در این مطلب، ویدئو آموزش پایتون DataTable (تجزیه و تحلیل داده ها در پایتون) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:27:48
تصاویر این ویدئو:

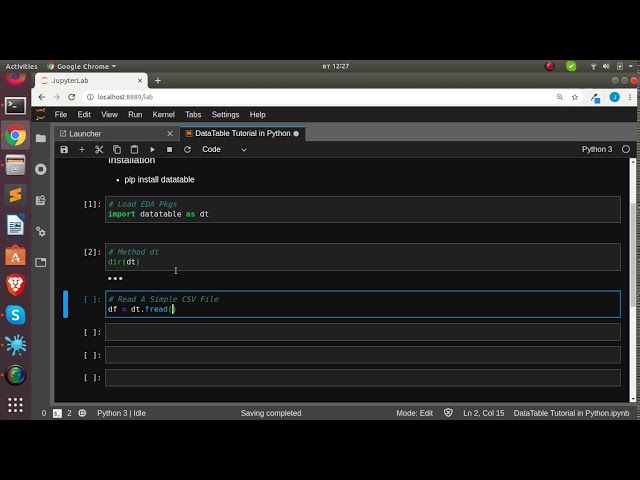
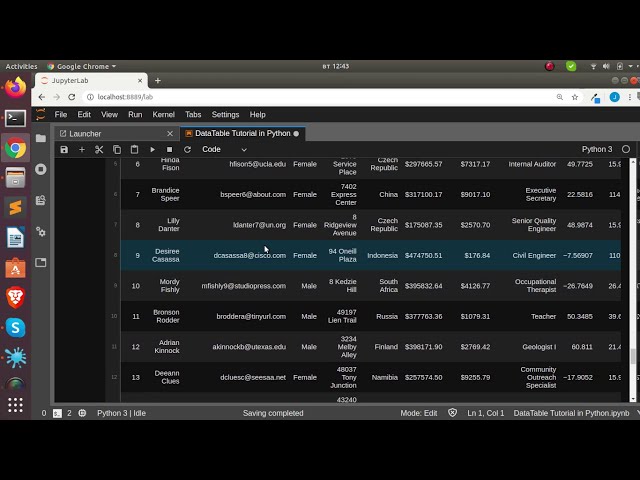
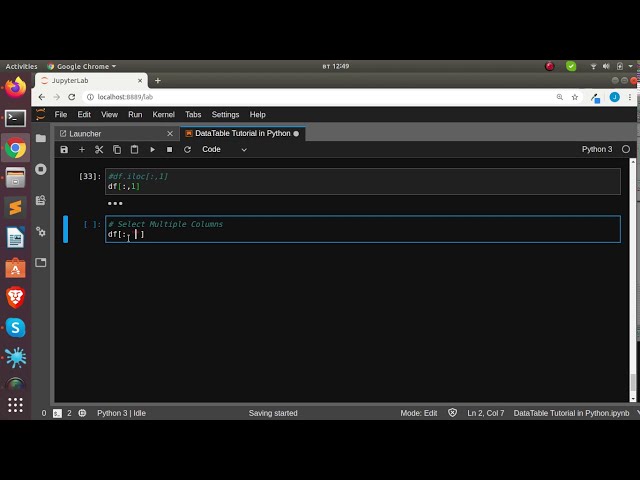
قسمتی از زیرنویس این فیلم:
00:00:00,399 –> 00:00:01,839
سلام به همه خوش آمدید دوباره
2
00:00:01,839 –> 00:00:03,360
نام من جسی است و در این آموزش عاشقانه
3
00:00:03,360 –> 00:00:04,000
4
00:00:04,000 –> 00:00:05,680
سعی می کنیم ببینیم که چگونه با یک
5
00:00:05,680 –> 00:00:07,600
بسته بسیار زیبا به نام جدول
6
00:00:07,600 –> 00:00:09,679
داده کار کنیم بنابراین جدول داده جایگزینی برای
7
00:00:09,679 –> 00:00:11,840
پانداها است که بخشی از
8
00:00:11,840 –> 00:00:14,160
یک بسته در جدول داده کد ما است.
9
00:00:14,160 –> 00:00:15,360
که بسیار
10
00:00:15,360 –> 00:00:17,039
ساده و سپس بسیار زیبا است و
11
00:00:17,039 –> 00:00:18,640
زمانی که سعی می کنید با
12
00:00:18,640 –> 00:00:20,800
داده ها پاک و سپس تجزیه و تحلیل داده ها
13
00:00:20,800 –> 00:00:21,920
مانند پانداها
14
00:00:21,920 –> 00:00:23,760
کار کنید بسیار مفید است، بنابراین هدف اصلی و فایده
15
00:00:23,760 –> 00:00:25,439
اصلی جدول داده این است
16
00:00:25,439 –> 00:00:27,920
که روی سرعت تاکید می کند و برای
17
00:00:27,920 –> 00:00:30,160
پشتیبانی از داده های بزرگ از پانداهای درست می
18
00:00:30,160 –> 00:00:30,960
توان برای آن استفاده کرد،
19
00:00:30,960 –> 00:00:32,719
اما جدول داده نیز می تواند برای آن استفاده شود،
20
00:00:32,719 –> 00:00:34,640
حالا بیایید ببینیم چگونه با
21
00:00:34,640 –> 00:00:36,399
جدول داده کار کنیم، بنابراین اول از همه فقط با
22
00:00:36,399 –> 00:00:38,480
جدول داده نصب pip بروید تا آن را نصب کنید
23
00:00:38,480 –> 00:00:41,760
و اکنون شروع به کار کنید.
24
00:00:42,160 –> 00:00:43,360
اشکالی ندارد پس اول از همه من فقط به
25
00:00:43,360 –> 00:00:45,840
سلول خود باز می گردم سپس
26
00:00:45,840 –> 00:00:49,280
یک بسته eda را بارگذاری می کنیم
27
00:00:49,280 –> 00:00:50,399
که بسیار ساده است و قرار است
28
00:00:50,399 –> 00:00:54,160
داده های جدول داده ها را وارد کنیم
29
00:00:54,399 –> 00:00:57,600
جدول سمت راست s dt
30
00:00:57,600 –> 00:00:58,960
درست طبق قراردادی که نامی است
31
00:00:58,960 –> 00:01:01,039
که ما استفاده می کنیم. به عنوان dt سپس
32
00:01:01,039 –> 00:01:03,039
w روشها و
33
00:01:03,039 –> 00:01:04,159
توابع مختلف
34
00:01:04,159 –> 00:01:06,720
dt را درست میبینم، بنابراین روشهای ابعاد مختلف
35
00:01:06,720 –> 00:01:07,439
36
00:01:07,439 –> 00:01:10,479
و سپس توابع به این صورت است که اگر با dnl خود بروم،
37
00:01:10,479 –> 00:01:12,400
آیا جدول دادهای درست داشتید، ما
38
00:01:12,400 –> 00:01:13,760
رایگان داریم، بنابراین بیشتر
39
00:01:13,760 –> 00:01:15,680
آنها با فریم درست مانند
40
00:01:15,680 –> 00:01:17,119
پانداها کار میکنند. قاب داده است
41
00:01:17,119 –> 00:01:19,040
اما جدول داده به آن فریم راست
42
00:01:19,040 –> 00:01:20,560
گفته می شود که مهمترین
43
00:01:20,560 –> 00:01:22,560
کلاسی است که استفاده می کنید، بنابراین بیایید کارهای شلوغی را ببینیم
44
00:01:22,560 –> 00:01:24,479
که می توانید با
45
00:01:24,479 –> 00:01:26,640
46
00:01:26,640 –> 00:01:28,320
47
00:01:28,320 –> 00:01:30,479
آن انجام دهید. f read که یک تابع بسیار بسیار
48
00:01:30,479 –> 00:01:31,520
قدرتمند است
49
00:01:31,520 –> 00:01:34,880
که میتوانید انجام دهید join شما میتوانید گزارشها را
50
00:01:34,880 –> 00:01:36,320
انجام دهید، میتوانید کارهای زیادی انجام دهید، بنابراین
51
00:01:36,320 –> 00:01:38,240
بیایید برخی از آنها را در این آموزش
52
00:01:38,240 –> 00:01:39,520
ببینیم، بنابراین اول از همه بیایید ببینیم چگونه یک
53
00:01:39,520 –> 00:01:40,240
54
00:01:40,240 –> 00:01:41,840
فایل را بخوانم. یک فایل ساده را بخوانید، بنابراین
55
00:01:41,840 –> 00:01:43,200
من فقط به این مکان باز می گردم و
56
00:01:43,200 –> 00:01:44,320
بیایید ببینیم چگونه
57
00:01:44,320 –> 00:01:49,119
یک فایل csv ساده را درست بخوانیم،
58
00:01:49,119 –> 00:01:51,920
بنابراین دیتافریم به شما یک عملکرد را می دهد
59
00:01:51,920 –> 00:01:54,079
تا آن را قادر به خواندن فایل csv برای خواندن
60
00:01:54,079 –> 00:01:55,520
فایل های tst برای خواندن فایل اکسل و
61
00:01:55,520 –> 00:01:57,200
فرمت آلفای سرور می کند. بنابراین بیایید ببینیم که این مثال
62
00:01:57,200 –> 00:01:58,479
اکنون df من خواهد بود
63
00:01:58,479 –> 00:02:01,600
بیایید با dt dot
64
00:02:01,600 –> 00:02:03,600
f read right، بنابراین با f read میتوانم
65
00:02:03,600 –> 00:02:04,880
هر فایلی را بخوانم،
66
00:02:04,880 –> 00:02:07,360
چه csv باشد، چه tst باشد تا به
67
00:02:07,360 –> 00:02:08,318
طور خودکار
68
00:02:08,318 –> 00:02:10,160
فرمتهای فایل را شناسایی کند و سپس جداکننده و
69
00:02:10,160 –> 00:02:11,520
سپس ابتدا آن را بخواند، بنابراین اجازه
70
00:02:11,520 –> 00:02:14,239
دهید به سایت خود در اینجا برگردیم.
71
00:02:14,239 –> 00:02:15,760
مجموعه داده ما مجموعه دادههایمان را در اینجا داریم و
72
00:02:15,760 –> 00:02:17,120
شما چندین مثال در اینجا دارید، بنابراین من
73
00:02:17,120 –> 00:02:18,720
این مورد خاص را انتخاب میکنم، بنابراین
74
00:02:18,720 –> 00:02:20,560
75
00:02:20,560 –> 00:02:24,000
مجموعه دادههای
76
00:02:24,000 –> 00:02:27,599
77
00:02:27,599 –> 00:02:30,480
من خواهد
78
00:02:30,480 –> 00:02:31,040
79
00:02:31,040 –> 00:02:32,239
بود. میخواهیم
80
00:02:32,239 –> 00:02:34,319
فایل خاص را شناسایی کنیم و سپس آن را
81
00:02:34,319 –> 00:02:35,680
به روشی بسیار ساده برای ما بخوانید، بنابراین
82
00:02:35,680 –> 00:02:37,760
اگر با
83
00:02:37,760 –> 00:02:40,800
هد نقطهای df کار کنم، اگر با
84
00:02:40,800 –> 00:02:42,080
سر کار کنم، میتوانید آن را کاملاً خوب ببینید،
85
00:02:42,080 –> 00:02:43,360
درست مانند پانداها. این
86
00:02:43,360 –> 00:02:45,440
چیزی است که در مورد
87
00:02:45,440 –> 00:02:47,120
جدول داده ها بسیار جالب است، بنابراین بسیار جالب است، بنابراین
88
00:02:47,120 –> 00:02:49,120
با f3d می توان یک فایل csv را خواند، بنابراین
89
00:02:49,120 –> 00:02:50,000
بیایید سعی کنیم
90
00:02:50,000 –> 00:02:51,920
ببینیم چگونه یک فرمت فایل متفاوت
91
00:02:51,920 –> 00:02:53,360
را بخوانیم تا سعی کنیم فرمت های مختلف فایل را بخوانیم،
92
00:02:53,360 –> 00:02:55,120
بنابراین فرمت های
93
00:02:55,120 –> 00:02:58,480
مختلف فایل را
94
00:02:58,480 –> 00:03:00,239
امتحان کنیم و ببینیم. چگونه یک فایل اکسل ساده را بخوانید،
95
00:03:00,239 –> 00:03:01,599
96
00:03:01,599 –> 00:03:05,200
بنابراین PD بیایید آن را df بنامیم، مگر اینکه
97
00:03:05,200 –> 00:03:07,680
بنابراین من فقط با dt برای جدول دادهها استفاده میکنم.
98
00:03:07,680 –> 00:03:09,120
نقطه f read
99
00:03:09,120 –> 00:03:11,120
اکنون به همان دایرکتوری بروید که
100
00:03:11,120 –> 00:03:12,480
101
00:03:12,480 –> 00:03:14,959
مجموعههای دادهای دارم.
102
00:03:14,959 –> 00:03:15,760
103
00:03:15,760 –> 00:03:17,519
بنابراین ما یک فایل اکسل
104
00:03:17,519 –> 00:03:19,120
در اینجا داریم
105
00:03:19,120 –> 00:03:20,159
تا سعی کنیم ببینیم چگونه این
106
00:03:20,159 –> 00:03:22,239
فایل خاص را بخوانیم، بیایید فقط با
107
00:03:22,239 –> 00:03:25,360
مثال برویم و به آن data dot
108
00:03:25,360 –> 00:03:28,159
sl s x right می گویند، بنابراین اگر آن را بخوانم به
109
00:03:28,159 –> 00:03:29,120
طور خودکار
110
00:03:29,120 –> 00:03:31,200
نوع فایل خاص را شناسایی کرده و
111
00:03:31,200 –> 00:03:32,239
آن را می خوانیم. برای
112
00:03:32,239 –> 00:03:35,040
ما کاملاً بدون هیچ مشکلی، بنابراین
113
00:03:35,040 –> 00:03:36,799
با خواندن روزمره فایلهای اکسل،
114
00:03:36,799 –> 00:03:38,560
شما واقعاً میتوانید این فایلها را ببینید، بنابراین من میتوانم
115
00:03:38,560 –> 00:03:39,920
به این موضوع برگردم
116
00:03:39,920 –> 00:03:43,519
، سر انجام تسلا
117
00:03:43,519 –> 00:03:45,360
به شما این امکان را میدهد که آن را کاملاً
118
00:03:45,360 –> 00:03:47,360
درست کار کند و این یک
119
00:03:47,360 –> 00:03:48,640
چیز بسیار جالب است. خوب
120
00:03:48,640 –> 00:03:51,680
در مورد جدول داده ها بسیار ساده است حالا بیایید
121
00:03:51,680 –> 00:03:53,120
ببینیم چگونه یک فرمت فایل متفاوت را بخوانیم
122
00:03:53,120 –> 00:03:54,319
که اکسل نیست،
123
00:03:54,319 –> 00:03:56,640
بنابراین سعی می کنم فرمت دیگری را بخوانم
124
00:03:56,640 –> 00:03:58,159
که یک فایل tsc است،
125
00:03:58,159 –> 00:03:59,519
بنابراین فقط به همان مکان برگرد و
126
00:03:59,519 –> 00:04:01,280
سپس اجازه دهید آن را به عنوان نامگذاری کنیم. خواندن درست کردن
127
00:04:01,280 –> 00:04:04,480
یک فایل tsv یا یک فایل آزمایشی،
128
00:04:04,480 –> 00:04:06,319
بنابراین اگر میخواهم یک فایل آزمایشی را بخوانم،
129
00:04:06,319 –> 00:04:08,080
میتوانم از همین گزینه استفاده کنم، بنابراین بیایید با tst برویم،
130
00:04:08,080 –> 00:04:09,360
131
00:04:09,360 –> 00:04:12,480
سپس من به دایرکتوری
132
00:04:12,480 –> 00:04:14,000
دیگری برمیگردم که در اینجا یک فایل tst دارم.
133
00:04:14,000 –> 00:04:14,879
من میخواهم این
134
00:04:14,879 –> 00:04:16,639
فایل tst خاص را بخوانم، فقط پسوند tst را تغییر میدهم و
135
00:04:16,639 –> 00:04:18,320
136
00:04:18,320 –> 00:04:20,000
سپس به طور خودکار آن
137
00:04:20,000 –> 00:04:22,320
فایل خاص را
138
00:04:22,320 –> 00:04:24,080
کاملاً درست تشخیص میدهم تا کاملاً اشتباه دیکته شود
139
00:04:24,080 –> 00:04:25,520
140
00:04:25,520 –> 00:04:29,120
و سپس میتوانم آن را با هد بخوانم
141
00:04:29,120 –> 00:04:30,720
که کاملاً کار میکند، بنابراین
142
00:04:30,720 –> 00:04:32,400
چیزی بسیار جالب در مورد
143
00:04:32,400 –> 00:04:34,000
داده است. جدول با جدول داده ما میتوانیم
144
00:04:34,000 –> 00:04:36,000
هر یک از قالبهای خود را بدون
145
00:04:36,000 –> 00:04:38,880
تعیین پسوند سمت راست فایل خاص
146
00:04:38,880 –> 00:04:39,680
147
00:04:39,680 –> 00:04:41,120
بخوانیم، فقط با f read اکنون موارد دیگری را ببینیم که
148
00:04:41,120 –> 00:04:42,800
میتوانیم این کار را انجام دهیم در صورتی که بخواهم
149
00:04:42,800 –> 00:04:43,360
150
00:04:43,360 –> 00:04:45,520
شکل اشکال مجموعه داده را بررسی کنم.
151
00:04:45,520 –> 00:04:46,800
برای اینکه df من
152
00:04:46,800 –> 00:04:49,759
درست باشد، ما از csv استفاده می کنیم، این
153
00:04:49,759 –> 00:04:50,960
154
00:04:50,960 –> 00:04:54,639
شکل نقطه df خاص نیز
155
00:04:54,639 –> 00:04:55,840
برای ما کاملاً کار می کند، بنابراین این یک
156
00:04:55,840 –> 00:04:57,280
شکل است، بنابراین درست مانند پانداها،
157
00:04:57,280 –> 00:04:58,800
بیشتر ویژگی های پانداها را می توان
158
00:04:58,800 –> 00:05:00,880
در اینجا یافت، اما پانداها o هستند.
159
00:05:00,880 –> 00:05:02,560
البته توسعهیافتهتر از این با بسیاری از
160
00:05:02,560 –> 00:05:04,400
ویژگیها، بنابراین آیا شما میتوانید شکل را
161
00:05:04,400 –> 00:05:05,600
دریافت کنید در صورتی که میخواهم ردیف را دریافت
162
00:05:05,600 –> 00:05:06,560
163
00:05:06,560 –> 00:05:08,479
کنم زیرا میخواهم ردیفها را دریافت کنم فقط
164
00:05:08,479 –> 00:05:10,240
با df.ship من
165
00:05:10,240 –> 00:05:13,440
این اولین روش است پس این
166
00:05:13,440 –> 00:05:15,520
از آنجایی که این مثل یک سه گانه است، فقط با
167
00:05:15,520 –> 00:05:17,759
صفر بروید و حدس میزنم ردیف درست است که
168
00:05:17,759 –> 00:05:19,759
یک طرفه است، اجازه دهید با
169
00:05:19,759 –> 00:05:22,960
ردیف و ردیفهای df.n برویم، آنگاه
170
00:05:22,960 –> 00:05:24,160
کاملاً برای ما درست میشود، بنابراین این
171
00:05:24,160 –> 00:05:25,440
یک راه دیگر برای به دست
172
00:05:25,440 –> 00:05:27,919
آوردن قوانین است که وجود دارد. برای اینکه روش بعدی
173
00:05:27,919 –> 00:05:28,960
درست باشد
174
00:05:28,960 –> 00:05:30,400
و اگر میخواهم ستونها را دریافت کنم،
175
00:05:30,400 –> 00:05:32,560
میتوانم همان کاری را که ستونها انجام میدهند، انجام دهم،
176
00:05:32,560 –> 00:05:35,759
از شکل نقطهای df خود استفاده میکنم
177
00:05:35,759 –> 00:05:37,680
که کمتر از ستونهایی
178
00:05:37,680 –> 00:05:38,880
است که یک
179
00:05:38,880 –> 00:05:40,960
ستون سمت راست میشود. در هر صورت من میتوانم
180
00:05:40,960 –> 00:05:44,240
همین کار را انجام دهم که بهعنوان
181
00:05:44,240 –> 00:05:47,360
اثر درست df.n است، بنابراین
182
00:05:47,360 –> 00:05:48,000
نحوه کار
183
00:05:48,000 –> 00:05:49,840
با فریمهای داده است، بنابراین اگر
184
00:05:49,840 –> 00:05:51,199
میخواهید تمام ویژگیهای مختلفی را
185
00:05:51,199 –> 00:05:52,960
که میتوانیم با این کار انجام دهیم بررسی کنید، بیایید
186
00:05:52,960 –> 00:05:55,280
این را صدا کنیم. تمام روشهای
187
00:05:55,280 –> 00:05:58,319
مختلف قاب داده ما از فریم ما
188
00:05:58,319 –> 00:06:00,479
درست است که در df قرار میگیریم
189
00:06:00,479 –> 00:06:02,800
بیایید آن را تبدیل به dir کنیم سپس شناسه های عبوری خود را
190
00:06:02,800 –> 00:06:04,240
طوری شناسه غیرفعال کنیم که می توانید ببینید
191
00:06:04,240 –> 00:06:05,440
تنوع چه کاری می تواند انجام دهد،
192
00:06:05,440 –> 00:06:06,800
بنابراین اینها برخی از چیزهایی هستند که
193
00:06:06,800 –> 00:06:09,120
فقط
194
00:06:09,120 –> 00:06:10,960
می توانید موها را بررسی کنید.
195
00:06:10,960 –> 00:06:12,880
196
00:06:12,880 –> 00:06:15,199
ویژگی های
197
00:06:15,199 –> 00:06:16,639
بسیار بسیار جالب درست است،
198
00:06:16,639 –> 00:06:18,319
حتی می توانید جزئیات را به درستی انجام دهید، بنابراین در صورتی که من
199
00:06:18,319 –> 00:06:19,360
بخواهم دم را بررسی کنم، می توانید مانند پانداها
200
00:06:19,360 –> 00:06:21,120
به صورت df به دم بروید
201
00:06:21,120 –> 00:06:22,639
، این نیز
202
00:06:22,639 –> 00:06:24,319
برای ما کاملاً کار می کند و همچنین می توانید
203
00:06:24,319 –> 00:06:26,000
یک مقدار
204
00:06:26,000 –> 00:06:28,720
را ارسال کنید. بیایید یک مقدار را برای head ارسال کنیم تا
205
00:06:28,720 –> 00:06:29,440
برای پیشنمایش آن
206
00:06:29,440 –> 00:06:32,240
، فرض کنیم اولین و سپس ردیفهای df.head
207
00:06:32,240 –> 00:06:33,039
و فرض کنید
208
00:06:33,039 –> 00:06:35,280
ابتدا آن را به پنج تبدیل کنید، همچنین
209
00:06:35,280 –> 00:06:36,560
درست مانند پانداها برای ما کاملاً کار میکند،
210
00:06:36,560 –> 00:06:37,680
211
00:06:37,680 –> 00:06:39,280
بنابراین بسیار جالب است حالا بیایید چیزهای دیگر را ببینیم.
212
00:06:39,280 –> 00:06:40,720
شما همچنین می توانید جدای
213
00:06:40,720 –> 00:06:41,120
از
214
00:06:41,120 –> 00:06:43,199
موارد pdf انجام دهید در صورتی که من
215
00:06:43,199 –> 00:06:44,560
بخواهم ستون ها
216
00:06:44,560 –> 00:06:46,639
را نه طول ستون
217
00:06:46,639 –> 00:06:48,160
بلکه نام ستون های من را بررسی کنم، فقط این کار را انجام می دهم.
218
00:06:48,160 –> 00:06:49,599
219
00:06:49,599 –> 00:06:51,039
220
00:06:51,039 –> 00:06:53,440
درست این تفاوت است
221
00:06:53,440 –> 00:06:55,039
اگر آن ستونها
222
00:06:55,039 –> 00:06:56,880
را انجام دهید، درست کار نمیکند، بنابراین چگونه میتوانید همه
223
00:06:56,880 –> 00:06:58,319
نامهای ستونها را
224
00:06:58,319 –> 00:07:01,199
که نامهای ستونها بسیار جالب هستند، دریافت کنید
225
00:07:01,199 –> 00:07:02,880
و اگر بخواهید
226
00:07:02,880 –> 00:07:04,720
انواع دادههایی را
227
00:07:04,720 –> 00:07:07,919
که قرار است انجام دهید، دریافت کنید، اینطور خواهد بود.
228
00:07:07,919 –> 00:07:10,080
برای انواع دادههای ما درست است، زیرا میخواهم
229
00:07:10,080 –> 00:07:11,360
انواع دادهها را دریافت کنم که
230
00:07:11,360 –> 00:07:14,400
df dot خواهد بود
231
00:07:14,400 –> 00:07:17,440
نه dt درست، این نوع
232
00:07:17,440 –> 00:07:20,400
دادهها است که برای انواع دادهها برای این است، بر خلاف
233
00:07:20,400 –> 00:07:21,120
پانداها
234
00:07:21,120 –> 00:07:22,400
در شرکا، چیزی
235
00:07:22,400 –> 00:07:24,800
شبیه به این df نقطه d
236
00:07:24,800 –> 00:07:27,840
درست است. اما در جدول داده
237
00:07:27,840 –> 00:07:30,400
ها نوع df dot s درست است که نحوه بدست آوردن
238
00:07:30,400 –> 00:07:31,759
این است، همه
239
00:07:31,759 –> 00:07:33,360
مقادیر انواع داده ها را برای هر یک
240
00:07:33,360 –> 00:07:34,960
از ستون ها به ما می دهد بسیار جالب است، شما بچه ها
241
00:07:34,960 –> 00:07:36,000
همچنین می خواهید
242
00:07:36,000 –> 00:07:37,520
ابعاد را بررسی کنید، همچنین می توانید این کار را با
243
00:07:37,520 –> 00:07:39,919
این گزینه انجام دهید تا در صورتی که
244
00:07:39,919 –> 00:07:41,520
245
00:07:41,520 –> 00:07:45,680
بخواهم ابعاد را بررسی کنم تا بعد من بازی های df.n من باشد،
246
00:07:45,680 –> 00:07:48,560
بنابراین دو بعد به ما می دهد
247
00:07:48,560 –> 00:07:50,639
که ایده اصلی
248
00:07:50,639 –> 00:07:52,479
پشت نمای کلی برخی از چیزها است.
249
00:07:52,479 –> 00:07:54,240
شما می توانید با
250
00:07:54,240 –> 00:07:57,680
جداول داده کامل انجام دهید ct، بنابراین این چند
251
00:07:57,680 –> 00:07:58,960
چیز اساسی است که اکنون می توانید انجام دهید، اجازه دهید
252
00:07:58,960 –> 00:07:59,280
چند
253
00:07:59,280 –> 00:08:01,280
چیز ساده را ببینیم، در صورتی که می خواهم آن را نیز
254
00:08:01,280 –> 00:08:03,199
بررسی کنم،
255
00:08:03,199 –> 00:08:04,479
مثلاً اگر مقادیری را از دست داده اید، تعداد
256
00:08:04,479 –> 00:08:07,039
مقادیر از دست رفته را بررسی کنیم،
257
00:08:07,039 –> 00:08:10,720
بنابراین فقط با
258
00:08:10,720 –> 00:08:13,199
هر تابعی از df dot count استفاده کنید. درست است، بنابراین این شبیه به
259
00:08:13,199 –> 00:08:14,400
انجام کاری شبیه
260
00:08:14,400 –> 00:08:17,520
به پانداها مانند این گزینه است
261
00:08:17,520 –> 00:08:20,160
مانند df dot s na درست چیزی شبیه به
262
00:08:20,160 –> 00:08:22,319
آن، بنابراین این ایده اصلی در پشت
263
00:08:22,319 –> 00:08:24,319
جداول داده است، درست است که شما برای تعداد
264
00:08:24,319 –> 00:08:25,599
مقادیر از دست رفته دریافت می کنید و سپس
265
00:08:25,599 –> 00:08:27,039
از مجموعه داده های ما ما نمی گیریم. هیچ
266
00:08:27,039 –> 00:08:29,280
مقدار گم شده ای نداشته باشید، بسیار جالب است،
267
00:08:29,280 –> 00:08:31,599
شما همچنین می توانید انجام دهید، همانطور که ما انجام دادیم،
268
00:08:31,599 –> 00:08:33,279
اینجا را تایپ کنید.
269
00:08:33,279 –> 00:08:35,440
270
00:08:35,440 –> 00:08:37,440
271
00:08:37,440 –> 00:08:40,479
272
00:08:40,479 –> 00:08:44,000
.l خیلی خوب تایپ میکند
273
00:08:44,000 –> 00:08:45,120
، یک کار دیگری که باید
274
00:08:45,120 –> 00:08:47,519
انجام دهم، میتوانید آن یکی یا
275
00:08:47,519 –> 00:08:48,800
آن گزینه را نیز انجام دهید، که تقریباً مشابه این گزینه است،
276
00:08:48,800 –> 00:08:50,560
277
00:08:50,560 –> 00:08:51,760
بسیار جالب است، بنابراین اینها برخی
278
00:08:51,760 –> 00:08:54,000
از کارهای تجاری هستند که میتوانید با
279
00:08:54,000 –> 00:08:56,720
جداول داده انجام دهید، حالا ببینیم برخی از
280
00:08:56,720 –> 00:08:57,519
جنبه های دیگر
281
00:08:57,519 –> 00:08:58,800
بنابراین برای من چیزهای دیگر نیز میتوانید این کار را انجام دهید در
282
00:08:58,800 –> 00:09:00,000
صورتی که میخواهید کل
283
00:09:00,000 –> 00:09:01,680
موارد را مشاهده کنید و فقط آن را
284
00:09:01,680 –> 00:09:03,279
پیشنمایش صدا بزنید تا در صورتی که بخواهم
285
00:09:03,279 –> 00:09:05,839
آن را پیشنمایش کنم.
286
00:09:05,839 –> 00:09:08,000
287
00:09:08,000 –> 00:09:09,360
کل مجموعه داده
288
00:09:09,360 –> 00:09:11,480
بسیار جالب است با این گزینه سمت راست
289
00:09:11,480 –> 00:09:13,360
df.view
290
00:09:13,360 –> 00:09:15,519
pivot، بنابراین بیایید ببینیم چگونه
291
00:09:15,519 –> 00:09:16,399
فایل های خود را به
292
00:09:16,399 –> 00:09:19,920
درستی انتخاب کنیم، بنابراین
293
00:09:19,920 –> 00:09:21,600
اگر می خواهید
294
00:09:21,600 –> 00:09:22,880
ستون ها و قوانین را انتخاب کنید چگونه ستون ها و سپس ردیف ها را
295
00:09:22,880 –> 00:09:23,519
انتخاب
296
00:09:23,519 –> 00:09:26,480
کنیم. نحو اصلی برای انتخاب و سپس
297
00:09:26,480 –> 00:09:26,800
در
298
00:09:26,800 –> 00:09:29,120
جدول داده ها فقط با جدول داده های من
299
00:09:29,120 –> 00:09:31,120
بروید، سپس من فقط i خود را ایجاد می کنم که
300
00:09:31,120 –> 00:09:31,920
301
00:09:31,920 –> 00:09:34,880
انرژی ردیف من خواهد بود و سپس هر کاری را که
302
00:09:34,880 –> 00:09:35,519
می خواهم انجام دهم را ارائه می دهم.
303
00:09:35,519 –> 00:09:37,519
بنابراین به طور خلاصه باید انجام
304
00:09:37,519 –> 00:09:39,760
شود مانند dt
305
00:09:39,760 –> 00:09:42,640
dt که قرار است ردیف من باشد، ردیف من را بنویسید
306
00:09:42,640 –> 00:09:44,080
هر چیزی را که میخواهم انتخاب
307
00:09:44,080 –> 00:09:46,800
کنم، انتخابگر ردیف من خواهد بود و
308
00:09:46,800 –> 00:09:47,120
سپس
309
00:09:47,120 –> 00:09:50,880
مورد بعدی انتخابگر ستون من خواهد بود،
310
00:09:50,880 –> 00:09:52,640
سپس من فقط هر چیزی را که میخواهم
311
00:09:52,640 –> 00:09:53,920
در آن قرار میدهم و هر تابعی را در آنجا قرار میدهم.
312
00:09:53,920 –> 00:09:56,240
هر کاری که
313
00:09:56,240 –> 00:09:57,839
میخواهم انجام دهم، این اساس است جمله c برای
314
00:09:57,839 –> 00:10:01,120
انتخاب ستونها و سپس ردیفها در جدول دادهها،
315
00:10:01,120 –> 00:10:03,360
پس بیایید ببینیم چگونه با آن کار کنیم،
316
00:10:03,360 –> 00:10:04,320
بنابراین من فقط آن را به
317
00:10:04,320 –> 00:10:05,839
این شکل میکنم تا بتوانید آن را
318
00:10:05,839 –> 00:10:08,000
خیلی خوب ببینید، بنابراین ما میتوانیم این
319
00:10:08,000 –> 00:10:08,640
یکی را
320
00:10:08,640 –> 00:10:11,360
به عنوان یک مرجع
321
00:10:11,760 –> 00:10:13,360
خوب نگه داریم. پس بیایید آن را امتحان کنیم، بنابراین اول از همه
322
00:10:13,360 –> 00:10:15,200
بیایید ببینیم چگونه
323
00:10:15,200 –> 00:10:18,800
ستونها را به صورت فهرست انتخاب کنیم، بنابراین در صورتی که میخواهم
324
00:10:18,800 –> 00:10:20,560
ستونی به فهرست انتخاب کنم،
325
00:10:20,560 –> 00:10:22,399
میتوانیم این کار را در قالب سادهتر
326
00:10:22,399 –> 00:10:24,000
مثلاً df انجام دهیم،
327
00:10:24,000 –> 00:10:26,320
سپس میخواهم ستون اول را دریافت کنم.
328
00:10:26,320 –> 00:10:27,680
این یکی می شود، بنابراین به
329
00:10:27,680 –> 00:10:29,040
یکی می روم، اولین ستون را برای
330
00:10:29,040 –> 00:10:30,560
ما درست انتخاب می کنم، بنابراین بیایید آن را پیش نمایش کنیم تا
331
00:10:30,560 –> 00:10:31,279
منظورم را ببینید
332
00:10:31,279 –> 00:10:34,959
اگر با این df.head بروید، بیایید با
333
00:10:34,959 –> 00:10:38,399
سه سمت راست برویم، زیرا من میخواهم
334
00:10:38,399 –> 00:10:41,440
ستون یک را درست بگیرم، فقط با df
335
00:10:41,440 –> 00:10:44,000
یک سمت راست میروم تا اولین ستون را بر اساس نمایه درست به دست بیاورم
336
00:10:44,000 –> 00:10:44,800
337
00:10:44,800 –> 00:10:46,880
که یکی از راههای انجام این کار است،
338
00:10:46,880 –> 00:10:47,920
بنابراین این
339
00:10:47,920 –> 00:10:49,680
شبیه انجام کاری در روزهای گذشته در پانداها است،
340
00:10:49,680 –> 00:10:51,519
بنابراین اجازه دهید آن را
341
00:10:51,519 –> 00:10:53,600
در قالب pandas بیاورم. در اینجا، بنابراین
342
00:10:53,600 –> 00:10:54,800
برای پانداها
343
00:10:54,800 –> 00:10:57,519
خواهد بود، در صورتی که این کار را انجام دهیم، df dot خواهد بود.
344
00:10:57,519 –> 00:10:58,800
آن را در شرکا
345
00:10:58,800 –> 00:11:01,120
بنویسید سپس یک اسلش به سمت راست به طوری که
346
00:11:01,120 –> 00:11:02,480
ایندکس یاب به سمت راست باشد،
347
00:11:02,480 –> 00:11:04,320
به طوری که
348
00:11:04,320 –> 00:11:06,079
اگر شما آن را در پانداها درست انجام می دهید، درست
349
00:11:06,079 –> 00:11:07,519
از این گزینه خاص استفاده می
350
00:11:07,519 –> 00:11:11,120
کنید، اما در
351
00:11:13,519 –> 00:11:15,279
قالب توضیحات این است
352
00:11:15,279 –> 00:11:16,480
که تنها تابعی که ما برای این
353
00:11:16,480 –> 00:11:17,839
فرمت خاص داریم،
354
00:11:17,839 –> 00:11:19,839
حق انتخاب ما بسیار جالب است، بنابراین
355
00:11:19,839 –> 00:11:20,959
بیایید ببینیم چگونه
356
00:11:20,959 –> 00:11:22,399
انتخاب کنیم، شما مشاهده کرده اید که چگونه بر اساس نمایه توزیع شده
357
00:11:22,399 –> 00:11:24,160
است، مگر اینکه مجبور باشید با نام انتخاب کنید،
358
00:11:24,160 –> 00:11:25,200
بنابراین اگر
359
00:11:25,200 –> 00:11:29,040
بخواهم یک ستون را
360
00:11:29,040 –> 00:11:31,279
با نام درست انتخاب کنم، بنابراین ما متوجه شدم که
361
00:11:31,279 –> 00:11:32,640
ما چیزی شبیه
362
00:11:32,640 –> 00:11:34,320
به این برای دریافت نام
363
00:11:34,320 –> 00:11:35,600
همه ستونها داریم، بنابراین اگر میخواهم
364
00:11:35,600 –> 00:11:36,560
ایمیل را انتخاب
365
00:11:36,560 –> 00:11:38,480
کنم، میتوانم به همان مکان برگردم
366
00:11:38,480 –> 00:11:40,320
و سپس با این گزینه آن را با این گزینه انتخاب
367
00:11:40,320 –> 00:11:43,519
کنم و i’m ارسال
368
00:11:43,519 –> 00:11:44,959
نام در اینجا، بنابراین ایمیل
369
00:11:44,959 –> 00:11:47,360
درست کنید، بنابراین من نام را دقیقاً
370
00:11:47,360 –> 00:11:48,880
مانند پانداها ارسال می کنم،
371
00:11:48,880 –> 00:11:50,480
بنابراین این همه
372
00:11:50,480 –> 00:11:51,920
چیز را برای ما به درستی انتخاب می کند
373
00:11:51,920 –> 00:11:53,760
بسیار بسیار ساده است، بنابراین اگر می
374
00:11:53,760 –> 00:11:55,200
خواستم این کار را در پانداها انجام دهم، این کار انجام می شد.
375
00:11:55,200 –> 00:11:56,480
پس مثل این
376
00:11:56,480 –> 00:11:59,120
df من در همان مورد به درستی پاس کردم
377
00:11:59,120 –> 00:12:00,560
زیرا پانداها همان
378
00:12:00,560 –> 00:12:01,920
چیزی بودند، بنابراین اگر می خواستم این کار را با
379
00:12:01,920 –> 00:12:03,200
پانداها انجام دهم این بود
380
00:12:03,200 –> 00:12:05,920
اما برای نوع داده بسیار جالب است،
381
00:12:05,920 –> 00:12:07,360
بنابراین چگونه می توانم
382
00:12:07,360 –> 00:12:09,839
نه فقط بر اساس شاخص و توسط انتخاب کنم نام، اما در
383
00:12:09,839 –> 00:12:11,839
صورتی که بخواهم
384
00:12:11,839 –> 00:12:14,880
گروهی از ردیفها را انتخاب کنم یا مثلاً
385
00:12:14,880 –> 00:12:16,240
چند ستون را انتخاب کنم، آن را بررسی کنید تا
386
00:12:16,240 –> 00:12:17,519
387
00:12:17,519 –> 00:12:20,480
چندین ستون
388
00:12:20,800 –> 00:12:22,720
را انتخاب کنید تا به سمت راست میروند تا ما
389
00:12:22,720 –> 00:12:24,320
این ستونهای مختلف را
390
00:12:24,320 –> 00:12:25,600
داشته باشیم، یک ستون وجود دارد، اما فکر میکنم این
391
00:12:25,600 –> 00:12:27,040
نحوه انتخاب است. یک ستون چندگانه چگونه انجام دهم
392
00:12:27,040 –> 00:12:28,720
که فقط می توانم با این گزینه
393
00:12:28,720 –> 00:12:30,560
بروم، بیایید با df برویم، سپس
394
00:12:30,560 –> 00:12:31,839
این گزینه خاص را اینجا می آورم، بنابراین
395
00:12:31,839 –> 00:12:32,480
396
00:12:32,480 –> 00:12:33,760
قبل از اینکه بخواهیم چندین ستون را انتخاب
397
00:12:33,760 –> 00:12:35,519
کنیم، ابتدا چیزی را امتحان
398
00:12:35,519 –> 00:12:37,279
کنیم قبل از اینکه به چندین ستون
399
00:12:37,279 –> 00:12:38,639
بنابراین در شرکای شما می توانید کاری شبیه به این انجام
400
00:12:38,639 –> 00:12:40,399
دهید. من درست قفل می شود،
401
00:12:40,399 –> 00:12:41,920
سپس این
402
00:12:41,920 –> 00:12:44,240
مقدار خاص را درست همانطور که در بالا انجام دادیم، وارد می کنید،
403
00:12:44,240 –> 00:12:46,160
سپس در ایندکس خاص خود در
404
00:12:46,160 –> 00:12:47,920
اینجا درست ارسال می کنید، اما در جدول داده ها نیز می توانید
405
00:12:47,920 –> 00:12:49,680
کاری را انجام دهید. milar با رفتن به این
406
00:12:49,680 –> 00:12:51,360
گزینه، ستون را بیاورید،
407
00:12:51,360 –> 00:12:53,120
سپس مقدار خود را به اینجا منتقل می کنید،
408
00:12:53,120 –> 00:12:54,880
بنابراین این شبیه همان
409
00:12:54,880 –> 00:12:56,079
چیزی است که در اینجا در بالا آمده
410
00:12:56,079 –> 00:12:58,240
است، به شما امکان کار در پانداها را می
411
00:12:58,240 –> 00:12:59,760
دهد، بنابراین بیایید آن یکی را امتحان کنیم، بنابراین اگر من به اینجا برگردم،
412
00:12:59,760 –> 00:13:00,079
413
00:13:00,079 –> 00:13:01,519
این کار را انجام می دهد. ما همان نتیجه ای را
414
00:13:01,519 –> 00:13:03,839
داشتیم که درست داشتیم، بنابراین این
415
00:13:03,839 –> 00:13:05,680
گزینه مشابه این گزینه در پانداها است،
416
00:13:05,680 –> 00:13:07,040
درست بسیار ساده است،
417
00:13:07,040 –> 00:13:09,360
حالا بیایید از آنجایی که ما چگونه این کار را انجام
418
00:13:09,360 –> 00:13:11,120
دهیم، می توانیم از همان شی برای
419
00:13:11,120 –> 00:13:12,560
انتخاب چندین ستون درست استفاده کنیم، بنابراین
420
00:13:12,560 –> 00:13:13,760
این برای ستون یک
421
00:13:13,760 –> 00:13:15,279
نامیده می شود. نام کامل، بنابراین اگر میخواهم
422
00:13:15,279 –> 00:13:16,800
چندین ستون را انتخاب کنم و همچنین
423
00:13:16,800 –> 00:13:18,079
به همان گزینه برگردم،
424
00:13:18,079 –> 00:13:19,519
سپس آن
425
00:13:19,519 –> 00:13:21,279
ستون چندگانه خاص را ارائه میکنم، میخواهم همه چیز را درست انتخاب کنم، بنابراین
426
00:13:21,279 –> 00:13:22,880
میتوانم یا فهرست را بنویسم یا
427
00:13:22,880 –> 00:13:24,720
اجازه دهید نام را ارسال کنم تا بتوانم پاس بدهم. در
428
00:13:24,720 –> 00:13:26,320
یک نام واحد مانند اجازه دهید بگوییم
429
00:13:26,320 –> 00:13:28,399
ایمیل درست است، بنابراین این
430
00:13:28,399 –> 00:13:30,000
یک ستون سمت راست خواهد بود، بنابراین اگر من می خواهم
431
00:13:30,000 –> 00:13:32,480
در چندین ستون عبور کنم، بیایید گزینه را بالا
432
00:13:32,480 –> 00:13:33,440
ببریم، ببینیم چگونه
433
00:13:33,440 –> 00:13:37,279
نام کامل را درست دریافت کنیم، بنابراین در این مورد
434
00:13:37,279 –> 00:13:38,480
باید قرار دهم آنها با هم
435
00:13:38,480 –> 00:13:40,320
در یک براکت بنابراین در آن کلید
436
00:13:40,320 –> 00:13:43,120
چیزی شبیه به این خواهد بود،
437
00:13:43,120 –> 00:13:45,199
درست مانند پانداها، سپس به این گزینه برمی گردم، سپس
438
00:13:45,199 –> 00:13:46,240
439
00:13:46,240 –> 00:13:48,000
ایمیل و سپس
440
00:13:48,000 –> 00:13:49,600
نام کامل را