در این مطلب، ویدئو ارزش تاریخی در معرض خطر (VaR) با پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:02
تصاویر این ویدئو:

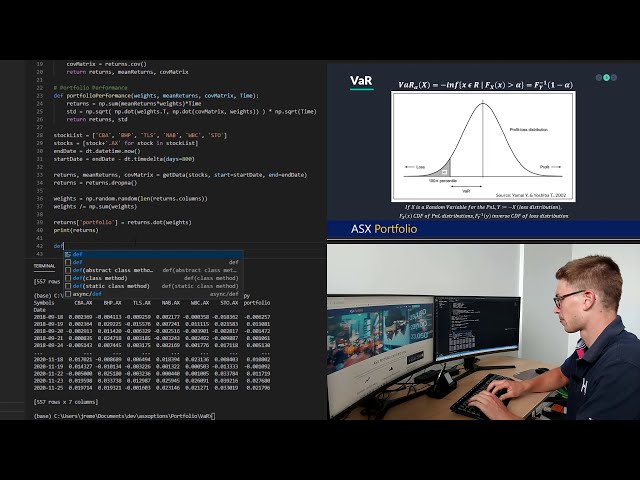
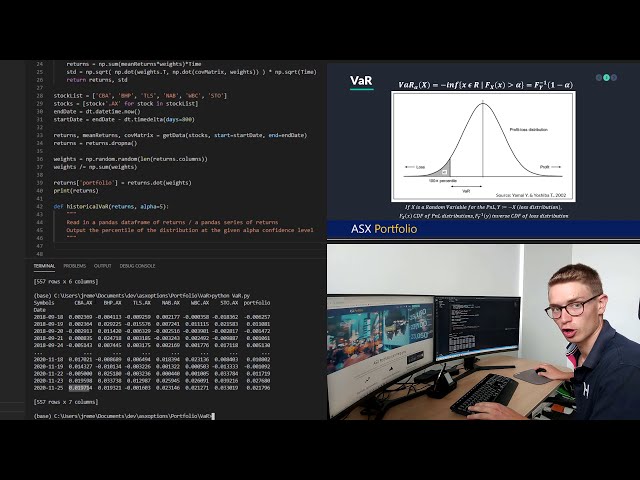
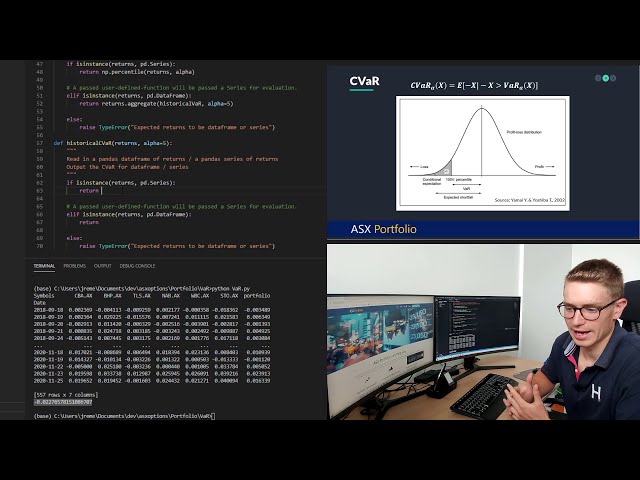
قسمتی از زیرنویس این فیلم:
00:00:02,320 –> 00:00:03,360
یوتیوب چه خبر است
2
00:00:03,360 –> 00:00:05,279
و به کانال نمونه کارها asx خوش آمدید،
3
00:00:05,279 –> 00:00:06,799
بنابراین امروز
4
00:00:06,799 –> 00:00:07,680
در
5
00:00:07,680 –> 00:00:09,679
مورد اجرای ارزش در معرض خطر و
6
00:00:09,679 –> 00:00:12,000
ارزش شرطی در معرض خطر در پایتون
7
00:00:12,000 –> 00:00:13,440
صحبت خواهیم کرد و به طور خاص در حال حاضر در
8
00:00:13,440 –> 00:00:15,040
مورد
9
00:00:15,040 –> 00:00:18,080
روش تاریخی صحبت خواهیم کرد. قرار است
10
00:00:18,080 –> 00:00:19,439
این دو مدل را پیاده سازی
11
00:00:19,439 –> 00:00:21,199
کنیم و از روش تاریخی،
12
00:00:21,199 –> 00:00:22,800
روش پارامتریک و
13
00:00:22,800 –> 00:00:24,000
روش مونت کارلو
14
00:00:24,000 –> 00:00:26,800
در دو سری بعدی استفاده خواهیم کرد، بنابراین
15
00:00:26,800 –> 00:00:29,679
بیایید امروز در مورد روش تاریخی صحبت کنیم،
16
00:00:29,679 –> 00:00:31,359
من چیزهایی را از
17
00:00:31,359 –> 00:00:33,600
مرز کارآمد به عاریت گرفته ام. قسمتها
18
00:00:33,600 –> 00:00:36,559
و من کد را در وبسایت خود ارسال میکنم،
19
00:00:36,559 –> 00:00:38,320
بنابراین راحت از آن استفاده کنید
20
00:00:38,320 –> 00:00:40,399
یا آن را در خودتان تایپ کنید، اما
21
00:00:40,399 –> 00:00:41,680
اساساً ماژولهایی را
22
00:00:41,680 –> 00:00:43,040
که امروز از
23
00:00:43,040 –> 00:00:46,879
پانداها استفاده میکنیم
24
00:00:46,879 –> 00:00:48,879
و از دستگاه خوان دادههای پاندا استفاده میکنیم تا بتوانیم
25
00:00:48,879 –> 00:00:50,960
آن را در اطلاعات موجودی
26
00:00:50,960 –> 00:00:54,160
از یاهو فاینانس، بنابراین
27
00:00:54,160 –> 00:00:56,879
اگر به خاطر دارید ما دادههای واردات را داشتیم، دادههایی را
28
00:00:56,879 –> 00:00:57,280
دریافت کردیم
29
00:00:57,280 –> 00:01:01,039
که فهرست موجودی سهام
30
00:01:01,039 –> 00:01:04,479
تاریخ شروع و تاریخ پایان را نیز
31
00:01:04,479 –> 00:01:05,600
داشتیم،
32
00:01:05,600 –> 00:01:07,680
بنابراین ما تمام قیمتهای بسته را در نظر میگیریم.
33
00:01:07,680 –> 00:01:09,360
بازده را به عنوان
34
00:01:09,360 –> 00:01:10,560
درصد تغییر
35
00:01:10,560 –> 00:01:12,560
در نظر می گیریم که همان چیزی است که امروز برای تحلیل خود به آن نیاز داریم.
36
00:01:12,560 –> 00:01:14,000
37
00:01:14,000 –> 00:01:15,600
38
00:01:15,600 –> 00:01:17,200
39
00:01:17,200 –> 00:01:19,600
40
00:01:19,600 –> 00:01:21,200
41
00:01:21,200 –> 00:01:24,159
ماژول
42
00:01:24,159 –> 00:01:27,200
که ما آرگومان های وزن
43
00:01:27,200 –> 00:01:31,119
های تخصیص پرتفوی خود را داریم،
44
00:01:31,119 –> 00:01:33,920
ماتریس کوواریانس ماتریس بازده را داریم و من در
45
00:01:33,920 –> 00:01:34,560
46
00:01:34,560 –> 00:01:37,600
واقع این پارامتر زمان را اضافه کرده ام زیرا
47
00:01:37,600 –> 00:01:39,680
دیگر نمی خواهیم عملکرد پرتفوی را
48
00:01:39,680 –> 00:01:40,799
49
00:01:40,799 –> 00:01:42,799
در یک دوره سالانه نگاه کنیم،
50
00:01:42,799 –> 00:01:45,360
می خواهیم تعریف کنیم که مرحله زمانی چیست. است
51
00:01:45,360 –> 00:01:46,880
و مرحله زمانی که
52
00:01:46,880 –> 00:01:49,920
ارزش خود را در معرض خطر ارزیابی می کنیم،
53
00:01:49,920 –> 00:01:51,920
بنابراین می توانید ببینید که من فقط
54
00:01:51,920 –> 00:01:53,600
55
00:01:53,600 –> 00:01:56,640
بازده روزانه میانگین وزنی بازده را در
56
00:01:56,640 –> 00:02:00,399
زمان و البته جذر دوم
57
00:02:00,399 –> 00:02:01,200
قانون زمان
58
00:02:01,200 –> 00:02:05,280
برای نوسانات و انحراف معیار ضرب کردم.
59
00:02:05,280 –> 00:02:07,200
بسیار عالی، بنابراین ما امروز لیست سهام خود را
60
00:02:07,200 –> 00:02:09,520
داریم cba bhp
61
00:02:09,520 –> 00:02:12,560
um telstra nab
62
00:02:12,560 –> 00:02:16,879
westpac و santos،
63
00:02:16,879 –> 00:02:19,360
همانطور که قبلاً تاریخ پایانی را تعریف
64
00:02:19,360 –> 00:02:20,879
کردیم که فقط می خواهیم بگوییم که اکنون
65
00:02:20,879 –> 00:02:23,599
یک تاریخ شروع داریم. h ما دوره تاریخی را
66
00:02:23,599 –> 00:02:24,959
67
00:02:24,959 –> 00:02:27,920
می خواهیم زیرا فقط 800 روز پیش گفتیم
68
00:02:27,920 –> 00:02:29,040
داده های
69
00:02:29,040 –> 00:02:31,599
زیادی به ما بدهید، بنابراین ماتریس بازده میانگین
70
00:02:31,599 –> 00:02:33,840
و کوواریانس را
71
00:02:33,840 –> 00:02:36,000
از داده های دریافتی با اطلاعات زیر محاسبه می کنیم
72
00:02:36,000 –> 00:02:37,440
73
00:02:37,440 –> 00:02:41,360
و سپس به سادگی در داده ها را حذف می کنم.
74
00:02:41,360 –> 00:02:44,879
تنظیم شده است
75
00:02:44,879 –> 00:02:47,040
و این اتفاق می افتد زیرا ما
76
00:02:47,040 –> 00:02:49,040
درصد تغییر بین
77
00:02:49,040 –> 00:02:49,680
روزها
78
00:02:49,680 –> 00:02:52,160
را ارزیابی می کنیم و ارزش یک روز اطلاعات را از دست می دهیم
79
00:02:52,160 –> 00:02:52,879
80
00:02:52,879 –> 00:02:54,959
و این درجاتی از آزادی است، بنابراین
81
00:02:54,959 –> 00:02:56,000
اولین کاری که می خواهیم انجام دهیم این
82
00:02:56,000 –> 00:02:58,000
است که می خواهیم بفهمیم
83
00:02:58,000 –> 00:02:59,680
تخصیص پورتفولیوی ما در
84
00:02:59,680 –> 00:03:01,920
حال حاضر چقدر است. بدانید که ما فقط
85
00:03:01,920 –> 00:03:05,200
وزنهای تصادفی را برای این پورتفولیو تنظیم میکنیم،
86
00:03:05,200 –> 00:03:08,720
بنابراین وزنها برابر با
87
00:03:08,720 –> 00:03:12,720
ما از توزیع تصادفی استفاده میکنیم
88
00:03:12,720 –> 00:03:15,519
که مقادیر را از 0
89
00:03:15,519 –> 00:03:16,080
به 1 برمیگرداند
90
00:03:16,080 –> 00:03:19,200
همانطور که در آن تابع میبینید و
91
00:03:19,200 –> 00:03:22,000
باید طول را تعریف کنیم. از این
92
00:03:22,000 –> 00:03:22,640
بردار
93
00:03:22,640 –> 00:03:24,560
و طول این بردار قرار است
94
00:03:24,560 –> 00:03:26,319
95
00:03:26,319 –> 00:03:29,120
از بازده ها
96
00:03:30,000 –> 00:03:32,560
به طور خاص تر از ستون های نقطه بازگشتی تعریف شود،
97
00:03:32,560 –> 00:03:33,680
98
00:03:33,680 –> 00:03:35,760
بنابراین
99
00:03:35,760 –> 00:03:37,920
تعداد سهامی را که در این
100
00:03:37,920 –> 00:03:40,480
لیست بازده داریم به ما باز می گرداند، بنابراین اگر ما سهام را به اینجا اضافه کنید
101
00:03:40,480 –> 00:03:42,640
این به طور خودکار به طول صحیح به روز می
102
00:03:42,640 –> 00:03:43,840
103
00:03:43,840 –> 00:03:46,239
شود اگر ما مقادیر تصادفی
104
00:03:46,239 –> 00:03:47,599
بین صفر و
105
00:03:47,599 –> 00:03:49,120
یک را برگردانیم، بدیهی است که می توانید حدس بزنید که
106
00:03:49,120 –> 00:03:50,959
تخصیص
107
00:03:50,959 –> 00:03:53,200
دقیقاً صد درصد نمی شود، بنابراین باید
108
00:03:53,200 –> 00:03:54,000
109
00:03:54,000 –> 00:03:57,840
با مجموع عادی سازی کنیم. از تمام این وزن ها،
110
00:03:57,840 –> 00:04:01,840
بنابراین مرحله بعدی فقط استفاده از وزن است
111
00:04:01,840 –> 00:04:03,519
و ما از
112
00:04:03,519 –> 00:04:05,120
عملگر تقسیم و برابر استفاده می کنیم،
113
00:04:05,120 –> 00:04:07,519
بنابراین هر عنصر در این آرایه
114
00:04:07,519 –> 00:04:08,640
بر مجموع مجموع تمام وزن
115
00:04:08,640 –> 00:04:12,319
های مربوطه تقسیم می شود،
116
00:04:12,319 –> 00:04:16,399
117
00:04:16,399 –> 00:04:18,639
بنابراین آن را عادی می کنیم تا همه
118
00:04:18,639 –> 00:04:20,959
وزنهای ما به یک اضافه میشوند،
119
00:04:20,959 –> 00:04:22,880
بنابراین کاری که من در اینجا انجام میدهم این است
120
00:04:22,880 –> 00:04:24,160
که
121
00:04:24,160 –> 00:04:27,759
قاب دادههای بازگشتی را چاپ کنم تا
122
00:04:27,759 –> 00:04:31,840
پایتون برگرداند یا نه،
123
00:04:31,840 –> 00:04:34,400
من این فایل را var نامیدهام و میخواهم
124
00:04:34,400 –> 00:04:35,919
این کار را انجام دهم تا ساختار واقعی را به شما نشان دهم.
125
00:04:35,919 –> 00:04:37,520
قاب داده پانداها،
126
00:04:37,520 –> 00:04:40,880
بنابراین ما تاریخها را در اینجا در فهرست خود
127
00:04:40,880 –> 00:04:44,240
در ستونهایمان داریم، همه سهام خود را
128
00:04:44,240 –> 00:04:46,000
داریم و البته
129
00:04:46,000 –> 00:04:47,919
درصد بازده روزانه مربوطه را در
130
00:04:47,919 –> 00:04:50,720
اینجا در هر ستون داریم، بنابراین آنچه میخواهیم
131
00:04:50,720 –> 00:04:51,759
انجام دهیم این است که اکنون
132
00:04:51,759 –> 00:04:54,840
از این وزن بردار و ac استفاده کنیم. به طور کلی
133
00:04:54,840 –> 00:04:56,720
134
00:04:56,720 –> 00:05:00,080
هر یک از این دارایی های مربوطه
135
00:05:00,080 –> 00:05:02,560
را در آن وزن مربوطه ضرب
136
00:05:02,560 –> 00:05:05,039
کنید تا نتیجه سبد را
137
00:05:05,039 –> 00:05:08,479
برای آن روز به صورت تاریخی بدست
138
00:05:08,479 –> 00:05:10,320
آوریم، بنابراین ما از اطلاعات تاریخی استفاده می کنیم تا
139
00:05:10,320 –> 00:05:12,560
140
00:05:12,560 –> 00:05:14,080
141
00:05:14,080 –> 00:05:17,360
بفهمیم که اگر این وزن های داده شده را برای آن
142
00:05:17,360 –> 00:05:20,400
داشتیم، سبد ما چه می شد. ما می خواهیم بگوییم بازده،
143
00:05:20,400 –> 00:05:22,840
ما یک ستون جدید به نام
144
00:05:22,840 –> 00:05:24,560
نمونه
145
00:05:24,560 –> 00:05:26,800
کارها می سازیم و آن را برابر
146
00:05:26,800 –> 00:05:29,120
با بازده
147
00:05:29,120 –> 00:05:31,759
می کنیم و حاصل ضرب نقطه ای را
148
00:05:31,759 –> 00:05:32,479
با
149
00:05:32,479 –> 00:05:35,039
وزن ها انجام می دهیم و این یک آرایه کم رنگ است که
150
00:05:35,039 –> 00:05:39,840
باید کار کند.
151
00:05:40,639 –> 00:05:44,479
بسیار عالی است، بنابراین بیایید بازده ها را اکنون
152
00:05:44,479 –> 00:05:47,199
در زیر دوره
153
00:05:48,080 –> 00:05:52,000
ذخیره چاپ کنیم و باید
154
00:05:52,000 –> 00:05:54,400
نمونه کارها را در سمت راست
155
00:05:54,400 –> 00:05:56,000
با بازده روزانه خود
156
00:05:56,000 –> 00:05:58,880
عالی داشته باشیم، بنابراین اکنون از داده های تاریخی
157
00:05:58,880 –> 00:06:00,800
برای تعریف یک
158
00:06:00,800 –> 00:06:03,120
نمونه کار با وزن های داده شده استفاده کرده ایم، بنابراین
159
00:06:03,120 –> 00:06:04,240
اکنون چه می کنیم. ما قصد
160
00:06:04,240 –> 00:06:06,000
داریم از این توزیع نظری پورتفولیو استفاده کنیم
161
00:06:06,000 –> 00:06:08,240
و این یک
162
00:06:08,240 –> 00:06:10,000
توزیع تاریخی با توجه به آن
163
00:06:10,000 –> 00:06:10,639
وزن ها است
164
00:06:10,639 –> 00:06:12,720
و ما می خواهیم ارزش خود را در
165
00:06:12,720 –> 00:06:14,160
معرض خطر و تابع ریسک ارزش شرطی خود ایجاد کنیم.
166
00:06:14,160 –> 00:06:15,120
167
00:06:15,120 –> 00:06:21,759
بنابراین بیایید این را به عنوان تاریخی تعریف کنیم
168
00:06:21,759 –> 00:06:27,199
و میخواهیم بازده
169
00:06:27,440 –> 00:06:30,800
را وارد کنیم و میخواهیم
170
00:06:30,800 –> 00:06:34,160
آلفا را وارد کنیم که سطح اطمینان ما است،
171
00:06:34,160 –> 00:06:36,160
اکنون اگر
172
00:06:36,160 –> 00:06:37,840
تعریف نشده باشد، آن را روی 5 تنظیم میکنیم، بنابراین
173
00:06:37,840 –> 00:06:41,840
فاصله اطمینان 5 درصدی،
174
00:06:41,840 –> 00:06:45,440
پس چه میخواهیم برای عملکرد خوب
175
00:06:45,440 –> 00:06:49,840
در این تابع،
176
00:06:50,000 –> 00:06:54,639
میخواهیم در یک چارچوب دادههای
177
00:06:54,639 –> 00:06:57,919
بازدهی
178
00:06:57,919 –> 00:07:01,280
پانداها یا مجموعهای
179
00:07:01,280 –> 00:07:05,599
از بازدههای پاندا بخوانیم که چه چیزی را میخواهیم خروجی
180
00:07:05,599 –> 00:07:07,680
بگیریم، فقط میخواهیم یک عدد خروجی بگیریم که
181
00:07:07,680 –> 00:07:10,720
صدکی است
182
00:07:10,720 –> 00:07:14,800
که میخواهیم صدک توزیع را در خروجی بگیریم.
183
00:07:15,680 –> 00:07:19,120
184
00:07:20,960 –> 00:07:24,479
با توجه به سطح اطمینان سطح آلفا و سطح
185
00:07:27,039 –> 00:07:31,120
186
00:07:31,120 –> 00:07:33,520
187
00:07:34,639 –> 00:07:37,120
عالی،
188
00:07:38,479 –> 00:07:42,720
بنابراین ما در اینجا دو سناریو داریم،
189
00:07:42,720 –> 00:07:44,800
یکی
190
00:07:44,800 –> 00:07:47,360
اینکه اطلاعاتی در مورد اینکه
191
00:07:47,360 –> 00:07:51,440
صدک برای هر یک از این دارایی ها به
192
00:07:51,440 –> 00:07:54,560
صورت جداگانه چقدر است مفید خواهد بود و سپس البته
193
00:07:54,560 –> 00:07:56,400
ما فقط به یک مورد علاقه مند هستیم.
194
00:07:56,400 –> 00:07:59,680
با برگرداندن یک مقدار که
195
00:07:59,680 –> 00:08:00,879
مقدار پورتفولیو است،
196
00:08:00,879 –> 00:08:03,039
بنابراین ما می خواهیم بررسی کنیم که آیا در
197
00:08:03,039 –> 00:08:03,919
واقع
198
00:08:03,919 –> 00:08:06,479
یک سری یا یک قاب داده را درگیر می کنیم اگر
199
00:08:06,479 –> 00:08:07,840
چارچوب داده را
200
00:08:07,840 –> 00:08:10,240
با تمام ستون ها دریافت کنیم، سپس می خواهیم
201
00:08:10,240 –> 00:08:10,960
مشخص کنیم
202
00:08:10,960 –> 00:08:14,879
صدک هر ستون چقدر است،
203
00:08:14,879 –> 00:08:16,720
اما اگر فقط یک سری باشد، ما فقط می خواهیم
204
00:08:16,720 –> 00:08:18,400
یک مقدار را برگردانیم،
205
00:08:18,400 –> 00:08:20,400
بنابراین از تابع پایتون استفاده می کنیم تا بفهمیم که
206
00:08:20,400 –> 00:08:22,160
207
00:08:22,160 –> 00:08:26,400
آیا این
208
00:08:26,400 –> 00:08:29,039
قاب داده را برمی گرداند یک قاب داده است
209
00:08:29,039 –> 00:08:30,720
یا یک سری منفرد.
210
00:08:30,720 –> 00:08:34,799
بنابراین بیایید از
211
00:08:34,799 –> 00:08:37,279
if is instance استفاده کنیم، اجازه دهید با این مورد شروع
212
00:08:37,279 –> 00:08:39,039
کنیم که قرار است یک سری پانداها باشد،
213
00:08:39,039 –> 00:08:41,760
بنابراین ما شیئی را
214
00:08:41,760 –> 00:08:43,360
خواهیم داشت که ما علاقه مند به بررسی
215
00:08:43,360 –> 00:08:45,440
آن هستیم که فریم داده بازگشتی است
216
00:08:45,440 –> 00:08:50,480
و آنچه می خواهیم بگوییم آیا این از نوع
217
00:08:50,640 –> 00:08:54,640
سری قاب داده pandas است حالا اگر
218
00:08:54,640 –> 00:08:56,399
یک سری باشد، کاری که میخواهیم انجام دهیم این است که میخواهیم
219
00:08:56,399 –> 00:08:57,920
220
00:08:57,920 –> 00:09:01,040
صدک را برگردانیم، بنابراین میخواهیم صدک برگرداندهای
221
00:09:01,040 –> 00:09:04,959
222
00:09:04,959 –> 00:09:08,000
223
00:09:08,000 –> 00:09:11,440
را برگردانیم و میخواهیم صدک را
224
00:09:11,440 –> 00:09:14,959
به آلفا برگردانیم، بنابراین اینطور خواهد شد.
225
00:09:14,959 –> 00:09:18,640
به طور خودکار صدک 5،
226
00:09:18,640 –> 00:09:21,120
بنابراین آنچه که ما می خواهیم در اینجا انجام دهیم این است که بررسی کنیم آیا
227
00:09:21,120 –> 00:09:21,760
228
00:09:21,760 –> 00:09:25,680
بازگردانده شده یک قاب داده واقعی پانداها است
229
00:09:25,680 –> 00:09:27,760
یا خیر، اگر می خواهیم از یک
230
00:09:27,760 –> 00:09:30,000
تابع خاص در پانداها به نام
231
00:09:30,000 –> 00:09:33,360
aggregate یا به اختصار ag
232
00:09:33,360 –> 00:09:36,240
استفاده کنیم، بنابراین با استفاده از این تابع من فقط آنچه را
233
00:09:36,240 –> 00:09:38,320
که قطعی یکی از آنها اینجاست،
234
00:09:38,320 –> 00:09:40,480
بنابراین اساساً کاری که میتوانیم انجام دهیم این است که بتوانیم
235
00:09:40,480 –> 00:09:43,519
یک تابع تعریفشده توسط کاربر
236
00:09:43,519 –> 00:09:46,640
از یک سری را برای ارزیابی ارسال کنیم و کاری
237
00:09:46,640 –> 00:09:47,440
که قرار است انجام دهد
238
00:09:47,440 –> 00:09:50,080
ارزیابی عملکرد برای هر
239
00:09:50,080 –> 00:09:50,640
ستون
240
00:09:50,640 –> 00:09:52,959
از آن فریم داده است، بنابراین
241
00:09:52,959 –> 00:09:54,800
هر سری را بهصورت جداگانه ارسال میکند.
242
00:09:54,800 –> 00:09:58,399
پس بیایید برویم elsif
243
00:09:58,399 –> 00:10:02,839
است که نمونه
244
00:10:02,839 –> 00:10:06,399
قاب داده PD را برمی گرداند
245
00:10:06,399 –> 00:10:09,920
و کاری که می خواهیم انجام دهیم این است که
246
00:10:09,920 –> 00:10:13,839
تجمع نقطه را برمی گرداند
247
00:10:15,680 –> 00:10:18,560
و کاری که می خواهیم انجام دهیم این است که در واقع
248
00:10:18,560 –> 00:10:20,800
تابع
249
00:10:20,800 –> 00:10:23,839
history var را به خوبی پاس کنیم
250
00:10:23,839 –> 00:10:26,000
و با شرایط واقعی که
251
00:10:26,000 –> 00:10:27,279
می خواهیم برای آن
252
00:10:27,279 –> 00:10:33,839
استفاده کنیم آلفا
253
00:10:39,200 –> 00:10:41,760
عالی است، بنابراین برای هر یک از این
254
00:10:41,760 –> 00:10:42,880
عناوین ستون
255
00:10:42,880 –> 00:10:46,240
، متغیر تاریخی را برمی گرداند،
256
00:10:46,240 –> 00:10:48,959
بنابراین هر بار که این را می زند،
257
00:10:48,959 –> 00:10:50,320
اگر یک قاب داده آلت تناسلی
258
00:10:50,320 –> 00:10:51,760
باشد، فقط
259
00:10:51,760 –> 00:10:53,920
مقدار صدک را برمی گردانیم،
260
00:10:53,920 –