در این مطلب، ویدئو نحوه برنامهریزی سنتز گفتار در دهان انیماترونیک با استفاده از پایتون و آردوینو با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:10:31
تصاویر این ویدئو:


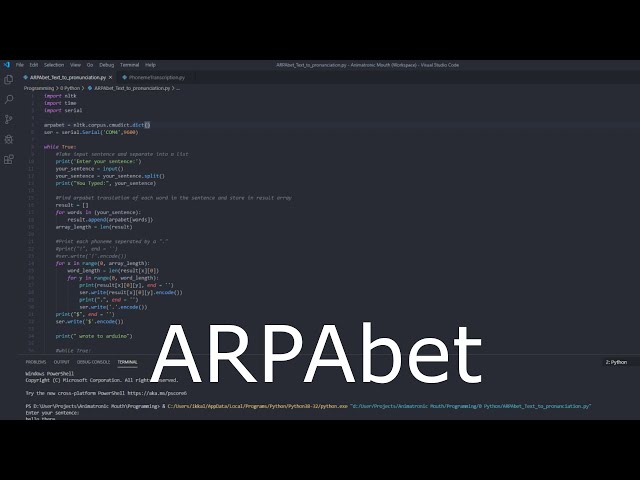

قسمتی از زیرنویس این فیلم:
00:00:00,060 –> 00:00:02,790
این ویدئو در مورد سیستمی است که من برای
2
00:00:02,790 –> 00:00:05,850
گرفتن یک جمله تایپ شده و استفاده از آن برای
3
00:00:05,850 –> 00:00:09,200
متحرک کردن دهان روباتیک خود استفاده می کنم،
4
00:00:10,990 –> 00:00:14,870
بنابراین در گفتار می توانید نام خز را
5
00:00:14,870 –> 00:00:17,660
به عنوان واحدی از صدا توصیف کنید که یک کلمه
6
00:00:17,660 –> 00:00:20,779
را تشکیل می دهد و از طرف دیگر بینایی نیز روشی است
7
00:00:20,779 –> 00:00:22,910
که دهان زمانی به نظر می رسد که واج های خاصی
8
00:00:22,910 –> 00:00:25,130
ساخته می شوند، بنابراین می توانید آن
9
00:00:25,130 –> 00:00:27,349
را مانند موقعیت دهان وقتی
10
00:00:27,349 –> 00:00:30,169
صدای خاصی از دهان شما خارج می شود توصیف کنید، بنابراین
11
00:00:30,169 –> 00:00:32,540
روش های کنترلی که من استفاده می کنم
12
00:00:32,540 –> 00:00:35,120
بر یافتن ترجمه آوایی یک
13
00:00:35,120 –> 00:00:36,890
جمله و سپس ترجمه تمرکز دارند. این
14
00:00:36,890 –> 00:00:39,170
به دنباله ای از نام های خز است که سپس
15
00:00:39,170 –> 00:00:40,460
به دهان انیماترونیک فرستاده می شود و
16
00:00:40,460 –> 00:00:43,190
به عنوان دنباله ای از کیف های دهان
17
00:00:43,190 –> 00:00:45,890
یا رویاها قبل از انجام هر یک از این موارد بیان می شود.
18
00:00:45,890 –> 00:00:47,780
19
00:00:47,780 –> 00:00:51,410
20
00:00:51,410 –> 00:00:52,850
به این دلیل که من یک
21
00:00:52,850 –> 00:00:55,010
تست سرور یا چند ویدیو پیش ساختهام، زیرا
22
00:00:55,010 –> 00:00:56,570
میخواستم بتوانم تعداد زیادی
23
00:00:56,570 –> 00:00:59,000
سرور مختلف را به طور همزمان ژست بگیرم تا
24
00:00:59,000 –> 00:01:01,790
موقعیت دهان را برای دیدهای مختلف به دست
25
00:01:01,790 –> 00:01:03,410
بیاورم، بنابراین از تستر سرور خود برای یافتن
26
00:01:03,410 –> 00:01:05,659
موقعیت هر یک از آنها استفاده میکنم. نه سرور در
27
00:01:05,659 –> 00:01:07,310
مکانیسم دهان در
28
00:01:07,310 –> 00:01:09,200
موزههای مختلف که میخواستم استفاده کنم و آنها
29
00:01:09,200 –> 00:01:12,229
را در آرایههایی در برنامه آردوینو نوشتم، بنابراین
30
00:01:12,229 –> 00:01:13,579
با وجود اینکه تعداد زیادی
31
00:01:13,579 –> 00:01:16,130
واج و چشماندازهای مختلف برای اهداف من وجود دارد،
32
00:01:16,130 –> 00:01:18,799
آن را ساده کردم فقط یک حالت هشت تصویری است،
33
00:01:18,799 –> 00:01:20,569
زیرا بسیاری از آنها در واقع
34
00:01:20,569 –> 00:01:22,460
بسیار شبیه به نظر می رسند. این ممکن است
35
00:01:22,460 –> 00:01:25,039
و برای شما بسیار آسان است که کد من را تغییر دهید
36
00:01:25,039 –> 00:01:27,049
تا یک بار حالت های مختلف بیشتری به کد اضافه کنید،
37
00:01:27,049 –> 00:01:29,359
اما ژست هایی که من دارم
38
00:01:29,359 –> 00:01:37,100
برای صداهای a یا b g مثل l و f
39
00:01:37,100 –> 00:01:40,369
است که یک بار. شما همه این چشم اندازها
40
00:01:40,369 –> 00:01:42,439
را در برنامه آردوینو به صورت آرایههایی برنامهریزی کردهاید، این
41
00:01:42,439 –> 00:01:44,749
تنها چیزی است که
42
00:01:44,749 –> 00:01:47,149
برای سادهترین شکل سنتز گفتار
43
00:01:47,149 –> 00:01:48,380
لازم است که میتوانید انجام دهید و میتوانید با
44
00:01:48,380 –> 00:01:49,729
یکی از برنامههای بسته دانلود من
45
00:01:49,729 –> 00:01:51,889
برنامه آردوینو به نام mouth
46
00:01:51,889 –> 00:01:54,350
basic ver name انجام دهید. بنابراین با استفاده از این برنامه می
47
00:01:54,350 –> 00:01:56,119
توانید به سادگی به دهان بگویید که برای یک
48
00:01:56,119 –> 00:01:58,490
واج خاص با استفاده از تابع pose name FIR ژست بگیرد،
49
00:01:58,490 –> 00:02:00,590
می توانید چند مورد از این حالت
50
00:02:00,590 –> 00:02:02,389
ها یا با توجه به جمله ای
51
00:02:02,389 –> 00:02:04,009
که در ذهن دارید را نشان دهید و سپس اکنون یک لایه
52
00:02:04,009 –> 00:02:06,740
بین هر ژست اضافه کرده است که
53
00:02:06,740 –> 00:02:09,258
واقعا وقت گیر خواهد بود، اما از نظر تئوری
54
00:02:09,258 –> 00:02:11,720
می تواند کاملاً دقیق باشد شما می توانید
55
00:02:11,720 –> 00:02:14,209
تمام وقت را به حالت کامل برسانید – نمونه صوتی
56
00:02:14,209 –> 00:02:15,740
که دارید و می توانید آن را
57
00:02:15,740 –> 00:02:17,630
واقعاً خوب جلوه دهید، اما چیزی که من به آن علاقه داشتم این
58
00:02:17,630 –> 00:02:19,940
بود یافتن راهی برای توالیبندی بیناییها
59
00:02:19,940 –> 00:02:21,970
از ورودی کاربر،
60
00:02:21,970 –> 00:02:24,550
بنابراین اولین روشی که برای سرعت
61
00:02:24,550 –> 00:02:26,620
بخشیدن به روند توالییابی
62
00:02:26,620 –> 00:02:29,170
ویژنها استفاده میکنم، استفاده از نمایشگر سریال آردوینو
63
00:02:29,170 –> 00:02:32,050
بهعنوان ورودی برای جمله کاربر بود، سپس
64
00:02:32,050 –> 00:02:33,850
چند کد ساده نوشتم که
65
00:02:33,850 –> 00:02:36,010
جمله را جدا میکند. در هر حرف با استفاده از
66
00:02:36,010 –> 00:02:39,100
تابعی به نام تطابق واج و
67
00:02:39,100 –> 00:02:40,240
نحوه برنامهریزی آن
68
00:02:40,240 –> 00:02:42,220
اساساً فقط یک بلوک بزرگ از
69
00:02:42,220 –> 00:02:44,170
عبارات ورودی است که از طریق
70
00:02:44,170 –> 00:02:46,150
اتصال سریال میآید، هر حرف
71
00:02:46,150 –> 00:02:48,010
توسط کد نگاه میشود و اگر یک گوش است
72
00:02:48,010 –> 00:02:50,110
برای هوا برای نام اگر زنبور
73
00:02:50,110 –> 00:02:52,120
است برای واج V و غیره عکس می
74
00:02:52,120 –> 00:02:54,640
گیرد کمی مشکل
75
00:02:54,640 –> 00:02:56,410
با واج هفتم وجود دارد زیرا بدیهی است که
76
00:02:56,410 –> 00:02:58,750
دو حرف است بنابراین اگر برنامه یک t i را تشخیص دهد
77
00:02:58,750 –> 00:03:00,940
. t منتظر حرف بعدی می ماند قبل از
78
00:03:00,940 –> 00:03:02,260
تصمیم گیری در مورد استفاده مجدد از واج
79
00:03:02,260 –> 00:03:05,709
برای T یا th،
80
00:03:05,709 –> 00:03:07,690
رسیدن به این امر با دستورات if بسیار ساده است، بنابراین
81
00:03:07,690 –> 00:03:09,459
برنامه اصلاً خیلی پیچیده نیست، هیچ کدام
82
00:03:09,459 –> 00:03:11,280
از اینها واقعاً اکنون از نظر
83
00:03:11,280 –> 00:03:14,470
همگام سازی واقعی لب این روش نیست.
84
00:03:14,470 –> 00:03:17,110
خیلی خوب نیست، زیرا همانطور که می دانیم کلمات
85
00:03:17,110 –> 00:03:18,640
هرگز واقعاً به صورت حرف به حرف تلفظ نمی شوند
86
00:03:18,640 –> 00:03:21,220
، حداقل نه به زبان انگلیسی، بنابراین
87
00:03:21,220 –> 00:03:22,810
نتایج حاصل از این روش
88
00:03:22,810 –> 00:03:25,030
خیلی واقعی نخواهد بود، این یک راه خوب برای
89
00:03:25,030 –> 00:03:26,440
دیدن اینکه آیا همه چیز با دهان کار می کند یا خیر است.
90
00:03:26,440 –> 00:03:29,050
حالت ها و اگر
91
00:03:29,050 –> 00:03:30,850
کلمات را به صورت آوایی املا کنید، می تواند
92
00:03:30,850 –> 00:03:32,680
به خوبی کار کند، بنابراین مرحله بعدی که من به آن رفتم
93
00:03:32,680 –> 00:03:35,320
استفاده از پایتون و استفاده از
94
00:03:35,320 –> 00:03:36,850
چند کتابخانه در پایتون برای یافتن
95
00:03:36,850 –> 00:03:38,709
ترجمه آوایی بسیار دقیق تر
96
00:03:38,709 –> 00:03:40,959
از کلماتی بود که در برنامه تایپ کردم.
97
00:03:40,959 –> 00:03:44,260
بنابراین روشی که این کار را انجام می دهد با استفاده
98
00:03:44,260 –> 00:03:47,920
از کتابخانه NL ck در پایتون است که
99
00:03:47,920 –> 00:03:50,680
مخفف جعبه ابزار زبان طبیعی کاربر است
100
00:03:50,680 –> 00:03:53,200
و به عنوان یک جمله که
101
00:03:53,200 –> 00:03:56,019
به هر کلمه جداگانه و فاصله های
102
00:03:56,019 –> 00:03:58,600
ar جدا می شود. حذف هر کلمه جداگانه
103
00:03:58,600 –> 00:04:01,269
توسط کتابخانه مراقبت NLT پردازش
104
00:04:01,269 –> 00:04:03,970
می شود که کلمات را در CMU تلفظ شده
105
00:04:03,970 –> 00:04:06,549
در فرهنگ لغت جستجو می کند.
106
00:04:06,549 –> 00:04:09,850
107
00:04:09,850 –> 00:04:12,370
108
00:04:12,370 –> 00:04:14,650
109
00:04:14,650 –> 00:04:16,390
نسبت به IPA که ممکن
110
00:04:16,390 –> 00:04:18,548
است در فرهنگ لغت ها و هر
111
00:04:18,548 –> 00:04:20,560
جای دیگری دیده باشید، این الفبا برای انگلیسی آمریکایی طراحی شده است،
112
00:04:20,560 –> 00:04:22,930
مطمئن نیستم که آیا معادل انگلیسی انگلیسی وجود دارد یا خیر،
113
00:04:22,930 –> 00:04:25,000
اما اگر چنین
114
00:04:25,000 –> 00:04:26,650
بود به من گفته می شود که احتمالاً
115
00:04:26,650 –> 00:04:28,750
برای من کاربرد زیادی ندارند. قالب
116
00:04:28,750 –> 00:04:30,220
الفبا
117
00:04:30,220 –> 00:04:33,490
رشته ای از یک دو سه کاراکتر را کد می کند، بنابراین
118
00:04:33,490 –> 00:04:35,230
یک یا دو کاراکتر مربوط به
119
00:04:35,230 –> 00:04:37,510
صدایی است که ایجاد می شود و سپس گاهی
120
00:04:37,510 –> 00:04:39,220
اوقات یک عدد در انتهای آن وجود دارد
121
00:04:39,220 –> 00:04:41,560
که فشار روی آن نام خز خاص را نشان می دهد،
122
00:04:41,560 –> 00:04:44,710
بنابراین استرس می تواند باشد. 1 a 2 یا
123
00:04:44,710 –> 00:04:48,220
3 و 1 نشان دهنده استرس اولیه است،
124
00:04:48,220 –> 00:04:49,840
به این معنی که شما
125
00:04:49,840 –> 00:04:52,180
مدت زیادی روی آن صدا درنگ می کنید، 2
126
00:04:52,180 –> 00:04:54,160
استرس ثانویه خواهد بود، بنابراین
127
00:04:54,160 –> 00:04:56,890
استرس کمتری در w است. اما شما
128
00:04:56,890 –> 00:04:59,020
همچنان به آن صدای خاص استرس می دهید
129
00:04:59,020 –> 00:05:01,300
و سپس 3 می تواند استرس تری باشد،
130
00:05:01,300 –> 00:05:02,470
اما فکر نمی کنم در واقع از آن استفاده شود،
131
00:05:02,470 –> 00:05:04,690
شما همچنین می توانید یک عدد 0 داشته باشید که
132
00:05:04,690 –> 00:05:06,910
نشان دهنده استرس پرستار است و
133
00:05:06,910 –> 00:05:08,860
این جایی است که دوست دارید از روی یک صدا بگذرید.
134
00:05:08,860 –> 00:05:10,360
سپس این رشته ها در قسمت سریال چاپ می شوند
135
00:05:10,360 –> 00:05:12,880
که آن را از
136
00:05:12,880 –> 00:05:15,460
رایانه من از طریق پورت USB به
137
00:05:15,460 –> 00:05:18,550
آردوینو می برد و سپس رشته های کاراکتر را رمزگشایی می کند.
138
00:05:18,550 –> 00:05:20,650
اسکریپت پایتون نیز یک نقطه
139
00:05:20,650 –> 00:05:23,230
یا نقطه بین هر واج قرار می دهد
140
00:05:23,230 –> 00:05:25,120
و سپس در انتهای آن عبارت
141
00:05:25,120 –> 00:05:26,740
است یک نماد دلار برای نشان
142
00:05:26,740 –> 00:05:29,320
دادن پایان عبارت audrina سپس
143
00:05:29,320 –> 00:05:31,630
به هر کاراکتر ورودی