در این مطلب، ویدئو ساخت مدل طبقه بندی خط پایه برای پروژه های یادگیری ماشین با استفاده از پایتون با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:07:20
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:00,080 –> 00:00:01,839
سلام به همه به کانال یوتیوب من خوش آمدید
2
00:00:01,839 –> 00:00:04,160
نام من مدرک است
3
00:00:04,160 –> 00:00:06,240
و در ویدیوی امروز به
4
00:00:06,240 –> 00:00:07,520
شما نشان می دهم که چگونه
5
00:00:07,520 –> 00:00:10,240
یک مدل طبقه بندی پایه ایجاد کنید، بنابراین من
6
00:00:10,240 –> 00:00:12,400
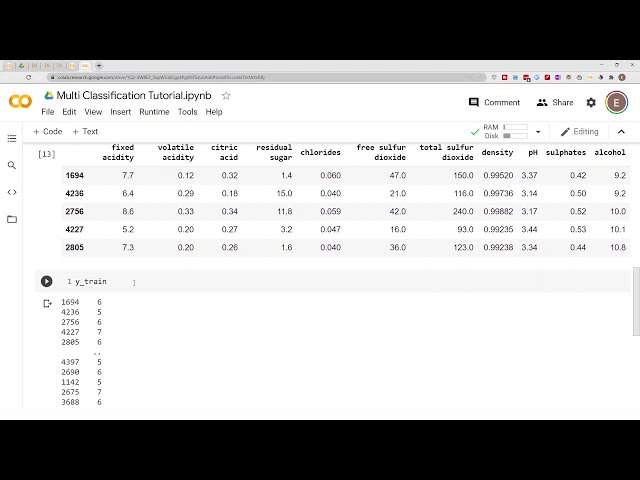
قبلاً داده های خود را آماده کرده ام
7
00:00:12,400 –> 00:00:14,880
و آنها را به مجموعه داده های آموزشی و آزمایشی تقسیم کرده ام
8
00:00:14,880 –> 00:00:15,519
9
00:00:15,519 –> 00:00:17,760
و ما میتوانید پیشنمایش دادهها را
10
00:00:17,760 –> 00:00:18,640
در اینجا دریافت کنید
11
00:00:18,640 –> 00:00:22,160
این مجموعه دادهها برای
12
00:00:22,160 –> 00:00:25,439
کیفیت شراب است، بنابراین ما سعی
13
00:00:25,439 –> 00:00:26,480
میکنیم کیفیت شراب را پیشبینی کنیم
14
00:00:26,480 –> 00:00:29,920
و اینها
15
00:00:29,920 –> 00:00:32,000
ویژگیهای شرابی
16
00:00:32,000 –> 00:00:33,680
هستند که قرار است از آنها برای
17
00:00:33,680 –> 00:00:35,120
پیشبینی کیفیت
18
00:00:35,120 –> 00:00:37,920
استفاده کنیم تا فقط یک پیشنمایش دادهها
19
00:00:37,920 –> 00:00:39,920
به طور خلاصه
20
00:00:39,920 –> 00:00:42,239
وقتی میگویید پایه، اساساً
21
00:00:42,239 –> 00:00:43,600
میگویید
22
00:00:43,600 –> 00:00:46,800
که من
23
00:00:46,800 –> 00:00:50,079
نتیجه کیفیت شراب را بدون اجرای
24
00:00:50,079 –> 00:00:52,000
مجموعه دادههای من
25
00:00:52,000 –> 00:00:55,120
از طریق هر مدلی مانند
26
00:00:55,120 –> 00:00:58,320
مدل طبقهبندی یا مدل رگرسیون پیشبینی میکنم.
27
00:00:58,320 –> 00:00:59,359
28
00:00:59,359 –> 00:01:02,320
برای یک مسئله رگرسیون می توان از میانگین
29
00:01:02,320 –> 00:01:03,039
30
00:01:03,039 –> 00:01:06,400
به عنوان خط مبنا استفاده کرد و برای
31
00:01:06,400 –> 00:01:09,360
یک مسئله رگرسیونی برای یک
32
00:01:09,360 –> 00:01:11,119
مسئله طبقه بندی
33
00:01:11,119 –> 00:01:13,439
حالت حالت را می توان به عنوان خط مبنا استفاده کرد که
34
00:01:13,439 –> 00:01:14,479
اساساً حالت
35
00:01:14,479 –> 00:01:18,000
عبارت t است. کلاه اغلب اتفاق میافتد،
36
00:01:18,000 –> 00:01:21,520
بنابراین با این
37
00:01:21,520 –> 00:01:23,680
اطلاعات پسزمینه اولیه، بیایید جلو برویم
38
00:01:23,680 –> 00:01:24,799
و
39
00:01:24,799 –> 00:01:28,560
به مدل پایه خود نگاه کنیم، اگر من ادامه
40
00:01:28,560 –> 00:01:28,960
دهم و
41
00:01:28,960 –> 00:01:32,159
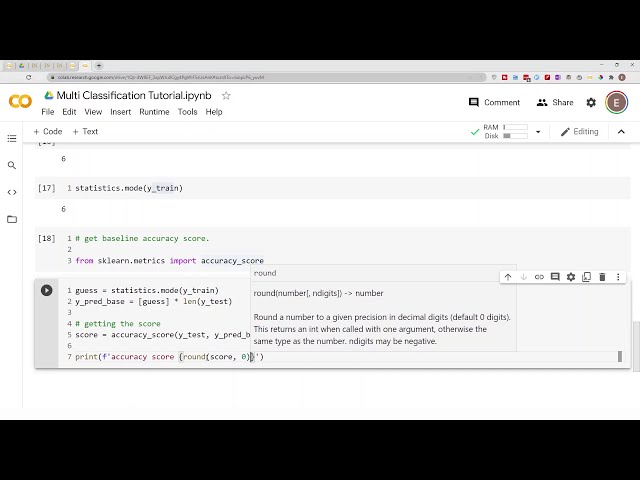
آمار آمار واردات
42
00:01:32,479 –> 00:01:35,920
یک ماژول پایتون است،
43
00:01:35,920 –> 00:01:39,280
سپس برای دریافت طبقهبندی
44
00:01:39,280 –> 00:01:40,000
پایه یا پیشبینی خط پایه،
45
00:01:40,000 –> 00:01:45,040
میتوانیم به سادگی حالت نقطه آمار را انجام دهیم.
46
00:01:45,200 –> 00:01:48,399
و سپس پرانتزهای
47
00:01:48,399 –> 00:01:52,720
y train را انجام می دهیم یا می توانیم حالت را در کل
48
00:01:52,720 –> 00:01:55,600
قاب داده
49
00:01:58,240 –> 00:02:00,560
تا شش انجام دهیم و حتی اگر این کار را فقط روی
50
00:02:00,560 –> 00:02:01,600
51
00:02:01,600 –> 00:02:05,600
داده های آموزشی انجام دهیم، دوباره نتایج مشابهی به ما می دهد
52
00:02:06,840 –> 00:02:09,280
53
00:02:09,280 –> 00:02:11,680
و پیش بینی شش است بنابراین
54
00:02:11,680 –> 00:02:12,640
اساساً
55
00:02:12,640 –> 00:02:15,760
شش مورد است.
56
00:02:15,760 –> 00:02:19,120
که اغلب در دادههای معاملاتی ما رخ میدهد
57
00:02:19,120 –> 00:02:19,840
58
00:02:19,840 –> 00:02:25,200
که کیفیت شراب با کیفیت عالی است،
59
00:02:25,200 –> 00:02:29,200
اما اگر پیشبینی کنیم که این
60
00:02:29,200 –> 00:02:32,319
حالت یا کسبوکار ما است،
61
00:02:32,319 –> 00:02:35,440
هنوز باید دقت را محاسبه
62
00:02:35,440 –> 00:02:36,319
کنیم، بنابراین میخواهیم
63
00:02:36,319 –> 00:02:39,280
بدانیم پیشبینی پایه ما چقدر دقیق
64
00:02:39,280 –> 00:02:40,640
است.
65
00:02:40,640 –> 00:02:42,080
یکی از دلایل
66
00:02:42,080 –> 00:02:44,400
خوب ایجاد یک خط مبنا این است
67
00:02:44,400 –> 00:02:47,040
که وقتی شروع به کار روی
68
00:02:47,040 –> 00:02:47,760
مدل های دیگر
69
00:02:47,760 –> 00:02:50,160
کردید، می خواهید یک خط پایه داشته باشید تا
70
00:02:50,160 –> 00:02:51,360
آن را با آن مقایسه کنید تا ببینید
71
00:02:51,360 –> 00:02:53,519
آیا مدل شما خوب است یا نه یا اینکه
72
00:02:53,519 –> 00:02:54,879
مدل در حال بهبود است
73
00:02:54,879 –> 00:02:56,480
و اگر روی یک
74
00:02:56,480 –> 00:02:58,400
مشکل رگرسیون کار میکنید، اگر روی یک مشکل طبقهبندی کار میکنید، از معیارهای رگرسیون استفاده میکنید، از
75
00:02:58,400 –> 00:02:59,920
76
00:02:59,920 –> 00:03:00,959
77
00:03:00,959 –> 00:03:04,000
معیارهای طبقهبندی استفاده میکنید، بنابراین در
78
00:03:04,000 –> 00:03:05,280
این شرایط من
79
00:03:05,280 –> 00:03:09,120
فقط از دقت به عنوان معیار طبقهبندی خود استفاده میکنم،
80
00:03:09,120 –> 00:03:12,879
بنابراین از
81
00:03:12,879 –> 00:03:16,080
واردات معیارهای sklearn dot
82
00:03:16,080 –> 00:03:18,720
امتیاز دقت، پس بیایید جلو برویم
83
00:03:18,720 –> 00:03:19,360
و
84
00:03:19,360 –> 00:03:23,120
پایه قرمز را پاک
85
00:03:24,159 –> 00:03:27,440
کنیم، برابر است با در واقع
86
00:03:27,440 –> 00:03:29,760
اجازه دهید پیش برویم و بیایید جلو برویم
87
00:03:29,760 –> 00:03:30,720
و حالت خود را
88
00:03:30,720 –> 00:03:33,440
در یک متغیر قرار دهیم و آن را
89
00:03:33,440 –> 00:03:34,319
حدس خود بنامیم،
90
00:03:34,319 –> 00:03:35,680
زیرا واقعاً این همان کاری است که ما در
91
00:03:35,680 –> 00:03:38,319
اینجا انجام می
92
00:03:38,319 –> 00:03:41,440
دهیم و حدس می زنیم که حدس ما برابر است. به
93
00:03:41,440 –> 00:03:46,159
حالت آمار نقطه ای قطار y ما
94
00:03:46,159 –> 00:03:49,599
درست است، بنابراین پیش بینی ما برابر است
95
00:03:49,599 –> 00:03:52,720
با حدس ما ضربدر طول تست سفی


![فیلم آموزشی: [GA 6] اجرای پایتون الگوریتم ژنتیک مثال کامل (مسئله کوله پشتی با استفاده از GA)](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/QWs-uf8YTYUimage2.jpg)