در این مطلب، ویدئو TF IDF | مثال پایتون TFIDF با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:08:54
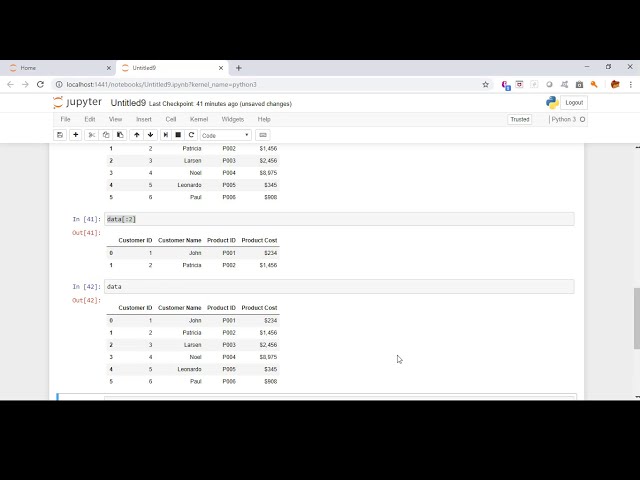
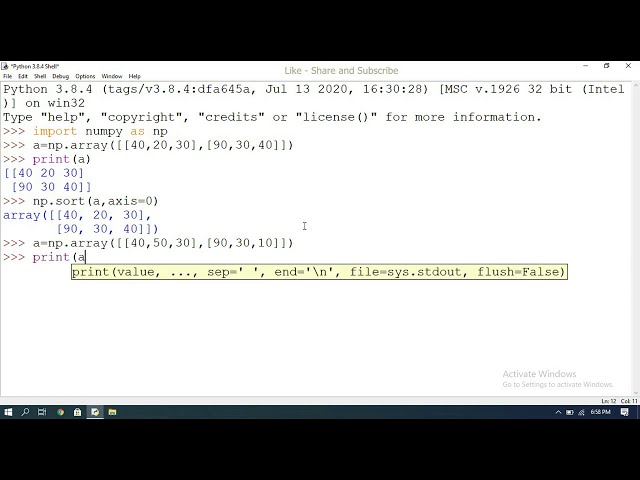
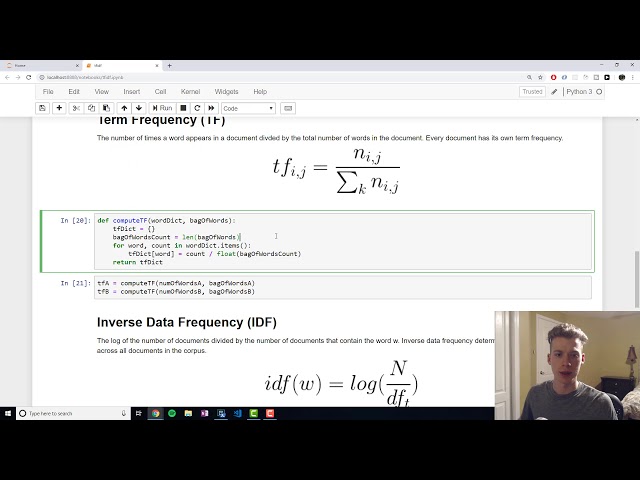
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:01,979
در این ویدیو ما نگاهی به
2
00:00:01,979 –> 00:00:06,569
فرکانس معکوس داده فرکانس tf-idf یا اصطلاح فرکانس معکوس خواهیم داشت
3
00:00:06,569 –> 00:00:09,690
تا به شما دوستان کمی
4
00:00:09,690 –> 00:00:13,170
زمینه زمینه
5
00:00:13,170 –> 00:00:15,920
6
00:00:15,920 –> 00:00:18,990
7
00:00:18,990 –> 00:00:21,300
8
00:00:21,300 –> 00:00:25,470
را ارائه دهیم. در
9
00:00:25,470 –> 00:00:28,590
یادگیری ماشینی شرکتها را وادار کردهاند که
10
00:00:28,590 –> 00:00:31,679
کارهایی مانند
11
00:00:31,679 –> 00:00:36,140
رباتهای چت ترجمه و فیلتر کردن نامزدها را دنبال کنند و
12
00:00:36,140 –> 00:00:40,739
کاری که معمولاً انجام میدهید این است که از
13
00:00:40,739 –> 00:00:46,079
کلاسی مانند بردار tf-idf از
14
00:00:46,079 –> 00:00:49,680
کتابخانه یادگیری sk برای آماده
15
00:00:49,680 –> 00:00:51,899
کردن دادههای خود استفاده میکنید و بنابراین ما در این ویدیو مثالی را مرور خواهم کرد،
16
00:00:51,899 –> 00:00:55,860
بنابراین برای شروع
17
00:00:55,860 –> 00:01:00,690
، فقط این را اجرا میکنم، از دو سند ساده استفاده میکنیم که
18
00:01:00,690 –> 00:01:04,319
هر کدام شامل یک
19
00:01:04,319 –> 00:01:06,510
جمله واحد است، بنابراین اولین مورد این است که
20
00:01:06,510 –> 00:01:09,270
مرد بیرون رفته برای پیادهروی
21
00:01:09,270 –> 00:01:11,700
و دومی یکی از آنها بچههایی است که
22
00:01:11,700 –> 00:01:18,360
دور آتش نشستهاند، بنابراین بهطور پیشفرض، اکثر
23
00:01:18,360 –> 00:01:21,210
مدلهای یادگیری ماشینی نمیتوانند مستقیماً با
24
00:01:21,210 –> 00:01:27,960
متن خام سروکار داشته باشند، بنابراین برای ارسال آن
25
00:01:27,960 –> 00:01:30,450
به مدل خود، باید دادههای خود را برداری کنیم، به
26
00:01:30,450 –> 00:01:34,850
این معنی که ما اساساً
27
00:01:35,600 –> 00:01:39,750
28
00:01:39,750 –> 00:01:41,280
راههای مختلفی برای انجام این کار وجود دارد،
29
00:01:41,280 –> 00:01:43,680
اما متداولترین راه استفاده
30
00:01:43,680 –> 00:01:47,240
از رویکرد کیسهای از کلمات است و اساساً
31
00:01:47,240 –> 00:01:51,659
کاری که ما انجام میدهیم این است که جملات
32
00:01:51,659 –> 00:01:55,729
یا متن خود را به کلمات جداگانه تقسیم
33
00:01:55,729 –> 00:01:59,130
میکنیم و دلیل اینکه چرا تماس میگیریم این مدل یک کیسه کلمات به
34
00:01:59,130 –> 00:02:03,750
این دلیل است که شما اطلاعات
35
00:02:03,750 –> 00:02:07,320
مربوط به ساختار متن را از دست می دهید و بنابراین
36
00:02:07,320 –> 00:02:09,360
در پایان آن
37
00:02:09,360 –> 00:02:13,740
نمی دانم که آیا می توانم به شما بچه ها نشان دهم یا نه،
38
00:02:13,740 –> 00:02:17,730
بنابراین در پایان آن فقط
39
00:02:17,730 –> 00:02:22,470
با یک لیست مواجه می شوید. اما شما
40
00:02:22,470 –> 00:02:24,930
نظم و ترتیب را از دست می دهید و بنابراین معنای
41
00:02:24,930 –> 00:02:30,090
معنایی جمله از بین می رود، بنابراین اساساً
42
00:02:30,090 –> 00:02:35,340
جملات را با استفاده از یک فاصله به
43
00:02:35,340 –> 00:02:41,160
عنوان جداکننده تقسیم کردم و سپس آن را
44
00:02:41,160 –> 00:02:43,920
در مجموعه ای ریختم تا همه کلمات منحصر به فرد را به دست بیاورم
45
00:02:43,920 –> 00:02:47,400
و سپس ما می
46
00:02:47,400 –> 00:02:49,950
خواهیم انجام دهیم این است که یک فرهنگ لغت
47
00:02:49,950 –> 00:02:56,130
برای دو سند خود ایجاد می کنیم و نشان می دهد که
48
00:02:56,130 –> 00:02:59,370
هر کلمه منحصر به فرد چند بار
49
00:02:59,370 –> 00:03:03,420
در سند وجود دارد، به عنوان مثال و
50
00:03:03,420 –> 00:03:06,330
اولین سند ما کلمه for یک بار
51
00:03:06,330 –> 00:03:11,459
و سپس دوباره در سند وجود دارد. سند اول
52
00:03:11,459 –> 00:03:13,680
کلمه یک بار رخ می دهد d در سند دوم
53
00:03:13,680 –> 00:03:17,880
دو بار اتفاق میافتد، بنابراین
54
00:03:17,880 –> 00:03:19,950
چیز دیگری که معمولاً در پردازش زبان طبیعی مشاهده میکنید این است که
55
00:03:19,950 –> 00:03:25,140
56
00:03:25,140 –> 00:03:29,640
فهرست کلمات خود را با استفاده از کلمات توقف فیلتر میکند
57
00:03:29,640 –> 00:03:33,030
و به شما بچهها کمی زمینه میدهد
58
00:03:33,030 –> 00:03:36,000
تا متداولترین کلمه در
59
00:03:36,000 –> 00:03:38,850
زبان انگلیسی باشد. این است که در واقع
60
00:03:38,850 –> 00:03:41,940
نشان دهنده 7٪ از کل کلماتی است که
61
00:03:41,940 –> 00:03:45,330
نوشته شده یا گفته می شود، اما کلمه
62
00:03:45,330 –> 00:03:48,810
هیچ معنای معنایی به متن
63
00:03:48,810 –> 00:03:51,690
اضافه نمی کند، مانند اینکه هیچ اطلاعاتی اضافه نمی کند، به
64
00:03:51,690 –> 00:03:55,019
عنوان مثال چیزهایی مانند کلمات خوب و عالی
65
00:03:55,019 –> 00:03:58,380
که ممکن است به شما بگوید که آیا
66
00:03:58,380 –> 00:04:02,250
رتبهبندی مثبت است یا خیر، اما کلمه
67
00:04:02,250 –> 00:04:05,130
پس از آن واقعاً هیچ اطلاعاتی را ارائه نمیکند
68
00:04:05,130 –> 00:04:08,810
که در
69
00:04:08,810 –> 00:04:12,330
هنگام کار با پایتون
70
00:04:12,330 –> 00:04:14,820
71
00:04:14,820 –> 00:04:17,130
72
00:04:17,130 –> 00:04:18,560
73
00:04:18,560 –