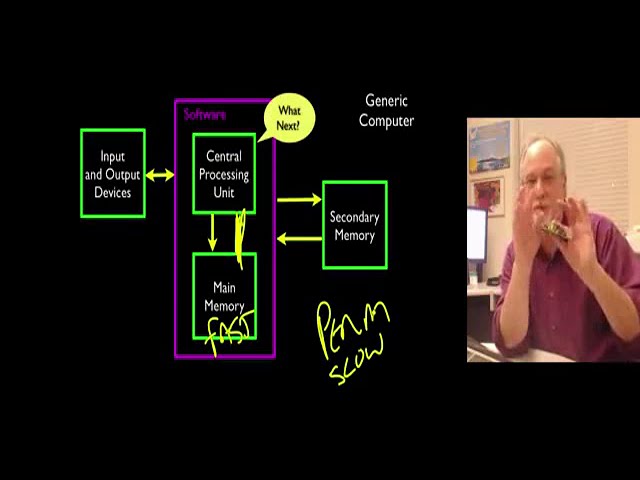
در این مطلب، ویدئو آموزش PySpark | آموزش PySpark برای مبتدیان | آموزش آپاچی اسپارک با پایتون | Simplile Learn با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:58:11
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,399 –> 00:00:02,240
صبح همگی بخیر و عصر بخیر
2
00:00:02,240 –> 00:00:03,760
به این
3
00:00:03,760 –> 00:00:06,879
جلسه در مورد آموزش پی اسپارک خوش آمدید و
4
00:00:06,879 –> 00:00:09,360
در اینجا ما
5
00:00:09,360 –> 00:00:10,160
6
00:00:10,160 –> 00:00:12,880
با ویژگی های پی اسپارک چیست پی اسپارک با
7
00:00:12,880 –> 00:00:13,519
پایتون
8
00:00:13,519 –> 00:00:16,800
و اسکالا پی محتویات اسپارک خرید
9
00:00:16,800 –> 00:00:20,160
شرکت های بسته های فرعی اسپارک با استفاده از اسپای اسپارک
10
00:00:20,160 –> 00:00:20,800
و همچنین
11
00:00:20,800 –> 00:00:23,600
ما آشنا می شویم برخی از دموهایی را با استفاده از اسپارک پی خواهید دید،
12
00:00:23,600 –> 00:00:24,960
بنابراین اکنون پی اسپارک
13
00:00:24,960 –> 00:00:28,240
چیست که در api پایتون است تا از اسپارک آپاچی پشتیبانی کند،
14
00:00:28,240 –> 00:00:31,199
اکنون همه شما در
15
00:00:31,199 –> 00:00:31,679
16
00:00:31,679 –> 00:00:33,920
مورد اسپارک آپاچی میدانستید یا در
17
00:00:33,920 –> 00:00:36,559
حال حاضر که این اسپارک است کمی در مورد اسپارک آپاچی میدانید.
18
00:00:36,559 –> 00:00:39,280
– چارچوب محاسباتی حافظه
19
00:00:39,280 –> 00:00:40,239
20
00:00:40,239 –> 00:00:43,200
که اساساً قابلیت پردازش سریعتری را به شما میدهد
21
00:00:43,200 –> 00:00:44,719
22
00:00:44,719 –> 00:00:47,600
و به طور گسترده از نظر
23
00:00:47,600 –> 00:00:49,039
پردازش بلادرنگ
24
00:00:49,039 –> 00:00:51,039
یا یادگیری ماشینی استفاده میشود و پس
25
00:00:51,039 –> 00:00:52,559
از آن موارد استفاده مختلف دیگری وجود دارد،
26
00:00:52,559 –> 00:00:54,800
بنابراین وقتی در مورد اسپارک آپاچی صحبت میکنیم
27
00:00:54,800 –> 00:00:57,199
از زبانهای برنامهنویسی مختلف
28
00:00:57,199 –> 00:01:00,239
مانند پایتون پشتیبانی میکند. scala r
29
00:01:00,239 –> 00:01:01,920
و حتی شما میتوانید با استفاده از spark sql بر روی
30
00:01:01,920 –> 00:01:04,000
ساختارهای داده ساختاریافته کار کنید،
31
00:01:04,000 –> 00:01:07,040
اکنون همه میدانیم
32
00:01:07,040 –> 00:01:10,640
که فضای جرقه نقطه ورود
33
00:01:10,640 –> 00:01:14,000
به هر عملکرد جرقه است. بنابراین خواهیم دید
34
00:01:14,000 –> 00:01:14,640
که
35
00:01:14,640 –> 00:01:17,360
اکنون در اینجا وقتی در مورد اسپارک pi صحبت می
36
00:01:17,360 –> 00:01:19,200
کنیم، اساساً راهی برای استفاده از
37
00:01:19,200 –> 00:01:21,280
پایتون است یا برای افرادی که
38
00:01:21,280 –> 00:01:22,960
با زبان برنامه نویسی پایتون راحت تر هستند،
39
00:01:22,960 –> 00:01:23,680
40
00:01:23,680 –> 00:01:27,280
از پایتون استفاده کنند و با اسپارک آپاچی کار کنند
41
00:01:27,280 –> 00:01:30,159
و این چیزی است که شما به عنوان یک جزء
42
00:01:30,159 –> 00:01:31,119
از آن دارید. جرقه ای
43
00:01:31,119 –> 00:01:33,600
به نام pi spark اکنون اینجاست فقط برای اینکه به
44
00:01:33,600 –> 00:01:36,079
شما نشان دهم که اکنون دو ماشین
45
00:01:36,079 –> 00:01:38,880
دارم من قبلاً یک
46
00:01:38,880 –> 00:01:40,880
کلاستر مستقل اسپارک
47
00:01:40,880 –> 00:01:43,119
روی این دو ماشین راه اندازی کرده ام بنابراین اگر اینجا را ببینید
48
00:01:43,119 –> 00:01:45,200
من دستور start all را داده ام
49
00:01:45,200 –> 00:01:47,600
و اساساً توسط spark master شروع شده است.
50
00:01:47,600 –> 00:01:49,680
دو گره کارگر، بنابراین ما میتوانیم
51
00:01:49,680 –> 00:01:51,759
این را فقط با انجام یک jps
52
00:01:51,759 –> 00:01:54,000
در این دستگاه بررسی کنیم و اگر من به دستگاه دوم خود بروم
53
00:01:54,000 –> 00:01:56,079
و اگر یک jps برای دیدن فرآیندهای مربوط به جاوا انجام دهم،
54
00:01:56,079 –> 00:01:57,759
55
00:01:57,759 –> 00:02:00,560
دو کارگر را در یک گره اصلی
56
00:02:00,560 –> 00:02:01,200
57
00:02:01,200 –> 00:02:04,240
میبینم که در حال اجرا هستند، بنابراین جرقه من به عنوان یک خوشه مستقل
58
00:02:04,240 –> 00:02:06,640
اکنون در حال اجرا است، اگر به مرورگر خود می روم همیشه می توانیم
59
00:02:06,640 –> 00:02:08,080
با استفاده از spark
60
00:02:08,080 –> 00:02:11,440
UI آن را بررسی کنیم و
61
00:02:11,440 –> 00:02:14,480
اگر فقط http را
62
00:02:14,480 –> 00:02:17,920
اسلش کنم و سپس اگر می گویم um1
63
00:02:17,920 –> 00:02:20,720
و 8080 به من نشان می دهد که spark
64
00:02:20,720 –> 00:02:22,640
cluster من دارای دو گره کارگر است.
65
00:02:22,640 –> 00:02:25,120
آدرس آنها را نشان می دهد و همه این
66
00:02:25,120 –> 00:02:25,840
جزئیات
67
00:02:25,840 –> 00:02:28,319
اکنون اگر به ترمینال برگردیم و
68
00:02:28,319 –> 00:02:29,280
اگر در
69
00:02:29,280 –> 00:02:31,920
باینری ها نگاه کنم، برنامه های مرتبط با اسپارک زیادی را می بینم
70
00:02:31,920 –> 00:02:34,239
مانند شما spark shell
71
00:02:34,239 –> 00:02:36,959
دارید، اگر به صورت تعاملی
72
00:02:36,959 –> 00:02:38,239
با استفاده از اسکالا کار
73
00:02:38,239 –> 00:02:40,080
می کنید و می خواهید با اسپارک کار
74
00:02:40,080 –> 00:02:41,280
کنید، می توانید از spark r استفاده کنید
75
00:02:41,280 –> 00:02:43,599
اگر این راهاندازی شده است و میتوانید
76
00:02:43,599 –> 00:02:44,480
از دانش زبان برنامهنویسی r خود استفاده کنید،
77
00:02:44,480 –> 00:02:46,959
78
00:02:46,959 –> 00:02:47,599
میتوانید از
79
00:02:47,599 –> 00:02:50,239
spark sql برای کار با دادههای ساختاریافته استفاده
80
00:02:50,239 –> 00:02:51,120
کنید، میتوانید از
81
00:02:51,120 –> 00:02:54,160
pi spark استفاده کنید که api پایتون است
82
00:02:54,160 –> 00:02:56,720
که به کاربران اجازه میدهد از پایتون برای کار
83
00:02:56,720 –> 00:02:58,879
با اسپارک استفاده کنند و بدیهی است که شما همچنین
84
00:02:58,879 –> 00:03:01,120
اکنون اسپارک را ارسال کنید، راه دیگر این است
85
00:03:01,120 –> 00:03:03,200
که اگر دستگاه شما پایتون را
86
00:03:03,200 –> 00:03:04,879
نصب کرده است، می توانید
87
00:03:04,879 –> 00:03:06,640
برنامه های خود را در یک
88
00:03:06,640 –> 00:03:09,040
فایل پایتون بنویسید که فایلی با پسوند
89
00:03:09,040 –> 00:03:10,000
dot py است
90
00:03:10,000 –> 00:03:12,800
و سپس می توانید از آن استفاده کنید، بنابراین
91
00:03:12,800 –> 00:03:14,959
اگر می خواهم در اینجا استفاده کنید. با پی اسپارک کار
92
00:03:14,959 –> 00:03:18,319
کنم من فقط میتوانم بگویم bin pi spark و این
93
00:03:18,319 –> 00:03:19,440
باید
94
00:03:19,440 –> 00:03:22,480
پوسته تعاملی من در
95
00:03:22,480 –> 00:03:25,440
پایتون شروع شود و سپس اساساً میتوانم از
96
00:03:25,440 –> 00:03:26,400
97
00:03:26,400 –> 00:03:28,959
زبان پایتونم در اینجا استفاده کنم اگر دیدید میگوید
98
00:03:28,959 –> 00:03:30,480
جلسه
99
00:03:30,480 –> 00:03:32,720
اسپارک به عنوان اسپارک در دسترس است و سپس به
100
00:03:32,720 –> 00:03:34,080
طور پیش فرض هنگامی که
101
00:03:34,080 –> 00:03:37,360
پوسته اسپارک یا اساساً پی اسپارک خود را شروع می کنید،
102
00:03:37,360 –> 00:03:40,799
زمینه جرقه ای دارد که
103
00:03:40,799 –> 00:03:42,480
نقطه ورود برنامه شما
104
00:03:42,480 –> 00:03:44,879
در دسترس است به طوری که اکنون می توانید پردازش خود را
105
00:03:44,879 –> 00:03:46,480
106
00:03:46,480 –> 00:03:47,200
انجام دهید،
107
00:03:47,200 –> 00:03:50,959
به عنوان مثال اگر من فقط بگویم روش های مختلفی برای انجام آن وجود دارد.
108
00:03:50,959 –> 00:03:54,560
فایل متنی x sc dot در حال حاضر فایل متنی اساساً
109
00:03:54,560 –> 00:03:55,439
یک
110
00:03:55,439 –> 00:03:58,000
روش برای زمینه جرقه است و همانطور که گفتم وقتی
111
00:03:58,000 –> 00:03:58,480
از
112
00:03:58,480 –> 00:04:00,879
روش تعاملی کار با اسپارک
113
00:04:00,879 –> 00:04:03,760
مانند استفاده از اسپارک pi یا پوسته جرقه استفاده
114
00:04:03,760 –> 00:04:06,560
می کنیم، در صورت تمایل، زمینه جرقه و جلسه جرقه به
115
00:04:06,560 –> 00:04:07,280
116
00:04:07,280 –> 00:04:09,599
طور خودکار مقداردهی اولیه
117
00:04:09,599 –> 00:04:11,599
می شود. ساختن برنامه خودمان با استفاده از
118
00:04:11,599 –> 00:04:12,640
یک ایده
119
00:04:12,640 –> 00:04:15,120
برای مثال در مورد پایتون با استفاده از
120
00:04:15,120 –> 00:04:15,920
pycharm
121
00:04:15,920 –> 00:04:19,440
یا اینکه شما کد خود را در فایلهای dot py مینویسید،
122
00:04:19,440 –> 00:04:20,959
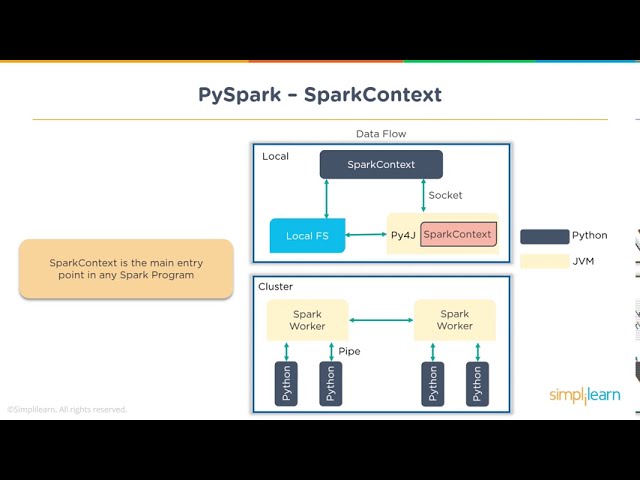
در این صورت باید
123
00:04:20,959 –> 00:04:22,800
زمینه جرقه را مقداردهی اولیه کنید،
124
00:04:22,800 –> 00:04:26,000
اکنون در اینجا میتوانم به فایل خاصی اشاره کنم
125
00:04:26,000 –> 00:04:27,280
126
00:04:27,280 –> 00:04:30,400
که میتواند که از دستگاه من وارد می شود
127
00:04:30,400 –> 00:04:32,639
، به عنوان مثال می توانم این کار را انجام دهم
128
00:04:32,639 –> 00:04:34,880
129
00:04:34,880 –> 00:04:37,919
فایل های نمونه اسلش sdu
130
00:04:37,919 –> 00:04:41,120
اسلش، بیایید فایلی را برداریم که فکر می کنم
131
00:04:41,120 –> 00:04:44,160
باید اینجا در این مکان وجود داشته باشد.
132
00:04:44,160 –> 00:04:46,560
فایل و این دایرکتوری
133
00:04:46,560 –> 00:04:47,600
در
134
00:04:47,600 –> 00:04:50,000
تمام یادداشتهای کارگر شما وجود دارد، بنابراین اگر من فقط این کار را انجام دهم،
135
00:04:50,000 –> 00:04:50,720
136
00:04:50,720 –> 00:04:53,759
میدانیم که از آنجایی که ما از فضای
137
00:04:53,759 –> 00:04:54,400
جرقه
138
00:04:54,400 –> 00:04:56,880
استفاده میکنیم که یک نقطه ورودی است،
139
00:04:56,880 –> 00:04:57,840
یک rdd ایجاد
140
00:04:57,840 –> 00:05:00,720
میکند و حالا rdds بلوکهای سازنده
141
00:05:00,720 –> 00:05:01,360
جرقه هستند
142
00:05:01,360 –> 00:05:03,520
که ممکن است داشته باشید. از طریق
143
00:05:03,520 –> 00:05:04,800
144
00:05:04,800 –> 00:05:07,600
آموزش های قبلی در مورد آن یاد گرفتیم، اگر فقط بگویم x چیست، به من نشان می دهد
145
00:05:07,600 –> 00:05:08,479
که یک
146
00:05:08,479 –> 00:05:11,840
پارتیشن نقشه rdd است که ایجاد شده است
147
00:05:11,840 –> 00:05:13,199
زیرا ما اکنون از یک
148
00:05:13,199 –> 00:05:16,199
زمینه جرقه استفاده کرده ایم اگر
149
00:05:16,199 –> 00:05:17,600
تبدیل های بیشتری
150
00:05:17,600 –> 00:05:20,720
در این rdd انجام دهیم،
151
00:05:20,720 –> 00:05:23,199
rdd های متعددی ایجاد می کند. ما آن را خواهیم دید، اما
152
00:05:23,199 –> 00:05:24,240
این یک نگاه سریع
153
00:05:24,240 –> 00:05:27,120
به استفاده از اسپارک پی شما بود، اکنون
154
00:05:27,120 –> 00:05:28,800
اجرای کامل را ندیدهایم،
155
00:05:28,800 –> 00:05:32,560
اما اگر به اینجا بروم، اگر بگویم رابط کاربری خود را رفرش
156
00:05:32,560 –> 00:05:34,560
کنید، به من میگوید که برنامهای
157
00:05:34,560 –> 00:05:36,560
در حال اجرا است، بنابراین ما پی را شروع کردهایم.
158
00:05:36,560 –> 00:05:38,960
spark shell که از تمام
159
00:05:38,960 –> 00:05:40,240
هسته های دستگاه استفاده می
160
00:05:40,240 –> 00:05:43,680
کند، اساساً از حافظه 1 گیگ استفاده می کند
161
00:05:43,680 –> 00:05:45,840
و سپس ما یک برنامه داریم که
162
00:05:45,840 –> 00:05:48,160
راه اندازی شده است زیرا ما pi spark shell را شروع کردیم،
163
00:05:48,160 –> 00:05:48,639
164
00:05:48,639 –> 00:05:50,639
اکنون روی آن کلیک می کنم و می توانم به
165
00:05:50,639 –> 00:05:52,240
جزئیات برنامه
166
00:05:52,240 –> 00:05:55,280
بروم d تا کنون
167
00:05:55,280 –> 00:05:58,319
هیچ اجرایی از نظر جرقه انجام نداده ام
168
00:05:58,319 –> 00:06:01,199
تا زمانی که عملی را فراخوانی نکنید،
169
00:06:01,199 –> 00:06:02,880
همه چیز با تنبلی ارزیابی می شود،
170
00:06:02,880 –> 00:06:05,039
بنابراین ما چیزی در اینجا نمی
171
00:06:05,039 –> 00:06:06,080
بینیم اما می بینیم
172
00:06:06,080 –> 00:06:08,720
که پوسته اسپارک pi برنامه ای را راه اندازی کرده
173
00:06:08,720 –> 00:06:10,720
است که برنامه از آن استفاده می کند.
174
00:06:10,720 –> 00:06:12,240
برخی از منابع
175
00:06:12,240 –> 00:06:14,720
و اساساً همانطور که پردازش های بیشتری انجام می
176
00:06:14,720 –> 00:06:16,080
دهیم، وقتی در مورد اسپارک pi صحبت می کنیم، می بینیم
177
00:06:16,080 –> 00:06:18,560
که داگ مربوط به برنامه
178
00:06:18,560 –> 00:06:19,360
179
00:06:19,360 –> 00:06:22,160
ایجاد می شود، همانطور که
180
00:06:22,160 –> 00:06:23,840
گفتم اکنون api پایتون است،
181
00:06:23,840 –> 00:06:25,919
اگر به ویژگی های اسپارک pi بیشتر نگاه کنیم،
182
00:06:25,919 –> 00:06:27,680
اساساً
183
00:06:27,680 –> 00:06:30,400
همانطور که گفتم وقتی با آن کار می کنید. اسپارک یک
184
00:06:30,400 –> 00:06:30,720
185
00:06:30,720 –> 00:06:33,280
چارچوب محاسباتی خوشه ای درون حافظه است
186
00:06:33,280 –> 00:06:34,560
که چند زبانه است
187
00:06:34,560 –> 00:06:36,400
که اساساً از
188
00:06:36,400 –> 00:06:37,680
زبان های برنامه نویسی
189
00:06:37,680 –> 00:06:40,240
مختلف پشتیبانی می کند، مثلاً می توانید کارهایی را
190
00:06:40,240 –> 00:06:41,280
با اسکالا
191
00:06:41,280 –> 00:06:43,680
انجام دهید، می توانید کارهایی را با پایتون انجام دهید و
192
00:06:43,680 –> 00:06:44,639
می توانید
193
00:06:44,639 –> 00:06:46,880
با r کار کنید یا می توانید
194
00:06:46,880 –> 00:06:48,639
از spark sql نیز استفاده کنید.
195
00:06:48,639 –> 00:06:50,720
هنگامی که ما در مورد ویژگی های دیگر صحبت می کنیم، جرقه
196
00:06:50,720 –> 00:06:53,520
همچنین به شما امکان می دهد پردازش سریع تری انجام دهید
197
00:06:53,520 –> 00:06:56,080
، به شما امکان می دهد تجزیه و تحلیل در زمان واقعی انجام دهید
198
00:06:56,080 –> 00:06:58,000
و همچنین ویژگی هایی وجود دارد که می
199
00:06:58,000 –> 00:06:58,560
توانید در آنها
200
00:06:58,560 –> 00:07:01,520
ذخیره کنید. محاسبات شما که
201
00:07:01,520 –> 00:07:03,360
محاسبات متناوب است، بنابراین
202
00:07:03,360 –> 00:07:05,120
میتوانید در حافظه پنهان باشید و
203
00:07:05,120 –> 00:07:07,120
همچنین میتوانید پایداری دیسک را داشته باشید،
204
00:07:07,120 –> 00:07:09,520
بنابراین اینها ویژگیهای اسپارک شما هستند
205
00:07:09,520 –> 00:07:11,360
و وقتی با پایتون
206
00:07:11,360 –> 00:07:15,039
کار میکنید،
207
00:07:15,039 –> 00:07:17,680
اکنون که در مورد اسپارک صحبت میکنیم، میتوانید از همه ویژگیهای اسپارک استفاده کنید.
208
00:07:17,680 –> 00:07:19,520
با پایتون و اسکالا و اگر ما یک مقایسه سریع انجام دهیم
209
00:07:19,520 –> 00:07:20,720
210
00:07:20,720 –> 00:07:23,599
اگر در مورد عملکرد صحبت کنیم،
211
00:07:23,599 –> 00:07:25,039
پایتون در هنگام استفاده از اسپارک کندتر از اسکالا است،
212
00:07:25,039 –> 00:07:27,199
اما وقتی
213
00:07:27,199 –> 00:07:28,639
در مورد اسپارک صحبت میکنید،
214
00:07:28,639 –> 00:07:30,800
چون در اسکالا نوشته شده است، به
215
00:07:30,800 –> 00:07:32,000
خوبی ادغام میشود
216
00:07:32,000 –> 00:07:34,800
و سریعتر از
217
00:07:34,800 –> 00:07:35,759
منحنی یادگیری پایتون است.
218
00:07:35,759 –> 00:07:38,400
بدیهی است که ما می دانیم که هر دوی این
219
00:07:38,400 –> 00:07:40,800
زبان ها از کد مختصر پشتیبانی می کنند و
220
00:07:40,800 –> 00:07:42,400
پایتون با
221
00:07:42,400 –> 00:07:44,479
تعداد کتابخانه های موجود در
222
00:07:44,479 –> 00:07:45,680
پشتیبانی جامعه
223
00:07:45,680 –> 00:07:48,560
و غیره بسیار غنی است، اما پایتون نحو ساده ای دارد
224
00:07:48,560 –> 00:07:48,960
225
00:07:48,960 –> 00:07:51,440
و زبان سطح بالایی است که یادگیری آن آسان است
226
00:07:51,440 –> 00:07:52,000
227
00:07:52,000 –> 00:07:55,039
Scala دارای کمی
228
00:07:55,039 –> 00:07:58,240
سینتکس پیچیده از آنجایی که در مقایسه
229
00:07:58,240 –> 00:07:59,039
با پایتون جدیدتر
230
00:07:59,039 –> 00:08:01,039
است اما به شما امکان می دهد
231
00:08:01,039 –> 00:08:02,240
کد مختصر بنویسید
232
00:08:02,240 –> 00:08:04,960
و گاهی اوقات ممکن است برای برنامه جدید باشد.
233
00:08:04,960 –> 00:08:05,759
234
00:08:05,759 –> 00:08:08,720
235
00:08:08,720 –> 00:08:10,720
هنگامی که ما در مورد خوانایی کد صحبت می کنیم، ممکن است یادگیری اسکالا در مقایسه با پایتون چندان آسان نباشد،
236
00:08:10,720 –> 00:08:13,120
بنابراین در صورت
237
00:08:13,120 –> 00:08:14,000
238
00:08:14,000 –> 00:08:16,639
حفظ خوانایی پایتون و آشنایی با کد
239
00:08:16,639 –> 00:08:18,160
در python api بهتر است،
240
00:08:18,160 –> 00:08:20,879
اکنون scala یک زبان پیچیده است
241
00:08:20,879 –> 00:08:22,240
که توسعه دهندگان باید
242
00:08:22,240 –> 00:08:24,080
توجه زیادی به
243
00:08:24,080 –> 00:08:25,440
خوانایی کد
244
00:08:25,440 –> 00:08:27,440
و اگر در مورد کتابخانه های علوم داده صحبت کنیم
245
00:08:27,440 –> 00:08:28,479
همانطور که
246
00:08:28,479 –> 00:08:30,560
قبلاً ذکر کردم پایتون مجموعه ای غنی
247
00:08:30,560 –> 00:08:33,039
از کتابخانه ها را برای تجسم داده ها
248
00:08:33,039 –> 00:08:35,360
و مدل سازی ارائه می دهد ، اکنون محقق در
249
00:08:35,360 –> 00:08:37,440
ارائه کتابخانه های علوم داده
250
00:08:37,440 –> 00:08:39,919
و ابزارهایی برای تجسم داده ها کمبود دارد
251
00:08:39,919 –> 00:08:41,519
، کار زیادی انجام می
252
00:08:41,519 –> 00:08:43,760
شود که به علم داده و
253
00:08:43,760 –> 00:08:44,959
یادگیری ماشین
254
00:08:44,959 –> 00:08:48,399
با مولفههای مختلف spark مانند
255
00:08:48,399 –> 00:08:51,600
mlib و ml میپردازد که به شما امکان میدهد
256
00:08:51,600 –> 00:08:53,519
با پروژههای علم داده کار کنید،
257
00:08:53,519 –> 00:08:54,720
اما پایتون
258
00:08:54,720 –> 00:08:57,440
در آن مورد پیشرفتهتر خواهد بود، در حال حاضر
259
00:08:57,440 –> 00:08:59,279
وقتی در مورد محتویات اسپارک pi صحبت میکنیم،
260
00:08:59,279 –> 00:09:03,040
بنابراین اینها یک لیست سریع هستند.
261
00:09:03,040 –> 00:09:06,000
از محتوای pi spark، بنابراین شما اکنون یک spark
262
00:09:06,000 –> 00:09:06,880
conf دارید
263
00:09:06,880 –> 00:09:09,760
که اساساً اینگونه است که ما پیکربندی خود را تعریف می کنیم
264
00:09:09,760 –> 00:09:11,600
تا ما باشیم ایجاد یک
265
00:09:11,600 –> 00:09:12,480
266
00:09:12,480 –> 00:09:15,920
شیء پیکربندی با استفاده از spark spark conf کلاس
267
00:09:15,920 –> 00:09:18,399
spark context اساساً نقطه ورود
268
00:09:18,399 –> 00:09:19,920
برنامه شما است
269
00:09:19,920 –> 00:09:21,279
که اساساً برنامه شما را
270
00:09:21,279 –> 00:09:23,200
به مدیر خوشه میبرد،
271
00:09:23,200 –> 00:09:24,640
خواه yarn باشد
272
00:09:24,640 –> 00:09:27,440
یا spark master در صورت مستقل بودن اسپارک
273
00:09:27,440 –> 00:09:28,880
یا حتی
274
00:09:28,880 –> 00:09:31,600
محلی، اکنون ما اسپارک داریم. فایلهایی که اکنون
275
00:09:31,600 –> 00:09:32,880
به شما امکان میدهد
276
00:09:32,880 –> 00:09:35,440
فایلها را از یک سیستم فایل بخوانید، چه این
277
00:09:35,440 –> 00:09:37,519
یک سیستم فایل محلی باشد یا یک
278
00:09:37,519 –> 00:09:38,320
سیستم فایل توزیع شده
279
00:09:38,320 –> 00:09:40,959
که
280
00:09:40,959 –> 00:09:42,160
281
00:09:42,160 –> 00:09:44,959
282
00:09:44,959 –> 00:09:47,760
283
00:09:47,760 –> 00:09:50,080
شما دارید. در اقدامی که
284
00:09:50,080 –> 00:09:52,080
هر زمان که از روشی از
285
00:09:52,080 –> 00:09:53,839
زمینه جرقه یا جلسه جرقه استفاده
286
00:09:53,839 –> 00:09:55,760
میکنید، تغییراتی را انجام میدهید،
287
00:09:55,760 –> 00:09:56,880
همیشه یک rdp ایجاد میکنید
288
00:09:56,880 –> 00:10:00,000
که یک مجموعه داده توزیعشده انعطافپذیر
289
00:10:00,000 –> 00:10:01,279
از حافظه است
290
00:10:01,279 –> 00:10:04,880
و از یک جهت یک مرحله منطقی است
291
00:10:04,880 –> 00:10:07,519
که بخشی از یک داگ است. یک
292
00:10:07,519 –> 00:10:10,000
نمودار چرخهای را هدایت کنید که با
293
00:10:10,000 –> 00:10:12,079
فراخوانی یک عمل اجرا میشود،
294
00:10:12,079 –> 00:10:13,440
اکنون سطح ذخیرهسازی
295
00:10:13,440 –> 00:10:15,200
و کلاسهای مختلفی در آن وجود دارد که
296
00:10:15,200 –> 00:10:16,880
به شما امکان میدهد با تداوم،
297
00:10:16,880 –> 00:10:20,000
میتوانید از api بالاتری از جرقهها
298
00:10:20,000 –> 00:10:22,880
مانند قاب داده یا مجموعههای داده استفاده کنید و سپس
299
00:10:22,880 –> 00:10:23,200
300
00:10:23,200 –> 00:10:25,680
راههایی نیز دارید که میتوانید با استفاده از پخش و
301
00:10:25,680 –> 00:10:26,800
302
00:10:26,800 –> 00:10:29,440
انباشتهکنندهها، تبدیلهای گستردهتر یا عملیات گستردهتر را به طور موثر انجام دهید،
303
00:10:29,440 –> 00:10:31,360
304
00:10:31,360 –> 00:10:32,480
305
00:10:32,480 –> 00:10:35,040
اکنون که درباره جرقههای conf صحبت میکنیم، spark conf
306
00:10:35,040 –> 00:10:35,680
307
00:10:35,680 –> 00:10:38,320
تنظیماتی را برای اجرا فراهم میکند. یک برنامه spark
308
00:10:38,320 –> 00:10:39,360
309
00:10:39,360 –> 00:10:41,200
در حال حاضر، خواهیم دید که وقتی
310
00:10:41,200 –> 00:10:43,360
برنامه های خود را با استفاده از pi spark
311
00:10:43,360 –> 00:10:46,079
now می سازیم، اگر به بلوک کد
312
00:10:46,079 –> 00:10:46,800
313
00:10:46,800 –> 00:10:49,600
کلاس spark conf نگاه کنیم که استفاده می شود تا
314
00:10:49,600 –> 00:10:50,320
315
00:10:50,320 –> 00:10:52,800
کلاس به spark dot spark conf را به شما نشان دهد و
316
00:10:52,800 –> 00:10:54,160
دارای پیش فرض های بار
317
00:10:54,160 –> 00:10:56,800
باشد. برای پیکربندی jvm و j
318
00:10:56,800 –> 00:10:57,839
که اکنون میتوان آن را پاس کرد،
319
00:10:57,839 –> 00:11:00,480
اگر بیشتر نگاه کنیم، اینها برخی
320
00:11:00,480 –> 00:11:02,320
از متداولترین ویژگیهای
321
00:11:02,320 –> 00:11:03,360
spark conf هستند،
322
00:11:03,360 –> 00:11:05,200
بنابراین شما چیزی به نام کلید
323
00:11:05,200 –> 00:11:07,040
و مقدار تنظیم برای تنظیم یک ویژگی پیکربندی دارید
324
00:11:07,040 –> 00:11:07,680
325
00:11:07,680 –> 00:11:09,600
و اینجاست که ما میتوانیم آن را منتقل کنیم.
326
00:11:09,600 –> 00:11:11,839
ویژگیهای پیکربندی ما و ارسال
327
00:11:11,839 –> 00:11:12,880
مقادیر،
328
00:11:12,880 –> 00:11:16,000
اساساً میتوانیم بگوییم چه تعداد مجری برای برنامهمان
329
00:11:16,000 –> 00:11:18,320
میخواهیم،
330
00:11:18,320 –> 00:11:21,519
توانیم بگوییم هر اجراکننده چقدر حافظه دارد. یا
331
00:11:21,519 –> 00:11:21,839
332
00:11:21,839 –> 00:11:23,920
course per executor و بسیاری از
333
00:11:23,920 –> 00:11:25,519
ویژگی های دیگر که می توانند به
334
00:11:25,519 –> 00:11:26,560
صورت مقدار کلید تنظیم شوند،
335
00:11:26,560 –> 00:11:29,360
اکنون می توانید بگویید set master
336
00:11:29,360 –> 00:11:30,959
و سپس مقداری
337
00:11:30,959 –> 00:11:33,519
را وارد کنید که URL استاد شما را
338
00:11:33,519 –> 00:11:34,240
می گیرد، می توانید یک
339
00:11:34,240 –> 00:11:36,800
نام برنامه را تنظیم کنید که اساساً مقدار آن است.
340
00:11:36,800 –> 00:11:38,079
یک نام برنامه را تنظیم کنید
341
00:11:38,079 –> 00:11:40,800
و می توانید یک کلید دریافت و مقدار پیش فرض
342
00:11:40,800 –> 00:11:42,959
را برای بدست آوردن مقدار پیکربندی یک
343
00:11:42,959 –> 00:11:44,480
کلید خاص انجام دهید، اکنون گزینه های مختلفی وجود دارد
344
00:11:44,480 –> 00:11:46,320
که می توانید
345
00:11:46,320 –> 00:11:49,200
با pi spark dot spark conf خود استفاده کنید، بنابراین اگر
346
00:11:49,200 –> 00:11:49,519
347
00:11:49,519 –> 00:11:52,240
اکنون به زمینه جرقه نگاه کنیم. گفت:
348
00:11:52,240 –> 00:11:54,480
وقتی نگاه میکنیم یا وقتی معماری اسپارک را میفهمیم
349
00:11:54,480 –> 00:11:55,920
350
00:11:55,920 –> 00:11:57,760
که از آموزشهای قبلی
351
00:11:57,760 –> 00:12:01,279
یا برخی از روشهای خودآموزی
352
00:12:01,279 –> 00:12:04,800
که در اصل اسپارک دارد یاد میگرفتیم یا هر زمان
353
00:12:04,800 –> 00:12:06,880
که برنامههایی برای کار با
354
00:12:06,880 –> 00:12:09,120
اسپارک بهعنوان چارچوب پردازشی میسازید،
355
00:12:09,120 –> 00:12:11,440
برنامههای شما یک درایور دارند. برنامه
356
00:12:11,440 –> 00:12:13,839
و برنامه درایور اساساً دارای یک
357
00:12:13,839 –> 00:12:16,240
زمینه جرقه است، اکنون زمینه جرقه
358
00:12:16,240 –> 00:12:19,600
نقطه ورود اصلی در هر برنامه اسپارک است،
359
00:12:19,600 –> 00:12:22,079
بنابراین اگر به جریان داده نگاه کنیم، بنابراین
360
00:12:22,079 –> 00:12:24,399
از نظر محلی، صحبت می کنیم. در مورد
361
00:12:24,399 –> 00:12:27,200
spark context که اساساً به شما امکان می دهد
362
00:12:27,200 –> 00:12:29,120
با سیستم فایل محلی صحبت کنید
363
00:12:29,120 –> 00:12:31,519
و سپس شما اساساً چیزی
364
00:12:31,519 –> 00:12:33,040
به نام pi 4j دارید،
365
00:12:33,040 –> 00:12:35,600
بنابراین وقتی هر برنامه spark را اجرا می کنید یک
366
00:12:35,600 –> 00:12:37,040
برنامه درایور شروع می شود
367
00:12:37,040 –> 00:12:39,360
که عملکرد اصلی را دارد و دارای
368
00:12:39,360 –> 00:12:40,240
369
00:12:40,240 –> 00:12:42,480
زمینه جرقه شما است که اکنون شروع می شود.
370
00:12:42,480 –> 00:12:43,760
371
00:12:43,760 –> 00:12:46,160
سپس برنامه درایور عملیاتهای داخل مجریها را اجرا میکند،
372
00:12:46,160 –> 00:12:48,399
بنابراین چه
373
00:12:48,399 –> 00:12:49,920
اجراکنندههایی هستند، اینها فرآیندهای jvm هستند،
374
00:12:49,920 –> 00:12:53,120
اکنون فضای جرقهای از pi
375
00:12:53,120 –> 00:12:56,240
4j برای راهاندازی یک jvm استفاده میکند و بهطور پیشفرض یک
376
00:12:56,240 –> 00:12:57,120
377
00:12:57,120 –> 00:12:59,600
378
00:12:59,600 –> 00:13:01,360
379
00:13:01,360 –> 00:13:03,120
زمینه javaspark ایجاد میکند. ماشین و
380
00:13:03,120 –> 00:13:05,680
این اسکلت شماست، بنابراین
381
00:13:05,680 –> 00:13:07,680
382
00:13:07,680 –> 00:13:09,760
اگر به روشی تعاملی کار می کنید، نیازی به ایجاد یک زمینه جرقه جدید نیست،
383
00:13:09,760 –> 00:13:10,800
اما اگر برنامه خود را
384
00:13:10,800 –> 00:13:11,600
385
00:13:11,600 –> 00:13:15,120
با استفاده از یک ایده یا اساساً در یک فایل توسعه
386
00:13:15,120 –> 00:13:16,800
می دهید، باید اکنون زمینه جرقه خود را مقداردهی اولیه کنید.
387
00:13:16,800 –> 00:13:19,040
388
00:13:19,040 –> 00:13:22,320
به اینجا نگاه کنید تا متوجه شویم که فضای جرقه
389
00:13:22,320 –> 00:13:22,959
390
00:13:22,959 –> 00:13:24,560
نوعی اتصال سوکت با اجرای
391
00:13:24,560 –> 00:13:26,320
اسپارک pi 4 j دارد
392
00:13:26,320 –> 00:13:28,639
که همان jvm است و سپس
393
00:13:28,639 –> 00:13:29,360
می توانید آن را داشته باشید.
394
00:13:29,360 –> 00:13:31,600
g یک خوشه زیربنایی که دارای
395
00:13:31,600 –> 00:13:33,120
چندین گره کارگر است
396
00:13:33,120 –> 00:13:35,120
که در آن روی آن گرههای کارگر،
397
00:13:35,120 –> 00:13:37,200
فرآیندهایی را اجرا میکنید که اکنون اجرای شما را بر عهده میگیرند،
398
00:13:37,200 –> 00:13:38,079
399
00:13:38,079 –> 00:13:41,600
اگر به این
400
00:13:41,600 –> 00:13:43,600
کد نگاه کنیم، میبینیم که این یک
401
00:13:43,600 –> 00:13:45,120
پیادهسازی از کلاس pi spar است
402
00:13:45,120 –> 00:13:48,399
و پارامترهای par context میتوانند
403
00:13:48,399 –> 00:13:51,040
انجام دهند. بنابراین ما میتوانیم مقادیری را برای
404
00:13:51,040 –> 00:13:53,680
همه این پارامترها ارسال کنیم، مانند
405
00:13:53,680 –> 00:13:56,560
نام برنامه اصلی، فایلهای home pi و غیره،
406
00:13:56,560 –> 00:13:57,519
بنابراین،
407
00:13:57,519 –> 00:14:00,240
اکنون اینجا جایی است که نشانی اینترنتی
408
00:14:00,240 –> 00:14:02,000
خوشهای را که به آن متصل
409
00:14:02,000 –> 00:14:04,959
میشود، میگویید تا ما علاقه مند به استفاده از
410
00:14:04,959 –> 00:14:05,600
پایتون باشیم.
411
00:14:05,600 –> 00:14:07,920
کار با اسپارک و اسپارک
412
00:14:07,920 –> 00:14:09,839
یا بهعنوان یک خوشه مستقل
413
00:14:09,839 –> 00:14:12,639
خواهد بود یا با مزوس هادوپ
414
00:14:12,639 –> 00:14:15,120
یا آپاچی و غیره ادغام میشود، بنابراین استاد
415
00:14:15,120 –> 00:14:17,279
شما آدرس url
416
00:14:17,279 –> 00:14:19,600
نام برنامه کلاستر را نشان میدهد که اساساً نام برنامه شما است.
417
00:14:19,600 –> 00:14:21,199
Spark home
418
00:14:21,199 –> 00:14:23,600
اساساً میگوید که جرقه شما به کجا مربوط است.
419
00:14:23,600 –> 00:14:25,600
jars یا فایلهای پیکربندی
420
00:14:25,600 –> 00:14:27,839
یا فایلهای pi دایرکتوری نصب spark شما در
421
00:14:27,839 –> 00:14:28,959
422
00:14:28,959 –> 00:14:32,240
اصل به فایلهای dot zip یا dot py میگوید که
423
00:14:32,240 –> 00:14:33,600
424
00:14:33,600 –> 00:14:36,160
به خوشه بفرستند و به مسیر پایتون اضافه
425
00:14:36,160 –> 00:14:38,399
کنند. او جایی است که میتوانید
426
00:14:38,399 –> 00:14:40,639
فایلهای پایتون را مشخص کنید که در آن
427
00:14:40,639 –> 00:14:42,320
کدهایی را نوشتهاید که باید به
428
00:14:42,320 –> 00:14:43,120
429
00:14:43,120 –> 00:14:45,279
مسیر کلاس اضافه شود، یک
430
00:14:45,279 –> 00:14:46,480
محیط پارامتر دارید که در آن
431
00:14:46,480 –> 00:14:48,720
432
00:14:48,720 –> 00:14:50,000
متغیرهای محیط گره کارگر
433
00:14:50,000 –> 00:14:53,279
مانند jvm یا حافظه
434
00:14:53,279 –> 00:14:55,519
و هستههای خود را که نیاز دارند را مشخص کنید. برای استفاده شما
435
00:14:55,519 –> 00:14:57,120
چیزی به نام اندازه دسته ای دارید،
436
00:14:57,120 –> 00:15:00,000
بنابراین این تعداد اشیاء پایتون است
437
00:15:00,000 –> 00:15:03,120
که به عنوان یک شی جاوا نشان داده شده است،
438
00:15:03,120 –> 00:15:06,959
اکنون یک تنظیم شده است تا دسته بندی صفر را غیرفعال
439
00:15:06,959 –> 00:15:09,279
کند تا به طور خودکار اندازه دسته را
440
00:15:09,279 –> 00:15:11,839
بر اساس اندازه اشیا انتخاب کند یا منهای 1
441
00:15:11,839 –> 00:15:14,399
برای استفاده از یک دسته نامحدود اندازه
442
00:15:14,399 –> 00:15:16,639
را نیز میتوانید مشخص کنید
443
00:15:16,639 –> 00:15:19,279
و این سریالسازی است که
444
00:15:19,279 –> 00:15:20,079
استفاده میشود،
445
00:15:20,079 –> 00:15:22,480
بنابراین سریالساز rtd اکنون در اینجا میتوانیم
446
00:15:22,480 –> 00:15:24,000
مثلاً
447
00:15:24,000 –> 00:15:26,480
سریالساز pickle را مشخص کنیم، بنابراین به طور پیشفرض میدانیم
448
00:15:26,480 –> 00:15:28,560
که وقتی با اسپارک کار میکنیم و
449
00:15:28,560 –> 00:15:30,000
با
450
00:15:30,000 –> 00:15:32,800
rdds spark به صورت داخلی کار میکنیم. یا یک
451
00:15:32,800 –> 00:15:34,800
سریالساز cairo یا سریالساز جاوا
452
00:15:34,800 –> 00:15:36,720
، چیزی به نام conf دارید، اکنون
453
00:15:36,720 –> 00:15:38,000
این یک شی
454
00:15:38,000 –> 00:15:41,040
از conf شما است تا تمام ویژگیهای اسپارک خود را درست تنظیم کنید.
455
00:15:41,040 –> 00:15:41,839
456
00:15:41,839 –> 00:15:43,839
او جایی است که ما در حال ایجاد یک
457
00:15:43,839 –> 00:15:45,120
شی پیکربندی
458
00:15:45,120 –> 00:15:47,759
هستیم، چیزی به نام دروازه
459
00:15:47,759 –> 00:15:49,759
داریم اکنون می توانیم از یک دروازه موجود استفاده کنیم
460
00:15:49,759 –> 00:15:52,560
و jvm در غیر این صورت یک jvm جدید را مقداردهی اولیه کنیم،
461
00:15:52,560 –> 00:15:54,480
شما یک نمونه متنی java spark دارید
462
00:15:54,480 –> 00:15:57,440
که jsc است و شما profiler دارید،
463
00:15:57,440 –> 00:15:58,560
464
00:15:58,560 –> 00:16:00,880
اکنون این یک کلاس از پروفایلرهای سفارشی است.
465
00:16:00,880 –> 00:16:02,480
برای انجام پروفایل استفاده می شود
466
00:16:02,480 –> 00:16:04,959
و به عنوان مثال می توانیم در pi spark
467
00:16:04,959 –> 00:16:08,240
dot profiler dot pass batch profiler ارسال کنیم، بنابراین
468
00:16:08,240 –> 00:16:10,880
در تمام این پارامترهای بالا، نام اصلی و
469
00:16:10,880 –> 00:16:11,600
نام برنامه
470
00:16:11,600 –> 00:16:15,279
عمدتاً استفاده می شود اکنون اساساً می
471
00:16:15,279 –> 00:16:17,600
توانیم یک کد خاص بنویسیم و
472
00:16:17,600 –> 00:16:19,199
در اسلایدهای بعدی نشان خواهم داد که در
473
00:16:19,199 –> 00:16:22,560
آن ما فقط میتوانیم از pi spark
474
00:16:22,560 –> 00:16:25,040
import spark context بگوییم و سپس میتوانیم پارامترهایی را
475
00:16:25,040 –> 00:16:25,920
مشخص کنیم
476
00:16:25,920 –> 00:16:28,000
که وارد زمینه spark میشوند،
477
00:16:28,000 –> 00:16:30,160
اگر جلوتر
478
00:16:30,160 –> 00:16:33,360
برویم، میتوانیم ببینیم که چگونه به نظر میرسد فایلهای spark
479
00:16:33,360 –> 00:16:35,759
حالا برای چه چیزی استفاده میشود، بنابراین شما
480
00:16:35,759 –> 00:16:37,920
فایلهای spark را به شما امکان میدهد. برای
481
00:16:37,920 –> 00:16:40,959
آپلود فایل های خود با استفاده از
482
00:16:40,959 –> 00:16:43,519
روش های زمینه جرقه مانند افزودن
483
00:16:43,519 –> 00:16:44,079
فایل
484
00:16:44,079 –> 00:16:46,880
و حتی می توانید مسیر را در
485
00:16:46,880 –> 00:16:47,759
گره کارگر
486
00:16:47,759 –> 00:16:50,800
با استفاده از فایل های اسپارک دریافت کنید، بنابراین این
487
00:16:50,800 –> 00:16:52,399
فقط یک مثال ساده است
488
00:16:52,399 –> 00:16:55,440
که ما می توانیم استفاده کنید تا این روشهای کلاس را داشته
489
00:16:55,440 –> 00:16:56,079
490
00:16:56,079 –> 00:16:58,639
باشید، یکی get است، بنابراین میتوانید نام فایل را دریافت کنید
491
00:16:58,639 –> 00:17:01,040
و حتی میتوانید
492
00:17:01,040 –> 00:17:03,040
اگر میخواهید مسیر را نگاه کنید، میتوانید بگویید get root directory. بنابراین
493
00:17:03,040 –> 00:17:04,640
این یک مثال ساده است
494
00:17:04,640 –> 00:17:07,599
حالا تابع دایرکتوری ریشه را در اینجا دریافت کنید یا
495
00:17:07,599 –> 00:17:08,559
متد را در اینجا مشخص کنید.
496
00:17:08,559 –> 00:17:11,280
مسیر دایرکتوری ریشه
497
00:17:11,280 –> 00:17:13,359
که اساساً حاوی فایلی است
498
00:17:13,359 –> 00:17:14,720
که از طریق
499
00:17:14,720 –> 00:17:17,760
روش فایل افزودن شما اضافه میشود، بنابراین اگر میخواهم
500
00:17:17,760 –> 00:17:19,679
کد را در یک فایل بنویسم
501
00:17:19,679 –> 00:17:21,839
و آن را به صورت تعاملی ان
502
00:17:21,839 –> 00:17:23,599
ام ندهم، میتوانم از pi spark impor
503
00:17:23,599 –> 00:17:26,160
spark context از pi spark impor
504
00:17:26,160 –> 00:17:28,720
spark انجام دهم. فایل، بنابراین اگر ما این کار را
505
00:17:28,720 –> 00:17:30,720
از راه تعاملی انجام می دهیم، نیازی
506
00:17:30,720 –> 00:17:32,000
به استفاده واقعی از فضای
507
00:17:32,000 –> 00:17:34,320
اسپارک نداریم، می توانیم فقط فایل های اسپارک را وارد کنیم
508
00:17:34,320 –> 00:17:35,039
509
00:17:35,039 –> 00:17:37,679
و این کافی است، در اینجا من می
510
00:17:37,679 –> 00:17:38,080
511
00:17:38,080 –> 00:17:40,799
گویم فاصله را پیدا کنید و مسیری را برای یک فایل مشخص می کنم.
512
00:17:40,799 –> 00:17:42,000
513
00:17:42,000 –> 00:17:45,280
اساساً من میگویم نام فاصله را پیدا کن
514
00:17:45,280 –> 00:17:46,080
515
00:17:46,080 –> 00:17:49,120
و سپس به این فایل اشاره میکنم که در اینجا به این فایل اشاره
516
00:17:49,120 –> 00:17:51,200
517
00:17:51,200 –> 00:17:53,679
518
00:17:53,679 –> 00:17:55,679
519
00:17:55,679 –> 00:17:57,919
میکنم.
520
00:17:57,919 –> 00:18:00,240
اراده l نام برنامه من باشد
521
00:18:00,240 –> 00:18:03,440
و من می گویم spark file app و
522
00:18:03,440 –> 00:18:06,320
سپس از روش add file استفاده می
523
00:18:06,320 –> 00:18:08,400
کنم که در این فاصله کم رد می شوم که در آن
524
00:18:08,400 –> 00:18:08,960
525
00:18:08,960 –> 00:18:11,520
یک متغیر ایجاد کرده ایم تا به یک فایل اشاره کند
526
00:18:11,520 –> 00:18:12,160
در نهایت
527
00:18:12,160 –> 00:18:15,200
من یک چاپ مطلق انجام می دهم مسیر
528
00:18:15,200 –> 00:18:18,880
و همچنین میتوانم بگویم که فایلهای اسپارک
529
00:18:18,880 –> 00:18:22,080
دایرکتوری اصلی این
530
00:18:22,080 –> 00:18:22,960
فایل خاص را دریافت میکنند،
531
00:18:22,960 –> 00:18:25,200
بنابراین ما میتوانیم این کار را به روشی ساده
532
00:18:25,200 –> 00:18:27,520
انجام دهیم و من چند نمونه را در اینجا به شما نشان میدهم،
533
00:18:27,520 –> 00:18:31,440
بنابراین وقتی در مورد pi spark rdd
534
00:18:31,440 –> 00:18:34,160
اکنون rdd صحبت میکنیم بلوک سازنده جرقه است،
535
00:18:34,160 –> 00:18:36,160
بنابراین شما مجموعه داده های توزیع شده انعطاف پذیری دارید
536
00:18:36,160 –> 00:18:36,640
537
00:18:36,640 –> 00:18:39,440
که اساساً انتزاع اولیه
538
00:18:39,440 –> 00:18:40,240
در اسپارک است، بنابراین
539
00:18:40,240 –> 00:18:43,039
هر کاری را که در اسپارک انجام می دهید تا زمانی که
540
00:18:43,039 –> 00:18:44,400
بخواهید نتیجه
541
00:18:44,400 –> 00:18:47,919
را از استفاده از روش sc dot خود
542
00:18:47,919 –> 00:18:50,559
تا انجام تبدیل
543
00:18:50,559 –> 00:18:51,360
هایی مانند نقشه
544
00:18:51,360 –> 00:18:53,520
مسطح نقشه ببینید، ببینید. فیلتر یا هر تغییر دیگری
545
00:18:53,520 –> 00:18:54,559
546
00:18:54,559 –> 00:18:57,120
که می تواند یک
547
00:18:57,120 –> 00:18:59,200
مجموعه داده توزیع شده انعطاف پذیر ایجاد کند و اینکه
548
00:18:59,200 –> 00:19:02,720
اساساً یک مجموعه داده منطقی است
549
00:19:02,720 –> 00:19:05,440
وقتی داده ها ارزیابی نمی شوند شما
550
00:19:05,440 –> 00:19:06,960
هیچ تغییری انجام نمی دهید
551
00:19:06,960 –> 00:19:09,919
هر مرحله در برنامه شما در حال پایان است
552
00:19:09,919 –> 00:19:10,960
. p ایجاد یک
553
00:19:10,960 –> 00:19:14,160
rdt و آن rdd اساساً یک
554
00:19:14,160 –> 00:19:16,799
مرحله در تگ است و این دگ
555
00:19:16,799 –> 00:19:18,720
هنگام فراخوانی در عمل اجرا می شود، بنابراین
556
00:19:18,720 –> 00:19:19,280
یک
557
00:19:19,280 –> 00:19:21,520
مجموعه پارتیشن بندی
558
00:19:21,520 –> 00:19:23,679
شده غیرقابل تغییر از عناصر است که اکنون به طور پیش فرض هر زمان که یک
559
00:19:23,679 –> 00:19:24,640
rdd ایجاد
560
00:19:24,640 –> 00:19:27,440
شود، همیشه دارای پارتیشن خواهد بود و ما
561
00:19:27,440 –> 00:19:29,520
همیشه می توانیم به پارتیشنها نگاه کنید،
562
00:19:29,520 –> 00:19:31,600
میتوانیم ببینیم چند پارتیشن وجود دارد
563
00:19:31,600 –> 00:19:33,520
و هر چه تعداد پارتیشنهای
564
00:19:33,520 –> 00:19:33,919
565
00:19:33,919 –> 00:19:35,840
شما بیشتر باشد، تعداد وظایف موازی بیشتری
566
00:19:35,840 –> 00:19:37,039
خواهید داشت، بنابراین
567
00:19:37,039 –> 00:19:39,360
وقتی در مورد rdd صحبت میکنیم، عمدتاً
568
00:19:39,360 –> 00:19:40,960
دو نوع عملیات وجود دارد،
569
00:19:40,960 –> 00:19:43,760
بنابراین شما تبدیلها دارید، بنابراین اینها عملیات هستند.
570
00:19:43,760 –> 00:19:45,280
مانند map
571
00:19:45,280 –> 00:19:48,240
filter join union و غیره
572
00:19:48,240 –> 00:19:50,000
که روی یک rdd انجام می شود
573
00:19:50,000 –> 00:19:52,559
که اساساً منجر به یک rdd جدید می
574
00:19:52,559 –> 00:19:54,720
575
00:19:54,720 –> 00:19:56,960
576
00:19:56,960 –> 00:19:58,080
577
00:19:58,080 –> 00:20:01,360
شود. از زمینه جرقه
578
00:20:01,360 –> 00:20:04,000
مانند مثالی که در این جلسه در ابتدا به شما نشان دادم،
579
00:20:04,000 –> 00:20:05,440
580
00:20:05,440 –> 00:20:07,679
عمل زمانی است که می خواهید نتیجه را ببینید،
581
00:20:07,679 –> 00:20:09,679
بنابراین اینها عملیاتی هستند مانند
582
00:20:09,679 –> 00:20:10,400
کاهش
583
00:20:10,400 –> 00:20:13,440
اولین شمارش و
584
00:20:13,440 –> 00:20:16,240
غیره lly اجرای dag
585
00:20:16,240 –> 00:20:17,120
را از همان
586
00:20:17,120 –> 00:20:19,520
ابتدا آغاز می کند، بنابراین این یک مثال ساده از
587
00:20:19,520 –> 00:20:20,720
ایجاد یک pi spark
588
00:20:20,720 –> 00:20:24,400
rdd است، بنابراین در اینجا شما از کلاس pi spark
589
00:20:24,400 –> 00:20:24,799
dot
590
00:20:24,799 –> 00:20:27,919
rdd استفاده می کنید و سپس می گویید jrdd
591
00:20:27,919 –> 00:20:30,000
می توانید هر نامی را که
592
00:20:30,000 –> 00:20:31,600
می خواهید مانند آن بدهید.
593
00:20:31,600 –> 00:20:33,679
میتوانید سریالساز خود را مشخص کنید
594
00:20:33,679 –> 00:20:35,280
که میخواهید از آن استفاده
595
00:20:35,280 –> 00:20:38,000
کنید، بنابراین اگر این کار را در یک فایل انجام میدادم،
596
00:20:38,000 –> 00:20:38,799
597
00:20:38,799 –> 00:20:41,039
اکنون با کدی مانند این مینویسم،
598
00:20:41,039 –> 00:20:43,039
این فقط یک برنامه ساده pi spark
599
00:20:43,039 –> 00:20:44,159
برای برگرداندن تعداد
600
00:20:44,159 –> 00:20:46,880
عناصر در rdd است. بنابراین شما در حال ایجاد
601
00:20:46,880 –> 00:20:48,080
یک زمینه جرقه ای
602
00:20:48,080 –> 00:20:50,880
هستید که می گویید sc dot parallelize اکنون sc dot
603
00:20:50,880 –> 00:20:52,720
parallelize روشی برای کار بر روی
604
00:20:52,720 –> 00:20:54,080
مجموعه عناصر است
605
00:20:54,080 –> 00:20:56,080
و در اینجا چند کلمه دارید که در
606
00:20:56,080 –> 00:20:57,760
حال ارسال هستند، بنابراین این
607
00:20:57,760 –> 00:20:59,679
درست مانند یک مجموعه یا لیستی است که می توانید
608
00:20:59,679 –> 00:21:01,679
بگویید و سپس شما در حال انجام اکانت
609
00:21:01,679 –> 00:21:02,080
هایی هستید که در آن
610
00:21:02,080 –> 00:21:05,200
این rdd را می گیرید و اکنون فقط
611
00:21:05,200 –> 00:21:05,440
یک
612
00:21:05,440 –> 00:21:07,679
عمل روی آن انجام می دهید که نتیجه را به شما می دهد
613
00:21:07,679 –> 00:21:09,760
و در نهایت دارید آن را چاپ
614
00:21:09,760 –> 00:21:10,320
615
00:21:10,320 –> 00:21:13,919
616
00:21:13,919 –> 00:21:16,799
می کنید. n
617
00:21:16,799 –> 00:21:17,760
روش تعاملی،
618
00:21:17,760 –> 00:21:20,159
بنابراین اجازه دهید من اینجا به کنسول خود بروم و کاری
619
00:21:20,159 –> 00:21:20,880
که می توانم انجام دهم این
620
00:21:20,880 –> 00:21:24,400
است که به عنوان مثال می توانم
621
00:21:24,400 –> 00:21:27,280
به یک فایل اشاره کنم، همانطور که گفتم با
622
00:21:27,280 –> 00:21:28,320
623
00:21:28,320 –> 00:21:31,200
spark شما، فضای اسپارک شما و جلسه اسپارک
624
00:21:31,200 –> 00:21:31,760
هر دو
625
00:21:31,760 –> 00:21:35,120
مقدار دهی اولیه می شوند، بنابراین در اینجا می توانیم از sc
626
00:21:35,120 –> 00:21:37,440
و سپس استفاده کنیم. با sc شما روش های مختلفی دارید
627
00:21:37,440 –> 00:21:39,280
که می توان از آنها
628
00:21:39,280 –> 00:21:43,039
برای کار با اسپارک خود استفاده کرد، اکنون در اینجا
629
00:21:43,039 –> 00:21:46,159
می توانیم به روشی مانند
630
00:21:46,159 –> 00:21:48,240
فایل متنی نگاه کنیم که اساساً به شما امکان می دهد
631
00:21:48,240 –> 00:21:50,159
یک فایل را انتخاب کنید، بنابراین فرض
632
00:21:50,159 –> 00:21:54,080
کنید فایل متنی و سپس می توانم آن را
633
00:21:54,080 –> 00:21:56,400
به یک مسیر نشان دهم. بنابراین میتوانم بگویم که
634
00:21:56,400 –> 00:21:59,840
فایلهای نمونه خانگی htu اکنون یک دایرکتوری
635
00:21:59,840 –> 00:22:00,480
در
636
00:22:00,480 –> 00:22:03,440
دستگاه من است و این دایرکتوری
637
00:22:03,440 –> 00:22:03,840
در
638
00:22:03,840 –> 00:22:05,679
هر دو گره کارگر وجود دارد، زیرا
639
00:22:05,679 –> 00:22:07,840
ما روی یک خوشه مستقل جرقه کار میکنیم
640
00:22:07,840 –> 00:22:10,840
و در اینجا برای مثال میتوانم people.tx را انتخاب
641
00:22:10,840 –> 00:22:12,159
642
00:22:12,159 –> 00:22:14,320
کنم، بنابراین میدانم که آنجا وجود دارد. یک فایل در اینجا در
643
00:22:14,320 –> 00:22:16,240
این مسیر است و اجازه دهید این را نیز
644
00:22:16,240 –> 00:22:18,400
به صورت نقل قول بدهیم، بنابراین
645
00:22:18,400 –> 00:22:19,360
646
00:22:19,360 –> 00:22:22,559
اگر فقط x را انجام دهم، یک rdd ایجاد میکند، به من نشان
647
00:22:22,559 –> 00:22:25,679
میدهد که با استفاده از روش فایل متنی، یک نقشه پارتیشنهای rdd ایجاد کرده است،
648
00:22:25,679 –> 00:22:29,120
اکنون میتوانم
649
00:22:29,120 –> 00:22:31,520
چند تغییر دیگر در آن انجام دهم. آن را به
650
00:22:31,520 –> 00:22:32,720
عنوان مثال من می توان گفت
651
00:22:32,720 –> 00:22:36,240
نقشه و نقشه y x نقطه
652
00:22:36,240 –> 00:22:39,360
اساساً تبدیلی است که من
653
00:22:39,360 –> 00:22:39,760
654
00:22:39,760 –> 00:22:42,640
روی یک rdd انجام می دهم که قبلاً با استفاده
655
00:22:42,640 –> 00:22:43,520
از روشی
656
00:22:43,520 –> 00:22:45,840
از زمینه جرقه ایجاد شده است، بنابراین در اینجا وقتی می
657
00:22:45,840 –> 00:22:47,120
خواهم نقشه ای انجام دهم
658
00:22:47,120 –> 00:22:49,120
باید در یک تابع اکنون
659
00:22:49,120 –> 00:22:50,400
در جرقه عبور کنم.
660
00:22:50,400 –> 00:22:52,320
و هنگامی که از پایتون استفاده می کنید، می توانید
661
00:22:52,320 –> 00:22:54,000
از توابع لامبدا استفاده کنید
662
00:22:54,000 –> 00:22:56,720
که برای توابع ناشناس است، بنابراین می توانم بگویم
663
00:22:56,720 –> 00:22:57,520
لامبدا
664
00:22:57,520 –> 00:22:59,919
و سپس می توانم بگویم هر عنصری را
665
00:22:59,919 –> 00:23:01,760
اینجا بگیرید و با آن چه کاری می خواهید انجام دهید
666
00:23:01,760 –> 00:23:02,159
667
00:23:02,159 –> 00:23:05,840
تا بتوانم بگویم n نقطه بالایی اکنون یک است.
668
00:23:05,840 –> 00:23:08,320
تابع داخلی که می توانیم از آن استفاده کنیم
669
00:23:08,320 –> 00:23:09,840
و وقتی این کار را انجام می دهم،
670
00:23:09,840 –> 00:23:12,960
این یکی دوباره یک rdd ایجاد می کند
671
00:23:12,960 –> 00:23:15,200
و در اینجا می بینیم که یک rdp پایتون ایجاد کرده است
672
00:23:15,200 –> 00:23:16,559
و این
673
00:23:16,559 –> 00:23:19,440
rdd دوباره واقعاً ارزیابی را انجام نداده است،
674
00:23:19,440 –> 00:23:21,600
مگر اینکه و تا زمانی که
675
00:23:21,600 –> 00:23:23,120
بخواهیم به در نتیجه
676
00:23:23,120 –> 00:23:25,360
هیچ ارزیابی در اینجا اتفاق نمی افتد بنابراین
677
00:23:25,360 –> 00:23:27,600
در مورد اول ما
678
00:23:27,600 –> 00:23:30,720
با استفاده از یک فایل یک rdd ایجاد کردیم در دومی یک
679
00:23:30,720 –> 00:23:32,640
تابع را با استفاده از نقشه اعمال کردیم اکنون می توانم یک فیلتر انجام دهم
680
00:23:32,640 –> 00:23:33,360
681
00:23:33,360 –> 00:23:36,159
من فقط می توانم یک جمع آوری ساده y نقطه انجام دهم
682
00:23:36,159 –> 00:23:37,520
و این اساساً یک
683
00:23:37,520 –> 00:23:40,000
عمل است که شما انجام می دهید. در حال استناد هستند که اجازه می
684
00:23:40,000 –> 00:23:41,279
دهد این داگ
685
00:23:41,279 –> 00:23:44,480
اجرا شود و سپس به محتوای فایل خود نگاه می
686
00:23:44,480 –> 00:23:47,120
کنم که
687
00:23:47,120 –> 00:23:48,240
به حروف بزرگ تبدیل شده است
688
00:23:48,240 –> 00:23:50,559
این یک مثال است اکنون می
689
00:23:50,559 –> 00:23:52,240
توانم بگویم ایجاد یک لیست
690
00:23:52,240 –> 00:23:54,320
برای مثال بیایید یک لیست از
691
00:23:54,320 –> 00:23:56,960
رشته ها ایجاد کنیم پس بیایید سلام
692
00:23:56,960 –> 00:24:00,720
کنیم بگو جهان بیایید بگوییم خنک
693
00:24:00,720 –> 00:24:04,320
بیایید بگوییم زمستان خوب است و
694
00:24:04,320 –> 00:24:07,120
بیایید بگوییم تابستان، بنابراین من می توانم
695
00:24:07,120 –> 00:24:08,559
چند کلمه بگویم و این
696
00:24:08,559 –> 00:24:10,799
معمولاً یک لیست درست می کند، بنابراین من
697
00:24:10,799 –> 00:24:11,919
یک لیست ایجاد کرده ام
698
00:24:11,919 –> 00:24:14,559
و اساساً می توانم ببینم این چیست، بنابراین
699
00:24:14,559 –> 00:24:16,559
یک تاپل ایجاد کرده است و این نیز
700
00:24:16,559 –> 00:24:16,960
خوب است،
701
00:24:16,960 –> 00:24:19,679
بنابراین اساساً اکنون شما یک لیست
702
00:24:19,679 –> 00:24:21,520
یا یک تاپل ایجاد کرده اید و می خواهید
703
00:24:21,520 –> 00:24:23,039
روی آن کار کنید، بنابراین مجموعه ای از
704
00:24:23,039 –> 00:24:25,200
عناصر است اکنون می توانم اساساً بگویم
705
00:24:25,200 –> 00:24:28,640
b و سپس می توانم دوباره از sc dot استفاده کنم
706
00:24:28,640 –> 00:24:30,559
و این بار به من علاقه مند خواهم بود.
707
00:24:30,559 –> 00:24:33,600
با استفاده از این روش که موازی شده است
708
00:24:33,600 –> 00:24:35,679
که به شما امکان می دهد روی
709
00:24:35,679 –> 00:24:37,919
مجموعه عناصر کار کنید بنابراین من فقط می توانم
710
00:24:37,919 –> 00:24:40,480
a را در اینجا پاس کنم و اگر به b نگاه کنم
711
00:24:40,480 –> 00:24:42,640
اساساً یک مجموعه موازی ایجاد کرده است
712
00:24:42,640 –> 00:24:43,279
rdd
713
00:24:43,279 –> 00:24:46,000
با استفاده از روش موازی کردن زمینه جرقه
714
00:24:46,000 –> 00:24:46,799
715
00:24:46,799 –> 00:24:49,679
اکنون می توانیم چاپ کنیم. برخی از مقادیر را
716
00:24:49,679 –> 00:24:50,640
از اینجا
717
00:24:50,640 –> 00:24:53,440
بیرون بیاورم، به عنوان مثال، من می توانم یک عمل را نیز فراخوانی
718
00:24:53,440 –> 00:24:53,760
719
00:24:53,760 –> 00:24:57,039
کنم، بنابراین می توانم بگویم b dot
720
00:24:57,039 –> 00:24:58,880
count و این باید تعداد
721
00:24:58,880 –> 00:25:00,880
عناصر را در این rdd خاص به من
722
00:25:00,880 –> 00:25:03,760
بدهد، بنابراین این دو برنامه هستند که
723
00:25:03,760 –> 00:25:04,640
من فقط
724
00:25:04,640 –> 00:25:07,520
از ایجاد یک لیست شروع به کار کردم. آن را
725
00:25:07,520 –> 00:25:08,640
به صورت موازی
726
00:25:08,640 –> 00:25:10,559
و سپس انجام اکانت یا در
727
00:25:10,559 –> 00:25:11,760
مثال قبلی خود
728
00:25:11,760 –> 00:25:15,600
، فایلی را خواندیم، یک تابع نقشه را اعمال کردیم
729
00:25:15,600 –> 00:25:18,000
و سپس اساساً یک جمع آوری انجام دادیم، بنابراین
730
00:25:18,000 –> 00:25:19,679
اگر
731
00:25:19,679 –> 00:25:22,880
به spark UI خود برگردم، اگر یک رفرش انجام دهم،
732
00:25:22,880 –> 00:25:24,960
در اینجا به من نشان می دهد که برنامهای
733
00:25:24,960 –> 00:25:26,240
که
734
00:25:26,240 –> 00:25:28,080
اکنون در حال اجرا است، میتوانید به
735
00:25:28,080 –> 00:25:30,799
رابط کاربری جزئیات برنامه نگاه کنید و این دو کار را به من نشان میدهد
736
00:25:30,799 –> 00:25:31,679
737
00:25:31,679 –> 00:25:34,880
که از اولین rdd ایجاد شده تا زمانی
738
00:25:34,880 –> 00:25:36,880
که عمل فراخوانی شده است اجرا شدهاند، بنابراین اگر به این یکی نگاه کنید،
739
00:25:36,880 –> 00:25:39,039
این یکی دگ را به من نشان میدهد
740
00:25:39,039 –> 00:25:41,200
و نشان میدهد. من آن را با یک فایل متنی شروع کردید
741
00:25:41,200 –> 00:25:42,080
742
00:25:42,080 –> 00:25:44,880
و سپس شما اساساً یک نقشه انجام دادید، بنابراین
743
00:25:44,880 –> 00:25:47,039
به من نشان می دهد که چند کار
744
00:25:47,039 –> 00:25:47,679
اجرا شده است،
745
00:25:47,679 –> 00:25:49,600
بنابراین این بدان معناست که دو
746
00:25:49,600 –> 00:25:51,679
پارتیشن برای این
747
00:25:51,679 –> 00:25:52,320
فایل خاص ایجاد شده است
748
00:25:52,320 –> 00:25:54,480
و من همچنین می توانم به s نگاه کنم. در
749
00:25:54,480 –> 00:25:55,679
مراحل مختلف
750
00:25:55,679 –> 00:25:57,840
برنامه من
751
00:25:57,840 –> 00:25:59,039
که دو کار دارد،
752
00:25:59,039 –> 00:26:01,360
می توانید به ذخیره سازی نگاه کنید، اگر
753
00:26:01,360 –> 00:26:02,320
ذخیره سازی انجام شده است،
754
00:26:02,320 –> 00:26:03,760
می توانید به متغیرهای محیط نگاه کنید،
755
00:26:03,760 –> 00:26:06,240
می توانید ببینید که چه تعداد
756
00:26:06,240 –> 00:26:09,200
مجری برای این
757
00:26:09,200 –> 00:26:10,159
برنامه خاص استفاده شده است
758
00:26:10,159 –> 00:26:12,960
و چه مقدار حافظه استفاده شده است. برای ذخیره سازی
759
00:26:12,960 –> 00:26:14,080
چقدر برای
760
00:26:14,080 –> 00:26:16,320
پردازش بود اگر درهم ریختگی
761
00:26:16,320 –> 00:26:18,240
اتفاق افتاد و همچنین می توانید به یک spark sql نگاه کنید،
762
00:26:18,240 –> 00:26:20,320
اگرچه ما در اینجا از هیچ
763
00:26:20,320 –> 00:26:22,080
جزء spark sql استفاده نمی کنیم
764
00:26:22,080 –> 00:26:24,080
اگر به دومی نگاه کنم که
765
00:26:24,080 –> 00:26:25,840
چهار کار را به من نشان می دهد بنابراین با
766
00:26:25,840 –> 00:26:26,880
موازی سازی شروع شد.
767
00:26:26,880 –> 00:26:29,279
و سپس اساساً ما یک پایتون
768
00:26:29,279 –> 00:26:29,919
rtd ایجاد
769
00:26:29,919 –> 00:26:32,080
کردیم و در نهایت به یک شمارش رسیدیم و
770
00:26:32,080 –> 00:26:33,600
این به من میگوید که چند
771
00:26:33,600 –> 00:26:36,480
کار انجام دادهایم، بنابراین ما همیشه میتوانیم
772
00:26:36,480 –> 00:26:36,880
773
00:26:36,880 –> 00:26:39,120
به تعداد پارتیشنهای یک
774
00:26:39,120 –> 00:26:40,320
rdd خاص نگاه کنیم،
775
00:26:40,320 –> 00:26:43,360
بنابراین هر زمان که یک rdd ایجاد کردید.
776
00:26:43,360 –> 00:26:45,120
به عنوان مثال، ما در اینجا b داریم
777
00:26:45,120 –> 00:26:48,640
یا در این مورد، y را در اینجا داریم،
778
00:26:48,640 –> 00:26:51,600
بنابراین شما همیشه می توانید یک نقطه y انجام دهید و
779
00:26:51,600 –> 00:26:52,320
780
00:26:52,320 –> 00:26:54,480
روش های مختلفی را که در دسترس هستند جستجو کنید
781
00:26:54,480 –> 00:26:56,720
و سپس می توانید اساساً این را بررسی کنید.
782
00:26:56,720 –> 00:26:58,720
اگر میخواهم به
783
00:26:58,720 –> 00:27:00,559
تعداد پارتیشنهایی نگاه
784
00:27:00,559 –> 00:27:04,080
کنم که برای این y در هنگام
785
00:27:04,080 –> 00:27:05,120
تبدیل
786
00:27:05,120 –> 00:27:07,600
متن خود به حروف بزرگ ایجاد شد و سپس میتوانم
787
00:27:07,600 –> 00:27:08,720
این کار را انجام دهم
788
00:27:08,720 –> 00:27:10,000
و اگر جستجو کنید، این به من میگوید که چند
789
00:27:10,000 –> 00:27:12,480
پارتیشن به طور مشابه ایجاد شده است.
790
00:27:12,480 –> 00:27:14,000
b
791
00:27:14,000 –> 00:27:16,320
که زمانی بود که ما روی یک لیست کار می کردیم و
792
00:27:16,320 –> 00:27:17,440
اگر می خواهید ببینید
793
00:27:17,440 –> 00:27:19,279
که تعداد پارتیشن
794
00:27:19,279 –> 00:27:20,559
ها 4 عدد بوده است و
795
00:27:20,559 –> 00:27:23,200
همچنین به من می گوید که بر اساس
796
00:27:23,200 –> 00:27:25,039
تعداد پارتیشن ها
797
00:27:25,039 –> 00:27:26,960
تعداد کارهایی را می بینید که
798
00:27:26,960 –> 00:27:29,840
به صورت خودکار اجرا شده اند. بر اساس اندازه دادههای شما
799
00:27:29,840 –> 00:27:31,520
یا بر اساس تعداد کدهایی
800
00:27:31,520 –> 00:27:34,080
که استفاده میشوند، پارتیشنهایی ایجاد کرده است
801
00:27:34,080 –> 00:27:37,200
و در هر پارتیشن شما یک وظیفه
802
00:27:37,200 –> 00:27:40,000
درست اجرا میکنید، به عنوان مثال، ما این
803
00:27:40,000 –> 00:27:41,039
را داشتیم که در آن
804
00:27:41,039 –> 00:27:44,480
یک لیست ایجاد میکردیم و سپس در b
805
00:27:44,480 –> 00:27:46,679
همان چیزی است که من بودم. انجام دادن بود که من sc.parallelize را انجام می
806
00:27:46,679 –> 00:27:48,960
دادم حالا اگر چنین کاری انجام می دادم،
807
00:27:48,960 –> 00:27:50,240
808
00:27:50,240 –> 00:27:51,919
پس اگر چنین کاری انجام
809
00:27:51,919 –> 00:27:53,520
می دادم،
810
00:27:53,520 –> 00:27:56,240
b من دو پارتیشن درست می کرد
811
00:27:56,240 –> 00:27:57,760
و سپس اگر
812
00:27:57,760 –> 00:28:01,200
روی b مانند کاری که انجام دادیم، اجرا می کردم.
813
00:28:01,200 –> 00:28:03,360
count بنابراین هنوز تعداد را به من می دهد اما
814
00:28:03,360 –> 00:28:05,440
اکنون پارتیشن ها دو نفر بودند
815
00:28:05,440 –> 00:28:08,080
بنابراین می توانیم دوباره ببینیم چند کار
816
00:28:08,080 –> 00:28:09,360
اجرا شده است ، بنابراین اگر به
817
00:28:09,360 –> 00:28:12,559
اینجا برگردم و اگر به مشاغل بروم و
818
00:28:12,559 –> 00:28:14,320
سپس یک کار دیگر را ببینم که اجرا شده است
819
00:28:14,320 –> 00:28:16,960
و شما می بینید دو کار را به من نشان می دهد، بنابراین
820
00:28:16,960 –> 00:28:18,880
همان کاری که قبلاً چهار کار را
821
00:28:18,880 –> 00:28:19,440
822
00:28:19,440 –> 00:28:21,120
نشان می داد، اکنون دو کار را نشان می دهد و این
823
00:28:21,120 –> 00:28:23,200
اساساً به این معنی است که تعداد
824
00:28:23,200 –> 00:28:24,720
پارتیشن ها تغییر کرده است
825
00:28:24,720 –> 00:28:27,360
و در هر پارتیشن شما یک کار
826
00:28:27,360 –> 00:28:29,679
در حال اجرا خواهید داشت، بنابراین این فقط یک مثال ساده
827
00:28:29,679 –> 00:28:30,000
برای
828
00:28:30,000 –> 00:28:32,720
دیدن نحوه کار است. اکنون می توانید اساساً از pi spark استفاده کنید،
829
00:28:32,720 –> 00:28:34,799
من همچنین می توانم
830
00:28:34,799 –> 00:28:35,760
کل این
831
00:28:35,760 –> 00:28:38,399
مورد را بگیرم و در یک فایل قرار دهم و سپس آن را
832
00:28:38,399 –> 00:28:39,520
اجرا کنم
833
00:28:39,520 –> 00:28:41,600
و بعداً آن را نشان خواهم داد، بنابراین وقتی
834
00:28:41,600 –> 00:28:43,600
اکنون در مورد سطح ذخیره سازی صحبت می کنید، این یک
835
00:28:43,600 –> 00:28:45,039
مفهوم بسیار مهم است
836
00:28:45,039 –> 00:28:47,440
و اگر دارید آموزشهای قبلی را دنبال
837
00:28:47,440 –> 00:28:49,120
میکردیم که در آن
838
00:28:49,120 –> 00:28:50,399
درباره سطح ذخیرهسازی صحبت
839
00:28:50,399 –> 00:28:52,880
میکردیم، بنابراین اساساً این تصمیم میگیرد که آیا
840
00:28:52,880 –> 00:28:53,760
rdd
841
00:28:53,760 –> 00:28:55,919
باید در حافظه ذخیره شود یا باید
842
00:28:55,919 –> 00:28:56,960
روی دیسک ذخیره شود
843
00:28:56,960 –> 00:29:00,480
یا هر دو، بنابراین وقتی در مورد
844
00:29:00,480 –> 00:29:03,520
سطح ذخیرهسازی شما صحبت میکنیم، اگر به بسته نگاه کنیم.
845
00:29:03,520 –> 00:29:04,320
846
00:29:04,320 –> 00:29:07,600
که برای اسپارک می آید، اساساً
847
00:29:07,600 –> 00:29:09,520
سطح ذخیره سازی دارد و همیشه می توانید به
848
00:29:09,520 –> 00:29:10,640
گوگل بروید و
849
00:29:10,640 –> 00:29:13,919
این مورد را بیشتر بررسی کنید، بنابراین در اینجا کاری که می توانیم انجام دهیم این
850
00:29:13,919 –> 00:29:14,480
است
851
00:29:14,480 –> 00:29:16,799
که اساساً می توانیم استفاده
852
00:29:16,799 –> 00:29:17,919
از سطح ذخیره سازی را ببینیم،
853
00:29:17,919 –> 00:29:20,159
بنابراین در این مثال اگر می بینید ما می
854
00:29:20,159 –> 00:29:21,039
گوییم
855
00:29:21,039 –> 00:29:23,840
اکنون میتوانیم
856
00:29:23,840 –> 00:29:24,480
بگوییم
857
00:29:24,480 –> 00:29:26,640
که باید از دیسک استفاده کند یا از حافظه استفاده کند باید
858
00:29:26,640 –> 00:29:28,080
859
00:29:28,080 –> 00:29:30,480
از پشته استفاده کند یا
860
00:29:30,480 –> 00:29:32,000
اینکه باید تکرار شود،
861
00:29:32,000 –> 00:29:35,120
بنابراین سطح ذخیرهسازی راهی است که در آن میتوانید
862
00:29:35,120 –> 00:29:36,399
863
00:29:36,399 –> 00:29:39,440
rdd خود را ایجاد کنید. در
864
00:29:39,440 –> 00:29:41,760
هر مرحله از برنامه شما باید در
865
00:29:41,760 –> 00:29:44,240
حافظه پنهان ذخیره شود، به طوری که اساساً محاسبات شما در
866
00:29:44,240 –> 00:29:45,279
867
00:29:45,279 –> 00:29:48,320
حافظه نهان ذخیره می شود یا محاسبات ادامه پیدا می کند،
868
00:29:48,320 –> 00:29:51,200
به طوری که اگر برنامه شما پایین آمد، اگر
869
00:29:51,200 –> 00:29:52,080
870
00:29:52,080 –> 00:29:54,480
دوباره از همان مرحله در همان سری از مراحل استفاده
871
00:29:54,480 –> 00:29:56,799
می کنید، مجبور نخواهید بود که
872
00:29:56,799 –> 00:29:57,760
تگ کامل شما
873
00:29:57,760 –> 00:30:00,080
دقیقاً از آن اجرا شود. در ابتدا، اما
874
00:30:00,080 –> 00:30:02,240
میتوانید از rdd محاسبهشده ذخیرهشده یا
875
00:30:02,240 –> 00:30:03,360
876
00:30:03,360 –> 00:30:06,559
تداومشده بهره ببرید، اکنون در اینجا میگوییم از
877
00:30:06,559 –> 00:30:08,000
878
00:30:08,000 —




![فیلم آموزشی: [5] دریافت و تجسم داده های سهام با پایتون با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/h8cdlHFSIDoimage2.jpg)