در این مطلب، ویدئو XGBoost در پایتون از شروع تا پایان با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:56:43
تصاویر این ویدئو:


قسمتی از زیرنویس این فیلم:
00:00:00,880 –> 00:00:03,360
xg boost
2
00:00:03,360 –> 00:00:07,839
فوق العاده است اما این وبینار
3
00:00:07,839 –> 00:00:10,940
هم کاملاً فوق العاده است بله steadquest
4
00:00:10,940 –> 00:00:15,440
[موسیقی]
5
00:00:15,440 –> 00:00:18,320
هورای من جاش استارمر هستم و
6
00:00:18,320 –> 00:00:19,199
به وبینار stat quest
7
00:00:19,199 –> 00:00:22,720
در xgboost در پایتون
8
00:00:22,720 –> 00:00:25,840
از ابتدا تا انتها خوش آمدید
9
00:00:25,840 –> 00:00:27,920
این نوت بوک مشتری است که ما قصد داریم
10
00:00:27,920 –> 00:00:29,519
به آن برویم تا امروز
11
00:00:29,519 –> 00:00:31,920
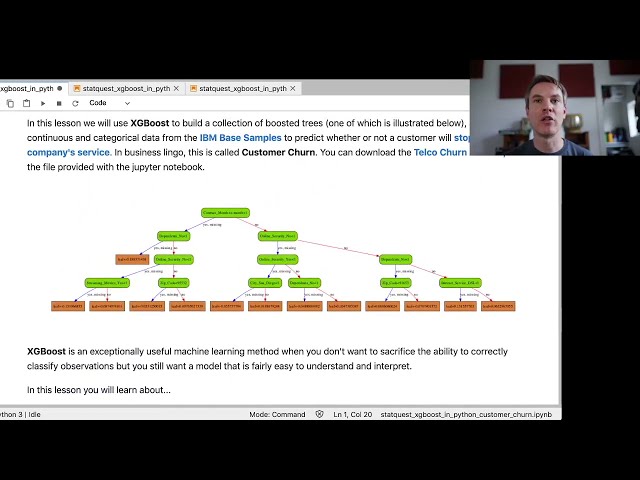
ما از xgboost برای ساخت مجموعهای از درختان تقویتشده استفاده میکنیم که
12
00:00:31,920 –> 00:00:34,000
13
00:00:34,000 –> 00:00:36,079
یکی از آنها در زیر نشان داده شده است، بنابراین
14
00:00:36,079 –> 00:00:38,079
این شخص در اینجا
15
00:00:38,079 –> 00:00:40,960
و از دادههای مستمر و طبقهبندی شده
16
00:00:40,960 –> 00:00:43,520
از وبسایت نمونههای پایه ibm استفاده میکند
17
00:00:43,520 –> 00:00:45,600
تا پیشبینی کند که آیا مشتری
18
00:00:45,600 –> 00:00:47,600
استفاده از آن را متوقف میکند یا خیر. سرویس این شرکت
19
00:00:47,600 –> 00:00:51,039
در زبان تجاری به این اصطلاح
20
00:00:51,039 –> 00:00:52,559
ریزش مشتری
21
00:00:52,559 –> 00:00:54,800
می گویند، می توانید مجموعه داده تلکو چروک را دانلود
22
00:00:54,800 –> 00:00:57,039
کنید یا از فایل ارائه شده به همراه
23
00:00:57,039 –> 00:00:58,160
دفترچه یادداشت jupyter استفاده کنید
24
00:00:58,160 –> 00:00:59,600
و اگر می خواهید در مورد
25
00:00:59,600 –> 00:01:02,000
مجموعه داده های تلکو churn اطلاعات بیشتری کسب کنید، می توانید روی
26
00:01:02,000 –> 00:01:03,680
این لینک در نوت بوک jupyter کلیک کنید. این به صورت
27
00:01:03,680 –> 00:01:04,239
زنده است
28
00:01:04,239 –> 00:01:05,760
یا اگر فقط میخواهید درباره نمونههای پایه اطلاعات بیشتری کسب کنید
29
00:01:05,760 –> 00:01:09,200
، انواع
30
00:01:09,200 –> 00:01:10,880
مجموعه دادهها در اینجا وجود دارد که میتوانید از آنها برای
31
00:01:10,880 –> 00:01:12,400
آزمایشهای دیگر
32
00:01:12,400 –> 00:01:15,040
در یادگیری ماشین استفاده کنید، بنابراین این یک ابزار
33
00:01:15,040 –> 00:01:16,880
عالی است. منبعی برای
34
00:01:16,880 –> 00:01:20,400
آزمایش این مدلها بهطور کلی،
35
00:01:20,400 –> 00:01:23,600
xgboost یک
36
00:01:23,600 –> 00:01:25,600
روش یادگیری ماشینی فوقالعاده مفید است،
37
00:01:25,600 –> 00:01:28,000
زمانی که نمیخواهید توانایی طبقهبندی صحیح مشاهدات را قربانی کنید،
38
00:01:28,000 –> 00:01:29,600
39
00:01:29,600 –> 00:01:32,159
اما همچنان
40
00:01:32,159 –> 00:01:34,560
مدلی میخواهید که درک
41
00:01:34,560 –> 00:01:36,079
و تفسیر آن
42
00:01:36,079 –> 00:01:38,720
در این درس به شما آسان باشد. در مورد
43
00:01:38,720 –> 00:01:41,040
وارد کردن داده ها از یک فایل
44
00:01:41,040 –> 00:01:43,680
داده از دست رفته، از جمله برخورد با
45
00:01:43,680 –> 00:01:44,479
داده های از دست رفته
46
00:01:44,479 –> 00:01:47,119
سبک تقویت xg که نسبتاً
47
00:01:47,119 –> 00:01:48,240
منحصر به فرد است، یاد می گیرد
48
00:01:48,240 –> 00:01:49,840
و سپس ما می خواهیم داده ها را برای تقویت xg قالب بندی کنیم،
49
00:01:49,840 –> 00:01:52,159
از جمله با استفاده از یک رمزگذاری داغ
50
00:01:52,159 –> 00:01:52,960
51
00:01:52,960 –> 00:01:56,320
و در واقع به دلیل روشی که
52
00:01:56,320 –> 00:01:59,280
xgboost از داده های از دست رفته استفاده می کند. ما در میانه این وبینار
53
00:01:59,280 –> 00:02:01,119
یک کوئست کوچک پشته خواهیم
54
00:02:01,119 –> 00:02:03,360
داشت تا به
55
00:02:03,360 –> 00:02:05,200
نوعی ویژگی های یک کدگذاری داغ
56
00:02:05,200 –> 00:02:06,000
57
00:02:06,000 –> 00:02:08,080
و چگونگی ارتباط آن با نحوه رسیدگی به داده های از دست رفته را
58
00:02:08,080 –> 00:02:09,598
59
00:02:09,598 –> 00:02:11,440
توضیح دهیم، می خواهیم یک
60
00:02:11,440 –> 00:02:12,640
61
00:02:12,640 –> 00:02:14,560
مدل تقویت اولیه xg بسازیم و سپس
62
00:02:14,560 –> 00:02:16,400
پارامترها را با
63
00:02:16,400 –> 00:02:18,080
اعتبارسنجی متقاطع و جستجوی شبکه ای بهینه سازی می
64
00:02:18,080 –> 00:02:20,879
کنیم و در آخر می خواهیم
65
00:02:20,879 –> 00:02:21,680
اعتبارسنجی
66
00:02:21,680 –> 00:02:24,160
و ساخت واضح و و t را ترسیم کنیم. ما
67
00:02:24,160 –> 00:02:25,520
قصد داریم eval را تفسیر کرده
68
00:02:25,520 –> 00:02:28,319
و مدل بهینه سازی xg boost را
69
00:02:28,319 –> 00:02:29,680
ارزیابی کنیم،
70
00:02:29,680 –> 00:02:33,120
توجه داشته باشید که این آموزش از قبل فرض می کند که
71
00:02:33,120 –> 00:02:35,280
شما اصول پایتون را می دانید و
72
00:02:35,280 –> 00:02:38,080
با تئوری پشت
73
00:02:38,080 –> 00:02:41,120
اعتبارسنجی متقاطع xgboost و ماتریس های سردرگمی آشنا هستید، در
74
00:02:41,120 –> 00:02:43,200
صورتی که با کلیک کردن بر روی جستجوی آماری را بررسی نکنید.
75
00:02:43,200 –> 00:02:46,000
پیوندهای مربوط به هر موضوع
76
00:02:46,000 –> 00:02:48,879
نیز توجه داشته باشید من شدیداً شما را تشویق می کنم که
77
00:02:48,879 –> 00:02:50,879
با کد
78
00:02:50,879 –> 00:02:53,280
بازی کنید بازی با کد بهترین راه برای
79
00:02:53,280 –> 00:02:55,920
یادگیری از آن است،
80
00:02:55,920 –> 00:02:58,879
بنابراین اولین کاری که ما انجام می دهیم این است که در
81
00:02:58,879 –> 00:03:01,120
یک دسته از ماژول های
82
00:03:01,120 –> 00:03:03,280
پایتون بارگذاری کنیم، پایتون فقط به ما یک
83
00:03:03,280 –> 00:03:04,640
زبان برنامه نویسی اصلی
84
00:03:04,640 –> 00:03:06,480
این ماژول ها به ما عملکرد اضافی می دهند
85
00:03:06,480 –> 00:03:08,640
تا داده ها
86
00:03:08,640 –> 00:03:11,360
را پاکسازی و قالب بندی کنیم و سپس یادداشت مدل تقویت
87
00:03:11,360 –> 00:03:13,840
xgb را ارزیابی و ترسیم
88
00:03:13,840 –> 00:03:17,360
کنیم، به پایتون 3
89
00:03:17,360 –> 00:03:19,440
و حداقل این نسخه از
90
00:03:19,440 –> 00:03:21,360
نسخه های ماژول های زیر
91
00:03:21,360 –> 00:03:24,799
pandas numpy نیاز دارید. scikit-learn و xg boost
92
00:03:24,799 –> 00:03:26,959
من دستورالعملهایی در مورد نحوه نصب
93
00:03:26,959 –> 00:03:29,040
همه این موارد در اینجا
94
00:03:29,040 –> 00:03:31,280
و همچنین دستورالعملهایی در مورد اینکه آیا میخواهید
95
00:03:31,280 –> 00:03:32,080
واقعاً
96
00:03:32,080 –> 00:03:34,080
آن درخت زیبا را ترسیم کنید، دارم.
97
00:03:34,080 –> 00:03:35,519
دستورالعملهایی در مورد نحوه نصب
98
00:03:35,519 –> 00:03:38,959
graphviz نیز برای اینکه
99
00:03:38,959 –> 00:03:40,560
همه چیز به درستی انجام شود، بنابراین اینجا جایی است که
100
00:03:40,560 –> 00:03:42,319
دادهها را بارگیری میکنیم، زیرا
101
00:03:42,319 –> 00:03:45,440
این یک نوت بوک مشتری است که میتوانیم آن را بارگذاری کنیم، میتوانیم
102
00:03:45,440 –> 00:03:46,000
103
00:03:46,000 –> 00:03:48,159
کد پایتون را با کلیک کردن اجرا کنیم.
104
00:03:48,159 –> 00:03:50,159
روی دکمه
105
00:03:50,159 –> 00:03:53,200
پخش یا می توانیم اجرای سلول های انتخاب شده را انتخاب
106
00:03:53,200 –> 00:03:55,120
کنیم یا می توانیم این ترکیب صفحه کلید را
107
00:03:55,120 –> 00:03:56,480
108
00:03:56,480 –> 00:03:59,360
برای اجرای سلول
109
00:03:59,360 –> 00:04:00,000
110
00:04:00,000 –> 00:04:02,239
111
00:04:02,239 –> 00:04:03,439
112
00:04:03,439 –> 00:04:05,200
113
00:04:05,200 –> 00:04:06,480
114
00:04:06,480 –> 00:04:09,920
ها انتخاب کنیم. برای اجرای این
115
00:04:10,000 –> 00:04:12,480
و ما یک عدد در اینجا دریافت می کنیم که به ما می گوید
116
00:04:12,480 –> 00:04:13,360
که ما
117
00:04:13,360 –> 00:04:16,319
کد را اجرا
118
00:04:17,040 –> 00:04:20,079
کرده ایم،
119
00:04:20,079 –> 00:04:22,000
بنابراین اگر پایتون همچنان در حال حرکت است،
120
00:04:22,000 –> 00:04:23,199
اگر کاری کمی
121
00:04:23,199 –> 00:04:25,360
پیچیده تر از بارگذاری در برخی
122
00:04:25,360 –> 00:04:28,400
ماژول ها انجام می دهید، عالی است.
123
00:04:28,400 –> 00:04:31,840
وقتی پایتون در حال دور شدن است، ستارهای را در اینجا
124
00:04:31,840 –> 00:04:34,880
میبینیم، اما ما فقط یک عدد دریافت میکنیم، بنابراین خوب است،
125
00:04:34,880 –> 00:04:36,960
اکنون آماده ایم دادههایی را
126
00:04:36,960 –> 00:04:38,800
که قرار است بارگذاری کنیم در یک مجموعه داده از نمونههای
127
00:04:38,800 –> 00:04:39,680
پایه ibm به
128
00:04:39,680 –> 00:04:42,240
طور خاص وارد کنیم. قرار است
129
00:04:42,240 –> 00:04:44,320
از مجموعه داده انقباض مخابراتی استفاده کنید
130
00:04:44,320 –> 00:04:46,720
که به ما امکان می دهد پیش بینی کنیم
131
00:04:46,720 –> 00:04:48,720
که آیا شخصی استفاده از خدمات مخابراتی را متوقف می کند
132
00:04:48,720 –> 00:04:51,759
یا از انواع مختلف داده های
133
00:04:51,759 –> 00:04:52,880
پیوسته
134
00:04:52,880 –> 00:04:56,240
و طبقه بندی شده استفاده نمی کند. هنگامی که
135
00:04:56,240 –> 00:04:57,120
136
00:04:57,120 –> 00:04:59,759
پانداها در داده ها می خوانند، یک قاب داده را برمی گرداند
137
00:04:59,759 –> 00:05:01,919
که بسیار شبیه به داده های صفحه گسترده است
138
00:05:01,919 –> 00:05:04,400
که در ردیف ها و ستون ها سازماندهی شده اند.
139
00:05:04,400 –> 00:05:06,479
و هر سطر می تواند حاوی ترکیبی از
140
00:05:06,479 –> 00:05:07,919
متن و
141
00:05:07,919 –> 00:05:09,840
اعداد باشد. نام متغیر استاندارد برای یک
142
00:05:09,840 –> 00:05:11,199
قاب داده، حروف اول
143
00:05:11,199 –> 00:05:12,960
df است و این چیزی است که ما در اینجا استفاده می
144
00:05:12,960 –> 00:05:14,639
کنیم، بنابراین کاری که انجام می دهیم این است
145
00:05:14,639 –> 00:05:16,320
که یک قاب داده جدید ایجاد می کنیم. ‘در حال
146
00:05:16,320 –> 00:05:17,680
فراخوانی df
147
00:05:17,680 –> 00:05:19,759
هستیم و آن را روی
148
00:05:19,759 –> 00:05:21,680
خروجی تابع pandas
149
00:05:21,680 –> 00:05:25,360
read csv تنظیم می کنیم، بنابراین این یک
150
00:05:25,360 –> 00:05:28,560
فایل csv است که در حال بارگیری آن هستیم،
151
00:05:28,560 –> 00:05:31,759
بنابراین بیایید
152
00:05:31,759 –> 00:05:34,080
اکنون که داده ها را در یک قاب داده بارگذاری کرده ایم، این bam را انجام دهیم.
153
00:05:34,080 –> 00:05:35,600
به نام df
154
00:05:35,600 –> 00:05:37,280
ما
155
00:05:37,280 –> 00:05:39,039
با استفاده از تابع head به پنج ردیف اول نگاه می کنیم،
156
00:05:39,039 –> 00:05:41,520
بنابراین این قاب داده ما df است و
157
00:05:41,520 –> 00:05:43,360
یک تابع مرتبط به نام
158
00:05:43,360 –> 00:05:45,840
head وجود دارد که می خواهیم اجرا کنیم و کاری که
159
00:05:45,840 –> 00:05:48,160
انجام می دهد این است که پنج ردیف اول را چاپ می کند.
160
00:05:48,160 –> 00:05:52,160
بنابراین می گوید پنج ردیف در 33 ستون
161
00:05:52,160 –> 00:05:54,160
و ما s ورق بزنید همه این ستون ها را می بینیم
162
00:05:54,160 –> 00:05:56,319
که همه آنها
163
00:05:56,319 –> 00:05:57,680
روی صفحه چاپ نشده اند،
164
00:05:57,680 –> 00:05:59,039
نمی دانم آیا می توانید ببینید که بین جنسیت و قرارداد یک نقطه نقطه وجود دارد یا نه
165
00:05:59,039 –> 00:06:00,720
166
00:06:00,720 –> 00:06:03,520
و این فقط به این معنی است
167
00:06:03,520 –> 00:06:04,319
که
168
00:06:04,319 –> 00:06:06,160
اگرچه 33 ستون وجود دارد که ما چاپ نکرده ایم.
169
00:06:06,160 –> 00:06:09,840
همه آنها به صفحه نمایش
170
00:06:10,560 –> 00:06:14,080
توجه داشته باشید
171
00:06:14,080 –> 00:06:17,360
چهار ستون آخر دلیل cltv برگرداندن
172
00:06:17,360 –> 00:06:18,319
نمره
173
00:06:18,319 –> 00:06:22,720
174
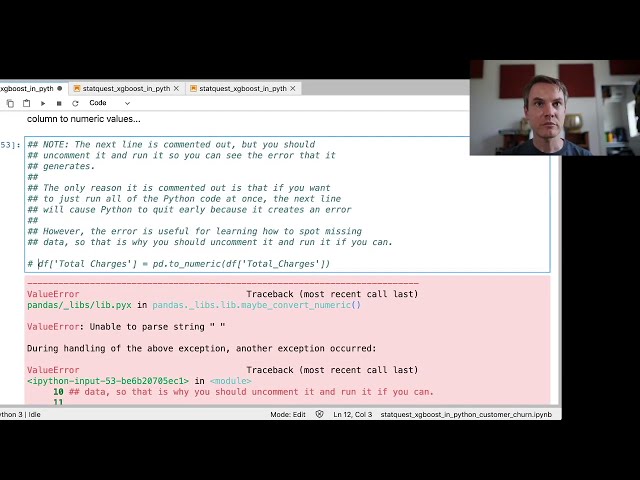
00:06:23,120 –> 00:06:26,160
ام اینها امم اینها چیست اینها نوعی
175
00:06:26,160 –> 00:06:29,120
مصاحبه خروجی هستند اوه داده هایی که
176
00:06:29,120 –> 00:06:30,400
از افرادی
177
00:06:30,400 –> 00:06:33,680
که مخابرات را ترک کرده اند جمع آوری شده است و فقط افرادی که
178
00:06:33,680 –> 00:06:34,160
179
00:06:34,160 –> 00:06:37,199
مخابرات را ترک کرده اند پاسخ داده اند در اینجا،
180
00:06:37,199 –> 00:06:40,319
بنابراین ما نمیخواهیم از این دادهها در پیشبینی خود استفاده کنیم،
181
00:06:40,319 –> 00:06:41,199
182
00:06:41,199 –> 00:06:44,080
زیرا به طور کلی، کسی قرار نیست
183
00:06:44,080 –> 00:06:45,520
184
00:06:45,520 –> 00:06:48,639
قبل از ترک شرکت مصاحبه خروج
185
00:06:48,639 –> 00:06:51,599
را انجام دهد، بنابراین از آنجایی که این چیزها به ما
186
00:06:51,599 –> 00:06:52,400
187
00:06:52,400 –> 00:06:55,199
توانایی پیشبینی کامل میدهد، تواناییهای پیشبینی کامل
188
00:06:55,199 –> 00:06:56,000
189
00:06:56,000 –> 00:06:58,720
را به ما میدهد. آنها را از مجموعه داده
190
00:06:58,720 –> 00:06:59,360
um،
191
00:06:59,360 –> 00:07:02,880
بنابراین ما این کار را با استفاده
192
00:07:02,880 –> 00:07:04,479
از تابع drop انجام می دهیم، بنابراین قاب داده داریم،
193
00:07:04,479 –> 00:07:05,840
این قاب داده ما است و ما
194
00:07:05,840 –> 00:07:07,360
از تابع drop استفاده می کنیم و سپس
195
00:07:07,360 –> 00:07:08,800
196
00:07:08,800 –> 00:07:11,520
ستون هایی را که می خواهیم لیست می کنیم. t برای رها کردن،
197
00:07:11,520 –> 00:07:13,199
دسترسی را برابر با 1 قرار می دهیم
198
00:07:13,199 –> 00:07:15,280
تا مشخص کنیم که به جای سطرها، ستون ها را حذف می
199
00:07:15,280 –> 00:07:16,720
200
00:07:16,720 –> 00:07:19,840
کنیم و در جای خود روی true قرار می دهیم، به این معنی
201
00:07:19,840 –> 00:07:22,639
که می خواهیم df این قاب داده
202
00:07:22,639 –> 00:07:24,800
به نام df را مستقیماً تغییر دهیم، ما
203
00:07:24,800 –> 00:07:25,840
204
00:07:25,840 –> 00:07:29,039
کپی نمی کنیم. از قاب داده
205
00:07:29,039 –> 00:07:32,240
و فقط در کپی uh است که
206
00:07:32,240 –> 00:07:35,520
یا uh حاوی این
207
00:07:35,520 –> 00:07:37,440
یا بدون این ستون ها است، این
208
00:07:37,440 –> 00:07:39,039
ستون ها حذف می شوند و بعد از
209
00:07:39,039 –> 00:07:39,520
210
00:07:39,520 –> 00:07:41,919
آنچه که پس از آن هستیم، کاری که می خواهیم انجام دهیم این است
211
00:07:41,919 –> 00:07:42,960
که می خواهیم
212
00:07:42,960 –> 00:07:46,000
چاپ کنیم پنج ردیف اول دوباره فقط برای
213
00:07:46,000 –> 00:07:48,000
تأیید اینکه همه چیز را به درستی انجام دادهایم،
214
00:07:48,000 –> 00:07:50,160
بنابراین بیایید این کار را انجام دهیم،
215
00:07:50,160 –> 00:07:53,199
بنابراین وقتی به سمت راست پیمایش
216
00:07:53,199 –> 00:07:56,960
میکنیم، میبینیم که دلیل و cltv
217
00:07:56,960 –> 00:07:59,840
آن چیزها از بین رفتهاند،
218
00:08:00,960 –> 00:08:04,080
برخی از ستونهای دیگر در این مجموعه داده
219
00:08:04,080 –> 00:08:04,639
220
00:08:04,639 –> 00:08:07,120
فقط حاوی یک مقدار هستند. و
221
00:08:07,120 –> 00:08:09,199
برای طبقه بندی مفید نخواهد بود،
222
00:08:09,199 –> 00:08:12,400
به عنوان مثال تعداد این ستون ها، ما
223
00:08:12,400 –> 00:08:13,840
فقط یک دسته از آنها را
224
00:08:13,840 –> 00:08:16,160
می بینیم که می توانیم تأیید کنیم که تنها مقدار در
225
00:08:16,160 –> 00:08:17,759
این ستون یک به یک است
226
00:08:17,759 –> 00:08:20,240
با قاب داده خود که مشخص می کنیم
227
00:08:20,240 –> 00:08:22,000
می خواهیم به ستون شمارش نگاه کنیم و
228
00:08:22,000 –> 00:08:23,919
سپس آن را فراخوانی می کنیم. عملکرد منحصر
229
00:08:23,919 –> 00:08:26,639
به فرد برای چاپ تمام مقادیر منحصربفرد در
230
00:08:26,639 –> 00:08:28,639
آن ستون را حذف کنید و وقتی اجرا می
231
00:08:28,639 –> 00:08:31,759
کنیم می بینیم که تنها مقدار منحصر به فرد یک است،
232
00:08:31,759 –> 00:08:34,559
بنابراین این تعداد ستون فقط حاوی یک است
233
00:08:34,559 –> 00:08:35,360
و
234
00:08:35,360 –> 00:08:38,399
235
00:08:38,399 –> 00:08:41,440
همینطور اگر به مقادیر منحصر به فرد
236
00:08:41,440 –> 00:08:43,519
در کشور نگاه کنیم، آن را برای پیش بینی بی فایده می کند. در آن ما
237
00:08:43,519 –> 00:08:45,680
چندین بار ایالات متحده را می بینیم و اگر
238
00:08:45,680 –> 00:08:47,519
مقادیر منحصر به فرد را در
239
00:08:47,519 –> 00:08:49,440
ستون کشور چاپ
240
00:08:49,440 –> 00:08:51,519
کنیم، می بینیم که تنها مقدار
241
00:08:51,519 –> 00:08:53,760
ایالات متحده ایالات متحده است
242
00:08:53,760 –> 00:08:56,080
به طور مشابه در ستون State،
243
00:08:56,080 –> 00:08:57,600
دسته ای از ورودی ها را برای کالیفرنیا می بینیم، بیایید
244
00:08:57,600 –> 00:09:00,320
همه موارد منحصر به فرد را چاپ کنیم. مقادیر در حالت
245
00:09:00,320 –> 00:09:03,040
دوباره فقط یک مقدار کالیفرنیا
246
00:09:03,040 –> 00:09:04,640
را می بینیم، به این معنی که می توانیم
247
00:09:04,640 –> 00:09:07,440
تعداد کشور و حالت را از
248
00:09:07,440 –> 00:09:08,000
تجزیه و تحلیل حذف کنیم،
249
00:09:08,000 –> 00:09:09,200
زیرا آنها به
250
00:09:09,200 –> 00:09:12,640
پیش بینی ها در
251
00:09:12,640 –> 00:09:15,360
شهر متضاد کمک نمی کنند، ستونی به نام شهر حاوی
252
00:09:15,360 –> 00:09:17,200
دسته ای از نام های شهر مختلف است، بنابراین بیایید
253
00:09:17,200 –> 00:09:19,440
نگاه کنیم.
254
00:09:19,440 –> 00:09:22,240
بنابراین بله، ما می بینیم که پارک هانتینگتون لس آنجلس بورلی هیلز
255
00:09:22,240 –> 00:09:23,279
256
00:09:23,279 –> 00:09:26,640
همه چیز
257
00:09:26,640 –> 00:09:28,320
را در خود جای داده است، بنابراین ما می خواهیم شهر را در آنجا ترک کنیم، زیرا
258
00:09:28,320 –> 00:09:29,680
ممکن است شهر در پیش بینی به ما کمک کند،
259
00:09:29,680 –> 00:09:32,000
اما ما نیز در این زمینه
260
00:09:32,000 –> 00:09:33,600
هستیم. برای حذف
261
00:09:33,600 –> 00:09:36,880
شناسه مشتری و ما قصد داریم این را
262
00:09:36,880 –> 00:09:40,080
263
00:09:40,080 –> 00:09:41,440
حذف کنیم، شناسه مشتری را حذف می کنیم
264
00:09:41,440 –> 00:09:42,800
زیرا برای هر فرد مقدار متفاوتی وجود دارد،
265
00:09:42,800 –> 00:09:44,240
بنابراین
266
00:09:44,240 –> 00:09:46,320
برای پیش بینی ها خیلی مفید نخواهد بود
267
00:09:46,320 –> 00:09:48,240
و همچنین ستونی به نام lat
268
00:09:48,240 –> 00:09:49,680
long وجود دارد
269
00:09:49,680 –> 00:09:51,839
که شامل هر دو طول و عرض
270
00:09:51,839 –> 00:09:52,720
271
00:09:52,720 –> 00:09:54,640
جغرافیایی ساکن آن
272
00:09:54,640 –> 00:09:56,480
مشتری بود، اما ما همچنین
273
00:09:56,480 –> 00:09:58,640
ستونهای جداگانهای برای طول و عرض
274
00:09:58,640 –> 00:09:59,600
جغرافیایی
275
00:09:59,600 –> 00:10:01,680
داریم، بنابراین به ستونی که این دو چیز را ادغام میکند، نیاز
276
00:10:01,680 –> 00:10:02,880
277
00:10:02,880 –> 00:10:05,440
نداریم، بنابراین ما میخواهیم اوه آن را رها کنیم.
278
00:10:05,440 –> 00:10:07,360
آن ستونها نیز درست مانند
279
00:10:07,360 –> 00:10:09,600
قبل،
280
00:10:09,600 –> 00:10:11,279
بنابراین ما از تابع drop
281
00:10:11,279 –> 00:10:12,640
استفاده میکنیم، سپس در آرایهای از
282
00:10:12,640 –> 00:10:14,560
283
00:10:14,560 –> 00:10:15,680
284
00:10:15,680 –> 00:10:17,519
ستونهایی که میخواهیم رها کنیم، مشخص میکنیم که به جای ردیفها، ستونها را حذف میکنیم.
285
00:10:17,519 –> 00:10:19,440
و دوباره درست مثل
286
00:10:19,440 –> 00:10:20,079
287
00:10:20,079 –> 00:10:22,880
قبل که از in place استفاده می کنیم روی true به طوری که
288
00:10:22,880 –> 00:10:25,360
289
00:10:25,360 –> 00:10:28,000
خود قاب داده df را تغییر می دهیم و مانند همیشه
290
00:10:28,000 –> 00:10:29,600
پنج ردیف اول را چاپ می کنیم تا
291
00:10:29,600 –> 00:10:32,959
مطمئن شویم همه چیز را درست
292
00:10:32,959 –> 00:10:35,920
انجام داده ایم. فقط
293
00:10:35,920 –> 00:10:36,880
خوبه
294
00:10:36,880 –> 00:10:40,560
اکنون فقط به یادداشت 24 ستونی رسیده ایم،
295
00:10:40,560 –> 00:10:43,519
اگرچه اشکالی ندارد که در نام شهرها
296
00:10:43,519 –> 00:10:44,000
فضای سفید وجود داشته باشد،
297
00:10:44,000 –> 00:10:47,360
بنابراین می بینید که
298
00:10:47,360 –> 00:10:49,360
ما داریم لس آنجلس داریم و
299
00:10:49,360 –> 00:10:51,360
یک فضای خالی بین از دست دادن و
300
00:10:51,360 –> 00:10:52,079
فرشته وجود دارد
301
00:10:52,079 –> 00:10:54,399
و آن را می بینید وقتی
302
00:10:54,399 –> 00:10:56,320
مقادیر منحصربفرد
303
00:10:56,320 –> 00:10:57,200
نام هر شهر را چاپ
304
00:10:57,200 –> 00:10:59,120
کردیم، یک فضای خالی بین بورلی
305
00:10:59,120 –> 00:11:00,880
و تپهها و یک فضای خالی بین
306
00:11:00,880 –> 00:11:03,120
هانتینگتون و پارک داریم،
307
00:11:03,120 –> 00:11:06,399
این فضاهای خالی
308
00:11:06,399 –> 00:11:09,680
برای تقویت
309
00:11:09,680 –> 00:11:11,120
xg کاملاً مشکلی ندارند. برای این کار از یک
310
00:11:11,120 –> 00:11:13,040
کدگذاری داغ استفاده
311
00:11:13,040 –> 00:11:15,839
خواهیم کرد، اما
312
00:11:15,839 –> 00:11:18,000
اگر بخواهیم
313
00:11:18,000 –> 00:11:18,640
314
00:11:18,640 –> 00:11:22,240
درخت واقعی را بکشیم،
315
00:11:22,240 –> 00:11:24,800
اگر بخواهیم بعداً این درخت را بکشیم، نمیتوانیم فضای خالی یا فضای خالی
316
00:11:24,800 –> 00:11:26,399
داشته باشیم. در پایان
317
00:11:26,399 –> 00:11:30,000
باید فاصلههای سفید را حذف
318
00:11:30,000 –> 00:11:32,800
کنیم، بنابراین این کار را انجام میدهیم، چون
319
00:11:32,800 –> 00:11:34,399
میدانیم فضای سفید زیادی در
320
00:11:34,399 –> 00:11:35,600
ستون شهر وجود دارد،
321
00:11:35,600 –> 00:11:37,680
مشخص میکنیم که چارچوب دادههایمان را
322
00:11:37,680 –> 00:11:39,279
داریم و مشخص میکنیم که به ستون شهر علاقه مند هستیم.
323
00:11:39,279 –> 00:11:40,560
324
00:11:40,560 –> 00:11:42,560
و سپس می توانیم از تابع جایگزین استفاده کنیم
325
00:11:42,560 –> 00:11:43,760
و این یک ju است یک
326
00:11:43,760 –> 00:11:46,240
تابع جستجو و جایگزینی uh
327
00:11:46,240 –> 00:11:48,160
را مانند هر جای دیگری پیدا کنید،
328
00:11:48,160 –> 00:11:50,160
ما در حال جستجوی فضاهای خالی
329
00:11:50,160 –> 00:11:52,160
هستیم و
330
00:11:52,160 –> 00:11:55,200
هر فضای خالی را با یک زیرخط جایگزین می
331
00:11:55,200 –> 00:11:57,680
کنیم، regex را روی true قرار می دهیم که
332
00:11:57,680 –> 00:12:00,160
regex کوتاه برای عبارت منظم است
333
00:12:00,160 –> 00:12:02,079
و اگر شما با اصطلاح
334
00:12:02,079 –> 00:12:04,720
regex یا عبارات منظم آشنا نیستید نگران نباشید
335
00:12:04,720 –> 00:12:06,480
فقط به آن به عنوان
336
00:12:06,480 –> 00:12:09,519
ویژگی های پیشرفته برای عملکرد جستجو و جایگزینی فکر
337
00:12:09,519 –> 00:12:10,560
338
00:12:10,560 –> 00:12:11,839
کنید و دوباره درست مانند
339
00:12:11,839 –> 00:12:13,120
قبل از انجام این
340
00:12:13,120 –> 00:12:14,079
اصلاحات
341
00:12:14,079 –> 00:12:16,880
در جای خود. ما مستقیماً df را اصلاح می کنیم
342
00:12:16,880 –> 00:12:17,680
343
00:12:17,680 –> 00:12:19,600
و سپس پنج ردیف اول را چاپ می
344
00:12:19,600 –> 00:12:22,480
کنیم تا مطمئن شویم که این کار را درست انجام
345
00:12:22,480 –> 00:12:25,360
داده ایم و یک خط زیر
346
00:12:25,360 –> 00:12:25,760
بین
347
00:12:25,760 –> 00:12:28,720
لس آنجلس می بینیم و همچنین می توانیم
348
00:12:28,720 –> 00:12:29,440
349
00:12:29,440 –> 00:12:33,680
10 ام اول نام شهر را چاپ کنیم و
350
00:12:33,680 –> 00:12:35,760
10 اولین نام منحصر به فرد را نیز چاپ کنیم. نام شهرها و
351
00:12:35,760 –> 00:12:37,120
بررسی کنید که ما
352
00:12:37,120 –> 00:12:40,160
بین بورلی و تپه ها
353
00:12:40,160 –> 00:12:42,000
بین هانتینگتون و پارک شده
354
00:12:42,000 –> 00:12:44,560
بین مارینا و دل و دل و ری
355
00:12:44,560 –> 00:12:45,279
داریم، بنابراین
356
00:12:45,279 –> 00:12:48,160
آن فضاهای سفید را حذف کرده ایم همچنین
357
00:12:48,160 –> 00:12:50,000
باید فضاهای سفید
358
00:12:50,000 –> 00:12:51,200
در ستون را حذف کنیم. نامگذاری کنید، بنابراین ما میخواهیم
359
00:12:51,200 –> 00:12:51,839
360
00:12:51,839 –> 00:12:55,120
آنها را با زیرخط جایگزین کنیم، همچنین این کار را
361
00:12:55,120 –> 00:12:56,880
کمی متفاوت
362
00:12:56,880 –> 00:12:59,120
انجام میدهیم، بنابراین قاب دادههایمان df است و
363
00:12:59,120 –> 00:13:00,079
مشخص
364
00:13:00,079 –> 00:13:02,240
کردهایم که به ستونها نه در یک
365
00:13:02,240 –> 00:13:05,040
ستون خاص، بلکه به نام ستونها
366
00:13:05,040 –> 00:13:06,800
و آنچه که میخواهیم علاقهمندیم. انجام این کار این است که
367
00:13:06,800 –> 00:13:08,800
نام ستون ها را به رشته تبدیل می کنیم و سپس
368
00:13:08,800 –> 00:13:10,560
تابع جایگزین را فراخوانی می کنیم و دوباره این
369
00:13:10,560 –> 00:13:12,320
فقط یک جستجو و جایگزینی است
370
00:13:12,320 –> 00:13:14,240
که ما فضای سفید را جستجو می کنیم و
371
00:13:14,240 –> 00:13:15,839
با زیر خط جایگزین می کنیم
372
00:13:15,839 –> 00:13:17,440
و دقیقاً همانطور که قبل از چاپ انجام دادیم.
373
00:13:17,440 –> 00:13:20,880
از پنج ردیف اول
374
00:13:20,880 –> 00:13:23,360
بام، بنابراین اکنون ما یک خط زیر خطی بین
375
00:13:23,360 –> 00:13:25,040
کد پستی و کد
376
00:13:25,040 –> 00:13:27,920
پستی و شهروندی و ماه ها و
377
00:13:27,920 –> 00:13:30,079
غیره می
378
00:13:30,079 –> 00:13:33,040
بینیم، همه داده
379
00:13:33,040 –> 00:13:34,639
هایی را که به ما
380
00:13:34,639 –> 00:13:37,440
در ایجاد یک مدل تقویت xg کمکی نمی کند حذف کرده
381
00:13:37,440 –> 00:13:40,000
ایم و دوباره قالب بندی کرده ایم. نام ستون ها
382
00:13:40,000 –> 00:13:41,199
و نام شهرها
383
00:13:41,199 –> 00:13:44,560
به طوری که ما اکنون می توانیم یک درخت ترسیم کنیم، بنابراین
384
00:13:44,560 –> 00:13:46,320
اکنون آماده شناسایی و مقابله
385
00:13:46,320 –> 00:13:46,639
با
386
00:13:46,639 –> 00:13:50,399
داده های از دست رفته هستیم،
387
00:13:50,399 –> 00:13:52,880
متأسفانه بزرگترین بخش هر پروژه تجزیه و تحلیل داده
388
00:13:52,880 –> 00:13:54,639
، اطمینان از
389
00:13:54,639 –> 00:13:56,959
اینکه داده ها به درستی قالب بندی
390
00:13:56,959 –> 00:13:59,199
و اصلاح شده اند. هنگامی
391
00:13:59,199 –> 00:14:00,800
که اولین بخش از این فرآیند نیست،
392
00:14:00,800 –> 00:14:02,639
شناسایی داده های از دست رفته داده های
393
00:14:02,639 –> 00:14:05,360
از دست رفته صرفاً یک فضای خالی یا
394
00:14:05,360 –> 00:14:06,639
یک مقدار جایگزین مانند
395
00:14:06,639 –> 00:14:08,560
n a است که نشان می دهد ما نتوانستیم
396
00:14:08,560 –> 00:14:10,160
یک
397
00:14:10,160 –> 00:14:11,920
یا چند ویژگی را جمع آوری کنیم و برای یک یا چند ویژگی موفق به جمع آوری
398
00:14:11,920 –> 00:14:13,600
داده ها نشدیم.
399
00:14:13,600 –> 00:14:15,760
به عنوان مثال، اگر فراموش کرده ایم
400
00:14:15,760 –> 00:14:18,320
سن شخصی را بپرسیم یا فراموش
401
00:14:18,320 –> 00:14:20,399
کرده ایم آن را یادداشت کنیم، در این مجموعه داده ها یک فضای خالی در
402
00:14:20,399 –> 00:14:22,000
کنار
403
00:14:22,000 –> 00:14:25,600
سن آن فرد
404
00:14:25,600 –> 00:14:25,920
405
00:14:25,920 –> 00:14:28,880
خواهیم داشت.
406
00:14:28,880 –> 00:14:31,120
برای رسیدگی به
407
00:14:31,120 –> 00:14:33,760
داده های از دست رفته انتظار آن را دارد،
408
00:14:33,760 –> 00:14:37,199
بنابراین تنها کاری که باید انجام دهیم این است
409
00:14:37,199 –> 00:14:39,040
که مقادیر از دست رفته را شناسایی کنیم و مطمئن شویم که
410
00:14:39,040 –> 00:14:39,680
411
00:14:39,680 –> 00:14:43,440
در وبیناری که
412
00:14:43,440 –> 00:14:44,959
چند بار ارائه
413
00:14:44,959 –> 00:14:46,720
کردم، آنها روی صفر تنظیم شده اند.
414
00:14:46,720 –> 00:14:48,240
زیرا چه اتفاقی میافتد اگر
415
00:14:48,240 –> 00:14:51,199
قبلاً یک صفر در مجموعه دادههای شما وجود داشته باشد، من میخواهم
416
00:14:51,199 –> 00:14:52,720
417
00:14:52,720 –> 00:14:55,360
در نیمه راه یک جستجوی آماری کوچک داشته باشم
418
00:14:55,360 –> 00:14:56,800
که نشان میدهد چگونه
419
00:14:56,800 –> 00:15:00,240
میتوانیم آن کد را برای چیزها صفر داشته باشیم
420
00:15:00,240 –> 00:15:03,120
و همچنین از xero برای کد کردن استفاده کنیم. برای
421
00:15:03,120 –> 00:15:05,839
از دست دادن داده ها و در واقع جواب می دهد
422
00:15:05,839 –> 00:15:07,680
و حتی در شرایطی من فقط
423
00:15:07,680 –> 00:15:09,120
یک سناریو را به شما نشان می دهم
424
00:15:09,120 –> 00:15:11,199
و حتی اگر سناریویی وجود داشته
425
00:15:11,199 –> 00:15:12,720
426
00:15:12,720 –> 00:15:15,120
باشد که آنطور که من نشان می دهم کار نمی کند، من
427
00:15:15,120 –> 00:15:17,040
این را نیز حذف خواهم کرد.
428
00:15:17,040 –> 00:15:20,240
نویسنده xgboost گفته است
429
00:15:20,240 –> 00:15:22,399
که حتی وقتی چیزی را با
430
00:15:22,399 –> 00:15:23,839
xero کدنویسی میکنید و از
431
00:15:23,839 –> 00:15:27,360
صفر به معنای دادههای از دست رفته استفاده میکنید، xgboost باز هم
432
00:15:27,360 –> 00:15:28,320
کار بسیار
433
00:15:28,320 –> 00:15:30,240
خوبی انجام میدهد، به دلایلی این
434
00:15:30,240 –> 00:15:32,000
کار را انجام نمیدهد که واقعاً در عملکرد
435
00:15:32,000 –> 00:15:33,440
آن اختلالی ایجاد نمیکند.
436
00:15:33,440 –> 00:15:35,920
اولین کاری که
437
00:15:35,920 –> 00:15:37,600
میخواهیم انجام دهیم این است که ببینیم چه نوع
438
00:15:37,600 –> 00:15:39,360
دادههایی در هر ستون وجود دارد، این همان کاری است که من همیشه
439
00:15:39,360 –> 00:15:42,079
انجام میدهم وقتی به دنبال دادههای از دست رفته هستم
440
00:15:42,079 –> 00:15:44,079
، انواع دادهها را برای هر
441
00:15:44,079 –> 00:15:46,000
ستون چاپ میکنم، زیرا این میتواند نشان دهد
442
00:15:46,000 –> 00:15:49,040
اگر چیزی بهم ریخته باشد یا نه، میبینیم
443
00:15:49,040 –> 00:15:51,600
که بسیاری از ستونها شی هستند
444
00:15:51,600 –> 00:15:54,480
و این اشکالی ندارد، زیرا در بالای اینجا وقتی
445
00:15:54,480 –> 00:15:54,800
446
00:15:54,800 –> 00:15:57,920
که سر را انجام دادیم، دیدیم که
447
00:15:57,920 –> 00:15:59,519
یک شهروند سالخورده یکسری «نه» دارد و
448
00:15:59,519 –> 00:16:01,279
احتمالاً تعدادی «بله» دارد.
449
00:16:01,279 –> 00:16:03,680
وابستگی به بله و نه دارد بله
450
00:16:03,680 –> 00:16:04,639
و نه
451
00:16:04,639 –> 00:16:07,440
همینطور است منطقی است که بسیاری از این
452
00:16:07,440 –> 00:16:08,160
ستون
453
00:16:08,160 –> 00:16:12,320
ها شی um هستند زیرا
454
00:16:12,320 –> 00:16:14,639
پاسخ های متنی مانند بله و خیر دارند،
455
00:16:14,639 –> 00:16:17,680
اما ما همیشه باید تأیید
456
00:16:17,680 –> 00:16:19,519
کنیم که آنچه را که در هر ستون انتظار داریم دریافت می کنیم
457
00:16:19,519 –> 00:16:20,160
458
00:16:20,160 –> 00:16:22,800
، به عنوان مثال به ستون خدمات تلفن نگاه می کنیم
459
00:16:22,800 –> 00:16:25,040
و ما از تابع منحصربفرد خود استفاده می کنیم
460
00:16:25,040 –> 00:16:26,320
461
00:16:26,320 –> 00:16:28,560
تا بررسی کنیم ببینیم چه چیزی دریافت می کنیم و
462
00:16:28,560 –> 00:16:31,040
چه چیزی به دست می آوریم بله و خیر است و این
463
00:16:31,040 –> 00:16:33,839
عالی است زیرا این بدان معناست که
464
00:16:33,839 –> 00:16:35,519
علامت سوالی در این ستون وجود
465
00:16:35,519 –> 00:16:36,320
ندارد
466
00:16:36,320 –> 00:16:40,959
و یک مکان نگهدارنده برای داده های از دست رفته
467
00:16:40,959 –> 00:16:44,399
وجود ندارد. ما میتوانیم تأیید کنیم که این ستون
468
00:16:44,399 –> 00:16:45,360
فقط حاوی
469
00:16:45,360 –> 00:16:48,800
بله و خیر است و این خیلی
470
00:16:48,800 –> 00:16:50,720
خوب است، اکنون در عمل باید این کار را انجام دهیم
471
00:16:50,720 –> 00:16:52,800
برای هر ستون تأیید کنیم که
472
00:16:52,800 –> 00:16:53,519
473
00:16:53,519 –> 00:16:55,519
نوع دادهای دارد که ما انتظار داریم
474
00:16:55,519 –> 00:16:57,440
و فقط پاسخهایی را دارد که ما داریم.
475
00:16:57,440 –> 00:16:58,560
انتظار
476
00:16:58,560 –> 00:17:01,600
داشتم و به من اعتماد کنید من این کار را انجام دادم اما در حال حاضر
477
00:17:01,600 –> 00:17:03,759
روی یک ستون خاص تمرکز می کنیم
478
00:17:03,759 –> 00:17:05,359
که به نظر می رسد ممکن است یک مشکل باشد
479
00:17:05,359 –> 00:17:08,400
و آن مجموع هزینه ها است،
480
00:17:08,400 –> 00:17:11,520
بنابراین اگر به این خروجی در اینجا
481
00:17:11,520 –> 00:17:13,679
نگاه کنیم می بینیم که کل هزینه ها مانند یک
482
00:17:13,679 –> 00:17:15,599
دسته از اعداد است.
483
00:17:15,599 –> 00:17:18,720
با این حال، اگر به نوع داده برای
484
00:17:18,720 –> 00:17:21,359
بارهای کل نگاه کنیم، می بینیم که این یک شی است
485
00:17:21,359 –> 00:17:23,199
و معمولاً زمانی که ترکیبی از اعداد و نویسه ها را به دست می آوریم، آن شی را
486
00:17:23,199 –> 00:17:25,039
دریافت می کنیم،
487
00:17:25,039 –> 00:17:28,160
488
00:17:28,160 –> 00:17:30,160
بنابراین یک کاری که می توانیم انجام دهیم این است که فقط
489
00:17:30,160 –> 00:17:32,160
مقادیر منحصر به فرد و هزینه های کل را چاپ کنیم.
490
00:17:32,160 –> 00:17:33,120
و ببینیم
491
00:17:33,120 –> 00:17:37,360
چه چیزی را میبینیم، پس بیایید آن بام را انجام دهیم
492
00:17:37,360 –> 00:17:39,039
و وقتی این کار را انجام دادیم، میبینیم که
493
00:17:39,039 –> 00:17:40,960
مقادیر زیادی برای چاپ وجود دارد،
494
00:17:40,960 –> 00:17:41,360
این
495
00:17:41,360 –> 00:17:44,400
نقطه نقطه را دقیقاً در وسط داریم، اما
496
00:17:44,400 –> 00:17:45,600
چیزی که میبینیم
497
00:17:45,600 –> 00:17:48,960
یک دسته به نظر میرسد. با این حال،
498
00:17:48,960 –> 00:17:51,520
اگر بخواهیم ستون را به
499
00:17:51,520 –> 00:17:52,320
500
00:17:52,320 –> 00:17:54,799
داده های عددی یا مقادیر عددی تبدیل کنیم و همینجا سعی می
501
00:17:54,799 –> 00:17:55,919
کنم
502
00:17:55,919 –> 00:17:58,559
وقتی این کد را اجرا می کنیم، با خطا مواجه می شویم،
503
00:17:58,559 –> 00:18:00,400
بنابراین اگر
504
00:18:00,400 –> 00:18:01,280
بخواهید همه را اجرا کنید، نظر می دهم.
505
00:18:01,280 –> 00:18:06,320
کد به یکباره اوم
506
00:18:06,320 –> 00:18:08,000
و بیایید به این خطا نگاه
507
00:18:08,000 –> 00:18:09,120
کنیم. نکته خوب در مورد این خطا و
508
00:18:09,120 –> 00:18:10,720
دلیل اینکه من می خواستم این خطا را به شما نشان دهم این
509
00:18:10,720 –> 00:18:12,400
است که در واقع به شما می گوید چه
510
00:18:12,400 –> 00:18:16,080
مشکلی با داده ها وجود دارد
511
00:18:16,080 –> 00:18:19,840
که می گوید قادر به تجزیه
512
00:18:19,840 –> 00:18:23,200
نقل قول رشته هیچ چیز نیست یا نقل قول انتهای فضای خالی
513
00:18:23,200 –> 00:18:25,360
و چه چیزی این را به ما می گوید به ما می
514
00:18:25,360 –> 00:18:27,520
گوید که فضاهای خالی
515
00:18:27,520 –> 00:18:31,360
در این ستون
516
00:18:31,440 –> 00:18:34,880
در مجموع هزینه ها وجود دارد و
517
00:18:34,880 –> 00:18:38,240
بنابراین ما باید با آنها کنار
518
00:18:38,240 –> 00:18:40,000
بیاییم، بنابراین اکنون ما آماده هستیم که با داده های از دست رفته
519
00:18:40,000 –> 00:18:42,559
سبک تقویت xg مقابله
520
00:18:42,559 –> 00:18:44,320
کنیم، همانطور که قبلاً یک چیز را گفتم.
521
00:18:44,320 –> 00:18:46,000
نسبتا منحصر به فرد
522
00:18:46,000 –> 00:18:48,880
در مورد xgboost این است که
523
00:18:48,880 –> 00:18:51,280
رفتار پیش فرض را برای داده های از دست رفته تعیین می کند،
524
00:18:51,280 –> 00:18:53,360
بنابراین تنها کاری که باید انجام دهیم این است که مقادیر از دست رفته را شناسایی کرده
525
00:18:53,360 –> 00:18:54,960
و مطمئن شویم که آنها روی صفر تنظیم شده اند،
526
00:18:54,960 –> 00:18:56,080
527
00:18:56,080 –> 00:18:58,640
اما قبل از انجام این کار، بیایید ببینیم
528
00:18:58,640 –> 00:19:00,320
چند ردیف داده از دست رفته است
529
00:19:00,320 –> 00:19:02,400
و آیا تعداد آنها زیاد است ما ممکن است
530
00:19:02,400 –> 00:19:03,840
مشکلی در دستانمان داشته باشیم که
531
00:19:03,840 –> 00:19:06,080
بزرگتر از آن چیزی است که بوست xg می تواند به تنهایی انجام دهد
532
00:19:06,080 –> 00:19:06,880
533
00:19:06,880 –> 00:19:08,799
و اگر زیاد نباشد،
534
00:19:08,799 –> 00:19:10,400
آنها را روی صفر قرار می دهیم،
535
00:19:10,400 –> 00:19:14,799
بنابراین این کار را با
536
00:19:14,799 –> 00:19:18,400
جستجوی مکان استفاده می کنیم.
537
00:19:18,400 –> 00:19:20,240
تابع uh بنابراین ما قاب داده خود را دریافت کرده
538
00:19:20,240 –> 00:19:21,919
ایم و از آن استفاده می کنیم و می
539
00:19:21,919 –> 00:19:25,360
گوییم ردیف هایی که این درست است را به من بدهید
540
00:19:25,360 –> 00:19:28,000
تا مقدار در ستون بارهای کل
541
00:19:28,000 –> 00:19:29,280
542
00:19:29,280 –> 00:19:32,000
برابر با صفر باشد و سپس
543
00:19:32,000 –> 00:19:33,280
همه آن را در لنز
544
00:19:33,280 –> 00:19:35,120
یا طول قرار می دهیم. تابع و
545
00:19:35,120 –> 00:19:38,000
تعداد ردیف هایی که s خالی دارند را می شمارد
546
00:19:38,000 –> 00:19:41,039
در ستون کل شارژها حرکت می کند
547
00:19:41,039 –> 00:19:43,520
و می بینیم که فقط 11 ردیف وجود دارد که
548
00:19:43,520 –> 00:19:45,200
مقادیر کم دارند، بنابراین از آنجایی که فقط
549
00:19:45,200 –> 00:19:46,640
11 ردیف است، می توانیم آنها را نگاه کنیم، بنابراین می خواهیم
550
00:19:46,640 –> 00:19:49,120
آنها را چاپ کنیم
551
00:19:49,120 –> 00:19:52,160
تا ببینیم
552
00:19:52,160 –> 00:19:55,200
اگر به اینجا برویم، می بینیم
553
00:19:55,200 –> 00:19:57,840
که در ستون کل هزینهها آه، ما
554
00:19:57,840 –> 00:20:00,240
هیچ ارزشی
555
00:20:00,240 –> 00:20:03,280
نداریم، همچنین میبینیم که در ستون ماههای تصدی
556
00:20:03,280 –> 00:20:03,840
557
00:20:03,840 –> 00:20:06,080
، برای همه صفر است و این
558
00:20:06,080 –> 00:20:06,960
بدان معناست
559
00:20:06,960 –> 00:20:08,960
که دلیل اینکه این افراد
560
00:20:08,960 –> 00:20:11,200
مجموع هزینهها برابر با خالی هستند
561
00:20:11,200 –> 00:20:13,440
این است که هزینهای از آنها دریافت نشده است.
562
00:20:13,440 –> 00:20:15,919
هر چیزی هنوز مشترک شده اند و بنابراین
563
00:20:15,919 –> 00:20:17,360
آنها در برنامه ای
564
00:20:17,360 –> 00:20:19,840
هستند که دارند، اوه ما
565
00:20:19,840 –> 00:20:21,039
مقدار پول مورد انتظاری را داریم که
566
00:20:21,039 –> 00:20:22,720
از آنها دریافت می کنیم اما آنها
567
00:20:22,720 –> 00:20:22,960
568
00:20:22,960 –> 00:20:27,600
هنوز چیزی به ما پرداخت نکرده اند و از آنجایی
569
00:20:27,600 –> 00:20:29,039
که تعداد انگشت شماری است از افرادی که
570
00:20:29,039 –> 00:20:30,720
قرار است این مجموع را تنظیم کنیم
571
00:20:30,720 –> 00:20:35,760
اوم
572
00:20:35,760 –> 00:20:39,360
تا اوم اوه ما فقط مجموع
573
00:20:39,360 –> 00:20:41,280
هزینهها را صفر
574
00:20:41,280 –> 00:20:44,559
میکنیم و روشی که انجام
575
00:20:44,640 –> 00:20:47,120
میدهیم بسیار شبیه همان کاری است که قبلا انجام میدادیم، اما
576
00:20:47,120 –> 00:20:49,039
این بار
577
00:20:49,039 –> 00:20:51,679
به جای اینکه مشخص کنیم داشتن
578
00:20:51,679 –> 00:20:52,159
579
00:20:52,159 –> 00:20:55,520
uh loc کل ردیف را برمی گرداند که همان
580
00:20:55,520 –> 00:20:57,200
کاری است که قبلا انجام می داد
581
00:20:57,200 –> 00:20:59,200
ما مشخص میکنیم که فقط
582
00:20:59,200 –> 00:21:00,720
مجموع هزینهها
583
00:21:00,720 –> 00:21:03,280
را میخواهیم و دوباره
584
00:21:03,280 –> 00:21:04,159
585
00:21:04,159 –> 00:21:06,720
به مکانهایی که مجموع هزینهها برابر است با
586
00:21:06,720 –> 00:21:08,400
فضای خالی علاقهمندیم
587
00:21:08,400 –> 00:21:10,320
و آن مقدار را در
588
00:21:10,320 –> 00:21:12,240
ستون کل هزینهها
589
00:21:12,240 –> 00:21:15,280
روی صفر قرار میدهیم، بنابراین اجازه دهید این کار را انجام دهیم تا
590
00:21:15,280 –> 00:21:17,440
بتوانیم تأیید کنیم. اینکه ما مجموع
591
00:21:17,440 –> 00:21:19,600
هزینهها را به درستی با بررسی همه افراد
592
00:21:19,600 –> 00:21:20,000
دارای
593
00:21:20,000 –> 00:21:22,720
ماههای 10 ساله روی صفر تغییر دادیم.
594
00:21:22,720 –> 00:21:24,480
595
00:21:24,480 –> 00:21:26,080
596
00:21:26,080 –> 00:21:27,919
597
00:21:27,919 –> 00:21:29,120
598
00:21:29,120 –> 00:21:30,880
برای چند ماه آنها
599
00:21:30,880 –> 00:21:33,039
ممکن است قبلاً
600
00:21:33,039 –> 00:21:36,240
صفر داشته باشند، اما من کاملاً مطمئن هستم
601
00:21:36,240 –> 00:21:38,720
که همه کسانی که ماه های تصدی
602
00:21:38,720 –> 00:21:39,919
برابر با صفر
603
00:21:39,919 –> 00:21:42,080
داشتند فضای خالی داشتند زیرا آنها به تازگی
604
00:21:42,080 –> 00:21:43,440
ثبت نام کرده
605
00:21:43,440 –> 00:21:46,559
بودند و پرداخت نکرده بودند. یک صورتحساب است، بنابراین ما این کار را انجام
606
00:21:46,559 –> 00:21:46,960
می
607
00:21:46,960 –> 00:21:48,960
دهیم و می بینیم که ماه 10 ساله
608
00:21:48,960 –> 00:21:50,799
برابر با صفر است و وقتی
609
00:21:50,799 –> 00:21:52,480
به سمت راست حرکت می کنیم، مجموع
610
00:21:52,480 –> 00:21:54,400
هزینه ها برابر با صفر است
611
00:21:54,400 –> 00:21:58,640
به طوری که بام کار کرده،
612
00:21:58,640 –> 00:22:01,200
چارچوب داده خود را تأیید کرده ایم. df به جای فاصله شامل صفر
613
00:22:01,200 –> 00:22:03,919
است برای مقادیر از دست رفته،
614
00:22:03,919 –> 00:22:07,200
توجه داشته باشید که هزینههای کل هنوز دارای
615
00:22:07,200 –> 00:22:10,000
نوع داده شی هستند و این خوب نیست زیرا
616
00:22:10,000 –> 00:22:13,520
تقویت xgb فقط به انواع دادههای شناور و بولی اجازه میدهد،
617
00:22:13,520 –> 00:22:16,159
بنابراین ما میخواهیم این مشکل را با
618
00:22:16,159 –> 00:22:18,559
تبدیل آن ستون با دو عددی
619
00:22:18,559 –> 00:22:20,400
حل کنیم، راههای مختلفی برای تبدیل
620
00:22:20,400 –> 00:22:21,440
ستونها از
621
00:22:21,440 –> 00:22:23,679
یک نوع به دیگری این فقط یکی از
622
00:22:23,679 –> 00:22:25,200
آنهاست،
623
00:22:25,200 –> 00:22:27,919
بنابراین من از دو عدد استفاده می کنم و اوه این یک
624
00:22:27,919 –> 00:22:29,760
تابع pandas است
625
00:22:29,760 –> 00:22:31,760
و من مشخص می کنم که می خواهم
626
00:22:31,760 –> 00:22:34,159
ستون کل هزینه ها را تبدیل کنم و
627
00:22:34,159 –> 00:22:34,960
آن را
628
00:22:34,960 –> 00:22:37,679
در شکاف اصلی هزینه کل ذخیره می کنم و
629
00:22:37,679 –> 00:22:39,360
وقتی کارم تمام شد، دارم انواع دادهها را چاپ
630
00:22:39,360 –> 00:22:40,960
میکنم تا مطمئن شوم که این کار را درست انجام دادهایم،
631
00:22:40,960 –> 00:22:42,320
632
00:22:42,320 –> 00:22:45,200
بنابراین بیایید آن bam را انجام دهیم و به اینجا
633
00:22:45,200 –> 00:22:46,640
میرویم و میبینیم که مجموع
634
00:22:46,640 –> 00:22:49,919
هزینهها اکنون 64 شناور است.
635
00:22:49,919 –> 00:22:51,360
با داده های از دست رفته،
636
00:22:51,360 –> 00:22:53,120
کاری که ما می خواهیم انجام دهیم این است که
637
00:22:53,120 –> 00:22:54,240
638
00:22:54,240 –> 00:22:56,480
تمام فضاهای سفید دیگر را در
639
00:22:56,480 –> 00:22:58,080
تمام ستون ها با زیرخط جایگزین می
640
00:22:58,080 –> 00:22:59,120
کنیم، ممکن است
641
00:22:59,120 –> 00:23:00,880
ستون های دیگری دارای فاصله سفید باشند و ما
642
00:23:00,880 –> 00:23:03,280
فقط این کار را انجام می دهیم. به یکباره
643
00:23:03,280 –> 00:23:06,400
اوم، بنابراین ما می خواهیم این کار را انجام دهیم
644
00:23:06,400 –> 00:23:08,000
ما قبل از اینکه قاب داده خود را بدست
645
00:23:08,000 –> 00:23:10,000
آوریم و از تابع جایگزین استفاده می کنیم
646
00:23:10,000 –> 00:23:12,240
این کار را انجام دادیم، اما این بار ستون خاصی را مشخص نمی
647
00:23:12,240 –> 00:23:13,919
کنیم، فقط می خواهیم
648
00:23:13,919 –> 00:23:14,480
این
649
00:23:14,480 –> 00:23:17,679
قاب داده را به صورت گسترده انجام دهیم، فضای خالی را با زیرخط جایگزین می کنیم
650
00:23:17,679 –> 00:23:19,520
651
00:23:19,520 –> 00:23:20,880
و سپس ما
652
00:23:20,880 –> 00:23:22,960
پنج ردیف اول را چاپ می کنیم تا بررسی کنیم که این کار را
653
00:23:22,960 –> 00:23:24,080
به درستی
654
00:23:24,080 –> 00:23:27,280
انجام داده ایم، بنابراین اگر
655
00:23:27,280 –> 00:23:29,679
به سمت راست حرکت کنیم، می بینیم که یکی از
656
00:23:29,679 –> 00:23:31,520
مواردی که اصلاح کردیم،
657
00:23:31,520 –> 00:23:34,960
در زیر ستون روش
658
00:23:34,960 –> 00:23:37,120
پرداخت قرار داشت. از فضاهای خالی بین پستی
659
00:23:37,120 –> 00:23:38,240
و چک،
660
00:23:38,240 –> 00:23:41,360
اکنون ما یک um، یک زیرخط
661
00:23:41,360 –> 00:23:42,720
الکترونیکی در چک داریم، ما
662
00:23:42,720 –> 00:23:45,360
زیرخط داریم، بنابراین به
663
00:23:45,360 –> 00:23:47,279
یاد داشته باشید که تنها دلیل اینکه چرا
664
00:23:47,279 –> 00:23:49,679
ما همه این فضاهای خالی را جایگزین می کنیم
665
00:23:49,679 –> 00:23:51,840
این است که بتوانیم یک چاپ کنیم.
666
00:23:51,840 –> 00:23:53,840
درخت زیبا و زیبا
667
00:23:53,840 –> 00:23:56,400
xjboot xgboost خود واقعاً تا حدی اهمیتی نمیدهد،
668
00:23:56,400 –> 00:23:57,200
669
00:23:57,200 –> 00:23:59,520
زیرا ما
670
00:23:59,520 –> 00:24:04,080
بعداً این چیزها را یکبار رمزگذاری
671
00:24:04,080 –> 00:24:06,400
میکنیم، در هر صورت مشکلی نیست، بنابراین اکنون که با همه
672
00:24:06,400 –> 00:24:07,840
آن مسائل برخورد
673
00:24:07,840 –> 00:24:10,159
کردیم، اکنون میتوانیم قالببندی دادهها را
674
00:24:10,159 –> 00:24:12,320
برای تقویت xg شروع کنیم. مدل و صنوبر مرحله اول این است
675
00:24:12,320 –> 00:24:14,559
که آن را به دو قسمت تقسیم
676
00:24:14,559 –> 00:24:17,600
می کنیم، می خواهیم
677
00:24:17,600 –> 00:24:19,240
ستون هایی را که برای طبقه بندی استفاده می کنیم
678
00:24:19,240 –> 00:24:20,640
679
00:24:20,640 –> 00:24:24,159
از ستونی که می خواهیم پیش بینی
680
00:24:24,159 –> 00:24:25,520
کنیم جدا کنیم، بنابراین از
681
00:24:25,520 –> 00:24:27,679
نماد متعارف بزرگ x
682
00:24:27,679 –> 00:24:29,760
برای نشان دادن آن استفاده می کنیم. ستونهایی از دادهها را که
683
00:24:29,760 –> 00:24:31,679
برای طبقهبندی
684
00:24:31,679 –> 00:24:34,720
استفاده خواهیم کرد و از حروف کوچک y برای
685
00:24:34,720 –> 00:24:36,320
نشان دادن چیزی که میخواهیم
686
00:24:36,320 –> 00:24:38,080
پیشبینی کنیم استفاده میکنیم، در این مورد
687
00:24:38,080 –> 00:24:41,279
میخواهیم مقدار ریزش
688
00:24:41,279 –> 00:24:43,440
689
00:24:43,440 –> 00:24:45,360
را پیشبینی کنیم. صفر برای
690
00:24:45,360 –> 00:24:48,720
افرادی که um را ترک نکردهاند
691
00:24:49,279 –> 00:24:51,600
و بنابراین کاری که ما انجام میدهیم این است
692
00:24:51,600 –> 00:24:54,480
که در اینجا x بزرگ ایجاد
693
00:24:54,480 –> 00:24:56,159
میکنیم و فریم دادههای خود را داریم و
694
00:24:56,159 –> 00:24:58,000
دقیقاً مانند قبل هستیم که تابع drop را فراخوانی
695
00:24:58,000 –> 00:25:00,559
میکنیم و ما دوباره مشخص
696
00:25:00,559 –> 00:25:03,760
میکنیم که میخواهیم مقدار churn را کاهش
697
00:25:03,760 –> 00:25:05,679
دهیم، اما مانند قبل در جای خود این
698
00:25:05,679 –> 00:25:06,559
کار را انجام نمیدهیم
699
00:25:06,559 –> 00:25:08,480
و نتایج را در یک متغیر جدید ذخیره میکنیم و
700
00:25:08,480 –> 00:25:09,919
701
00:25:09,919 –> 00:25:13,360
پنج ردیف اول آن متغیر جدید
702
00:25:13,360 –> 00:25:15,600
را چاپ میکنیم. به آنجا می رویم و اگر روی آن اسکرول کنیم می
703
00:25:15,600 –> 00:25:17,360
بینیم که مقدار churn است از دست رفته
704
00:25:17,360 –> 00:25:18,960
ما همه چیز دیگری را داریم که عالی
705
00:25:18,960 –> 00:25:21,120
است، دقیقاً همان چیزی است که ما میخواستیم،
706
00:25:21,120 –> 00:25:23,120
اکنون این متغیر کوچک y را میسازیم
707
00:25:23,120 –> 00:25:25,200
و
708
00:25:25,200 –> 00:25:28,080
فقط ستونی در قاب داده به نام
709
00:25:28,080 –> 00:25:29,600
مقدار زیرخط churn خواهد بود
710
00:25:29,600 –> 00:25:31,200
و سپس میخواهیم آن را چاپ کنیم.
711
00:25:31,200 –> 00:25:33,600
پنج سطر اول برای تأیید اینکه
712
00:25:33,600 –> 00:25:35,200
آنطور که باید
713
00:25:35,200 –> 00:25:38,400
به نظر می رسد و
714
00:25:38,400 –> 00:25:41,279
اکنون که بزرگ x را ایجاد کرده ایم که
715
00:25:41,279 –> 00:25:43,360
دارای داده هایی است که می خواهیم برای پیش بینی استفاده کنیم
716
00:25:43,360 –> 00:25:44,240
717
00:25:44,240 –> 00:25:46,559
و y را با حروف کوچک ساخته ایم که
718
00:25:46,559 –> 00:25:48,240
داده هایی را دارد که میخواهیم پیشبینی
719
00:25:48,240 –> 00:25:50,640
کنیم که آماده ادامه قالببندی x یا
720
00:25:50,640 –> 00:25:51,600
بزرگ x
721
00:25:51,600 –> 00:25:53,520
بهگونهای هستیم که برای ساختن مدلی با تقویت xg مناسب است، به
722
00:25:53,520 –> 00:25:54,840
723
00:25:54,840 –> 00:25:58,000
طوری که
724
00:25:58,000 –> 00:26:02,240
725
00:26:02,240 –> 00:26:04,240
اکنون که فریم داده را
726
00:26:04,240 –> 00:26:06,880
به دو قسمت تقسیم کردهایم، ما را به یک کدگذاری داغ میرساند. باید
727
00:26:06,880 –> 00:26:09,919
نگاه دقیقتری به متغیرهای داخل x سرمایه بیندازیم،
728
00:26:09,919 –> 00:26:11,520
بنابراین فهرستی که در زیر
729
00:26:11,520 –> 00:26:16,000
از وبسایت ibm برای این
730
00:26:16,000 –> 00:26:17,919
مجموعه داده دریافت کردم، به ما میگوید که آیا
731
00:26:17,919 –> 00:26:19,760
هر ستون باید شناور یا
732
00:26:19,760 –> 00:26:21,440
طبقهبندی شود، بنابراین میبینیم که
733
00:26:21,440 –> 00:26:25,200
شهر یک دستهبندی طول جغرافیایی است. جنسیت شناور
734
00:26:25,200 –> 00:26:27,440
یک دسته است شهروند ارشد ry
735
00:26:27,440 –> 00:26:29,039
دستهای است که ما دستههایی داریم
736
00:26:29,039 –> 00:26:29,840
ماههای تصدی
737
00:26:29,840 –> 00:26:33,279
یک شناور است، بنابراین ما ستونهای زیادی داریم
738
00:26:33,279 –> 00:26:35,279
اکنون فقط برای بررسی، میخواهیم به
739
00:26:35,279 –> 00:26:37,360
انواع دادهها در x نگاه کنیم تا به یاد بیاوریم که
740
00:26:37,360 –> 00:26:41,200
پایتون چگونه میبیند دادهها در حال حاضر
741
00:26:43,760 –> 00:26:46,159
بنابراین میبینیم که
742
00:26:46,159 –> 00:26:47,840
هزینههای ماهانه طول جغرافیایی و کل هزینهها
743
00:26:47,840 –> 00:26:50,080
همه float64 هستند که عالی است این
744
00:26:50,080 –> 00:26:52,080
دقیقاً همان چیزی است که ما میخواهیم،
745
00:26:52,080 –> 00:26:53,919
همه ستونهای دیگر که شی
746
00:26:53,919 –> 00:26:55,760
هس
747
00:26:55,760 –> 00:26:57,760
ند به یکی نیاز دارند، باید آنها را بر
748
00:26:57,760 –> 00:26:59,360
سی کنیم تا مطمئن شویم فق
749
00:26:59,360 –> 00:27:03,120
هر کدام حاوی یک مقدار معقول است
750
00:27:03,120 –> 00:27:05,520
و سپس ما همچنین باید آنها را
751
00:27:05,520 –> 00:27:07,840
با یک کدگذاری داغ تغییر دهیم. یک رمزگذاری
752
00:27:07,840 –> 00:27:11,279
داغ ترفندی است برای
753
00:27:11,279 –> 00:27:14,720
گرفتن داده
754
00:27:14,720 –> 00:27:16,960
های دسته بندی شده و تقسیم آن
755
00:27:16,960 –> 00:27:19,200
به قالبی که xg بوست و بسیاری
756
00:27:19,200 –> 00:27:20,880
از
757
00:27:20,880 –> 00:27:24,000
الگوریتم های دیگر می توانند استفاده کنند. مشکل این است
758
00:27:24,000 –> 00:27:24,320
که
759
00:27:24,320 –> 00:27:26,399
xgboost و بسیاری از الگوریتمهای یادگیری ماشینی دیگر به
760
00:27:26,399 –> 00:27:28,240
761
00:27:28,240 –> 00:27:30,799
صورت بومی از دادههای پیوسته
762
00:27:30,799 –> 00:27:33,360
مانند هزینههای ماهانه و هزینههای کل
763
00:27:33,360 –> 00:27:35,440
پشتیبانی میکنند، اما بهطور بومی از
764
00:27:35,440 –> 00:27:36,720
دادههای طبقهبندی مانند
765
00:27:36,720 –> 00:27:38,559
خدمات تلفن پشتیبانی نمیکنند. دو دسته مختلف،
766
00:27:38,559 –> 00:27:39,840
767
00:27:39,840 –> 00:27:41,840
بنابراین اگر میخواهیم از دادههای طبقهبندی
768
00:27:41,840 –> 00:27:43,679
با مدل خود استفاده
769
00:27:43,679 –> 00:27:46,840
کنیم، باید آنها را با یک رمزگذاری داغ تبدیل کنیم
770
00:27:46,840 –> 00:27:48,720
771
00:27:48,720 –> 00:27:52,480
تا به نوعی این محدودیت را دور
772
00:27:52,480 –> 00:27:54,559
بزنیم، بنابراین در این مرحله ممکن است
773
00:27:54,559 –> 00:27:56,159
تعجب کنید که چه اشکالی دارد با
774
00:27:56,159 –> 00:27:58,159
دادههای طبقهای مانند دادههای پیوسته رفتار کنیم.
775
00:27:58,159 –> 00:27:59,039
776
00:27:59,039 –> 00:28:02,320
نمیتوانیم، فقط میتوانیم دستهها را
777
00:28:02,320 –> 00:28:04,399
به اعداد تبدیل کنیم و با آن کار تمام شود
778
00:28:04,399 –> 00:28:06,720
و برای پاسخ به این سؤال،
779
00:28:06,720 –> 00:28:07,840
میخواهیم به یک مثال نگاه کنیم
780
00:28:07,840 –> 00:28:11,039
و من روش پرداخت را انتخاب کردهام
781
00:28:11,039 –> 00