در این مطلب، ویدئو با استفاده از الگوریتم یادگیری ماشین Python & K-Means یک مجموعه سهام متنوع بسازید با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:20:28
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:01,599 –> 00:00:03,600
سلام به همه و به این ویدیو
2
00:00:03,600 –> 00:00:04,960
در مورد زبان برنامه نویسی پایتون و
3
00:00:04,960 –> 00:00:06,080
یادگیری ماشین خوش آمدید،
4
00:00:06,080 –> 00:00:07,839
بنابراین در این ویدیو سعی می کنم
5
00:00:07,839 –> 00:00:09,519
6
00:00:09,519 –> 00:00:12,000
با استفاده از خوشه بندی k-means یک سبد سهام متنوع بسازم اکنون
7
00:00:12,000 –> 00:00:14,160
تنوع سهام یک استراتژی مدیریتی است
8
00:00:14,160 –> 00:00:15,679
که سهام های مختلف را در یک سبد سهام قرار می دهد.
9
00:00:15,679 –> 00:00:17,920
10
00:00:17,920 –> 00:00:19,760
تنوع سهام به این معناست که
11
00:00:19,760 –> 00:00:21,520
انواع مختلف سهام بازدهی بالاتری را به همراه خواهد داشت
12
00:00:21,520 –> 00:00:22,240
13
00:00:22,240 –> 00:00:24,320
و نشان می دهد که سرمایه گذاران با ریسک های کمتری مواجه خواهند شد،
14
00:00:24,320 –> 00:00:25,439
15
00:00:25,439 –> 00:00:29,199
بنابراین تنوع سهام یک گام کلیدی
16
00:00:29,199 –> 00:00:32,640
برای ایجاد پرتفوی است اکنون
17
00:00:32,640 –> 00:00:34,559
به عنوان یک سرمایه گذار شما می توانید دارایی ها را
18
00:00:34,559 –> 00:00:36,239
از بخش های مختلف انتخاب کنید، اما ما
19
00:00:36,239 –> 00:00:38,879
تلاش خواهیم کرد تا آن را اعمال کنیم. یک راه حل مبتنی بر داده بیشتر
20
00:00:38,879 –> 00:00:39,920
21
00:00:39,920 –> 00:00:42,079
با استفاده از یک الگوریتم خوشه بندی به نام الگوریتم خوشه بندی
22
00:00:42,079 –> 00:00:44,160
k-means
23
00:00:44,160 –> 00:00:47,440
برای شناسایی خوشه های مختلف سهام، بنابراین
24
00:00:47,440 –> 00:00:49,280
قبل از شروع، اگر
25
00:00:49,280 –> 00:00:50,879
ویدیوهای این کانال را دوست دارید، حتماً روی
26
00:00:50,879 –> 00:00:52,879
دکمه اشتراک و لایک کلیک کنید
27
00:00:52,879 –> 00:00:54,480
و در مورد آن مطلع شوید. ویدیوهای جدید
28
00:00:54,480 –> 00:00:56,879
این کانال به آن اعلان زنگ زده می شود
29
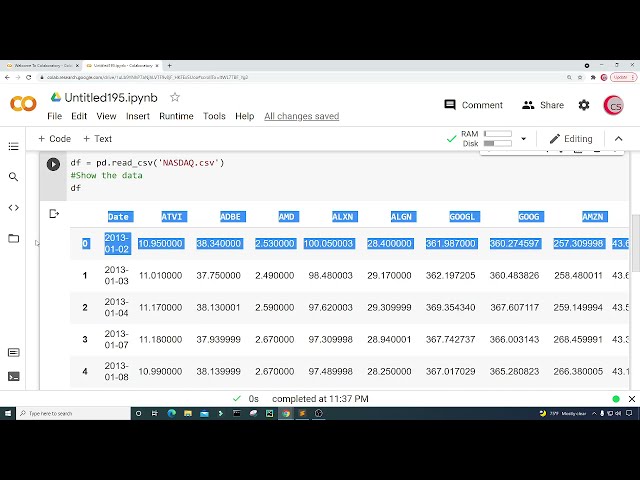
00:00:56,879 –> 00:00:59,199
و مطالب این ویدیو کاملاً است
30
00:00:59,199 –> 00:01:01,199
آموزشی است و نباید به عنوان
31
00:01:01,199 –> 00:01:02,960
مشاوره سرمایه گذاری حرفه ای تلقی شود
32
00:01:02,960 –> 00:01:06,799
زیرا من یک مشاور مالی نیستم، بنابراین
33
00:01:06,799 –> 00:01:09,600
لطفاً قبل از انجام هر نوع سرمایه گذاری مطمئن شوید که تحقیقات خود را انجام دهید
34
00:01:09,600 –> 00:01:10,240
35
00:01:10,240 –> 00:01:14,320
36
00:01:14,320 –> 00:01:16,159
بنابراین من در حال حاضر در
37
00:01:16,159 –> 00:01:17,560
وب سایت Google به نام
38
00:01:17,560 –> 00:01:18,720
codelab.research.google.com هستم.
39
00:01:18,720 –> 00:01:20,720
و من در آن هستم زیرا
40
00:01:20,720 –> 00:01:23,040
شروع برنامه نویسی در پایتون را بسیار آسان می کند،
41
00:01:23,040 –> 00:01:24,560
بنابراین تنها کاری که باید انجام دهید این است که به این
42
00:01:24,560 –> 00:01:26,080
وب سایت بروید و سپس با استفاده از
43
00:01:26,080 –> 00:01:27,360
حساب Google خود وارد شوید و نوشتن
44
00:01:27,360 –> 00:01:28,799
کد پایتون خود را شروع کنید،
45
00:01:28,799 –> 00:01:30,320
بنابراین اجازه دهید نوشتن این کد را شروع کنیم.
46
00:01:30,320 –> 00:01:32,079
با کلیک بر روی فایل و سپس کلیک بر روی یک
47
00:01:32,079 –> 00:01:33,280
نوت بوک جدید
48
00:01:33,280 –> 00:01:35,200
و یک برگه جدید برای شما باز می شود و
49
00:01:35,200 –> 00:01:36,880
در نهایت یک سلول جدید
50
00:01:36,880 –> 00:01:38,720
و در سلولی که می خواهم در برخی از
51
00:01:38,720 –> 00:01:40,079
نظرات قرار دهم،
52
00:01:40,079 –> 00:01:41,759
توضیحاتی در مورد برنامه
53
00:01:41,759 –> 00:01:43,600
قرار می دهم. من فقط می خواهم در اینجا
54
00:01:43,600 –> 00:01:44,880
55
00:01:44,880 –> 00:01:48,640
خوشه بندی بازار سهام را با k-means
56
00:01:48,640 –> 00:01:51,600
با استفاده از پایتون تایپ کنم، خوب بعد،
57
00:01:51,600 –> 00:01:53,119
با کلیک کردن روی
58
00:01:53,119 –> 00:01:54,560
دکمه کد در بالا سمت چپ، یک سلول جدید ایجاد
59
00:01:54,560 –> 00:01:57,439
می کنم و در اینجا می خواهم کتابخانه های پایتون را وارد
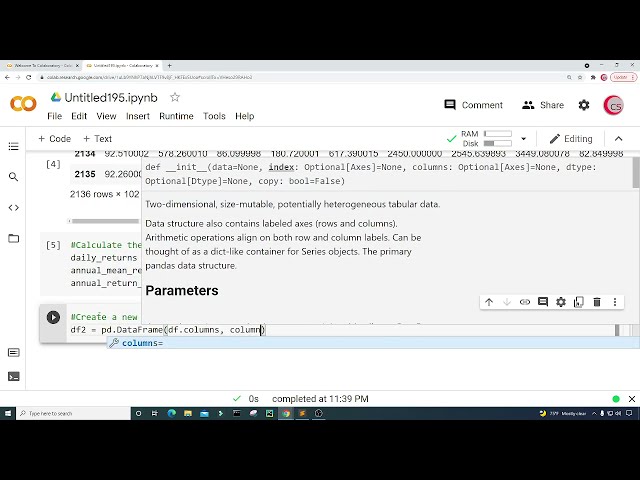
60
00:01:57,439 –> 00:01:58,240
61
00:01:58,240 –> 00:02:01,920
کنم. میخواهم وارد کنم به
62
00:02:01,920 –> 00:02:05,680
عنوان pd من numpy را به عنوان np وارد می کنم
63
00:02:05,680 –> 00:02:08,959
و سپس از sklearn
64
00:02:08,959 –> 00:02:12,000
dot cluster وارد می کنم
65
00:02:12,000 –> 00:02:16,879
k به معنای خوب است و من می خواهم
66
00:02:16,879 –> 00:02:21,200
matplot live dot pi نمودار را
67
00:02:21,200 –> 00:02:23,760
به صورت plt وارد کنم و سپس می دهم
68
00:02:23,760 –> 00:02:26,040
یک استایل را رسم کنید، بنابراین من plt.style.use را تایپ می
69
00:02:26,040 –> 00:02:27,440
کنم
70
00:02:27,440 –> 00:02:31,440
و در حال حاضر از سبک 538 استفاده
71
00:02:31,440 –> 00:02:34,959
می کنم،
72
00:02:34,959 –> 00:02:36,160
این سلول را با کلیک کردن روی این دکمه در اینجا
73
00:02:36,160 –> 00:02:37,360
به سمت چپ اجرا می کنم
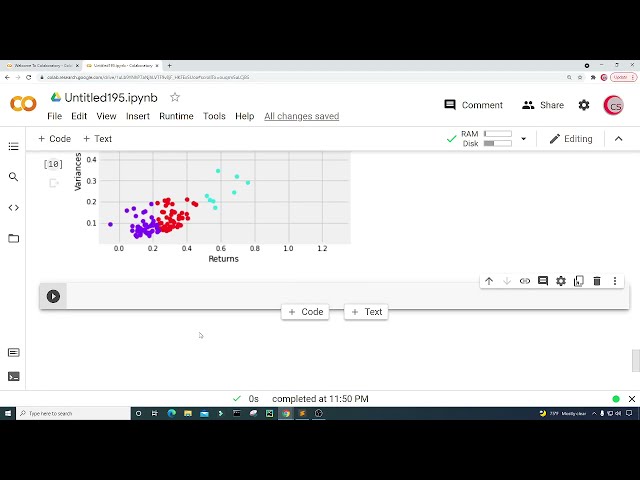
74
00:02:37,360 –> 00:02:41,519
تا بررسی کنم که آیا من هر گونه
75
00:02:41,599 –> 00:02:43,200
خطا درستی انجام دادم، بنابراین اجازه ندادم ادامه دهیم و
76
00:02:43,200 –> 00:02:45,760
یک سلول جدید ایجاد کنیم و اکنون میخواهم
77
00:02:45,760 –> 00:02:50,000
دادهها را بارگیری کنم، بنابراین از
78
00:02:50,000 –> 00:02:52,879
google.colab میخواهم فایلها را وارد کنم و
79
00:02:52,879 –> 00:02:55,599
تایپ کنم files.upload برای آپلود
80
00:02:55,599 –> 00:02:58,800
فایل پس بیایید روی انتخاب
81
00:02:58,800 –> 00:03:01,159
فایل ها کلیک کنیم و من این فایل nasdaq.csv را آپلود می
82
00:03:01,159 –> 00:03:04,319
کنم، بنابراین
83
00:03:04,319 –> 00:03:08,239
این فایل حاوی اطلاعاتی در مورد
84
00:03:08,239 –> 00:03:12,400
قیمت های بسته شدن سهام در nasdaq است
85
00:03:12,400 –> 00:03:13,680
و ما به این
86
00:03:13,680 –> 00:03:17,040
زمان کمی بیشتر می دهیم تا آپلود به پایان برسد.
87
00:03:17,040 –> 00:03:18,959
بنابراین به نظر می رسد که کار تقریباً انجام
88
00:03:18,959 –> 00:03:20,800
شده است و انجام شده است، بنابراین اجازه دهید یک سلول جدید ایجاد کنیم
89
00:03:20,800 –> 00:03:22,319
90
00:03:22,319 –> 00:03:25,040
و اجازه دهید نگاهی به داده ها بیندازیم، بنابراین
91
00:03:25,040 –> 00:03:26,400
ابتدا می خواهم در داده ها را بخوانم a بنابراین
92
00:03:26,400 –> 00:03:27,599
من یک متغیر به نام df
93
00:03:27,599 –> 00:03:28,959
ایجاد می کنم و آن را برابر
94
00:03:28,959 –> 00:03:31,760
با pd.read underscore csv می کنم و
95
00:03:31,760 –> 00:03:32,799
نام آن
96
00:03:32,799 –> 00:03:37,120
فایل را که nasdaq.csv است وارد می
97
00:03:37,120 –> 00:03:40,480
کنم و سپس داده ها را نشان می دهم.
98
00:03:40,560 –> 00:03:43,680
من فقط میخواهم df را اینجا تایپ کنم
99
00:03:43,680 –> 00:03:47,360
و اجازه دهید این را اجرا کنیم، بنابراین اکنون
100
00:03:47,360 –> 00:03:48,640
میتوانیم این مجموعه داده
101
00:03:48,640 –> 00:03:51,760
را ببینیم و نمادهای سهام خود
102
00:03:51,760 –> 00:03:54,319
را در بالا ببینیم، بنابراین میتوانیم مانند گوگل
103
00:03:54,319 –> 00:03:56,319
ببینیم،
104
00:03:56,319 –> 00:04:00,080
میتوانیم آمازون را ببینیم، اپل را میبینیم و
105
00:04:00,080 –> 00:04:02,400
فکر میکنم شما مهربان هستید ایده اینجا را به درستی دریافت کنید،
106
00:04:02,400 –> 00:04:03,760
بنابراین ما همه این
107
00:04:03,760 –> 00:04:04,720
شرکت ها را می بینیم
108
00:04:04,720 –> 00:04:07,200
و دوباره این قیمت ها در اینجا یا
109
00:04:07,200 –> 00:04:09,439
قیمت های هر یک از این ردیف
110
00:04:09,439 –> 00:04:12,319
ها قیمت های نزدیک برای هر یک از این
111
00:04:12,319 –> 00:04:14,000
نمادهای سهام هستند،
112
00:04:14,000 –> 00:04:15,760
بنابراین بیایید به اینجا
113
00:04:15,760 –> 00:04:17,759
برگردیم و نگاهی به آن بیندازیم. این ستون تاریخ را
114
00:04:17,759 –> 00:04:21,519
می بینیم که از
115
00:04:21,519 –> 00:04:25,280
یک تا 2013 تا
116
00:04:25,280 –> 00:04:30,400
625 2021 داده داریم و این به ما 2136 ردیف
117
00:04:30,400 –> 00:04:31,280
داده
118
00:04:31,280 –> 00:04:33,840
و 103 ستون می دهد، اما ما
119
00:04:33,840 –> 00:04:35,840
این 102 ستون را می سازیم زیرا می خواهیم
120
00:04:35,840 –> 00:04:36,880
خلاص شویم. از آن
121
00:04:36,880 –> 00:04:38,240
ستون تاریخ، پس بیایید جلو برویم و این کار را اکنون انجام دهیم،
122
00:04:38,240 –> 00:04:41,600
بنابراین من قصد دارم آن را
123
00:04:41,600 –> 00:04:44,800
حذف کنم، آن را با یک بزرگ r حذف
124
00:04:44,800 –> 00:04:46,000
t
125
00:04:46,000 –> 00:04:48,800
برای انجام این کار، من فقط می خواهم
126
00:04:48,800 –> 00:04:51,600
df.drop را تایپ کنم و سپس
127
00:04:51,600 –> 00:04:53,440
نام ستونی را که می
128
00:04:53,440 –> 00:04:56,240
خواهم رها کنم که تاریخ نام دارد وارد
129
00:04:56,240 –> 00:04:58,960
می کنم و می خواهم در دسترسی برابر
130
00:04:58,960 –> 00:05:01,520
با یک باشد تا این ستون باشد.
131
00:05:01,520 –> 00:05:04,639
و سپس میخواهم این را از
132
00:05:04,639 –> 00:05:05,840
داخل مجموعه دادهها حذف
133
00:05:05,840 –> 00:05:08,800
کنم، بنابراین من فقط میخواهم آن را برابر true قرار دهم
134
00:05:08,800 –> 00:05:09,520
135
00:05:09,520 –> 00:05:13,120
و حالا اگر دوباره این را اجرا کنم،
136
00:05:13,120 –> 00:05:14,720
میبینیم که ستون تاریخ حذف شده است
137
00:05:14,720 –> 00:05:16,639
و اکنون
138
00:05:16,639 –> 00:05:20,080
102 ستون در آن داریم. این مجموعه داده بسیار خوب است،
139
00:05:20,080 –> 00:05:22,960
بنابراین بیایید یک سلول جدید ایجاد کنیم و اکنون
140
00:05:22,960 –> 00:05:24,160
میخواهم
141
00:05:24,160 –> 00:05:27,440
142
00:05:27,440 –> 00:05:31,600
میانگین سالانه بازده و واریانس را محاسبه کنم،
143
00:05:31,600 –> 00:05:32,720
بنابراین یک متغیر خلاق
144
00:05:32,720 –> 00:05:34,720
به نام بازده روزانه زیر خط و من
145
00:05:34,720 –> 00:05:35,440
میخواهم آن را
146
00:05:35,440 –> 00:05:38,560
برابر با تغییر خط زیر خط df dot pct تنظیم
147
00:05:38,560 –> 00:05:41,520
148
00:05:41,919 –> 00:05:43,039
کنم و سپس می خواهم متغیری
149
00:05:43,039 –> 00:05:45,280
به نام
150
00:05:45,280 –> 00:05:48,000
بازده میانگین زیرخط سالانه ایجاد کنم، من
151
00:05:48,000 –> 00:05:49,600
این را برابر با
152
00:05:49,600 –> 00:05:54,240
بازده زیرخط روزانه تنظیم
153
00:05:54,320 –> 00:05:56,160
154
00:05:56,160 –> 00:05:57,840
155
00:05:57,840 –> 00:06:01,440
می کنم. می خواهید در 253 ضرب کنید
156
00:06:01,440 –> 00:06:03,039
157
00:06:03,039 –> 00:06:06,720
بنابراین حدود 252 یا 253 می شود روزهای داد و ستد
158
00:06:06,720 –> 00:06:07,840
159
00:06:07,840 –> 00:06:11,199
در سال بسیار خوب و
160
00:06:11,199 –> 00:06:12,880
بعد بیایید جلو برویم و واریانس بازده سالانه را بدست آوریم،
161
00:06:12,880 –> 00:06:14,080
بنابراین
162
00:06:14,080 –> 00:06:16,000
متغیری به نام
163
00:06:16,000 –> 00:06:19,680
164
00:06:19,680 –> 00:06:21,919
واریانس
165
00:06:21,919 –> 00:06:22,720
166
00:06:22,720 –> 00:06:26,560
زیرخط بازده سالانه
167
00:06:26,560 –> 00:06:29,440
ایجاد می کنیم. برای ضرب کردن این در 252
168
00:06:29,440 –> 00:06:30,400
نیز،
169
00:06:30,400 –> 00:06:33,039
پس بیایید ادامه دهیم و این سلول را اجرا کنیم و
170
00:06:33,039 –> 00:06:35,280
بیایید یک سلول جدید ایجاد کنیم، بسیار
171
00:06:35,280 –> 00:06:38,560
خوب، بنابراین اکنون میخواهم یک
172
00:06:38,560 –> 00:06:41,199
قاب داده پاندا جدید با ستونی به نام
173
00:06:41,199 –> 00:06:42,400
نماد سهام ایجاد کنم،
174
00:06:42,400 –> 00:06:46,160
بنابراین اجازه دهید اینجا یک قاب داده جدید ایجاد کنیم.
175
00:06:46,160 –> 00:06:49,280
بسیار خوب، بنابراین من
176
00:06:49,280 –> 00:06:52,720
این df2 را صدا می زنم و آن را برابر با قاب داده dt dot قرار می دهم
177
00:06:52,720 –> 00:06:56,080
178
00:06:56,080 –> 00:06:59,440
179
00:06:59,440 –> 00:07:01,360
و نام ستون ها را از
180
00:07:01,360 –> 00:07:04,000
مجموعه داده وارد می کنیم تا این داده ها باشد
181
00:07:04,000 –> 00:07:08,319
و من می خواهم ستونی به نام
182
00:07:08,400 –> 00:07:12,000
نماد زیرخط سهام ایجاد کنید
183
00:07:12,000 –> 00:07:13,440
یا شاید من آن را اینجا قرار دهم
184
00:07:13,440 –> 00:07:15,120
نمادهای زیرخط سهام
185
00:07:15,120 –> 00:07:17,599
خوب است و سپس می خواهم دو ستون دیگر اضافه کنم
186
00:07:17,599 –> 00:07:19,120
بنابراین
187
00:07:19,120 –> 00:07:22,479
فقط df2 را تایپ کنید و ستون اول
188
00:07:22,479 –> 00:07:25,039
حاوی واریانس ها باشد، بنابراین من می خواهم
189
00:07:25,039 –> 00:07:26,639
تماس بگیرم. این ستون واریانس می شود و ما
190
00:07:26,639 –> 00:07:27,919
آن را برابر t قرار می دهیم o
191
00:07:27,919 –> 00:07:31,120
مقادیر نقطه واریانس زیرخط برگردان سالانه زیرخط
192
00:07:31,120 –> 00:07:32,240
193
00:07:32,240 –> 00:07:35,599
و سپس من
194
00:07:35,599 –> 00:07:39,120
ستون دیگری به نام df2 ایجاد
195
00:07:39,199 –> 00:07:42,840
میکنم و آن را میگوییم این ستون
196
00:07:42,840 –> 00:07:46,000
کاملاً درست برمیگردد، بنابراین ما بازده ستون خود
197
00:07:46,000 –> 00:07:48,479
را داریم و
198
00:07:48,479 –> 00:07:51,919
شامل میانگین سالانه بازدهی است
199
00:07:51,919 –> 00:07:55,599
که مقادیر ok است. سپس میخواهم دادهها را نشان
200
00:07:55,599 –> 00:07:56,800
201
00:07:56,800 –> 00:07:58,720
دهم، بنابراین فقط میخواهم df2 را در اینجا تایپ کنم و
202
00:07:58,720 –> 00:08:00,479
بیایید نگاهی
203
00:08:00,479 –> 00:08:03,599
به مجموعه دادههای تازه
204
00:08:03,599 –> 00:08:06,639
تشکیلشده بیندازیم تا بتوانیم نمادهای سهام در
205
00:08:06,639 –> 00:08:07,840
این ستون را در
206
00:08:07,840 –> 00:08:10,240
اینجا ببینیم و واریانسهای هر یک از آن سهام را ببینیم.
207
00:08:10,240 –> 00:08:11,599
اینجا
208
00:08:11,599 –> 00:08:13,039
و سپس بازده هر یک از آن
209
00:08:13,039 –> 00:08:16,240
سهام در اینجا در این ستون
210
00:08:16,240 –> 00:08:18,639
کاملاً خوب است، بنابراین واقعاً خوب به نظر می رسد، بیایید ادامه دهیم
211
00:08:18,639 –> 00:08:20,160
و یک
212
00:08:20,160 –> 00:08:24,080
سلول جدید درست کنیم، بنابراین اکنون در این سلول
213
00:08:24,080 –> 00:08:27,039
قصد دارم از روش elbow برای
214
00:08:27,039 –> 00:08:28,960
تعیین تعداد خوشه ها استفاده کنم.
215
00:08:28,960 –> 00:08:31,039
برای گروه بندی سهام استفاده کنید، بنابراین اجازه دهید من فقط
216
00:08:31,039 –> 00:08:32,559
این را در نظرات اینجا قرار
217
00:08:32,559 –> 00:08:36,080
دهم، من قصد دارم
218
00:08:36,080 –> 00:08:40,799
برای تعیین
219
00:08:40,799 –> 00:08:46,480
تعداد خوشه های مورد استفاده برای گروه بندی
220
00:08:46,480 –> 00:08:49,519
سهام استفاده کنم،
221
00:08:49,839 –> 00:08:53,120
بنابراین در تجزیه و تحلیل خوشه ای
222
00:08:53,120 –> 00:08:54,480
روش زانویی یک روش اکتشافی است
223
00:08:54,480 –> 00:08:55,839
که در د خاتمه دادن به تعداد
224
00:08:55,839 –> 00:08:57,680
خوشه ها در یک مجموعه داده
225
00:08:57,680 –> 00:09:00,080
و این مطابق ویکی پدیا است همچنین
226
00:09:00,080 –> 00:09:02,640
طبق ویکی پدیا ایده
227
00:09:02,640 –> 00:09:05,600
آرنج یا زانو یک منحنی این است که یک
228
00:09:05,600 –> 00:09:06,480
نقطه برش
229
00:09:06,480 –> 00:09:08,640
برای تعیین تعداد خوشه ها
230
00:09:08,640 –> 00:09:10,000
برای استفاده
231
00:09:10,000 –> 00:09:12,320
در اصطلاح ریاضی باشد.
232
00:09:12,320 –> 00:09:14,399
در جایی که بازده کاهشی دیگر
233
00:09:14,399 –> 00:09:16,240
ارزش هزینه اضافی را ندارد
234
00:09:16,240 –> 00:09:18,800
و در خوشه بندی این بدان معناست که باید
235
00:09:18,800 –> 00:09:20,959
تعدادی خوشه را انتخاب کرد به طوری که
236
00:09:20,959 –> 00:09:23,680
اضافه کردن یک خوشه دیگر مدلسازی خیلی
237
00:09:23,680 –> 00:09:24,480
بهتری
238
00:09:24,480 –> 00:09:27,519
از داده ها را ارائه
239
00:09:27,519 –> 00:09:30,640
نکند، بنابراین بیایید
240
00:09:30,640 –> 00:09:33,680
ابتدا
241
00:09:33,680 –> 00:09:36,880
اجازه دهید تا سالانه را بگیریم و
242
00:09:36,880 –> 00:09:40,320
ذخیره کنیم.
243
00:09:40,320 –> 00:09:45,040
بازده و واریانس های سالانه
244
00:09:45,040 –> 00:09:45,839
بسیار خوب است، بنابراین من می خواهم
245
00:09:45,839 –> 00:09:47,279
متغیری به نام x ایجاد کنم و اجازه دهید آن را
246
00:09:47,279 –> 00:09:48,720
برابر با df
247
00:09:48,720 –> 00:09:51,839
2 قرار دهیم و