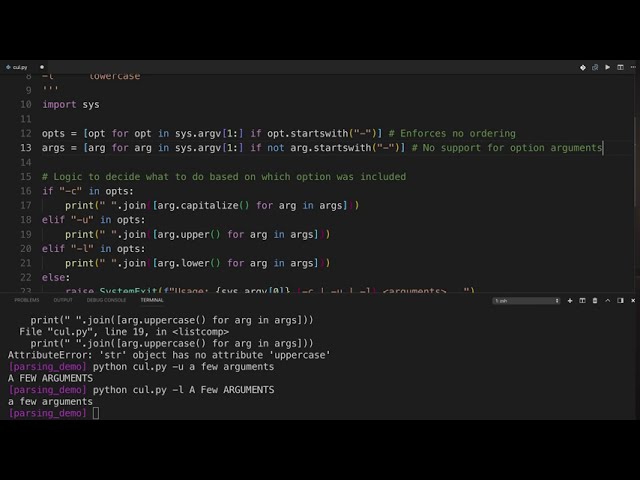
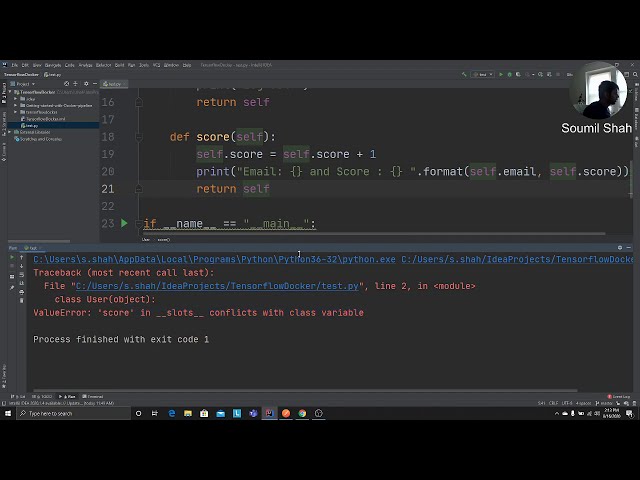
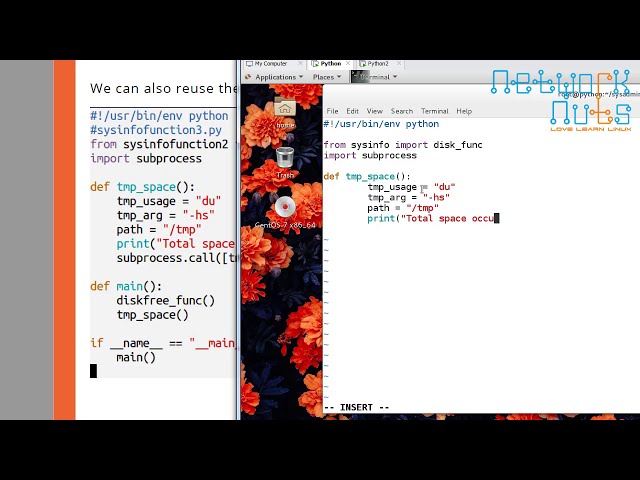
در این مطلب، ویدئو ویکتور استینر – عملکرد پایتون: گذشته، حال و آینده با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:47:42
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:01,800 –> 00:00:04,590
بنابراین سلام به همه، نام من ویکتور استینا است،
2
00:00:04,590 –> 00:00:07,020
من برای reddit کار می کنم تا
3
00:00:07,020 –> 00:00:10,199
جریان پایتون انجام شده را حفظ کنم که به معنی همکار در
4
00:00:10,199 –> 00:00:13,289
لینوکس Red Hat Enterprise است، اما من
5
00:00:13,289 –> 00:00:15,209
همچنین توسط یک upstream نگهداری می شوم، به عنوان مثال
6
00:00:15,209 –> 00:00:17,220
، CI را اصلاح کنید تا مطمئن شوید که CI
7
00:00:17,220 –> 00:00:20,310
همیشه وجود دارد. سبز و من اینجا هستم تا در مورد
8
00:00:20,310 –> 00:00:23,310
عملکرد پایتون در گذشته حال و
9
00:00:23,310 –> 00:00:26,490
آینده صحبت کنم، بنابراین می خواهم
10
00:00:26,490 –> 00:00:28,920
سفر خود را با شروع پایتون
11
00:00:28,920 –> 00:00:33,120
و آنچه در گذشته امتحان شده است شروع کنم تا
12
00:00:33,120 –> 00:00:35,160
پیاده سازی متفاوت
13
00:00:35,160 –> 00:00:37,470
و اولی نداشته باشم. یکی
14
00:00:37,470 –> 00:00:41,630
تقریباً 30 سال پیش توسط Guido van Rossum ساخته
15
00:00:41,630 –> 00:00:45,960
شده است که به آن سی
16
00:00:45,960 –> 00:00:49,770
17
00:00:49,770 –> 00:00:52,230
18
00:00:52,230 –> 00:00:55,920
19
00:00:55,920 –> 00:00:59,430
پایتون می گویند. ابتدا Python نامیده شد
20
00:00:59,430 –> 00:01:03,899
و بعداً به یک آیتم تغییر نام داد و این
21
00:01:03,899 –> 00:01:07,249
مورد توسط جیم ایجاد شده است که
22
00:01:07,249 –> 00:01:10,679
برای همزمانی پروژه
23
00:01:10,679 –> 00:01:12,619
ای با نام stackless python
24
00:01:12,619 –> 00:01:16,109
stackless ایجاد شده است به این معنی که شما می توانید به
25
00:01:16,109 –> 00:01:19,759
روال های اصلی مختلف تغییر دهید و
26
00:01:19,759 –> 00:01:23,060
پایتون بدون پشته آن را کارآمد می کند
27
00:01:23,060 –> 00:01:25,499
این یکی توسط کریستین دیمال ساخته شده است
28
00:01:25,499 –> 00:01:29,549
و همین جیم نیز
29
00:01:29,549 –> 00:01:32,069
پایتون را اجرا کردم که در CG
30
00:01:32,069 –> 00:01:36,299
در زمان اجرا مایکروسافت نوشته شده است و اکنون
31
00:01:36,299 –> 00:01:38,789
اخیرا میکرو پایتون را دیدیم که
32
00:01:38,789 –> 00:01:41,670
برای میکروکنترلر طراحی شده است و این
33
00:01:41,670 –> 00:01:43,439
یکی دارای توسط دیمین جورج ایجاد شده است،
34
00:01:43,439 –> 00:01:49,259
بنابراین برای سریعتر کردن پایتون، ما
35
00:01:49,259 –> 00:01:51,270
لیستی طولانی از پروژه های مختلف بهینه سازی داریم،
36
00:01:51,270 –> 00:01:54,869
بنابراین اولین آنها کامپایلر JIT بود
37
00:01:54,869 –> 00:01:57,749
که توسط آمینا ویگو ایجاد شد به نام web psycho،
38
00:01:57,749 –> 00:02:01,079
این یکی فقط برای یک عملکرد واحد
39
00:02:01,079 –> 00:02:03,989
بود و از یک دکوراتور استفاده می کرد.
40
00:02:03,989 –> 00:02:05,789
این تابع را برای اولین بار فراخوانی کنید
41
00:02:05,789 –> 00:02:08,580
، این یک JIT کامپایل شده است و تماس بعدی
42
00:02:08,580 –> 00:02:11,280
سریعتر خواهد بود، اما ابزار ما
43
00:02:11,280 –> 00:02:14,130
بنابراین طراحی طراحی واقعا
44
00:02:14,130 –> 00:02:15,420
کارآمدترین راه برای
45
00:02:15,420 –> 00:02:18,750
جاسوسی من نیست، بنابراین بعداً یک پروژه
46
00:02:18,750 –> 00:02:21,300
تحقیقاتی توسط اتحادیه اروپا تأسیس شد
47
00:02:21,300 –> 00:02:25,050
و به عنوان حق ثبت اختراع، پروژه ID pipe
48
00:02:25,050 –> 00:02:27,300
ایجاد شده است که یک کامپایلر JIT
49
00:02:27,300 –> 00:02:32,489
برای پایتون است، Google همچنین یک کارآموز
50
00:02:32,489 –> 00:02:35,430
داشت که پرستو بدون بار ایجاد می کرد که فرض
51
00:02:35,430 –> 00:02:40,170
می کرد پایتون را 5 برابر سریعتر Dropbo می کند. x
52
00:02:40,170 –> 00:02:42,830
همچنین سعی کرد با استفاده از
53
00:02:42,830 –> 00:02:48,269
کامپایلر LLVM JIT به نام piston it پایتون را سریعتر کند،
54
00:02:48,269 –> 00:02:50,640
فکر میکنم چند سالی یک یا دو نفر
55
00:02:50,640 –> 00:02:54,630
در ساعت چهار استقبال کردند و مایکروسافت
56
00:02:54,630 –> 00:02:57,410
نیز پروژه خود را به نام کبوتر داشت و
57
00:02:57,410 –> 00:03:00,480
اگر به تاریخها توجه کنید میتوانید ببینید که
58
00:03:00,480 –> 00:03:03,090
بیشتر این پروژه بهعنوان تاریخهای پایان،
59
00:03:03,090 –> 00:03:06,540
ما سعی میکنیم بفهمیم که چرا آنها
60
00:03:06,540 –> 00:03:10,319
تاریخهای پایان هستند، وقتی محدودیت بتا جدیدی ایجاد
61
00:03:10,319 –> 00:03:12,510
میکنید، دو رویکرد اصلی دارید
62
00:03:12,510 –> 00:03:15,030
، یکی شروع از
63
00:03:15,030 –> 00:03:18,239
پایتون فعلی C و دیگری
64
00:03:18,239 –> 00:03:22,290
شروع از صفر. اگر
65
00:03:22,290 –> 00:03:25,739
از C Python شروع کنید، این
66
00:03:25,739 –> 00:03:28,640
رویکردی است که توسط پیستون بلع بدون بار
67
00:03:28,640 –> 00:03:32,370
و PG انتخاب شده
68
00:03:32,370 –> 00:03:34,769
است، نکته جالب این است که شما مستقیماً
69
00:03:34,769 –> 00:03:37,290
از همه کدهای موجود پشتیبانی نمیکنید،
70
00:03:37,290 –> 00:03:40,140
زیرا قبلاً پایتون را میبینید
71
00:03:40,140 –> 00:03:42,630
که همه برنامههای افزودنی را پشتیبانی میکنید. کار می کند و شما
72
00:03:42,630 –> 00:03:44,640
فقط می توانید تغییرات خود را در بالای آن قرار دهید،
73
00:03:44,640 –> 00:03:48,660
اما وقتی این کار را انجام می دهید، تمام
74
00:03:48,660 –> 00:03:52,829
کدهای قدیمی مورد و تمام
75
00:03:52,829 –> 00:03:55,769
طراحی قدیمی C Python را ایجاد می کنید که دوباره
76
00:03:55,769 –> 00:03:58,620
40 سال پیش ایجاد شده است و شاید برخی
77
00:03:58,620 –> 00:04:01,500
فناوری های جدید تغییراتی که 30 سال پیش انجام شد
78
00:04:01,500 –> 00:04:05,250
30 سال پیش منطقی بود، اما امروزه CPU ما
79
00:04:05,250 –> 00:04:10,079
بیشتر فراخوانی می کند و برخی از طراحی ها
80
00:04:10,079 –> 00:04:13,889
به خوبی با مقیاس مناسب نیستند، به عنوان مثال در
81
00:04:13,889 –> 00:04:15,359
پایتون چیزی به نام
82
00:04:15,359 –> 00:04:17,728
قفل مفسر جهانی Gil داریم
83
00:04:17,728 –> 00:04:20,130
و Gil اساساً شما را محدود می کند. به یک
84
00:04:20,130 –> 00:04:23,810
رشته، اما ما همچنین
85
00:04:23,810 –> 00:04:27,060
ساختارهای دیدنی خاصی را داریم که روی یک
86
00:04:27,060 –> 00:04:28,889
زباله جمعکننده خاص حساب میکنند
87
00:04:28,889 –> 00:04:31,050
که همچنین مانع از اجرای
88
00:04:31,050 –> 00:04:35,009
نوعی سازماندهی در طرف دیگر میشوند،
89
00:04:35,009 –> 00:04:37,229
اگر اجرای جدیدی را از
90
00:04:37,229 –> 00:04:43,050
ابتدا شروع کنید، طرح انتخاب شده توسط لوله، من
91
00:04:43,050 –> 00:04:46,110
میتوانم آن را برگردانم. arrow پایتون لازم نیست
92
00:04:46,110 –> 00:04:48,780
و همه این کدهای قدیمی و همه این
93
00:04:48,780 –> 00:04:51,750
طراحی ها می توانید هر کاری که می خواهید انجام دهید
94
00:04:51,750 –> 00:04:55,139
و به عنوان مثال جاتین در ironpython
95
00:04:55,139 –> 00:04:58,469
ما هیچ گیرو ندارد بنابراین آنها می توانند
96
00:04:58,469 –> 00:05:01,550
از همان ابتدا روی چندین CPU مقیاس شوند.
97
00:05:01,550 –> 00:05:05,189
به Sousa GBM و زمان
98
00:05:05,189 –> 00:05:08,729
اجرا مایکروسافت و مثال دیگر این است
99
00:05:08,729 –> 00:05:11,189
که PI pi PI از شمارش مرجع به صورت داخلی استفاده نمی کند،
100
00:05:11,189 –> 00:05:13,560
اما آنها از یک
101
00:05:13,560 –> 00:05:15,840
جمع آوری زباله ردیابی استفاده می کنند که
102
00:05:15,840 –> 00:05:19,199
کارآمدتر است، اما زمانی که شما
103
00:05:19,199 –> 00:05:22,469
مشکل اصلی این است که
104
00:05:22,469 –> 00:05:24,629
برای پسوندهای C یا اصلا
105
00:05:24,629 –> 00:05:27,060
از آنها پشتیبانی نمی کنید که
106
00:05:27,060 –> 00:05:28,620
بسته به نوع برنامه شما می تواند مشکل ساز باشد
107
00:05:28,620 –> 00:05:32,370
یا اینکه سرعت آن از C
108
00:05:32,370 –> 00:05:32,759
peyten کمتر است
109
00:05:32,759 –> 00:05:36,479
و به عنوان مثال برای PI PI آنها یک مشکل دارند.
110
00:05:36,479 –> 00:05:40,259
ماژول به نام C pi X که یک
111
00:05:40,259 –> 00:05:42,870
شی PI C پایتون را در صورت تقاضا ایجاد می کند، بنابراین وقتی
112
00:05:42,870 –> 00:05:45,270
به چیزی دسترسی پیدا می کنید که
113
00:05:45,270 –> 00:05:47,190
برای پسوندهای ass است، آنها باید
114
00:05:47,190 –> 00:05:51,839
ساختارهای C Python و API را شبیه سازی کنند
115
00:05:51,839 –> 00:05:55,009
و این شیء جدید
116
00:05:55,009 –> 00:05:58,020
باید با آن همگام شود. اشیاء pi PI
117
00:05:58,020 –> 00:06:01,349
که به بهترین شکل پیادهسازی میشوند
118
00:06:01,349 –> 00:06:03,900
بسیار پیچیده هستند و شاید
119
00:06:03,900 –> 00:06:06,629
کارآمدترین راه برای رابط با
120
00:06:06,629 –> 00:06:11,460
برنامه افزودنی نباشد و یکی دیگر از مسائل
121
00:06:11,460 –> 00:06:13,259
پیادهسازی متفاوت پایتون این است
122
00:06:13,259 –> 00:06:15,930
که شما در رقابت با C
123
00:06:15,930 –> 00:06:19,740
Python و C Python به عنوان تقریباً 30 توسعهدهنده کد فعال هستید.
124
00:06:19,740 –> 00:06:23,669
صرفاً
125
00:06:23,669 –> 00:06:25,589
نقشهبرداری مجدد یا درخواست و راه رفتن مستقیم است،
126
00:06:25,589 –> 00:06:27,360
اما بدیهی است که ما مشارکتکنندگان بیشتری داریم
127
00:06:27,360 –> 00:06:30,710
که تغییرات را پیشنهاد میکنند و
128
00:06:30,710 –> 00:06:33,599
مسئله دیگری برای
129
00:06:33,599 –> 00:06:35,610
پیادهسازی Python در منطقه یورو این است. اصلاً
130
00:06:35,610 –> 00:06:37,979
ویژگیهای جدیدی که برای اولین بار در کد C Python آموخته شد،
131
00:06:37,979 –> 00:06:41,370
به این معنی است که پیادهسازی دیگر
132
00:06:41,370 –> 00:06:42,610
133
00:06:42,610 –> 00:06:46,330
برای رسیدن به پایتون، بنابراین برای دریافت این
134
00:06:46,330 –> 00:06:50,530
ویژگیهای جدید و پس چرا یک کاربر
135
00:06:50,530 –> 00:06:52,780
یک پیادهسازی قدیمی یا ناقص
136
00:06:52,780 –> 00:06:55,629
و یک پاسخ Woo-wee را ترجیح میدهد.
137
00:06:55,629 –> 00:06:58,240
همه پیشرفتها اگر پیادهسازی دیگری دارید
138
00:06:58,240 –> 00:07:02,889
و آنچه در
139
00:07:02,889 –> 00:07:05,050
مورد پروژه قبلی
140
00:07:05,050 –> 00:07:06,939
که برای سریعتر کردن پایتون فهرست
141
00:07:06,939 –> 00:07:10,389
کردم بسیار جالب است این است که خلاصهای
142
00:07:10,389 –> 00:07:13,210
از اینکه چرا تصمیم گرفتند پروژهها را متوقف کنند
143
00:07:13,210 –> 00:07:16,569
یا چرا پروژه بلند است و برای در
144
00:07:16,569 –> 00:07:19,120
مورد یک پرستو لندنی
145
00:07:19,120 –> 00:07:21,669
سه دلیل اصلی وجود دارد که دلیل اول این است که
146
00:07:21,669 –> 00:07:23,919
در پایتون های گوگل از زبان پایتون
147
00:07:23,919 –> 00:07:25,689
واقعا برای کدهای حیاتی عملکرد استفاده نمی شود،
148
00:07:25,689 –> 00:07:28,180
بنابراین
149
00:07:28,180 –> 00:07:32,050
سریعتر کردن پایتون خوب است اما
150
00:07:32,050 –> 00:07:36,159
برای گوگل اولویت ندارد و یک
151
00:07:36,159 –> 00:07:38,550
مفسر پایتون متفاوت دارد. به دلیل برخی
152
00:07:38,550 –> 00:07:41,139
مشکلات استقرار، استقرار آن خیلی سخت بود،
153
00:07:41,139 –> 00:07:44,139
به عنوان یک جایگزین،
154
00:07:44,139 –> 00:07:48,520
کافی نبود و من فکر می کنم که برای من
155
00:07:48,520 –> 00:07:50,770
مهمترین دلیل این است که پات ما
156
00:07:50,770 –> 00:07:53,770
مشتریان اصلی در نهایت راه دیگری را برای
157
00:07:53,770 –> 00:07:56,500
حل مشکل عملکرد ایجاد کردند زیرا
158
00:07:56,500 –> 00:07:59,020
در پایتون وقتی میتوانید
159
00:07:59,020 –> 00:08:02,279
گلوگاه عملکرد خود را شناسایی کنید،
160
00:08:02,279 –> 00:08:04,360
گزینههای
161
00:08:04,360 –> 00:08:08,020
زیادی برای سریعتر کردن آن وجود دارد که
162
00:08:08,020 –> 00:08:12,909
نیازی به کار روی آن پروژه بهینهسازی دیگر ندارید.
163
00:08:12,909 –> 00:08:15,490
پیستونی
164
00:08:15,490 –> 00:08:19,300
بود که برای سالهای رایگان توسعه داده شد و دوباره
165
00:08:19,300 –> 00:08:21,729
گزارشی نوشتند و توضیح دادند که چرا
166
00:08:21,729 –> 00:08:26,319
تصمیم به توقف گرفتند و دوباره یک دلیل این بود
167
00:08:26,319 –> 00:08:28,060
که جعبه تلهای است
168
00:08:28,060 –> 00:08:31,990
که شروع به بازنویسی
169
00:08:31,990 –> 00:08:34,448
کد گلوگاه عملکرد به زبانهای دیگر
170
00:08:34,448 –> 00:08:38,740
مانند go کردند، اما در مورد آن نیز بسیار خوشبین بودند.
171
00:08:38,740 –> 00:08:41,979
بهینهسازیای که
172
00:08:41,979 –> 00:08:44,529
میتوان در Dropbox پیادهسازی کرد، اما
173
00:08:44,529 –> 00:08:48,160
آنها متوجه میشوند که اگر بخواهید
174
00:08:48,160 –> 00:08:50,260
هر نوع برنامه پایتون را اجرا کنید
175
00:08:50,260 –> 00:08:52,810
، سازگاری به عقب و
176
00:08:52,810 –> 00:08:55,329
سازگاری با C Python برای داشتن یک
177
00:08:55,329 –> 00:08:56,530
178
00:08:56,530 –> 00:09:00,070
رفتار بسیار نزدیک بسیار دشوار است که آن را به
179
00:09:00,070 –> 00:09:03,300
درستی انجام دهید و آن را سریعتر کنید،
180
00:09:03,300 –> 00:09:06,610
بنابراین خلاصه کردن cpython به
181
00:09:06,610 –> 00:09:08,800
عنوان پیاده سازی مرجع باقی می ماند، اما نشان
182
00:09:08,800 –> 00:09:11,740
می دهد که در سنین بالا است که چندین عملیات وجود دارد
183
00:09:11,740 –> 00:09:14,640
پروژه زمانبندی که شکست میخورد و
184
00:09:14,640 –> 00:09:17,910
خط لوله یک جایگزین کشویی است،
185
00:09:17,910 –> 00:09:21,220
چهار برابر سریعتر است، اما هنوز به طور گسترده مورد
186
00:09:21,220 –> 00:09:26,760
استفاده قرار نگرفته است، بنابراین میخواهم بپرسم چرا
187
00:09:26,760 –> 00:09:31,830
خوب است،
188
00:09:31,830 –> 00:09:34,000
وقتی دوباره شناسایی کردید از گلوگاه کدهایی که دارید استفاده میکنید، به زمان
189
00:09:34,000 –> 00:09:37,450
حال برویم.
190
00:09:37,450 –> 00:09:39,600
گزینه های مختلف برای سریعتر کردن آن
191
00:09:39,600 –> 00:09:44,620
قبل از هر چیز لطفاً pi PI را امتحان کنید
192
00:09:44,620 –> 00:09:47,350
زیرا برای بسیاری از کاربران اینطور عمل
193
00:09:47,350 –> 00:09:50,370
می کند که پایتون را با pi PI جایگزین کنید و
194
00:09:50,370 –> 00:09:53,170
برنامه شما دو برابر
195
00:09:53,170 –> 00:09:55,900
سریعتر یا ده برابر سریعتر می شود یا حتی بیشتر
196
00:09:55,900 –> 00:09:58,840
به حجم کاری شما بستگی دارد.
197
00:09:58,840 –> 00:10:02,290
نوع عملکردی که در برنامه خود انجام می دهید
198
00:10:02,290 –> 00:10:04,420
و بسیاری از
199
00:10:04,420 –> 00:10:07,570
کاربران هستند که فقط پایتون را با pi PI جایگزین می کنند
200
00:10:07,570 –> 00:10:11,560
و بسیار سریع بود و بخش بسیار
201
00:10:11,560 –> 00:10:14,020
خوبی از pi pi وجود دارد این است که
202
00:10:14,020 –> 00:10:18,360
واقعاً کاملاً با C Python سازگار است
203
00:10:18,360 –> 00:10:21,280
اما وجود دارد. برخی از مسائل توضیح می دهد
204
00:10:21,280 –> 00:10:24,760
که چرا به طور گسترده مورد استفاده قرار نمی گیرد و من فکر می
205
00:10:24,760 –> 00:10:26,800
کنم اولین دلیل آن پشتیبانی از
206
00:10:26,800 –> 00:10:32,110
پسوند C است، بنابراین همانطور که توضیح دادم
207
00:10:32,110 –> 00:10:34,480
کمی کندتر از C Python است، حتی اگر
208
00:10:34,480 –> 00:10:37,950
بسیار زیاد باشد. بله، اخیراً ptimized شد،
209
00:10:37,950 –> 00:10:40,330
اما میخواهم بعداً در مورد آن صحبت
210
00:10:40,330 –> 00:10:43,420
کنم، دو مشکل نیز
211
00:10:43,420 –> 00:10:45,520
دارد که ردپای حافظه دارد که یکی از عوارض
212
00:10:45,520 –> 00:10:48,640
جانبی کامپایلر JIT است زیرا کامپایلرهای JIT
213
00:10:48,640 –> 00:10:51,520
به تنهایی از حافظه استفاده میکنند و
214
00:10:51,520 –> 00:10:53,080
شما نسخه قابل تغییر کد را دارید،
215
00:10:53,080 –> 00:10:56,500
بنابراین در برخی موارد بارگذاری کار می تواند یک مشکل باشد
216
00:10:56,500 –> 00:10:59,800
و مشکل کوچکتر دیگر
217
00:10:59,800 –> 00:11:01,900
زمان شروع زمانی است که برای مثال یک
218
00:11:01,900 –> 00:11:04,620
رابط خط فرمان دارید که ممکن است
219
00:11:04,620 –> 00:11:08,560
بخواهید آن را سریع اجرا کنید اما
220
00:11:08,560 –> 00:11:10,210
کامپایلر JIT آن را کمی
221
00:11:10,210 –> 00:11:13,180
کندتر از پایتون C می کند، اما اگر شما از
222
00:11:13,180 –> 00:11:15,640
حالت جیوه L استفاده می کنید زمانی که همان
223
00:11:15,640 –> 00:11:18,399
چند بار مشترک را اجاره می کنید یک راه حل می تواند این
224
00:11:18,399 –> 00:11:20,950
باشد که یک سرور در
225
00:11:20,950 –> 00:11:23,170
پس زمینه اجرا شود و یک کلاینت ما فقط
226
00:11:23,170 –> 00:11:25,060
به سرور متصل می شویم و این
227
00:11:25,060 –> 00:11:27,820
طرحی است که توسط مرکوریال انتخاب شده و لوله
228
00:11:27,820 –> 00:11:32,680
در آن کارآمد است. در این مورد و اکنون من
229
00:11:32,680 –> 00:11:35,070
می خواهم به
230
00:11:35,070 –> 00:11:39,339
قفل مفسر جهانی بسیار بدنام برگردم تا سعی کنم
231
00:11:39,339 –> 00:11:42,100
آن را توضیح دهم، فرض کنید که شما
232
00:11:42,100 –> 00:11:44,200
سه رشته در برنامه خود دارید و
233
00:11:44,200 –> 00:11:47,950
همه آنها محدودیت های CPU هستند، به عنوان مثال، شما
234
00:11:47,950 –> 00:11:50,140
هر چیزی را با وی محاسبه می کنید. انتگرال یا
235
00:11:50,140 –> 00:11:53,529
عدد ممیز شناور و به دلیل وجود
236
00:11:53,529 –> 00:11:54,100
آبشش
237
00:11:54,100 –> 00:11:56,200
حتی اگر چیزی به نام نخ داشته باشید از نظر
238
00:11:56,200 –> 00:11:58,300
فنی آنها رشته های پایتون هستند
239
00:11:58,300 –> 00:12:02,080
و پایتون سی شما فقط
240
00:12:02,080 –> 00:12:05,230
می تواند آن را یک بار در همان زمان اجرا کند، بنابراین
241
00:12:05,230 –> 00:12:07,779
کارایی فقط یک بار تصور می شود که می دانید زیرا من می دانم.
242
00:12:07,779 –> 00:12:12,310
CPU رایگان دارید اما باید
243
00:12:12,310 –> 00:12:14,860
بدانید که Gil
244
00:12:14,860 –> 00:12:18,520
شما را از نوشتن کدهای کارآمد منع نمی کند زیرا
245
00:12:18,520 –> 00:12:21,370
مشکل فقط برای کدهای محدود به CPU است، اما
246
00:12:21,370 –> 00:12:22,810
برای مثال اگر
247
00:12:22,810 –> 00:12:27,490
بار کاری متفاوتی در استفاده از توابع C دارید، ما
248
00:12:27,490 –> 00:12:30,580
به پایتون پایتون نیازی نداریم. گیل میتوانید گیل را
249
00:12:30,580 –> 00:12:33,160
آزاد کنید و به این معنی است که
250
00:12:33,160 –> 00:12:35,800
میتوانید دو رشته را به صورت موازی اجرا کنید،
251
00:12:35,800 –> 00:12:37,570
مثلاً وقتی آتشی را از دیسک پایتون میخوانید،
252
00:12:37,570 –> 00:12:40,180
253
00:12:40,180 –> 00:12:44,050
وقتی خاکستر sha-1 را محاسبه میکنید احساس گناه را برای شما
254
00:12:44,050 –> 00:12:47,050
آزاد کنید، همچنین یک آبشش را نیز آزاد میکنید یا هنگامی که
255
00:12:47,050 –> 00:12:49,540
داده ها را با visib فشرده می کنید – برای مثال
256
00:12:49,540 –> 00:12:52,600
شما Gil را نیز منتشر کردید، بنابراین در عمل
257
00:12:52,600 –> 00:12:53,980
موارد زیادی وجود دارد که می توانید
258
00:12:53,980 –> 00:12:56,589
واقعاً از چندین رشته استفاده کنید و
259
00:12:56,589 –> 00:13:00,820
کارایی بهینه است، اما اگر
260
00:13:00,820 –> 00:13:04,329
به CPU محدود شده است، مشکل وجود دارد. ey
261
00:13:04,329 –> 00:13:08,250
راه حل زمین است و یکی از راه های آسان برای
262
00:13:08,250 –> 00:13:11,890
استفاده از تمام CPU شما ماژولی به نام
263
00:13:11,890 –> 00:13:16,899
پردازش چندگانه است که مسیر را
264
00:13:16,899 –> 00:13:19,680
برای ایجاد چندین کار در
265
00:13:19,680 –> 00:13:22,450
فرآیند تفاوت در تفاوت آسان تر می کند زیرا
266
00:13:22,450 –> 00:13:24,100
در هر فرآیند شما
267
00:13:24,100 –> 00:13:26,639
Aguila را دارید بنابراین به لطف آن شما قادر به
268
00:13:26,639 –> 00:13:30,009
توزیع بار کار بر روی تمام CPU خود هستید
269
00:13:30,009 –> 00:13:32,889
و دوباره کارایی زمانی است که من
270
00:13:32,889 –> 00:13:37,060
دهقان را میخوانم، بنابراین
271
00:13:37,060 –> 00:13:39,579
ماژول پردازش چندگانه محدودیت زیگی-زاگی را طی میکند
272
00:13:39,579 –> 00:13:42,610
و دو خبر بسیار خوب
273
00:13:42,610 –> 00:13:44,860
برای شما برای انتشار بعدی
274
00:13:44,860 –> 00:13:48,730
باتوم وجود دارد. حافظه مشترک اکنون
275
00:13:48,730 –> 00:13:51,220
پشتیبانی میشود و این بسیار مهم است
276
00:13:51,220 –> 00:13:54,329
زمانی که دادههای زیادی را
277
00:13:54,329 –> 00:13:57,209
بین پردازش اصلی و کارگر رد و بدل میکنید،
278
00:13:57,209 –> 00:13:59,440
زیرا اگر بهعنوان مثال یک
279
00:13:59,440 –> 00:14:02,440
آرایه اعداد بسیار بزرگ را به
280
00:14:02,440 –> 00:14:05,589
جای دو کپی، یک آرایه بزرگ بین
281
00:14:05,589 –> 00:14:08,350
هر فرآیند توضیح دهید، میتوانید فقط آن را در
282
00:14:08,350 –> 00:14:11,380
حافظه مشترک قرار دهید و همه فرآیندها
283
00:14:11,380 –> 00:14:15,279
بلافاصله آن را دریافت می کنند و همچنین یک
284
00:14:15,279 –> 00:14:18,639
بهینه سازی در پروتکل
285
00:14:18,639 –> 00:14:22,839
ترشی وجود دارد. pickle یک ماژول سریال سازی است که توسط
286
00:14:22,839 –> 00:14:25,480
پردازش چندگانه استفاده می شود. دادهها را
287
00:14:25,480 –> 00:14:29,920
در سرتاسر کارگر توزیع کنید و یک اصلاح
288
00:14:29,920 –> 00:14:32,380
در یک AIDS رایگان پایتون تطبیق داده شده است که
289
00:14:32,380 –> 00:14:36,910
از کپیهای حافظه جلوگیری میکند، بنابراین
290
00:14:36,910 –> 00:14:39,250
میتوانید آرایه خود را بردارید و آن را در
291
00:14:39,250 –> 00:14:41,740
سوکت بنویسید و نیازی به کپی
292
00:14:41,740 –> 00:14:45,459
کردن اشیاء ندارید زیرا قبلاً
293
00:14:45,459 –> 00:14:49,779
اوج استفاده از حافظه بسیار بالا فقط برای
294
00:14:49,779 –> 00:14:52,990
سریال سازی است و اکنون
295
00:14:52,990 –> 00:14:58,660
کارآمدتر گزینه دیگری برای بهینه سازی
296
00:14:58,660 –> 00:15:02,500
پایتون استفاده از seitan است و خوبی
297
00:15:02,500 –> 00:15:04,360
seitan این است که می توانید
298
00:15:04,360 –> 00:15:07,269
کدهای پایتون خود را بردارید و آن را
299
00:15:07,269 –> 00:15:10,630
با seitan کامپایلر کنید. فقط
300
00:15:10,630 –> 00:15:12,850
یک بار انجام می شود و بعد از
301
00:15:12,850 –> 00:15:14,800
آن کد کامپایل شده را برای شما توزیع می کنید،
302
00:15:14,800 –> 00:15:17,860
این یک کامپایلر JIT نیست و اگر این کار را انجام دهید
303
00:15:17,860 –> 00:15:19,930
کمی سریعتر است، اما
304
00:15:19,930 –> 00:15:23,139
اگر توضیحی در مورد
305
00:15:23,139 –> 00:15:25,810
نوع seitan اضافه کنید می تواند کدهای بسیار کارآمدی ایجاد کند
306
00:15:25,810 –> 00:15:29,380
زیرا می داند داخلی
307
00:15:29,380 –> 00:15:33,069
پایتون و می تواند به نوع آن تکیه کند تا
308
00:15:33,069 –> 00:15:35,620
از کارآمدترین راه برای اجرای
309
00:15:35,620 –> 00:15:37,059
کد شما استفاده کند
310
00:15:37,059 –> 00:15:40,029
و خوبی seitan این است که
311
00:15:40,029 –> 00:15:43,089
سیپا را برای شما شکار می کند تا شما
312
00:15:43,089 –> 00:15:45,399
نداشته باشید. برای مثال نگران
313
00:15:45,399 –> 00:15:47,439
نسخه پایتون، لازم نیست
314
00:15:47,439 –> 00:15:50,169
نگران شمارش ارجاع باشید که
315
00:15:50,169 –> 00:15:54,369
برای درست کردن آن مشکل است، مانند استفاده از یک
316
00:15:54,369 –> 00:15:56,709
تخصیص دهنده حافظه بهتر از این است که
317
00:15:56,709 –> 00:16:00,219
پایتون این کار را برای شما انجام دهد، بنابراین راه بسیار
318
00:16:00,219 –> 00:16:03,459
خوبی برای نوشتن پسوند c است. و من
319
00:16:03,459 –> 00:16:05,469
به شما پیشنهاد می کنم به
320
00:16:05,469 –> 00:16:10,329
جای استفاده مستقیم از C API برای استفاده از seitan بنویسید، اگر
321
00:16:10,329 –> 00:16:13,029
برنامه شما بیشتر از numpy استفاده
322
00:16:13,029 –> 00:16:16,479
می کند، گزینه های دیگری نیز دارید، به عنوان مثال
323
00:16:16,479 –> 00:16:20,669
شماره یک کامپایلر JIT است که
324
00:16:20,669 –> 00:16:23,709
تخصصی در عدم پرداخت است و
325
00:16:23,709 –> 00:16:26,979
زیرمجموعه ای از پایتون و شما را ترجمه می کند.
326
00:16:26,979 –> 00:16:29,649
کد سریع numpy در کد سریع به این معنی است که برای مثال
327
00:16:29,649 –> 00:16:33,279
میتوانید تابع خود را بگیرید
328
00:16:33,279 –> 00:16:36,249
و با گیل آزاد آن را اجرا کنید
329
00:16:36,249 –> 00:16:38,499
و به لطف آن میتوانید
330
00:16:38,499 –> 00:16:41,769
یک کار را در دو رشته مختلف توزیع کنید
331
00:16:41,769 –> 00:16:45,159
و آنها را
332
00:16:45,159 –> 00:16:47,739
به صورت موازی اجرا کنید. شماره من انجام آن را به سرعت انجام میدهم،
333
00:16:47,739 –> 00:16:52,749
واقعاً آسان است و نه تنها
334
00:16:52,749 –> 00:16:57,279
در مورد رشتهبندی، بلکه در مورد
335
00:16:57,279 –> 00:17:00,089
بردارسازی دادههای چندگانه با یک دستورالعمل است،
336
00:17:00,089 –> 00:17:03,339
بنابراین به این معنی است که شما در یک دستورالعمل واحد CPU
337
00:17:03,339 –> 00:17:05,769
میتوانید ضرب را اجرا کنید.
338
00:17:05,769 –> 00:17:08,740
کارهایی که وقتی کدی دارید که از اعداد زیاد استفاده می کند بسیار کارآمد است
339
00:17:08,740 –> 00:17:12,909
340
00:17:12,909 –> 00:17:15,059
به خصوص عدد ممیز شناور
341
00:17:15,059 –> 00:17:19,628
به عنوان مثال CPU از SSE ivx
342
00:17:19,628 –> 00:17:22,689
نسخه جدیدتر و Avex پشتیبانی می کند و وقتی
343
00:17:22,689 –> 00:17:25,509
این کار را انجام می دهید می توانید کد را به عنوان مثال تا حد ممکن افزایش دهید.
344
00:17:25,509 –> 00:17:29,320
یک زمان سریعتر و همچنین می
345
00:17:29,320 –> 00:17:31,799
توانید از شتاب شتاب GPU
346
00:17:31,799 –> 00:17:36,399
با استفاده از اعداد استفاده کنید، به این معنی که
347
00:17:36,399 –> 00:17:38,730
کد خود را که شبیه پایتون است،
348
00:17:38,730 –> 00:17:41,710
اجرا کنید و آن را روی GPU خود اجرا کنید، زیرا
349
00:17:41,710 –> 00:17:44,499
GPU واقعاً برای اجرای
350
00:17:44,499 –> 00:17:47,559
اعداد ممیز شناور بسیار سریع است و Nvidia CUDA را پشتیبانی می کند.
351
00:17:47,559 –> 00:17:48,580
352
00:17:48,580 –> 00:17:50,240
و همچنین یک
353
00:17:50,240 –> 00:17:57,440
راک راک رم و یکی از مسائلی که
354
00:17:57,440 –> 00:18:00,559
یکی دو سال پیش در پایتون
355
00:18:00,559 –> 00:18:04,429
داشتیم این بود که پیشنهادهای زیادی برای تغییرات بهینه سازی دریافت
356
00:18:04,429 –> 00:18:07,669
کردیم اما نتوانستیم
357
00:18:07,669 –> 00:18:11,360
تصمیم بگیریم که آیا این نوع تغییر
358
00:18:11,360 –> 00:18:14,120
باعث سریعتر یا کندتر شدن پایتون می شود.
359
00:18:14,120 –> 00:18:17,210
ما وقتی معیار را اجرا می کنیم،
360
00:18:17,210 –> 00:18:20,480
گاهی اوقات معیار کندتر است، اما اگر دوباره آن را اجرا
361
00:18:20,480 –> 00:18:21,110
کنید
362
00:18:21,110 –> 00:18:24,080
، سریعتر می گوید، بنابراین تصمیم گیری هوشمندانه واقعاً سخت است
363
00:18:24,080 –> 00:18:27,230
، بنابراین من برای کار بر روی بنچمارک Suites وقت می گذارم تا آن را انجام دهم.
364
00:18:27,230 –> 00:18:30,169
365
00:18:30,169 –> 00:18:33,590
بسیار پایدارتر است که بتوان
366
00:18:33,590 –> 00:18:36,440
نتایج را بازتولید کرد و به لطف آن
367
00:18:36,440 –> 00:18:38,510
اکنون سرعتی داریم که
368
00:18:38,510 –> 00:18:41,270
وب سایت های جنگنده و نه سازمانی در اینجا می توانید
369
00:18:41,270 –> 00:18:45,289
عملکرد ماژول اعشاری را برای
370
00:18:45,289 –> 00:18:48,799
سال ها مشاهده کنید و مخابرات یک معیار برای
371
00:18:48,799 –> 00:18:50,630
محاسبه تعداد زیادی اعداد است. با استفاده از
372
00:18:50,630 –> 00:18:52,970
ماژول اعشاری و خبر خوب این است
373
00:18:52,970 –> 00:18:55,779
که اگر پایین بیاید به این معنی است که
374
00:18:55,779 –> 00:18:59,960
بازگشت سریعتر و این
375
00:18:59,960 –> 00:19:02,809
برای ما بسیار مهم است که بتوانیم
376
00:19:02,809 –> 00:19:08,330
یک بهینه سازی برای
377
00:19:08,330 –> 00:19:11,179
خلاصه کردن pie-pie را بپذیریم یا رد کنیم، نیازی به تغییر کد ندارد.
378
00:19:11,179 –> 00:19:14,210
لطفاً مجدداً فقط
379
00:19:14,210 –> 00:19:16,760
کدهای خود را پایپینگ کنید زیرا اگر قادر به توزیع بار کاری در یک فرآیند متفاوت
380
00:19:16,760 –> 00:19:19,750
هستید، نیازی به تغییر
381
00:19:19,750 –> 00:19:22,970
مقیاس ماژول چند پردازشی
382
00:19:22,970 –> 00:19:26,570
با تعداد CPU
383
00:19:26,570 –> 00:19:28,130
384
00:19:28,130 –> 00:19:32,179
نیست، اما مشکل اینجاست که شما شما
385
00:19:32,179 –> 00:19:34,700
باید داده ها را سریالی کنید که ممکن است
386
00:19:34,700 –> 00:19:37,070
کمی گران باشد، اما اکنون ما
387
00:19:37,070 –> 00:19:39,830
حافظه مشترک و انتخابگر سریعتر داریم،
388
00:19:39,830 –> 00:19:42,380
باید از seitan استفاده کنید و مستقیماً از C API استفاده نکنید
389
00:19:42,380 –> 00:19:48,190
و شماره باعث سریعتر شدن numpy می شود،
390
00:19:48,190 –> 00:19:53,510
بنابراین بیایید به آینده حرکت کنیم.
391
00:19:53,510 –> 00:19:57,350
میخواهم به نقطهای برگردم که
392
00:19:57,350 –> 00:19:59,690
برای من بسیار مهم شد، یک
393
00:19:59,690 –> 00:20:03,559
API Python C است، زیرا همانطور که دیدیم
394
00:20:03,559 –> 00:20:05,899
CIPA با برنامه افزودنی مشکل زیادی ایجاد میکند،
395
00:20:05,899 –> 00:20:08,679
به خصوص در pi PI،
396
00:20:08,679 –> 00:20:11,450
فکر میکنم باید این مشکل را برطرف کنیم.
397
00:20:11,450 –> 00:20:16,610
پایتون را برای همه قابل استفاده کنید و برای
398
00:20:16,610 –> 00:20:18,830
توضیح این موضوع باید بدانید
399
00:20:18,830 –> 00:20:21,769
که در اوایل پیدایش پایتون،
400
00:20:21,769 –> 00:20:25,970
CIP من به صورت ارگانیک تکامل یافت، به
401
00:20:25,970 –> 00:20:28,549
این معنی که هیچ طراحی واضحی از آنچه که
402
00:20:28,549 –> 00:20:30,440
باید عمومی باشد، چه باید خصوصی باشد،
403
00:20:30,440 –> 00:20:32,620
چه باید در مودها نمایش داده شود وجود نداشت. و
404
00:20:32,620 –> 00:20:35,779
به همین دلیل ما به اشتباه بسیاری از عملکردهای داخلی را در معرض دید قرار دادیم
405
00:20:35,779 –> 00:20:38,779
زیرا
406
00:20:38,779 –> 00:20:41,659
طراحی اساساً به این صورت بود که پایتون از
407
00:20:41,659 –> 00:20:44,860
چندین فایل C ساخته شده است و فقط برای استفاده از یک تابع
408
00:20:44,860 –> 00:20:47,899
تعریف شده در یک فایل و فراخوانی آن در
409
00:20:47,899 –> 00:20:50,960
یک فایل دیگر باید به نحوی و برای راحتی آن را در معرض نمایش قرار دهید.
410
00:20:50,960 –> 00:20:56,539
411
00:20:56,539 –> 00:20:59,740
به راحتی میتوان همه چیز را در معرض دید قرار داد و
412
00:20:59,740 –> 00:21:03,049
در ابتدا از آن برای اولین بار
413
00:21:03,049 –> 00:21:06,169
در پایتون استفاده میشد، اما برخی افراد برای اینکه
414
00:21:06,169 –> 00:21:07,669
استفاده از آن در خارج از
415
00:21:07,669 –> 00:21:10,519
پایتون جالب باشد، بنابراین برخی از افراد شروع به
416
00:21:10,519 –> 00:21:13,369
نوشتن گستردهها کردند. یون با استفاده از نقاط و این
417
00:21:13,369 –> 00:21:16,570
نیز بخشی از موفقیت پایتون است
418
00:21:16,570 –> 00:21:21,169
زیرا از آنجایی که شما قادر به استفاده از تمام
419
00:21:21,169 –> 00:21:24,139
کدهای C موجود هستید، قرار دادن
420
00:21:24,139 –> 00:21:26,389
مبارزه در بالای آن بسیار آسان است و باعث می شود که بایت
421
00:21:26,389 –> 00:21:29,210
و به عنوان مثال
422
00:21:29,210 –> 00:21:33,679
دنیای علمی با یک داور بسیار موفق باشد. اما
423
00:21:33,679 –> 00:21:37,190
به دلیل طراحی اولیه C
424
00:21:37,190 –> 00:21:41,149
API، ما جزئیات پیاده سازی بسیار زیادی را در معرض دید قرار می دهیم،
425
00:21:41,149 –> 00:21:44,659
اما قبل از پرداختن
426
00:21:44,659 –> 00:21:48,289
به جزئیات، اولین خبر خوب این است
427
00:21:48,289 –> 00:21:51,499
که وضعیت در پایتون 3 بهتر شد،
428
00:21:51,499 –> 00:21:53,690
یعنی نسخه 8 که نسخه بعدی
429
00:21:53,690 –> 00:21:57,200
پایتون است، بنابراین برای توضیح شما
430
00:21:57,200 –> 00:21:59,830
قبلاً همه فایلهایمان را در یک فهرست داشتیم،
431
00:21:59,830 –> 00:22:03,769
به این معنی که اگر میخواهید
432
00:22:03,769 –> 00:22:06,369
تابع را از API عمومی C مخفی
433
00:22:06,369 –> 00:22:09,799
کنید، باید با استفاده از بلوک if death از آن انصراف دهید
434
00:22:09,799 –> 00:22:11,750
تا بگویید اوه این بخش
435
00:22:11,750 –> 00:22:14,690
خصوصی است، از آن استفاده نکنید. و ما
436
00:22:14,690 –> 00:22:17,210
چیزی به نام stable ABI
437
00:22:17,210 –> 00:22:20,090
stable API داریم اما برای اعلام توابع
438
00:22:20,090 –> 00:22:22,520
که بخشی از این API نیستند دوباره
439
00:22:22,520 –> 00:22:25,090
باید با استفاده از if dev انصراف دهید و
440
00:22:25,090 –> 00:22:27,980
به دلیل طراحی if deaf گاهی اوقات
441
00:22:27,980 –> 00:22:31,159
ما توابعی را با اشتباه اضافه می کنیم. ke به
442
00:22:31,159 –> 00:22:35,000
API پایدار یا اشتباهاً تابع خصوصی را اضافه کردیم،
443
00:22:35,000 –> 00:22:38,750
بنابراین راه حل برای آن
444
00:22:38,750 –> 00:22:42,049
کار با X شروع شده بود ایجاد یک
445
00:22:42,049 –> 00:22:44,990
زیر شاخه است و من این کار را
446
00:22:44,990 –> 00:22:49,730
در کمکهای رایگان پایتون ادامه میدهم تا C Python
447
00:22:49,730 –> 00:22:53,630
را برای API مخصوص C Python داشته باشم و
448
00:22:53,630 –> 00:22:55,760
داخلی API است که
449
00:22:55,760 –> 00:22:59,539
نباید از آن استفاده کنید، اما ما تصمیم گرفتیم به
450
00:22:59,539 –> 00:23:02,600
هر حال آن را افشا کنیم زیرا برای موارد استفاده بسیار
451
00:23:02,600 –> 00:23:05,210
خاص مانند خشونت اپرا گدا
452
00:23:05,210 –> 00:23:07,370
ممکن است بخواهید به قسمت های داخلی C Python
453
00:23:07,370 –> 00:23:10,700
دسترسی داشته باشید و برای دسترسی به داخل
454
00:23:10,700 –> 00:23:13,789
گاهی اوقات نمی توانید کدهایی را اجرا کنید که
455
00:23:13,789 –> 00:23:15,890
نمی توانید تماس بگیرید. عملکرد زمانی که شما
456
00:23:15,890 –> 00:23:19,250
داخلی پایتون را بررسی می کنید، بنابراین ما باید
457
00:23:19,250 –> 00:23:22,429
تمام این ساختارها را در معرض نمایش قرار دهیم و اکنون
458
00:23:22,429 –> 00:23:25,190
دایرکتوری include فقط چیزی است که من
459
00:23:25,190 –> 00:23:28,789
آن را پایدار C API stable می نامم به این معنی که
460
00:23:28,789 –> 00:23:31,370
شما باید بتوانید از همان API
461
00:23:31,370 –> 00:23:35,570
و چندین نسخه پایتون استفاده کنید و در طول
462
00:23:35,570 –> 00:23:38,630
در این پیاده روی ما موفق شدیم بسیاری از
463
00:23:38,630 –> 00:23:41,000
توابع خصوصی را از
464
00:23:41,000 –> 00:23:43,640
هدرهای عمومی به هدر داخلی منتقل کنیم و
465
00:23:43,640 –> 00:23:46,039
همچنین شروع به انتقال ساختاری مانند حالت های
466
00:23:46,039 –> 00: