در این مطلب، ویدئو پایتون: مقدمه ای بر مدل سازی آماری با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:31:24
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,949 –> 00:00:03,510
سلام، در این ویدیو می خواهیم نگاهی
2
00:00:03,510 –> 00:00:05,549
به مقدمه ای بر
3
00:00:05,549 –> 00:00:10,110
مدل سازی آماری و پایتون بیندازیم تا بدانید یک بار
4
00:00:10,110 –> 00:00:11,130
دیگر در حال کار روی
5
00:00:11,130 –> 00:00:13,920
آمار مقدماتی با
6
00:00:13,920 –> 00:00:16,529
کتاب درسی پایتون هستیم و می توانیم کد اصلی
7
00:00:16,529 –> 00:00:23,640
را از این وب سایت دریافت کنیم، بنابراین در
8
00:00:23,640 –> 00:00:24,900
این سخنرانی ما ما به
9
00:00:24,900 –> 00:00:27,599
مدلهای آماری و پانداها نگاهی خواهیم انداخت، بنابراین
10
00:00:27,599 –> 00:00:28,800
میدانیم که مدتی است با پانداها
11
00:00:28,800 –> 00:00:30,570
در این کلاس کار میکنیم، بنابراین باید
12
00:00:30,570 –> 00:00:33,270
با آن احساس راحتی کنیم، بنابراین
13
00:00:33,270 –> 00:00:36,120
پانداها تا حد زیادی استاندارد کار با پانداها
14
00:00:36,120 –> 00:00:38,399
هستند. دادهها در پایتون،
15
00:00:38,399 –> 00:00:40,410
بنابراین دادههای ساختاریافته را به خاطر بسپارید به این معنی است که
16
00:00:40,410 –> 00:00:42,120
دادههایی را که میتوانیم در قالب
17
00:00:42,120 –> 00:00:45,899
جادهها و ستونها قرار دهیم، هر دادهای را
18
00:00:45,899 –> 00:00:47,520
که نمیتوانیم در آن قالب قرار دهیم،
19
00:00:47,520 –> 00:00:51,780
غیرساختار نامیده میشود و وقتی میگویم سطرها
20
00:00:51,780 –> 00:00:54,390
و ستونها تعداد ردیفهای مساوی برای
21
00:00:54,390 –> 00:00:56,010
هر ستون برابر با تعداد ستون برای
22
00:00:56,010 –> 00:01:00,390
هر ردیف، جدولی از داده ها است، بنابراین در
23
00:01:00,390 –> 00:01:02,760
این قالب خواندن پدر برای رایانه یا انسان بسیار آسان تر است
24
00:01:02,760 –> 00:01:05,339
، بسته
25
00:01:05,339 –> 00:01:07,920
به اینکه چگونه آن را قالب بندی می کنیم و
26
00:01:07,920 –> 00:01:10,670
ذخیره و خواندن داده ها در آن بسیار آسان است. این قالب
27
00:01:10,670 –> 00:01:13,200
به دلیل اینکه همه چیز بسیار تمیز
28
00:01:13,200 –> 00:01:16,140
سازماندهی شده است مدل های آمار یک
29
00:01:16,140 –> 00:01:17,909
بسته پیشرفته برای مدل سازی آماری با
30
00:01:17,909 –> 00:01:18,540
پایتون
31
00:01:18,540 –> 00:01:19,950
است که
32
00:01:19,950 –> 00:01:21,570
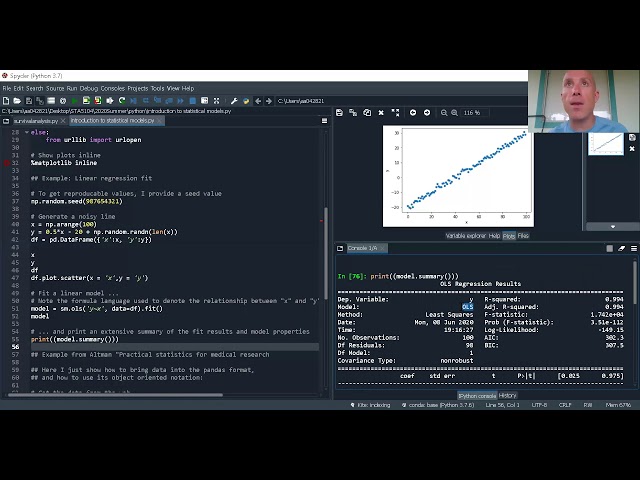
در این کلاس فقط سطح را لمس می کنیم و
33
00:01:21,570 –> 00:01:24,330
خیلی عمیق نمی شویم، امیدوارم آنچه
34
00:01:24,330 –> 00:01:26,159
در مورد آن صحبت می کنیم این کلاس آغازگر خوبی است
35
00:01:26,159 –> 00:01:28,049
برای اینکه شما را علاقه مند و هیجان زده کند
36
00:01:28,049 –> 00:01:30,509
و شروع به کندوکاو در این مورد
37
00:01:30,509 –> 00:01:34,170
کنید، چیزهای خوبی در این بسته وجود دارد و اگر
38
00:01:34,170 –> 00:01:36,299
می خواهید شروع به کندوکاو کنید به موارد دیگر نگاه کنید، در
39
00:01:36,299 –> 00:01:38,040
اینجا اطلاعات
40
00:01:38,040 –> 00:01:40,590
خوبی برای شما وجود دارد، پس حالا بیایید ادامه دهیم
41
00:01:40,590 –> 00:01:45,479
و شروع به وارد کردن
42
00:01:45,479 –> 00:01:48,090
بستههایمان به فضای کاری خود کنیم، بنابراین من واقعاً f9 را روی عنکبوتم فشار میدهم،
43
00:01:48,090 –> 00:01:52,259
بنابراین بیایید
44
00:01:52,259 –> 00:01:56,159
بیحرکت شویم، بیایید پاندا بگیریم، بیایید CyHi را دریافت کنیم یا
45
00:01:56,159 –> 00:02:00,119
آمار را از Sify
46
00:02:00,119 –> 00:02:03,719
دریافت کنیم و بیایید ادامه دهیم و api فرمول مدلهای تنظیم شده را دریافت کنیم و
47
00:02:03,719 –> 00:02:08,008
بیایید sis را درست کنیم. نماد فرمول
48
00:02:08,008 –> 00:02:10,378
یک جنبه مهم در علم گاز است
49
00:02:10,378 –> 00:02:12,900
در اینجا ما به آنچه که
50
00:02:12,900 –> 00:02:13,830
برای فرم استفاده خواهیم
51
00:02:13,830 –> 00:02:16,320
کرد در چند خط کد
52
00:02:16,320 –> 00:02:17,820
53
00:02:17,820 –> 00:02:19,860
خواهیم پرداخت. برای اینکه بگوییم
54
00:02:19,860 –> 00:02:21,810
متغیر وابسته به متغیر مستقل بستگی دارد
55
00:02:21,810 –> 00:02:24,030
و ما
56
00:02:24,030 –> 00:02:26,280
از یک tilde برای نشان دادن این موضوع استفاده می کنیم که متوجه خواهید شد
57
00:02:26,280 –> 00:02:28,020
وقتی به آن رسیدیم از
58
00:02:28,020 –> 00:02:30,090
علامت مساوی استفاده نمی کنیم، می گوییم که از نظر
59
00:02:30,090 –> 00:02:31,710
آماری به آن بستگی دارد.
60
00:02:31,710 –> 00:02:35,510
و برخی از
61
00:02:35,510 –> 00:02:37,530
جنبههای فرضی رابطه وجود خواهد داشت، اما از
62
00:02:37,530 –> 00:02:39,900
نظر آماری کاملاً خوب است، بنابراین اکنون
63
00:02:39,900 –> 00:02:44,010
این بخش بعدی کد آنچه
64
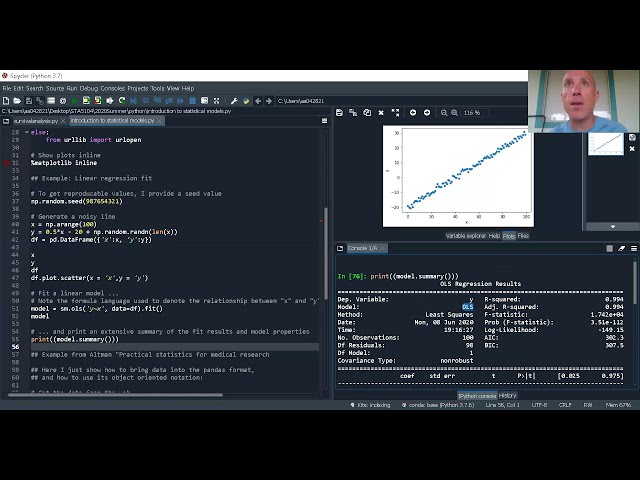
00:02:44,010 –> 00:02:48,270
در اینجا اتفاق میافتد قبل از اینکه پایتون مانند
65
00:02:48,270 –> 00:02:49,680
سه نسخه مختلف در حال حاضر داشته باشد،
66
00:02:49,680 –> 00:02:54,180
پایتون یک پایتون 2 پایتون 3 است و این
67
00:02:54,180 –> 00:02:56,550
یکی از سقوط پایتون یکی
68
00:02:56,550 –> 00:02:58,500
از معایب اصلی آن است، زیرا
69
00:02:58,500 –> 00:03:00,810
باید بدانید اگر در یکی از آنها خوب می شوید
70
00:03:00,810 –> 00:03:02,630
و به یک محیط کاری دیگر می روید، در
71
00:03:02,630 –> 00:03:06,690
دفتر دیگری کار دیگری می شناسید،
72
00:03:06,690 –> 00:03:08,400
ممکن است مجبور شوید یکی دیگر را انتخاب کنید.
73
00:03:08,400 –> 00:03:12,870
74
00:03:12,870 –> 00:03:14,070
شما سه نسخه مختلف را می شناسید، اما
75
00:03:14,070 –> 00:03:15,930
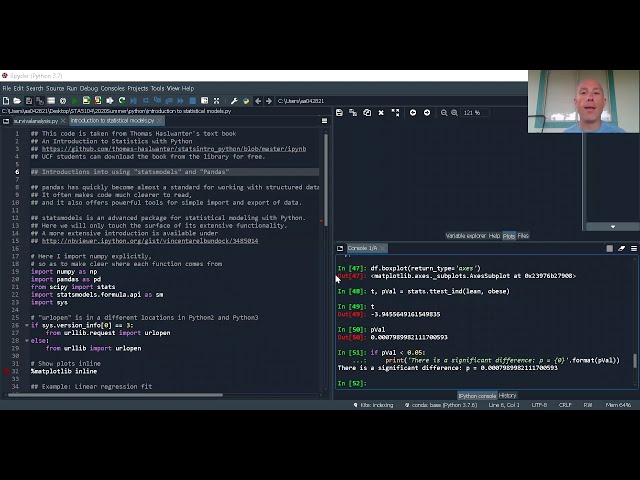
یک تفاوت دیگر وجود دارد که باعث ایجاد
76
00:03:15,930 –> 00:03:18,420
مشکل می شود، بنابراین این قسمت از کد کاری که
77
00:03:18,420 –> 00:03:21,780
انجام می دهد این است که
78
00:03:21,780 –> 00:03:24,600
بسته خاص بسته به نسخه
79
00:03:24,600 –> 00:03:27,000
پایتون را بارگیری می کند. خوب از همه استفاده میکنید، پس
80
00:03:27,000 –> 00:03:28,800
بیایید جلوتر برویم و
81
00:03:28,800 –> 00:03:34,910
اطلاعات این نسخه را بررسی کنیم، بنابراین بیایید به
82
00:03:36,380 –> 00:03:40,760
نسخه sis با کد اسکریپت برویم، اطلاعات اصلی
83
00:03:40,760 –> 00:03:44,250
خوب بود، بنابراین در اینجا میتوانیم ببینیم که
84
00:03:44,250 –> 00:03:48,450
ماژور 3 مینور، 7 میکرو، 6 است و سطح انتشار
85
00:03:48,450 –> 00:03:51,630
سریال نهایی 0 است، بنابراین
86
00:03:51,630 –> 00:03:55,620
این به من می گوید که نسخه
87
00:03:55,620 –> 00:03:58,650
عنکبوت من از پایتون 3 استفاده می کند به دلیل
88
00:03:58,650 –> 00:04:05,910
اصلی اگر بخواهم می توانم آن را بالا بکشم تا
89
00:04:05,910 –> 00:04:07,590
در موقعیت صفر باشد به یاد داشته باشید که
90
00:04:07,590 –> 00:04:11,519
شاخص های پایتون از 0 در موقعیت 0 شروع می شود.
91
00:04:11,519 –> 00:04:17,519
بنابراین من از پایتون 3 استفاده می کنم، بنابراین اگر
92
00:04:17,519 –> 00:04:19,290
بخواهم می توانم فقط از یک کد برای کشیدن مستقیم آن استفاده کنم،
93
00:04:19,290 –> 00:04:20,640
اما
94
00:04:20,640 –> 00:04:24,330
اگر دستور بسیار
95
00:04:24,330 –> 00:04:27,090
زیبا است و خوب است، این را اجرا می کنم، بیایید
96
00:04:27,090 –> 00:04:27,690
جلو برویم و عصبانی شویم
97
00:04:27,690 –> 00:04:34,080
نمودار lib خوب است، بنابراین برای اولین
98
00:04:34,080 –> 00:04:36,360
مثال ما کاری که میخواهیم انجام دهیم، میخواهیم
99
00:04:36,360 –> 00:04:38,100
فقط یک مدل رگرسیون خطی ساده
100
00:04:38,100 –> 00:04:41,070
با دادههای تولید شده تصادفی انجام دهیم، بنابراین
101
00:04:41,070 –> 00:04:42,780
این دادههای واقعی نیستند، ما فقط
102
00:04:42,780 –> 00:04:44,790
از مولد اعداد تصادفی برای تولید برخی چیزها استفاده میکنیم.
103
00:04:44,790 –> 00:04:47,750
104
00:04:47,750 –> 00:04:50,490
من می خواهم یک متغیر Y بسازم که در آن می
105
00:04:50,490 –> 00:04:53,220
دانم wh از آنجایی که به نظر می رسد
106
00:04:53,220 –> 00:04:56,220
رابطه بین x و y چگونه است
107
00:04:56,220 –> 00:04:58,350
و از این طریق می توانم نگاهی بیندازم و ببینم
108
00:04:58,350 –> 00:05:00,270
چه اتفاقی می افتد، این یک راه خوب برای
109
00:05:00,270 –> 00:05:02,910
ایجاد شهود در مورد رگرسیون است
110
00:05:02,910 –> 00:05:05,190
و صادقانه بگویم که هر نوع
111
00:05:05,190 –> 00:05:09,030
مدل سازی آماری برای ساختن است. تصادفی شما می دانید
112
00:05:09,030 –> 00:05:11,700
داده های متغیر را بسازید که در آن
113
00:05:11,700 –> 00:05:15,290
می دانید مقادیر واقعی جمعیت را
114
00:05:15,290 –> 00:05:18,300
تولید می کنند اعداد تصادفی ایجاد می کنند، یک مدل بسازید
115
00:05:18,300 –> 00:05:19,830
و نگاهی بیندازید و ببینید که چگونه چیزها متفاوت هستند
116
00:05:19,830 –> 00:05:22,260
و این می تواند به شما بینشی در
117
00:05:22,260 –> 00:05:25,590
مورد چگونگی وضعیت واقعی در
118
00:05:25,590 –> 00:05:27,410
هنگام شروع ارائه دهد. در حال اجرا با داده های واقعی
119
00:05:27,410 –> 00:05:30,150
کاملاً درست است، بنابراین در اینجا من فقط
120
00:05:30,150 –> 00:05:35,700
100 مقدار مختلف را برای X خود دریافت می کنم و سپس
121
00:05:35,700 –> 00:05:38,490
کاری که می خواهیم انجام دهیم این است که
122
00:05:38,490 –> 00:05:41,220
مقادیر X را که در 1/2 من ضرب می
123
00:05:41,220 –> 00:05:44,340
کنم، می گیرم. من 20 را کم می کنم و سپس می
124
00:05:44,340 –> 00:05:46,610
گذرم و
125
00:05:46,610 –> 00:05:49,590
مقداری نویز تصادفی ایجاد می کنم و این
126
00:05:49,590 –> 00:05:53,700
عبارت خطای تصادفی خواهد بود و سپس
127
00:05:53,700 –> 00:05:56,520
x و y را با هم قرار می دهم تا
128
00:05:56,520 –> 00:05:58,470
یک قاب ایجاد کنیم. نگاه کنید
129
00:05:58,470 –> 00:06:00,390
این چه شکلی است خوب است تا بتوانید ببینید
130
00:06:00,390 –> 00:06:04,560
وقتی من از تابع a range در
131
00:06:04,560 –> 00:06:08,010
X استفاده کنید که 100 مقدار اول را به من داده است که
132
00:06:08,010 –> 00:06:11,310
از 0 شروع می شود و از 0 به 99 می رسد
133
00:06:11,310 –> 00:06:14,570
و در قالب یک آرایه است در حال حاضر
134
00:06:14,570 –> 00:06:16,740
وقتی نگاه می کنیم چه چیزی به دست می آوریم. نگاهی
135
00:06:16,740 –> 00:06:21,000
به Y خوب است تا بتوانیم ببینید این به نوعی
136
00:06:21,000 –> 00:06:25,470
نگاه کردن به این است که همانطور که من نگاهی
137
00:06:25,470 –> 00:06:27,810
به آن انداختم به نظر می رسد که تقریباً به
138
00:06:27,810 –> 00:06:29,669
نظر می رسد که از ابتدا تا انتها می روم مقادیر بزرگتر یا مقادیر بیشتری دریافت
139
00:06:29,669 –> 00:06:33,030
می کنم
140
00:06:33,030 –> 00:06:36,600
بنابراین در اینجا از حدود منفی 2 شروع می کنیم
141
00:06:36,600 –> 00:06:41,670
و در پایان با
142
00:06:41,670 –> 00:06:44,910
شما کمی کمتر از 30 می دانید، بنابراین
143
00:06:44,910 –> 00:06:47,880
دقیقاً حدود 30 سال است و بله، می توانم
144
00:06:47,880 –> 00:06:49,710
ببینم که
145
00:06:49,710 –> 00:06:51,480
از اولین ورودی به آخرین ورودی، رشد کاملی ندارد و
146
00:06:51,480 –> 00:06:55,230
به همین دلیل است، بنابراین اگر قرار بود
147
00:06:55,230 –> 00:06:57,480
این را دوباره انجام دهم، گفتم خوب می خواهم برای اینکه به شما نشان دهم
148
00:06:57,480 –> 00:07:01,530
اگر این کار را به این صورت انجام دهیم چه اتفاقی میافتد، من این را خوب میدانم،
149
00:07:01,530 –> 00:07:10,020
بنابراین در اینجا
150
00:07:10,020 –> 00:07:12,120
مقدار واقعی باید باشد اگر اصلاً
151
00:07:12,120 –> 00:07:15,480
تصادفی در دادههای ما وجود نداشته باشد
152
00:07:15,480 –> 00:07:17,940
، معادله همان چیزی است که اتفاق میافتد،
153
00:07:17,940 –> 00:07:24,750
مولد اعداد تصادفی است. شما می
154
00:07:24,750 –> 00:07:26,640
دانید شبیه سازی مانند متغیرهایی است
155
00:07:26,640 –> 00:07:28,920
که ما نمی توانیم در آنها حساب کنیم زندگی واقعی
156
00:07:28,920 –> 00:07:31,470
و به این ترتیب میدانید که
157
00:07:31,470 –> 00:07:35,010
جنبههایی از دادههای ما وجود دارد که ما داریم،
158
00:07:35,010 –> 00:07:37,830
ما همه متغیرهای مهم را نمیبینیم،
159
00:07:37,830 –> 00:07:39,000
بنابراین همیشه
160
00:07:39,000 –> 00:07:40,980
یک دسته از Wiggles وجود دارد، یک دسته از آنها در اطراف پرش میکنند، بنابراین
161
00:07:40,980 –> 00:07:42,510
چیزها هرگز به
162
00:07:42,510 –> 00:07:44,640
مدل آماری کاملاً نمیرسند. با
163
00:07:44,640 –> 00:07:45,960
مدل آماری مطابقت داشته باشید، احتمالاً
164
00:07:45,960 –> 00:07:48,630
کار اشتباهی انجام میدهید، بنابراین در اینجا
165
00:07:48,630 –> 00:07:53,550
مانند جنبه اصلی واقعی است قبل از
166
00:07:53,550 –> 00:07:57,080
اینکه متغیرهای نامشخص در آن
167
00:07:57,080 –> 00:08:01,230
گنجانده شود و میتوانید ببینید که به
168
00:08:01,230 –> 00:08:03,840
خوبی برای هر مرحله به نصف افزایش مییابد
169
00:08:03,840 –> 00:08:07,260
تا زمانی که از منفی 20 میرود.
170
00:08:07,260 –> 00:08:13,080
اکنون اگر
171
00:08:13,080 –> 00:08:14,760
به مرگ برای هدف نگاهی بیندازم وقتی
172
00:08:14,760 –> 00:08:17,250
آنها را کنار هم می گذارم، می توانم ببینم که
173
00:08:17,250 –> 00:08:18,570
از طریق الگویی که قبلاً
174
00:08:18,570 –> 00:08:23,220
در مورد آن صحبت کرده ایم، بسیار خوب است، بنابراین اکنون بسیار خوب
175
00:08:23,220 –> 00:08:25,320
این داده های جفت شده است. بهترین راه برای
176
00:08:25,320 –> 00:08:27,630
بررسی این موضوع این است که من یک
177
00:08:27,630 –> 00:08:29,160
متغیر عددی جفت شده با متغیر عددی دارم
178
00:08:29,160 –> 00:08:31,830
، بهترین راه برای انجام این کار این است که به
179
00:08:31,830 –> 00:08:34,289
آن به عنوان یک نمودار پراکنده نگاه کنیم، بنابراین به
180
00:08:34,289 –> 00:08:36,840
نمودار پراکندگی نگاهی بیندازید.
181
00:08:36,840 –> 00:08:38,370
در به نظر می رسد مانند یک خط در حال حاضر این یک
182
00:08:38,370 –> 00:08:40,289
خط کامل نیست، متوجه می شوید که
183
00:08:40,289 –> 00:08:42,990
کاملاً به خوبی تراز نشده است، بسیار نزدیک به نظر می رسد
184
00:08:42,990 –> 00:08:46,170
شما هرگز هرگز این
185
00:08:46,170 –> 00:08:47,820
داده های خوب را در زندگی واقعی نخواهید دید فقط به
186
00:08:47,820 –> 00:08:50,820
شما اجازه می دهد تا بدانید فقط به آن عادت کنید که
187
00:08:50,820 –> 00:08:52,530
هرگز نخواهید داشت هر چیزی به این زیبا
188
00:08:52,530 –> 00:08:54,780
تا شیرین با دادههای واقعی شما
189
00:08:54,780 –> 00:08:55,380
،
190
00:08:55,380 –> 00:08:58,170
اگر به نظر خوب است، احتمالاً چیزی در
191
00:08:58,170 –> 00:09:05,670
طول مسیر جعل شده است،
192
00:09:05,670 –> 00:09:07,920
بیایید پیش برویم که یک مدل رگرسیون خطی را
193
00:09:07,920 –> 00:09:10,830
برای این دادهها تطبیق دهیم، بنابراین در اینجا
194
00:09:10,830 –> 00:09:14,490
میتوانم ببینم که شما را دریافت کردهام. خیلی
195
00:09:14,490 –> 00:09:17,180
نزدیک به یک خط مستقیم میدانم، میتوانم ببینم
196
00:09:17,180 –> 00:09:20,310
که تقاطع y حدود منفی 20 است
197
00:09:20,310 –> 00:09:22,950
و میتوانم ببینم که شیب حدود
198
00:09:22,950 –> 00:09:25,980
1/2 است و میدانم که درست است زیرا من
199
00:09:25,980 –> 00:09:29,160
آن را ایجاد کردم و همچنین میتوانم به
200
00:09:29,160 –> 00:09:31,170
نمودار پراکندگی نگاه کنم و اکنون بررسی کنید
201
00:09:31,170 –> 00:09:33,270
که دقیقاً 1/2 برای شیب
202
00:09:33,270 –> 00:09:36,000
نخواهد بود، دقیقاً منفی 20 برای
203
00:09:36,000 –> 00:09:38,040
تقاطع y نخواهد بود، اما نزدیک به
204
00:09:38,040 –> 00:09:39,860
آن خواهد بود، بنابراین بیایید این کار را به درستی انجام دهیم،
205
00:09:39,860 –> 00:09:43,190
بنابراین توجه کنید که
206
00:09:43,190 –> 00:09:48,390
در مدلسازی آن در اینجا چه خبر است. این tilde من
207
00:09:48,390 –> 00:09:51,180
Y دارم به X بستگی دارد این همان چیزی است که till می
208
00:09:51,180 –> 00:09:53,310
خواند، بنابراین ما می گوییم که این نماد وجود دارد
209
00:09:53,310 –> 00:09:55,320
این نماد فرمول می گوید
210
00:09:55,320 –> 00:09:58,350
که Y از نظر آماری به X بستگی
211
00:09:58,350 –> 00:10:00,180
دارد اکنون متغیرهای دیگری وجود دارند که
212
00:10:00,180 –> 00:10:03,180
وقتی از این نماد tilde استفاده می کنم به طور کامل به حساب نمی آیند
213
00:10:03,180 –> 00:10:05,010
، به همین دلیل است که من آن را ندارم.
214
00:10:05,010 –> 00:10:07,500
علامت مساوی با علامت مساوی
215
00:10:07,500 –> 00:10:09,150
میدانید میخواهم بگویم Y
216
00:10:09,150 –> 00:10:12,030
دقیقاً همین مقدار خاص است نه من
217
00:10:12,030 –> 00:10:13,410
میگویم که یک رابطه آماری وجود
218
00:10:13,410 –> 00:10:15,150
دارد و ما باید
219
00:10:15,150 –> 00:10:19,170
بفهمیم که چه چیزی درست است و اگر به مدل نگاه کنیم
220
00:10:19,170 –> 00:10:21,390
خیلی جالب نخواهد بود،
221
00:10:21,390 –> 00:10:22,740
اما بیایید جلوتر برویم و آن را در آنجا قرار
222
00:10:22,740 –> 00:10:25,140
دهیم تا بتوانیم ببینیم که یک
223
00:10:25,140 –> 00:10:29,100
مدل خطی رگرسیون ایجاد کردهایم و بیایید
224
00:10:29,100 –> 00:10:31,020
جلوتر برویم و به خلاصه مدل نگاهی بیندازیم،
225
00:10:31,020 –> 00:10:36,540
خوب ما همه چیز را
226
00:10:36,540 –> 00:10:39,780
اینجا چاپ میکنیم. خوب برو بنابراین می بینیم که
227
00:10:39,780 –> 00:10:42,060
متغیر وابسته به نام Y است، این یک
228
00:10:42,060 –> 00:10:44,490
مدل معمولی با حداقل مربعات است، حداقل
229
00:10:44,490 –> 00:10:47,490
مربعات به این معنی است که اگر
230
00:10:47,490 –> 00:10:51,300
مقدار Y مشاهده شده را منهای مقدار مدل
231
00:10:51,300 –> 00:10:53,790
مربع بگیرم، همه آن ها را مجذور کنیم
232
00:10:53,790 –> 00:10:56,550
و سپس آن را جمع کنیم.
233
00:10:56,550 –> 00:10:59,040
تمام مشاهدات فردی که
234
00:10:59,040 –> 00:11:01,890
کوچکترین مقداری است که من می توانم از
235
00:11:01,890 –> 00:11:04,920
مجذور کردن اختلاف و سپس جمع کردن
236
00:11:04,920 –> 00:11:07,830
بدست بیاورم و با استفاده از حداقل مربعات محاسبه می
237
00:11:07,830 –> 00:11:08,970
شود،
238
00:11:08,970 –> 00:11:11,670
بنابراین می دانید که کوچکترین
239
00:11:11,670 –> 00:11:14,910
مقدار مجموع مربعات تاریخی است
240
00:11:14,910 –> 00:11:16,410
که ایجاد شده است، تعداد زمانی
241
00:11:16,410 –> 00:11:18,899
مشاهدات یک عدد است. صد خوب
242
00:11:18,899 –> 00:11:22,139
درجه آزادی 98 است چرا 98 است تا
243
00:11:22,139 –> 00:11:24,720
به حال در مورد مدل های شما صحبت می کردیم
244
00:11:24,720 –> 00:11:26,519
که منهای 1 درجه آزادی داشتند
245
00:11:26,519 –> 00:11:29,699
خوب اینجا منهای 2 برای
246
00:11:29,699 –> 00:11:32,459
درجات آزادی n منهای 2 است چرا – خوب
247
00:11:32,459 –> 00:11:34,110
من ‘دو پارامتر دارم،
248
00:11:34,110 –> 00:11:36,120
شیب را دارم و فاصله y را دارم
249
00:11:36,120 –> 00:11:38,639
که دوتا از آنهاست، بنابراین برای هر پارامتری
250
00:11:38,639 –> 00:11:41,310
که مدل می کنم
251
00:11:41,310 –> 00:11:44,970
یکی را از حجم نمونه کم کنم درجه
252
00:11:44,970 –> 00:11:48,480
آزادی مدل یک است. و
253
00:11:48,480 –> 00:11:52,470
نوع کوواریانس غیر مستحکم است، بنابراین این
254
00:11:52,470 –> 00:11:54,720
مانند روش استاندارد برای انجام آن است که اکنون
255
00:11:54,720 –> 00:11:57,899
r-squared من 0.99 است، زیرا شما هرگز
256
00:11:57,899 –> 00:11:59,850
چیزی به این خوبی را در زندگی واقعی نخواهید دید که در زندگی واقعی
257
00:11:59,850 –> 00:12:01,379
چیزی خوب
258
00:12:01,379 –> 00:12:03,980
را
259
00:12:03,980 –> 00:12:07,379
ببینید. sted r-squared 0.99 برای همه چیز درست است،
260
00:12:07,379 –> 00:12:09,389
چیزی که همیشه می خواهید بررسی کنید
261
00:12:09,389 –> 00:12:12,449
که آیا این دو مقدار از یکدیگر منحرف می شوند
262
00:12:12,449 –> 00:12:14,339
، نشانه ای وجود دارد که شما
263
00:12:14,339 –> 00:12:18,540
یک مدل بیش از حد برازش دارید، اگر من
264
00:12:18,540 –> 00:12:20,550
یک دسته کامل از متغیرهای پیش بینی داشته
265
00:12:20,550 –> 00:12:23,579
باشم و قرار دهم، کاملاً درست است. آنها را به یک مدل رگرسیونی تبدیل می کنند، هر
266
00:12:23,579 –> 00:12:25,889
چه متغیرهای پیش بینی کننده بیشتر باشد، بیشتر
267
00:12:25,889 –> 00:12:28,470
در معرض خطر قرار دادن بیش از حد داده هایم قرار می گیرم،
268
00:12:28,470 –> 00:12:31,050
درست همانطور که از نامش پیداست، اگر بگویم
269
00:12:31,050 –> 00:12:33,389
تطبیق
270
00:12:33,389 –> 00:12:36,709
271
00:12:36,709 –> 00:12:39,769
بیش از حد چیز بدی خواهد بود. زیر برازش
272
00:12:39,769 –> 00:12:42,540
به خاطر داشته باشید که بیش
273
00:12:42,540 –> 00:12:45,089
از حد برازش بدتر از برازش است، بنابراین چیزی که ما
274
00:12:45,089 –> 00:12:48,209
همیشه میخواهیم مراقب آن باشیم، بیش از حد برازش کردن
275
00:12:48,209 –> 00:12:50,370
مدلمان است، به این معنی که من پیشبینیکنندههایی دارم
276
00:12:50,370 –> 00:12:54,389
که بهطور مؤثری یک پیشبینیکننده
277
00:12:54,389 –> 00:12:58,069
به مدل من اضافه میکنند، در واقع
278
00:12:58,069 –> 00:13:01,079
نتایجی را که به دست میآورم کاهش میدهند. در واقع
279
00:13:01,079 –> 00:13:03,300
بهتر است با حذف برخی از چیزها،
280
00:13:03,300 –> 00:13:06,990
ایده بیش از حد برازش است، بنابراین در این
281
00:13:06,990 –> 00:13:08,639
شرایط ما یک متغیر پیش بینی
282
00:13:08,639 –> 00:13:10,889
داریم که فقط X است.
283
00:13:10,889 –> 00:13:12,930
e و
284
00:13:12,930 –> 00:13:14,850
متغیرهای پیش بینی بیشتر و ما باید
285
00:13:14,850 –> 00:13:16,139
مراقب ایده این
286
00:13:16,139 –> 00:13:19,500
بیش از حد برازش باشیم، اولین راه که می
287
00:13:19,500 –> 00:13:21,630
خواهیم بررسی کنیم واقعاً آسان است اگر ببینم
288
00:13:21,630 –> 00:13:22,590
این دو که
289
00:13:22,590 –> 00:13:24,270
از r-squared و r-squared تنظیم شده استفاده می
290
00:13:24,270 –> 00:13:26,520
کنند مانند انحراف شروع می شوند. از
291
00:13:26,520 –> 00:13:28,130
یکدیگر شروع میکنند، تفاوتی وجود دارد،
292
00:13:28,130 –> 00:13:32,340
پس باید مراقب باشم و r-
293
00:13:32,340 –> 00:13:34,080
squared بزرگتر از r-squared تنظیم شده خواهد بود،
294
00:13:34,080 –> 00:13:38,040
بنابراین اگر مانند 0.01 باشد،
295
00:13:38,040 –> 00:13:40,140
منظورم این است که عملاً یکسان است، اما اگر
296
00:13:40,140 –> 00:13:43,590
چیزی شبیه به نقطه 95 را ببینم و
297
00:13:43,590 –> 00:13:45,420
من نقطه 9 را می بینم که تفاوت دیگری است
298
00:13:45,420 –> 00:13:47,160
من اکنون شروع به
299
00:13:47,160 –> 00:13:50,730
نگرانی
300
00:13:50,730 –> 00:13:52,590
خواهم کرد، زمانی که تفاوت زیادی وجود دارد مانند مشکل ساز، زمانی که
301
00:13:52,590 –> 00:13:54,990
باید نگران آن باشم اوه
302
00:13:54,990 –> 00:13:57,930
واقعاً خاکستری است و شما نمی توانید
303
00:13:57,930 –> 00:14:01,050
برای دانستن آن فقط تجربه مدلینگ داشته باشید.
304
00:14:01,050 –> 00:14:04,380
چقدر انحراف مهم است در حال حاضر
305
00:14:04,380 –> 00:14:07,370
آمار F آمار F در حال
306
00:14:07,370 –> 00:14:10,440
اندازه گیری است آیا من یک
307
00:14:10,440 –> 00:14:12,960
مدل آماری معنی دار دارم اکنون وقتی می گویم از نظر
308
00:14:12,960 –> 00:14:15,420
آماری معنی دار است که به این معنی است که آیا
309
00:14:15,420 –> 00:14:19,500
من برخی از متغیرهای من در اطلاعات
310
00:14:19,500 –> 00:14:23,250
مدل هستند. برای متغیر وابسته من
311
00:14:23,250 –> 00:14:28,860
اکنون آمار F می
312
00:14:28,860 –> 00:14:32,340
پرسد آیا من یک یا چند متغیر پیش بینی مفید دارم آیا اکنون یک یا چند
313
00:14:32,340 –> 00:14:34,710
متغیر دارم،
314
00:14:34,710 –> 00:14:37,500
ممکن است فقط یکی
315
00:14:37,500 –> 00:14:39,620
داشته باشم اگر داشته باشم، فرض کنید
316
00:14:39,620 –> 00:14:42,210
200 متغیر پیش بینی دارم. یک
317
00:14:42,210 –> 00:14:45,210
عدد دیوانه را مدل کنید و یک آمار بزرگ است
318
00:14:45,210 –> 00:14:47,610
که به من می گوید حداقل یک
319
00:14:47,610 –> 00:14:49,650
متغیر پیش بینی کننده خوب در آنجا
320
00:14:49,650 –> 00:14:51,000
دارم، به من نمی گوید که همه آنها
321
00:14:51,000 –> 00:14:52,890
خوب هستند، به من نمی گوید که آیا هر یک از آنها
322
00:14:52,890 –> 00:14:55,350
بد هستند یا خیر. به من می گوید حداقل یکی خوب است،
323
00:14:55,350 –> 00:14:58,800
به یاد داشته باشید که آمار F
324
00:14:58,800 –> 00:15:01,680
همیشه بر اساس است و اکنون به یک
325
00:15:01,680 –> 00:15:04,080
اندازه گیری واریانس نگاه می کنیم،
326
00:15:04,080 –> 00:15:08,340
این به نسبت واریانس اندازه گیری شده در
327
00:15:08,340 –> 00:15:10,980
مدل رگرسیون نگاه می کند، این به معنای واقعی
328
00:15:10,980 –> 00:15:12,690
کل