در این مطلب، ویدئو جاسازی کلمه با استفاده از لایه embedding keras | آموزش عمیق یادگیری 40 (Tensorflow، Keras و Python) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:21:34
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,000 –> 00:00:02,399
آخرین آموزشی که
2
00:00:02,399 –> 00:00:03,679
3
00:00:03,679 –> 00:00:06,319
در این آموزش به تعبیههای کلمه پرداختیم، میخواهیم
4
00:00:06,319 –> 00:00:08,960
نحوه محاسبه تعبیههای کلمه
5
00:00:08,960 –> 00:00:10,960
را بررسی کنیم. آنها با استفاده از دو تکنیک محاسبه میشوند
6
00:00:10,960 –> 00:00:13,679
یکی یادگیری تحت نظارت و
7
00:00:13,679 –> 00:00:16,640
دیگری یادگیری خود نظارتی مانند کلمه
8
00:00:16,640 –> 00:00:17,440
به کار یا
9
00:00:17,440 –> 00:00:19,680
کره در در این ویدیو ما می خواهیم
10
00:00:19,680 –> 00:00:20,720
11
00:00:20,720 –> 00:00:23,439
تکنیک یادگیری نظارت شده برای جاسازی کلمات را
12
00:00:23,439 –> 00:00:24,160
13
00:00:24,160 –> 00:00:26,400
در ویدیوی آینده بررسی کنیم، آنچه را که
14
00:00:26,400 –> 00:00:28,560
باید ضربه بزنید و درخشید را پوشش خواهیم داد و ویدیوی امروز به
15
00:00:28,560 –> 00:00:29,519
16
00:00:29,519 –> 00:00:32,960
برخی از نظریه ها در مورد نحوه عملکرد یادگیری نظارت
17
00:00:32,960 –> 00:00:34,800
شده برای جاسازی کلمه می پردازد و سپس
18
00:00:34,800 –> 00:00:36,800
برخی از آنها را خواهیم نوشت. کد پایتون همچنین
19
00:00:36,800 –> 00:00:39,360
در جلسه گذشته دیدیم که چگونه می توانید
20
00:00:39,360 –> 00:00:40,399
21
00:00:40,399 –> 00:00:44,000
کلمات را با استفاده از بردارهایی مانند این نشان دهید که
22
00:00:44,000 –> 00:00:46,399
می تواند معنی کلمه را به
23
00:00:46,399 –> 00:00:48,320
طور معنی دار نشان دهد، به عنوان مثال
24
00:00:48,320 –> 00:00:50,800
در اینجا من دو بازیکن کریکت dhonian
25
00:00:50,800 –> 00:00:52,000
cummins دارم
26
00:00:52,000 –> 00:00:54,879
و یکی از راه های نشان دادن
27
00:00:54,879 –> 00:00:55,280
کلمه
28
00:00:55,280 –> 00:00:57,680
vector این است که با استفاده از ویژگی هایی مانند
29
00:00:57,680 –> 00:01:00,399
موقعیت مکانی افراد سالم و غیره
30
00:01:00,399 –> 00:01:03,199
و هنگامی که این کار را انجام می دهید آنچه را که می یابید،
31
00:01:03,199 –> 00:01:04,239
بردارهای
32
00:01:04,239 –> 00:01:06,479
dhoni و افراد معمولی است که بازی کریکت هستند.
33
00:01:06,479 –> 00:01:08,400
اگر آنها کاملاً شبیه به نظر می رسند، شما مانند یک
34
00:01:08,400 –> 00:01:10,320
یک نقطه نه نقطه هشت هفت و غیره می بینید،
35
00:01:10,320 –> 00:01:12,560
در حالی که بردار
36
00:01:12,560 –> 00:01:15,759
استرالیا که یک کشور است
37
00:01:15,759 –> 00:01:19,920
کاملاً متفاوت به نظر می رسد و می توانید
38
00:01:19,920 –> 00:01:23,200
تعدادی ویژگی داشته باشید که می توانید برای جاسازی کلمات از آنها استفاده کنید
39
00:01:23,200 –> 00:01:25,840
تا بدانید چه
40
00:01:25,840 –> 00:01:27,439
زمانی در حال مقایسه انسان ها و dhoni که
41
00:01:27,439 –> 00:01:29,040
بازیکنان کریکت هستند، وکتورهای آنها یکسان به نظر می رسد
42
00:01:29,040 –> 00:01:29,759
43
00:01:29,759 –> 00:01:31,119
و وقتی تیم های استرالیا و زیمبابوه را با هم مقایسه می کنید،
44
00:01:31,119 –> 00:01:33,200
وکتورهای آنها
45
00:01:33,200 –> 00:01:34,720
نیز یک جور به نظر می رسند،
46
00:01:34,720 –> 00:01:37,759
اکنون سؤال این است که
47
00:01:37,759 –> 00:01:40,720
چگونه به این ویژگی ها دست پیدا می کنید، به نظر می رسد
48
00:01:40,720 –> 00:01:43,040
کار بسیار دشواری است.
49
00:01:43,040 –> 00:01:45,439
نکته خوب این است که شبکه های عصبی می توانند
50
00:01:45,439 –> 00:01:46,320
51
00:01:46,320 –> 00:01:49,280
این ویژگی ها را برای شما محاسبه کنند.
52
00:01:49,280 –> 00:01:51,119
53
00:01:51,119 –> 00:01:53,600
54
00:01:53,600 –> 00:01:54,479
55
00:01:54,479 –> 00:01:55,840
56
00:01:55,840 –> 00:01:57,840
57
00:01:57,840 –> 00:01:59,600
58
00:01:59,600 –> 00:02:01,040
59
00:02:01,040 –> 00:02:02,719
می توانید درخشش
60
00:02:02,719 –> 00:02:04,159
61
00:02:04,159 –> 00:02:06,000
تکنیک های یادگیری خود نظارتی هستند در این ویدیو ما در مورد
62
00:02:06,000 –> 00:02:07,200
63
00:02:07,200 –> 00:02:09,520
تکنیک یادگیری نظارت شده صحبت می کنیم
64
00:02:09,520 –> 00:02:11,360
آنچه در این تکنیک اتفاق
65
00:02:11,360 –> 00:02:15,360
می افتد یک مشکل nlp
66
00:02:15,360 –> 00:02:17,599
و سپس شما سعی می کنید آن مشکل nlp را
67
00:02:17,599 –> 00:02:18,879
حل کنید
68
00:02:18,879 –> 00:02:21,680
و به عنوان یک عارضه جانبی با جاسازی کلمه مواجه می شوید
69
00:02:21,680 –> 00:02:22,959
اکنون اصطلاح
70
00:02:22,959 –> 00:02:24,959
عارضه جانبی بسیار مهم است و
71
00:02:24,959 –> 00:02:26,480
خواهید دید که
72
00:02:26,480 –> 00:02:29,440
چرا فرض کنید در حال انجام یک طبقه بندی بررسی مواد غذایی هستید
73
00:02:29,440 –> 00:02:30,480
74
00:02:30,480 –> 00:02:32,480
که آیا بررسی غذا درست است.
75
00:02:32,480 –> 00:02:33,920
مثبت یا منفی
76
00:02:33,920 –> 00:02:37,519
این یک کار معمولی nlp است در حال حاضر
77
00:02:37,519 –> 00:02:38,319
برای
78
00:02:38,319 –> 00:02:41,360
انجام این طبقه بندی بررسی مواد غذایی
79
00:02:41,360 –> 00:02:43,760
باید شبکه عصبی خود را آموزش دهید
80
00:02:43,760 –> 00:02:45,760
و پس از آموزش شبکه عصبی،
81
00:02:45,760 –> 00:02:48,160
جاسازی کلمات را به عنوان یک عارضه جانبی دریافت خواهید کرد،
82
00:02:48,160 –> 00:02:48,959
83
00:02:48,959 –> 00:02:50,800
بنابراین مشکلی که در اینجا حل می کنید.
84
00:02:50,800 –> 00:02:52,879
برای طبقهبندی مرور مواد غذایی تقریباً
85
00:02:52,879 –> 00:02:53,360
مانند یک
86
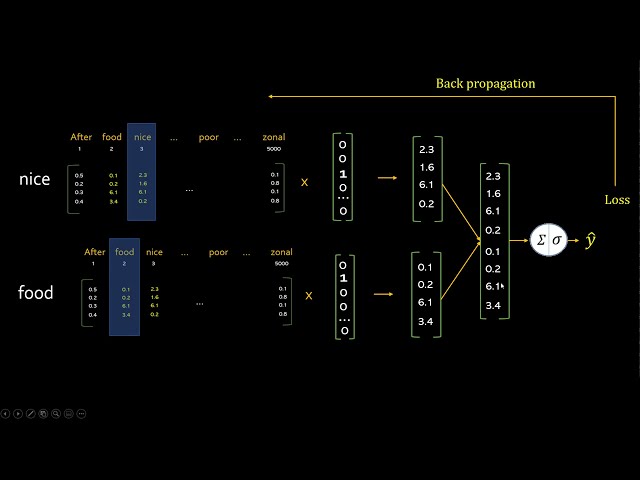
00:02:53,360 –> 00:02:55,200
مشکل جعلی است، میدانید که به
87
00:02:55,200 –> 00:02:56,959
این مشکل
88
00:02:56,959 –> 00:03:00,800
اهمیتی نمیدهید، بیشتر به واژههای embedding اهمیت
89
00:03:00,800 –> 00:03:04,959
میدهید، حالا فرض کنید 100 بررسی غذا دارید،
90
00:03:04,959 –> 00:03:07,440
برای اینکه کاری که انجام خواهید داد این است که
91
00:03:07,440 –> 00:03:09,040
ابتدا
92
00:03:09,040 –> 00:03:12,239
درباره واژگان تصمیم میگیرید. بنابراین واژگان
93
00:03:12,239 –> 00:03:14,239
تمام کلماتی هستند که در بررسی کامل ظاهر می شوند،
94
00:03:14,239 –> 00:03:16,560
بنابراین فرض کنید شما 5000 کلمه
95
00:03:16,560 –> 00:03:18,720
در دایره لغات
96
00:03:18,720 –> 00:03:20,720
خود دارید، هدف شما این است که به این
97
00:03:20,720 –> 00:03:22,080
بردار جاسازی کلمه
98
00:03:22,080 –> 00:03:25,519
با بعد 4 آن بپردازید. بعد
99
00:03:25,519 –> 00:03:25,920
10
100
00:03:25,920 –> 00:03:29,120
بعد 300 بسیار متداول است،
101
00:03:29,120 –> 00:03:30,799
بنابراین این چیزی شبیه آزمون و
102
00:03:30,799 –> 00:03:33,040
خطا است، فرض کنید برای مشکل من
103
00:03:33,040 –> 00:03:35,599
میگویم من یک بردار کلمه میخواهم که
104
00:03:35,599 –> 00:03:38,080
بعد 4 باشد
105
00:03:38,080 –> 00:03:41,840
و این اعداد به گونهای محاسبه میشوند
106
00:03:41,840 –> 00:03:44,239
که کلمه مشابه
107
00:03:44,239 –> 00:03:44,959
108
00:03:44,959 –> 00:03:48,239
نوع مشابهی از بردارها دارید،
109
00:03:48,239 –> 00:03:50,959
بنابراین در نهایت هدف شما این است که
110
00:03:50,959 –> 00:03:51,519
به این
111
00:03:51,519 –> 00:03:54,400
ماتریس تعبیه شده چهار در پنج هزار دست پیدا کنید
112
00:03:54,400 –> 00:03:55,439
که به عنوان e نیز شناخته می
113
00:03:55,439 –> 00:03:59,680
شود، بنابراین اولین کاری که باید انجام دهید این است
114
00:03:59,680 –> 00:04:02,720
که باید یک
115
00:04:02,720 –> 00:04:04,560
بردار رمزگذاری شده داغ ایجاد کنید که همه آن را می شناسید.
116
00:04:04,560 –> 00:04:06,400
رمزگذاری داغ از قبل
117
00:04:06,400 –> 00:04:08,879
جایی که شما می دانید برای بعد از این است
118
00:04:08,879 –> 00:04:09,920
این
119
00:04:09,920 –> 00:04:12,239
ردیف همان بردار کدگذاری شده داغ است که در آن می دانید یک بردار در
120
00:04:12,239 –> 00:04:13,840
اینجا وجود دارد و اعداد باقی مانده
121
00:04:13,840 –> 00:04:15,040
صفر هستند
122
00:04:15,040 –> 00:04:16,798
به طور مشابه برای چهار یک اینجاست و
123
00:04:16,798 –> 00:04:19,199
اعداد باقی مانده صفر هستند،
124
00:04:19,199 –> 00:04:21,759
بنابراین اکنون آموزش شبکه عصبی خود را شروع می کنید.
125
00:04:21,759 –> 00:04:23,360
بنابراین کاری که شما انجام می دهید این است که
126
00:04:23,360 –> 00:04:25,199
اولین نمونه آموزشی خود را
127
00:04:25,199 –> 00:04:28,080
می گیرید که می دانید فقط برای ساده نگه داشتن این موضوع
128
00:04:28,080 –> 00:04:29,440
من می گویم
129
00:04:29,440 –> 00:04:32,400
نظر من فقط دو کلمه غذای خوب است
130
00:04:32,400 –> 00:04:33,919
در واقع طولانی خواهد بود شما می دانید مانند
131
00:04:33,919 –> 00:04:37,040
20 30 40 کلمه
132
00:04:37,040 –> 00:04:41,360
سپس شما com با یک وزن تصادفی
133
00:04:41,360 –> 00:04:43,520
در ماتریس تعبیه شده خود ببینید این
134
00:04:43,520 –> 00:04:45,120
ماتریس تعبیه شده این است که
135
00:04:45,120 –> 00:04:47,680
چهار در پنج هزار خوب است اجازه دهید به شما نشان
136
00:04:47,680 –> 00:04:48,160
137
00:04:48,160 –> 00:04:50,639
دهم این ماتریس خوب است، آن را
138
00:04:50,639 –> 00:04:52,880
با این یک بردار کدگذاری شده داغ اشتباه نگیرید،
139
00:04:52,880 –> 00:04:55,199
بنابراین این ماتریس است بنابراین می خواهید
140
00:04:55,199 –> 00:04:56,479
این ماتریس را محاسبه کنید، بنابراین
141
00:04:56,479 –> 00:04:58,400
در ابتدا
142
00:04:58,400 –> 00:04:59,680
وزنهای تصادفی
143
00:04:59,680 –> 00:05:02,240
به دست خواهید آورد، فرض کنید اینها وزنهای 0.5
144
00:05:02,240 –> 00:05:05,039
0.2.3 هستند که در ابتدا به صورت تصادفی مقداردهی اولیه میشوند
145
00:05:05,039 –> 00:05:08,240
، حالا شما یک
146
00:05:08,240 –> 00:05:11,440
بردار کدگذاری شده داغ را برای کلمه nice انتخاب
147
00:05:11,440 –> 00:05:14,880
میکنید، بنابراین میبینید که nice یک کلمه سوم است، بنابراین 0 0 1
148
00:05:14,880 –> 00:05:17,600
و شما آن را با ماتریس تعبیه ضرب می
149
00:05:17,600 –> 00:05:19,039
150
00:05:19,039 –> 00:05:21,600
کنید اگر در مورد ضرب ماتریس بدانید که در
151
00:05:21,600 –> 00:05:23,520
نتیجه چه اتفاقی خواهد افتاد
152
00:05:23,520 –> 00:05:28,479
این ستون خاص را دریافت خواهید کرد
153
00:05:28,479 –> 00:05:30,560
زیرا برای ضرب ماتریس
154
00:05:30,560 –> 00:05:32,000
اولین سطر
155
00:05:32,000 –> 00:05:34,800
را با ستون ضرب می کنید و
156
00:05:34,800 –> 00:05:35,840
ستون دارای
157
00:05:35,840 –> 00:05:38,080
یک در ستون است. ستون سوم پس ستون سوم
158
00:05:38,080 –> 00:05:39,919
1 است بنابراین در اینجا 0.9 می گیرید
159
00:05:39,919 –> 00:05:41,280
زیرا اعداد باقی مانده
160
00:05:41,280 –> 00:05:43,919
0 می شوند. شما همین کار را برای
161
00:05:43,919 –> 00:05:45,840
ردیف دوم انجام می دهید ردیف دوم
162
00:05:45,840 –> 00:05:49,199
آن را در اینجا ضرب کنید عنصر سوم
163
00:05:49,199 –> 00:05:51,440
دارای یک سوم است. عنصر 1 تا
164
00:05:51,440 –> 00:05:54,240
3.2 است، بنابراین اگر در مورد ضرب ماتریس اطلاعات زیادی ندارید، در اینجا 0.2 دریافت می کنید،
165
00:05:54,240 –> 00:05:55,759
166
00:05:55,759 –> 00:05:58,400
من به شما توصیه می کنم مفاهیم خود را تازه کنید،
167
00:05:58,400 –> 00:06:00,080
168
00:06:00,080 –> 00:06:02,960
سپس بردار را صاف کنید، بنابراین من
169
00:06:02,960 –> 00:06:04,479
دو
170
00:06:04,479 –> 00:06:06,240
بردار کلمه جاسازی شده دارم، اکنون اینها
171
00:06:06,240 –> 00:06:08,160
شبکه عصبی کامل نیستند آموزش دیده است،
172
00:06:08,160 –> 00:06:12,240
هنوز هم آموزش عالی است بنابراین این دو
173
00:06:12,240 –> 00:06:14,080
بردار کلمه منفرد برای
174
00:06:14,080 –> 00:06:17,120
غذا هستند و شما آنها را صاف می کنید تا مانند
175
00:06:17,120 –> 00:06:19,600
بردار هشت بعدی به دست آورید سپس آن را
176
00:06:19,600 –> 00:06:21,039
به تابع سیگموئید وارد
177
00:06:21,039 –> 00:06:23,120
کنید، مانند یک تابع سیگموئیدی تک نورونی
178
00:06:23,120 –> 00:06:24,479
است
179
00:06:24,479 –> 00:06:26,319
که به شما کلاه y می دهد، به همین دلیل
180
00:06:26,319 –> 00:06:28,960
پیش بینی کردم که آن را با آن مقایسه کنید. حقیقت سفید شما
181
00:06:28,960 –> 00:06:29,759
182
00:06:29,759 –> 00:06:32,560
بسیار خوب است بررسی مثبت است،
183
00:06:32,560 –> 00:06:34,000
بنابراین شما کلاه y را با
184
00:06:34,000 –> 00:06:36,160
بررسی مثبت خود مقایسه کنید که یکی است، سپس
185
00:06:36,160 –> 00:06:37,280
ضرر دریافت می کنید
186
00:06:37,280 –> 00:06:39,680
و شما پس از انتشار آن ضرر را در حال حاضر
187
00:06:39,680 –> 00:06:41,520
هنگامی که به درستی پشت سر می گذارید این ضرر را با استفاده از نزول گرادیان دریافت کنید،
188
00:06:41,520 –> 00:06:43,680
189
00:06:43,680 –> 00:06:45,759
این وزنه ها در حال حاضر عمل می کنند.
190
00:06:45,759 –> 00:06:46,720
این 0.9
191
00:06:46,720 –> 00:06:49,199
0.2 است و به همین ترتیب ببینید وزن ها
192
00:06:49,199 –> 00:06:50,080
به روز
193
00:06:50,080 –> 00:06:53,520
می شوند می بینید 0.9 0.2 بود اکنون
194
00:06:53,520 –> 00:06:57,120
2.3 1.6 دوستان اعداد تصادفی گذاشته ام
195
00:06:57,120 –> 00:06:58,000
196
00:06:58,000 –> 00:07:02,240
اما شما به این نکته پی می برید پس در این پیگیری
197
00:07:02,240 –> 00:07:05,280
مادر شما ماتریس تعبیه شده trix
198
00:07:05,280 –> 00:07:08,880
به تغییر ادامه خواهد داد، سپس
199
00:07:08,880 –> 00:07:11,599
نمونه آموزشی دوم را می گیرید، می دانید
200
00:07:11,599 –> 00:07:12,639
غذای بی کیفیت،
201
00:07:12,639 –> 00:07:15,759
این بررسی البته منفی است، بنابراین
202
00:07:15,759 –> 00:07:17,759
همان فرآیند را تکرار می کنید و بردار را صاف می
203
00:07:17,759 –> 00:07:19,919
کنید، آن را با
204
00:07:19,919 –> 00:07:23,440
نحوه انتشار مجدد مقایسه کنید و شما
205
00:07:23,440 –> 00:07:26,080
دوباره این ها را تغییر دهید. وزن ها، بنابراین این بار شما
206
00:07:26,080 –> 00:07:27,919
وزن ها را برای
207
00:07:27,919 –> 00:07:29,440
غذای بی کیفیت مانند این
208
00:07:29,440 –> 00:07:32,319
دو سه ستون تغییر
209
00:07:32,960 –> 00:07:35,599
می دهید، حالا از من یک سوال بپرسید که
210
00:07:35,599 –> 00:07:37,919
در نمونه اول ما فقط دو
211
00:07:37,919 –> 00:07:40,319
کلمه داشتیم، نمونه دوم ما سه کلمه داریم،
212
00:07:40,319 –> 00:07:42,240
بنابراین معماری شبکه عصبی باید
213
00:07:42,240 –> 00:07:44,240
درست شود، در لایه قبلی درست تغییر نمی
214
00:07:44,240 –> 00:07:46,400
کند، من فقط هشت
215
00:07:46,400 –> 00:07:48,400
نورون در لایه اولم داشتم در
216
00:07:48,400 –> 00:07:51,280
اینجا من 12 نورون دارم چطور
217
00:07:51,280 –> 00:07:52,240
ممکن
218
00:07:52,240 –> 00:07:55,039
است شما حداکثر اندازه جمله را
219
00:07:55,039 –> 00:07:55,840
بگیرید و
220
00:07:55,840 –> 00:07:58,639
برای کلمات باقیمانده padding انجام
221
00:07:58,639 –> 00:08:00,560
دهید، بنابراین بیایید حداکثر من را بگوییم اندازه جمله
222
00:08:00,560 –> 00:08:02,080
سه است
223
00:08:02,080 –> 00:08:04,560
وقتی غذای خوبی دارم سومین کلمه
224
00:08:04,560 –> 00:08:05,120
می گویم
225
00:08:05,120 –> 00:08:07,680
padding padding به معنی یا صفر است بنابراین همه
226
00:08:07,680 –> 00:08:08,720
صفرها همه صفرها را می گیرید
227
00:08:08,720 –> 00:08:11,520
بنابراین معماری شبکه عصبی من اینطور است
228
00:08:11,520 –> 00:08:12,080
229
00:08:12,080 –> 00:08:14,080
بدون تغییر لایه اول دارای
230
00:08:14,080 –> 00:08:15,759
تعداد ثابتی از نورون ها است
231
00:08:15,759 –> 00:08:19,280
که برابر با کلمه جاسازی
232
00:08:19,280 –> 00:08:20,080
233
00:08:20,080 –> 00:08:23,919
جمله حداکثر طول است
234
00:08:23,919 –> 00:08:26,160
و شما تمام نمونه های خود را تغذیه می کنید، فرض کنید
235
00:08:26,160 –> 00:08:28,000
10 000 نمونه را تغذیه می کنید
236
00:08:28,000 –> 00:08:29,879
شبکه عصبی ادامه دهید آموزش را ادامه دهید در
237
00:08:29,879 –> 00:08:34,320
نهایت بالا خواهد آمد. با یک
238
00:08:34,320 –> 00:08:37,440
ماتریس، ماتریس تعبیهشده را میشناسید
239
00:08:37,440 –> 00:08:39,760
که میتواند کلمات را به خوبی نمایش دهد، بنابراین
240
00:08:39,760 –> 00:08:43,039
اگر به این مثال خاص نگاه کنید
241
00:08:43,039 –> 00:08:45,519
خوب و خوب کلمات مشابه هستند،
242
00:08:45,519 –> 00:08:46,480
243
00:08:46,480 –> 00:08:49,720
بنابراین اعداد به نوعی شبیه هستند،
244
00:08:49,720 –> 00:08:51,240
0.4.38 8.18.2 را میبینید،
245
00:08:51,240 –> 00:08:55,040
بنابراین وقتی این دو بردار را با هم مقایسه میکنید.
246
00:08:55,040 –> 00:08:57,200
خواهد گفت بله این دو
247
00:08:57,200 –> 00:08:59,360
کلمه شبیه به هم ضعیف و ضعیف
248
00:08:59,360 –> 00:09:00,240
شبیه
249
00:09:00,240 –> 00:09:03,519
به هم هستند، بنابراین
250
00:09:03,519 –> 00:09:05,680
بردارها را به گونه ای محاسبه می کند که آن اعداد
251
00:09:05,680 –> 00:09:06,800
با شما مطابقت دارند
252
00:09:06,800 –> 00:09:10,399
و اگر به
253
00:09:10,399 –> 00:09:13,040
شباهت کسینوس بین این دو بردار نگاه کنید
254
00:09:13,040 –> 00:09:14,000
،
255
00:09:14,000 –> 00:09:15,760
اساساً به شما نزدیک می شود. دانستن
256
00:09:15,760 –> 00:09:17,680
شباهت کسینوس یک به این معنی است که بردارها
257
00:09:17,680 –> 00:09:18,560
بسته هستند،
258
00:09:18,560 –> 00:09:21,519
بنابراین اینطور خواهد بود، بنابراین این
259
00:09:21,519 –> 00:09:22,800
نظریه سریع پشت
260
00:09:22,800 –> 00:09:25,120
رویکرد یادگیری نظارت شده برای
261
00:09:25,120 –> 00:09:26,320
تعبیه معیارها است،
262
00:09:26,320 –> 00:09:28,160
این رویکرد خیلی خوب نیست.
263
00:09:28,160 –> 00:09:30,560
امروزه محبوبترین روشهای رایجتر
264
00:09:30,560 –> 00:09:33,120
برای کار بودند، اما من همچنان میخواستم به
265
00:09:33,120 –> 00:09:34,080
شما نشان دهم
266
00:09:34,080 –> 00:09:36,800
که این روش خاص چگونه کار میکند
267
00:09:36,800 –> 00:09:38,880
و اکنون
268
00:09:38,880 –> 00:09:42,240
قبل از شروع، کد پایتون برای این مشکل
269
00:09:42,240 –> 00:09:42,800
270
00:09:42,800 –> 00:09:44,880
مینویسیم، میخواهم از جیسون براونلی برای مقاله عالیاش تشکر
271
00:09:44,880 –> 00:09:46,800
کنم. برای
272
00:09:46,800 –> 00:09:49,200
ارائه لینک در توضیحات ویدیوی
273
00:09:49,200 –> 00:09:51,680
زیر مقاله کلمه embeddings را
274
00:09:51,680 –> 00:09:52,880
به روشی زیبا ذکر کرده است و
275
00:09:52,880 –> 00:09:54,480
برخی از کدهایی که من نوشته ام
276
00:09:54,480 –> 00:09:55,920
بر اساس این
277
00:09:55,920 –> 00:09:58,000
مقاله عالی است.
278
00:09:58,000 –> 00:09:59,920
279
00:09:59,920 –> 00:10:01,920
280
00:10:01,920 –> 00:10:03,680
281
00:10:03,680 –> 00:10:06,560
در اینجا من کتابخانههای مهم
282
00:10:06,560 –> 00:10:07,519
283
00:10:07,5