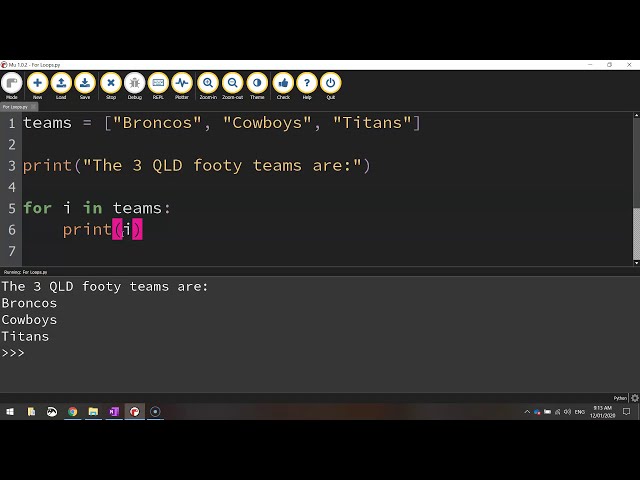
در این مطلب، ویدئو آموزش: برنامه نویسی CUDA در پایتون با numba و cupy با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:45:43
تصاویر این ویدئو:


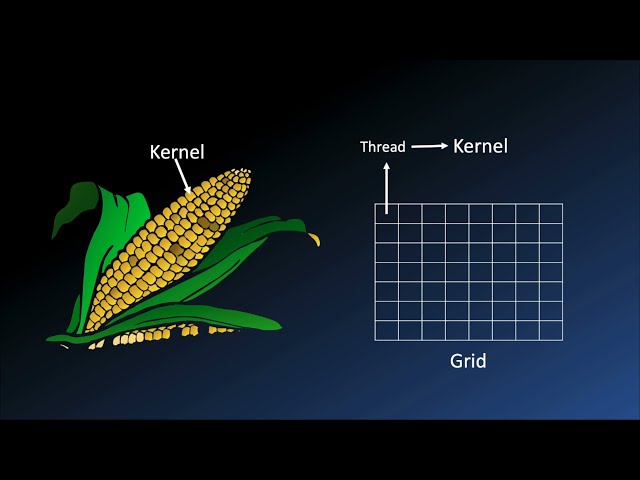

قسمتی از زیرنویس این فیلم:
00:00:01,360 –> 00:00:03,280
این روزها فرار از
2
00:00:03,280 –> 00:00:04,880
اخبار در مورد یادگیری ماشینی و
3
00:00:04,880 –> 00:00:07,120
هوش مصنوعی غیرممکن است،
4
00:00:07,120 –> 00:00:08,639
اگر روزنامه ها و
5
00:00:08,639 –> 00:00:10,719
مجلاتی مانند بینش های اقتصاددان یا مکینزی را باور
6
00:00:10,719 –> 00:00:11,440
7
00:00:11,440 –> 00:00:13,200
کنید، به نظر می رسد که انقلاب ربات ها نزدیک
8
00:00:13,200 –> 00:00:15,280
است
9
00:00:15,280 –> 00:00:16,560
، درست است که ما تعدادی
10
00:00:16,560 –> 00:00:18,240
برنامه بسیار جالب دیده ایم. یادگیری ماشینی
11
00:00:18,240 –> 00:00:19,920
در زمانهای اخیر
12
00:00:19,920 –> 00:00:21,920
مانند وسایل نقلیه خودران و رباتهای شطرنج،
13
00:00:21,920 –> 00:00:22,960
14
00:00:22,960 –> 00:00:24,560
اما در سطحی اساسی، این
15
00:00:24,560 –> 00:00:26,240
الگوریتمها واقعاً فقط یک
16
00:00:26,240 –> 00:00:27,840
تابع بسیار پیچیده
17
00:00:27,840 –> 00:00:29,599
با پارامترهای زیادی را برای بسیاری از
18
00:00:29,599 –> 00:00:31,039
دادههای ورودی تطبیق میدهند،
19
00:00:31,039 –> 00:00:32,640
ایدههای یادگیری ماشین
20
00:00:32,640 –> 00:00:34,640
برای دههها وجود داشته است، پس چرا در حال حاضر چنین علاقه ای وجود دارد
21
00:00:34,640 –> 00:00:35,280
22
00:00:35,280 –> 00:00:36,880
که سنگ بنای عصر کنونی
23
00:00:36,880 –> 00:00:38,879
یادگیری ماشین یا
24
00:00:38,879 –> 00:00:40,879
هوش مصنوعی شبکه عصبی
25
00:00:40,879 –> 00:00:43,120
به خصوص شبکه های عصبی عمیق است که
26
00:00:43,120 –> 00:00:44,960
ورودی ها از طریق لایه ورودی تغذیه می شوند
27
00:00:44,960 –> 00:00:46,480
و از لایه های متعدد
28
00:00:46,480 –> 00:00:47,440
گره های پنهان عبور می کنند
29
00:00:47,440 –> 00:00:50,719
تا در نهایت به گره خروجی می رسند.
30
00:00:50,719 –> 00:00:52,559
ساختارهایی که از اجزای بسیار ساده ای ساخته شده اند
31
00:00:52,559 –> 00:00:54,160
32
00:00:54,160 –> 00:00:55,600
که می توانند به ba نزدیک شوند و نشان دهند
33
00:00:55,600 –> 00:00:58,160
توابع پیچیده به طور دلخواه
34
00:00:58,160 –> 00:00:59,840
، شبکه تصمیم میگیرد
35
00:00:59,840 –> 00:01:02,000
از طریق مجموعهای از وزنهای ذخیرهشده در
36
00:01:02,000 –> 00:01:03,359
هر گره ورودی، چه کاری با ورودیها انجام دهد
37
00:01:03,359 –> 00:01:05,519
که تعیین میکند هر ورودی
38
00:01:05,519 –> 00:01:08,479
به گره چقدر به خروجی آن کمک میکند،
39
00:01:08,479 –> 00:01:10,159
این وزنها را میتوان با
40
00:01:10,159 –> 00:01:12,400
مقایسه خروجی شبکه
41
00:01:12,400 –> 00:01:15,200
و بهینهسازی کرد. نتیجه مورد انتظار و
42
00:01:15,200 –> 00:01:17,040
انتشار خطاها به صورت معکوس از طریق شبکه
43
00:01:17,040 –> 00:01:19,280
به اصطلاح به
44
00:01:19,280 –> 00:01:21,280
روز رسانی و بهبود مستمر
45
00:01:21,280 –> 00:01:22,240
وزن های شبکه
46
00:01:22,240 –> 00:01:25,040
چیزی است که ما آموزش شبکه می نامیم
47
00:01:25,040 –> 00:01:26,400
البته این نوع
48
00:01:26,400 –> 00:01:28,159
نمایش تصویری فقط برای درک خود ما
49
00:01:28,159 –> 00:01:30,560
در زیر هود است.
50
00:01:30,560 –> 00:01:31,600
واقعاً
51
00:01:31,600 –> 00:01:34,880
اتفاق میافتد، جبر ماتریسی زیادی که برای کارایی بهینهسازی شدهاند،
52
00:01:34,880 –> 00:01:36,479
53
00:01:36,479 –> 00:01:37,600
معلوم میشود که این نوع
54
00:01:37,600 –> 00:01:40,079
محاسبات میتوانند به شدت فلج شوند
55
00:01:40,079 –> 00:01:42,159
و بنابراین وقتی
56
00:01:42,159 –> 00:01:44,479
روی یک واحد پردازش گرافیکی
57
00:01:44,479 –> 00:01:48,399
یا یک gpu انجام میشوند، تسریع میشوند.
58
00:01:48,399 –> 00:01:50,399
59
00:01:50,399 –> 00:01:52,799
فناوری که
60
00:01:52,799 –> 00:01:53,520
61
00:01:53,520 –> 00:01:56,159
انفجار در یادگیری ماشین را فعال کرده است nd ai
62
00:01:56,159 –> 00:01:56,640
فضای
63
00:01:56,640 –> 00:01:59,200
بدون gpus بسیار غیر عملی
64
00:01:59,200 –> 00:02:00,399
و زمان بر است
65
00:02:00,399 –> 00:02:02,479
برای آموزش این شبکه های عصبی بسیار عمیق
66
00:02:02,479 –> 00:02:03,920
که برای انواع
67
00:02:03,920 –> 00:02:04,719
برنامه
68
00:02:04,719 –> 00:02:07,280
هایی استفاده می شود که این روزها ما بدیهی می دانیم
69
00:02:07,280 –> 00:02:09,280
مانند تشخیص تصویر
70
00:02:09,280 –> 00:02:11,038
این روزها که نیازی به برنامه ریزی هیچ
71
00:02:11,038 –> 00:02:12,959
عصبی نیست. در شبکهها از ابتدا
72
00:02:12,959 –> 00:02:14,800
میتوانید از یک کتابخانه سطح بالا
73
00:02:14,800 –> 00:02:17,440
مانند tensorflow یا pytorch استفاده کنید،
74
00:02:17,440 –> 00:02:18,800
اما قدرت واقعی در این
75
00:02:18,800 –> 00:02:21,920
کتابخانهها شتاب gpu آنها است
76
00:02:21,920 –> 00:02:22,640
که
77
00:02:22,640 –> 00:02:25,840
با اتصالهای cuda فعال میشود، اگر فقط به شبکههای عصبی نیاز
78
00:02:25,840 –> 00:02:26,480
79
00:02:26,480 –> 00:02:28,080
دارید، لازم نیست با این سطح پایینتر سروکار داشته باشید.
80
00:02:28,080 –> 00:02:29,920
به هیچ وجه و شما می
81
00:02:29,920 –> 00:02:31,599
توانید با دانستن
82
00:02:31,599 –> 00:02:33,360
کتابخانه های سطح بالاتر کاملاً
83
00:02:33,360 –> 00:02:34,720
راضی باشید، اما اگر به
84
00:02:34,720 –> 00:02:36,400
شبکه های عصبی نیاز ندارید اما انواع دیگری از
85
00:02:36,400 –> 00:02:37,040
مشکلات
86
00:02:37,040 –> 00:02:38,720
دارید که ممکن است بخواهید با یک gpu تسریع کنید،
87
00:02:38,720 –> 00:02:41,599
چطور می دانید که یک gpu
88
00:02:41,599 –> 00:02:42,160
چه می کند؟ کمک
89
00:02:42,160 –> 00:02:44,239
به مشکل شما برای این کار ما باید
90
00:02:44,239 –> 00:02:46,640
تفاوت های اساسی بین
91
00:02:46,640 –> 00:02:50,319
cpus و gpus را درک کنیم در اینجا نمودار سطح بسیار
92
00:02:50,319 –> 00:02:51,280
93
00:02:51,280 –> 00:02:55,120
ابتدایی یک cpu در مقابل یک gpu را مشاهده می کنید که به طور کلاسیک
94
00:02:55,120 –> 00:02:57,760
همه برنامه های خود را اجرا می کنیم روی cpus که
95
00:02:57,760 –> 00:03:00,319
در اجرای سریال تخصص دارند به
96
00:03:00,319 –> 00:03:03,360
این معنی که یک پردازنده مدرن یکی پس از دیگری
97
00:03:03,360 –> 00:03:05,440
حاوی چندین هسته است
98
00:03:05,440 –> 00:03:07,120
و می توان از آنها در
99
00:03:07,120 –> 00:03:09,680
برخی از برنامه ها با پردازش چندگانه
100
00:03:09,680 –> 00:03:11,519
101
00:03:11,519 –> 00:03:13,840
102
00:03:13,840 –> 00:03:15,840
استفاده کرد.
103
00:03:15,840 –> 00:03:19,040
حافظه بسته بندی شده نزدیک به این هسته ها
104
00:03:19,040 –> 00:03:21,760
به پردازنده اجازه می دهد تا
105
00:03:21,760 –> 00:03:23,200
نتایج متوسط زیادی را ذخیره کند و چ
106
00:03:23,200 –> 00:03:26,480
خه های ساعت cpu به طور بهینه استفاده مجدد از داده ها
107
00:03:26,480 –> 00:03:28,879
یز بسیار سریع هستند، ام
108
00:03:28,879 –> 00:03:31,519
به طور معمول یک cpu شامل از دو تا شا
109
00:03:31,519 –> 00:03:33,440
د ده ها است البته در
110
00:03:33,440 –> 00:03:36,080
قابل یک gpu معمولاً شامل صد
111
00:03:36,080 –> 00:03:37,920
ا یا البته هزاران نفر
112
00:03:37,920 –> 00:03:39,680
که همگی می توانند محاسبات را به طور مستقل انجام دهند،
113
00:03:39,680 –> 00:03:41,360
114
00:03:41,360 –> 00:03:44,080
با این حال فضای کمتری برای حافظه پنهان وجود دارد، بنابراین
115
00:03:44,080 –> 00:03:46,159
یک پردازنده گرافیکی برای یک منطق کنترل پیچیده مناسب نیست
116
00:03:46,159 –> 00:03:47,440
117
00:03:47,440 –> 00:03:50,080
و معمولاً یک هسته واحد پردازشگر گرافیکی
118
00:03:50,080 –> 00:03:51,920
، محاسبات را بسیار کندتر
119
00:03:51,920 –> 00:03:55,040
از یک هسته cpu انجام می دهد و در واقع از طریق
120
00:03:55,040 –> 00:03:56,480
موازی سازی عظیم انجام می شود.
121
00:03:56,480 –> 00:03:58,959
که یک gpu در برخی از مشکلات به سرعت برتر خود می رسد،
122
00:03:58,959 –> 00:04:00,879
123
00:04:00,879 –> 00:04:03,040
بنابراین یک gpu روی مشکلاتی که
124
00:04:03,040 –> 00:04:04,560
می تواند می درخشد به
125
00:04:04,560 –> 00:04:06,720
هزاران کار کوچک ساده تقسیم شود که
126
00:04:06,720 –> 00:04:08,959
همگی می توانند به طور مستقل اجرا شوند
127
00:04:08,959 –> 00:04:11,519
و به موازات آن اغلب
128
00:04:11,519 –> 00:04:13,519
شامل عملیات بر روی مناطق وسیعی از
129
00:04:13,519 –> 00:04:14,239
اعداد
130
00:04:14,239 –> 00:04:16,160
با برنامه های کاربردی در پردازش تصویر
131
00:04:16,160 –> 00:04:18,079
گرافیکی رندر سه بعدی
132
00:04:18,079 –> 00:04:19,918
و همانطور که قبلا ذکر شد شبکه های عصبی است،
133
00:04:19,918 –> 00:04:22,000
بنابراین اگر با شبکه های عصبی سروکار ندارید.
134
00:04:22,000 –> 00:04:23,199
شبکهها
135
00:04:23,199 –> 00:04:24,800
وقتی ممکن است به برنامهنویسی gpu به
136
00:04:24,800 –> 00:04:26,880
خوبی اهمیت دهید، محتملترین
137
00:04:26,880 –> 00:04:28,160
سناریو این است که شما
138
00:04:28,160 –> 00:04:30,320
نوعی دانشمند هستید که باید پردازش دادههای زیادی انجام دهید
139
00:04:30,320 –> 00:04:31,600
140
00:04:31,600 –> 00:04:34,240
یا محاسبات علمی انجام دهید، ممکن است
141
00:04:34,240 –> 00:04:35,440
با پایتون
142
00:04:35,440 –> 00:04:37,120
و پشته علمی پایتون مانند
143
00:04:37,120 –> 00:04:38,720
numpy و scipy آشنا باشید.
144
00:04:38,720 –> 00:04:40,400
پردازش مجموعه داده های عظیم شما برای همیشه طول می کشد
145
00:04:40,400 –> 00:04:42,400
و می خواهید ببینید که یک gpu چه کاری
146
00:04:42,400 –> 00:04:44,320
می تواند انجام دهد
147
00:04:44,320 –> 00:04:45,919
یا شاید شما فقط یک سرگرمی هستید که
148
00:04:45,919 –> 00:04:47,360
دوست دارید در هر زمینه ای که دارید کمی عمیق تر به
149
00:04:47,360 –> 00:04:48,880
اصول اولیه
150
00:04:48,880 –> 00:04:50,080
بپردازید،
151
00:04:50,080 –> 00:04:52,639
متوجه خواهید شد که برنامه نویسی gpu معمولاً
152
00:04:52,639 –> 00:04:54,880
به آسانی نیست. به عنوان نوشتن یک اسکریپت پایتون
153
00:04:54,880 –> 00:04:56,639
و بنابراین یک فیلد کاملاً خاص که
154
00:04:56,639 –> 00:04:57,680
به طور سنتی
155
00:04:57,680 –> 00:05:00,479
یک دامنه رزرو شده برای شروع
156
00:05:00,479 –> 00:05:01,120
واقعی است.
157
00:05:01,120 –> 00:05:04,160
برنامه نویسان c و c plus plus من دقیقاً در
158
00:05:04,160 –> 00:05:06,320
چنین موقعیتی قرار گرفتم و با این
159
00:05:06,320 –> 00:05:08,240
ویدیو قصد داشتم موضوعاتی را معرفی کنم تا
160
00:05:08,240 –> 00:05:10,800
حداقل کمی این شکاف را پر
161
00:05:10,800 –> 00:05:12,960
کنم. برای یادگیری c plus plus خیلی سرسخت
162
00:05:12,960 –> 00:05:14,560
بودم بنابراین به دنبال راه حل های
163
00:05:14,560 –> 00:05:16,000
موجود برای پایتون بودم.
164
00:05:16,000 –> 00:05:18,160
و در این ویدیو من شما را با
165
00:05:18,160 –> 00:05:20,160
cupi و number آشنا می کنم،
166
00:05:20,160 –> 00:05:21,759
بنابراین
167
00:05:21,759 –> 00:05:23,199
168
00:05:23,199 –> 00:05:25,680
169
00:05:25,680 –> 00:05:27,360
اگر می خواهید با شبکه های عصبی کار کنید
170
00:05:27,360 –> 00:05:29,280
و شانس یادگیری ماشین بالا است،
171
00:05:29,280 –> 00:05:32,160
فقط به tensorflow نیاز دارید، چگونه ابزاری را که می خواهید برای سرعت بخشیدن به محاسبات خود با gpu استفاده کنید انتخاب کنید. مشعل pi
172
00:05:32,160 –> 00:05:33,840
اگر از طرف دیگر می خواهید
173
00:05:33,840 –> 00:05:35,360
بالاترین سطح کنترل بر روی
174
00:05:35,360 –> 00:05:36,320
سخت افزار را
175
00:05:36,320 –> 00:05:38,639
داشته باشید، احتمالاً راهی برای
176
00:05:38,639 –> 00:05:39,919
استفاده از cuda در c
177
00:05:39,919 –> 00:05:43,120
یا c به علاوه وجود ندارد به علاوه یک کتابخانه پایتون
178
00:05:43,120 –> 00:05:43,759
به نام pi
179
00:05:43,759 –> 00:05:46,000
qr وجود دارد که قصد دارد تمام قدرت را برای شما به ارمغان بیاورد.
180
00:05:46,000 –> 00:05:47,199
cuda c
181
00:05:47,199 –> 00:05:50,320
در پایتون، اما برای کار با آن،
182
00:05:50,320 –> 00:05:52,400
اساساً کد cuda c را در
183
00:05:52,400 –> 00:05:54,320
رشته های پایتون می نویسید، بنابراین نمی توانید از
184
00:05:54,320 –> 00:05:55,280
یادگیری
185
00:05:55,280 –> 00:05:58,720
نحو c و c plus در این ویدیو اجتناب کنید، ما
186
00:05:58,720 –> 00:06:01,039
در مورد دو راه حل میانی
187
00:06:01,039 –> 00:06:04,319
q pi و عدد q pi صحبت خواهیم کرد
188
00:06:04,319 –> 00:06:06,080
. مطمئناً ساده ترین کار برای کار
189
00:06:06,080 –> 00:06:07,919
با آن است و اگر دانشمندی هستید که
190
00:06:07,919 –> 00:06:09,759
با numpy و scipy کار می
191
00:06:09,759 –> 00:06:12,160
کنید، احتمالاً این تنها چیزی است که نیاز
192
00:06:12,160 –> 00:06:13,520
دارید، سطح بسیار بالایی است که
193
00:06:13,520 –> 00:06:15,199
تقریباً با تنسورفلو و مشعل پی همتراز است،
194
00:06:15,199 –> 00:06:17,759
اما به طور خاص
195
00:06:17,759 –> 00:06:19,600
شبکه های عصبی
196
00:06:19,600 –> 00:06:22,160
را هدف قرار نمی دهد.
197
00:06:22,160 –> 00:06:24,000
198
00:06:24,000 –> 00:06:26,479
اگر به الگوریتمهای سفارشی نیاز دارید، در gpu رفتار کنید
199
00:06:26,479 –> 00:06:28,160
اما نمیتوانید هستههای cuda خود را بنویسید
200
00:06:28,160 –> 00:06:29,680
201
00:06:29,680 –> 00:06:31,440
، بعداً در این ویدیو در مورد هستهها صحبت
202
00:06:31,440 –> 00:06:32,800
203
00:06:32,800 –> 00:06:34,639
204
00:06:34,639 –> 00:06:36,000
205
00:06:36,000 –> 00:06:37,759
خواهیم کرد. برای نوشتن هستههای cuda
206
00:06:37,759 –> 00:06:39,039
در پایتون،
207
00:06:39,039 –> 00:06:41,199
بنابراین میتوانید جدا
208
00:06:41,199 –> 00:06:43,759
c را از نزدیک با استفاده از پایتون تقریب بزنید،
209
00:06:43,759 –> 00:06:45,759
اما همه ویژگیهای cuda c پشتیبانی نمیشوند،
210
00:06:45,759 –> 00:06:46,880
211
00:06:46,880 –> 00:06:49,680
بنابراین اگر c و cuda را میدانید، بهترین شرط
212
00:06:49,680 –> 00:06:51,120
شما احتمالاً
213
00:06:51,120 –> 00:06:54,479
pi cuda خواهد بود، بنابراین ابتدا به طور خلاصه به آن میپردازیم. q
214
00:06:54,479 –> 00:06:55,599
pi
215
00:06:55,599 –> 00:06:57,680
همانطور که قبلاً گفتم q pi کم و بیش یک
216
00:06:57,680 –> 00:06:59,919
افت در جایگزینی numpy است
217
00:06:59,919 –> 00:07:01,199
اما به جای اینکه
218
00:07:01,199 –> 00:07:02,960
محاسبات را روی
219
00:07:02,960 –> 00:07:05,919
cpu انجام دهید آنها را روی gpu انجام دهید، به
220
00:07:05,919 –> 00:07:08,560
طور خلاصه به یک مثال در یک نوت بوک نگاه می کنیم.
221
00:07:08,560 –> 00:07:10,720
برای استفاده از cupi چند
222
00:07:10,720 –> 00:07:14,479
نکته وجود دارد که باید از آنها آگاه باشید
223
00:07:14,639 –> 00:07:16,720
مفهوم اصلی که باید درک کنید
224
00:07:16,720 –> 00:07:17,759
این است که تمایز
225
00:07:17,759 –> 00:07:21,039
بین هاست و دستگاهی است که
226
00:07:21,039 –> 00:07:22,639
میزبان در واقع پردازنده مرکزی است
227
00:07:22,639 –> 00:07:26,160
و رم دستگاه پردازنده گرافیکی شما است
228
00:07:26,160 –> 00:07:27,759
معمولاً این اجزا بسیار زیاد هستند.
229
00:07:27,759 –> 00:07:29,440
در کامپیوتر شما جدا شده
230
00:07:29,440 –> 00:07:31,599
و شما بیشتر با cpu و ram در تعامل هستید
231
00:07:31,599 –> 00:07:32,880
232
00:07:32,880 –> 00:07:35,199
تا محاسبات را روی دستگاه
233
00:07:35,199 –> 00:07:37,199
234
00:07:37,199 –> 00:07:40,400
235
00:07:40,400 –> 00:07:41,039
236
00:07:41,039 –> 00:07:43,599
237
00:07:43,599 –> 00:07:44,080
238
00:07:44,080 –> 00:07:46,240
239
00:07:46,240 –> 00:07:47,840
اجرا کنید.
240
00:07:47,840 –> 00:07:50,960
و نتایج را به هاست برمی گرداند،
241
00:07:50,960 –> 00:07:52,479
در اینجا دو نکته مهم وجود دارد که ابتدا باید به آن توجه کرد
242
00:07:52,479 –> 00:07:56,000
این است که رم در gpu
243
00:07:56,000 –> 00:07:58,400
و ram قابل دسترسی توسط cpu داده های
244
00:07:58,400 –> 00:08:00,400
بسیار جدا
245
00:08:00,400 –> 00:08:03,120
شده ای هستند که باید در این حافظه gpu کپی
246
00:08:03,120 –> 00:08:04,720
شود تا بتواند کار کند. بر روی
247
00:08:04,720 –> 00:08:06,400
آن و باید بازگردانده شود
248
00:08:06,400 –> 00:08:08,160
تا نتایج بیشتر با
249
00:08:08,160 –> 00:08:12,240
cpu عمل کند، این انتقال ها کاملاً واضح است
250
00:08:12,240 –> 00:08:14,639
و همچنین با cupi همیشه باید
251
00:08:14,639 –> 00:08:16,080
آگاه باشید که آیا با آن سروکار دارید یا خیر. با
252
00:08:16,080 –> 00:08:17,280
دادههای روی هاست
253
00:08:17,280 –> 00:08:20,080
یا دستگاه، ثانیاً این
254
00:08:20,080 –> 00:08:21,680
انتقال دادهها زمان میبرد
255
00:08:21,680 –> 00:08:23,440
و برای محاسبات ساده، اینها
256
00:08:23,440 –> 00:08:25,919
در واقع میتوانند مرحله محدودکننده زمان باشند،
257
00:08:25,919 –> 00:08:26,479
بنابراین
258
00:08:26,479 –> 00:08:28,080
تمرین خوبی است که
259
00:08:28,080 –> 00:08:29,919
کپیهای غیرضروری داده را به حداقل برسانید
260
00:08:29,919 –> 00:08:32,000
و
261
00:08:32,000 –> 00:08:33,039
262
00:08:33,039 –> 00:08:36,080
قبل از ارسال مجدد، همه محاسبات لازم را روی gpu انجام دهید. به
263
00:08:36,080 –> 00:08:37,760
یک نوت بوک برای نشان دادن این مفاهیم
264
00:08:37,760 –> 00:08:39,440
با cupi نگاه کنید
265
00:08:39,440 –> 00:08:41,839
تا با cupi و numba آزمایش کنید،
266
00:08:41,839 –> 00:08:42,719
ما در این محیط
267
00:08:42,719 –> 00:08:44,560
نوت بوک ژوپیتر همکاری آزمایشگاهی google کار خواهیم کرد
268
00:08:44,560 –> 00:08:46,240
269
00:08:46,240 –> 00:08:47,920
، متوجه خواهید شد که اگر سعی
270
00:08:47,920 –> 00:08:50,399
271
00:08:53,680 –> 00:08:57,120
کنم cupi را وارد کنم، یک خطا ایجاد می کند زیرا ماژول
272
00:08:57,120 –> 00:08:58,320
اینطور نیست. متوجه
273
00:08:58,320 –> 00:09:00,320
شدیم که به این دلیل است که ما واقعاً باید یک
274
00:09:00,320 –> 00:09:01,680
gpu در دسترس
275
00:09:01,680 –> 00:09:04,959
برای qpi داشته باشیم تا به وضوح کار کند،
276
00:09:04,959 –> 00:09:07,920
بنابراین برای انجام این کار وارد زمان تغییر
277
00:09:07,920 –> 00:09:09,680
نوع زمان اجرا
278
00:09:09,680 –> 00:09:14,399
برای شتاب دهنده سخت افزار می شویم gpu را انتخاب
279
00:09:14,800 –> 00:09:19,200
کنید، به نظر می رسد که در حال تخصیص اولیه اتصال است
280
00:09:19,200 –> 00:09:22,320
و هنگامی که ما متصل
281
00:09:22,320 –> 00:09:26,240
شدیم قادر به وارد کردن qpi
282
00:09:26,240 –> 00:09:28,959
به عنوان cp هستیم
283
00:09:30,640 –> 00:09:34,480
و اکنون می توانیم با cupi کار
284
00:09:34,480 –> 00:09:36,800
کنیم، همچنین numpy را وارد می کنیم تا
285
00:09:36,800 –> 00:09:39,200
تفاوت بین cpu
286
00:09:39,200 –> 00:09:41,920
و gpu
287
00:09:45,519 –> 00:09:48,000
را نشان دهیم، بنابراین ابتدا اجازه دهید ایجاد کنیم یک آرایه در
288
00:09:48,000 –> 00:09:48,880
حافظه اصلی
289
00:09:48,880 –> 00:09:51,839
در حافظه میزبان
290
00:09:59,200 –> 00:10:01,839
و ما مقادیر تصادفی بین 0
291
00:10:01,839 –> 00:10:03,839
تا 255 را
292
00:10:03,839 –> 00:10:08,720
با اندازه فرض کنید
293
00:10:08,720 –> 00:10:12,720
2000 در 2000 می گوییم.
294
00:10:14,160 –> 00:10:17,279
ما می توانیم آرایه را مشاهده کنیم.
295
00:10:17,519 –> 00:10:20,000
296
00:10:20,000 –> 00:10:20,959
297
00:10:20,959 –> 00:10:23,440
اندازه دو هزار
298
00:10:23,440 –> 00:10:26,240
در دو هزار
299
00:10:26,240 –> 00:10:29,279
اکنون متوجه خواهید شد که ما می توانیم بررسی کنیم که
300
00:10:29,279 –> 00:10:29,839
این
301
00:10:29,839 –> 00:10:33,839
ماتریس از نظر حجم حافظه
302
00:10:37,519 –> 00:10:40,000
چقدر است.
303
00:10:40,000 –> 00:10:42,560
304
00:10:43,920 –> 00:10:47,760
305
00:10:47,760 –> 00:10:51,839
306
00:10:51,839 –> 00:10:55,120
کاری که ما باید انجام دهیم این است که بگوییم آرایه
307
00:10:55,120 –> 00:10:58,720
gpu برابر با cp است، بنابراین اکنون به
308
00:10:58,720 –> 00:11:02,800
q pi به عنوان
309
00:11:02,800 –> 00:11:06,320
cpu آرایه آرایه نیاز داریم
310
00:11:06,720 –> 00:11:09,040
و این کار وظیفه ارسال این
311
00:11:09,040 –> 00:11:11,519
اطلاعات یا کپی کردن این اطلاعات
312
00:11:11,519 –> 00:11:15,200
بر روی حافظه gpu را بر عهده دارد و در واقع می توانیم
313
00:11:15,200 –> 00:11:20,560
داده هایی را که در اینجا وجود دارد مشاهده کنیم.
314
00:11:20,560 –> 00:11:23,279
و همان چیزی خواهد بود که در
315
00:11:23,279 –> 00:11:23,839
ناحیه c
316
00:11:23,839 –> 00:11:26,640
روی cpu بود، اکنون برای دریافت این نمای،
317
00:11:26,640 –> 00:11:28,000
در واقع باید
318
00:11:28,000 –> 00:11:31,839
اطلاعات را از حافظه gpu برگردانیم،
319
00:11:31,839 –> 00:11:34,240
320
00:11:36,880 –> 00:11:40,240
اکنون این ارسال اطلاعات در واقع
321
00:11:40,240 –> 00:11:41,360
322
00:11:41,360 –> 00:11:44,640
زمان می برد.
323
00:11:44,640 –> 00:11:46,959
چقدر طول می کشد با تابع جادویی
324
00:11:46,959 –> 00:11:49,839
ti
325
00:11:50,240 –> 00:11:53,680
اگر cp dot را بهعنوان
326
00:11:53,680 –> 00:11:57,760
cpu آرایهای
327
00:11:57,760 –> 00:11:59,519
انجام دهیم، کمی زمان میبرد تا
328
00:11:59,519 –> 00:12:01,200
این را چند بار اجرا کنیم تا ببینیم چقدر طول میکشد
329
00:12:01,200 –> 00:12:01,839
330
00:12:01,839 –> 00:12:05,279
و
331
00:12:05,279 –> 00:12:09,440
اگر این ناحیه را بزرگتر کنیم، پنج میلیثانیه طول میکشد، فرض
332
00:12:09,440 –> 00:12:13,440
کنید چهار برابر میدانید بزرگ است،
333
00:12:13,440 –> 00:12:17,600
پس اگر این
334
00:12:18,800 –> 00:12:20,880
زمان را تعیین کنیم، خیلی بیشتر طول می کشد، بنابراین هر
335
00:12:20,880 –> 00:12:23,440
چه داده های بیشتری را باید به gpu ارسال کنید،
336
00:12:23,440 –> 00:12:25,120
بدیهی است که زمان بیشتری طول می
337
00:12:25,120 –> 00:12:27,360
کشد،
338
00:12:27,600 –> 00:12:30,079
اگر بررسی کنیم که نوع
339
00:12:30,079 –> 00:12:31,040
آرایه
340
00:12:31,040 –> 00:12:34,160
gpu ما چیست، خواهیم دید
341
00:12:34,160 –> 00:12:38,240
که واقعاً چنین است. یک آرایه کوپه i
342
00:12:38,240 –> 00:12:40,720
اکنون برای سادگی، بیایید یک عملیات کوچک روی
343
00:12:40,720 –> 00:12:41,360
344
00:12:41,360 –> 00:12:44,399
آرایه های cupi و numpy انجام
345
00:12:44,399 –> 00:12:47,440
دهیم، اجازه دهید تبدیل فوریه را بگیریم، بنابراین برای
346
00:12:47,440 –> 00:12:50,000
آرایه numpy، از scipy fft وارد می کنیم
347
00:12:50,000 –> 00:12:55,279
348
00:12:57,200 –> 00:12:59,760
و
349
00:13:00,480 –> 00:13:03,600
اجازه دهید مدت
350
00:13:03,600 –> 00:13:05,680
زمان طول بکشد تا
351
00:13:05,680 –> 00:13:08,240
352
00:13:09,839 –> 00:13:12,880
تبدیل فوریه آرایه را در آن انجام دهیم. cpu
353
00:13:12,880 –> 00:13:15,760
بنابراین اکنون ما این آرایه نسبتاً بزرگ را داریم
354
00:13:15,760 –> 00:13:21,680
4000 در 4000 بسیار
355
00:13:21,680 –> 00:13:25,120
خوب، شما
356
00:13:25,120 –> 00:13:28,399
کمی کمتر از 400 میلیثانیه زمان میبرد
357
00:13:28,399 –> 00:13:31,680
تا همین کار را در آرایه gpu انجام دهید،
358
00:13:31,680 –> 00:13:34,240
در واقع ما نمیتوانیم از همان تابع استفاده کنیم،
359
00:13:34,240 –> 00:13:36,440
بنابراین اگر fft را امتحان کنید
360
00:13:36,440 –> 00:13:38,880
.
361
00:13:38,880 –> 00:13:42,399
آرایه
362
00:13:42,399 –> 00:13:44,800
fftn gpu که کار می کند g برای پرتاب خطا به دلیل اینکه
363
00:13:44,800 –> 00:13:45,600
این
364
00:13:45,600 –> 00:13:48,560
داده در حافظه اصلی
365
00:13:48,560 –> 00:13:50,880
موجود نیست، آرایه
366
00:13:50,880 –> 00:13:53,040
numpy نیست.
367
00:13:53,040 –> 00:13:55,360
368
00:13:55,360 –> 00:13:58,480
369
00:13:58,480 –> 00:14:02,399
370
00:14:02,399 –> 00:14:06,079
از
371
00:14:06,079 –> 00:14:06,880
372
00:14:06,880 –> 00:14:10,160
cup x dot scipy import fft بهعنوان fft
373
00:14:10,160 –> 00:14:14,240
gpu پیدا میشود
374
00:14:14,240 –> 00:14:16,240
و این دقیقاً
375
00:14:16,240 –> 00:14:17,279
376
00:14:17,279 –> 00:14:21,519
مانند پیادهسازی علمی تخیلی برای cpu عمل میکند،
377
00:14:21,519 –> 00:14:26,639
بنابراین اگر این کار را انجام دهیم
378
00:14:28,560 –> 00:14:33,760
fft gpu dot fftn
379
00:14:33,760 –> 00:14:37,360
آرایه
380
00:14:42,720 –> 00:14:46,399
gpu حدود 64 میکروثانیه طول میکشد.
381
00:14:46,399 –> 00:14:48,639
پس این واقعاً منشا بزرگی
382
00:14:48,639 –> 00:14:51,040
سریعتر از پیادهسازی cpu است،
383
00:14:51,040 –> 00:14:53,279
اکنون توجه کنید اینجا چه میگوید کندترین
384
00:14:53,279 –> 00:14:54,320
385
00:14:54,320 –> 00:14:58,000
اجرا حدود 24000 برابر بیشتر از سریعترین اجرا طول کشید،
386
00:14:58,000 –> 00:15:01,360
بنابراین دلیل آن این است
387
00:15:01,360 –> 00:15:04,160
که این توابع در واقع
388
00:15:04,160 –> 00:15:06,240
زیر
389
00:15:06,240 –> 00:15:08,959
هستههای مختلف هستند که باید در
390
00:15:08,959 –> 00:15:11,519
هنگام کامپایل شدن شما اولین بار آنها را فراخوانی می کنید،
391
00:15:11,519 –> 00:15:13,600
سپس پس از کامپایل آنها را در حافظه پنهان نگه می دارید
392
00:15:13,600 –> 00:15:15,120
و سریع اجرا می شود، اما این
393
00:15:15,120 –> 00:15:16,000
کامپایل
394
00:15:16,000 –> 00:15:17,839
مدتی طول می کشد، بنابراین اولین باری
395
00:15:17,839 –> 00:15:19,839
که یک تابع کوپید را فراخوانی
396
00:15:19,839 –> 00:15:22,000
می کنید، تجربه خواهید کرد که اغلب اوقات فرا می رسد.
397
00:15:22,000 –> 00:15:23,040
نسبتا کند است
398
00:15:23,040 –> 00:15:25,120
و به این دلیل است که باید
399
00:15:25,120 –> 00:15:26,160
هسته را کامپایل
400
00:15:26,160 –> 00:15:29,040
کند تا کار کند تا داده ها را از
401
00:15:29,040 –> 00:15:30,800
gpu به cpu برگرداند،
402
00:15:30,800 –> 00:15:35,360
باید از تابع cp.as numpy استفاده کنیم
403
00:15:35,360 –> 00:15:40,160
و بنابراین اجازه دهید fft
404
00:15:40,160 –> 00:15:42,720
405
00:15:44,560 –> 00:15:47,839
ناحیه خود را در gpu برگردانیم.
406
00:15:50,720 –> 00:15:55,839
فرض کنید این fft برگردانده شده است
407
00:15:57,839 –> 00:16:00,720
و سپس یک بار دیگر این را محاسبه می کنیم که
408
00:16:00,720 –> 00:16:01,360
409
00:16:01,360 –> 00:16:06,639
cpu fft fft ff
410
00:16:06,839 –> 00:16:09,360
tn آرایه
411
00:16:09,360 –> 00:16:14,240
cp باشد، سپس
412
00:16:14,240 –> 00:16:18,160
می توانیم بررسی کنیم که آیا اینها مشابه هستند یا خیر،
413
00:16:20,839 –> 00:16:23,839
414
00:16:34,480 –> 00:16:37,839
در واقع ما در اینجا اشتباه کردیم،
415
00:16:37,839 –> 00:16:41,440
ناحیه um در
416
00:16:41,440 –> 00:16:44,959
gpu هنوز 2000 است. تا سال 2000. بنابراین ما میتوانیم
417
00:16:44,959 –> 00:16:47,440
418
00:16:48,560 –> 00:16:52,240
شنیدن یک cpu را در اینجا حل کنیم، سپس یک gpu را پخش
419
00:16:52,240 –> 00:17:05,839
کنیم، دادههای
420
00:17:06,319 –> 00:17:08,559
ah
421
00:17:12,240 –> 00:17:14,559
را ارسال میکنیم و میبینیم که هر دو ناحیه یکسان هستند،
422
00:17:14,559 –> 00:17:16,640
بنابراین مهمترین چیزی که باید در
423
00:17:16,640 –> 00:17:18,640
مورد q cupid
424
00:17:18,640 –> 00:17:21,119
در نظر داشته باشید این است که به خاطر بسپارید اطلاعات شما کجاست. آن را
425
00:17:21,119 –> 00:17:21,679
روی
426
00:17:21,679 –> 00:17:24,079
حافظه میزبان یا در حافظه دستگاه
427
00:17:24,079 –> 00:17:25,280
اگر روی حافظه میزبان است،
428
00:17:25,280 –> 00:17:27,119
باید از توابع علمی تخیلی معمولی استفاده کنید،
429
00:17:27,119 –> 00:17:28,960
در غیر این صورت اگر روی
430
00:17:28,960 –> 00:17:30,720
دستگاه است، باید از اجرای cupi
431
00:17:30,720 –> 00:17:34,559
این توابع با استفاده از پیاده سازی fft
432
00:17:34,559 –> 00:17:38,080
gpu
433
00:17:38,080 –> 00:17:41,760
در
434
00:17:41,760 –> 00:17:46,320
آرایه cpu استفاده کنید. کار نخواهد کرد
435
00:17:46,320 –> 00:17:48,080
، یک خطا ایجاد می کند زیرا این کار را انجام می دهد
436
00:17:48,080 –> 00:17:50,640
آرایه را اشغال نمی کند و به طور مشابه
437
00:17:50,640 –> 00:17:55,039
fft همانطور که قبلاً نشان دادیم که fftn
438
00:17:55,039 –> 00:17:59,280
در آرایه gpu نیز کار نخواهد کرد،
439
00:17:59,280 –> 00:18:00,720
بنابراین این مهمترین چیز
440
00:18:00,720 –> 00:18:03,520
در مورد q pi است و تقریباً تمام چیزی که
441
00:18:03,520 –> 00:18:04,400
در آن
442
00:18:04,400 –> 00:18:07,120
وجود دارد اکنون یک اخطار کوچک وجود دارد و آن این
443
00:18:07,120 –> 00:18:07,760
است که
444
00:18:07,760 –> 00:18:10,000
برخی از توابع numpy روی نواحی کوپید کار می کنند، به
445
00:18:10,000 –> 00:18:13,600
عنوان مثال
446
00:18:13,600 –> 00:18:17,520
آرایه mp.max gpu این در واقع
447
00:18:17,520 –> 00:18:19,600
یک مقدار را برمی گرداند و می بینید که در
448
00:18:19,600 –> 00:18:21,120
واقع
449
00:18:21,120 –> 00:18:24,320
مقداری آرایه است، بنابراین اگر تایپ کنیم اگر نوع
450
00:18:24,320 –> 00:18:28,240
451
00:18:28,240 –> 00:18:32,720
این را بررسی کنیم، همچنان یک آرایه q pi um خواهد بود.
452
00:18:32,720 –> 00:18:35,679
از بعد 1. بنابراین استفاده از
453
00:18:35,679 –> 00:18:37,440
توابع numpy در یک کوپن آرایه زوجی
454
00:18:37,440 –> 00:18:39,440
به اندازه کافی هوشمند است تا بفهمیم
455
00:18:39,440 –> 00:18:41,440
که اگر میخواهید دادهها را به هر طریقی از میزبان کپی کنید، باید دادهها را حفظ کرده و
456
00:18:41,440 –> 00:18:42,240
به
457
00:18:42,240 –> 00:18:45,360
جای روی پردازنده مرکزی روی پردازنده گرافیکی کار کند.
458
00:18:45,360 –> 00:18:48,400
459
00:18:48,400 –> 00:18:48,960
460
00:18:48,960 –> 00:18:50,880
به دستگاه یا از
461
00:18:50,880 –> 00:18:52,720
دستگاه به
462
00:18:52,720 –> 00:18:55,840
هاست باید این کار را به صراحت انجام دهید زیرا
463
00:18:55,840 –> 00:18:57,520
این عملیات
464
00:18:57,520 –> 00:18:58,160
زمان زیادی می برد
465
00:18:58,160 –> 00:19:00,559
و آخرین نکته ای که باید به خاطر بسپارید این است که
466
00:19:00,559 –> 00:19:01,520
گاهی اوقات
467
00:19:01,520 –> 00:19:03,919
اشکالی ندارد اگر داده ای دارید که از یک فایل می آید،
468
00:19:03,919 –> 00:19:05,919
البته باید ارسال کنید. آن را
469
00:19:05,919 –> 00:19:08,240
از میزبان دستگاه است اما
470
00:19:08,240 –> 00:19:10,320
اگر در حال ایجاد یک آرایه هستید
471
00:19:10,320 –> 00:19:12,720
، بهتر است آن را مستقیماً روی gpu ایجاد کنید،
472
00:19:12,720 –> 00:19:13,760
473
00:19:13,760 –> 00:19:16,960
بنابراین به عنوان مثال به جای ارسال این
474
00:19:16,960 –> 00:19:18,080
آرایه تصادفی
475
00:19:18,080 –> 00:19:20,400
به gpu، بهتر است فقط
476
00:19:20,400 –> 00:19:24,320
از cp.random.randint استفاده کنید
477
00:19:24,320 –> 00:19:27,440
اندازه 0 255
478
00:19:27,440 –> 00:19:32,400
برابر با 4 است. 000 4 000
479
00:19:32,559 –> 00:19:34,400
و این کمی زمان می برد
480
00:19:34,400 –> 00:19:36,320
زیرا باید کامپایل شود،
481
00:19:36,320 –> 00:19:39,760
اما در اینجا می بینید
482
00:19:39,760 –> 00:19:41,840
که همان کار را انجام داد، اوه در واقع
483
00:19:41,840 –> 00:19:43,679
ما این را کمی
484
00:19:43,679 –> 00:19:47,200
خیلی بزرگ کردیم، اما در آنجا به یک منطقه تصادفی دیگر می روید
485
00:19:47,200 –> 00:19:47,679
486
00:19:47,679 –> 00:19:50,160
و در واقع سریعتر خواهد شد. به غیر از
487
00:19:50,160 –> 00:19:52,240
ایجاد آرایه بر روی هاست
488
00:19:52,240 –> 00:19:54,799
و ارسال آن به دستگاه برای
489
00:19:54,799 –> 00:19:55,520
خلاصه
490
00:19:55,520 –> 00:19:58,320
کردن رفتارهای qpi به روشهای مختلف مانند numpy
491
00:19:58,320 –> 00:20:00,320
، چند نکته وجود دارد که میتوانید آنها
492
00:20:00,320 –> 00:20:03,039
را در مستندات توضیح دهید.
493
00:20:03,039 –> 00:20:04,960
494
00:20:04,960 –> 00:20:07,600
495
00:20:07,600 –> 00:20:08,159
میزبان
496
00:20:08,159 –> 00:20:11,679
یا روی دستگاه و مربوط به آن این
497
00:20:11,679 –> 00:20:13,120
است که اگر می خواهید از عملکرد علمی تخیلی
498
00:20:13,120 –> 00:20:15,280
در مناطق
499
00:20:15,280 –> 00:20:17,520
qpi استفاده کنید، در واقع نمی توانید از scipy استفاده کنید، باید
500
00:20:17,520 –> 00:20:19,360
از پیاده سازی های
501
00:20:19,360 –> 00:20:23,919
داخل
502
00:20:23,919 –> 00:20:26,159
cupi استفاده کنید.
503
00:20:26,159 –> 00:20:28,080
یو اگر به
504
00:20:28,080 –> 00:20:31,200
یک الگوریتم سفارشی نیاز دارید numpy و
505
00:20:31,200 –> 00:20:32,960
cupi یک دسته از توابع پیاده سازی شده در
506
00:20:32,960 –> 00:20:35,520
c که سریع هستند و روی بردارها یا آرایه های چند بعدی کار می کنند، اساساً گیر کرده اید،
507
00:20:35,520 –> 00:20:37,679
508
00:20:37,679 –> 00:20:39,200
اما اگر
509
00:20:39,200 –> 00:20:41,440
برای برخی از الگوریتم های سفارشی نیاز به حلقه روی عناصر در آن منطقه دارید.
510
00:20:41,440 –> 00:20:42,159
511
00:20:42,159 –> 00:20:44,400
شما خوش شانس نیستید زیرا به
512
00:20:44,400 –> 00:20:47,440
مفسر پایتون نیاز دارد که کند است
513
00:20:47,440 –> 00:20:49,280
در این مورد اغلب افراد به
514
00:20:49,280 –> 00:20:50,799
نوشتن بخش های مهم عملکرد
515
00:20:50,799 –> 00:20:51,679
کد خود
516
00:20:51,679 –> 00:20:55,440
در cc به علاوه پایتون یا حتی فرترن متوسل می شوند
517
00:20:55,440 –> 00:20:57,679
اما در واقع می توانید با
518
00:20:57,679 –> 00:21:00,880
استفاده از کامپایلر به موقع پایتون را حفظ کنید.
519
00:21:00,880 –> 00:21:02,320
ما در مورد جزئیات عدد زیاد بحث نمی
520
00:21:02,320 –> 00:21:04,400
کنیم، اما نگاهی
521
00:21:04,400 –> 00:21:04,720
522
00:21:04,720 –> 00:21:06,640
به استفاده از اعداد برای نوشتن هسته های جدا سفارشی در پایتون خواهیم انداخت،
523
00:21:06,640 –> 00:21:08,640
524
00:21:08,640 –> 00:21:10,880
بنابراین این اساساً به این معنی است که اگر هر کاری که می
525
00:21:10,880 –> 00:21:12,720
خواهید انجام دهید نیاز به حلقه دارد
526
00:21:12,720 –> 00:21:15,039
و نمی تواند به طور موثر با cupi انجام شود،
527
00:21:15,039 –> 00:21:18,000
می توانید به گزینه شماره نگاه کنید
528
00:21:18,000 –> 00:21:19,520
این بخش کمی تئوری تر خواهد بود،
529
00:21:19,520 –> 00:21:21,120
اما امیدوارم
530
00:21:21,120 –> 00:21:22,480
درک اولیه
531
00:21:22,480 –> 00:21:24,640
ای از برنامه نویسی موازی به شما بدهد تا بتوانید
532
00:21:24,640 –> 00:21:26,480
خارج شوید و الک خود را ایجاد کنید. گوریتمها،
533
00:21:26,480 –> 00:21:28,400
بنابراین ما در مورد هستههای cuda صحبت کردهایم،
534
00:21:28,400 –> 00:21:30,799
اما آنچه در واقع یک
535
00:21:30,799 –> 00:21:33,120
چاه هسته است، قیاسی با یک بلال
536
00:21:33,120 –> 00:21:35,120
ذرت است که از تعدادی هسته تشکیل شده است.
537
00:21:35,120 –> 00:21:36,080
538
00:21:36,080 –> 00:21:38,640
539
00:21:38,640 –> 00:21:39,760
540
00:21:39,760 –> 00:21:42,799
در مورد یک
541
00:21:42,799 –> 00:21:44,080
برنامه cuda،
542
00:21:44,080 –> 00:21:46,640
ما مشکل را به شبکهای از رشتهها تقسیم میکنیم
543
00:21:46,640 –> 00:21:47,840
544
00:21:47,840 –> 00:21:50,320
و یک هسته برنامهای است که
545
00:21:50,320 –> 00:21:52,320
بر روی هر یک از این رشتهها به
546
00:21:52,320 –> 00:21:54,640
طور مستقل اجرا میشود، این در واقع
547
00:21:54,640 –> 00:21:56,320
با نحوه ایجاد یک برنامه cpu بسیار متفاوت
548
00:21:56,320 –> 00:21:57,200
است،
549
00:21:57,200 –> 00:21:59,200
زیرا در آنجا باید هر
550
00:21:59,200 –> 00:22:00,240
عملیاتی را که
551
00:22:00,240 –> 00:22:03,200
روی آرایهها حلقه میزند
552
00:22:03,200 –> 00:22:05,440
و رشتههای cpu جدید و غیره
553
00:22:05,440 –> 00:22:07,520
با cuda ایجاد میکند، توضیح دهید. مدل اصلی
554
00:22:07,520 –> 00:22:09,760
مسئله یک شبکه است و یک هسته باید
555
00:22:09,760 –> 00:22:11,200
بتواند روی هر یک از این رشتهها
556
00:22:11,200 –> 00:22:13,840
در شبکه به طور مستقل یک شبکه اجرا کند و
557
00:22:13,840 –> 00:22:15,520
رشتهها البته تا حدودی
558
00:22:15,520 –> 00:22:16,320
مفاهیم انتزاعی هستند.
559
00:22:16,320 –> 00:22:19,280
بیایید به یک مثال نگاه کنیم، فرض
560
00:22:19,280 –> 00:22:21,520
کنیم یک ماتریس a داریم که در آن میخواهیم 1 را
561
00:22:21,520 –> 00:22:23,760
به هر یک از عناصر
562
00:22:23,760 –> 00:22:26,240
در یک پیادهسازی سریالی برای cpu اضافه
563
00:22:26,240 –> 00:22:27,919
کنیم و در تمام سطرها و
564
00:22:27,919 –> 00:22:29,200
ستونهای m حلقه بزنیم. atrix
565
00:22:29,200 –> 00:22:32,880
و هر عنصر را 1 افزایش دهید.
566
00:22:32,880 –> 00:22:34,640
بنابراین چگونه این ظاهر به عنوان یک هسته gpu پیاده سازی می
567
00:22:34,640 –> 00:22:36,080
568
00:22:36,080 –> 00:22:38,640
شود در ساده ترین حالت، ما یک
569
00:22:38,640 –> 00:22:39,200
شبکه
570
00:22:39,200 –> 00:22:40,880
از رشته ها ایجاد می کنیم که تقریباً
571
00:22:40,880 –> 00:22:43,919
به اندازه آرایه است
572
00:22:43,919 –> 00:22:45,679
. بعداً به شما نشان خواهم داد که چگونه می توانیم
573
00:22:45,679 –> 00:22:47,440
چنین شبکه ای را راه اندازی کنیم. با عدد
574
00:22:47,440 –> 00:22:49,039
در حال حاضر فقط فرض کنید که ما
575
00:22:49,039 –> 00:22:50,880
مشکل را اینگونه تعریف می کنیم،
576
00:22:50,880 –> 00:22:53,039
ایده اینجا این است که یک
577
00:22








![فیلم آموزشی: 18. وراثت چندگانه [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/ttMX3Ns_0oYimage2.jpg)