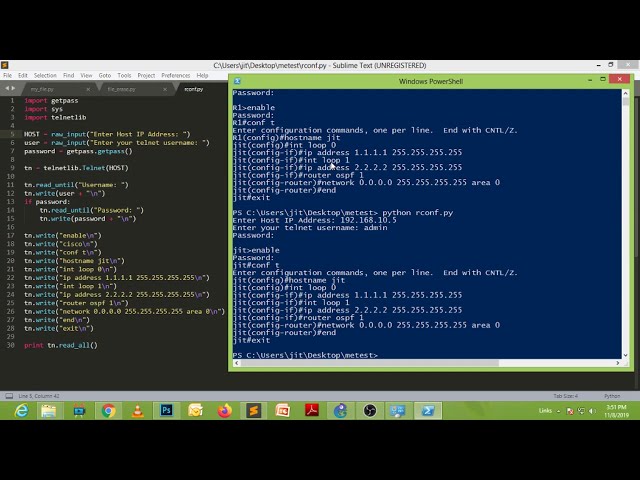
در این مطلب، ویدئو پروژه پایتون شبکه عصبی – تشخیص رقم دست نویس با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:22:47
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:04,230 –> 00:00:09,200
[موسیقی]
2
00:00:09,200 –> 00:00:10,719
بچهها در ویدیوی امروز به چه اتفاقی میافتد خوش آمدید
3
00:00:10,719 –> 00:00:12,240
ما میخواهیم یک
4
00:00:12,240 –> 00:00:14,000
شبکه عصبی بسازیم که
5
00:00:14,000 –> 00:00:16,160
ارقام دستنویس را در پایتون تشخیص میدهد، بنابراین بیایید همین
6
00:00:16,160 –> 00:00:17,920
الان به
7
00:00:17,920 –> 00:00:19,279
همه چیز بپردازیم، من قبلاً یک ویدیو در این
8
00:00:19,279 –> 00:00:20,880
کانال در مورد تشخیص رقم دستنویس دارم.
9
00:00:20,880 –> 00:00:23,439
و python بخشی
10
00:00:23,439 –> 00:00:25,519
از یکی از اولین مجموعه های آموزشی من در مورد
11
00:00:25,519 –> 00:00:27,439
یادگیری ماشینی است اما ویدیو کاملا
12
00:00:27,439 –> 00:00:29,279
قدیمی است و کیفیت خوبی ندارد بنابراین
13
00:00:29,279 –> 00:00:31,599
می خواستم یک بازسازی مدرن از این ویدیو بسازم
14
00:00:31,599 –> 00:00:33,200
زیرا فکر می کنم موضوع ویدیو بسیار
15
00:00:33,200 –> 00:00:35,040
جالب است و مخصوصاً برای آنهایی از
16
00:00:35,040 –> 00:00:37,040
شما که در یادگیری ماشین
17
00:00:37,040 –> 00:00:38,399
هستید و اصول اولیه را یاد می گیرید و می خواهید
18
00:00:38,399 –> 00:00:39,680
با شبکه های عصبی شروع کنید و
19
00:00:39,680 –> 00:00:41,840
می خواهید یک پروژه ساده داشته باشید، این ویدئو به
20
00:00:41,840 –> 00:00:43,840
نوعی یک پروژه مبتدی خوب
21
00:00:43,840 –> 00:00:46,160
در مورد کار با شبکه های عصبی است،
22
00:00:46,160 –> 00:00:47,360
بنابراین ما قرار است این کار را انجام دهیم این است که
23
00:00:47,360 –> 00:00:49,520
مجموعه دادههای به اصطلاح mnist را
24
00:00:49,520 –> 00:00:51,440
از tensorflow keras بارگیری میکنیم که فقط یک
25
00:00:51,440 –> 00:00:53,199
مجموعه داده با دستهای از
26
00:00:53,199 –> 00:00:56,960
ارقام دستنویس در قالب 28 x 28 پیکسل است، بنابراین
27
00:00:56,960 –> 00:00:58,960
شما فقط مقداری دستنویس داشته باشید. این ارقام
28
00:00:58,960 –> 00:01:01,280
و اوه برچسب های مربوطه هستند، بنابراین اگر
29
00:01:01,280 –> 00:01:03,920
یک دو وجود دارد، شما نیز برچسب دو را دارید و
30
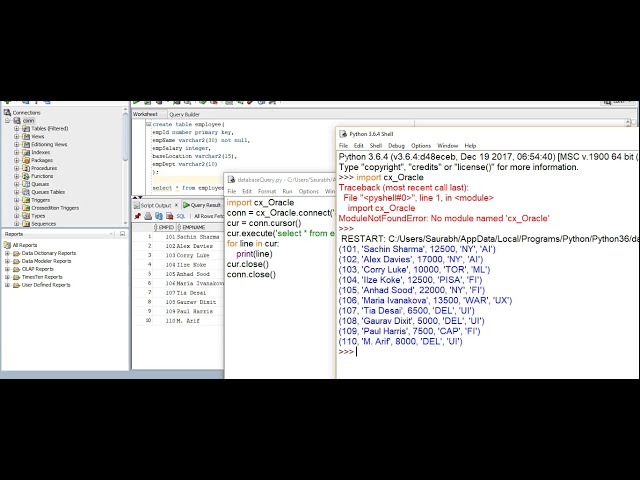
00:01:03,920 –> 00:01:05,600
اگر سه است، برچسب سه
31
00:01:05,600 –> 00:01:07,520
را نیز دارید و ما از آن به عنوان
32
00:01:07,520 –> 00:01:09,520
داده های آموزشی برای شبکه عصبی خود استفاده می
33
00:01:09,520 –> 00:01:10,960
کنیم. یک شبکه عصبی را
34
00:01:10,960 –> 00:01:12,880
با آن مجموعه داده آموزش میدهیم، سپس آن را
35
00:01:12,880 –> 00:01:14,479
آزمایش میکنیم و در پایان میخواهیم
36
00:01:14,479 –> 00:01:16,479
تصاویر خودمان را ارائه
37
00:01:16,479 –> 00:01:18,640
دهیم، رنگ یا هر ابزار دیگری را که
38
00:01:18,640 –> 00:01:20,159
میخواهیم انجام دهیم. ارقام دستنویس را
39
00:01:20,159 –> 00:01:22,640
نیز میتوانید اگر میخواهید آنها را مانند
40
00:01:22,640 –> 00:01:24,400
ارقام دستنویس واقعی اسکن کنید
41
00:01:24,400 –> 00:01:25,680
و در رایانه اسکن کنید و سپس میدانید که
42
00:01:25,680 –> 00:01:27,040
آنها را کوچک کنید،
43
00:01:27,040 –> 00:01:28,640
اما در پایان ما میخواهیم
44
00:01:28,640 –> 00:01:31,280
ارقام خودمان را با استفاده از شبکه عصبی پیشبینی کنیم،
45
00:01:31,280 –> 00:01:32,560
بنابراین اولین چیز ما میخواهیم این کار را انجام دهیم این است که
46
00:01:32,560 –> 00:01:34,320
میخواهیم مجموعهای از کتابخانهها را برای
47
00:01:34,320 –> 00:01:35,920
این کار نصب کنیم، میخواهیم
48
00:01:35,920 –> 00:01:37,759
خط فرمان cmd را در ویندوز باز کنیم یا اگر
49
00:01:37,759 –> 00:01:39,600
البته از لینوکس یا مک هستید، میتوانید
50
00:01:39,600 –> 00:01:43,119
ترمینال خود را باز کنید و pip را تایپ کنید. نصب کنید
51
00:01:43,119 –> 00:01:46,240
من ابتدا به numpy نیاز
52
00:01:46,240 –> 00:01:47,520
دارم، من آنها را نصب نمی کنم زیرا قبلاً آن را نصب کرده ام
53
00:01:47,520 –> 00:01:48,960
همه این ابزارها را
54
00:01:48,960 –> 00:01:52,159
داریم که به آنها نیاز داریم numpy، ما به
55
00:01:52,159 –> 00:01:53,439
cv
56
00:01:53,439 –> 00:01:57,200
dash python باز مانند آن opencv python نیاز
57
00:01:57,200 –> 00:01:59,680
داریم، ما به
58
00:01:59,680 –> 00:02:01,680
matplotlib
59
00:02:01,680 –> 00:02:03,360
نیاز داریم و به آخرین تنسورفلو نیاز داریم که
60
00:02:03,360 –> 00:02:05,640
مشخصا
61
00:02:05,640 –> 00:02:08,239
tensorflow شبیه آن است. اینها چهار
62
00:02:08,239 –> 00:02:10,239
کتابخانه ای هستند که ما به numpy
63
00:02:10,239 –> 00:02:13,599
matplotlib tensorflow و opencv python
64
00:02:13,599 –> 00:02:16,640
um نیاز داریم و ما با وارد کردن
65
00:02:16,640 –> 00:02:17,920
um
66
00:02:17,920 –> 00:02:20,160
67
00:02:20,160 –> 00:02:22,000
68
00:02:22,000 –> 00:02:26,520
cv2 که opencv python است شروع می کنیم. ‘
69
00:02:26,520 –> 00:02:29,040
میخواهیم matplotlib.pipeplot splt را وارد کنیم و
70
00:02:29,040 –> 00:02:31,280
71
00:02:31,280 –> 00:02:33,760
um tensorflow
72
00:02:33,760 –> 00:02:35,519
stf را وارد میکنیم
73
00:02:35,519 –> 00:02:37,040
و بعداً به
74
00:02:37,040 –> 00:02:39,519
ماژول OS نیز نیاز خواهیم داشت، بنابراین بیایید آن را
75
00:02:39,519 –> 00:02:41,920
در ابتدا وارد کنیم import OS به هر حال
76
00:02:41,920 –> 00:02:43,680
اجازه دهید من فقط موقعیت خود را تغییر دهم. دوربین
77
00:02:43,680 –> 00:02:46,959
چون فکر میکنم من این کار را نکردم،
78
00:02:46,959 –> 00:02:48,480
79
00:02:48,480 –> 00:02:50,239
پس اینها کتابخانههایی هستند
80
00:02:50,239 –> 00:02:51,840
که اکنون به
81
00:02:51,840 –> 00:02:54,080
آنها
82
00:02:54,080 –> 00:02:55,920
83
00:02:55,920 –> 00:02:58,000
نیاز خواهیم داشت. numpy
84
00:02:58,000 –> 00:03:00,879
فقط برای کار با w مهم است ith uh numpy
85
00:03:00,879 –> 00:03:04,640
arrays cv2 درباره بینایی کامپیوتر است، بنابراین
86
00:03:04,640 –> 00:03:06,080
cv مخفف بینایی کامپیوتری است
87
00:03:06,080 –> 00:03:07,840
که
88
00:03:07,840 –> 00:03:10,480
برای بارگذاری تصاویر و پردازش تصاویر به آن نیاز داریم و
89
00:03:10,480 –> 00:03:12,159
tensorflow چیزی است که در واقع
90
00:03:12,159 –> 00:03:15,280
برای بخش یادگیری ماشین استفاده می
91
00:03:15,280 –> 00:03:17,200
کنیم، پس بیایید شروع کنیم. با بارگذاری مجموعه داده
92
00:03:17,200 –> 00:03:19,680
، میخواهیم بگوییم mnist برابر است
93
00:03:19,680 –> 00:03:21,280
تا مجموعه داده را بدست آوریم، فقط میتوانیم
94
00:03:21,280 –> 00:03:22,560
از tf
95
00:03:22,560 –> 00:03:26,480
dot keras dot مجموعههای داده
96
00:03:26,480 –> 00:03:29,440
dot mnist استفاده کنیم، با انجام این کار میتوانیم
97
00:03:29,440 –> 00:03:30,959
آن را مستقیماً از tensorflow بارگیری کنیم که
98
00:03:30,959 –> 00:03:32,799
نیازی به دانلود نداریم. فایلهای csv و پردازش
99
00:03:32,799 –> 00:03:34,560
آنها، ما آن را از قبل در
100
00:03:34,560 –> 00:03:35,599
ماژول
101
00:03:35,599 –> 00:03:38,239
داریم و سپس آنها را به
102
00:03:38,239 –> 00:03:40,080
دادههای آموزشی و دادههای آزمایشی تقسیم میکنیم برای آن دسته
103
00:03:40,080 –> 00:03:41,760
از شما که کاملاً در یادگیری ماشینی تازه
104
00:03:41,760 –> 00:03:42,799
کار هستند، تجربه زیادی در
105
00:03:42,799 –> 00:03:44,640
مورد آنچه که دارید ندارید. معمولاً وقتی
106
00:03:44,640 –> 00:03:46,480
یک مدل را آموزش میدهید، دادههایی را
107
00:03:46,480 –> 00:03:48,080
که دارید دریافت میکنید، تمام دادههای برچسبگذاریشده را
108
00:03:48,080 –> 00:03:49,519
با تمام این ارقام دارید و
109
00:03:49,519 –> 00:03:52,159
طبقهبندی دادههای برچسبگذاری شده به این معنی است که ما
110
00:03:52,159 –> 00:03:53,519
قبلاً میدانیم
111
00:03:53,519 –> 00:03:55,439
چه ارقامی هستند و برای
112
00:03:55,439 –> 00:03:57,599
حدس زدن نیازی به آن نداریم. برای ارزیابی آنها ما
113
00:03:57,599 –> 00:03:59,599
قبلاً برچسبها را داریم و کاری که
114
00:03:59,599 –> 00:04:01,280
با آن دادهها انجام میدهیم این است که آنها را به
115
00:04:01,280 –> 00:04:02,879
دادههای آموزشی تقسیم میکنیم و دادههای آزمایشی.
116
00:04:02,879 –> 00:04:04,640
117
00:04:04,640 –> 00:04:06,640
118
00:04:06,640 –> 00:04:08,720
119
00:04:08,720 –> 00:04:10,640
برای ارزیابی
120
00:04:10,640 –> 00:04:12,640
مدل تا ببینیم که چقدر خوب
121
00:04:12,640 –> 00:04:15,040
روی دادههایی که قبلاً ندیده بود
122
00:04:15,040 –> 00:04:16,238
کار
123
00:04:16,238 –> 00:04:19,120
میکند، این ایده آزمایش و آموزش است
124
00:04:19,120 –> 00:04:21,759
و معمولاً ما به دنبال تقسیم 80 20
125
00:04:21,759 –> 00:04:23,360
میرویم اما در این مورد فقط میتوانیم از بار استفاده کنیم.
126
00:04:23,360 –> 00:04:25,680
تابع داده مجموعه داده amnest و
127
00:04:25,680 –> 00:04:27,600
در حال حاضر به داده های آموزشی
128
00:04:27,600 –> 00:04:29,440
و داده های آزمایشی تقسیم شده است و به همین دلیل
129
00:04:29,440 –> 00:04:33,040
می خواهیم بگوییم x train
130
00:04:33,280 –> 00:04:34,800
و y train
131
00:04:34,800 –> 00:04:36,800
x
132
00:04:36,800 –> 00:04:38,479
داده پیکسل و y
133
00:04:38,479 –> 00:04:40,160
طبقه بندی است
134
00:04:40,160 –> 00:04:42,080
بنابراین داده x تصویر است.
135
00:04:42,080 –> 00:04:44,400
خود رقم دستنویس و دادههای y
136
00:04:44,400 –> 00:04:46,880
فقط طبقهبندی است، بنابراین
137
00:04:46,880 –> 00:04:48,160
عدد رقم
138
00:04:48,160 –> 00:04:51,360
um است و سپس یک تاپل با تست x
139
00:04:51,360 –> 00:04:53,840
و تست y داریم
140
00:04:53,840 –> 00:04:56,000
و این دادههای بار نقطهای mnist است،
141
00:04:56,000 –> 00:04:58,240
بنابراین تابع داده بار را فراخوانی میکنیم
142
00:04:58,240 –> 00:05:00,639
و این در حال بازگشت t wo tuples
143
00:05:00,639 –> 00:05:03,440
اوه با آموزش و آزمایش دادهها
144
00:05:03,440 –> 00:05:05,440
کاملاً درست است، بنابراین اکنون به عنوان گام بعدی ما میخواهیم
145
00:05:05,440 –> 00:05:07,039
آن را عادی سازی کنیم.
146
00:05:07,039 –> 00:05:09,039
147
00:05:09,039 –> 00:05:11,600
148
00:05:11,600 –> 00:05:13,919
149
00:05:13,919 –> 00:05:15,919
150
00:05:15,919 –> 00:05:18,880
اگر مقادیر rgb را نادیده بگیریم، پیکسل می تواند از صفر تا 255 روشنایی داشته باشد
151
00:05:18,880 –> 00:05:20,479
152
00:05:20,479 –> 00:05:21,840
و اگر آن را عادی کنید
153
00:05:21,840 –> 00:05:23,440
، همه چیز را بین
154
00:05:23,440 –> 00:05:25,360
صفر و یک کوچک می کنید،
155
00:05:25,360 –> 00:05:26,160
بنابراین
156
00:05:26,160 –> 00:05:28,880
به جای اینکه نمی دانم
157
00:05:28,880 –> 00:05:31,919
اگر دنبال نصف 125
158
00:05:31,919 –> 00:05:33,560
کمی بیشتر، شما 125 نخواهید داشت
159
00:05:33,560 –> 00:05:35,840
یا کمی بیشتر
160
00:05:35,840 –> 00:05:38,240
، چیزی در حدود 0.5 خواهید داشت، بنابراین
161
00:05:38,240 –> 00:05:40,000
اساساً فقط همه چیز را کوچک کنید تا
162
00:05:40,000 –> 00:05:42,639
این کار را انجام دهید که می گوییم قطار x می
163
00:05:42,639 –> 00:05:46,360
رود. به tf.keras.utils.normalize
164
00:05:48,160 –> 00:05:49,680
و ما
165
00:05:49,680 –> 00:05:51,759
خود داده های آموزشی را عادی می کنیم
166
00:05:51,759 –> 00:05:55,120
و باید دسترسی برابر یک را فراهم
167
00:05:55,120 –> 00:05:56,560
کنیم و همین کار را با
168
00:05:56,560 –> 00:05:59,120
آموزش و یا در واقع با داده های تست انجام می
169
00:05:59,120 –> 00:06:00,560
دهیم زیرا ما انجام نمی دهیم نمیخواهم واقعاً
170
00:06:00,560 –> 00:06:02,960
ارقامی را که فقط میزنیم عادی کنیم برای
171
00:06:02,960 –> 00:06:04,720
نرمال کردن پیکسل ها، زیرا این کار
172
00:06:04,720 –> 00:06:06,639
انجام محاسبات را برای یک شبکه عصبی آسان تر می کند،
173
00:06:06,639 –> 00:06:08,080
174
00:06:08,080 –> 00:06:12,080
بنابراین x تست برابر است با t f dot keras با
175
00:06:12,080 –> 00:06:14,160
176
00:06:14,160 –> 00:06:16,800
استفاده از تست نرمال کردن x و محور
177
00:06:16,800 –> 00:06:18,800
یکی است،
178
00:06:18,800 –> 00:06:20,720
بنابراین این تمام پیش پردازشی است که
179
00:06:20,720 –> 00:06:23,759
ما اکنون باید انجام دهیم. می تواند روی شبکه عصبی شروع به کار
180
00:06:23,759 –> 00:06:25,280
کند و برای این کار
181
00:06:25,280 –> 00:06:27,120
ما خود مدل را ایجاد می کنیم،
182
00:06:27,120 –> 00:06:29,759
می گوییم مدل شبکه عصبی
183
00:06:29,759 –> 00:06:31,280
tf
184
00:06:31,280 –> 00:06:32,400
dot
185
00:06:32,400 –> 00:06:34,080
keras.models
186
00:06:34,080 –> 00:06:36,479
و سپس ترتیبی است که فقط
187
00:06:36,479 –> 00:06:38,960
مدل پایه پایه عصبی متوالی است.
188
00:06:38,960 –> 00:06:40,000
شبکه
189
00:06:40,000 –> 00:06:41,919
um و اتفاقاً
190
00:06:41,919 –> 00:06:44,080
در مورد هیچ نظریه ای در اینجا زیاد صحبت نمی کنیم،
191
00:06:44,080 –> 00:06:46,160
وقتی صحبت از توابع فعال سازی یا
192
00:06:46,160 –> 00:06:49,199
بهینه سازها یا توابع از دست دادن و
193
00:06:49,199 –> 00:06:50,960
انواع لایه ها می شود، ما فقط می خواهیم آن را بسازیم
194
00:06:50,960 –> 00:06:53,199
و از آن استفاده خواهیم کرد.
195
00:06:53,199 –> 00:06:54,800
اگر میخواهید محتوای نظری بیشتری
196
00:06:54,800 –> 00:06:56,560
را در مورد شبکههای عصبی ببینید
197
00:06:56,560 –> 00:06:57,919
، در بخش نظرات در زیر به من اطلاع دهید، سپس
198
00:06:57,919 –> 00:07:00,080
میخواهم مطالب مرتبط با تئوری بیشتری بسازم،
199
00:07:00,080 –> 00:07:02,960
اما همچنین یک
200
00:07:02,960 –> 00:07:05,199
ویدیوی نظری در مورد توضیح شبکههای عصبی دارم، بنابراین
201
00:07:05,199 –> 00:07:07,199
میتوانید آن را در سایت من پیدا کنید. کانال
202
00:07:07,199 –> 00:07:09,280
بنابراین کاری که اکنون برای اضافه کردن چند لایه به
203
00:07:09,280 –> 00:07:12,319
این مدل انجام می دهیم این است که می گوییم مدل dot add و
204
00:07:12,319 –> 00:07:14,720
وقتی می گوییم model.add باید یک
205
00:07:14,720 –> 00:07:18,000
لایه اضافه کنیم تا بتوانیم بگوییم
206
00:07:18,000 –> 00:07:20,319
لایه های نقطه tf.keras و حالا می توانیم یک لایه را
207
00:07:20,319 –> 00:07:21,680
انتخاب کنیم و با یک لایه مسطح شروع می کنیم
208
00:07:21,680 –> 00:07:23,599
و یک لایه
209
00:07:23,599 –> 00:07:25,360
مسطح اساساً به این معنی است که یک
210
00:07:25,360 –> 00:07:27,039
شکل ورودی خاص را صاف می کنیم، بنابراین فرض کنید
211
00:07:27,039 –> 00:07:28,840
شکل ورودی
212
00:07:28,840 –> 00:07:30,479
um را
213
00:07:30,479 –> 00:07:32,800
28 ضربدر 28 داریم زیرا ما 28 پیکسل داریم و
214
00:07:32,800 –> 00:07:35,520
28 پیکسل و کاری که لایه مسطح
215
00:07:35,520 –> 00:07:37,440
انجام می دهد این است.
216
00:07:37,440 –> 00:07:40,400
پرو آن ها را به یک لایه مسطح تبدیل می کند،
217
00:07:40,400 –> 00:07:43,120
بنابراین شبکه ای 28 در 28 نیست،
218
00:07:43,120 –> 00:07:46,720
آنها را به 28 ضربدر 28 تبدیل می کند، اما در یک چیز
219
00:07:46,720 –> 00:07:48,080
بنابراین اساساً
220
00:07:48,080 –> 00:07:52,639
می گوید uh 28 ضربدر 28، آن را به
221
00:07:52,639 –> 00:07:54,199
222
00:07:54,199 –> 00:07:57,280
جای داشتن یک خط بزرگ از 784 پیکسل تبدیل می کند. این شبکه
223
00:07:57,280 –> 00:07:59,360
پس این همان کاری است که یک لایه مسطح انجام میدهد،
224
00:07:59,360 –> 00:08:02,000
پس از این لایه مسطح
225
00:08:02,000 –> 00:08:03,680
میخواهیم یک لایه متراکم داشته باشیم و یک
226
00:08:03,680 –> 00:08:05,280
لایه متراکم اساسیترین لایهای است که
227
00:08:05,280 –> 00:08:07,199
میتوانید داشته باشید، فقط یک
228
00:08:07,199 –> 00:08:10,400
لایه شبکه عصبی پایه است که به هم متصل است یا
229
00:08:10,400 –> 00:08:12,800
هر نورون کجاست. به نورون دیگری متصل است
230
00:08:12,800 –> 00:08:15,680
لایه ها بنابراین اساساً
231
00:08:15,680 –> 00:08:18,639
ما فقط می گوییم لایه های keras متراکم
232
00:08:18,639 –> 00:08:20,879
ترین لایه است، فقط باید
233
00:08:20,879 –> 00:08:23,759
تعداد واحدها را مشخص کنیم مثلاً 128
234
00:08:23,759 –> 00:08:25,280
و سپس باید یک
235
00:08:25,280 –> 00:08:26,960
تابع فعال سازی را مشخص کنیم اکنون می توانید این کار را
236
00:08:26,960 –> 00:08:28,720
به روش های مختلف انجام دهید و می توانید بگویید فعال سازی
237
00:08:28,720 –> 00:08:29,639
برابر با
238
00:08:29,639 –> 00:08:32,080
tf.nn است و سپس
239
00:08:32,080 –> 00:08:34,159
اگر میخواهید تابع فعالسازی را انتخاب کنید یا فقط میتوانید
240
00:08:34,159 –> 00:08:36,159
یک رشته با تابع فعالسازی ارائه
241
00:08:36,159 –> 00:08:37,919
کنید، به عنوان مثال relu چیزی است
242
00:08:37,919 –> 00:08:41,200
که ما میخواهیم از آن استفاده کنیم یک
243
00:08:41,200 –> 00:08:44,159
چیز بسیار ابتدایی، اگر منفی باشید، اساساً فقط یک ام
244
00:08:44,159 –> 00:08:45,920
صفر است.
245
00:08:45,920 –> 00:08:48,560
سپس مستقیماً به صورت خطی بالا می رود، اوه، می
246
00:08:48,560 –> 00:08:50,320
توانید آن را در گوگل جستجو کنید و می توانید ویدیوی من را تماشا کنید
247
00:08:50,320 –> 00:08:52,720
، فکر می کنم خیلی پیچیده نیست،
248
00:08:52,720 –> 00:08:54,160
سپس ما یک لایه دیگر از
249
00:08:54,160 –> 00:08:55,920
آن لایه ها را دقیقاً همان لایه خواهیم داشت و
250
00:08:55,920 –> 00:08:57,600
در پایان می رویم برای داشتن یک
251
00:08:57,600 –> 00:08:59,279
لایه متراکم دیگر اما این
252
00:08:59,279 –> 00:09:01,279
یکی 10 واحد خواهد داشت زیرا این
253
00:09:01,279 –> 00:09:03,200
لایه خروجی ما خواهد بود و ما می خواهیم این 10
254
00:09:03,200 –> 00:09:05,760
واحد نشان دهنده ارقام جداگانه
255
00:09:05,760 –> 00:09:08,320
باشند بنابراین 0 دو سه چهار پنج شش
256
00:09:08,320 –> 00:09:10,720
هفت هشت نه نه داریم پس ده داریم. نورونها
257
00:09:10,720 –> 00:09:12,320
و تابع فعالسازی
258
00:09:12,320 –> 00:09:13,920
دوباره بارگذاری نمیشود، تابع فعالسازی
259
00:09:13,920 –> 00:09:16,080
260
00:09:16,080 –> 00:09:18,240
261
00:09:18,240 –> 00:09:20,160
نرمافزار میشود و softmax اساساً کاری است که softmax انجام میدهد این است
262
00:09:20,160 –> 00:09:22,320
که مطمئن میشود همه خروجیها
263
00:09:22,320 –> 00:09:25,200
همه 10 نورون به یک عدد میرسند تا بتوانید
264
00:09:25,200 –> 00:09:26,240
آن را تفسیر کنید.
265
00:09:26,240 –> 00:09:28,560
شما می توانید این را به عنوان یک اطمینان تفسیر کنید،
266
00:09:28,560 –> 00:09:30,800
بنابراین در پایان هر نورون قرار
267
00:09:30,800 –> 00:09:32,720
است هر یک از آن نورون های 10 رقمی
268
00:09:32,720 –> 00:09:36,320
را داشته باشد، مقداری بین 0 و 1 خواهد داشت
269
00:09:36,320 –> 00:09:39,200
و نشان می دهد که چقدر احتمال
270
00:09:39,200 –> 00:09:41,440
دارد این رقم تصویر باشد، به عنوان مثال اگر این رقم را
271
00:09:41,440 –> 00:09:43,200
داشته باشیم. یک عدد 2 آشکار،
272
00:09:43,200 –> 00:09:46,480
چیزی شبیه 0.95 را
273
00:09:46,480 –> 00:09:50,959
در نورون سوم مشاهده خواهیم کرد، زیرا 0 1 2 3
274
00:09:50,959 –> 00:09:52,560
و
275
00:09:52,560 –> 00:09:54,880
در تمام نورون های دیگر، اطمینان پایینی را مشاهده خواهیم کرد،
276
00:09:54,880 –> 00:09:58,160
بنابراین حداکثر نرم افزار به ما این احتمال را می دهد که
277
00:09:58,160 –> 00:10:00,720
هر رقم پاسخ درستی باشد.
278
00:10:00,720 –> 00:10:03,440
پس از آن ما مدل را کامپایل می کنیم، بنابراین می
279
00:10:03,440 –> 00:10:06,560
گوییم کامپایل نقطه مدل و یک
280
00:10:06,560 –> 00:10:09,680
بهینه ساز را انتخاب می کنیم، اتم را به عنوان بهینه ساز
281
00:10:09,680 –> 00:10:11,600
انتخاب می کنیم، یک تابع ضرر را انتخاب می کنیم، با آنتروپی متقاطع طبقه بندی پراکنده پیش می رویم،
282
00:10:11,600 –> 00:10:13,040
283
00:10:13,040 –> 00:10:15,120
284
00:10:15,120 –> 00:10:16,560
285
00:10:16,560 –> 00:10:20,560
بنابراین از دست دادن برابر است با آنتروپی متقاطع طبقه ای پراکنده
286
00:10:20,560 –> 00:10:22,959
287
00:10:22,959 –> 00:10:26,959
و معیارهایی که ما به آنها علاقه مندیم
288
00:10:26,959 –> 00:10:28,640
289
00:10:28,640 –> 00:10:30,160
دقت
290
00:10:30,160 –> 00:10:33,760
یا دقت خواهند بود،
291
00:10:33,760 –> 00:10:35,760
بنابراین هنگامی که مدل کامپایل شد،
292
00:10:35,760 –> 00:10:38,000
باید مدل را متناسب کنیم، بنابراین اساساً
293
00:10:38,000 –> 00:10:40,000
مدل را آموزش می
294
00:10:40,000 –> 00:10:42,160
دهیم و این کار را با فراخوانی تابع fit
295
00:10:42,160 –> 00:10:46,399
و انجام می دهیم. انتقال دادههای آموزشی
296
00:10:46,399 –> 00:10:50,560
به این ترتیب x train و y train
297
00:10:50,560 –> 00:10:53,920
و هنگامی که این مرحله انجام شد، یک
298
00:10:53,920 –> 00:10:55,600
مدل کاملاً کارآمد داریم، بنابراین آنچه که
299
00:10:55,600 –> 00:10:57,360
اکنون میخواهیم انجام دهیم این است که فقط این مرحله را اجرا میکنیم
300
00:10:57,360 –> 00:10:59,360
اما پس از آن زمانی که
301
00:10:59,360 –> 00:11:01,040
مدل آموزش داده شد ما آن را ذخیره میکنیم، بنابراین
302
00:11:01,040 –> 00:11:03,279
میگویم model.save و میخواهیم اسمش را بگذاریم،
303
00:11:03,279 –> 00:11:04,800
304
00:11:04,800 –> 00:11:08