در این مطلب، ویدئو PYTHON SKLEARN – انتخاب مدل: Train_test_split، Cross Validation، GridSearchCV (21/30) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:49
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:01,979
سلام و به این 21 خوش آمدید
2
00:00:01,979 –> 00:00:04,710
ویدیوی سری پایتون ویژه ماشین
3
00:00:04,710 –> 00:00:06,839
در آخرین ویدیو دیدیم که چگونه
4
00:00:06,839 –> 00:00:08,809
توسعه مدل های یادگیری
5
00:00:08,809 –> 00:00:11,940
تحت نظارت با شش که اکنون می دهد
6
00:00:11,940 –> 00:00:13,889
من تکنیک ها را به شما نشان خواهم داد
7
00:00:13,889 –> 00:00:16,789
برای آموزش یک مدل آن را بهینه کنید
8
00:00:16,789 –> 00:00:19,920
آن را با روش شناسی صحیح ارزیابی کنید
9
00:00:19,920 –> 00:00:22,680
نحوه ایجاد 1 37 و 1 فنجان را خواهیم دید
10
00:00:22,680 –> 00:00:25,890
7 با تابع traint تقسیم می شود
11
00:00:25,890 –> 00:00:28,470
سپس خواهیم دید که چگونه a را اعتبار سنجی کنیم
12
00:00:28,470 –> 00:00:30,689
مدل با تکنیک متقاطع
13
00:00:30,689 –> 00:00:32,759
اعتبار سنجی سپس خواهیم دید که چگونه
14
00:00:32,759 –> 00:00:35,340
بهبود یک مدل با استفاده از شبکه
15
00:00:35,340 –> 00:00:38,100
جستجو و همچنین منحنی یادگیری شما
16
00:00:38,100 –> 00:00:41,149
آماده ای بیا بریم
17
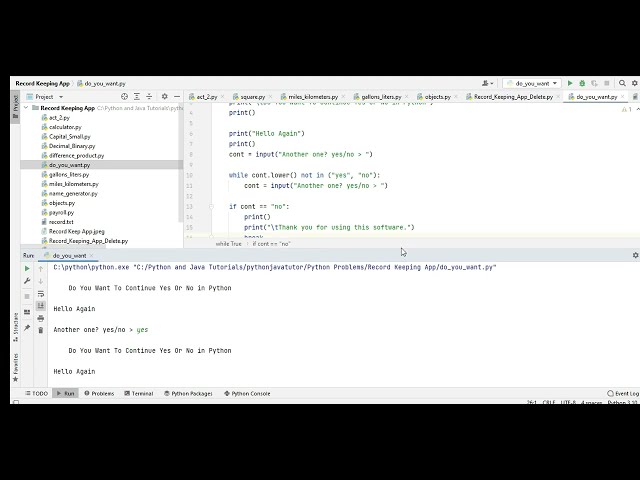
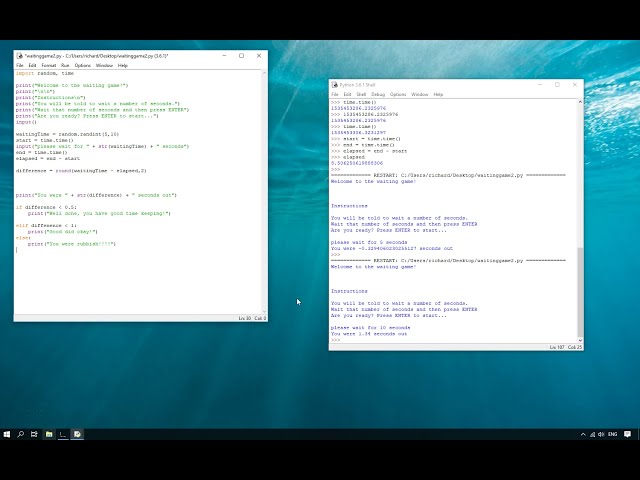
00:00:43,770 –> 00:00:46,690
در ماشین آنلاین هرگز نباید
18
00:00:46,690 –> 00:00:48,760
عملکرد مدل خود را ارزیابی کنید
19
00:00:48,760 –> 00:00:51,040
بر روی همان داده هایی که استفاده می شد
20
00:00:51,040 –> 00:00:53,600
آموزش او چرا
21
00:00:53,600 –> 00:00:55,640
خوب تصور کنید آموزش الف
22
00:00:55,640 –> 00:00:57,980
ماشین زیر عکس گربه ها سپس
23
00:00:57,980 –> 00:01:00,410
شما آن را در همان عکس ها در
24
00:01:00,410 –> 00:01:03,440
این خیلی آسان است که ماشین بداند
25
00:01:03,440 –> 00:01:05,209
که آنها گربه هستند زیرا او قبلاً بوده است
26
00:01:05,209 –> 00:01:06,350
این تصاویر را دید
27
00:01:06,350 –> 00:01:08,810
با این حال آنچه جالب تر است
28
00:01:08,810 –> 00:01:10,940
این است که دستگاه را روی آن تست کنید
29
00:01:10,940 –> 00:01:13,729
داده هایی که او هرگز تا ما ندیده است
30
00:01:13,729 –> 00:01:16,100
ایده ای از عملکرد آینده خود خواهد داشت
31
00:01:16,100 –> 00:01:17,090
در زندگی واقعی
32
00:01:17,090 –> 00:01:19,100
بنابراین وقتی یادگیری ماشینی را انجام می دهیم
33
00:01:19,100 –> 00:01:22,460
ما همیشه داده های خود را 7 به دو تقسیم می کنیم
34
00:01:22,460 –> 00:01:25,670
قطعات 1 37 که داده ها هستند
35
00:01:25,670 –> 00:01:28,520
برای آموزش مدل استفاده می شود
36
00:01:28,520 –> 00:01:31,220
یک آزمون فقط برای
37
00:01:31,220 –> 00:01:33,679
ارزیابی مدل به طور کلی قرار داده ایم
38
00:01:33,679 –> 00:01:36,409
80 درصد از داده های دنباله 17 و 20 درصد
39
00:01:36,409 –> 00:01:37,670
در آزمون 7
40
00:01:37,670 –> 00:01:40,970
پس از آن ما تابلوئیدهای فشار y سلطنت می کنند
41
00:01:40,970 –> 00:01:43,429
که در روش برازش استفاده خواهد شد
42
00:01:43,429 –> 00:01:45,920
برای آموزش مدل و جداول
43
00:01:45,920 –> 00:01:48,950
x تست ها y تست هایی که در آن استفاده خواهیم کرد
44
00:01:48,950 –> 00:01:51,590
روش نمره برای ارزیابی مدل ما
45
00:01:51,590 –> 00:01:53,780
برای انجام همه این کارها در پایتون ما
46
00:01:53,780 –> 00:01:56,780
از تابع تقسیم تست کرنش استفاده کنید
47
00:01:56,780 –> 00:01:59,119
که از ماژول مدل به ما می رسد
48
00:01:59,119 –> 00:02:01,219
انتخاب علاوه بر آن در این است
49
00:02:01,219 –> 00:02:03,049
ماژول که ما همه را پیدا خواهیم کرد
50
00:02:03,049 –> 00:02:04,759
توابع مهمی که در آن خواهیم دید
51
00:02:04,759 –> 00:02:05,390
این ویدیو
52
00:02:05,390 –> 00:02:07,880
بنابراین من در اینجا مجموعه داده های را وارد می کنم
53
00:02:07,880 –> 00:02:09,799
گل زنبق را می توانیم ببینیم که شامل
54
00:02:09,799 –> 00:02:13,579
150 نمونه برای تقسیم این مجموعه داده
55
00:02:13,579 –> 00:02:16,670
ما تقسیم تست کرنش تابع را وارد می کنیم
56
00:02:16,670 –> 00:02:19,430
سپس آرایه های x 13 x ایجاد می کنیم
57
00:02:19,430 –> 00:02:23,000
تست ها در آنجا قرار می گیرند و آنجا می مانند و ما انجام می دهیم
58
00:02:23,000 –> 00:02:24,709
پاس داده x y
59
00:02:24,709 –> 00:02:27,350
در عملکرد سه بعدی بعد از آن
60
00:02:27,350 –> 00:02:29,600
شما می توانید درصدی را برای دادن انتخاب کنید
61
00:02:29,600 –> 00:02:33,140
به m در مجموعه روند و در آزمون 7
62
00:02:33,140 –> 00:02:36,380
برای مثال اگر بنویسم که اندازه آزمون است
63
00:02:36,380 –> 00:02:38,299
برابر با 0.5
64
00:02:38,299 –> 00:02:40,910
زمانی که ما 50 درصد از داده ها را در آن خواهیم داشت
65
00:02:40,910 –> 00:02:43,670
شمع هفت و 50 درصد در ست سوم
66
00:02:43,670 –> 00:02:45,590
این نتیجه زیر را به ما می دهد
67
00:02:45,590 –> 00:02:48,859
75 امتیاز در ست سوم و 75 امتیاز
68
00:02:48,859 –> 00:02:51,530
در تست 7 همانطور که دیدیم قرار دادیم
69
00:02:51,530 –> 00:02:53,140
عمومی 20% 2
70
00:02:53,140 –> 00:02:55,360
در تست 7 بنابراین من می نویسم شما دارید
71
00:02:55,360 –> 00:02:58,660
zeit در پایان برابر 0.2 است
72
00:02:58,660 –> 00:03:01,840
این چیزی است که 37 ما به نظر می رسد و ما
73
00:03:01,840 –> 00:03:03,819
تست 7 بعد از این تقسیم
74
00:03:03,819 –> 00:03:05,680
اگر شما همان ابرها را دریافت نکنید
75
00:03:05,680 –> 00:03:08,410
امتیاز در هنگام استفاده طبیعی است
76
00:03:08,410 –> 00:03:10,600
عملکرد تقسیم تست تریم
77
00:03:10,600 –> 00:03:13,770
داده ها را 7 و به طور تصادفی به هم بزنید
78
00:03:13,770 –> 00:03:16,660
قبل از اینکه به دو قسمت تقسیم شود
79
00:03:16,660 –> 00:03:19,030
اگر بخواهی می توانی کنترل کنی
80
00:03:19,030 –> 00:03:22,450
تصادفی بودن با تنظیم آرگومان تصادفی
81
00:03:22,450 –> 00:03:24,700
روی یک عدد مثلا من I بنویسید
82
00:03:24,700 –> 00:03:27,820
برای این آموزش نیز 5 مورد را انتخاب می کنم
83
00:03:27,820 –> 00:03:29,500
شما باید ابرها را از
84
00:03:29,500 –> 00:03:31,690
نکات بعدی اکنون وقت آن است
85
00:03:31,690 –> 00:03:34,080
برای راندن یک مدل ماشین از
86
00:03:34,080 –> 00:03:37,090
بنابراین بازی یک مدل از kane & poor’s ایجاد می کند
87
00:03:37,090 –> 00:03:39,190
طبقه پایین تر با تثبیت عدد
88
00:03:39,190 –> 00:03:41,830
از همسایگان به 1 برای لحظه و برای
89
00:03:41,830 –> 00:03:43,630
مدل خود را به درستی آموزش دهیم
90
00:03:43,630 –> 00:03:46,300
x trail و y trail را می گذراند
91
00:03:46,300 –> 00:03:49,780
در روش برازش و ما می توانیم آن را ببینیم
92
00:03:49,780 –> 00:03:52,480
اگر مدل خود را بر روی همین موارد ارزیابی کنیم
93
00:03:52,480 –> 00:03:54,730
داده ها سپس امتیازی را بدست می آوریم
94
00:03:54,730 –> 00:03:57,730
100% اما آیا این به این معنی است
95
00:03:57,730 –> 00:04:00,100
مدل ما در 100٪ موفقیت خود را
96
00:04:00,100 –> 00:04:03,549
البته پیش بینی در آینده
97
00:04:03,549 –> 00:04:05,560
نه، این همان چیزی است که در ابتدای کتاب دیدیم
98
00:04:05,560 –> 00:04:07,930
ویدیو با مثال گربه ها برای
99
00:04:07,930 –> 00:04:09,820
از عملکرد آینده ایده بگیرید
100
00:04:09,820 –> 00:04:12,640
مدل ما باید روی آن تست شود
101
00:04:12,640 –> 00:04:14,079
داده های تست 7
102
00:04:14,079 –> 00:04:16,180
یعنی داده هایی که هرگز
103
00:04:16,180 –> 00:04:18,950
بنابراین همه آن را با 100 جایگزین کنید
104
00:04:18,950 –> 00:04:23,890
و در آنجا ما نمره 90٪ را می گیریم
105
00:04:26,940 –> 00:04:29,100
حالا شما می دانید چگونه
106
00:04:29,100 –> 00:04:32,610
یک مدل را آموزش دهید و به درستی ارزیابی کنید
107
00:04:32,610 –> 00:04:33,960
فراگیری ماشین
108
00:04:33,960 –> 00:04:35,940
اکنون به عنوان داده های ساده
109
00:04:35,940 –> 00:04:38,820
وظیفه شما بهبود اوست
110
00:04:38,820 –> 00:04:43,220
مدل کنید و امتیاز 91 92 را بگیرید
111
00:04:43,220 –> 00:04:47,730
99٪ برای آن لازم است که تنظیم شود
112
00:04:47,730 –> 00:04:50,070
کمی مدل خود را هایپر تنظیمات کنید
113
00:04:50,070 –> 00:04:51,810
مثل زمانی که دستگیره های a را می چرخانید
114
00:04:51,810 –> 00:04:54,210
رادیو برای یافتن بهترین سیگنال
115
00:04:54,210 –> 00:04:56,220
به عنوان مثال اگر تعداد را تغییر دهیم
116
00:04:56,220 –> 00:04:59,580
همسایگان با تنظیم آن روی 3 سپس می بینیم
117
00:04:59,580 –> 00:05:02,520
که ما امتیاز 93% را در مورد آن بدست می آوریم
118
00:05:02,520 –> 00:05:04,380
داده های آزمایشی بهبود یافته است
119
00:05:04,380 –> 00:05:06,990
حالا بد نیست بگوییم چالش
120
00:05:06,990 –> 00:05:09,750
تعدادی از همسایگان برابر با 6 سپس ما
121
00:05:09,750 –> 00:05:11,280
96% می گیرد
122
00:05:11,280 –> 00:05:14,310
اما اگر مدل خود را تنظیم می کنیم مراقب باشیم
123
00:05:14,310 –> 00:05:17,490
با بهینه سازی عملکرد آن در آزمون
124
00:05:17,490 –> 00:05:19,280
7 کاری که ما انجام می دهیم را دوست داریم
125
00:05:19,280 –> 00:05:22,170
پس ما دیگر نمی توانیم از آن استفاده کنیم
126
00:05:22,170 –> 00:05:24,600
داده های تست 7 انجام شود
127
00:05:24,600 –> 00:05:27,300
ارزیابی نهایی مدل ما
128
00:05:27,300 –> 00:05:29,400
چرا خوب این چیزی است که ما در آن دیدیم
129
00:05:29,400 –> 00:05:31,919
شروع ویدیو برای ارزیابی یک مدل
130
00:05:31,919 –> 00:05:34,890
باید در معرض داده هایی قرار گیرد که آن را نشان می دهد
131
00:05:34,890 –> 00:05:38,250
طلا ندیده است اگر ما حل و فصل خود را
132
00:05:38,250 –> 00:05:40,650
مدل بر روی داده های آزمون 7
133
00:05:40,650 –> 00:05:44,100
سپس او به طور غیر مستقیم اینها را دیده است
134
00:05:44,100 –> 00:05:47,100
داده از آنجایی که برای آن تنظیم شده است
135
00:05:47,100 –> 00:05:49,800
به همین دلیل یک سوم را حذف کردیم
136
00:05:49,800 –> 00:05:51,600
بخش در داده های ما 7
137
00:05:51,600 –> 00:05:55,110
اعتبار 7 این نامیده می شود
138
00:05:55,110 –> 00:05:57,480
بخش به ما امکان جستجوی
139
00:05:57,480 –> 00:05:59,490
تنظیمات مدل که می دهد
140
00:05:59,490 –> 00:06:01,650
عملکرد بهتر در حین نگهداری
141
00:06:01,650 –> 00:06:04,470
جدا از داده های آزمون 7 برای
142
00:06:04,470 –> 00:06:06,210
ارزیابی ماشین بر روی داده ها
143
00:06:06,210 –> 00:06:08,669
که او هرگز چنین ندیده است وقتی ما
144
00:06:08,669 –> 00:06:10,710
می خواهد دو مدل ماشین را با هم مقایسه کند
145
00:06:10,710 –> 00:06:11,100
یادگیری
146
00:06:11,100 –> 00:06:13,260
برای مثال یک کلاس kane و edge i
147
00:06:13,260 –> 00:06:15,330
کمتر با سه سال و یک سال دیگر
148
00:06:15,330 –> 00:06:16,860
با شش همسایه
149
00:06:16,860 –> 00:06:18,990
ما با آموزش این دو شروع می کنیم
150
00:06:18,990 –> 00:06:20,940
مدل در چت سپس ما
151
00:06:20,940 –> 00:06:23,190
کسی را انتخاب می کند که آن را داشته باشد
152
00:06:23,190 –> 00:06:25,800
عملکرد بهتر در اعتبارسنجی
153
00:06:25,800 –> 00:06:26,220
7
154
00:06:26,220 –> 00:06:29,820
سپس میتوانیم این مدل را ارزیابی کنیم
155
00:06:29,820 –> 00:06:32,220
که هفت تا ایده ای از آن بدست آورید
156
00:06:32,220 –> 00:06:32,670
ضرر – زیان
157
00:06:32,670 –> 00:06:34,650
همان سال در زندگی واقعی اینجا اگر شما
158
00:06:34,650 –> 00:06:37,470
فهمیدی که عالیه
159
00:06:37,470 –> 00:06:39,600
تقریباً همه چیز فهمیده می شود زیرا باقی می ماند
160
00:06:39,600 –> 00:06:40,890
آخرین چیزی که باید دید
161
00:06:40,890 –> 00:06:43,320
در واقع چه چیزی این را به ما تضمین می کند
162
00:06:43,320 –> 00:06:47,130
روشی که ما داده ها را تقسیم می کنیم 7 است
163
00:06:47,130 –> 00:06:49,740
خوب است اگر در حین تمرین اتفاق بیفتد
164
00:06:49,740 –> 00:06:52,170
سپس با اعتبارسنجی دو مدل ما در
165
00:06:52,170 –> 00:06:54,450
بخش دیگری از داده ها و سپس ما
166
00:06:54,450 –> 00:06:56,700
متوجه خواهد شد که مدل b است
167
00:06:56,700 –> 00:06:57,150
بهترین
168
00:06:57,150 –> 00:07:00,090
چه کنیم پس خوب صورت
169
00:07:00,090 –> 00:07:02,220
برای این وضعیت راه حلی وجود دارد
170
00:07:02,220 –> 00:07:10,830
این لاکراس اعتبارسنجی لاکراس است
171
00:07:10,830 –> 00:07:13,860
اعتبار سنجی شامل آموزش است
172
00:07:13,860 –> 00:07:16,440
مدل ما را روی چندین مورد تایید کرد
173
00:07:16,440 –> 00:07:20,040
خطوط احتمالی حرم 7 در
174
00:07:20,040 –> 00:07:22,440
به عنوان مثال با برش مجموعه دوقلو به پنج
175
00:07:22,440 –> 00:07:24,450
قطعات ما می توانیم مدل خود را آموزش دهیم
176
00:07:24,450 –> 00:07:27,060
در چهار قسمت اول سپس
177
00:07:27,060 –> 00:07:29,880
سپس در قسمت پنجم اعتبار سنجی کنید
178
00:07:29,880 –> 00:07:32,220
ما همه چیز را دوباره برای همه انجام خواهیم داد
179
00:07:32,220 –> 00:07:33,600
تنظیمات ممکن
180
00:07:33,600 –> 00:07:36,360
در انتها ما به طور میانگین پنج را خواهیم گرفت
181
00:07:36,360 –> 00:07:38,880
نمره هایی که می گیریم و غیره
182
00:07:38,880 –> 00:07:41,130
وقتی می خواهید دو مدل را با هم مقایسه کنید
183
00:07:41,130 –> 00:07:44,370
سپس ما مطمئن خواهیم شد که کسی را که دارد می گیریم
184
00:07:44,370 –> 00:07:46,260
به طور متوسط بهترین ها را داشت
185
00:07:46,260 –> 00:07:46,890
کارایی
186
00:07:46,890 –> 00:07:49,350
گذرا بدانید که چندین وجود دارد
187
00:07:49,350 –> 00:07:51,510
روش های حکاکی 3 هفت
188
00:07:51,510 –> 00:07:53,640
با تکنیک اعتبارسنجی لاکراس
189
00:07:53,640 –> 00:07:55,770
همه آنها در سایت به تفصیل آمده است
190
00:07:55,770 –> 00:07:57,660
از این کیت های اسکله و آن چیزی که ما از آن آمده ایم
191
00:07:57,660 –> 00:08:00,480
برای دیدن بیل او از کیس تا می شود
192
00:08:00,480 –> 00:08:02,700
همه این کارها را در پایتون انجام دهید و ما آن را وارد می کنیم
193
00:08:02,700 –> 00:08:06,720
تابع امتیاز متقاطع val در این
194
00:08:06,720 –> 00:08:09,000
تابع فقط عبور ما
195
00:08:09,000 –> 00:08:12,840
داده های دنباله x و y را مدل کنید
196
00:08:12,840 –> 00:08:15,780
و همچنین تعداد انشعابات که ما
197
00:08:15,780 –> 00:08:17,760
می خواهد در اعتبار سنجی متقاطع ما توسط
198
00:08:17,760 –> 00:08:20,430
نمونه cv برابر با 5 به صورت اختیاری در
199
00:08:20,430 –> 00:08:22,770
همچنین می تواند نشان دهد که متریک است
200
00:08:22,770 –> 00:08:24,720
ما می خواهیم برای ارزیابی خود استفاده کنیم
201
00:08:24,720 –> 00:08:27,060
مدل پیش فرض خواهد بود
202
00:08:27,060 –> 00:08:29,220
معیارهای مرتبط با برآوردگر ما
203
00:08:29,220 –> 00:08:30,700
پس اینجا
204
00:08:30,700 –> 00:08:32,980
اگر بتوانیم معیارها افزایش یافته است
205
00:08:32,980 –> 00:08:35,860
دیگری را در ماژول متریک انتخاب کنید
206
00:08:35,860 –> 00:08:39,250
بنابراین با اجرای همه اینها 5 می گیریم
207
00:08:39,250 –> 00:08:41,590
امتیاز برای پنج تقسیم لاکراس ما
208
00:08:41,590 –> 00:08:44,049
بنابراین ما می توانیم اعتبار سنجی را انجام دهیم
209
00:08:44,049 –> 00:08:47,110
میانگین اکنون ما می توانیم ارزیابی کنیم
210
00:08:47,110 –> 00:08:49,720
مدل های مختلف برای حفظ یکی
211
00:08:49,720 –> 00:08:51,580
که بهترین عملکرد را دارد
212
00:08:51,580 –> 00:08:53,830
مثال وقتی و اعداد 1 است
213
00:08:53,830 –> 00:08:56,860
ما 97 درصد می گیریم
214
00:08:56,860 –> 00:09:00,370
کی و اعداد 2 96 است
215
00:09:00,370 –> 00:09:04,750
زمانی که دوباره برابر با 3.97 شد
216
00:09:04,750 –> 00:09:08,560
برابر است با 4 96 پس بیشتر برویم
217
00:09:08,560 –> 00:09:10,390
به سرعت ما می توانیم همه آن را در یک آزمایش کنیم
218
00:09:10,390 –> 00:09:13,270
حلقه قوی ضبط هر امتیاز
219
00:09:13,270 –> 00:09:15,310
که در یک لیست قرار می دهیم
220
00:09:15,310 –> 00:09:18,310
سپس با نمایش امتیاز اعتبارسنجی
221
00:09:18,310 –> 00:09:21,280
نتایج او را با مارک لیب به دست می آوریم
222
00:09:21,280 –> 00:09:22,510
نمودار زیر
223
00:09:22,510 –> 00:09:25,540
و بنابراین می توانیم ببینیم که به دست خواهیم آورد
224
00:09:25,540 –> 00:09:27,160
بهترین عملکرد زمانی که
225
00:09:27,160 –> 00:09:29,950
تعداد همسایگانی خواهد داشت که در هستند
226
00:09:29,950 –> 00:09:32,290
حدود 10 در این آب ها
227
00:09:32,290 –> 00:09:34,270
اما شما می دانید که این کل حلقه چیست
228
00:09:34,270 –> 00:09:36,070
با صدای بلند حتی لازم نیست
229
00:09:36,070 –> 00:09:37,900
آن را بنویسید زیرا یک تابع وجود دارد
230
00:09:37,900 –> 00:09:40,060
از این کیت های هلند که اجازه می دهد تا ایجاد
231
00:09:40,060 –> 00:09:40,960
این نوع گرافیک
232
00:09:40,960 –> 00:09:45,450
این تابع اعتبارسنجی اصلی است
233
00:09:47,649 –> 00:09:50,839
توسط تابع اعتبارسنجی منحنی دارند
234
00:09:50,839 –> 00:09:53,300
مدل ما را که من تعریف کردم می گذراند
235
00:09:53,300 –> 00:09:55,399
اینجا در خط دیگری و همچنین ما
236
00:09:55,399 –> 00:09:58,519
داده های خرد شده و سپس ما نشان می دهیم
237
00:09:58,519 –> 00:10:00,980
در یک رشته کاراکتر نام
238
00:10:00,980 –> 00:10:02,779
پارامترهای هایپر مورد نظر
239
00:10:02,779 –> 00:10:03,589
تنظیم کنید
240
00:10:03,589 –> 00:10:06,290
سپس در قالب تئاتر می رویم
241
00:10:06,290 –> 00:10:08,360
مقادیر مختلف را تعیین کنید که
242
00:10:08,360 –> 00:10:10,399
ما می خواهیم برای این هایپر تست کنیم
243
00:10:10,399 –> 00:10:12,589
پارامترها بنابراین من در اینجا ایجاد یک
244
00:10:12,589 –> 00:10:15,800
جدول از 1 به 50 می رسد
245
00:10:15,800 –> 00:10:17,660
در نهایت فراموش نکنید که مشخص کنید
246
00:10:17,660 –> 00:10:19,850
تعداد برش هایی که می خواهید داشته باشید
247
00:10:19,850 –> 00:10:22,639
در اعتبار متقاطع ما این است
248
00:10:22,639 –> 00:10:25,430
بنابراین تابع تمام نمرات را محاسبه می کند
249
00:10:25,430 –> 00:10:27,529
برای ست دوقلو و تمام امتیازات برای
250
00:10:27,529 –> 00:10:28,639
اعتبار سنجی 7
251
00:10:28,639 –> 00:10:31,940
بنابراین اگر ابعاد آن را بررسی کنیم
252
00:10:31,940 –> 00:10:34,160
برای مثال امتیاز اعتبار سنجی را بدست می آوریم
253
00:10:34,160 –> 00:10:37,310
49 خط برای 49 مقداری که داریم
254
00:10:37,310 –> 00:10:40,370
در اینجا و پنج ستون برای پنج مورد آزمایش شده است
255
00:10:40,370 –> 00:10:42,589
بنابراین ستون های اعتبار متقاطع ما
256
00:10:42,589 –> 00:10:45,290
برای به دست آوردن میانگین نمره برای هر کدام
257
00:10:45,290 –> 00:10:47,660
اعتبار متقاطع ما هنوز باید انجام دهیم
258
00:10:47,660 –> 00:10:51,290
میانگین 2 هر ردیف یعنی
259
00:10:51,290 –> 00:10:54,800
میانگین با توجه به kz1 ما
260
00:10:54,800 –> 00:10:57,139
آرایه ای از نی را به دست می آوریم
261
00:10:57,139 –> 00:11:00,649
آرایه ای که به سادگی شامل 49 خواهد بود
262
00:11:00,649 –> 00:11:03,079
عناصر و این آرایه ما قادر خواهیم بود
263
00:11:03,079 –> 00:11:05,959
پوستر با نوشته mc laughlin
264
00:11:05,959 –> 00:11:08,329
روی آبسیسا،