در این مطلب، ویدئو آموزش 4- Pyspark با Python-Pyspark DataFrames- عملیات فیلتر با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:08:58
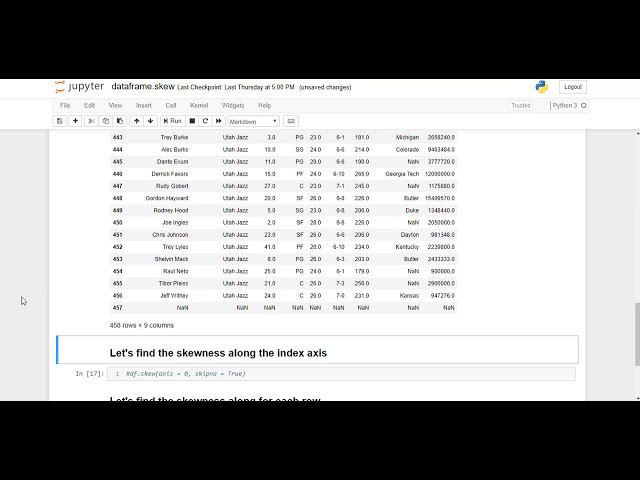
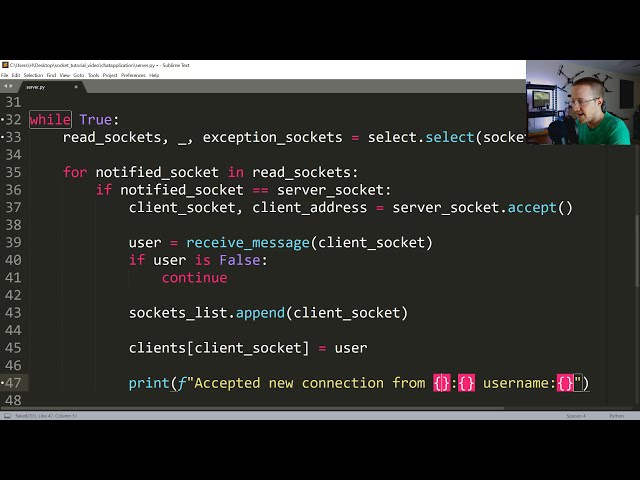
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,730 –> 00:00:13,759
[موسیقی]
2
00:00:13,759 –> 00:00:15,200
سلام همه اسم من کریشناک است و
3
00:00:15,200 –> 00:00:16,800
به کانال یوتیوب من خوش آمدید، پس بچه ها
4
00:00:16,800 –> 00:00:18,480
ما سریال لیست پخش پی اسپارک را ادامه خواهیم داد
5
00:00:18,480 –> 00:00:20,000
6
00:00:20,000 –> 00:00:21,520
و وقتی این سریال خاص را
7
00:00:21,520 –> 00:00:23,359
شروع کردم، بچه ها از افراد زیادی درخواست
8
00:00:23,359 –> 00:00:24,480
داشتند که لطفاً
9
00:00:24,480 –> 00:00:27,519
دنباله من با لیست پخش پایتون را نیز تکمیل کنند.
10
00:00:27,519 –> 00:00:28,160
11
00:00:28,160 –> 00:00:31,519
همچنین حالا بچه ها نگران نباشید،
12
00:00:31,519 –> 00:00:33,760
زیرا شما آن درخواست خاص را دارید،
13
00:00:33,760 –> 00:00:35,200
همچنین
14
00:00:35,200 –> 00:00:37,520
کاری که من انجام خواهم داد این است که هر روز یک
15
00:00:37,520 –> 00:00:38,879
ویدیوی اسپارک، یک
16
00:00:38,879 –> 00:00:41,760
ویدیوی دنباله دار حداقل سعی می کنم این کار را انجام
17
00:00:41,760 –> 00:00:43,040
دهم، همچنین می خواستم آن
18
00:00:43,040 –> 00:00:44,000
لیست پخش خاص را تکمیل کنم.
19
00:00:44,000 –> 00:00:45,920
به دلیل زمان نتوانستم
20
00:00:45,920 –> 00:00:47,840
مطالب بیشتری بسازم، به همین دلیل
21
00:00:47,840 –> 00:00:49,200
تاخیر داشت،
22
00:00:49,200 –> 00:00:51,840
اما دوباره نگران نباشید، هدف اصلی
23
00:00:51,840 –> 00:00:52,480
آپلود
24
00:00:52,480 –> 00:00:54,800
ویدیوهای بیشتر و بیشتر برای همه
25
00:00:54,800 –> 00:00:56,559
شماست تا بتوانید آنها را به درستی دنبال
26
00:00:56,559 –> 00:00:58,879
کنید. میتوانم از آنها برای
27
00:00:58,879 –> 00:01:01,280
انتقال موفقیتآمیز خود در هر حرفهای که
28
00:01:01,280 –> 00:01:02,559
درست پیش میروید استفاده کنم،
29
00:01:02,559 –> 00:01:04,959
بنابراین لطفاً مطمئن شوید که فقط
30
00:01:04,959 –> 00:01:06,799
صبور باشید، سعی میکنم هر دو را به طور موازی آپلود
31
00:01:06,799 –> 00:01:07,200
32
00:01:07,200 –> 00:01:08,880
کنم و سعی میکنم لیست پخش را تکمیل کنم،
33
00:01:08,880 –> 00:01:10,880
بنابراین از این لذت ببرید. همتراز بچه ها
34
00:01:10,880 –> 00:01:12,320
سلام همه اسم من کریشناک است و
35
00:01:12,320 –> 00:01:13,920
به کانال یوتیوب من خوش آمدید پس بچه ها
36
00:01:13,920 –> 00:01:15,600
امروز در آموزش
37
00:01:15,600 –> 00:01:17,680
فریم های داده پی اسپارک هستیم و در اینجا در این
38
00:01:17,680 –> 00:01:19,200
ویدیوی خاص می خواهیم در مورد
39
00:01:19,200 –> 00:01:19,920
40
00:01:19,920 –> 00:01:22,880
عملکرد فیلتر بحث کنیم یک عملیات فیلتر
41
00:01:22,880 –> 00:01:24,159
بسیار مهم است. برای
42
00:01:24,159 –> 00:01:25,520
تکنیک پیش پردازش داده ها،
43
00:01:25,520 –> 00:01:26,720
اگر می خواهید برخی از
44
00:01:26,720 –> 00:01:29,280
رکوردها را بر اساس یک نوع شرایط
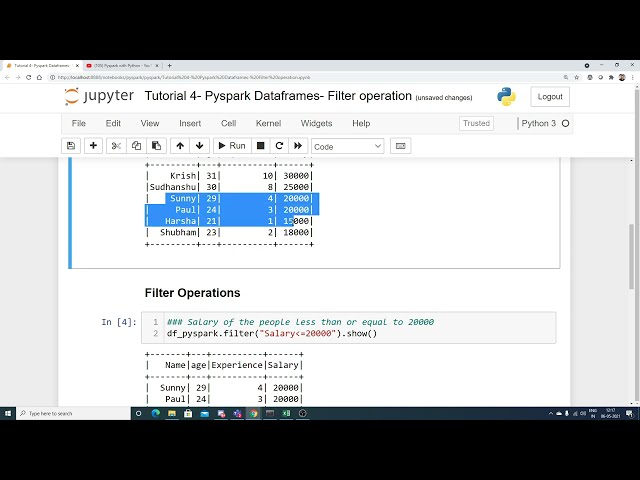
45
00:01:29,280 –> 00:01:30,880
یا یک نوع شرایط بولی بازیابی کنید،
46
00:01:30,880 –> 00:01:32,320
قطعاً می توانیم با کمک
47
00:01:32,320 –> 00:01:33,439
عملیات فیلتر این کار را انجام دهیم،
48
00:01:33,439 –> 00:01:34,720
بچه ها لطفاً مطمئن شوید
49
00:01:34,720 –> 00:01:35,920
که این لیست پخش خاص را با
50
00:01:35,920 –> 00:01:37,360
با احترام به pi
51
00:01:37,360 –> 00:01:39,280
spark، هرچه جلوتر میرویم، ویدیوهای بیشتری را آپلود خواهم کرد
52
00:01:39,280 –> 00:01:40,400
53
00:01:40,400 –> 00:01:41,840
و یک چیز دیگر را به خاطر داشته باشید،
54
00:01:41,840 –> 00:01:43,600
شکایات زیادی از طرف مردم وجود داشت که
55
00:01:43,600 –> 00:01:45,280
میگفتند sql را با پایتون آپلود کنید
56
00:01:45,280 –> 00:01:46,799
، نگران نباشید، من شروع به
57
00:01:46,799 –> 00:01:48,479
آپلود sql با
58
00:01:48,479 –> 00:01:49,840
پایتون میکنم. به دلیل تاخیر بسیار متاسفم
59
00:01:49,840 –> 00:01:51,840
زیرا مشغول انجام کاری
60
00:01:51,840 –> 00:01:52,320
61
00:01:52,320 –> 00:01:54,159
درگیر چیزی بودم، اما مطمئن
62
00:01:54,159 –> 00:01:55,759
خواهم شد که سعی می کنم تمام ویدیوها
63
00:01:55,759 –> 00:01:56,399
را به
64
00:01:56,399 –> 00:01:58,479
طور موازی با sql wi آپلود کنم python نیز
65
00:01:58,479 –> 00:02:00,000
آپلود خواهد شد، بنابراین بیایید همین حالا ادامه دهیم،
66
00:02:00,000 –> 00:02:02,240
اول از همه اجازه دهید من بروم و
67
00:02:02,240 –> 00:02:04,399
امروز یک سلول
68
00:02:04,399 –> 00:02:06,000
69
00:02:06,000 –> 00:02:08,000
70
00:02:08,000 –> 00:02:10,479
ایجاد کنم.
71
00:02:10,479 –> 00:02:12,080
تجربه و حقوق
72
00:02:12,080 –> 00:02:13,840
و من فقط از این استفاده می کنم و سعی
73
00:02:13,840 –> 00:02:15,440
می کنم نمونه
74
00:02:15,440 –> 00:02:17,200
هایی از عملکرد فیلتر را
75
00:02:17,200 –> 00:02:19,200
در ابتدا به شما نشان دهم هر زمان که می خواهید با
76
00:02:19,200 –> 00:02:21,040
pi spark کار کنید، باید مطمئن شوید که
77
00:02:21,040 –> 00:02:22,720
تمام کتابخانه ها را نصب کرده اید،
78
00:02:22,720 –> 00:02:25,840
بنابراین من از spicebug.sql import
79
00:02:25,840 –> 00:02:27,040
spark session استفاده می کنیم
80
00:02:27,040 –> 00:02:29,360
و این در واقع به ما کمک می کند تا
81
00:02:29,360 –> 00:02:30,640
یک جلسه spark
82
00:02:30,640 –> 00:02:32,000
درست ایجاد کنیم و این اولین قدم است
83
00:02:32,000 –> 00:02:34,239
هر زمان که بخواهیم
84
00:02:34,239 –> 00:02:37,599
اساساً با یک spark pi درست
85
00:02:37,599 –> 00:02:40,000
کار کنیم بنابراین از برنامه نقطه سازنده نقطه پراکنده جلسه استفاده خواهیم کرد.
86
00:02:40,000 –> 00:02:41,040
87
00:02:41,040 –> 00:02:45,200
نام اوه پس من فقط می
88
00:02:45,200 –> 00:02:48,000
خواهم نام برنامه خود را به عنوان قاب داده ایجاد کنم و
89
00:02:48,000 –> 00:02:49,840
اساساً تابع get یا ایجاد را بنویسم
90
00:02:49,840 –> 00:02:52,080
که در واقع به من کمک می کند تا به
91
00:02:52,080 –> 00:02:53,840
سرعت یک جلسه جرقه ایجاد کنم.
92
00:02:53,840 –> 00:02:55,360
93
00:02:55,360 –> 00:02:56,080
94
00:02:56,080 –> 00:02:58,480
بیایید تی سعی کنید
95
00:02:58,480 –> 00:03:00,080
یک مجموعه داده خاص را بخوانید،
96
00:03:00,080 –> 00:03:01,519
بنابراین در اینجا کاری که قرار است انجام دهم،
97
00:03:01,519 –> 00:03:03,280
فقط می خواهم یک متغیر
98
00:03:03,280 –> 00:03:05,599
uh df underscore pi spark ایجاد کنم و
99
00:03:05,599 –> 00:03:07,440
از متغیر spark
100
00:03:07,440 –> 00:03:10,879
dot read یا dot csv
101
00:03:10,879 –> 00:03:12,640
و در اینجا من استفاده کنم. من فقط می خواهم
102
00:03:12,640 –> 00:03:14,560
مجموعه داده های خود را test1
103
00:03:14,560 –> 00:03:17,599
dot csv در نظر بگیرم و در
104
00:03:17,599 –> 00:03:19,519
اینجا فقط می خواهم مطمئن شوم که
105
00:03:19,519 –> 00:03:21,280
این گزینه خاص
106
00:03:21,280 –> 00:03:23,519
هدر انتخاب شده برابر با true است و in for
107
00:03:23,519 –> 00:03:24,720
108
00:03:24,720 –> 00:03:26,560
schema برابر با true است.
109
00:03:26,560 –> 00:03:28,560
به شما توضیح دادم پس
110
00:03:28,560 –> 00:03:30,959
اگر df dot pyspark dot show را
111
00:03:30,959 –> 00:03:33,519
در اینجا بنویسم، می توانید مجموعه داده های خود را ببینید
112
00:03:33,519 –> 00:03:34,080
خوب است،
113
00:03:34,080 –> 00:03:36,000
بنابراین در حال خواندن است، بیایید ببینیم چگونه خروجی را دریافت می
114
00:03:36,000 –> 00:03:38,560
کنیم، بنابراین این کل خروجی من است
115
00:03:38,560 –> 00:03:41,200
حالا بچه ها همانطور که به شما نشان دادم که ما
116
00:03:41,200 –> 00:03:43,200
روی
117
00:03:43,200 –> 00:03:44,959
عملیات فیلتر کار خواهم کرد، من سعی خواهم کرد
118
00:03:44,959 –> 00:03:46,239
برخی از رکوردها را
119
00:03:46,239 –> 00:03:48,319
بر اساس برخی شرایط بازیابی کنم، به یاد داشته باشید که
120
00:03:48,319 –> 00:03:49,680
فیلترها
121
00:03:49,680 –> 00:03:52,239
در پانداها نیز موجود هستند، اما در آنجا
122
00:03:52,239 –> 00:03:54,080
سعی می کنید به روشی متفاوت بنویسید،
123
00:03:54,080 –> 00:03:55,840
اجازه دهید من فقط به شما نشان دهم که چگونه می توانیم
124
00:03:55,840 –> 00:03:57,840
عملیات فیلتر را با استفاده از آن انجام دهیم.
125
00:03:57,840 –> 00:04:00,879
pi spark خوب است، بنابراین عملیات فیلتر
126
00:04:00,879 –> 00:04:02,879
اجازه دهید این را به عنوان علامت گذاری کنم بنابراین
127
00:04:02,879 –> 00:04:05,439
بزرگ به نظر می رسد شگفت انگیز به نظر می رسد
128
00:04:05,439 –> 00:04:08,319
اوه اجازه دهید چند سلول دیگر را کامل کنم،
129
00:04:08,319 –> 00:04:08,640
حالا
130
00:04:08,640 –> 00:04:10,480
قدم اول چگونه می توانم یک عملیات فیلتر انجام دهم،
131
00:04:10,480 –> 00:04:12,959
فرض کنید می خواهم
132
00:04:12,959 –> 00:04:16,320
حقوق افرادی را که
133
00:04:16,320 –> 00:04:19,519
احتمالاً کمتر از بیست هزار نفر هستند، پیدا کنم،
134
00:04:19,519 –> 00:04:21,040
خوب کمتر یا مساوی بیست
135
00:04:21,040 –> 00:04:23,120
هزار من اکنون می توانم کمتر
136
00:04:23,120 –> 00:04:26,720
یا مساوی بیست هزار بنویسم برای این کار
137
00:04:26,720 –> 00:04:28,320
دو راه وجود دارد که چگونه می توانیم آن را بنویسیم
138
00:04:28,320 –> 00:04:30,320
روش اول من فقط سعی می کنم از
139
00:04:30,320 –> 00:04:32,320
عملیات فیلتر استفاده کنم تا شما مانند
140
00:04:32,320 –> 00:04:34,000
فیلتر نقطه ای داشته باشید و در