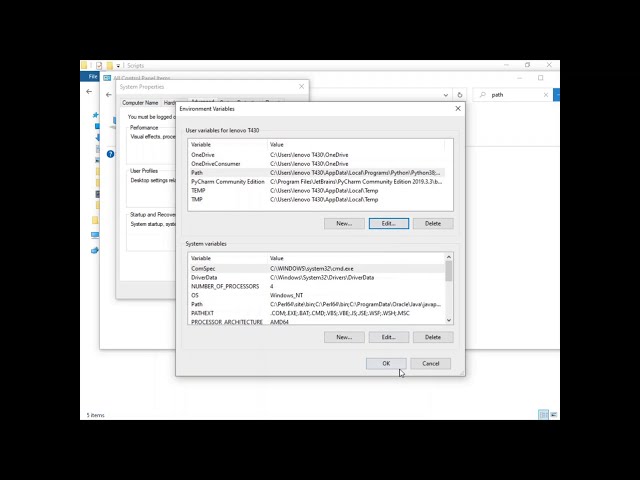
در این مطلب، ویدئو Python Series 26 چگونه داده های CSV را با استفاده از پانداها در پایتون وارد و صادر کنیم با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:03:55
تصاویر این ویدئو:
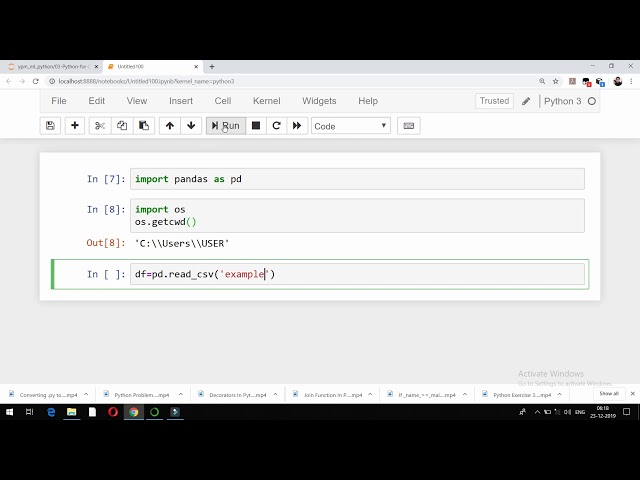

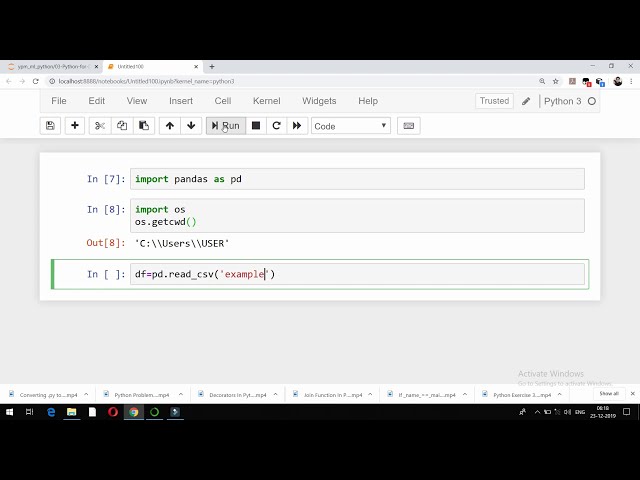

قسمتی از زیرنویس این فیلم:
00:00:00,120 –> 00:00:02,909
سلام دوستان در این ویدیو می
2
00:00:02,909 –> 00:00:05,580
خواهیم ببینیم که چگونه یک فایل CSV را وارد کنیم چگونه
3
00:00:05,580 –> 00:00:07,319
فایل CSV را با استفاده از
4
00:00:07,319 –> 00:00:09,870
بسته pandas در پایتون بخوانیم و سپس در مورد
5
00:00:09,870 –> 00:00:14,370
نحوه صادرات به یک CSU صحبت می کنیم که چگونه
6
00:00:14,370 –> 00:00:17,070
داده ها را به یک فایل CSV صادر کنیم. برای
7
00:00:17,070 –> 00:00:18,660
آوردن همان کاری که ما باید انجام دهیم این است که
8
00:00:18,660 –> 00:00:20,220
اول از همه باید بستهای
9
00:00:20,220 –> 00:00:25,039
به نام pandas وارد کنیم، بنابراین pandas را به عنوان
10
00:00:25,039 –> 00:00:30,150
زیبا وارد کنیم، اجازه دهید اکنون آن را برگردانم، اول از همه
11
00:00:30,150 –> 00:00:31,529
به شما نشان خواهم داد که آن فایل در کدام فایل قرار
12
00:00:31,529 –> 00:00:34,110
است وارد کنم.
13
00:00:34,110 –> 00:00:35,870
دایرکتوری کاری فعلی من در واقع
14
00:00:35,870 –> 00:00:39,390
روی آن کلیک راست کرده و سعی کنید آن را باز کنید، بنابراین اجازه
15
00:00:39,390 –> 00:00:41,880
دهید آن را با برنامه ای مانند
16
00:00:41,880 –> 00:00:43,770
WordPad باز کنم تا یک فایل CSV را مشاهده کنید که
17
00:00:43,770 –> 00:00:46,770
فایل جداگانه ای با کاما است مانند این، بنابراین می
18
00:00:46,770 –> 00:00:49,050
توانید ببینید که این همان چیزی است که داده ها ارائه می کنند. در
19
00:00:49,050 –> 00:00:53,850
سلولهای من ABCD را در یک US 0 4 8 12
20
00:00:53,850 –> 00:00:57,840
در B 1 5 9 13 مانند این پیدا میکنیم، بنابراین کاری که
21
00:00:57,840 –> 00:01:00,660
سعی میکنم انجام دهم این است که سعی میکنم
22
00:01:00,660 –> 00:01:03,300
این فایل CSV خاص را با استفاده از
23
00:01:03,300 –> 00:01:05,039
بسته pandas در پایتون وارد کنم تا آن فایل از
24
00:01:05,039 –> 00:01:06,630
قبل موجود باشد.
25
00:01:06,630 –> 00:01:08,579
اگر میخواهم ببینم چه چیزی مستقیماً کار نمیکند،
26
00:01:08,579 –> 00:01:10,950
مستقیماً در کارم حضور دارم، پس چه چیزی ما می توانیم انجام دهیم این است که سیستم عامل را وارد کنیم
27
00:01:10,950 –> 00:01:13,799
و سپس چه کسی دایرکتوری کاری فعلی را دریافت کند
28
00:01:13,799 –> 00:01:15,630
، بنابراین کاربران و کاربر دایرکتوری فعلی من را به من نشان می دهد،
29
00:01:15,630 –> 00:01:18,299
30
00:01:18,299 –> 00:01:20,249
بنابراین من قبلاً آن
31
00:01:20,249 –> 00:01:23,069
نمونه خاص فایل CSV را در این مسیر خاص قرار
32
00:01:23,069 –> 00:01:25,799
داده ام.
33
00:01:25,799 –> 00:01:30,109
برای خواندن آن داده CSV خاص در
34
00:01:30,109 –> 00:01:32,670
پایتون کاری که می توانم انجام دهم این است که به عنوان مثال برخی از
35
00:01:32,670 –> 00:01:35,159
متغیرهای DF برابر است با می توانم بگویم من
36
00:01:35,159 –> 00:01:39,990
PD dot read نمی کنم و اگر tab را فشار دهم
37
00:01:39,990 –> 00:01:41,369
می توانید ببینید تعدادی گزینه وجود دارد بنابراین
38
00:01:41,369 –> 00:01:43,170
می خواهیم از آن استفاده کنیم. زیرخط را بخوانید زیرا
39
00:01:43,170 –> 00:01:45,450
فایل ما CSV است من از CSV نیاز به خط خطی استفاده خواهم کرد
40
00:01:45,450 –> 00:01:49,560
و سپس از مسیر استفاده خواهم کرد، بنابراین در مورد من
41
00:01:49,560 –> 00:01:51,090
فایل من از قبل در
42
0