در این مطلب، ویدئو AdaBoost در پایتون – یادگیری ماشینی از ابتدا 13 – آموزش پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:27:34
تصاویر این ویدئو:

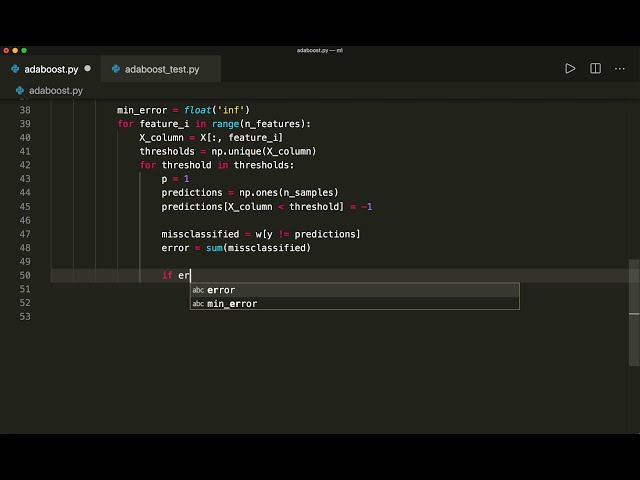
قسمتی از زیرنویس این فیلم:
00:00:00,079 –> 00:00:02,460
سلام بچه ها به یکی دیگر
2
00:00:02,460 –> 00:00:04,799
از آموزش های یادگیری ماشینی از ابتدا خوش آمدید، امروز
3
00:00:04,799 –> 00:00:06,390
می خواهیم
4
00:00:06,390 –> 00:00:08,880
الگوریتم adaboost را با استفاده از
5
00:00:08,880 –> 00:00:11,759
6
00:00:11,759 –> 00:00:13,740
7
00:00:13,740 –> 00:00:15,990
ماژول های numpy
8
00:00:15,990 –> 00:00:18,480
9
00:00:18,480 –> 00:00:20,820
و داخلی پایتون پیاده سازی کنیم. در عمل واقعاً خوب کار می
10
00:00:20,820 –> 00:00:23,310
کند، بنابراین
11
00:00:23,310 –> 00:00:25,980
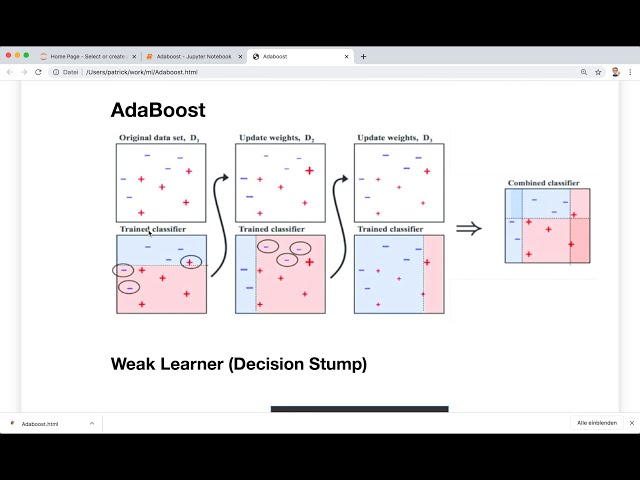
قبل از اینکه به سراغ کد برویم، بیایید با یک نظریه شروع کنیم، بنابراین
12
00:00:25,980 –> 00:00:28,199
بیایید نگاهی به این مثال 2 بعدی در اینجا بیاندازیم تا
13
00:00:28,199 –> 00:00:30,599
مفهوم را درک کنیم، بنابراین در اینجا
14
00:00:30,599 –> 00:00:33,000
ما نمونه های خود را با تنها دو
15
00:00:33,000 –> 00:00:35,840
ویژگی متفاوت در محور x و در y داریم. محور
16
00:00:35,840 –> 00:00:38,850
و اکنون طبقهبندیکننده اول
17
00:00:38,850 –> 00:00:41,340
بر اساس محور y در این مثال یک شکاف ایجاد میکند،
18
00:00:41,340 –> 00:00:44,370
بنابراین یک
19
00:00:44,370 –> 00:00:47,219
خط تصمیم افقی در آستانهای رسم میکند، بنابراین
20
00:00:47,219 –> 00:00:50,430
خط چین که میتوانیم اینجا ببینیم و
21
00:00:50,430 –> 00:00:52,079
میتوانیم ببینیم که برخی از پیشبینیها درست هستند،
22
00:00:52,079 –> 00:00:53,660
اما طبقهبندیهای اشتباه هم داریم.
23
00:00:53,660 –> 00:00:56,390
و اکنون با این دسته
24
00:00:56,390 –> 00:00:58,530
بندی های اشتباه می توانیم
25
00:00:58,530 –> 00:01:01,680
یک معیار عملکرد را محاسبه کنیم تا
26
00:01:01,680 –> 00:01:04,199
دقت این طبقه بندی کننده و با این
27
00:01:04,199 –> 00:01:06,630
اندازه گیری محاسبه شود وزنها را
28
00:01:06,630 –> 00:01:09,720
برای تمام نمونههای تمرینی خورد و بهروزرسانی کرد و اکنون
29
00:01:09,720 –> 00:01:12,360
طبقهبندیکننده دوم وارد میشود و از
30
00:01:12,360 –> 00:01:14,939
این وزنها استفاده میکند و
31
00:01:14,939 –> 00:01:18,000
مرز تصمیم متفاوت و احتمالاً بهتری را پیدا میکند، بنابراین
32
00:01:18,000 –> 00:01:19,860
طبقهبندیکننده دوم در این مثال در اینجا
33
00:01:19,860 –> 00:01:22,560
یک ویژگی را در محور x انتخاب میکند و
34
00:01:22,560 –> 00:01:25,619
یک خط عمودی میکشد و سپس دوباره
35
00:01:25,619 –> 00:01:27,780
عملکرد را محاسبه می کنیم و وزن ها را به روز می کنیم
36
00:01:27,780 –> 00:01:30,150
و سپس این مرحله را برای
37
00:01:30,150 –> 00:01:33,329
هر تعداد طبقه بندی کننده که می خواهیم تکرار می کنیم و سپس
38
00:01:33,329 –> 00:01:35,520
در اینجا در انتها همه
39
00:01:35,520 –> 00:01:37,799
خطوط تصمیم گیری مختلف و
40
00:01:37,799 –> 00:01:39,570
همچنین عملکردهای مختلف طبقه بندی کننده
41
00:01:39,570 –> 00:01:42,560
را داریم و سپس ترکیب می کنیم. همه طبقهبندیکنندههای ما،
42
00:01:42,560 –> 00:01:45,390
بنابراین میتوانیم
43
00:01:45,390 –> 00:01:47,939
با عملکردهای محاسبهشده یک جمع وزنی ایجاد کنیم و
44
00:01:47,939 –> 00:01:50,520
این به ما امکان میدهد
45
00:01:50,520 –> 00:01:52,860
خط تصمیم کاملی را که در اینجا میبینیم ترسیم کنیم که
46
00:01:52,860 –> 00:01:55,350
میتواند پیچیدهتر از یک
47
00:01:55,350 –> 00:01:58,920
خط تصمیم خطی ساده و ایده با روشی باشد
48
00:01:58,920 –> 00:02:01,860
که برخی در اینجا در پایان به این معنی است که
49
00:02:01,860 –> 00:02:04,860
هرچه طبقهبندیکننده بهتر باشد، تأثیر بیشتری بر
50
00:02:04,860 –> 00:02:07,950
نتیجه نهایی میگذارد، بنابراین این
51
00:02:07,950 –> 00:02:10,378
اساساً مفهوم است و اکنون بیایید به
52
00:02:10,378 –> 00:02:12,480
همه موارد نگاه کنیم. مراحل مختلف و
53
00:02:12,480 –> 00:02:16,110
همچنین ریاضیات پشت آن به تفصیل، بنابراین
54
00:02:16,110 –> 00:02:18,599
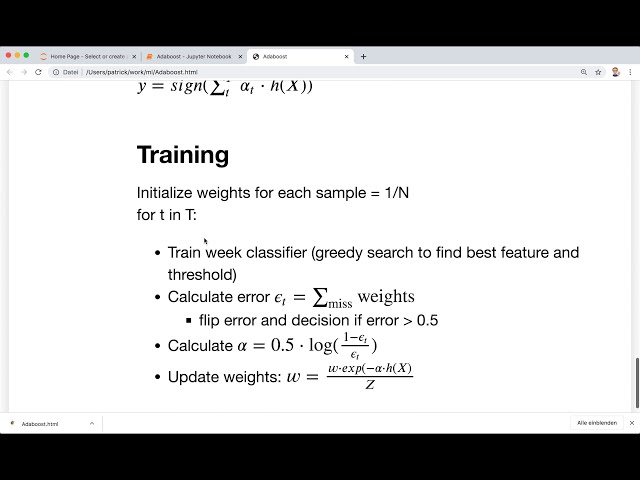
اولین چیزی که ما نیاز داریم یک
55
00:02:18,599 –> 00:02:21,599
طبقه بندی کننده ضعیف است و به آن یادگیرنده ضعیف نیز می گویند،
56
00:02:21,599 –> 00:02:25,560
بنابراین یک یادگیرنده ضعیف همیشه یک
57
00:02:25,560 –> 00:02:28,170
طبقه بندی کننده بسیار ساده است و در
58
00:02:28,170 –> 00:02:30,569
مورد adaboost ما از یک طبقه بندی کننده به اصطلاح استفاده می کنیم.
59
00:02:30,569 –> 00:02:33,330
تمبر تصمیم برای این کار، بنابراین یک
60
00:02:33,330 –> 00:02:36,599
تمبر کامیون تصمیم اساساً یک درخت تصمیم است
61
00:02:36,599 –> 00:02:39,870
که تنها یک تقسیم دارد، بنابراین آنچه را که
62
00:02:39,870 –> 00:02:42,930
در اینجا میتوانیم ببینیم، بنابراین ما فقط به یک ویژگی
63
00:02:42,930 –> 00:02:46,200
از نمونههای خود و فقط در یک آستانه نگاه میکنیم
64
00:02:46,200 –> 00:02:49,379
و سپس بر اساس اینکه آیا ارزش ویژگی ما
65
00:02:49,379 –> 00:02:51,750
بیشتر است یا نه. کوچکتر از آستانه
66
00:02:51,750 –> 00:02:55,230
می گوییم کلاس منهای 1 یا کلاس
67
00:02:55,230 –> 00:02:59,099
بعلاوه 1 است، بنابراین این مهر تصمیم گیری است و
68
00:02:59,099 –> 00:03:02,720
سپس به فرمول خطا نیاز داریم،
69
00:03:02,720 –> 00:03:05,849
بنابراین اولین بار در اولین بار
70
00:03:05,849 –> 00:03:07,890
در طول تکرار، خطا به
71
00:03:07,890 –> 00:03:09,890
عنوان تعداد محاسبه می شود.
72
00:03:09,890 –> 00:03:12,329
طبقه بندی اشتباه بر
73
00:03:12,329 –> 00:03:14,879
تعداد کل نمونه ها تقسیم می شود و این
74
00:03:14,879 –> 00:03:17,370
رویکرد طبیعی برای خطا است، بنابراین اگر
75
00:03:17,370 –> 00:03:20,730
دوباره به مثال ما نگاه کنید،
76
00:03:20,730 –> 00:03:23,099
می بینیم که در این مورد 10 نمونه داریم
77
00:03:23,099 –> 00:03:25,919
و در اولین مورد در صنوبر
78
00:03:25,919 –> 00:03:28,950
طبقهبندی st ما 3 طبقهبندی اشتباه داریم،
79
00:03:28,950 –> 00:03:32,669
به این معنی که میزان خطای ما 0.3
80
00:03:32,669 –> 00:03:37,470
یا 30 درصد است، بنابراین این اولین بار است، اما
81
00:03:37,470 –> 00:03:39,840
دفعه بعد میخواهیم وزنها را نیز در نظر بگیریم
82
00:03:39,840 –> 00:03:42,810
، بنابراین اگر یک نمونه
83
00:03:42,810 –> 00:03:45,810
اشتباه طبقهبندی شده بود، به آن وزن بیشتری میدهیم.
84
00:03:45,810 –> 00:03:48,329
برای تکرار بعدی و
85
00:03:48,329 –> 00:03:51,150
این بدان معنی است که فرمول ما سپس
86
00:03:51,150 –> 00:03:54,450
به عنوان مجموع وزنها
87
00:03:54,450 –> 00:03:56,639
برای همه طبقهبندیهای اشتباه محاسبه میشود
88
00:03:56,639 –> 00:04:01,290
و اگر خطای ما بزرگتر از 0.5 باشد،
89
00:04:01,290 –> 00:04:04,379
به سادگی خطا را برمیگردانیم، بنابراین تمام
90
00:04:04,379 –> 00:04:07,019
موقعیتها را برمیگردانیم و همه تصمیمها را برمیگردانیم.
91
00:04:07,019 –> 00:04:10,739
سپس 1 منهای
92
00:04:10,739 –> 00:04:14,340
خطا است، بنابراین این خطا است و اکنون ما
93
00:04:14,340 –> 00:04:17,039
به وزن ها نیاز داریم، بنابراین وزن ها
94
00:04:17,039 –> 00:04:19,949
در ابتدا برای هر نمونه روی 1 روی N تنظیم می شوند
95
00:04:19,949 –> 00:04:23,070
و این نیز با
96
00:04:23,070 –> 00:04:25,800
محاسبه خطا در مرحله اول مطابقت دارد، بنابراین اگر
97
00:04:25,800 –> 00:04:26,220
98
00:04:26,220 –> 00:04:29,220
بگوییم خطا را محاسبه می کنیم. به عنوان مجموع
99
00:04:29,220 –> 00:04:32,250
تمام اوزان طبقه بندی اشتباه و همچنین
100
00:04:32,250 –> 00:04:35,310
می گوییم که هر وزن در ابتدا 1 بر N است،
101
00:04:35,310 –> 00:04:38,250
سپس برابر است با تعداد
102
00:04:38,250 –> 00:04:40,770
طبقه بندی های اشتباه تقسیم بر
103
00:04:40,770 –> 00:04:45,180
تعداد نمونه هایی مانند اینجا، بنابراین بله
104
00:04:45,180 –> 00:04:47,700
به همین دلیل است که وزن های اولیه
105
00:04:47,700 –> 00:04:51,540
برای هر نمونه 1 بر N است و سپس ما
106
00:04:51,540 –> 00:04:53,970
به قانون به روز رسانی نیز نیاز داریم که در اینجا تعریف شده
107
00:04:53,970 –> 00:04:57,270
است، بنابراین ما ضربات انتظار قدیمی برابر
108
00:04:57,270 –> 00:05:00,300
تابع نمایی منهای آلفا
109
00:05:00,300 –> 00:05:05,100
ضربدر y واقعی ضربدر H از X را داریم که در آن H
110
00:05:05,100 –> 00:05:08,660
از X پیش بینی ما است و آلفا
111
00:05:08,660 –> 00:05:12,090
دقت طبقهبندیکننده است، بنابراین اگر این
112
00:05:12,090 –> 00:05:15,030
منهای 1 باشد، یک طبقهبندی اشتباه داریم
113
00:05:15,030 –> 00:05:19,770
و اگر در اینجا به اضافه 1 باشد
114
00:05:19,770 –> 00:05:22,710
، طبقهبندی درستی داریم و کل این
115
00:05:22,710 –> 00:05:24,680
فرمول اساساً اطمینان میدهد که
116
00:05:24,680 –> 00:05:27,419
نمونههای طبقهبندی اشتباه کلاسیک
117
00:05:27,419 –> 00:05:30,140
تأثیر بیشتری برای طبقهبندیکننده بعدی دارند. بنابراین
118
00:05:30,140 –> 00:05:32,280
بله این چیزی است که شما باید
119
00:05:32,280 –> 00:05:35,460
از وزن ها و اکنون عملکرد
120
00:05:35,460 –> 00:05:38,490
به خاطر بسپارید، بنابراین باید عملکرد
121
00:05:38,490 –> 00:05:41,940
یا آلفا را برای هر طبقه بندی کننده محاسبه کنیم و می
122
00:05:41,940 –> 00:05:44,370
توانیم این کار را انجام دهیم و برای پیش بینی نهایی به این نیاز داریم
123
00:05:44,370 –> 00:05:47,570
و فرمول
124
00:05:47,570 –> 00:05:51,120
عملکرد به صورت محاسبه می شود. این
125
00:05:51,120 –> 00:05:55,260
یعنی نقطه 5 برابر ثبت 1
126
00:05:55,260 –> 00:05:58,590
منهای خطا تقسیم بر خطا، بنابراین اجازه دهید
127
00:05:58,590 –> 00:06:01,500
این را کمی برای شما بزرگتر کنم، بنابراین
128
00:06:01,500 –> 00:06:05,520
عملکرد این است و خطای ما
129
00:06:05,520 –> 00:06:09,330
همیشه بین n 0 و 1 بنابراین من
130
00:06:09,330 –> 00:06:12,840
آلفا را برای فلش های مختلف در این محدوده
131
00:06:12,840 –> 00:06:16,470
در اینجا رسم کردم و می بینیم که در
132
00:06:16,470 –> 00:06:18,990
جایی بین یک
133
00:06:18,990 –> 00:06:24,350
مقدار مثبت در اینجا و یک مقدار منفی در اینجا به طور مساوی توزیع شده است بنابراین
134
00:06:24,350 –> 00:06:28,080
با یک خطای کم یک مقدار مثبت بالا
135
00:06:28,080 –> 00:06:31,020
و با یک مقدار زیاد داریم. خطا در اینجا نزدیک
136
00:06:31,020 –> 00:06:34,680
به 1 مقدار منفی بالایی
137
00:06:34,680 –> 00:06:36,810
داریم، اما از آنجایی که تصمیم را تغییر می دهیم، پس
138
00:06:36,810 –> 00:06:38,789
این
139
00:06:38,789 –> 00:06:40,319
دوباره طبقه بندی های صحیحی خواهد بود
140
00:06:40,319 –> 00:06:43,139
که سهم زیادی در جنبه منفی
141
00:06:43,139 –> 00:06:45,899
دارد، بنابراین طرفی که در اینجا کلاس
142
00:06:45,899 –> 00:06:49,349
منهای یک است، بنابراین این مفهوم است
143
00:06:49,349 –> 00:06:54,240
آلفا و اکنون ما به پیش بینی نیاز داریم،
144
00:06:54,240 –> 00:06:56,759
بنابراین اگر همه اینها را فهمیده باشیم، درک
145
00:06:56,759 –> 00:06:58,949
پیش بینی نهایی بسیار آسان است،
146
00:06:58,949 –> 00:07:01,619
بنابراین ما فقط این
147
00:07:01,619 –> 00:07:05,369
علامت را در اینجا علامت جمع را بر روی همه
148
00:07:05,369 –> 00:07:07,879
پیش بینی ها انتخاب می کنیم که در آن هر
149
00:07:07,879 –> 00:07:10,229
پیش بینی را با عملکرد وزن می کنیم.
150
00:07:10,229 –> 00:07:13,379
طبقهبندیکننده پس آلفا برابر پیشبینی
151
00:07:13,379 –> 00:07:17,399
در اینجا است، بنابراین طبقهبندیکننده ما بهتر،
152
00:07:17,399 –> 00:07:19,800
تأثیر بیشتری بر
153
00:07:19,800 –> 00:07:22,830
پیشبینی نهایی میگذارد و طبقهبندیکننده بهتر
154
00:07:22,830 –> 00:07:25,529
، بیشتر به منفی یا
155
00:07:25,529 –> 00:07:28,499
p اشاره میکند. سمت مثبت و سپس
156
00:07:28,499 –> 00:07:31,020
طرف بهتر را به عنوان پیشبینی برای کلاس خود در نظر میگیریم،
157
00:07:31,020 –> 00:07:33,479
بنابراین بله، این مفهوم
158
00:07:33,479 –> 00:07:36,689
پیشبینی است و میتواند
159
00:07:36,689 –> 00:07:39,270
با فرمولهای مختلف و چرخش طرف کمی
160
00:07:39,270 –> 00:07:41,879
گیجکننده باشد، اما مفهوم اصلی چندان
161
00:07:41,879 –> 00:07:44,639
دشوار نیست و بیایید همه موارد را خلاصه کنیم.
162
00:07:44,639 –> 00:07:46,860
مراحل آموزشی مختلفی که باید
163
00:07:46,860 –> 00:07:49,680
در کد انجام دهیم، بنابراین ابتدا
164
00:07:49,680 –> 00:07:52,709
وزنهای خود را برای هر نمونه مقداردهی اولیه میکنیم
165
00:07:52,709 –> 00:07:55,830
و مقدار آن را 1 روی
166
00:07:55,830 –> 00:07:58,439
n قرار میدهیم، سپس تعداد هفتههای
167
00:07:58,439 –> 00:08:00,449
یادگیری را به دلخواه انتخاب میکنیم و سپس روی آن
168
00:08:00,449 –> 00:08:03,259
تکرار میکنیم و سپس هر
169
00:08:03,259 –> 00:08:07,289
تمبر تصمیم را آموزش می دهیم تا جستجوی حریصانه انجام
170
00:08:07,289 –> 00:08:10,349
دهیم تا بهترین ویژگی تقسیم و
171
00:08:10,349 –> 00:08:13,680
بهترین آستانه تقسیم را پیدا کنیم، سپس
172
00:08:13,680 –> 00:08:16,199
خطای این استامپ تصمیم را محاسبه می کنیم، بنابراین
173
00:08:16,199 –> 00:08:18,449
این با فرمول حاصل جمع بر
174
00:08:18,449 –> 00:08:21,419
وزن های طبقه بندی شده اشتباه است، سپس
175
00:08:21,419 –> 00:08:23,849
خطا را در تصمیم بگیرید اگر
176
00:08:23,849 –> 00:08:27,479
بزرگتر از 0.5 باشد،
177
00:08:27,479 –> 00:08:31,409
آلفا را با فرمول محاسبه می کنیم و سپس به
178
00:08:31,409 –> 00:08:34,110
پیش بینی ها نیاز داریم و سپس با
179
00:08:34,110 –> 00:08:36,630
پیش بینی ها و آلفا می
180
00:08:36,630 –> 00:08:40,880
توانیم محاسبه کنیم و سپس می توانیم به روز کنیم. وزن ها،
181
00:08:40,880 –> 00:08:44,130
بنابراین این همان کاری است که ما باید اکنون در کد انجام
182
00:08:44,130 –> 00:08:47,399
دهیم و بله، به شما قول می دهم که از زمانی که
183
00:08:47,399 –> 00:08:49,410
جدید است، اکنون که همه فرمول ها
184
00:08:49,410 –> 00:08:51,060
و تمام مراحل آموزشی در اینجا داریم،
185
00:08:51,060 –> 00:08:52,889
پیاده سازی بسیار ساده است
186
00:08:52,889 –> 00:08:53,850
و
187
00:08:53,850 –> 00:08:57,000
نباید آنقدر سخت باشد، بنابراین اجازه دهید به
188
00:08:57,000 –> 00:09:01,680
بنابراین اولین کاری که انجام می دهیم این است که numpy را وارد کنیم،
189
00:09:01,680 –> 00:09:05,759
بنابراین numpy SNP را وارد کنیم و این تنها
190
00:09:05,759 –> 00:09:07,949
ماژولی است که به آن نیاز داریم و اکنون
191
00:09:07,949 –> 00:09:11,490
یک کلاس برای مهر تصمیم ایجاد می کنیم، بنابراین
192
00:09:11,490 –> 00:09:17,490
کلاس تصمیم گیری است و این یک init می گیرد،
193
00:09:17,490 –> 00:09:21,209
بنابراین یک init تعریف کنید و این فقط
194
00:09:21,209 –> 00:09:23,910
خودش را دارد و در اینجا ما میخواهیم
195
00:09:23,910 –> 00:09:26,610
چند چیز را ذخیره کنیم، بنابراین اولین چیزی که
196
00:09:26,610 –> 00:09:29,579
میخواهیم ذخیره کنیم اصطلاحاً قطبیت است،
197
00:09:29,579 –> 00:09:34,470
بنابراین قطبیت نقطه خود برابر یک است و این
198
00:09:34,470 –> 00:09:36,839
به ما میگوید که آیا نمونه باید
199
00:09:36,839 –> 00:09:40,620
طبقهبندی شود یا منهای 1 یا به اضافه 1 برای
200
00:09:40,620 –> 00:09:42,959
آستانه داده شده، بنابراین اگر می
201
00:09:42,959 –> 00:09:45,329
خواهیم به سمت راست یا چپ نگاه کنیم و
202
00:09:45,329 –> 00:09:47,779
این مورد نیاز است زیرا اگر می خواهیم
203
00:09:47,779 –> 00:09:51,209
فلش را برگردانیم و همچنین باید
204
00:09:51,209 –> 00:09:54,240
قطبیت را برگردانیم تا این در یک ثانیه واضح تر شود
205
00:09:54,240 –> 00:09:57,029
و اکنون مورد دوم که ما
206
00:09:57,029 –> 00:09:59,519
می خواهیم او را ذخیره کنیم e شاخص ویژگی است
207
00:09:59,519 –> 00:10:04,050
بنابراین شاخص ویژگی self dot در ابتدا برابر با هیچ است
208
00:10:04,050 –> 00:10:06,660
و همچنین می خواهیم
209
00:10:06,660 –> 00:10:09,480
آستانه را ذخیره کنیم بنابراین آستانه تقسیم
210
00:10:09,480 –> 00:10:13,110
خود نقطه برابر با هیچ کدام در
211
00:10:13,110 –> 00:10:15,779
ابتدا نیست و همچنین می خواهیم
212
00:10:15,779 –> 00:10:19,529
متغیر a را برای عملکرد ذخیره کنیم تا
213
00:10:19,529 –> 00:10:24,449
آلفا بنابراین می گوییم self dot alpha برابر است با
214
00:10:24,449 –> 00:10:28,019
هیچ، بنابراین این چیزهایی است که می
215
00:10:28,019 –> 00:10:31,050
خواهیم ذخیره کنیم و سپس یک
216
00:10:31,050 –> 00:10:33,959
روش پیش بینی برای استامپ تصمیم نیز تعریف می کنیم، بنابراین
217
00:10:33,959 –> 00:10:37,860
می گوییم پیش بینی تعریف کنید و خودش می
218
00:10:37,860 –> 00:10:40,800
شود و X می شود بنابراین مجموعه نمونه
219
00:10:40,800 –> 00:10:43,470
باید پیش بینی کند. و اکنون کاری که ما می خواهیم
220
00:10:43,470 –> 00:10:48,410
در اینجا انجام دهیم این است که فقط به یک
221
00:10:48,410 –> 00:10:53,519
ویژگی از این نمونه نگاه کنیم و سپس
222
00:10:53,519 –> 00:10:55,589
آن را با آستانه مقایسه کنیم و بگوییم که آیا
223
00:10:55,589 –> 00:10:58,350
از منهای یک آن کوچکتر است و در غیر
224
00:10:58,350 –> 00:11:00,959
این صورت مثبت یک است، بنابراین این کل
225
00:11:00,959 –> 00:11:04,500
مفهوم خرده تصمیم است، پس بیایید
226
00:11:04,500 –> 00:11:06,520
این کار را انجام دهید، بنابراین فرض کنید
227
00:11:06,520 –> 00:11:13,690
تعداد نمونه ها برابر است با شکل X نقطه 0 و
228
00:11:13,690 –> 00:11:16,570
سپس فقط این ویژگی را به دست آوریم، بنابراین فرض کنید
229
00:11:16,570 –> 00:11:23,050
ستون X برابر است با x و سپس می توانیم از یک دو نقطه استفاده
230
00:11:23,050 –> 00:11:26,380
کنیم، بنابراین ما هنوز همه نمونه ها را می خواهیم
231
00:11:26,380 –> 00:11:29,230
اما فقط این شاخص ویژگی
232
00:11:29,230 –> 00:11:32,410
بعداً در طول آموزش محاسبه می کنیم بنابراین
233
00:11:32,410 –> 00:11:36,670
شاخص ویژگی self dot را محاسبه می کنیم و اکنون
234
00:11:36,670 –> 00:11:39,880
پیش بینی خود را انجام می دهیم بنابراین می گوییم پیش بینی ها
235
00:11:39,880 –> 00:11:43,930
برابر است و به طور پیش فرض می گوییم این 1 است
236
00:11:43,930 –> 00:11:48,010
بنابراین یک بار با
237
00:11:48,010 –> 00:11:52,300
اندازه تعداد نمونه ها فرض کنید numpy و سپس باید
238
00:11:52,300 –> 00:11:56,100
بررسی کنیم قطبیت ها را می گوییم اگر قطب خود نقطه
239
00:11:56,100 –> 00:12:00,070
برابر با 1 باشد، بنابراین این
240
00:12:00,070 –> 00:12:04,360
حالت پیش فرض است، پس می گوییم که تمام
241
00:12:04,360 –> 00:12:07,750
پیش بینی هایی که کوچکتر هستند در جایی که
242
00:12:07,750 –> 00:12:10,630
بردار ویژگی کوچکتر از
243
00:12:10,630 –> 00:12:13,980
آستانه است، آنگاه منهای 1 است، بنابراین بیایید
244
00:12:13,980 –> 00:12:18,040
پیش بینی ها را بگوییم و سپس در این شاخص ها
245
00:12:18,040 –> 00:12:23,020
که در آن X است. ستون کوچکتر از آستانه خود نقطه
246
00:12:23,020 –> 00:12:26,110
است، پس این پیش بینی ها
247
00:12:26,110 –> 00:12:30,340
منهای 1 هستند و در حالت دیگر،
248
00:12:30,340 –> 00:12:34,810
بنابراین اگر قطب ما منهای 1 باشد،
249
00:12:34,810 –> 00:12:36,940
می خواهیم دقیقاً برعکس این کار را انجام دهیم،
250
00:12:36,940 –> 00:12:40,030
بنابراین اجازه دهید این را کپی کنم، اما می
251
00:12:40,030 –> 00:12:43,810
خواهیم بگوییم که آیا x مقدار بیشتر از
252
00:12:43,810 –> 00:12:47,170
آستانه ما است، پس اینها پیش بینی های منهای 1 هستند،
253
00:12:47,170 –> 00:12:50,740
بنابراین بله، این تمام کاری است که
254
00:12:50,740 –> 00:12:53,680
بیخ تصمیم ما انجام می دهد و سپس
255
00:12:53,680 –> 00:12:57,370
می توانیم پیش بینی ها را برگردانیم، بنابراین
256
00:12:57,370 –> 00:12:59,290
این کلاس برای تصمیم گیری
257
00:12:59,290 –> 00:13:02,110
s




![فیلم آموزشی: پیپ [حل شده] به عنوان یک دستور داخلی یا خارجی، برنامه قابل اجرا یا فایل دسته ای شناسایی نمی شود](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/An2UBGAlzpUimage2.jpg)