در این مطلب، ویدئو آموزش یادگیری ماشین پایتون – 19: تجزیه و تحلیل اجزای اصلی (PCA) با کد پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:24:09
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,799 –> 00:00:02,720
تجزیه و تحلیل مولفه اصلی
2
00:00:02,720 –> 00:00:04,720
تکنیکی است که در یادگیری ماشین برای
3
00:00:04,720 –> 00:00:07,120
کاهش ابعاد استفاده می شود. در این ویدیو می
4
00:00:07,120 –> 00:00:08,960
خواهیم به چیستی آن نگاه کنیم،
5
00:00:08,960 –> 00:00:10,960
تعدادی کد پایتون می نویسیم و در پایان
6
00:00:10,960 –> 00:00:12,799
تمرین جالبی برای شما وجود خواهد داشت که می توانید
7
00:00:12,799 –> 00:00:14,000
روی آن کار
8
00:00:14,000 –> 00:00:16,320
کنید. در حال کار بر روی ساخت یک
9
00:00:16,320 –> 00:00:17,920
مدل یادگیری ماشینی برای پیشبینی
10
00:00:17,920 –> 00:00:19,920
قیمت ملک
11
00:00:19,920 –> 00:00:21,920
در اینجا همه ستونهای سمت چپ
12
00:00:21,920 –> 00:00:24,080
13
00:00:24,080 –> 00:00:25,199
ویژگیها
14
00:00:25,199 –> 00:00:28,080
یا ویژگیهای دارایی هستند که قیمت را تعیین میکنند
15
00:00:28,080 –> 00:00:31,279
، بنابراین ستون سبز رنگ
16
00:00:31,279 –> 00:00:34,399
در واقع متغیر هدف
17
00:00:34,399 –> 00:00:37,360
شما است که احتمالاً قبلاً میدانید. اینکه
18
00:00:37,360 –> 00:00:41,200
قیمت خانه عمدتاً به منطقه ای بستگی دارد
19
00:00:41,200 –> 00:00:44,559
که در کدام شهر در قطعه است و
20
00:00:44,559 –> 00:00:46,079
غیره بستگی به تعداد حمام
21
00:00:46,079 –> 00:00:48,480
شما در یک ملک دارد اما نه به اندازه خانه به
22
00:00:48,480 –> 00:00:49,600
عنوان مثال
23
00:00:49,600 –> 00:00:52,239
2600 فوت مربع با دو حمام
24
00:00:52,239 –> 00:00:54,399
در مقابل سه حمام قیمت نخواهد بود.
25
00:00:54,399 –> 00:00:55,680
که متفاوت است،
26
00:00:55,680 –> 00:00:58,800
اما اگر از 2600 به 3000 فوت مربع بروید،
27
00:00:58,800 –> 00:01:01,039
قیمت به طور قابل توجهی متفاوت خواهد بود،
28
00:01:01,039 –> 00:01:04,159
بنابراین به وضوح
29
00:01:04,159 –> 00:01:06,720
طرح مساحت نقش مهمی در
30
00:01:06,720 –> 00:01:08,640
تعیین آخرین قیمت
31
00:01:08,640 –> 00:01:11,600
ایفا می کند. نقش کمی دارد
32
00:01:11,600 –> 00:01:13,360
و اینکه در مورد این درختان ستون خاص در این
33
00:01:13,360 –> 00:01:14,960
نزدیکی هست،
34
00:01:14,960 –> 00:01:16,960
چه دو درخت در نزدیکی خانه خود داشته باشید
35
00:01:16,960 –> 00:01:19,600
یا سه درخت در نزدیکی
36
00:01:19,600 –> 00:01:22,320
خانه، به آن اهمیتی نمی دهید به طوری که احتمالاً آن ستون به
37
00:01:22,320 –> 00:01:24,000
هیچ وجه بر
38
00:01:24,000 –> 00:01:27,280
قیمت آخر تأثیر نمی گذارد یا یا
39
00:01:27,280 –> 00:01:29,840
40
00:01:29,840 –> 00:01:31,200
هنگامی که شما در حال حل
41
00:01:31,200 –> 00:01:32,880
مشکلات یادگیری ماشینی واقعی هستید، فقط اندکی بر آن تأثیر می
42
00:01:32,880 –> 00:01:35,200
گذارد، ستون های زیادی صد هزار و
43
00:01:35,200 –> 00:01:38,479
دو هزار ستون یا ویژگی
44
00:01:38,479 –> 00:01:40,560
خواهید داشت و باید
45
00:01:40,560 –> 00:01:43,360
کاری انجام دهید تا ویژگی
46
00:01:43,360 –> 00:01:45,600
هایی را که بسیار
47
00:01:45,600 –> 00:01:47,840
مهم هستند، مثلاً دست نویس، شناسایی کنید.
48
00:01:47,840 –> 00:01:49,600
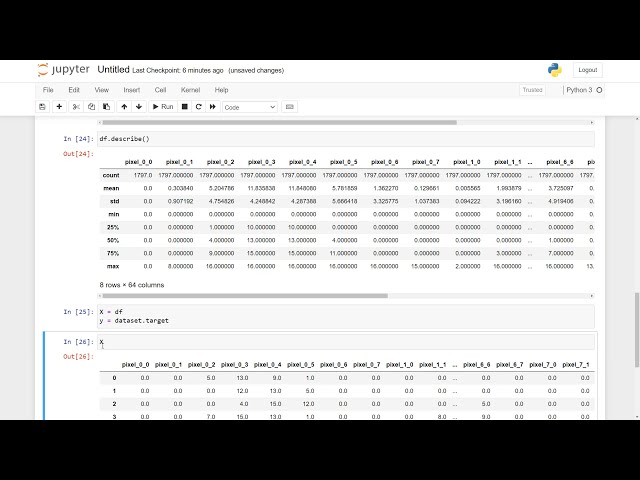
طبقه بندی رقمی
49
00:01:49,600 –> 00:01:51,200
که در آن می دانید ارقامی دارید که
50
00:01:51,200 –> 00:01:53,280
با دست نوشته می شوند و سپس سعی می کنید به
51
00:01:53,280 –> 00:01:54,399
عنوان
52
00:01:54,399 –> 00:01:56,960
یکی از اعداد از 0 تا 9 طبقه بندی
53
00:01:56,960 –> 00:01:58,000
کنید. در اینجا
54
00:01:58,000 –> 00:02:00,640
این تصویر به صورت پیکسل نشان داده می شود،
55
00:02:00,640 –> 00:02:04,159
فرض کنید این یک نمره 8 در 8 است و هر
56
00:02:04,159 –> 00:02:06,240
عدد ارائه می شود.
57
00:02:06,240 –> 00:02:10,000
رنگ بنابراین 0 به معنای سیاه 16 به معنای بالاترین میزان
58
00:02:10,000 –> 00:02:11,440
سفیدی است که شما می شناسید
59
00:02:11,440 –> 00:02:14,080
و از آنجایی که یک شبکه 8 در 8 است در
60
00:02:14,080 –> 00:02:18,319
مجموع 64 پیکسل یا اعداد وجود دارد که به
61
00:02:18,319 –> 00:02:21,120
تعیین تعداد کمک می کند بنابراین این 64
62
00:02:21,120 –> 00:02:23,599
پیکسل ویژگی نامیده می شود. و
63
00:02:23,599 –> 00:02:25,920
64
00:02:25,920 –> 00:02:28,480
اگر اکنون به
65
00:02:28,480 –> 00:02:30,640
برخی از پیکسلهای این تصاویر فکر
66
00:02:30,640 –> 00:02:32,560
کنید، متوجه میشوید که آن پیکسلها اصلاً نقشی
67
00:02:32,560 –> 00:02:33,920
68
00:02:33,920 –> 00:02:34,879
69
00:02:34,879 –> 00:02:39,360
در تشخیص اینکه چه رقمی است،
70
00:02:39,360 –> 00:02:41,599
مثلاً این دو پیکسل
71
00:02:41,599 –> 00:02:44,480
در اینجا یا تقریباً چقدر است، ندارند. هر پیکسلی در این
72
00:02:44,480 –> 00:02:47,120
ستون آخر
73
00:02:47,440 –> 00:02:49,920
فرقی نمیکند چه عددی باشد، این
74
00:02:49,920 –> 00:02:51,840
پیکسلها همیشه سیاه هستند، بنابراین میتوان گفت که
75
00:02:51,840 –> 00:02:56,000
این پیکسلها ویژگی مهمی نیستند
76
00:02:56,000 –> 00:02:59,840
و اگر از شر این ویژگیها
77
00:02:59,840 –> 00:03:03,040
خلاص شویم، دو مزیت به دست میآوریم که اول
78
00:03:03,040 –> 00:03:04,959
اینکه آموزش سریعتر میشود. بدانید
79
00:03:04,959 –> 00:03:06,640
آموزش یادگیری ماشین زمان
80
00:03:06,640 –> 00:03:09,440
زیادی را از منابع محاسباتی زیادی میبرد، بنابراین
81
00:03:09,440 –> 00:03:12,080
میخواهید آموزشی را که میخواهید ذخیره کنید تا آن را
82
00:03:12,080 –> 00:03:13,519
کمی سبک
83
00:03:13,519 –> 00:03:15,840
کنید و همچنین استنتاج شما میتواند سریعتر باشد
84
00:03:15,840 –> 00:03:18,239
و تجسم دادهها آسانتر میشود
85
00:03:18,239 –> 00:03:20,159
، فرض کنید ۱۰۰ ویژگی دارید و
86
00:03:20,159 –> 00:03:22,879
به نوعی آنها را کاهش میدهید. 100 ویژگی
87
00:03:22,879 –> 00:03:25,519
را فقط در دو ویژگی یا سه ویژگی قرار دهید،
88
00:03:25,519 –> 00:03:27,120
سپس به عنوان یک انسان
89
00:03:27,120 –> 00:03:29,760
می توانید آن را بر روی یک نمودار 2 بعدی یا 3 بعدی ترسیم کنید،
90
00:03:29,760 –> 00:03:32,720
می توانید آن را تجسم کنید و تجسم
91
00:03:32,720 –> 00:03:34,080
92
00:03:34,080 –> 00:03:36,480
93
00:03:36,480 –> 00:03:39,599
داده ها به تجسم داده عالی کمک می کند تا به شما کمک زیادی کند.
94
00:03:39,599 –> 00:03:41,920
از نظر تصمیم گیری نهایی شما
95
00:03:41,920 –> 00:03:44,319
با توجه به اینکه چه نوع مدلی
96
00:03:44,319 –> 00:03:46,480
می خواهید
97
00:03:46,480 –> 00:03:49,680
pca بسازید، فرآیندی است برای کشف
98
00:03:49,680 –> 00:03:51,760
مهمترین ویژگی ها
99
00:03:51,760 –> 00:03:54,239
یا مؤلفه اصلی که
100
00:03:54,239 –> 00:03:57,120
حداکثر تأثیر را بر روی متغیر هدف
101
00:03:57,120 –> 00:03:58,879
pca می
102
00:03:58,879 –> 00:04:01,840
گذارد در واقع مدل جدید را ایجاد می کند. ویژگی به نام
103
00:04:01,840 –> 00:04:04,560
مؤلفه اصلی که pc1 pc2 را می شناسید و
104
00:04:04,560 –> 00:04:05,760
به
105
00:04:05,760 –> 00:04:07,200
همین ترتیب دوباره به مثال اعداد برمی گردیم
106
00:04:07,200 –> 00:04:08,560
107
00:04:08,560 –> 00:04:10,640
، فرض کنید من 64
108
00:04:10,640 –> 00:04:12,879
ویژگی دارم که من فقط
109
00:04:12,879 –> 00:04:15,040
دو ویژگی پیکسل گوشه و پیکسل مرکزی را رسم می کنم
110
00:04:15,040 –> 00:04:16,478
111
00:04:16,478 –> 00:04:18,798
اکنون در اینجا این خوشه
112
00:04:18,798 –> 00:04:20,320
ارقام مختلفی را نشان
113
00:04:20,320 –> 00:04:22,960
می دهد که بلافاصله متوجه می شوید که پیکسل گوشه
114
00:04:22,960 –> 00:04:26,240
نقش مهمی ایفا نمی کند
115
00:04:26,240 –> 00:04:30,000
حداکثر تغییر در محور y یا
116
00:04:30,000 –> 00:04:33,360
حداکثر واریانس در محور y است
117
00:04:33,360 –> 00:04:35,520
که یک پیکسل مرکزی است، بنابراین اگر از شما
118
00:04:35,520 –> 00:04:37,520
بخواهم این دو بعدی را به یک
119
00:04:37,520 –> 00:04:40,160
بعد کاهش دهید، می توانید به راحتی این کار را انجام دهید. با
120
00:04:40,160 –> 00:04:42,800
خلاص شدن از شر پیکسل گوشه،
121
00:04:42,800 –> 00:04:44,400
بنابراین این نموداری که در
122
00:04:44,400 –> 00:04:46,320
سمت راست کشیدهام یک بعدی است،
123
00:04:46,320 –> 00:04:48,000
یعنی میدانم که نمودار
124
00:04:48,000 –> 00:04:49,759
کامل نیست، همچنان مانند دو بعدی به نظر میرسد.
125
00:04:49,759 –> 00:04:52,800
اما متوجه شدید که کاهش
126
00:04:52,800 –> 00:04:54,960
این از دوبعدی به یک بعدی
127
00:04:54,960 –> 00:04:55,840
128
00:04:55,840 –> 00:04:57,199
آسانتر است،
129
00:04:57,199 –> 00:04:58,880
بیایید به
130
00:04:58,880 –> 00:05:01,840
مجموعه دادههای گل زنبق نگاه کنیم که در آن عرض
131
00:05:01,840 –> 00:05:03,600
کاسبرگ و ارتفاع کاسبرگ تعیین میکند که چه نوع
132
00:05:03,600 –> 00:05:05,039
گلی است،
133
00:05:05,039 –> 00:05:07,520
اگر یک طرح پراکندگی مانند این داشته
134
00:05:07,520 –> 00:05:10,720
باشید، میتوانید یک خط بکشید. که
135
00:05:10,720 –> 00:05:14,400
حداکثر واریانس را پوشش می دهد بنابراین این خط
136
00:05:14,400 –> 00:05:16,560
حداکثر واریانس یا
137
00:05:16,560 –> 00:05:20,160
حداکثر اطلاعات را از نظر ویژگی ها
138
00:05:20,160 –> 00:05:22,400
139
00:05:22,400 –> 00:05:25,600
پوشش می دهد و شما می توانید یک خط عمودی رسم کنید که دومین
140
00:05:25,600 –> 00:05:27,280
واریانسی که می دانید را پوشش می دهد
141
00:05:27,280 –> 00:05:30,479
و به آنها جزء اصلی می گویند
142
00:05:30,479 –> 00:05:32,880
بنابراین در اینجا pc1 این
143
00:05:32,880 –> 00:05:35,840
محور است که بیشتر
144
00:05:35,840 –> 00:05:39,600
واریانس pc2 محوری است که
145
00:05:39,600 –> 00:05:42,960
دومین واریانس را پوشش می دهد،
146
00:05:43,360 –> 00:05:45,600
بنابراین وقتی از pca استفاده
147
00:05:45,600 –> 00:05:48,479
می کنید نموداری مانند این دریافت می کنید و می دانم که
148
00:05:48,479 –> 00:05:50,080
من فقط
149
00:05:50,080 –> 00:05:52,639
این نمودار را برای دو بعدی انجام داده ام اما واقعاً
150
00:05:52,639 –> 00:05:54,240
اگر بعد 100 دارید و اگر
151
00:05:54,240 –> 00:05:57,840
از pca استفاده می کنید می توانید می توانید بفهمید فرض کنید
152
00:05:57,840 –> 00:06:01,120
10 جزء اصلی
153
00:06:01,120 –> 00:06:02,560
مهم است،
154
00:06:02,560 –> 00:06:04,720
بنابراین برای 100 ویژگی می
155
00:06:04,720 –> 00:06:07,520
توانید 100 جزء اصلی را به ترتیب نزولی ایجاد کنید.
156
00:06:07,520 –> 00:06:10,800
157
00:06:10,800 –> 00:06:13,600
متغیر هدف،
158
00:06:13,600 –> 00:06:15,600
بنابراین برای ارقام،
159
00:06:15,600 –> 00:06:17,280
اگر مجبور باشم این را در یک قاب داده بارگذاری کنم،
160
00:06:17,280 –> 00:06:19,440
قاب داده پاندا به این شکل خواهد
161
00:06:19,440 –> 00:06:21,120
بود، یک خطای کوچک مانند پیکسل
162
00:06:21,120 –> 00:06:24,240
63 وجود دارد، زیرا من با پیکسل 0 شروع می کنم،
163
00:06:24,240 –> 00:06:25,600
اما شما قبلاً می بینید که
164
00:06:25,600 –> 00:06:28,479
پیکسل 0 و 1 دارای
165
00:06:28,479 –> 00:06:30,160
همه مقادیر 0 هستند. خیلی
166
00:06:30,160 –> 00:06:31,199
مهم نیستند،
167
00:06:31,199 –> 00:06:33,680
بنابراین وقتی از sk Learn library استفاده می کنید و
168
00:06:33,680 –> 00:06:36,560
روش pca را فرا می خوانید، جایی که می گویید خوب است و
169
00:06:36,560 –> 00:06:39,360
کامپوننت ها شش است، اساساً
170
00:06:39,360 –> 00:06:43,120
از pca می خواهید که ششمین مؤلفه مهم را استخراج کند
171
00:06:43,120 –> 00:06:45,360
172
00:06:45,360 –> 00:06:48,000
و این چیزی شبیه به این خواهد بود،
173
00:06:48,000 –> 00:06:50,240
بنابراین کاری که این کار انجام می دهد است. محاسبه ویژگیهای جدید
174
00:06:50,240 –> 00:06:51,280
175
00:06:51,280 –> 00:06:53,759
و این ویژگیها به گونهای است که pc1
176
00:06:53,759 –> 00:06:56,479
بیشترین
177
00:06:56,479 –> 00:06:58,800
واریانس را از نظر ویژگیهایی که میدانید
178
00:06:58,800 –> 00:07:00,560
از نظر استخراج اطلاعات
179
00:07:00,560 –> 00:07:03,599
180
00:07:03,599 –> 00:07:06,000
181
00:07:06,000 –> 00:07:07,759
182
00:07:07,759 –> 00:07:10,960
از مجموعه دادههای شما پوشش میدهد
183
00:07:10,960 –> 00:07:13,759
. شش را بدهید، می توانید هر چیزی را به آن بدهید،
184
00:07:13,759 –> 00:07:16,240
می توانید دو سه چهار پنج داشته باشید،
185
00:07:16,240 –> 00:07:17,919
آزمون و خطا
186
00:07:17,919 –> 00:07:19,440
را می دانید، همچنین می توانید
187
00:07:19,440 –> 00:07:20,880
یک
188
00:07:20,880 –> 00:07:23,440
پارامتر متفاوت به این روش بدهید که
189
00:07:23,440 –> 00:07:27,280
مانند 0.95 خواهد بود که یعنی
190
00:07:27,280 –> 00:07:30,720
میدانی 95 درصد اطلاعات
191
00:07:30,720 –> 00:07:33,360
را از نظر ویژگیها به من بده.
192
00:07:33,360 –> 00:07:35,680
193
00:07:35,680 –> 00:07:38,000
194
00:07:38,000 –> 00:07:40,080
195
00:07:40,080 –> 00:07:42,800
196
00:07:42,800 –> 00:07:45,360
ویژگی ها زیرا اگر آن را مقیاس ندهید
197
00:07:45,360 –> 00:07:46,400
198
00:07:46,400 –> 00:07:48,639
درست کار نمی کند به عنوان مثال
199
00:07:48,639 –> 00:07:50,000
در اینجا یک نمودار وجود دارد
200
00:07:50,000 –> 00:07:52,160
و اگر این نمودار به میلیون باشد و
201
00:07:52,160 –> 00:07:54,560
این نمودار در یک مقدار عادی باشد،
202
00:07:54,560 –> 00:07:57,120
می دانید که نمودار ممکن است کج شود
203
00:07:57,120 –> 00:08:00,639
و کامپیوتر و کامپیوتر بر اساس انتظارات شما کار نمی کند
204
00:08:00,639 –> 00:08:03,039
205
00:08:03,039 –> 00:08:05,520
دقت ممکن است کاهش یابد، بنابراین
206
00:08:05,520 –> 00:08:07,520
زمانی که می خواهید کاهش
207
00:08:07,520 –> 00:08:10,400
دهید این یک مبادله است، فرض کنید 100 ویژگی دارید و اگر
208
00:08:10,400 –> 00:08:12,400
همه صد ویژگی مهم هستند و
209
00:08:12,400 –> 00:08:14,800
آنها سعی می کنند به متغیر هدف نهایی کمک کنند.
210
00:08:14,800 –> 00:08:17,360
211
00:08:17,360 –> 00:08:19,520
از 100 تا 5 شما
212
00:08:19,520 –> 00:08:21,440
اطلاعات زیادی را از دست خواهید داد، بنابراین ما
213
00:08:21,440 –> 00:08:24,000
همه آن ها را در جلسه کدنویسی خواهیم دید،
214
00:08:24,000 –> 00:08:26,080
اما صرفاً برای خلاصه کردن رایانه، تکنیک کاهش ابعاد نامیده می شود
215
00:08:26,080 –> 00:08:28,800
216
00:08:28,800 –> 00:08:29,759
زیرا
217
00:08:29,759 –> 00:08:32,320
به ما کمک می کند ابعاد را کاهش دهیم که قبلاً
218
00:08:32,320 –> 00:08:35,120
در این مورد دیدیم. 64
219
00:08:35,120 –> 00:08:36,320
روز داشت
220
00:08:36,320 –> 00:08:38,159
این به ما کمک کرد
221
00:08:38,159 –> 00:08:40,399
تا به شش بعدی برسیم و وقتی
222
00:08:40,399 –> 00:08:42,479
تعداد ستونهای کمتری دارید،
223
00:08:42,479 –> 00:08:46,720
محاسبات شما بسیار سریعتر
224
00:08:46,800 –> 00:08:49,279
میشود و همچنین به شما کمک میکند تا
225
00:08:49,279 –> 00:08:51,920
مشکل دوره بعد در یادگیری ماشین را حل کنید.
226
00:08:51,920 –> 00:08:54,640
227
00:08:54,640 –> 00:08:56,880
228
00:08:56,880 –> 00:08:58,240
229
00:08:58,240 –> 00:08:59,920
بسیاری از ستونها را میدانید ابعاد بسیار زیادی را میدانید
230
00:08:59,920 –> 00:09:02,560
و این باعث میشود که تجسم مدل ما
231
00:09:02,560 –> 00:09:05,600
واقعاً پیچیده باشد و
232
00:09:05,600 –> 00:09:08,640
رایانه یک تکنیک عالی است که به شما کمک میکند
233
00:09:08,640 –> 00:09:10,720
با نفرین ابعاد مقابله کنید،
234
00:09:10,720 –> 00:09:13,440
بیایید به کدنویسی پایتون
235
00:09:13,440 –> 00:09:15,120
برویم، من نوتبوک jupyter خود را باز کردم و
236
00:09:15,120 –> 00:09:17,600
چند کتابخانه مهم را
237
00:09:17,600 –> 00:09:19,920
وارد کردم. برای استفاده از مجموعه دادههای دستنویس ارقام
238
00:09:19,920 –> 00:09:22,160
از ماژول مجموعه دادههای sklearn،
239
00:09:22,160 –> 00:09:24,880
240
00:09:24,880 –> 00:09:25,920
اجازه دهید
241
00:09:25,920 –> 00:09:28,880
مجموعه دادهها را با فراخوانی تابع load digits بارگیری
242
00:09:28,880 –> 00:09:30,320
کنیم،
243
00:09:30,320 –> 00:09:31,760
زمانی که این کار را انجام میدهید که
244
00:09:31,760 –> 00:09:34,560
مجموعه دادهها را بارگیری میکند و شما میتوانید
245
00:09:34,560 –> 00:09:35,320
246
00:09:35,320 –> 00:09:38,000
dataset.keys را فراخوانی کنید تا ایده بگیرید که
247
00:09:38,000 –> 00:09:40,640
میدانید مجموعه داده چیست.
248
00:09:40,640 –> 00:09:43,040
می توانید ببینید که dataset.data
249
00:09:43,040 –> 00:09:44,160
شامل
250
00:09:44,160 –> 00:09:46,160
تمام پیکسل ها خواهد بود
251
00:09:46,160 –> 00:09:47,920
و این نام ویژگی ها است و
252
00:09:47,920 –> 00:09:50,560
این آرایه هدف
253
00:09:50,560 –> 00:09:51,760
254
00:09:51,760 –> 00:09:52,560
در حال حاضر است،
255
00:09:52,560 –> 00:09:54,240
اجازه دهید به
256
00:09:54,240 –> 00:09:58,120
da نگاه کنیم. taset.data.shape
257
00:09:58,640 –> 00:10:00,240
بنابراین
258
00:10:00,240 –> 00:10:04,480
17 تقریباً 1700 یا 1800 نمونه وجود دارد که هر
259
00:10:04,480 –> 00:10:05,839
نمونه دارای
260
00:10:05,839 –> 00:10:08,800
64 ستون است بنابراین اگر به
261
00:10:08,800 –> 00:10:10,399
نمونه اول نگاه
262
00:10:10,399 –> 00:10:13,760
کنید یک آرایه تک بعدی مسطح از 64
263
00:10:13,760 –> 00:10:16,480
پیکسل است و اگر می خواهید این
264
00:10:16,480 –> 00:10:19,040
داده ها را با استفاده از کتابخانه matplotlib تجسم کنید به آن نیاز دارید.
265
00:10:19,040 –> 00:10:22,160
برای تبدیل آن به آرایه دو بعدی
266
00:10:22,160 –> 00:10:24,320
و روشی که شما این کار را انجام می دهید با فراخوانی
267
00:10:24,320 –> 00:10:26,079
تابع reshape است که به این دلیل است که این
268
00:10:26,079 –> 00:10:28,640
آرایه numpy است و وقتی هشت در هشت را انجام
269
00:10:28,640 –> 00:10:31,279
می دهید فقط یک
270
00:10:31,279 –> 00:10:32,399
آرایه بعدی را به آرایه
271
00:10:32,399 –> 00:10:34,079
دو بعدی
272
00:10:34,079 –> 00:10:36,399
پیکسل تبدیل می کند
273
00:10:36,399 –> 00:10:37,440
اکنون
274
00:10:37,440 –> 00:10:39,120
می توانید matplotlib را وارد کنید
275
00:10:39,120 –> 00:10:41,360
276
00:10:41,360 –> 00:10:42,320
و
277
00:10:42,320 –> 00:10:44,640
از طرحی استفاده کنید
278
00:10:44,640 –> 00:10:47,519
که می دانید من فقط یک تصویر خاکستری را رسم می کنم
279
00:10:47,519 –> 00:10:50,320
280
00:10:50,320 –> 00:10:52,720
و هنگامی که نمودار نقطه ای را نشان می دهید مانند نمایش متریک
281
00:10:52,720 –> 00:10:54,480
282
00:10:54,480 –> 00:10:56,720
نشان می
283
00:10:56,720 –> 00:10:59,440
دهد که تصویری از آن آرایه را نشان می دهد
284
00:10:59,440 –> 00:11:01,440
که آرایه من است این آرایه من است
285
00:11:01,440 –> 00:11:03,519
بیایید آرایه دو بعدی را ببینیم بنابراین
286
00:11:03,519 –> 00:11:06,720
من فقط می خواهم ctrl c ctrl v
287
00:11:06,720 –> 00:11:08,560
را بگذارم و رقم اول من به
288
00:11:08,560 –> 00:11:11,200
این شکل به نظر می رسد که
289
00:11:11,200 –> 00:11:12,800
اگر به نمونه داده دوم خود نگاه کنم می
290
00:11:12,800 –> 00:11:14,720
291
00:11:14,720 –> 00:11:15,440
بینم
292
00:11:15,440 –> 00:11:16,880
که
293
00:11:16,880 –> 00:11:18,959
یک و دو است
294
00:11:18,959 –> 00:11:21,519
و به همین ترتیب می دانم که پنجاهمین نمونه خواهد
295
00:11:21,519 –> 00:11:22,959
بود
296
00:11:22,959 –> 00:11:24,880
من فکر می کنم این است. دو
297
00:11:24,880 –> 00:11:25,760
298
00:11:25,760 –> 00:11:28,560
بسیار خوب، پس این نحوه تجسم آن است
299
00:11:28,560 –> 00:11:29,680
حالا
300
00:11:29,680 –> 00:11:31,040
بیایید
301
00:11:31,040 –> 00:11:33,360
به هدف نگاه کنیم وقتی مجموعه داده را انجام میدهید، هدف نقطهای،
302
00:11:33,360 –> 00:11:35,839
303
00:11:36,160 –> 00:11:37,120
304
00:11:37,120 –> 00:11:40,560
اوه، آرایهای بزرگ است، اما این
305
00:11:40,560 –> 00:11:43,600
کلاس نهایی شماست که میدانید اگر منحصربهفرد انجام دهید
306
00:11:43,600 –> 00:11:45,120
307
00:11:45,120 –> 00:11:48,079
308
00:11:50,480 –> 00:11:52,880
، روشی را که منحصربهفرد انجام میدهید، با فراخوانی
309
00:11:52,880 –> 00:11:54,480
np پیدا خواهید کرد. .unik
310
00:11:54,480 –> 00:11:55,680
و می بینید
311
00:11:55,680 –> 00:11:57,760
که اعداد بین محدوده صفر تا
312
00:11:57,760 –> 00:11:59,360
نه هستند
313
00:11:



![فیلم آموزشی: تراز ساده کدگذار پایتون - نمونه کدهای پایتون [2020] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/3R6BHCR78-8image2.jpg)