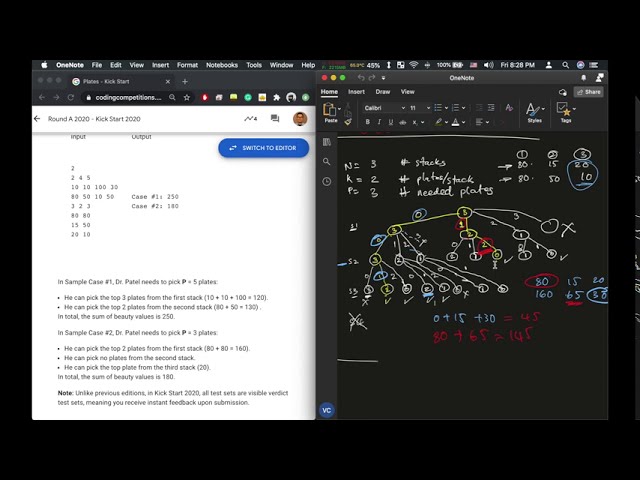
در این مطلب، ویدئو رگرسیون خطی در پایتون | یادگیری ماشینی | الگوریتم رگرسیون خطی | یادگیری عالی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 2:02:51
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,160 –> 00:00:02,879
در دنیای امروزی بیشتر داده ها
2
00:00:02,879 –> 00:00:03,760
نیمه ساختاری
3
00:00:03,760 –> 00:00:06,160
یا بدون ساختار هستند تا بتوانیم به آن
4
00:00:06,160 –> 00:00:07,359
داده هایی دست پیدا کنیم که برای
5
00:00:07,359 –> 00:00:09,599
استفاده از مفاهیم یادگیری ماشین نیاز داریم و
6
00:00:09,599 –> 00:00:11,599
یادگیری ماشینی به سه
7
00:00:11,599 –> 00:00:12,160
بخش
8
00:00:12,160 –> 00:00:13,840
یادگیری نظارت شده یادگیری بدون نظارت
9
00:00:13,840 –> 00:00:15,599
و یادگیری تقویتی در
10
00:00:15,599 –> 00:00:17,680
آموزش امروزی که در مورد خطی بحث خواهیم کرد تقسیم می شود.
11
00:00:17,680 –> 00:00:19,760
رگرسیون که تحت
12
00:00:19,760 –> 00:00:22,800
یادگیری نظارت شده قرار می گیرد
13
00:00:29,119 –> 00:00:31,519
خوب است طبق معمول نقشه راه ما در
14
00:00:31,519 –> 00:00:32,479
حالت پیشگویانه هستیم
15
00:00:32,479 –> 00:00:35,200
هفته یکی از جلسات پنج هفته درست
16
00:00:35,200 –> 00:00:35,840
معمولاً
17
00:00:35,840 –> 00:00:37,760
بعد از آمارهای پیشرفته چه اتفاقی می افتد
18
00:00:37,760 –> 00:00:39,280
این مدل سازی پیش بینی
19
00:00:39,280 –> 00:00:39,840
وجود خواهد داشت
20
00:00:39,840 –> 00:00:41,360
اوه اکنون نمی دانم چه بود به این دلیل
21
00:00:41,360 –> 00:00:43,360
که آنها داده کاوی را
22
00:00:43,360 –> 00:00:44,960
قبل از مدل سازی پیش بینی قرار داده اند که
23
00:00:44,960 –> 00:00:46,399
24
00:00:46,399 –> 00:00:49,760
مزاحمت زیادی ایجاد نمی کند، اما هنوز هم
25
00:00:49,760 –> 00:00:52,480
ممکن است ترتیبی را فراموش کنیم که r مجذور
26
00:00:52,480 –> 00:00:54,000
همبستگی چیست،
27
00:00:54,000 –> 00:00:55,760
بنابراین من یک جمع بندی کوچک ارائه خواهم داد که چه چیزی یک
28
00:00:55,760 –> 00:00:57,440
همبستگی است. r مربع
29
00:00:57,440 –> 00:00:58,800
و سپس ما با این موضوع ادامه خواهیم داد.
30
00:00:58,800 –> 00:01:00,640
31
00:01:00,640 –> 00:01:02,800
32
00:01:02,800 –> 00:01:03,920
33
00:01:03,920 –> 00:01:06,400
رگرسیون
34
00:01:06,400 –> 00:01:07,200
35
00:01:07,200 –> 00:01:10,000
خطی رگرسیون لجستیک
36
00:01:10,000 –> 00:01:12,560
تجزیه و تحلیل تفکیک خطی
37
00:01:12,560 –> 00:01:14,080
همه درست هدف یادگیری این
38
00:01:14,080 –> 00:01:16,000
جلسه این است که چه چیزی در
39
00:01:16,000 –> 00:01:17,600
رگرسیون خطی ساده
40
00:01:17,600 –> 00:01:20,400
و چه رگرسیون خطی چندگانه است
41
00:01:20,400 –> 00:01:22,560
این دو هدف اصلی برای
42
00:01:22,560 –> 00:01:24,400
این جلسه هستند،
43
00:01:24,400 –> 00:01:28,000
بنابراین من خواهم داشت و پاپ امتحان
44
00:01:28,000 –> 00:01:30,400
طبق معمول، بنابراین معادله در
45
00:01:30,400 –> 00:01:32,400
رگرسیون خطی ساده چیست
46
00:01:32,400 –> 00:01:36,240
y برابر mx به علاوه c y برابر است با mx
47
00:01:36,240 –> 00:01:36,960
به علاوه c
48
00:01:36,960 –> 00:01:39,360
حالا من یک سوال متفاوت دارم، خوب اجازه
49
00:01:39,360 –> 00:01:40,000
دهید ابتدا
50
00:01:40,000 –> 00:01:43,040
آن را بنویسم y برابر است با
51
00:01:43,040 –> 00:01:46,720
mx به علاوه c در اینجا
52
00:01:46,720 –> 00:01:51,200
می خواهید بگویید y است بله
53
00:01:52,840 –> 00:01:54,960
c نقطه قطع
54
00:01:54,960 –> 00:01:59,759
است این m چیزی است که m اینجاست
55
00:01:59,759 –> 00:02:02,000
بدون شیب توان آهسته شما می توانید
56
00:02:02,000 –> 00:02:03,119
ضریب
57
00:02:03,119 –> 00:02:06,159
ضریب ضریب x را در حال حاضر بگویید
58
00:02:06,159 –> 00:02:06,640
چه y
59
00:02:06,640 –> 00:02:10,239
در اینجا متفاوت است چه y در اینجا
60
00:02:10,239 –> 00:02:13,599
متغیر
61
00:02:13,599 –> 00:02:16,879
وابسته متغیر وابسته یا چه شما می
62
00:02:16,879 –> 00:02:17,920
توانید آن را به عنوان
63
00:02:17,920 –> 00:02:22,000
گوش دادن به مقدار پیش بینی شده y
64
00:02:22,000 –> 00:02:25,200
برای مشاهده i بنامید،
65
00:02:25,200 –> 00:02:28,239
باید همیشه y i
66
00:02:28,239 –> 00:02:31,680
و سرپوش y را قرار دهید، بنابراین
67
00:02:31,680 –> 00:02:33,840
هر زمان که باید یک
68
00:02:33,840 –> 00:02:36,000
معادله رگرسیون خطی
69
00:02:36,000 –> 00:02:39,120
ساده بگویید، همیشه st است. arts با y i
70
00:02:39,120 –> 00:02:42,400
y cap برابر است با m x
71
00:02:42,400 –> 00:02:46,000
به علاوه c یا می توانید m i x i را قرار دهید
72
00:02:46,000 –> 00:02:48,080
زیرا یک رگرسیون خطی ساده است،
73
00:02:48,080 –> 00:02:51,040
خوب می توانید آن را ذکر کنید زیرا
74
00:02:51,040 –> 00:02:54,800
y برابر است با y کلاه برابر با
75
00:02:54,800 –> 00:02:58,400
mx به اضافه c است، بنابراین حالا یکی
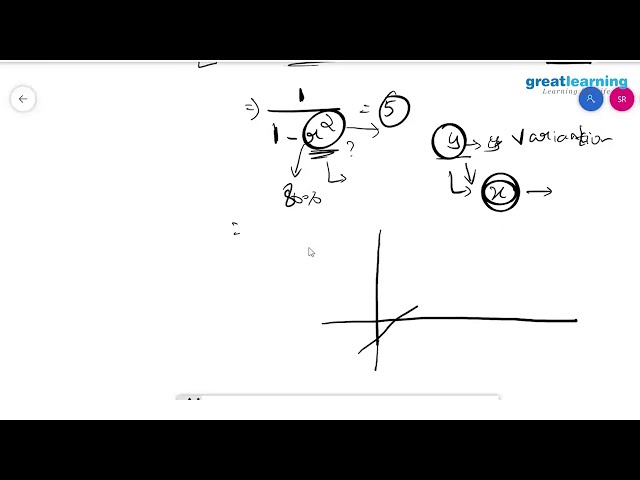
76
00:02:58,400 –> 00:03:00,879
از شما می پرسد خطی ساده چیست؟
77
00:03:00,879 –> 00:03:02,400
مدل رگرسیون
78
00:03:02,400 –> 00:03:03,760
اکنون می خواهم از شما بپرسم که در مدل رگرسیون خطی ساده چه چیزی وجود دارد
79
00:03:03,760 –> 00:03:05,920
80
00:03:05,920 –> 00:03:08,879
چگونه تغییر می کند، بنابراین اینکه
81
00:03:08,879 –> 00:03:10,480
مدل رگرسیون خطی
82
00:03:10,480 –> 00:03:14,640
ساده با سرمایه y i برابر با
83
00:03:14,640 –> 00:03:18,239
b هیچ به اضافه b 1
84
00:03:18,239 –> 00:03:22,560
x i به علاوه e است که عبارت
85
00:03:22,560 –> 00:03:25,280
خطا بسیار بسیار مهم است. بچه ها توجه داشته باشید، بنابراین
86
00:03:25,280 –> 00:03:26,799
هر زمان که ما در مورد
87
00:03:26,799 –> 00:03:30,080
پیش بینی اشاره می کنیم، آن را به عنوان y درج می کنیم
88
00:03:30,080 –> 00:03:33,200
و در اینجا هیچ عبارت خطایی وجود ندارد،
89
00:03:33,200 –> 00:03:35,280
وقتی می خواهید برای
90
00:03:35,280 –> 00:03:36,400
جمعیت
91
00:03:36,400 –> 00:03:38,480
بگویید، همیشه آن را با حروف یونانی
92
00:03:38,480 –> 00:03:40,560
نشان می دهید که بتا
93
00:03:40,560 –> 00:03:44,640
uh که e و به جای e. میتوانیم آن را
94
00:03:44,640 –> 00:03:44,879
بهعنوان
95
00:03:44,879 –> 00:03:48,159
epsilon epsilon i قرار دهیم،
96
00:03:48,159 –> 00:03:51,840
بنابراین آنچه میخواهم در اینجا بگویم این است که
97
00:03:51,840 –> 00:03:55,760
آیا من یک محور x و y
98
00:03:55,760 –> 00:03:59,840
درست دارم و این یک خطی است،
99
00:03:59,840 –> 00:04:04,640
اجازه دهید رنگ b را
100
00:04:04,879 –> 00:04:08,799
برای b هیچ برای تغییر واحد در x تغییر دهم
101
00:04:08,799 –> 00:04:12,080
. واحد تغییر می کند y
102
00:04:12,080 –> 00:04:15,360
این محور x است این محور y برای
103
00:04:15,360 –> 00:04:19,120
یک واحد تغییر در x دلتا x
104
00:04:19,120 –> 00:04:22,160
چیست یک واحد تغییر
105
00:04:22,160 –> 00:04:25,600
دلتا y درست است، بنابراین
106
00:04:25,600 –> 00:04:27,759
وقتی در معادله خطی ساده از ما خواسته
107
00:04:27,759 –> 00:04:28,720
می شود،
108
00:04:28,720 –> 00:04:32,400
y cap برابر با m x به اضافه c است
109
00:04:32,400 –> 00:04:34,639
، فکر می کنم در ویدیوی شما نیز ذکر شده است
110
00:04:34,639 –> 00:04:36,960
که همیشه آن را به عنوان y cap ذکر می کنید
111
00:04:36,960 –> 00:04:40,560
، چرا زیرا مقدار پیشبینی شده
112
00:04:40,560 –> 00:04:44,639
y برای مشاهده
113
00:04:44,639 –> 00:04:47,759
من برای مشاهده من
114
00:04:47,759 –> 00:04:49,759
پیشبینی شما چیست،
115
00:04:49,759 –> 00:04:50,960
به
116
00:04:50,960 –> 00:04:52,479
همین دلیل است که شما همیشه
117
00:04:52,479 –> 00:04:54,840
آن را بهعنوان کلید y ذکر
118
00:04:54,840 –> 00:04:57,520
119
00:04:57,520 –> 00:05:00,240
میکنید، بنابراین در اینجا شما چیزی را پیشبینی نمیکنید.
120
00:05:00,240 –> 00:05:00,880
121
00:05:00,880 –> 00:05:03,600
آیا این همان چیزی است که شما آن را
122
00:05:03,600 –> 00:05:04,000
به عنوان
123
00:05:04,000 –> 00:05:07,680
متغیر وابسته می نامید در اینجا ما آن را به عنوان متغیر وابسته می نامیم
124
00:05:07,680 –> 00:05:10,320
این نیز
125
00:05:10,320 –> 00:05:11,600
متغیر مستقل است
126
00:05:11,600 –> 00:05:13,919
اما این مقدار پیش بینی پیش
127
00:05:13,919 –> 00:05:15,520
بینی y
128
00:05:15,520 –> 00:05:18,080
نیست شما نیستید y واقعی را ندارید
129
00:05:18,080 –> 00:05:19,840
بنابراین هر زمان که بخواهیم هر کدام را بنویسیم رگرسیون خطی
130
00:05:19,840 –> 00:05:21,280
131
00:05:21,280 –> 00:05:24,320
که شما آن را ذکر می کنید به عنوان y cap برابر است با n
132
00:05:24,320 –> 00:05:26,880
max به اضافه c
133
00:05:27,440 –> 00:05:31,520
v j آیا همه چیز درست است بله قربان،
134
00:05:31,520 –> 00:05:34,800
بنابراین برای یک واحد تغییر در x مقدار
135
00:05:34,800 –> 00:05:36,080
معکوس تغییر واحد
136
00:05:36,080 –> 00:05:39,199
چقدر است که مفهوم اصلی این
137
00:05:39,199 –> 00:05:40,639
رگرسیون خطی ساده برای آن ماده
138
00:05:40,639 –> 00:05:41,919
reg است. خود
139
00:05:41,919 –> 00:05:44,400
رگرسیون حتی رگرسیون لجستیک
140
00:05:44,400 –> 00:05:46,800
همان چیزی را برای تغییر واحد در x حل
141
00:05:46,800 –> 00:05:48,720
می کند. تغییر واحد در y
142
00:05:48,720 –> 00:05:51,039
چیست که ما آن را به
143
00:05:51,039 –> 00:05:54,320
عنوان بخشی از مدل رگرسیون شما پیدا می
144
00:05:54,320 –> 00:05:58,560
کنیم درست سوال دوم ما این است که آیا می توانیم
145
00:05:58,560 –> 00:06:00,800
بیشتر از دو متغیر مستقل در
146
00:06:00,800 –> 00:06:03,520
رگرسیون خطی ساده
147
00:06:03,520 –> 00:06:04,960
آیا میتوانیم بیش از دو
148
00:06:04,960 –> 00:06:08,400
متغیر مستقل در رگرسیون خطی ساده
149
00:06:10,160 –> 00:06:13,440
داشته باشیم، خوب
150
00:06:13,440 –> 00:06:15,919
نمیدانم
151
00:06:18,000 –> 00:06:21,520
زیرا این چند متغیره خواهد بود بله
152
00:06:21,520 –> 00:06:23,440
که در حال حاضر به یک رگرسیون خطی چندگانه تبدیل میشود،
153
00:06:23,440 –> 00:06:24,880
154
00:06:24,880 –> 00:06:27,360
سوال دوم
155
00:06:27,360 –> 00:06:28,880
معادله یک خطی چندگانه چیست؟
156
00:06:28,880 –> 00:06:30,000
رگرسیون
157
00:06:30,000 –> 00:06:33,039
y cap برابر است با m1 x1 به علاوه m2 x2
158
00:06:33,039 –> 00:06:37,360
به علاوه 2 کلاهک کامل y برابر با
159
00:06:37,680 –> 00:06:40,720
m 1 نیز خوب است b هیچ به علاوه
160
00:06:40,720 –> 00:06:45,199
b 1 x 1 به علاوه b 2 x 2
161
00:06:45,199 –> 00:06:48,800
بسیار خوب شما اشاره کردید که اوه
162
00:06:48,800 –> 00:06:51,599
حروف یونانی بتا اپسیلون فرد برای
163
00:06:51,599 –> 00:06:52,400
جمعیت
164
00:06:52,400 –> 00:06:55,520
این این چیزی است که ما می خواهیم پیش بینی
165
00:06:55,520 –> 00:06:56,479
کنیم، بنابراین ما همیشه از الفبای b استفاده می کنیم
166
00:06:56,479 –> 00:06:59,919
، بنابراین
167
00:06:59,919 –> 00:07:02,720
در ابتدای کلاس آمار من
168
00:07:02,720 –> 00:07:04,240
همیشه از
169
00:07:04,240 –> 00:07:06,160
حروف یونانی همیشه برای جمعیت ذکر می کردم بنابراین بتا را
170
00:07:06,160 –> 00:07:07,919
ذکر می کردم. یون
171
00:07:07,919 –> 00:07:11,360
و حروف الفبای نمونه
172
00:07:11,599 –> 00:07:13,440
کاملاً درست است این رگرسیون چندگانه
173
00:07:13,440 –> 00:07:15,440
فقط یک بسط این
174
00:07:15,440 –> 00:07:18,880
رگرسیون حداقل مربعی معمولی yls است
175
00:07:18,880 –> 00:07:21,840
درست آن حداقل پرس و جو معمولی
176
00:07:21,840 –> 00:07:23,759
که شامل بیش از یک متغیر توضیحی
177
00:07:23,759 –> 00:07:24,960
178
00:07:24,960 –> 00:07:26,800
بیش از یک متغیر توضیحی است که ما
179
00:07:26,800 –> 00:07:28,160
داریم، سپس آن را به عنوان یک متغیر توضیحی می نامیم.
180
00:07:28,160 –> 00:07:31,360
رگرسیون خطی چندگانه
181
00:07:31,360 –> 00:07:34,319
در حال حاضر چند تکنیک برای مقابله
182
00:07:34,319 –> 00:07:36,639
با
183
00:07:36,639 –> 00:07:38,479
184
00:07:38,479 –> 00:07:42,080
185
00:07:42,720 –> 00:07:44,720
چند خطی بودن داده ها نام ببرید.
186
00:07:44,720 –> 00:07:46,240
187
00:07:46,240 –> 00:07:48,319
188
00:07:48,319 –> 00:07:49,680
189
00:07:49,680 –> 00:07:52,080
190
00:07:52,080 –> 00:07:53,520
191
00:07:53,520 –> 00:07:55,680
همبستگی
192
00:07:55,680 –> 00:07:56,560
193
00:07:56,560 –> 00:07:59,599
دو متغیر مستقل بین دو متغیر مستقل
194
00:07:59,599 –> 00:08:02,960
بسیار خوب است، بنابراین هر گزینه دیگری
195
00:08:02,960 –> 00:08:06,240
در رگرسیون اتفاق می افتد این است که زمانی که شما
196
00:08:06,240 –> 00:08:07,919
سعی می کنید یک رگرسیون را اجرا کنید
197
00:08:07,919 –> 00:08:10,840
هیچ یک از ضرایب مهم نمی
198
00:08:10,840 –> 00:08:13,280
199
00:08:13,280 –> 00:08:16,400
شوند، این منجر به
200
00:08:16,400 –> 00:08:19,759
این سوال می شود که آیا
201
00:08:19,759 –> 00:08:21,759
خطی بودن چندگانه در داده های
202
00:08:21,759 –> 00:08:24,000
زمانی که من سعی می کنم یک reg خطی را اجرا کنم
203
00:08:24,000 –> 00:08:24,879
204
00:08:24,879 –> 00:08:26,400
اگر هیچ یک از ضرایب
205
00:08:26,400 –> 00:08:28,160
معنی دار نیستند، امیدوارم بدانید که چه چیزی
206
00:08:28,160 –> 00:08:29,280
معنی دار است، درست
207
00:08:29,280 –> 00:08:33,120
بر اساس مقدار p جدول کلی
208
00:08:33,120 –> 00:08:35,679
بر اساس مقدار ضرایب،
209
00:08:35,679 –> 00:08:37,679
به مقدار p
210
00:08:37,679 –> 00:08:39,839
درست می رسید، بنابراین هیچ یک از ضرایب
211
00:08:39,839 –> 00:08:41,039
معنی دار نمی شوند،
212
00:08:41,039 –> 00:08:42,440
پس وجود
213
00:08:42,440 –> 00:08:44,240
چند خطی وجود دارد. دادههایی
214
00:08:44,240 –> 00:08:47,279
که باید رد کنید که
215
00:08:47,279 –> 00:08:50,959
مفهوم بعدی
216
00:08:50,959 –> 00:08:55,760
واریانس vif واریانس فاکتور تورم واریانس فاکتور
217
00:08:55,760 –> 00:09:00,480
تورم
218
00:09:01,519 –> 00:09:04,880
است، بخشی از این
219
00:09:04,880 –> 00:09:06,240
محدوده این جلسه وجود ندارد،
220
00:09:06,240 –> 00:09:08,800
احتمالاً جلسه بعدی یا جلسه دیگر
221
00:09:08,800 –> 00:09:10,880
ما در مورد چیستی vaf بحث خواهیم کرد،
222
00:09:10,880 –> 00:09:13,760
اما تقریباً من در مورد آن صحبت خواهم کرد. به شما بگویم که vf چیست؟
223
00:09:13,760 –> 00:09:16,320
vf با فرمول 1 تقسیم بر 1
224
00:09:16,320 –> 00:09:16,880
منهای
225
00:09:16,880 –> 00:09:21,440
r مربع به دست می آید.
226
00:09:27,920 –> 00:09:29,680
ما آن را به عنوان ضریب تعیین درست می نامیم.
227
00:09:29,680 –> 00:09:30,959
228
00:09:30,959 –> 00:09:33,600
229
00:09:33,600 –> 00:09:35,920
230
00:09:35,920 –> 00:09:36,240
231
00:09:36,240 –> 00:09:39,440
توسط متغیر مستقل
232
00:09:39,440 –> 00:09:41,760
x
233
00:09:41,760 –> 00:09:43,920
مقداری تغییر مقداری واریانس موجود در
234
00:09:43,920 –> 00:09:45,600
y
235
00:09:45,600 –> 00:09:48,800
مقداری تغییر وجود دارد
236
00:09:49,519 –> 00:09:52,480
که متغیرهای x پیش بینی من چقدر است
237
00:09:52,480 –> 00:09:53,760
متغیرهای مستقل
238
00:09:53,760 –> 00:09:57,279
قادر هستند برای توضیح آن
239
00:09:57,279 –> 00:10:00,399
که به عنوان r مربع نامیده می شود، ما می
240
00:10:00,399 –> 00:10:01,440
خواهیم پیش بینی کنیم که
241
00:10:01,440 –> 00:10:04,720
چرا آخر روز، بنابراین چقدر
242
00:10:04,720 –> 00:10:07,680
پیش بینی y از y می تواند توسط متغیرهای x من انجام دهد،
243
00:10:07,680 –> 00:10:10,160
244
00:10:10,160 –> 00:10:13,519
این همان چیزی است که آن را به عنوان r مربع می نامیم،
245
00:10:13,519 –> 00:10:17,360
بنابراین اگر آن را طبق یک قانون پیش فرض انگشت شست
246
00:10:17,360 –> 00:10:19,200
ما آن را به عنوان پنج
247
00:10:19,200 –> 00:10:22,480
خواهیم داشت، چیزی نیست، اما اگر شما
248
00:10:22,480 –> 00:10:25,600
هشتاد درصد r مربع را
249
00:10:25,600 –> 00:10:27,680
درست داشته باشید، مقدار va برابر با پنج دریافت خواهید کرد،
250
00:10:27,680 –> 00:10:30,079
اگر مقداری بیش از پنج آن را به عنوان حضور بسیار همبسته می نامیم.
251
00:10:30,079 –> 00:10:30,480
252
00:10:30,480 –> 00:10:32,240
253
00:10:32,240 –> 00:10:34,800
خطی بودن چندگانه
254
00:10:34,800 –> 00:10:36,320
خواهیم دید که در جلسه بعدی با جزئیات،
255
00:10:36,320 –> 00:10:37,839
درست
256
00:10:37,839 –> 00:10:39,440
و اوه یک چیز دیگر که می خواستم
257
00:10:39,440 –> 00:10:41,360
در اینجا بگویم این بود که
258
00:10:41,360 –> 00:10:44,720
در اینجا توضیحی را
259
00:10:44,720 –> 00:10:47,360
با رگرسیون به درستی ذکر کردم که چقدر
260
00:10:47,360 –> 00:10:49,120
تغییر در
261
00:10:49,120 –> 00:10:53,440
y می تواند با متغیر x توضیح دهد.
262
00:10:53,440 –> 00:10:56,480
بررسی کنید که چگونه در
263
00:10:56,480 –> 00:10:58,000
محور x و y چنین است،
264
00:10:58,000 –> 00:11:01,920
من در خط خطی رسم میکنم،
265
00:11:01,920 –> 00:11:06,560
بنابراین میخواهم مقداری را برای اوه پیشبینی
266
00:11:06,880 –> 00:11:09,279
267
00:11:09,279 –> 00:11:10,720
268
00:11:10,720 –> 00:11:15,760
کنم. – محور کاملاً راست است، بنابراین
269
00:11:15,760 –> 00:11:20,160
در مجموع مجموع مجموع مجذورها به این مجموع مجموع مربع گفته
270
00:11:20,160 –> 00:11:22,720
می شود. es
271
00:11:22,720 –> 00:11:24,000
در مجموع
272
00:11:24,000 –> 00:11:26,800
مجموع مربعات رگرسیون من چقدر می
273
00:11:26,800 –> 00:11:29,200
تواند توضیح دهد
274
00:11:29,200 –> 00:11:32,240
متأسفانه این رگرسیون می آید
275
00:11:32,240 –> 00:11:35,680
ما آن را به عنوان مجموع رگرسیون مربع
276
00:11:35,680 –> 00:11:39,360
277
00:11:39,360 –> 00:11:42,000
ها می نامیم و واریانس غیر قابل توضیح من چقدر است.
278
00:11:42,000 –> 00:11:42,800
279
00:11:42,800 –> 00:11:44,480
در
280
00:11:44,480 –> 00:11:46,959
رگرسیون کل مجموع مجذورات
281
00:11:46,959 –> 00:11:50,639
مجذور خطا را به عنوان خطای مجموع مربعات خطا می نامیم
282
00:11:50,639 –> 00:11:52,399
آه مجموع مربعات
283
00:11:52,399 –> 00:11:54,399
کامل هستند، خطا چیزی نیست جز
284
00:11:54,399 –> 00:11:55,600
مجموع مجذور خطا
285
00:11:55,600 –> 00:11:57,600
مجموع مربع بله مجموع مربع
286
00:11:57,600 –> 00:11:58,720
خطا صحیح است بنابراین
287
00:11:58,720 –> 00:12:01,279
در مجموع مجموع مربعات اشتباه است. با مربع خطای
288
00:12:01,279 –> 00:12:03,440
رگرسیون من چقدر می تواند توضیح دهد
289
00:12:03,440 –> 00:12:06,639
که
290
00:12:06,639 –> 00:12:09,360
رگرسیون uh من قادر به توضیح نیست، بنابراین من به
291
00:12:09,360 –> 00:12:10,560
صورت بصری در اکسل به شما نشان خواهم داد
292
00:12:10,560 –> 00:12:13,360
همچنین این رگرسیون uh
293
00:12:13,360 –> 00:12:13,760
چگونه است و چقدر
294
00:12:13,760 –> 00:12:15,120
رگرسیون توضیح می دهد که چقدر
295
00:12:15,120 –> 00:12:17,600
رگرسیون توضیح دهنده
296
00:12:17,600 –> 00:12:19,519
درست نیست رگرسیون چیزی نیست جز
297
00:12:19,519 –> 00:12:21,200
متغیرهای مستقل.
298
00:12:21,200 –> 00:12:22,079
299
00:12:22,079 –> 00:12:24,240
300
00:12:24,240 –> 00:12:26,639
301
00:12:26,639 –> 00:12:29,279
302
00:12:29,279 –> 00:12:30,639
در جلسه است،
303
00:12:30,639 –> 00:12:32,399
شما درک بسیار روشنی
304
00:12:32,399 –> 00:12:34,480
در مورد تابع رگرسیون خواهید داشت،
305
00:12:34,480 –> 00:12:38,959
بنابراین در رگرسیون خطی ساده، بنابراین
306
00:12:38,959 –> 00:12:41,760
ah در اینجا y برابر است با b هیچ به اضافه b1
307
00:12:41,760 –> 00:12:42,800
x1 که آنها ذکر کردند،
308
00:12:42,800 –> 00:12:44,720
اما می توانید آن را به عنوان y cap برابر با
309
00:12:44,720 –> 00:12:47,200
b روی v هیچ به علاوه قرار دهید. b1 x1
310
00:12:47,200 –> 00:12:49,200
در رگرسیون خطی ساده،
311
00:12:49,200 –> 00:12:51,519
یعنی زمانی که اگر بیش از
312
00:12:51,519 –> 00:12:54,560
یک متغیر درست باشد، نمیتوانیم آن را
313
00:12:54,560 –> 00:12:56,000
در دو xs توضیح دهیم،
314
00:12:56,000 –> 00:12:58,240
بنابراین یک برنامه کاربردی صنعتی
315
00:12:58,240 –> 00:12:59,760
داریم، دو برنامه صنعتی
316
00:12:59,760 –> 00:13:02,160
داریم، یکی آن را میبینیم و بعد از
317
00:13:02,160 –> 00:13:03,440
آن به یک مطالعه موردی
318
00:13:03,440 –> 00:13:05,680
و سپس ما فقط یک کاربرد صنعتی دیگر را بررسی
319
00:13:05,680 –> 00:13:06,720
320
00:13:06,720 –> 00:13:08,240
خواهیم کرد و سپس مطالعه موردی دوم را حل خواهیم کرد،
321
00:13:08,240 –> 00:13:09,920
بنابراین مطمئن خواهم شد که
322
00:13:09,920 –> 00:13:13,279
یکی توضیح داده شده است، اوه ما 30 متغیر داریم
323
00:13:13,279 –> 00:13:15,600
، حداقل من 10 متغیر را انتخاب می کنم و آنها این کار را انجام
324
00:13:15,600 –> 00:13:17,120
می دهند. سعی کنید آن را به طور عالی حل کنید در
325
00:13:17,120 –> 00:13:18,000
واقع
326
00:13:18,000 –> 00:13:19,760
بسیار خوب می تواند کسی پیشرو باشد و
327
00:13:19,760 –> 00:13:21,760
اوه این سوال
328
00:13:21,760 –> 00:13:25,680
را مطالعه کنید مطالعه موردی چگونه کسی لطفا
329
00:13:25,680 –> 00:13:27,839
کاربرد صنعت vijay رگرسیون خطی
330
00:13:27,839 –> 00:13:29,839
در تجزیه و تحلیل ورزشی در تجزیه و تحلیل
331
00:13:29,839 –> 00:13:32,560
ورزشی یک رشته پررونق است
332
00:13:32,560 –> 00:13:33,440
افتخارات
333
00:13:33,440 –> 00:13:36,240
مربیان و طرفداران با استفاده از
334
00:13:36,240 –> 00:13:37,600
معیارها و مدلهای آماری
335
00:13:37,600 –> 00:13:40,240
انواع مطالعه برای
336
00:13:40,240 –> 00:13:42,720
مطالعه عملکرد بازیکنان و تیمها،
337
00:13:42,720 –> 00:13:46,959
بیلی که مدیر اوکلند
338
00:13:46,959 –> 00:13:50,560
است، با پیتر براون، دختر جوانی که
339
00:13:50,560 –> 00:13:52,000
فارغالتحصیل اقتصاد است،
340
00:13:52,000 –> 00:13:54,399
با ایدههای بنیادی در مورد چگونگی ارزیابی
341
00:13:54,399 –> 00:13:56,160
ارزشهای بازیکنان
342
00:13:56,160 –> 00:13:58,160
به جای تکیه بر انتخابکنندگان ملاقات کرده است.
343
00:13:58,160 –> 00:14:00,000
344
00:14:00,000 –> 00:14:03,199
برند تجربه و شهود از رگرسیون خطی استفاده میکند و
345
00:14:03,199 –> 00:14:04,399
بازیکنان را بر
346
00:14:04,399 –> 00:14:07,680
اساس درصد پایه خودشان انتخاب میکند، در حالی که ضعفهای درکشدهشان را نادیده میگیرد، برندون
347
00:14:07,680 –> 00:14:09,600
348
00:14:09,600 –> 00:14:12,880
b از این
349
00:14:12,880 –> 00:14:17,600
روش فلزی برای استخدام بازیکنان
350
00:14:17,600 –> 00:14:20,079
کمارزششده استفاده میکند، با یک سوم بودجه که طرح بودجهای که
351
00:14:20,079 –> 00:14:20,959
352
00:14:20,959 –> 00:14:23,040
با بالاترین تیمهای پیشپرداخت انجام شده است،
353
00:14:23,040 –> 00:14:24,480
354
00:14:24,480 –> 00:14:26,240
انجام میشود. تکامل جریان
355
00:14:26,240 –> 00:14:28,399
جدید تجزیه و تحلیل که به عنوان subarumatics شناخته می شود،
356
00:14:28,399 –> 00:14:32,959
بنابراین امیدوارم اگر کسی
357
00:14:32,959 –> 00:14:35,360
فیلم پول
358
00:14:35,360 –> 00:14:37,839
را تماشا کرده باشد، کسی توپ پول ضعیف را تماشا کرده است،
359
00:14:37,839 –> 00:14:39,199
بله،
360
00:14:39,199 –> 00:14:42,399
بنابراین فقط از آن گرفته شده است، بنابراین اگر
361
00:14:42,399 –> 00:14:43,440
شما درست
362
00:14:43,440 –> 00:14:47,360
می دانستید، اصطلاح خروج حومه شهر شکل می گرفت.
363
00:14:47,360 –> 00:14:50,399
فقط بعد از این
364
00:14:50,399 –> 00:14:53,120
روش انتخاب بازیکنان درست بر اساس درصد پایه،
365
00:14:53,120 –> 00:14:54,959
366
00:14:54,959 –> 00:14:56,639
درست است، بنابراین اگر داشتید فیلمی را تماشا کرد
367
00:14:56,639 –> 00:14:58,800
که میدانید اوه آنها بودجه بسیار کمی
368
00:14:58,800 –> 00:15:01,040
برای استخدام تعداد بازیکنان داشتند،
369
00:15:01,040 –> 00:15:04,800
بنابراین پس از یک رکود بزرگ در
370
00:15:04,800 –> 00:15:08,480
اوکلند، تیم دقیقاً
371
00:15:08,480 –> 00:15:12,560
میخواست در مسابقات پیروز شود، بنابراین از
372
00:15:12,560 –> 00:15:14,959
تکنیک متفاوتی استفاده کرد تا حتی
373
00:15:14,959 –> 00:15:15,760
بازیهای خاصی
374
00:15:15,760 –> 00:15:18,720
آسیب ببینند و بازیکنان پایه برای آنها بسیار کمتر
375
00:15:18,720 –> 00:15:19,360
بودند،
376
00:15:19,360 –> 00:15:22,079
بنابراین او با استفاده از تکنیک ها و ایده های
377
00:15:22,079 –> 00:15:23,120
خود بازیکنانی را انتخاب کرد که
378
00:15:23,120 –> 00:15:26,800
قیمت بسیار کمتری داشتند و سپس آنها هنوز هم در آنجا
379
00:15:26,800 –> 00:15:27,680
بودند که توانستند
380
00:15:27,680 –> 00:15:31,199
در مجموع با آنها رقابت
381
00:15:31,199 –> 00:15:33,519
کنند تا شما بتوانید به شما برسید.
382
00:15:33,519 –> 00:15:34,399
383
00:15:34,399 –> 00:15:35,839
subbermetics است من
384
00:15:35,839 –> 00:15:38,399
مرجع ارائه کرده ام، بنابراین
385
00:15:38,399 –> 00:15:39,839
اگر فیلم را تماشا نکرده اید،
386
00:15:39,839 –> 00:15:41,680
توپ فلیپ پول چیست، بنابراین بسیار خوب است،
387
00:15:41,680 –> 00:15:44,320
بنابراین چگونه آنها بازیکنان را استخدام کرده اند،
388
00:15:44,320 –> 00:15:47,759
بنابراین آنها از
389
00:15:47,759 –> 00:15:48,079
390
00:15:48,079 –> 00:15:50,079
اساس این obp استفاده نکرده اند. رگرسیون خطی
391
00:15:50,079 –> 00:15:52,639
همان چیزی است که آنها
392
00:15:52,639 –> 00:15:55,839
برای انتخاب تعداد بازیکنان استفاده کرده اند، اجازه دهید من
393
00:15:55,839 –> 00:15:57,360
به مطالعه موردی بروم که اکنون می خواستم در
394
00:15:57,360 –> 00:15:58,720
مورد آن بحث کنم
395
00:15:58,720 –> 00:16:00,240
، پیش بینی های حقوق در یک
396
00:16:00,240 –> 00:16:02,160
سازمان حقوق یک کارمند
397
00:16:02,160 –> 00:16:04,720
به متفاوتی بستگی دارد. عوامل
398
00:16:04,720 –> 00:16:05,279
درست
399
00:16:05,279 –> 00:16:08,880
بر اساس ساخت و مدل داده داده شده
400
00:16:08,880 –> 00:16:10,880
با استفاده از رگرسیون خطی ساده برای
401
00:16:10,880 –> 00:16:13,040
پیش بینی حقوق یک کارمند
402
00:16:13,040 –> 00:16:15,360
بر اساس تجربه
403
00:16:15,360 –> 00:16:16,959
کارفرما،
404
00:16:16,959 –> 00:16:19,759
اکنون به سراغ این می روم که آن را حل کرده
405
00:16:19,759 –> 00:16:21,440
ام و آن را جدید حل
406
00:16:21,440 –> 00:16:24,560
می کنم تا سال ها فرصت داشته باشیم تجربه و
407
00:16:24,560 –> 00:16:26,480
408
00:16:26,480 –> 00:16:29,440
حقوق را در برگه اکسل جدید قرار می دهم تا
409
00:16:29,440 –> 00:16:31,680
سال ها سابقه
410
00:16:31,680 –> 00:16:34,399
و حقوق به طوری که با افزایش سنوات سابقه
411
00:16:34,399 –> 00:16:35,040
412
00:16:35,040 –> 00:16:38,639
حقوق نیز افزایش می یابد
413
00:16:38,720 –> 00:16:41,920
آیا درست است یا خیر بنابراین این یک
414
00:16:41,920 –> 00:16:43,360
متغیر خطی است
415
00:16:43,360 –> 00:16:45,519
زیرا حقوق و دستمزد سنوات افزایش می یابد.
416
00:16:45,519 –> 00:16:47,120
یک روز تجربه کن چون سالها
417
00:16:47,120 –> 00:16:48,320
تجربه
418
00:16:48,320 –> 00:16:51,519
حقوق فرد را افزایش می دهد
419
00:16:51,519 –> 00:16:54,320
الان هم می خواهم یک نفر را فرد جدید پیش بینی کنم
420
00:16:54,320 –> 00:16:56,639
421
00:16:56,639 –> 00:16:59,759
یا بگویم یک ساعت در شرکت یک نفر
422
00:16:59,759 –> 00:17:01,680
می آید با پنج سال سابقه
423
00:17:01,680 –> 00:17:05,039
و پوست درخواستی و حقوق یک لک
424
00:17:05,039 –> 00:17:09,919
چیزی غیرعادی درست است، بنابراین شما باید مقدار مناسبی را
425
00:17:09,919 –> 00:17:12,559
پیشبینی کنید که حقوق برنامه چقدر است که
426
00:17:12,559 –> 00:17:15,760
باید به شخص
427
00:17:15,760 –> 00:17:17,839
داده شود، بر اساس سالها تجربه
428
00:17:17,839 –> 00:17:19,599
و دستمزد است،
429
00:17:19,599 –> 00:17:23,039
بنابراین اگر میتوانید طرحریزی کنید، اجازه دهید من فقط سعی کنم
430
00:17:23,039 –> 00:17:24,640
در اینجا
431
00:17:24,640 –> 00:17:27,280
به عنوان تجربه طراحی کنم راینس حقوق را
432
00:17:27,280 –> 00:17:29,039
افزایش می دهد
433
00:17:29,039 –> 00:17:31,840
بله حقوق و دستمزد افزایش می یابد بنابراین
434
00:17:31,840 –> 00:17:33,440
اگر فردی که با پنج سال سابقه کار می آید
435
00:17:33,440 –> 00:17:34,480
436
00:17:34,480 –> 00:17:36,720
بنابراین می توانید بدانید که می توانید برای
437
00:17:36,720 –> 00:17:37,520
پنج
438
00:17:37,520 –> 00:17:39,360
سال ارزش درست را ترسیم کنید می تواند
439
00:17:39,360 –> 00:17:41,039
چیزی حدود پنجاه و پنج هزار
440
00:17:41,039 –> 00:17:43,280
یا شصت هزار بپرسد. پرسیدن غیرعادی
441
00:17:43,280 –> 00:17:44,400
یک کمبود
442
00:17:44,400 –> 00:17:47,600
یا یک امتیاز دو لک درست، به این
443
00:17:47,600 –> 00:17:49,919
ترتیب ما میتوانیم پیشبینی کنیم که کجا
444
00:17:49,919 –> 00:17:52,720
میخواهیم پیشبینی کنیم، بعداً درست میخواهیم
445
00:17:52,720 –> 00:17:53,520
446
00:17:53,520 –> 00:17:56,080
حقوق و دستمزد درست
447
00:17:56,080 –> 00:17:58,240
448
00:17:58,240 –> 00:18:02,640
را
449
00:18:02,640 –> 00:18:04,799
پیشبینی کنیم. سالها بر اساس سالها
450
00:18:04,799 –> 00:18:05,679
451
00:18:05,679 –> 00:18:07,840
تجربه این درست است جامد اکنون می خواهم
452
00:18:07,840 –> 00:18:08,799
یک اصطلاح جدید معرفی کنم
453
00:18:08,799 –> 00:18:11,919
یک اصطلاح جدید نه به
454
00:18:11,919 –> 00:18:13,039
عنوان یک اصطلاح جدید به آن نمی
455
00:18:13,039 –> 00:18:16,880
گویم اکنون دامنه
456
00:18:16,880 –> 00:18:18,080
این رگرسیونی که می
457
00:18:18,080 –> 00:18:20,640
خواهیم بسازیم چیست؟ دارای یک سال
458
00:18:20,640 –> 00:18:23,440
تجربه کارمندان بین 1.1 سال
459
00:18:23,440 –> 00:18:26,559
تا 10.5 سال، بنابراین برای
460
00:18:26,559 –> 00:18:29,200
هر کارمندی که بین این تجربه به شرکت می آید
461
00:18:29,200 –> 00:18:29,840
462
00:18:29,840 –> 00:18:31,760
فقط بین این
463
00:18:31,760 –> 00:18:34,320
تجربه می توانم درست را پیش بینی کنم.
464
00:18:34,320 –> 00:18:37,840
ساکت کردن حقوق پیش بینی شده
465
00:18:37,840 –> 00:18:40,080
اگر شخصی با 20 سال
466
00:18:40,080 –> 00:18:42,799
تجربه بیاید مدل من شکست خورده است،
467
00:18:42,799 –> 00:18:45,520
ما شاهد کاهش قربانیان هستیم،
468
00:18:45,520 –> 00:18:46,320
بنابراین اگر
469
00:18:46,320 –> 00:18:48,240
کسی از پس زمینه mba باشد، می
470
00:18:48,240 –> 00:18:50,080
دانید که
471
00:18:50,080 –> 00:18:52,880
بازدهی کاهش می یابد، بنابراین اگر هزار روپیه خرج کنم در بازاریابی وجود دارد
472
00:18:52,880 –> 00:18:53,760
473
00:18:53,760 –> 00:18:55,440
.
474
00:18:55,440 –> 00:18:56,799
475
00:18:56,799 –> 00:18:58,320
اگر دو هزار روپیه خرج کنم میتوانم دوباره دو درصد افزایش فروش داشته
476
00:18:58,320 –> 00:19:00,720
باشم، یعنی
477
00:19:00,720 –> 00:19:01,760
478
00:19:01,760 –> 00:19:03,760
اگر من به
479
00:19:03,760 –> 00:19:05,520
افزایش هزار و هزار ارزش برای
480
00:19:05,520 –> 00:19:06,400
بازاریابی ادامه
481
00:19:06,400 –> 00:19:09,200
دهم، فروش من دوباره چهار درصد افزایش مییابد. درست افزایش پیدا کنید،
482
00:19:09,200 –> 00:19:10,640
483
00:19:10,640 –> 00:19:13,440
484
00:19:13,440 –> 00:19:13,840
485
00:19:13,840 –> 00:19:16,240
اگر من 5000 روپیه خرج کنم، سود کمتری بیش از یک نقطه
486
00:19:16,240 –> 00:19:17,679
وجود ندارد، 10 درصد افزایش
487
00:19:17,679 –> 00:19:19,039
در فروش وجود نخواهد داشت
488
00:19:19,039 –> 00:19:21,039
که ما آن را به عنوان نقطه کاهش اعتبار می نامیم،
489
00:19:21,039 –> 00:19:22,480
مشابه
490
00:19:22,480 –> 00:19:24,640
با استفاده از همان مفهوم برای ما.
491
00:19:24,640 –> 00:19:25,520
رگرسیون
492
00:19:25,520 –> 00:19:29,679
مدل من میتواند
493
00:19:29,679 –> 00:19:32,640
فرد جدیدی را پیشبینی کند که فقط با
494
00:19:32,640 –> 00:19:33,600
495
00:19:33,600 –> 00:19:37,360
تجربه 1.1 تا 10.5 سال تجربه داشته باشد،
496
00:19:37,360 –> 00:19:39,679
اگر کسی بین
497
00:19:39,679 –> 00:19:40,480
498
00:19:40,480 –> 00:19:43,360
8.5 نباشد اگر شخصی با
499
00:19:43,360 –> 00:19:44,880
تجربه 8.5
500
00:19:44,880 –> 00:19:46,799
من می توانم پیش بینی کنم حقوق مناسب چقدر است
501
00:19:46,799 –> 00:19:48,480
502
00:19:48,480 –> 00:19:51,039
اگر
503
00:19:51,039 –> 00:19:52,960
فردی با 20 سال تجربه بیاید می توانم پیش بینی
504
00:19:52,960 –> 00:19:56,480
کنم که مدل من با 25 سال
505
00:19:56,480 –> 00:19:59,679
تجربه شکست می خورد.
506
00:19:59,760 –> 00:20:03,039
507
00:20:03,039 –> 00:20:04,000
508
00:20:04,000 –> 00:20:06,080
اگر یک نقطه داده جدید
509
00:20:06,080 –> 00:20:08,960
بیاید، نمی توانم
510
00:20:08,960 –> 00:20:12,400
حقوق مناسب را برای شخص پیش بینی کنم، روشن است
511
00:20:12,400 –> 00:20:14,640
بچه ها
512
00:20:16,080 –> 00:20:19,280
، آیا در اینجا شک دارید،
513
00:20:19,280 –> 00:20:21,600
بنابراین ما فقط
514
00:20:21,600 –> 00:20:22,720
بین
515
00:20:22,720 –> 00:20:24,799
محدوده ای که من گرفته ام فاصله اطمینان نداریم، می توانم
516
00:20:24,799 –> 00:20:27,280
پیشبینی را کاملاً
517
00:20:27,280 –> 00:20:30,159
درست انجام دهید، بنابراین انجام آن در اکسل بسیار ساده است.
518
00:20:30,159 –> 00:20:30,799
519
00:20:30,799 –> 00:20:33,679
من این دو متغیر را انتخاب میکنم. به
520
00:20:33,679 –> 00:20:34,000
521
00:20:34,000 –> 00:20:37,600
تجزیه و تحلیل دادههای رگرسیون
522
00:20:37,600 –> 00:20:41,120
v1 میروم، بنابراین برای
523
00:20:41,120 –> 00:20:43,360
منظور نمایش، اجازه دهید
524
00:20:43,360 –> 00:20:44,880
همه این موارد را حذف کنم، زیرا اگر شروع به
525
00:20:44,880 –> 00:20:46,320
نوشتن فرم از دست دادن
526
00:20:46,320 –> 00:20:48,960
کنم، اینطور خواهد شد. بسیار دشوار است، بنابراین تجزیه و تحلیل داده ها بسیار دشوار است،
527
00:20:48,960 –> 00:20:50,159
528
00:20:50,159 –> 00:20:53,919
بنابراین من فقط آن را حذف می کنم،
529
00:20:53,919 –> 00:20:56,080
این یکی را امتحان کردم، متغیر y
530
00:20:56,080 –> 00:20:58,320
حقوق
531
00:20:58,320 –> 00:21:01,200
و x سال تجربه است و
532
00:21:01,200 –> 00:21:03,520
من می خواهم برچسب ها را اینجا انتخاب
533
00:21:03,520 –> 00:21:06,880
کنم و می خواهم برای نشان دادن مقدار
534
00:21:06,880 –> 00:21:11,840
به روشی بسیار ساده می توانم از
535
00:21:11,840 –> 00:21:14,000
رگرسیون گزینه در اکسل استفاده کنم و می توانم
536
00:21:14,000 –> 00:21:16,000
با مقادیر
537
00:21:16,000 –> 00:21:17,679
r مربع مقادیر r تنظیم شده به دست بیاورم
538
00:21:17,679 –> 00:21:20,640
بنابراین خطای استاندارد درست است بنابراین
539
00:21:20,640 –> 00:21:22,240
مجذور r مجذور کل تنظیم شده چیزی در حدود است.
540
00:21:22,240 –> 00:21:23,280
90 درصد
541
00:21:23,280 –> 00:21:25,039
درست در اینجا فقط برای نمایش از آنجایی
542
00:21:25,039 –> 00:21:27,200
که من آن را 69 درصد نشان دادم،
543
00:21:27,200 –> 00:21:30,480
اکنون خواهیم دید که هر یک از متغیرها
544
00:21:30,480 –> 00:21:33,760
چگونه آن را با استفاده از فرمول حل
545
00:21:33,760 –> 00:21:36,480
کنیم بسیار ساده است، اما باید بدانید که
546
00:21:36,480 –> 00:21:36,799
یک
547
00:21:36,799 –> 00:21:39,760
r مربع چگونه مشتق می شود که یک مربع r تنظیم شده چگونه
548
00:21:39,760 –> 00:21:41,520
است. مشتق شده
549
00:21:41,520 –> 00:21:44,960
و اوه اوه چگونه یک خطای
550
00:21:44,960 –> 00:21:46,159
استاندارد به درستی مشتق می شود
551
00:21:46,159 –> 00:21:49,360
چگونه b not b1 درست مشتق می شود
552
00:21:49,360 –> 00:21:53,120
بنابراین شما به من مقدار
553
00:21:53,120 –> 00:21:56,159
y cap y
554
00:21:56,159 –> 00:21:59,360
bar برابر با b هیچ است که b هیچ است
555
00:21:59,360 –> 00:22:02,559
به اضافه b 1 x 1
556
00:22:02,559 –> 00:22:04,720
این فرمول است شما الان به من داده
557
00:22:04,720 –> 00:22:07,840
اید پیش بینی من بین این است که مثل
558
00:22:07,840 –> 00:22:10,799
یک فرد با 2.5 سال
559
00:22:10,799 –> 00:22:12,080
سابقه این دستمزد چقدر است
560
00:22:12,080 –> 00:22:15,280
این هدف من است اجازه
561
00:22:15,280 –> 00:22:18,080
دهید هدف را در
562
00:22:18,080 –> 00:22:19,200
ابتدای جلسه
563
00:22:19,200 –> 00:22:21,039
شروع حل این سوال
564
00:22:21,039 –> 00:22:22,480
برای دو سال پنج سال قرار دهم.
565
00:22:22,480 –> 00:22:24,559
با توجه به تجربه، حقوق مناسب چقدر است،
566
00:22:24,559 –> 00:22:26,240
حتی اگر امتیاز داده ها
567
00:22:26,240 –> 00:22:27,200
بسیار کمتر باشد، این
568
00:22:27,200 –> 00:22:29,440
مدل یک مدل کامل نیست، اما هنوز هم
569
00:22:29,440 –> 00:22:31,600
فقط برای توضیح هدف، من
570
00:22:31,600 –> 00:22:34,080
از داده های واقعی استفاده کرده ام، حدود 30
571
00:22:34,080 –> 00:22:34,880
نقطه داده دارم
572
00:22:34,880 –> 00:22:37,280
که برای توضیح درست کافی است.
573
00:22:37,280 –> 00:22:38,799
574
00:22:38,799 –> 00:22:40,880
من آن را برای تمام 30 امتیاز
575
00:22:40,880 –> 00:22:42,640
در حال حاضر حل کرده ام،
576
00:22:42,640 –> 00:22:44,880
پس اتفاقی که می افتد این است که باید بروم
577
00:22:44,880 –> 00:22:47,039
پایین، باید به شما نشان دهم این چیست و
578
00:22:47,039 –> 00:22:49,120
چگونه انجامش دهید، بنابراین من فقط 10 امتیاز را می گیرم این
579
00:22:49,120 –> 00:22:51,039
است که بچه ها،
580
00:22:51,039 –> 00:22:54,000
خیلی خوب است. و یک هدف دیگر در اینجا
581
00:22:54,000 –> 00:22:55,039
این
582
00:22:55,039 –> 00:22:58,559
است که یاد بگیریم msc rmse
583
00:22:58,559 –> 00:23:02,159
mape چیست، مانند
584
00:23:02,159 –> 00:23:04,720
مقدار حساسیت ما، مقدار ویژگی
585
00:23:04,720 –> 00:23:05,919
586
00:23:05,919 –> 00:23:08,960
و دقت، دقت
587
00:23:08,960 –> 00:23:12,240
در مسئله طبقه بندی را به یاد بیاوریم، اکنون ما شروع به
588
00:23:12,240 –> 00:23:14,480
حل مشکل رگرسیون یک
589
00:23:14,480 –> 00:23:15,679
مقدار پیوسته می کنیم،
590
00:23:15,679 –> 00:23:17,360
بنابراین برای مقدار پیوسته نمی
591
00:23:17,360 –> 00:23:19,760
توانید مقادیر را در آن قرار دهید. این سردرگمی است،
592
00:23:19,760 –> 00:23:22,720
بنابراین شما باید از ماتریسی مانند msc
593
00:23:22,720 –> 00:23:23,520
594
00:23:23,520 –> 00:23:26,640
rmse mep استفاده کنید، درست است من به شما خیلی گفتم،
595
00:23:26,640 –> 00:23:29,600
یعنی قبل از زمان، ما آن را حل
596
00:23:29,600 –> 00:23:30,960
خواهیم کرد، وقتی به تجزیه و تحلیل پیش بینی رسیدیم، به
597
00:23:30,960 –> 00:23:31,840
شما
598
00:23:31,840 –> 00:23:35,200
توضیح می دهم که msc rm چیست se و mvp بنابراین
599
00:23:35,200 –> 00:23:37,200
فقط اگر آن را با استفاده از فرمول حل کنم، متوجه
600
00:23:37,200 –> 00:23:38,880
601
00:23:38,880 –> 00:23:42,559
خواهید شد که میانگین مربعات mse چیست، بنابراین
602
00:23:42,559 –> 00:23:46,880
اجازه دهید من فقط چند سلول را در اینجا اضافه
603
00:23:46,880 –> 00:23:51,840
کنم، من یک مقدار متوسط
604
00:23:52,000 –> 00:23:55,360
تغیر x خود و سپس می
605
00:23:55,360 –> 00:23:59,760
نگین متغیر y را می
606
00:23:59,760 –> 00:24:02,400
گیرم. میانگین متغیر y اکنون می خواهم
607
00:24:02,400 –> 00:24:03,520
608
00:24:03,520 –> 00:24:06,960
y i منهای نوار y را پیش بینی کنم درست
609
00:24:06,960 –> 00:24:10,640
y من چیزی نیست اما این متغیر منهای
610
00:24:10,640 –> 00:24:13,919
y نوار چیزی نیست اما میانگین دادن
611
00:24:13,919 –> 00:24:17,120
f4 f4 مانند قفل کردن متغیر است
612
00:24:17,120 –> 00:24:21,279
بنابراین من فقط فرمول را در
613
00:24:21,279 –> 00:24:22,159
تمام سلول ها کپی می
614
00:24:22,159 –> 00:24:24,320
کنم. چه اتفاقی می افتد که علائم منفی در
615
00:24:24,320 –> 00:24:26,320
اینجا برای غلبه بر علائم منفی وجود دارد،
616
00:24:26,320 –> 00:24:26,880
617
00:24:26,880 –> 00:24:29,600
من فقط مقدار مربع
618
00:24:29,600 –> 00:24:30,240
این
619
00:24:30,240 –> 00:24:33,679
y i منهای y میله را مشابه مشکل anova
620
00:24:33,679 –> 00:24:34,720
که حل کرده بودیم
621
00:24:34,720 –> 00:24:36,320
مشابه نحوه یافتن عدم تغییر و
622
00:24:36,320 –> 00:24:37,919
انحراف معیار را در نظر می گیرم، همه
623
00:24:37,919 –> 00:24:40,960
دوباره همان فرمول
624
00:24:40,960 –> 00:24:43,279
درست است من فقط مقدار مربع
625
00:24:43,279 –> 00:24:45,039
همه متغیرهایی را
626
00:24:45,039 –> 00:24:49,360
که اینجا پیدا کردم y یک نوار منهای y
627
00:24:49,360 –> 00:24:53,279
درست میگیرم، اجازه دهید فقط یک کادر را در اینجا قرار دهم،
628
00:24:53,279 –> 00:24:58,240
بعد x من منهای x نوار
629
00:24:58,559 –> 00:25:02,640
x من منهای x نوار و
630
00:25:02,799 –> 00:25:05,840
x من منهای x نوار کل مربع را
631
00:25:05,840 –> 00:25:08,720
به o علامت منفی را دوباره درست غلبه
632
00:25:08,720 –> 00:25:09,200
کنید
633
00:25:09,200 –> 00:25:13,120
x i منهای x نوار
634
00:25:13,120 –> 00:25:16,159
من فقط آن را درست می
635
00:25:17,679 –> 00:25:20,159
کنم و مربع همه این
636
00:25:20,159 –> 00:25:22,559
مقادیر را
637
00:25:25,039 –> 00:25:29,760
درست می گیرم بنابراین از همان
638
00:25:29,760 –> 00:25:33,200
کادر در اینجا استفاده می کنم اکنون می خواهم
639
00:25:33,200 –> 00:25:35,679
x i
640
00:25:37,039 –> 00:25:40,320
x i منهای
641
00:25:40,320 –> 00:25:43,919
x نوار را در
642
00:25:43,919 –> 00:25:48,640
نوار y i منهای y پیدا کنم
643
00:25:48,640 –> 00:25:51,760
درست است بنابراین x a منهای x میله ما
644
00:25:51,760 –> 00:25:52,240
آن را
645
00:25:52,240 –> 00:25:58,320
به y یک نوار منهای y حل کردیم، بنابراین من یک مقدار
646
00:25:59,360 –> 00:26:02,480
درست دارم، بنابراین میانگین همه
647
00:26:02,480 –> 00:26:05,200
این مقادیر
648
00:26:06,720 –> 00:26:09,600
و میانگین همه این مقادیر را
649
00:26:09,600 –> 00:26:11,679
می گیرم بنابراین ممکن است شما را گیج کند، فقط به شما توضیح می دهم
650
00:26:11,679 –> 00:26:13,600
نحوه حل مجدد این مشکل
651
00:26:13,600 –> 00:26:15,919
را توضیح دهید
652
00:26:19,760 –> 00:26:22,799
و اکنون هدف ما این
653
00:26:22,799 –> 00:26:26,240
است که آنچه b1 است را حل کنیم چه
654
00:26:26,240 –> 00:26:28,720
b
655
00:26:29,279 –> 00:26:32,720
درست نیست اگر من بدانم چه چیزی b هیچ است و b1
656
00:26:32,720 –> 00:26:36,240
من یک مقدار y در اینجا
657
00:26:36,240 –> 00:26:39,919
دارم گفتم اگر می دانم باید مقدار y را اینجا پیدا
658
00:26:39,919 –> 00:26:43,520
کنم b هیچ و b یک
659
00:26:43,520 –> 00:26:46,640
من می توانم مقادیر را در اینجا قرار
660
00:26:46,640 –> 00:26:49,520
دهم و می توانم نوار y خود را پیدا کنم که مقدار y
661
00:26:49,520 –> 00:26:50,720
662
00:26:50,720 –> 00:26:55,120
برای سال ها تجربه 2.5
663
00:26:55,200 –> 00:26:56,880
چیست این است که بچه ها درست است آیا
664
00:26:56,880 –> 00:26:59,919
تا اینجا اینجا ابهامی وجود دارد
665
00:27:01,360 –> 00:27:04,240
بنابراین هدف من یافتن b1 و b است.
666
00:27:04,240 –> 00:27:04,960
667
00:27:04,960 –> 00:27:07,600
درست نیست اگر میتوانستم b one و b را پیدا
668
00:27:07,600 –> 00:27:09,520
کنم، میتوانستم در این فرمول
669
00:27:09,520 –> 00:27:11,520
تلقی کنم و ممکن است بیاید یک مقدار پیشبینیشده چیست
670
00:27:11,520 –> 00:27:13,120
حالا
671
00:27:13,120 –> 00:27:16,799
من یک مقدار دارم b چگونه میتوان b را پیدا کرد.
672
00:27:16,799 –> 00:27:20,320
673
00:27:21,600 –> 00:27:25,039
674
00:27:25,039 –> 00:27:28,480
675
00:27:28,480 –> 00:27:31,760
676
00:27:31,760 –> 00:27:35,360
677
00:27:35,360 –> 00:27:38,720
بنابراین من این فرمول y را در اینجا دارم،
678
00:27:38,720 –> 00:27:43,440
سپس b هیچ با نوار y
679
00:27:43,440 –> 00:27:49,039
منهای b 1 x 1 داده می شود.
680
00:27:49,039 –> 00:27:52,320
خیلی خوب است، بنابراین من می خواهم هیچ b را
681
00:27:52,320 –> 00:27:52,960
در اینجا پیدا کنم
682
00:27:52,960 –> 00:27:57,360
برابر است با مقدار نوار y در اینجا
683
00:27:58,320 –> 00:28:02,240
من کل را می گیرم. میانگین
684
00:28:02,240 –> 00:28:05,120
منهای b در اینجا
685
00:28:07,440 –> 00:28:10,799
b1 به x1 تبدیل میشود، بنابراین
686
00:28:10,799 –> 00:28:13,120
من دو متغیر مهم
687
00:28:13,120 –> 00:28:14,000
b1 و
688
00:28:14,000 –> 00:28:17,919
b را پیدا کردم، بنابراین اگر b 1
689
00:28:17,919 –> 00:28:18,720
و v چیزی را پیدا کرده
690
00:28:18,720 –> 00:28:24,159
بودم، میتوانستم برای متغیر جدید
691
00:28:24,159 –> 00:28:27,600
برای متغیر
692
00:28:28,000 –> 00:28:31,600
2.5 b به اضافه
693
00:28:31,600 –> 00:28:34,080
b آن را نسبت دهم. 1
694
00:28:36,000 –> 00:28:39,919
به 1 مقداری است
695
00:28:39,919 –> 00:28:43,360
که حقوق پیش بینی شده او حدوداً
696
00:28:43,360 –> 00:28:44,880
پنجاه و یک هزار و پانصد و
697
00:28:44,880 –> 00:28:47,279
نود است.
698
00:28:47,679 –> 00:28:51,279
بچه ها من اینجا سکوت زیادی می بینم
699
00:28:51,279 –> 00:28:53,120
پس آیا در اینجا شک دارید
700
00:28:53,120 –> 00:28:55,679
701
00:28:57,120 –> 00:29:00,320
یا ادامه دهم یا می خواهید فقط در این مورد دقیق باشید
702
00:29:00,320 –> 00:29:03,919
اوه python پس میشه یه بار دیگه توضیحش بدی
703
00:29:03,919 –> 00:29:05,279
704
00:29:05,279 –> 00:29:07,600
آره خیلی خب پس چطوری پیدا
705
00:29:07,600 –> 00:29:09,360
نکردم b1 یا اوه
706
00:29:09,360 –> 00:29:10,880
چی میخوای بازی نه نه فقط
707
00:29:10,880 –> 00:29:12,480
دوست دارم برای
708
00:29:12,480 –> 00:29:15,520
بعضی ها فقط خلاصه کردن
709
00:29:15,520 –> 00:29:16,320
همه چیز درست است،
710
00:29:16,320 –> 00:29:20,000
بله، بنابراین
711
00:29:20,000 –> 00:29:23,039
من y را یک نوار منهای y می گیرم کل
712
00:29:23,039 –> 00:29:23,840
مربع
713
00:29:23,840 –> 00:29:26,720
نوار y با مقدار متوسط داده می شود تا
714
00:29:26,720 –> 00:29:28,399
ر مقادیر منفی غلبه کن
715
00:29:28,399 –> 00:29:31,520
که مربع آن را گرفته ام. y ی
716
00:29:31,520 –> 00:29:32,399
نوار منهای y
717
00:29:32,399 –> 00:29:35,919
بنابراین من دوباره مقادیر x a منهای x نوار را دریافت می کنم
718
00:29:35,919 –> 00:29:36,480
719
00:29:36,480 –> 00:29:38,960
این نیز برای غلبه بر مقادیر منفی است.
720
00:29:38,960 –> 00:29:39,520
721
00:29:39,520 –> 00:29:42,640
من از فرمول x i منهای x نوار در اینجا استفاده می کنم
722
00:29:42,640 –> 00:29:45,200
، آن را به عنوان نوار x قرار می دهم،
723
00:29:45,200 –> 00:29:48,480
بنابراین x i منهای x نوار را به y
724
00:29:48,480 –> 00:29:49,440
منهای y می گذارم. نوار
725
00:29:49,440 –> 00:29:53,520
این برای پیدا کردن یک متغیر b1 استفاده می شود،
726
00:29:53,520 –> 00:29:57,039
بنابراین برای پیدا کردن b1 ضریب x1
727
00:29:57,039 –> 00:30:00,159
باید این مقدار را بر این مقدار تقسیم
728
00:30:00,159 –> 00:30:02,240
729
00:30:02,240 –> 00:30:05,279
کنید، بسیار خوب است،
730
00:30:05,360 –> 00:30:07,039
بنابراین زیاد
731
00:30:07,039 –> 00:30:08,799
پیچیده نشوید، ما از آن
732
00:30:08,799 –> 00:30:09,520
در زمان واقعی استفاده
733
00:30:09,520 –> 00:30:12,080
نمی کنیم. من می خواستم به شما نشان دهم که mse
734
00:30:12,080 –> 00:30:12,880
rmse و mep
735
00:30:12,880 –> 00:30:14,880
در راه چیست من خودم هدفی ایجاد کردم
736
00:30:14,880 –> 00:30:16,399
که می تواند یک
737
00:30:16,399 –> 00:30:18,799
مقدار پیش بینی شده برای سالهای
738
00:30:18,799 –> 00:30:20,799
تجربه باشد 2.5 چه حقوقی می تواند
739
00:30:20,799 –> 00:30:22,880
برای همان
740
00:30:22,880 –> 00:30:25,760
حالا هدف من یک هدف بیشتر باشد یا
741
00:30:25,760 –> 00:30:27,039
این هدف من
742
00:30:27,039 –> 00:30:29,120
آنچه را برای سالها تجربه حل کرده اند 2.5
743
00:30:29,120 –> 00:30:30,159
این چه چیزی است
744
00:30:30,159 –> 00:30:34,000
اکنون می خواهم بفهمم که mod من
745
00:30:34,000 –> 00:30:35,919
چقدر خوب است مدل من چقدر خوب است مدل من چقدر خوب
746
00:30:35,919 –> 00:30:38,240
است توسط msc
747
00:30:38,240 –> 00:30:41,600
rmse mape
748
00:30:41,600 –> 00:30:44,640
توضیح داده شده است.
749
00:30:44,640 –> 00:30:47,919
750
00:30:47,919 –> 00:30:50,080
751
00:30:50,080 –> 00:30:52,559
معادله اولیه y برابر است با b
752
00:30:52,559 –> 00:30:55,760
هیچ به اضافه b 1 به
753
00:30:55,760 –> 00:30:58,799
نوار x باید x میله باشد درست
754
00:30:58,799 –> 00:31:02,880
این یکی در اینجا من آه
755
00:31:02,880 –> 00:31:05,840
خوب
756
00:31:06,000 –> 00:31:08,880
این را دارم می توانیم آن را به عنوان v1 ستاره x مربع
757
00:31:08,880 –> 00:31:09,919
سمت راست
758
00:31:09,919 –> 00:31:14,880
v1 قرار دهیم زیرا نه
759
00:31:14,880 –> 00:31:18,080
نه نه این قرار است فقط x1 باشید
760
00:31:18,080 –> 00:31:21,120
چرا برای r ببینید
761
00:31:21,120 –> 00:31:24,720
نه این یکی نیست باید آن را به عنوان i
762
00:31:24,720 –> 00:31:27,840
ba و xa قرار دهم زیرا به شما می گویم چرا در
763
00:31:27,840 –> 00:31:29,919
پیش بینی y می خواهم ارزش y را پیش بینی کنم
764
00:31:29,919 –> 00:31:30,960
765
00:31:30,960 –> 00:31:34,480
این حق واقعی است این حقوق
766
00:31:34,480 –> 00:31:35,120
چیزی نیست اما
767
00:31:35,120 –> 00:31:38,399
y واقعی اکنون می خواهم
768
00:31:38,399 –> 00:31:40,640
y را در اینجا پیش بینی کنم چگونه می توانم پیش بینی کنم
769
00:31:40,640 –> 00:31:42,960
که چرا با استفاده از این فرمول
770
00:31:42,960 –> 00:31:46,960
b هیچ به اضافه b1
771
00:31:46,960 –> 00:31:50,880
در x1 استفاده می شود، بنابراین
772
00:31:50,880 –> 00:31:54,399
این واقعی است این پیش بینی شده است،
773
00:31:54,399 –> 00:31:58,720
بنابراین این برای همه رکوردهای اینجا صدق می کند،
774
00:31:58,720 –> 00:32:01,919
پس چگونه قرار دهم آن را به عنوان نوار x وارد کردید، بنابراین شما
775
00:32:01,919 –> 00:32:05,039
این را با محاسبه b
776
00:32:05,039 –> 00:32:10,000
0 خوب y نوار و نوار x وارد
777
00:32:10,480 –> 00:32:13,919
کردید، بنابراین نمی خواهید
778
00:32:13,919 –> 00:32:15,279
ضریب را ببینید.
779
00:32:15,279 –> 00:32:17,120
من هیچ ماتریس دیگری
780
00:32:17,120 –> 00:32:19,360
جز در نظر گرفتن میانگین ندارم،
781
00:32:19,360 –> 00:32:22,159
بنابراین این b هیچ و b 1 با میانگین کلی گرفته می شود
782
00:32:22,159 –> 00:32:24,000
783
00:32:24,000 –> 00:32:26,240
آره چقدر است بنابراین معادله دوم b
784
00:32:26,240 –> 00:32:27,440
هیچ برابر است با y bar
785
00:32:27,440 –> 00:32:31,039
منهای b 1 به x میله خوب
786
00:32:31,039 –> 00:32:34,320
این یکی شما از من می خواهید که شرایط
787
00:32:34,320 –> 00:32:38,080
درست باشد حتی سوال شما دقیق تر است
788
00:32:38,080 –> 00:32:39,360
صبر کنید درست
789
00:32:39,360 –> 00:32:40,880
همان چیزی که می خواهید بپرسید این است که اگر می
790
00:32:40,880 –> 00:32:42,559
خواهید x در سال قرار دهید چرا
791
00:32:42,559 –> 00:32:44,720
792
00:32:45,519 –> 00:32:47,200
به جای نوار من اینجا را کاوش نکنید باید کلاه من یا چیزی را بنویسیم
793
00:32:47,200 –> 00:32:49,200
794
00:32:49,200 –> 00:32:50,960
بله این در واقع کلاه سفید است و این همان
795
00:32:50,960 –> 00:32:53,760
چیزی است که من میخواستم اضافه کنم
796
00:32:53,760 –> 00:32:56,799
آیا باید سوالی داشته باشم
797
00:32:56,799 –> 00:32:59,919
بله بله بنابراین
798
00:32:59,919 –> 00:33:03,760
در مورد ما b i ثابت است درست است
799
00:33:03,760 –> 00:33:04,960
ما فقط b
800
00:33:04,960 –> 00:33:07,279
یک را محاسبه کردهایم و در همه جا از آن استفاده میکنیم بنابراین
801
00:33:07,279 –> 00:33:08,159
نمیشود b
802
00:33:08,159 –> 00:33:12,000
i این است b1 متاسفم
803
00:33:12,000 –> 00:33:14,720
این است b1 اوه مشکل بزرگی است که من
804
00:33:14,720 –> 00:33:15,200
امتحان کردم
805
00:33:15,200 –> 00:33:18,399
خوب ببینید اینجا چه چیزی را اینجا قرار دادم
806
00:33:18,399 –> 00:33:21,440
فرمولی که من نوشتم این است ah
807
00:33:21,440 –> 00:33:24,880
it is y cap است بنابراین من چون نتوانستم
808
00:33:24,880 –> 00:33:25,840
آن را به عنوان y cap ذکر کنم آن را به
809
00:33:25,840 –> 00:33:29,279
عنوان y قرار دادم نوار این در واقع y
810
00:33:29,279 –> 00:33:32,399
cap است، پس
811
00:33:32,399 –> 00:33:35,840
اگر دوباره به اینجا برگردم
812
00:33:35,840 –> 00:33:38,880
، چه می شود y cap
813
00:33:38,880 –> 00:33:41,440
بنابراین من می خواستم آن را به عنوان y cap
814
00:33:41,440 –> 00:33:43,200
در داخل آن نشان دهم، اشتباهاً آن را به عنوان y نوار قرار دادم
815
00:33:43,200 –> 00:33:45,440
816
00:33:45,440 –> 00:33:48,799
اوه این x 1 است من آن را به عنوان x
817
00:33:48,799 –> 00:33:52,399
1 در اینجا قرار می دهم y آن x نوار است
818
00:33:52,399 –> 00:33:54,640
من هیچ کدام را ندارم. هر
819
00:33:54,640 –> 00:33:56,799
معیار دیگری برای یافتن ضریب کلی
820
00:33:56,799 –> 00:33:57,840
این مورد برای همه رکوردها اعمال می شود
821
00:33:57,840 –> 00:34:01,679
، بنابراین من نمی توانم آن را
822
00:34:01,679 –> 00:34:05,279
فقط x i اینجا x یک در اینجا بگیرم، بنابراین
823
00:34:05,279 –> 00:34:06,080
824
00:34:06,080 –> 00:34:08,719
میانگین همه مقادیر را برای یافتن مقدار
825
00:34:08,719 –> 00:34:09,599
ضریب b
826
00:34:09,599 –> 00:34:13,280
هیچ و b1 در اینجا همیشه باید بگیرم می گیرم.
827
00:34:13,280 –> 00:34:14,320
فقط میانگین است
828
00:34:14,320 –> 00:34:17,599
که نباید یک رکورد
829
00:34:17,599 –> 00:34:21,520
ساگار بگیرم، آیا شما را گیج میکنم یا مونیکا
830
00:34:21,520 –> 00:34:24,560
ساگار و مونیخ آیا واضح است که میتوانم شما
831
00:34:24,560 –> 00:34:26,949
را متقاعد کنم یا هنوز
832
00:34:26,949 –> 00:34:29,440
[موسیقی] است،
833
00:34:29,440 –> 00:34:34,399
بنابراین ما تقریباً آن را دریافت کردیم، اما
834
00:34:34,399 –> 00:34:37,520
در اینجا بله در این فرمول x1
835
00:34:37,520 –> 00:34:40,079
یک راست ثابت نخواهد بود،
836
00:34:40,079 –> 00:34:42,239
x i خواهد بود زیرا ما در حال پیش بینی کلاهک y
837
00:34:42,239 –> 00:34:43,280
درست است
838
00:34:43,280 –> 00:34:45,760
بله بله، اما b 1 و b هیچ ما
839
00:34:45,760 –> 00:34:47,599
به عنوان
840
00:34:47,599 –> 00:34:49,280
v یک v هیچ و v یک همیشه
841
00:34:49,280 –> 00:34:51,679
ثابت است خوب است،
842
00:34:51,679 –> 00:34:53,359
بنابراین در واقع زمانی که ما در
843
00:34:53,359 –> 00:34:55,199
فرمول رگرسیون واقعاً می نویسیم، آن را به صورت b a
844
00:34:55,199 –> 00:34:55,679
در x
845
00:34:55,679 –> 00:34:59,440
i می نویسیم، اما سپس این فرض را
846
00:34:59,440 –> 00:35:00,160
داریم که t
847
00:35:00,160 –> 00:35:03,440
شیب uh تغییر نمی کند بنابراین ما از آن استفاده می
848
00:35:03,440 –> 00:35:06,800
کنیم تغییر نمی کند آن را تغییر نمی دهد
849
00:35:07,839 –> 00:35:10,960
بنابراین در اینجا دوباره اگر می خواهید پیش بینی کنید که چرا
850
00:35:10,960 –> 00:35:14,160
پیش بینی کنید که پیش بینی y
851
00:35:14,160 –> 00:35:15,280
چیست با
852
00:35:15,280 –> 00:35:19,280
b هیچ به
853
00:35:19,280 –> 00:35:23,040
اضافه b1 شیب همیشه
854
00:35:23,040 –> 00:35:26,720
در اکسل کاهش می یابد. بنابراین این واقعی است
855
00:35:26,720 –> 00:35:29,760
که آن را به عنوان 46205 پیش بینی می کند،
856
00:35:29,760 –> 00:35:32,320
اما پیش بینی من فقط 39
857
00:35:32,320 –> 00:35:33,839
351 را به
858
00:35:33,839 –> 00:35:36,079
من می دهد. مدل من در اینجا مدل ضعیف است همانطور که
859
00:35:36,079 –> 00:35:38,320
قبلاً گفتم زیرا رکوردها بسیار کمتر هستند
860
00:35:38,320 –> 00:35:39,920
اما هنوز فقط برای نمایش و
861
00:35:39,920 –> 00:35:41,520
درک فرمول نحوه حل کردن هستند.
862
00:35:41,520 –> 00:35:42,720
پر جنب
863
00:35:42,720 –> 00:35:46,480
و جوش من آن را دوباره گرفته
864
00:35:49,760 –> 00:35:53,200
ام، فقط این مقادیر
865
00:35:53,280 –> 00:35:56,839
b هیچ و b 1 را تغییر نمی دهم،
866
00:35:56,839 –> 00:36:00,240
بنابراین مقادیر کلی مقادیر با استفاده
867
00:36:00,240 –> 00:36:01,520
از فرمول این
868
00:36:01,520 –> 00:36:03,680
با استفاده از این b هیچ و b 1 می
869
00:36:03,680 –> 00:36:06,800
توانم مقدار y را چاپ کنم
870
00:36:06,800 –> 00:36:10,000
حالا باید پیدا کنم چه
871
00:36:10,000 –> 00:36:13,520
خطایی دارد که خطا با y منهای y چاپ
872
00:36:13,520 –> 00:36:16,400
y واقعی داده می شود، بنابراین برای دقیق تر بودن y واقعی
873
00:36:16,400 –> 00:36:16,960
منهای
874
00:36:16,960 –> 00:36:20,720
y پیش بینی
875
00:36:21,520 –> 00:36:23,599
آه، فکر می کنم بالاخره بتوانم
876
00:36:23,599 –> 00:36:25,280
به این هر دو سوال پاسخ دهم
877
00:36:25,280 –> 00:36:27,280
یا در حین خلاصه کردن، می توانم همین الان
878
00:36:27,280 –> 00:36:28,720
به شما بگویم
879
00:36:28,720 –> 00:36:31,440
ریگ حالا شما فقط تمرکز کنید که چگونه
880
00:36:31,440 –> 00:36:33,119
این خطا را محاسبه میکنم، خطای واقعی
881
00:36:33,119 –> 00:36:33,760
882
00:36:33,760 –> 00:36:37,119
883
00:36:37,119 –> 00:36:40,640
منهای پیشبینیکننده داده میشود، بنابراین
884
00:36:40,640 –> 00:36:46,079
هر کجا که میروید منهای پیشبینیکننده واقعی
885
00:36:46,720 –> 00:36:48,800
، خطا را محاسبه میکنم تا بر
886
00:36:48,800 –> 00:36:50,160
این مقدار منفی غلبه کنم
887
00:36:50,160 –> 00:36:54,079
دوباره خطا
888
00:36:54,079 –> 00:36:59,119
کل مربع خطا مجذور کل میتوانم
889
00:36:59,119 –> 00:37:02,480
میانگین
890
00:37:02,480 –> 00:37:08,320
همه این خطاها را پیدا کنید، من آن را به عنوان
891
00:37:08,320 –> 00:37:14,000
892
00:37:14,000 –> 00:37:17,200
893
00:37:18,000 –> 00:37:21,280
894
00:37:21,280 –> 00:37:22,079
895
00:37:22,079 –> 00:37:25,520
896
00:37:25,520 –> 00:37:29,280
میانگین msc می نامم
897
00:37:29,280 –> 00:37:31,359
. آن را در اینجا مربع کردهام، میخواهم
898
00:37:31,359 –> 00:37:32,800
آن را در همان
899
00:37:32,800 –> 00:37:36,000
واحدهای این متغیر y
900
00:37:36,000 –> 00:37:37,760
بیاورم، میخواهم آن را در همان واحدها بیاورم
901
00:37:37,760 –> 00:37:40,880
، به همین دلیل است که آن را به عنوان
902
00:37:40,880 –> 00:37:44,079
جذر
903
00:37:44,079 –> 00:37:47,599
mse در نظر میگیرم، مقدار rmse را میگیرم، بنابراین این هر دو ماتریس
904
00:37:47,599 –> 00:37:49,520
هستند بسیار مهم و یک
905
00:37:49,520 –> 00:37:51,200
معیار مهم دیگر که می خواستم به
906
00:37:51,200 –> 00:37:51,760
شما
907
00:37:51,760 –> 00:37:53,520
بگویم این بخشی از محدوده
908
00:37:53,520 –> 00:37:55,119
این جلسه نیست، اما با این حال از آنجایی که من
909
00:37:55,119 –> 00:37:55,760
این
910
00:37:55,760 –> 00:37:59,440
mse و rmse را پوشش داده ام، می خواستم این نقشه را پوشش دهم
911
00:37:59,440 –> 00:38:00,079
همچنین به
912
00:38:00,079 –> 00:38:03,440
معنای درصد مطلق خطا است که چگونه محاسبه کنم
913
00:38:03,440 –> 00:38:04,000
914
00:38:04,000 –> 00:38:07,760
e میانگین درصد خطای مطلق درصد خطا
915
00:38:07,760 –> 00:38:10,640
میانگین مطلق همیشه
916
00:38:10,640 –> 00:38:11,680
آن را به صورت معکوس به خاطر بسپارید، در طول جلسه
917
00:38:11,680 –> 00:38:13,200
بارها آن را حل می کنیم
918
00:38:13,200 –> 00:38:15,359
، اما باز هم
919
00:38:15,359 –> 00:38:20,079
ابتدا خطای خطا با
920
00:38:20,079 –> 00:38:23,440
اوه خطا
921
00:38:23,440 –> 00:38:26,800
تقسیم بر متأسفم بنابراین
922
00:38:26,800 –> 00:38:30,079
اول مطلق است تمام خطای مطلق
923
00:38:30,079 –> 00:38:34,079
تقسیم بر واقعی
924
00:38:34,079 –> 00:38:37,839
کاملاً درست است، بنابراین من مقادیر را برای
925
00:38:37,839 –> 00:38:39,280
همه
926
00:38:39,280 –> 00:38:42,800
در نظر میگیرم، اکنون
927
00:38:42,800 –> 00:38:46,560
میانگین همه این مقادیر را میگیرم و آن را
928
00:38:46,560 –> 00:38:47,200
به
929
00:38:47,200 –> 00:38:50,480
مقیاس درصد تبدیل میکنم، بنابراین این
930
00:38:50,480 –> 00:38:52,079
مقدار را به عنوان
931
00:38:52,079 –> 00:38:55,520
932
00:38:55,520 –> 00:38:59,119
صفحه شخص مطلق مینامم. این یک متریک متفاوت
933
00:38:59,119 –> 00:38:59,599
934
00:38:59,599 –> 00:39:01,440
در سری زمانی در طول جلسه سری زمانی است
935
00:39:01,440 –> 00:39:02,720
، ما این نقشه را حل خواهیم کرد این
936
00:39:02,720 –> 00:39:05,839
یک
937
00:39:05,839 –> 00:39:09,200
متریک کاملاً متفاوت است m a p m a دوباره میانگین
938
00:39:09,200 –> 00:39:10,079
خطای مطلق
939
00:39:10,079 –> 00:39:11,599
من درصد میانگین
940
00:39:11,599 –> 00:39:13,359
درصد خطای مطلق را گرفته ام
941
00:39:13,359 –> 00:39:15,599
بنابراین نکته مهمی که در اینجا باید به آن توجه شود این است که من
942
00:39:15,599 –> 00:39:16,720
آن را گرفته ام خطا
943
00:39:16,720 –> 00:39:19,920
y واقعی منهای y پیش بینی می کنم و من
944
00:39:19,920 –> 00:39:20,640
945
00:39:20,640 –> 00:39:23,680
میانگین مربع خطا را درست حل کرده
946
00:39:23,680 –> 00:39:26,240
ام اگر جذر آن را
947
00:39:26,240 –> 00:39:26,960
بگیرم،
948
00:39:26,960 –> 00:39:29,680
ریشه میانگین مربع خطا را برای مقدار جدیدی
949
00:39:29,680 –> 00:39:31,200
که بین
950
00:39:31,200 –> 00:39:33,920
ran قرار می گیرد، دریافت می کنم. ge از 1.1 تا 3.2 چقدر است
951
00:39:33,920 –> 00:39:35,440
حقوق پیش بینی شده
952
00:39:35,440 –> 00:39:38,560
با مقادیر v1 و b هیچ
953
00:39:38,560 –> 00:39:41,440
من می توانم پیش بینی کنم که حقوق
954
00:39:41,440 –> 00:39:42,079
برای آن
955
00:39:42,079 –> 00:39:45,119
چقدر است اکنون چگونه این b1 b1 را حل کردم
956
00:39:45,119 –> 00:39:45,839
من آن را با
957
00:39:45,839 –> 00:39:49,920
xa منهای x بار به y a منهای پیدا کردم نوار y
958
00:39:49,920 –> 00:39:52,720
تقسیم بر x i منهای x بر
959
00:39:52,720 –> 00:39:54,240
کل مربع
960
00:39:54,240 –> 00:39:57,040
درست است، بنابراین آه برای دادن دوباره
961
00:39:57,040 –> 00:39:59,119
اشتباه کردم با y نوار که سفید را به عنوان نوار y ذکر
962
00:39:59,119 –> 00:39:59,599
963
00:39:59,599 –> 00:40:02,640
کردم در اینجا کلاه y دارد
964
00:40:02,960 –> 00:40:04,720
یا فقط برای سادگی شما آن را ذکر کردید
965
00:40:04,720 –> 00:40:06,880
زیرا y نیز y برابر است با b هیچ به اضافه
966
00:40:06,880 –> 00:40:10,240
b یک به x یک در حال حاضر برای پیش بینی این
967
00:40:10,240 –> 00:40:13,599
b هیچ باید این b
968
00:40:13,599 –> 00:40:17,280
را منهای
969
00:40:17,280 –> 00:40:21,440
b uh چه مقدار است متاسفم چه چیزی
970
00:40:21,440 –> 00:40:25,359
خوب است میانگین همه مقدار y
971
00:40:25,359 –> 00:40:28,720
منهای این b1 به میانگین
972
00:40:28,720 –> 00:40:32,000
همه x من متاسفم بچه ها
973
00:40:32,000 –> 00:40:38,880
میانگین همه مقادیر x
974
00:40:38,880 –> 00:40:41,599
آیا می توانید این دو قسمت را درک کنید
975
00:40:41,599 –> 00:40:43,280
اگر گیج نمی کنم می خواهید
976
00:40:43,280 –> 00:40:48,079
یک بار دیگر یک مونیکا
977
00:40:48,079 –> 00:40:51,200
ساگار این قسمت را روشن کند
978
00:40:52,460 –> 00:40:56,800
[موسیقی]
979
00:40:56,800 –> 00:41:00,240
خوب است پس در این فرمول من
980
00:41:00,240 –> 00:41:01,680
نمیدانم b مقدار صفر چیست،
981
00:41:01,680 –> 00:41:03,920
بنابراین من فقط این b را در اینجا نگه میدارم
982
00:41:03,920 –> 00:41:06,000
و این b را یک
983
00:41:06,000 –> 00:41:09,119
مقدار b1 x1 را به si دیگر میبرم
984
00:41:09,119 –> 00:41:11,680
درست است، بنابراین هر زمان که میخواهم این b را پیدا
985
00:41:11,680 –> 00:41:12,319
986
00:41:12,319 –> 00:41:14,880
کنم، معیاری جامع برای
987
00:41:14,880 –> 00:41:16,000
همه رکوردها است،
988
00:41:16,000 –> 00:41:18,839
بنابراین از آنجایی که من تمام رکوردها را میگیرم،
989
00:41:18,839 –> 00:41:20,240
این
990
00:41:20,240 –> 00:41:24,240
مقدار y به عنوان میانگین تمام
991
00:41:24,240 –> 00:41:28,160
مقادیر x منهای b 1 v من میدانم
992
00:41:28,160 –> 00:41:31,440
و میانگین آن در نظر گرفته میشود. همه y ضبط می کند،
993
00:41:31,440 –> 00:41:32,560
بنابراین همیشه با
994
00:41:32,560 –> 00:41:34,480
میانگین تمام مقادیر x داده می شود و
995
00:41:34,480 –> 00:41:36,640
میانگین همه مقادیر y
996
00:41:36,640 –> 00:41:39,119
این را با این اشتباه نگیرید، اما
997
00:41:39,119 –> 00:41:40,480
یک
998
00:41:40,480 –> 00:41:42,160
جمله وجود داشت که در ویدیو گفته شد
999
00:41:42,160 –> 00:41:44,240
که بهترین تناسب را دارد. خط
1000
00:41:44,240 –> 00:41:49,839
همیشه از طریق x نوار کاما y نوار درست می گذرد،
1001
00:42:01,359 –> 00:42:05,200
شاید آه این فرمول گیج کننده باشد
1002
00:42:05,200 –> 00:42:06,640
اگر فرمولی وجود نداشته باشد، فکر می کنم شما
1003
00:42:06,640 –> 00:42:08,960
واضح تر خواهید بود، بنابراین من فقط شما را
1004
00:42:08,960 –> 00:42:10,400
با این فرمول
1005
00:42:10,400 –> 00:42:14,720
گیج کردم.
1006
00:42:14,720 –> 00:42:16,160
1007
00:42:16,160 –> 00:42:19,440
آنچه را که b1 در x1 اتفاق میافتد،
1008
00:42:19,440 –> 00:42:22,560
اشتباه نگیرید، بنابراین این
1009
00:42:22,560 –> 00:42:25,920
x1 و ycap این مقدار y
1010
00:42:25,920 –> 00:42:28,079
خلاصه همه این مقادیر است، بنابراین
1011
00:42:28,079 –> 00:42:30,640
من تقریباً مقدار متوسط
1012
00:42:30,640 –> 00:42:33,200
x را میگیرم و میانگین تمام مقادیر x را میگیرم تا b را
1013
00:42:33,200 –> 00:42:36,000
بیابم
1014
00:42:36,000 –> 00:42:39,680
این و بهترین مقدار این b1 و x1
1015
00:42:39,680 –> 00:42:44,079
بدون هیچ شرط دیگری،
1016
00:42:44,079 –> 00:42:46,160
من در نظر دارم که این بهترین است
1017
00:42:46,160 –> 00:42:47,760
مانند میانگین مقادیر y
1018
00:42:47,760 –> 00:42:50,319
و میانگین مقادیر uh x بهترین
1019
00:42:50,319 –> 00:42:52,400
خط است، بنابراین من میانگین
1020
00:42:52,400 –> 00:42:55,599
مقدار x و y را میگیرم تا نقطه قطع
1021
00:42:55,599 –> 00:42:59,200
b را درست پیدا کنم، بنابراین نکته مهم
1022
00:42:59,200 –> 00:43:00,160
دیگری که
1023
00:43:00,160 –> 00:43:02,800
به شما گفتم این است که خطای نحوه یافتن
1024
00:43:02,800 –> 00:43:06,240
mse و
1025
00:43:08,160 –> 00:43:11,119
rmse کاملاً درست است، بنابراین به اینجا برگردید تا
1026
00:43:11,119 –> 00:43:12,800
مضاعف r مربع چگونه می خواهم
1027
00:43:12,800 –> 00:43:14,240
r مضاعف را پیدا کنم
1028
00:43:14,240 –> 00:43:17,040
چند r مربعی چیزی نیست
1029
00:43:17,040 –> 00:43:19,760
اما توسط همبستگی
1030
00:43:19,760 –> 00:43:23,760
بین x کاما y
1031
00:43:23,760 –> 00:43:26,319
همبستگی بین x و x x کاما
1032
00:43:26,319 –> 00:43:28,240
y با
1033
00:43:28,240 –> 00:43:31,119
r مضرب مجذور داده می شود، پس چه مقدار r مربع است
1034
00:43:31,119 –> 00:43:34,160
چگونه می توانم r مربع را محاسبه کنم
1035
00:43:34,160 –> 00:43:37,280
r مربع همیشه با
1036
00:43:37,280 –> 00:43:40,480
مقدار رگرسیون من از مجموع توضیح داده می شود،
1037
00:43:40,480 –> 00:43:44,560
بنابراین چگونه می توانم
1038
00:43:44,560 –> 00:43:47,520
مربع r را دقیقاً در اینجا محاسبه کنم، همه حل
1039
00:43:47,520 –> 00:43:47,920
کردن
1040
00:43:47,920 –> 00:43:49,760
اکسل یک تابع معکوس دارد تا
1041
00:43:49,760 –> 00:43:52,160
آن را درست حل کند، اما هنوز باید بدانید
1042
00:43:52,160 –> 00:43:54,400
که یک r مربع چیست چگونه رگرسیون کل را حل می
1043
00:43:54,400 –> 00:43:56,160
کند
1044
00:43:56,160 –> 00:43:58,240
و باقیمانده رگرسیون من چقدر
1045
00:43:58,240 –> 00:43:59,599
توانسته است توضیح دهید
1046
00:43:59,599 –> 00:44:01,920
که چگونه d
1047
00:44:01,920 –> 00:44:04,000
بر اساس درجات
1048
00:44:04,000 –> 00:44:04,800
آزادی
1049
00:44:04,800 –> 00:44:08,640
درجات آزادی رگرسیون محاسبه
1050
00:44:08,640 –> 00:44:10,960
شده است، بنابراین تفاوت
1051
00:44:10,960 –> 00:44:12,880
بین این r مربع تنظیم شده و مربع r چیست،
1052
00:44:12,880 –> 00:44:14,319
1053
00:44:14,319 –> 00:44:16,160
بنابراین فکر می کنم همه اینها در ویدیو توضیح داده شده است.
1054
00:44:16,160 –> 00:44:17,520
تفاوت بین
1055
00:44:17,520 –> 00:44:19,960
این مربع r و جنبه تعدیل شده چیست،
1056
00:44:19,960 –> 00:44:22,960
1057
00:44:22,960 –> 00:44:26,560
متغیرهای مستقل مهم شناخته شده را در نظر نمی گیرد، به
1058
00:44:26,560 –> 00:44:29,200
عنوان مثال یک داده جمعیت
1059
00:44:29,200 –> 00:44:30,400
وجود دارد و یک متغیر
1060
00:44:30,400 –> 00:44:33,040
وجود دارد که برای
1061
00:44:33,040 –> 00:44:34,400
متغیر وابسته کمکی
1062
00:44:34,400 –> 00:44:37,599
نمی کند، اما با ترسیم نمونه هایی که قرار است به آن ها بپردازند.
1063
00:44:37,599 –> 00:44:39,599
ساده از آن جامعه
1064
00:44:39,599 –> 00:44:41,839
، مقداری سهم توسط
1065
00:44:41,839 –> 00:44:43,440
متغیر مستقل
1066
00:44:43,440 –> 00:44:45,520
بر اساس متغیر مستقل نشان داده شده است، بنابراین
1067
00:44:45,520 –> 00:44:48,800
آنچه را که من میخواهم آن را به صورت ساده در
1068
00:44:48,800 –> 00:44:51,040
مجذور r قرار دهم، من فقط محاسبه
1069
00:44:51,040 –> 00:44:52,960
میکنم که رگرسیون من چقدر را توضیح میدهد،
1070
00:44:52,960 –> 00:44:55,200
مانند آنچه شما درست توضیح دادید
1071
00:44:55,200 –> 00:44:56,720
r مربع تعدیل شده
1072
00:44:56,720 –> 00:45:00,160
بر اساس تعداد مقادیر
1073
00:45:00,160 –> 00:45:02,319
بر اساس تعداد رکوردها
1074
00:45:02,319 –> 00:45:04,400
نیز باید در اینجا درجات آزادی در نظر گرفته شود.
1075
00:45:04,400 –> 00:45:06,560
1076
00:45:06,560 –> 00:45:09,839
باید در نظر گرفته
1077
00:45:10,240 –> 00:45:13,599
شود با در نظر گرفتن درجات
1078
00:45:13,599 –> 00:45:15,920
آزادی تعداد متغیرهای مستقل
1079
00:45:15,920 –> 00:45:16,800
مقدار مناسب چقدر است،
1080
00:45:16,800 –> 00:45:19,839
بنابراین وقتی i برای
1081
00:45:19,839 –> 00:45:21,440
یک رگرسیون خطی ساده
1082
00:45:21,440 –> 00:45:23,119
میتوانید r مربع را در نظر بگیرید وقتی
1083
00:45:23,119 –> 00:45:24,720
رگرسیون خطی چندگانه را در نظر میگیرید.
1084
00:45:24,720 –> 00:45:25,839
1085
00:45:25,839 –> 00:45:27,760
1086
00:45:27,760 –> 00:45:29,280
آیا وجود دارد که
1087
00:45:29,280 –> 00:45:31,920
همیشه بنویسد r تنظیم شده مربع
1088
00:45:31,920 –> 00:45:33,599
مقدار مناسبی است
1089
00:45:33,599 –> 00:45:35,280
برای در نظر گرفتن اینکه آیا مدل من در مدولاسیون خوب است
1090
00:45:35,280 –> 00:45:37,920
1091
00:45:37,920 –> 00:45:40,319
یا um تنظیم شده است r مربع، این معیار خوبی است
1092
00:45:40,319 –> 00:45:42,160
برای تشخیص اینکه آیا مدل من
1093
00:45:42,160 –> 00:45:44,319
عملکرد
1094
00:45:44,319 –> 00:45:47,280
خوبی دارد چگونه می توانم مربع تنظیم شده را شناسایی کنم
1095
00:45:47,280 –> 00:45:48,240
1096
00:45:48,240 –> 00:45:51,599
نشانی تنظیم شده r مربع
1097
00:45:51,599 –> 00:45:56,240
توسط من داده می شود، آن را در اینجا می گذارم،
1098
00:45:56,240 –> 00:45:58,240
آن را با 1 منهای از منهای آن به
1099
00:45:58,240 –> 00:45:59,760
صورت معکوس می دهم، بنابراین
1100
00:45:59,760 –> 00:46:01,040
1101
00:46:01,040 –> 00:46:04,319
مجموع باقیمانده مربع ها را تقسیم
1102
00:46:04,319 –> 00:46:07,440
بر درجه آزادی می گیرم.
1103
00:46:09,280 –> 00:46:13,520
و مجموع مجموع مجذورها
1104
00:46:13,520 –> 00:46:17,200
تقسیم بر درجات آزادی
1105
00:46:17,839 –> 00:46:20,480
از آنجایی که من می خواهم رگرسیون
1106
00:46:20,480 –> 00:46:22,000
1 منهای
1107
00:46:22,000 –> 00:46:24,720
باقیمانده تقسیم بر مجموع مجموع
1108
00:46:24,720 –> 00:46:26,400
مربعات را تشخیص
1109
00:46:26,400 –> 00:46:28,000
دهم که این همان r تنظیم شده
1110
00:46:28,000 –> 00:46:29,680
مربع است. محاسبه شده است
1111
00:46:29,680 –> 00:46:32,240
خطای
1112
00:46:32,240 –> 00:46:34,640
استاندارد چیست خطای استاندارد چیزی نیست جز جذر
1113
00:46:34,640 –> 00:46:35,520
1114
00:46:35,520 –> 00:46:40,319
مربع جذر این
1115
00:46:40,960 –> 00:46:43,359
ریشه مربع باقی مانده از میانگین مربع
1116
00:46:43,359 –> 00:46:44,800
باقیمانده
1117
00:46:44,800 –> 00:46:46,880
من نمی خواهم دوباره بروم و
1118
00:46:46,880 –> 00:46:48,880
این جدول آنووا را
1119
00:46:48,880 –> 00:46:49,760
توضیح دهم. زمان،
1120
00:46:49,760 –> 00:46:51,839
بنابراین آنچه که میخواهم بگویم، ما توانستیم
1121
00:46:51,839 –> 00:46:53,040
1122
00:46:53,040 –> 00:46:55,760
هر مرحله را در اکسل
1123
00:46:55,760 –> 00:46:57,119
با استفاده از فرمول
1124
00:46:57,119 –> 00:47:00,160
درست حل کنیم، میتوانیم مقایسه کنیم و
1125
00:47:00,160 –> 00:47:02,720
مقادیر درست جدول رگرسیون را
1126
00:47:02,720 –> 00:47:03,839
در اکسل
1127
00:47:03,839 –> 00:47:05,920
درست به دست آوریم و فکر میکنم این جدول آنووا را حل کردهایم
1128
00:47:05,920 –> 00:47:07,760
. شما بچه ها می دانید که چگونه
1129
00:47:07,760 –> 00:47:08,240
آن را
1130
00:47:08,240 –> 00:47:11,040
درست حل کنید این f اهمیت معنی
1131
00:47:11,040 –> 00:47:12,960
f چیزی نیست جز مقدار p
1132
00:47:12,960 –> 00:47:15,520
بنابراین p کم است سپس l خواهد رفت بنابراین
1133
00:47:15,520 –> 00:47:16,480
مدل رگرسیون
1134
00:47:16,480 –> 00:47:19,920
ارزش اجرای درست را دارد چگونه
1135
00:47:19,920 –> 00:47:21,359
آه این نشان می دهد
1136
00:47:21,359 –> 00:47:24,559
که حقوق در پیش بینی خوبی است برای
1137
00:47:24,559 –> 00:47:28,240
شناسایی سالها
1138
00:47:28,240 –> 00:47:29,920
متأسفم سالها تجربه یک
1139
00:47:29,920 –> 00:47:33,599
پیش بینی خوب برای شناسایی حقوق است،
1140
00:47:33,760 –> 00:47:36,160
بنابراین آیا این واضح است من یک قدم اضافی برای
1141
00:47:36,160 –> 00:47:38,240
حل آن
1142
00:47:38,240 –> 00:47:39,680
1143
00:47:39,680 –> 00:47:41,680
در اکسل برداشتم. هدف
1144
00:47:41,680 –> 00:47:42,720
جلسه،
1145
00:47:42,720 –> 00:47:44,960
بنابراین میخواستم نشان دهم که چگونه mse و
1146
00:47:44,960 –> 00:47:45,920
rmse
1147
00:47:45,920 –> 00:47:47,359
و این b naught و v1 چگونه
1148
00:47:47,359 –> 00:47:49,760
در اکسل محاسبه میشود، بنابراین ارزش
1149
00:47:49,760 –> 00:47:50,400
حل کردن را داشت
1150
00:47:50,400 –> 00:47:53,680
چگونه متوجه میشوید که گیجکننده است آیا اشکالی
1151
00:47:53,680 –> 00:47:57,119
ندارد که به پایتون بروم
1152
00:47:57,359 –> 00:48:01,119
، بسیار مفید بود. پس
1153
00:48:01,119 –> 00:48:04,839
خوب است، همین را در پایتون خواهیم دید،
1154
00:48:04,839 –> 00:48:06,079
1155
00:48:06,079 –> 00:48:08,079
ما دو مطالعه موردی داریم، یکی اضافه کردن bnb
1156
00:48:08,079 –> 00:48:10,160
و
1157
00:48:10,720 –> 00:48:13,040
نگه داشتن آن
1158
00:48:14,480 –> 00:48:17,680
خوب است، این راه حل دانشجویی است،
1159
00:48:17,680 –> 00:48:20,400
اکنون من کتابخانه ها را وارد می کنم pandas numpy
1160
00:48:20,400 –> 00:48:21,200
1161
00:48:21,200 –> 00:48:24,960
cbone و مدل خطی
1162
00:48:24,960 –> 00:48:27,280
همه این متغیرها را فقط
1163
00:48:27,280 –> 00:48:29,520
در اینجا وارد می کنم.
1164
00:48:30,800 –> 00:48:33,280
یک لحظه به من داده و داده های حقوق و دستمزد
1165
00:48:33,280 –> 00:48:35,520
را که فقط وارد می کنم،
1166
00:48:35,520 –> 00:48:38,640
دستور ذخیره را بزنید تا به من نشان دهد اینها
1167
00:48:38,640 –> 00:48:38,960
همه
1168
00:48:38,960 –> 00:48:42,240
موارد اولیه هستند که ما برای انجام
1169
00:48:42,240 –> 00:48:44,559
این اسکریپت استفاده می کردیم خلاصه سال ها تجربه را به من می دهد
1170
00:48:44,559 –> 00:48:45,839
1171
00:48:45,839 –> 00:48:48,000
خلاصه کل بنابراین مقدار میانگین
1172
00:48:48,000 –> 00:48:48,960
1173
00:48:48,960 –> 00:48:51,119
خلاصه هفتاد و شش هزار صفر صفر سه است
1174
00:48:51,119 –> 00:48:52,160
چرا متفاوت نشان می دهد
1175
00:48:52,160 –> 00:48:53,839
ما فقط ده رکورد در اکسل
1176
00:48:53,839 –> 00:48:56,880
برای نشان دادن آن گرفته ایم اما در اینجا اوه من
1177
00:48:56,880 –> 00:48:59,280
کل سی رکورد وجود دارد
1178
00:48:59,280 –> 00:49:00,079
درست است،
1179
00:49:00,079 –> 00:49:01,760
بنابراین اگر می خواستم این 30 رکورد را نشان دهم.
1180
00:49:01,760 –> 00:49:03,440
خیلی گیج کننده خواهد بود، بنابراین
1181
00:49:03,440 –> 00:49:06,559
من فقط 10 رکورد گرفته ام، بنابراین
1182
00:49:06,559 –> 00:49:10,000
انحراف استاندارد 27
1183
00:49:10,000 –> 00:49:13,440
404 برای دستمزد است.
1184
00:49:13,440 –> 00:49:14,880
1185
00:49:14,880 –> 00:49:16,160
1186
00:49:16,160 –> 00:49:17,920
1187
00:49:17,920 –> 00:49:21,119
1188
00:49:21,119 –> 00:49:22,800
در اینجا میتوانیم
1189
00:49:22,800 –> 00:49:24,400
ببینیم که دادهها به صورت خطی
1190
00:49:24,400 –> 00:49:27,040
توزیع شدهاند
1191
00:49:27,359 –> 00:49:31,200
و نمودار همبستگی
1192
00:49:31,200 –> 00:49:34,400
در اینجا فقط یک متغیر وجود دارد،
1193
00:49:34,400 –> 00:49:37,599
بنابراین همبستگی بالایی دارد،
1194
00:49:37,599 –> 00:49:40,559
بنابراین این همبستگی خوب است یا بد، این
1195
00:49:40,559 –> 00:49:44,970
همبستگی خوب است یا بد
1196
00:49:44,970 –> 00:49:48,050
[موسیقی]
1197
00:49:48,880 –> 00:49:52,079
خوب نزدیک به یک است،
1198
00:49:52,079 –> 00:49:55,599
بنابراین در داده های خطی چندگانه این یک
1199
00:49:55,599 –> 00:49:57,280
رگرسیون خطی ساده است، بنابراین این
1200
00:49:57,280 –> 00:49:59,280
همبستگی خوب است،
1201
00:49:59,280 –> 00:50:02,160
این خوب است در واقع ما در حال یافتن یک
1202
00:50:02,160 –> 00:50:03,760
همبستگی بین متغیر مستقل
1203
00:50:03,760 –> 00:50:05,599
و متغیر وابسته هستیم،
1204
00:50:05,599 –> 00:50:08,640
بنابراین همیشه همبستگی بین
1205
00:50:08,640 –> 00:50:10,000
متغیر مستقل و
1206
00:50:10,000 –> 00:50:11,599
متغیر و متغیر وابسته
1207
00:50:11,599 –> 00:50:13,359
باید بسیار زیاد باشد.
1208
00:50:13,359 –> 00:50:15,599
سپس نشان میدهد که
1209
00:50:15,599 –> 00:50:17,760
1210
00:50:17,760 –> 00:50:20,480
یافتن متغیر y در اینجا یک
1211
00:50:20,480 –> 00:50:22,400
پیشبینیکننده بسیار خوب است، درست پیشبینیکننده بسیار خوبی است
1212
00:50:22,400 –> 00:50:27,920
، بنابراین بچهها در اینجا شک دارید
1213
00:50:27,920 –> 00:50:30,240
شکی نیست پس چرا همبستگی بالا است
1214
00:50:30,240 –> 00:50:32,880
y مشکل
1215
00:50:34,240 –> 00:50:37,599
مونیکا ساگار بدون شک پس من
1216
00:50:37,599 –> 00:50:38,839
1217
00:50:38,839 –> 00:50:42,160
خوب هستم بنابراین تست قطار تقسیم شد
1218
00:50:42,160 –> 00:50:44,319
بنابراین ما چندین بار آن را دیده ایم که در حال حاضر
1219
00:50:44,319 –> 00:50:45,359
از
1220
00:50:45,359 –> 00:50:47,680
sql و انتخاب مدل از
1221
00:50:47,680 –> 00:50:50,720
تقسیم تست قطار انتخاب مدل استفاده
1222
00:50:50,720 –> 00:50:53,760
می کنیم دو گزینه برای
1223
00:50:53,760 –> 00:50:55,760
پیدا کردن مدل خطی به درستی وجود دارد، یکی از
1224
00:50:55,760 –> 00:50:56,800
1225
00:50:56,800 –> 00:50:58,640
کتابخانه آمار ah و دیگری از این کیت
1226
00:50:58,640 –> 00:50:59,920
1227
00:50:59,920 –> 00:51:02,480
درست یاد بگیرید، اجازه دهید ابتدا شروع کنیم چگونه این کار را
1228
00:51:02,480 –> 00:51:03,520
در کتابخانه کیت آسمان انجام دهیم
1229
00:51:03,520 –> 00:51:06,559
همیشه در این sql یاد بگیرید
1230
00:51:06,559 –> 00:51:10,880
که باید مشخص کنیم چه
1231
00:51:10,880 –> 00:51:13,920
چیزی باید ارائه کنیم. یک نام شی
1232
00:51:13,920 –> 00:51:18,160
برای تابع رگرسیون
1233
00:51:19,280 –> 00:51:21,599
خطی رگرسیون خطی من فقط آن را
1234
00:51:21,599 –> 00:51:24,000
به عنوان مدل رگرسیون مدل
1235
00:51:24,000 –> 00:51:26,640
رگرسیون ارجاع می دهم،
1236
00:51:27,359 –> 00:51:32,160
بنابراین در مدل رگرسیون
1237
00:51:32,319 –> 00:51:34,559
بیایید ببینیم وقتی مدل رگرسیون می
1238
00:51:34,559 –> 00:51:35,520
خواهم انجام دهم
1239
00:51:35,520 –> 00:51:39,440
، سعی می کنم مقادیر را
1240
00:51:39,599 –> 00:51:43,200
بین آنچه np
1241
00:51:43,280 –> 00:51:45,119
uh i’m برازش کنم این را به عنوان یک آرایه تبدیل می کنیم
1242
00:51:45,119 –> 00:51:46,800
زیرا این تمام چیزی است که در یک
1243
00:51:46,800 –> 00:51:51,280
آرایه x train وجود ندارد
1244
00:51:51,280 –> 00:51:54,800
و این همه داده شده است زیرا
1245
00:51:54,800 –> 00:51:57,040
ما
1246
00:51:57,040 –> 00:51:58,240
فقط این x train را
1247
00:51:58,240 –> 00:52:01,119
درست از چارچوب داده استخراج کرده ایم بنابراین آنچه اتفاق می افتد مانند
1248
00:52:01,119 –> 00:52:02,240
تبدیل از
1249
00:52:02,240 –> 00:52:04,000
یک بردار به uh قاب داده به و
1250
00:52:04,000 –> 00:52:05,440
بردار،
1251
00:52:05,440 –> 00:52:07,839
بنابراین من فقط به یک آرایه تغییر شکل می دهم
1252
00:52:07,839 –> 00:52:09,440
1253
00:52:09,440 –> 00:52:12,480
20 کاما 1
1254
00:52:14,480 –> 00:52:17,839
چند درصد 30 نرم و صاف است
1255
00:52:17,839 –> 00:52:23,119
21 خواهد بود و y قطار
1256
00:52:24,720 –> 00:52:27,760
بنابراین ما مدل رگرسیون
1257
00:52:27,760 –> 00:52:28,640
مدل را
1258
00:52:28,640 –> 00:52:31,200
برای مقدار x قطار متناسب کرده ایم. و حلقه سفیدی
1259
00:52:31,200 –> 00:52:33,200
که شما این تغییر شکل را در آرایه np فراموش میکنید،
1260
00:52:33,200 –> 00:52:33,680
1261
00:52:33,680 –> 00:52:35,280
من فقط به آرایه تبدیل میکنم، زیرا
1262
00:52:35,280 –> 00:52:37,520
اتفاقی که میافتد زمانی است که
1263
00:52:37,520 –> 00:52:40,720
این x و y را تقسیم میکردم،
1264
00:52:45,440 –> 00:52:48,000
بنابراین وقتی سعی میکردم این
1265
00:52:48,000 –> 00:52:49,040
x و y را
1266
00:52:49,040 –> 00:52:50,960
از قاب داده جا بدهم، این i را تقسیم کردم. فقط
1267
00:52:50,960 –> 00:52:52,160
دو ستون
1268
00:52:52,160 –> 00:52:53,839
آن را به عنوان یک بردار تبدیل می کند به طوری
1269
00:52:53,839 –> 00:52:55,200
که برخی از خطاها در حال آمدن است، بنابراین من
1270
00:52:55,200 –> 00:52:56,960
آن را به عنوان یک آرایه تبدیل می
1271
00:52:56,960 –> 00:53:00,720
کنم و آن را به عنوان 20 کاما 21 تغییر شکل می دهم
1272
00:53:00,720 –> 00:53:03,040
، بنابراین این مرحله تنها زمانی مورد نیاز خواهد بود
1273
00:53:03,040 –> 00:53:04,640
که ما در حال انجام کارهای ساده هستیم. رگرسیون خطی
1274
00:53:04,640 –> 00:53:05,359
1275
00:53:05,359 –> 00:53:08,640
به این دلیل که بله بله ممکن است
1276
00:53:08,640 –> 00:53:09,599
مورد نیاز باشد بله
1277
00:53:09,599 –> 00:53:13,760
خوب من به شما نشان خواهم داد که چرا از آن استفاده کردم
1278
00:53:13,760 –> 00:53:17,440
خیلی خوب
1279
00:53:17,440 –> 00:53:20,079
بله من همان خطا را گرفتم بنابراین امروز این سوال را داشتم بسیار
1280
00:53:20,079 –> 00:53:21,520
1281
00:53:21,520 –> 00:53:24,960
خوب پس اگر می توانید ببینید
1282
00:53:24,960 –> 00:53:28,000
که چرا تست درست انجام نشده
1283
00:53:28,000 –> 00:53:30,319
است یک آرایه بنابراین اگر می توانید از
1284
00:53:30,319 –> 00:53:31,119
1285
00:53:31,119 –> 00:53:34,559
numpy از یک آرایه استفاده کنید بنابراین این بود کار
1286
00:53:34,559 –> 00:53:36,480
اجرا می شود من آن را به عنوان یک
1287
00:53:36,480 –> 00:53:40,079
آرایه تبدیل می کنم و آن را به صورت
1288
00:53:40,079 –> 00:53:43,760
reshape به مقدار یک دو سه تبدیل می کنم و
1289
00:53:43,760 –> 00:53:46,960
سپس یک را شروع می
1290
00:53:46,960 –> 00:53:48,800
کنم بنابراین فقط آن را به یک آرایه تبدیل می
1291
00:53:48,800 –> 00:53:50,640
کنم تا ورودی این
1292
00:53:50,640 –> 00:53:51,440
خطی به این صورت باشد. مدلی
1293
00:53:51,440 –> 00:53:54,160
که دلیل استفاده از آن در آرایه p
1294
00:53:54,160 –> 00:53:55,280
1295
00:53:55,280 –> 00:53:58,480
بود، خوب است که جای گیج نیست، بنابراین
1296
00:53:58,480 –> 00:54:01,040
حالا ضریب مدلی
1297
00:54:01,040 –> 00:54:02,800
که من
1298
00:54:02,800 –> 00:54:06,880
1299
00:54:07,359 –> 00:54:10,800
در مدل رگرسیون در مدل رگرسیونی ساختهام
1300
00:54:10,800 –> 00:54:13,839
چقدر است، میخواهم ضریب آن را پیدا کنم
1301
00:54:13,839 –> 00:54:26,079
ضریب 0 که به من می دهد این است که سعی می کند ضریب یک ثانیه را به من بگوید
1302
00:54:26,079 –> 00:54:30,480
1303
00:54:32,880 –> 00:54:38,240
ضریب نقطه مدل رگرسیون بچه ها
1304
00:54:38,240 –> 00:54:41,440
همیشه در 0
1305
00:54:41,440 –> 00:54:44,240
سمت راست یک ثانیه
1306
00:54:47,119 –> 00:54:48,799
کاملاً درست است بنابراین ضریب که
1307
00:54:48,799 –> 00:54:53,280
به درستی برای سال ها تجربه است
1308
00:54:53,280 –> 00:54:55,440
بنابراین ضریب برای سال
1309
00:54:55,440 –> 00:54:56,880
1310
00:54:56,880 –> 00:54:58,240
تجربه ضریب سالهای
1311
00:54:58,240 –> 00:55:00,000
سابقه کار نه دو صفر دو
1312
00:55:00,000 –> 00:55:01,599
یک واحد افزایش در سال
1313
00:55:01,599 –> 00:55:03,440
تجربه است، حقوق 9 به صفر افزایش می یابد
1314
00:55:03,440 –> 00:55:05,520
1315
00:55:05,520 –> 00:55:07,839
که در اینجا
1316
00:55:07,839 –> 00:55:09,520
مستقیماً در رگرسیون خطی نکته مهمی است. n
1317
00:55:09,520 –> 00:55:11,040
شما قادر خواهید بود
1318
00:55:11,040 –> 00:55:12,720
یک واحد افزایش را در سالهای
1319
00:55:12,720 –> 00:55:14,160
تجربه حل کنید
1320
00:55:14,160 –> 00:55:15,760
که چقدر حقوق
1321
00:55:15,760 –> 00:55:21,839
افزایش مییابد نه به صفر دو افزایش مییابد،
1322
00:55:22,240 –> 00:55:27,200
بنابراین رهگیری به
1323
00:55:27,200 –> 00:55:31,119
چه معناست که رهگیری از درک شما
1324
00:55:32,839 –> 00:55:35,839
1325
00:55:39,839 –> 00:55:42,799
1326
00:55:42,799 –> 00:55:43,599
چیست.
1327
00:55:43,599 –> 00:55:46,480
به طور کلی شما
1328
00:55:46,480 –> 00:55:47,440
به من بگویید
1329
00:55:47,440 –> 00:55:49,760
که آن رهگیر چیست وقتی
1330
00:55:49,760 –> 00:55:52,079
همه متغیرهای مستقل 0
1331
00:55:52,079 –> 00:55:54,640
1332
00:55:54,640 –> 00:55:55,520
1333
00:55:55,520 –> 00:55:57,839
1334
00:55:57,839 –> 00:55:59,839
1335
00:55:59,839 –> 00:56:02,319
1336
00:56:02,319 –> 00:56:03,440
1337
00:56:03,440 –> 00:56:06,240
هستند. سه یا به عنوان مثال
1338
00:56:06,240 –> 00:56:08,240
10 متغیر مستقل
1339
00:56:08,240 –> 00:56:11,680
همه چیز نیست متغیر y من
1340
00:56:11,680 –> 00:56:14,079
ممکن است با این متغیر یازدهم y
1341
00:56:14,079 –> 00:56:16,079
یازدهمین متغیر مستقل
1342
00:56:16,079 –> 00:56:19,200
که در این مدل در نظر گرفته
1343
00:56:19,200 –> 00:56:20,799
1344
00:56:20,799 –> 00:56:23,040
نشده است توضیح
1345
00:56:23,040 –> 00:56:24,400
1346
00:56:24,400 –> 00:56:26,240
داده شود. یک
1347
00:56:26,240 –> 00:56:27,680
متغیر مهم دیگر می
1348
00:56:27,680 –> 00:56:30,000
تواند پنج درصد بیشتر
1349
00:56:30,000 –> 00:56:31,359
هشتاد و هشتاد و پنج درصد را توضیح دهد تغییر کل
1350
00:56:31,359 –> 00:56:31,920
1351
00:56:31,920 –> 00:56:33,839
در y را می توان با آن متغیر یازدهم توضیح داد،
1352
00:56:33,839 –> 00:56:36,000
1353
00:56:36,000 –> 00:56:38,720
بنابراین می توانستیم جایی را از دست بدهیم به طوری
1354
00:56:38,720 –> 00:56:39,280
که
1355
00:56:39,280 –> 00:56:42,079
فقدان آن اثر گمشده
1356
00:56:42,079 –> 00:56:44,160
در
1357
00:56:44,160 –> 00:56:46,559
رهگیری سمت راست گرفته می شود، حاوی
1358
00:56:46,559 –> 00:56:47,359
تأثیر همه
1359
00:56:47,359 –> 00:56:49,760
متغیرهای حذف شده است که
1360
00:56:49,760 –> 00:56:52,640
در مدل در نظر نگرفته ایم.
1361
00:56:52,640 –> 00:56:55,280
درست گفتن آن بسیار مهم است،
1362
00:56:55,280 –> 00:56:59,839
بنابراین رهگیری برای این
1363
00:57:00,319 –> 00:57:01,760
مدل باید پیدا کنم رهگیری نرخ
1364
00:57:01,760 –> 00:57:05,359
رهگیری توسط
1365
00:57:05,359 –> 00:57:08,400
یک مدل رگرسیون رگرسیون
1366
00:57:08,400 –> 00:57:13,040
نقطه رهگیری s داده می شود، بنابراین
1367
00:57:13,040 –> 00:57:13,920
1368
00:57:13,920 –> 00:57:16,480
اگر x من صفر باشد مقدار رهگیری برای
1369
00:57:16,480 –> 00:57:17,359
1370
00:57:17,359 –> 00:57:19,359
من 2260 است. سالها تجربه تازهسازی
1371
00:57:19,359 –> 00:57:21,040
میآید حقوق مناسبی
1372
00:57:21,040 –> 00:57:23,040
که میتوانیم بدهیم بیست و شش هزار و
1373
00:57:23,040 –> 00:57:24,319
چهل و نه روپیه،
1374
00:57:24,319 –> 00:57:27,839
۴۹ واحد، من نمیتوانم آن را به عنوان روپیه بگویم،
1375
00:57:27,839 –> 00:57:30,559
بنابراین این همان چیزی است که n از این
1376
00:57:30,559 –> 00:57:32,640
رگرسیون حذف میکند که r مربع است
1377
00:57:32,640 –> 00:57:35,040
چگونه مجدداً r مربع را برای
1378
00:57:35,040 –> 00:57:36,400
پیدا کردن r مربع
1379
00:57:36,400 –> 00:57:40,400
استفاده می کنم. من از
1380
00:57:40,400 –> 00:57:42,640
مدل رگرسیون استفاده می کنم.
1381
00:57:42,640 –> 00:57:44,240
1382
00:57:44,240 –> 00:57:48,640
1383
00:57:48,960 –> 00:57:52,799
sion x آموزش و تغییر شکل
1384
00:57:52,799 –> 00:57:56,240
به 21 کاما 1 و y
1385
00:57:56,240 –> 00:58:00,480
3 بنابراین 96 درصد
1386
00:58:00,480 –> 00:58:04,240
از تغییرات در y می تواند
1387
00:58:04,240 –> 00:58:07,359
با این متغیر مستقل
1388
00:58:07,359 –> 00:58:10,480
1389
00:58:10,480 –> 00:58:13,119
توضیح دهد.
1390
00:58:13,119 –> 00:58:15,520
تنظیم کنید که چقدر می
1391
00:58:15,520 –> 00:58:17,040
1392
00:58:17,040 –> 00:58:20,720
تواند همان تست زیرخط x را توضیح دهد،
1393
00:58:20,720 –> 00:58:24,079
بنابراین در اینجا طول آزمون ثابت است
1394
00:58:24,079 –> 00:58:24,799
یا می توانید
1395
00:58:24,799 –> 00:58:28,559
9 متغیر باقیمانده را با کاما 1 قرار دهید،
1396
00:58:28,559 –> 00:58:30,720
بنابراین 92 درصد می تواند برای من توضیح دهد،
1397
00:58:30,720 –> 00:58:32,480
1398
00:58:32,480 –> 00:58:35,520
بنابراین اگر متغیر جدیدی وارد شود، می توانم
1399
00:58:35,520 –> 00:58:37,839
با توجه به اطمینان 96 درصد و
1400
00:58:37,839 –> 00:58:38,720
اطمینان نسبت
1401
00:58:38,720 –> 00:58:40,880
به منطقه سالهای تجربه
1402
00:58:40,880 –> 00:58:42,240
پنج سال سابقه
1403
00:58:42,240 –> 00:58:45,040
این می تواند حقوقی باشد مشروط بر اینکه او
1404
00:58:45,040 –> 00:58:47,119
در همان فاصله اطمینانی باشد که
1405
00:58:47,119 –> 00:58:50,559
من برای آموزش مدل در نظر گرفته ام، در غیر این
1406
00:58:50,559 –> 00:58:51,359
صورت
1407
00:58:51,359 –> 00:58:55,200
اثرات کاهشی مدل می آید
1408
00:58:55,200 –> 00:58:58,400
اگر من
1409
00:58:58,400 –> 00:59:01,680
از محدوده متغیر x که در حال حاضر امتحان کردم،
1410
00:59:01,680 –> 00:59:04,640
گزینه دو را با استفاده از مدل آمار
1411
00:59:04,640 –> 00:59:05,520
1412
00:59:05,520 –> 00:59:08,079
با استفاده از مدل آمار در اینجا فراتر میبرم، چند
1413
00:59:08,079 –> 00:59:09,440
موردی که تایپ کردم، فکر میکنم
1414
00:59:09,440 –> 00:59:11,119
این فایلی بود که در اختیار شما
1415
00:59:11,119 –> 00:59:13,440
عزیزان قرار گرفت
1416
00:59:13,760 –> 00:59:14,960
. این فایلی است که
1417
00:59:14,960 –> 00:59:17,040
در حال حاضر در کلمبوس آپلود
1418
00:59:17,040 –> 00:59:20,000
شده است قطار داده برابر است با من به هم
1419
00:59:20,000 –> 00:59:22,559
پیوسته این ترن p را گسترش می دهم و
1420
00:59:22,559 –> 00:59:23,359
حلقه سفید
1421
00:59:23,359 –> 00:59:25,520
را می سازم آن را دوباره
1422
00:59:25,520 –> 00:59:27,599
همان فریم داده
1423
00:59:27,599 –> 00:59:31,359
درست می کنم و با مدل بی سیم معمولی مطابقت دارد
1424
00:59:31,359 –> 00:59:34,000
مدل مربعی نحوه متناسب کردن
1425
00:59:34,000 –> 00:59:37,359
مدل مربع معمولی در اینجا
1426
00:59:37,680 –> 00:59:42,400
ما از مدل آمار وارد می کنیم،
1427
00:59:42,400 –> 00:59:47,839
فرمول api، فرض کنید خوب است،
1428
00:59:47,839 –> 00:59:52,480
m f برخی از نام های آمار مدل مدل فرمول ap
1429
00:59:52,480 –> 00:59:55,119
ما فقط آن را به عنوان smf می دهیم
1430
00:59:55,119 –> 00:59:56,559
مهم نیست هر چه می دهید، اکنون فقط یک
1431
00:59:56,559 –> 00:59:57,839
نام متحد است
1432
00:59:57,839 –> 01:00:00,559
. متر ساختمان در مدل خطی مدل
1433
01:00:00,559 –> 01:00:01,359
1434
01:00:01,359 –> 01:00:04,079
یک می خواهم آن را به صورت sm یک
1435
01:00:04,079 –> 01:00:06,880
رگرسیون حداقل مربعات معمولی
1436
01:00:06,880 –> 01:00:11,200
بدهم چه معنی دارد
1437
01:00:11,200 –> 01:00:16,319
فرمول برابر است با حقوق
1438
01:00:16,319 –> 01:00:19,359
و دستمزد تابعی از
1439
01:00:19,359 –> 01:00:23,200
بله بله
1440
01:00:23,200 –> 01:00:26,839
یک ثانیه خوب می توانم اینجا ببینم سال
1441
01:00:26,839 –> 01:00:28,480
تجربه
1442
01:00:28,480 –> 01:00:31,599
بله تجربه
1443
01:00:31,599 –> 01:00:35,760
چه داده ای برابر با
1444
01:00:35,760 –> 01:00:39,839
data train است و من می خواهم
1445
01:00:39,839 –> 01:00:41,200
مدل را
1446
01:00:41,200 –> 01:00:44,880
در حال حاضر برازش کنم مدل من مناسب است و
1447
01:00:44,880 –> 01:00:47,920
پارامترهای نقطه lm1 من چیست اگر قرار
1448
01:00:47,920 –> 01:00:49,839
است مقدار رهگیری
1449
01:00:49,839 –> 01:00:51,440
و چند سال تجربه را بدهم
1450
01:00:51,440 –> 01:00:54,559
را مقدار ضریب
1451
01:00:54,559 –> 01:00:56,640
رهگیری بیست و شش هزار صفر
1452
01:00:56,640 –> 01:00:58,160
چهل و نه است و سالهای
1453
01:00:58,160 –> 01:00:59,680
تجربه نه به صفر دو است
1454
01:00:59,680 –> 01:01:02,000
اگر مجبورید از
1455
01:01:02,000 –> 01:01:02,960
r استفاده کنید
1456
01:01:02,960 –> 01:01:04,720
فقط این تنها راه حل
1457
01:01:04,720 –> 01:01:06,640
رگرسیون است
1458
01:01:06,640 –> 01:01:08,880
که با جزئیات بیشتر بیشتر آشنا خواهیم شد.
1459
01:01:08,880 –> 01:01:10,000
در r در مدل آمار
1460
01:01:10,000 –> 01:01:11,839
حتی در اینجا فقط در مدل شروع،
1461
01:01:11,839 –> 01:01:14,079
شما جزئیات زیادی را دریافت خواهید کرد که احتمال آماری تنظیم شده
1462
01:01:14,079 –> 01:01:15,920
r مربع r مجذور f است،
1463
01:01:15,920 –> 01:01:16,880
1464
01:01:16,880 –> 01:01:20,079
اما در sk Learn uh شما نمی توانید دریافت کنید،
1465
01:01:20,079 –> 01:01:21,760
زیرا این توسط آماردانی توسعه داده شده است
1466
01:01:21,760 –> 01:01:23,200
که در
1467
01:01:23,200 –> 01:01:24,960
برنامه،
1468
01:01:24,960 –> 01:01:27,920
بنابراین یک تفاوت اصلی وجود دارد
1469
01:01:27,920 –> 01:01:28,960
به همین دلیل است
1470
01:01:28,960 –> 01:01:31,200
که وقتی میخواهم
1471
01:01:31,200 –> 01:01:32,079
1472
01:01:32,079 –> 01:01:34,799
مدلی با استفاده از مدل آمار درست بسازم، اطلاعات آماری بیشتری به دست میآوریم،
1473
01:01:34,799 –> 01:01:35,839
1474
01:01:35,839 –> 01:01:38,160
بنابراین
1475
01:01:38,160 –> 01:01:39,040
اگر یک
1476
01:01:39,040 –> 01:01:41,200
واحد ت