در این مطلب، ویدئو پاندای پایتون: ردیفها و ستونهای داده را بر اساس فهرست یا شرطیها انتخاب، برش و فیلتر کنید با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:24:38
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,580
سلام من جو جیمز هستم در این ویدیو می
2
00:00:02,580 –> 00:00:04,830
خواهیم یاد بگیریم که چگونه
3
00:00:04,830 –> 00:00:07,200
ردیف ها و ستون های مختلف
4
00:00:07,200 –> 00:00:10,019
داده را در پانداها برش بزنیم و فیلتر کنیم، بنابراین
5
00:00:10,019 –> 00:00:11,610
تکنیک های مختلفی را برای
6
00:00:11,610 –> 00:00:12,269
انجام این کار یاد می
7
00:00:12,269 –> 00:00:13,500
گیریم که از آنها استفاده می کنیم. دو مجموعه داده متفاوت
8
00:00:13,500 –> 00:00:16,470
و هم این نوت بوک و هم آن
9
00:00:16,470 –> 00:00:18,810
دو مجموعه داده من قرار است طبق معمول
10
00:00:18,810 –> 00:00:20,730
در سایت github خود پست کنم و لینکی را در
11
00:00:20,730 –> 00:00:22,230
پایین در نظرات ارسال خواهم کرد که می
12
00:00:22,230 –> 00:00:25,410
توانید مجموعه داده ها و دفترچه یادداشت را دانلود کنید
13
00:00:25,410 –> 00:00:28,890
و همه اینها را اجرا کنید. خودتان کدنویسی کنید، بنابراین ما می
14
00:00:28,890 –> 00:00:29,939
خواهیم با برخی از
15
00:00:29,939 –> 00:00:32,130
دستورات واردات شروع کنیم، باید
16
00:00:32,130 –> 00:00:36,989
تاریخ/زمان و کتابخانه های تصادفی پانداهای ناتوان را وارد
17
00:00:36,989 –> 00:00:39,050
کنیم، بنابراین این را اجرا می کنیم،
18
00:00:39,050 –> 00:00:42,570
یک قاب داده جدید ایجاد می کنیم و این کار
19
00:00:42,570 –> 00:00:46,739
را انجام می دهیم. با وارد کردن یک فایل CSV، Reed
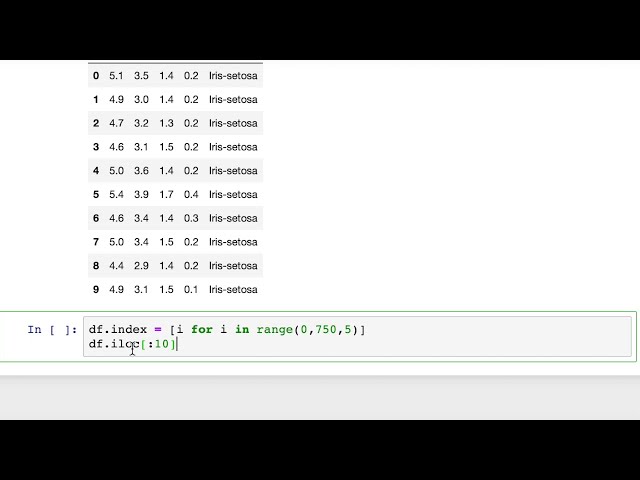
20
00:00:46,739 –> 00:00:50,910
زیر خط CSV و سپس نام
21
00:00:50,910 –> 00:00:56,190
فایل ما که داده های نقطه عنبیه است، قرار می دهیم و سپس نام
22
00:00:56,190 –> 00:00:57,539
هایی را قرار می دهیم که این
23
00:00:57,539 –> 00:01:01,079
نام ستون ها a b c d است زیرا ما
24
00:01:01,079 –> 00:01:03,210
چهار ستون داده های عددی داریم و سپس
25
00:01:03,210 –> 00:01:06,570
یک برچسب داریم که یک متن است و سپس
26
00:01:06,570 –> 00:01:09,299
سر نقطه AF را چاپ می کنیم، بنابراین این همان
27
00:01:09,299 –> 00:01:11,340
است اولین روشی که میتوانیم دادهها را برای
28
00:01:11,340 –> 00:01:13,979
نشان دادن head انتخاب کنیم به شما امکان میدهد از
29
00:01:13,979 –> 00:01:16,560
بالای قاب داده هر تعداد ردیف را نشان دهید
30
00:01:16,560 –> 00:01:18,540
، پیشفرض آن 5 است، بنابراین اگر من اصلاً هیچ آرگومانی را رد نکنم
31
00:01:18,540 –> 00:01:20,880
32
00:01:20,880 –> 00:01:23,400
، پنج ردیف بالا را به ما نشان میدهد یا اگر بخواهم میتوانم
33
00:01:23,400 –> 00:01:25,020
یک آرگومان عدد صحیح در آنجا قرار دهم و
34
00:01:25,020 –> 00:01:27,840
هفت یا نه ردیف بالا یا
35
00:01:27,840 –> 00:01:29,460
هر تعداد که میخواهید ببینید را نشان میدهد تا
36
00:01:29,460 –> 00:01:30,780
مجبور نباشید کل قاب داده را چاپ کنید،
37
00:01:30,780 –> 00:01:32,340
من فقط پنج ردیف بالا را نشان میدهم.
38
00:01:32,340 –> 00:01:35,640
در اینجا ما آن را اجرا می کنیم و در اینجا
39
00:01:35,640 –> 00:01:38,340
پنج ردیف اول داده ها را دریافت می کنیم، بنابراین
40
00:01:38,340 –> 00:01:40,470
می توانیم ببینیم که وقتی فایل CSV را وارد کرده
41
00:01:40,470 –> 00:01:43,500
و در یک قاب داده بارگذاری می کنیم،
42
00:01:43,500 –> 00:01:46,049
به طور خودکار مقادیر صحیح را
43
00:01:46,049 –> 00:01:48,869
برای شاخص های ردیف ما که با صفر شروع می شود، اختصاص می
44
00:01:48,869 –> 00:01:52,259
دهد، بنابراین طبیعی است که
45
00:01:52,259 –> 00:01:55,649
پانداها به این ترتیب کار میکنند و میبینید که برچسبهای ستونهای ما
46
00:01:55,649 –> 00:01:57,360
در بالای صفحه به
47
00:01:57,360 –> 00:02:02,310
نامهای ABCD و برچسب نامیده میشوند، سپس میتوانید
48
00:02:02,310 –> 00:02:04,469
ببینید ABCD همه مقادیر ممیز شناور هستند
49
00:02:04,469 –> 00:02:06,030
و یک رقم اعشار خواهید داشت، بنابراین
50
00:02:06,030 –> 00:02:08,068
این مجموعه دادههای تمیز و خوبی برای کار است.
51
00:02:08,068 –> 00:02:09,508
با و هیچ مقدار از دست رفته یا
52
00:02:09,508 –> 00:02:12,900
هیچ چیز دیگری
53
00:02:12,900 –> 00:02:14,879
وجود ندارد اولین راه برای برش داده ها
54
00:02:14,879 –> 00:02:16,799
از بالا و سپس اگر می خواهید
55
00:02:16,799 –> 00:02:19,680
داده ها را از پایین برش دهید، می توانید از tail استفاده کنید تا
56
00:02:19,680 –> 00:02:24,540
بتوانیم از D F dot tail استفاده کنیم و اگر می خواهید
57
00:02:24,540 –> 00:02:26,430
دوباره در یک آرگومان عبور دهید می توانید
58
00:02:26,430 –> 00:02:29,489
سه را بگویید سپس چاپ می شود سه
59
00:02:29,489 –> 00:02:32,159
ردیف آخر داده در قاب داده ما تا
60
00:02:32,159 –> 00:02:34,200
بتوانیم ببینیم چند ردیف وجود دارد از 0 تا
61
00:02:34,200 –> 00:02:38,129
149، 150 ردیف داده در
62
00:02:38,129 –> 00:02:42,120
مجموعه داده وجود دارد و اگر بخواهیم می توانیم
63
00:02:42,120 –> 00:02:46,829
شکل نقطه DF را نیز قرار دهیم و آنها به شما خواهند گفت.
64
00:02:46,829 –> 00:02:48,480
ما که 150 سطر و 5
65
00:02:48,480 –> 00:02:50,790
ستون داده وجود دارد، بنابراین این شکلی از
66
00:02:50,790 –> 00:02:53,040
قاب داده ما است، سپس به تابع loke نگاه خواهیم کرد
67
00:02:53,040 –> 00:02:57,120
soloq برای مکان یابی است که می
68
00:02:57,120 –> 00:02:59,970
توانیم cloak DF را انجام دهیم و سپس
69
00:02:59,970 –> 00:03:01,709
از پرانتز برای این کار استفاده نمی کنیم. ما
70
00:03:01,709 –> 00:03:03,840
از براکت استفاده می کنیم، خوب این یک
71
00:03:03,840 –> 00:03:06,480
روش نمایه سازی است، بنابراین ما می
72
00:03:06,480 –> 00:03:10,560
خواهیم شاخص های 146 را به بعد ببریم، بنابراین
73
00:03:10,560 –> 00:03:12,659
یک مرحله از یک به و یک مرحله وجود دارد، این نوع
74
00:03:12,659 –> 00:03:15,269
مانند یک تابع محدوده یا برخی از
75
00:03:15,269 –> 00:03:17,400
نمایه سازی استاندارد آنها کار می کند. از
76
00:03:17,400 –> 00:03:20,430
پایتون از 146 به بعد استفاده شده است و اگر بخواهیم فقط
77
00:03:20,430 –> 00:03:23,310
کلمه on را خالی می گذاریم اگر بخواهیم می
78
00:03:23,310 –> 00:03:26,549
توانیم ty کنیم pe 150 در اینجا و سپس ما همچنین میتوانیم
79
00:03:26,549 –> 00:03:29,310
یک افزایش برای نوشتن هر
80
00:03:29,310 –> 00:03:32,400
سطر دیگر قرار دهیم، اگر بخواهیم،
81
00:03:32,400 –> 00:03:33,989
ایش را خالی میگذارم که به معنای هر سطر است و م
82
00:03:33,989 –> 00:03:35,370
این را خالی میگذارم که به
83
00:03:35,370 –> 00:03:37,699
ین معنی است که فقط به پا
84
00:03:37,699 –> 00:03:42,299
به ما می دهد 146 به بعد و سپس اگر
85
00:03:42,299 –> 00:03:46,290
ما cloak DF را انجام دادیم و سپس فرض کنید
86
00:03:46,290 –> 00:03:53,299
که یک محدوده را در اینجا قرار داده ایم مثلاً 54 تا 59
87
00:03:53,299 –> 00:03:55,440
و سپس می توانیم همانطور که گفتم می
88
00:03:55,440 –> 00:03:59,849
توانیم هر ردیف دیگر را قرار دهیم اگر می خواهید 54 56
89
00:03:59,849 –> 00:04:02,449
و
90
00:04:02,659 –> 00:04:05,099
بنابراین، تابع loke برای
91
00:04:05,099 –> 00:04:08,790
انتخاب ردیفهای دادهها به صورت عددی مفید است، اما
92
00:04:08,790 –> 00:04:10,739
این شاخصهای ردیف نیز میتوانند رشتهای باشند
93
00:04:10,739 –> 00:04:12,479
و میتوانید از تابع محلی برای
94
00:04:12,479 –> 00:04:14,459
رشتهها نیز استفاده کنید و اگر
95
00:04:14,459 –> 00:04:17,988
از را به هر دو خالی بگذارید و ما
96
00:04:17,988 –> 00:04:23,880
فقط افزایش یا مرحله را وارد کنید. مقدار را
97
00:04:23,880 –> 00:04:25,860
از ابتدا
98
00:04:25,860 –> 00:04:27,510
میتوانیم به
99
00:04:27,510 –> 00:04:30,900
خوبی بگوییم زیرا آن را خالی میگذاریم و سپس برای خوب، آن را خالی میگذاریم – و سپس
100
00:04:30,900 –> 00:04:32,610
فقط یک مقدار افزایشی قرار میدهیم،
101
00:04:32,610 –> 00:04:34,650
بگذارید 40 بگذاریم تا هر چهلمین ردیف از آن چاپ شود
102
00:04:34,650 –> 00:04:39,320
. داده ها با
103
00:04:39,350 –> 00:04:42,390
صدای بلند D F dot Lok و سپس من برای هر
104
00:04:42,390 –> 00:04:47,310
چهلمین ردیف داده گریه خواهم کرد تا ما 0 48 + 1
105
00:04:47,310 –> 00:04:50,010
20 را دریافت کنید، بنابراین اگر میخواهید میتوانید مرحله
106
00:04:50,010 –> 00:04:52,860
را نیز با استفاده از look قرار دهید، همچنین میتوانید
107
00:04:52,860 –> 00:04:55,940
در لیستی از ردیفها قرار دهید، فرض کنید من میخواهم
108
00:04:55,940 –> 00:05:00,870
ردیفهای 5، 12 و 17 را چاپ کنیم تا بتوانیم
109
00:05:00,870 –> 00:05:03,750
به D F dot Lok برویم و سپس این کاری است که
110
00:05:03,750 –> 00:05:05,190
ما انجام میدهیم، هرچند باید یک
111
00:05:05,190 –> 00:05:07,230
پرانتز دوتایی در اینجا قرار دهیم، زیرا
112
00:05:07,230 –> 00:05:10,050
به مجموعهای از پرانتز نیاز داریم، یک لیست
113
00:05:10,050 –> 00:05:13,500
در داخل پرانتزها، بنابراین
114
00:05:13,500 –> 00:05:17,970
میگوییم 5 کاما 12 کاما 17 هر آنچه را که
115
00:05:17,970 –> 00:05:20,820
میتوانید در هر فهرستی که میخواهید ارسال کنید. در اینجا اما
116
00:05:20,820 –> 00:05:22,370
شما فقط باید مطمئن شوید که
117
00:05:22,370 –> 00:05:25,200
دو براکت مربع باز کننده 2 براکت مربع بسته
118
00:05:25,200 –> 00:05:28,010
برای لیست خود دارید و سپس
119
00:05:28,010 –> 00:05:31,230
بیایید ببینیم که ردیف های 5 12 و 17 را دریافت می کنیم، بنابراین
120
00:05:31,230 –> 00:05:34,560
اگر می خواهیم چاپ کنیم، می توانید لیستی از ردیف ها را نیز
121
00:05:34,560 –> 00:05:36,390
ارسال کنید.
122
00:05:36,390 –> 00:05:38,520
میتوانیم ستون داده را چاپ کنیم،
123
00:05:38,520 –> 00:05:40,530
چند روش مختلف برای انجام این کار،
124
00:05:40,530 –> 00:05:43,080
میتوانیم بگوییم فقط D F نقطه B و این
125
00:05:43,080 –> 00:05:47,460
به ما چاپ ستون B را میدهد
126
00:05:47,460 –> 00:05:49,380
تا ستون B از دادههایی را که میتوانید ببینید به ما میدهد.
127
00:05:49,380 –> 00:05:51,900
در این ستون B میتوانید از براکتهای مربع نیز استفاده کنید،
128
00:05:51,900 –> 00:05:55,230
بنابراین ما نیز میتوانیم این کار
129
00:05:55,230 –> 00:05:57,570
و سپس B را به عنوان یک رشته انجام دهیم بنابراین ما
130
00:05:57,570 –> 00:05:59,910
آن را در داخل یک نقل قول قرار می دهیم و
131
00:05:59,910 –> 00:06:01,380
این نیز کار خواهد کرد.
132
00:06:01,380 –> 00:06:05,310
133
00:06:05,310 –> 00:06:11,460
134
00:06:11,460 –> 00:06:21,360
135
00:06:21,360 –> 00:06:24,330
به دو براکت مربع نیاز دارید
136
00:06:24,330 –> 00:06:27,000
که برای دیدن دو براکت کار می کند تا دو براکت را باز
137
00:06:27,000 –> 00:06:28,920
کنید تا بسته شود و بنابراین
138
00:06:28,920 –> 00:06:30,930
ما لیستی از ستون ها را داریم که می خواهیم
139
00:06:30,930 –> 00:06:33,660
چاپ کنیم تا بتوانیم این کار را انجام دهیم و سپس
140
00:06:33,660 –> 00:06:36,840
می توانید به اینجا سر اضافه کنید.
141
00:06:36,840 –> 00:06:38,340
اگر فقط میخواهید
142
00:06:38,340 –> 00:06:41,220
ده ردیف بالای داده را ببینید که به
143
00:06:41,220 –> 00:06:44,970
خوبی کار میکنند، به ده ردیف بالا بروید
144
00:06:44,970 –> 00:06:49,680
یا این توابع با
145
00:06:49,680 –> 00:06:50,820
چسباندن آنها به اینجا کار میکنند،
146
00:06:50,820 –> 00:06:54,479
زمانی که odf dot lok بسیار همهکاره است،
147
00:06:54,479 –> 00:06:57,090
میتوانید یک محدوده و لیستی از
148
00:06:57,090 –> 00:06:59,580
آیتم ها و اگر می خواهید می توانید هر دو سطر و ستون را با هم ترکیب
149
00:06:59,580 –> 00:07:02,220
کنید، بنابراین این را بررسی کنید، می
150
00:07:02,220 –> 00:07:04,680
توانیم بگوییم که ما ردیف می خواهیم، ردیف ها ابتدا می آی
151
00:07:04,680 –> 00:07:06,960
د و سپس ستون ها، بنابراین می توانیم بگ
152
00:07:06,960 –> 00:07:12,410
ییم که ما سطر می خواهیم، مثلاً ردیف 52 چرا بی
153
00:07:12,410 –> 00:07:17,550
یید فرض کنید 60 و سپس یک
154
00:07:17,550 –> 00:07:19,680
کاما می گذاریم و حالا یک فیلد در اینجا داریم
155
00:07:19,680 –> 00:07:23,340
ما میتوانیم ستونهایی قرار دهیم که کدام ستونها را
156
00:07:23,340 –> 00:07:25,700
میخواهیم خوب، اوه، من فقط میخواهم یک ستون
157
00:07:25,700 –> 00:07:28,700
خوب باشد که خوب است، شما فقط ستون a را
158
00:07:28,700 –> 00:07:32,760
برای ردیفهای 50 تا 60 دریافت کنید یا اگر میخواهید
159
00:07:32,760 –> 00:07:34,560
در لیست خود در اینجا پاس کنید، میتوانید در
160
00:07:34,560 –> 00:07:39,780
لیست ارسال کنید تا ما بتوانیم می گوییم ما ستون های a
161
00:07:39,780 –> 00:07:46,500
و برچسب ستون را می خواهیم و این نیز کار خواهد کرد.
162
00:07:46,500 –> 00:07:48,180
اوه، ما براکت را در آنجا رها کردیم
163
00:07:48,180 –> 00:07:49,680
، بنابراین اگر آن بوم براکت را
164
00:07:49,680 –> 00:07:53,430
داشته باشیم، دوباره لیستی برای
165
00:07:53,430 –> 00:07:55,860
ستون های خود داریم که می خواهیم محدوده ای را
166
00:07:55,860 –> 00:07:58,830
با دو نقطه نشان دهیم. ردیف هایی را که می
167
00:07:58,830 –> 00:08:02,820
خواهیم نشان دهیم و از Loken استفاده می کنیم و
168
00:08:02,820 –> 00:08:04,950
شما می توانید لیستی برای سطرهایی که
169
00:08:04,950 –> 00:08:07,770
می خواهید نشان دهید به جای یک محدوده قرار دهید
170
00:08:07,770 –> 00:08:10,320
و همچنین می توانید یک محدوده را
171
00:08:10,320 –> 00:08:12,570
به جای یک لیست در اینجا قرار دهید بنابراین loke در آن بسیار
172
00:08:12,570 –> 00:08:14,460
انعطاف پذیر است. شرایطی که میتوانید با آن انجام دهید
173
00:08:14,460 –> 00:08:15,000
174
00:08:15,000 –> 00:08:18,690
تا بلوکهای داده را جدا کنید، ما همچنین میتوانیم
175
00:08:18,690 –> 00:08:22,380
از loke برای فیلتر کردن دادهها استفاده کنیم، بنابراین فرض کنید
176
00:08:22,380 –> 00:08:27,630
میخواهیم DF dot Lok انجام دهیم و سپس در داخل
177
00:08:27,630 –> 00:08:29,720
براکتهای مربع میتوانیم فیلتری را در اینجا قرار دهیم
178
00:08:29,720 –> 00:08:35,870
DF dot a کمتر از اینکه ببینیم چه چیزی است.
179
00:08:35,870 –> 00:08:39,779
فرض کنید کمتر از پنج است، بنابراین
180
00:08:39,779 –> 00:08:42,870
سطرهایی را که در آن col است چاپ می کند umn a
181
00:08:42,870 –> 00:08:45,089
کمتر از پنج است
182
00:08:45,089 –> 00:08:47,940
، تمام سطر را چاپ میکند، بنابراین میبینید که چگونه از
183
00:08:47,940 –> 00:08:50,520
یک سری ردیف صرفنظر کرده است، ردیف ده را رد کرده است.
184
00:08:50,520 –> 00:08:53,940
185
00:08:53,940 –> 00:08:56,250
186
00:08:56,250 –> 00:08:58,980
a کمتر از
187
00:08:58,980 –> 00:09:01,530
پنج است، بنابراین میتوانیم در واقع فیلترهای سادهای را
188
00:09:01,530 –> 00:09:03,300
در داخل کروشههای مربع
189
00:09:03,300 –> 00:09:06,300
با نقطه Lok انجام دهیم، بنابراین اگر میخواهید فیلتر دیگری را امتحان کنید،
190
00:09:06,300 –> 00:09:10,440
بیایید D F نقطه لوک
191
00:09:10,440 –> 00:09:14,520
براکتهای مربع را ببینیم، D F از C برابر با
192
00:09:14,520 –> 00:09:16,320
یک نقطه چهار است و دوباره اینجا ما
193
00:09:16,320 –> 00:09:18,180
دو برابر را بدست آوردیم زیرا ما به یک
194
00:09:18,180 –> 00:09:21,360
نتیجه بولی از این آزمایش نیاز داریم در اینجا ما به یک
195
00:09:21,360 –> 00:09:24,330
نتیجه بولی از آن نیاز داریم و
196
00:09:24,330 –> 00:09:26,910
برای هر ردیف از داده ها به
197
00:09:26,910 –> 00:09:29,550
DFC نگاه می کنیم و آن را با یک نقطه چهار مقایسه می کنیم
198
00:09:29,550 –> 00:09:31,650
و اگر برابر است در یک
199
00:09:31,650 –> 00:09:33,000
نقطه چهار، آن سطر
200
00:09:33,000 –> 00:09:37,980
را چاپ می کند و کل ردیف را چاپ می کند، بنابراین به این ترتیب،
201
00:09:37,980 –> 00:09:38,820
202
00:09:38,820 –> 00:09:41,760
تمام ردیف های داده به ما می دهد که در آن
203
00:09:41,760 –> 00:09:44,190
C برابر با یک نقطه چهار است، فرض کنید شما
204
00:09:44,190 –> 00:09:46,590
فقط می خواهید برچسب را برای کسانی ببینید.
205
00:09:46,590 –> 00:09:58,050
می توانید این برچسب کاما را انجام دهید، اکنون
206
00:09:58,050 –> 00:09:59,490
فقط می خواهم g برچسب
207
00:09:59,490 –> 00:10:03,920
سطرهایی که در آنها C برابر با یک نقطه است چهار
208
00:10:04,340 –> 00:10:06,870
soloq بسیار متنوع است، میتوانید با
209
00:10:06,870 –> 00:10:08,400
آن مقداری فیلتر کنید که میتوانید
210
00:10:08,400 –> 00:10:10,830
ردیفها و ستونهای داده را فیلتر کنید،
211
00:10:10,830 –> 00:10:13,350
میتوانید سطرها و ستونهای مختلف
212
00:10:13,350 –> 00:10:16,950
فهرست دادههای ردیفها و غیره را انتخاب کنید. و
213
00:10:16,950 –> 00:10:19,620
بیایید یک فیلتر دیگر در اینجا با loke d انجام دهیم بله،
214
00:10:19,620 –> 00:10:22,950
اجازه دهید این کار را انجام دهیم DF D روی Rho D فیلتر می کند
215
00:10:22,950 –> 00:10:26,730
و سپس Lok را نقطه و سپس
216
00:10:26,730 –> 00:10:28,920
براکت ها را نقطه می کنیم، بنابراین ما می خواهیم روی
217
00:10:28,920 –> 00:10:32,390
ستون D فیلتر کنیم، از یک تابع
218
00:10:32,390 –> 00:10:35,340
لامبدا لامبدا استفاده می کنیم که متغیر ما X است. X
219
00:10:35,340 –> 00:10:38,370
چاه X سلول D برای آن سطر است
220
00:10:38,370 –> 00:10:41,850
زیرا در اینجا ستون D را انتخاب کردیم
221
00:10:41,850 –> 00:10:44,100
بنابراین ستون D X ستون
222
00:10:44,100 –> 00:10:46,910
D است و اگر بزرگتر از دو نقطه یک
223
00:10:46,910 –> 00:10:49,950
باشد آن را چاپ می کند بنابراین فقط
224
00:10:49,950 –> 00:10:52,200
ردیف های داده را چاپ می کند. در جایی که ستون
225
00:10:52,200 –> 00:10:55,410
D بزرگتر از دو نقطه یک است، می
226
00:10:55,410 –> 00:10:56,730
توانید تمام مواردی را که در اینجا بزرگتر
227
00:10:56,730 –> 00:10:59,010
از دو نقطه یک دارند را ببینید و سپس در پایین به ما می گوید
228
00:10:59,010 –> 00:11:02,310
که نام آن D است زیرا این
229
00:11:02,310 –> 00:11:04,320
ستون D است که ما همین الان چاپ کردیم،
230
00:11:04,320 –> 00:11:07,640
آن ها اعداد یا شاخص های ردیف هستند.
231
00:11:07,640 –> 00:11:10,560
بنابراین دوباره می توانیم از ساده استفاده کنیم
232
00:11:10,560 –> 00:11:11,790
توابع لامبدا من فکر نمیکنم
233
00:11:11,790 –> 00:11:14,220
توابع لامبدا پیچیدهتر در
234
00:11:14,220 –> 00:11:17,370
واقع با مرگ با Loke کار میکنند، اما
235
00:11:17,370 –> 00:11:19,260
توابع لامبدا ساده با Lok به خوبی کار میکنند،
236
00:11:19,260 –> 00:11:20,970
میخواهم راهی را به شما نشان دهم که میتوانید
237
00:11:20,970 –> 00:11:22,980
عملکردهای پیچیدهتری را برای
238
00:11:22,980 –> 00:11:26,730
فیلتر کردن انجام دهید، بنابراین پانداهای تایپ شده را نگه دارید
239
00:11:26,730 –> 00:11:29,640
همچنین این مورد را به نام eye Lok دارد و آن
240
00:11:29,640 –> 00:11:32,280
مکان عدد صحیح است که کمی
241
00:11:32,280 –> 00:11:36,860
پیچیده تر است آیا شما دارید – من
242
00:11:36,860 –> 00:11:41,250
مکان عدد صحیح بلوط را انتخاب می کنم، فرض کنید تا 10
243
00:11:41,250 –> 00:11:45,270
244
00:11:45,270 –> 00:11:47,640
را انتخاب کنید.
245
00:11:47,640 –> 00:11:49,830
فقط میتوانیم به این
246
00:11:49,830 –> 00:11:52,770
شاخصهای ردیف در اینجا نگاه کنیم و تا 10 را انتخاب کرده
247
00:11:52,770 –> 00:11:55,020
و آنها را چاپ میکند که در واقع
248
00:11:55,020 –> 00:11:57,510
چیزی نیست که اتفاق میافتد، بنابراین کاری که
249
00:11:57,510 –> 00:12:00,450
مکان عدد صحیح انجام میدهد این است که یک شاخص جداگانه دارد
250
00:12:00,450 –> 00:12:03,150
که ما نمیتوانیم آن را ببینیم و یک
251
00:12:03,150 –> 00:12:04,920
شاخص برای آن دارد. سطرها و دارای شاخصی برای
252
00:12:04,920 –> 00:12:09,720
ستون ها است بنابراین a ستون 0 است ما از ستون 1 استفاده می کنیم
253
00:12:09,720 –> 00:12:13,500
C از ستون 2 ستون 3 و برچسب
254
00:12:13,500 –> 00:12:16,590
ستون 4 است بنابراین می توانیم ستون 4 را انتخاب کنیم و