در این مطلب، ویدئو نحوه ادغام چندین فایل اکسل در پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:08:26
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,320 –> 00:00:02,480
سلام به همه خوش آمدید در این
2
00:00:02,480 –> 00:00:04,640
ویدیو ما می خواهیم یاد بگیریم که چگونه
3
00:00:04,640 –> 00:00:06,720
چندین فایل اکسل را در پایتون ادغام کنیم.
4
00:00:06,720 –> 00:00:08,800
عملیات ادغام به ترکیب چندین
5
00:00:08,800 –> 00:00:11,679
فایل بر اساس یک کلید منحصر به فرد مشترک یا یک
6
00:00:11,679 –> 00:00:13,519
ستون برای کسانی که
7
00:00:13,519 –> 00:00:15,200
با پرس و جوی اکسل پاور این ادغام آشنا هستند اشاره دارد.
8
00:00:15,200 –> 00:00:16,960
عملیات مشابه عملیات ادغام
9
00:00:16,960 –> 00:00:19,600
پرس و جو در اولویت اکسل است،
10
00:00:19,600 –> 00:00:21,359
گاهی اوقات بین
11
00:00:21,359 –> 00:00:24,000
آنچه ظاهر می شود و آنچه که اضافه نمی شود سردرگمی وجود دارد، بنابراین
12
00:00:24,000 –> 00:00:26,240
بیایید روشن کنیم که
13
00:00:26,240 –> 00:00:28,000
عمل الحاق به این معنی است که ما در حال
14
00:00:28,000 –> 00:00:29,679
ترکیب فایل ها با
15
00:00:29,679 –> 00:00:32,238
افزودن داده های جدید در پایین هستیم. از
16
00:00:32,238 –> 00:00:34,320
دادههای موجود به این معنی است که
17
00:00:34,320 –> 00:00:37,360
زمانی که فایلهای ما
18
00:00:37,360 –> 00:00:40,079
تقریباً فرمت یا ستونهای مشابهی دارند، دادهها را به صورت عمودی اضافه
19
00:00:40,079 –> 00:00:42,480
میکنیم و میخواهیم فایلهایی را که از آنها استفاده میکنیم جمعبندی کنیم، از
20
00:00:42,480 –> 00:00:44,960
سوی دیگر عملیات ادغام
21
00:00:44,960 –> 00:00:47,600
اساساً با
22
00:00:47,600 –> 00:00:49,840
افزودن دادهها به صورت افقی هنگامی که فایلهایی داریم،
23
00:00:49,840 –> 00:00:52,239
فایلها را ترکیب میکند. حاوی جنبه های مختلف
24
00:00:52,239 –> 00:00:54,079
رکوردهای داده مشابه است و می خواهیم
25
00:00:54,079 –> 00:00:56,320
آن فایل ها را جمع آوری کنیم، سپس از ادغام استفاده می کنیم
26
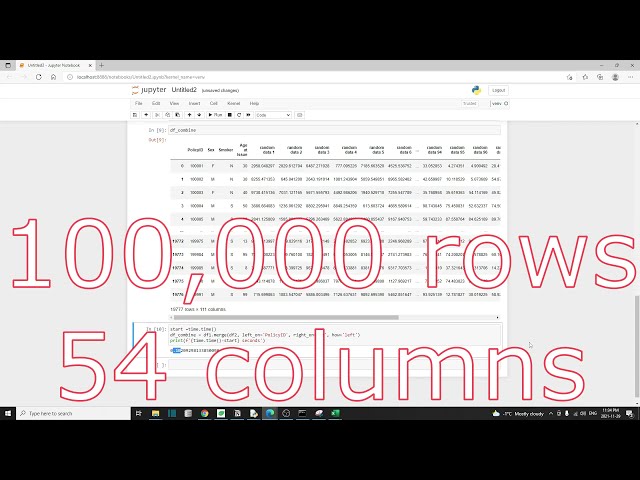
00:00:56,320 –> 00:00:58,960
، سه مجموعه داده ماکت ایجاد کرده ام.
27
00:00:58,960 –> 00:01:00,559
برای دانلود آنها و دنبال کردن
28
00:01:00,559 –> 00:01:04,319
برگه 1 و صفحه 2 شامل حدود
29
00:01:04,319 –> 00:01:07,280
100000 رکورد و تقریباً 50
30
00:01:07,280 –> 00:01:09,200
ستون است و آنها اساساً برخی از
31
00:01:09,200 –> 00:01:11,680
سوابق داده های بیمه نشانه گذاری هستند و در
32
00:01:11,680 –> 00:01:14,240
برگ 3 این نوعی گزارش فوت
33
00:01:14,240 –> 00:01:16,640
برای یک شرکت بیمه است و برگ 3
34
00:01:16,640 –> 00:01:19,040
شامل حدود 20000 نقطه داده است و
35
00:01:19,040 –> 00:01:21,840
هدف ما ایجاد یک پایگاه داده اصلی
36
00:01:21,840 –> 00:01:23,600
برای ذخیره تمام اطلاعات در یک
37
00:01:23,600 –> 00:01:25,920
مکان است، بنابراین در دنیای مالی ما
38
00:01:25,920 –> 00:01:27,840
در واقع از Excel به عنوان پایگاه داده برای
39
00:01:27,840 –> 00:01:30,240
ذخیره اطلاعات استفاده می کنیم، می دانم که اینطور نیست،
40
00:01:30,240 –> 00:01:32,079
قطعاً این را توصیه نمی کنم
41
00:01:32,079 –> 00:01:34,000
اما نوعی روش معمول
42
00:01:34,000 –> 00:01:37,040
در صنعت اگر به سه
43
00:01:37,040 –> 00:01:39,680
فایل نگاه کنیم، متوجه میشویم که هر فایل
44
00:01:39,680 –> 00:01:42,320
دارای ستونی با شناسه سیاست
45
00:01:42,320 –> 00:01:44,880
sheet1 است و فایلهای sheet3 پایینی دارند که شناسه سیاست نامیده میشود،
46
00:01:44,880 –> 00:01:48,240
در حالی که در sheet2 آن
47
00:01:48,240 –> 00:01:51,119
ستون فقط به سادگی id است، بنابراین میتوانیم از این
48
00:01:51,119 –> 00:01:54,560
شناسه خط مشی یا ستون شناسه برای تطبیق
49
00:01:54,560 –> 00:01:56,320
رکوردها یکی یکی استفاده کنید، زیرا ما
50
00:01:56,320 –> 00:01:58,880
یک رابطه یک به یک داریم، میتوانیم
51
00:01:58,880 –> 00:02:02,479
تمام اطلاعات sheet3 و sheet2
52
00:02:02,479 –> 00:02:06,240
را به sheet1 بیاوریم تا یک پایگاه داده اصلی تشکیل دهیم.
53
00:02:06,240 –> 00:02:08,639
و اگر بخواهیم این کار را در اکسل انجام دهیم،
54
00:02:08,639 –> 00:02:11,038
یکی از راه ها استفاده از
55
00:02:11,038 –> 00:02:12,959
توابع جستجو است و البته به دلیل
56
00:02:12,959 –> 00:02:14,640
تعداد نقاط داده ای که داریم،
57
00:02:14,640 –> 00:02:16,720
باید میلیون ها و میلیون ها
58
00:02:16,720 –> 00:02:19,360
فرمول جستجو ایجاد کنیم که ایده آل نیست و
59
00:02:19,360 –> 00:02:21,360
ما فقط با انجام این کار زمان زیادی را تلف میکنیم،
60
00:02:21,360 –> 00:02:23,520
پس بیایید ببینیم چگونه میتوانیم از
61
00:02:23,520 –> 00:02:25,360
پایتون برای ادغام این سه فایل
62
00:02:25,360 –> 00:02:27,920
با هم استفاده کنیم، بدون هیچ تلاشی برای
63
00:02:27,920 –> 00:02:30,000
شروع، من کتابخانه پانداها را وارد میکنم
64
00:02:30,000 –> 00:02:32,319
و همچنین کتابخانههای زمان را وارد
65
00:02:32,319 –> 00:02:33,920
میکنم تا ما میتوانیم
66
00:02:33,920 –> 00:02:35,760
عملکرد عملیات ادغام پایتون
67
00:02:35,760 –> 00:02:37,760
را بررسی کنیم و سپس میخواهم تمام
68
00:02:37,760 –> 00:02:41,360
آن سه فایل را در پایتون بخوانم،
69
00:02:41,840 –> 00:02:43,599
بنابراین این مرحله ممکن است کمی طول بکشد تا زمانی
70
00:02:43,599 –> 00:02:45,920
که میتوانید ببینید تا زمانی که این
71
00:02:45,920 –> 00:02:48,400
علامت ستاره در جلوی کد شما وجود داشته باشد،
72
00:02:48,400 –> 00:02:50,640
آن را مسدود کند. به این معنی است که کد در حال اجرا است،
73
00:02:50,640 –> 00:02:52,720
اما ما میتوانیم
74
00:02:52,720 –> 00:02:55,200
در زمانی که این کد در حال اجرا است، به نوشتن کد جدید در بلوک کد بعدی ادامه دهیم
75
00:02:55,200 –> 00:02:57,920
، بنابراین اکنون که تمام شد، اجازه دهید
76
00:02:57,920 –> 00:03:01,120
اندازه فریمهای داده خود را چاپ کنیم تا
77
00:03:01,120 –> 00:03:02,560
مطمئن شویم که با فایلهای مناسب کار میکنیم.
78
00:03:02,560 –> 00:03:05,040
به نظر می رسد درست است
79
00:03:05,040 –> 00:03:07,760
دو فایل اول شامل حدود 100000
80
00:03:07,760 –> 00:03:10,080
سطر و 50 ستون و فایل سوم
81
00:03:10,080 –> 00:03:12,560
شامل حدود 20000 سطر است. من می
82
00:03:12,560 –> 00:03:14,800
خواهم دو فایل
83
00:03:14,800 –> 00:03:16,800
اول یا دو فریم داده اول را با هم ادغام کنم تا
84
00:03:16,800 –> 00:03:19,760
df1 و df2 و فریم داده ترکیبی من باشند.
85
00:03:19,760 –> 00:03:22,640
من آن را bf ترکیب می
86
00:03:22,640 –> 00:03:26,239
نامم تا برابر با df1 dot merge در داخل این متد ادغام باشد
87
00:03:26,239 –> 00:03:28,159
، اولین آرگومانی که می خواهیم
88
00:03:28,159 –> 00:03:30,400
عبور دهیم فریم داده ای است که می خواهیم
89
00:03:30,400 –> 00:03:33,519
با آن ادغام کنیم تا df2 باشد و
90
00:03:33,519 –> 00:03:36,480
در اینجا df1 گاهی
91
00:03:36,480 –> 00:03:39,760
اوقات به آن اشاره می شود. جدول سمت چپ و df2
92
00:03:39,760 –> 00:03:43,680
به عنوان جدول سمت راست در df1
93
00:03:43,680 –> 00:03:46,720
نامیده می شود. به ستون id سیاست و در
94
00:03:46,720 –> 00:03:48,879
df2 ستون id نامیده می شود بنابراین آنها
95
00:03:48,879 –> 00:03:51,040
نام های مختلفی دارند، کاری که ما باید انجام دهیم این است که
96
00:03:51,040 –> 00:03:53,519
باید به پانداها بگوییم از چه ستون هایی استفاده
97
00:03:53,519 –> 00:03:56,080
کنند. از آرگومان left on برای
98
00:03:56,080 –> 00:03:59,040
تعیین آرگومان برای نام ستون
99
00:03:59,040 –> 00:04:01,519
در جدول اول یا در جدول سمت چپ
100
00:04:01,519 –> 00:04:03,920
که شناسه سیاست است استفاده می کنیم و از
101
00:04:03,920 –> 00:04:06,879
آرگومان سمت راست برای تعیین نام ستون
102
00:04:06,879 –> 00:04:09,760
برای ستونی که در جدول دوم
103
00:04:09,760 –> 00:04:11,920
یا سمت راست است استفاده می کنیم.