در این مطلب، ویدئو رگرسیون لجستیک SKLearn – مثال یادگیری ماشین با استفاده از Python – قسمت 1 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:25:24
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:01,560
سلام به همه و خوش آمدید به این
2
00:00:01,560 –> 00:00:03,179
مقدمه برای آموزش یادگیری ماشین
3
00:00:03,179 –> 00:00:05,730
در این ویدئو، ما
4
00:00:05,730 –> 00:00:07,710
یک مثال رگرسیون لجستیک باینری را
5
00:00:07,710 –> 00:00:10,500
برای مبتدیان مرور می کنیم، بنابراین من قصد دارم
6
00:00:10,500 –> 00:00:12,750
این آموزش را با
7
00:00:12,750 –> 00:00:14,790
توضیح مختصر یادگیری ماشین شروع کنم و
8
00:00:14,790 –> 00:00:16,890
سپس ما
9
00:00:16,890 –> 00:00:19,410
فرآیند یادگیری ماشینی را طی خواهیم کرد، بنابراین تمام مراحلی
10
00:00:19,410 –> 00:00:21,150
که باید برای اجرای
11
00:00:21,150 –> 00:00:23,250
مدلهای یادگیری ماشینی و تمام
12
00:00:23,250 –> 00:00:26,400
وظایف در هر مرحله انجام دهید، ما
13
00:00:26,400 –> 00:00:27,960
اساساً این
14
00:00:27,960 –> 00:00:30,689
فرآیند یادگیری ماشینی را گام به گام دنبال میکنیم.
15
00:00:30,689 –> 00:00:32,040
برای شروع با مرحله فرمولبندی مسئله،
16
00:00:32,040 –> 00:00:34,020
بنابراین آنچه من سعی
17
00:00:34,020 –> 00:00:36,180
خواهم کرد حلش کنم مشکل بود، سپس
18
00:00:36,180 –> 00:00:38,510
به سمت پیش پردازش دادهها حرکت میکنیم، بنابراین
19
00:00:38,510 –> 00:00:41,940
تجزیه و تحلیل دادههای اکتشافی
20
00:00:41,940 –> 00:00:44,910
با بررسی روابط بررسی دادههای خام ما،
21
00:00:44,910 –> 00:00:46,829
سپس برخی از ویژگیها را
22
00:00:46,829 –> 00:00:49,410
انتخاب میکنیم تا انتخاب کنیم.
23
00:00:49,410 –> 00:00:51,870
مهمترین ویژگیهایی که در واقع بر
24
00:00:51,870 –> 00:00:54,809
متغیر وابسته Y ما تأثیر میگذارند و
25
00:00:54,809 –> 00:00:56,850
پس از آن، دادههای ردیف خود
26
00:00:56,850 –> 00:00:58,949
را با استفاده از اعتبار سنجی holdout تقسیم میکنیم. n
27
00:00:58,949 –> 00:01:00,899
تکنیک پس از آن ما می خواهیم
28
00:01:00,899 –> 00:01:03,750
توضیح دهیم که رگرسیون لجستیک چیست
29
00:01:03,750 –> 00:01:06,540
و چگونه کار می کند و تخمین حداکثر احتمال چگونه
30
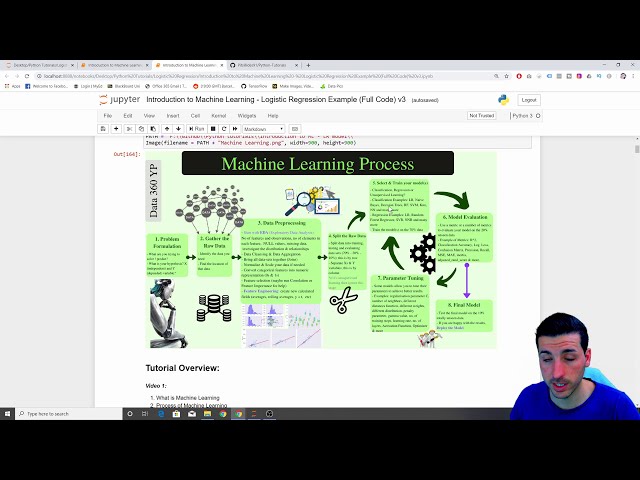
00:01:06,540 –> 00:01:09,240
کار می کند، سپس می خواهیم
31
00:01:09,240 –> 00:01:11,280
حول یک مدل رگرسیون لجستیک
32
00:01:11,280 –> 00:01:14,610
آموزش ببینیم و شروع به ارزیابی مدل خود کنیم
33
00:01:14,610 –> 00:01:17,009
تا در هنگام ارزیابی از مهمترین ماتریس عبور
34
00:01:17,009 –> 00:01:18,840
کنیم. یک
35
00:01:18,840 –> 00:01:21,330
مدل رگرسیون لجستیک پس از آن، ما
36
00:01:21,330 –> 00:01:23,759
میخواهیم مقداری تنظیم پارامترهای
37
00:01:23,759 –> 00:01:25,500
فوقالعاده انجام دهیم، بنابراین برخی از
38
00:01:25,500 –> 00:01:28,110
پارامترهای ترکیبی رگرسیون لجستیک را حلقهزنی میکنیم تا
39
00:01:28,110 –> 00:01:30,150
پارامترهایی را پیدا کنیم که بهترین عملکرد را به شما ارائه میدهند
40
00:01:30,150 –> 00:01:32,610
، سپس
41
00:01:32,610 –> 00:01:34,590
برخی از جایگزینها را بررسی میکنیم.
42
00:01:34,590 –> 00:01:36,479
وقتی نوبت به اجرای پارامترهای ترکیبی میرسد،
43
00:01:36,479 –> 00:01:37,799
وقتی نوبت به بررسی پارامترهای ترکیبی میرسد
44
00:01:37,799 –> 00:01:39,990
، میخواهیم
45
00:01:39,990 –> 00:01:42,780
یک طبقهبندیکننده ساختگی آموزش دهیم، بنابراین نمیتوانیم
46
00:01:42,780 –> 00:01:44,970
آن را مقایسه کنیم و از آن به عنوان یک معیار
47
00:01:44,970 –> 00:01:48,570
در مقابل مدل خود استفاده کنیم، سپس
48
00:01:48,570 –> 00:01:50,970
از آن پارامترهای ترکیبی استفاده میکنیم. یک
49
00:01:50,970 –> 00:01:53,850
مدل جدید شخص لجستیکی جدید را آموزش دهید که
50
00:01:53,850 –> 00:01:55,290
در آن از آن برای انجام برخی
51
00:01:55,290 –> 00:01:57,570
پیش بینی ها استفاده می کنیم و در پایان می
52
00:01:57,570 –> 00:02:00,149
خواهیم در مورد چگونگی انجام آن بحث کنیم. اگر میخواهید این آموزش را از طریق دنبال کنید، میتوانید از این
53
00:02:00,149 –> 00:02:02,009
مدل رگرسیون در برخی از سناریوهای زندگی واقعی
54
00:02:02,009 –> 00:02:03,899
استفاده کنید،
55
00:02:03,899 –> 00:02:05,670
من پیوندی
56
00:02:05,670 –> 00:02:07,290
در توضیحات خواهم داشت که
57
00:02:07,290 –> 00:02:09,119
شما را به داستان کیت فابریک من میبرد،
58
00:02:09,119 –> 00:02:10,979
جایی که من سه فایل اولی خواهم داشت.
59
00:02:10,979 –> 00:02:12,629
فایل قرار است داده خام
60
00:02:12,629 –> 00:02:13,530
برای این آموزش
61
00:02:13,530 –> 00:02:15,390
باشد، فایل دیگر آنها این
62
00:02:15,390 –> 00:02:18,030
نوت بوک با کد است و فایل سوم
63
00:02:18,030 –> 00:02:20,130
این دفترچه یادداشت
64
00:02:20,130 –> 00:02:21,959
با عنوان است، بنابراین شما می توانید در
65
00:02:21,959 –> 00:02:24,240
حین تماشای این برنامه، کد را تمرین
66
00:02:24,240 –> 00:02:25,800
کنید. ویدیویی که در واقع بهترین
67
00:02:25,800 –> 00:02:28,140
راه یادگیری است،
68
00:02:28,140 –> 00:02:29,790
69
00:02:29,790 –> 00:02:31,290
70
00:02:31,290 –> 00:02:33,480
اگر به یادگیری ماشینی علاقه مند هستید، به
71
00:02:33,480 –> 00:02:33,930
72
00:02:33,930 –> 00:02:36,750
طور کلی به تجزیه و تحلیل داده ها علاقه
73
00:02:36,750 –> 00:02:38,940
مندید، واقعاً ممنون می شوم اگر روی دکمه لایک کلیک کنید و در کانال من مشترک شوید.
74
00:02:38,940 –> 00:02:41,370
اکنون علم و هنر
75
00:02:41,370 –> 00:02:43,530
برنامه نویسی کامپیوترها است تا بتوانند
76
00:02:43,530 –> 00:02:46,260
از داده ها بیاموزند و این توسط
77
00:02:46,260 –> 00:02:47,730
کتاب اورلیون شارون است که من لینکی در توضیح آن خواهم داشت که
78
00:02:47,730 –> 00:02:49,019
79
00:02:49,019 –> 00:02:51,840
یادگیری ماشینی از مدل های آماری
80
00:02:51,840 –> 00:02:54,300
و الگوریتم استفاده می کند. برای انجام کارهایی مانند
81
00:02:54,300 –> 00:02:56,880
پیشبینیها و طبقهبندیها بدون
82
00:02:56,880 –> 00:02:59,790
دستورالعملهای صریح، مقداری از
83
00:02:59,790 –> 00:03:02,069
دادههای خام را میگیریم و آنها را به یک
84
00:03:02,069 –> 00:03:04,739
الگوریتم یادگیری ماشینی وارد میکنیم، الگوریتم یا
85
00:03:04,739 –> 00:03:07,260
مدل از آن دادهها یاد میگیرد و
86
00:03:07,260 –> 00:03:10,019
سپس میتوانیم از آن مدل برای
87
00:03:10,019 –> 00:03:12,230
پیشبینی دادههای دیده نشده استفاده کنیم.
88
00:03:12,230 –> 00:03:14,160
یادگیری ماشین
89
00:03:14,160 –> 00:03:16,410
زیرمجموعهای از هوش مصنوعی است
90
00:03:16,410 –> 00:03:18,150
که به سمت فرآیند یادگیری ماشینی حرکت میکند
91
00:03:18,150 –> 00:03:20,489
، اولین گام مرحله فرمولبندی مسئله است،
92
00:03:20,489 –> 00:03:22,920
بنابراین اینجا جایی است که
93
00:03:22,920 –> 00:03:24,630
شما سعی میکنید بفهمید و
94
00:03:24,630 –> 00:03:27,510
بیان کنید مشکل چیست و چه
95
00:03:27,510 –> 00:03:29,250
چیزی را میخواهید حل کنید و بسیار خوب است.
96
00:03:29,250 –> 00:03:32,070
سوالی که در اینجا باید از خود بپرسید این است
97
00:03:32,070 –> 00:03:35,070
که متغیر Y چیست اگر درآمد متغیر Y شما
98
00:03:35,070 –> 00:03:38,100
فوتبال باشد حجم
99
00:03:38,100 –> 00:03:40,590
آن ایمیل های اسپم است آیا حساب های آموزشی
100
00:03:40,590 –> 00:03:44,850
و غیره است و بعد از اینکه مشخص
101
00:03:44,850 –> 00:03:46,799
کردید متغیر Y شما چیست، باید
102
00:03:46,799 –> 00:03:49,890
تمام داده های خام را جمع آوری کنید. که مربوط به آن
103
00:03:49,890 –> 00:03:53,160
متغیر Y است و در حالی که این مرحله آسان به نظر می رسد
104
00:03:53,160 –> 00:03:55,560
در واقع
105
00:03:55,560 –> 00:03:58,590
در سناریوهای زندگی واقعی بسیار چالش برانگیز است به عنوان داده های خامی
106
00:03:58,590 –> 00:04:01,049
که به آن نیاز دارید. در یک مکان
107
00:04:01,049 –> 00:04:03,480
مانند مسابقات مسافرتی یا
108
00:04:03,480 –> 00:04:06,000
آموزش های آنلاین نخواهد بود، بلکه در همه
109
00:04:06,000 –> 00:04:07,470
جا در شلوغی
110
00:04:07,470 –> 00:04:09,900
دپارتمان های مختلف پایگاه های داده مختلف شما
111
00:04:09,900 –> 00:04:11,640
قرار نیست به همه آن
112
00:04:11,640 –> 00:04:13,530
بخش ها و پایگاه های داده
113
00:04:13,530 –> 00:04:15,739
دسترسی داشته باشید که می توانید درخواست دسترسی داشته باشید و برنده شوید. بعد از اینکه تمام داده های خام مورد نیاز خود را جمع آوری کردید، نمی توانید
114
00:04:15,739 –> 00:04:18,298
خطوط لوله را به طور کلی تنظیم کنید، بسیار
115
00:04:18,298 –> 00:04:20,100
چالش برانگیز و وقت گیر است،
116
00:04:20,100 –> 00:04:22,019
117
00:04:22,019 –> 00:04:24,130
118
00:04:24,130 –> 00:04:26,440
بنابراین در اینجا قرار است
119
00:04:26,440 –> 00:04:28,630
داده های خود را برای آن آماده کنید. آن را
120
00:04:28,630 –> 00:04:32,170
به یک مدل یادگیری ماشینی وارد کنید، بنابراین برخی
121
00:04:32,170 –> 00:04:34,750
از وظایفی که ممکن است در
122
00:04:34,750 –> 00:04:36,870
این مرحله انجام دهید، انحصاری نیستند،
123
00:04:36,870 –> 00:04:39,640
تجزیه و تحلیل داده های اکتشافی است، بنابراین
124
00:04:39,640 –> 00:04:42,160
بررسی روابط مشاهدات
125
00:04:42,160 –> 00:04:44,950
تعداد عناصر مقادیر تهی مقادیر از دست رفته
126
00:04:44,950 –> 00:04:48,090
داده ها پاکسازی داده ها تجمیع
127
00:04:48,090 –> 00:04:51,100
داده ها را به هم نزدیک می کند تا همه را به هم بپیوندد.
128
00:04:51,100 –> 00:04:53,020
داده های خامی که ممکن است برای
129
00:04:53,020 –> 00:04:55,120
عادی سازی داده های خود نیاز داشته باشید و
130
00:04:55,120 –> 00:04:56,710
ویژگی های طبقه بندی شده را به ارائه عددی تبدیل
131
00:04:56,710 –> 00:04:58,930
کنید، ممکن است بخواهید برخی از
132
00:04:58,930 –> 00:05:00,910
ویژگی ها را انتخاب کنید. اگر ویژگیهای زیادی
133
00:05:00,910 –> 00:05:02,770
دارید، ممکن است بخواهید
134
00:05:02,770 –> 00:05:05,440
مهندسی ویژگیها را انجام دهید و بسته به اینکه
135
00:05:05,440 –> 00:05:08,650
این مرحله پیشپردازش دادهها چقدر خوب است،
136
00:05:08,650 –> 00:05:10,690
بنابراین بسته به اینکه چقدر آن را خوب انجام میدهید،
137
00:05:10,690 –> 00:05:13,090
138
00:05:13,090 –> 00:05:15,070
بعد از اتمام کار با
139
00:05:15,070 –> 00:05:16,570
دادههای قبل، بر عملکرد مدل شما تأثیر میگذارد. -مرحله پردازش شما
140
00:05:16,570 –> 00:05:18,100
به مرحله بعدی می روید که
141
00:05:18,100 –> 00:05:20,440
تقسیم داده های خام است، اما داده های خام را تقسیم نمی کنیم،
142
00:05:20,440 –> 00:05:22,840
این است که می خواهیم
143
00:05:22,840 –> 00:05:26,350
مدل خود را بر روی برخی از داده ها زیرمجموعه ای
144
00:05:26,350 –> 00:05:28,390
در مورد داده ها آموزش دهیم، بنابراین فرض کنید هشت درصد
145
00:05:28,390 –> 00:05:30,790
و سپس از بقیه داده ها استفاده کنید و
146
00:05:30,790 –> 00:05:33,670
20 درصد بقیه را برای آزمایش مدل خود بر روی
147
00:05:33,670 –> 00:05:36,580
داده های مشابه خود استفاده کنید و ببینید که چقدر خوب
148
00:05:36,580 –> 00:05:39,850
بر روی داده هایی که قبلاً ندیده بودم در اینجا کار
149
00:05:39,850 –> 00:05:41,650
150
00:05:41,650 –> 00:05:44,230
151
00:05:44,230 –> 00:05:47,710
می کند. مدل بر روی 70 درصد
152
00:05:47,710 –> 00:05:51,190
روی بیست درصد تست شد و سپس
153
00:05:51,190 –> 00:05:52,870
در پایان پس از اتمام با یک پارامتر ترکیبی و
154
00:05:52,870 –> 00:05:55,870
تنظیم آن، در نهایت
155
00:05:55,870 –> 00:05:58,060
مدل خود را به طور کامل روی آن ده درصد آزمایش کردم
156
00:05:58,060 –> 00:05:59,860
و داده هایی را با بهترین
157
00:05:59,860 –> 00:06:01,810
پارامترهای ترکیبی که انتخاب کردم مشاهده کردم.
158
00:06:01,810 –> 00:06:03,520
کمی منطقی است قدم بعدی این
159
00:06:03,520 –> 00:06:06,430
است که مادرتان را انتخاب کنید و آموزش دهید، بنابراین
160
00:06:06,430 –> 00:06:07,900
اگر نمیدانید از چه مدلی
161
00:06:07,900 –> 00:06:09,780
استفاده میکنید، سه گزینه خواهید داشت:
162
00:06:09,780 –> 00:06:11,680
طبقهبندی رگرسیون و
163
00:06:11,680 –> 00:06:13,270
مدلهای یادگیری بدون نظارت،
164
00:06:13,270 –> 00:06:16,720
آرامسازی پیشبینی میکند رگرسیون کلاس
165
00:06:16,720 –> 00:06:19,000
، عددی را پیشبینی میکند و بدون نظارت.
166
00:06:19,000 –> 00:06:21,520
یادگیری متغیر y ندارد،
167
00:06:21,520 –> 00:06:23,620
فقط خوشهبندی یا تقسیمبندی دادههای شما
168
00:06:23,620 –> 00:06:26,650
بر اساس الگوها است، نمونههایی از
169
00:06:26,650 –> 00:06:28,720
طبقهبندی،
170
00:06:28,720 –> 00:06:31,330
تحلیل رگرسیون لجستیک
171
00:06:31,330 –> 00:06:32,560
است که در این
172
00:06:32,560 –> 00:06:34,930
آموزش، درختهای تصمیم ساده بیز
173
00:06:34,930 –> 00:06:37,240
جنگلهای تصادفی و غیره
174
00:06:37,240 –> 00:06:39,639
را نشان میدهیم. به عنوان مثال، رگرسیون خطی است
175
00:06:39,639 –> 00:06:41,320
که آموزش قبلی ما،
176
00:06:41,320 –> 00:06:43,449
جنگلهای تصادفی در تمام
177
00:06:43,449 –> 00:06:46,479
پشتیبانهای رگرسیور ماشین بردار و غیره بود،
178
00:06:46,479 –> 00:06:49,360
برخی از مثالهای یادگیری بدون نظارت،
179
00:06:49,360 –> 00:06:51,550
k-means یا خوشهبندی سلسله مراتبی است،
180
00:06:51,550 –> 00:06:54,400
حالا وقتی
181
00:06:54,400 –> 00:06:57,280
مدلی را که میخواهید اجرا کنید انتخاب کنید، میروید.
182
00:06:57,280 –> 00:06:59,350
باید مدل خود را بر اساس
183
00:06:59,350 –> 00:07:02,440
70٪ آموزش دهید و این 70٪ داده های آموزشی دیگر را
184
00:07:02,440 –> 00:07:05,770
که بر روی ساعت تقسیم کرده اید ببینید معمولاً
185
00:07:05,770 –> 00:07:07,780
شما فقط یک مدل را اجرا نمیکنید،
186
00:07:07,780 –> 00:07:10,150
سه یا پنج مدل را اجرا میکنید و سپس
187
00:07:10,150 –> 00:07:12,910
آنهایی را انتخاب میکنید که بالاترین عملکرد را دارند
188
00:07:12,910 –> 00:07:15,370
و سپس به ارزیابی آنها
189
00:07:15,370 –> 00:07:17,470
میپردازید و
190
00:07:17,470 –> 00:07:19,120
بعد از آموزش مدل خود، پارامترهای بزرگراه آنها را تنظیم میکنید.
191
00:07:19,120 –> 00:07:21,280
برای ارزیابی مدل خود بر اساس
192
00:07:21,280 –> 00:07:23,080
داده های ناپسند، بنابراین به یاد داشته باشید که وقتی
193
00:07:23,080 –> 00:07:25,870
داده ها را در 70 20 و 10 تقسیم کردیم، اکنون
194
00:07:25,870 –> 00:07:28,300
از آن 20 درصد برای
195
00:07:28,300 –> 00:07:30,400
ارزیابی مدل خود استفاده می کنیم و از یک
196
00:07:30,400 –> 00:07:32,470
متریک یا تعدادی معیار استفاده می کنیم. برای
197
00:07:32,470 –> 00:07:35,229
ارزیابی مدل ما طبقهبندیکنندههای
198
00:07:35,229 –> 00:07:36,720
مختلف بنابراین مدلهای مختلف معیارهای متفاوتی دارند
199
00:07:36,720 –> 00:07:39,340
برخی از آنها بیشتر هستند برخی از
200
00:07:39,340 –> 00:07:41,860
آنها کمتر دارند اکنون برخی از
201
00:07:41,860 –> 00:07:44,500
نمونههای اخلاقی هستند طبقهبندی r-square
202
00:07:44,500 –> 00:07:46,599
دقت قفل ضریب تلفات ماتریس
203
00:07:46,599 –> 00:07:49,090
دقت یادآوری میانگین مربع خطا
204
00:07:49,090 –> 00:07:52,150
خطا مطلق بوده و غیره بعد از شما در پایان
205
00:07:52,150 –> 00:07:53,949
با مرحله ارزیابی مدل،
206
00:07:53,949 –> 00:07:55,810
میخواهید وارد پارامتر یا
207
00:07:55,810 –> 00:07:58,840
تنظیم پارامترهایپر شوید، برخی از مدلها
208
00:07:58,840 –> 00:08:01,510
اکنون این پارامترهای ترکیبی را دارند که به
209
00:08:01,510 –> 00:08:04,690
شما امکان میدهد آنها را تنظیم کنید تا بتوانید از
210
00:08:04,690 –> 00:08:07,060
تطبیق بیش از حد خود جلوگیری کنید. مدل ur بر روی داده های آموزشی
211
00:08:07,060 –> 00:08:09,880
و همچنین مدل خود را تا
212
00:08:09,880 –> 00:08:11,470
حد امکان تعمیم دهید تا
213
00:08:11,470 –> 00:08:14,949
در کل عملکرد خوبی داشته باشد و با دیدن داده ها برخی از
214
00:08:14,949 –> 00:08:17,110
نمونه ها در حال حاضر پارامترهای فیبر
215
00:08:17,110 –> 00:08:19,720
پارامتر گالاتی است C تعداد
216
00:08:19,720 –> 00:08:21,820
همسایگان عملکردهای فاصله
217
00:08:21,820 –> 00:08:23,520
مختلف راه های مختلف تجدید نظرهای مختلف
218
00:08:23,520 –> 00:08:27,130
پارامترهای انرژی و غیره بعد از
219
00:08:27,130 –> 00:08:28,780
اینکه پارامترهای ترکیبی را تنظیم کردید،
220
00:08:28,780 –> 00:08:30,370
باید دوباره مدل خود را آموزش دهید و سپس مدل خود را دوباره
221
00:08:30,370 –> 00:08:32,349
بر روی داده های نادیده ارزیابی
222
00:08:32,349 –> 00:08:34,958
کنید، سپس پارامترهای ترکیبی را تنظیم کرده
223
00:08:34,958 –> 00:08:36,820
و مدل خود را با
224
00:08:36,820 –> 00:08:39,610
مشاهده دوباره داده ها آموزش می دهید و
225
00:08:39,610 –> 00:08:42,099
این روند را تا زمانی که به یک عدد برسید ادامه دهید.
226
00:08:42,099 –> 00:08:43,719
نقطه ای که در آن
227
00:08:43,719 –> 00:08:45,550
از عملکرد مدل یا
228
00:08:45,550 –> 00:08:48,430
داده های دیده نشده خود راضی خواهید بود و بعد از
229
00:08:48,430 –> 00:08:49,930
اینکه خوشحال شدید، پارامترهای حیدر را
230
00:08:49,930 –> 00:08:50,740
231
00:08:50,740 –> 00:08:52,930
که شناسایی کرده اید
232
00:08:52,930 –> 00:08:55,450
انتخاب می کنید که بهترین مدل جدید آموزش عملکرد را
233
00:08:55,450 –> 00:08:57,730
بر اساس آن فیبر به شما ارائه می دهد. پارامترها و
234
00:08:57,730 –> 00:09:01,120
سپس آن مدل جدید را روی آن 10 درصد آزمایش کنید،
235
00:09:01,120 –> 00:09:03,010
به یاد می آورید که کل 10 درصد
236
00:09:03,010 –> 00:09:05,800
داده های کاملاً دیده نشده را حذف کرده ایم و ببینید آیا شما
237
00:09:05,800 –> 00:09:07,990
از نتایج راضی هستم اگر از
238
00:09:07,990 –> 00:09:09,459
نتایج راضی هستید، پس
239
00:09:09,459 –> 00:09:12,010
میروید و مدل را پیادهسازی میکنید، در غیر این صورت
240
00:09:12,010 –> 00:09:13,959
به تنظیم پارامترهای بزرگراه برمیگردید
241
00:09:13,959 –> 00:09:15,580
و دوباره همان فرآیند
242
00:09:15,580 –> 00:09:17,709
را به درستی شروع میکنید، بنابراین این مراحلی است
243
00:09:17,709 –> 00:09:19,270
که باید دنبال کنید. وقتی نوبت به
244
00:09:19,270 –> 00:09:21,520
اجرای یادگیری ماشینی میرسد،
245
00:09:21,520 –> 00:09:23,649
من نمیگویم که
246
00:09:23,649 –> 00:09:26,110
این مراحل را به طور انحصاری دنبال میکنید، ممکن است مجبور شوید
247
00:09:26,110 –> 00:09:29,410
برخی از مراحل را برای برخی وظایف دیگر انجام دهید، اما
248
00:09:29,410 –> 00:09:32,110
میتوانم بگویم در 90٪ مواقع
249
00:09:32,110 –> 00:09:33,850
این فرآیندی است که شما انجام میدهید. در
250
00:09:33,850 –> 00:09:35,380
مورد اجرای
251
00:09:35,380 –> 00:09:37,899
مدلهای یادگیری ماشینی، به هر حال، اگر
252
00:09:37,899 –> 00:09:39,790
این کار را انجام میدهید، آن را دنبال میکنید و من برای این ویدیو ارزش قائل
253
00:09:39,790 –> 00:09:41,350
هستم، اگر
254
00:09:41,350 –> 00:09:42,970
روی دکمه لایک کلیک کنید و در کانال من مشترک شوید،
255
00:09:42,970 –> 00:09:44,980
به مرحله اول بروید، واقعا متشکر میشوم
256
00:09:44,980 –> 00:09:46,240
.
257
00:09:46,240 –> 00:09:48,970
مرحله فرمولبندی مسئله در این مثال، ما
258
00:09:48,970 –> 00:09:51,370
میخواهیم عوامل یا
259
00:09:51,370 –> 00:09:54,670
متغیرهایی را بررسی کنیم که بر یک وام خوب یا یک وام بد تأثیر میگذارند،
260
00:09:54,670 –> 00:09:57,190
بنابراین مشاهده میکنیم که
261
00:09:57,190 –> 00:09:59,470
کسی فرض کنیم ستونی
262
00:09:59,470 –> 00:10:00,580
در پایان دارد که قرار است این باشد. متغیر Y
263
00:10:00,580 –> 00:10:03,310
و می گوید اگر وام خوب است
264
00:10:03,310 –> 00:10:07,060
بله یا خیر یا وام خوب اما وام است و ما
265
00:10:07,060 –> 00:10:09,580
می خواهیم پیش بینی کنیم که آیا یک
266
00:10:09,580 –> 00:10:12,100
مشتری جدید باید وام خود را
267
00:10:12,100 –> 00:10:14,620
تأیید کند یا خیر بر اساس
268
00:10:14,620 –> 00:10:17,650
ویژگی های آنها
269
00:10:17,650 –> 00:10:20,290
متغیر وابسته ما تأییدیه وام بله است. یا خیر
270
00:10:20,290 –> 00:10:23,110
یا اگر وام خوب است یا بخشی
271
00:10:23,110 –> 00:10:26,290
که همان چیزی است که ما در
272
00:10:26,290 –> 00:10:28,570
دادههای خام خود خوب یا بد داریم، اما روشی که میخواهیم
273
00:10:28,570 –> 00:10:31,779
از آن در تجارت واقعی استفاده کنیم این است که بگوییم
274
00:10:31,779 –> 00:10:33,970
آیا مشتری باید دریافت کند وام
275
00:10:33,970 –> 00:10:36,100
تأیید شده است. بله یا خیر، پس این همان
276
00:10:36,100 –> 00:10:38,050
چیزی است که یک طبقهبندی باینری بله یا خیر
277
00:10:38,050 –> 00:10:40,570
است که به
278
00:10:40,570 –> 00:10:42,370
کتابخانهها یا بستههایی که قرار است
279
00:10:42,370 –> 00:10:43,900
برای این آموزش استفاده کنیم، استفاده میکنم. من از سیستم عامل استفاده خواهم کرد.
280
00:10:43,900 –> 00:10:44,260
281
00:10:44,260 –> 00:10:46,959
282
00:10:46,959 –> 00:10:50,170
شما نمی
283
00:10:50,170 –> 00:10:52,149
دانید چگونه از هیچ یک از این کتابخانه ها استفاده کنید، من
284
00:10:52,149 –> 00:10:54,610
آموزش های صریح در مورد هر یک از آن
285
00:10:54,610 –> 00:10:56,740
کتابخانه ها دارم، می توانید کانال یوتیوب من را جستجو
286
00:10:56,740 –> 00:10:58,959
کنید، اگر هیچ یک از این کتابخانه را نصب ندارید، می توانید آنها را پیدا کنید، تنها کاری که
287
00:10:58,959 –> 00:11:01,270
288
00:11:01,270 –> 00:11:03,190
باید انجام دهید این است که آناکوندا
289
00:11:03,190 –> 00:11:05,949
پایان و تی ype in t IP نصب شده و
290
00:11:05,949 –> 00:11:09,279
سپس Numpy یا Panda’s Permit Leap اگر
291
00:11:09,279 –> 00:11:11,290
زمین SK ندارید، باید
292
00:11:11,290 –> 00:11:13,449
ترمینال آناکوندا را باز کنید و نامه
293
00:11:13,449 –> 00:11:16,300
کیت نصب numpy side-by-side PRP را تایپ کنید و
294
00:11:16,300 –> 00:11:18,940
به سمت بارگیری
295
00:11:18,940 –> 00:11:21,550
داده های خام ما بروید. برای بارگیری دادههای خام یا
296
00:11:21,550 –> 00:11:25,720
باید بگوییم دادههای جاده برابر است با P lib انحرافی
297
00:11:25,720 –> 00:11:29,769
زیرخط C زیرا پرسی دارای V است، سپس
298
00:11:29,769 –> 00:11:31,899
پرانتزها را باز کنید و سپس در نقل قولها
299
00:11:31,899 –> 00:11:33,879
باید مسیری را که
300
00:11:33,879 –> 00:11:36,220
دادههای خام را دانلود کردهاید، بچسبانیم تا پس از
301
00:11:36,220 –> 00:11:38,379
دانلود دادههای خام از
302
00:11:38,379 –> 00:11:40,600
لینک مخزن github من در توضیحات، سپس
303
00:11:40,600 –> 00:11:42,550
به پوشه ای می روید که
304
00:11:42,550 –> 00:11:45,310
اگر روی مسیری که آن را کپی می کنید، ایمنی دارید،
305
00:11:45,310 –> 00:11:47,500
و سپس بخشی را به
306
00:11:47,500 –> 00:11:50,079
کد پایتون خود وارد می کنید، آن را در کدی که در
307
00:11:50,079 –> 00:11:53,019
اینجا قرار دارد، قرار می دهید، ما می خواهیم از یک دوبل فوروارد استفاده کنیم.
308
00:11:53,019 –> 00:11:56,139
اسلش کنید بنابراین از همه آن دوتایی ها تشکر
309
00:11:56,139 –> 00:11:58,569
کنید و در اینجا در پایان می خواهیم
310
00:11:58,569 –> 00:12:00,579
نام فایل را اضافه کنیم بنابراین اگر به
311
00:12:00,579 –> 00:12:03,370
پوشه برگردم روی فایل کلیک می کنم ممکن
312
00:12:03,370 –> 00:12:05,829
است نام فایل باشد سپس آن را
313
00:12:05,829 –> 00:12:08,319
دوباره در اینجا و سپس در اینجا قرار می دهم. من می گویم تاد به دنبال
314
00:12:08,319 –> 00:12:11,680
sv در پایان است، اکنون فقط i اجرا کنید خطای دریافت میکنم که
315
00:12:11,680 –> 00:12:13,930
میگوید PD تعریف نشده است،
316
00:12:13,930 –> 00:12:16,240
به این دلیل است که من در اطراف کتابخانههایم هستم، بنابراین اگر
317
00:12:16,240 –> 00:12:19,509
دوباره کتابخانههایم را اجرا کنم
318
00:12:19,509 –> 00:12:22,149
اولین بار است که به همین دلیل بارگیری را میبینم، پس
31