در این مطلب، ویدئو 60 – چگونه از Random Forest در پایتون استفاده کنیم؟ با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:32:17
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,110 –> 00:00:02,550
سلام بچه ها شما در حال تماشای ویدیوهای آموزشی پایتون
2
00:00:02,550 –> 00:00:04,440
در کانال یوتیوب من Python برای
3
00:00:04,440 –> 00:00:07,020
میکروسکوپ هستید، بنابراین در آخرین آموزش
4
00:00:07,020 –> 00:00:09,870
در مورد تئوری یا اصول
5
00:00:09,870 –> 00:00:12,179
پشت جنگل های تصادفی صحبت کردم و امروز بیایید
6
00:00:12,179 –> 00:00:14,460
جلوتر برویم و چند خط کد برای
7
00:00:14,460 –> 00:00:16,699
پیاده سازی جنگل های تصادفی در پایتون بنویسیم. به
8
00:00:16,699 –> 00:00:21,060
همین دلیل من از یک جدول نیمه ساخته شده استفاده می کنم
9
00:00:21,060 –> 00:00:23,490
در واقع اجازه دهید ادامه دهم و
10
00:00:23,490 –> 00:00:26,010
داده هایی را که قصد کار با آنها را دارم به شما نشان دهم، بنابراین در
11
00:00:26,010 –> 00:00:29,670
اینجا فقط برای توضیح سریع اینجاست
12
00:00:29,670 –> 00:00:31,859
که من چند کاربر خوب دارم،
13
00:00:31,859 –> 00:00:35,270
بنابراین کاربر شماره 1 2 3 4 و غیره و
14
00:00:35,270 –> 00:00:37,500
هر کاربری
15
00:00:37,500 –> 00:00:40,170
که منظورم این است که با مشخصات این
16
00:00:40,170 –> 00:00:41,040
کاربر خاص همراه است،
17
00:00:41,040 –> 00:00:43,680
منظورم کاربری شماره 1 23 ساله است، خوب
18
00:00:43,680 –> 00:00:46,530
کاربر شماره 2 65 ساله است و به همین ترتیب
19
00:00:46,530 –> 00:00:48,600
من چند کاربر از این قبیل دارم که تعداد آنها زیاد نیست
20
00:00:48,600 –> 00:00:52,500
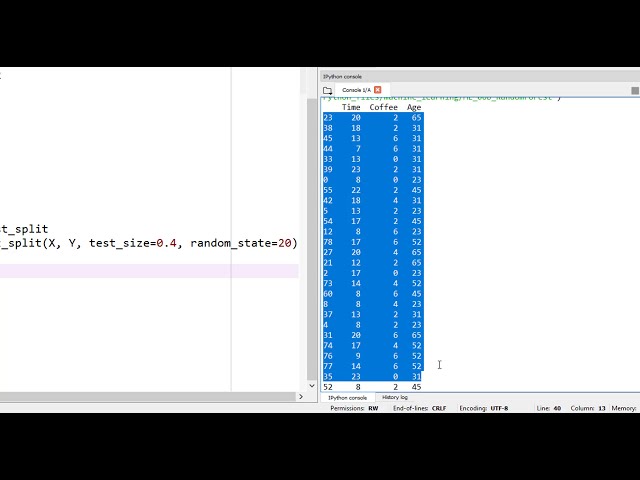
در واقع فکر می کنم دارم. اکنون 5 کاربر هر
21
00:00:52,500 –> 00:00:56,190
کاربر در یک زمان خاص از روز تصاویر را تجزیه و تحلیل می کند،
22
00:00:56,190 –> 00:00:58,940
بنابراین در ساعت 8 صبح
23
00:00:58,940 –> 00:01:03,149
این کاربر قهوه نخورده و توانست
24
00:01:03,149 –> 00:01:05,640
20 تصویر را تجزیه و تحلیل کند و برای آن می گوییم
25
00:01:05,640 –> 00:01:08,340
بهره وری بسیار خوب است
26
00:01:08,340 –> 00:01:13,890
و همین کاربر فرض کنید. در 1700 مانند
27
00:01:13,890 –> 00:01:17,240
بعد از ظهر بدون c offee تجزیه و تحلیل 18
28
00:01:17,240 –> 00:01:19,409
بهره وری کمی پایین آمد، باید
29
00:01:19,409 –> 00:01:23,009
بگویم که این چیزی نیست جز اینکه
30
00:01:23,009 –> 00:01:25,830
یک کاربر خاص در
31
00:01:25,830 –> 00:01:28,439
یک زمان معین از روز با داشتن
32
00:01:28,439 –> 00:01:30,270
مقدار مشخصی فنجان قهوه، چند تصویر را تجزیه و تحلیل کرده است.
33
00:01:30,270 –> 00:01:33,030
34
00:01:33,030 –> 00:01:36,450
اگر تعداد تصاویر
35
00:01:36,450 –> 00:01:39,750
تجزیه و تحلیل شده 17 یا بیشتر یا بیشتر
36
00:01:39,750 –> 00:01:42,329
باشد، روز خوبی است بله یا
37
00:01:42,329 –> 00:01:44,130
بهره وری خوب است و اگر کمتر باشد
38
00:01:44,130 –> 00:01:46,770
بهره وری بد است، این بهترین
39
00:01:46,770 –> 00:01:49,560
داده ای است که می توانم دوباره به دست بیاورم اگر
40
00:01:49,560 –> 00:01:51,840
داده های واقعی داشته باشید. بدیهی است که ادامه دهید
41
00:01:51,840 –> 00:01:54,750
و روی دادههای خود کار کنید، اما این
42
00:01:54,750 –> 00:01:57,750
به ما کمک میکند تا اجرای جنگلهای تصادفی را درک کنیم،
43
00:01:57,750 –> 00:01:59,820
این سؤال در
44
00:01:59,820 –> 00:02:03,619
آینده درست است، وقتی اطلاعاتی در مورد
45
00:02:03,619 –> 00:02:07,409
افراد خاص در سن خاص دریافت کنیم که
46
00:02:07,409 –> 00:02:09,598
مقدار مشخصی قهوه میخورند و
47
00:02:09,598 –> 00:02:11,760
در زمان معینی روی تصاویر کار میکنند. ما
48
00:02:11,760 –> 00:02:13,230
باید بتوانیم پیش بینی کنیم که آیا
49
00:02:13,230 –> 00:02:13,800
50
00:02:13,800 –> 00:02:15,780
محصول خوب یا بد خواهد بود،
51
00:02:15,780 –> 00:02:18,510
این موضوع مشکلی ندارد، بنابراین اکنون بیایید وارد
52
00:02:18,510 –> 00:02:22,310
رابط عنکبوتی شویم و کدنویسی
53
00:02:22,310 –> 00:02:25,700
را شروع کنیم و با وارد کردن درست شروع کنیم. t
54
00:02:25,700 –> 00:02:30,960
کتابخانه بنابراین پانداها به عنوان PD زیرا ما باید
55
00:02:30,960 –> 00:02:34,710
داده ها را در یک قاب داده مدیریت کنیم و
56
00:02:34,710 –> 00:02:40,470
از matplotlib دوباره نمودار PI را به عنوان PLT وارد
57
00:02:40,470 –> 00:02:42,420
کنیم، این در صورتی است که بخواهیم رسم کنیم
58
00:02:42,420 –> 00:02:46,380
و اجازه بدهیم ادامه دهم و numpy را وارد
59
00:02:46,380 –> 00:02:48,540
کنم. من به آن نیاز دارم، اما
60
00:02:48,540 –> 00:02:50,070
اینها سه کتابخانه هستند که من معمولاً به
61
00:02:50,070 –> 00:02:53,070
طور پیش فرض وارد می کنم، بنابراین بیایید
62
00:02:53,070 –> 00:03:00,660
قاب داده خود را DF به صورت CSV خواندن نقطه پاندا تعریف کنیم،
63
00:03:00,660 –> 00:03:05,240
فایل من یک فایل CSV است، بنابراین به نام
64
00:03:05,240 –> 00:03:11,580
بهره وری تجزیه و تحلیل تصاویر است، اجازه دهید من به
65
00:03:11,580 –> 00:03:14,730
پوشه یک نقطه نگاه کنم CSV بسیار خوب است. این
66
00:03:14,730 –> 00:03:16,530
نام فایل است و اجازه دهید من ادامه دهم و
67
00:03:16,530 –> 00:03:18,870
این را اجرا کنم تا مطمئن شوم هیچ مشکلی وجود ندارد،
68
00:03:18,870 –> 00:03:23,520
بنابراین می توانید ادامه دهید و
69
00:03:23,520 –> 00:03:26,489
سر نقطه D F را چاپ کنید تا در واقع
70
00:03:26,489 –> 00:03:29,340
به اولین تبلیغ H نگاهی بیندازید تا در واقع
71
00:03:29,340 –> 00:03:33,480
به اولین مورد نگاه کنید. پنج ردیف و درست به نظر می رسد،
72
00:03:33,480 –> 00:03:35,580
منظورم ستون اول دوباره است، در
73
00:03:35,580 –> 00:03:37,050
صورتی که در مورد پانداها تازه کار هستید، لطفاً ادامه دهید
74
00:03:37,050 –> 00:03:38,400
و آموزش های من در مورد
75
00:03:38,400 –> 00:03:40,410
پانداها را
76
00:03:40,410 –> 00:03:42,870
77
00:03:42,870 –> 00:03:46,920
تماشا کنید. فایل باشه پس
78
00:03:46,920 –> 00:03:48,720
من خوبم اجازه بدید ادامه بدم و نظر بدم
79
00:03:48,720 –> 00:03:49,350
این
80
00:03:49,350 –> 00:03:51,450
معمولاً من نظرات زیادی اضافه می کنم،
81
00:03:51,450 –> 00:03:54,750
اما وقتی این آموزش را انجام می دهم، بدیهی است که می
82
00:03:54,750 –> 00:03:57,300
خواهم این ویدیوها را تا
83
00:03:57,300 –> 00:03:59,700
حد امکان کوتاه کنم، بنابراین نظری اضافه نمی کنم، بنابراین در
84
00:03:59,700 –> 00:04:02,880
برخی زمان ها قصد دارم این کد را به اشتراک
85
00:04:02,880 –> 00:04:05,520
بگذارم، سپس احتمالاً تعدادی اضافه خواهم کرد. نظرات پس
86
00:04:05,520 –> 00:04:08,489
به هر حال بیایید ادامه دهیم و اول از همه
87
00:04:08,489 –> 00:04:11,640
بیایید ببینیم
88
00:04:11,640 –> 00:04:14,160
که اگر فایل CSV را باز کنم چگونه مقادیر تقسیم می شوند مانند تعداد،
89
00:04:14,160 –> 00:04:16,140
یعنی می توانید بهره وری را ببینید.
90
00:04:16,140 –> 00:04:19,890
91
00:04:19,890 –> 00:04:22,440
92
00:04:22,440 –> 00:04:26,520
تقریباً مانند 50/50 50% خوب 50% بد، پس
93
00:04:26,520 –> 00:04:27,510
بیایید
94
00:04:27,510 –> 00:04:32,910
ببینیم چگونه میتوانیم چه کار کنم خوب، اجازه
95
00:04:32,910 –> 00:04:35,670
دهید فقط پارامتری به نام اندازهها تعریف کنیم و
96
00:04:35,670 –> 00:04:37,920
من فقط میگویم خوب است از
97
00:04:37,920 –> 00:04:41,760
چارچوب دادهام به ستون بهرهوری نگاه کنید خوب است.
98
00:04:41,760 –> 00:04:45,240
داده های من و سپس به
99
00:04:45,240 –> 00:04:49,590
شمارش ارزش ها نگاه کنید و اجازه دهید فقط بگویم نمک
100
00:04:49,590 –> 00:04:52,800
برابر با یک است، بنابراین آنها را مرتب می
101
00:04:52,800 –> 00:04:55,290
کنم و اکنون در واقع اندازه ها را چاپ می کنم خوب است،
102
00:04:55,290 –> 00:04:58,440
بنابراین اگر جلوتر بروم و آن را چاپ کنم، باید
103
00:04:58,440 –> 00:05:00,720
بگویم خوب و بد. در حال انجام است
104
00:05:00,720 –> 00:05:03,000
به ستون بهره وری نگاه می کند و
105
00:05:03,000 –> 00:05:05,400
سپس v را شمارش می کند نشانه ها و سپس
106
00:05:05,400 –> 00:05:07,350
مرتب کردن آنها خوب است، بنابراین اساساً می
107
00:05:07,350 –> 00:05:09,810
گویند خوب است، بد من این است که من چهل و دو
108
00:05:09,810 –> 00:05:12,020
تا از آنها خوب است سی و هشت،
109
00:05:12,020 –> 00:05:16,200
که بد نیست در واقع تقریباً حتی
110
00:05:16,200 –> 00:05:19,170
اندازه داده ها خوب است، بنابراین من می توانم ادامه دهم
111
00:05:19,170 –> 00:05:21,690
و این دو را نظر بدهم که ما نداریم.
112
00:05:21,690 –> 00:05:24,600
برای کد واقعی ما به این نیاز ندارم، بنابراین من تمایل دارم که
113
00:05:24,600 –> 00:05:26,880
همه چیز را بررسی کنم تا
114
00:05:26,880 –> 00:05:30,990
مطمئن شوم همه چیز خوب است، بنابراین اکنون
115
00:05:30,990 –> 00:05:35,190
مرحله بعدی این است که دادههای ما قادر به
116
00:05:35,190 –> 00:05:37,140
پیشبینی
117
00:05:37,140 –> 00:05:39,300
مجدد متغیرهای مستقل برای یادگیری ماشینی باشند.
118
00:05:39,300 –> 00:05:41,190
شما یک متغیر وابسته را پیشبینی میکنید
119
00:05:41,190 –> 00:05:43,920
که بهرهوری مبتنی
120
00:05:43,920 –> 00:05:46,230
بر دستهای از متغیرهای مستقل است، بنابراین
121
00:05:46,230 –> 00:05:48,240
در مورد ما متغیرهای
122
00:05:48,240 –> 00:05:51,270
مستقل زمان روز هستند، شماره کاربر
123
00:05:51,270 –> 00:05:53,010
یک متغیر مستقل نیست، درست منظورم
124
00:05:53,010 –> 00:05:54,750
این است که این فقط برای اهداف حسابداری ما
125
00:05:54,750 –> 00:05:58,560
است، بنابراین ما میتوانیم در واقع
126
00:05:58,560 –> 00:06:02,130
زمان ستون کاربر را که به آن نیاز داریم کاهش می دهیم زیرا
127
00:06:02,130 –> 00:06:04,590
بر بهره وری قهوه
128
00:06:04,590 –> 00:06:08,400
که ما به آن نیاز داریم تأثیر می گذارد و همچنین به تعداد
129
00:06:08,400 –> 00:06:10,500
تصاویر تجزیه و تحلیل شده نیاز داریم که می توانیم آن را کاهش دهیم زیرا
130
00:06:10,500 –> 00:06:12,000
بهره وری ما چیزی نیست. اما
131
00:06:12,000 –> 00:06:14,280
اساساً تعداد تصاویر میگویند
132
00:06:14,280 –> 00:06:16,080
در واقع به جای بهرهوری تجزیه و
133
00:06:16,080 –> 00:06:18,180
تحلیل شدهاند، من میتوانم از تعداد تصاویر تجزیهوتحلیلشده بهعنوان یک
134
00:06:18,180 –> 00:06:21,360
متریک استفاده کنم، بسیار خوب، من فقط از بهرهوری استفاده
135
00:06:21,360 –> 00:06:23,220
میکنم زیرا میخواستم به شما نشان دهم که
136
00:06:23,220 –> 00:06:27,840
دادههای غیر صحیح یا غیر عددی دارید که میدانید
137
00:06:27,840 –> 00:06:29,700
خوب هستند و بد چگونه می توانی
138
00:06:29,700 –> 00:06:32,250
درست از پس آن بر بیایی، من سعی می کنم هر دو را با
139
00:06:32,250 –> 00:06:36,990
یک سنگ در اینجا به دست بیاورم، بنابراین در این مرحله بیایید در
140
00:06:36,990 –> 00:06:40,200
واقع ستون هایی را که به آن ها
141
00:06:40,200 –> 00:06:41,370
نیاز نداریم، رها کنیم، پس
142
00:06:41,370 –> 00:06:45,360
رها کنیم و چه چیزی را می خواهم رها کنم،
143
00:06:45,360 –> 00:06:47,460
اول بیایید جلو برویم و انجام دهیم تصاویر
144
00:06:47,460 –> 00:06:51,960
تجزیه و تحلیل شده تصاویر زیر خط a در یک سی دی
145
00:06:51,960 –> 00:06:56,790
قرار می گیرند، پس این را رها کنید و دوباره به
146
00:06:56,790 –> 00:06:58,530
عقب برگردید و به آموزش پانداهای من نگاه کنید.
147
00:06:58,530 –> 00:07:00,180
148
00:07:00,180 –> 00:07:02,430
149
00:07:02,430 –> 00:07:06,449
150
00:07:06,449 –> 00:07:08,669
در واقع تقریباً
151
00:07:08,669 –> 00:07:11,760
همان چیزی را تعریف کردهاند که DF برابر با این است
152
00:07:11,760 –> 00:07:14,280
و این را در جای خود معادل درست نمینویسم، اما
153
00:07:14,280 –> 00:07:16,650
وقتی یک خط از کد را مینویسم، نقطه F
154
00:07:16,650 –> 00:07:18,960
در جای خود افت میکند، که اساساً
155
00:07:18,960 –> 00:07:21,870
چارچوب دادههای من را بهروزرسانی میکند، بنابراین اگر من ادامه دهم
156
00:07:21,870 –> 00:07:25,350
و چاپ قاب داده من ctrl C ادامه دهید
157
00:07:25,350 –> 00:07:27,570
و این را چاپ کنید اکنون می بینید که در
158
00:07:27,570 –> 00:07:29,630
قاب داده جدید من این تصویر را ندارم
159
00:07:29,630 –> 00:07:34,080
ستون مورد تجزیه و تحلیل قرار گرفته است خوب، بنابراین شما
160
00:07:34,080 –> 00:07:34,500
می روید
161
00:07:34,500 –> 00:07:36,750
و ستون بعدی که می خواهیم
162
00:07:36,750 –> 00:07:38,760
حذف کنیم کاربر 1 است،
163
00:07:38,760 –> 00:07:41,130
پس بیایید به اینجا برگردیم و اجازه دهید من فقط
164
00:07:41,130 –> 00:07:46,710
کاربر را تایپ می کنم و باید درست باشد
165
00:07:46,710 –> 00:07:49,530
، بنابراین در این مرحله کاری که ما انجام می دهیم
166
00:07:49,530 –> 00:07:54,690
اساساً این است که ستون ها را بی ربط رها می
167
00:07:54,690 –> 00:07:59,310
کنیم، بگذارید بگوییم خوب است، پس از این که
168
00:07:59,310 –> 00:08:02,400
پیاده سازی واقعی
169
00:08:02,400 –> 00:08:05,520
جنگل های تصادفی را رها کردیم، دو خط خواهد بود، بنابراین اگر
170
00:08:05,520 –> 00:08:07,950
می خواهید ببینید که فقط به
171
00:08:07,950 –> 00:08:11,070
انتهای این ویدیو بروید، خوب است، اما 80
172
00:08:11,070 –> 00:08:12,960
درصد بیشتر از زمانی که
173
00:08:12,960 –> 00:08:16,139
صرف میکنید، دادههایتان را
174
00:08:16,139 –> 00:08:17,970
سازماندهی میکند که تقریباً همین طور است و
175
00:08:17,970 –> 00:08:20,789
پیادهسازی بسیار سریع است، بنابراین
176
00:08:20,789 –> 00:08:22,680
این کاری است که ما در اینجا انجام میدهیم، بنابراین
177
00:08:22,680 –> 00:08:25,080
موارد نامربوط را رها کنید. ستونها و سپس
178
00:08:25,080 –> 00:08:27,479
اگر هر کدام دارید، میتوانم به شما نشان دهم که آیا
179
00:08:27,479 –> 00:08:30,860
مقادیری مانند مقادیر از
180
00:08:30,860 –> 00:08:33,179
دست رفته دسته دارید،
181
00:08:33,179 –> 00:08:34,740
مانند اگر ستونهای خاصی
182
00:08:34,740 –> 00:08:37,219
مانند تعداد قهوهای مانند قهوه برای یک ردیف
183
00:08:37,219 –> 00:08:39,179
ندارید، بدیهی است که میخواهید آن را مدیریت کنید. آی تی
184
00:08:39,179 –> 00:08:43,279
چگونه می توان آن DF برابر با DF dot
185
00:08:43,279 –> 00:08:48,000
drop شود و خوب کاری که این کار انجام می دهد این است که
186
00:08:48,000 –> 00:08:51,209
تمام سطرها یا حتی ستون
187
00:08:51,209 –> 00:08:53,700
هایی را که هیچ ندارند
188
00:08:53,700 –> 00:08:54,840
189
00:08:54,840 –> 00:08:57,360
حذف می کند. بنابراین
190
00:08:57,360 –> 00:09:00,180
از آنجایی که ما آن را نداریم
191
00:09:00,180 –> 00:09:03,300
نگران نباشیم زیرا در
192
00:09:03,300 –> 00:09:05,370
هر ستون بعدی دادهای داریم، اجازه دهید
193
00:09:05,370 –> 00:09:10,550
این دادههای غیر عددی را
194
00:09:10,550 –> 00:09:11,700
خوب مدیریت کنیم،
195
00:09:11,700 –> 00:09:14,730
بنابراین اجازه دهید من فقط تبدیل
196
00:09:14,730 –> 00:09:20,610
دادههای غیر عددی به عددی را تایپ کنم، بنابراین چگونه این کار را
197
00:09:20,610 –> 00:09:22,320
انجام دهیم. بنابراین در این مورد ما دو
198
00:09:22,320 –> 00:09:24,420
مقدار خوب و بد داریم، بنابراین اجازه دهید
199
00:09:24,420 –> 00:09:27,570
خوب را به یک و بد را به دو
200
00:09:27,570 –> 00:09:31,380
اختصاص دهم، بنابراین اگر شما
201
00:09:31,380 –> 00:09:33,510
من را تماشا کردید، من به رگرسیون خطی اعتقاد
202
00:09:33,510 –> 00:09:35,550
دارم، تقریباً
203
00:09:35,550 –> 00:09:36,900
همان فرآیند را طی کردم، بنابراین اگر شما آن
204
00:09:36,900 –> 00:09:39,390
ویدیو را در مقابل فقط
205
00:09:39,390 –> 00:09:42,029
چند دقیقه به جلو میبرید و سپس مستقیماً
206
00:09:42,029 –> 00:09:44,190
به سمت جنگل تصادفی میروید، بنابراین
207
00:09:44,190 –> 00:09:50,700
اگر مقدار بهرهوری
208
00:09:50,700 –> 00:09:56,130
برابر با خوب باشد، آن را
209
00:09:56,130 –> 00:09:58,470
به 1 خوب تغییر دهید تا این خط باشد. می گوید
210
00:09:58,470 –> 00:10:02,010
و اجازه دهید من پیش بروم تکرار کنید که برای
211
00:10:02,010 –> 00:10:07,980
بد مساوی با بد رها کردن آن به – باشه
212
00:10:07,980 –> 00:10:10,320
و حالا بعد از این بیایید جلو برویم و
213
00:10:10,320 –> 00:10:13,170
چاپ نکنیم اندازه این چاپ چاپی
214
00:10:13,170 –> 00:10:15,900
که سر نقطهای من زیاد است.
215
00:10:15,900 –> 00:10:20,060
216
00:10:20,060 –> 00:10:23,010
سر نقطه D F چاپ کنید که اشکالی ندارد،
217
00:10:23,010 –> 00:10:25,890
218
00:10:25,890 –> 00:10:27,960
اگر میخواهید
219
00:10:27,960 –> 00:10:30,030
ادامه دهید و آن را بخوانید، فقط به من چند هشدار میدهد، اما اینجاست که
220
00:10:30,030 –> 00:10:32,250
بهرهوری من یک دو، دو یک
221
00:10:32,250 –> 00:10:34,680
درست است، منظورم خوب بد خوب بد و خوب است،
222
00:10:34,680 –> 00:10:37,560
بنابراین به نظر میرسد که درست همانجا کار خوبی انجام دهید
223
00:10:37,560 –> 00:10:39,300
، بنابراین تبدیل
224
00:10:39,300 –> 00:10:42,240
دادههای غیر عددی یا غیر عددی را دوباره به عددی انجام میدهیم
225
00:10:42,240 –> 00:10:43,830
، ما هنوز در تلاش هستیم تا به نقطهای
226
00:10:43,830 –> 00:10:45,720
برسیم که مجموعه دادهها را برای جنگلهای تصادفی آماده کنیم،
227
00:10:45,720 –> 00:10:48,120
خوب این همه
228
00:10:48,120 –> 00:10:51,779
فرآیند مدیریت است، بنابراین فکر میکنم چه چیزی باقی مانده است.
229
00:10:51,779 –> 00:10:54,330
ما خوب هستیم اکنون در این مرحله
230
00:10:54,330 –> 00:10:57,080
باید تعریف کنیم که تعریف
231
00:10:57,080 –> 00:10:58,470
مستقل
232
00:10:58,470 –> 00:11:03,180
به چه چیزهایی بستگی دارد و اجازه دهید این کار را انجام دهیم، خوب
233
00:11:03,180 –> 00:11:08,240
متغیرهای وابسته EP در حال حاضر
234
00:11:08,240 –> 00:11:10,790
یا متغیر وابسته معمولاً
235
00:11:10,790 –> 00:11:13,010
آن را میگویید چرا درست است منظورم این است که شما مستقل هستید
236
00:11:13,010 –> 00:11:15,320
X شما وابسته هستند nt به همین دلیل است
237
00:11:15,320 –> 00:11:17,990
که ما سعی میکنیم خوب را پیشبینی
238
00:11:17,990 –> 00:11:20,120
کنیم، یعنی سعی میکنیم آن را پیشبینی کنیم،
239
00:11:20,120 –> 00:11:22,270
یعنی چیزی به جز یا
240
00:11:22,270 –> 00:11:25,550
ستون بهرهوری وجود ندارد، بنابراین متغیر وابسته من
241
00:11:25,550 –> 00:11:27,649
برای آموزش در این
242
00:11:27,649 –> 00:11:30,709
مورد از ستون بهرهوری میآید،
243
00:11:30,709 –> 00:11:36,050
بنابراین در واقع اجازه دهید ادامه دهیم
244
00:11:36,050 –> 00:11:37,370
و این را اجرا کنیم، میخواهم یک
245
00:11:37,370 –> 00:11:40,310
چیز را در اینجا به شما نشان دهم، بنابراین اگر به Y خود در اینجا نگاه
246
00:11:40,310 –> 00:11:44,149
کنید، یک شی است که 80 ورودی
247
00:11:44,149 –> 00:11:48,080
دارد، یک شی آرایه ND است، بنابراین برای
248
00:11:48,080 –> 00:11:50,810
اهداف یادگیری ماشینی، میخواهید Y شما
249
00:11:50,810 –> 00:11:53,300
یک عدد صحیح باشد. یک شی
250
00:11:53,300 –> 00:11:54,560
در این مورد کمکی نمی کند، بنابراین من می خواهم
251
00:11:54,560 –> 00:12:00,980
این شی را به نوع T تبدیل
252
00:12:00,980 –> 00:12:03,500
253
00:12:03,500 –> 00:12:08,300
254
00:12:08,300 –> 00:12:10,850
کنم.
255
00:12:10,850 –> 00:12:13,880
int 32 است، بنابراین اکنون یک عدد صحیح است،
256
00:12:13,880 –> 00:12:16,160
من مقادیر را اکنون می بینم 1 2 1 و به همین ترتیب،
257
00:12:16,160 –> 00:12:18,920
پس دوباره 3 مدیریت پیش پردازش،
258
00:12:18,920 –> 00:12:20,690
اجازه دهید من ادامه دهم و فضای بیشتری ایجاد کنم،
259
00:12:20,690 –> 00:12:26,240
بنابراین اکنون Y خود را آماده کرده ایم، اکنون
260
00:12:26,240 –> 00:12:30,459
باید خود را تعریف کنیم. X پس
261
00:12:30,459 –> 00:12:37,820
متغیرهای وابسته dep dep را تعریف کنید خوب متأسفم
262
00:12:37,820 –> 00:12:40,190
من را نگه می دارم این متغیرهای مستقل
263
00:12:40,190 –> 00:12:42,500
را انتخاب کنم، اگر پشتیبان بگیرم،
264
00:12:42,500 –> 00:12:45,290
اینها زمان قهوه و سن
265
00:12:45,290 –> 00:12:47,870
ما هستند، بله، زمان قهوه و سن
266
00:12:47,870 –> 00:12:50,329
ما است، یعنی تمام کاری که باید انجام دهیم از
267
00:12:50,329 –> 00:12:52,459
فریم داده اصلی است که DF است، فقط باید
268
00:12:52,459 –> 00:12:54,410
ستون را رها کنم. بهره وری که
269
00:12:54,410 –> 00:12:55,160
تقریباً
270
00:12:55,160 –> 00:12:57,350
مشکلی ندارد، بنابراین روشی که ما انجام می دهیم دوباره این است
271
00:12:57,350 –> 00:13:00,050
که من تعریف می کنم X من چیزی نیست به جز D F نقطه
272
00:13:00,050 –> 00:13:06,200
رها کردن خوب است اگر بتوانم درست تایپ کنم به کدام ستون ها نیاز دارم.
273
00:13:06,200 –> 00:13:09,740
274
00:13:09,740 –> 00:13:16,699
275
00:13:16,699 –> 00:13:19,100
ما می خواهیم رها کنیم و دوباره محور ما
276
00:13:19,100 –> 00:13:22,130
برابر با 1 است، بنابراین بیایید ببینیم
277
00:13:22,130 –> 00:13:25,009
آیا من اینجا اشتباه کردم نقطه F را افت
278
00:13:25,009 –> 00:13:28,130
می کنم.
279
00:13:28,130 –> 00:13:30,470
280
00:13:30,470 –> 00:13:33,380
فریم داده
281
00:13:33,380 –> 00:13:35,480
های هشتاد در سه یعنی من
282
00:13:35,480 –> 00:13:37,160
سه ستون دارم که چیزی نیست جز زمان
283
00:13:37,160 –> 00:13:41,449
قهوه و سن خوب است بالاخره همه
284
00:13:41,449 –> 00:13:41,959
285
00:13:41,959 –> 00:13:44,630
ما آماده ایم ما آماده ایم پس اگر شما از
286
00:13:44,630 –> 00:13:46,880
قبل داده ای دارید که آماده است
287
00:13:46,880 –> 00:13:51,139
بدانید مانند x و y هستید خوش شانس
288
00:13:51,139 –> 00:13:54,050
بیشتر زمانی را که صرف تجزیه و تحلیل یا
289
00:13:54,050 –> 00:13:56,829
آوردن دا می کنید تا به این مرحله خوب است
290
00:13:56,829 –> 00:14:01,160
تا اینجا چه کردیم x خود را تعریف کردیم و
291
00:14:01,160 –> 00:14:04,190
Y خود را تعریف کردیم.
292
00:14:04,190 –> 00:14:06,829
293
00:14:06,829 –> 00:14:10,339
294
00:14:10,339 –> 00:14:13,100
295
00:14:13,100 –> 00:14:15,560
بنابراین حالا
296
00:14:15,560 –> 00:14:19,670
بیایید برویم و جنگل تصادفی را شروع
297
00:14:19,670 –> 00:14:23,120
کنیم، جایی که ما تعریف می کنیم که X و Y ما در حال حاضر چیست،
298
00:14:23,120 –> 00:14:26,630
معمولاً ایده بسیار خوبی است اگر
299
00:14:26,630 –> 00:14:30,529
داده های خود را بردارید و آنها را به یک
300
00:14:30,529 –> 00:14:33,319
مجموعه آموزشی و یک مجموعه آزمایشی تقسیم کنید
301
00:14:33,319 –> 00:14:35,480
تا بتوانید الگوریتم خود را با استفاده از
302
00:14:35,480 –> 00:14:37,639
آموزش آموزش دهید. و سپس آن را با استفاده از
303
00:14:37,639 –> 00:14:40,310
دادههای آزمایشی که الگوریتم قبلاً هرگز ندیده است، آزمایش کنید
304
00:14:40,310 –> 00:14:42,410
، بنابراین این همان چیزی است
305
00:14:42,410 –> 00:14:44,990
که باید بگویم تنها راهی است که
306
00:14:44,990 –> 00:14:47,000
میدانید دقت هر
307
00:14:47,000 –> 00:14:49,009
الگوریتم تصادفی شما برای ماشینهای بردار پشتیبان ما،
308
00:14:49,009 –> 00:14:50,839
رگرسیون خطی هر چیزی است که میخواهید انجام دهید، چقدر
309
00:14:50,839 –> 00:14:53,360
است. با شما به مقداری
310
00:14:53,360 –> 00:14:55,730
داده آزمایشی نیاز دارید تا بتوانید الگوریتم را اعتبار سنجی کنید
311
00:14:55,730 –> 00:14:59,000
تا راه بعدی تقسیم
312
00:14:59,000 –> 00:15:04,399
داده ها به مجموعه های قطار و آزمایش باشد، خوب است،
313
00:15:04,399 –> 00:15:08,240
بنابراین چگونه این کار را دوباره انجام دهیم،
314
00:15:08,240 –> 00:15:09,290
من در چند مورد قبلی به این موضوع پرداختم.
315
00:15:09,290 –> 00:15:11,660
آموزشها اما ارزش آن را دارد که دوباره
316
00:15:11,660 –> 00:15:15,740
بپوشانید بسیار خوب از SK Learn scikit-learn
317
00:15:15,740 –> 00:15:21,370
انتخاب مدل خوب انتخاب مدل واردات
318
00:15:21,370 –> 00:15:29,540
قطار تست تقسیم خوب است بنابراین وقتی وارد کردیم
319
00:15:29,540 –> 00:15:34,880
که اکنون میتوانم من را باز کنم منظورم این است که
320
00:15:34,880 –> 00:15:36,060
راه اجرای این
321
00:15:36,060 –> 00:15:38,910
تقسیم آزمایشی قطار نیست و شما خودتان را بدهید
322
00:15:38,910 –> 00:15:41,190
مقادیر X شما و مقادیر Y چه هستند،
323
00:15:41,190 –> 00:15:43,260
اما چیزی که از آن به دست می آورید X
324
00:15:43,260 –> 00:15:46,610
underscore است متأسفم underscore train خوب است
325
00:15:46,610 –> 00:15:49,860
و من فقط
326
00:15:49,860 –> 00:15:53,970
برای خروجی خود چند متغیر برای من می دهم و فقط
327
00:15:53,970 –> 00:15:57,030
این X train X را تست می کنم. وقتی مجموعه
328
00:15:57,030 –> 00:15:59,520
دادههای آموزشی
329
00:15:59,520 –> 00:16:01,710
و مجموعه دادههای تست را برای X دریافت میکنید،
330
00:16:01,710 –> 00:16:03,570
مجموعه دادههای آموزشی و مجموعه دادههای آزمایشی را
331
00:16:03,570 –> 00:16:06,810
برای y دریافت میکنید که تقریباً همینطور است، بنابراین چرا نمیتوانید
332
00:16:06,810 –> 00:16:11,040
زیرخط قطار و چرا
333
00:16:11,040 –> 00:16:17,180
تست زیرخط خوب این با قطار من برابر است. تست
334
00:16:17,180 –> 00:16:24,560
تقسیم X من از Y خوب است، من
335
00:16:24,560 –> 00:16:27,660
میتوانم آنجا را رها کنم، اما باید
336
00:16:27,660 –> 00:16:32,120
اندازه تست خود را برابر با 0.4 ارائه
337
00:16:32,120 –> 00:16:37,670
کنم که به این معنی است که میخواهم 40٪ از دادههایم بهطور
338
00:16:37,670 –> 00:16:40,740
تصادفی انتخاب شده و به
339
00:16:40,740 –> 00:16:44,100
مجموعه دادههای آزمایشی من تخصیص داده شود. بنابراین از این 80 ورودی
340
00:16:44,100 –> 00:16:47,880
کل 40% از آنها
341
00:16






![فیلم آموزشی: ایجاد یک برنامه آب و هوا در جنگو با استفاده از درخواست های پایتون [قسمت 1] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/v7xjdXWZafYimage2.jpg)
![فیلم آموزشی: Python [pygame] 05 Sprites با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/vDFJouaOqNsimage2.jpg)