در این مطلب، ویدئو برازش معادله Michaelis-Menten با استفاده از پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:19:13
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:02,760
سلام به یک ویدیوی جدید در این ویدیو خوش آمدید،
2
00:00:02,760 –> 00:00:04,560
من به شما نشان خواهم داد که چگونه برخی از
3
00:00:04,560 –> 00:00:07,020
داده های جنبشی آنزیم را به معادله Michaelis Menten
4
00:00:07,020 –> 00:00:11,040
برازش دهید تا داده ها
5
00:00:11,040 –> 00:00:12,870
سرعت واکنش باشد که به عنوان
6
00:00:12,870 –> 00:00:16,289
تابعی از غلظت سوبسترا اندازه گیری شده است که
7
00:00:16,289 –> 00:00:18,449
می خواهیم V- را تخمین بزنیم. حداکثر و کیلومتر
8
00:00:18,449 –> 00:00:21,840
برای آنزیم اکنون می خواهم این کار را
9
00:00:21,840 –> 00:00:24,750
با استفاده از پایتون انجام دهم و این همان چیزی است که در
10
00:00:24,750 –> 00:00:26,970
مقابل خود روی صفحه می بینید، در
11
00:00:26,970 –> 00:00:29,880
واقع برنامه ای به نام spider spider
12
00:00:29,880 –> 00:00:33,840
3 است که می تواند برای کمک به آن استفاده شود که می توان
13
00:00:33,840 –> 00:00:35,460
از آن استفاده کرد. به شما کمک کنم پایتون بنویسید و پایتون را اجرا کنید
14
00:00:35,460 –> 00:00:38,730
من کاملاً دوست دارم این
15
00:00:38,730 –> 00:00:41,940
ابزار نسبتاً رایج برای استفاده را دارد، در واقع
16
00:00:41,940 –> 00:00:44,100
در اکثر توزیعها موجود است توزیعهای پایتون،
17
00:00:44,100 –> 00:00:46,579
بنابراین در سمت راست
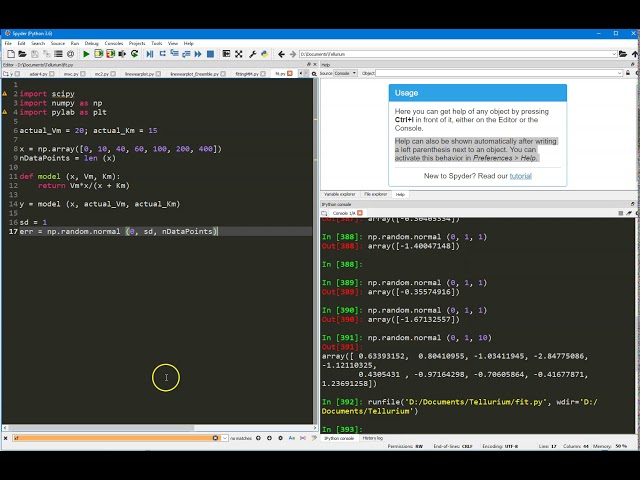
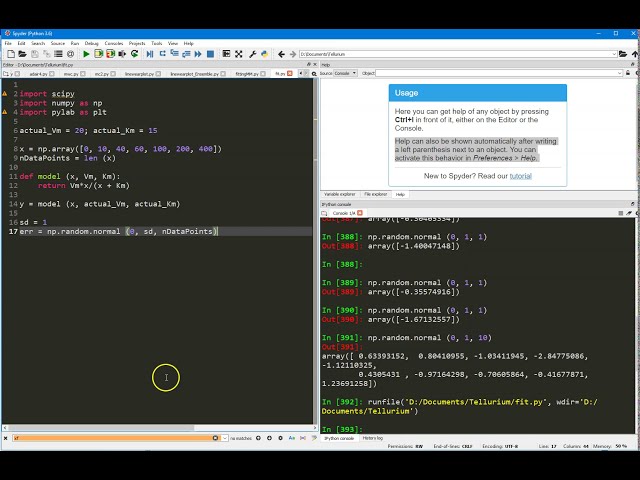
18
00:00:46,579 –> 00:00:53,129
ما کنسول پایتون داریم، خوب 9 در
19
00:00:53,129 –> 00:00:56,600
سمت چپ است، من یک ویرایشگر دارم.
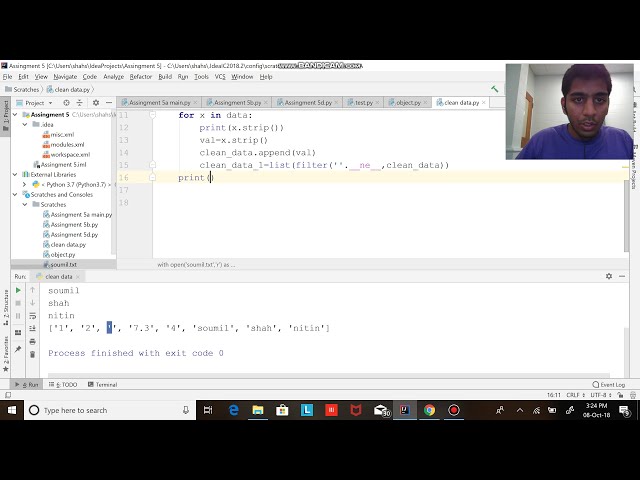
20
00:00:56,600 –> 00:01:12,689
قرار دادن اسکریپتها در اینجا و بنابراین میتوانم آن را ذخیره
21
00:01:12,689 –> 00:01:15,000
کنم که اینجا دکمه Save است،
22
00:01:15,000 –> 00:01:16,920
قبلاً یک نام فایل به نام fit دارد و اگر
23
00:01:16,920 –> 00:01:18,570
این را برای اجرای آن اجرا کنم، از دکمه سبز رنگ
24
00:01:18,570 –> 00:01:23,100
در اینجا استفاده میکنم، آن را اجرا میکنم.
25
00:01:23,100 –> 00:01:27,030
26
00:01:27,030 –> 00:01:30,090
پایتون و پایتون را خوب اجرا کنید، بنابراین بیایید
27
00:01:30,090 –> 00:01:33,829
ابتدا شروع کنیم و گرسنه هستیم تا برخی از
28
00:01:33,829 –> 00:01:40,140
بستههای مورد نیاز خود را وارد کنیم، بنابراین اولین مورد Sai PI است،
29
00:01:40,140 –> 00:01:42,899
بنابراین اینجاست که
30
00:01:42,899 –> 00:01:44,880
الگوریتمهای مناسب پیدا میشوند، زبان علمی
31
00:01:44,880 –> 00:01:48,149
برای پایتون که بسیار رایج است، دومی
32
00:01:48,149 –> 00:01:51,600
numpy است. زبان بسیار رایج
33
00:01:51,600 –> 00:01:53,189
دیگری که در
34
00:01:53,189 –> 00:01:55,470
محاسبات علمی استفاده میشود این است که برای مدیریت
35
00:01:55,470 –> 00:01:58,950
آرایهها استفاده میشود که من آن را numpy NP مینامم،
36
00:01:58,950 –> 00:02:02,159
زیرا گفتن آنها همیشه PI بیش از
37
00:02:02,159 –> 00:02:04,380
حد است و زبان دوم سومین موردی
38
00:02:04,380 –> 00:02:06,030
که میخواهم انجام دهم این است که مقداری نمودار اضافه کنم.
39
00:02:06,030 –> 00:02:07,860
پشتیبانی بدون ترسیم در لوله به طور معمول
40
00:02:07,860 –> 00:02:11,459
با matplotlib انجام می شود و من هرگز نمی
41
00:02:11,459 –> 00:02:13,290
توانم وضعیت واردات را به خاطر بیاورم به
42
00:02:13,290 –> 00:02:16,470
طوری که بسیار طولانی است، بنابراین در
43
00:02:16,470 –> 00:02:19,140
عوض در Port pylab که
44
00:02:19,140 –> 00:02:21,480
matplotlib را برای من می کشد و چند
45
00:02:21,480 –> 00:02:23,900
چیز مهم نیست، چه کاری انجام می دهم. چیزهای دیگر
46
00:02:23,900 –> 00:02:25,590
و من آن را
47
00:02:25,590 –> 00:02:31,409
PLT برای طرح مینامم، خوب حالا چگونه میخواهم این کار را به
48
00:02:31,409 –> 00:02:34,739
خوبی انجام دهم، میخواهم برخی
49
00:02:34,739 –> 00:02:37,079
دادههای جنبشی آنزیم جعلی ایجاد کنم و
50
00:02:37,079 –> 00:02:40,290
سعی میکنم مدلی را برای آن وفادار
51
00:02:40,290 –> 00:02:43,530
بهعنوان یک سینتیک تنظیم کنم. داده ها و ارتباط آنزیمی
52
00:02:43,530 –> 00:02:45,180
ct دادههای جعلی از یک
53
00:02:45,180 –> 00:02:48,690
آنزیم واقعی که من میخواهم بسازم به دست میآید
54
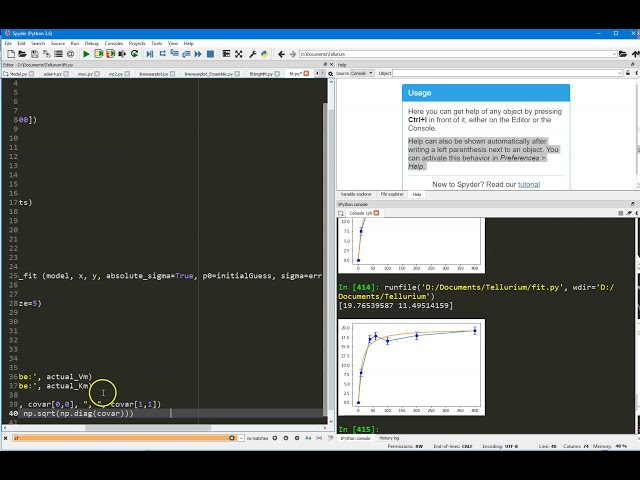
00:02:48,690 –> 00:02:54,000
که کیلومتر آن 20 است و v-max ما 20 و
55
00:02:54,000 –> 00:02:57,870
کیلومتر 15 است، بنابراین آیا این آنزیم در
56
00:02:57,870 –> 00:03:00,090
جایی است که این
57
00:03:00,090 –> 00:03:03,659
پارامترها را دارد پس ما ماده 20 در یک KML 15 است
58
00:03:03,659 –> 00:03:07,349
و من سعی می کنم
59
00:03:07,349 –> 00:03:10,290
داده های تجربی جعلی را از این آنزیم تولید
60
00:03:10,290 –> 00:03:13,170
کنم، سپس آن داده ها را در
61
00:03:13,170 –> 00:03:14,810
معادله Michaelis Menten قرار می دهم تا ببینم آیا می توانم
62
00:03:14,810 –> 00:03:19,260
این دو مقدار 20 و 50 را بازیابی
63
00:03:19,260 –> 00:03:21,690
کنم. این کار این است که یک آرایه ایجاد میکند
64
00:03:21,690 –> 00:03:22,349
که غلظتهای زیرلایه را در خود نگه
65
00:03:22,349 –> 00:03:26,099
میدارد و به X گفته میشود، بنابراین
66
00:03:26,099 –> 00:03:27,629
این غلظتهای زیرلایه خواهد بود،
67
00:03:27,629 –> 00:03:33,599
خوب این
68
00:03:33,599 –> 00:03:36,569
همه چیز است و من طول آن
69
00:03:36,569 –> 00:03:44,730
آرایه و نقاط داده را ثبت میکنم اولین
70
00:03:44,730 –> 00:03:47,190
مقدار 0 است. این به معنای غلظت زیرلایه
71
00:03:47,190 –> 00:03:49,109
0 است و به این معنی است
72
00:03:49,109 –> 00:03:51,449
که سرعت واکنش ابتدا نقطه صفر خواهد بود
73
00:03:51,449 –> 00:03:53,129
و سپس غلظت بستر
74
00:03:53,129 –> 00:03:56,519
افزایش می یابد.
75
00:03:56,519 –> 00:03:58,590
76
00:03:58,590 –> 00:03:59,940
77
00:03:59,940 –> 00:04:02,459
تابعی
78
00:04:02,459 –> 00:04:05,699
به نام m odel سه
79
00:04:05,699 –> 00:04:08,280
آرگومان خواهد داشت که اولین آرگومان
80
00:04:08,280 –> 00:04:10,379
بردار یا آرایه غلظت زیرلایه است
81
00:04:10,379 –> 00:04:13,019
و سپس 2i
82
00:04:13,019 –> 00:04:15,810
دو آرگومان باقیمانده v-max و km و از
83
00:04:15,810 –> 00:04:18,199
این تابع مقدار K را برمی گرداند،
84
00:04:18,199 –> 00:04:24,049
85
00:04:29,720 –> 00:04:31,770
بنابراین این فقط michaelis- را محاسبه می کند.
86
00:04:31,770 –> 00:04:35,460
معادله منتن برای من است و
87
00:04:35,460 –> 00:04:39,180
در واقع این است که در واقع
88
00:04:39,180 –> 00:04:42,900
محفظه و منحنی آنزیم کامل ما را
89
00:04:42,900 –> 00:04:46,680
در اینجا با v-max 22 کیلومتر از 50 محاسبه می کند،
90
00:04:46,680 –> 00:04:49,980
بنابراین تنها کاری که باید انجام دهم این است که مدل را با
91
00:04:49,980 –> 00:04:56,520
بردار X و با پارامترهای جنبشی واقعی
92
00:04:56,520 –> 00:04:58,290
که می خواهم فراخوانی کنم. برای استفاده برای این
93
00:04:58,290 –> 00:05:01,050
آنزیم خاص، پس اجازه دهید این را اجرا کنم،
94
00:05:01,050 –> 00:05:04,230
بیایید آن را رسم کنیم، بنابراین من
95
00:05:04,230 –> 00:05:06,450
فقط از نمودار PLT استفاده کردم و سپس از تابع نمودار
96
00:05:06,450 –> 00:05:09,690
که X یا Y را می گیرد و آژانس
97
00:05:09,690 –> 00:05:12,960
که داده های کامل من است، اکنون می خواهم
98
00:05:12,960 –> 00:05:15,630
داده های کامل خود را به جعلی تبدیل کنم.
99
00:05:15,630 –> 00:05:18,120
دادههای آزمایشی یکی از راههای انجام این کار این است که
100
00:05:18,120 –> 00:05:21,230
به هر نقطه داده مقداری نویز اضافه کنید،
101
00:05:21,230 –> 00:05:24,540
اکنون یک تابع مناسب در
102
00:05:24,540 –> 00:05:28,980
dump وجود دارد که من آن را random normal مینامم و کاری که
103
00:05:28,980 –> 00:05:31,290
انجام میدهد این است که یک عدد تصادفی را
104
00:05:31,290 –> 00:05:33,180
از یک توزیع عادی ترسیم میکند، بنابراین من میروم.
105
00:05:33,180 –> 00:05:34,920
با فرض اینکه خطاها یا نویز
106
00:05:34,920 –> 00:05:37,350
در اطراف هر نقطه داده به طور معمول
107
00:05:37,350 –> 00:05:40,740
توزیع شده است و خطا در
108
00:05:40,740 –> 00:05:43,440
اطراف هر نقطه داده مثبت یا منفی خواهد بود
109
00:05:43,440 –> 00:05:46,110
پس بزرگ است عدد تصادفی دارای
110
00:05:46,110 –> 00:05:46,650
میانگین صفر است،
111
00:05:46,650 –> 00:05:49,190
اجازه دهید انحراف استاندارد را 1 به آن بدهیم.
112
00:05:49,190 –> 00:05:51,780
یک نقطه داده را برگردانید، بنابراین
113
00:05:51,780 –> 00:05:54,300
این سه آرگومان میانگین انحراف
114
00:05:54,300 –> 00:05:56,100
استاندارد توزیع نرمال
115
00:05:56,100 –> 00:05:57,720
برای توزیع نرمال
116
00:05:57,720 –> 00:05:59,460
و تعداد اعداد تصادفی که میخواهم
117
00:05:59,460 –> 00:06:01,440
از آن توزیع عادی ترسیم
118
00:06:01,440 –> 00:06:04,770
کنم، یکی است، بنابراین اگر اجرا کنم، این
119
00:06:04,770 –> 00:06:10,410
عدد یک عدد منفرد به دست میآید – اکنون 0.77 است
120
00:06:10,410 –> 00:06:12,240
– البته چون میانگین بر روی 0 متمرکز شده است،
121
00:06:12,240 –> 00:06:14,430
بنابراین ممکن است اعداد
122
00:06:14,430 –> 00:06:15,990
تصادفی به سمت چپ میانگین
123
00:06:15,990 –> 00:06:17,820
که در ربع منفی است یا
124
00:06:17,820 –> 00:06:19,020
در سمت راست میانگین که در
125
00:06:19,020 –> 00:06:21,390
ربع مثبت است رسم شوند.
126
00:06:21,390 –> 00:06:23,760
البته باز هم این را میگیرم،
127
00:06:23,760 –> 00:06:26,340
هر بار که این کار را انجام میدهم یک عدد تصادفی متفاوت دریافت میکنم،
128
00:06:26,340 –> 00:06:28,410
همچنین میتوانم از شما بخواهم که ده عدد را محاسبه کنید، در غیر
129
00:06:28,410 –> 00:06:30,450
این صورت آنها برای من خوب نخواهند بود و اینها
130
00:06:30,450 –> 00:06:32,940
اعداد تصادفی معمولی من هستند.
131
00:06:32,940 –> 00:06:35,430
و من اساساً میخواهم آنها را
132
00:06:35,430 –> 00:06:38,289
به دادههای کامل خود اضافه کنم، بنابراین
133
00:06:38,289 –> 00:06:40,089
بیایید این کار را انجام دهیم تا
134
00:06:40,089 –> 00:06:41,860
متغیری به نام s T را برای انحراف استاندارد
135
00:06:41,860 –> 00:06:45,159
، آرایهای به نام Earth تعریف کنیم که
136
00:06:45,159 –> 00:06:46,599
اوه
137
00:06:46,599 –> 00:06:55,689
خواهد بود که میانگین عادی من از
138
00:06:55,689 –> 00:06:58,749
انحراف استاندارد صفر خواهد بود. از s T و
139
00:06:58,749 –> 00:07:02,889
من برمی گردم و نقاط داده آنها را برمی گردم،
140
00:07:02,889 –> 00:07:04,210
بنابراین اجرا می شود که فقط به شما نشان می دهد
141
00:07:04,210 –> 00:07:08,349
که خیلی خوب به نظر می رسد این اعداد تصادفی من هستند
142
00:07:08,349 –> 00:07:12,089
و من می خواهم آنها را به بدن اضافه
143
00:07:12,089 –> 00:07:17,189
کنم.
144
00:07:17,189 –> 00:07:20,469
من مقداری هوا دریافت کردم، چیز عجیبی نیست که متوجه خواهید
145
00:07:20,469 –> 00:07:23,740
شد این است که اولین مقدار یک
146
00:07:23,740 –> 00:07:25,509
مقدار منفی است و من می دانم که
147
00:07:25,509 –> 00:07:27,819
با غلظت زیر لایه صفر مطابقت دارد،
148
00:07:27,819 –> 00:07:29,259
می دانم که در
149
00:07:29,259 –> 00:07:31,149
غلظت زیر لایه صفر
150
00:07:31,149 –> 00:07:33,639
سرعت واکنش صفر خواهد بود، بنابراین من می دانم همچنین ممکن
151
00:07:33,639 –> 00:07:35,789
است آن را روی
152
00:07:35,789 –> 00:07:42,610
صفر تنظیم کنید، اولین مورد را روی صفر قرار دهید بسیار خوب است و
153
00:07:42,610 –> 00:07:43,870
بیایید آن را ترسیم کنیم تا ببینیم چه
154
00:07:43,870 –> 00:07:49,680
چیزی خوب است، بنابراین اکنون در واقع برخی از
155
00:07:49,680 –> 00:07:53,709
خطاها در آن وجود دارد، بسیار خوب به نظر نمی
156
00:07:53,709 –> 00:07:56,589
رسد، اما اگر آن را اجرا کنم، انجام می شود. دوباره شاید
157
00:07:56,589 –> 00:07:59,050
شما آن را کمی متفاوت است
158
00:07:59,050 –> 00:08:01,089
خوب است که قطعاً
159
00:08:01,089 –> 00:08:03,449
اینجا از بین رفته است،
160
00:08:03,449 –> 00:08:06,839
اشکالی ندارد، بنابراین من تقریباً همیشه اکنون آماده
161
00:08:06,839 –> 00:08:09,309
هستم، بنابراین باید بدانم این
162
00:08:09,309 –> 00:08:11,889
داده های تجربی من است و باید
163
00:08:11,889 –> 00:08:14,379
مدل را با این داده های آزمایشی تطبیق دهیم، خوب است، بنابراین
164
00:08:14,379 –> 00:08:17,159
اجازه دهید به من دست پیدا کنم
165
00:08:17,159 –> 00:08:20,050
اولین چیزی که من نیاز دارم این است که الگوریتم برازش منحنی
166
00:08:20,050 –> 00:08:22,839
نیاز به حدس اولیه
167
00:08:22,839 –> 00:08:25,629
برای v-max و کیلومتر دارد. آنها را روی یک تنظیم می کنم
168
00:08:25,629 –> 00:08:27,399
و می توان آنها را روی هر کدام از آنها
169
00:08:27,399 –> 00:08:28,740
هر طور
170
00:08:28,740 –> 00:08:31,360
که می خواهید تنظیم کرد. فراخوانی
171
00:08:31,360 –> 00:08:33,339
به منحنی مناسب من فقط
172
00:08:33,339 –> 00:08:34,779
آن را در شما جایگذاری میکنم و شما را
173
00:08:34,779 –> 00:08:38,649
از طریق آن راهنمایی میکنم، بنابراین این
174
00:08:38,649 –> 00:08:45,790
یک تغییر بسیار طولانی است که به بله،
175
00:08:45,790 –> 00:08:49,120
بنابراین تعدادی آرگومان دارد، بنابراین تابع
176
00:08:49,120 –> 00:08:51,970
خود را فراخوانی میکند. آیا منحنی بهینه شده CyHi مناسب است،
177
00:08:51,970 –> 00:08:54,370
این همان چیزی است که شما می خواهید نامش را بگذارید، مجموعه
178
00:08:54,370 –> 00:08:55,840
ای کامل از پارامترها را می طلبد،
179
00:08:55,840 –> 00:08:57,580
اولی مدل است اگر می خواهید
180
00:08:57,580 –> 00:08:59,860
دو را برازش دهید، بنابراین مدل البته
181
00:08:59,860 –> 00:09:02,730
مدل michaelis-menten ما است، سپس یک بار
182
00:09:02,730 –> 00:09:06,610
دو مجموعه داده را انتخاب کنید. x و y بنابراین
183
00:09:06,610 –> 00:09:08,410
غلظت سوبسترا در واکنش
184
00:09:08,410 –> 00:09:11,260
v است elocity اجازه دهید فعلاً یک بار از روی این یکی بپرم
185
00:09:11,260 –> 00:09:14,380
، حدس اولیه خوب است، اما
186
00:09:14,380 –> 00:09:17,830
من حدس اولیه من 1 1 است و سپس
187
00:09:17,830 –> 00:09:20,290
می خواهد خطاهای داده های من چیست
188
00:09:20,290 –> 00:09:22,360
زیرا از آنها برای صبر کردن استفاده می شود،
189
00:09:22,360 –> 00:09:25,840
بنابراین اگر نقطه 7 باشد. خطاهای بیشتری داشتند
190
00:09:25,840 –> 00:09:28,540
و بقیه اکنون من می خواهم
191
00:09:28,540 –> 00:09:32,800
وزن کمتری روی آن نقاط
192
00:09:32,800 –> 00:09:36,160
بگذارم، خوب حالا در مورد من چه چیزی وجود دارد و خطاهای
193
00:09:36,160 –> 00:09:38,770
مورد من تقریباً همه یکسان
194
00:09:38,770 –> 00:09:40,390
دارند انحراف معیار یک دارند
195
00:09:40,390 –> 00:09:42,460
هر نقطه دارای انحراف معیار است.
196
00:09:42,460 –> 00:09:45,040
یکی و بنابراین، کاری که باید انجام دهم این است که
197
00:09:45,040 –> 00:09:49,060
یک آرایه ایجاد کنم یک خطای آرایه ای که
198
00:09:49,060 –> 00:09:52,120
از این ر