در این مطلب، ویدئو پیش بینی قیمت با پایتون و پاور بی آی با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:19:10
تصاویر این ویدئو:
قسمتی از زیرنویس این فیلم:
00:00:01,120 –> 00:00:03,840
سلام، من قصد دارم شما را از طریق
2
00:00:03,840 –> 00:00:06,240
یک مدل پیشبینی الماس که
3
00:00:06,240 –> 00:00:07,040
ایجاد کردهام
4
00:00:07,040 –> 00:00:10,719
و با چند
5
00:00:10,719 –> 00:00:12,559
مدل مختلف رگرسیون یادگیری ماشینی با استفاده از
6
00:00:12,559 –> 00:00:16,480
مجموعه دادهای از 54000 الماس آشنا کنم
7
00:00:16,480 –> 00:00:19,199
و
8
00:00:19,199 –> 00:00:20,160
کد
9
00:00:20,160 –> 00:00:22,480
را مرور میکنیم تا ببینید پیشبینی چگونه کار میکند و
10
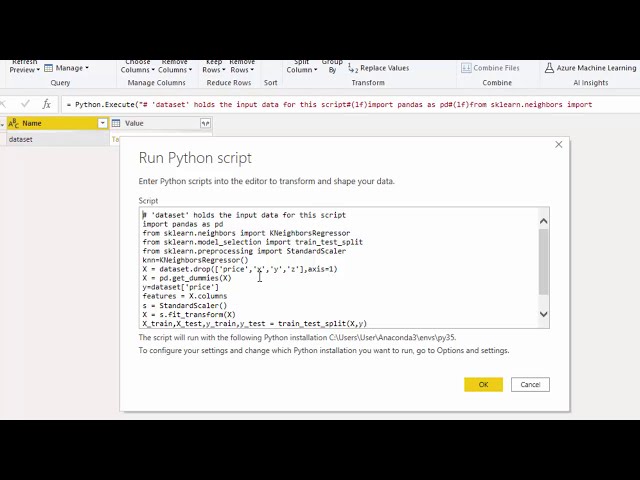
00:00:22,480 –> 00:00:24,000
کار می کند و می بینید
11
00:00:24,000 –> 00:00:27,359
که می دانید چه مدل هایی را برای استفاده انتخاب کرده ایم،
12
00:00:27,359 –> 00:00:30,400
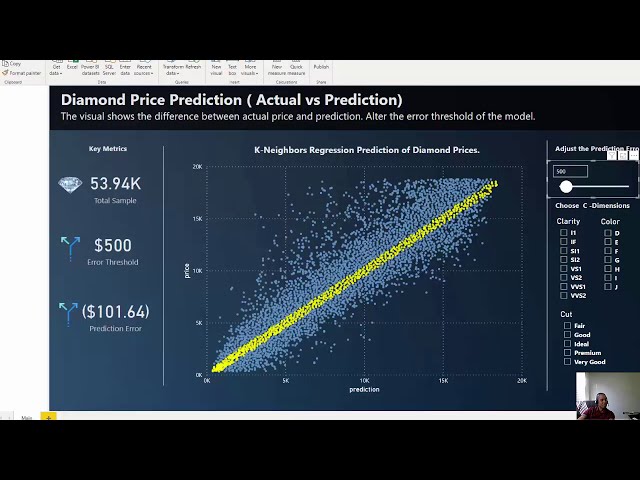
من این را به power bi انتقال دادم که
13
00:00:30,400 –> 00:00:33,600
در حال حاضر به آن نگاه می کنید و
14
00:00:33,600 –> 00:00:34,719
سپس
15
00:00:34,719 –> 00:00:39,280
توانستم آن را سفارشی کنم تا
16
00:00:39,840 –> 00:00:42,840
بتوانیم با استفاده از یک
17
00:00:42,840 –> 00:00:44,320
پارامتر
18
00:00:44,320 –> 00:00:49,200
و یک گزینه رنگی، آستانه های مختلف را بررسی کنیم. به ما اجازه می دهد تا ببینیم
19
00:00:49,200 –> 00:00:52,640
کدام مقادیر
20
00:00:52,640 –> 00:00:55,039
در پارامتر مورد نظر قرار می گیرند
21
00:00:55,039 –> 00:00:55,840
،
22
00:00:55,840 –> 00:00:58,800
بنابراین بیایید ابتدا با
23
00:00:58,800 –> 00:01:00,800
نگاهی به کدی که در نوت بوک jupyter دارم شروع کنیم،
24
00:01:00,800 –> 00:01:03,280
25
00:01:11,040 –> 00:01:14,640
بنابراین اولین کاری که می خواهم انجام دهم این
26
00:01:14,640 –> 00:01:17,119
است که وابستگی ها را بارگیری کنیم. بنابراین من
27
00:01:17,119 –> 00:01:19,040
در pandas numpy بارگذاری کرده ام
28
00:01:19,040 –> 00:01:22,080
که کتابخانه دستکاری داده های ما
29
00:01:22,080 –> 00:01:23,600
numpy
30
00:01:23,600 –> 00:01:28,640
به ما امکان می دهد جبر خطی انجام دهیم.
31
00:01:29,119 –> 00:01:31,360
من قبلاً در یک regressor جنگل تصادفی
32
00:01:31,360 –> 00:01:33,520
33
00:01:33,520 –> 00:01:36,720
یک رگرسیور خطی یک رگرسیور کمند و
34
00:01:36,720 –> 00:01:37,280
یک k
35
00:01:37,280 –> 00:01:39,439
همسایه regressor بارگذاری کرده ام.
36
00:01:39,439 –> 00:01:41,600
مدل هایی را که می خواهم امتحان کنم تا ببینم
37
00:01:41,600 –> 00:01:45,439
کدام یک بهترین نتیجه را به من می دهد،
38
00:01:45,439 –> 00:01:47,360
سپس از تست قطار استفاده می کنم
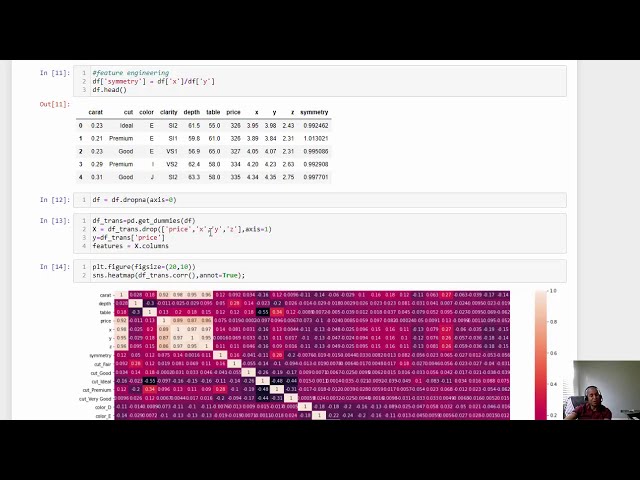
39
00:01:47,360 –> 00:01:49,600
و برای تقسیم داده ها به یک
40
00:01:49,600 –> 00:01:50,479
مجموعه آموزشی
41
00:01:50,479 –> 00:01:53,680
و یک مجموعه آزمایشی um
42
00:01:53,680 –> 00:01:56,119
من از آن استفاده خواهم کرد برخی
43
00:01:56,119 –> 00:01:58,479
از کتابخانههای پیش پردازش مانند اسکالر استاندارد و
44
00:01:58,479 –> 00:01:59,439
45
00:01:59,439 –> 00:02:01,280
یک رمزگذار داغ، اما فکر میکنم ما
46
00:02:01,280 –> 00:02:03,520
از یک pandas git dummies استفاده
47
00:02:03,520 –> 00:02:05,680
میکنیم که همان کار را انجام میدهد
48
00:02:05,680 –> 00:02:09,440
49
00:02:09,440 –> 00:02:11,840
50
00:02:11,840 –> 00:02:13,200
. از numpy
51
00:02:13,200 –> 00:02:14,239
52
00:02:14,239 –> 00:02:16,879
برای تبدیل آن به یک ریشه میانگین
53
00:02:16,879 –> 00:02:18,000
مربع خطا
54
00:02:18,000 –> 00:02:21,120
به عنوان معیار موفقیت مدل استفاده
55
00:02:21,120 –> 00:02:22,720
خواهم کرد، سپس
56
00:02:22,720 –> 00:02:25,280
seabourn یا و matplotlib را
57
00:02:25,280 –> 00:02:28,400
برای انجام برخی تجسمسازی وارد میکنم، بنابراین
58
00:02:28,400 –> 00:02:28,959
59
00:02:28,959 –> 00:02:30,959
خط بعدی من را وارد میکنم. مجموعه دادههای خود را
60
00:02:30,959 –> 00:02:32,480
61
00:02:32,480 –> 00:02:35,280
بهعنوان یک csv وارد میکنم و سپس میتوانیم با استفاده از تابع head در df نگاهی گذرا
62
00:02:35,280 –> 00:02:35,760
63
00:02:35,760 –> 00:02:38,959
به مجموعه دادهها در اینجا بیاندازیم،
64
00:02:39,360 –> 00:02:42,160
بنابراین
65
00:02:42,160 –> 00:02:43,280
من
66
00:02:43,280 –> 00:02:46,400
CSV را با استفاده از متغیر
67
00:02:46,400 –> 00:02:50,000
df خواندهام و
68
00:02:50,000 –> 00:02:53,599
از یک تابع چارچوب داده به نام info استفاده کردم.
69
00:02:53,599 –> 00:02:56,640
ببینید آیا مقادیر تهی دارم یا نه
70
00:02:56,640 –> 00:02:59,840
و انواع دادهها چه هستند،
71
00:02:59,840 –> 00:03:02,239
بنابراین میتوانید ببینید که ما یکی داریم دو سه
72
00:03:02,239 –> 00:03:03,680
چهار
73
00:03:03,680 –> 00:03:06,879
چهار ویژگی طبقهبندی یا رشتهای
74
00:03:06,879 –> 00:03:10,000
و بقیه آنها عددی هستند، بنابراین
75
00:03:10,000 –> 00:03:13,840
من میتوانم یک تابع df.describe را اجرا کنم
76
00:03:13,840 –> 00:03:18,400
تا ببینم
77
00:03:18,400 –> 00:03:22,640
معیارهای خلاصه آماری من برای همه
78
00:03:22,640 –> 00:03:25,920
اعداد عددی چیست،
79
00:03:25,920 –> 00:03:28,400
سپس ستونهایی را که
80
00:03:28,400 –> 00:03:29,920
میخواستم
81
00:03:29,920 –> 00:03:31,840
جدا کردم. با استفاده از ستونهای df و تنها
82
00:03:31,840 –> 00:03:33,680
دلیلی که من این کار را انجام
83
00:03:33,680 –> 00:03:35,840
84
00:03:35,840 –> 00:03:37,519
میدهم این است که وقتی میخواهم ستونها را جداسازی کنم
85
00:03:37,519 –> 00:03:40,720
به جای تایپ مجدد، فقط میتوانم آنها را کپی و جایگذاری کنم،
86
00:03:40,720 –> 00:03:43,920
نگاهی گذرا به انواع دادهها میاندازیم
87
00:03:43,920 –> 00:03:48,080
و سپس میخواهم این فیلد صفر بی نام را رها کنید
88
00:03:48,080 –> 00:03:50,480
که گاهی اوقات وقتی
89
00:03:50,480 –> 00:03:52,159
در یک csv می خوانید اتفاق می افتد
90
00:03:52,159 –> 00:03:55,439
و من آن را روی محور
91
00:03:55,439 –> 00:03:58,840
برابر یک می گذارم زیرا می خواهم ستون را رها کنم
92
00:03:58,840 –> 00:04:00,400
93
00:04:00,400 –> 00:04:01,920
و سپس اگر سریع سر را بررسی
94
00:04:01,920 –> 00:04:03,760
کنم می توانید ببینید که آن
95
00:04:03,760 –> 00:04:06,400
ستون از بین رفته است بنابراین اولین کاری که
96
00:04:06,400 –> 00:04:09,519
می خواستم انجام دهم این است که از کتابخانه دریایی خود استفاده کنم
97
00:04:09,519 –> 00:04:12,319
تا ببینم چه ارتباطی بین
98
00:04:12,319 –> 00:04:13,360
برخی از
99
00:04:13,360 –> 00:04:15,760
معیارها وجود دارد و چون این یک
100
00:04:15,760 –> 00:04:16,399
مجموعه داده الماسی است،
101
00:04:16,399 –> 00:04:19,519
ما شفافیت رنگی مانند برش را داریم
102
00:04:19,519 –> 00:04:21,279
که همان چیزی است که آنها
103
00:04:21,279 –> 00:04:22,800
c’s بزرگ می
104
00:04:22,800 –> 00:04:25,520
نامند. عمق الماس d جدولی
105
00:04:25,520 –> 00:04:27,600
که قسمت بالای الماس است، قسمت
106
00:04:27,600 –> 00:04:28,479
107
00:04:28,479 –> 00:04:30,720
مسطح، قیمتی که قرار است
108
00:04:30,720 –> 00:04:32,960
از آن به عنوان متغیر پیش بینی کننده خود استفاده کنیم،
109
00:04:32,960 –> 00:04:34,960
متغیر هدفمان
110
00:04:34,960 –> 00:04:36,560
و سپس x y و z
111
00:04:36,560 –> 00:04:39,199
و x y و z هستند، ابعاد هستند و
112
00:04:39,199 –> 00:04:41,120
اینها بدیهی است که می روند. برای همبستگی زیاد
113
00:04:41,120 –> 00:04:42,560
114
00:04:42,560 –> 00:04:46,479
و میتوانیم ببینیم که در اینجا، بنابراین من فقط یک
115
00:04:46,479 –> 00:04:50,080
df dot cor را برای همبستگی اجرا کردم
116
00:04:50,080 –> 00:04:53,360
و سپس آن را در یک نقشه حرارتی قرار دادم
117
00:04:53,360 –> 00:04:57,199
و میتوانیم اینجا
118
00:04:57,199 –> 00:04:59,680
ببینیم که 0.95 بسیار
119
00:04:59,680 –> 00:05:02,639
همبسته هستند و اینها همه ابعاد هستند،
120
00:05:02,639 –> 00:05:05,120
بنابراین من میخواهیم مجموعهای از دادهها را آماده کنیم و
121
00:05:05,120 –> 00:05:06,240
روی
122
00:05:06,240 –> 00:05:09,600
مهندسی ویژگیها کار کنیم، زیرا میخواهیم
123
00:05:09,600 –> 00:05:10,400
برخی از آن
124
00:05:10,400 –> 00:05:11,919
متغیرهایی را که همبستگی بسیار بالایی
125
00:05:11,919 –> 00:05:14,479
دارند حذف کنیم، زیرا آنها غیرضروری هستند.
126
00:05:14,479 –> 00:05:14,880
127
00:05:14,880 –> 00:05:17,840
128
00:05:17,840 –> 00:05:21,360
129
00:05:21,360 –> 00:05:23,520
هر مقدار na
130
00:05:23,520 –> 00:05:26,000
در آن وجود دارد، بنابراین فکر میکنم خوب هستیم و
131
00:05:26,000 –> 00:05:26,880
اینجاست
132
00:05:26,880 –> 00:05:30,479
که متغیرهای طبقهبندی
133
00:05:30,479 –> 00:05:32,800
را به متغیرهای عددی تغییر میدهم، زیرا
134
00:05:32,800 –> 00:05:35,840
این برای یادگیری روانی
135
00:05:35,840 –> 00:05:38,639
برای داشتن همه متغیرهای عددی ضروری است،
136
00:05:38,639 –> 00:05:40,240
بنابراین من بهجای استفاده از
137
00:05:40,240 –> 00:05:43,919
یک رمزگذار داغ از آن استفاده میکنم. دریافت
138
00:05:43,919 –> 00:05:47,280
تابع dummies که همین کار را انجام میدهد و من
139
00:05:47,280 –> 00:05:50,560
آن را در کل فریم داده اجرا کردم،
140
00:05:50,560 –> 00:05:54,000
سپس آن
141
00:05:54,000 –> 00:05:57,280
متغیر x را
142
00:05:57,280 –> 00:06:00,560
فقط با انداختن
143
00:06:00,560 –> 00:06:03,919
قیمت x the y و متغیر z جدا کردم
144
00:06:03,919 –> 00:06:05,360
و من اوه هستم و متاسفم
145
00:06:05,360 –> 00:06:07,039
که انجام دادیم یک مهندسی ویژگی کوچک انجام دهید
146
00:06:07,039 –> 00:06:08,479
147
00:06:08,479 –> 00:06:12,000
که به جای استفاده از x y و z،
148
00:06:12,000 –> 00:06:15,520
فقط یک ستون جدید به نام تقارن ایجاد کردم
149
00:06:15,520 –> 00:06:18,720
و فقط x را تقسیم بر
150
00:06:18,720 –> 00:06:22,000
y کردم تا تقارن به دست بیاید و این
151
00:06:22,000 –> 00:06:22,960
ستون را دوباره
152
00:06:22,960 –> 00:06:26,400
به اینجا اضافه کردم
153
00:06:26,400 –> 00:06:31,120
سپس یک
154
00:06:31,120 –> 00:06:33,440
متغیر جدید به نام df trans ایجاد کردم زیرا
155
00:06:33,440 –> 00:06:34,319
رها کردم. همه
156
00:06:34,319 –> 00:06:37,600
uh the
157
00:06:37,600 –> 00:06:40,000
i همه
158
00:06:40,000 –> 00:06:41,919
متغیرهای طبقهبندی را به متغیرهای عددی تبدیل کردم
159
00:06:41,919 –> 00:06:45,360
و سپس
160
00:06:45,360 –> 00:06:48,560
قیمت را از مجموعه دادههای x به x و z you
161
00:06:48,560 –> 00:06:52,240
uh کاهش
162
00:06:52,240 –> 00:06:54,000
دادم زیرا میخواستم قیمت را حذف کنم
163
00:06:54,000 –> 00:06:56,080
زیرا این متغیر هدف داده هدف ما
164
00:06:56,080 –> 00:06:58,479
است و سپس من هر x y
165
00:06:58,479 –> 00:06:59,360
و z را انجام دادم
166
00:06:59,360 –> 00:07:02,319
زیرا آن متغیر مهندسی ویژگی جدید
167
00:07:02,319 –> 00:07:04,560
به نام تقارن را ایجاد کردم،
168
00:07:04,560 –> 00:07:07,120
سپس y را که
169
00:07:07,120 –> 00:07:08,080
متغیر هدف ما است
170
00:07:08,080 –> 00:07:11,120
با آوردن قیمت با استفاده از نماد براکت جدا کردم
171
00:07:11,120 –> 00:07:12,319
172
00:07:12,319 –> 00:07:15,360
و سپس ستون های x را ذخیره کردم
173
00:07:15,360 –> 00:07:18,400
چیزی به نام
174
00:07:18,400 –> 00:07:21,440
ویژگیها به خاطر نمیآورد که چرا این کار را انجام دادم، اما تنها کاری که انجام میدهد این است
175
00:07:21,440 –> 00:07:23,919
که تمام
176
00:07:23,919 –> 00:07:26,560
نام ستونهای
177
00:07:26,560 –> 00:07:31,120
بعدی را ذخیره میکند.
178
00:07:31,120 –> 00:07:34,240
179
00:07:34,240 –> 00:07:38,000
180
00:07:38,000 –> 00:07:42,720
می توانید
181
00:07:42,800 –> 00:07:44,800
همه این چیزها را ببینید این کل
182
00:07:44,800 –> 00:07:46,080
مجموعه داده است uh نه
183
00:07:46,080 –> 00:07:49,360
x و y بنابراین ما هنوز آن متغیرهای x y و z را
184
00:07:49,360 –> 00:07:50,400
داریم
185
00:07:50,400 –> 00:07:52,240
آه شما می توانید همه این
186
00:07:52,240 –> 00:07:53,440
187
00:07:53,440 –> 00:07:56,080
داده های بسیار همبسته را اینجا ببینید و سپس می توانیم ببینیم که
188
00:07:56,080 –> 00:08:00,080
متغیر تقارن که من در اینجا دارم.
189
00:08:00,720 –> 00:08:03,520
سپس میخواهم این دادهها
190
00:08:03,520 –> 00:08:04,240
191
00:08:04,240 –> 00:08:06,960
را مقیاسبندی کنم، زیرا همه آنها در مقیاسهای مختلف هستند و ما
192
00:08:06,960 –> 00:08:07,919
میخواستیم
193
00:08:07,919 –> 00:08:13,840
مقیاسی مشابه برای همه معیارها داشته باشیم،
194
00:08:16,560 –> 00:08:19,440
سپس این کار را با استفاده از اسکالر استاندارد انجام
195
00:08:19,440 –> 00:08:19,840
دادم
196
00:08:19,840 –> 00:08:22,319
و دادهها را برازش کردم و فقط با عبور از متغیر x آنها را تبدیل کردم.
197
00:08:22,319 –> 00:08:24,960
198
00:08:24,960 –> 00:08:28,319
اکنون که متغیر x و y خود را دارم
199
00:08:28,319 –> 00:08:31,280
، یک تقسیم تست قطار انجام دادم تا مجموعه آموزشی و مجموعه آزمایشی را دریافت کنم،
200
00:08:31,280 –> 00:08:32,399
201
00:08:32,399 –> 00:08:35,200
اکنون میتوانیم شروع به
202
00:08:35,200 –> 00:08:36,000
پیشبینی
203
00:08:36,000 –> 00:08:39,440
و استفاده از مدلهایی کنیم که در اختیار داریم،
204
00:08:39,440 –> 00:08:41,279
بنابراین اولین کاری که انجام دادم ایجاد یک
205
00:08:41,279 –> 00:08:43,679
چارچوب داده برای نگه داشتن همه نتایجی
206
00:08:43,679 –> 00:08:47,519
که من می خواهم من
207
00:08:47,519 –> 00:08:51,440
چیزی را دریافت کردم که ما آن را پیش بینی تهی می نامیم
208
00:08:51,440 –> 00:08:54,880
که فقط
209
00:08:54,880 –> 00:08:58,800
میانگین um متغیر ما در آنجا است،
210
00:08:58,800 –> 00:09:00,880
بنابراین من فقط میانگین را گرفتم و می خواهم آن را به
211
00:09:00,880 –> 00:09:02,480
آن پاس بدهم، به طوری که به
212
00:09:02,480 –> 00:09:09,839
نوعی مانند خط پایه ما است
213
00:09:10,000 –> 00:09:13,200
که میانگین متغیر هدف y است
214
00:09:13,200 –> 00:09:16,399
سپس اولین مدلی که من از آن استفاده میکنم یک k
215
00:09:16,399 –> 00:09:20,839
در رگرسیور است و من آن را آوردم که
216
00:09:20,839 –> 00:09:22,160
از
217
00:09:22,160 –>



![فیلم آموزشی: [10] اعتبارسنجی طرحواره فایل با سربروس کتابخانه پایتون با زیرنویس فارسی](http://pezhvak24.ir/dl/learn/wp-content/uploads/upyt/ugu8mjrmYbsimage2.jpg)