در این مطلب، ویدئو پایتون – تست دو جمله ای با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:04:45
تصاویر این ویدئو:
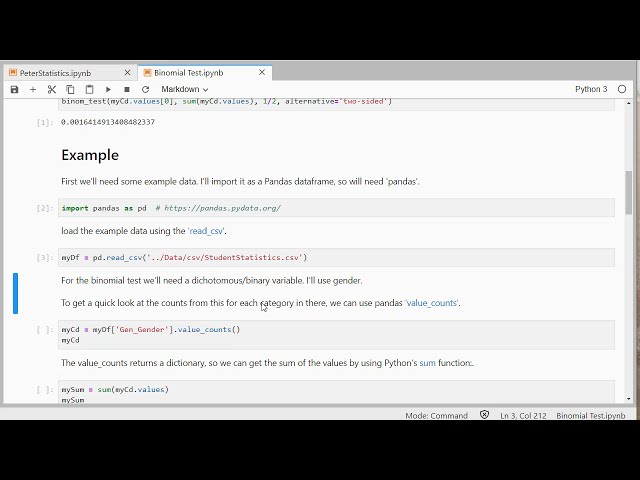
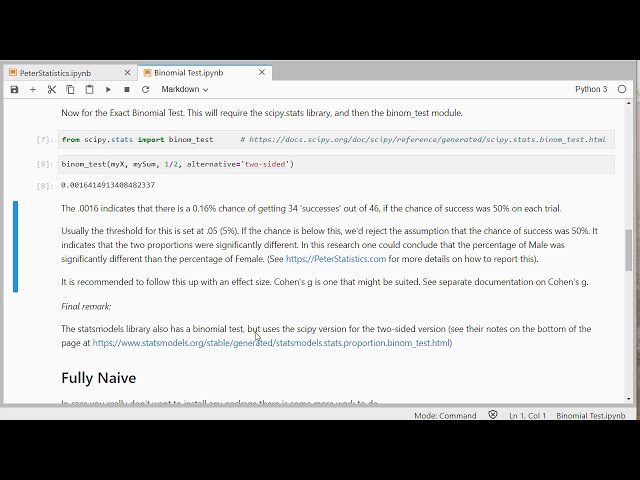
قسمتی از زیرنویس این فیلم:
00:00:01,129 –> 00:00:03,840
خوش آمدید در این ویدیو به
2
00:00:03,840 –> 00:00:06,500
شما نشان خواهم داد که چگونه می توانید یک تست دو جمله ای را
3
00:00:06,500 –> 00:00:09,120
با استفاده از
4
00:00:09,120 –> 00:00:13,590
5
00:00:13,590 –> 00:00:16,109
6
00:00:16,109 –> 00:00:21,259
7
00:00:21,259 –> 00:00:23,999
پایتون انجام دهید.
8
00:00:23,999 –> 00:00:25,949
چقدر احتمال دارد که K موفقیت از بین n
9
00:00:25,949 –> 00:00:28,949
کارآزمایی با شانس موفقیت برای
10
00:00:28,949 –> 00:00:33,120
هر آزمایش داده شده چیزی باشد، اکنون
11
00:00:33,120 –> 00:00:34,920
میتوانیم از آن استفاده کنیم اگر به عنوان مثال از
12
00:00:34,920 –> 00:00:37,560
مردم بپرسیم کدام مارک را ترجیح میدهند برند a
13
00:00:37,560 –> 00:00:40,950
یا مارک B و سپس اگر فرض کنیم که
14
00:00:40,950 –> 00:00:43,410
5050 می شود،
15
00:00:43,410 –> 00:00:47,190
سپس می توانیم به عنوان شانس
16
00:00:47,190 –> 00:00:50,610
موفقیت 0.5 استفاده کنیم و سپس می توانیم
17
00:00:50,610 –> 00:00:52,500
به سادگی بررسی کنیم که آیا این دو درصد
18
00:00:52,500 –> 00:00:55,800
ممکن است واقعاً با آن تفاوت داشته باشند، به طوری
19
00:00:55,800 –> 00:00:59,250
که به احتمال زیاد در
20
00:00:59,250 –> 00:01:04,530
جمعیت 50/50 وجود ندارد و ظاهر ترسناکی به نظر نمی رسد.
21
00:01:04,530 –> 00:01:07,560
فرمول برای آن و اما نگران نباشید،
22
00:01:07,560 –> 00:01:09,240
اگر از پایتون استفاده می کنیم، نیازی به دانستن آن فرمول نداریم
23
00:01:09,240 –> 00:01:13,770
و همانطور که می بینید می
24
00:01:13,770 –> 00:01:15,600
توانیم از چند کتابخانه
25
00:01:15,600 –> 00:01:18,450
استفاده کنیم و زندگی ما را آسان
26
00:01:18,450 –> 00:01:21,270
می کند. بیش از این در کمی
27
00:01:21,270 –> 00:01:23,880
متر جزئیات سنگ معدن در مثال، اما فقط برای
28
00:01:23,880 –> 00:01:28,880
نشان دادن نتیجه به شما یک عدد خواهد بود و
29
00:01:28,880 –> 00:01:32,130
واقعاً خوب نقطه 0:01 6 است که در
30
00:01:32,130 –> 00:01:35,579
این مورد کمتر از 0.05 است، بنابراین معمولاً در
31
00:01:35,579 –> 00:01:37,139
این مورد می گویند که این دو
32
00:01:37,139 –> 00:01:39,450
درصد به طور قابل توجهی با
33
00:01:39,450 –> 00:01:40,310
یکدیگر متفاوت هستند.
34
00:01:40,310 –> 00:01:43,799
اکنون برای بررسی
35
00:01:43,799 –> 00:01:46,350
جزییات بیشتر این موضوع، ابتدا باید مقداری داده به دست
36
00:01:46,350 –> 00:01:49,259
بیاورم، بنابراین از پانداها برای آن استفاده خواهم کرد و سپس
37
00:01:49,259 –> 00:01:52,109
از CSV خوانده شده استفاده میکنم تا در واقع
38
00:01:52,109 –> 00:01:55,229
به اصطلاح چارچوب داده را دریافت کنم و من فقط به
39
00:01:55,229 –> 00:01:59,329
یک متغیر در اینجا نیاز دارم. باید
40
00:01:59,329 –> 00:02:01,469
دوگانگی باشد. من سعی نمی کنم
41
00:02:01,469 –> 00:02:05,399
این انگلیسی زبان مادری را تلفظ کنم، اما
42
00:02:05,399 –> 00:02:08,549
معمولاً از اصطلاح باینری برای آن
43
00:02:08,549 –> 00:02:09,869
استفاده می کنم که به این معنی است که فقط دو گزینه وجود دارد
44
00:02:09,869 –> 00:02:11,459
و در این مورد از نظر جنسیت و
45
00:02:11,459 –> 00:02:13,530
روز فقط دو گزینه مرد
46
00:02:13,530 –> 00:02:18,120
زن وجود دارد. بنابراین من واقعاً می توانم انتخاب کنم که با
47
00:02:18,120 –> 00:02:20,310
استفاده از شمارش مقادیر می توانم ببینم که
48
00:02:20,310 –> 00:02:22,950
تعداد هر کدام چقدر بوده است، در این مورد 34 مرد
49
00:02:22,950 –> 00:02:27,750
و 12 ماده، فرهنگ لغت
50
00:02:27,750 –> 00:02:30,030
را برمی گرداند در واقع یک سری پاندا




![فیلم آموزشی: [آموزش سالومه] بیایید یک بلوک بتنی با مصالح با پایتون در سالومه بسازیم! با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/MwHQIvgH5xUimage2.jpg)

![فیلم آموزشی: 21. ژنراتورها [آموزش برنامه نویسی پایتون 3] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/66HNCg7_gfEimage2.jpg)