در این مطلب، ویدئو آموزش Python Quants 5 – علم داده های مالی | توسعه دهندگان Refinitiv با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:37
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:01,520 –> 00:00:03,040
با سلام و خوش آمدید
2
00:00:03,040 –> 00:00:06,480
به این آموزش icon data api
3
00:00:06,480 –> 00:00:09,040
نام من این است که اگر من بنیانگذار و
4
00:00:09,040 –> 00:00:09,679
شریک
5
00:00:09,679 –> 00:00:13,360
مدیریت python quants هستم با
6
00:00:13,360 –> 00:00:15,599
معرفی موضوع و ارائه یک
7
00:00:15,599 –> 00:00:16,640
نمای کلی از
8
00:00:16,640 –> 00:00:19,840
دستور کار به شما شروع می کنم. موضوع
9
00:00:19,840 –> 00:00:21,600
از علم داده های مالی است به
10
00:00:21,600 –> 00:00:23,039
ویژه ما
11
00:00:23,039 –> 00:00:24,880
در مورد تجزیه و تحلیل مالی متقابل دارایی صحبت کنید
12
00:00:24,880 –> 00:00:27,279
و ما
13
00:00:27,279 –> 00:00:29,760
14
00:00:29,760 –> 00:00:33,040
با کمی جزئیات بیشتر به فرضیه رندر راهپیمایی نگاه
15
00:00:33,040 –> 00:00:36,079
خواهیم کرد. با بررسی اینکه فرضیه پیاده روی تصادفی چیست شروع می
16
00:00:36,079 –> 00:00:38,239
17
00:00:38,239 –> 00:00:41,040
کنیم و سپس داده های متقاطع دارایی های تاریخی را
18
00:00:41,040 –> 00:00:42,000
از
19
00:00:42,000 –> 00:00:45,760
icon data api می خوانیم. نشان دهید که چگونه می
20
00:00:45,760 –> 00:00:46,399
توان به راحتی
21
00:00:46,399 –> 00:00:49,760
چنین داده هایی را تجسم کرد و
22
00:00:49,760 –> 00:00:51,920
سپس به تجزیه و تحلیل داده ها
23
00:00:51,920 –> 00:00:54,079
بر اساس یک
24
00:00:54,079 –> 00:00:55,520
25
00:00:55,520 –> 00:00:59,840
رویکرد رگرسیون حداقل مربعات معمولی می پردازیم. با یک خلاصه
26
00:01:00,000 –> 00:01:03,600
به این نتیجه می رسم که اجازه دهید به کد تغییر کنم
27
00:01:04,640 –> 00:01:07,600
همه کدها به عنوان
28
00:01:07,600 –> 00:01:08,720
دفترچه یادداشت
29
00:01:08,720 –> 00:01:10,240
jupyter و دفترچه یادداشت jupyter در دسترس هستند.
30
00:01:10,240 –> 00:01:13,360
مستقل است همه چیز مورد
31
00:01:13,360 –> 00:01:16,159
نیاز در آن وجود دارد و تنها چیزی که
32
00:01:16,159 –> 00:01:17,600
باید مطمئن شوید
33
00:01:17,600 –> 00:01:20,400
این است که یا نماد در حال اجرا در
34
00:01:20,400 –> 00:01:21,680
ویندوز یا
35
00:01:21,680 –> 00:01:24,720
حداقل نماد pr برای مثال، oxy در حال اجرا
36
00:01:24,720 –> 00:01:27,759
بر روی مک بوک است که من در اینجا از آن استفاده می
37
00:01:27,759 –> 00:01:30,080
کنم
38
00:01:30,479 –> 00:01:33,439
، فرضیه پیاده روی تصادفی اساساً
39
00:01:33,439 –> 00:01:35,280
می گوید
40
00:01:35,280 –> 00:01:38,479
که تجزیه و تحلیل داده های تاریخی
41
00:01:38,479 –> 00:01:41,360
هیچ فایده ای ندارد اگر می
42
00:01:41,360 –> 00:01:43,520
خواهید در بازارها درآمد کسب کنید،
43
00:01:43,520 –> 00:01:47,040
بنابراین ایده اصلی این است که بازارهای سهام
44
00:01:47,040 –> 00:01:49,040
و در نمی توان قیمت سهام خاص یا به
45
00:01:49,040 –> 00:01:50,640
این قیمت و سایر ابزارهای مالی
46
00:01:50,640 –> 00:01:51,520
47
00:01:51,520 –> 00:01:53,360
را پیش بینی کرد که آنها صرفاً
48
00:01:53,360 –> 00:01:55,200
تصادفی هستند و هیچ کس نمی تواند یک پیاده روی تصادفی را پیش بینی کند
49
00:01:55,200 –> 00:01:56,479
50
00:01:56,479 –> 00:01:59,920
به همان روشی که هیچ کس نمی
51
00:01:59,920 –> 00:02:03,040
تواند از نظر تئوری نتیجه
52
00:02:03,040 –> 00:02:05,920
بازی های ساده ای مانند پرتاب یک سکه را پیش بینی
53
00:02:05,920 –> 00:02:06,960
54
00:02:06,960 –> 00:02:08,959
کند. کمی رسمی تر، مایکل
55
00:02:08,959 –> 00:02:11,038
جنسن در دهه 70 اظهار داشت که بازار
56
00:02:11,038 –> 00:02:12,239
با توجه به مجموعه اطلاعاتی کارآمد است به گونه
57
00:02:12,239 –> 00:02:14,160
ای که گویی امروزه نمی
58
00:02:14,160 –> 00:02:15,520
توان از
59
00:02:15,520 –> 00:02:17,920
طریق تجارت بر اساس مجموعه اطلاعاتی سود اقتصادی به دست آورد
60
00:02:17,920 –> 00:02:19,520
61
00:02:19,520 –> 00:02:22,879
، شاید بتوانیم بگوییم که در اینجا در یک مجموعه
62
00:02:22,879 –> 00:02:26,640
فنی هستیم. زمینه ای که ما
63
00:02:26,640 –> 00:02:29,040
مجموعه اطلاعات را با مجموعه ای از داده ها جایگزین می کنیم و
64
00:02:29,040 –> 00:02:30,400
در اینجا در پایتون ممکن است
65
00:02:30,400 –> 00:02:32,720
یک قاب داده پر از داده های مالی باشد
66
00:02:32,720 –> 00:02:34,000
و این چیزی است که می
67
00:02:34,000 –> 00:02:36,319
خواهیم انجام دهیم. انجام این کار یکی از
68
00:02:36,319 –> 00:02:38,239
اولین گامهای ما برای دریافت دادهها از
69
00:02:38,239 –> 00:02:40,239
icon data api خواهد بود،
70
00:02:40,239 –> 00:02:42,239
زمانی که دادهها را در آنجا داشته باشیم،
71
00:02:42,239 –> 00:02:44,720
میتوانیم با تجزیه و تحلیل شروع کنیم، چه
72
00:02:44,720 –> 00:02:47,040
تجسم یا سپس
73
00:02:47,040 –> 00:02:48,800
رگرسیون مربعهای معمولی، چرا معمولاً
74
00:02:48,800 –> 00:02:50,480
رگرسیون quest
75
00:02:50,480 –> 00:02:53,760
است. تفسیر فرضیه رندر
76
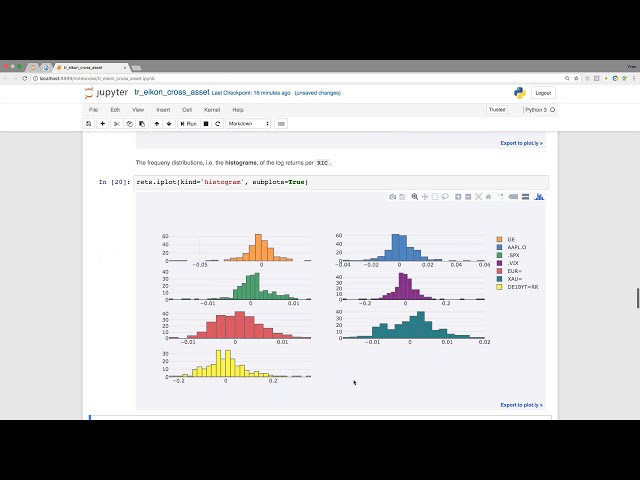
00:02:53,760 –> 00:02:55,760
رک این است
77
00:02:55,760 –> 00:02:58,319
که بهترین پیش بینی کننده برای
78
00:02:58,319 –> 00:03:00,560
قیمت سهام فردا در حداقل مربعات
79
00:03:00,560 –> 00:03:03,040
، قیمت سهام امروز است، با توجه به اینکه این
80
00:03:03,040 –> 00:03:04,319
فرضیه
81
00:03:04,319 –> 00:03:07,440
درست است،
82
00:03:08,000 –> 00:03:10,560
اجازه دهید با وارد کردن
83
00:03:10,560 –> 00:03:12,159
بسته های مورد نیاز شروع
84
00:03:12,159 –> 00:03:14,480
کنم، البته در آنجا زیاد نیست.
85
00:03:14,480 –> 00:03:15,280
نیاز به
86
00:03:15,280 –> 00:03:18,000
آیکون در بسته python wrapper که به
87
00:03:18,000 –> 00:03:19,440
نام خود آیکون است
88
00:03:19,440 –> 00:03:22,239
، numpy قرار میدهیم، پانداها را وارد میکنیم و همچنین دکمههای سرآستین را
89
00:03:22,239 –> 00:03:23,920
که
90
00:03:23,920 –> 00:03:28,400
تجسم تعاملی را به میزان قابل توجهی ساده میکند،
91
00:03:30,080 –> 00:03:32,560
در اینجا میبینید که کدام نسخهها استفاده میکنم
92
00:03:32,560 –> 00:03:33,519
همه
93
00:03:33,519 –> 00:03:37,519
بر اساس پایتون 3.6 هستند و همچنین
94
00:03:37,519 –> 00:03:41,280
نسخههای مربوطه را مشاهده میکنید.
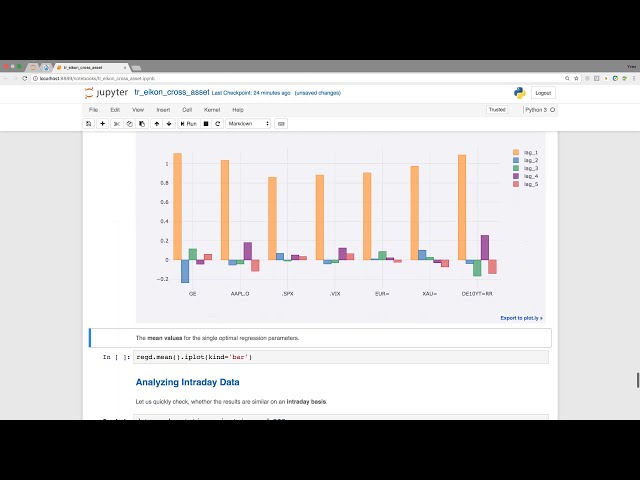
95
00:03:41,280 –> 00:03:43,760
بسته های تکی که من از آنها استفاده می کنم مرحله اول و
96
00:03:43,760 –> 00:03:45,840
البته بسیار مهم این است که
97
00:03:45,840 –> 00:03:46,720
به icon
98
00:03:46,720 –> 00:03:49,840
data api متصل شوم برای این منظور در حال
99
00:03:49,840 –> 00:03:53,120
خواندن m y اعتبارنامه را از یک فایل پیکربندی
100
00:03:53,120 –> 00:03:53,840
101
00:03:53,840 –> 00:03:57,280
و من شناسه برنامه خود را تنظیم کردم.
102
00:03:57,280 –> 00:04:00,879
103
00:04:00,879 –> 00:04:02,640
104
00:04:02,640 –> 00:04:05,280
105
00:04:05,280 –> 00:04:07,439
106
00:04:07,439 –> 00:04:08,799
107
00:04:08,799 –> 00:04:11,120
ما مجموعه دادههای زیادی را بازیابی نمیکنیم،
108
00:04:11,120 –> 00:04:12,560
109
00:04:12,560 –> 00:04:15,840
اما تعدادی از
110
00:04:15,840 –> 00:04:17,279
مجموعههای داده در اینجا
111
00:04:17,279 –> 00:04:20,478
هفت مورد است که در
112
00:04:20,478 –> 00:04:23,440
لیست شی فهرست شده است.
113
00:04:23,440 –> 00:04:25,840
114
00:04:25,840 –> 00:04:28,639
115
00:04:28,639 –> 00:04:30,000
116
00:04:30,000 –> 00:04:32,000
به قیمت طلا و همچنین قیمت ده ساله نرخ دهید،
117
00:04:32,000 –> 00:04:33,440
118
00:04:33,440 –> 00:04:35,360
بنابراین یک طیف متنوع است، اگرچه
119
00:04:35,360 –> 00:04:36,720
ما فقط هفت
120
00:04:36,720 –> 00:04:39,040
ریسک مختلف را در اینجا مشخص کرده ایم، اما
121
00:04:39,040 –> 00:04:40,080
با این وجود
122
00:04:40,080 –> 00:04:43,280
، فکر می کنم ما خواهیم دید که این رفتار
123
00:04:43,280 –> 00:04:46,800
بر حسب um،
124
00:04:46,800 –> 00:04:48,479
پیش بینی پذیری و فرضیه رندر راه اندازی
125
00:04:48,479 –> 00:04:50,880
است. برای همه این داراییها تقریباً مشابه است،
126
00:04:50,880 –> 00:04:51,680
127
00:04:51,680 –> 00:04:55,280
بنابراین وقتی اینها را مشخص کردم
128
00:04:55,280 –> 00:04:57,280
میتوانم دادههای سری زمانی تاریخی را بازیابی
129
00:04:57,280 –> 00:04:58,720
کنم. y
130
00:04:58,720 –> 00:05:02,160
i k dot سریهای زمانی را در اینجا دریافت میکنم، به سادگی
131
00:05:02,160 –> 00:05:04,800
شی لیست را با تمام ریگها ارسال
132
00:05:04,800 –> 00:05:06,560
میکنم و فیلد مورد نیاز را مشخص میکنم. من فقط
133
00:05:06,560 –> 00:05:08,560
به قیمت های بسته در اینجا علاقه مند هستم
134
00:05:08,560 –> 00:05:10,639
و یک تاریخ شروع و یک تاریخ پایان تعریف می کنم،
135
00:05:10,639 –> 00:05:12,560
بنابراین تجزیه و تحلیل بر اساس
136
00:05:12,560 –> 00:05:13,440
داده های
137
00:05:13,440 –> 00:05:17,280
سال 2017 خواهد بود، بنابراین ارزش یک سال داده های پایان روز
138
00:05:17,280 –> 00:05:18,080
139
00:05:18,080 –> 00:05:21,120
به این دلیل است که اندازه نوار به
140
00:05:21,120 –> 00:05:22,160
طور پیش فرض است.
141
00:05:22,160 –> 00:05:25,199
اجرای روزانه این سلول
142
00:05:25,199 –> 00:05:28,400
کمی طول می کشد و پنج ردیف اول اکنون
143
00:05:28,400 –> 00:05:32,080
um را در ابتدای مجموعه داده به من نشان می دهد
144
00:05:32,080 –> 00:05:36,000
و می بینید که ما
145
00:05:36,000 –> 00:05:37,919
مجموعه داده کامل نداریم بنابراین برای
146
00:05:37,919 –> 00:05:39,520
هر
147
00:05:39,520 –> 00:05:43,199
روز یک ردیف داده کامل نداریم.
148
00:05:43,199 –> 00:05:44,240
149
00:05:44,240 –> 00:05:46,479
وقتی به پنج
150
00:05:46,479 –> 00:05:48,479
ردیف پایانی نگاه میکنم همین موضوع صدق میکند،
151
00:05:48,479 –> 00:05:50,720
بنابراین برای جلوگیری از هر گونه عارضهای
152
00:05:50,720 –> 00:05:52,720
در این زمینه، یکی از اولین
153
00:05:52,720 –> 00:05:55,680
قدمهای من در اینجا خلاص شدن از شر تمام
154
00:05:55,680 –> 00:05:56,800
ردیفهایی است
155
00:05:56,800 –> 00:05:59,840
که در آنها مقدار عددی نداریم، در
156
00:05:59,840 –> 00:06:02,880
حالی که من اکنون یک عدد داریم. به
157
00:06:02,880 –> 00:06:05,440
اطلاعات متر مجموعه داده ها
158
00:06:05,440 –> 00:06:08,000
نگاه کنید، می بینیم که برای هر ریگ به همان تعداد
159
00:06:08,000 –> 00:06:09,840
غیر ردیف
160
00:06:09,840 –> 00:06:13,199
داریم که
161
00:06:13,199 –> 00:06:16,880
داده های بازیابی شده برای مجموعه داده کامل داریم،
162
00:06:16,880 –> 00:06:18,840
اگرچه بیشتر تحلیل ها
163
00:06:18,840 –> 00:06:20,240
با
164
00:06:20,240 –> 00:06:22,960
مجموعه داده های ناقص نیز انجام می شود، اما در اینجا ما
165
00:06:22,960 –> 00:06:25,360
مطمئن می شویم که یک نوع
166
00:06:25,360 –> 00:06:27,600
مجموعه داده کامل داریم در تمام
167
00:06:27,600 –> 00:06:29,600
مناطق زمانی مختلف
168
00:06:29,600 –> 00:06:32,720
که بازده قفل را محاسبه میکنند، بنابراین بیشتر
169
00:06:32,720 –> 00:06:35,039
تحلیلهای آماری بر اساس
170
00:06:35,039 –> 00:06:37,120
بازده است. من در اینجا برای بازگشت قفل تصمیم
171
00:06:37,120 –> 00:06:38,240
172
00:06:38,240 –> 00:06:40,000
173
00:06:40,000 –> 00:06:41,680
174
00:06:41,680 –> 00:06:46,000
میگیرم، زیرا معمولاً بهطور ریاضیاتی با پایتون و به ویژه در اینجا
175
00:06:46,000 –> 00:06:48,080
بر اساس شی قاب داده، کنترل آنها از نظر ریاضی آسانتر است. به
176
00:06:48,080 –> 00:06:50,000
نوعی کارآمد است زیرا من می
177
00:06:50,000 –> 00:06:52,000
توانم بازده قفل
178
00:06:52,000 –> 00:06:54,000
مجموعه داده کامل خود را
179
00:06:54,000 –> 00:06:56,400
برای هفت ستون خود در اینجا در یک
180
00:06:56,400 –> 00:06:57,759
خط کد محاسبه کنم
181
00:06:57,759 –> 00:07:00,479
و این یک ردیف دیگر با
182
00:07:00,479 –> 00:07:02,319
مقادیر عددی ندارد اما این
183
00:07:02,319 –> 00:07:04,479
فقط به این دلیل است که برای در این حالت
184
00:07:04,479 –> 00:07:08,319
ما هیچ مرجع قبلی نداریم.
185
00:07:09,919 –> 00:07:12,720
ماتریس همبستگی به ستون
186
00:07:12,720 –> 00:07:14,880
به راحتی قابل محاسبه است مانند بسیاری از چیزهای دیگر
187
00:07:14,880 –> 00:07:16,000
هنگامی که با
188
00:07:16,000 –> 00:07:18,400
پانداها و به ویژه شی قاب داده کار می کنید
189
00:07:18,400 –> 00:07:19,680
190
00:07:19,680 –> 00:07:22,000
و ما یک نوع رفتار معمولی می
191
00:07:22,000 –> 00:07:22,720
بینیم که
192
00:07:22,720 –> 00:07:24,560
هر دو همبستگی مثبت را می بینیم. و همچنین
193
00:07:24,560 –> 00:07:26,160
همبستگی منفی، این چیزی است که با
194
00:07:26,160 –> 00:07:27,680
195
00:07:27,680 –> 00:07:30,319
توجه به جهان کوچکی
196
00:07:30,319 –> 00:07:31,599
از
197
00:07:31,599 –> 00:07:34,240
خطرات نمادهایی که ما بازیابی کرده ایم، انتظار می رود.
198
00:07:34,240 –> 00:07:36,000
ta برای اما اجازه دهید ما
199
00:07:36,000 –> 00:07:39,039
به صورت بصری به داده ها نگاهی بیندازیم،
200
00:07:39,039 –> 00:07:42,240
بنابراین من می خواهم داده ها را در اینجا رسم کنم
201
00:07:42,240 –> 00:07:44,319
اولین خط کد من در اینجا
202
00:07:44,319 –> 00:07:46,560
نمودار را به حالت آفلاین تنظیم می کند که به این معنی است که
203
00:07:46,560 –> 00:07:49,039
تمام نمودارهایی که در
204
00:07:49,039 –> 00:07:49,680
ادامه
205
00:07:49,680 –> 00:07:51,919
خواهید دید به صورت محلی ارائه می شوند. و نه در
206
00:07:51,919 –> 00:07:53,199
سرور plotly،
207
00:07:53,199 –> 00:07:56,400
اما ما با این وجود از موتور استفاده می کنیم،
208
00:07:56,400 –> 00:07:59,360
موتور جاوا اسکریپت از
209
00:07:59,360 –> 00:08:01,919
210
00:08:02,319 –> 00:08:04,800
خط تک خط کد، داده ها را نرمال می کنم و
211
00:08:04,800 –> 00:08:06,319
روش iplot را فراخوانی
212
00:08:06,319 –> 00:08:08,400
می کنم و می گویم می خواهم این قطعه را به عنوان
213
00:08:08,400 –> 00:08:10,720
نمودار خطوط داشته باشم، اکنون
214
00:08:10,720 –> 00:08:11,759
نمودار نرمال شده
215
00:08:11,759 –> 00:08:14,800
um را می بینیم. تک رنگ
216
00:08:14,800 –> 00:08:18,080
ها در اینجا در افسانه نمایش داده می شوند و
217
00:08:18,080 –> 00:08:20,000
البته در اینجا در محور
218
00:08:20,000 –> 00:08:23,199
x زمان
219
00:08:23,199 –> 00:08:25,919
نشان داده شده است مانند فواصل ماهانه
220
00:08:25,919 –> 00:08:27,039
کم و
221
00:08:27,039 –> 00:08:30,160
بیش در اینجا کمی کمتر از توزیع فرکانس
222
00:08:30,160 –> 00:08:32,000
که به این معنی است که هیستوگرام های قفل
223
00:08:32,000 –> 00:08:33,440
نیز به راحتی قابل مشاهده هستند.
224
00:08:33,440 –> 00:08:37,440
تجسم کنید که من فقط
225
00:08:37,440 –> 00:08:40,559
نوع um نمودار را تغییر میدهم که در اینجا
226
00:08:40,559 –> 00:08:43,440
با پارامتر نوع به هیستوگرام معنی میدهد
227
00:08:43,440 –> 00:08:46,720
و برای دید بهتر، من از
228
00:08:46,720 –> 00:08:48,800
طرحهای فرعی نیز درخواست میکنم، بنابراین اکنون
229
00:08:48,800 –> 00:08:49,920
هر ستون را به
230
00:08:49,920 –> 00:08:53,200
ازای هر ریک میبینیم. یک طرح فرعی
231
00:08:53,200 –> 00:08:55,680
با هیستوگرام مربوطه
232
00:08:55,680 –> 00:08:58,480
قفل دریافت کنید،
233
00:08:58,800 –> 00:09:01,440
یکی دیگر از روش های تجسم جالب
234
00:09:01,440 –> 00:09:02,480
235
00:09:02,480 –> 00:09:04,720
مرتبط با ماتریس همبستگی ما،
236
00:09:04,720 –> 00:09:06,240
نقشه حرارتی است، بنابراین
237
00:09:06,240 –> 00:09:09,040
در اینجا متوجه می شوید که من ابتدا
238
00:09:09,040 –> 00:09:10,080
همبستگی را محاسبه می کنم
239
00:09:10,080 –> 00:09:13,680
و سپس یک نقشه حرارتی را رسم می کنم
240
00:09:13,680 –> 00:09:17,200
، دکمه های سر دست سیم را رسم می کنم
241
00:09:17,200 –> 00:09:20,399
و رنگ را به صورت نموداری تعریف می کنم. در مقیاس بلوز
242
00:09:20,399 –> 00:09:22,800
و در اینجا می بینید که هر چه
243
00:09:22,800 –> 00:09:25,120
آبی تیره تر باشد همبستگی بیشتر است،
244
00:09:25,120 –> 00:09:27,279
بنابراین وقتی همبستگی داریم
245
00:09:27,279 –> 00:09:28,800
که برای هر
246
00:09:28,800 –> 00:09:30,480
ساز با خودش صدق
247
00:09:30,480 –> 00:09:32,640
می کند، به نوعی آبی تیره است، هر
248
00:09:32,640 –> 00:09:34,560
چه رنگ روشن تر باشد، نور آبی
249
00:09:34,560 –> 00:09:37,760
تقریباً می شود. در اینجا خیلی سفید،
250
00:09:37,760 –> 00:09:40,320
هر چه همبستگی کمتر باشد، به
251
00:09:40,320 –> 00:09:40,959
عنوان مثال
252
00:09:40,959 –> 00:09:43,920
apple و geos دارای همبستگی
253
00:09:43,920 –> 00:09:46,120
منهای
254
00:09:46,120 –> 00:09:49,120
0.888 هستند،
255
00:09:49,600 –> 00:09:51,680
حالا اجازه دهید داده های کم را برای
256
00:09:51,680 –> 00:09:53,279
تجزیه و تحلیل آماده
257
00:09:53,279 –> 00:09:56,560
کنیم، ما با داده های کم کار خواهیم کرد به یاد داشته باشید
258
00:09:56,560 –> 00:09:58,000
که تفسیر پروتز جنگی تصادفی می
259
00:09:58,000 –> 00:09:59,760
گوید
260
00:09:59,760 –> 00:10:03,440
که جایزه امروز بهترین پیش بینی کننده
261
00:10:03,440 –> 00:10:05,040
به معنای حداقل مربع
262
00:10:05,040 –> 00:10:08,399
برای قیمت فردا است، بنابراین این نشان می
263
00:10:08,399 –> 00:10:10,160
دهد که
264
00:10:10,160 –> 00:10:13,440
دیروز قیمت یا قیمت پنج
265
00:10:13,440 –> 00:10:16,079
روز پیش یا قیمت 10 روز پیش
266
00:10:16,079 –> 00:10:17,040
احتمالاً
267
00:10:17,040 –> 00:10:19,040
چیز زیادی برای گفتن در مورد
268
00:10:19,040 –> 00:10:20,800
قیمت فردا ندارد، بنابراین اینها به
269
00:10:20,800 –> 00:10:24,079
نوعی نتیجه ای خارج از فرضیه قرمز و
270
00:10:24,079 –> 00:10:25,519
راه رفتن هستند
271
00:10:25,519 –> 00:10:28,720
و برای این منظور اکنون من ایجاد خواهم کرد.
272
00:10:28,720 –> 00:10:33,120
فریم های داده ای که من فاقد داده
273
00:10:33,120 –> 00:10:36,240
274
00:10:36,240 –> 00:10:39,680
275
00:10:39,680 –> 00:10:41,360
هستم، فرض کنید برای یک روز دیگر روز سوم چهار تا پنج روز قبل، بنابراین ما در اینجا
276
00:10:41,360 –> 00:10:44,399
با پنج تأخیر کار می
277
00:10:44,399 –> 00:10:47,600
کنیم و خواهیم دید که کدام تأخیر
278
00:10:47,600 –> 00:10:50,720
بیشترین وزن را در
279
00:10:50,720 –> 00:10:52,160
رگرسیون مجذور معمولی دارد و
280
00:10:52,160 –> 00:10:54,480
از نظر اقتصادی می توان گفت خوب است.
281
00:10:54,480 –> 00:10:55,600
هر چه
282
00:10:55,600 –> 00:10:59,440
وزن بیشتر باشد، این تاخیر
283
00:10:59,440 –> 00:11:01,680
خاص برای پیشبینی قیمت فردا مهمتر است،
284
00:11:01,680 –> 00:11:03,600
285
00:11:03,600 –> 00:11:07,440
بنابراین در اینجا یک تابع کمکی کوچک وجود دارد
286
00:11:07,440 –> 00:11:09,519
که تمام تاخیرها را ایجاد میکند، بنابراین وقتی
287
00:11:09,519 –> 00:11:11,120
پاهایم را تعریف کردم
288
00:11:11,120 –> 00:11:13,760
و یک شی قاب داده برای یک ریگ خاص را به این تابع منتقل کردم،
289
00:11:13,760 –> 00:11:14,959
290
00:11:14,959 –> 00:11:17,519
سپس پنج تأخیر لازم را ایجاد می کند
291
00:11:17,519 –> 00:11:18,399
292
00:11:18,399 –> 00:11:21,839
293
00:11:21,839 –> 00:11:24,560
و در اینجا اکنون عملکرد وارد عمل می
294
00:11:24,560 –> 00:11:26,880
شود و برای هر ریگ منفرد
295
00:11:26,880 –> 00:11:28,959
همین کار را انجام می
296
00:11:28,959 –> 00:11:31,360
دهم بسیار سریع است زیرا مجموعه
297
00:11:31,360 –> 00:11:33,200
داده خیلی بزرگ نیست
298
00:11:33,200 –> 00:11:36,480
d هنگامی که من اکنون به نام ستونها
299
00:11:36,480 –> 00:11:38,959
برای تاخیرهایی که میبینیم نگاهی میاندازم،
300
00:11:38,959 –> 00:11:41,440
مانند یک مانند دو مانند سه مانند چهار
301
00:11:41,440 –> 00:11:42,240
مانند