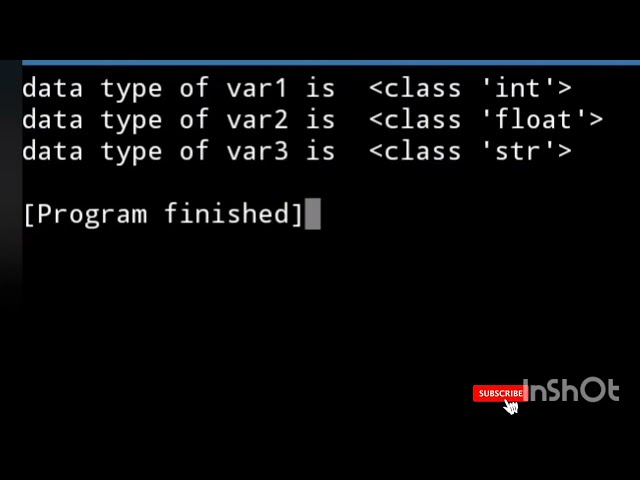
در این مطلب، ویدئو نوشتن K به معنای خوشه بندی در پایتون از ابتدا است! با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:11:41
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:00,320 –> 00:00:02,240
پس سلام و به یک آموزش دیگر خوش آمدید،
2
00:00:02,240 –> 00:00:04,560
نام من tanmay باکشی است و
3
00:00:04,560 –> 00:00:05,120
امروز
4
00:00:05,120 –> 00:00:06,799
می خواهیم وارد
5
00:00:06,799 –> 00:00:08,800
دنیای k-means clustering و
6
00:00:08,800 –> 00:00:10,400
کمی یادگیری بدون نظارت
7
00:00:10,400 –> 00:00:12,080
شویم، اکنون قبل از اینکه عمیق تر به این موضوع بپردازیم، من می
8
00:00:12,080 –> 00:00:13,519
خواهم شروع کنم. با گفتن اینکه
9
00:00:13,519 –> 00:00:14,880
اگر از این نوع محتوا لذت می برید و می
10
00:00:14,880 –> 00:00:15,839
خواهید بیشتر آن را ببینید،
11
00:00:15,839 –> 00:00:17,440
لطفاً حتماً در کانال مشترک شوید
12
00:00:17,440 –> 00:00:19,119
و اعلان ها را روشن کنید
13
00:00:19,119 –> 00:00:20,560
و همچنین ویدیو را
14
00:00:20,560 –> 00:00:22,000
لایک کنید البته اگر سؤالی دارید،
15
00:00:22,000 –> 00:00:23,519
پیشنهاد یا بازخوردی دارید، راحت باشید. برای
16
00:00:23,519 –> 00:00:24,880
اینکه آن را در بخش نظرات
17
00:00:24,880 –> 00:00:26,160
زیر رها کنید یا با من تماس بگیرید
18
00:00:26,160 –> 00:00:27,760
و من دوست دارم ادامه دهم و به سوالات شما پاسخ
19
00:00:27,760 –> 00:00:29,519
دهم و بشنوم که اکنون چه می گویید و
20
00:00:29,519 –> 00:00:31,439
در حال غواصی به دنیای
21
00:00:31,439 –> 00:00:33,280
k-means clustering این یک
22
00:00:33,280 –> 00:00:34,960
الگوریتم واقعا جالب است.
23
00:00:34,960 –> 00:00:37,360
به طور موثر این یک خانواده است، آه،
24
00:00:37,360 –> 00:00:39,200
در خانواده الگوریتمهای یادگیری بدون نظارت قرار میگیرد
25
00:00:39,200 –> 00:00:40,000
26
00:00:40,000 –> 00:00:42,000
که الگوریتمهایی هستند که
27
00:00:42,000 –> 00:00:44,239
برای یادگیری به دادههای برچسبدار نیاز ندارند،
28
00:00:44,239 –> 00:00:45,840
بنابراین ممکن است تجربه آموزش
29
00:00:45,840 –> 00:00:47,520
شبکههای عصبی عمیق را داشته باشید، به عنوان مثال و این
30
00:00:47,520 –> 00:00:49,039
n عمیق شبکههای الکترونیکی به
31
00:00:49,039 –> 00:00:51,120
نقشهبرداری از دادهها نیاز دارند، بهعنوان مثال
32
00:00:51,120 –> 00:00:52,800
میتوانید بگویید اینجا تصویری از یک گربه است
33
00:00:52,800 –> 00:00:54,559
و در اینجا تصویری از یک سگ است که نمیتوانید
34
00:00:54,559 –> 00:00:56,160
فقط تصاویر مورد نیاز را به آن بدهید و همچنین
35
00:00:56,160 –> 00:00:57,440
برچسبهایی به آن ارائه دهید
36
00:00:57,440 –> 00:00:59,359
که به آن یادگیری نظارت شده،
37
00:00:59,359 –> 00:01:00,640
یادگیری بدون نظارت
38
00:01:00,640 –> 00:01:02,160
میگویند. میتوانید مدل را با
39
00:01:02,160 –> 00:01:03,920
دادههای خود تغذیه کنید و از آن
40
00:01:03,920 –> 00:01:05,119
بخواهید بینشهایی را برای
41
00:01:05,119 –> 00:01:07,119
شما استخراج کند، اما بهطور دستی
42
00:01:07,119 –> 00:01:09,439
اطلاعاتی درباره آن دادهها به آن نمیدهید،
43
00:01:09,439 –> 00:01:11,040
اکنون در این دنیای یادگیری بدون نظارت
44
00:01:11,040 –> 00:01:12,720
، خوشهبندی k-means یکی
45
00:01:12,720 –> 00:01:12,960
46
00:01:12,960 –> 00:01:15,040
از کلاسیکترین کلاسها است. الگوریتمهایی
47
00:01:15,040 –> 00:01:16,560
که بسیاری از افراد
48
00:01:16,560 –> 00:01:18,479
آن را پیادهسازی میکنند و یکی از آنهایی است که قبلاً از آن
49
00:01:18,479 –> 00:01:21,040
استفاده کردهام، در واقع بارها
50
00:01:21,040 –> 00:01:22,880
از آن استفاده کردهام، اما هرگز مجبور نبودم آن را از ابتدا پیادهسازی
51
00:01:22,880 –> 00:01:24,240
52
00:01:24,240 –> 00:01:26,400
کنم چند روز پیش، بهانهای برای
53
00:01:26,400 –> 00:01:27,920
پیادهسازی آن داشتم.
54
00:01:27,920 –> 00:01:30,479
من و باید بگویم که از
55
00:01:30,479 –> 00:01:32,479
اینکه الگوریتم در پسزمینه چقدر ساده
56
00:01:32,479 –> 00:01:35,600
است شگفتزده هستم، روشی که
57
00:01:35,600 –> 00:01:37,200
خوشهبندی k-means کار میکند به
58
00:01:37,200 –> 00:01:39,040
این صورت که شما با دادههای خود شروع میکنید، این
59
00:01:39,040 –> 00:01:41,200
میتواند عملاً در هر فضای بعدی باشد.
60
00:01:41,200 –> 00:01:42,960
مثال ساده او ما
61
00:01:42,960 –> 00:01:44,960
از نقاط Uh دو بعدی استفاده خواهیم کرد،
62
00:01:44,960 –> 00:01:46,799
اما شما می توانید نقاط n بعدی
63
00:01:46,799 –> 00:01:48,399
داشته باشید، بنابراین اگر خروجی از یک
64
00:01:48,399 –> 00:01:49,560
شبکه عصبی
65
00:01:49,560 –> 00:01:51,920
10-24 بعدی دارید، مثلاً از برت بزرگ،
66
00:01:51,920 –> 00:01:53,759
می توانید کاملاً همچنان از
67
00:01:53,759 –> 00:01:54,640
خوشه بندی k-means استفاده کنید.
68
00:01:54,640 –> 00:01:55,439
اما بیایید بگوییم که شما به
69
00:01:55,439 –> 00:01:57,520
طور موثر داده های دو بعدی دارید، تنها کاری که
70
00:01:57,520 –> 00:01:58,320
باید انجام دهید
71
00:01:58,320 –> 00:02:00,399
این است که چند نقطه تصادفی برای
72
00:02:00,399 –> 00:02:02,640
مرکزهای خود بیابید که
73
00:02:02,640 –> 00:02:04,719
مراکز خوشه هایی هستند که خوشه بندی k-means
74
00:02:04,719 –> 00:02:05,680
75
00:02:05,680 –> 00:02:07,920
آنها را شناسایی می کند، وقتی نقاط تصادفی برای آنها داشتید،
76
00:02:07,920 –> 00:02:08,878
مشخص می کنید که کدام
77
00:02:08,878 –> 00:02:11,440
نقاط. در دادههای واقعی شما به کدام مرکز تعلق دارد، یعنی به
78
00:02:11,440 –> 00:02:12,560
کدام مرکز نزدیکتر
79
00:02:12,560 –> 00:02:14,319
80
00:02:14,319 –> 00:02:16,000
هستند، معمولاً از چیزی مانند
81
00:02:16,000 –> 00:02:17,760
فاصله اقلیدسی برای این کار استفاده میکنید
82
00:02:17,760 –> 00:02:20,000
و سپس تنها کاری که انجام میدهید این است که اکنون
83
00:02:20,000 –> 00:02:22,400
بفهمید کدام نقاط واقعاً
84
00:02:22,400 –> 00:02:23,840
با کدام مرکز مرتبط هستند
85
00:02:23,840 –> 00:02:26,400
و سپس محاسبه میکنید. میانگین
86
00:02:26,400 –> 00:02:27,760
آن نقاط
87
00:02:27,760 –> 00:02:29,599
و شما مرکز را به سمت
88
00:02:29,599 –> 00:02:31,840
میانگین حرکت می دهید
89
00:02:31,840 –> 00:02:33,920
و ناگهان می توانید
90
00:02:33,920 –> 00:02:35,360
داده های خود را در
91
00:02:35,360 –> 00:02:37,760
n خوشه مختلف گروه بندی کنید. s که در آن n
92
00:02:37,760 –> 00:02:38,400
تعداد
93
00:02:38,400 –> 00:02:40,319
خوشه هایی است که اکنون به دنبال آنها هستید،
94
00:02:40,319 –> 00:02:42,879
تعیین اینکه چه تعداد خوشه باید استفاده کنید
95
00:02:42,879 –> 00:02:44,879
، مسئله دیگری است که در برخی
96
00:02:44,879 –> 00:02:46,879
موارد ممکن است از قبل تعداد آن را بدانید،
97
00:02:46,879 –> 00:02:48,400
به عنوان مثال اگر از ارقام mnist استفاده
98
00:02:48,400 –> 00:02:50,400
می کنیم، می دانیم که
99
00:02:50,400 –> 00:02:52,160
10 خوشه می خواهیم زیرا 10 رقم مختلف وجود دارد،
100
00:02:52,160 –> 00:02:54,239
اما از آنجایی که
101
00:02:54,239 –> 00:02:55,760
در بسیاری از موارد این یادگیری بدون نظارت است، در
102
00:02:55,760 –> 00:02:56,239
واقع
103
00:02:56,239 –> 00:02:58,560
نمیدانید به چه تعداد خوشه نیاز دارید، میتوانید
104
00:02:58,560 –> 00:03:00,959
کارهایی مانند تجزیه و تحلیل آرنج را در اینجا انجام دهید،
105
00:03:00,959 –> 00:03:03,519
اما کاری که ما انجام میدهیم
106
00:03:03,519 –> 00:03:06,400
صرفاً تمرکز بر روی k- است. به این معنی است
107
00:03:06,400 –> 00:03:08,400
که الگوریتم چگونه کار می کند و چگونه می توانید
108
00:03:08,400 –> 00:03:10,159
آن را از ابتدا در پایتون پیاده سازی کنید
109
00:03:10,159 –> 00:03:11,440
و بنابراین اکنون اجازه دهید به جلو برویم
110
00:03:11,440 –> 00:03:13,599
و به پیاده سازی k-means
111
00:03:13,599 –> 00:03:15,440
از ابتدا نگاهی بیندازیم، این فقط چند
112
00:03:15,440 –> 00:03:17,120
خط کد است و کمی بیشتر به شما می دهد.
113
00:03:17,120 –> 00:03:18,000
114
00:03:18,000 –> 00:03:20,400
شاید یک راه عالی برای
115
00:03:20,400 –> 00:03:21,040
شروع
116
00:03:21,040 –> 00:03:22,959
این باشد که در واقع با بحث در مورد اینکه
117
00:03:22,959 –> 00:03:24,720
یک خوشه حتی
118
00:03:24,720 –> 00:03:27,360
خوشه ای خوب است شروع کنید، همانطور که احتمالاً می دانید
119
00:03:27,360 –> 00:03:28,959
اساساً بسیاری از نقاط
120
00:03:28,959 –> 00:03:29,440
121
00:03:29,440 –> 00:03:30,879
داده های شما نزدیک به یکدیگر هستند. که می
122
00:03:30,879 –> 00:03:32,959
خواهید به عنوان یک
123
00:03:32,959 –> 00:03:34,720
گروه از نقاط مشخص کنید، آنها به یک دسته تعلق دارند
124
00:03:34,720 –> 00:03:36,959
زیرا نزدیک به هم
125
00:03:36,959 –> 00:03:39,120
هستند، آنها یک ابر خاص از داده های شما هستند
126
00:03:39,120 –> 00:03:40,879
که به عنوان خوشه نیز شناخته می شوند،
127
00:03:40,879 –> 00:03:43,440
اما چگونه می توانید مشخص کنید که آن خوشه کجاست.
128
00:03:43,440 –> 00:03:44,000
129
00:03:44,000 –> 00:03:45,680
شما با k-
130
00:03:45,680 –> 00:03:47,760
means خوشه بندی انجام می دهید با تعریف چیزی که به
131
00:03:47,760 –> 00:03:49,040
عنوان مرکز شناخته می شود
132
00:03:49,040 –> 00:03:52,080
یک مرکز نقطه ای در مرکز
133
00:03:52,080 –> 00:03:53,200
آن خوشه است به
134
00:03:53,200 –> 00:03:55,519
طوری که تمام نقاطی که
135
00:03:55,519 –> 00:03:56,239
نزدیک ترین
136
00:03:56,239 –> 00:03:58,879
فاصله را به آن مرکز
137
00:03:58,879 –> 00:04:00,879
دارند اگر به آن نزدیکتر باشند بخشی از آن خوشه هستند. یک
138
00:04:00,879 –> 00:04:02,000
مرکز متفاوت،
139
00:04:02,000 –> 00:04:04,720
آنها بخشی از آن خوشه مرکزی هستند
140
00:04:04,720 –> 00:04:06,480
و بنابراین، روشی که k-means کار میکند
141
00:04:06,480 –> 00:04:08,080
این است که شما با قرار دادن این
142
00:04:08,080 –> 00:04:10,239
مرکزها در مکانهای تصادفی
143
00:04:10,239 –> 00:04:12,239
به روشی که من آن را مقداردهی اولیه میکنم، با
144
00:04:12,239 –> 00:04:14,239
گرفتن میانگین نقطه کل
145
00:04:14,239 –> 00:04:16,478
دادهها شروع میکنید. فضا و فقط ایجاد
146
00:04:16,478 –> 00:04:18,798
چند نوع تغییر در اطراف آن
147
00:04:18,798 –> 00:04:19,759
148
00:04:19,759 –> 00:04:21,759
ناحیه مرکزی کلی چیزی که به من می دهد یک دسته
149
00:04:21,759 –> 00:04:23,600
از نقاط است که می توانند به فضاهای خوشه ای خود حرکت کنند،
150
00:04:23,600 –> 00:04:25,840
151
00:04:25,840 –> 00:04:28,240
حالا برای رسیدن به این هدف،
152
00:04:28,240 –> 00:04:30,000
من دو تا دارم. توابع روی صفحه در حال
153
00:04:30,000 –> 00:04:31,759
حاضر عملکرد تخصیص به روز رسانی و سپس عملکرد
154
00:04:31,759 –> 00:04:34,080
به روز رسانی centroids
155
00:04:34,080 –> 00:04:36,080
اکنون این دو عملکرد دو کار متفاوت انجام
156
00:04:36,080 –> 00:04:37,199
می دهند اول از
157
00:04:37,199 –> 00:04:39,440
همه عملکرد تخصیص به روز رسانی
158
00:04:39,440 –> 00:04:41,040
مجموعه ای از داده ها و همچنین
159
00:04:41,040 –> 00:04:42,560
مکان های سانتروئید
160
00:04:42,560 –> 00:04:44,160
را می گیرد و به شما می گوید کدام یک
161
00:04:44,160 –> 00:04:46,720
مرکزهایی که نقاط داده به آن تعلق دارند،
162
00:04:46,720 –> 00:04:48,400
به عنوان مثال نقطه داده اول
163
00:04:48,400 –> 00:04:50,800
به مرکز دوم نزدیک است و غیره
164
00:04:50,800 –> 00:04:51,680
و غیره
165
00:04:51,680 –> 00:04:53,840
اکنون با استفاده از آن اطلاعات می توانیم دو کار انجام
166
00:04:53,840 –> 00:04:54,720
دهیم
167
00:04:54,720 –> 00:04:56,320
اول از همه می توانیم آن را به گونه ای انجام دهیم که
168
00:04:56,320 –> 00:04:58,320
داده های داده شده و یک دسته از مرکزها ما
169
00:04:58,320 –> 00:05:00,320
میتوانیم بفهمیم کدام نقاط داده متعلق
170
00:05:00,320 –> 00:05:01,360
به کدام خوشهها هستند،
171
00:05:01,360 –> 00:05:03,120
بنابراین میتوانیم به عنوان مثال آنها را
172
00:05:03,120 –> 00:05:05,759
بر اساس
173
00:05:05,759 –> 00:05:07,440
174
00:05:07,440 –> 00:05:07,840
175
00:05:07,840 –> 00:05:10,000
176
00:05:10,000 –> 00:05:12,320
آن رنگسازی کنیم. حدس اولیه
177
00:05:12,320 –> 00:05:12,720
178
00:05:12,720 –> 00:05:14,560
از اینکه دقیقاً آن مرکزها باید
179
00:05:14,560 –> 00:05:16,960
در کجا باشند در جهتی که ما فکر می کنیم جهت صحیح است
180
00:05:16,960 –> 00:05:17,919
181
00:05:17,919 –> 00:05:19,680
. روش کار این تکرارها بسیار
182
00:05:19,680 –> 00:05:21,120
ساده است و می توانید آن را
183
00:05:21,120 –> 00:05:23,840
در u ببینید عملکرد pdate centroids در
184
00:05:23,840 –> 00:05:25,759
داخل بهروزرسانی تابع centroids آنچه
185
00:05:25,759 –> 00:05:26,400
من انجام میدهم اساساً این است که میگویم خیلی خوب
186
00:05:26,400 –> 00:05:28,400
است، بیایید
187
00:05:28,400 –> 00:05:30,240
188
00:05:30,240 –> 00:05:32,320
در حال حاضر به همه انتسابهای خوشهای مختلف نگاهی بیندازیم
189
00:05:32,320 –> 00:05:34,479
و بگوییم ما فقط دو مرکز داریم و 10
190
00:05:34,479 –> 00:05:35,759
191
00:05:35,759 –> 00:05:37,759
نقطه داده داریم. بخشی
192
00:05:37,759 –> 00:05:38,960
از اولین خوشه
193
00:05:38,960 –> 00:05:40,400
و نقاط داده ای هستند که بخشی از
194
00:05:40,400 –> 00:05:42,320
خوشه دوم هستند
195
00:05:42,320 –> 00:05:44,960
و وسط هر دو
196
00:05:44,960 –> 00:05:46,639
حد




![فیلم آموزشی: [8/8] نوشتن ماتریس های سختی جهانی عنصر با پایتون با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/puNfKknnQUQimage2.jpg)