در این مطلب، ویدئو تجزیه و تحلیل داده های اکتشافی در پایتون با استفاده از Mito با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:04:58
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:02,960 –> 00:00:04,560
سلام، این جیک از mido است، من به
2
00:00:04,560 –> 00:00:06,640
شما نشان خواهم داد که چگونه میتوانید
3
00:00:06,640 –> 00:00:07,120
دادهها را
4
00:00:07,120 –> 00:00:09,440
با استفاده از mido کاوش و نمودار کنید، بنابراین برای کسانی که نمیدانند
5
00:00:09,440 –> 00:00:10,400
mido یک
6
00:00:10,400 –> 00:00:13,040
پسوند صفحهگسترده به مشتری است،
7
00:00:13,040 –> 00:00:14,320
اساساً معنی آن این است که
8
00:00:14,320 –> 00:00:16,480
میتوانید این صفحهگسترده تصویری را در اینجا به آن فراخوانی کنید.
9
00:00:16,480 –> 00:00:17,840
محیط
10
00:00:17,840 –> 00:00:19,760
jupyter شما و هر ویرایشی که انجام میدهید کد پایتون معادل را ایجاد میکند
11
00:00:19,760 –> 00:00:21,600
،
12
00:00:21,600 –> 00:00:23,199
بنابراین برای فراخوانی آن تنها کاری که باید انجام دهیم این است که
13
00:00:23,199 –> 00:00:24,680
import miter sheet و سپس
14
00:00:24,680 –> 00:00:26,320
mitosheet.cheap را اجرا کنیم،
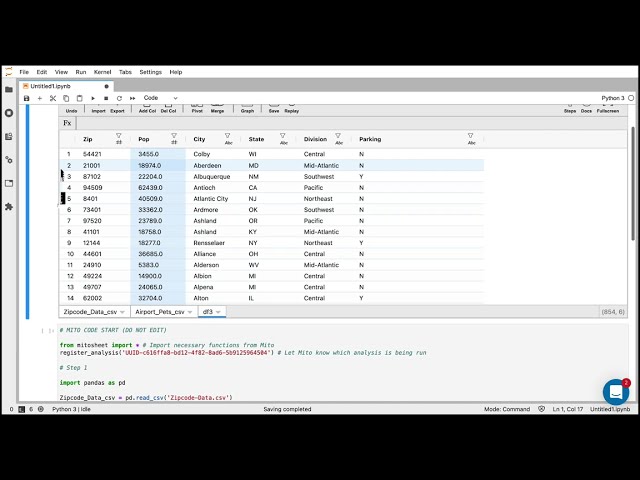
15
00:00:26,320 –> 00:00:27,519
اما قبل از آن باید بسته را وارد کنیم،
16
00:00:27,519 –> 00:00:29,279
من به مستندات mito میروم.
17
00:00:29,279 –> 00:00:30,800
خیلی سریع
18
00:00:30,800 –> 00:00:32,479
فقط سه خط تنها کاری که باید انجام دهم این است که
19
00:00:32,479 –> 00:00:34,960
یک نصب کننده mito را با پیپ نصب کنم
20
00:00:34,960 –> 00:00:36,640
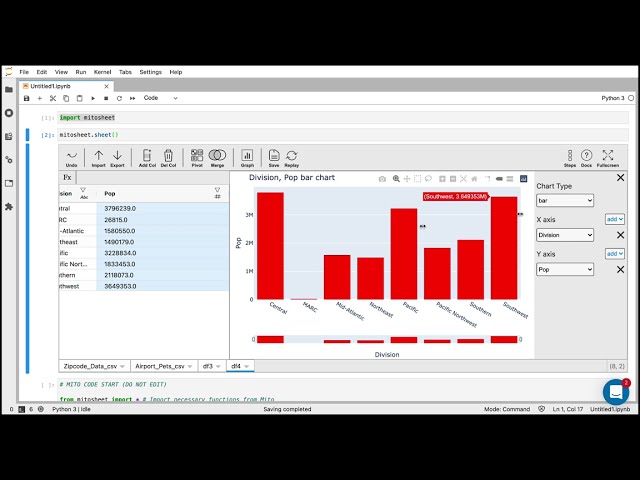
و سپس در داخل
21
00:00:36,640 –> 00:00:38,399
نصب کننده دستور install را اجرا کنید و سپس jupyter
22
00:00:38,399 –> 00:00:39,760
lab را
23
00:00:39,760 –> 00:00:41,120
باز کنید و سپس دوباره فقط این دو خط
24
00:00:41,120 –> 00:00:42,800
را اجرا کنید و رابط را مشاهده خواهیم
25
00:00:42,800 –> 00:00:44,000
کرد تا همه چیز را تکرار کنیم. ما در این رابط انجام می دهیم
26
00:00:44,000 –> 00:00:45,280
، قرار است پایتون معادل زیر را تولید کنیم،
27
00:00:45,280 –> 00:00:46,960
28
00:00:46,960 –> 00:00:48,160
اولین کاری که می خواهم انجام دهم البته این است که
29
00:00:48,160 –> 00:00:50,320
مقداری داده را در ابزار وارد کنم، بنابراین می
30
00:00:50,320 –> 00:00:52,320
توانم این کار را با عبور دادن یک قاب داده موجود در یک قاب داده موجود انجام دهم.
31
00:00:52,320 –> 00:00:54,239
نکته اینجاست که
32
00:00:54,239 –> 00:00:56,480
شما می توانید از هر
33
00:00:56,480 –> 00:00:58,000
نقطه ای از تحلیل خود در یک قاب داده عبور دهید، بنابراین در
34
00:00:58,000 –> 00:00:59,440
هر نقطه تجزیه و تحلیل خود را می توانید
35
00:00:59,440 –> 00:01:01,520
در برگه میتر فراخوانی
36
00:01:01,520 –> 00:01:02,960
کنید و قاب داده خود را تجسم کنید و با آن تعامل کنید
37
00:01:02,960 –> 00:01:04,080
و دوباره
38
00:01:04,080 –> 00:01:06,320
کد را برای شما تولید می کند. jetta رایگان شما انجام می دهید
39
00:01:06,320 –> 00:01:09,040
ما همچنین می توانیم مستقیماً از فایل های خود وارد کنیم،
40
00:01:09,040 –> 00:01:10,799
بنابراین من روی افزودن فایل از
41
00:01:10,799 –> 00:01:12,960
پوشه فعلی خود کلیک می کنم، می خواهم
42
00:01:12,960 –> 00:01:15,840
دو فایل را از پوشه محلی خود اضافه کنم، این را می
43
00:01:15,840 –> 00:01:17,280
بندم و اکنون می خواهم
44
00:01:17,280 –> 00:01:18,880
با آن کار کنم این داده ها کمی هستند، بنابراین آنچه که
45
00:01:18,880 –> 00:01:20,799
من در اینجا برای این داده ها به آن علاقه دارم،
46
00:01:20,799 –> 00:01:21,759
این تقسیم بندی ها است
47
00:01:21,759 –> 00:01:24,799
و می خواهم ببینم کل
48
00:01:24,799 –> 00:01:26,960
49
00:01:26,960 –> 00:01:28,560
جمعیت
50
00:01:28,560 –> 00:01:31,840
برای هر بخش در اینجا چقدر است، اما بدیهی است که
51
00:01:31,840 –> 00:01:33,200
این دو ستون در داده های متفاوتی هستند.
52
00:01:33,200 –> 00:01:34,079
تنظیم می شود، بنابراین ما مجبور خواهیم شد
53
00:01:34,079 –> 00:01:35,439
اینها را در یک نقطه با هم جمع کنیم، اما
54
00:01:35,439 –> 00:01:36,720
اولین کاری که می خواهم انجام دهم
55
00:01:36,720 –> 00:01:38,079
این است که کمی دقیق تر به این ستون ها نگاه
56
00:01:38,079 –> 00:01:40,560
کنم، روی این ستون کلیک می کنم،
57
00:01:40,560 –> 00:01:42,159
این دکمه را در اینجا انتخاب می کنم
58
00:01:42,159 –> 00:01:43,280
و سپس من من به آمار خلاصه
59
00:01:43,280 –> 00:01:45,600
برای آن ستون می روم d من واقعاً می
60
00:01:45,600 –> 00:01:46,960
61
00:01:46,960 –> 00:01:49,040
توانم این ستون و توزیع را در اینجا تجسم کنم،
62
00:01:49,040 –> 00:01:50,399
بنابراین می توانیم ببینیم که
63
00:01:50,399 –> 00:01:54,560
بخش مرکزی 21
64
00:01:54,560 –> 00:01:57,600
211 نمونه دارد، بخش اقیانوس آرام دارای
65
00:01:57,600 –> 00:02:00,159
148 نمونه است و غیره و غیره
66
00:02:00,159 –> 00:02:01,600
و سپس در زیر می توانم آمار خلاصه ای را
67
00:02:01,600 –> 00:02:03,840
برای این ستون به دست بیاورم. خوب
68
00:02:03,840 –> 00:02:06,640
این را ببندید و من میخواهم به سرعت به
69
00:02:06,640 –> 00:02:08,080
آمار خلاصه این ستون
70
00:02:08,080 –> 00:02:10,399
در اینجا نگاه کنم، فقط روی همان دکمههایی کلیک
71
00:02:10,399 –> 00:02:12,160
72
00:02:12,160 –> 00:02:15,200
کنید که فرکانسهای um را برای این جمعیتها در اینجا داریم،
73
00:02:15,200 –> 00:02:17,840
اکنون این را میبندم
74
00:02:17,840 –> 00:02:19,280
و دوباره چون این ستونها
75
00:02:19,280 –> 00:02:20,480
در دادههای متفاوتی هستند. مجموعهها واقعاً میخواهم
76
00:02:20,480 –> 00:02:21,840
77
00:02:21,840 –> 00:02:23,920
قبل از ایجاد نموداری از آنها، آنها را در یک مجموعه داده جمع کنم،
78
00:02:23,920 –> 00:02:26,239
بنابراین من فقط از مدل ادغام خود در اینجا استفاده میکنم
79
00:02:26,239 –> 00:02:27,920
این به ما امکان میدهد واقعاً به راحتی
80
00:02:27,920 –> 00:02:30,239
مجموعههای داده را به هم بپیوندیم. کلید ادغام
81
00:02:30,239 –> 00:02:31,680



![فیلم آموزشی: ایجاد بدافزار پایتون در 20 دقیقه - Yan Orestes [PyBR14] با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/G6bHl8Ert6Uimage2.jpg)