در این مطلب، ویدئو آموزش پایتون: آزمون تی دانشجویی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:04:11
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,580 –> 00:00:03,189
میتوان انواع
2
00:00:03,189 –> 00:00:04,470
الگوها را در دادههای
3
00:00:04,470 –> 00:00:07,509
sar مورد انتظار پیدا کرد، در حالی که سایرین
4
00:00:07,509 –> 00:00:11,559
شگفتانگیزتر هستند، اما اکثر مجموعههای داده
5
00:00:11,559 –> 00:00:14,469
شامل تغییرات تصادفی نیز هستند، با دانستن این موضوع
6
00:00:14,469 –> 00:00:17,490
چگونه میتوانیم از یک مشاهده ساده
7
00:00:17,490 –> 00:00:21,880
به نتیجه قابل اعتماد برویم، فرض کنیم
8
00:00:21,880 –> 00:00:23,650
وزن بدن دو نمونه از دو نمونه را داریم.
9
00:00:23,650 –> 00:00:28,029
گروههای افراد a و B وقتی آن را ترسیم
10
00:00:28,029 –> 00:00:30,699
میکنیم، به نظر میرسد روندی را مشاهده میکنیم که در آن
11
00:00:30,699 –> 00:00:33,910
میانگین گروه برای نمونه B بزرگتر از آن است که
12
00:00:33,910 –> 00:00:37,690
برای برخی بازیها، این تفاوت واقعی است یا
13
00:00:37,690 –> 00:00:41,160
تغییرات ساده تصادفی
14
00:00:41,410 –> 00:00:44,320
برای نتیجهگیری، باید
15
00:00:44,320 –> 00:00:46,510
بین دو حالت یا
16
00:00:46,510 –> 00:00:50,740
فرضیههای آماری نقطه شروع ما
17
00:00:50,740 –> 00:00:53,860
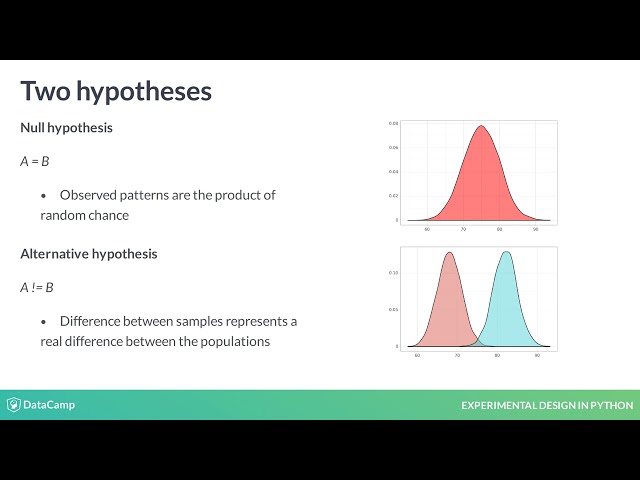
فرضیه صفر است،
18
00:00:53,860 –> 00:00:56,290
هیچ اتفاق جالبی روی نمیدهد و
19
00:00:56,290 –> 00:00:58,540
الگوهای مشاهدهشده فقط
20
00:00:58,540 –> 00:01:00,690
محصول شانس تصادفی هستند
21
00:01:00,690 –> 00:01:03,600
با شواهد کافی که میتوانیم فرضیه صفر را رد
22
00:01:03,600 –> 00:01:06,360
کنیم و
23
00:01:06,360 –> 00:01:08,940
24
00:01:08,940 –> 00:01:11,270
در تفاوت بین اینها به فرضیه جایگزین جالبتر روی آوریم. نمونه
25
00:01:11,270 –> 00:01:13,260
ها تفاوت واقعی بین
26
00:01:13,260 –> 00:01:15,899
جمعیت ها را نشان می دهد،
27
00:01:15,899 –> 00:01:18,179
اما چه زمانی می دانیم که فرضیه صفر را
28
00:01:18,179 –> 00:01:21,600
در اینجا رد کنیم، به سراغ آن می رویم. دو
29
00:01:21,600 –> 00:01:25,109
آمار، p-value نشان دهنده این
30
00:01:25,109 –> 00:01:27,359
احتمال است که
31
00:01:27,359 –> 00:01:29,609
اگر فرضیه صفر درست باشد، توزیع مقادیر جدید مشاهده شده رخ می دهد
32
00:01:29,609 –> 00:01:32,080
،
33
00:01:32,080 –> 00:01:35,650
ما نمی توانیم 100٪ مطمئن باشیم که الگوی ما
34
00:01:35,650 –> 00:01:37,330
به دلیل شانس تصادفی ظاهر نشده است،
35
00:01:37,330 –> 00:01:39,580
اما می توانیم احتمال را پیدا کنیم.
36
00:01:39,580 –> 00:01:41,950
شانس تصادفی
37
00:01:41,950 –> 00:01:44,200
یک الگوی داده شده را تولید می کند، این مقدار
38
00:01:44,200 –> 00:01:48,130
p است، هر چه مقدار p کوچکتر باشد،
39
00:01:48,130 –> 00:01:51,130
احتمال کمتری وجود دارد که فرضیه صفر بتواند
40
00:01:51,130 –> 00:01:54,940
مشاهدات ما را توضیح دهد،
41
00:01:54,940 –> 00:01:57,430
زمانی که پیوی زیر یک مقدار



![فیلم آموزشی: 18. وراثت چندگانه [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/ttMX3Ns_0oYimage2.jpg)