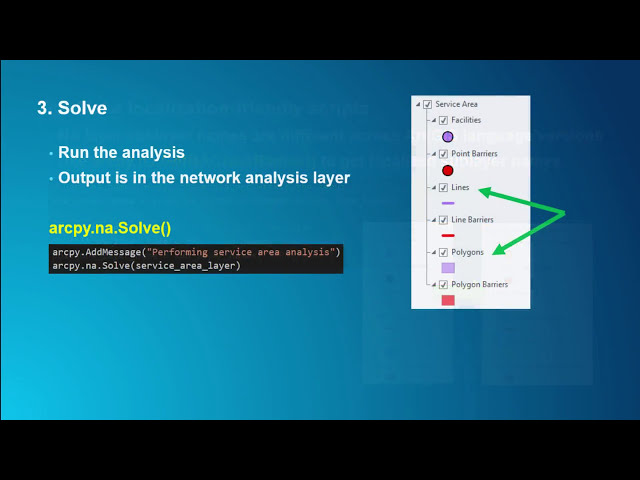
در این مطلب، ویدئو پروژه علم داده پایتون برای پیش بینی دیابت | پروژه پایان به پایان با چندین الگوریتم ML با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:54:50
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:00,240 –> 00:00:03,280
با سلام و خوش آمدید به
2
00:00:03,280 –> 00:00:06,720
مطالعه موردی پایتون یا پروژه پایتون
3
00:00:06,720 –> 00:00:10,639
که در آن دادههای بیماران دیابتی را ارزیابی میکنیم
4
00:00:10,639 –> 00:00:12,880
و
5
00:00:12,880 –> 00:00:15,040
اساساً پیشبینی میکنیم که بر
6
00:00:15,040 –> 00:00:17,279
اساس متغیرهای داده شده میتوانیم
7
00:00:17,279 –> 00:00:19,680
تشخیص دهیم که فردی دیابتی است یا نه، بنابراین به این
8
00:00:19,680 –> 00:00:21,600
فکر کنید که این نوع دیابت است. یک
9
00:00:21,600 –> 00:00:24,720
مشکل بسیار رایج و اگر می توانید
10
00:00:24,720 –> 00:00:27,039
فرض کنید مدلی ایجاد کنید که با آن بتوانید
11
00:00:27,039 –> 00:00:29,279
به راحتی پیش بینی کنید که آیا فردی
12
00:00:29,279 –> 00:00:32,320
دیابتی است یا نه می تواند خوب باشد همچنین می
13
00:00:32,320 –> 00:00:34,640
توان آن را پیشرفته کرد.
14
00:00:34,640 –> 00:00:37,680
15
00:00:37,680 –> 00:00:40,320
دیابتی است یا
16
00:00:40,320 –> 00:00:42,079
خیر، اما این کاملاً خارج از
17
00:00:42,079 –> 00:00:45,120
محدوده است زیرا مجموعه داده هایی که ما داریم
18
00:00:45,120 –> 00:00:47,200
فقط در مورد بیمار دیابتی یا
19
00:00:47,200 –> 00:00:49,520
غیر دیابتی است همچنین می توانید به این
20
00:00:49,520 –> 00:00:52,160
فکر کنید که می توانید یک وب سایت ایجاد کنید که اساساً می تواند
21
00:00:52,160 –> 00:00:54,480
به کاربر اجازه دهد پارامترهای خاصی را وارد کند
22
00:00:54,480 –> 00:00:57,600
و سپس با این شما اساساً می توانید
23
00:00:57,600 –> 00:00:58,960
24
00:00:58,960 –> 00:01:02,320
تشخیص دهید که آیا فردی دیابتی است یا
25
00:01:02,320 –> 00:01:05,119
خیر، بنابراین می تواند به عنوان یک
26
00:01:05,119 –> 00:01:07,439
برنامه کاربردی عمومی باشد که می تواند یک وب سایت بر روی آن
27
00:01:07,439 –> 00:01:09,840
ساخته شود یا می تواند به عنوان کار کند. یک
28
00:01:09,840 –> 00:01:10,880
نرم افزار عمومی
29
00:01:10,880 –> 00:01:12,880
که می تواند فروخته
30
00:01:12,880 –> 00:01:14,799
شود، مثلاً به پزشکان،
31
00:01:14,799 –> 00:01:17,520
این بیمارستان ها یا آزمایشگاه
32
00:01:17,520 –> 00:01:19,280
هایی که در حال انجام آزمایشات هستند،
33
00:01:19,280 –> 00:01:21,040
مطمئن هستم که تا این زمان احتمالاً این کار را
34
00:01:21,040 –> 00:01:23,680
خواهند داشت، اما اگر نه، می تواند یک
35
00:01:23,680 –> 00:01:26,159
فرصت شگفت انگیز باشد، اما این پروژه
36
00:01:26,159 –> 00:01:28,880
اساساً برای یادگیری و درک اینکه چگونه
37
00:01:28,880 –> 00:01:31,520
میتوانید این نوع پیشبینیها را انجام دهید،
38
00:01:31,520 –> 00:01:33,600
اساساً مدلهای متعددی را بسازید که من
39
00:01:33,600 –> 00:01:36,560
آن را در اینجا نشان دادهام و
40
00:01:36,560 –> 00:01:38,720
سپس حداکثر استفاده را از آن ببرید، بنابراین ما این
41
00:01:38,720 –> 00:01:41,200
15 سؤال مختلف در مورد شروع
42
00:01:41,200 –> 00:01:43,280
از وارد کردن مجموعه داده داریم تا بررسی
43
00:01:43,280 –> 00:01:45,360
کنیم که آیا دارای مقادیر تهی است یا نه
44
00:01:45,360 –> 00:01:47,040
چند سطر و ستون وجود دارد
45
00:01:47,040 –> 00:01:49,759
فقط برای بدست آوردن اطلاعات مربوط به مجموعه داده ها،
46
00:01:49,759 –> 00:01:52,479
بررسی هر نوع داده ستونی
47
00:01:52,479 –> 00:01:54,560
48
00:01:54,560 –> 00:01:56,479
برای ایجاد آمار برای هر ستون
49
00:01:56,479 –> 00:01:58,000
مانند میانگین
50
00:01:58,000 –> 00:02:00,719
میانگین یا این میانه یا این
51
00:02:00,719 –> 00:02:02,240
صدک های مختلف مقادیری که
52
00:02:02,240 –> 00:02:03,280
دارید،
53
00:02:03,280 –> 00:02:04,640
عدم تعادل داده را با
54
00:02:04,640 –> 00:02:06,240
تجسم آن در
55
00:02:06,240 –> 00:02:08,639
کاوش هر متغیر و شناسایی
56
00:02:08,639 –> 00:02:12,640
نمودار پراکندگی شکل و نقاط پرت برای هر
57
00:02:12,640 –> 00:02:14,400
متغیر به visua بررسی کنید. جدول همبستگی رابطه لایز که
58
00:02:14,400 –> 00:02:16,640
همبستگی را تجسم می
59
00:02:16,640 –> 00:02:18,560
60
00:02:18,560 –> 00:02:20,400
کند، ایده ای را به دست آورید که چگونه متغیر هدف
61
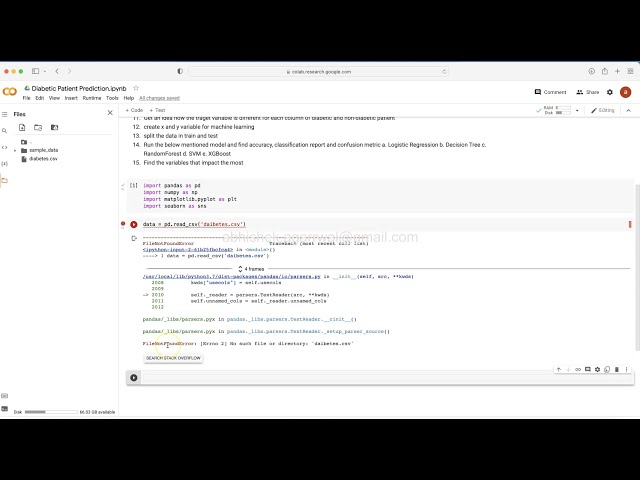
00:02:20,400 –> 00:02:22,480
برای هر ستون متفاوت است، فقط یک
62
00:02:22,480 –> 00:02:24,480
ایده سطح بالا قبل از
63
00:02:24,480 –> 00:02:26,319
شروع یادگیری ماشینی و سپس می دانید که
64
00:02:26,319 –> 00:02:28,400
در اینجا یادگیری ماشین اساساً
65
00:02:28,400 –> 00:02:30,800
با ایجاد متغیر x و y شروع می شود.
66
00:02:30,800 –> 00:02:32,879
سپس مجموعه دادهها را
67
00:02:32,879 –> 00:02:34,640
که یک روش معمول برای هر
68
00:02:34,640 –> 00:02:37,519
پروژه یادگیری ماشینی است، تقسیم میکنیم، جایی که شما
69
00:02:37,519 –> 00:02:39,760
آن را در مجموعه دادههای آموزشی مد آموزشی
70
00:02:39,760 –> 00:02:42,000
و آزمایش تقسیم میکنید تا
71
00:02:42,000 –> 00:02:43,440
بتوانید مدل را آموزش دهید و
72
00:02:43,440 –> 00:02:46,080
اعتبار دادههای آزمایشی را بررسی کنید و
73
00:02:46,080 –> 00:02:49,280
سپس این موارد مختلف را داریم. مدلهایی
74
00:02:49,280 –> 00:02:51,280
مانند درخت تصمیمگیری رگرسیون لجستیک
75
00:02:51,280 –> 00:02:55,120
به شما نشان میدهم جنگل تصادفی svm xg boost
76
00:02:55,120 –> 00:02:57,040
همه این مدلهای مختلف را به
77
00:02:57,040 –> 00:02:59,200
شما نشان میدهم، به شما نشان میدهم که چگونه میتوانید آن را اجرا کنید و
78
00:02:59,200 –> 00:03:01,440
گزارش طبقهبندی دقت آنها و
79
00:03:01,440 –> 00:03:05,120
متریک سردرگمی را پیدا کنید که بیشتر برای
80
00:03:05,120 –> 00:03:07,360
انجام تفسیر دادهها
81
00:03:07,360 –> 00:03:09,200
و دریافت آن است. بیشترین سود را در مورد اینکه چگونه
82
00:03:09,200 –> 00:03:11,440
می خواهید نتایج را از
83
00:03:11,440 –> 00:03:13,920
این مدل های مختلف دریافت کنید و در نهایت
84
00:03:13,920 –> 00:03:15,680
متغیر را پیدا کنید تواناییهایی که بیشترین تأثیر را دارند
85
00:03:15,680 –> 00:03:18,000
معمولاً یک سؤال بسیار متداول است که
86
00:03:18,000 –> 00:03:19,680
کاربران میپرسند
87
00:03:19,680 –> 00:03:21,280
چه متغیرهایی هستند که بیشتر تأثیر میگذارند
88
00:03:21,280 –> 00:03:24,159
یا کدامیک بیشتر بر
89
00:03:24,159 –> 00:03:27,280
مدل
90
00:03:27,280 –> 00:03:29,280
تأثیر میگذارند، بنابراین آیا مانند یک متغیر است که بیشترین تأثیر را دارد
91
00:03:29,280 –> 00:03:30,879
یا دو متغیر که بیشترین تأثیر را دارد
92
00:03:30,879 –> 00:03:33,599
یا بیایید بگوییم کاملاً برعکس
93
00:03:33,599 –> 00:03:35,599
که در متغیرها کمترین تأثیر را میگذارند،
94
00:03:35,599 –> 00:03:37,840
احتمالاً حتی میتوانید به این فکر کنید که
95
00:03:37,840 –> 00:03:39,760
اگر بتوانیم آنها را حذف کنیم، آیا این
96
00:03:39,760 –> 00:03:42,319
میتواند دقت مدل را بهبود بخشد یا خیر،
97
00:03:42,319 –> 00:03:44,000
بنابراین چیزی بسیار جالب است که
98
00:03:44,000 –> 00:03:47,360
میتوانید در این
99
00:03:47,360 –> 00:03:48,959
پروژه استودیویی در این مورد،
100
00:03:48,959 –> 00:03:50,959
به طور کلی پیدا کنید. این
101
00:03:50,959 –> 00:03:52,959
تقریباً یک پروژه پایان به پایان خواهد بود
102
00:03:52,959 –> 00:03:55,680
که ما آن را مرحله به مرحله به شما نشان خواهیم داد
103
00:03:55,680 –> 00:03:56,560
104
00:03:56,560 –> 00:03:59,200
و اینجا فایل
105
00:03:59,200 –> 00:04:01,200
فایل دیابت است و اگر تا به حال
106
00:04:01,200 –> 00:04:04,159
مشاهده کرده بودید من از Google collab استفاده می کنم
107
00:04:04,159 –> 00:04:05,680
108
00:04:05,680 –> 00:04:08,720
که collab است.
109
00:04:08,720 –> 00:04:12,720
.research.google.com آنلاین است، همانطور که می
110
00:04:12,720 –> 00:04:15,439
توانید دفترچه یادداشت پایتون را ببینید، همانطور که می توانید
111
00:04:15,439 –> 00:04:17,279
علامت نوت بوک را ببینید وجود دارد
112
00:04:17,279 –> 00:04:19,519
و دلیل استفاده از آن این است
113
00:04:19,519 –> 00:04:21,759
که اشتراک گذاری آن با شما مشکل است. y
114
00:04:21,759 –> 00:04:24,639
آسان من می توانم شما به سادگی می توانید لینک
115
00:04:24,639 –> 00:04:26,080
116
00:04:26,080 –> 00:04:29,120
این دفترچه یادداشت را در
117
00:04:29,120 –> 00:04:31,520
توضیحات به همراه پیوند مجموعه داده پیدا کنید
118
00:04:31,520 –> 00:04:33,360
تا بتوانید هر دوی این موارد را
119
00:04:33,360 –> 00:04:35,840
به راحتی دریافت کنید و یک بار آن را تمرین کنید،
120
00:04:35,840 –> 00:04:37,600
فرض کنید این ویدیو را گذرانده اید. یا
121
00:04:37,600 –> 00:04:39,759
اگر میخواهید این کار را در کنار هم انجام دهید، اشکالی ندارد،
122
00:04:39,759 –> 00:04:42,320
بنابراین اولین کاری که
123
00:04:42,320 –> 00:04:44,960
انجام دادهام این است که دادهها را
124
00:04:44,960 –> 00:04:46,720
با استفاده از این پیوند
125
00:04:46,720 –> 00:04:50,080
یا با استفاده از این دکمه
126
00:04:50,080 –> 00:04:53,440
آپلود کردهام که اساساً میگوید آپلود در ذخیرهسازی جلسه
127
00:04:53,440 –> 00:04:55,759
یعنی برای این جلسه
128
00:04:55,759 –> 00:04:57,759
وقتی جلسه تمام شد، این
129
00:04:57,759 –> 00:05:00,639
داده را آپلود میکنید، فایل درست حذف میشود، بنابراین اگر
130
00:05:00,639 –> 00:05:02,160
میخواهید دوباره این فایل را اجرا کنید،
131
00:05:02,160 –> 00:05:05,280
ممکن است لازم باشد این فایل را دوباره آپلود کنید،
132
00:05:05,280 –> 00:05:07,360
بنابراین ابتدا
133
00:05:07,360 –> 00:05:09,680
کتابخانهها را وارد میکنیم و انجام ندهیم.
134
00:05:09,680 –> 00:05:11,520
نگران نباشید من همه
135
00:05:11,520 –> 00:05:14,000
کتابخانه ها را به یکباره وارد نمی کنم،
136
00:05:14,000 –> 00:05:16,400
زمانی که نیاز وجود داشته باشد، کتابخانه را وارد می کنم، بنابراین
137
00:05:16,400 –> 00:05:18,240
شما می دانید که
138
00:05:18,240 –> 00:05:21,280
وقتی یک کتابخانه خاص نیاز دارد،
139
00:05:21,280 –> 00:05:23,600
بر اساس نیاز شما نیاز دارید،
140
00:05:23,600 –> 00:05:26,000
بسیار خوب است، بنابراین ابتدا پانداها را وارد کنید
141
00:05:26,000 –> 00:05:27,759
s pd زیرا ما باید مجموعه داده را وارد
142
00:05:27,759 –> 00:05:30,240
کنیم و میتوانیم بسیاری از عملیات مربوط به مجموعه داده را
143
00:05:30,240 –> 00:05:32,400
اجرا کنیم، بنابراین اولین چیز
144
00:05:32,400 –> 00:05:34,639
وارد کردن پانداها و وارد کردن numpy
145
00:05:34,639 –> 00:05:37,199
بهعنوان np است زیرا ممکن است برخی از عملیاتها
146
00:05:37,199 –> 00:05:39,199
به کتابخانه numpy نیاز داشته باشند، بنابراین اگر بخواهید به دو کتابخانه بسیار
147
00:05:39,199 –> 00:05:41,680
استاندارد نیاز دارید. ما میتوانیم
148
00:05:41,680 –> 00:05:45,600
فرض کنیم matplotlib را نیز وارد کنیم، بنابراین
149
00:05:45,600 –> 00:05:48,160
matplotlib کتابخانه تجسم است،
150
00:05:48,160 –> 00:05:50,160
بنابراین ما گامی
151
00:05:50,160 –> 00:05:53,280
برای تجسم داریم، بنابراین matplotlib
152
00:05:53,280 –> 00:05:54,479
نقطه
153
00:05:54,479 –> 00:05:57,199
فی نمودار را
154
00:05:57,280 –> 00:05:59,919
به صورت plt وارد میکنیم و من یک
155
00:05:59,919 –> 00:06:03,199
کتابخانه تجسم کتابخانه دیگر را وارد
156
00:06:03,199 –> 00:06:06,319
میکنم، c متولد شده بهعنوان sns که همچنین در تجسم مفید است،
157
00:06:06,319 –> 00:06:08,960
بنابراین حداقل
158
00:06:08,960 –> 00:06:12,479
برای نقطه شماره 11 ما کتابخانه را وارد کرده ایم
159
00:06:12,479 –> 00:06:14,400
هر چیزی که مربوط
160
00:06:14,400 –> 00:06:16,880
به یادگیری ماشین است که از
161
00:06:16,880 –> 00:06:19,120
مرحله شماره 12 تا مرحله شماره 15 است،
162
00:06:19,120 –> 00:06:21,120
چیزی است که من آن را رها کرده ام و
163
00:06:21,120 –> 00:06:22,800
از آن استفاده خواهم کرد یا خواهم کرد. هر زمان
164
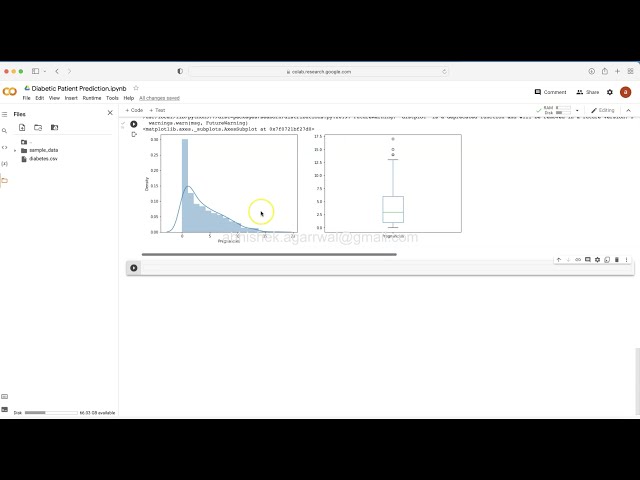
00:06:22,800 –> 00:06:26,400
که نیاز باشد، وارد کنید، بنابراین اگر اجرا کنم،
165
00:06:26,400 –> 00:06:28,880
می بینید که یک اجرا در حال انجام است
166
00:06:28,880 –> 00:06:32,000
و اکنون تقریباً انجام شده است،
167
00:06:32,000 –> 00:06:34,479
زیرا در حال تکمیل است، بنابراین چهار ثانیه طول کشید.
168
00:06:34,479 –> 00:06:35,600
169
00:06:35,600 –> 00:06:36,720
170
00:06:36,720 –> 00:06:39,520
در حال حاضر بعد از اینکه این کار انجام شد،
171
00:06:39,520 –> 00:06:42,720
چیز بعدی این است که داده ها را وارد کنم، بنابراین من از همان داده ها
172
00:06:42,720 –> 00:06:44,240
استفاده می
173
00:06:44,240 –> 00:06:47,440
کنم، این داده های شی را ایجاد می کنم
174
00:06:47,440 –> 00:06:50,080
و از pandas pd
175
00:06:50,080 –> 00:06:53,759
pd dot read underscore csv استفاده می کنم
176
00:06:53,759 –> 00:06:56,800
و آن دیابت خواهد بود
177
00:06:56,800 –> 00:06:59,039
، فکر می کنم املای آن باید یکسان باشد. d i
178
00:06:59,039 –> 00:07:02,560
a b e t es dot csv
179
00:07:02,560 –> 00:07:05,039
بنابراین اگر اجرا
180
00:07:05,039 –> 00:07:06,800
کنم
181
00:07:06,800 –> 00:07:08,639
یک خطا
182
00:07:08,639 –> 00:07:12,319
می بینید درست است هیچ فایل یا دایرکتوری
183
00:07:12,319 –> 00:07:13,680
مانندی که گفتم
184
00:07:13,680 –> 00:07:15,120
این نباید
185
00:07:15,120 –> 00:07:19,520
خطا داشته باشد بنابراین d a i نیست اما d i a
186
00:07:19,520 –> 00:07:21,199
و اجرا کنید
187
00:07:21,199 –> 00:07:23,280
بنابراین اکنون اجرا شده است
188
00:07:23,280 –> 00:07:26,960
پس بیایید چند ردیف اول و حتی i را مرور کنیم
189
00:07:26,960 –> 00:07:29,360
قبل از این می توان گفت
190
00:07:29,360 –> 00:07:31,520
که قبل از اینکه مقادیر تهی را بررسی کنیم
191
00:07:31,520 –> 00:07:34,000
یا بیایید مقادیر تهی را بررسی کنیم
192
00:07:34,000 –> 00:07:36,000
تا مقادیر تهی را بررسی کنیم، دستوری که
193
00:07:36,000 –> 00:07:38,080
باید بنویسید data
194
00:07:38,080 –> 00:07:39,039
195
00:07:39,039 –> 00:07:42,840
dot است این است که آیا دارای مقدار تهی است یا خیر،
196
00:07:42,840 –> 00:07:45,919
پس وقتی آن را اجرا
197
00:07:45,919 –> 00:07:47,919
کردید با دیدن
198
00:07:47,919 –> 00:07:49,360
هر متغیر
199
00:07:49,360 –> 00:07:52,479
و اینکه آیا مقدار تهی دارد یا نه
200
00:07:52,479 –> 00:07:53,599
درست است، بنابراین
201
00:07:53,599 –> 00:07:56,160
هیچ ستونی مقدار تهی ندارد و هیچ چیز
202
00:07:56,160 –> 00:07:58,240
نمی تواند بهتر از این باشد، با این حال
203
00:07:58,240 –> 00:07:59,759
وضعیت زندگی واقعی بسیار
204
00:07:59,759 –> 00:08:02,400
متفاوت خواهد بود، شما در این مرحله با مشکلات زیادی روبرو خواهید شد،
205
00:08:02,400 –> 00:08:04,319
بنابراین احتمالاً در یک
206
00:08:04,319 –> 00:08:06,720
مجموعه داده متفاوت، وقتی موقعیتی
207
00:08:06,720 –> 00:08:09,199
مانند این داشته باشیم، با آن مقابله می کنیم،
208
00:08:09,199 –> 00:08:10,080
209
00:08:10,080 –> 00:08:12,240
بنابراین اولین کاری که می توانم انجام دهم این
210
00:08:12,240 –> 00:08:14,479
است که می توانم
211
00:08:14,479 –> 00:08:15,360
212
00:08:15,360 –> 00:08:18,080
با استفاده از سر نقطه داده عملیات، چند ردیف را برای شما بررسی کنم
213
00:08:18,080 –> 00:08:20,800
و این کار ادامه خواهد داشت.
214
00:08:20,800 –> 00:08:22,080
215
00:08:22,080 –> 00:08:24,240
216
00:08:24,240 –> 00:08:26,960
اگر میخواهید
217
00:08:26,960 –> 00:08:28,960
به هر ردیفی دسترسی داشته
218
00:08:28,960 –> 00:08:32,080
باشید، میتوانید به سادگی بگویید داده 0 و
219
00:08:32,080 –> 00:08:34,880
آن سطر خاص را
220
00:08:34,880 –> 00:08:35,760
برای شما دریافت خواهید کرد
221
00:08:35,760 –> 00:08:39,399
222
00:08:41,279 –> 00:08:42,559
.
223
00:08:42,559 –> 00:08:46,240
قفل i
224
00:08:46,240 –> 00:08:47,279
225
00:08:47,279 –> 00:08:49,920
را از دست دادید و این اکنون مقدار ردیف اول را به ما می
226
00:08:49,920 –> 00:08:50,880
دهد
227
00:08:50,880 –> 00:08:54,720
بنابراین بارداری 6 همان چیزی است که شما دارید 6
228
00:08:54,720 –> 00:08:58,800
گلوکز 148 شما 148 فشار خون
229
00:08:58,800 –> 00:09:00,560
72
230
00:09:00,560 –> 00:09:03,600
ضخامت پوست 35 و غیره دارید بنابراین
231
00:09:03,600 –> 00:09:04,880
فقط می خواستم یک عمل متفاوت را به شما نشان دهم
232
00:09:04,880 –> 00:09:07,600
که از طریق آن اگر شما پنج
233
00:09:07,600 –> 00:09:10,080
ردیف میخواهید یا اگر هر ردیف خاصی را
234
00:09:10,080 –> 00:09:13,200
با استفاده از ایندکس میخواهید، چگونه میتوانید این را واکشی کنید،
235
00:09:13,200 –> 00:09:16,000
بنابراین این چیزی است که میخواهیم دریافت کنیم،
236
00:09:16,000 –> 00:09:16,959
اکنون
237
00:09:16,959 –> 00:09:19,680
بررسی کنید که چند ردیف و
238
00:09:19,680 –> 00:09:21,519
ستون در مجموعه دادهها وجود دارد،
239
00:09:21,519 –> 00:09:22,480
خوب
240
00:09:22,480 –> 00:09:25,680
اجازه دهید شکل نقطه داده را
241
00:09:25,680 –> 00:09:28,160
به سادگی با این کار انجام دهیم. این را به ما خواهد
242
00:09:28,160 –> 00:09:32,240
گفت شما در حال حاضر 768 سطر و 9 ستون دارید و
243
00:09:32,240 –> 00:09:33,200
244
00:09:33,200 –> 00:09:34,959
پس از
245
00:09:34,959 –> 00:09:36,560
آن تعداد سطر و ستونی که می
246
00:09:36,560 –> 00:09:37,760
شناسید،
247
00:09:37,760 –> 00:09:40,399
نوع داده هر ستون را بررسی کنید
248
00:09:40,399 –> 00:09:41,279
خوب است،
249
00:09:41,279 –> 00:09:44,240
بنابراین آنچه شما نیاز دارید اطلاعات نقطه
250
00:09:44,240 –> 00:09:45,200
اطلاعات
251
00:09:45,200 –> 00:09:47,680
و پرانتز است که
252
00:09:47,680 –> 00:09:48,399
253
00:09:48,399 –> 00:09:51,519
هر متغیر را همانطور که می بینید به شما می دهد.
254
00:09:51,519 –> 00:09:53,040
و
255
00:09:53,040 –> 00:09:56,399
این همه عدد صحیح است.
256
00:09:56,399 –> 00:09:58,480
257
00:09:58,480 –> 00:10:00,399
258
00:10:00,399 –> 00:10:02,000
259
00:10:02,000 –> 00:10:04,480
260
00:10:04,480 –> 00:10:06,640
261
00:10:06,640 –> 00:10:08,800
یک عدد صحیح
262
00:10:08,800 –> 00:10:10,640
یا فرض کنید از یک شناور
263
00:10:10,640 –> 00:10:12,560
به عنوان مثال در این مورد،
264
00:10:12,560 –> 00:10:16,399
بنابراین ما این را تا اینجا دریافت کرده ایم
265
00:10:16,399 –> 00:10:20,000
همچنین به هر دلیلی بگوییم اگر شما هستید
266
00:10:20,000 –> 00:10:21,920
اگر فقط می خواهید نام
267
00:10:21,920 –> 00:10:23,040
ستون ها را بدست
268
00:10:23,040 –> 00:10:25,360
آورید، می توانید از این دستور استفاده کنید:
269
00:10:25,360 –> 00:10:27,320
فقط چیزهای اضافی است که من به شما
270
00:10:27,320 –> 00:10:30,240
data.columns می گویم و با این کار
271
00:10:30,240 –> 00:10:33,360
نام تمام ستون ها را به شما می دهد، فرض
272
00:10:33,360 –> 00:10:35,760
کنید می خواهید نام همه ستون ها را دریافت کنید، بنابراین
273
00:10:35,760 –> 00:10:38,160
به جای نوشتن یک به یک، فقط
274
00:10:38,160 –> 00:10:40,880
کل لیست را دریافت کنید و کارتان تمام شد.
275
00:10:40,880 –> 00:10:42,560
درست است پس این یک افزودنی است چیزهای زیادی که
276
00:10:42,560 –> 00:10:44,480
می خواستم به شما بگویم و به
277
00:10:44,480 –> 00:10:46,000
غیر از
278
00:10:46,000 –> 00:10:47,279
279
00:10:47,279 –> 00:10:48,640
سؤالی که اینجا گذاشته ام
280
00:10:48,640 –> 00:10:51,040
به شما می گویم به محض اینکه احساس کنم این
281
00:10:51,040 –> 00:10:52,880
چیزی است که می تواند برای شما مفید باشد
282
00:10:52,880 –> 00:10:54,959
همچنین می تواند سؤالات مصاحبه باشد.
283
00:10:54,959 –> 00:10:56,640
284
00:10:56,640 –> 00:10:59,680
هر دستور را در اینجا
285
00:10:59,680 –> 00:11:02,240
به عنوان سؤال مصاحبه بیان کنید که چگونه می توانید به یک
286
00:11:02,240 –> 00:11:05,519
ردیف خاص بر اساس نمایه دسترسی داشته باشید، بنابراین
287
00:11:05,519 –> 00:11:07,360
این دستوری است که ممکن است لازم باشد بگویید
288
00:11:07,360 –> 00:11:10,720
همچنین چگونه
289
00:11:10,720 –> 00:11:13,040
مقدار گم شده برای هر ستون را بررسی کنید، سپس
290
00:11:13,040 –> 00:11:14,800
این دستوری است که اساساً به آن نیاز دارید.
291
00:11:14,800 –> 00:11:16,959
292
00:11:16,959 –> 00:11:17,839
293
00:11:17,839 –> 00:11:21,680
همین حالا به آنها بگویید پس حالا بیایید به مرحله بعدی خود
294
00:11:21,680 –> 00:11:25,600
295
00:11:25,600 –> 00:11:26,480
296
00:11:26,480 –> 00:11:28,640
297
00:11:28,640 –> 00:11:31,600
298
00:11:31,600 –> 00:11:33,040
299
00:11:33,040 –> 00:11:36,079
برویم و آماری را برای هر ستون تولید کنیم، این کار را میتوانید با استفاده از دستور describe انجام دهید، یک بار که بگویید data.describe
300
00:11:36,079 –> 00:11:38,399
در اینجا یک جدول زیبا
301
00:11:38,399 –> 00:11:40,880
در بالا خواهید داشت.
302
00:11:40,880 –> 00:11:43,519
تعداد استاندارد را داشته باشید
303
00:11:43,519 –> 00:11:45,440
متأسفم میانگین انحراف
304
00:11:45,440 –> 00:11:48,000
معیار حداقل مقدار حداکثر مقدار و
305
00:11:48,000 –> 00:11:51,040
سپس صدک 25 صدک 15
306
00:11:51,040 –> 00:11:53,760
که همچنین مقدار متوسط و صدک 17 اس
307
00:11:53,760 –> 00:11:56,240
این اساساً به ما کمک می کند تا در
308
00:11:56,240 –> 00:11:58,399
به داده ها کمی بیشتر در عمق
309
00:11:58,399 –> 00:12:02,240
به عنوان حداقل مقدار 0 و 15 است
310
00:12:02,240 –> 00:12:05,120
به طور مشابه اگر مقدار bmi را می بینید حداقل
311
00:12:05,120 –> 00:12:08,639
مقدار 0 و حداکثر مقدار 16 است که
312
00:12:08,639 –> 00:12:10,720
به من می گوید که
313
00:12:10,720 –> 00:12:13,600
bmi متاسفم این حداقل مقدار برای bmi
314
00:12:13,600 –> 00:12:16,800
در هیچ کدام نمی تواند صفر باشد. اگر
315
00:12:16,800 –> 00:12:19,120
اشتباه نمیکنم، پس این نوع
316
00:12:19,120 –> 00:12:21,600
آمار میتواند به شما کمک کند تا
317
00:12:21,600 –> 00:12:24,160
اگر این میانگین 3
318
00:12:24,160 –> 00:12:28,079
و میانگین 3.8 را میبینید سریعاً تفسیر کنید، همانطور که اگر
319
00:12:28,079 –> 00:12:29,200
320
00:12:29,200 –> 00:12:31,760
دوره آمار را انجام داده باشید، میدانید که میانگین
321
00:12:31,760 –> 00:12:35,040
تحت تأثیر مقدار شدید است. یا
322
00:12:35,040 –> 00:12:37,440
در سمت بالا یا پایین، بنابراین
323
00:12:37,440 –> 00:12:39,680
در بیشتر موارد خواهید دید که مقدار
324
00:12:39,680 –> 00:12:41,200
با میانگین متفاوت است،
325
00:12:41,200 –> 00:12:43,519
اما نباید خیلی متفاوت باشد،
326
00:12:43,519 –> 00:12:44,720
درست
327
00:12:44,720 –> 00:12:47,600
مثل 3 تا 3.8 خوب است، اما اگر 3 باشد و
328
00:12:47,600 –> 00:12:49,360
این 10 باشد، به این معنی است که چیزی
329
00:12:49,360 –> 00:12:50,639
واقعا اشتباه است.
330
00:12:50,639 –> 00:12:54,720
این جدول
331
00:12:54,720 –> 00:12:58,320
اساساً در مورد اینکه آمار چیست و
332
00:12:58,320 –> 00:13:00,399
چگونه میتوانید انواع
333
00:13:00,399 –> 00:13:03,120
مختلف آمارهای مختلف را تفسیر کنید و از آن بهترین بهره
334
00:13:03,120 –> 00:13:04,160
را ببرید، توضیح میدهد،
335
00:13:04,160 –> 00:13:07,279
بنابراین پس از آن
336
00:13:07,279 –> 00:13:08,240
337
00:13:08,240 –> 00:13:11,279
آمار برای هر ستون تولید
338
00:13:11,279 –> 00:13:13,920
کنید، عدم تعادل دادهها را اساساً بررسی کنید.
339
00:13:13,920 –> 00:13:15,279
این
340
00:13:15,279 –> 00:13:17,200
در مورد متغیر هدف است
341
00:13:17,200 –> 00:13:18,560
که به
342
00:13:18,560 –> 00:13:21,360
343
00:13:21,360 –> 00:13:23,680
عنوان مثال در اینجا در این مورد
344
00:13:23,680 –> 00:13:26,320
نتیجه داده چند متغیر وجود دارد،
345
00:13:26,320 –> 00:13:29,440
بنابراین
346
00:13:30,800 –> 00:13:32,560
347
00:13:32,560 –> 00:13:36,399
مقدار نقطه زیر خط نتیجه داده
348
00:13:37,200 –> 00:13:38,720
ها درست حساب می شود
349
00:13:38,720 –> 00:13:39,920
350
00:13:39,920 –> 00:13:41,760
و چیزی که به شما می دهد
351
00:13:41,760 –> 00:13:45,680
این است که صفر غیر دیابتی چند مقدار دارد
352
00:13:45,680 –> 00:13:48,480
و یک. که دیابتی است اکنون در
353
00:13:48,480 –> 00:13:49,519
این مورد
354
00:13:49,519 –> 00:13:52,880
مقادیر دیابتی
355
00:13:52,880 –> 00:13:55,440
نیمی از مقادیر غیر دیابتی است
356
00:13:55,440 –> 00:13:58,320
که به این معنی است که مجموعه داده های شما یا شانس خوبی وجود دارد
357
00:13:58,320 –> 00:14:02,320
که پیش بینی های شما ممکن
358
00:14:02,320 –> 00:14:05,279
است کمی بیشتر تحت تأثیر
359
00:14:05,279 –> 00:14:07,680
این مشاهدات غیر دیابتی باشد.
360
00:14:07,680 –> 00:14:10,320
به این معناست که یک فرد دیابتی وجود دارد اما
361
00:14:10,320 –> 00:14:11,680
مدل ما پیشبینی میکند که این فرد
362
00:14:11,680 –> 00:14:14,000
غیر دیابتی است و در این صورت ممکن است
363
00:14:14,000 –> 00:14:16,959
لازم باشد با
364
00:14:16,959 –> 00:14:19,839
گرفتن تعداد زیادی از مجموعه دادههای آزمایشی و دادن
365
00:14:19,839 –> 00:14:22,000
مقادیر حساس به آنها و بررسی
366
00:14:22,000 –> 00:14:23,920
اینکه آیا داده است یا خیر، دادهها را به درستی تأیید کنیم. خروجی ما خوب است
367
00:14:23,920 –> 00:14:25,519
یا نه بنابراین این برای اطلاع شماست
368
00:14:25,519 –> 00:14:27,600
اما بسیار مهم است که ما
369
00:14:27,600 –> 00:14:28,800
این را ببینیم
370
00:14:28,800 –> 00:14:29,600
اما
371
00:14:29,600 –> 00:14:32,000
در این مورد در این مورد این کار بسیار آسان است
372
00:14:32,000 –> 00:14:34,880
اما اگر فرض کنیم به
373
00:14:34,880 –> 00:14:36,880
دلایلی نمی توانید این را تفسیر کنید
374
00:14:36,880 –> 00:14:39,360
که درصد مقادیر اینجا
375
00:14:39,360 –> 00:14:41,600
چقدر است و در اینجا چند درصد است، پس چه
376
00:14:41,600 –> 00:14:43,600
کاری انجام خواهید داد، بنابراین این می تواند یک
377
00:14:43,600 –> 00:14:46,000
سؤال مصاحبه نیز باشد، بنابراین آنچه باید
378
00:14:46,000 –> 00:14:47,920
در این مورد انجام دهید این است که باید به اینجا بیایید
379
00:14:47,920 –> 00:14:51,040
و به سادگی بگویید نرمال کردن برابر است. درست است
380
00:14:51,040 –> 00:14:52,720
و وقتی این کار را انجام
381
00:14:52,720 –> 00:14:55,360
دادید به شما درصدی می دهد که
382
00:14:55,360 –> 00:14:56,560
به این معنی است که
383
00:14:56,560 –> 00:15:00,079
شما 65 مورد از مقادیر
384
00:15:00,079 –> 00:15:02,639
دیابتی را دارید که 34
385
00:15:02,639 –> 00:15:05,600
یا تقریباً 35 درصد
386
00:15:05,600 –> 00:15:07,760
آن را دارید که اساساً به شما یک مقدار مطلق می
387
00:15:07,760 –> 00:15:10,160
دهد یا احتمالاً کاربر نهایی یا
388
00:15:10,160 –> 00:15:12,000
مدیریت شما می دهد. به دنبال
389
00:15:12,000 –> 00:15:14,160
این باشید که با چه چیزی سر و کار داریم یا در حال حاضر با کدام طرف داده سروکار
390
00:15:14,160 –> 00:15:15,360
391
00:15:15,360 –> 00:15:16,959
392
00:15:16,959 –> 00:15:19,199
داریم چه می شود اگر بخواهید
393
00:15:19,199 –> 00:15:21,760
همراه با این تجسم کنید، بنابراین راهی که می
394
00:15:21,760 –> 00:15:24,079
خواهید این کار را انجام دهید، من از
395
00:15:24,079 –> 00:15:27,440
پیوند c استفاده خواهم کرد. کتابخانهها sns sns
396
00:15:27,440 –> 00:15:29,519
و من از نمودار شمارش برای شمارش
397
00:15:29,519 –> 00:15:33,920
این مقادیر استفاده خواهم کرد که در آن متغیر x من
398
00:15:33,920 –> 00:15:35,360
نتیجه است
399
00:15:35,360 –> 00:15:38,160
و دادههای من داده است.
400
00:15:38,160 –> 00:15:40,240
401
00:15:40,240 –> 00:15:43,199
402
00:15:43,199 –> 00:15:44,800
403
00:15:44,800 –> 00:15:47,839
به عنوان یک خروجی ut یک
404
00:15:47,839 –> 00:15:50,399
نمودار نواری ساده است که اساساً به ما کمک می کند تا
405
00:15:50,399 –> 00:15:53,040
تمام این اطلاعات را که
406
00:15:53,040 –> 00:15:56,000
به تازگی آن ها را در اینجا رسم کرده ایم تجسم کنیم، بنابراین همانطور که
407
00:15:56,000 –> 00:15:56,959
می
408
00:15:56,959 –> 00:15:58,639
بینید، نتیجه
409
00:15:58,639 –> 00:16:01,920
0 و 1 0 دارای مقادیر بیشتری است، یک مقدار کمتر
410
00:16:01,920 –> 00:16:04,399
و تقریباً
411
00:16:04,399 –> 00:16:06,959
نصف درست است، اما این درصد می تواند
412
00:16:06,959 –> 00:16:09,279
اساساً به طور کامل روشن کنید
413
00:16:09,279 –> 00:16:12,000
که ما چیستیم که دقیقاً چه
414
00:16:12,000 –> 00:16:13,199
چیزی در مجموعه داده وجود دارد،
415
00:16:13,199 –> 00:16:16,000
بنابراین این یک چیزی است که
416
00:16:16,000 –> 00:16:19,839
اساساً باید با او انجام دهید تا
417
00:16:19,839 –> 00:16:21,839
آن را ترسیم کنید، اما
418
00:16:21,839 –> 00:16:24,959
آنچه من می خواهم شما انجام دهید اساساً این است که من
419
00:16:24,959 –> 00:16:26,079
420
00:16:26,079 –> 00:16:28,560
یکی را به شما نشان خواهم داد. روش دیگری که بود
421
00:16:28,560 –> 00:16:30,720
یا یک مرحله
422
00:16:30,720 –> 00:16:33,440
هر متغیر را کاوش کنید و شکل
423
00:16:33,440 –> 00:16:34,880
و حالت پرت را شناسایی کنید،
424
00:16:34,880 –> 00:16:38,399
بنابراین چگونه میتوانیم این مرحله را تکمیل کنیم،
425
00:16:38,399 –> 00:16:39,440
استفاده
426
00:16:39,440 –> 00:16:40,320
از
427
00:16:40,320 –> 00:16:42,240
هیستوگرام
428
00:16:42,240 –> 00:16:45,040
و نمودار کادر درست است، بنابراین اساساً
429
00:16:45,040 –> 00:16:47,440
آنچه را که باید ترسیم کنیم دو رقم است، بنابراین من
430
00:16:47,440 –> 00:16:50,160
از کتابخانه matplotlib استفاده خواهم کرد.
431
00:16:50,160 –> 00:16:52,240
که من در اینجا استفاده کرده ام
432
00:16:52,240 –> 00:16:54,800
matplotlib را به صورت plt و در
433
00:16:54,800 –> 00:16:56,880
ترکیب
434
00:16:56,880 –> 00:16:59,120
با کتابخانه cbon وارد می کنم،
435
00:16:59,120 –> 00:17:01,199
بنابراین اینجاست که همه چیز کمی
436
00:17:01,199 –> 00:17:03,759
مشکل خواهد بود، اما این کد را نگه دارید یا از
437
00:17:03,759 –> 00:17:06,559
این کد برای آسان کردن
438
00:17:06,559 –> 00:17:09,520
پروژه یا کتاب کار خود
439
00:17:09,520 –> 00:17:11,439
در مدت زمان استفاده کنید. از ایجاد این نوع
440
00:17:11,439 –> 00:17:13,520
خروجیها، بنابراین
441
00:17:13,520 –> 00:17:16,240
شکل نقطهای من میگویم من به دو شکل نیاز دارم و به زیر نمودار نقطهای نیاز داریم
442
00:17:16,240 –> 00:17:18,959
443
00:17:18,959 –> 00:17:19,839
444
00:17:19,839 –> 00:17:21,919
445
00:17:21,919 –> 00:17:24,400
و نمودار فرعی اساساً
446
00:17:24,400 –> 00:17:27,679
چیزی است که ما نیاز داریم یک دو یک، اوه، اساساً
447
00:17:27,679 –> 00:17:30,000
این اولین نمودار خواهد بود، بنابراین
448
00:17:30,000 –> 00:17:34,799
این چیزی که ما مشخص می کنیم یک دو یک است
449
00:17:34,799 –> 00:17:37,919
و روشی که ما آن را تفسیر می کنیم اساساً
450
00:17:37,919 –> 00:17:40,320
یک ردیف
451
00:17:40,320 –> 00:17:42,400
اول است و اساساً نشان می دهد که
452
00:17:42,400 –> 00:17:44,880
شما یک سطر دو ستون دارید و این اولین نمودار خواهد بود.
453
00:17:44,880 –> 00:17:47,120
454
00:17:47,120 –> 00:17:49,120
این همان چیزی است که یک دو یک
455
00:17:49,120 –> 00:17:50,320
نشان می دهد
456
00:17:50,320 –> 00:17:52,960
خوب است. Plt نقطه فرعی یک دو یک
457
00:17:52,960 –> 00:17:56,640
sns نقطه فاصله من گفتم uh هیستوگرام
458
00:17:56,640 –> 00:17:58,559
بنابراین ما از این نمودار یا
459
00:17:58,559 –> 00:18:01,120
نمودار توزیع و
460
00:18:01,120 –> 00:18:02,320
داده ها استفاده
461
00:18:02,320 –> 00:18:06,160
خواهیم کرد، فرض کنید از یک متغیر استفاده
462
00:18:06,160 –> 00:18:08,799
463
00:18:08,799 –> 00:18:11,600
464
00:18:11,600 –> 00:18:12,559
465
00:18:12,559 –> 00:18:15,039
466
00:18:15,039 –> 00:18:16,880
کنیم.
467
00:18:16,880 –> 00:18:19,919
نمودار فرعی نقطه
468
00:18:19,919 –> 00:18:21,840
اول سطر اول بود و
469
00:18:21,840 –> 00:18:24,960
یک سطر دو ستون نمودار دوم پس
470
00:18:24,960 –> 00:18:27,200
یک دو دو بنابراین هر زمان که
471
00:18:27,200 –> 00:18:30,320
آن را می نویسید این چیزی را که من می گفتم تکرار کنید
472
00:18:30,320 –> 00:18:34,480
و در اینجا ما قرار بود آه
473
00:18:34,480 –> 00:18:37,760
ترسیم کنیم آه نمودار جعبه را رسم کنیم تا
474
00:18:37,760 –> 00:18:40,400
حاملگی
475
00:18:40,400 –> 00:18:41,360
نقطه
476
00:18:41,360 –> 00:18:44,559
طرح جعبه نقطه
477
00:18:44,559 –> 00:18:47,360
و ما با از اندازه شکل
478
00:18:47,360 –> 00:18:50,799
اجازه دهید در این مورد
479
00:18:50,799 –> 00:18:53,120
15 کاما است.
480
00:18:53,120 –> 00:18:55,440
481
00:18:55,440 –> 00:18:58,160
482
00:18:58,160 –> 00:18:59,679
483
00:18:59,679 –> 00:19:02,320
484
00:19:02,320 –> 00:19:05,120
و همانطور
485
00:19:05,120 –> 00:19:06,240
که می بینید
486
00:19:06,240 –> 00:19:08,240
مقادیر در اینجا در سمت چپ منحرف شده اند
487
00:19:08,240 –> 00:19:10,720
و در اینجا شما
488
00:19:10,720 –> 00:19:12,960
حاملگی ها را دارید که می بینید برخی
489
00:19:12,960 –> 00:19:14,480
نقاط پرت
490
00:19:14,480 –> 00:19:16,400
وجود دارد که در نزدیکی این
491
00:19:16,400 –> 00:19:17,840
مشاهدات وجود دارد
492
00:19:17,840 –> 00:19:20,160
و تاخیر طولانی تری دارد که به این معنی است که بیشتر
493
00:19:20,160 –> 00:19:22,000
مقادیر در
494
00:19:22,000 –> 00:19:24,400
اینجا در میانه وجود دارد. مقدار این مقدار کمی
495
00:19:24,400 –> 00:19:28,000
در پایین 2.5 است، بنابراین این عکس ها یا
496
00:19:28,000 –> 00:19:29,440
این
497
00:19:29,440 –> 00:19:31,280
نقشه ها بسیار صحبت می کنند
498
00:19:31,280 –> 00:19:33,679
و کاری که باید انجام دهید، مانند من در
499
00:19:33,679 –> 00:19:35,679
مورد بارداری انجام دادم، این
500
00:19:35,679 –> 00:19:38,480
کار را برای قند خون انجام دهید.
501
00:19:38,480 –> 00:19:42,720
502
00:19:42,720 –> 00:19:44,960
و سن و سال را
503
00:19:44,960 –> 00:19:47,679
ببینید و ببینید که چه خروجی به دست می آورید
504
00:19:47,679 –> 00:19:50,160
تا پایان این، شما می دانید
505
00:19:50,160 –> 00:19:53,039
که حتی در
506
00:19:53,039 –> 00:19:54,880
نیمه های شب کسی از شما
507
00:19:54,880 –> 00:19:57,440
می خواهد که این را طرح کنید، شما قادر خواهید بود این موضوع را
508
00:19:57,440 –> 00:19:59,120
فراموش کنید.
509
00:19:59,120 –> 00:20:00,720
شما قادر خواهید بود حتی در
510
00:20:00,720 –> 00:20:03,120
نیمه های شب نقشه
511
00:20:03,120 –> 00:20:05,760
بکشید، بنابراین امیدوارم از تکرار کردن آن لذت ببرید
512
00:20:05,760 –> 00:20:06,559
513
00:20:06,559 –> 00:20:08,720
و
514
00:20:08,720 –> 00:20:11,039
مطمئنم تا زمانی که
515
00:20:11,039 –> 00:20:13,520
به آخرین متغیری
516
00:20:13,520 –> 00:20:15,760
که انجام می دهید برسید حتی زمانی که چشمان
517
00:20:15,760 –> 00:20:17,440
شما کاملاً بسته هستند،
518
00:20:17,440 –> 00:20:19,120
519
00:20:19,120 –> 00:20:23,760
بعد از آن، نکته بعدی این است که um
520
00:20:23,760 –> 00:20:26,240
یک نمودار پراکندگی ایجاد کنید
521
00:20:26,240 –> 00:20:27,919
خوب،
522
00:20:27,919 –> 00:20:29,520
ما هر متغیر را بررسی کرده ایم
523
00:20:29,520 –> 00:20:31,120
برای هر متغیر برای
524
00:20:31,120 –> 00:20:34,000
تجسم رابطه ایجاد نمودار پراکندگی درست است، بیایید این
525
00:20:34,000 –> 00:20:36,159
کار را انجام دهیم و فقط با یک دستور ساده
526
00:20:36,159 –> 00:20:38,080
این کار را انجام خواهیم داد. انجام این کار بسیار طول می
527
00:20:38,080 –> 00:20:40,720
کشد زیرا ما از این نسخه آنلاین استفاده می کنیم
528
00:20:40,720 –> 00:20:42,799
و گاهی اوقات داده ها و پهنای باند
529
00:20:42,799 –> 00:20:46,320
یک چیز است اما جفت نقطه sns ترسیم می کند و
530
00:20:46,320 –> 00:20:49,679
به سادگی داده را مشخص
531
00:20:49,679 –> 00:20:52,400
کنید که چند ثانیه طول می کشد،
532
00:20:52,400 –> 00:20:54,880
مثل اینکه نشان داده می شود. بیایید ببینیم
533
00:20:54,880 –> 00:20:56,559
534
00:20:56,559 –> 00:20:57,440
535
00:20:57,440 –> 00:20:58,880
536
00:20:58,880 –> 00:21:00,640
بر اساس تعداد ستونها و
537
00:21:00,640 –> 00:21:03,120
تعداد جریانها چقدر زمان میبرد که به این معنی است که
538
00:21:03,120 –> 00:21:06,559
مجموعه دادهها چقدر بزرگ است و بر این اساس
539
00:21:06,559 –> 00:21:08,640
زمان میبرد زیرا هر پردازشی
540
00:21:08,640 –> 00:21:11,679
درست آنلاین انجام میشود. بنابراین اکنون می بینید که ما
541
00:21:11,679 –> 00:21:13,280
542
00:21:13,280 –> 00:21:16,240
اولین اعلان را دریافت کردیم مبنی بر اینکه شبکه جفت دسترسی خوب
543
00:21:16,240 –> 00:21:17,840
در حال آمدن است
544
00:21:17,840 –> 00:21:18,960
545
00:21:18,960 –> 00:21:21,600
546
00:21:21,600 –> 00:21:23,760
و همین الان طول می کشد تا
547
00:21:23,760 –> 00:21:26,080
چند ثانیه بیشتر طول بکشد،
548
00:21:26,080 –> 00:21:28,559
بنابراین بیایید ببینیم چقدر زمان می برد که به این
549
00:21:28,559 –> 00:21:31,760
ترتیب زمان واقعی دریافت خواهید کرد.
550
00:21:31,760 –> 00:21:33,919
551
00:21:33,919 –> 00:21:36,240
خوب فکر کن که اگر هر
552
00:21:36,240 –> 00:21:38,720
متغیری
553
00:21:38,720 –> 00:21:40,559
را ترسیم میکردی چقدر زمان میبرد، باید
554
00:21:40,559 –> 00:21:42,240
طرح داشته باشی،
555
00:21:42,240 –> 00:21:44,640
اما با کمک این،
556
00:21:44,640 –> 00:21:47,280
همه متغیرها اکنون در مقابل
557
00:21:47,280 –> 00:21:49,120
شما هستند، میتوانید به وضوح ببینید
558
00:21:49,120 –> 00:21:51,840
این یک نوع رابطه است،
559
00:21:51,840 –> 00:21:54,159
هیچ چیزی اینجا بیرون نمی آید،
560
00:21:54,159 –> 00:21:57,360
این هم طرحی است که ما
561
00:21:57,360 –> 00:21:59,120
ترسیم کردیم، این همان طرحی است که
562
00:21:59,120 –> 00:22:01,200
قبلاً ترسیم کرده بودیم اگر این یکی را
563
00:22:01,200 –> 00:22:02,400
درست ببینید،
564
00:22:02,400 –> 00:22:04,320
بنابراین
565
00:22:04,320 –> 00:22:05,840
تقریباً هیچ
566
00:22:05,840 –> 00:22:08,640
چیز خاصی در اینجا نشان نمی دهد.
567
00:22:08,640 –> 00:22:10,640
شیب مانند این
568
00:22:10,640 –> 00:22:11,520
درست است
569
00:22:11,520 –> 00:22:12,559
570
00:22:12,559 –> 00:22:15,120
و اساساً می دانید که وقتی شروع کنید،
571
00:22:15,120 –> 00:22:17,200
یک بار با آن می نشینید،
572
00:22:17,200 –> 00:22:18,960
ساعت ها وقت صرف تفسیر آن خواهید کرد
573
00:22:18,960 –> 00:22:20,640
و حتی برای پزشکانی که پزشک
574
00:22:20,640 –> 00:22:21,840
هستند، مشاهدات جالبی برای من پیدا خواهند کرد.
575
00:22:21,840 –> 00:22:23,360
576
00:22:23,360 –> 00:22:25,200
من فقط میخواهم به
577
00:22:25,200 –> 00:22:27,200
شما نشان دهم که چگونه میتوانید یک
578
00:22:27,200 –> 00:22:29,280
متریک رابطه یا دادههای نمودار دعایی
579
00:22:29,280 –> 00:22:31,440
مانند این تولید کنید، اما
580
00:22:31,440 –> 00:22:33,120
581
00:22:33,120 –> 00:22:36,640
اگر بخواهید مقادیر دقیق همبستگی um را به دست آورید چه میشود، به
582
00:22:36,640 –> 00:22:38,640
583
00:22:38,640 –> 00:22:40,720
584
00:22:40,720 –> 00:22:43,120
طوری که فکر میکنم این است سوال بعدی
585
00:22:43,120 –> 00:22:44,159
اگر اشتباه
586
00:22:44,159 –> 00:22:45,520
587
00:22:45,520 –> 00:22:47,520
588
00:22:47,520 –> 00:22:49,919
میکنم، شما میروید همبستگی ایجاد میکنید و
589
00:22:49,919 –> 00:22:53,520
همبستگی را کامل تجسم میکنید،
590
00:22:53,520 –> 00:22:55,120
بیایید پایین برویم
591
00:22:55,120 –> 00:22:56,559
و
592
00:22:56,559 –> 00:22:57,919
این را ببینیم،
593
00:22:57,919 –> 00:22:59,039
بنابراین برای
594
00:22:59,039 –> 00:23:01,039
بدست آوردن متریک همبستگی تابع بسیار ساده
595
00:23:01,039 –> 00:23:03,679
دادههای نقطه کور
596
00:23:03,679 –> 00:23:05,919
و شما تمام شدهاید،
597
00:23:05,919 –> 00:23:07,919
این متریک همبستگی را
598
00:23:07,919 –> 00:23:09,280
با هر
599
00:23:09,280 –> 00:23:12,559
تفسیری تولید میکند. و رفتن یکی یکی
600
00:23:12,559 –> 00:23:14,400
مثل bmi اینجا
601
00:23:14,400 –> 00:23:15,360
خوب
602
00:23:15,360 –> 00:23:16,320
ضعیف
603
00:23:16,320 –> 00:23:18,080
کمی زیاد
604
00:23:18,080 –> 00:23:22,080
بله کم چیزی مثل ضعیف نیست پس
605
00:23:22,080 –> 00:23:24,159
چطور تصور می کنید این چیزی است که
606
00:23:24,159 –> 00:23:25,600
در مرحله بعد به شما نشان خواهم داد بنابراین یک
607
00:23:25,600 –> 00:23:28,000
چیز دیدن شماره واقعی است
608
00:23:28,000 –> 00:23:30,000
اما اگر اینها را دارید این کار مفید نیست
609
00:23:30,000 –> 00:23:32,720
بسیاری از متغیرها یا حتی بیشتر از آن
610
00:23:32,720 –> 00:23:34,960
چیزی که من می گویم این است که من ماتریس همبستگی را تولید می کنم
611
00:23:34,960 –> 00:23:37,200
612
00:23:37,200 –> 00:23:39,120
و
613
00:23:39,120 –> 00:23:41,279
نتیجه هسته نقطه داده را ذخیره می کنم، بنابراین
614
00:23:41,279 –> 00:23:43,520
هر خروجی که به
615
00:23:43,520 –> 00:23:46,880
اینجا می آید در همبستگی ذخیره می شود. ماتریس بسیار
616
00:23:46,880 –> 00:23:49,440
خوب است و ما از نقشه حرارتی از
617
00:23:49,440 –> 00:23:52,880
sns sns نقطه نقشه حرارتی
618
00:23:52,880 –> 00:23:54,640
هسته زیر خط
619
00:23:54,640 –> 00:23:56,320
ماتریس
620
00:23:56,320 –> 00:23:57,600
cmap
621
00:23:57,600 –> 00:24:00,400
برابر است با اجازه دهید از سرد گرم استفاده کنیم شما
622
00:24:00,400 –> 00:24:02,080
چندین
623
00:24:02,080 –> 00:24:06,960
الگو دارید من از سرد گرم در اینجا استفاده می کنم
624
00:24:06,960 –> 00:24:09,760
پس وقتی این را اجرا کردیم این همان چیزی است که
625
00:24:09,760 –> 00:24:12,480
به عنوان خروجی دریافت می کنید بنابراین واضح است که
626
00:24:12,480 –> 00:24:14,720
ضخامت پوست و انسولین
627
00:24:14,720 –> 00:24:17,120
با متغیر در اینجا همبستگی دارد
628
00:24:17,120 –> 00:24:18,480
دیابت
629
00:24:18,480 –> 00:24:21,360
عملکرد شجره نامه دیابت وجود ندارد متأسفم h
630
00:24:21,360 –> 00:24:24,080
با ضخامت
631
00:24:24,080 –> 00:24:26,080
همبستگی دارد اینجا
632
00:24:26,080 –> 00:24:27,919
و اینجا شما همبستگی کمی منفی
633
00:24:27,919 –> 00:24:29,279
634
00:24:29,279 –> 00:24:30,799
برای این
635
00:24:30,799 –> 00:24:32,880
سن و بارداری دارید
636
00:24:32,880 –> 00:24:35,520
همان سن آینده و بارداری در اینجا
637
00:24:35,520 –> 00:24:37,360
بنابراین این یک راه جالب برای
638
00:24:37,360 –> 00:24:39,840
تجسم این است، اما اگر
639
00:24:39,840 –> 00:24:42,320
میخواهید کمی کنترل بیشتری روی این
640
00:24:42,320 –> 00:24:45,760
معیار خاص داشته باشید، اساساً میتوانید
641
00:24:45,760 –> 00:24:47,760
بنویسید که میتوانید آن را با matplotlib ترکیب کنید،
642
00:24:47,760 –> 00:24:49,360
بنابراین
643
00:24:49,360 –> 00:24:50,640
من راه دیگری را به شما نشان خواهم داد که
644
00:24:50,640 –> 00:24:53,600
با آن
645
00:24:53,600 –> 00:24:55,760
میتوانید اساساً این را کمی افزایش دهید،
646
00:24:55,760 –> 00:25:01,039
بنابراین شانس فرعی نقطه را رسم کنید و
647
00:25:01,039 –> 00:25:04,159
اندازه ثابت است
648
00:25:04,159 –> 00:25:05,440
اساساً
649
00:25:05,440 –> 00:25:07,919
اجازه دهید
650
00:25:07,919 –> 00:25:12,000
12 کاما 8 را در نظر بگیریم، اندازه بزرگ خوب خواهد بود
651
00:25:12,000 –> 00:25:15,520
12 کاما 8 خوب است
652
00:25:15,520 –> 00:25:18,960
o Plt dot subplots و این این است
653
00:25:18,960 –> 00:25:23,559
و بعد از آن چیزی که ما نیاز داریم
654
00:25:23,559 –> 00:25:26,320
نقشه sns.heat است
655
00:25:26,320 –> 00:25:29,760
و ما به ماتریس هسته بسیار ساده مانند این نیاز داریم
656
00:25:29,760 –> 00:25:31,200
657
00:25:31,200 –> 00:25:34,720
و اوه ما از c map و
658
00:25:34,720 –> 00:25:38,559
nc map استفاده می
659
00:25:38,559 –> 00:25:42,080
کنیم.
660
00:25:42,080 –> 00:25:46,320
661
00:25:46,640 –> 00:25:49,360
پس از انجام این کار، چیزی که به شما می
662
00:25:49,360 –> 00:25:52,240
دهد اساساً یک خروجی مانند این است، بنابراین این
663
00:25:52,240 –> 00:25:55,200
یکی اشکالی ندارد، اما این یکی بهتر است همانطور
664
00:25:55,200 –> 00:25:57,039
که می بینید به تجسم خود نگاه کنید
665
00:25:57,039 –> 00:25:59,360
و دلیل آن این است
666
00:25:59,360 –> 00:26:00,559
که ما
667
00:26:00,559 –> 00:26:02,720
اندازه شکل را تنظیم می کنیم. مثل این یکی برای
668
00:26:02,720 –> 00:26:04,640
هر چیزی که در اینجا طرح می کنیم و به این
669
00:26:04,640 –> 00:26:07,440
ترتیب شما تصویر بهتری از آن می گیرید،
670
00:26:07,440 –> 00:26:09,200
بنابراین این چیزی است که می خواستم به شما نشان دهم
671
00:26:09,200 –> 00:26:12,880
که چگونه می توانید اساساً این کار را انجام دهید، اکنون اجازه دهید
672
00:26:12,880 –> 00:26:16,880
به سؤال بعدی برویم که این است
673
00:26:16,880 –> 00:26:18,799
که ایده ای برای هدف پیدا کنید. متغیر
674
00:26:18,799 –> 00:26:21,200
برای هر ستون متفاوت است،
675
00:26:21,200 –> 00:26:22,480
676
00:26:22,480 –> 00:26:25,360
فقط برای دریافت ایده، دستوری که میخواهیم
677
00:26:25,360 –> 00:26:26,640
678
00:26:26,640 –> 00:26:29,200
اجرا کنیم به صورت گروهی است
679
00:26:29,200 –> 00:26:32,159
و نتیجه
680
00:26:32,159 –> 00:26:35,200
را میگوییم و میانگین
681
00:26:35,200 –> 00:26:37,120
را به طور میانگین برای
682
00:26:37,120 –> 00:26:39,840
هر ستون متفاوت میکنیم، بنابراین نتیجه غیر دیابتی است.
683
00:26:39,840 –> 00:26:42,960
حاملگی دیابتی پس غیر دیابتی
684
00:26:42,960 –> 00:26:47,679
3.2 درجه است ne دارای 4.8 است که به این معنی است که آنها به
685
00:26:47,679 –> 00:26:50,000
طور قابل توجهی متفاوت هستند به طور مشابه 109
686
00:26:50,000 –> 00:26:54,400
141 متفاوت 68 70 تا حدودی شبیه 19
687
00:26:54,400 –> 00:26:55,919
به 22.
688
00:26:55,919 –> 00:26:57,600
اوه ممکن است
689
00:26:57,600 –> 00:26:59,760
متفاوت باشد من در این مورد متخصص نیستم
690
00:26:59,760 –> 00:27:02,559
اساساً شاید پزشکان بتوانند یا کسانی
691
00:27:02,559 –> 00:27:04,559
که اساساً با این کار می کنند می توانند کمی صحبت کنند.
692
00:27:04,559 –> 00:27:07,360
سطح کمی بالاست اما برای من فقط با
693
00:27:07,360 –> 00:27:09,919
نگاه کردن به آن مانند انسولین 68 و 100 به
694
00:27:09,919 –> 00:27:12,080
طور قابل توجهی با آنچه که می توانم ببینم متفاوت است،
695
00:27:12,080 –> 00:27:14,720
بنابراین فقط برای دریافت ایده ای در مورد اینکه
696
00:27:1