در این مطلب، ویدئو تشخیص اخبار جعلی و واقعی با استفاده از پایتون و یادگیری ماشین با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:22:03
تصاویر این ویدئو:

قسمتی از زیرنویس این فیلم:
00:00:02,000 –> 00:00:03,760
سلام به همه و به این ویدیو
2
00:00:03,760 –> 00:00:04,960
در مورد زبان برنامه نویسی پایتون و
3
00:00:04,960 –> 00:00:07,120
یادگیری ماشین خوش آمدید، بنابراین در این ویدیو سعی می کنم
4
00:00:07,120 –> 00:00:09,599
اخبار جعلی را شناسایی و طبقه بندی کنم
5
00:00:09,599 –> 00:00:11,759
اکنون اخبار جعلی اطلاعات نادرست یا گمراه کننده ای هستند
6
00:00:11,759 –> 00:00:14,240
که به عنوان اخبار ارائه شده اند،
7
00:00:14,240 –> 00:00:15,920
بنابراین اگر ویدیوهای مربوط به این را دوست دارید قبل از شروع شروع کنیم.
8
00:00:15,920 –> 00:00:17,119
کانال سپس مطمئن شوید
9
00:00:17,119 –> 00:00:18,640
که روی دکمه اشتراک و لایک کلیک کنید و
10
00:00:18,640 –> 00:00:20,000
در مورد ویدیوهای جدید از
11
00:00:20,000 –> 00:00:22,240
کانال مطلع شوید که اعلان زنگ را بزنید،
12
00:00:22,240 –> 00:00:24,000
بنابراین من در حال حاضر در وب سایت گوگل هستم که به آن
13
00:00:24,000 –> 00:00:24,840
14
00:00:24,840 –> 00:00:26,560
collab.research.google.com می گویند، این جایی است که
15
00:00:26,560 –> 00:00:28,560
من انجام خواهم داد. توسعه من
16
00:00:28,560 –> 00:00:29,679
و من فقط به این دلیل است که
17
00:00:29,679 –> 00:00:31,199
شروع برنامه نویسی در پایتون را بسیار آسان می کند، بنابراین
18
00:00:31,199 –> 00:00:32,479
تنها کاری که باید انجام دهید این است که به این وب سایت بروید
19
00:00:32,479 –> 00:00:33,600
و سپس با استفاده از حساب Google خود وارد
20
00:00:33,600 –> 00:00:34,960
شوید و نوشتن کد پایتون را شروع
21
00:00:34,960 –> 00:00:35,920
کنید،
22
00:00:35,920 –> 00:00:37,360
بنابراین اگر دنبال می کنید ادامه دهید
23
00:00:37,360 –> 00:00:38,559
و روی فایل کلیک کنید، سپس روی دفترچه یادداشت خود کلیک کنید،
24
00:00:38,559 –> 00:00:40,079
جایی که یک برگه جدید برای شما باز می شود
25
00:00:40,079 –> 00:00:42,320
و سپس در نهایت یک سلول جدید و
26
00:00:42,320 –> 00:00:43,360
در سلولی که می خواهم در برخی از
27
00:00:43,360 –> 00:00:44,960
نظرات قرار دهم، توضیحاتی در مورد آن خواهم گذاشت.
28
00:00:44,960 –> 00:00:47,039
برنامه ای که من فقط می خواهم
29
00:00:47,039 –> 00:00:48,480
این برنامه را تایپ کنم
30
00:00:48,480 –> 00:00:49,680
متن
31
00:00:49,680 –> 00:00:51,520
واقعی و
32
00:00:51,520 –> 00:00:53,360
33
00:00:53,360 –> 00:00:55,680
اخبار جعلی
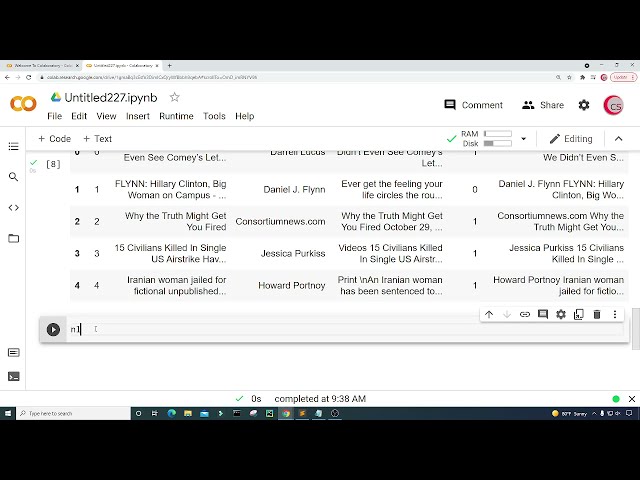
34
00:00:55,920 –> 00:00:56,879
خوب است
35
00:00:56,879 –> 00:00:59,039
و مجموعه داده ای که من استفاده خواهم کرد
36
00:00:59,039 –> 00:01:00,480
37
00:01:00,480 –> 00:01:02,239
اخبار جعلی را
38
00:01:02,239 –> 00:01:04,799
با عدد صحیح 1 طبقه بندی می کند
39
00:01:04,799 –> 00:01:07,040
یا اخبار جعلی را با عدد صحیح
40
00:01:07,040 –> 00:01:09,840
1 نشان می دهد و اخبار واقعی را با عدد صحیح نشان می دهد.
41
00:01:09,840 –> 00:01:11,040
42
00:01:11,040 –> 00:01:13,920
مقدار صحیح صفر
43
00:01:13,920 –> 00:01:14,960
کاملاً درست است، بنابراین اجازه دهید
44
00:01:14,960 –> 00:01:16,240
با کلیک روی این دکمه کد
45
00:01:16,240 –> 00:01:18,080
در بالا سمت چپ، یک سلول جدید ایجاد کنیم و اکنون در این سلول
46
00:01:18,080 –> 00:01:20,000
، کتابخانههایی را وارد میکنم
47
00:01:20,000 –> 00:01:21,200
که ظاهراً
48
00:01:21,200 –> 00:01:22,799
در برنامه استفاده میشوند،
49
00:01:22,799 –> 00:01:25,119
بنابراین numpy را وارد میکنم.
50
00:01:25,119 –> 00:01:28,640
دارای mp است من می خواهم پانداها را به عنوان pd وارد
51
00:01:28,640 –> 00:01:31,840
کنم، می خواهم در ltk وارد کنم و سپس از
52
00:01:31,840 –> 00:01:34,640
nltk.corpus می خواهم کلمات توقف
53
00:01:34,640 –> 00:01:38,000
54
00:01:38,000 –> 00:01:40,720
را وارد کنم و رشته را وارد
55
00:01:40,720 –> 00:01:42,079
کنم بسیار خوب، بنابراین این سلول را اجرا می کنم با
56
00:01:42,079 –> 00:01:43,200
کلیک کردن روی این دکمه در اینجا به سمت چپ
57
00:01:43,200 –> 00:01:44,720
و این به من اطلاع می دهد که آیا
58
00:01:44,720 –> 00:01:46,720
اشتباهی مرتکب شده ام،
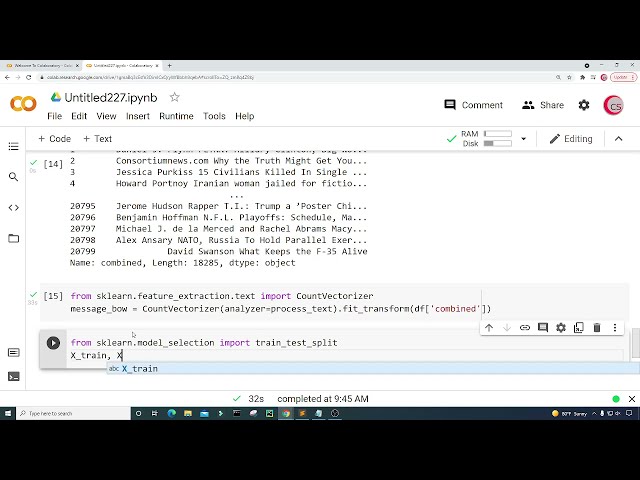
59
00:01:46,720 –> 00:01:49,439
بنابراین اجازه دهید
60
00:01:49,439 –> 00:01:51,200
همه چیز را ببینیم، به نظر می رسد که من خوب هستم که برویم،
61
00:01:51,200 –> 00:01:52,720
بیایید یک سلول جدید ایجاد کنیم
62
00:01:52,720 –> 00:01:55,360
و اکنون در این سلول می خواهم
63
00:01:55,360 –> 00:01:56,560
بارگیری کنم داده ها،
64
00:01:56,560 –> 00:01:58,719
بنابراین من می خواهم از کتابخانه گوگل برای
65
00:01:58,719 –> 00:02:02,000
این کار استفاده کنم، بنابراین از google.colab
66
00:02:02,000 –> 00:02:04,159
i’ m فایلها را وارد میکنم و سپس فایلهای
67
00:02:04,159 –> 00:02:06,719
آپلود را تایپ میکنم
68
00:02:06,719 –> 00:02:08,720
و این را اجرا میکنیم
69
00:02:08,720 –> 00:02:10,479
و روی انتخاب فایلها کلیک میکنیم و
70
00:02:10,479 –> 00:02:12,959
این فایل زیر خط جعلی news.csv
71
00:02:12,959 –> 00:02:15,760
را برای آپلود
72
00:02:15,760 –> 00:02:18,319
انتخاب میکنم و به نظر میرسد که کمی طول میکشد.
73
00:02:18,319 –> 00:02:19,599
زمان،
74
00:02:19,599 –> 00:02:21,040
بنابراین کاری که میخواهم انجام دهم این است
75
00:02:21,040 –> 00:02:22,959
که ویدیو را موقتاً متوقف میکنم تا برای شما خیلی سریع باشد
76
00:02:22,959 –> 00:02:24,720
و
77
00:02:24,720 –> 00:02:26,720
پس از اتمام آن برمیگردم، وقتی
78
00:02:26,720 –> 00:02:29,680
این فایل بارگذاری درست انجام شد، آن را لغو مکث خواهم کرد
79
00:02:29,680 –> 00:02:32,560
بنابراین به زودی شما را می بینم،
80
00:02:33,200 –> 00:02:34,160
81
00:02:34,160 –> 00:02:37,120
بنابراین به نظر می رسد که بارگذاری تمام شده است،
82
00:02:37,120 –> 00:02:40,480
بنابراین بیایید ادامه دهیم و یک سلول جدید ایجاد کنیم
83
00:02:40,480 –> 00:02:42,160
و اکنون در این سلول می خواهم داده ها را بخوانم
84
00:02:42,160 –> 00:02:43,040
، بنابراین می خواهم
85
00:02:43,040 –> 00:02:44,480
متغیری به نام df ایجاد کنم و آن را برابر قرار دهم. به
86
00:02:44,480 –> 00:02:46,000
pd.read
87
00:02:46,000 –> 00:02:47,519
underscore csv
88
00:02:47,519 –> 00:02:48,959
و من میخواهم نام
89
00:02:48,959 –> 00:02:51,120
فایلی را که دروغین underscore news.csv است وارد
90
00:02:51,120 –> 00:02:52,080
کنم، بنابراین فقط آن را برجسته میکنم و
91
00:02:52,080 –> 00:02:54,640
با استفاده از ctrl c کپی میکنم
92
00:02:54,640 –> 00:02:56,000
و سپس اینجا میروم. و
93
00:02:56,000 –> 00:02:58,400
آن را با استفاده از ctrl v
94
00:02:58,400 –> 00:02:59,599
کاملاً جایگذاری کنید و سپس میخواهم دادهها را نشان
95
00:02:59,599 –> 00:03:01,400
دهم، بنابراین فقط
96
00:03:01,400 –> 00:03:03,200
df.head را در
97
00:03:03,200 –> 00:03:04,800
اینجا تایپ میکنم و اولین fi را نشان میدهم. ردیفهایی از
98
00:03:04,800 –> 00:03:07,760
دادهها، بنابراین اجازه دهید این را اجرا کنیم
99
00:03:07,760 –> 00:03:09,920
و به آنجا برویم تا
100
00:03:09,920 –> 00:03:12,319
بتوانیم مجموعه دادههای خود را ببینیم و بتوانیم شناسه ستونها را ببینیم،
101
00:03:12,319 –> 00:03:15,360
متن نویسنده و برچسب
102
00:03:15,360 –> 00:03:17,599
و برچسب مهم است زیرا این
103
00:03:17,599 –> 00:03:20,560
به ما نشان میدهد که آیا خبر جعلی است یا
104
00:03:20,560 –> 00:03:21,440
واقعی است.
105
00:03:21,440 –> 00:03:23,280
بسیار خوب،
106
00:03:23,280 –> 00:03:25,840
اجازه دهید پیش برویم و یک
107
00:03:25,840 –> 00:03:28,560
سلول جدید ایجاد
108
00:03:28,560 –> 00:03:29,920
109
00:03:29,920 –> 00:03:32,480
کنیم و شکل داده ها را بدست آوریم،
110
00:03:32,480 –> 00:03:35,440
بنابراین فقط df.shape را تایپ کنید
111
00:03:35,440 –> 00:03:37,840
و اجازه دهید این را اجرا کنیم و
112
00:03:37,840 –> 00:03:39,840
این تعداد ردیف های مجموعه داده را به ما می گوید، بنابراین به
113
00:03:39,840 –> 00:03:41,599
نظر می رسد که ما 20
114
00:03:41,599 –> 00:03:43,360
800 داریم. ردیف های داده و البته آن
115
00:03:43,360 –> 00:03:44,959
پنج ستونی
116
00:03:44,959 –> 00:03:47,680
که در اینجا دیدیم، شناسه عنوان متن و برچسب نویسنده،
117
00:03:47,680 –> 00:03:49,840
118
00:03:49,840 –> 00:03:51,200
بنابراین بسیار جالب است، اجازه دهید پیش برویم و
119
00:03:51,200 –> 00:03:53,680
یک سلول جدید ایجاد کنیم
120
00:03:53,680 –> 00:03:55,920
و بیایید موارد تکراری را بررسی کنیم
121
00:03:55,920 –> 00:03:58,159
و سپس آنها را حذف کنیم تا این کار را انجام دهیم،
122
00:03:58,159 –> 00:04:00,720
فقط df dot drop را تایپ کنیم.
123
00:04:00,720 –> 00:04:01,840
124
00:04:01,840 –> 00:04:03,599
موارد تکراری را زیر خط بکشید
125
00:04:03,599 –> 00:04:06,239
و سپس در محل برابر قرار دهید و من
126
00:04:06,239 –> 00:04:08,080
فقط آن را اینجا میآورم، بنابراین
127
00:04:08,080 –> 00:04:10,319
ما میخواهیم در جای خود برابر با
128
00:04:10,319 –> 00:04:11,760
true قرار دهیم
129
00:04:11,760 –> 00:04:13,040
و سپس
130
00:04:13,040 –> 00:04:15,519
131
00:04:15,519 –> 00:04:17,199
شکل دادهها
132
00:04:17,199 –> 00:04:19,600
را میگیرم تا ببینم آیا ردیفی وجود دارد یا خیر.
133
00:04:19,600 –> 00:04:21,839
134
00:04:21,839 –> 00:04:22,800
برو
135
00:04:22,800 –> 00:04:24,800
یا اگر ببینیم آیا هر ردیفی حذف شده است، پس
136
00:04:24,800 –> 00:04:26,840
بیایید به جلو برویم d این
137
00:04:26,840 –> 00:04:30,080
سلول را اجرا کنید و به نظر می رسد
138
00:04:30,080 –> 00:04:31,680
هیچ مورد
139
00:04:31,680 –> 00:04:33,280
تکراری در این مجموعه داده
140
00:04:33,280 –> 00:04:35,199
وجود ندارد زیرا ردیف های گم شده ای وجود ندارد، بنابراین بیایید
141
00:04:35,199 –> 00:04:37,520
پیش برویم و یک سلول جدید ایجاد کنیم
142
00:04:37,520 –> 00:04:39,440
و اکنون در
143
00:04:39,440 –> 00:04:42,400
این سلول می خواهم تعداد
144
00:04:42,400 –> 00:04:43,919
145
00:04:43,919 –> 00:04:46,080
داده های از دست رفته یا مقادیر از دست رفته را نشان دهم.
146
00:04:46,080 –> 00:04:48,639
برای انجام هر ستون، من
147
00:04:48,639 –> 00:04:51,919
df.is null
148
00:04:51,919 –> 00:04:54,639
dot sum
149
00:04:54,720 –> 00:04:56,960
را تایپ می کنم و این را به خوبی اجرا می کنم،
150
00:04:56,960 –> 00:04:58,720
بنابراین اکنون
151
00:04:58,720 –> 00:05:00,960
می توانم ببینم که
152
00:05:00,960 –> 00:05:02,800
مقادیری در این مجموعه داده وجود دارد،
153
00:05:02,800 –> 00:05:05,360
بنابراین آنها مقادیری را از دست داده
154
00:05:05,360 –> 00:05:08,320
اند. ستون عنوان در ستون نویسنده
155
00:05:08,320 –> 00:05:11,039
و در ستون متن
156
00:05:11,039 –> 00:05:12,880
کاملاً خوب است، بنابراین
157
00:05:12,880 –> 00:05:15,039
من میروم و
158
00:05:15,039 –> 00:05:16,800
فقط آنها را حذف میکنم،
159
00:05:16,800 –> 00:05:18,000
بنابراین مقادیر گمشده
160
00:05:18,000 –> 00:05:20,400
را از مجموعه دادهها حذف میکنم و برای انجام این کار
161
00:05:20,400 –> 00:05:23,800
فقط تایپ کنید df.drop
162
00:05:24,800 –> 00:05:25,919
n a
163
00:05:25,919 –> 00:05:28,080
و سپس دسترسی را برابر با
164
00:05:28,080 –> 00:05:30,400
صفر قرار دهید
165
00:05:30,639 –> 00:05:32,479
و سپس من می خواهم در محل برابر با true قرار دهم
166
00:05:32,479 –> 00:05:34,800
167
00:05:34,800 –> 00:05:38,479
و سپس می خواهم شکل داده ها را بدست بیاورم،
168
00:05:38,479 –> 00:05:41,680
بنابراین اجازه دهید این را اجرا کنیم
169
00:05:41,680 –> 00:05:44,000
تا حالا ببینیم که برخی از
170
00:05:44,000 –> 00:05:46,880
قوانین حذف شده اند. زیرا مجموعه داده های ما اکنون
171
00:05:46,880 –> 00:05:48,800
کوچکتر از آنچه قبلا بود است،
172
00:05:48,800 –> 00:05:51,680
اما هنوز 18 285 رکورد داریم و فکر می
173
00:05:51,680 –> 00:05:53,520
کنم کلاه برای
174
00:05:53,520 –> 00:05:56,639
این پروژه کوچک بسیار
175
00:05:56,800 –> 00:05:58,560
مناسب است، پس بیایید پیش برویم و یک سلول جدید ایجاد کنیم
176
00:05:58,560 –> 00:06:00,960
177
00:06:01,039 –> 00:06:02,319
و اکنون کاری که می خواهم انجام دهم این است
178
00:06:02,319 –> 00:06:04,639
که ستون هایی را که
179
00:06:04,639 –> 00:06:06,800
فکر می کنم مهم هستند و می خواهم حفظ کنم ترکیب کنم.
180
00:06:06,800 –> 00:06:08,560
می توانید با آنها بازی کنید
181
00:06:08,560 –> 00:06:10,080
و می توانید تصمیم بگیرید کدام ستون ها
182
00:06:10,080 –> 00:06:11,680
مهم هستند یا کدام ستون ها
183
00:06:11,680 –> 00:06:14,000
برای تعیین
184
00:06:14,000 –> 00:06:16,639
اخبار جعلی و واقعی مهم هستند، اما
185
00:06:16,639 –> 00:06:18,639
در اینجا می رویم اینها ستون هایی هستند که
186
00:06:18,639 –> 00:06:21,280
فکر می کنم مهم هستند، بنابراین بیایید جلوتر برویم
187
00:06:21,280 –> 00:06:24,319
و فقط
188
00:06:24,479 –> 00:06:25,600
189
00:06:25,600 –> 00:06:28,160
ستون های مهم را ترکیب کنیم ستون های مهم
190
00:06:28,160 –> 00:06:29,919
191
00:06:29,919 –> 00:06:30,960
192
00:06:30,960 –> 00:06:32,479
بسیار خوب، بنابراین من می خواهم یک
193
00:06:32,479 –> 00:06:34,319
ستون جدید به نام
194
00:06:34,319 –> 00:06:36,800
ترکیب ایجاد
195
00:06:36,960 –> 00:06:39,600
کنم بله، آن را با یک d ترکیب می کنم
196
00:06:39,600 –> 00:06:41,199
در پایان می خواهم آن
197
00:06:41,199 –> 00:06:43,840
را برابر با df
198
00:06:43,840 –> 00:06:45,759
author
199
00:06:45,759 –> 00:06:48,000
به اضافه یک فاصله
200
00:06:48,000 –> 00:06:49,759
به اضافه عنوان df تنظیم
201
00:06:49,759 –> 00:06:50,639
202
00:06:50,639 –> 00:06:53,120
کنم، بنابراین من فقط می خواهم ترکیب کنم دو ستون
203
00:06:53,120 –> 00:06:54,639
از مجموعه دادههای ما که ستون نویسنده
204
00:06:54,639 –> 00:06:56,800
در ستون عنوان است، من قطعاً
205
00:06:56,800 –> 00:06:58,639
فکر نمیکنم ستون id اصلاً مهم باشد
206
00:06:58,639 –> 00:07:00,319
،
207
00:07:00,319 –> 00:07:01,440
208
00:07:01,440 –> 00:07:03,360
اما قطعاً معتقدم
209
00:07:03,360 –> 00:07:05,280
ستون نویسنده بسیار مهم است،
210
00:07:05,280 –> 00:07:07,759
بنابراین این ستون جدید من به نام
211
00:07:07,759 –> 00:07:10,080
ترکیب خواهد بود.
212
00:07:10,080 –> 00:07:11,919
و سپس
213
00:07:11,919 –> 00:07:14,639
پنج ردیف اول داده را نشان می دهم، بنابراین
214
00:07:14,639 –> 00:07:17,360
فقط df.head را اینجا تایپ می کنم
215
00:07:17,360 –> 00:07:18,800
و اکنون می توانیم این ستون جدید
216
00:07:18,800 –> 00:07:20,080
به نام
217
00:07:20,080 –> 00:07:22,800
ترکیبی را ببینیم که دوباره
218
00:07:22,800 –> 00:07:26,720
عنوان ستون و نویسنده ستون را
219
00:07:26,800 –> 00:07:29,039
کاملاً ترکیب
220
00:07:29,039 –> 00:07:32,160
می کند. به نظر می رسد خوب است، بنابراین من می
221
00:07:32,160 –> 00:07:34,639
خواهم یک سلول جدید ایجاد
222
00:07:34,639 –> 00:07:36,639
کنم که همه آن داده ها را
223
00:07:36,639 –> 00:07:38,160
در یک مکان
224
00:07:38,160 –> 00:07:39,280
کاملاً خوب دارم، بنابراین می خواهم چند
225
00:07:39,280 –> 00:07:41,520
کلمه توقف را دانلود کنم تا بتوانم بعداً از آنها استفاده کنم
226
00:07:41,520 –> 00:07:43,199
و کلمات و پردازش زبان طبیعی را متوقف کنم.
227
00:07:43,199 –> 00:07:46,400
کلمات یا داده های بی فایده ای هستند، بنابراین
228
00:07:46,400 –> 00:07:47,840
برای دانلود این کلمات توقف، کافیست
229
00:07:47,840 –> 00:07:49,599
nltk dot
230
00:07:49,599 –> 00:07:51,919
download را تایپ کنید
231
00:07:51,919 –> 00:07:55,520
و سپس آن را در استاپ
232
00:07:55,520 –> 00:07:56,879
قرار دهید، بسیار خوب است، بنابراین بیایید این را اجرا کنیم و
233
00:07:56,879 –> 00:07:58,960
باید نسبتاً سریع باشد و تمام شد،
234
00:07:58,960 –> 00:08:02,400
بیایید یک سلول جدید ایجاد کنیم
235
00:08:02,639 –> 00:08:04,720
و اکنون می خواهم یک تابع برای
236
00:08:04,720 –> 00:08:06,400
پردازش متن ایجاد کنید
237
00:08:06,400 –> 00:08:07,680
تا
238
00:08:07,680 –> 00:08:10,160
این تابع علائم نگارشی
239
00:08:10,160 –> 00:08:13,280
مانند علامت تعجب
240
00:08:13,280 –> 00:08:16,240
را از متن حذف کند و کلمات توقف را از متن حذف کند
241
00:08:16,240 –> 00:08:17,120
و
242
00:08:17,120 –> 00:08:18,479
243
00:08:18,479 –> 00:08:20,800
سپس فهرستی از این متن تمیز
244
00:08:20,800 –> 00:08:21,840
245
00:08:21,840 –> 00:08:22,960
کلمات را برگردانم،
246
00:08:22,960 –> 00:08:23,759
بنابراین
247
00:08:23,759 –> 00:08:25,680
اجازه دهید این را صدا کنیم.
248
00:08:25,680 –> 00:08:28,160
فرآیند عملکرد زیر است متن اصلی
249
00:08:28,160 –> 00:08:31,440
و متنی به درستی وارد می شود
250
00:08:31,440 –> 00:08:33,200
251
00:08:33,200 –> 00:08:34,880
و
252
00:08:34,880 –> 00:08:36,399
من نشانه های نگارشی را از متن حذف می کنم
253
00:08:36,399 –> 00:08:37,440
،
254
00:08:37,440 –> 00:08:39,279
بنابراین
255
00:08:39,279 –> 00:08:41,039
می خواهم
256
00:08:41,039 –> 00:08:42,479
کاراکتر را
257
00:08:42,479 –> 00:08:43,279
برای
258
00:08:43,279 –> 00:08:45,120
char در
259
00:08:45,120 –> 00:08:46,160
متنی
260
00:08:46,160 –> 00:08:48,320
که در رشته
261
00:08:48,320 –> 00:08:51,839
نقطه نقطه نگاری
262
00:08:52,560 –> 00:08:53,920
نیست برگردانم و من می خواهم این را
263
00:08:53,920 –> 00:08:55,120
برابر قرار دهید،
264
00:08:55,120 –> 00:08:56,880
من می خواهم آن را بدون پانک بدون
265
00:08:56,880 –> 00:08:59,600
علامت گذاری بنامم
266
00:09:00,240 –> 00:09:01,519
267
00:09:01,519 –> 00:09:04,480
و سپس می خواهم کاراکترها را
268
00:09:04,480 –> 00:09:06,720
دوباره به هم بپیوندم تا یک رشته جدید بسازم،
269
00:09:06,720 –> 00:09:08,720
بنابراین می خواهم هیچ پانک را
270
00:09:08,720 –> 00:09:11,120
برابر با
271
00:09:11,120 –> 00:09:11,920
um
272
00:09:11,920 –> 00:09:14,800
نقطه اتصال رشته خالی قرار دهم.
273
00:09:14,800 –> 00:09:17,279
نه پانک
274
00:09:18,959 –> 00:09:20,320
خوب است،
275
00:09:20,320 –> 00:09:22,320
پس
276
00:09:22,320 –> 00:09:24,480
حالا که باید از شر هر یک
277
00:09:24,480 –> 00:09:25,680
278
00:09:25,680 –> 00:09:27,600
از علائم نگارشی متن خلاص می شد،
279
00:09:27,600 –> 00:09:30,399
بنابراین در مرحله بعد، تمام کلمات توقف را
280
00:09:30,399 –> 00:09:32,000
از متن حذف می کنم، بنابراین
281
00:09:32,000 –> 00:09:33,120
متغیری به نام
282
00:09:33,120 –> 00:09:34,959
کلمات زیر خط تمیز ایجاد می کنم. این را
283
00:09:34,959 –> 00:09:36,720
برابر
284
00:09:36,720 –> 00:09:37,920
کلمه
285
00:09:37,920 –> 00:09:42,240
به کلمه در بدون تقسیم نقطه پانک قرار دهید
286
00:09:42,320 –> 00:09:45,200
287
00:09:45,760 –> 00:09:46,800
اگر
288
00:09:46,800 –> 00:09:50,399
کلمه نقطه
289
00:09:50,399 –> 00:09:52,720
پایین در
290
00:09:52,720 –> 00:09:54,240
کلمات توقف
291
00:09:54,240 –> 00:09:56,000
کلمات نقطه نیست
292
00:09:56,000 –> 00:09:59,680
و من می خواهم از انگلیسی در اینجا استفاده کنم
293
00:09:59,680 –> 00:10:02,160
بسیار خوب بنابراین فکر می کنم این کار را انجام دهم
294
00:10:02,160 –> 00:10:04,000
بنابراین فقط باید کلماتی را
295
00:10:04,000 –> 00:10:06,240
که نه در کلمات توقف
296
00:10:06,240 –> 00:10:08,079
و دوباره در اینجا ما
297
00:10:08,079 –> 00:10:09,519
شخصیت هایی را که
29