در این مطلب، ویدئو تشخیص و حذف نقاط پرت با استفاده از صدک | آموزش مهندسی ویژگی python # 2 با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:17:18
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,820
نقاط پرت داده های غیرعادی هستند که
2
00:00:02,820 –> 00:00:04,799
بسیار متفاوت از بقیه
3
00:00:04,799 –> 00:00:06,750
مشاهدات شما هستند، برای مثال شما در حال
4
00:00:06,750 –> 00:00:09,210
تجزیه و تحلیل مجموعه داده ای هستید که
5
00:00:09,210 –> 00:00:12,570
سن افراد در آن وجود دارد، اکنون ممکن است تا نود
6
00:00:12,570 –> 00:00:15,210
یا صد سال سن را مشاهده کنید، اما اگر
7
00:00:15,210 –> 00:00:17,970
نقطه داده ای را ببینید که دارای هزاران است. سالها پس
8
00:00:17,970 –> 00:00:20,250
این یک نقطه پرت است که به وضوح نشان میدهد
9
00:00:20,250 –> 00:00:23,039
که خطا در جمعآوری دادهها
10
00:00:23,039 –> 00:00:26,609
11
00:00:26,609 –> 00:00:28,769
وجود دارد، گاهی اوقات پرت میتواند اتفاق بیفتد فقط به این دلیل که ماهیت تغییر
12
00:00:28,769 –> 00:00:31,019
در مجموعه دادههای شما وجود دارد، به عنوان مثال،
13
00:00:31,019 –> 00:00:33,809
نقطه دادهای را با سن 120 سال میبینید که
14
00:00:33,809 –> 00:00:36,239
نمیتواند یک خطا باشد، شاید این یک خطا باشد.
15
00:00:36,239 –> 00:00:40,050
نقطه داده معتبر قانونی است، اما از آنجایی
16
00:00:40,050 –> 00:00:41,910
که با بقیه نقاط داده بسیار متفاوت است
17
00:00:41,910 –> 00:00:44,760
، می تواند
18
00:00:44,760 –> 00:00:48,360
قدرت آماری فرآیند تجزیه و تحلیل داده ها را منحرف کند، به
19
00:00:48,360 –> 00:00:51,449
همین دلیل اغلب، اگر نه همیشه،
20
00:00:51,449 –> 00:00:54,570
منطقی است که نقاط پرت را شناسایی
21
00:00:54,570 –> 00:00:57,629
کنید و حذف کنید که اکنون تعداد زیادی وجود دارد.
22
00:00:57,629 –> 00:01:00,000
روش های مختلف تشخیص و حذف نقاط پرت
23
00:01:00,000 –> 00:01:02,910
و تکنیک های آماری
24
00:01:02,910 –> 00:01:06,390
مانند صدک انحراف معیار z-score وجود دارد
25
00:01:06,390 –> 00:01:08,869
که می توانید از تجسم
26
00:01:08,869 –> 00:01:11,850
با استفاده از نمودار جعبه ای اسکا نیز استفاده کنید. طرح دوم برای تشخیص
27
00:01:11,850 –> 00:01:14,070
نقاط پرت در این آموزش خاص،
28
00:01:14,070 –> 00:01:16,770
ما قصد داریم به روش صدک
29
00:01:16,770 –> 00:01:18,990
تشخیص و حذف نقاط پرت نگاه
30
00:01:18,990 –> 00:01:21,570
کنیم، ابتدا کد ساده پایتون را روی یک
31
00:01:21,570 –> 00:01:23,850
مجموعه داده ساده می نویسیم سپس
32
00:01:23,850 –> 00:01:26,040
به مجموعه داده های پیچیده نگاه می
33
00:01:26,040 –> 00:01:27,750
کنیم و ما با استفاده از صدک، نقاط پرت را از آن حذف
34
00:01:27,750 –> 00:01:30,930
خواهم کرد و در پایان
35
00:01:30,930 –> 00:01:33,180
تمرین جالبی برای شما خواهیم داشت تا روی
36
00:01:33,180 –> 00:01:35,729
این آموزش کار کنید، ببینید بسیار عالی
37
00:01:35,729 –> 00:01:38,400
خواهد بود زیرا
38
00:01:38,400 –> 00:01:41,220
برای هر یک از تکنیک های تشخیص نقاط پرت ویدیوهای مختلفی تولید خواهم کرد.
39
00:01:41,220 –> 00:01:44,909
اجازه دهید شروع کنیم، اجازه دهید ابتدا
40
00:01:44,909 –> 00:01:47,579
بفهمیم اگر صدک
41
00:01:47,579 –> 00:01:49,380
می دانید دقیقاً صدک چیست، پس می توانید از
42
00:01:49,380 –> 00:01:51,600
این بخش رد شوید. من جدول زمانی این
43
00:01:51,600 –> 00:01:54,149
ویدیو را در توضیحات ویدیو دارم تا
44
00:01:54,149 –> 00:01:56,329
بتوانید به راحتی به بخش بعدی بروید،
45
00:01:56,329 –> 00:01:59,729
اما ممکن است متوجه شده باشید که در برخی
46
00:01:59,729 –> 00:02:02,189
از تکنیک های امتیاز طعم آنها استفاده می کنند.
47
00:02:02,189 –> 00:02:04,829
امتیازات نسبی آن در اینجا در این
48
00:02:04,829 –> 00:02:07,469
فایل اکسل من
49
00:02:07,469 –> 00:02:09,899
از صد نفر در حال حاضر امتیاز افراد مختلف را اضافه کرده ام اگر از
50
00:02:09,899 –> 00:02:12,540
فرد معمولی خود برای امتیاز دادن استفاده کنید، این
51
00:02:12,540 –> 00:02:13,920
یک نفر برای اسکو خواهد بود. چون
52
00:02:13,920 –> 00:02:17,610
اینها اعدادی هستند که از 100 خارج می شوند،
53
00:02:17,610 –> 00:02:19,980
بنابراین درصد همان است، اما
54
00:02:19,980 –> 00:02:22,739
گاهی اوقات افراد از یک تکنیک نمره دهی نسبی
55
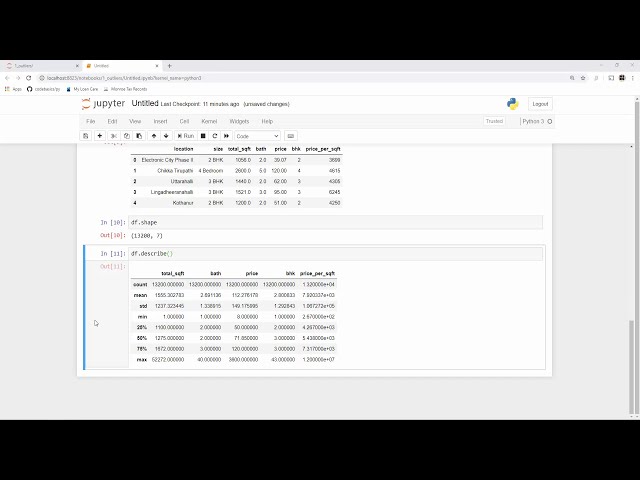
00:02:22,739 –> 00:02:26,310
استفاده می کنند که در آن 69 بالاترین امتیاز است،
56
00:02:26,310 –> 00:02:28,500
بنابراین می گویند اوه این شخص
57
00:02:28,500 –> 00:02:34,680
100٪ خوب است و 27 کمترین
58
00:02:34,680 –> 00:02:37,230
امتیاز است بنابراین ما می گوییم که این شخص
59
00:02:37,230 –> 00:02:39,450
به صفر رسیده است بنابراین اساساً او در
60
00:02:39,450 –> 00:02:42,920
پایین است و این مرد در بالا است
61
00:02:42,920 –> 00:02:45,989
اکنون تعریف صدک این است که به هر حال این
62
00:02:45,989 –> 00:02:48,120
یک رتبه صدک است بنابراین در اینجا
63
00:02:48,120 –> 00:02:53,670
50 آن 50 درصد است که به این معنی است که 50 درصد از
64
00:02:53,670 –> 00:02:57,540
نمونه ها زیر مقدار 56 هستند، بنابراین بیایید
65
00:02:57,540 –> 00:03:02,459
آن را بشماریم، بنابراین 4 نمونه 1 2 3
66
00:03:02,459 –> 00:03:10,140
و 4 وجود دارد، بنابراین برای 4 از 8 ما بسیار خوب است، بنابراین اگر
67
00:03:10,140 –> 00:03:11,819
این نمونه داده را شمارش نکنید
68
00:03:11,819 –> 00:03:14,819
، در مجموع 8 مورد وجود دارد بدون اینکه
69
00:03:14,819 –> 00:03:18,750
56 8 نمونه را حذف کنید. از 8 4
70
00:03:18,750 –> 00:03:22,579
زیر 56 است که به این معنی است که این 50 درصد
71
00:03:22,579 –> 00:03:23,730
صدک است
72
00:03:23,730 –> 00:03:26,700
این صدک 100 درصد است زیرا تمام
73
00:03:26,700 –> 00:03:29,970
نقاط داده زیر 69 خوب است بنابراین این
74
00:03:29,970 –> 00:03:33,540
موارد پایه ای در مورد رتبه صدک است اکنون در
75
00:03:33,540 –> 00:03:36,049
این آموزش ما می خواهیم
76
00:03:36,049 –> 00:03:40,380
مجموعه داده های قد یک فرد را بررسی کنیم. فرض
77
00:03:40,380 –> 00:03:43,290
کنید یک لباس قابل استفاده وجود دارد
78
00:03:43,290 –> 00:03:45,480
شرکتی که می خواهد داده های
79
00:03:45,480 –> 00:03:48,209
مربوط به قد افراد را تجزیه و تحلیل کند تا
80
00:03:48,209 –> 00:03:52,320
بتوانند لباس های زمین مربوطه را بر اساس آن طراحی کنند،
81
00:03:52,320 –> 00:03:56,670
دوباره
82
00:03:56,670 –> 00:03:59,250
نام افراد ساختگی وجود دارد و سپس در آنجا
83
00:03:59,250 –> 00:04:01,739
تمام ارتفاعات را در اینجا لیست کرده ام مجموعه داده
84
00:04:01,739 –> 00:04:03,930
ها بسیار ساده است، بنابراین با بررسی بصری
85
00:04:03,930 –> 00:04:07,049
شما نیز می توان به راحتی موارد پرت را تشخیص داد، اما
86
00:04:07,049 –> 00:04:09,630
ایده این است که در زندگی واقعی مجموعه داده های شما
87
00:04:09,630 –> 00:04:12,200
بسیار بزرگتر خواهد بود و باید از
88
00:04:12,200 –> 00:04:14,970
تکنیک های آماری استفاده کنید، بنابراین من می خواهم
89
00:04:14,970 –> 00:04:17,488
این داده ها را در نوت بوک مشتری
90
00:04:17,488 –> 00:04:19,769
خود بارگیری کنم، بنابراین آنها را در اینجا در داده های پاندا خود بارگذاری کرده ام.
91
00:04:19,769 –> 00:04:23,720
فریم و سپس من از
92
00:04:23,720 –> 00:04:27,540
ویژگی صدک پانداها استفاده می کنم،
93
00:04:27,540 –> 00:04:29,790
بنابراین همه شما می دانید که اگر می خواهید به
94
00:04:29,790 –> 00:04:33,120
ستون ارتفاع دسترسی داشته باشید و سپس می
95
00:04:33,120 –> 00:04:35,970
توانید با این کار به ستون ارتفاع دسترسی پیدا
96
00:04:35,970 –> 00:04:39,090
کنید و آن آرایه اعداد را به شما برمی گرداند
97
00:04:39,090 –> 00:04:43,590
که می توانید quantile را فراخوانی کنید. بنابراین
98
00:04:43,590 –> 00:04:45,450
quantile مقدار صدک را به شما میدهد
99
00:04:45,450 –> 00:04:51,960
و اگر میخواهید نمونههای دادهای
100
00:04:51,960 –> 00:04:57,750
که حدود 95 درصد هستند
101
00:04:57,750 –> 00:04:59,520
، این مقدار را دریافت میکنید که این به این معنی
102
00:04:59,520 –> 00:05:06,390
است که 9.68 است 95 درصد هر چیزی
103
00:05:06,390 –> 00:05:10,140
در مورد thi s چیزی است که میتوانیم آن را
104
00:05:10,140 –> 00:05:15,540
بهعنوان نقطهای در نظر بگیریم، حالا چه چیزی
105
00:05:15,540 –> 00:05:17,340
میخواهید آستانه خود را روی آن تنظیم کنید، واقعاً
106
00:05:17,340 –> 00:05:20,100
به موقعیت بستگی دارد، بنابراین اگر
107
00:05:20,100 –> 00:05:22,290
دستورالعمل ثابتی وجود ندارد، اما در اینجا من فقط
108
00:05:22,290 –> 00:05:25,580
از 95 درصد استفاده میکنم، بنابراین اجازه دهید این را در
109
00:05:25,580 –> 00:05:29,010
متغیری به نام حداکثر ذخیره کنم. آستانه
110
00:05:29,010 –> 00:05:32,250
و حداکثر مقدار آستانه این است که اکنون
111
00:05:32,250 –> 00:05:37,320
در قاب داده شما وجود دارد، بنابراین به این صورت است که
112
00:05:37,320 –> 00:05:41,760
نقاط پرت را شناسایی می کنید، بنابراین در اینجا ببینید که
113
00:05:41,760 –> 00:05:45,690
سلامت فرد 14 فوت است
114
00:05:45,690 –> 00:05:47,430
که نمی تواند درست باشد.
115
00:05:47,430 –> 00:05:50,850
116
00:05:50,850 –> 00:05:55,140
به تازگی یک نقطه دورافتاده را شناسایی کردهایم، ما همچنین میتوانیم
117
00:05:55,140 –> 00:05:59,100
نقطه پرت را در حداقل تشخیص دهیم و با
118
00:05:59,100 –> 00:06:01,290
انجام این کار میتوانیم بگوییم که حداقل
119
00:06:01,290 –> 00:06:08,240
آستانه من چندک 0.05 است، بنابراین هر چیزی را به من بدهید
120
00:06:08,240 –> 00:06:13,680
که کمتر از 5٪ باشد، بنابراین
121
00:06:13,680 –> 00:06:20,100
من این مقدار را دریافت میکنم و زمانی که شما کمتر از آن را انجام دهید.
122
00:06:20,100 –> 00:06:23,310
این حداقل آستانه نیز به
123
00:06:23,310 –> 00:06:25,170
شما برخی از نقاط پرت را در اینجا نشان می دهد
124
00:06:25,170 –> 00:06:29,400
قد یوزف 1.2 است فرض کنید این
125
00:06:29,400 –> 00:06:33,510
مجموعه داده برای بزرگسالان با ارتفاع 1.2 فوت است
126
00:06:33,510 –> 00:06:36,990
، به نظر می رسد واقعا کمتر باشد و به
127
00:06:36,990 –> 00:06:39,540
احتمال زیاد یک خطای داده است و ما می توانیم
128
00:06:39,540 –> 00:06:40,320
129
00:06:40,320 –> 00:06:44,640
eas را حذف کنیم. اکنون اگر دانش دامنه
130
00:06:44,640 –> 00:06:48,180
دارید یا واقعاً می توانید از
131
00:06:48,180 –> 00:06:50,040
دانش دامنه خود برای مثال برای
132
00:06:50,040 –> 00:06:52,440
قد افراد استفاده کنید، می دانیم که حداکثر
133
00:06:52,440 –> 00:06:54,650
ارتفاع می تواند حدود 7 فوت یا شاید
134
00:06:54,650 –> 00:06:57,690
7.5 فوت باشد، بنابراین حتی اگر من نمی خواهم
135
00:06:57,690 –> 00:07:00,450
چندک را انجام دهم، می توانم مستقیما اگر
136
00:07:00,450 –> 00:07:02,640
قد بزرگتر از 7.5 باشد، بگوییم خوب است، آنگاه یک حالت پرت وجود دارد،
137
00:07:02,640 –> 00:07:04,050
138
00:07:04,050 –> 00:07:07,590
اما متأسفانه وقتی با
139
00:07:07,590 –> 00:07:10,110
نتایج در زندگی واقعی سروکار داریم،
140
00:07:10,110 –> 00:07:11,910
آنقدر دانش دامنه نداریم و ویژگی ها
141
00:07:11,910 –> 00:07:14,160
بسیار بسیار پیچیده هستند، بنابراین
142
00:07:14,160 –> 00:07:16,680
یافتن یک مورد ثابت بسیار سخت می شود. آستانه
143
00:07:16,680 –> 00:07:20,160
و در آن زمان استفاده از کوانتیل می تواند
144
00:07:20,160 –> 00:07:22,500
بسیار مفید باشد، زیرا کاری که شما انجام می دهید این
145
00:07:22,500 –> 00:07:27,060
است که نمونه ها را در
146
00:07:27,060 –> 00:07:30,570
انتهای سمت چپ و همچنین
147
00:07:30,570 –> 00:07:34,710
دور سمت راست حذف می کنید، بنابراین چندک
148
00:07:34,710 –> 00:07:37,200
یکی از تکنیک هایی است که می توانید
149
00:07:37,200 –> 00:07:41,670
از آن استفاده کنید. حالا در اینجا در مثال ما، اگر میخواهید
150
00:07:41,670 –> 00:07:44,220
این موارد پرت را حذف کنید، کاری که میتوانید انجام دهید
151
00:07:44,220 –> 00:07:47,580
این است که در چارچوب دادههای خود، میتوانیم بگوییم که
152
00:07:47,580 –> 00:07:50,040
اگر ارتفاع کمتر از حداکثر آستانه است
153
00:07:50,040 –> 00:07:53,490
و اگر ارتفاع از منتوس بیشتر است،
154
00:07:53,490 –> 00:07:56,300
فقط این مثال را نگه دارید تا
155
00:07:56,300 –> 00:07:59,670
تمام این مثالها را دریافت میکنید و میبینید
156
00:07:59,670 –> 00:08:01,650
که خودتان با
157
00:08:01,650 –> 00:08:06,360
ارتفاع 1.2 در اینجا وجود ندارد و همچنین ما این
158
00:08:06,360 –> 00:08:10,320
نمونه خاص را که ارتفاع 14.5 فوتی داشت حذف کردیم،
159
00:08:10,320 –> 00:08:14,190
حالا بیایید مجموعه دادههای پیچیده کمی
160
00:08:14,190 –> 00:08:17,010
161
00:08:17,010 –> 00:08:19,710
را بررسی کنیم. Cagle من
162
00:08:19,710 –> 00:08:21,900
آن را کمی از قبل پردازش کرده
163
00:08:21,900 –> 00:08:24,720
ام و می خواهم این فایل CSV را در قاب داده خود بارگذاری کنم،
164
00:08:24,720 –> 00:08:27,060
اکنون می توانید ببینید که
165
00:08:27,060 –> 00:08:31,740
حدود 13000 ردیف وجود دارد و در
166
00:08:31,740 –> 00:08:34,409
اینجا برخی از ویژگی های بسیار اساسی
167
00:08:34,




![فیلم آموزشی: آموزش Blender Python: طراحی سفارشی / بهبود چیدمان [یادگیری پایتون برای مبتدیان] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/uh8vkM8xTzYimage2.jpg)

![فیلم آموزشی: دستورات کنترل در پایتون - 17 [ادامه، شکستن، عبور] | پایتون برای مبتدیان | Simplile Learn](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/gkV14SRCD-4image2.jpg)