در این مطلب، ویدئو پایتون: تجزیه و تحلیل داده های طبقه بندی شده با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:29:50
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,829 –> 00:00:03,810
سلام، در این ویدیو میخواهیم به
2
00:00:03,810 –> 00:00:06,390
بررسی آمار مقدماتی با
3
00:00:06,390 –> 00:00:08,370
پایتون
4
00:00:08,370 –> 00:00:10,710
ادامه دهیم، بهطور خاص، چند آزمایش دادههای طبقهبندی شده را بررسی میکنیم، بنابراین میخواهیم
5
00:00:10,710 –> 00:00:12,150
6
00:00:12,150 –> 00:00:13,110
آزمایش فرضیهای را بررسی
7
00:00:13,110 –> 00:00:15,020
کنیم.
8
00:00:15,020 –> 00:00:18,630
9
00:00:18,630 –> 00:00:21,600
بنابراین ما از مقدمه کتاب جنسیت آمار با پایتون استفاده میکنیم. این از
10
00:00:21,600 –> 00:00:23,550
11
00:00:23,550 –> 00:00:25,199
طریق Springer است
12
00:00:25,199 –> 00:00:30,179
اینجا وبسایتی برای کدی است که
13
00:00:30,179 –> 00:00:33,630
من در اینجا استفاده میکنم و به یاد داشته باشید
14
00:00:33,630 –> 00:00:36,149
که اگر دانشآموز UCF هستید، میتوانید از
15
00:00:36,149 –> 00:00:39,030
مستقیم مستقیم برای دانلود این کتاب درسی استفاده کنید. فکر
16
00:00:39,030 –> 00:00:41,219
میکنید این کتاب خوبی است برای اینکه بدانید
17
00:00:41,219 –> 00:00:42,239
اگر میخواهید با پایتون وارد دادهها شوید، حتماً با آن همراه باشید،
18
00:00:42,239 –> 00:00:46,890
زیرا میدانید
19
00:00:46,890 –> 00:00:48,239
که آمار مقدماتی
20
00:00:48,239 –> 00:00:50,579
برای شما بیشتر از سایر جنبههای
21
00:00:50,579 –> 00:00:52,590
داده آشنا خواهد بود اگر مانند یک کلاس آمار مقدماتی در نظر گرفته
22
00:00:52,590 –> 00:00:54,870
باشید. انجام دادهاید شما میدانید معنی و
23
00:00:54,870 –> 00:00:56,820
انحراف معیار چیزهایی مانند آن را انجام دادهاید که
24
00:00:56,820 –> 00:00:59,430
این قطعاً به حساب خواهد آمد.
25
00:00:59,430 –> 00:01:02,370
26
00:01:02,370 –> 00:01:04,080
27
00:01:04,080 –> 00:01:06,840
28
00:01:06,840 –> 00:01:09,150
به نحوه تجزیه و تحلیل داده های باینری نگاه کنید اگر
29
00:01:09,150 –> 00:01:10,710
ما علاقه مند به تجزیه و تحلیل
30
00:01:10,710 –> 00:01:14,130
نسبت موفقیت یا شکست
31
00:01:14,130 –> 00:01:16,939
هستیم، سپس به تجزیه و تحلیل
32
00:01:16,939 –> 00:01:20,070
جداول تعداد نگاه می کنیم و بنابراین وقتی در
33
00:01:20,070 –> 00:01:21,750
مورد جدولی صحبت می کنم که یک جدول مستطیل شکل
34
00:01:21,750 –> 00:01:26,009
از اعداد است، ما به
35
00:01:26,009 –> 00:01:28,979
آزمونهای ویژهای که برای جدولهای شمارش دو در دو است
36
00:01:28,979 –> 00:01:32,460
نگاه میکنیم، سپس به
37
00:01:32,460 –> 00:01:34,740
وضعیتی نگاه میکنیم که در آن
38
00:01:34,740 –> 00:01:37,560
چندین داور و چندین موضوع یا
39
00:01:37,560 –> 00:01:40,799
چندین کار و چندین موضوع داریم به
40
00:01:40,799 –> 00:01:42,810
نحوی که مانند یک
41
00:01:42,810 –> 00:01:47,009
ارزیابی در حال انجام است و ما
42
00:01:47,009 –> 00:01:49,979
سوژههایی داریم که میدانید، زیرا ما چندین
43
00:01:49,979 –> 00:01:51,689
موضوع و روشهای متعددی برای
44
00:01:51,689 –> 00:01:53,850
ارزیابی آنها داریم و سپس
45
00:01:53,850 –> 00:01:55,890
با تجزیه و تحلیل دادههای دستهبندیهای جفت شده آن را به پایان میرسانیم،
46
00:01:55,890 –> 00:02:00,719
بنابراین بیایید ادامه دهیم
47
00:02:00,719 –> 00:02:03,149
و بستههای خود را بارگیری کنیم.
48
00:02:03,149 –> 00:02:07,860
f9 در عنکبوت برای دریافت اینها برای ورود به داخل،
49
00:02:07,860 –> 00:02:10,169
بنابراین من ناتوان می شوم و سپس
50
00:02:10,169 –> 00:02:12,480
از matplotlib اندازه لوله می گیرم
51
00:02:12,480 –> 00:02:13,850
52
00:02:13,850 –> 00:02:18,200
آمار Sify خوب است، بنابراین اکنون می خواهیم به
53
00:02:18,200 –> 00:02:20,510
تجزیه و تحلیل یک نسبت نگاه
54
00:02:20,510 –> 00:02:22,490
کنیم تا چه کاری انجام دهیم. در این مورد میخواهیم
55
00:02:22,490 –> 00:02:24,650
فاصله اطمینان
56
00:02:24,650 –> 00:02:27,460
جمعیتی را محاسبه کنیم که در آن دادههای باینری وجود دارد،
57
00:02:27,460 –> 00:02:30,140
بنابراین هر زمان که من دو
58
00:02:30,140 –> 00:02:33,820
نتیجه ممکن برای
59
00:02:33,820 –> 00:02:36,380
مشاهداتم داشته باشم، میتوانم بگویم که یکی از
60
00:02:36,380 –> 00:02:38,450
آنهایی که خارج از یکی از سطوح است با
61
00:02:38,450 –> 00:02:40,880
1 مطابقت دارد و دیگری با 0 مطابقت دارد و به
62
00:02:40,880 –> 00:02:44,000
این ترتیب من مزایایی
63
00:02:44,000 –> 00:02:46,340
با آن دارم، به عنوان مثال اگر
64
00:02:46,340 –> 00:02:48,350
میانگین آن صفرها و یک ها را در نظر
65
00:02:48,350 –> 00:02:52,220
بگیرم که به من می گوید چه نسبتی
66
00:02:52,220 –> 00:02:55,130
سطح دقیقی را بدست می آورد که با یک مطابقت دارد
67
00:02:55,130 –> 00:02:58,190
، خوب است، همین که این کار را انجام می دهم نیز خوب
68
00:02:58,190 –> 00:02:59,840
است. ما میتوانیم از
69
00:02:59,840 –> 00:03:02,390
توزیع دوجملهای استفاده کنیم و اگر
70
00:03:02,390 –> 00:03:04,580
توزیع دوجملهای را داشته باشم و شروع به گرفتن
71
00:03:04,580 –> 00:03:06,560
میانگینها کنم، از طریق قضیه حد مرکزی
72
00:03:06,560 –> 00:03:08,120
میتوانم از توزیع نرمال استفاده
73
00:03:08,120 –> 00:03:10,070
کنم تا اطلاعات بیشتری
74
00:03:10,070 –> 00:03:13,690
در مورد آن نسبتها به من بدهم، بنابراین
75
00:03:13,690 –> 00:03:15,530
کار زیادی است. بسیاری از
76
00:03:15,530 –> 00:03:19,280
کلماتی که من به تازگی گفته ام اساساً آنچه را که
77
00:03:19,280 –> 00:03:20,630
می خواهم انجام دهم، می خواهم
78
00:03:20,630 –> 00:03:22,790
نسبت را محاسبه کنم و می خواهم
79
00:03:22,790 –> 00:03:26,240
بازخوردی در مورد اینکه تخمین من از
80
00:03:26,240 –> 00:03:28,880
آن نسبت چقدر دقیق است. درست است پس کاری که
81
00:03:28,880 –> 00:03:30,260
در آمار انجام می دهیم کاری به نام فاصله اطمینان انجام می دهیم
82
00:03:30,260 –> 00:03:33,020
اگر فاصله اطمینان بسیار وسیعی داشته باشم
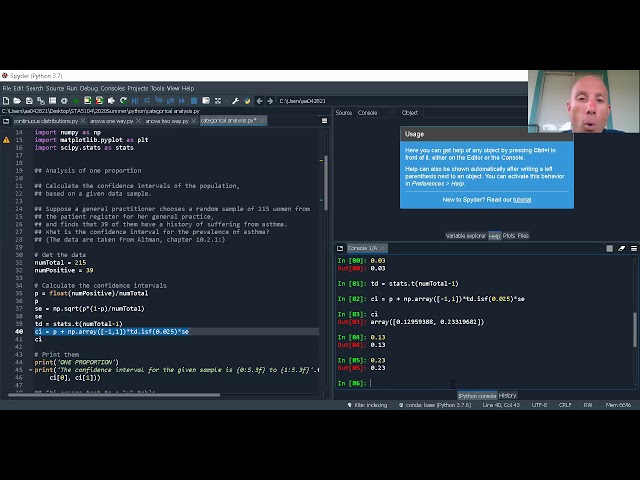
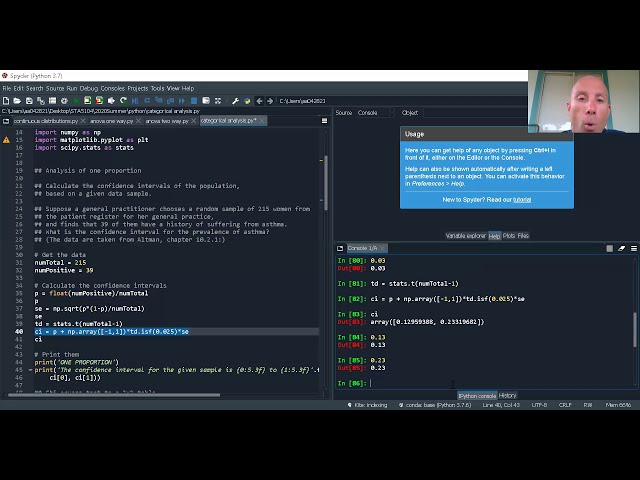
83
00:03:33,020 –> 00:03:36,020
فوق عریض
84
00:03:36,020 –> 00:03:39,650
فوق عریض دقت بسیار کمی
85
00:03:39,650 –> 00:03:41,870
دارم من به
86
00:03:41,870 –> 00:03:44,240
دقت تخمینی که دارم خیلی اعتماد ندارم
87
00:03:44,240 –> 00:03:46,130
اما اگر من واقعاً واقعاً
88
00:03:46,130 –> 00:03:48,200
واقعاً اطمینان دارم که قایقهای ما
89
00:03:48,200 –> 00:03:50,570
واقعاً کوچک هستند، بنابراین بسیار مطمئن
90
00:03:50,570 –> 00:03:53,990
هستم که اندازهگیری صحیح
91
00:03:53,990 –> 00:03:56,750
در آن عرض است، بنابراین آنچه میخواهیم انجام
92
00:03:56,750 –> 00:03:59,360
دهیم، میخواهیم فاصلهای از
93
00:03:59,360 –> 00:04:02,090
اعداد را به دست بیاوریم. برخی از بازخوردها در مورد
94
00:04:02,090 –> 00:04:06,290
اینکه اندازهگیری من چقدر دقیق است و چقدر
95
00:04:06,290 –> 00:04:12,110
میتوانم اطمینان داشته باشم، بنابراین
96
00:04:12,110 –> 00:04:13,850
در این مشکل داستان فرض کنید
97
00:04:13,850 –> 00:04:15,230
که یک پزشک عمومی وجود دارد که
98
00:04:15,230 –> 00:04:17,810
یک نمونه تصادفی از 215 زن را
99
00:04:17,810 –> 00:04:21,019
از فهرست بیماران خود انتخاب میکند و آنها
100
00:04:21,019 –> 00:04:23,600
متوجه میشوند که 39 نفر از آنها سابقه دارند. از
101
00:04:23,600 –> 00:04:26,090
مبتلا شدن به آسم و بنابراین میزان
102
00:04:26,090 –> 00:04:28,160
اطمینان از شیوع
103
00:04:28,160 –> 00:04:31,850
آسم در جمعیت نمونه او چقدر است، خوب است،
104
00:04:31,850 –> 00:04:34,610
بنابراین چیزی در این مورد این است که وقتی شما
105
00:04:34,610 –> 00:04:37,820
در مورد این صحبت می کنید ما همیشه باید در نظر داشته
106
00:04:37,820 –> 00:04:39,860
باشیم r وقتی جمعیت نمونه Z،
107
00:04:39,860 –> 00:04:41,840
جمعیت نمونه، ثبت نام بیمار اوست،
108
00:04:41,840 –> 00:04:44,780
بنابراین در مقایسه با
109
00:04:44,780 –> 00:04:46,760
جمعیت عمومی
110
00:04:46,760 –> 00:04:48,800
احتمالاً عددی بزرگتر از نسبت
111
00:04:48,800 –> 00:04:50,750
کل جمعیت خواهد بود،
112
00:04:50,750 –> 00:04:52,250
وقتی شروع
113
00:04:52,250 –> 00:04:53,840
به تفسیرهای خوب از نتایج خود می کنید باید به آن فکر کنید.
114
00:04:53,840 –> 00:04:58,100
بنابراین بیایید برویم و داده ها را بدست آوریم،
115
00:04:58,100 –> 00:04:59,810
بنابراین در اینجا ما داریم که تعداد کل
116
00:04:59,810 –> 00:05:05,000
215 است و تعداد مثبت 39 است، بنابراین
117
00:05:05,000 –> 00:05:06,530
حالا بیایید این را بشماریم و
118
00:05:06,530 –> 00:05:09,230
فاصله های اطمینان را محاسبه کنیم، بنابراین
119
00:05:09,230 –> 00:05:11,360
قبل از هر چیز می خواهم بدانم
120
00:05:11,360 –> 00:05:15,710
نسبت تخمینی من چقدر است. بیماران
121
00:05:15,710 –> 00:05:18,530
مبتلا به آسم در رجیستری هستند، بنابراین به نظر می
122
00:05:18,530 –> 00:05:23,210
رسد که اکنون حدود 18 درصد مشکلی ندارد،
123
00:05:23,210 –> 00:05:26,420
ممکن است چند مورد را از دست داده باشم،
124
00:05:26,420 –> 00:05:28,670
شاید تشخیص اشتباهی در طول مسیر وجود داشته باشد، شاید
125
00:05:28,670 –> 00:05:30,200
می دانید که برخی از بیماران
126
00:05:30,200 –> 00:05:31,760
مبتلا به آسم تشخیص داده شده اند، در حالی که
127
00:05:31,760 –> 00:05:34,150
شاید آنها نبودند. باید تشخیص داده می شد که مبتلا به
128
00:05:34,150 –> 00:05:38,510
آسم هستیم، اما ما این کار را نکردیم، بنابراین شما می دانید که ما
129
00:05:38,510 –> 00:05:40,970
اینها می دانید که ما می خواهیم در مورد اینکه
130
00:05:40,970 –> 00:05:43,010
چقدر به این نسبت صحیح نزدیک
131
00:05:43,010 –> 00:05:45,590
هستیم، خوب هستیم، بنابراین چه ما
132
00:05:45,590 –> 00:05:48,919
قصد داریم انجام دهیم، از برخی
133
00:05:48,919 –> 00:05:51,560
ترفندها در ریاضیات استفاده می کنیم که به من
134
00:05:51,560 –> 00:05:55,640
راهی برای تخمین زدن
135
00:05:55,640 –> 00:05:58,070
انحراف معیار این تخمین می دهد، بنابراین
136
00:05:58,070 –> 00:06:00,800
انحراف معیار یک میانگین،
137
00:06:00,800 –> 00:06:03,410
خطای استاندارد نامیده می شود، خطای استاندارد خوب
138
00:06:03,410 –> 00:06:05,930
است. انحراف معیار
139
00:06:05,930 –> 00:06:08,240
نوعی اندازه گیری اما ما یک
140
00:06:08,240 –> 00:06:10,820
خطای استاندارد می نامیم تا مشخص کنیم که چه
141
00:06:10,820 –> 00:06:14,360
نوع خاصی وجود دارد خوب است بنابراین من باینری
142
00:06:14,360 –> 00:06:17,390
پایین شده ام دو سطح دارم بنابراین در واقع
143
00:06:17,390 –> 00:06:19,300
من با توزیع دو جمله ای سروکار دارم
144
00:06:19,300 –> 00:06:22,310
اکنون توزیع دوجمله
145
00:06:22,310 –> 00:06:24,140
ای است یک نوع کار مستقیم با آن مشکل است،
146
00:06:24,140 –> 00:06:26,600
شما می دانید که ما می
147
00:06:26,600 –> 00:06:27,770
توانیم نیروی بی رحمانه ای داشته باشیم، بنابراین می توانیم از طریق
148
00:06:27,770 –> 00:06:31,790
آن کار کنیم، اما نتیجه می دهد که اگر من به
149
00:06:31,790 –> 00:06:34,070
قضیه حد مرکزی نگاه کنم هر زمانی
150
00:06:34,070 –> 00:06:36,740
که میانگین می گیرم، می توانم توزیع نرمال را بگیرم
151
00:06:36,740 –> 00:06:38,930
که منحنی زنگی نیز
152
00:06:38,930 –> 00:06:41,450
توزیع گاوسی نامیده می شود، بنابراین می
153
00:06:41,450 –> 00:06:42,169
دانید که
154
00:06:42,169 –> 00:06:43,879
امروزی است زیرا بسیار مهم است و
155
00:06:43,879 –> 00:06:45,409
به همین دلیل است که بسیار مهم است که
156
00:06:45,409 –> 00:06:48,110
هر زمان که شروع به انجام میانگین های نمونه
157
00:06:48,110 –> 00:06:52,029
کردم تقریباً همیشه می توانم آن را فراخوانی کنم.
158
00:06:52,029 –> 00:06:55,279
به جای آن، توزیع نرمال را صدا کنید که
159
00:06:55,279 –> 00:06:56,960
چیز را استاندارد می کند، بنابراین من می دانم که
160
00:06:56,960 –> 00:07:00,740
چگونه همه چیز را هر بار کنترل کنم، بنابراین
161
00:07:00,740 –> 00:07:03,499
کاری که می خواهیم انجام دهیم این است
162
00:07:03,499 –> 00:07:08,090
که خطای استانداردی را که
163
00:07:08,090 –> 00:07:11,949
قضیه حد مرکزی برای یک مسئله دوجمله ای مانند این به من می دهد، دریافت کنم.
164
00:07:11,949 –> 00:07:15,560
بیایید جلو برویم و
165
00:07:15,560 –> 00:07:18,589
محاسبه کنیم که بنابراین واریانس
166
00:07:18,589 –> 00:07:21,949
توزیع دوجمله ای n
167
00:07:21,949 –> 00:07:24,830
ضربدر P ضربدر 1 منهای P است و اگر کمی
168
00:07:24,830 –> 00:07:28,310
تنظیم کنیم،
169
00:07:28,310 –> 00:07:32,120
می بینیم که خطای استاندارد
170
00:07:32,120 –> 00:07:35,300
P ضربدر 1 منهای P تقسیم می شود. با
171
00:07:35,300 –> 00:07:37,610
تعداد کل، من جذر را
172
00:07:37,610 –> 00:07:39,770
می گیرم، همانطور که در خطای استاندارد من به من می گوید که
173
00:07:39,770 –> 00:07:41,509
چه چیزی خوب است، بنابراین
174
00:07:41,509 –> 00:07:44,089
برای یک خطای استاندارد چه چیزی به دست می آوریم، بنابراین
175
00:07:44,089 –> 00:07:50,000
این حدود 0.03 است، بنابراین تخمین نقطه من
176
00:07:50,000 –> 00:07:54,919
حدود 0.18 و استاندارد من است. خطا
177
00:07:54,919 –> 00:08:00,469
تقریباً درست است، بنابراین خانم فروشنده
178
00:08:00,469 –> 00:08:02,689
که به من می گوید
179
00:08:02,689 –> 00:08:04,639
نسبت تخمینی بیماران مبتلا به آسم در
180
00:08:04,639 –> 00:08:07,490
ثبت نام بوده است و اکنون این به من
181
00:08:07,490 –> 00:08:11,599
ایده ای درباره آن می دهد، بنابراین اگر این عدد واقعاً بزرگ بود،
182
00:08:11,599 –> 00:08:13,099
پس خانم ها بیایید بگوییم که این عدد
183
00:08:13,099 –> 00:08:16,460
l بود. مثلاً نقطه 9 اگر 0.9 بود، من به
184
00:08:16,460 –> 00:08:18,800
عنوان تخمین به این عدد خیلی اعتقاد نداشتم،
185
00:08:18,800 –> 00:08:21,169
زیرا نقطه 9
186
00:08:21,169 –> 00:08:23,449
از نظر اعدادی که از 0 به 1 می روند، عدد بزرگی است،
187
00:08:23,449 –> 00:08:29,479
حالا اگر نقطه اووو 1 بود،
188
00:08:29,479 –> 00:08:31,310
من بسیار مطمئن بودم. که من
189
00:08:31,310 –> 00:08:34,479
تخمین خوبی در این مقدار در اینجا دارم و
190
00:08:34,479 –> 00:08:38,029
نقطه O 3 خیلی بد نیست، بنابراین کاری که
191
00:08:38,029 –> 00:08:41,120
اکنون میخواهیم انجام دهیم، میخواهیم پیش برویم و
192
00:08:41,120 –> 00:08:45,079
بفهمیم که محدوده واقعی مشابه چقدر است
193
00:08:45,079 –> 00:08:48,470
که میتوان 95% اطمینان داشت
194
00:08:48,470 –> 00:08:52,730
که تخمین درست در محدوده است، بنابراین کاری که
195
00:08:52,730 –> 00:08:54,279
میخواهیم انجام دهیم، به
196
00:08:54,279 –> 00:08:55,730
یاد داشته باشید که
197
00:08:55,730 –> 00:08:58,040
توزیع دوجملهای را انجام
198
00:08:58,040 –> 00:09:00,620
میدهیم قضیه حد مرکزی توزیع نرمال توزیع نرمال را به ما میدهد
199
00:09:00,620 –> 00:09:03,079
که
200
00:09:03,079 –> 00:09:05,060
همه چیز درباره آن نمیدانیم، بنابراین از توزیع T نیز استفاده میکنیم.
201
00:09:05,060 –> 00:09:07,339
بنابراین منظورم این است که
202
00:09:07,339 –> 00:09:09,470
نوعی زنجیرهای در اینجا در جریان است، شما متوجه خواهید شد
203
00:09:09,470 –> 00:09:12,079
که در این مرحله من توزیع T را فراخوانی میکنم،
204
00:09:12,079 –> 00:09:14,899
بنابراین اگر کارهای دوجملهای را انجام میدهم، چه چیزی را باید
205
00:09:14,899 –> 00:09:18,470
به خاطر بسپارید تا به آینده ادامه دهید.
206
00:09:18,470 –> 00:09:22,040
207
00:09:22,040 –> 00:09:23,959
این محاسبات را انجام دهید من
208
00:09:23,959 –> 00:09:26,660
در واقع از فاصله T استفاده خواهم کرد ribution به
209
00:09:26,660 –> 00:09:30,139
جای توزیع دو جمله ای به جای
210
00:09:30,139 –> 00:09:33,410
توزیع عادی که
211
00:09:33,410 –> 00:09:35,930
برخی از شکاف ها را برای من پر می کند، بسیار خوب، پس بیایید جلو برویم
212
00:09:35,930 –> 00:09:40,760
و این را بزنیم، بیایید جلو برویم و
213
00:09:40,760 –> 00:09:44,089
آن را اجرا کنیم خوب، بنابراین این یک
214
00:09:44,089 –> 00:09:47,810
سری چیزها در حال انجام است، بنابراین در اینجا ما در حال
215
00:09:47,810 –> 00:09:52,010
رقم زدن هستیم ما از توزیع T استفاده می کنیم تا بفهمیم که
216
00:09:52,010 –> 00:09:55,310
چگونه
217
00:09:55,310 –> 00:09:57,050
مقادیری وجود دارد که باید
218
00:09:57,050 –> 00:09:59,389
برای ما پخش شوند و سپس آن را تغییر می
219
00:09:59,389 –> 00:10:03,290
دهیم زیرا این
220
00:10:03,290 –> 00:10:05,360
خطای استاندارد به من می گوید مانند سطح
221
00:10:05,360 –> 00:10:05,930
دقت
222
00:10:05,930 –> 00:10:07,970
من به توزیع نیاز دارم و
223
00:10:07,970 –> 00:10:10,760
درک من از دقت با هم مخلوط شد
224
00:10:10,760 –> 00:10:13,730
تا با هم جمع شوند تا به من
225
00:10:13,730 –> 00:10:16,910
ایده بدهند که واقعاً چقدر گسترش یافته است.
226
00:10:16,910 –> 00:10:19,730
227
00:10:19,730 –> 00:10:21,319
228
00:10:21,319 –> 00:10:24,440
229
00:10:24,440 –> 00:10:27,279
اوه
230
00:10:27,279 –> 00:10:31,610
لطفاً 3 توسط من
231
00:10:31,610 –> 00:10:34,100
تخمین زده شود، من تخمینم را می گیرم، 1 را می گیرم،
232
00:10:34,100 –> 00:10:37,339
همه این ها را اضافه می کنم تا
233
00:10:37,339 –> 00:10:39,470
حد بالایی فاصله اطمینان خود را بدست
234
00:10:39,470 –> 00:10:42,620
بیاورم و سپس می روم تا
235
00:10:42,620 –> 00:10:44,810
مقدار بزرگتر و فاصله اطمینان
236
00:10:44,810 –> 00:10:47,690
من باشد m برای اینکه اکنون به آن نگاه
237
00:10:47,690 –> 00:10:52,970
نکنم، تخمین خود را میگیرم و این مقدار را
238
00:10:52,970 –> 00:10:55,430
کم میکنم تا مقدار پایینتر را به دست بیاورم، بنابراین من همجنسگرا هستم، به
239
00:10:55,430 –> 00:10:58,190
پایینتر میروم، به بالا میروم تا فاصلهای
240
00:10:58,190 –> 00:11:01,699
در اطراف تخمینم به دست بیاورم، پس
241
00:11:01,699 –> 00:11:04,760
این چه شکلی است بسیار خوب، بنابراین ما می
242
00:11:04,760 –> 00:11:10,029
توانیم حدود 0.1 3 را ببینیم و می توانیم حدود
243
00:11:10,029 –> 00:11:14,360
0.23 مانند آن را ببینیم، بنابراین آنچه که می
244
00:11:14,360 –> 00:11:17,779
گوید این است که ما 95٪ مطمئن هستیم
245
00:11:17,779 –> 00:11:23,180
که نسبت واقعی بیماران در
246
00:11:23,180 –> 00:11:25,700
رجیستری مبتلا به آسم it R بین
247
00:11:25,700 –> 00:11:30,620
نقطه 1 3 و نقطه است. 2 3 خوب
248
00:11:30,620 –> 00:11:36,860
یعنی این یعنی محدوده 10 درصد است، حالا
249
00:11:36,860 –> 00:11:39,620
میدانید که میتوانیم کاملاً مطمئن باشیم که
250
00:11:39,620 –> 00:11:41,680
نسبت واقعی کمتر از 1/4 است و
251
00:11:41,680 –> 00:11:44,390
به جای اینکه 0.1 درست را بدانید،
252
00:11:44,390 –> 00:11:46,010
بنابراین قطعاً
253
00:11:46,010 –> 00:11:50,870
بین 10 دقیقه و 25 بود. ٪ به ما می دهد
254
00:11:50,870 –> 00:11:57,230
که اکنون چه اتفاقی می افتد،
255
00:11:57,230 –> 00:12:00,380
256
00:12:00,380 –> 00:12:02,330
هر زمان
257
00:12:02,330 –> 00:12:03,980
که یک مقدار منفی برای نسبتی دریافت کردم
258
00:12:03,980 –> 00:12:04,940
که منطقی نیست،
259
00:12:04,940 –> 00:12:08,810
آن را با صفر جایگزین می کنم، ممکن است در فاصله اطمینان شما یک مقدار منفی دریافت کنیم.
260
00:12:08,810 –> 00:12:11,240
برای کران بالا مقداری بزرگتر از یک
261
00:12:11,240 –> 00:12:13,070
که معنی ندارد زیرا
262
00:12:13,070 –> 00:12:14,720
نسبت بزرگتر از 1 منطقی نیست،
263
00:12:14,720 –> 00:12:19,610
من آن را به 1 کاهش می دهم، پس
264
00:12:19,610 –> 00:12:21,350
حالا بیایید ادامه دهیم و نگاهی بیندازیم که
265
00:12:21,350 –> 00:12:22,760
برای فاصله اطمینان واقعی چه چیزی داریم،
266
00:12:22,760 –> 00:12:26,839
بنابراین از نقطه 1 3 2
267
00:12:26,839 –> 00:12:31,250
امتیاز 2 3 3 ما 95% اطمینان داریم
268
00:12:31,250 –> 00:12:34,640
اینکه نسبت واقعی بین این دو
269
00:12:34,640 –> 00:12:36,709
مقدار است در حال حاضر چیزی که در
270
00:12:36,709 –> 00:12:38,900
مورد آمار عجیب است این است که
271
00:12:38,900 –> 00:12:41,450
ما همیشه باید بگوییم که من 95٪ مطمئن هستم
272
00:12:41,450 –> 00:12:43,910
که مقدار واقعی بین این دو
273
00:12:43,910 –> 00:12:47,570
مقدار است چرا باید این کار را به خوبی انجام دهیم اگر
274
00:12:47,570 –> 00:12:49,670
من تقریباً 100 درصد مطمئن
275
00:12:49,670 –> 00:12:53,089
هستم که اگر میخواهم
276
00:12:53,089 –> 00:12:55,279
با شما صادق باشم تا 100
277
00:12:55,279 –> 00:12:58,700
اعتماد کامل
278
00:12:58,700 –> 00:13:00,440
به چیزی داشته باشم باید 0
279
00:13:00,440 –> 00:13:01,970
280
00:13:01,970 –> 00:13:04,430
تا 1 بروم. واقعاً
281
00:13:04,430 –> 00:13:07,850
100% مطمئن باشید وقتی میگویم 95 درصد
282
00:13:07,850 –> 00:13:10,010
اطمینان دارم کاری که انجام میدهم
283
00:13:10,010 –> 00:13:13,310
، دو و نیم درصد
284
00:13:13,310 –> 00:13:15,589
شدید در سمت راست و دو و
285
00:13:15,589 –> 00:13:17,870
نیم درصد شدید در سمت چپ، من شدیداً اصلاح میکنم.
286
00:13:17,870 –> 00:13:20,060
ارزش ها و من فقط به آنچه
287
00:13:20,060 –> 00:13:22,640
در وسط است نگاه می کنم و به همین دلیل است که ما با اطمینان 95 درصد خدمت
288
00:13:22,640 –> 00:13:23,350
289
00:13:23,350 –> 00:13:27,160
می کنیم، بنابراین برخی از
290
00:13:27,160 –> 00:13:29,230
جنبه ها
291
00:13:29,230 –> 00:13:31,990
را متعادل
292
00:13:31,990 –> 00:13:33,820
293
00:13:33,820 –> 00:13:35,350
294
00:13:35,350 –> 00:13:38,110
می کنیم.
295
00:13:38,110 –> 00:13:40,000
آنها نمی خواهند
296
00:13:40,000 –> 00:13:41,320
به فواصل مطمئن فکر کنند و
297
00:13:41,320 –> 00:13:42,610
نمی خواهند به
298
00:13:42,610 –> 00:13:46,060
مقادیر p که ممکن است بپذیرند معمولاً
299
00:13:46,060 –> 00:13:47,860
تجربه من این است که اگر آنها
300
00:13:47,860 –> 00:13:48,430
مشکل
301
00:13:48,430 –> 00:13:50,980
را بدانند، تخمین را می دانند و آنها را نمی دانند.
302
00:13:50,980 –> 00:13:53,520
اندازه نمونه را بدانند معمولاً آنها به طور شهودی
303
00:13:53,520 –> 00:13:56,560
میدانند که چه جنبهای از خطای استاندارد
304
00:13:56,560 –> 00:13:58,890
که اسپرد قرار است چقدر باشد،
305
00:13:58,890 –> 00:14:03,550
بهطور شهودی به نوعی میفهمند
306
00:14:03,550 –> 00:14:06,910
که ارزش یک تخمین چقدر است، بنابراین در
307
00:14:06,910 –> 00:14:08,890
تجربه من از ارائه مردم
308
00:14:08,890 –> 00:14:11,710
این است که شما باید چه کاری انجام دهید.
309
00:14:11,710 –> 00:14:13,840
تخمین امتیاز را ارائه دهید و سپس
310
00:14:13,840 –> 00:14:15,280
فاصله اطمینان را در
311
00:14:15,280 –> 00:14:17,710
خطای استاندارد مانند جیب پشتی خود آماده
312
00:14:17,710 –> 00:14:19,870
نگه دارید تا اگر شروع به پرسیدن چنین سوالاتی کردند، آن را بیرون بیاورید،
313
00:14:19,870 –> 00:14:22,750
در غیر این صورت شما حتی نمی توانید آن را
314
00:14:22,750 –> 00:14:25,390
بپرسید. آن را بالا ببرید، زیرا اگر شروع
315
00:14:25,390 –> 00:14:27,010
به پایین آوردن آمار حفره خرگوش کنید