

در این مطلب، ویدئو آموزش پایتون پانداها (قسمت 3): ایندکس ها – نحوه تنظیم، بازنشانی و استفاده از ایندکس ها با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:26
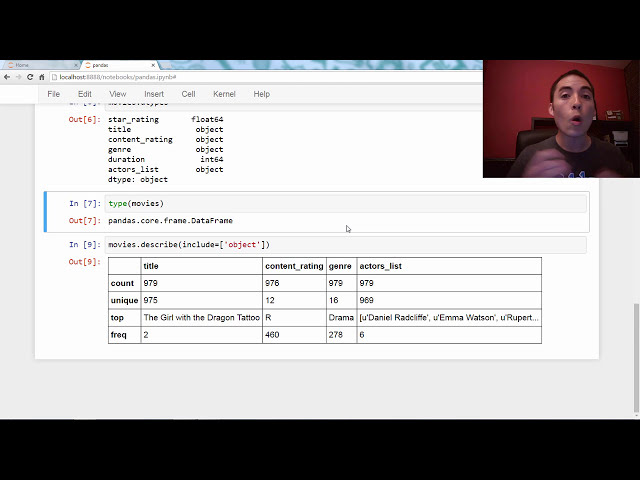
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:01,380
سلام، همه چیز چطور پیش می رود در
2
00:00:01,380 –> 00:00:02,850
این ویدیو، ما در
3
00:00:02,850 –> 00:00:05,520
مورد نمایه ها بیشتر یاد می گیریم، بنابراین
4
00:00:05,520 –> 00:00:08,039
نمایه های پیش فرض اولیه و ویدیوهای قبلی را دیده ایم، اما
5
00:00:08,039 –> 00:00:09,780
در این ویدیو نحوه تنظیم
6
00:00:09,780 –> 00:00:12,389
نمایه های سفارشی و مزایای انجام این کار را
7
00:00:12,389 –> 00:00:14,250
در حال حاضر می آموزیم. همچنین میخواهم اشاره کنم
8
00:00:14,250 –> 00:00:15,839
که ما یک حامی برای این سری از
9
00:00:15,839 –> 00:00:18,270
ویدیوها داریم و آن سازمانی درخشان است، بنابراین من
10
00:00:18,270 –> 00:00:19,619
واقعاً میخواهم از برلیان برای
11
00:00:19,619 –> 00:00:21,210
حمایت مالی از این مجموعه تشکر کنم و
12
00:00:21,210 –> 00:00:22,260
اگر همه بتوانید آنها را
13
00:00:22,260 –> 00:00:23,609
با استفاده از پیوند در بررسی کنید عالی خواهد بود. بخش توضیحات
14
00:00:23,609 –> 00:00:25,320
زیر و حمایت از حامیان مالی
15
00:00:25,320 –> 00:00:26,789
و من فقط در مدت کوتاهی در مورد خدمات آنها بیشتر صحبت خواهم کرد،
16
00:00:26,789 –> 00:00:29,189
بنابراین با این گفته بیایید
17
00:00:29,189 –> 00:00:31,410
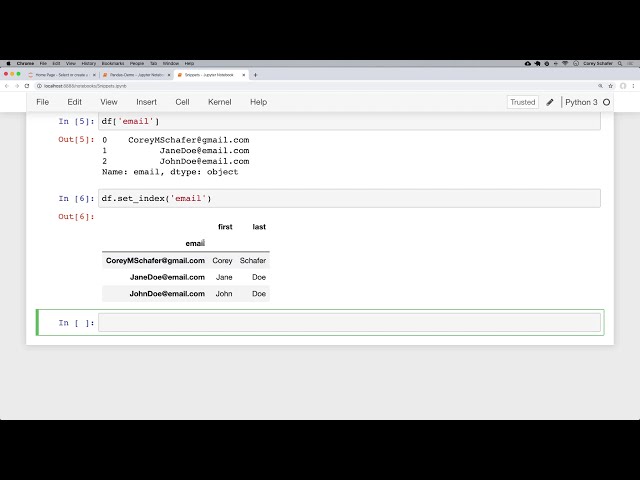
ادامه دهیم و شروع کنیم خوب است، بنابراین
18
00:00:31,410 –> 00:00:33,809
من فایل snippets خود را اینجا باز کنم یا دفترچه Snippets خود را
19
00:00:33,809 –> 00:00:35,340
اینجا باز کنم تا بتوانیم به
20
00:00:35,340 –> 00:00:37,890
نمایهها با استفاده از یک قاب داده ساده
21
00:00:37,890 –> 00:00:40,050
با کمی داده نگاه کنید و سپس خواهیم
22
00:00:40,050 –> 00:00:41,670
دید که چگونه از آنها با
23
00:00:41,670 –> 00:00:43,860
مجموعه دادههای نظرسنجی بزرگتر خود که تا
24
00:00:43,860 –> 00:00:45,930
کنون در این سری استفاده کردهایم استفاده کنیم، بنابراین در این قطعهها
25
00:00:45,930 –> 00:00:48,450
همان کوچک را داریم. چارچوب داده ای که در
26
00:00:48,450 –> 00:00:50,489
آن دیدیم آخرین ویدئو که در آن ما
27
00:00:50,489 –> 00:00:52,289
فقط سه نفر را با
28
00:00:52,289 –> 00:00:54,989
نام خانوادگی و آدرس ایمیل خود داریم و من
29
00:00:54,989 –> 00:00:57,780
این قاب داده را اینجا
30
00:00:57,780 –> 00:01:00,480
در پایین سمت راست اینجا نمایش داده ام، بنابراین همانطور که در
31
00:01:00,480 –> 00:01:02,609
ویدیوهای قبلی گفتم فریم های داده ما
32
00:01:02,609 –> 00:01:05,040
این مورد را در سمت چپ دارند. در اینجا
33
00:01:05,040 –> 00:01:07,590
که مانند یک ستون بدون نام به نظر می رسد
34
00:01:07,590 –> 00:01:12,030
و این یک شاخص است، بنابراین از آنجایی که ما به
35
00:01:12,030 –> 00:01:14,040
تازگی این شاخص های پیش فرض و تنظیم شده را دیده ایم، در
36
00:01:14,040 –> 00:01:16,500
حال حاضر فقط محدوده ای از
37
00:01:16,500 –> 00:01:18,780
اعداد است که اساساً یک شناسه عدد صحیح
38
00:01:18,780 –> 00:01:22,140
برای ردیف ها است، بنابراین این یک 0 a است.
39
00:01:22,140 –> 00:01:25,020
1 و 2 در حال حاضر گاهی اوقات ممکن است
40
00:01:25,020 –> 00:01:26,909
منطقی تر باشد که برای هر ردیف یک شناسه متفاوت داشته باشیم
41
00:01:26,909 –> 00:01:29,400
و این
42
00:01:29,400 –> 00:01:31,799
اساساً برچسب آن ردیف خواهد بود،
43
00:01:31,799 –> 00:01:34,259
بنابراین معمولاً منحصر به فرد است اکنون پانداها
44
00:01:34,259 –> 00:01:36,329
واقعاً منحصر به فرد بودن ایندکس ها را اعمال نمی کنند
45
00:01:36,329 –> 00:01:38,610
و گاهی اوقات چنین نمی شود. باشد اما
46
00:01:38,610 –> 00:01:40,950
بیشتر اوقات این مقادیر منحصر به فرد خواهند بود، بنابراین
47
00:01:40,950 –> 00:01:42,840
چه چیزی ممکن است شاخص بهتری برای
48
00:01:42,840 –> 00:01:43,860
داده های نمونه ما در اینجا
49
00:01:43,860 –> 00:01:45,840
باشد، شاید آدرس ایمیل
50
00:01:45,840 –> 00:01:48,570
شاخص خوبی برای این داده ها باشد، زیرا
51
00:01:48,570 –> 00:01:50,909
معمولاً برای اکثر افراد یک مقدار منحصر به فرد است.
52
00:01:50,909 –> 00:01:53,880
در حال حاضر اگر میخواستم
53
00:01:53,880 –> 00:01:57,000
همه آدرسهای ایمیل را ببینم، میتوانیم بگوییم DF
54
00:01:57,000 –> 00:02:00,990
و به ستون ایمیل دسترسی پیدا کنیم و
55
00:02:00,990 –> 00:02:02,909
این را در آخرین ویدیو دیدیم، اما میتوانیم ببینیم
56
00:02:02,909 –> 00:02:04,950
که اکنون همه این آدرسهای ایمیل را نمایش میدهد
57
00:02:04,950 –> 00:02:07,560
چه میشود اگر بخواهیم
58
00:02:07,560 –> 00:02:10,020
اینها را تنظیم کنیم. آدرس های ایمیل به عنوان شاخص برای
59
00:02:10,020 –> 00:02:12,480
این قاب داده به خوبی انجام می شود که ما
60
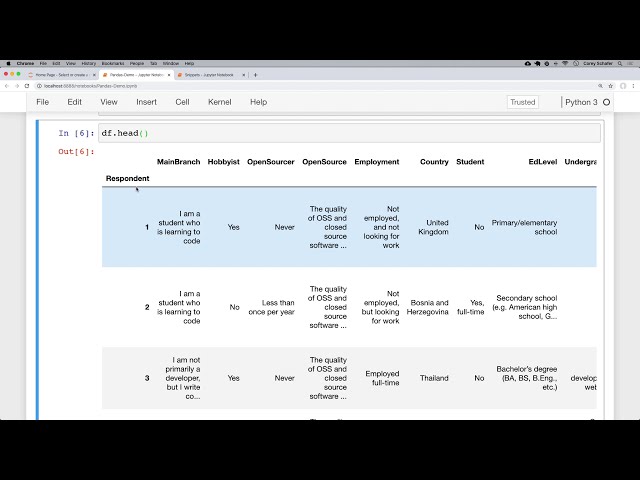
00:02:12,480 –> 00:02:13,650
فقط می توانیم بگوییم DF
61
00:02:13,650 –> 00:02:17,640
dot set underscore index و سپس فقط می توانیم
62
00:02:17,640 –> 00:02:20,069
نام ستونی را که
63
00:02:20,069 –> 00:02:22,650
برای ایندکس می خواهیم ارسال کنیم، بنابراین اگر این را اجرا کنم،
64
00:02:22,650 –> 00:02:25,230
اکنون می توانیم ببینیم که ایمیل
65
00:02:25,230 –> 00:02:27,599
در سمت چپ است و پررنگ است و
66
00:02:27,599 –> 00:02:29,700
در واقع به نوعی شبیه یک ستون معمولی به نظر
67
00:02:29,700 –> 00:02:32,760
می رسد زیرا این فهرست دارای نامی
68
00:02:32,760 –> 00:02:35,400
است که وقتی آن را تنظیم می کنیم همان نام ستون ما است
69
00:02:35,400 –> 00:02:37,620
، بنابراین می خواهم چیزی را در اینجا به شما نشان دهم
70
00:02:37,620 –> 00:02:40,769
که می توانیم فقط این شاخص را در این
71
00:02:40,769 –> 00:02:43,680
سلول تنظیم کنید، اما اگر دوباره به قاب داده خود نگاه کنم، در
72
00:02:43,680 –> 00:02:47,519
زیر اینجا اگر بگویم DF برای
73
00:02:47,519 –> 00:02:49,500
چاپ این قاب داده، می
74
00:02:49,500 –> 00:02:50,879
بینیم که فریم داده ما در واقع
75
00:02:50,879 –> 00:02:53,459
تغییر نکرده است، هنوز هم ایندکس پیش فرض
76
00:02:53,459 –> 00:02:56,310
در اینجا وجود دارد. در سمت چپ و این به این دلیل است که
77
00:02:56,310 –> 00:02:59,220
پانداها کار زیادی انجام نمی دهند این تغییرات
78
00:02:59,220 –> 00:03:02,159
در جای خود هستند مگر اینکه ما به طور خاص به او بگوییم که این
79
00:03:02,159 –> 00:03:04,290
کار را انجام دهد و این در واقع خوب است
80
00:03:04,290 –> 00:03:06,269
زیرا به ما امکان می دهد
81
00:03:06,269 –> 00:03:08,250
بدون نگرانی در مورد تغییر
82
00:03:08,250 –> 00:03:09,870
چارچوب داده خود به روش های غیرمنتظره آزمایش
83
00:03:09,870 –> 00:03:12,569
کنیم، بنابراین بیایید بگوییم که ما واقعاً می خواستیم
84
00:03:12,569 –> 00:03:14,879
ایندکس خود را روی ستون ایمیل تنظیم کنیم. و آیا
85
00:03:14,879 –> 00:03:16,859
این تغییرات به
86
00:03:16,859 –> 00:03:19,829
سلولهای آینده منتقل میشوند، بنابراین برای انجام این کار پشتیبانگیری در اینجا،
87
00:03:19,829 –> 00:03:22,739
جایی که گفتیم فهرست را تنظیم کنید، میتوانیم
88
00:03:22,739 –> 00:03:24,810
آرگومان دیگری را در اینجا اضافه کنیم و بگوییم
89
00:03:24,810 –> 00:03:28,889
اگر آن را اجرا کنم و سپس قاب داده را دوباره اجرا کنم، در محل برابر با true است در اینجا
90
00:03:28,889 –> 00:03:34,169
سپس
91
00:03:34,169 –> 00:03:36,480
اکنون میتوانیم ببینیم که واقعاً مرده
92
00:03:36,480 –> 00:03:39,510
آن ایندکس را تنظیم کرده و آن قاب داده را اصلاح کرده
93
00:03:39,510 –> 00:03:41,479
است و ما میتوانیم به
94
00:03:41,479 –> 00:03:44,280
طور خاص فقط با
95
00:03:44,280 –> 00:03:47,879
گفتن شاخص نقطهای DF به آن شاخص نگاه کنیم و اگر آن را اجرا کنم،
96
00:03:47,879 –> 00:03:50,400
میتوانیم ببینیم که یک شاخص
97
00:03:50,400 –> 00:03:53,879
در اینجا داریم و آن را مقادیر را به عنوان لیستی
98
00:03:53,879 –> 00:03:56,190
از همه مقادیر ایندکس دارد و
99
00:03:56,190 –> 00:03:57,989
همچنین به ما می گوید که نام برابر با
100
00:03:57,989 –> 00:04:01,049
ایمیل است، خوب است، بنابراین چرا این واقعاً
101
00:04:01,049 –> 00:04:04,139
مفید است همانطور که قبل از آدرس ایمیل گفتم
102
00:04:04,139 –> 00:04:06,900
زیرا ایندکس یک واحد خوب به ما می دهد.
103
00:04:06,900 –> 00:04:09,299
شناسه que برای ردیف خود و
104
00:04:09,299 –> 00:04:11,760
به یاد داشته باشید که در ویدیوی قبلی
105
00:04:11,760 –> 00:04:14,549
از نقطه لوک برای جستجوی فریم به برچسب داده های خود استفاده کردیم،
106
00:04:14,549 –> 00:04:17,639
خوب این فهرست ها
107
00:04:17,639 –> 00:04:20,760
برچسب های این ردیف ها هستند، بنابراین قبل از اینکه فقط
108
00:04:20,760 –> 00:04:23,610
از شاخص محدوده پیش فرض استفاده کنیم اما اکنون
109
00:04:23,610 –> 00:04:27,150
می توانیم یک ردیف خاص را با استفاده از عبور دادن
110
00:04:27,150 –> 00:04:30,120
آن برچسب بنابراین اگر بگویم D F dot Lok این
111
00:04:30,120 –> 00:04:31,770
کار آسان تر خواهد بود اگر در اینجا فقط به
112
00:04:31,770 –> 00:04:34,760
یک مثال نگاه کنیم اگر
113
00:04:34,760 –> 00:04:38,880
قبل از اینکه صفر را به عنوان برچسب عبور می دادیم بگویم D F dot Lok
114
00:04:38,880 –> 00:04:42,330
اما اکنون می توانم بگویم خوب می خواهم
115
00:04:42,330 –> 00:04:45,210
ببینم اطلاعاتی برای Cory M Schafer
116
00:04:45,210 –> 00:04:47,970
در gmail.com و سپس باز میگردد
117
00:04:47,970 –> 00:04:50,970
و میگوید خوب است که آن شخص
118
00:04:50,970 –> 00:04:52,590
نام خانوادگی Cory Schaefer و
119
00:04:52,590 –> 00:04:55,080
غیره دارد، بنابراین اکنون ردیف مربوط به آن
120
00:04:55,080 –> 00:04:58,020
فهرست ایمیل خاص را دریافت میکنیم و مانند آنچه در آن دیدیم.
121
00:04:58,020 –> 00:05:00,120
آخرین ویدیو را همچنان میتوانیم در
122
00:05:00,120 –> 00:05:02,699
مقادیر برای ستونهای خاص ارسال
123
00:05:02,699 –> 00:05:05,910
کنیم، بنابراین اگر نام خانوادگی را میخواستیم،
124
00:05:05,910 –> 00:05:08,070
میتوانم آن را به عنوان مقدار دوم ارسال
125
00:05:08,070 –> 00:05:09,840
کنم، بنابراین فقط میگویم
126
00:05:09,840 –> 00:05:12,240
نام خانوادگی را میخواهم و میتوانیم آن را ببینیم
127
00:05:12,240 –> 00:05:14,669
ما اکنون شفر را دریافت می کنیم، در واقع دیگر
128
00:05:14,669 –> 00:05:16,860
آن اطلاعات پیش فرض را نداریم gers به عنوان ایندکس ما است، زی
129
00:05:16,860 –> 00:05:19,350
ا اکنون از ایمیل استفاده می کند، بنابراین اگر من سع
130
00:05:19,350 –> 00:05:21,479
کنم از آن اعداد صحیحی که قبلا استفاده می کردیم اس
131
00:05:21,479 –> 00:05:24,510
فاده کنم، بنابراین اگر بگویم اگر Rho صفر را با
132
00:05:24,510 –> 00:05:27,479
ستفاده از Lok می خواهم، یک خط
133
00:05:27,479 –> 00:05:30,090
ی نوع دریافت می کنیم و یک خطا دریافت می کنم زیرا اگر
134
00:05:30,090 –> 00:05:32,639
135
00:05:32,639 –> 00:05:35,280
میخواهید به جای برچسبها از مکان عدد صحیح استفاده کنید، دیگر نمایهای با آن برچسب ندارد،
136
00:05:35,280 –> 00:05:37,950
پس هنوز هم نمایه نگاه کردن به چشم
137
00:05:37,950 –> 00:05:40,530
در دسترس شما است و
138
00:05:40,530 –> 00:05:42,870
در آخرین ویدیو نیز شاهد بودیم، بنابراین اگر
139
00:05:42,870 –> 00:05:45,060
این را به چشم Lok تغییر دهم. به جای
140
00:05:45,060 –> 00:05:47,639
Lok، آن سطر اول را به ما
141
00:05:47,639 –> 00:05:49,800
می دهد تا اگر به
142
00:05:49,800 –> 00:05:51,690
طور تصادفی شاخص را تنظیم کنید و بخواهید
143
00:05:51,690 –> 00:05:53,729
آن را بازنشانی کنید، همچنان کار می کند، ما می توانیم این کار را با
144
00:05:53,729 –> 00:05:57,389
روش فهرست تنظیم مجدد انجام دهیم، بنابراین در اینجا من
145
00:05:57,389 –> 00:06:01,500
فقط می گویم D F dot reset underscore index
146
00:06:01,500 –> 00:06:04,860
و من یک in-place برابر با true
147
00:06:04,860 –> 00:06:06,720
انجام می دهم تا این تغییرات ادامه یابد و
148
00:06:06,720 –> 00:06:08,190
سپس من ادامه می دهم و آن فریم داده را چاپ می کنم،
149
00:06:08,190 –> 00:06:10,320
بنابراین اگر این را اجرا کنم، می توانیم
150
00:06:10,320 –> 00:06:11,729
ببینیم که اکنون به آن ایمیل بازگشته ایم.
151
00:06:11,729 –> 00:06:15,300
به عنوان یک ستون و شاخص محدوده پیشفرض
152
00:06:15,300 –> 00:06:17,880
حالا اگر واقعاً
153
00:06:17,880 –> 00:06:19,410
میدانید inde چیست x زمانی که
154
00:06:19,410 –> 00:06:21,510
قاب داده خود را ایجاد می کنید، می توانید
155
00:06:21,510 –> 00:06:23,639
به سادگی آن را به جای
156
00:06:23,639 –> 00:06:26,310
تنظیم بعداً با استفاده از روش شاخص تنظیم، در آنجا تنظیم کنید و
157
00:06:26,310 –> 00:06:29,520
ما می توانیم این کار را انجام دهیم زیرا در حال بارگیری داده ها
158
00:06:29,520 –> 00:06:32,580
از یک CSV یا منبع دیگری هستیم، بنابراین
159
00:06:32,580 –> 00:06:35,729
اجازه دهید من
160
00:06:35,729 –> 00:06:38,490
اینجا با دادههای سرریز پشتهای که
161
00:06:38,490 –> 00:06:39,930
تا کنون در این سری از آنها استفاده کردهایم، به نوتبوک
162
00:06:39,930 –> 00:06:40,980
163
00:06:40,980 –> 00:06:42,090
دیگرمان میروم و نگاهی به
164
00:06:42,090 –> 00:06:45,360
نمونههای واقعی میاندازیم که چرا استفاده از ایندکسها
165
00:06:45,360 –> 00:06:47,010
اکنون برای کسانی از شما مفید است.
166
00:06:47,010 –> 00:06:49,170
این سریال را تا
167
00:06:49,170 –> 00:06:52,560
کنون دنبال کردهاید، باید برای شما آشنا به نظر برسد، اما
168
00:06:52,560 –> 00:06:54,090
اگر دنبال نکردهاید و
169
00:06:54,090 –> 00:06:56,630
این اولین ویدیویی است که تماشا کردهاید، من
170
00:06:56,630 –> 00:06:59,820
در اینجا مروری مختصر از
171
00:06:59,820 –> 00:07:02,280
آنچه در پانداها میگذرد داریم، اینجا هستیم.
172
00:07:02,280 –> 00:07:05,130
در اینجا نیز در برخی از فایلهای CSV بارگیری میشود
173
00:07:05,130 –> 00:07:06,420
و من پیوندی در بخش توضیحات
174
00:07:06,420 –> 00:07:09,200
زیر به دادههایی که
175
00:07:09,200 –> 00:07:12,630
برای این فایلهای CSV استفاده میکنیم، دارم و سپس
176
00:07:12,630 –> 00:07:14,850
برخی از گزینهها را در اینجا در pandas تنظیم میکنیم
177
00:07:14,850 –> 00:07:16,830
تا حداکثر ستونها را تا جایی که میتوانیم
178
00:07:16,830 –> 00:07:18,870
ببینیم نمایش دهیم. تمام ستون ها و ردیف های حداکثر تا
179
00:07:18,870 –> 00:07:21,210
جایی که w e می تواند تعداد زیادی از این ردیف ها را ببیند و
180
00:07:21,210 –> 00:07:23,970
سپس این همان چیزی است که قاب داده ما به نظر می
181
00:07:23,970 –> 00:07:25,980
رسد این فقط نتایج نظرسنجی از
182
00:07:25,980 –> 00:07:26,880
Stack Overflow
183
00:07:26,880 –> 00:07:29,910
هستند تا کنون اگر به قاب داده خود در
184
00:07:29,910 –> 00:07:32,340
اینجا در این سری نگاه کنیم تا کنون
185
00:07:32,340 –> 00:07:36,510
از این شاخص پیش فرض استفاده کرده ایم. و میتوانیم
186
00:07:36,510 –> 00:07:38,310
اینجا را نگاه کنیم و ببینیم که اکنون فقط این
187
00:07:38,310 –> 00:07:41,370
محدوده از صفر یک دو و سه است، اگر
188
00:07:41,370 –> 00:07:44,280
به دادههای پاسخ نظرسنجی نگاه کنیم،
189
00:07:44,280 –> 00:07:46,020
به نظر میرسد که آنها در واقع یک
190
00:07:46,020 –> 00:07:48,030
مقدار منحصر به فرد در هر ردیف در خود داده دارند،
191
00:07:48,030 –> 00:07:51,210
بنابراین اگر به این نگاه کنیم
192
00:07:51,210 –> 00:07:54,600
ستون پاسخدهنده در اینجا این ستون پاسخدهنده در
193
00:07:54,600 –> 00:07:57,240
واقع یک شناسه منحصربهفرد است، بنابراین پاسخدهنده آن
194
00:07:57,240 –> 00:07:59,160
یک پاسخدهنده دو و سه و غیره،
195
00:07:59,160 –> 00:08:01,200
بنابراین احتمالاً باید کمی این موضوع را پاک
196
00:08:01,200 –> 00:08:03,780
کنیم و فقط از آن شناسه پاسخدهنده
197
00:08:03,780 –> 00:08:06,750
بهعنوان فهرست قاب دادهمان استفاده کنیم، اکنون میتوانیم این کار را
198
00:08:06,750 –> 00:08:09,600
درست مانند قبلاً با
199
00:08:09,600 –> 00:08:12,900
پایین آمدن از اینجا و گفتن D F dot set index
200
00:08:12,900 –> 00:08:16,530
و این کار را به این صورت دیدیم یا میتوانیم این کار را
201
00:08:16,530 –> 00:08:18,540
در حالی که در واقع در حال خواندن دادهها هستیم
202
00:08:18,540 –> 00:08:21,540
با انتقال یک آرگومان اضافی
203
00:08:21,540 –> 00:08:24,870
به متد خواندن CSV انجام دهیم تا اینجا جایی که
204
00:08:24,870 –> 00:08:28,440
بارگذاری کردیم. داده ها اجازه دهید فقط
205
00:08:28,440 –> 00:08:31,230
یک آرگومان دیگر را در اینجا اضافه کنید و ما
206
00:08:31,230 –> 00:08:34,440
این شاخص را فراخوانی زیر خط برابر می کنیم
207
00:08:34,440 –> 00:08:37,919
و اکنون نام ستونی که
208
00:08:37,919 –> 00:08:39,990
می خواهیم شاخص باشد و در این حالت من
209
00:08:39,990 –> 00:08:42,419
می خواهم این شناسه منحصر به فرد پاسخ دهنده
210
00:08
فیلم آموزشی: آموزش پایتون پانداها (قسمت 3): ایندکس ها – نحوه تنظیم، بازنشانی و استفاده از ایندکس ها
در این مطلب، ویدئو آموزش پایتون پانداها (قسمت 3): ایندکس ها – نحوه تنظیم، بازنشانی و استفاده از ایندکس ها را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند.
مدت زمان فیلم: 00:17:26
تصاویر این ویدئو:








![فیلم آموزشی: Python چگونه پروژه ها را به یک پایگاه داده متصل کنیم؟ [آموزش کامل 40 دقیقه ای] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/jndQ0i8Eresimage2.jpg)
![فیلم آموزشی: نحوه نصب پایتون 3.10.0 در ویندوز 11 [ به روز رسانی 2021 ] راهنمای کامل با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/CqZtV9-hGiIimage2.jpg)


