواهد بود بنابراین میخواهیم بگوییم
که دمای هوا در روز سرد در حال افزایش است
2019
02:33:11,930 –> 02:33:15,640
تا پنج درجه باشد، حداقل دما
را می گوییم، شاید چیزی باشد
2020
02:33:15,640 –> 02:33:22,351
مانند منفی پنج، و حداکثر می تواند چیزی در حدود 15 باشد،
یا مانند، بله، حدس می زنم 15. بنابراین ما
2021
02:33:22,351 –> 02:33:27,140
مقداری توزیع داشته باشد. این فقط چیزی است که ما
می خواهیم بفهمیم، درست است. و این مهربان است
2022
02:33:27,140 –> 02:33:31,680
یک توزیع عجیب است، زیرا ما با انحراف
معیار چیست، هر چند سروکار داریم
2023
02:33:31,680 –> 02:33:37,189
ما فقط می توانیم با مشاهدات درصد مستقیم
برخورد کنیم. مثلاً 20 درصد بود
2024
02:33:37,189 –> 02:33:43,110
به احتمال زیاد تیم خوشحال است یا 80
درصد احتمال دارد که او خوشحال باشد.
2025
02:33:43,110 –> 02:33:48,390
که می توانیم به عنوان احتمالات مشاهده خود در مدل داشته
باشیم. بسیار خوب، پس زبان انگلیسی زیادی وجود دارد.
2026
02:33:48,390 –> 02:33:52,090
چیزهای زیادی در حال انجام است، ما اکنون مانند یک
مثال عینی وارد آن خواهیم شد. پس امیدوارم،
2027
02:33:52,090 –> 02:33:56,550
این باید منطقی تر باشد. اما دوباره، فقط
مشاهدات انتقال حالت ها را درک کنید،
2028
02:33:56,550 –> 02:34:00,660
ما در واقع هرگز به ایالت ها نگاه نمی کنیم،
فقط باید بدانیم که در آن چند کشور داریم
2029
02:34:00,660 –> 02:34:07,180
احتمال انتقال و احتمال مشاهده در هر یک از
آنها. باشه. پس آنچه می خواهم بگویم
2030
02:34:07,180 –> 02:34:11,200
با این حال، آیا ما با این مدل چه کنیم؟ بنابراین
یک بار این را درست می کنم، یک بار درست می کنم
2031
02:34:11,200 –> 02:34:14,520
این مدل مارکوف پنهان، چه فایده ای
دارد؟ خوب، هدف آن پیش بینی است
2032
02:34:14,520 –> 02:34:19,080
رویدادهای آینده بر اساس رویدادهای گذشته بنابراین
ما آن توزیع احتمال را می دانیم و من
2033
02:34:19,080 –> 02:34:23,061
می خواهم آب و هوای هفته آینده را پیش بینی کنم. خوب، من
می توانم از آن مدل برای این کار استفاده کنم. زیرا
2034
02:34:23,061 –> 02:34:27,610
می توانم بگویم، خوب، اگر امروز امروز
گرم است، پس احتمال آن چقدر است
2035
02:34:27,610 –> 02:34:31,750
فردای آن روز سرد است، درست است؟ و این
کاری است که ما به نوعی انجام می دهیم
2036
02:34:31,750 –> 02:34:36,561
با این مدل ما در حال پیشبینیهایی برای
آینده بر اساس احتمال گذشته هستیم
2037
02:34:36,561 –> 02:34:43,021
حوادث رخ می دهد باشه. خیلی چیزای مهم بنابراین اجازه دهید
فقط این را که قبلاً بارگذاری شده است اجرا کنیم. وارد كردن
2038
02:34:43,021 –> 02:34:50,101
TensorFlow. و توجه کنید که در اینجا من احتمال TensorFlow
را TF P وارد کردهام. این به این دلیل است
2039
02:34:50,101 –> 02:34:55,020
این یک ماژول جداگانه از TensorFlow است که با احتمال
سروکار دارد. اکنون ما نیز نیاز داریم
2040
02:34:55,020 –> 02:35:00,160
TensorFlow قبل از این مدل مخفی مارکوف، ما
از فرآیند TensorFlow استفاده می کنیم.
2041
02:35:00,160 –> 02:35:02,220
ماژول را بسازید، نه یک معامله بزرگ.
2042
02:35:02,220 –> 02:35:06,640
خوب، پس آیا مدل. بنابراین این فقط تعریف می
کند که مدل ما در واقع چیست. بنابراین
2043
02:35:06,640 –> 02:35:11,050
قسمت های مختلف آن بنابراین این به طور مستقیم
از مستندات TensorFlow، شما گرفته شده است
2044
02:35:11,050 –> 02:35:14,310
بچه ها می توانند ببینند، می دانید، من همه این اطلاعات را
از کجا دارم، مثل اینکه همه آنها را تهیه کرده ام
2045
02:35:14,310 –> 02:35:17,431
آی تی. اما اساسا، مدلی که ما می خواهیم
ایجاد کنیم این است که روزهای سرد هستند
2046
02:35:17,431 –> 02:35:22,850
کدگذاری شده با صفر و روزهای گرم با یک،
اولین روز در دنباله ما 80٪ شانس دارد
2047
02:35:22,850 –> 02:35:26,990
از سرد بودن بنابراین هر روزی که شروع می
کنیم 80 درصد احتمال دارد که سرد باشد
2048
02:35:26,990 –> 02:35:31,090
به این معناست که 20 درصد احتمال دارد که یک روز باشد،
یک روز سرد 30 درصد احتمال دارد که به دنبال آن باشد
2049
02:35:31,090 –> 02:35:34,750
یک روز گرم و یک روز گرم 20 درصد احتمال دارد که یک روز
سرد به دنبال داشته باشد، که اینطور خواهد بود
2050
02:35:34,750 –> 02:35:40,229
یعنی می دانید 70% سرد، سرد و 80% گرم
گرم. در هر روز، دما به طور معمول است
2051
02:35:40,229 –> 02:35:44,610
با میانگین و انحراف معیار، صفر و پنج در یک
روز سرد و میانگین و استاندارد توزیع شده است
2052
02:35:44,610 –> 02:35:49,100
انحراف 15 و 10. در یک روز گرم. حال، آنچه به معنای
انحراف معیار است اساساً این است که
2053
02:35:49,100 –> 02:35:54,030
منظورم این است که میتوانیم اینجا بخوانیم
این است که در یک روز گرم، میانگین دما 15 است.
2054
02:35:54,030 –> 02:35:58,921
این میانگین است و از 5 تا 25 متغیر است.
زیرا انحراف معیار 10 از آن است که
2055
02:35:58,921 –> 02:36:03,910
فقط به معنای 10 در هر طرف است، نوعی حداقل مقدار
حداکثر. باز هم، من در آمار نیستم، بنابراین
2056
02:36:03,910 –> 02:36:07,950
لطفاً از من در مورد تعاریف انحراف معیار
نقل قول نکنید. فقط سعی کردم توضیح بدم
2057
02:36:07,950 –> 02:36:10,910
این کافی است تا بتوانید بفهمید که ما
چه می کنیم.
2058
02:36:10,910 –> 02:36:12,160
باشه پس چی
2059
02:36:12,160 –> 02:36:15,271
ما قصد داریم این کار را مدل سازی کنیم،
و من فقط به سرعت از آن عبور می کنم،
2060
02:36:15,271 –> 02:36:21,580
از آنجایی که انجام این کار واقعاً آسان
است، من احتمال TensorFlow را بارگیری می کنم
2061
02:36:21,580 –> 02:36:26,170
توزیع ها نوعی ماژول هستند و فقط آن را به عنوان TF D ذخیره
می کنند. و من فقط می خواهم این کار را انجام دهم.
2062
02:36:26,170 –> 02:36:31,350
بنابراین من نیازی
به نوشتن TF p.
2063
02:36:31,350 –> 02:36:36,440
آی تی. متوجه خواهید شد که من در اینجا به TFT
اشاره می کنم که فقط مخفف توزیع های TFP و
2064
02:36:36,440 –> 02:36:42,080
TFP احتمال TensorFlow است. خوب، بنابراین
توزیع اولیه من احتمال TensorFlow است
2065
02:36:42,080 –> 02:36:48,450
توزیع، طبقه بندی. و این احتمال 80 درصد است. و
درصد امتیاز. حالا این اشاره دارد
2066
02:36:48,450 –> 02:36:52,340
به نقطه دو پس بیایید به نقطه دو نگاه
کنیم، روز اول در دنباله ما 80٪ شانس دارد
2067
02:36:52,340 –> 02:36:56,910
از سرد بودن بنابراین ما می گوییم
که اساساً این همان توزیع اولیه است
2068
02:36:56,910 –> 02:37:02,140
سرد بودن 80 درصد است. و سپس 20٪، پس از طبقه بندی،
این فقط راهی است که ما می توانیم انجام دهیم
2069
02:37:02,140 –> 02:37:09,511
این توزیع باشه. بنابراین توزیع انتقال،
آیا احتمال TensorFlow مقوله ای بود،
2070
02:37:09,511 –> 02:37:16,790
احتمال 70% و 30% و 20% 80% است. اکنون توجه کنید
که از آنجایی که ما دو حالت داریم،
2071
02:37:16,790 –> 02:37:22,160
ما دو احتمال را تعریف کرده ایم. توجه کنید از آنجایی
که ما دو حالت داریم، دو احتمال را تعریف کرده ایم،
2072
02:37:22,160 –> 02:37:26,540
احتمال فرود بر روی هر یک از این حالت
ها در همان ابتدای دنباله ما،
2073
02:37:26,540 –> 02:37:30,520
این احتمال انتقال است که به نکات سه و چهار
در بالا اشاره شد. بنابراین این است
2074
02:37:30,520 –> 02:37:36,439
آنچه در اینجا داریم، به اصطلاح این 30٪، شانس،
20٪ شانس برای یک روز گرم است. و همین است
2075
02:37:36,439 –> 02:37:40,681
ما تعریف کرده ایم بنابراین ما می گوییم این سرد
خواهد بود، سپس یک را بیان کنید، ما 70٪ شانس داریم
2076
02:37:40,681 –> 02:37:44,750
از آنجایی که در آنجا سرد هستیم، دوباره، ما 30 درصد شانس
داریم که روز گرم را طی کنیم، و سپس می دانید، برعکس
2077
02:37:44,750 –> 02:37:46,609
اینجا. باشه،
2078
02:37:46,609 –> 02:37:51,140
بنابراین توزیع مشاهده حالا، این
یکی کمی متفاوت است، اما اساسا،
2079
02:37:51,140 –> 02:37:56,479
ما نقطه TFD را عادی انجام می دهیم. حالا، نمیدانم،
نمیخواهم توضیح دهم که این همه دقیقاً چیست.
2080
02:37:56,479 –> 02:37:59,100
اما وقتی انحراف معیار را انجام می دهید، این کار
را به این صورت انجام خواهید داد، جایی که هستید
2081
02:37:59,100 –> 02:38:03,910
میخواهیم بگویم loke، که مخفف میانگین یا میانگین شماست،
درست است. بنابراین میانگین آنها این بود
2082
02:38:03,910 –> 02:38:09,050
دمای هوا در یک روز گرم صفر خواهد بود.
15. در یک روز سرد، انحراف معیار
2083
02:38:09,050 –> 02:38:13,450
در روز سرد پنج است، به این معنی که ما از پنج،
یا منفی پنج تا پنج درجه متغیر هستیم.
2084
02:38:13,450 –> 02:38:19,680
و در یک روز گرم، 10 است. بنابراین ما
بین پنج تا 25 درجه خواهیم رفت.
2085
02:38:19,680 –> 02:38:23,680
و میانگین دمای ما 15 است. حالا دلیل اینکه ما نقطه
را در اینجا اضافه کرده ایم این است که اینها هستند
2086
02:38:23,680 –> 02:38:28,610
فقط باید مقادیر شناور باشد. بنابراین به جای
درج اعداد صحیح در اینجا، و داشتن بالقوه
2087
02:38:28,610 –> 02:38:33,570
خطاهای تایپ بعداً، ما فقط ورق زدیم. بسیار
خوب، پس آرگومان loake نشان دهنده این است
2088
02:38:33,570 –> 02:38:36,690
میانگین، و مقیاس، انحراف معیار، بله، دقیقا همان
چیزی است که ما در آنجا تعریف کردیم.
2089
02:38:36,690 –> 02:38:40,859
بسیار خوب، پس بیایید این را اجرا کنیم، من فکر می کنم ما در واقع قبلاً
انجام داده ایم. و اکنون می توانیم مدل خود را ایجاد کنیم.
2090
02:38:40,859 –> 02:38:45,510
بنابراین ایجاد مدل ها بسیار آسان است. منظورم این است که تنها
کاری که می کنیم این است که بگوییم مدل برابر با توزیع TensorFlow است
2091
02:38:45,510 –> 02:38:50,070
نقطه پنهان مدل مارکوف، توزیع اولیه را
به آن بدهید که برابر با توزیع اولیه است.
2092
02:38:50,070 –> 02:38:55,600
انتقال، توزیع، مشاهده، توزیع و مراحل. در حال
حاضر، آنچه که مراحل است مراحل است
2093
02:38:55,600 –> 02:39:00,470
برای چند روز می خواهیم پیش بینی کنیم. بنابراین
تعداد مراحل این است که چند بار می رویم
2094
02:39:00,470 –> 02:39:05,460
برای عبور از این چرخه احتمال، و اجرای
مدل اساسا. حالا یادت باشه چی
2095
02:39:05,460 –> 02:39:09,710
می خواهیم انجام دهیم، آیا می خواهیم میانگین دما را
در هر روز پیش بینی کنیم، درست است؟ مثل اون
2096
02:39:09,710 –> 02:39:15,130
هدف مثال ما پیش بینی دمای متوسط است.
بنابراین با توجه به این اطلاعات،
2097
02:39:15,130 –> 02:39:19,580
با استفاده از این مشاهدات و استفاده از این انتقال ها، کاری که ما انجام خواهیم
داد این است که پیش بینی کنیم، بنابراین من می روم
2098
02:39:19,580 –> 02:39:26,780
برای اجرای این مدل اینجا جریان از چه قرار است؟
تانسور روی هشتگ تانسور است. باشه بده
2099
02:39:26,780 –> 02:39:31,330
من یک ثانیه به اینجا نگاهی بیندازید، هر چند، من تا
به حال این مشکل را نداشتم. باشه. پس پس از دردناک
2100
02:39:31,330 –> 02:39:35,640
مقدار جستجو در Stack Overflow و Google
و در واقع فقط خواندن بیشتر
2101
02:39:35,640 –> 02:39:40,140
مستندات مربوط به TensorFlow، من مشکل را تعیین کرده ام. بنابراین
به یاد داشته باشید، خطا این بود که ما هستیم
2102
02:39:40,140 –> 02:39:44,210
در واقع در این خط اینجا. فکر می کنم بتوانم
ببینم خروجی این مورد چیست. باشه.
2103
02:39:44,210 –> 02:39:47,590
خب، این یک خطای متفاوت است، اما در
این خط خطایی وجود داشت. اساسا،
2104
02:39:47,590 –> 02:39:52,060
اتفاقی که در حال رخ دادن است این است که ما بین دو نسخه در
اینجا یک عدم تطابق داریم. بنابراین جدیدترین
2105
02:39:52,060 –> 02:39:57,780
نسخه TensorFlow با نسخه قدیمی احتمال
TensorFlow سازگار نیست،
2106
02:39:57,780 –> 02:40:01,310
حداقل به این معنا که چیزهایی که ما سعی می کنیم
با آن انجام دهیم. بنابراین من فقط نیاز داشتم
2107
02:40:01,310 –> 02:40:05,840
تا مطمئن شوم که آخرین نسخه احتمال
TensorFlow را نصب کرده ام. پس چی
2108
02:40:05,840 –> 02:40:10,510
اگر این در نوت بوک شما باشد، باید این کار را انجام
دهید، و در واقع باید برای شما خوب عمل کند
2109
02:40:10,510 –> 02:40:13,710
بچه ها، زیرا تا زمانی که شما به آنجا برسید
این به روز می شود. اما در صورت برخورد با
2110
02:40:13,710 –> 02:40:18,030
موضوع، می دانم، با آن مقابله کنید. اما در اصل،
ما قصد داریم نسخه انتخابی را انجام دهیم
2111
02:40:18,030 –> 02:40:21,760
دو نقطه x از TensorFlow، شما این دستورات نصب
را اجرا می کنید، می خواهید نصب کنید
2112
02:40:21,760 –> 02:40:27,200
احتمال TensorFlow، فقط این دستور را اجرا کنید،
سپس بعد از اجرای این دستور، می روید
2113
02:40:27,200 –> 02:40:32,090
برای خواندن باید زمان های اجرا خود را مجدداً راه اندازی کنید،
به Runtime بروید و سپس زمان اجرا را مجدداً راه اندازی کنید. و سپس
2114
02:40:32,090 –> 02:40:36,550
شما فقط می توانید با اسکریپت ادامه دهید، TensorFlow دو
نقطه x را انتخاب کنید، دوباره، کار خود را انجام دهید
2115
02:40:36,550 –> 02:40:40,551
واردات و سپس می دانید، ما آزمایش می کنیم که آیا
واقعاً در اینجا برای ما کار می کند، اجرا کنید
2116
02:40:40,551 –> 02:40:44,920
توزیع های ما، مدل را بدون هیچ مشکلی ایجاد کنید،
این بار متوجه هیچ متن قرمز رنگی نمی شوید،
2117
02:40:44,920 –> 02:40:49,491
و سپس این خط نهایی را اجرا کنید که خروجی را به شما
می دهد. حالا این همان چیزی است که من می خواستم
2118
02:40:49,491 –> 02:40:53,530
برای صحبت در مورد اینجا که ما کاملاً به آن نرسیدیم
زیرا با اشکالاتی روبرو بودیم. اما این
2119
02:40:53,530 –> 02:40:57,790
این است که چگونه می توانیم در واقع مدل خود را اجرا کنیم و خروجی
را ببینیم. بنابراین آنچه می توانید انجام دهید این است
2120
02:40:57,790 –> 02:41:02,880
آیا مدل نقطه به معنای. بنابراین شما می گویید میانگین برابر
است با میانگین نقطه مدل. و این به چه چیزی می رسد
2121
02:41:02,880 –> 02:41:07,500
do اساساً فقط محاسبه است، احتمال
اساساً آن را از
2122
02:41:07,500 –> 02:41:13,770
مدل. حالا، زمانی که میانگین نقطه مدل را داریم، این
چیزی است که ما به آن می گوییم، تا حدی تعریف شده
2123
02:41:13,770 –> 02:41:17,620
تانسور بنابراین به یاد داشته باشید، تانسورهای ما
مانند محاسبات نیمه تعریف شده بودند. خوب، همین است
2124
02:41:17,620 –> 02:41:22,560
آنچه مدل نقطه به معنای، در واقع است. این روش
همین است. پس اگر بخواهیم ارزش را بدست آوریم
2125
02:41:22,560 –> 02:41:28,460
کاری که در واقع باید انجام دهیم این است که یک جلسه
جدید در TensorFlow ایجاد کنیم، این قسمت را اجرا کنیم
2126
02:41:28,460 –> 02:41:32,370
نمودار، که ما قصد داریم با انجام آن به معنای NumPy
دریافت کنیم. و سپس می توانیم آن را چاپ کنیم
2127
02:41:32,370 –> 02:41:36,080
بیرون بنابراین می دانم که این ممکن است کمی گیج
کننده به نظر برسد، اما اساساً اجرای یک جلسه
2128
02:41:36,080 –> 02:41:40,990
در نسخه جدید TensorFlow، بنابراین دو نقطه x، یا
2.1، یا هر چیزی که باشد، شما می روید
2129
02:41:40,990 –> 02:41:48,290
برای تایپ با tF compat، جلسه v1 dot، به صورت ارسی.
و بعد منظورم این است که این واقعاً مهم است
2130
02:41:48,290 –> 02:41:51,880
آنچه شما اینجا دارید، اما هر آنچه که می خواهید،
و سپس کاری که من انجام می دهم فقط چاپ کردن است
2131
02:41:51,880 –> 02:41:57,330
NumPy. بنابراین برای به دست آوردن مقدار واقعی از
این در اینجا، این متغیر را NumPy نامیدم. و سپس
2132
02:41:57,330 –> 02:42:01,290
کاری که انجام می دهد این است که این آرایه را چاپ می
کند، که دمای مورد انتظار هر کدام را به من می دهد
2133
02:42:01,290 –> 02:42:09,120
روز بنابراین، می دانید، سه، شش، اساساً 7.5 8.25
داریم. و می توانید ببینید که این دماها هستند
2134
02:42:09,120 –> 02:42:13,470
بر اساس این واقعیت که ما با احتمال اولیه شروع
در یک روز سرد شروع می کنیم. بنابراین
2135
02:42:13,470 –> 02:42:17,360
ما به نوعی در اینجا دریافت می کنیم، درست است، ما از سه درجه
شروع می کنیم. این همان چیزی است که تعیین شده است
2136
02:42:17,360 –> 02:42:21,720
ما قصد داریم در شروع کنیم. و سپس ما همه این
دماهای دیگر را به عنوان پیش بینی داریم
2137
02:42:21,720 –> 02:42:27,330
برای روزهای بعد حالا توجه کنید که آیا این مدل را دوباره ایجاد
می کنیم، بنابراین فقط توزیع ها را دوباره اجرا کنید.
2138
02:42:27,330 –> 02:42:31,780
آنها را دوباره اجرا کن و برو مدل نقطه یعنی باز هم همین
حالت باقی می ماند، درست است؟ خوب، به دلیل احتمالات ما
2139
02:42:31,780 –> 02:42:35,050
یکسان هستند، این مدل قرار است محاسبه را دقیقاً
یکسان انجام دهد، واقعاً وجود ندارد
2140
02:42:35,050 –> 02:42:39,750
هر آموزشی که در این زمینه انجام شود. بنابراین، می
دانید، اگر دقیقاً یکسان نباشد، بسیار شبیه هستیم
2141
02:42:39,750 –> 02:42:43,391
مقادیر، نمیتوانم به یاد بیاورم که آیا اینها یکسان هستند
یا خیر. اما این چیزی است که برای من به نظر می رسد،
2142
02:42:43,391 –> 02:42:47,050
ما می توانیم این را دوباره اجرا کنیم، ببینید، همان یکی
را دریافت می کنیم. و ما یک بار دیگر مدل را ایجاد می کنیم.
2143
02:42:47,050 –> 02:42:50,240
و اجازه دهید من فقط این مقادیر را در اینجا بررسی
کنم تا مطمئن شوم که به شما دروغ نمی گویم. آره،
2144
02:42:50,240 –> 02:42:53,880
آنها دقیقا یکسان هستند خوب، پس بیایید با
چند احتمال شروع کنیم و ببینیم چه چیزی
2145
02:42:53,880 –> 02:42:59,170
ما می توانیم این دما را انجام دهیم و ببینیم چه تغییراتی می
توانیم ایجاد کنیم. بنابراین اگر 0.5 را انجام دهم، در اینجا،
2146
02:42:59,170 –> 02:43:04,580
و من 0.5 را برای احتمال طبقه بندی انجام می دهم،
به یاد داشته باشید، این به نقاط سه و
2147
02:43:04,580 –> 02:43:08,569
چهار بالا بنابراین یک روز سرد 30 درصد احتمال
دارد که یک روز گرم به دنبال داشته باشد و
2148
02:43:08,569 –> 02:43:12,000
پس از آن یک روز گرم 20٪ احتمال دارد که یک روز سرد به
دنبال آن باشد. پس کاری که الان انجام دادم
2149
02:43:12,000 –> 02:43:17,600
این است که احتمال را به 50٪ تغییر دهید. به طوری که
یک روز سرد اکنون 50 درصد احتمال دارد که دنبال شود
2150
02:43:17,600 –> 02:43:23,050
یک روز گرم و 50 درصد احتمال دارد که روز سرد به دنبال
آن باشد. و بیایید این مدل را دوباره بسازیم.
2151
02:43:23,050 –> 02:43:27,411
بیایید این را دوباره اجرا کنیم و ببینیم آیا
تفاوتی داریم یا خیر. اما ما متوجه این، دما هستیم
2152
02:43:27,411 –> 02:43:30,290
اکنون کمی بالاتر رفته است.
2153
02:43:30,290 –> 02:43:35,420
اکنون توجه کنید که دمای شروع یکسانی را بدست می آوریم،
زیرا این فقط میانگین بر اساس این است
2154
02:43:35,420 –> 02:43:39,390
احتمال اینکه ما اینجا داریم اما اگر میخواستیم به
طور بالقوه شروع کنیم، میدانید، داغتر، ما
2155
02:43:39,390 –> 02:43:45,270
میتوانیم این اعداد را معکوس کنیم، به 0.2 0.8 میرویم. بیایید
همه اینها را دوباره اجرا کنیم و حالا به این نگاه کنید،
2156
02:43:45,270 –> 02:43:48,820
دمای ما چقدر است، از 12 شروع می کنیم. و سپس
در واقع دمای خود را کاهش می دهیم
2157
02:43:48,820 –> 02:43:53,381
به 10. بنابراین این مدل مخفی مارکوف اینگونه
کار می کند. و این خوب است، زیرا شما
2158
02:43:53,381 –> 02:43:57,430
فقط می توانید احتمالات را تغییر دهید، این به خوبی فورا
اتفاق می افتد. و ما می توانیم نگاهی بیندازیم
2159
02:43:57,430 –> 02:44:01,890
در خروجی ما بسیار زیبا. بنابراین بدیهی است
که این نشان دهنده دمای مشابه ما است
2160
02:44:01,890 –> 02:44:06,340
روز اول، این روز دوم، روز سوم، روز چهارم،
پنجم، شش، هفت خواهد بود.
2161
02:44:06,340 –> 02:44:10,761
و بدیهی است که مانند روزهای بیشتری که ادامه
می دهید، این احتمالاً کمتر دقیق است
2162
02:44:10,761 –> 02:44:15,310
به این دلیل است که این احتمال وجود دارد. و اگر
بخواهید سعی کنید پیش بینی کنید، شما
2163
02:44:15,310 –> 02:44:17,560
می دانم، یک سال قبل، و شما از آب و هوای
که دارید استفاده می کنید، حدس می زنم
2164
02:44:17,560 –> 02:44:21,210
در سال گذشته، احتمالاً پیشبینی دقیقی
نخواهید داشت. اما به هر حال،
2165
02:44:21,210 –> 02:44:25,240
اینها مدلهای مخفی مارکوف هستند. آنها
خیلی مفید نیستند. شرایطی وجود دارد
2166
02:44:25,240 –> 02:44:29,250
جایی که ممکن است بخواهید از چیزی شبیه به این استفاده کنید.
بنابراین به همین دلیل است که ما آنها را اجرا می کنیم
2167
02:44:29,250 –> 02:44:32,530
در این دوره، و به شما نشان می دهد که چگونه کار می کنند.
این نیز یکی دیگر از ویژگی های TensorFlow است که
2168
02:44:32,530 –> 02:44:36,090
بسیاری از مردم در مورد دریافت صحبت نمی کنند. و،
می دانید، شخصاً من واقعاً این کار را نکرده بودم
2169
02:44:36,090 –> 02:44:40,100
تا زمانی که توسعه این دوره را شروع کردم، از مدل
های پنهان مارکوف شنیدم. پس یکی از اینها که
2170
02:44:40,100 –> 02:44:44,860
برای این ماژول هشت بوده است. اکنون، امیدوارم
که این نوع به شما کمک کرده باشد
2171
02:44:44,860 –> 02:44:48,430
ایده ای در مورد اینکه چگونه می توانیم برخی از این الگوریتم
های یادگیری ماشین را پیاده سازی کنیم،
2172
02:44:48,430 –> 02:44:52,710
کمی ایده در مورد نحوه کار با داده ها،
نحوه تغذیه آن به یک مدل، اهمیت
2173
02:44:52,710 –> 02:44:57,160
بین داده های تست و آموزش و سپس بدیهی است که
رگرسیون خطی زمانی است که ما تمرکز می کنیم
2174
02:44:57,160 –> 02:45:01,520
خیلی زیاد است، بنابراین امیدوارم بچه ها با این
الگوریتم خیلی راحت باشید. بعد آخرش چی بود
2175
02:45:01,520 –> 02:45:04,979
دومی را که انجام دادیم، به نوعی بالا رفتم تا دقیقاً
سکانسی را که اینجا داشتیم، به خاطر بسپارم.
2176
02:45:04,979 –> 02:45:09,000
بنابراین طبقه بندی که نیز مهم بود. پس امیدوارم
بچه ها واقعا این را فهمیده باشید
2177
02:45:09,000 –> 02:45:13,700
خوشه بندی ما زیاد در این مورد پیش نرفتیم.
اما باز هم این یک الگوریتم جالب است.
2178
02:45:13,700 –> 02:45:17,580
و اگر نیاز به انجام نوعی خوشه بندی دارید، اکنون
یک الگوریتم برای انجام آن می شناسید،
2179
02:45:17,580 –> 02:45:21,350
به نام k به معنای خوشه بندی است، و شما می دانید که
چگونه کار می کند. و حالا می دانید، مارکوف پنهان
2180
02:45:21,350 –> 02:45:24,760
مدل ها. بنابراین در ماژول بعدی، ما اکنون می
خواهیم پوشش شبکه های عصبی را آغاز کنیم
2181
02:45:24,760 –> 02:45:28,510
دانش داشته باشیم، ما باید واقعاً در آنجا شیرجه
بزنیم و شروع به انجام کارهای جالب کنیم.
2182
02:45:28,510 –> 02:45:31,851
و سپس در ماژول های آینده، ما می خواهیم دید عمیق کامپیوتری
را انجام دهیم، من معتقدم که این کار را انجام می دهیم
2183
02:45:31,851 –> 02:45:35,960
رباتهای چت را با شبکههای عصبی مکرر انجام
میدهیم و سپس نوعی یادگیری تقویتی
2184
02:45:35,960 –> 02:45:43,750
در پایان. بنابراین با این گفته، اجازه دهید
به ماژول بعدی برویم. همه را دوست دارم و
2185
02:45:43,750 –> 02:45:47,870
به ماژول چهار خوش آمدید. اکنون، در این ماژول
از این دوره، ما در مورد آن صحبت خواهیم کرد
2186
02:45:47,870 –> 02:45:52,690
شبکه های عصبی، بحث در مورد نحوه عملکرد شبکه
های عصبی، کمی از ریاضیات پشت آنها
2187
02:45:52,690 –> 02:45:58,100
صحبت در مورد نزول گرادیان، و انتشار به عقب، و چگونگی
جریان اطلاعات در واقع به سمت
2188
02:45:58,100 –> 02:46:02,290
شبکه عصبی. و سپس وارد مثالی می شویم که در آن از شبکه
عصبی برای طبقه بندی استفاده می کنیم
2189
02:46:02,290 –> 02:46:06,431
محصولات لباس بنابراین می دانم که خیلی زیاد بود،
اما این چیزی است که ما می خواهیم پوشش دهیم
2190
02:46:06,431 –> 02:46:10,810
اینجا. در حال حاضر، شبکه های عصبی پیچیده هستند،
به نوعی اجزای زیادی در آنها وجود دارد.
2191
02:46:10,810 –> 02:46:15,210
و من همین الان عذرخواهی می کنم، زیرا
توضیح یکباره آن بسیار دشوار است،
2192
02:46:15,210 –> 02:46:18,540
کاری که من سعی خواهم کرد انجام دهم این است
که چیزها را با هم جمع کنم و توضیح دهم
2193
02:46:18,540 –> 02:46:23,080
در بلوک ها و سپس در پایان، می دانید، به نوعی
همه چیز را با هم ترکیب کنید. اکنون،
2194
02:46:23,080 –> 02:46:26,439
من می گویم، اگر هر یک از شما شروع این
دوره را تماشا نکرد، من خیلی دارم
2195
02:46:26,439 –> 02:46:30,720
دست خط وحشتناک اما این ساده ترین راه برای توضیح
همه چیز برای شما بچه ها است. پس تحمل کن
2196
02:46:30,720 –> 02:46:33,810
با من، می دانید، من مطمئن هستم که شما می توانید
آنچه را که می گویم درک کنید. اما ممکن است
2197
02:46:33,810 –> 02:46:38,229
فقط خواندن برخی از آن دردناک است. خوب، پس
بیایید فورا وارد بحث شویم و شروع به بحث کنیم
2198
02:46:38,229 –> 02:46:42,510
شبکه های عصبی چیست و چگونه کار می
کنند. خوب، کل نکته یک شبکه عصبی
2199
02:46:42,510 –> 02:46:47,149
این است که، می دانید، طبقه بندی یا پیش بینی برای
ما ارائه دهید. بنابراین ما مقداری ورودی داریم
2200
02:46:47,149 –> 02:46:51,550
اطلاعات، آن را به شبکه عصبی تغذیه می کنیم
و سپس می خواهیم خروجی هایی به ما بدهد.
2201
02:46:51,550 –> 02:46:55,380
بنابراین اگر شبکه عصبی را به عنوان این جعبه سیاه در
نظر بگیریم، همه این ورودی را داریم، درست است،
2202
02:46:55,380 –> 02:46:58,500
ما همه این داده ها را به شبکه عصبی می دهیم، شاید
در مورد یک تصویر صحبت می کنیم، شاید
2203
02:46:58,500 –> 02:47:03,729
ما فقط در مورد چند نقطه داده تصادفی صحبت می کنیم،
شاید در مورد یک مجموعه داده صحبت می کنیم،
2204
02:47:03,729 –> 02:47:08,120
سپس مقداری خروجی معنی دار دریافت می کنیم. این چیزی است
که ما به آن نگاه می کنیم. بنابراین اگر ما فقط به دنبال
2205
02:47:08,120 –> 02:47:12,521
در یک شبکه عصبی از بیرون، ما آن را به عنوان
این جعبه سیاه جادویی در نظر می گیریم،
2206
02:47:12,521 –> 02:47:15,990
ما مقداری ورودی می دهیم، مقداری خروجی به ما می دهد. و منظورم
این است که ما می توانیم این جعبه سیاه را بنامیم،
2207
02:47:15,990 –> 02:47:19,979
فقط برخی از عملکردها، درست است؟ جایی که تابعی از ورودی
است، آن را به برخی از خروجی ها نگاشت می کند. و
2208
02:47:19,979 –> 02:47:24,350
این دقیقاً همان کاری است که یک شبکه عصبی انجام می دهد، ورودی
می گیرد و آن ورودی را برای برخی نقشه برداری می کند
2209
02:47:24,350 –> 02:47:29,440
خروجی، درست مانند هر تابع دیگری، درست است، درست
مانند اگر یک خط مستقیم داشته باشید
2210
02:47:29,440 –> 02:47:34,100
این، این یک تابع است، می دانید، این خط شماست،
می دانید، هر چه باشد، به دست می آورید
2211
02:47:34,100 –> 02:47:39,710
برای گفتن y برابر است با 4x، شاید این خط شما باشد،
مقداری ورودی x می دهید و آن را می دهد
2212
02:47:39,710 –> 02:47:45,600
شما مقداری مقدار y را دارید، این نگاشت ورودی
شما به خروجی شما است. خوب، پس حالا که
2213
02:47:45,600 –> 02:47:50,550
ما آن را پایین داریم، یک شبکه عصبی از چه چیزی تشکیل
شده است؟ خوب، یک شبکه عصبی ساخته شده است
2214
02:47:50,550 –> 02:47:54,270
از لایه ها و به یاد داشته باشید، زمانی که ما
در مورد نمایش لایه ای داده ها صحبت کردیم
2215
02:47:54,270 –> 02:47:59,351
در مورد شبکه های عصبی صحبت کنید بنابراین من می خواهم
یک شبکه عصبی بسیار اساسی ترسیم کنم، ما می رویم
2216
02:47:59,351 –> 02:48:06,480
برای شروع با لایه ورودی. لایه ورودی همیشه
اولین لایه در شبکه عصبی ما است.
2217
02:48:06,480 –> 02:48:11,590
و این چیزی است که داده های خام ما را می پذیرد.
حال منظور من از داده های خام هر چیزی است
2218
02:48:11,590 –> 02:48:16,990
دادههایی که دوست داریم میخواهیم به شبکه بدهیم، هر آنچه
را که میخواهیم هر اطلاعات ورودی خود را طبقهبندی کنیم
2219
02:48:16,990 –> 02:48:22,170
این همان چیزی است که این لایه قرار است در شبکه عصبی
دریافت کند. بنابراین می توانیم بگوییم، شما
2220
02:48:22,170 –> 02:48:26,370
بدانید، این فلش ها ورودی ما را نشان می دهند
و به اولین لایه ورودی ما می آیند.
2221
02:48:26,370 –> 02:48:31,290
بنابراین این به این معنی است که برای مثال، اگر شما یک تصویر
و این تصویر را داشتید، و من فقط مانند یک نقاشی می کشم
2222
02:48:31,290 –> 02:48:35,020
مثل این، فرض کنید این تصویر ماست، و این همه
پیکسل های مختلف را دارد، درست است؟
2223
02:48:35,020 –> 02:48:37,980
تمام این پیکسل های مختلف در تصویر، و شما می خواهید
یک طبقه بندی در این مورد ایجاد کنید
2224
02:48:37,980 –> 02:48:42,910
تصویر خوب، شاید عرض و ارتفاع داشته باشد و
یک نمونه عرض و ارتفاع کلاسیک باشد
2225
02:48:42,910 –> 02:48:48,170
28 در 28. اگر 28 در 28 پیکسل داشتید و می
خواهید در این مورد طبقه بندی کنید
2226
02:48:48,170 –> 02:48:53,930
تصور می کنید برای انجام این کار به چند نورون
ورودی در شبکه عصبی خود نیاز دارید؟
2227
02:48:53,930 –> 02:48:58,810
خوب، اگر اطلاعات زیادی در مورد شبکه های
عصبی ندارید، این یک سوال سخت است.
2228
02:48:58,810 –> 02:49:02,479
اگر برای تصویر پیشبینی میکنید، اگر
قرار است به کل تصویر نگاه کنید
2229
02:49:02,479 –> 02:49:07,591
یک پیشبینی کنید، به هر یک از آن پیکسلها
نیاز خواهید داشت که 28 برابر است
2230
02:49:07,591 –> 02:49:13,649
28 پیکسل، که من فکر می کنم چیزی شبیه به 784 است.
ممکن است در این عدد اشتباه کنم، اما
2231
02:49:13,649 –> 02:49:20,450
من معتقدم که همین است. بنابراین شما به 784
نورون ورودی نیاز دارید، که کاملاً است
2232
02:49:20,450 –> 02:49:23,590
خوب. ممکن است عدد بزرگی به نظر برسد. اما وقتی
صحبت می شود با اعداد انبوه سروکار داریم
2233
02:49:23,590 –> 02:49:27,801
به کامپیوترها پس این واقعاً زیاد نیست. اما این
مثالی است که شما می دانید چگونه هستید
2234
02:49:27,801 –> 02:49:33,670
اگر از یک لایه ورودی شبکه عصبی برای نمایش
یک تصویر استفاده کنید، 784 ورودی خواهید داشت
2235
02:49:33,670 –> 02:49:37,930
نورون ها، و شما یک پیکسل را به هر یک از آن نورون
ها ارسال می کنید. حالا، اگر ما هستیم
2236
02:49:37,930 –> 02:49:41,910
با انجام یک مثال، جایی که شاید ما فقط یک تکه
اطلاعات ورودی داشته باشیم، شاید این باشد
2237
02:49:41,910 –> 02:49:48,190
به معنای واقعی کلمه فقط یک عدد، خوب، پس تنها چیزی
که نیاز داریم یک نورون ورودی است. اگر ما یک
2238
02:49:48,190 –> 02:49:53,420
به عنوان مثال در جایی که ما چهار قطعه اطلاعات داریم،
به چهار نورون ورودی نیاز داریم. همین الان
2239
02:49:53,420 –> 02:49:57,680
این می تواند کمی پیچیده تر شود، اما این
مبنایی است که من می خواهم شما را درک کنید
2240
02:49:57,680 –> 02:50:00,720
این است که شما قطعات ورودی را می دانید، صرف نظر
از اینکه آنها چه چیزهایی را خواهید داشت
2241
02:50:00,720 –> 02:50:04,530
هستند، شما به یک نورون ورودی برای هر قطعه از
آن اطلاعات نیاز دارید، مگر اینکه بخواهید
2242
02:50:04,530 –> 02:50:08,590
آن اطلاعات را در اشکال مختلف تغییر شکل دهید
یا قرار دهید. خوب، پس اجازه دهید در واقع
2243
02:50:08,590 –> 02:50:13,960
به جلو بپرید و به لایه خروجی ما بروید. بنابراین
این خروجی ما خواهد بود. حالا چی
2244
02:50:13,960 –> 02:50:18,601
لایه خروجی ما است؟ خب، لایه خروجی ما به
همان تعداد نورون خواهد داشت و دوباره،
2245
02:50:18,601 –> 02:50:24,680
نورون ها فقط مانند یک گره در لایه به عنوان قطعات
خروجی که ما می خواهیم نشان می دهند.
2246
02:50:24,680 –> 02:50:29,939
حالا فرض کنید در حال انجام یک طبقه بندی برای تصاویر
هستیم، درست است. و شاید دو کلاس وجود داشته باشد
2247
02:50:29,939 –> 02:50:34,140
که می توانستیم نمایندگی کنیم خوب، چند راه مختلف وجود
دارد که بتوانیم خروجی خود را طراحی کنیم
2248
02:50:34,140 –> 02:50:39,240
لایه، کاری که میتوانیم انجام دهیم این است که بگوییم،
خوب، ما از یک نورون خروجی استفاده میکنیم، این خروجی
2249
02:50:39,240 –> 02:50:45,210
نورون مقداری مقدار به ما می دهد، ما می
خواهیم این مقدار بین صفر و یک باشد.
2250
02:50:45,210 –> 02:50:51,000
و ما می گوییم که شامل است. حالا، اگر دو کلاس را پیشبینی
کنیم، اکنون چه کاری میتوانیم انجام دهیم،
2251
02:50:51,000 –> 02:50:55,500
بگو، خوب، پس اگر نورون باز من قرار است مقداری
به من بدهد، اگر آن مقدار نزدیکتر باشد
2252
02:50:55,500 –> 02:51:00,439
به صفر برسد، آنگاه نزدیک به صفر خواهد بود.
اگر این مقدار به یک نزدیکتر باشد، این است
2253
02:51:00,439 –> 02:51:05,480
کلاس اول می شود، درست است؟ و این بدان معناست که
ما داده های آموزشی خود را داریم، درست است؟ و
2254
02:51:05,480 –> 02:51:10,319
ما در مورد آموزش و آزمایش داده ها صحبت کردیم، ورودی
خود را ارائه می دهیم و خروجی ما نیاز دارد
2255
02:51:10,319 –> 02:51:14,730
مقدار صفر باشد یا یک چون کلاس
صحیحی است که صفر است، درست است؟
2256
02:51:14,730 –> 02:51:19,030
یا کلاس صحیح که یکی است. بنابراین مانند
ما، چه می گویم برچسب های ما برای آموزش ما
2257
02:51:19,030 –> 02:51:23,689
مجموعه داده ها صفر و یک خواهد بود و سپس این
مقدار در نورون خروجی ما تضمین می شود
2258
02:51:23,689 –> 02:51:27,859
بین صفر و یک باشد، بر اساس چیزی که من
کمی در مورد آن صحبت خواهم کرد
2259
02:51:27,859 –> 02:51:31,140
بعد. این یک راه برای نزدیک شدن به آن است، درست است،
ما یک مقدار واحد داریم، ما به آن ارزش نگاه می کنیم.
2260
02:51:31,140 –> 02:51:37,359
و بر اساس مقدار آن، میتوانیم تعیین کنیم،
میدانید که چه کلاسی کار نمیکند
2261
02:51:37,359 –> 02:51:41,160
گاهی. اما در موارد دیگر، زمانی که ما در حال انجام
طبقه بندی هستیم، چه چیزی منطقی تر است
2262
02:51:41,160 –> 02:51:46,399
این است که به تعداد کلاس هایی که می خواهید پیش بینی کنید،
نورون های خروجی داشته باشید. پس بیایید بگوییم
2263
02:51:46,399 –> 02:51:49,771
می دانید، ما مانند پنج کلاس خواهیم داشت که شاید
برای این سه کلاس پیش بینی می کردند
2264
02:51:49,771 –> 02:51:54,270
تکههای اطلاعات ورودی برای انجام این پیشبینی
کافی است، خوب، ما در واقع این کار را انجام میدهیم
2265
02:51:54,270 –> 02:51:59,810
دارای پنج نورون خروجی است و هر یک از این
نورونها مقداری بین صفر و دارند
2266
02:51:59,810 –> 02:52:05,210
یکی و ترکیب، بنابراین مجموع هر یک
از این مقادیر برابر خواهد بود
2267
02:52:05,210 –> 02:52:11,090
به یک. حالا، آیا می توانید به این فکر کنید که اگر هر یک از
این نورون ها دارای یک عدد باشند، این به چه معناست
2268
02:52:11,090 –> 02:52:15,420
مقدار بین صفر و یک و مجموع آنها یک
است؟ این به نظر شما چگونه است؟ خوب،
2269
02:52:15,420 –> 02:52:19,660
به نظر من، این یک توزیع احتمال است. و اساساً
آنچه قرار است اتفاق بیفتد این است
2270
02:52:19,660 –> 02:52:25,100
ما پیشبینی میکنیم که هر کدام از
اطلاعات ورودی ما چقدر قوی هستند
2271
02:52:25,100 –> 02:52:26,100
کلاس
2272
02:52:26,100 –> 02:52:27,100
پس اگر فکر کنیم
2273
02:52:27,100 –> 02:52:30,700
که مثل کلاس یک است، شاید فقط اینها را
اینگونه برچسب بزنیم، پس چه کنیم
2274
02:52:30,700 –> 02:52:37,810
انجام دهید این است که بگویید، بسیار خوب، این 0.9 خواهد
بود، که نشان دهنده 90٪ است. شاید این مانند 0.001 باشد،
2275
02:52:37,810 –> 02:52:44,649
شاید این 0.05 0.003 باشد، درست است، نکته را
متوجه شدید، به یک اضافه می شود، و این
2276
02:52:44,649 –> 02:52:48,870
یک توزیع احتمال برای لایه خروجی ما است. بنابراین
این نیز راهی برای انجام آن است. و
2277
02:52:48,870 –> 02:52:53,140
پس بدیهی است، اگر ما در حال انجام نوعی کار رگرسیون
هستیم، می توانیم فقط یک نورون داشته باشیم
2278
02:52:53,140 –> 02:52:56,729
و این فقط مقداری ارزش را پیش بینی می کند. و ما تعریف
خواهیم کرد که بدانید ما آن مقدار را می خواهیم
2279
02:52:56,729 –> 02:53:01,870
بودن. باشه. بنابراین این مثال من برای خروجی من
است. حالا بیایید این را پاک کنیم. و اجازه دهید در واقع
2280
02:53:01,870 –> 02:53:06,370
فقط به یک نورون خروجی برگردید، زیرا این چیزی
است که من می خواهم برای این مثال استفاده کنم.
2281
02:53:06,370 –> 02:53:07,370
اکنون،
2282
02:53:07,370 –> 02:53:10,710
ما چیزی در بین این لایه ها داریم، زیرا
بدیهی است، می دانید، ما نمی توانیم
2283
02:53:10,710 –> 02:53:15,640
بدون هیچ چیز دیگری از ورودی به خروجی بروید. آنچه
در اینجا داریم لایه پنهان نامیده می شود.
2284
02:53:15,640 –> 02:53:19,069
اکنون در شبکههای عصبی، میتوانیم لایههای مخفی مختلفی داشته باشیم،
میدانیم، میتوانیم لایههای پنهان را اضافه کنیم.
2285
02:53:19,069 –> 02:53:23,510
لایههایی که به لایههای مخفی دیگر متصل میشوند،
و مانند ما میتوانیم صدها 1000 داشته باشیم
2286
02:53:23,510 –> 02:53:29,850
اگر بخواهیم، برای این مثال اولیه، از یکی استفاده می کنیم.
و من این را به عنوان پنهان می نویسم. بنابراین
2287
02:53:29,850 –> 02:53:33,650
اکنون ما سه لایه خود را داریم. حالا چرا به این میگن
مخفی؟ دلیل این امر پنهان نامیده می شود
2288
02:53:33,650 –> 02:53:37,840
به این دلیل است که ما آن را رعایت نمی کنیم. هنگامی که ما
از شبکه عصبی استفاده می کنیم، اطلاعات را منتقل می کنیم
2289
02:53:37,840 –> 02:53:41,899
به لایه ورودی، از لایه خروجی اطلاعات می
گیریم، نمی دانیم چه اتفاقی می افتد
2290
02:53:41,899 –> 02:53:46,540
در این لایه پنهان یا در این لایه های پنهان. حالا نحوه
اتصال این لایه ها به هر کدام چگونه است
2291
02:53:46,540 –> 02:53:50,030
دیگر؟ چگونه از این لایه ورودی به
لایه پنهان به لایه خروجی برسیم و
2292
02:53:50,030 –> 02:53:55,730
امید معناداری بدست آورید؟ خوب، هر
لایه با چیزی به یک لایه دیگر متصل است
2293
02:53:55,730 –> 02:53:59,830
وزن نامیده می شود. اکنون می توانیم انواع مختلفی
از معماری اتصالات را داشته باشیم که
2294
02:53:59,830 –> 02:54:04,250
یعنی میتوانم چیزی شبیه این داشته باشم که به
این وصل میشود، این به این وصل میشود، این
2295
02:54:04,250 –> 02:54:08,350
به این وصل می شود. و این می تواند مانند
معماری ارتباط من باشد، درست است؟ ما
2296
02:54:08,350 –> 02:54:12,990
می تواند یکی دیگر را داشته باشد که این یکی اینجا
می رود. و می دانید، شاید این یکی به اینجا برود.
2297
02:54:12,990 –> 02:54:17,560
و در واقع، بعد از اینکه این خط را کشیدم، اکنون
به آنچه در مورد آن صحبت می کنیم می پردازیم
2298
02:54:17,560 –> 02:54:23,460
بسیاری که به آن شبکه عصبی متصل متراکم می
گویند. در حال حاضر، یک عصبی متصل متراکم
2299
02:54:23,460 –> 02:54:28,620
شبکه، یا یک لایه متصل متراکم، اساساً به این
معنی است که به هر گره از آن متصل است
2300
02:54:28,620 –> 02:54:33,530
لایه قبلی بنابراین در این مورد، می توانید
تک تک گره ها را در لایه ورودی ببینید
2301
02:54:33,530 –> 02:54:37,979
به هر گره در لایه خروجی یا در لایه
پنهان، پشت من متصل است. و
2302
02:54:37,979 –> 02:54:42,700
این اتصالات همان چیزی است که ما وزن می نامیم. اکنون،
این وزن ها در واقع همان چیزی است که عصبی است
2303
02:54:42,700 –> 02:54:48,080
شبکه در حال تغییر و بهینه سازی برای
تعیین نگاشت از ورودی ما به ما است
2304
02:54:48,080 –> 02:54:51,580
خروجی زیرا دوباره، به یاد داشته باشید، این چیزی است
که ما در تلاشیم تا انجام دهیم. ما نوعی عملکرد داریم،
2305
02:54:51,580 –> 02:54:55,530
مقداری ورودی دریافت می کنیم، این مقداری خروجی به ما
می دهد. چگونه آن ورودی را خروجی بگیریم؟ خوب،
2306
02:54:55,530 –> 02:54:59,570
با تغییر این وزنه ها، کمی پیچیده
تر شدم، اما این شروع کار است.
2307
02:54:59,570 –> 02:55:02,720
بنابراین این خطوطی است که من ترسیم کرده
ام در واقع فقط اعداد هستند. و تک تک
2308
02:55:02,720 –> 02:55:07,110
از این خطوط مقداری عددی است. به طور معمول،
این مقادیر عددی بین صفر و
2309
02:55:07,110 –> 02:55:12,069
یکی، اما آنها می توانند بزرگ باشند، می توانند منفی باشند،
در واقع به نوع شبکه ای که شما هستید بستگی دارد
2310
02:55:12,069 –> 02:55:16,410
انجام می دهید و چگونه آن را طراحی کرده اید. حالا
بیایید فقط چند عدد تصادفی بنویسیم
2311
02:55:16,410 –> 02:55:20,800
مانند 0.1، این می تواند مانند 0.7 باشد، نکته را
متوجه شدید، درست است، ما فقط اعدادی برای
2312
02:55:20,800 –> 02:55:25,460
تک تک این خطوط و اینها همان چیزی است که ما
آن را پارامترهای آموزش پذیر می نامیم
2313
02:55:25,460 –> 02:55:31,350
که شبکه عصبی ما در واقع تغییر و تغییر خواهد کرد، همانطور
که ما آموزش می دهیم تا بهترین حالت ممکن را بدست آوریم
2314
02:55:31,350 –> 02:55:34,330
نتیجه بنابراین ما این ارتباطات را داریم. اکنون
لایه های مخفی ما به خروجی ما متصل می شوند
2315
02:55:34,330 –> 02:55:40,090
لایه نیز این دوباره یکی دیگر از لایه های
متصل متراکم است. زیرا هر لایه، یا هر
2316
02:55:40,090 –> 02:55:44,670
نورون نورون از لایه قبلی به هر نورون
از لایه بعدی متصل است، اگر شما
2317
02:55:44,670 –> 02:55:48,521
میخواهم تعیین کنم چند اتصال دارید، کاری که میتوانید
انجام دهید این است که بگویید سه اتصال وجود دارد
2318
02:55:48,521 –> 02:55:54,050
نورونها در اینجا، دو نورون در اینجا وجود دارد،
سه برابر دو برابر با شش اتصال است. که چگونه
2319
02:55:54,050 –> 02:55:58,609
که از لایه ها کار می کند. و سپس بدیهی است که شما
فقط می توانید تمام نورون ها را با هم ضرب کنید
2320
02:55:58,609 –> 02:56:04,530
همانطور که می گذرانید و تعیین می کنید که چه چیزی قرار است
باشد. بسیار خوب، بنابراین ما به این صورت متصل می شویم
2321
02:56:04,530 –> 02:56:08,229
این لایهها، ما این وزنها را داریم، پس بیایید یک W را
در اینجا بنویسیم. بنابراین ما آن را به یاد می آوریم
2322
02:56:08,229 –> 02:56:13,109
آنها وزن هستند حالا ما هم چیزی به نام سوگیری داریم. بنابراین
بیایید یک تعصب در اینجا اضافه کنیم، من هستم
2323
02:56:13,109 –> 02:56:18,250
به این ضرب و شتم برچسب می زنم. در حال حاضر سوگیری
ها کمی متفاوت از این گره ها هستند، ما
2324
02:56:18,250 –> 02:56:23,670
دارای منظم باشند، تنها یک سوگیری وجود دارد
و یک سوگیری در لایه قبلی به لایه وجود دارد
2325
02:56:23,670 –> 02:56:29,250
که تاثیر می گذارد. بنابراین در این مورد، چیزی که
ما در واقع داریم تعصبی است که به هر یک متصل می شود
2326
02:56:29,250 –> 02:56:34,560
نورون در لایه بعدی از این، درست است، بنابراین
هنوز به طور متراکم متصل است. اما این
2327
02:56:34,560 –> 02:56:39,069
فقط کمی متفاوت است حالا توجه کنید که
این سوگیری یک فلش در کنارش ندارد،
2328
02:56:39,069 –> 02:56:44,190
زیرا این اطلاعات ورودی را نمی گیرد. این یکی
دیگر از پارامترهای قابل آموزش برای
2329
02:56:44,190 –> 02:56:49,830
شبکه. و این سوگیری فقط مقداری عددی ثابت است
که ما قصد داریم آن را به هم وصل کنیم
2330
02:56:49,830 –> 02:56:55,300
به لایه پنهان، بنابراین ما می توانیم چند کار با آن
انجام دهیم. حالا این وزن ها همیشه یک ارزش دارند
2331
02:56:55,300 –> 02:56:59,340
از یک، ما در مورد اینکه چرا ارزش آنها یک
در ثانیه است صحبت خواهیم کرد. اما فقط
2332
02:56:59,340 –> 02:57:04,729
بدانید که هرگاه یک بایاس به لایه دیگری
یا به نورون دیگری متصل شود، وزن آن
2333
02:57:04,729 –> 02:57:09,819
به طور معمول یکی است. خوب، پس ما این ارتباط را داریم، ما تعصب
خود را داریم. و این در واقع به این معنی است
2334
02:57:09,819 –> 02:57:15,609
ما اینجا هم تعصب داریم. و این تعصب به این ارتباط
دارد، توجه کنید که تعصبات ما این کار را می کنند
2335
02:57:15,609 –> 02:57:19,410
با یکدیگر ارتباط برقرار نکنید دلیل این امر، دوباره،
این است که آنها فقط مقداری ثابت هستند
2336
02:57:19,410 –> 02:57:22,439
ارزش. و آنها فقط چیزی هستند که ما به نوعی به
شبکه اضافه می کنیم، آموزش پذیر دیگری است
2337
02:57:22,439 –> 02:57:27,880
پارامتری که می توانیم استفاده کنیم حالا بیایید
در مورد نحوه انتقال اطلاعات در واقع صحبت کنیم
2338
02:57:27,880 –> 02:57:33,000
شبکه و اینکه چرا ما حتی از این وزن ها و تعصبات کاری که آنها
انجام می دهند استفاده می کنیم. پس بیایید بگوییم ما
2339
02:57:33,000 –> 02:57:37,530
من واقعاً نمی توانم به نمونه های خوبی فکر کنم،
ما فقط کارهای خودسرانه انجام می دهیم.
2340
02:57:37,530 –> 02:57:43,470
بیایید بگوییم که نقاط داده مانند یک داده داریم، درست
است؟ x، y، z. و همه این نقاط داده مقداری دارند
2341
02:57:43,470 –> 02:57:47,050
ارزش نقشه، درست است؟ مقداری ارزش وجود دارد که
ما به دنبال آنها هستیم، یا مقداری وجود دارد
2342
02:57:47,050 –> 02:57:51,150
ما سعی می کنیم آنها را در کلاس قرار دهیم،
شاید آنها را بین نقاط قرمز و
2343
02:57:51,150 –> 02:57:58,030
نقطه های آبی پس بیایید این کار را انجام دهیم.
فرض کنید XYZ یا بخشی از کلاس قرمز است یا
2344
02:57:58,030 –> 02:58:03,240
کلاس آبی، بیایید این کار را انجام دهیم. بنابراین چیزی
که ما می خواهیم این درب بازکن به ما بدهد قرمز یا است
2345
02:58:03,240 –> 02:58:05,990
آبی. بنابراین کاری که من می خواهم انجام دهم این است که بگویم،
چون شما فقط یک کلاس هستید،
2346
02:58:05,990 –> 02:58:11,680
این نورون خروجی را در بین محدوده خود دریافت
خواهید کرد، یکی می گوید، خوب، اگر باشد
2347
02:58:11,680 –> 02:58:15,819
نزدیک به صفر، قرمز است، اگر به یک نزدیکتر باشد آبی
است. و این چیزی است که ما انجام خواهیم داد
2348
02:58:15,819 –> 02:58:20,260
برای این شبکه انجام دهید و برای این مثال،
در حال حاضر، نورون های ورودی ما بدیهی است
2349
02:58:20,260 –> 02:58:23,340
x، y و Zed باشد.
2350
02:58:23,340 –> 02:58:24,340
پس بیایید برخی را انتخاب کنیم
2351
02:58:24,340 –> 02:58:28,771
نقطه داده و بیایید بگوییم که شما ارزش
دو را می دانید. این نقطه داده ما است. و
2352
02:58:28,771 –> 02:58:33,600
ما می خواهیم پیش بینی کنیم که قرمز است یا آبی. چگونه
از آن عبور کنیم؟ خوب، آنچه ما نیاز داریم
2353
02:58:33,600 –> 02:58:39,990
میدانید که چگونه میتوانیم ارزش این
یادداشت لایه پنهان را پیدا کنیم
2354
02:58:39,990 –> 02:58:43,930
ارزش این گره ورودی را بدانید. اما اکنون باید
با استفاده از اینها به لایه بعدی برویم
2355
02:58:43,930 –> 02:58:47,930
اتصالات و ارزش این گره ها را پیدا کنید. خوب،
روشی که ما اینها را تعیین می کنیم
2356
02:58:47,930 –> 02:58:53,550
مقادیر این است که من می خواهم بگویم و من فقط n یکی
را گفتم، فقط برای نشان دادن این چنین یک گره است
2357
02:58:53,550 –> 02:58:58,700
مانند این گره یک است، شاید این یکی باید گره دو باشد،
برابر با چیزی است که ما آن را وزن دار می نامیم
2358
02:58:58,700 –> 02:59:04,561
مجموع تمام گره های قبلی که به آن
وصل شده اند، اگر منطقی باشد
2359
02:59:04,561 –> 02:59:09,230
شما بچه ها بنابراین یک مجموع وزنی چیزی شبیه به
این است، من فقط معادله را می نویسم، می خواهم
2360
02:59:09,230 –> 02:59:15,520
آن را توضیح دهید، من می خواهم بگویم n یک برابر است با
مجموع نگوییم n برابر با صفر است، بیایید بگوییم
2361
02:59:15,520 –> 02:59:24,729
من برابر با n صفر است. در این مورد، می گوییم w
i ضربدر x i به اضافه b. حالا من این را می دانم
2362
02:59:24,729 –> 02:59:29,260
معادله واقعاً ریاضی و پیچیده به نظر می
رسد، این واقعاً این نماد و این نیست
2363
02:59:29,260 –> 02:59:34,130
معادله در اینجا به این معنی است که مجموع وزنی تمام
نورون هایی را که به هم متصل هستند، می گیرد
2364
02:59:34,130 –> 02:59:40,410
به این نورون بنابراین در این حالت، نورون
x نورون y و نورون Zed به N one متصل شده است.
2365
02:59:40,410 –> 02:59:46,090
بنابراین وقتی مجموع وزنی را می گیریم، یا این را محاسبه
می کنیم، چیزی که واقعاً برابر است برابر است
2366
02:59:46,090 –> 02:59:51,940
وزن در نورون x. بنابراین می گوییم w x برابر
مقدار نورون x، که در این مورد، این است
2367
02:59:51,940 –> 02:59:57,530
فقط مساوی دو درسته؟ به علاوه هر وزنی که در
نورون y باشد. بنابراین در این مورد، این
2368
02:59:57,530 –> 03:00:04,600
است w y و سپس بار دو، و سپس به نقطه ای می
رسید که ما w Zed داریم، و من تلاش می کنم
2369
03:00:04,600 –> 03:00:08,819
روی لبه قرص طراحی من برای نوشتن این،
دو بار. در حال حاضر، بدیهی است، این وزن
2370
03:00:08,819 –> 03:00:12,500
مقداری عددی دارند اکنون، وقتی شبکه عصبی خود را
راه اندازی می کنیم، این وزن ها فقط هستند
2371
03:00:12,500 –> 03:00:16,390
کاملا تصادفی آنها هیچ معنایی ندارند. آنها فقط برخی
از مقادیر تصادفی هستند که ما می توانیم
2372
03:00:16,390 –> 03:00:21,000
استفاده کنید. همانطور که شبکه عصبی بهتر می شود، این وزن
ها به روز می شوند و تغییر می کنند تا بیشتر شوند
2373
03:00:21,000 –> 03:00:25,540
حس در شبکه ما بنابراین در حال حاضر، آنها را
به عنوان w XWYW می گذاریم. گفت، اما نه، اینها
2374
03:00:25,540 –> 03:00:29,860
برخی از مقادیر عددی هستند. بنابراین این به مقداری باز
می گردد، درست است، مقداری مقدار، اجازه دهید فقط
2375
03:00:29,860 –> 03:00:35,780
این مقدار را v. و این همان چیزی است که برابر است. بنابراین
V، سپس کاری که انجام می دهیم این است که اضافه می کنیم
2376
03:00:35,780 –> 03:00:42,450
تعصب حالا به یاد داشته باشید، سوگیری با
وزن یک مرتبط بود، یعنی اگر بگیریم
2377
03:00:42,450 –> 03:00:47,580
مجموع وزنی سوگیری، درست است، تمام کاری که ما انجام میدهیم
این است که هر چیزی را که ارزش سوگیری دارد اضافه کنیم
2378
03:00:47,580 –> 03:00:52,351
بود. بنابراین اگر این مقدار بایاس 100 بود، پس کاری که انجام میدهیم
این است که 100 اضافه میکنیم. حالا من فقط نوشتم
2379
03:00:52,351 –> 03:00:57,350
به علاوه B برای بیان این واقعیت که ما در حال اضافه
کردن سوگیری هستیم، اگرچه واقعاً می تواند
2380
03:00:57,350 –> 03:01:03,240
به عنوان بخشی از معادله جمع در نظر گرفته
شود. چون ارتباط دیگری با عصبی است
2381
03:01:03,240 –> 03:01:07,930
net، بیایید فقط در مورد معنای این نماد برای
هر کسی که در مورد آن سردرگم است صحبت کنیم.
2382
03:01:07,930 –> 03:01:13,641
در اصل، این مخفف برخی از AI مخفف یک شاخص است، یک N نشان
دهنده این است که چه شاخصی را انتخاب خواهیم کرد.
2383
03:01:13,641 –> 03:01:18,720
برو تا الان، m به این معنی است که در لایه
قبلی چند نورون داشتیم. و سپس آنچه هستیم
2384
03:01:18,720 –> 03:01:25,770
در اینجا انجام می دهیم، با گفتن wi xi، بنابراین می
گوییم وزن 0x، صفر به اضافه وزن 1x، یک به اضافه وزن
2385
03:01:25,770 –> 03:01:29,780
2 برابر دو تقریباً شبیه یک حلقه for است، ما فقط همه آنها
را با هم اضافه می کنیم. و سپس اضافه می کنیم
2386
03:01:29,780 –> 03:01:33,441
بوق و امیدوارم که به اندازه کافی منطقی باشد.
به طوری که ما آن را درک کنیم. پس این ماست
2387
03:01:33,441 –> 03:01:37,649
جمع وزنی، سوگیری را وارد کنید. بنابراین اساساً کاری که ما
انجام می دهیم این است که از آن عبور کرده و محاسبه می کنیم
2388
03:01:37,649 –> 03:01:43,160
این ارزش ها بنابراین مقداری مقدار میگیرد، شاید
این مقادیری مانند 0.3، شاید این مقدار هفت،
2389
03:01:43,160 –> 03:01:46,780
هر چه هست، و ما همین کار را اکنون در نورون خروجی
خود انجام می دهیم. بنابراین وزن را می گیریم
2390
03:01:46,780 –> 03:01:52,340
مجموع این مقدار ضربدر وزن آن است، و سپس مجموع وزنی
را می گیریم، بنابراین این مقدار برابر است
2391
03:01:52,340 –> 03:01:57,970
وزن آن، به علاوه سوگیری، در اینجا مقداری به آن داده
می شود، و سپس می توانیم به آن مقدار نگاه کنیم
2392
03:01:57,970 –> 03:02:02,661
و مشخص کنیم که خروجی شبکه عصبی ما چیست.
بنابراین تقریباً همینطور است
2393
03:02:02,661 –> 03:02:06,810
از نظر مجموع وزنی، اوزان و سوگیری ها کار می
کند. حالا بیایید در مورد نوع صحبت کنیم
2394
03:02:06,810 –> 03:02:10,790
از فرآیند آموزش و چیز دیگری به نام
تابع فعال سازی. پس دروغ گفته ام
2395
03:02:10,790 –> 03:02:13,760
کمی برای شما، چون گفتم، من تازه شروع به
پاک کردن بعضی چیزها می کنم. بنابراین
2396
03:02:13,760 –> 03:02:17,550
ما در اینجا کمی فضای بیشتری داریم. پس من
به شما دروغ گفتم و من این را گفته ام
2397
03:02:17,550 –> 03:02:21,880
به طور کامل چگونه این کار می کند. چیزی که ما یک ویژگی کلیدی
را از دست می دهیم که می خواهم در مورد آن صحبت کنم،
2398
03:02:21,880 –> 03:02:27,290
که تابع فعال سازی نامیده می شود. حال به یاد بیاورید
که می خواهیم این مقدار در این بین چگونه باشد
2399
03:02:27,290 –> 03:02:31,670
صفر و یک درست در لایه خروجی ما؟ خوب، در حال حاضر،
ما واقعا نمی توانیم آن را تضمین کنیم
2400
03:02:31,670 –> 03:02:35,080
این اتفاق خواهد افتاد منظورم این است،
به خصوص اگر با وزنه های تصادفی و
2401
03:02:35,080 –> 03:02:39,470
بایاس های تصادفی در شبکه عصبی ما، ما
در حال انتقال این اطلاعات هستیم
2402
03:02:39,470 –> 03:02:46,010
در اینجا به این نقطه برسیم، میتوانیم 700 را به عنوان
ارزش خود داشته باشیم. این یک نوع دیوانه است
2403
03:02:46,010 –> 03:02:49,450
من، درسته؟ ما این ارزش عظیم را داریم، چگونه
به 700 نگاه کنیم و تعیین کنیم که آیا این
2404
03:02:49,450 –> 03:02:53,490
قرمز است یا این آبی است؟ خوب، ما می توانیم از
چیزی به نام تابع فعال سازی استفاده کنیم.
2405
03:02:53,490 –> 03:02:57,540
حالا من به اسلایدهایم در اینجا برمی گردم، هر چه می
خواهیم اسمش را بگذاریم، این دفترچه، فقط
2406
03:02:57,540 –> 03:03:00,899
برای صحبت در مورد اینکه تابع فعال سازی چیست. و شما
بچه ها می توانید ببینید که می توانید دنبال کنید،
2407
03:03:00,899 –> 03:03:06,500
من تمام معادلات را در اینجا نیز به نوعی نوشته
شده است. پس بیایید به تابع فعال سازی برویم،
2408
03:03:06,500 –> 03:03:10,370
که همینجاست باشه. بنابراین اینها نمونه هایی
از یک تابع فعال سازی هستند. و من
2409
03:03:10,370 –> 03:03:13,990
فقط از شما می خواهم به آنچه آنها انجام می دهند نگاه
کنید. بنابراین این اولین خطی اصلاح شده نامیده می شود
2410
03:03:13,990 –> 03:03:19,650
واحد. اکنون توجه کنید که اساساً کاری که این تابع فعال
سازی انجام می دهد این است که هر مقداری را می گیرد
2411
03:03:19,650 –> 03:03:21,620
که کمتر از صفر هستند و فقط آنها را بسازید
2412
03:03:21,620 –> 03:03:27,021
صفر بنابراین، هر مقدار x که باشد، در حالت
منفی، فقط y آنها را صفر می کند.
2413
03:03:27,021 –> 03:03:30,530
و سپس هر ارزشی که مثبت باشد، با هر
ارزش مثبتی که باشد برابر است
2414
03:03:30,530 –> 03:03:35,090
است. بنابراین اگر 10 باشد، 10 می شود. این به ما
امکان می دهد تا تقریباً هر عدد منفی را حذف کنیم.
2415
03:03:35,090 –> 03:03:41,700
درست؟ این همان چیزی است که نقاط واحد خطی را
اصلاح می کند. حالا 10 H یا مماس هذلولی؟
2416
03:03:41,700 –> 03:03:46,340
این چه کاری انجام می دهد؟ این در واقع کوبیدن است،
ارزش های ما بین یک و یک منفی است. بنابراین
2417
03:03:46,340 –> 03:03:51,109
هر ارزشی که داریم را می گیرد. و هرچه مثبتتر
باشند، به یکی نزدیکتر میشوند
2418
03:03:51,109 –> 03:03:55,609
آنها هر چه منفی تر باشند به منفی نزدیکتر هستند.
بنابراین می توانیم دلیل آن را ببینیم
2419
03:03:55,609 –> 03:03:59,330
این ممکن است برای یک شبکه عصبی مفید باشد. و سپس آخرین
مورد سیگموئید است، این چه کاری انجام می دهد
2420
03:03:59,330 –> 03:04:04,240
این است که مقادیر خود را بین صفر و یک قرار دهیم.
بسیاری از مردم آن را مانند آتش مرکب می نامند
2421
03:04:04,240 –> 03:04:08,479
تابع، زیرا تنها کاری که انجام می دهد این است که
اعداد بسیار منفی را می گیرد و آنها را نزدیکتر می کند
2422
03:04:08,479 –> 03:04:12,660
به صفر و هر اعداد بسیار مثبت
و نزدیک به یک هر مقدار در بین،
2423
03:04:12,660 –> 03:04:15,920
شما بر اساس معادله یک عددی را به دست
خواهید آورد که بین آن عدد قرار دارد
2424
03:04:15,920 –> 03:04:21,300
بیش از یک به علاوه e به Zed منفی، و این یک مجموعه
داده است، حدس میزنم برابر با آن باشد. باشه،
2425
03:04:21,300 –> 03:04:25,040
بنابراین این چگونه کار می کند. بنابراین اینها برخی از
توابع فعال سازی هستند. حالا امیدوارم اینطور نباشد
2426
03:04:25,040 –> 03:04:28,710
ریاضی برای شما زیاد است اما بیایید در مورد نحوه استفاده
از آنها صحبت کنیم. درست. بنابراین اساسا، چه
2427
03:04:28,710 –> 03:04:34,160
ما در هر یک از نورون هایمان، یک تابع فعال
سازی خواهیم داشت که اعمال می شود
2428
03:04:34,160 –> 03:04:39,020
به خروجی آن نورون بنابراین ما این جمع وزنی
را به اضافه تعصب می گیریم و سپس
2429
03:04:39,020 –> 03:04:44,020
قبل از اینکه آن مقدار را به نورون بعدی بفرستیم، یک تابع
فعال سازی را به آن اعمال می کنیم. بنابراین
2430
03:04:44,020 –> 03:04:50,359
در این مورد، n یک در واقع فقط با این برابر
نیست، چیزی که n یک برابر است، n یک است
2431
03:04:50,359 –> 03:04:58,450
برابر با F، که مخفف تابع فعال سازی این معادله
است، درست است؟ پس بگو من برابر با صفر است
2432
03:04:58,450 –> 03:05:07,359
w i x i به علاوه b. و این همان چیزی است
که n ones برابر است با این نورون خروجی.
2433
03:05:07,359 –> 03:05:11,510
بنابراین هر کدام از اینها یک تابع فعال سازی روی
خود دارند و دوتا عملکرد فعال سازی یکسانی دارند
2434
03:05:11,510 –> 03:05:16,340
به عنوان یک. و ما می توانیم تعریف کنیم که چه تابع فعال
سازی را می خواهیم در هر نورون اعمال کنیم.
2435
03:05:16,340 –> 03:05:20,490
اکنون، در نورون خروجی ما، تابع فعال سازی
بسیار مهم است، زیرا ما نیاز داریم
2436
03:05:20,490 –> 03:05:23,700
برای تعیین اینکه میخواهیم ارزشمان چگونه
باشد، آیا میخواهیم آن را بین یک منفی و
2437
03:05:23,700 –> 03:05:27,850
یکی آیا آن را بین صفر و یک می خواهیم؟
یا می خواهیم عدد بسیار بزرگی باشد؟
2438
03:05:27,850 –> 03:05:34,069
آیا آن را بین صفر و بی نهایت مثبت می خواهیم؟ ما چه می خواهیم،
درست است؟ پس کاری که ما انجام می دهیم ما هستیم
2439
03:05:34,069 –> 03:05:38,660
چند تابع فعال سازی را برای نورون خروجی خود انتخاب
کنید. و بر اساس آنچه من گفتم، کجا ما
2440
03:05:38,660 –> 03:05:44,000
می خواهید مقادیر ما بین صفر و یک باشد،
من تابع سیگموئید را انتخاب می کنم.
2441
03:05:44,000 –> 03:05:50,700
بنابراین یادآوری سیگموئید، مقادیر ما بین صفر و یک له می شود. بنابراین
کاری که ما در اینجا انجام خواهیم داد این است که انجام خواهیم داد
2442
03:05:50,700 –> 03:05:57,520
n یکی، درست است، بنابراین n یک، برابر هر وزنی
که وجود دارد. بنابراین وزن صفر، به علاوه
2443
03:05:57,520 –> 03:06:06,930
n دو برابر وزن یک به اضافه یک بایاس و سیگموئید
اعمال کنید و سپس این مقداری ارزش به ما می دهد
2444
03:06:06,930 –> 03:06:11,050
بین صفر و یک، سپس می توانیم به آن مقدار نگاه
کنیم. و ما می توانیم تعیین کنیم که چیست
2445
03:06:11,050 –> 03:06:15,750
خروجی این شبکه می باشد. پس عالیه و این منطقی
است که چرا ما از آن استفاده می کنیم
2446
03:06:15,750 –> 03:06:19,970
در نورون خروجی، درست است؟ بنابراین ما میتوانیم ارزش
خود را بین نوعی ارزش پایین بیاوریم. بنابراین
2447
03:06:19,970 –> 03:06:22,780
ما در واقع می توانیم به آن نگاه کنیم و مشخص کنیم که
شما می دانید با آن چه کاری انجام دهید، نه فقط
2448
03:06:22,780 –> 03:06:27,950
با داشتن این دیوانه ها، و می خواهم ببینم آیا می
توانم این پاک کن را بزرگتر کنم. این خیلی است
2449
03:06:27,950 –> 03:06:32,700
بهتر. باشه. بنابراین ما به آنجا برویم. بیایید فقط مقداری از اینها
را پاک کنیم. و حالا بیایید در مورد چرایی صحبت کنیم
2450
03:06:32,700 –> 03:06:37,569
ما از تابع فعال سازی مانند یک لایه میانی
مانند این استفاده می کنیم. خوب، کل
2451
03:06:37,569 –> 03:06:43,130
نقطه یک تابع فعال سازی، وارد کردن پیچیدگی
به شبکه عصبی ما است. بنابراین اساسا،
2452
03:06:43,130 –> 03:06:47,550
ما، می دانید، ما فقط این وزن های اساسی و این
تعصب ها را داریم. و این به نوعی فقط است،
2453
03:06:47,550 –> 03:06:50,790
می دانید، مانند یک تابع پیچیده است. در این
مرحله، ما یک دسته وزن داریم، داریم
2454
03:06:50,790 –> 03:06:53,720
یک سری تعصب و اینها تنها چیزهایی هستند
که ما آموزش می دهیم و تنها چیزهایی هستند
2455
03:06:53,720 –> 03:06:59,000
که ما در حال تغییر هستیم تا شبکه خود را بهتر بدانیم
که یک تابع فعال سازی چه کاری می تواند انجام دهد،
2456
03:06:59,000 –> 03:07:02,950
به عنوان مثال، یک دسته از نقاط را در نظر بگیرید که در
همان سطح هستند، درست است، بنابراین اجازه دهید فقط
2457
03:07:02,950 –> 03:07:11,120
اگر بتوانیم یک تابع فعالسازی از اینها را اعمال
کنیم، بگوییم اینها در نقطه ای هستند
2458
03:07:11,120 –> 03:07:15,200
ابعاد بالاتر معرفی کنید. بنابراین یک تابع فعال سازی
مانند سیگموئید که مانند یک بالاتر است
2459
03:07:15,200 –> 03:07:21,439
تابع ابعاد، امیدواریم بتوانیم این نکات را گسترش
دهیم و آنها را به سمت بالا یا پایین حرکت دهیم
2460
03:07:21,439 –> 03:07:28,360
خارج از هواپیما به امید استخراج برخی
از ویژگی های مختلف. حالا، سخت است
2461
03:07:28,360 –> 03:07:33,380
برای توضیح این موضوع تا زمانی که وارد فرآیند
آموزش شبکه عصبی شویم. اما من امیدوارم
2462
03:07:33,380 –> 03:07:38,050
اگر بتوانیم یک تابع فعال سازی پیچیده را
معرفی کنیم، این شاید کمی به شما ایده بدهد
2463
03:07:38,050 –> 03:07:42,610
در این نوع فرآیند، سپس به ما امکان می دهد
پیش بینی های پیچیده تری انجام دهیم،
2464
03:07:42,610 –> 03:07:46,790
ما می توانیم الگوهای مختلف را انتخاب کنیم. اگر بتوانم
آن را ببینم، میدانید که وقتی سیگموئید است
2465
03:07:46,790 –> 03:07:51,220
یا واحد خطی اصلاح شده به این خروجی اعمال می شود، آن را
حرکت می دهد اپرا نقطه من آن را به سمت پایین حرکت می دهد
2466
03:07:51,220 –> 03:07:55,440
یا آن را در هر جهت و فضای n بعدی حرکت
می دهد، سپس می توانم تعیین کنم
2467
03:07:55,440 –> 03:07:59,620
الگوهای خاصی که در بعد قبلی نتوانستم
تعیین کنم. این دقیقاً مثل اگر است
2468
03:07:59,620 –> 03:08:03,640
ما به چیزی در دو بعد نگاه می کنیم. اگر بتوانم
آن را به سه بعدی منتقل کنم،
2469
03:08:03,640 –> 03:08:07,370
من بلافاصله جزئیات بیشتری را می بینم. چیزهای بیشتری وجود
دارد که می توانم به آنها نگاه کنم، درست است؟ و من خواهم
2470
03:08:07,370 –> 03:08:11,061
سعی کنید مثال خوبی برای اینکه چرا ممکن است از آن به این شکل استفاده
کنیم، ارائه دهید. بنابراین فرض کنید که یک مربع داریم
2471
03:08:11,061 –> 03:08:14,860
درست؟ مثل این، درست است؟ و من از شما پرسیدم،
می خواهم اطلاعاتی در این مورد به من بگویید
2472
03:08:14,860 –> 03:08:17,380
مربع؟ خوب، چیزی که می توانید بلافاصله به من بگویید این است
که می توانید عرض را به من بگویید، می توانید بگویید
2473
03:08:17,380 –> 03:08:20,040
من قد و حدس میزنم میتوانی جلد آن را به
من بگویی،
2474
03:08:20,040 –> 03:08:23,650
درست؟ شما می توانید به من بگویید که یک چهره دارد،
می توانید به من بگویید که در Tell چهار رأس است
2475
03:08:23,650 –> 03:08:27,290
من مقدار نسبتاً زیادی در مورد میدان، می توانید مساحت
آن را به من بگویید. حالا چه اتفاقی می افتد به زودی
2476
03:08:27,290 –> 03:08:31,820
همانطور که من این مربع را گسترش می دهم و آن را به یک مکعب
تبدیل می کنم؟ خوب، اکنون می توانید بلافاصله بگویید
2477
03:08:31,820 –> 03:08:37,190
اطلاعات بیشتری برای من وجود دارد، شما می توانید به من بگویید
که ارتفاع را می دانید، یا من عمق را حدس می زنم،
2478
03:08:37,190 –> 03:08:41,140
عرض، ارتفاع، عمق؟ آره اونجا هر چی میخوای
اسمشو بذار می تونی بگی چندتا
2479
03:08:41,140 –> 03:08:44,790
چهره هایی که دارد، می توانید به من بگویید هر کدام از
چهره ها چه رنگی دارند، می توانید بگویید چند تا
2480
03:08:44,790 –> 03:08:50,180
شما می توانید به من بگویید که آیا این مکعب
یا مربع این مستطیل یکنواخت است یا نه. و
2481
03:08:50,180 –> 03:08:54,640
شما می توانید اطلاعات بسیار بیشتری را دریافت کنید.
بنابراین به نوعی منظورم این است که این یک ساده سازی بسیار زیاد است
2482
03:08:54,640 –> 03:08:59,450
از آنچه که این در واقع انجام می دهد. اما این
نوعی مفهوم است، درست است که اگر ما باشیم
2483
03:08:59,450 –> 03:09:03,340
در دو بعد، اگر بتوانیم به نحوی نقاط داده
خود را به بعد بالاتر منتقل کنیم
2484
03:09:03,340 –> 03:09:07,729
با اعمال برخی از تابع ها به آنها، کاری که می توانیم انجام
دهیم این است که اطلاعات بیشتری به دست آوریم و استخراج کنیم
2485
03:09:07,729 –> 03:09:12,581
اطلاعات بیشتر در مورد نقاط داده، که منجر به
پیش بینی بهتر خواهد شد. باشه. بنابراین
2486
03:09:12,581 –> 03:09:15,601
اکنون که ما در مورد همه اینها صحبت کرده ایم، همانطور
که من در مورد نحوه آموزش شبکه های عصبی صحبت می کنم و
2487
03:09:15,601 –> 03:09:19,069
من فکر می کنم شما بچه ها برای این آماده هستید،
این کمی پیچیده تر است. اما دوباره،
2488
03:09:19,069 –> 03:09:23,420
آنقدرها هم دیوانه نیست خوب، پس ما در مورد این
وزن ها و سوگیری ها صحبت کردیم. و اینها
2489
03:09:23,420 –> 03:09:29,230
وزنها و سوگیریها چیزی است که شبکه ما به
آن خواهد رسید و تعیین میکند، میدانید،
2490
03:09:29,230 –> 03:09:32,350
شبکه را بهتر کنید بنابراین اساسا، کاری که اکنون می خواهیم
انجام دهیم این است که در مورد چیزی صحبت کنیم
2491
03:09:32,350 –> 03:09:37,569
تابع ضرر نامیده می شود. بنابراین همانطور که شبکه ما شروع
می شود، درست است، همانطور که ما آن را آموزش می دهیم
2492
03:09:37,569 –> 03:09:41,771
مانند شبکههای دیگر یا سایر مدلهای
یادگیری ماشینی را آموزش دادهایم
2493
03:09:41,771 –> 03:09:46,729
اطلاعات، خروجی مورد انتظار را به آن میدهیم
و سپس میبینیم که چه چیزی مورد انتظار است
2494
03:09:46,729 –> 03:09:51,030
خروجی یا آنچه که خروجی از شبکه در مقایسه با
خروجی مورد انتظار بود و اصلاح کنید
2495
03:09:51,030 –> 03:09:55,170
آن را مانند آن بنابراین اساساً چیزی که با آن شروع می کنیم
این است که می گوییم خوب، دو تا دو، ما این را می گوییم
2496
03:09:55,170 –> 03:10:00,430
کلاس قرمز است، که فراموش میکنم چه برچسبی به آن
زدم، اما اجازه دهید بگوییم شما آن را دوست دارید
2497
03:10:00,430 –> 03:10:05,390
یک صفر بود خوب، پس این کلاس صفر است. بنابراین
من می خواهم این شبکه به من یک عدد صفر بدهد
2498
03:10:05,390 –> 03:10:09,840
نکته دو به دو اکنون این شبکه با وزن های
کاملا تصادفی و کاملاً شروع می شود
2499
03:10:09,840 –> 03:10:11,160
سوگیری های تصادفی بنابراین
2500
03:10:11,160 –> 03:10:12,270
شانس ها … هستند
2501
03:10:12,270 –> 03:10:16,291
وقتی به این خروجی میرسیم، صفر نمیشویم،
شاید مقداری به دست آوریم
2502
03:10:16,291 –> 03:10:22,290
پس از اعمال تابع sigmoid که مانند
0.7 است. خوب، این خیلی دور است
2503
03:10:22,290 –> 03:10:27,120
قرمز. اما چقدر دور است؟ خوب، اینجا جایی است که
ما از چیزی به نام تابع ضرر استفاده می کنیم.
2504
03:10:27,120 –> 03:10:34,490
اکنون، کاری که یک تابع ضرر انجام می دهد این است که محاسبه
می کند که خروجی ما چقدر از انتظار ما فاصله دارد
2505
03:10:34,490 –> 03:10:39,080
خروجی بنابراین اگر خروجی مورد انتظار ما
صفر باشد و خروجی ما نقطه هفت شما باشد، ضرر
2506
03:10:39,080 –> 03:10:44,710
تابع مقداری ارزش به ما می دهد که نشان
دهنده میزان بد یا خوب بودن این شبکه است
2507
03:10:44,710 –> 03:10:50,359
بود. حالا به ما می گوید که این شبکه واقعاً بد
بوده است، به ما ضرر بسیار زیادی می دهد،
2508
03:10:50,359 –> 03:10:55,020
سپس این به ما می گوید که باید وزن ها و سوگیری
ها را بیشتر تغییر دهیم و شبکه را جابجا کنیم
2509
03:10:55,020 –> 03:10:59,720
در جهتی متفاوت ما در حال شروع به نزول
گرادیان هستیم. اما بیایید درک کنیم
2510
03:10:59,720 –> 03:11:03,399
ابتدا تابع ضرر بنابراین میخواهد بگوید اگر
واقعاً بد بود، بیایید آن را بیشتر حرکت دهیم،
2511
03:11:03,399 –> 03:11:06,540
بیایید وزن ها را شدیدتر تغییر دهیم، بیایید
سوگیری ها را شدیدتر تغییر دهیم.
2512
03:11:06,540 –> 03:11:11,140
در حالی که اگر واقعاً خوب بود، کاملاً خوب است،
به طوری که آن یکی واقعاً شایسته بود، شما
2513
03:11:11,140 –> 03:11:15,540
فقط باید کمی دستکاری کنید، و فقط باید این،
این و این را حرکت دهید. پس همین است
2514
03:11:15,540 –> 03:11:19,690
خوب و این نکته ماه گذشته است، فقط مقداری را
محاسبه می کند، هر چه مقدار بالاتر باشد
2515
03:11:19,690 –> 03:11:24,340
ارزش، شبکه ما بدتر بود. چند مثال از تابع
ضرر. بیا اینجا بریم پایین چون من
2516
03:11:24,340 –> 03:11:31,830
فکر می کنم من چند ضرر بهینه ساز در اینجا داشتم.
میانگین مربعات خطا به معنای خطای مطلق و
2517
03:11:31,830 –> 03:11:38,069
از دست دادن لولا حالا به معنای خطای مطلق است. می دانید چه،
اجازه دهید در واقع فقط یکی از اینجا را نگاه کنیم.
2518
03:11:38,069 –> 03:11:45,520
بنابراین، اشتباه مطلق، و نگاهی به آنچه که این
است. پس تصاویر، بیایید چیزی را انتخاب کنیم،
2519
03:11:45,520 –> 03:11:52,890
این به معنای خطای مطلق است. این معادله میانگین
خطای مطلق است. خوب، پس جمع بندی
2520
03:11:52,890 –> 03:12:00,319
قدر مطلق y i منهای لامبدا x i بر n.
حالا، این یک جورهایی پیچیده است،
2521
03:12:00,319 –> 03:12:03,570
من آنقدر که انتظارش را داشتم وارد آن نمیشوم،
امیدوار بودم که اینطور باشم
2522
03:12:03,570 –> 03:12:14,220
یک مثال بهتر برای میانگین مربعات خطا. خوب،
پس این سه تابع ضرر در اینجا هستند.
2523
03:12:14,220 –> 03:12:17,590
بنابراین میانگین مجذور خطا به معنای از دست دادن لولای
خطای مطلق است، بدیهی است که تعداد بیشتری وجود دارد
2524
03:12:17,590 –> 03:12:21,359
که میتوانیم از آن استفاده کنیم، در مورد اینکه هر کدام از
اینها به طور خاص چگونه کار میکنند صحبت نمیکنم،
2525
03:12:21,359 –> 03:12:25,830
منظورم این است که می توانید به راحتی آنها را جستجو کنید.
و همچنین، بنابراین می دانید، به این موارد نیز اشاره شده است
2526
03:12:25,830 –> 03:12:32,050
به عنوان تابع هزینه بنابراین هزینه یا ضرر، ممکن است
بشنوید که این اصطلاحات به نوعی مبادله را تغییر می دهند،
2527
03:12:32,050 –> 03:12:36,470
هزینه و ضرر اساساً به یک معنا هستند. شما می خواهید
شبکه شما کمترین هزینه را برای شما داشته باشد
2528
03:12:36,470 –> 03:12:40,609
می خواهید شبکه شما کمترین ضرر را داشته
باشد. خوب، حالا که صحبت کردیم
2529
03:12:40,609 –> 03:12:46,770
در مورد تابع از دست دادن، باید در مورد چگونگی
به روز رسانی این وزن ها و سوگیری ها صحبت کنیم.
2530
03:12:46,770 –> 03:12:50,470
حالا، اجازه دهید به اینجا برگردیم، زیرا فکر میکنم
یادداشتهایی روی آن داشتم. این چیزی است که
2531
03:12:50,470 –> 03:12:55,149
ما شیب نزول می نامیم. بنابراین اساساً
پارامترهای شبکه ما وزن ماست
2532
03:12:55,149 –> 03:12:59,780
و سوگیریها، و با تغییر این وزنها و سوگیریها،
متوجه میشویم که یا بسازید
2533
03:12:59,780 –> 03:13:04,100
شبکه بهتر یا بدتر کردن شبکه، عملکرد از
دست دادن تعیین خواهد کرد که آیا شبکه
2534
03:13:04,100 –> 03:13:07,580
اگر بدتر شود بهتر می شود و سپس می توانیم
تعیین کنیم که چگونه می خواهیم حرکت کنیم
2535
03:13:07,580 –> 03:13:12,890
شبکه برای تغییر آن. بنابراین این اکنون شیب
نزولی است که در آن ریاضیات کمی می شود
2536
03:13:12,890 –> 03:13:17,510
کمی پیچیده تر بنابراین این نمونه
ای از عملکرد شبکه عصبی شماست
2537
03:13:17,510 –> 03:13:24,070
شبیه. اکنون، از آنجایی که ریاضی ابعاد بالاتری
دارید، می دانید، ابعاد بسیار بیشتری دارید،
2538
03:13:24,070 –> 03:13:27,810
هنگام ایجاد پارامترهای مختلف و ایجاد
فضای بسیار بیشتری برای کاوش
2539
03:13:27,810 –> 03:13:33,070
سوگیری های مختلف و توابع فعال سازی و همه اینها. بنابراین
همانطور که ما فعال سازی خود را اعمال می کنیم
2540
03:13:33,070 –> 03:13:36,750
توابع، ما به نوعی شبکه خود را به ابعاد بالاتر
گسترش می دهیم، که فقط چیزها را می سازد
2541
03:13:36,750 –> 03:13:40,540
بسیار پیچیده تر اکنون، اساساً، آنچه میخواهیم
با شبکه عصبی انجام دهیم
2542
03:13:40,540 –> 03:13:45,340
بهینه سازی این تابع از دست دادن است. این تابع
ضرر به ما می گوید که چقدر خوب است یا چگونه
2543
03:13:45,340 –> 03:13:49,670
بد است بنابراین اگر بتوانیم این تابع تلفات را تا حد
امکان پایین بیاوریم، به این معنی است که باید
2544
03:13:49,670 –> 03:13:54,450
از نظر فنی بهترین شبکه عصبی را دارند. بنابراین
این نوع توابع از دست دادن ما است، مانند
2545
03:13:54,450 –> 03:13:58,590
نقشه برداری یا هر چیز دیگری، چیزی که ما به دنبال
آن هستیم چیزی به نام حداقل جهانی است، ما هستیم
2546
03:13:58,590 –> 03:14:04,970
به دنبال حداقل نقطه ای هستیم که کمترین
ضرر ممکن را از شبکه عصبی خود دریافت کنیم.
2547
03:14:04,970 –> 03:14:09,350
بنابراین اگر از جایی شروع کنیم که این دایره های قرمز
هستند، درست است، من این تصویر را از گوگل دزدیده ام
2548
03:14:09,350 –> 03:14:15,010
تصاویر، آنچه ما در تلاش هستیم انجام دهیم این است که به سمت پایین
به سمت این جهان، حداقل جهانی حرکت کنیم. و این
2549
03:14:15,010 –> 03:14:20,101
فرآیند نزول گرادیان نامیده می شود. بنابراین ما این
ضرر را محاسبه می کنیم و از یک الگوریتم استفاده می کنیم
2550
03:14:20,101 –> 03:14:25,830
گرادیان نزول نامیده می شود، که به ما می گوید
باید تابع خود را به چه جهتی حرکت دهیم
2551
03:14:25,830 –> 03:14:30,300
تعیین کنیم تا به این حداقل جهانی برسیم. بنابراین
اساساً به نظر می رسد که ما کجا هستیم
2552
03:14:30,300 –> 03:14:34,230
این ضرر بود و میگوید، خوب، من میخواهم چیزی را
محاسبه کنم که گرادیان نامیده میشود، که
2553
03:14:34,230 –> 03:14:38,939
به معنای واقعی کلمه فقط یک شیب یا جهت است.
و ما در این مسیر حرکت خواهیم کرد.
2554
03:14:38,939 –> 03:14:43,779
و سپس الگوریتمی به نام “backpropagation آورده شده”
از طریق شبکه به عقب می رود و
2555
03:14:43,779 –> 03:14:48,670
وزن ها و سوگیری ها را به روز کنید تا در آن جهت
حرکت کنیم. من فکر می کنم این تا آنجاست
2556
03:14:48,670 –> 03:14:52,439
از آنجایی که من واقعاً می خواهم بروم زیرا می دانم
که این موضوع در حال حاضر پیچیده تر شده است
2557
03:14:52,439 –> 03:14:56,950
برخی از شما احتمالاً می توانید با آن کنار بیایید، من
احتمالاً می توانم توضیح دهم، اما این به نوعی است
2558
03:14:56,950 –> 03:15:00,450
اصل اساسی ما به تابلوی نقاشی برمی گردیم
و یک خلاصه بسیار سریع انجام می دهیم
2559
03:15:00,450 –> 03:15:05,910
قبل از اینکه وارد برخی از موارد دیگر شویم، شبکه
های عصبی، ورودی، خروجی، لایه های پنهان
2560
03:15:05,910 –> 03:15:09,950
در ارتباط با وزنه ها، سوگیری هایی وجود دارد که به هر
لایه متصل می شوند. این سوگیری ها می تواند باشد
2561
03:15:09,950 –> 03:15:15,540
در نظر گرفته شده به عنوان رهگیری Y، آنها به سادگی به
طور کامل به بالا یا به طور کامل پایین حرکت می کنند
2562
03:15:15,540 –> 03:15:20,500
می دانید که کل تابع فعال سازی، راست، ما
چیزها را به چپ یا راست تغییر می دهیم،
2563
03:15:20,500 –> 03:15:24,350
زیرا این به ما این امکان را می دهد که پیش بینی بهتری
داشته باشیم و پارامتر دیگری داشته باشیم
2564
03:15:24,350 –> 03:15:29,649
ما می توانیم آموزش دهیم و کمی پیچیدگی را به مدل
شبکه عصبی خود اضافه کنیم. حالا راه
2565
03:15:29,649 –> 03:15:34,590
که اطلاعات از طریق این لایه ها منتقل می شود، ما
مجموع وزنی را از نورون ها خارج می کنیم
2566
03:15:34,590 –> 03:15:39,680
از تمام نورون های متصل به آن، سپس این نورون سوگیری
را اضافه می کنیم و تعدادی را اعمال می کنیم
2567
03:15:39,680 –> 03:15:45,100
تابع فعال سازی که قرار است این مقادیر
را بین دو مجموعه قرار دهد
2568
03:15:45,100 –> 03:15:48,950
ارزش های. به عنوان مثال، وقتی در مورد سیگموئید
صحبت می کنیم، ارزش های ما را از بین می برد
2569
03:15:48,950 –> 03:15:52,920
بین صفر و یک، وقتی در مورد مماس هذلولی صحبت می
کنیم، مقادیر ما را از بین می برد.
2570
03:15:52,920 –> 03:15:56,899
بین یک و یک منفی و وقتی در مورد واحد خطی اصلاح
شده صحبت می کنیم، این اتفاق خواهد افتاد
2571
03:15:56,899 –> 03:16:01,430
مقادیر خود را بین صفر و بی نهایت مثبت قرار دهید.
بنابراین ما آن توابع فعال سازی را اعمال می کنیم،
2572
03:16:01,430 –> 03:16:06,040
و سپس روند را ادامه می دهیم. بنابراین n، یکی ارزش
خود را می گیرد و دو مقدار آن را می گیرد. و
2573
03:16:06,040 –> 03:16:09,030
سپس در نهایت، ما به لایه خروجی خود می رسیم،
ممکن است از لایه دیگری عبور کرده باشیم
2574
03:16:09,030 –> 03:16:13,570
لایه های پنهان قبل از آن و سپس همین کار را
انجام می دهیم. جمع وزنی را می گیریم،
2575
03:16:13,570 –> 03:16:19,170
بایاس را اضافه می کنیم، یک تابع فعال سازی اعمال می کنیم،
به خروجی نگاه می کنیم و تعیین می کنیم که آیا
2576
03:16:19,170 –> 03:16:23,380
ما می دانیم که یک کلاس هستیم چرا ما کلاس هایی هستیم
که آیا این همان مقداری است که ما به دنبال آن هستیم
2577
03:16:23,380 –> 03:16:28,069
برای. و، و به این ترتیب کار می کند. حالا ما در مرحله
آموزش هستیم، درست است؟ بنابراین ما انجام می دهیم
2578
03:16:28,069 –> 03:16:32,279
این در حال حاضر، زمانی که ما پیشبینی میکردیم، این
به نوعی کار میکرد. بنابراین زمانی که ما هستیم
2579
03:16:32,279 –> 03:16:37,710
آموزش، اساسا، آنچه اتفاق می افتد این است که ما فقط
پیش بینی می کنیم، ما آن پیش بینی ها را با هم مقایسه می کنیم
2580
03:16:37,710 –> 03:16:43,550
به هر مقداری که این مقادیر مورد انتظار باید از
این تابع ضرر استفاده کنند، سپس محاسبه می کنیم
2581
03:16:43,550 –> 03:16:48,670
آنچه گرادیان نامیده می شود، گرادیان جهتی است که
ما باید حرکت کنیم تا این را به حداقل برسانیم
2582
03:16:48,670 –> 03:16:52,240
آخرین عملکرد و این جایی است که ریاضیات پیشرفته اتفاق میافتد
و دلیل اینکه من یک جورهایی در حال بیپروا هستم
2583
03:16:52,240 –> 03:16:57,819
بیش از این جنبه و سپس از الگوریتمی به نام انتشار برگشتی
استفاده می کنیم که در آن به عقب برمی گردیم
2584
03:16:57,819 –> 03:17:01,939
از طریق شبکه، و وزن ها و بایاس ها را با
توجه به گرادیان به روز رسانی کنید
2585
03:17:01,939 –> 03:17:05,800
محاسبه کردیم در حال حاضر، این تقریبا چگونه کار
می کند.
2586
03:17:05,800 –> 03:17:06,800
بنابراین
2587
03:17:06,800 –> 03:17:10,710
می دانید، هر چه اطلاعات بیشتری داشته باشیم، احتمالاً، مگر اینکه
بیش از حد مناسب باشیم، اما، می دانید، اگر داشته باشیم
2588
03:17:10,710 –> 03:17:15,250
بسیاری از داده ها، اگر بتوانیم به تغذیه
شبکه ادامه دهیم، واقعاً وحشتناک است،
2589
03:17:15,250 –> 03:17:19,359
بدون اطلاع از اینکه چه خبر است و سپس با ورود
اطلاعات بیشتر و بیشتر، به روز می شود
2590
03:17:19,359 –> 03:17:24,420
این وزن ها و سوگیری ها بهتر و بهتر می شود نمونه
های بیشتری را می بیند. و بعد از آن، مطمئناً
2591
03:17:24,420 –> 03:17:28,450
تعداد دوره ها یا مقدار مشخصی از اطلاعات،
شبکه ما در حال بهبود است
2592
03:17:28,450 –> 03:17:32,620
و پیش بینی های بهتر و داشتن ضرر کمتر
و کمتر. و روشی که محاسبه خواهیم کرد
2593
03:17:32,620 –> 03:17:38,050
میدانید که شبکه ما چقدر خوب کار میکند، میدانید
که مجموعه دادههای اعتبارسنجی ما در کجا قرار دارد
2594
03:17:38,050 –> 03:17:43,979
می تواند بگوید، بسیار خوب، بنابراین ما دقت 85 درصدی
را در این مجموعه داده داریم، ما خوب هستیم، می دانید،
2595
03:17:43,979 –> 03:17:47,990
بیایید این را تنظیم کنیم، بیایید آن را تنظیم کنیم، بیایید
این کار را انجام دهیم. بنابراین تابع ضرر، این کمتر است
2596
03:17:47,990 –> 03:17:53,200
این است که بهتر به عنوان تابع هزینه نیز شناخته
می شود. و این نوعی شبکه عصبی است. در یک
2597
03:17:53,200 –> 03:17:57,150
مخلص کلام. حالا، می دانم که این واقعاً
به طور خلاصه نبود، زیرا 30 دقیقه بود.
2598
03:17:57,150 –> 03:18:01,070
اما میدانید، تا آنجایی که من واقعاً میتوانم
بدون رفتن به شما توضیح بدهم، این است
2599
03:18:01,070 –> 03:18:05,210
خیلی به ریاضیات پشت همه چیز. و دوباره،
عملکرد فعال سازی را به خاطر بسپارید
2600
03:18:05,210 –> 03:18:10,319
این است که ما را در ابعاد به سمت بالا ببریم،
تعصب لایه دیگری از پیچیدگی و آموزش پذیر است
2601
03:18:10,319 –> 03:18:14,670
پارامتر شبکه ما به ما امکان می دهد این نوع
تابع فعال سازی را به چپ و راست تغییر دهیم
2602
03:18:14,670 –> 03:18:22,040
بالا پایین. و بله، این روش کار می کند. خوب،
پس اکنون ما یک بهینه ساز داریم. این هست
2603
03:18:22,040 –> 03:18:26,520
آخرین مورد در مورد نحوه عملکرد بهینه ساز شبکه
های عصبی به معنای واقعی کلمه فقط الگوریتم است
2604
03:18:26,520 –> 03:18:30,960
که شیب نزول و انتشار پس را برای ما انجام می دهد. بنابراین منظورم
این است که شما بچه ها می توانید کامل بخوانید
2605
03:18:30,960 –> 03:18:36,600
برخی از آنها در اینجا، ما احتمالاً از بهینه ساز
اتم برای بیشتر نمونه های خود استفاده خواهیم کرد.
2606
03:18:36,600 –> 03:18:41,210
اگر چه می دانید، بسیاری از موارد مختلف وجود
دارد که می توانیم از این بهینه سازی انتخاب کنیم
2607
03:18:41,210 –> 03:18:44,520
تکنیک، دوباره، این فقط یک الگوریتم متفاوت است.
برخی از آنها سریعتر هستند، برخی از آنها
2608
03:18:44,520 –> 03:18:47,560
کندتر هستند، برخی از آنها کمی متفاوت
عمل می کنند. و ما واقعا قرار نیست
2609
03:18:47,560 –> 03:18:52,069
در این دوره به انتخاب بهینه سازها بپردازید،
زیرا این بیشتر یک ماشین پیشرفته است
2610
03:18:52,069 –> 03:18:57,870
تکنیک یادگیری خوب، پس به اندازه کافی به اندازه کافی نقاشی های
ریاضی را توضیح می دهیم، به اندازه کافی صحبت می کنیم
2611
03:18:57,870 –> 03:19:03,990
اکنون زمان ایجاد اولین شبکه عصبی
رسمی است. حالا اینها واردات است
2612
03:19:03,990 –> 03:19:07,979
ما نیاز داریم بنابراین TensorFlow را به عنوان
TF TF از TensorFlow دوباره Kerris وارد کنید.
2613
03:19:07,979 –> 03:19:11,479
بنابراین این در واقع با TensorFlow همراه است، فراموش
می کنم اگر بگویم باید آن را نصب کنید
2614
03:19:11,479 –> 03:19:17,380
قبل از این، عذرخواهی می کنم و سپس NumPy را به عنوان
NP import import matplotlib.pi به عنوان PLT وارد کنید.
2615
03:19:17,380 –> 03:19:21,750
بسیار خوب، پس من واقعاً مشابه کاری را که
قبلا انجام می دادم انجام خواهم داد
2616
03:19:21,750 –> 03:19:24,490
مقداری از این کد را در یک نوت بوک دیگر کپی
می کنم،
2617
03:19:24,490 –> 03:19:28,900
فقط برای اینکه مطمئن شویم که میتوانیم همه چیز را در
انتها ببینیم، و سپس به نوعی گام برداریم
2618
03:19:28,900 –> 03:19:34,140
کد گام به گام به جای اینکه تمام متن
در اینجا اتفاق بیفتد. خوب، پس
2619
03:19:34,140 –> 03:19:38,720
مجموعه داده ها، و مشکلی که ما می خواهیم برای
اولین شبکه عصبی خود در نظر بگیریم، این است
2620
03:19:38,720 –> 03:19:44,240
مجموعه داده عفو مد اکنون مجموعه داده
های مد برجسته شامل 60000 تصویر برای
2621
03:19:44,240 –> 03:19:51,640
آموزش و 10000 تصویر برای اعتبارسنجی
و تست 70000 تصویر و اساسا
2622
03:19:51,640 –> 03:19:57,890
داده های پیکسلی مقالات لباس بنابراین برای بارگذاری
این مجموعه داده از چه کاری می خواهیم بکنیم
2623
03:19:57,890 –> 03:20:02,950
کارا بخشی است که در کارا به عنوان مربیان آن
ساخته شده است، مانند یک مبتدی، مانند آموزش تست
2624
03:20:02,950 –> 03:20:09,069
مجموعه دادهها، ما میخواهیم بگوییم که ژیمناستیک مد
برجسته برابر است با مجموعه دادههای نقطه کارا مد نقطه
2625
03:20:09,069 –> 03:20:14,620
فمینیست اکنون این شیء مجموعه داده را دریافت می کند. و سپس
می توانیم آن شی را با انجام دادن بارگذاری کنیم
2626
03:20:14,620 –> 03:20:19,880
مد این نقطه بار داده است. اکنون با انجام این
کار با داشتن سرنگونها، تصاویر قطار،
2627
03:20:19,880 –> 03:20:26,529
برچسبهای قطار، تصاویر آزمایشی، برچسبهای آزمایشی برابر است
با این، این به طور خودکار دادههای ما را تقسیم میکند
2628
03:20:26,529 –> 03:20:30,979
به مجموعه هایی که نیاز داریم بنابراین ما به آموزش
نیاز داریم. و ما به آزمایش نیاز داریم. و دوباره،
2629
03:20:30,979 –> 03:20:34,300
ما در مورد همه اینها صحبت کرده ایم. بنابراین من
قصد دارم به نوعی از آن عبور کنم. و اکنون داریم
2630
03:20:34,300 –> 03:20:39,700
آن را در تمام این نوع از سقوط در اینجا. خوب، پس بیایید
نگاهی به این مجموعه داده بیندازیم تا ببینیم
2631
03:20:39,700 –> 03:20:42,729
چیزی که ما با آن کار می کردیم خوب، پس بیایید مقداری از
این کد را اجرا کنیم. بیایید این واردات را دریافت کنیم
2632
03:20:42,729 –> 03:20:49,729
رفتن اگر برای همیشه طول نکشید، خوب، بیایید مجموعه
داده را دریافت کنیم. بله، این یک ثانیه طول می کشد
2633
03:20:49,729 –> 03:20:54,029
برای دانلود برای شما بچه ها، اگر قبلاً حافظه
پنهان ندارید. و سپس به تصاویر قطار می رویم
2634
03:20:54,029 –> 03:20:59,540
شکل نقطه ای و بیایید ببینیم یکی از تصاویر چگونه
است. یا با عرض پوزش، چه داده های ما
2635
03:20:59,540 –> 03:21:04,681
مجموعه به نظر می رسد بنابراین ما
60000 تصویر داریم که 28 در 28 هستند.
2636
03:21:04,681 –> 03:21:10,340
28 پیکسل یا 28 ردیف 28 پیکسلی، درست است؟ بنابراین،
می دانید، اطلاعات ما این گونه است
2637
03:21:10,340 –> 03:21:17,279
است. بنابراین در مجموع 784 پیکسل خواهیم داشت که در
اینجا مشخص کردم. پس بیایید نگاهی بیندازیم
2638
03:21:17,279 –> 03:21:22,330
در یک پیکسل بنابراین برای ارجاع به یک پیکسل،
این چیزی است که من انجام میدهم
2639
03:21:22,330 –> 03:21:26,720
a در واقع، من مطمئن نیستم که این چه نوع قاب داده
است، اما اجازه دهید نگاهی به آن بیندازیم.
2640
03:21:26,720 –> 03:21:32,450
بنابراین بیایید بگوییم که نوع تصاویر زیر خط قطار، زیرا
من می خواهم آن را ببینم. بنابراین این یک NumPy است
2641
03:21:32,450 –> 03:21:37,910
آرایه. بنابراین برای ارجاع به شاخص های مختلف
در این شبیه به پانداها، ما فقط می رویم
2642
03:21:37,910 –> 03:21:44,260
برای انجام کاما صفر 23، کاما 23، که مخفف
شما می دانید، تصویر صفر، 23، و سپس 23.
2643
03:21:44,260 –> 03:21:49,920
و این به ما یک پیکسل می دهد. بنابراین ردیف 23، ستون
23، که همان خواهد بود. باشه پس بیا فرار کنیم
2644
03:21:49,920 –> 03:21:56,270
این. و بیایید ببینیم، این مقدار 194 است. بسیار خوب،
پس این به نوعی جالب است. این چیزی است که
2645
03:21:56,270 –> 03:22:00,810
یک پیکسل به نظر می رسد بنابراین بیایید ببینیم که
چند پیکسل چگونه به نظر می رسند. پس چاپ می کنیم،
2646
03:22:00,810 –> 03:22:07,830
تصاویر زیر خط قطار و خوب، پس همه این صفرها را
می گیریم. بیایید تصاویر قطار را چاپ کنیم،
2647
03:22:07,830 –> 03:22:13,140
صفر کولون، که باید برای ما کار کند. و ما همه
این صفرها را می گیریم. خوب، پس همین است
2648
03:22:13,140 –> 03:22:17,930
حاشیه تصویر اشکالی ندارد، به هر حال نمی توانم
آنچه را که می خواستم به شما نشان دهم،
2649
03:22:17,930 –> 03:22:23,240
یک پیکسل، و من می خواستم از شما بچه ها بخواهم حدس
بزنید که فقط با یک عدد نشان داده شده است
2650
03:22:23,240 –> 03:22:28,310
بین صفر و 255. حال آنچه که این نشان دهنده آن
است، مقدار مقیاس خاکستری این پیکسل است.
2651
03:22:28,310 –> 03:22:33,430
بنابراین ما با تصاویر خاکستری سر و کار داریم، اگرچه میتوانیم
با تصاویر 3 بعدی 45 بعدی مقابله کنیم.
2652
03:22:33,430 –> 03:22:38,760
همچنین، یا نه پنج تصویر D، اما میتوانیم با تصاویری
که دارای مقادیر مشابه RGB هستند، برخورد کنیم
2653
03:22:38,760 –> 03:22:43,550
به عنوان مثال، ما می توانیم عددی بین
صفر تا 55 و عدد دیگری بین داشته باشیم
2654
03:22:43,550 –> 03:22:48,609
صفر و 255، و یک عدد دیگر بین صفر تا 255
برای هر پیکسل، درست است؟ در حالیکه
2655
03:22:48,609 –> 03:22:53,080
این یکی فقط یک مقدار استاتیک ساده است. بسیار خوب،
بنابراین به نظر می رسد که مقادیر پیکسل شما باشد
2656
03:22:53,080 –> 03:22:58,680
بین صفر و 205، صفر سیاه و 255 سفید است.
بنابراین اساسا، می دانید،
2657
03:22:58,680 –> 03:23:03,490
255 است، یعنی این سفید است. اگر صفر
باشد یعنی سیاه است. بسیار خوب،
2658
03:23:03,490 –> 03:23:08,229
پس بیایید نگاهی به 10 برچسب آموزشی اول بیندازیم.
پس این تصاویر آموزشی ما بود. اکنون،
2659
03:23:08,229 –> 03:23:12,890
برچسب های آموزشی چیست؟ خوب، پس ما یک آرایه
داریم و مقادیری از صفر دریافت می کنیم
2660
03:23:12,890 –> 03:23:20,060
تا نه اکنون، این به این دلیل است که ما 10 کلاس مختلف داریم که
میتوانیم برای مجموعه دادههای خود داشته باشیم.
2661
03:23:20,060 –> 03:23:24,310
بنابراین 10 لباس مختلف وجود دارد که نشان
داده شده اند، نمی دانم همه آنها چیست
2662
03:23:24,310 –> 03:23:29,080
از آنها هستند، اگرچه آنها در اینجا هستند. بنابراین
تی شرت، شلوار، پیراهن کش، مانتو،
2663
03:23:29,080 –> 03:23:34,950
پیراهن صندل، کیف کتانی، نیم بوت. خوب، پس بیایید
نام این کلاس ها را اجرا کنیم، فقط به این صورت
2664
03:23:34,950 –> 03:23:38,950
ما آن را ذخیره کرده ایم. و اکنون کاری که من می خواهم انجام دهم
این است که فقط از matplotlib استفاده کنم تا به شما نشان دهم چه چیزی
2665
03:23:38,950 –> 03:23:43,390
یکی از تصاویر به نظر می رسد بنابراین در این مورد، این
یک پیراهن است. من می دانم که این در حال چاپ است
2666
03:23:43,390 –> 03:23:47,000
کمی عجیب است، اما من فقط تصویر را نشان می دهم.
میدونم مثل رنگهای مختلفه اما همین است
2667
03:23:47,000 –> 03:23:51,180
زیرا اگر تعریف نکنیم که ما آن را در مقیاس خاکستری ترسیم
می کنیم، این کار را انجام می دهد. اما به هر حال،
2668
03:23:51,180 –> 03:23:54,240
این چیزی است که ما برای پیراهن دریافت می کنیم. پس
بریم سراغ تصویر دیگه. و بیایید نگاهی بیندازیم
2669
03:23:54,240 –> 03:23:59,890
در آنچه این یکی است. من در واقع نمی دانم آن چیست.
بنابراین ما از آن می گذریم. شاید همین باشد
2670
03:23:59,890 –> 03:24:06,950
a چیست؟ تی شرت یا تاپ؟ فکر می کنم این
شبیه یک لباس است. بله، پس ما داریم
2671
03:24:06,950 –> 03:24:09,850
اونجا لباس بپوش بیایید برویم و به این نگاه کنیم.
2672
03:24:09,850 –> 03:24:15,75


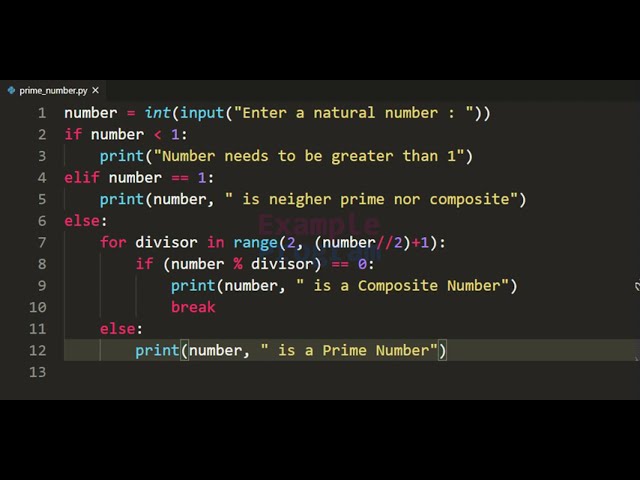



![فیلم آموزشی: نحوه نصب پایتون در ویندوز [2022] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/2Ndss5DOnVkimage2.jpg)
![فیلم آموزشی: مقدمه ای بر برنامه نویسی پایتون برای مبتدیان - روز اول - [Eng+Hindi] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/o99NIYYc6-cimage2.jpg)